Как увеличить в размере boxplot

Как мне сделать чтобы эти надписи не слипались можно ли как-то в размере увеличить? В датасете просто много колонок. И вот 2 этих значения на боксплоте где только минимальное значение и аномалии показаны это как понять
Отслеживать
задан 5 окт 2022 в 22:35
51 7 7 бронзовых знаков
код свой в вопросе приведите, если хотите конкретного ответа. код должен быть в текстовом виде.
6 окт 2022 в 5:05
что касается двух боксов на графике, которые слились в одну линию — нужно смотреть исходные данные. либо там мало значимых данных, либо у них действительно такое странное распределение.
7 окт 2022 в 13:50
@strawdog Да наверное там и то и другое судя по точкам этим сверху — и мало данных и распределены в ноль и вверх туда отдельными выбросами, вообще без промежуточных значений.
7 окт 2022 в 13:58
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Вы можете не только увеличить размер холста, но и управлять метками по осям. например, развернуть их на 90 градусов:
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns df = sns.load_dataset("titanic") df["deck"] = df["deck"].apply(lambda x: x*15) ax = sns.boxplot(data=df, y="fare", x="deck", hue="deck", dodge=False) ax.set_xticklabels(ax.get_xticklabels(), rotation=90) plt.tight_layout() plt.show() Как рисовать диаграммы в Seaborn

Начинающие аналитики могут смело класть эту шпаргалку в закладки, а мы приглашаем вас под кат за диаграммами и кодом, пока начинается наш курс по анализу данных. Для удобства мы сократили текст и перенесли его часть в комментарии, ближе к нужным строкам кода.
Благодаря возможности настроить каждую деталь диаграммы многие курсы для начинающих посвящены отображению данных в Matplotlib. Но я увязла во всей документации, обсуждениях в сообществе и множестве способов отрисовать простые диаграммы. И нашла Seaborn.
Seaborn — это лаконичный интерфейс к Matplotlib для создания и оформления статистических диаграмм из наборов данных Pandas. Читая эту статью, лучше иметь общее представление о figure, axes и axis Matplotlib.
Для примера воспользуемся набором данных об автомобилях от Kaggle под лицензией Open database. Код ниже импортирует необходимые библиотеки, устанавливает стиль и загружает набор данных.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns sns.set_style('darkgrid') sns.set(font_scale=1.3) cars = pd.read_csv('edited_cars.csv')Элементы Seaborn делятся на две группы: оси и диаграммы.
- Оси имитируют Matplotlib и с помощью параметра ax могут объединяться в поддиаграммы. Они возвращают объект axes и используют обычные функции стилизации Matplotlib.
- Диаграммы управляют диаграммой, создать можно только диаграммы с какими-то значениями и связанные поддиаграммы. Они не поддерживают параметр ax и возвращают объекты FacetGrid, PairGrid или JointGrid. Используют разные стили и кастомизацию входных данных.
Изучение отношений между числовыми столбцами
Значения числовых функций — это непрерывные данные или числа. Первые визуализации будут матричными. Чтобы отобразить все попарные распределения на одной диаграмме, в них передаётся весь фрейм данных.
1. Парные диаграммы
Pairplot для сравнения распределения пар числовых переменных создаёт сетку точечных диаграмм. Он также содержит гистограмму для каждой функции в диагональных прямоугольниках.
# Функции: sns.pairplot() # диаргамма.sns.pairplot(cars);Стоит обратить внимание на:
- Диаграммы рассеяния, показывающие положительные линейные отношения (когда x увеличивается, увеличивается y), либо отрицательные (когда x увеличивается, y уменьшается).
- Гистограммы в диагональных прямоугольниках, показывающие распределение конкретных признаков.
На парной диаграмме обведённые диаграммы показывают очевидную линейную зависимость. Диагональ указывает на гистограммы каждого признака; левый треугольник парной диаграммы — зеркальное отражение правого треугольника.
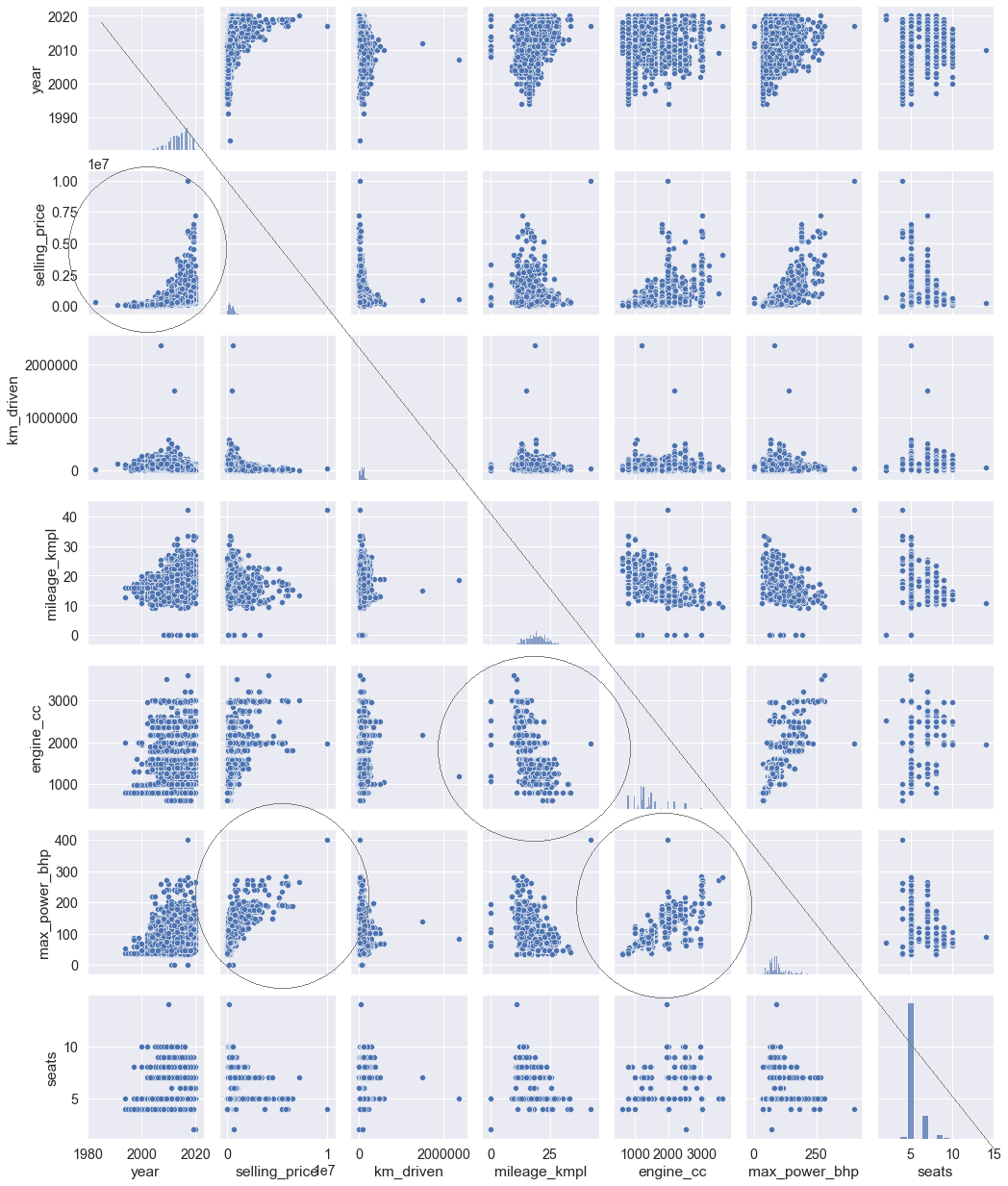
sns.pairplot( data=cars, aspect=.85, hue='transmission'); # hue='cat_col' подсвечивает указанную категорию другим цветом.
2. Тепловая карта
Тепловая карта — графическое представление значений в сетке цветовой кодировкой. Нанесённые значения — это коэффициенты корреляции пар, отражающие меру линейных отношений, поэтому диаграмма идеальна для пары. Тепловая карта отображает значения с помощью цвета, тогда как парная диаграмма показывает интуитивно понятные тенденции данных.
# Функции: sns.heatmap() # оси.# Сначала запускаем df.corr(), чтобы получить таблицу коэффициентов корреляции: cars.corr()
Эту таблицу называют матрицей корреляций. Эта таблица не очень понятна, поэтому с помощью sns.heatmap() отрисуем тепловую карту:
sns.set(font_scale=1.15) plt.figure(figsize=(8,4)) sns.heatmap( cars.corr(), cmap='RdBu_r', # задаёт цветовую схему annot=True, # рисует значения внутри ячеек vmin=-1, vmax=1); # указывает начало цветовых кодов от -1 до 1.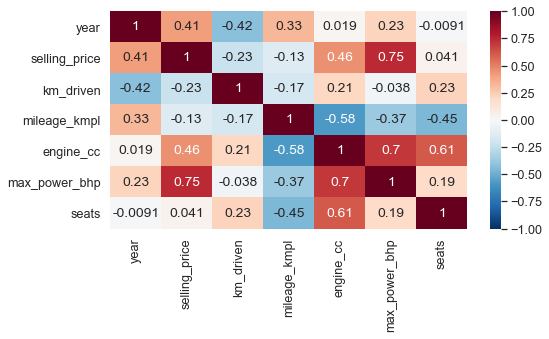

3. Диаграмма рассеяния
Диаграмма рассеяния показывает взаимосвязь между двумя числовыми признаками с помощью точек, показывающих движение этих переменных вместе.
# Функции: sns.scatterplot() # оси. sns.relplot(kind='line') # диаргамма. # Функции с линией регрессии: sns.regplot() # оси. sns.lmplot() # диаргамма.# Покажем объём двигателя и пробег автомобиля с помощью sns.scatterplot(x='num_col1', y='num_col2', data=df) sns.set(font_scale=1.3) sns.scatterplot( x='engine_cc', y='mileage_kmpl', data=cars) plt.xlabel( 'Engine size in CC') plt.ylabel( 'Fuel efficiency') 
Функция regplot рисует диаграмму рассеяния с линией регрессии, показывающей тенденцию в данных.
sns.regplot( x='engine_cc', y='mileage_kmpl', data=cars) plt.xlabel( 'Engine size in CC') plt.ylabel( 'Fuel efficiency') 
sns.scatterplot( x='mileage_kmpl', y='engine_cc', data=cars, palette='bright', hue='fuel'); # подсвечивает указанную категорию другим цветом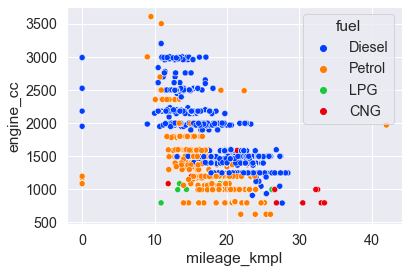
Диаграмма отношений relplot используется для создания диаграммы рассеяния с помощью kind=’scatter’ (установленного по умолчанию), или линейной диаграммы (kind=’line’). Для разделения по цвету в kind=’scatter’ используется hue=’cat_col’.
sns.relplot( x='mileage_kmpl', y='engine_cc', data=cars, palette='bright', kind='scatter', hue='fuel');
Обратите внимание, что две диаграммы выше аналогичны.
sns.relplot(x, y, data, kind='scatter', col='cat_col') # можно создавать поддиаграммы сегментов по столбцам, используя col='cat_col' и/или по строкам с помощью row='cat_col'ыки.sns.relplot( x='year', y='selling_price', data=cars, kind='scatter', col='transmission'); # данные разбиты на разные диаграммы по типу передачи автомобиля 
sns.relplot(x,y,data, hue='cat_col1', col='cat_col2') #sns.relplot( x='year', y='selling_price', data=cars, palette='bright', height=3, aspect=1.3, kind='scatter', hue='transmission', col='fuel', col_wrap=2); # указывает количество столбцов для измерений в одной визуализации
Описание в документации. lmplot — разновидность regplot на уровне диаграммы: она рисует диаграмму рассеяния с линией регрессии на FacetGrid. Параметра kind у implot нет.
sns.lmplot( x="seats", y="engine_cc", data=cars, palette='bright', col="transmission", hue="fuel");
4. Линейный график
Линейный график состоит из точек, соединённых линией, которая показывает связь между переменными x и y. Ось x обычно содержит временные интервалы, ось y — числовую переменную, изменения которой во времени нужно отследить.
# Функции: sns.lineplot() # оси. sns.relplot(kind='line') # диаргамма.sns.lineplot( x="year", y="selling_price", data=cars)
sns.lineplot( x="year", y="selling_price", data=cars, palette='bright', hue='fuel');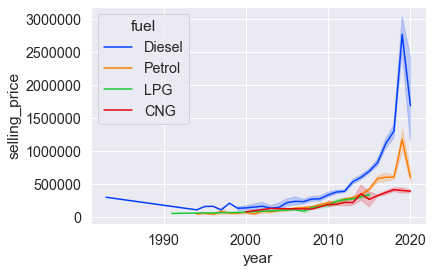
sns.relplot( x="year", y="selling_price", data=cars, color='blue', height=4 kind='line', # строит линейный график col='transmission'); # рисует график отношений двух классов 'transmission'. 
# Подобные диаграммы можно получить, используя kind='line' и hue: sns.relplot( x="year", y="selling_price", data=cars, palette='bright', height=4, kind='line', col='transmission', hue="fuel");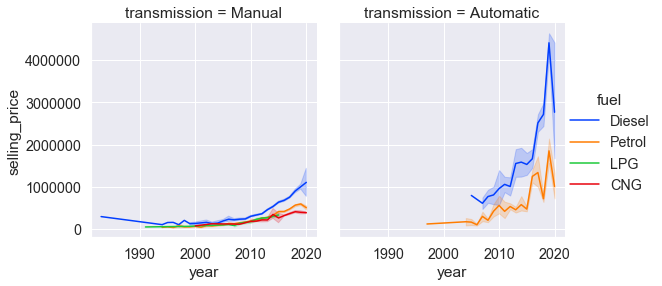
5. Сводная диаграмма
Состоит из трёх диаграмм в одной. Центр содержит бивариантную зависимость между переменными x и y. На диаграммах сверху и справа показано одномерное распределение переменных по осям x и у соответственно.
# Функции: sns.jointplot() # диаргамма. sns.jointplot(x='num_col1, y='num_col2, data=df) # по умолчанию центральная диаграмма — это диаграмма рассеяния (kind='scatter') # Боковые диаграммы — это гистограммы.sns.jointplot( x='max_power_bhp', y='selling_price', data=cars); 

sns.jointplot( x='selling_price', y='max_power_bhp', data=cars, palette='bright', hue='transmission');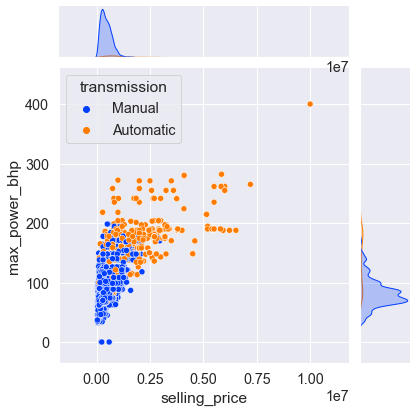
Изучение отношений между категориальными и числовыми данными
На следующих диаграммах ось x будет содержать категориальную переменную, а ось Y — числовую.
6. Гистограмма
Гистограмма использует столбцы разной высоты для сравнения распределения числовой переменной между группами категориальной переменной. По умолчанию высота столбца оценивается с помощью «среднего»: параметр estimator изменяет эту функцию агрегирования с помощью встроенных функций Python, таких как estimator=max или len, или функций NumPy наподобие np.max и np.median.
# Функции: sns.barplot() # оси. sns.catplot(kind='bar') # диаргамма. sns.barplot( x='fuel', y='selling_price', data=cars, color='blue', # estimator=sum, # estimator=np.median);
Ещё один пример:
sns.barplot( x='fuel', y='selling_price', data=cars, palette='bright' hue='transmission');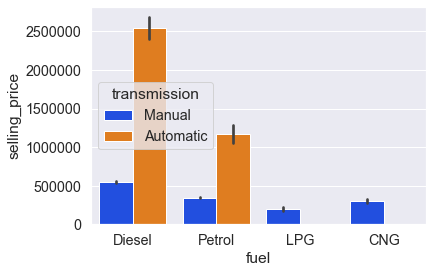
sns.catplot(x, y, data, kind='bar', hue='cat_col')Тип категориальной диаграммы указывается параметром kind, по умолчанию он равен ‘strip’. Допустимы значения ‘swarm’, ‘box’, ‘violin’, ‘boxen’, ‘point’ и ‘bar’ . Воспользуемся catplot для создания диаграммы, похожей на предыдущую.
sns.catplot( x='fuel', y='selling_price', data=cars, palette='bright', kind='bar', hue='transmission'); 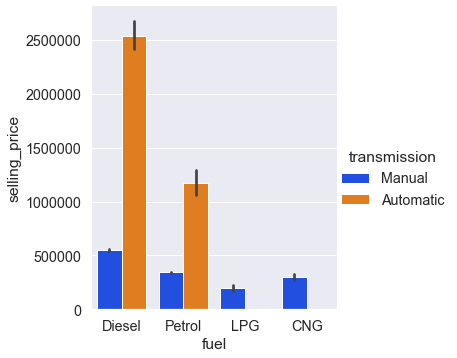
Пример гистограммы через catplot:
g = sns.catplot( x='fuel', y='selling_price', data=cars, palette='bright', height=3, aspect=1.3, kind='bar', hue='transmission', col ='seller_type', col_wrap=2) # указывает количество столбцов для измерений, отображаемых в одной визуализации g.set_titles( 'Seller: ');
7. Точечная диаграмма
Вместо столбцов точечная диаграмма отображает точки, представляющие среднее значение (или другую оценку) каждой группы категорий. Точки соединяются линией, что упрощает сравнение изменений центральной тенденции переменной y для групп.
# Функции: sns.pointplot() # оси. sns.catplot(kind='point') # диаргамма. sns.pointplot( x='seller_type', y='mileage_kmpl', data=cars); 
Когда вы добавляете третью категорию с помощью hue, точечная диаграмма становится информативнее гистограммы, потому что через каждый переданный hue класс проводится линия, которая упрощает сравнение изменений по группе переменной x.
Точечная диаграмма с catplot:
sns.catplot( x='transmission', y='selling_price', data=cars, palette='bright', kind='point', # точечная диаграмма hue='seller_type'); # Ту же диаграмму можно получить, используя sns.paitplot и параметр hue.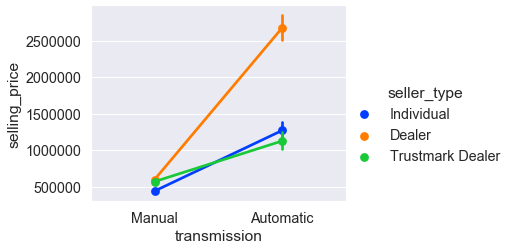
sns.catplot( x='fuel', y='year', data=cars, ci=None, height=5, # по умолчанию aspect=.8, kind='point', # В hue и col указана одна и та же категория hue='owner', col='owner', col_wrap=3);
8. Ящик с усами
Ящик с усами визуализирует распределение между числовыми и категориальными переменными, отображая информацию о квартилях.

На диаграммах видно наименьшее значение, медиану, наибольшее значение и выбросы для каждого класса категорий.
# Функции: sns.boxplot() # оси. sns.catplot(kind='box') # диаргамма.sns.boxplot(x='cat_col', y='num_col', data=df) sns.boxplot( x='owner', y='engine_cc', data=cars, color='blue') plt.xticks(rotation=45, ha='right');
Ещё один пример:
sns.boxplot( x='fuel', y='max_power_bhp', data=cars, palette='bright', hue='transmission'); 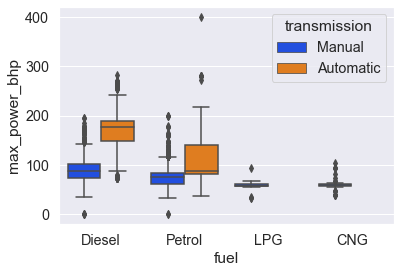
То же через catplot:
sns.catplot( x='fuel', y='max_power_bhp', data=cars, palette='bright', kind = 'box', # используйте catplot с kind='box' col='transmission'); # для создания поддиаграмм укажите параметр col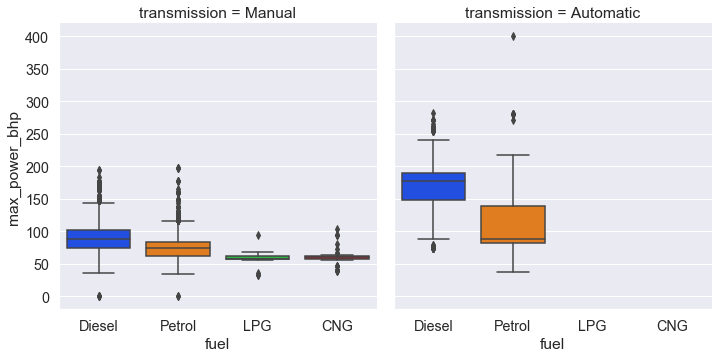
Пример с catplot сложнее:
g = sns.catplot( x='owner', y='year', data=cars, palette='bright', height=3, aspect=1.5, kind='box', hue='transmission', col='fuel', col_wrap=2) g.set_titles( 'Fuel: '); g.set_xticklabels( rotation=45, ha='right') 
9. Скрипичная диаграмма
В дополнение к квартилям ящика с усами, скрипичная диаграмма рисует кривую ядерной оценки плотности, отражающую вероятности наблюдений в различных областях.

# Функции: sns.violinplot() # оси. sns.catplot(kind='violin') # диаргамма.sns.violinplot(x='cat_col', y='num_col', data=df) sns.violinplot( x='transmission', y='engine_cc', data=cars, color='blue'); 
Другой пример с catplot:
g = sns.catplot( x='owner', y='year', data=cars, palette='bright', height=3, aspect=2 split=False, # split=True рисует половину диаграммы для каждого категориального класса. # Это работает, когда переменная hue имеет только два класса. # Смотрите ниже kind='violin', hue='transmission') g.set_xticklabels( rotation=45, ha='right') # Тот же результат можно получить через sns.violinplot c параметром hue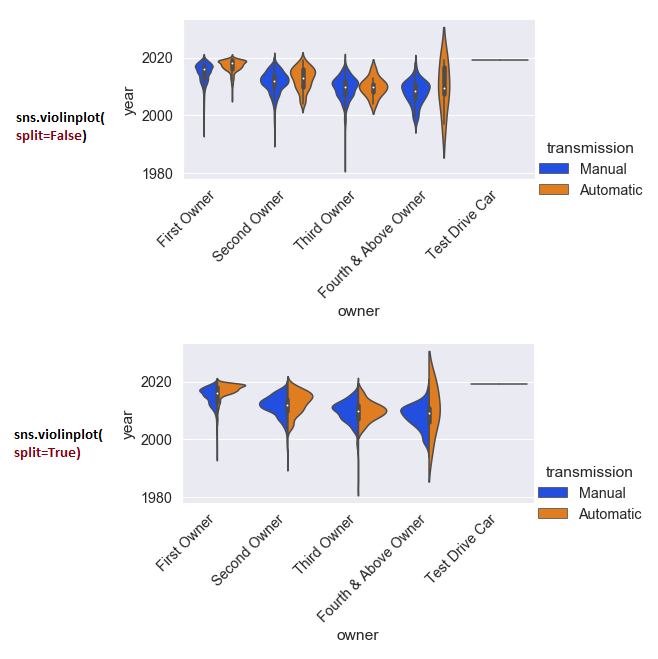
Фильтрация по двум классам через catplot:
# Здесь рассматриваем данные только для 'diesel' и 'patrol': my_df = cars[cars['fuel'].isin(['Diesel','Petrol'])] g = sns.catplot( x="owner", y="engine_cc", data=my_df, palette='bright', kind = 'violin', hue="transmission", col = 'fuel') g.set_xticklabels( rotation=90); 
10. Одномерная диаграмма рассеяния
Точки этой диаграммы показывают, как числовая переменная распределяется между классами категориальной переменной. Её можно представить как точечную диаграмму, где одна из осей отражает признак в данных.
# Функции: sns.stripplot() # оси. sns.catplot(kind='strip') # диаргамма. sns.stripplot(x='cat_col', y='num_col', data=df) plt.figure( figsize=(12, 6)) sns.stripplot( x='year', y='km_driven', data=cars, linewidth=.5, color='blue') plt.xticks(rotation=90); 
Пример через catplot:
sns.catplot( # kind='strip' по умолчанию x='seats', y='km_driven', data=cars, palette='bright', height=3, aspect=2.5, # Аргумент dodge=True (по умолчанию dodge='False') делит вертикальную линию точек по цвету kind='strip', hue='transmission');
Ещё один пример с catplot:
g = sns.catplot( x="seller_type", y="year", data=cars, palette='bright', height=3, aspect=1.6, kind='strip', hue='owner', col='fuel', col_wrap=2) g.set_xticklabels( rotation=45, ha='right');
Комбинация одномерной диаграммы рассеяния и скрипичной диаграммы
Одномерную диаграмму рассеяния можно комбинировать со скрипичной диаграммой или ящиком с усами, чтобы показать положение пропусков или выбросов в данных.
Пример с catplot:
g = sns.catplot( x='seats', y='mileage_kmpl', data=cars, palette='bright', aspect=2, inner=None, kind='violin') sns.stripplot( x='seats', y='mileage_kmpl', data=cars, color='k', linewidth=0.2, edgecolor='white', ax=g.ax); 
Замечания
- Столбцы категориальных диаграмм, таких как гистограммы и ящики с усами, можно сделать горизонтальными, поменяв местами переменные x и y.
- Совместно используемые параметры row и col объектов уровня фигуры FacetGrid могут добавить измерение к поддиаграмм. Однако col_wrap не работает с row.
- FacetGrid поддерживает различные параметры в зависимости от основной диаграммы. Например, sns.catplot(kind=’violin’) поддерживает параметр split, но другие ‘kind’ — не поддерживают его. Подробности о ‘kind’ смотрите в документации.
- Функции уровня диаграммы создают и двумерные диаграммы. Например, sns.catplot(x=’fuel’, y=’mileage_cc’, data=cars, kind=’bar’) отобразит простую столбцовую диаграмму.
Заключение
Мы проанализировали двумерный и многомерный набор данных. Чтобы найти числовые переменные с высокой корреляцией, создали матричные диаграммы, которые показали отношения в сетке. Затем использовали различные функции на уровне осей и на уровне диаграммы для создания диаграмм, которые показали отношения между числовыми и категориальными столбцами.
А мы поможем вам прокачать навыки или с самого начала освоить профессию, востребованную в любое время.
- Профессия Data Analyst
- Профессия Data Scientist
Seaborn Heatmaps: 13 способов настроить визуализацию матрицы корреляции
Для data scientist’ов проверка корреляций является важной частью процесса анализа поисковых данных. Этот анализ является одним из методов, используемых для определения того, какие функции больше всего влияют на целевую переменную, и, в свою очередь, используются при прогнозировании этой целевой переменной. Другими словами, это широко используемый метод выбора функций в машинном обучении.
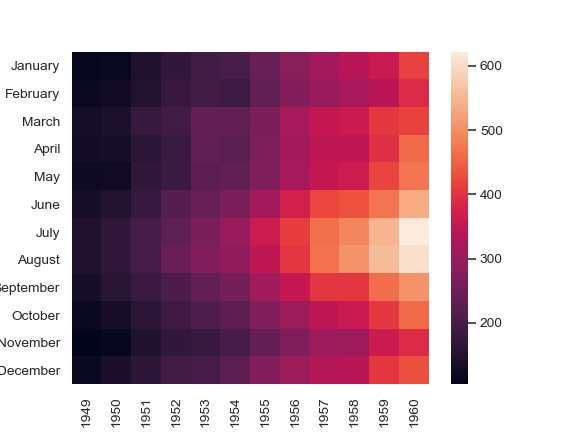
А поскольку визуализация обычно проще к пониманию, чем табличные данные, — тепловые карты, как правило, используются для визуализации корреляционных матриц. Простой способ построить тепловую карту в Python — это использовать библиотеку Seaborn.
Аргументы тепловой карты Seaborn
Тепловые карты Seaborn приятны для глаз, и они, как правило, почти сразу посылают четкие сообщения о данных. Вот почему этот метод визуализации корреляционной матрицы широко используется аналитиками данных.
Но что еще мы можем получить из тепловой карты, кроме простого графика корреляционной матрицы?
В двух словах: ОЧЕНЬ МНОГОЕ.
Удивительно, но функция тепловой карты Seaborn имеет 18 аргументов, которые можно использовать для настройки корреляционной матрицы, улучшая способ получения быстрых выводов. В рамках данного руководства мы разберем 13 из них.
Итак, перейдем к делу!
Начало работы с Seaborn
Чтобы немного упростить задачу для этого урока, мы будем использовать один из предварительно установленных наборов данных в Seaborn. Первое, что нам нужно сделать, это импортировать библиотеку Seaborn и загрузить данные.
1. #importing all the libraries needed
2. import seaborn as sns
3. import numpy as np
4. import pandas as pd
5. import matplotlib.pyplot as plt
6.
7. tips_df = sns.load_dataset('tips')
8. tips_df.head()
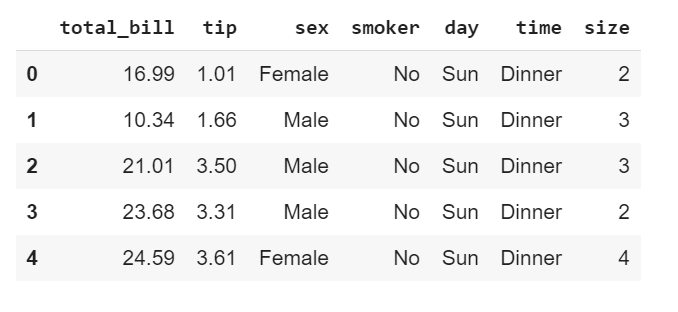
Обратите внимание: если вы используете Google Colab или какой-либо пакет Anaconda, вам не нужно устанавливать Seaborn; вам нужно только импортировать его. В противном случае, используйте эту ссылку для установки Seaborn.
Наши данные, которые называются Tips (предварительно установленный набор данных в библиотеке Seaborn), имеют 7 столбцов, состоящих из 3 числовых и 4 категориальных признаков. Каждая строка отражает тип клиента (будь то мужчина или женщина, курильщик или некурящий), который ужинает или обедает в определенный день недели. Также фиксируется общая сумма счета, чаевые и размер стола для гостя. (Для получения дополнительной информации о предварительно установленных наборах данных в библиотеке Seaborn, кликните здесь).
Важно отметить, что при построении матрицы корреляции полностью игнорируются любые нечисловые столбцы. В данном уроке все переменные категории были заменены на числовые.
Вот как выглядит DataFrame после обработки данных:
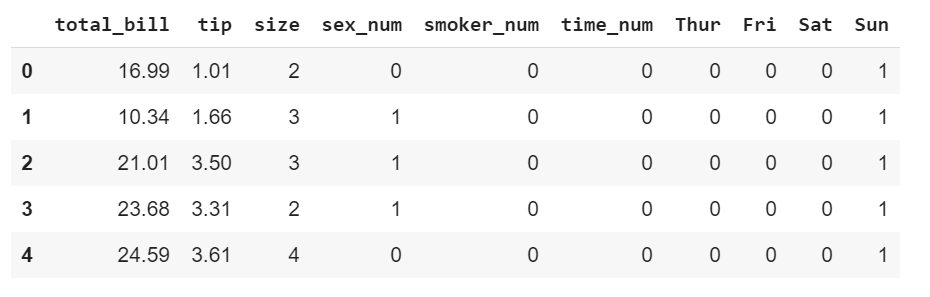
Посмотреть, как были обработаны данные, можно здесь.
Как упоминалось ранее, функция тепловой карты Seaborn может принимать 18 аргументов.
Вот как выглядит функция со всеми аргументами:
sns.heatmap(data, vmin=None, vmax=None, cmap=None,center=None, robust=False, annot=None, fmt=’.2g’, annot_kws=None, linewidths=0, linecolor=’white’, cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels=’auto’, yticklabels=’auto’, mask=None, ax=None, **kwargs)
Просто взглянуть на код и не иметь представления о том, как он работает, может быть весьма удручающе. Давайте разберем это вместе.
Чтобы лучше понять аргументы, мы сгруппируем их в 4 категории:
- Основы;
- Регулировка оси (измерительной шкалы);
- Эстетика;
- Изменение формы матрицы.
Основы
1. Самый важный аргумент в функции — ввод данных, поскольку конечной целью является построение корреляции. Метод .corr() будет добавлен к данным в качестве первого аргумента.
sns.heatmap(df_new.corr())
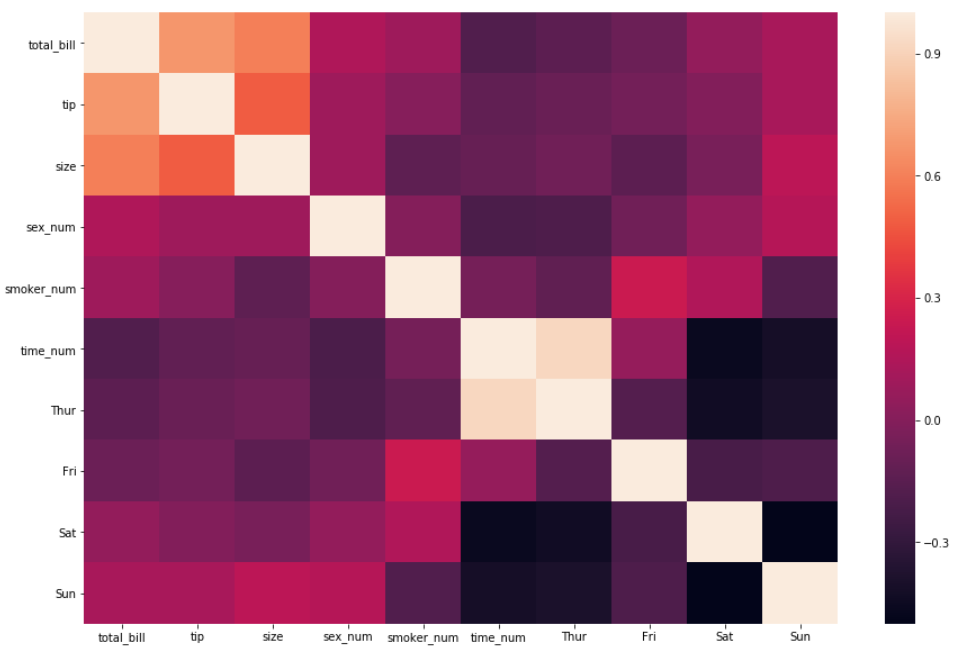
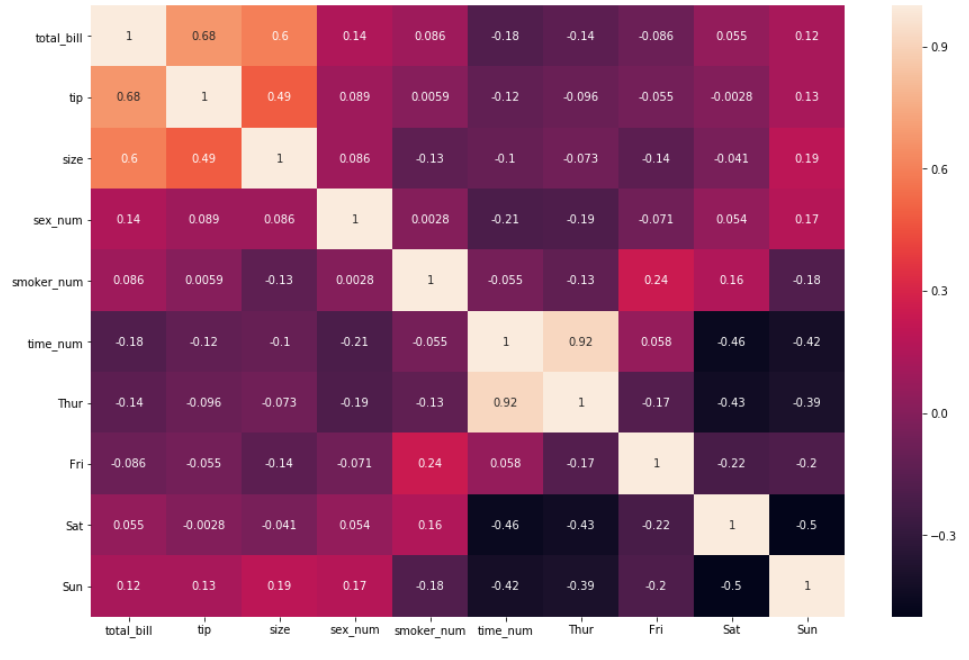
2. Достаточно интерпретировать данные, используя только первый аргумент. Для еще более точной интерпретации необходимо добавить аргумент annot=True , который помогает отобразить коэффициент корреляции.
sns.heatmap(df_new.corr(), annot = True)
3. В некоторых случаях, коэффициенты корреляции могут приближаться к 5 десятичным знакам. Хорошим приемом для уменьшения отображаемого числа и улучшения читабельности является вставка аргумента fmt =’.3g’ или fmt = ‘.1g’ , потому что, по умолчанию, функция отображает две цифры после запятой (больше нуля), т.е. fmt=’.2g’ (Это не означает, что она всегда отображает два знака после запятой). Давайте определим аргумент по умолчанию fmt=’.1g’ .
sns.heatmap(df_new.corr(), annot = True, fmt='.1g')
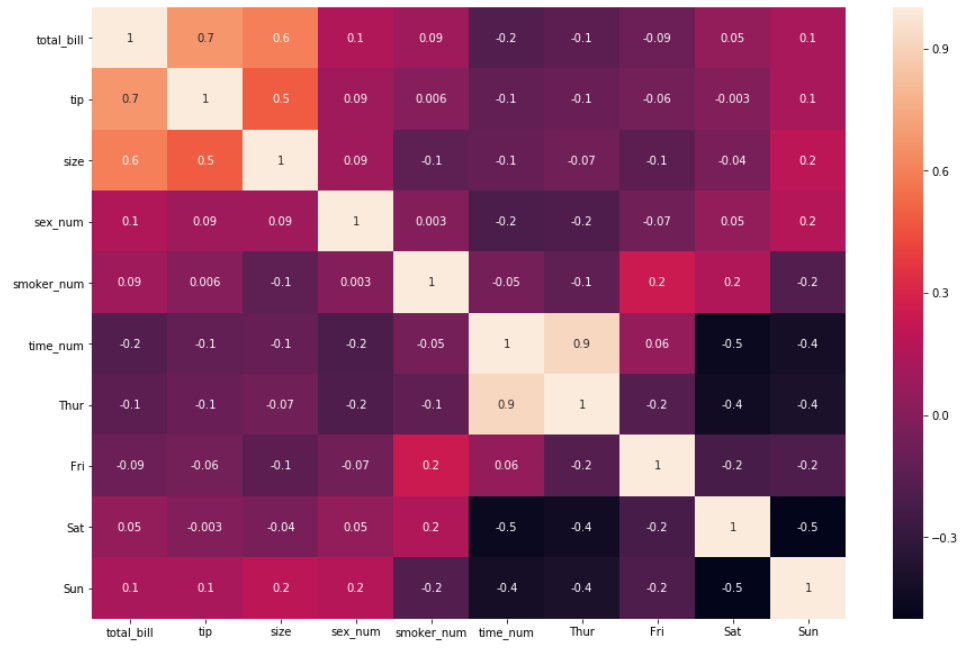
Для остальной части этого урока мы будем придерживаться значения по умолчанию fmt=’.2g’
Регулировка оси (измерительной шкалы)
4. Следующие три аргумента связаны с масштабированием цветовой шкалы. Бывают моменты, когда шкала не начинается с нуля, отрицательного числа или заканчивается на определенном числе — или даже имеет отдельный центр. Все это можно настроить, указав эти три аргумента: vmin минимальное значение шкалы; vmax максимальное значение шкалы; и center= . По умолчанию, все три не указаны. Допустим, мы хотим, чтобы наша цветовая шкала была от -1 до 1 и была центрирована на 0.
sns.heatmap(df_new.corr(), annot = True, vmin=-1, vmax=1, center= 0)
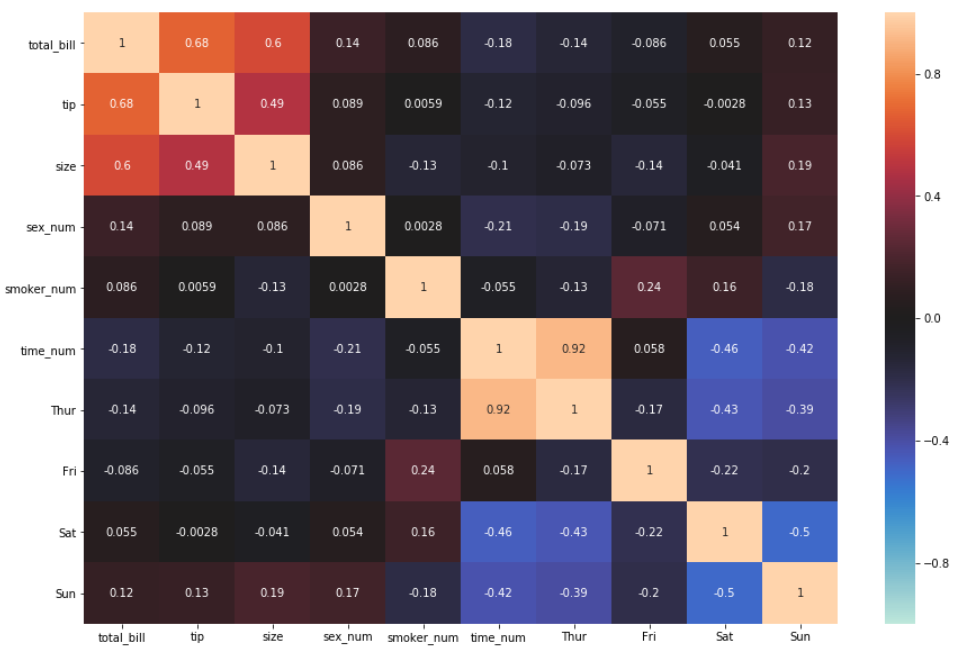
Одно очевидное изменение, кроме изменения масштаба, заключается в изменении цвета. Это связано с изменением center от None до Zero или любое другое число. Но это не означает, что мы не можем вернуть прошлый цвет или изменить его на любой другой. Сейчас посмотрим, как это сделать.
Эстетика
5. Сейчас изменим цвет, используя аргумент cmap
sns.heatmap(df_new.corr(), annot = True, vmin=-1, vmax=1, center= 0, cmap= 'coolwarm')
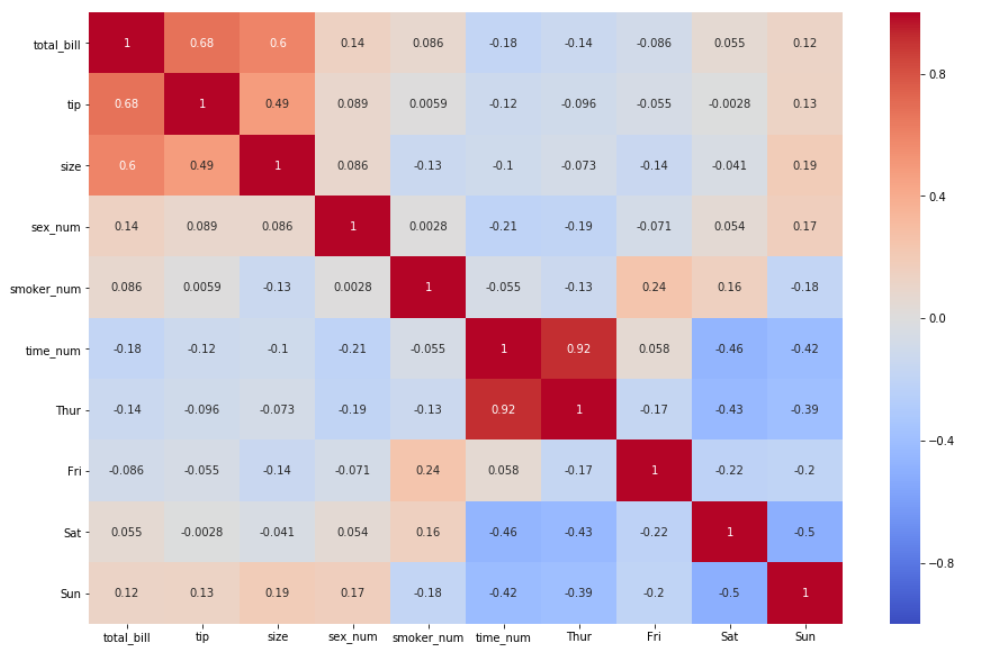
Для получения дополнительной информации о доступных цветовых кодах, кликните здесь.
6. По умолчанию, толщина и цвет границы каждой строки матрицы установлены на 0 и белый соответственно. Бывает, когда тепловая карта может выглядеть лучше с некоторой толщиной границы и изменением цвета. В этом случае, применяются аргументы linewidths и linecolor . Давайте укажем linewidths и linecolor на 3 и black соответственно.
sns.heatmap(df_new.corr(), annot = True, vmin=-1, vmax=1, center= 0, cmap= 'coolwarm', linewidths=3, linecolor='black')
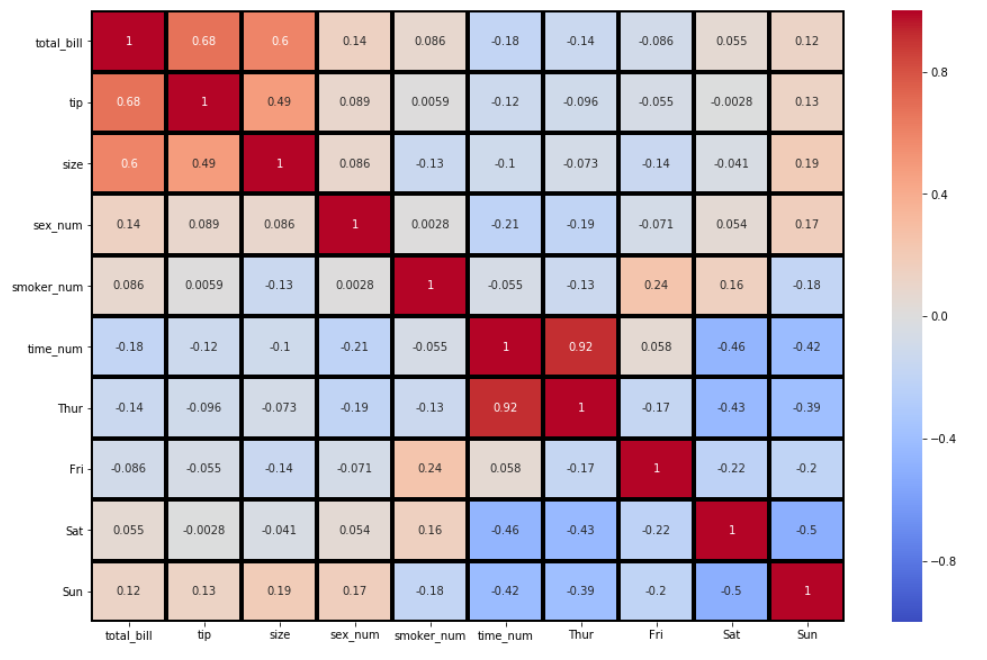
Для остальной части этого урока мы вернемся к значениям аргументов cmap , linecolor и linewidths по умолчанию. Это можно сделать с помощью вставки cmap=None , linecolor=’white’ и linewidths=0 или не вставляя аргументы вообще (что мы и собираемся делать).
7. На данный момент цветовая шкала тепловой карты отображается вертикально. Ее можно сделать горизонтальной, указав аргумент cbar_kws .
sns.heatmap(df_new.corr(), annot = True, cbar_kws= )
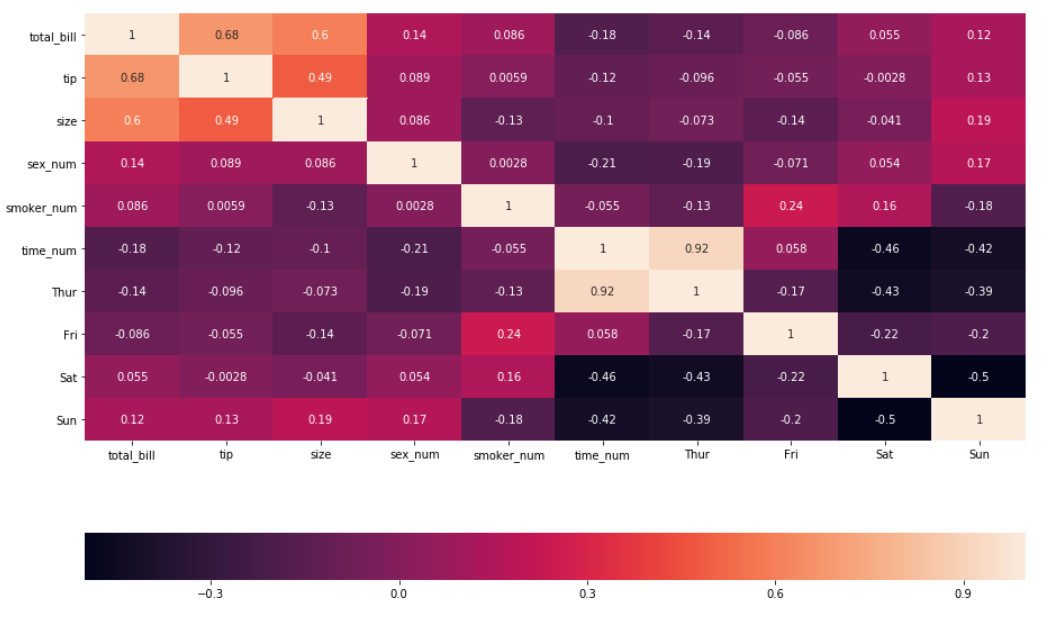
8. Также бывают случаи, когда лучше вообще убрать цветовую шкалу. Это можно сделать, указав cbar=False .
sns.heatmap(df_new.corr(), annot = True, cbar=False)
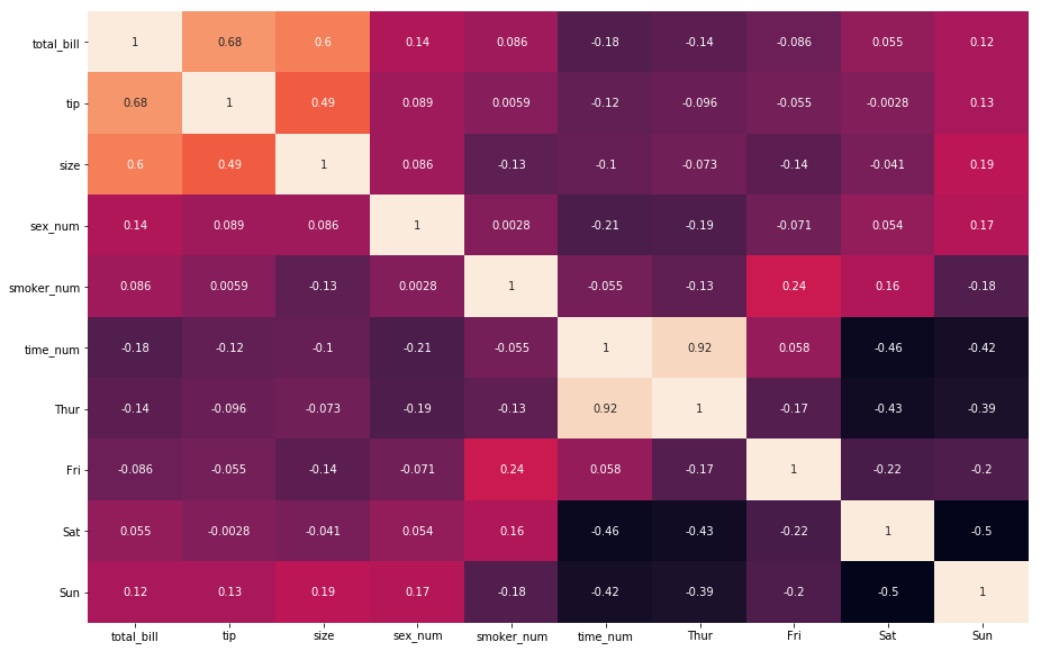
В оставшейся части этого урока мы будем отображать цветовую шкалу.
9. Посмотрите поближе на матрицу выше — каждая ячейка прямоугольной формы. Мы можем изменить форму ячеек на квадратную с помощью аргумента square=True .
sns.heatmap(df_new.corr(), annot = True,square=True)
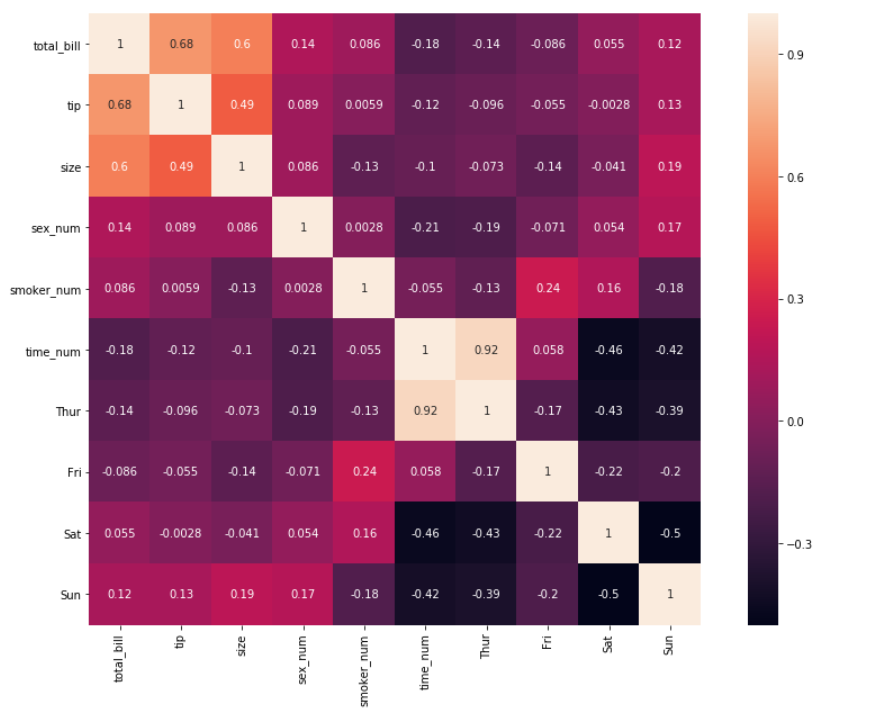
Изменение формы матрицы
Изменение всей формы матрицы с прямоугольной на треугольную не так просто. Для этого нам нужно импортировать методы NumPy .triu() и .tril() , а затем указать аргумент тепловой карты Seaborn, который называется mask=
.triu() является методом в NumPy, который возвращает нижний треугольник любой заданной ему матрицы, в то время как .tril() возвращает верхний треугольник любой заданной ему матрицы.
Идея состоит в том, чтобы отправить матрицу корреляции в метод NumPy, а затем передать ее в аргумент mask, чтобы создать маску в матрице тепловой карты. Давайте посмотрим, как это работает, ниже.
Сначала с помощью np.trui() метода:
matrix = np.triu(df_new.corr())
sns.heatmap(df_new.corr(), annot=True, mask=matrix)
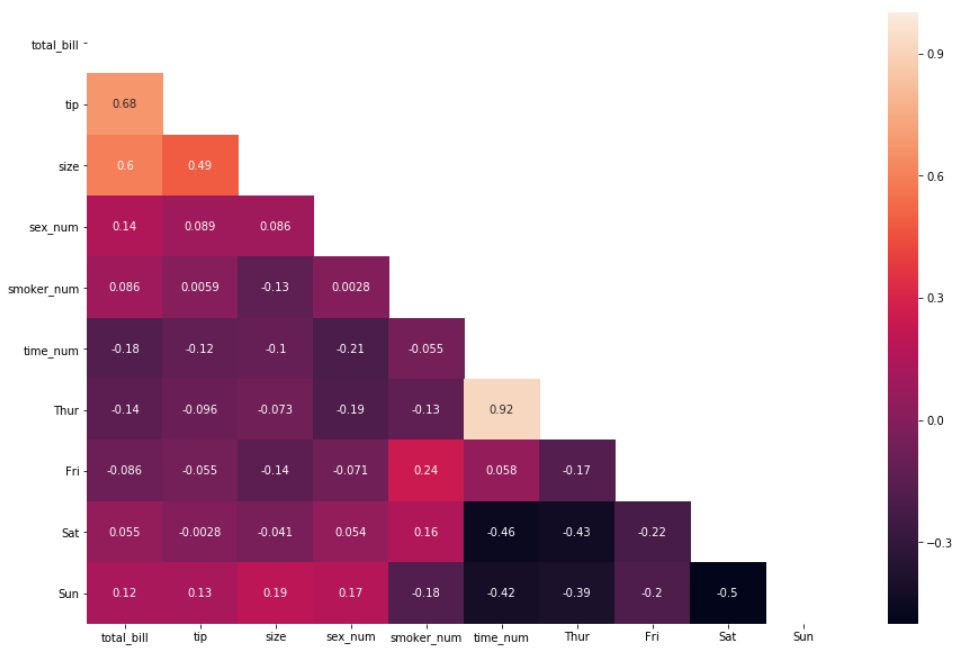
Теперь с помощью np.tril() метода:
mask = np.tril(df_new.corr())
sns.heatmap(df_new.corr(), annot=True, mask=mask)
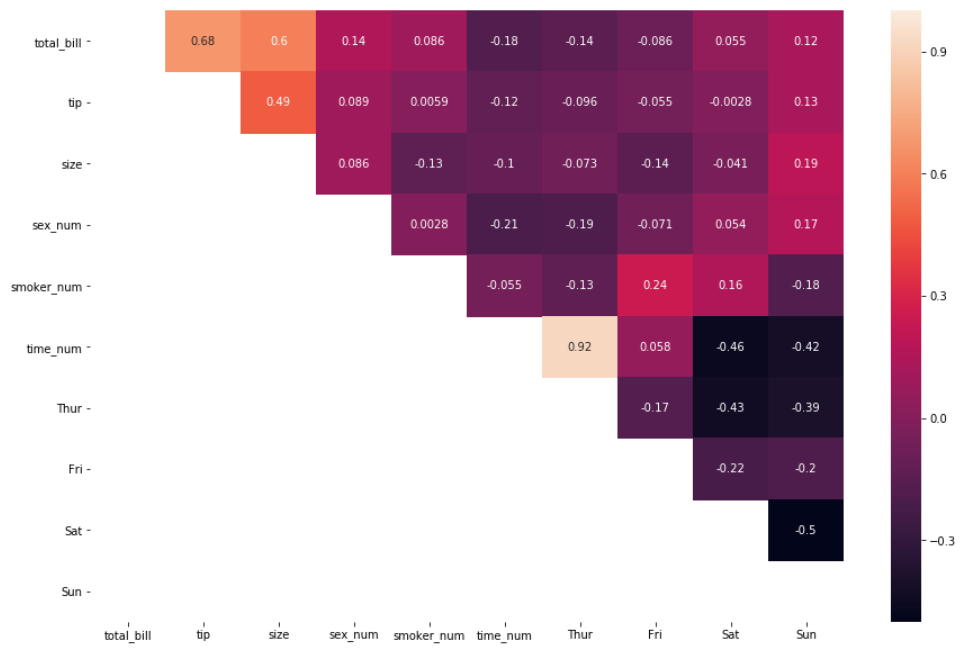
В заключение
Мы разобрали 13 способов настроить нашу тепловую карту Seaborn для корреляционной матрицы. Остальные 5 аргументов используются редко, поскольку они очень специфичны по характеру данных и сформулированным целям. Полный исходный код этого руководства можно найти на GitHub.
Как строить красивые графики на Python с Seaborn
Визуализация данных — это метод, который позволяет специалистам по анализу данных преобразовывать сырые данные в диаграммы и графики, которые несут ценную информацию. Диаграммы уменьшают сложность данных и делают более понятными для любого пользователя.
Есть множество инструментов для визуализации данных, таких как Tableau, Power BI, ChartBlocks и других, которые являются no-code инструментами. Они очень мощные, и у каждого своя аудитория. Однако для работы с сырыми данными, требующими обработки, а также в качестве песочницы, Python подойдет лучше всего.
Несмотря на то, что этот путь сложнее и требует умения программировать, Python позволит вам провести любые манипуляции, преобразования и визуализировать ваши данные. Он идеально подходит для специалистов по анализу данных.
Python — лучший инструмент для data science и этому много причин, но самая важная — это его экосистема библиотек. Для работы с данными в Python есть много замечательных библиотек, таких как numpy , pandas , matplotlib , tensorflow .
Matplotlib , вероятно, самая известная библиотека для построения графиков, которая доступна в Python и других языках программирования, таких как R. Именно ее уровень кастомизации и удобства в использовании ставит ее на первое место. Однако с некоторыми действиями и кастомизациями во время ее использования бывает справиться нелегко.
Разработчики создали новую библиотеку на основе matplotlib , которая называется seaborn . Seaborn такая же мощная, как и matplotlib , но в то же время предоставляет большую абстракцию для упрощения графиков и привносит некоторые уникальные функции.
В этой статье мы сосредоточимся на том, как работать с seaborn для создания первоклассных графиков. Если хотите, можете создать новый проект и повторить все шаги или просто обратиться к моему руководству по seaborn на GitHub.
Что такое Seaborn?
Seaborn — это библиотека для создания статистических графиков на Python. Она основывается на matplotlib и тесно взаимодействует со структурами данных pandas.
Архитектура Seaborn позволяет вам быстро изучить и понять свои данные. Seaborn захватывает целые фреймы данных или массивы, в которых содержатся все ваши данные, и выполняет все внутренние функции, нужные для семантического маппинга и статистической агрегации для преобразования данных в информативные графики.
Она абстрагирует сложность, позволяя вам проектировать графики в соответствии с вашими нуждами.
Установка Seaborn
Установить seaborn так же просто, как и любую другую библиотеку, для этого вам понадобится ваш любимый менеджер пакетов Python. Во время установки seaborn библиотека установит все зависимости, включая matplotlib , pandas , numpy и scipy .
Давайте уже установим seaborn и, конечно же, также пакет notebook , чтобы получить доступ к песочнице с данными.
pipenv install seaborn notebookПомимо этого, перед началом работы давайте импортируем несколько модулей.
import seaborn as sns import pandas as pd import numpy as np import matplotlibСтроим первые графики
Перед тем, как мы начнем строить графики, нам нужны данные. Прелесть seaborn в том, что он работает непосредственно с объектами dataframe из pandas , что делает ее очень удобной. Более того, библиотека поставляется с некоторыми встроенными наборами данных, которые можно использовать прямо из кода, и не загружать файлы вручную.
Давайте посмотрим, как это работает на наборе данных о рейсах самолетов.
flights_data = sns.load_dataset("flights") flights_data.head()