Тонкая настройка компьютера после сборки, до установки Windows
Итак, вы собрали компьютер и проверили, что он включается. Но не спешите сразу устанавливать Windows, есть много параметров, которые желательно настроить до установки ОС. В этом блоге я поделюсь с вами секретами тонкой настройки ПК после сборки.
27 июня 2020, суббота 00:10
Zystax [ ] для раздела Блоги
реклама
Практически всем из нас, посетителям overclockers.ru, знаком тот волнительный момент, когда мы первый раз жмем на кнопку Power на только что собранном компьютере.
Те несколько секунд, которые проходят между нажатием и появлением картинки загрузки BIOS на экране — кажутся бесконечно долгими.
реклама

И если пользователь собрал компьютер правильно и он включается, то обычно он сразу берет флешку с Windows и приступают к ее установке. Но не стоит спешить, есть целый ряд настроек ПК, которые желательно сделать до установки Windows.
реклама
В этом блоге я поделюсь с вами своим многолетним опытом настроек компьютеров, ведь через мои руки прошло уже несколько десятков собранных и настроенных ПК. Настройки в UEFI (BIOS) я буду иллюстрировать скриншотами настроек материнской платы MSI B450-A PRO MAX.
Первое, что стоит сделать, это перевести UEFI в режим опытного (Advanced) пользователя. Это даст вам доступ к множеству тонких настроек. Еще один плюс такого режима в том, что настройки выстроены более логично и понятно, списками.
Вот так UEFI MSI B450-A PRO MAX выглядит в простом режиме (EZ Mode).

реклама
А вот так, в Advanced Mode.

Начать настройку я хочу с главной проблемы новичков — неправильно настроенном приоритете накопителей.
Каждый пользователь ПК сталкивался с такой крайне неприятной ситуацией, когда Windows записывает загрузчик на один накопитель, а сама устанавливается на другой. Проблема в том, что выставление приоритета накопителей в BIOS никак не влияет на порядок приоритета накопителей для загрузчика Windows.
Windows всегда будет записывать загрузчик на тот накопитель, который стоит ближе к 0 по номеру. SATA 0, SATA 1 и так далее. Как узнать, правильно ли вы установили загрузочный накопитель, в самый первый SATA порт? Надо посмотреть в UEFI на очередность накопителей.

реклама
В моем случае это Samsung 850 EVO 120 Гб.
Точно также можно увидеть это порядок накопителей в диспетчере устройств Windows.

Если тот накопитель, на который вы хотите установить Windows, не первый в списке, то отключите другой накопитель на время установки. Или, что правильнее, включите загрузочный накопитель в в первый SATA порт.
Надеюсь, этот совет сэкономит вам немало нервов. Но давайте двигаться дальше.
Пока мы не вышли из меню SATA устройств, давайте проверим, что стоит правильный приоритет устройств загрузки.

Дополнительно, что стоит проверить — это режим ACHI, который необходим новым SATA устройствам.

Следующее, что стоит сделать — это отключить неиспользуемые устройства. Например, встроенную видеокарту, COM и последовательный порты.


Следующее, что стоит проверить и настроить — это температуры в простое и режим работы вентиляторов. Если у вас уже в UEFI процессор разогрелся выше 60 градусов, то надо не готовиться к установке Windows, а улучшать охлаждение ПК.
Перегрев может быть связан не только с дешевым кулером и плохой термопастой, но и с неправильно выставленными оборотами вентиляторов. В подразделе Hardware monitor нужно убедиться, что вентиляторы работают на достаточных оборотах.

Если с температурами все в порядке, можно задать кривые оборотов вентиляторов в зависимости от температуры процессора. Это даст вам тихий в простое и слабой загрузке ПК, который сам будет увеличивать обороты вентиляторов при серьезной нагрузке.
Это довольно сложный в настройке процесс и с первого раза может не получиться. Некоторые материнские платы умеют управлять и вентиляторами без PWM — трехпиновыми.

Стоит проверить, включен ли у вас XMP профиль памяти, ведь если вы не включили его, память будет работать на стандартной, низкой частоте.

А теперь еще несколько настроек, которые обычно делают только опытные пользователи. Стоит отключить показ логотипа компании производителя во весь экран, это поможет вам увидеть важную информацию при загрузке ПК. Скорость процессора, памяти и т.д.

Многие материнские платы любят завышать напряжение на процессоре, чипсете, System-on-a-Chip (SoC) и т.д., поэтому опытные пользователи фиксируют эти напряжения вручную.

Еще стоит настроить пробуждение компьютера из спящего режима по нужному вам событию, например — щелчку мышью.

И финальная настройка, которую я делаю уже много лет — автовключение компьютера при появлении питания. Эта опция может называться PWRON After PWR-Fail или Restore on AC Power Loss.
Это довольно удобно, щелкаете кнопкой на сетевом фильтре, а компьютер включается автоматически.

рекомендации
Ищем PHP-программиста для апгрейда конфы
Пишите, а какие вы настройки делаете перед установкой Windows? И есть ли у вас важные настройки, которые не встретились в этом гайде?
Основы Ansible, без которых ваши плейбуки — комок слипшихся макарон
Я делаю много ревью для чужого кода на Ансибл и много пишу сам. В ходе анализа ошибок (как чужих, так и своих), а так же некоторого количества собеседований, я понял основную ошибку, которую допускают пользователи Ансибла — они лезут в сложное, не освоив базового.
Для исправления этой вселенской несправедливости я решил написать введение в Ансибл для тех, кто его уже знает. Предупреждаю, это не пересказ манов, это лонгрид в котором много букв и нет картинок.
Ожидаемый уровень читателя — уже написано несколько тысяч строк ямла, уже что-то в продакшене, но «как-то всё криво».
Названия
Главная ошибка пользователя Ansible — это не знать как что называется. Если вы не знаете названий, вы не можете понимать то, что написано в документации. Живой пример: на собеседовании, человек, вроде бы заявлявший, что он много писал на Ансибле, не смог ответить на вопрос «из каких элементов состоит playbook’а?». А когда я подсказал, что «ожидался ответ, что playbook состоит из play», то последовал убийственный комментарий «мы этого не используем». Люди пишут на Ансибле за деньги и не используют play. На самом деле используют, но не знают, что это такое.
Так что начнём с простого: как что называется. Может быть вы это знаете, а может и нет, потому что не обратили внимания, когда читали документацию.
ansible-playbook исполняет playbook. Playbook — это файл с расширением yml/yaml, внутри которого что-то такое:
--- - hosts: group1 roles: - role1 - hosts: group2,group3 tasks: - debug:Мы уже поняли, что весь этот файл — плейбука. Мы можем показать где тут роли (roles), где таски (tasks). Но где тут play? И чем отличается play от role или playbook?
В документации это всё есть. И это пропускают. Начинающие — потому что там слишком много и всё сразу не запомнишь. Опытные — потому что «тривиальные вещи». Если вы опытный — перечитывайте эти страницы хотя бы раз в полгода, и ваш код станет классом лучше.
Итак, запоминайте: Playbook — это список, состоящий из play и import_playbook .
Вот это — одна play:
- hosts: group1 roles: - role1и вот это тоже ещё одна play:
- hosts: group2,group3 tasks: - debug:Что же такое play? Зачем она?
Play — это ключевой элемент для playbook, потому что play и только play связывает список ролей и/или тасок с списком хостов, на которых их надо выполнять. В глубоких недрах документации можно найти упоминание про delegate_to , локальные lookup-плагины, network-cli-специфичные настройки, jump-хосты и т.д. Они позволяют слегка поменять место исполнения тасок. Но, забудьте про это. У каждой из этих хитрых опций есть очень специальные применения, и они точно не являются универсальными. А мы говорим про базовые вещи, которые должны знать и использовать все.
Если вы хотите «что-то» исполнить «где-то» — вы пишете play. Не роль. Не роль с модулями и делегейтами. Вы берёте и пишете play. В которой, в поле hosts вы перечисляете где исполнять, а в roles/tasks — что исполнять.
Просто же, да? А как может быть иначе?
Одним из характерных моментов, когда у людей возникает желание сделать это не через play, это «роль, которая всё настраивает». Хочется иметь роль, которая настраивает и сервера первого типа, и сервера второго типа.
Архетипичным примером является мониторинг. Хочется иметь роль monitoring, которая настроит мониторинг. Роль monitoring назначается на хосты мониторинга (в соотв. play). Но, выясняется, что для мониторинга нам надо поставить пакеты на хосты, которые мы мониторим. Почему бы не использовать delegate? А ещё надо настроить iptables. delegate? А ещё надо написать/поправить конфиг для СУБД, чтобы мониторинг пускала. delegate! А если креатив попёр, то можно сделать делегацию include_role во вложенном цикле по хитрому фильтру на список групп, а внутри include_role можно ещё делать delegate_to снова. И понеслось.
Благое пожелание — иметь одну-единственную роль monitoring, которая «всё делает» — ведёт нас в кромешный ад из которого чаще всего один выход: всё переписать с нуля.
Где тут случилась ошибка? В тот момент, когда вы обнаружили, что для выполнения задачи «x» на хосте X вам надо пойти на хост Y и сделать там «y», вы должны были выполнить простое упражнение: пойти и написать play, которая на хосте Y делает y. Не дописывать что-то в «x», а написать с нуля. Пусть даже с захардкоженными переменными.
Вроде бы, в абзацах выше всё сказано правильно. Но это же не ваш случай! Потому что вы хотите написать переиспользуемый код, который DRY и похож на библиотеку, и нужно искать метод как это сделать.
Вот тут вот притаилась ещё одна грубая ошибка. Ошибка, которая превратила множество проектов из терпимо написанных (можно лучше, но всё работает и легко дописать) в совершенный ужас, в котором даже автор не может разобраться. Оно работает, но упаси боже что-то поменять.
Эта ошибка звучит так: роль — это библиотечная функция. Эта аналогия сгубила столько хороших начинаний, что просто грустно смотреть. Роль — не библиотечная функция. Она не может делать вычисления и она не может принимать решения уровня play. Напомните мне, какие решения принимает play?
Спасибо, вы правы. Play принимает решение (точнее, содержит в себе информацию) о том, какие таски и роли на каких хостах выполнять.
Если вы делегируете это решение на роль, да ещё и с вычислениями, вы обрекаете себя (и того, кто ваш код будет пытаться разобрать) на жалкое существование. Роль не решает где ей выполняться. Это решение принимает play. Роль делает то, что ей сказали, там, где ей сказали.
Почему заниматься программированием на Ансибле опасно и чем COBOL лучше Ансибла мы поговорим в главе про переменные и jinja. Пока что скажем одно — каждое ваше вычисление оставляет за собой нестираемый след из изменения глобальных переменных, и вы ничего с этим не можете сделать. Как только два «следа» пересеклись — всё пропало.
Замечание для въедливых: роль, безусловно, может влиять на control flow. Есть delegate_to и у него есть разумные применения. Есть meta: end host/play . Но! Помните, мы учим основы? Забыли про delegate_to . Мы говорим про самый простой и самый красивый код на Ансибл. Который легко читать, легко писать, легко отлаживать, легко тестировать и легко дописывать. Так что, ещё раз:
play и только play решает на каких хостах что исполняется.
В этом разделе мы разобрались с противостоянием play и role. Теперь поговорим про отношения tasks vs role.
Таски и Роли
- hosts: somegroup pre_tasks: - some_tasks1: roles: - role1 - role2 post_tasks: - some_task2: - some_task3:Допустим, вам надо сделать foo. И выглядит это как foo: name=foobar state=present . Куда это писать? в pre? post? Создавать role?
… И куда делись tasks?
Мы снова начинаем с азов — устройство play. Если вы плаваете в этом вопросе, вы не можете использовать play как основу для всего остального, и ваш результат получается «шатким».
Устройство play: директива hosts, настройки самой play и секции pre_tasks, tasks, roles, post_tasks. Остальные параметры для play нам сейчас не важны.
Порядок их секций с тасками и ролями: pre_tasks , roles , tasks , post_tasks . Поскольку семантически порядок исполнения между tasks и roles не понятен, то best practices говорит, что мы добавляем секцию tasks , только если нет roles . Если есть roles , то все прилагающиеся таски помещаются в секции pre_tasks / post_tasks .
Остаётся только то, что семантически всё понятно: сначала pre_tasks , потом roles , потом post_tasks .
Но мы всё ещё не ответили на вопрос: а куда вызов модуля foo писать? Надо ли нам под каждый модуль писать целую роль? Или лучше иметь толстую роль подо всё? А если не роль, то куда писать — в pre или в post?
Если на на эти вопросы нет аргументированного ответа, то это признак отсутствия интуиции, то есть те самые «шаткие основы». Давайте разбираться. Сначала контрольный вопрос: Если у play есть pre_tasks и post_tasks (и нет ни tasks, ни roles), то может ли что-то сломаться, если я первую таску из post_tasks перенесу в конец pre_tasks ?
Разумеется, формулировка вопроса намекает, что сломается. Но что именно?
… Хэндлеры. Чтение основ открывает важный факт: все хэндлеры flush’атся автоматом после каждой секции. Т.е. выполняются все таски из pre_tasks , потом все хэндлеры, которые были notify. Потом выполняются все роли и все хэндлеры, которые были notify в ролях. Потом post_tasks и их хэндлеры.
Таким образом, если вы таску перетащите из post_tasks в pre_tasks , то, потенциально, вы выполните её до выполнения handler’а. например, если в pre_tasks устанавливается и конфигурируется веб-сервер, а в post_tasks в него что-то засылается, то перенос этой таски в секцию pre_tasks приведёт к тому, что в момент «засылания» сервер будет ещё не запущен и всё сломается.
А теперь давайте ещё раз подумаем, а зачем нам pre_tasks и post_tasks ? Например, для того, чтобы выполнить всё нужное (включая хэндлеры) до выполнения роли. А post_tasks позволит нам работать с результатами выполнения ролей (включая хэндлеры).
Въедливый знаток Ansible скажет нам, что есть meta: flush_handlers , но зачем нам flush_handlers, если мы можем положиться на порядок исполнения секций в play? Более того, использование meta: flush_handlers может нам доставить неожиданного с повторяющимися хэндлерами, сделать нам странные варнинги в случае использования when у block и т.д. Чем лучше вы знаете ансибл, тем больше нюансов вы сможете назвать для «хитрого» решения. А простое решение — использование натурального разделения между pre/roles/post — не вызывает нюансов.
И, возвращаемся, к нашему ‘foo’. Куда его поместить? В pre, post или в roles? Очевидно, это зависит от того, нужны ли нам результаты работы хэндлера для foo. Если их нет, то foo не нужно класть ни в pre, ни в post — эти секции имеют специальный смысл — выполнение тасок до и после основного массива кода.
Теперь ответ на вопрос «роль или таска» сводится к тому, что уже есть в play — если там есть tasks, то надо дописать в tasks. Если есть roles — надо делать роль (пусть и из одной task). Напоминаю, tasks и roles одновременно не используются.
Понимание основ Ансибла даёт обоснованные ответы на, казалось бы, вопросы вкусовщины.
Таски и роли (часть вторая)
Теперь обсудим ситуацию, когда вы только начинаете писать плейбуку. Вам надо сделать foo, bar и baz. Это три таски, одна роль или три роли? Обобщая вопрос: в какой момент надо начинать писать роли? В чём смысл писать роли, когда можно писать таски?… А что такое роль?
Одна из грубейших ошибок (я про это уже говорил) — считать, что роль — это как функция в библиотеке у программы. Как выглядит обобщённое описание функции? Она принимает аргументы на вход, взаимодействует с side causes, делает side effects, возвращает значение.
Теперь, внимание. Что из этого можно сделать в роли? Вызвать side effects — всегда пожалуйста, это и есть суть всего Ансибла — делать сайд-эффекты. Иметь side causes? Элементарно. А вот с «передать значение и вернуть его» — вот тут-то и нет. Во-первых, вы не можете передать значение в роль. Вы можете выставить глобальную переменную со сроком жизни размером в play в секции vars для роли. Вы можете выставить глобальную переменную со сроком жизни в play внутри роли. Или даже со сроком жизни плейбуки ( set_fact / register ). Но вы не можете иметь «локальные переменные». Вы не можете «принимать значение» и «возвращать его».
Из этого вытекает главное: нельзя на ansible написать что-то и не вызвать сайд-эффекты. Изменение глобальных переменных — это всегда side effect для функции. В Rust, например, изменение глобальной переменной — это unsafe . А в Ансибл — единственный метод повлиять на значения для роли. Обратите внимание на используемые слова: не «передать значение в роль», а «изменить значения, которые использует роль». Между ролями нет изоляции. Между тасками и ролями нет изоляции.
Итого: роль — это не функция.
Что же хорошего есть в роли? Во-первых, у роли есть default values ( /default/main.yaml ), во-вторых у роли есть дополнительные каталоги для складывания файлов.
Чем же хороши default values? Тем, что в пирамиде Маслоу довольно извращённой таблице приоритетов переменных у Ансибла, role defaults — самые неприоритетные (за вычетом параметров командной строки ансибла). Это означает, что если вам надо предоставить значения по-умолчанию и не переживать что они перебъют значения из инвентори или групповых переменных, то дефолты роли — это единственное правильное место для вас. (Я немного вру — есть ещё |d(your_default_here) , но если говорить про стационарные места — то только дефолты ролей).
Что ещё хорошего в ролях? Тем, что у них есть свои каталоги. Это каталоги для переменных, как постоянных (т.е. вычисляемых для роли), так и для динамических (есть такой то ли паттерн, то ли анти-паттерн — include_vars вместе с >->.yml .). Это каталоги для files/ , templates/ . Ещё, оно позволяет иметь роли свои модули и плагины ( library/ ). Но, в сравнении с тасками у playbook’и (у которой тоже всё это может быть), польза тут только в том, что файлы свалены не в одну кучу, а несколько раздельных кучек.
Ещё одна деталь: можно пытаться делать роли, которые будут доступны для переиспользования (через galaxy). После появления коллекций распространение ролей можно считать почти забытым.
Таким образом, роли обладают двумя важными особенностями: у них есть дефолты (уникальная особенность) и они позволяют структурировать код.
Возвращаясь к исходному вопросу: когда делать таски а когда роли? Таски в плейбуке чаще всего используются либо как «клей» до/после ролей, либо как самостоятельный строительный элемент (тогда в коде не должно быть ролей). Груда нормальных тасок в перемешку с ролями — это однозначная неряшливость. Следует придерживаться конкретного стиля — либо таски, либо роли. Роли дают разделение сущностей и дефолты, таски позволяют прочитать код быстрее. Обычно в роли выносят более «стационарный» (важный и сложный) код, а в стиле тасок пишут вспомогательные скрипты.
Существует возможность делать import_role как таску, но если вы такое пишете, то будьте готовы к объяснительной для собственного чувства прекрасного, зачем вы это хотите делать.
Въедливый читатель может сказать, что роли могут импортировать роли, у ролей может быть зависимость через galaxy.yml, а ещё есть страшный и ужасный include_role — напоминаю, мы повышаем навыки в базовом Ансибле, а не в фигурной гимнастике.
Хэндлеры и таски
Давайте обсудим ещё одну очевидную вещь: хэндлеры. Умение их правильно использовать — это почти искусство. В чём разница между хэндлером и таской?
Так как мы вспоминаем основы, то вот пример:
- hosts: group1 tasks: - foo: notify: handler1 handlers: - name: handler1 bar:У роли handler’ы лежат в rolename/handlers/main.yaml. Handler’ы шарятся между всеми участниками play: pre/post_tasks могут дёргать handler’ы роли, а роль может дёргать handler’ы из плей. Однако, «кросс-ролевые» вызовы handler’ов вызывают куда больший wtf, чем повтор тривиального handler’а. (Ещё один элемент best practices — стараться не делать повторов имён handler’ов).
Основное различие в том, что таска выполняется (идемпотентно) всегда (плюс/минус теги и when ), а хэндлер — по изменению состояния (notify срабатывает только если был changed). Чем это чревато? Например, тем, что при повторном запуске, если не было changed, то не будет и handler. А почему может быть так, что нам нужно выполнить handler когда не было changed у порождающей таски? Например, потому что что-то сломалось и changed был, а до хэндлера выполнение не дошло. Например, потому что сеть временно лежала. Конфиг поменялся, сервис не перезапущен. При следующем запуске конфиг уже не меняется, и сервис остаётся со старой версией конфига.
Ситуация с конфигом не решаемая (точнее, можно самим себе изобрести специальный протокол перезапуска с файловыми флагами и т.д., но это уже не ‘basic ansible’ ни в каком виде). Зато есть другая частая история: мы поставили приложение, записали его .service -файл, и теперь хотим его daemon_reload и state=started . И натуральное место для этого, кажется, хэндлер. Но если сделать его не хэндлером а таской в конце тасклиста или роли, то он будет идемпотентно выполняться каждый раз. Даже если плейбука сломалась на середине. Это совершенно не решает проблемы restarted (нельзя делать таску с атрибутом restarted, т.к. теряется идемпотентность), но однозначно стоит делать state=started, общая стабильность плейбуки возрастает, т.к. уменьшается количество связей и динамического состояния.
Ещё одно положительное свойство handler’а состоит в том, что он не засоряет вывод. Не было изменений — нет лишних skipped или ok в выводе — легче читать. Оно же является и отрицательным свойством — если опечатку в линейно исполняемой task’е вы найдёте на первый же прогон, то handler’ы будут выполнены только при changed, т.е. при некоторых условиях — очень редко. Например, первый раз в жизни спустя пять лет. И, разумеется, там будет опечатка в имени и всё сломается. А второй раз их не запустить — changed-то нет.
Отдельно надо говорить про доступность переменных. Например, если вы notify для таски с циклом, то что будет в переменных? Можно аналитическим путём догадаться, но не всегда это тривиально, особенно, если переменные приходят из разных мест.
… Так что handler’ы куда менее полезны и куда более проблемны, чем кажется. Если можно что-то красиво (без выкрутас) написать без хэндлеров лучше делать без них. Если красиво не получается — лучше с ними.
Въедливый читатель справедливо отмечает, что мы не обсудили listen , что handler может вызывать notify для другого handler’а, что handler может включать в себя import_tasks (который может делать include_role c with_items), что система хэндлеров в Ансибле тьюринг-полная, что хэндлеры из include_role прелюбопытнейшим образом пересекаются с хэндлерами из плей и т.д. — всё это явно не «основы»).
Хотя есть один определённый WTF, который на самом деле фича, и о котором надо помнить. Если у вас таска выполняется с delegate_to и у неё есть notify, то соответствующий хэндлер выполняется без delegate_to , т.е. на хосте, на котором назначена play. (Хотя у хэндлера, разумеется, может быть delegate_to тоже).
Отдельно я хочу сказать пару слов про reusable roles. До появления коллекций была идея, что можно сделать универсальные роли, которые можно ansible-galaxy install и поехал. Работает на всех ОС всех вариантов во всех ситуациях. Так вот, моё мнение: это не работает. Любая роль с массовым include_vars , поддержкой 100500 случаев обречена на бездны corner case багов. Их можно затыкать массированным тестированием, но как с любым тестированием, либо у вас декартово произведение входных значений и тотальная функция, либо у вас «покрыты отдельные сценарии». Моё мнение — куда лучше, если роль линейная (цикломатическая сложность 1).
Чем меньше if’ов (явных или декларативных — в форме when или форме include_vars по набору переменных), тем лучше роль. Иногда приходится делать ветвления, но, повторю, чем их меньше, тем лучше. Так что вроде бы хорошая роль с galaxy (работает же!) с кучей when может быть менее предпочтительна, чем «своя» роль из пяти тасок. Момент, когда роль с galaxy лучше — когда вы что-то начинаете писать. Момент, когда она становится хуже — когда что-то ломается, и у вас есть подозрение, что это из-за «роли с galaxy». Вы её открываете, а там пять инклюдов, восемь таск-листов и стопка when ‘ов… И в этом надо разобраться. Вместо 5 тасок линейным списком, в котором и ломаться-то нечему.
В следующих частях
- Немного про инвентори
- групповые переменные, host_group_vars plugin, hostvars. Как из спагетти связать Гордиев узел. Scope и precedence переменных, модель памяти Ansible. «Так где же всё-таки хранить имя пользователя для базы данных?».
- jinja: > — nosql notype nosense мягкий пластилин. Оно всюду, даже там, где вы его не ожидаете. Немного про !!unsafe и вкусный yaml.
- ansible
- спасибо за чтение
Info block effect что это





Ваша оценка отправлена, спасибо. Сообщите нам, пожалуйста, как можно сделать ответ вам еще более полезным.
Я не смог найти информацию для решения моей проблемы
Я нашел информацию, но так и не смог решить свою проблему
Контент предоставляет неверную информацию
Контент устарел
Изображения не четкие
Шаги не ясны
Были технические трудности с сайтом, например битые ссылки
Ответ слишком длинный, чтобы читать
Другие предложения: :
Пожалуйста, не указывайте личную информацию в своем комментарии.
Если вам нужна дополнительная поддержка, обратитесь в MSI с.
Hot_Line Задайте вопрос None
Спасибо за то, что дали нам знать.
Пожалуйста, не указывайте личную информацию в своем комментарии.
![]()
Благодарим за ваше мнение.
[Материнская плата] Настройка и ввод функций BIOS материнской платы
January 4,2024
Функции BIOS материнских плат MSI подробно описаны в руководстве пользователя. Чтобы найти руководство пользователя BIOS, выполните следующие действия.
- Материнские платы с одним и тем же набором микросхем не обязательно имеют одинаковый интерфейс и функции BIOS.
- Неправильные настройки BIOS могут привести к нестабильной работе компьютера или сбою загрузки! Действуйте с осторожностью!
- Если компьютер не загружается после изменения настроек, перейдите к шагу 7 раздела [Материнская плата] Что делать, если после включения отсутствует питание или на мониторе отсутствует изображение: очистка CMOS, восстановление настроек BIOS до значений по умолчанию с повторной загрузкой.
Поиск руководства пользователя BIOS
1. Зайдите на официальный веб-сайт MSI и нажмите значок Лупы в правом верхнем углу. Выполните поиск по названию модели, например “MEG Z590 ACE”, затем нажмите “Enter” для поиска.

2. Найдите нужную модель и нажмите Download («Скачать»)
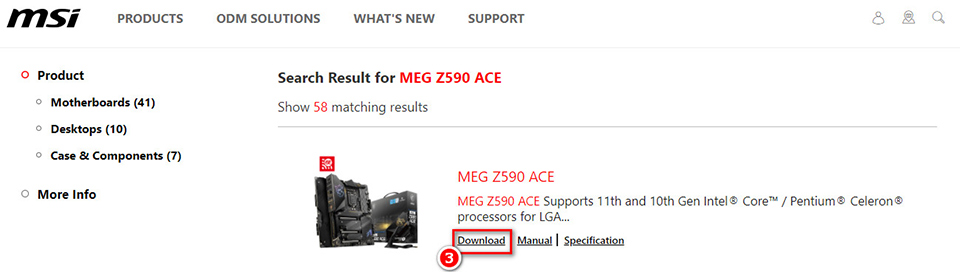
3. Нажмите Documents («Документация») и выберите Product Manual («Руководство пользователя»), чтобы загрузить руководство по эксплуатации материнской платы.
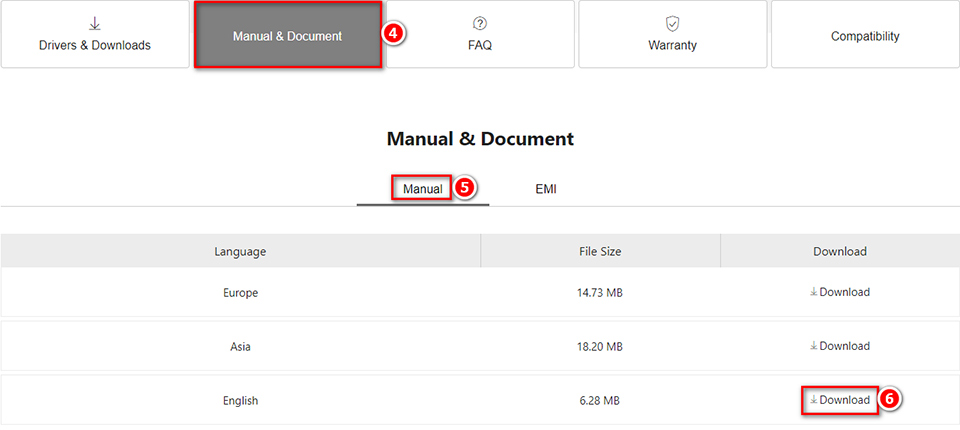
4. После загрузки PDF-файла дважды щелкните, чтобы открыть его, и найдите BIOS Setup («Настройка BIOS») в руководстве по продукту.
5. Ссылку на руководство пользователя BIOS для материнских плат этой серии можно найти в нижней части страницы инструкций по настройке горячих клавиш BIOS.

6. Нажмите на ссылку Руководства пользователя BIOS, чтобы войти и просмотреть подробные описания каждой функции.
Анонимизация данных на лету на основе шаблонов
Как работать с персональными данными в тестовых средах?
В продакшене часто требуется хранить и использовать чувствительные данные, включая персональные данные (ПД). Разработчикам в работе на тестовых окружениях иногда бывают нужны данные, максимально приближенные к реальным, уже имеющимся в продукте. Несмотря на то, что в хранении пользовательских данных всегда применяются лучшие практики, такие регламенты и законы как ФЗ «О защите персональных данных», HIPAA, HITECH, CPRA или GDPR требуют, чтобы любые персональные данные хранились и использовались только там, где это необходимо и были защищены или анонимизированы при передаче.
Есть разные способы решения этой проблемы. Например, строгое разделение таблиц в базе данных: в каких-то хранятся персональные данные, в каких-то нет. Таблицы с ПД можно пропускать при экспорте или заменять их искусственными данными в системах разработки. Минус такого подхода — система должна быть изначально спроектирована с учётом такого разделения данных. К тому же искусственные данные хранятся достаточно близко с реальными прототипами, что может вызывать вопросы с точки зрения безопасности.
Другой способ — генерировать «чистый» дамп на стороне продакшена, в котором персональные данные скрыты или заменены несуществующими данными, похожими по формату на реальные. Разработчики могут сразу импортировать его, а риск утечки ПД при этом становится гораздо ниже.
Именно на таком подходе и основан Datanymizer.
Фейкеры, анонимайзеры и обфускаторы — существует много инструментов с открытым исходным кодом для анонимизации данных. Они работают давно и весьма успешно. Так почему бы нам не создать ещё один? Только поддерживающий глобальные переменные, ограничения уникальности, встроенные правила и другие крутые функции.
Конечно же, у нас были свои особенные требования к этому инструменту. Мы не хотели, чтобы анонимайзеру приходилось брать «сырой» дамп и мутировать его. Вместо этого нужно было отдавать уже анонимизированный дамп, без доступа к реальным данным. Конфигурация, которая определяет, как именно данные реальной системы будут анонимизированы, должна храниться отдельно от этих данных.
Ну и наконец, мы хотели сделать инструмент более гибким, поэтому встроили шаблонизатор, с помощью которого можно сгенерировать любые данные: не только предустановленные, но и произвольного формата.
Datanymizer: ваш новый помощник, сохраняющий конфиденциальность данных
Datanymizer делает всё вышеперечисленное. Вы определяете конфигурацию, которая указывает, что делать (и не делать). Затем он выгружает данные непосредственно из вашей базы данных, применяя заданные правила. Ещё в него интегрирован движок шаблонов Tera, чтобы можно было синтезировать произвольный формат значений.
На выходе у вас получается анонимизированный SQL-дамп, записанный либо в файл, либо непосредственно в стандартный вывод, готовый к импорту с помощью родных инструментов базы данных.
Начало работы
Есть несколько способов установить pg_datanymizer. Выберите подходящий для вас.
Предварительно скомпилированный бинарный файл:
# Linux / macOS / Windows (MINGW and etc). Installs it into ./bin/ by default $ curl -sSfL https://raw.githubusercontent.com/datanymizer/datanymizer/main/cli/pg_datanymizer/install.sh | sh -s # Or more shorter way $ curl -sSfL https://git.io/pg_datanymizer | sh -s # Specify installation directory and version $ curl -sSfL https://git.io/pg_datanymizer | sh -s -- -b usr/local/bin v0.1.0 # Alpine Linux (wget) $ wget -q -O - https://git.io/pg_datanymizer | sh -s # Installs the latest stable release $ brew install datanymizer/tap/pg_datanymizer # Builds the latest version from the repository $ brew install --HEAD datanymizer/tap/pg_datanymizer $ docker run --rm -v `pwd`:/app -w /app datanymizer/pg_datanymizer README содержит пример конфигурации, которую можно использовать в качестве отправной точки.
Теперь вы можете вызвать Datanymizer для создания изменённого дампа ваших данных:
$ pg_datanymizer -f /tmp/dump.sql -c ./config.yml postgres://postgres:postgres@localhost/test_database Эти команды создают новый дамп-файл /tmp/dump.sql с нативным SQL файлом для базы PostgreSQL. Мы можете импортировать фейковые данные из этого дампа в новую базу данных с помощью команды:
$ psql -Upostgres -d new_database < /tmp/dump.sql Фильтры таблиц
Вы можете определить список таблиц, которые никогда не будут включаться в дамп. Например, для дампинга только public.markets и public.users data:
# config.yml #. filter: only: - public.markets - public.users А для игнорирования этих таблиц при создании дампа из остальных:
# config.yml #. filter: except: - public.markets - public.users Также вы можете управлять фильтрами данных и фильтрами схем независимо.
Глобальные переменные
Вы можете определить глобальные переменные доступные из любого шаблона правил:
# config.yml tables: users: bio: template: format: "User bio is >" age: template: format: > #. globals: var_a: Global variable 1 global_multiplicator: 6 Встроенные правила
Datanymizer имеет встроенную поддержку («правила») для определенных типов значений, а также pipeline, позволяющий генерировать значения, применяя цепочки существующих фильтров для одного поля. Другие фильтры также включают параметры email, ip, words, first_name, last_name, city, phone, capitalize, template, digit, random_number, password, datetime и другие.
Ограничения уникальности
Уникальность поддерживается правилами email, ip, phone, random_number.
Уникальность обеспечивается за счет отслеживания значений, которые были сгенерированы там, где требуется уникальность, и повторного генерирования любых, которые являются дубликатами.
Вы можете менять количество попыток параметром try_count. Это опциональное поле, количество по умолчанию зависит от правила.
Планы на будущее
Вот какие функции мы хотим добавить в следующих обновлениях:
Pre-filtering: например, если необходимо выдавливать не всех пользователей, а тех, которые соответствуют определенным критериям (например, 100 пользователей, в возрасте 27 лет и старше, по имени Александр), с поддержкой произвольных SQL-запросов для фильтрации. Генерация данных: если вам нужно не анонимизировать существующие данные, а генерировать синтетические, основанные на определенных правилах. Поддержка других RDBMS: сейчас Datanymizer поддерживает только базы PostgreSQL, но в будущем добавится mySQL и MariaDB. Присоединяйтесь к разработке Datanymizer и предлагайте свои идеи!
Оставить комментарий
3 years ago
Разные технологии для разных уровней (сборка через gulp)
Допустим, в моем проекте есть 2 уровня переопределения: "lib" и "project". На обоих уровнях присутствуют технологии "js" и "helper.js". Мне нужно, чтобы в итоговую сборку попали файлы "js" и "helper.js" из "project", и только "helper.js" из "lib". Т.е. что-то вроде этого:
const src = require('gulp-bem-src'); src( ['lib', 'project'] [< block: 'button' >], 'js', < config: < 'lib': < scheme: 'nested', techMap: ['helper.js'] >'project': < scheme: 'nested', techMap: ['js', 'helper.js'] >> > ) Можно ли такое реализовать в gulp? В документации ничего такого не нашел, даже в методологии такие кейсы не описываются. Есть, конечно, gulp-merge и другие способы объединить потоки в gulp, но они будут замедлять сборку, т.к. придется заново вызывать gulp-bem-src, он будет заново разрешать зависимости т.д..
Комментарии: 6
3 years ago
Когда использовать микс, а когда модификатор?
Здравствуйте. Использую бэм уже продолжительное время, но до сих пор иногда оказываюсь просто в растерянности в некоторых ситуациях Есть 2 кейса:
1. Первый кейс. У нас есть блок .contacts, который используется в header, footer и на странице контакты
.contacts .contacts__item .contacts__link Во всех 3-х случаях его элементы выглядят и позиционируются немного по разному. Для позиционирования я делаю микс
.contacts.header__contacts .contacts__item .contacts__link Но встает вопрос, как стилизовать элементы: Давать миксы header__item и header__link не вариант, т.к. в хэдере могут уже существовать эти классы вне контекста .contacts
1) Можно создать еще один пустой микс класс
.contacts.header__contacts.header-contacts .contacts__item.header-contacts__item .contacts__link.header-contacts__link Раньше я поступал именно так. Но мне все больше не нравится такой подход. Во-первых сам класс выглядит так будто пытается выдать себя за два. Во-вторых мы создаем новый блок просто ради того, чтобы задать косметические изменения, что как мне кажется не верно.
2) Можно делать кучу модификаторов для каждого элемента в отдельности, но тогда страшно представить сколько в проекте будет модификаторов, большинство из которых будет использоваться только 1 раз.
3) Можно сделать модификатор для блока и стилизовать каскадом
.contacts.contacts--theme--header.header__contacts .contacts__item .contacts__link .contacts--theme--header .contacts__link
Это вроде как противоречит идеям бэм, но мне кажется наиболее удачным решением.
2. Второй кейс. У нас есть базовый блок карточки
.card .card__img .card__inner .card__title .card__content .card__btn Допустим она используется в каталоге. Но так же на странице с портфолио, но выглядит немного иначе. Создавать пустой микс класс .portfolio-card мне кажется плохой практикой, т.к. мы привязываемся к контексту. А что если эта модифицированная карточка будет еще на какой-то странице? Тогда само слово portfolio уже будет ни к селу ни к городу. Микс portfolio__img , portfolio__inner и т.д. тоже не жизнеспособны, т.к. нам нужно менять элементы именно в контексте карточки.
Я пришел к тому, что лучше всего будет давать карточкам абстрактные модификаторы
.card.card--type--1 .card__img .card__inner .card__title .card__content .card__btn .card--type--1 .card__img
И стилизовать каскадом. Это дает нам полную модульность и свободу. Мы можем использовать модифицированные карточки где угодно в проекте. Более того, можно комбинировать модифицированные карточки с модификаторами элементов как угодно, например:
.card.card--type--1 .card__img.card__img--hover--green .card__inner.card__inner--color--red .card__title .card__content .card__btn .card--type--1 .card__img
Таким образом я прихожу к выводу, что миксы полезны в основном для позиционирования блока в контексте другого блока и совмещения стилей уже готовых независимых блоков используемых в проекте. А создавать их на лету, только для косметических изменений - бесполезно и даже вредно. А каскад же в данных случаях православен и полезен. И использовать его хочется все больше и больше, хотя он противоречит доктринам.
Был бы очень рад услышать аргументированную критику и ваши мысли на этот счет.