Как браузер рисует страницы
Как обрабатывается HTML, CSS и JS код перед тем, как станет веб-страницей.
Время чтения: 9 мин
Открыть/закрыть навигацию по статье
- Кратко
- Получение ресурсов, Fetching
- Парсинг, Parsing
- DOM
- Render Tree
- Глобальный и инкрементальный Layout
- «Грязные» элементы
- Порядок отрисовки
- Саша Беспоясов советует
- Что такое прогрессивный рендеринг (progressive rendering)?
Обновлено 8 марта 2023
Кратко
Скопировать ссылку «Кратко» Скопировано
Чтобы нарисовать на экране результат работы нашего кода, браузеру нужно выполнить несколько этапов:
- Сперва ему нужно скачать исходники.
- Затем их нужно прочитать и распарсить.
- После этого браузер приступает к рендерингу — отрисовке.
Каждый из процессов очень сложен, и мы не будем рассматривать их до мельчайших подробностей.
Мы лишь обратим внимание на те детали, которые необходимо знать фронтенд-разработчикам, чтобы лучше понимать, почему разные решения по-разному влияют на производительность и скорость отрисовки.
Начнём по порядку.
Получение ресурсов, Fetching
Скопировать ссылку «Получение ресурсов, Fetching» Скопировано
Ресурсы браузер получает с помощью запросов к серверу. В ответ он может получить как, например, данные в виде JSON, так и картинки, видео, файлы стилей и скриптов.
Самый первый запрос к серверу — обычно запрос на получение HTML-страницы (чаще всего index . html ).
В её коде содержатся ссылки на другие ресурсы, которые браузер тоже запросит у сервера:
Document 
DOCTYPE html> html lang="en"> head> link href="/style.css" rel="stylesheet"> title>Documenttitle> head> body> img src="/hello.jpg" alt="Привет!"> script src="/index.js"> script> body> html>В примере выше браузер запросит также:
- файл стилей style . css ;
- изображение hello . jpg ;
- и скрипт index . js .
Парсинг, Parsing
Скопировать ссылку «Парсинг, Parsing» Скопировано
По мере того как скачивается HTML-страница, браузер пытается её «прочитать» — распарсить.
DOM
Скопировать ссылку «DOM» Скопировано
Браузер работает не с текстом разметки, а с абстракциями над ним. Одна из таких абстракций, результат парсинга HTML-кода, называется DOM.
DOM (Document Object Model) — абстрактное представление HTML-документа, с помощью которого браузер может получать доступ к его элементам, изменять его структуру и оформление.
DOM — это дерево. Корень этого дерева — это элемент HTML, все остальные элементы — это дочерние узлы.
Для такого документа:
Hello Hello world
html> head> meta charset="utf-8"> title>Hellotitle> head> body> p class="text">Hello worldp> img src="/hello.jpg" alt="Привет!"> body> html>. получится такое дерево:
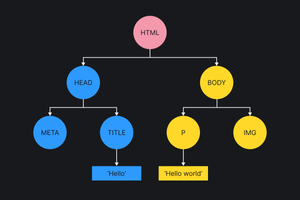
Пока браузер парсит документ и строит DOM, он натыкается на элементы типа , , , которые содержат ссылки на другие ресурсы.
Если ресурс неблокирующий (например, изображение), браузер запрашивает его параллельно с парсингом оставшейся части документа. Блокирующие ресурсы (например, скрипты) приостанавливают обработку до своей полной загрузки.
Мы можем указывать браузеру, как именно ему следует запрашивать некоторые ресурсы, например, скрипты. Это может быть полезно, когда в скрипте мы собираемся работать с элементами, которые находятся в разметке после тега :
// script.jsconst image = document.getElementById('image')// script.js const image = document.getElementById('image') body> script src="script.js"> script> img src="/hello.jpg" alt="Hello world" id="image"> body>В этом случае image = = = undefined , потому что браузер успел распарсить только часть документа до этого тега .
А в этом всё в порядке, изображение найдётся:
body> img src="/hello.jpg" alt="Hello world" id="image"> script src="script.js"> script> body>И в этом тоже порядок, атрибут defer скажет браузеру продолжать парсить страницу и выполнить скрипт потом:
body> script src="script.js" defer> script> img src="/hello.jpg" alt="Hello world" id="image"> body>CSSOM
Скопировать ссылку «CSSOM» Скопировано
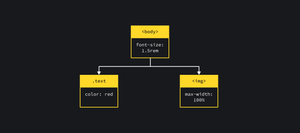
Когда браузер находит элемент , который указывает на файл стилей, браузер скачивает и парсит его. Результат парсинга CSS-кода — CSSOM.
CSSOM (CSS Object Model) — по аналогии с DOM, представление стилевых правил в виде дерева.
Для документа выше с такими стилями:
body font-size: 1.5rem;> .text color: red;> img max-width: 100%;>body font-size: 1.5rem; > .text color: red; > img max-width: 100%; >. получим такое дерево:
Чтение стилей приостанавливает чтение кода страницы. Поэтому рекомендуется в самом начале отдавать только критичные стили — которые есть на всех страницах и конкретно на этой. Так мы уменьшаем время ожидания, пока «страница загрузится».
Благодаря оптимизациям (например, сканеру предзагрузки) стили могут не блокировать чтение HTML, но они точно блокируют выполнение JavaScript, потому что в JS могут использоваться CSS-селекторы для выборки элементов.
Render Tree
Скопировать ссылку «Render Tree» Скопировано
После того как браузер составил DOM и CSSOM, он объединяет их в общее дерево рендеринга — Render Tree.
Render Tree — это термин, который используется движком WebKit, в других движках он может отличаться. Например, Gecko использует термин Frame Tree.
В итоге для нашего документа выше мы получим такое дерево:
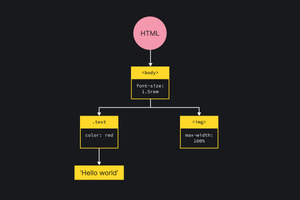
Обратите внимание, что в Render tree попадают только видимые элементы. Если бы у нас был элемент, спрятанный через display : none , он бы в это дерево не попал. Об этом подробнее мы ещё поговорим дальше.
Общая схема парсинга выглядит вот так:
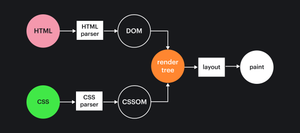
На первых шагах мы разбираемся с HTML и CSS, а затем объединяем их в Render Tree.
Вычисление позиции и размеров, Layout
Скопировать ссылку «Вычисление позиции и размеров, Layout» Скопировано
После того как у браузера появилось дерево рендеринга (Render Tree), он начинает «расставлять» элементы на странице. Этот процесс называется Layout.
Чтобы понимать, где какой элемент должен находиться и как он влияет на расположение других элементов, браузер рассчитывает размеры и положение каждого рекурсивно.
Расчёт начинается от корневого элемента дерева рендеринга, его размеры равны размеру вьюпорта. Далее браузер переходит поочерёдно к каждому из дочерних элементов.
Важно помнить, что Layout построен на поточной модели компоновки. Это значит, что если элементы не влияют на расположение и размеры других элементов, то их положение и размеры можно просчитать за один подход.
Именно поэтому при вёрстке макетов рекомендуется «находиться в потоке» — чтобы браузеру не приходилось несколько раз пересчитывать один и тот же элемент, так страница отрисовывается быстрее.
Глобальный и инкрементальный Layout
Скопировать ссылку «Глобальный и инкрементальный Layout» Скопировано
Глобальный Layout — это процесс просчёта всего дерева полностью, то есть каждого элемента. Инкрементальный — просчитывает только часть.
Глобальный Layout запускается, например, при изменении размера окна, потому что браузеру требуется подогнать всю страницу под новый размер экрана. Это очень дорогой процесс.
Инкрементальный Layout запускает пересчёт только «грязных» элементов.
«Грязные» элементы
Скопировать ссылку ««Грязные» элементы» Скопировано
Это те элементы, которые были изменены, и их дочерние элементы.
Если мы как-то поменяли блок, то браузер перерисует его и его детей, потому что их положение и размеры могут зависеть от родителя.
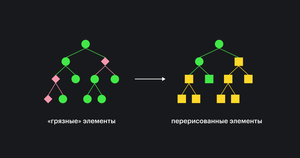
Дальше браузер приступает к, собственно, отрисовке.
Непосредственно отрисовка, Paint
Скопировать ссылку «Непосредственно отрисовка, Paint» Скопировано
Во время отрисовки (Paint) браузер наполняет пиксели на экране нужными цветами в зависимости от того, что в конкретном месте должно быть нарисовано: текст, изображение, цвет фона, тени, рамки и т. д.
Отрисовка тоже бывает глобальной и инкрементальной. Чтобы понять, какую часть вьюпорта надо перерисовать, браузер делит весь вьюпорт на прямоугольные участки. Логика тут та же, как и в Layout — если изменения ограничены одним участком, то пометится «грязным» и перерисуется лишь он.
Отрисовка — это самый дорогой процесс из всех, что мы уже перечислили.
Порядок отрисовки
Скопировать ссылку «Порядок отрисовки» Скопировано
Порядок отрисовки связан со стековым контекстом.
В общих чертах, отрисовка начинается с заднего плана и постепенно переходит к переднему:
- background — color ;
- background — image ;
- border ;
- children ;
- outline .
CPU и композитинг
Скопировать ссылку «CPU и композитинг» Скопировано
И Layout, и Paint работают за счёт CPU (central process unit), поэтому относительно медленные. Плавные анимации при таком раскладе невероятно дорогие.
Для плавных анимаций в браузерах предусмотрен композитинг (Compositing).
Композитинг — это разделение содержимого страницы на «слои», которые браузер будет перерисовывать. Эти слои друг от друга не зависят, из-за чего изменение элемента в одном слое не затрагивает элементы из других слоёв, и перерисовывать их становится не нужно.
Именно из-за разнесения элементов по разным композиционным слоям свойство transform не так сильно нагружает браузер. Поэтому чтобы анимации не тормозили, их рекомендуется делать с применением transform и opacity .
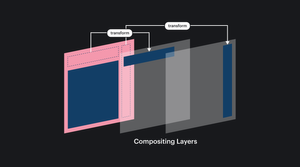
Применение таких свойств, как, например, transform , «выносит» элемент на отдельный композитный слой, где положение элемента не зависит от других и не влияет на них.
Чтобы узнать, вызывает ли конкретное CSS-свойство композитинг и перерисовку в браузере, воспользуйтесь инструментом «CSS Triggers».
Перерисовка, Reflow (relayout) и Repaint
Скопировать ссылку «Перерисовка, Reflow (relayout) и Repaint» Скопировано
Процесс отрисовки — циклический. Браузер перерисовывает экран каждый раз, когда на странице происходят какие-то изменения.
Если, например, в DOM-дереве добавился новый узел, или изменился текст, то браузер построит новое дерево рендеринга и запустит вычисление позиции и отрисовку заново.
Один цикл обновления — это animation frame.
Зная «расписание отрисовки» браузера, мы можем «предупредить» его, что хотим запустить какую-то анимацию на каждый новый фрейм. Это можно сделать с помощью request Animation Frame ( ) .
const animate = () => // Код анимации>const animate = () => // Код анимации >Эта функция запускает новый кадр анимации: обновляет какое-то свойство или перерисовывает canvas.
Если мы хотим добиться плавной анимации, используя функцию выше, мы должны обеспечить в среднем 60 обновлений экрана за секунду (60 fps — frames per second).
Это можно сделать топорно, через интервал:
// 60 раз в 1000 миллисекунд, приблизительно 16 мс.const intervalMS = 1000 / 60setInterval(animate, intervalMS)// 60 раз в 1000 миллисекунд, приблизительно 16 мс. const intervalMS = 1000 / 60 setInterval(animate, intervalMS)Либо использовать window . request Animation Frame ( ) :
window.requestAnimationFrame(animate)window.requestAnimationFrame(animate)Интервалы не всегда запускаются в нужный момент. set Interval ( ) не учитывает, на какой стадии отрисовки находится страница, и в итоге кадры отрисовки могут быть рваными или дёрганными.
С интервалом анимация может быть рваной, потому что перерисовка может быть запущена в неподходящее время.
А если вкладка была неактивна, то интервал может «попытаться догнать время», и несколько кадров запустятся разом:

С request Animation Frame ( ) анимация плавнее, потому что браузер знает, что в следующем фрейме надо запустить новый кадр анимации.
Она не гарантирует, что анимация будет запущена строго раз в 16 мс, но значение будет достаточно близким.

На практике
Скопировать ссылку «На практике» Скопировано
Саша Беспоясов советует
Скопировать ссылку «Саша Беспоясов советует» Скопировано
Для динамики всегда используйте transform и opacity , избегайте изменения остальных свойств (типа left , top , margin , background и так далее).
Таким образом вы дадите браузеру возможность оптимизировать отрисовку, отчего страница станет отзывчивее.
Для анимаций, которые необходимо перерисовывать на каждый фрейм, используйте request Animation Frame ( ) .
Это сделает тяжёлую анимацию менее рваной.
На собеседовании
Скопировать ссылку «На собеседовании» Скопировано
Что такое прогрессивный рендеринг (progressive rendering)?
Скопировать ссылку «Что такое прогрессивный рендеринг (progressive rendering)?» Скопировано
Скопировать ссылку «Марина Дорошук отвечает» Скопировано
Чтобы понять что такое progressive rendering, нужно понимать отличие client-side rendering от server-side rendering.
При client-side rendering (CSR) контент отрисовывается на стороне клиента (в браузере). Такой подход используется в React, когда браузеру отсылается практически пустой HTML-документ, а потом запускается скрипт, который генерирует HTML в указанном скрипту теге. Как правило это . Пользователь будет видеть пустую страницу, пока JS-файл полностью не загрузится.
При server-side rendering (SSR) HTML-разметка генерируется на сервере, отсылается браузеру и после этого отрисовывается на клиенте. Пользователь увидит контент сразу же, но не сможет взаимодействовать со страницей, пока не загрузится JS-файл.
При использовании прогрессивного рендеринга, кусочки HTML генерируется на сервере и отсылаются браузеру в порядке их приоритетности. То есть, элементы с самым высоким приоритетом (например , фон, главная интерактивная часть страницы) генерируются на сервере, отсылаются браузеру и отрисовываются в первую очередь. Это позволяет пользователю увидеть самый важный контент как можно скорее, не дожидаясь полной загрузки всего контента. То есть, progressive rendering что-то среднее между client-side rendering и server-side rendering.
Техники реализации прогрессивного рендеринга:
- Ленивая загрузка (Lazy Loading). Загрузка контента по мере необходимости. Например, если страница достаточно большая, не нужно загружать изображения вне вьюпорта. Загрузка изображения стартует за некоторое время до того как она появится во вьюпорте. Эту же технику можно использовать для загрузки контента изначально скрытых элементов. Например, можно загрузить контент закрытого меню когда пользователь наводит курсор на кнопку открытия.
- Приоритизация контента. Например, не загружать изначально все CSS-стили. Добавлять в загрузку только тех стилей, которые нужны для текущей видимой области HTML-документа. Остальные стили можно добавить в .
Что происходит, когда вы вбиваете доменное имя в браузере
Читатели нашего блога очень любят разборы задач с IT-собеседований. Сегодня мы решили рассмотреть еще один популярный кейс и ответить на вопрос «Что происходит, когда вы вбиваете адрес сайта в браузере?».
Пошаговый рассказ о том, что делает браузер, основан на статье «What happens when», опубликованной на Гитхабе. Мы сократили источник, убрав технические сложности, дополнили его примерами из жизни и небольшими схемами, чтобы разобраться смог каждый новичок.
Давайте представим, что вы решили ввести адрес REG.RU в поисковую строку. Что произойдет дальше?
Когда вы нажмете клавишу «R» (первую букву сайта), браузер получит команду и начнет предлагать вам варианты для автоподстановки. Они могут быть разными, например, популярные сайты, начинающиеся с «R» (RUTUBE, Rambler), самые посещаемые вами страницы или сайты из закладок.
Воспользовавшись подсказкой от браузера или напечатав адрес сайта полностью, вы нажимаете на «Enter». А дальше…
Начинается поиск сервера
…немного теории. Чтобы пользователь смог увидеть страницы сайта в любое время дня и ночи из любого уголка света, владелец сайта подключает хостинг. Ведь сайт — это набор файлов, который хранится на сервере.
Как только вы вводите доменное имя, браузер должен узнать, к какому серверу обратиться за данными.
В мире интернета адрес сайта называется IP-адресом. И «айпи» есть абсолютно у каждого сервера. Например, IP-адрес сервера, на котором расположен домен сайта REG.RU, — 194.58.116.31. Узнать его можно, используя специальные сервисы. У нас тоже есть такой. С его помощью можете «вычислить по айпи» любой сайт. В качестве примера мы покажем, какие IP у домена YANDEX.RU. Спойлер — очень красивые.
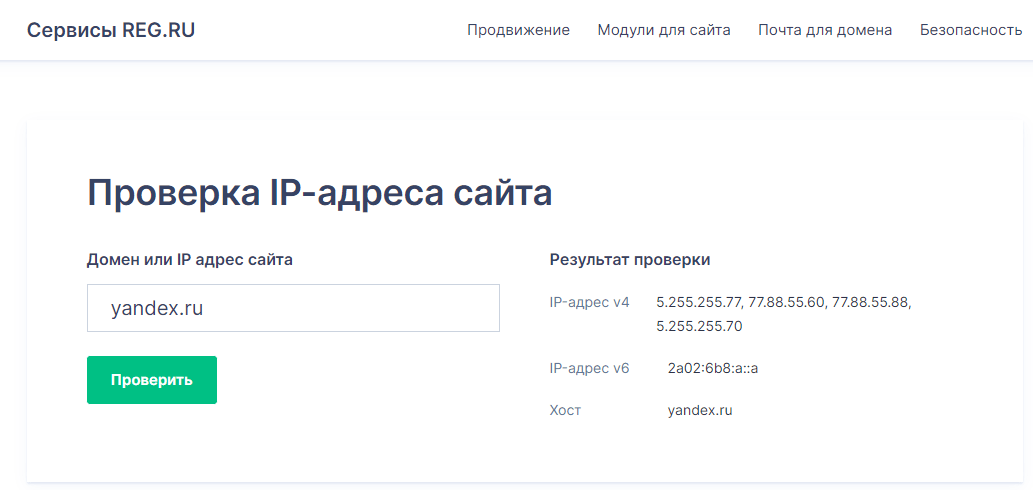
Эти числа и точки можно сравнить с геолокацией. Но разве вы ходите в гости к другу или отправляете посылку, используя геолокацию? Гораздо удобнее использовать почтовый адрес. Для этого придумали систему DNS — Domain Name Service.
Если коротко, DNS — это огромная таблица с данными о сайтах, которую можно сравнить с телефонной книгой. Хочешь позвонить Ване → нажми на его профиль в телефонной книге, за которым закреплен номер +7 999 999 99 99. Хочешь попасть на сайт Вани → введи в поисковую строку домен, за которым закреплен IP-адрес 99.99.99.99.
С теорией разобрались, можем возвращаться к нашему «Что происходит, когда…». Как только браузер отправил запрос, он должен понять, какой именно IP у сервера, на котором хранится сайт.
Сначала браузер смотрит, посещали вы этот сайт раньше или нет. А дальше есть два сценария.
1 вариант. Если посещали, браузер возьмет айпи из истории. На языке наших примеров — если почтальон доставляет вам посылки на дом каждый день, он прекрасно запомнит и дорогу к вашему дому.
2 вариант. Если же вы не посещали сайт, браузер начнет просматривать IP в конфигурационных файлах вашей операционной системы (ОС).
Если в настройках не найдется нужной информации, браузер начнет просматривать недавние адреса уже через ваш роутер.
Если нужной информации не окажется и там, браузер перестанет играть в Шерлока Холмса и отправит запрос на DNS-сервер, на котором 100% есть нужная информация. Кстати, большая часть серверов находится в Северной Америке. Но чтобы вам не приходилось минутами или часами сидеть в ожидании, когда же откроется сайт, по миру сделаны копии DNS. В России, например, копии расположены в:
- Москве,
- Санкт-Петербурге,
- Новосибирске,
- Ростове-на-Дону,
- Екатеринбурге.
Итак, браузер (aka грозный школьник из мемов) вычислил сайт по IP. Что же дальше?
Запрос отправляется и обрабатывается на сервере
Дальше браузер отправляет запрос серверу в духе «Привет, я знаю, что на твоем сервере есть файлы сайта REG.RU. Дай, пожалуйста».
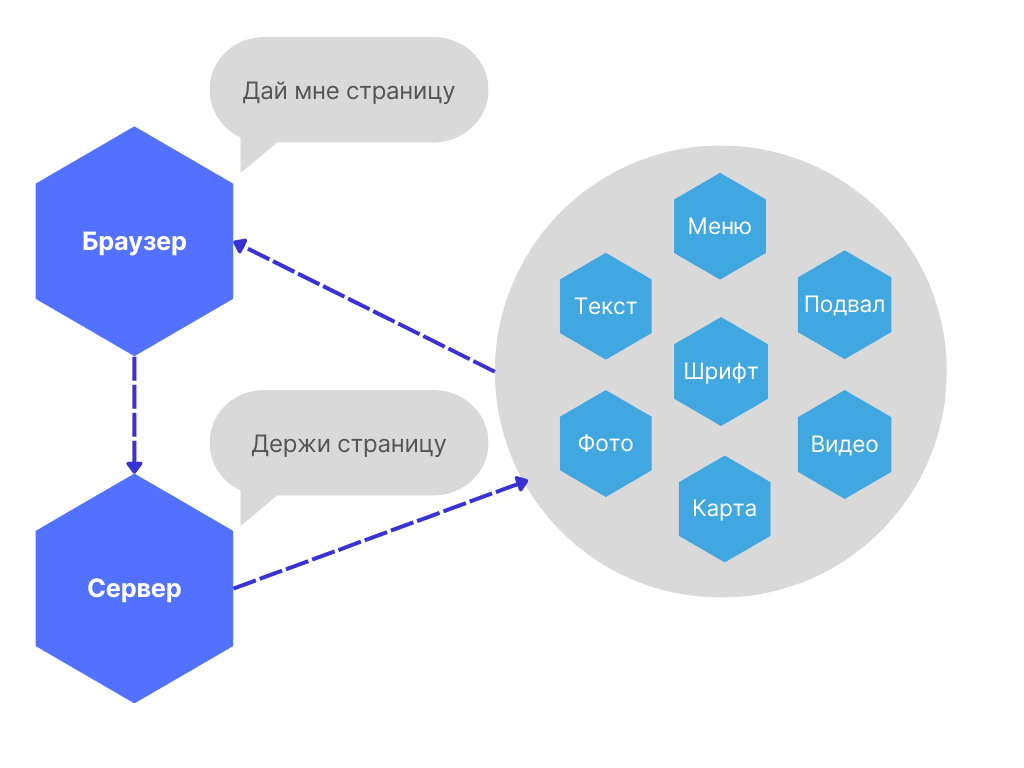
Но, даже если сервер знает об IP-адресе сайта, он не спешит передавать ему ценные данные. Чтобы было безопасно и никто не перехватил данные (как сайта, так и пользователя), браузер и сервер договариваются шифровать путь, по которому обмениваются информацией. Возможно это благодаря протоколу HTTPS и SAN или SSL-сертификату. О них подробнее рассказали в этой статье.
Как только все формальности соблюдены, сервер отвечает браузеру «Да, сейчас всё отправлю».
Данные отправляются в браузер
Согласившись передать данные, сервер обрабатывает и готовит данные к отправке. Для этого он смотрит, какие серверные программы отвечают за нужный сайт и другие составляющие страницы.
На этом шаге отправляется контент для отображения веб-страницы: информация о типе сжатия данных, способах кэширования, файлы cookie, которые нужно записать, и другие данные.
Чтобы обмен данными был быстрым, используют небольшие пакеты (в пределах 8 КБ). Каждый из пакетов пронумерован. Благодаря этому можно отследить последовательность и объем полученных данных браузером. Если что-то потерялось, браузер говорит серверу: «У меня потерялись пакеты, отправь их еще раз».

Браузер рендерит страницу
Итак, браузер получил все нужные пакеты. Теперь нужно собрать пазл из разложенного по пакетам контента в единую картинку, чтобы отобразить сайт на экране пользователя. Этот процесс называется рендерингом, рассказываем подробнее.
Когда браузер загружает HTML-код страницы, он строит на основании него объектную модель документа (Document Object Model или сокращенно DOM).
Упрощенно, в процессе рендеринга браузер выполняет два основных шага:
- анализирует HTML-документ, чтобы определить то, что в конечном итоге нужно отобразить на странице;
- выполняет отрисовку дополнительных элементов: картинок, таблиц, стилей и так далее.
Из всех этих файлов и строится DOM-модель.
Параллельно с этим сайт кешируется — на компьютер пользователя (как правило) сохраняется часть файлов сайта (статичные файлы), чтобы при следующем посещении не загружать их заново и быстрее отобразить пользователю содержимое страницы.
Когда кажется, что работа завершена, браузер и сервер продолжают взаимодействовать. Например:
- подгружать страницы, на которые переходят с этого сайта (прием используется для эффекта моментальный загрузки);
- записывать что-то в cookie;
- подгружать видео или музыку;
- анализировать, что пользователь делает на странице, и собирать эти данные.
По мере загрузки страницы браузер и сервер продолжают обмениваться между собой информацией, пока не завершится рендеринг — то есть пока каждый файл с сервера полностью не отобразится на загруженной странице.
Удивительно, какое большое количество шагов выполняется всего за пару секунд.
Мы же напомним, что время, потраченное пользователем на ожидание открытия сайта прямо влияет число отказов — закрытие сайта. Чем быстрее загружается сайт, тем скорее посетитель может воспользоваться его функциями — написать в поддержку, подписаться на рассылку или приобрести ваш товар. Поэтому, если вы владелец онлайн-проекта, выбирайте для него надежный и быстрый хостинг.
Как браузер рендерит страницу

Есть некоторые веб-разработчики, которые не заботятся о структуре кода HTML или игнорируют количество переопределяемых правил CSS просто потому, что они не знают о некоторых понятиях, которые мы увидим ниже.
Понимание концепций и процессов, используемых браузером для рендеринга веб-страницы, действительно важно, когда мы работаем над проектами, где производительность и пользовательский опыт имеют решающее значение.
DOM (Document Object Model) и CSSOM (CSS Object Model)
Сервер доставляет фрагмент HTML-кода, который анализируется браузером, и создается дерево. Это дерево называется DOM . Кроме того, браузер также получает инструкции CSS, которые анализируются, и это генерирует другое дерево, называемое CSSOM .

Render Tree (Дерево рендера)
После завершения двух процессов синтаксического анализа и определения DOM и CSSOM браузер создает дерево рендера. Дерево рендера — это другое дерево, хранящееся внутри браузера и используемое для представления визуальных элементов. Элементы внутри игнорируются, а также элементы, определенные с display: none . Однако стоит помнить, что элементы со свойством visibility: hidden по-прежнему являются частью дерева.
Как только рендер дерева завершен, браузер может выполнить процесс reflow (перекомпоновки) и repaint (перерисовки).
Процесс, используемый браузером для позиционирования элементов на экране, называется Reflow .
Этот процесс выполняется всегда, когда элементом DOM манипулируют, например, при изменении любого CSS правила положения или геометрии элемента, а также при изменении размера окна браузера. Процесс перекомпоновки выполняется для дочерних элементов, предков и элементов каждого элемента, которые появляются после него в DOM, после того, как ему необходимо пересчитать стили на основе целевого элемента.
Также известна как redraw . Repaint — это имя процесса, используемого браузером, когда ему нужно обновить какой-то стиль, который не относится к макету. Другими словами стили, не связанные с положением, шириной или высотой. Примером может служить манипулирование цветом фона.
Подход к снижению нежелательных эффектов, вызванных перекомпоновками и перерисовками, заключается в уменьшении количества запросов, сделанных информацией о стилях, избегая добавления или удаления элементов, обновлений или анимаций в DOM, изменения размера окон, изменения размера шрифта и ненужной прокрутки страницы.
Таким образом, перед выполнением DOM-манипуляций убедитесь, что нет альтернативного способа решения этой проблемы.
Как браузер рендерит веб-страницу

Цель статьи, если я собираюсь создавать быстрые и надежные веб-сайты, мне нужно действительно понимать механику каждого шага, который браузер выполняет для отображения веб-страницы, чтобы каждый шаг был обдуман и оптимизирован во время разработки. Этот пост представляет собой краткое изложение моих знаний о процессе отображения страниц на довольно высоком уровне.
Много идей основано на фантастическом (и БЕСПЛАТНОН!) курсе по оптимизации производительности веб-сайта Website Performance Optimization Ilya Grigorik и Cameron Pittman на Udacity. Я очень рекомендую это посмотреть.
Также очень полезной оказалась статья Пола Айриша и Тали Гарсиэль How Browsers Work: Behind the scenes of modern web browsers. Хотя эта статья 2011 года, но многие основы работы браузеров остаются актуальными до сих пор.
И так, поехали. Процесс отображения страниц можно разбить на следующие основные этапы:
- Начало разбора HTML
- Получение внешних ресурсов
- Разбор CSS и создание CSSOM
- Выполнение JavaScript
- Объединение DOM и CSSOM, для построения дерево рендеринга
- Расчет макета и отрисовка результата
1. Начало разбора HTML
Когда браузер начинает получать данные HTML страницы по сети, он немедленно запускает свой синтаксический анализатор parser для преобразования HTML в объектную модель документа (DOM) Document Object Model (DOM).
Объектная модель документа (DOM) – это представление данных объектов, которые составляют структуру и содержимое документа в Интернете.
Первый шаг этого процесса синтаксического анализа – разбить HTML на токены, которые представляют начальные теги (start tags), конечные теги (end tags) и их содержимое (contents). Из этого он строит DOM.

2. Получение внешних ресурсов
Когда парсер встречает внешний ресурс, такой как файл CSS или JavaScript, он пытается, получить его. Синтаксический анализатор будет продолжать работу по мере загрузки файла CSS, но он заблокирует рендеринг до тех пор, пока файл не будет загружен и проанализирован (подробнее об этом чуть позже).
Файлы JavaScript немного отличаются – по умолчанию они так же блокируют синтаксический анализ HTML, на время загрузки. Но у них есть два атрибута, которые могут быть добавлены в теги сценария, чтобы изменить это: defer и async. Оба позволяют синтаксическому анализатору продолжать работу, пока файл JavaScript загружается в фоновом режиме. Они отличаются друг от друга то, как они выполняются. Подробнее об этом тоже немного ниже, но вкратце:
defer означает, что выполнение файла будет отложено до завершения синтаксического анализа документа. Если несколько файлов имеют атрибут defer, то они будут выполняться в том порядке, в котором они были обнаружены в HTML.
async означает, что файл будет выполнен, как только он загрузится, это может быть во время или после процесса синтаксического анализа, и поэтому порядок, в котором выполняются асинхронные сценарии, не может быть гарантирован.
Предварительная загрузка ресурсов
Кроме того, современные браузеры будут продолжать сканировать HTML-код, пока анализатор блокирован, и «смотреть вперед» на то, какие внешние ресурсы появляются, а затем загружать их предположительно. То, как они это делают, варьируется в зависимости от браузера, поэтому нельзя полагаться на то, что они будут вести себя определенным образом. Чтобы пометить ресурс как важный и, следовательно, с большей вероятностью он должен быть загруженным на ранней стадии процесса рендеринга, можно использовать тег ссылки с rel = “preload”.

3. Разбор CSS и создание CSSOM
Возможно, вы слышали о DOM, но слышали ли вы о CSSOM (CSS Object Model) (объектной модели CSS)? До того, как я начал исследовать эту тему, я об этом ни чего не знал!
Объектная модель CSS (CSSOM) – это карта всех селекторов CSS и соответствующих свойств для каждого селектора в форме дерева с корневым узлом, родственником, потомком, дочерним элементом и другими отношениями. CSSOM очень похож на объектную модель документа (DOM). Оба они являются частью пути рендеринга, который представляет собой серию шагов, которые должны пройти для правильного рендеринга веб-сайта.
CSSOM вместе с DOM используется для построения дерева рендеринга, которое, в свою очередь, используется браузером для компоновки и раскраски веб-страницы.
Подобно файлам HTML и DOM, когда файлы CSS загружаются, они должны быть проанализированы и преобразованы в дерево – на этот раз CSSOM. Он описывает все селекторы CSS на странице, их иерархию и их свойства.
Чем CSSOM отличается от DOM, так это тем, что он не может быть построен постепенно, поскольку правила CSS могут перезаписывать друг друга в разных точках из-за specificity (порядка применения свойства). Вот почему загрузка CSS блокирует рендеринг, поскольку до тех пор, пока весь CSS не будет проанализирован и не будет построен CSSOM, браузер не может знать, где и как разместить каждый элемент на экране.

4. Выполнение JavaScript
Как и когда ресурсы JavaScript будут загружены, определяет, в какой-то момент они будут проанализированы, скомпилированы и выполнены. В разных браузерах для выполнения этой задачи используются разные механизмы JavaScript. Анализ JavaScript может быть дорогостоящим процессом с точки зрения ресурсов компьютера, в большей степени, чем другие типы ресурсов, поэтому его оптимизация так важна для достижения хорошей производительности. Прочтите этот фантастический пост, чтобы подробнее узнать, как работает движок JavaScript.
События загрузки
После того, как синхронно загруженный JavaScript и DOM будут полностью проанализированы и готовы, будет сгенерировано событие document.DOMContentLoaded. Для любых сценариев, которым требуется доступ к DOM, например, для управления им или прослушивания событий взаимодействия с пользователем, рекомендуется сначала дождаться этого события перед выполнением сценариев.
document.addEventListener('DOMContentLoaded', (event) => < // You can now safely access the DOM >);После того, как все остальное, например асинхронный JavaScript, изображения и т. д., завершили загрузку, запускается событие window.load.
window.addEventListener('load', (event) => < // The page has now fully loaded >);
5. Объединение DOM и CSSOM, для построения дерево рендеринга
Дерево рендеринга представляет собой комбинацию DOM и CSSOM и представляет все, что будет отображаться на странице. Это не обязательно означает, что все узлы в дереве рендеринга будут визуально присутствовать, например узлы со стилями opacity: 0 или visibility: hidden будут включены и могут быть прочитаны программой чтения с экрана и т. д., тогда как те, которые настроены на display: none будет исключены. Кроме того, такие теги, как , не содержащие визуальной информации, всегда будут пропущены.
Как и в случае с движками JavaScript, разные браузеры имеют разные механизмы рендеринга.

6. Расчет макета и отрисовка результата
Теперь, когда у нас есть полное дерево рендеринга, браузер знает, что рендерить, но не знает, где рендерить. Следовательно, необходимо рассчитать макет страницы (то есть положение и размер каждого узла). Механизм рендеринга проходит дерево рендеринга, начиная с вершины и идя вниз, вычисляет координаты, в которых должен отображаться каждый узел.
Как только это будет сделано, последний шаг – используя эту информацию о макете отрисовать пиксели на экране.
И вуаля! В конце концов, у нас есть полностью отрисованная веб-страница!