Парный двухвыборочный t-тест для средних EXCEL
Рассмотрим использование MS EXCEL при проверке статистических гипотез о разнице средних значений 2-х распределений в случае неизвестных дисперсий (парный тест). Вычислим значение тестовой статистики t 0 , рассмотрим соответствующую процедуру «двухвыборочный t -тест», вычислим Р-значение (Р- value ). С помощью надстройки Пакет анализа сделаем «Парный двухвыборочный t-тест для средних».
Здесь рассмотрен специальный случай двухвыборочного t-теста , когда наблюдения случайных величин из двух распределений производятся не независимо, а парами.
Примечание : Процедура двухвыборочного t-теста также изложена в статьях Двухвыборочный t-тест с одинаковыми дисперсиями и Двухвыборочный t-тест с различными дисперсиями , где выборки из распределений считались независимыми.
СОВЕТ : При первом знакомстве с процедурой двухвыборочного t -теста может быть полезным освежить в памяти процедуру одновыброчного t-теста для среднего при неизвестной дисперсии .
СОВЕТ : Для проверки гипотез нам потребуется знание следующих понятий:
- дисперсия и стандартное отклонение ,
- выборочное распределение статистики ,
- уровень доверия/ уровень значимости ,
- нормальное распределение ,
- t-распределение Стьюдента и его квантили .
Приведем пример . Имеется 2 прибора измеряющих твердость металлических образцов. Необходимо проверить, что эти приборы показывают одинаковые результаты на одном и том же образце ( нулевая гипотеза ).
Если для испытания на приборах образцы отбирать случайным образом: половину для проверки на приборе №1, другую на приборе №2, и использовать для проверки нулевой гипотезы t-тест с одинаковыми (или различающимися) дисперсиями, то можно сделать ошибочное заключение. Дело в том, что металлические образцы могут быть изготовлены из различных заготовок, прошедших различную термообработку и, следовательно, они могут иметь различную твердость. Таким образом, наблюденная разность между средними значениями твердости, полученными на каждом из приборов (Х ср1 и Х ср2 ), будет также включать различие в твердости, обусловленную самими образцами. Другими словами, при таком методе исследования у нас имеется 2 источника неопределенности (случайности): несовершенство приборов и случайные колебания твердости самих образцов.
Чтобы исключить случайность, обусловленную различием образцов, и тем самым увеличить мощность t -теста , используют парные выборки . В нашем случае, измерения одного и того же образца будем проводить сначала на одном, затем на другом приборе (предполагается, что после измерения твердости на первом приборе, образец не портится).
Таким образом, процедура проверки гипотезы сводится к определению разности твердостей полученных приборами на одном и том же образце. Если приборы настроены одинаково, то среднее разностей должно быть около 0 (отклонение не должно быть статистически значимым).
Пусть имеется набор из n пар наблюдений (n образцов). Т.к. результат каждого наблюдения является случайной величиной (приборы не идеальны, присутствует случайная ошибка измерений), то эти случайные величины имеют распределения с неизвестными средними значениями μ 1 и μ 2 (измерения полученные на приборе №1 и №2, соответственно). Дисперсии этих распределений неизвестны (обозначим их σ 1 2 и σ 2 2 ).
Будем рассматривать не сами наблюдения, а их разницу. Обозначим D i – разницу измерений, полученную приборами №1 и №2 на i-м образце. Разницу между μ 1 и μ 2 , которую нам необходимо оценить, обозначим μ D .
Проведем проверку гипотезы о равенстве μ D заданному значению Δ 0 , т.е. парный t -тест (англ. The Paired t-Test). Если Δ 0 равно 0, то речь идет о проверке равенства средних двух распределений.
Т.е. нам требуется проверить двухстороннюю гипотезу .
Тестовой статистикой является случайная величина t:
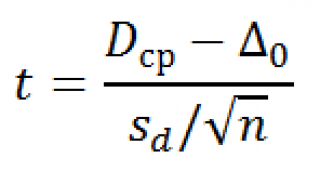
где D ср – среднее значение разностей, S d – стандартное отклонение этих разностей.
Как известно из статьи про одновыборочный t-тест , данная тестовая статистика , имеет t-распределение c n-1 степенью свободы. Значение, которое приняла эта t -статистика, обозначим t 0 .
Установим требуемый уровень значимости α (альфа) = 0,05 (допустимую для данной задачи ошибку первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна).
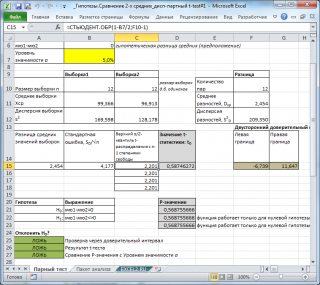
Если вычисленное на основе выборок значение t 0 , в случае двухсторонней гипотезы , не попадет в область значений ограниченной нижним и верхним α/2-квантилями t — распределения с n–1 степенями свободы, то у нас будет основание отвергнуть нулевую гипотезу. Это утверждение эквивалентно случаю, когда D ср окажется вне пределов соответствующего доверительного интервала. В файле примера на листе Парный тест показана эквивалентность доверительного интервала и соответствующего t -теста.
Примечание : Верхний α/2-квантиль — этотакое значение случайной величины t n–1 , что P ( t n-1 >=t α/2 , n-1 ) =α/2. Верхний α/2-квантиль t — распределения с n -1 степенью свободы обычно обозначают t α /2, n-1 . Подробнее о квантилях распределений см. статью Квантили распределений MS EXCEL .
В нашем случае, необходимо будет вычислить только верхний α/2-квантиль, т.к. он равен соответствующему нижнему квантилю со знаком минус. Следовательно, условие отклонения нулевой гипотезы можно записать как |t 0 |>t α/2 , n-1 .
Чтобы в MS EXCEL вычислить значение t α/2 , n-1 для различных уровней значимости (10%; 5%; 1%) и степеней свобод можно использовать несколько формул: =СТЬЮДЕНТ.ОБР.2Х(α; n-1) =СТЬЮДЕНТ.ОБР(1- α/2; n-1) =-СТЬЮДЕНТ.ОБР(α/2; n-1) =СТЬЮДРАСПОБР(α; n-1)
Примечание : Подробнее про функции MS EXCEL, связанные с t — распределением см. статью t-распределение .
Итак, если при проверке двухсторонней гипотезы формула =ABS(t 0 ) вернет значение больше, чем результат формулы =СТЬЮДЕНТ.ОБР.2Х(α; n-1) , то это означает, что необходимо отвергнуть нулевую гипотезу (вычисления приведены в файле примера на листе Парный тест ) .
Для односторонней альтернативной гипотезы μ D >Δ 0 , нулевая гипотеза будет отвергнута в случае t 0 > t α , n-1 .
Для односторонней альтернативной гипотезы μ D =2*(1-СТЬЮДЕНТ.РАСП(ABS(t 0 ); n-1;ИСТИНА))
Примечание : Вычисления приведены в файле примера на листе Парный тест .
Для односторонней гипотезы μ 1 -μ 2 >Δ 0 p -значение вычисляется по формуле: =1-СТЬЮДЕНТ.РАСП(t 0 ; n-1;ИСТИНА) В этом случае p-значение равно вероятности, что t -статистика примет значение больше t 0 .
Для односторонней гипотезы μ 1 -μ 2 = СТЬЮДЕНТ.РАСП(t 0 ; n-1;ИСТИНА) В этом случае p-значение равно вероятности, что t -статистика примет значение меньше t 0 .
В файле примера на листе Парный тест показана эквивалентность проверки гипотезы через доверительный интервал , статистику t 0 ( t -тест) и p -значение .
В MS EXCEL есть функция СТЬЮДЕНТ.TEСT() , которая вычисляет p-значение для 3-х различных двухвыборочных t -тестов (см. следующий раздел статьи) . К сожалению, эта функция может быть использована только для проверки гипотез с Δ 0 =0, то есть для проверки гипотез о равенстве средних μ 1 =μ 2 . Об этом легко догадаться, т.к. среди ее параметров отсутствует параметр Гипотетическая разность средних , т.е. Δ 0 .
Функция СТЬЮДЕНТ.ТЕСТ()
Функция СТЬЮДЕНТ.ТЕСТ() используется для оценки различия двух выборочных средних . До MS EXCEL 2010 имелась аналогичная функция ТТЕСТ() .
Примечание : В английской версии функция носит название T.TEST(), старая версия — TTEST().
Функция СТЬЮДЕНТ.ТЕСТ() имеет 4 параметра. Первые два – это ссылки на диапазоны ячеек, содержащие выборки из 2-х сравниваемых распределений.
Третий параметр имеет название «хвосты». Этот параметр задает тип проверяемой гипотезы: односторонняя (=1) или двухсторонняя (=2). Если мы проверяем двухстороннюю гипотезу , то смотрим, не попало ли значение тестовой статистики в один из 2-х хвостов соответствующего t-распределения . Если мы проверяем одностороннюю гипотезу (имеется ввиду гипотеза μ 1 файл примера ): =СТЬЮДЕНТ.ТЕСТ( выборка1 ; выборка2 ; 2; 1) или =2*(1-СТЬЮДЕНТ.РАСП(ABS(t 0 ); n-1;ИСТИНА))
Для односторонней гипотезы μ 1 =СТЬЮДЕНТ.ТЕСТ( выборка1 ; выборка2 ; 1; 1) или =СТЬЮДЕНТ.РАСП(t 0 ; n-1;ИСТИНА)
Для односторонней гипотезы μ 1 >μ 2 p -значение вычисляется по формуле: =1-СТЬЮДЕНТ.ТЕСТ( выборка1 ; выборка2 ; 1; 1) или =1-СТЬЮДЕНТ.РАСП(t 0 ; n-1;ИСТИНА)
Пакет анализа
В надстройке Пакет анализа для проведения Парного двухвыборочного t -теста имеется одноименный инструмент: Парный двухвыборочный t -тест для средних (t-Test: Paired Two-Sample for Means).
После выбора инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Пакет анализа ):
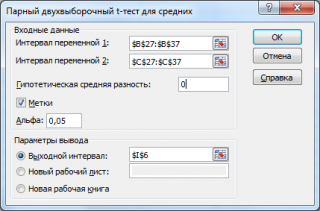
- интервал переменной 1 : ссылка на значения первой выборки . Ссылку указывать лучше с заголовком. В этом случае, при выводе результата надстройка выводит заголовки, которые делают результат нагляднее (в окне требуется установить галочку Метки );
- интервал переменной 2 : ссылка на значения второй выборки ;
- гипотетическая средняя разность : укажите значение Δ 0 , т.е. μ 1 -μ 2 . В нашем случае, введем 0;
- Метки: если в полях интервал переменной 1 и интервал переменной 2 указаны ссылки вместе с заголовками столбцов, то эту галочку нужно установить. В противном случае надстройка не позволит провести вычисления и пожалуется, что « входной интервал содержит нечисловые данные »;
- Альфа:уровень значимости ;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
В результате вычислений будет заполнен указанный Выходной интервал.
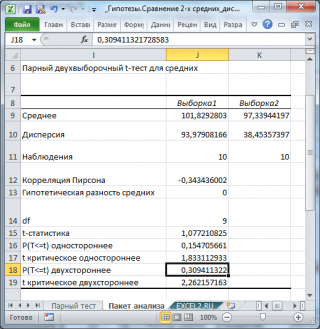
Тот же результат можно получить с помощью формул (см. файл примера лист Пакет анализа ):
Разберем результаты вычислений, выполненных надстройкой:
- Среднее : средние значения обеих выборок Хср 1 и Хср 2 . Вычисления можно сделать с помощью функции СРЗНАЧ() ;
- Дисперсия : дисперсии обеих выборок. Вычисления можно сделать с помощью функции ДИСП.В()
- Наблюдения : размер выборок. Вычисления можно сделать с помощью функции СЧЁТ()
- Корреляция Пирсона : коэффициент корреляции двух выборок . Вычисления можно сделать с помощью функции КОРРЕЛ() или PEARSON()
- Df : число степеней свободы : n-1, где n размер выборок ;
- t-статистика : значение тестовой статистикиt (в наших обозначениях – это t 0 ). Вычисление t 0 приведено в ячейке Е15 ;
- P(T Δ 0 . Эквивалентная формула =1-СТЬЮДЕНТ.РАСП(t 0 ; n-1;ИСТИНА) ;
- t критическое одностороннее : Верхний α-квантиль t-распределения. Эквивалентная формула =СТЬЮДЕНТ.ОБР(1- α; n-1) ;
- P(T Δ 0 . Эквивалентная формула =2*(1-СТЬЮДЕНТ.РАСП(ABS(t 0 ); n-1;ИСТИНА)) ;
- t критическое двухстороннее: Верхний α/2-Квантиль t-распределения . Эквивалентная формула =СТЬЮДЕНТ.ОБР(1- α/2; n-1) .
СОВЕТ : О проверке других видов гипотез см. статью Проверка статистических гипотез в MS EXCEL .
Проверка наличия связи между переменными
В статистическом анализе обычно различают следующие виды связей между факторами:
- функциональные;
- стохастические;
- статистические.
Функциональная связь — связь между переменными, при которой каждому значению одной величины соответствует строго определенное значение другой, то есть Y = F(X1, X2, …, Xn). Исследованием таких связей статистика не занимается.
Стохастическая связь — соответствует ситуации, когда изменение значения одной переменной ведет к изменению закона распределения другой. Для дискретного случая это означает, что каждому значению одной переменной соответствует набор значений другой, причем каждое значение имеет свою вероятность реализации. В данной книге не описаны методы, которые используются для изучения этих связей. В практических исследованиях наиболее известным видом таких связей являются марковские цепи.
Статистическая связь означает, что значение одной переменной изменяется в среднем в зависимости от того, какие значения принимает другая. Очень часто рассматривается как функциональная зависимость со случайной ошибкой, то есть
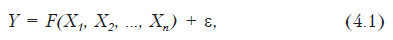
Где F(X1, X2,…, Xn) — функция, описывающая зависимость Y от совокупности независимых переменных X1,X2, …, Xn, а e — некоторая случайная ошибка. Известно, что сумма константы и случайной величины является случайной величиной. В связи с этим значения Y, рассчитанные по указанной формуле, будут вследствие добавления случайной величины e также случайными величинами.
В данном разделе рассматриваются методы, предназначенные для анализа (но не описания) статистических связей.
4.1. Выбор метода проверки наличия связи
Эти методы предназначены для проверки гипотез о наличии связей между переменными. Выбор метода зависит от шкал измерения, в которых измеряются анализируемые переменные, и от их количества (см. табл. 4.1).
Таблица 4.1
Выбор метода анализа связи между признаками
Шкалы измерения
Нормальный
Нормальный для зависимой переменной
Из таблицы видно, что корреляционный анализ (параметрический или непараметрический) применяется в тех случаях, когда переменные измеряются в шкалах отношений, интервалов или порядка.
Дисперсионный анализ используют, если зависимая переменная измеряется в шкале отношений, интервалов или порядка, а влияющие переменные имеют нечисловую природу (шкала наименований).
Анализ таблиц сопряженности используется, когда влияющие переменные имеют нечисловую природу (шкала наименований), а зависимая переменная показывает количество наблюдений (% или долю от общего количества), для которых признак присутствует или отсутствует.
4.2. Корреляционный анализ
Знания следствия зависит от знания причины
Корреляционная связь представляет собой частный случай статистической связи , то есть математическое ожидание переменной Y, при условии, что случайная величина Х принимает значение х.
4.2.1. Параметрическая корреляция
(коэффициент корреляции Пирсона)
Предпосылка
- Все наблюдения взаимно независимые.
- Наблюдения имеют нормальный закон распределения.
Описание метода
Значение коэффициента корреляции вычисляется по формуле:

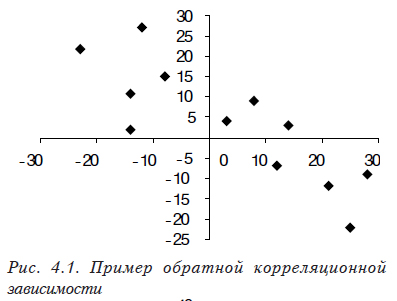
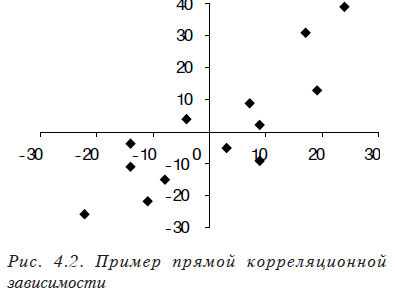
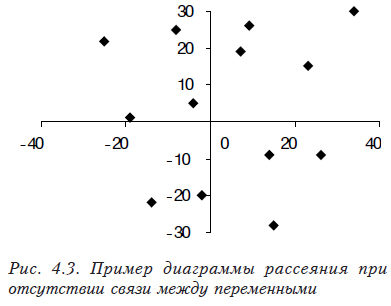
Коэффициент корреляции показывает тесноту линейной связи между двумя выборками случайных величин. Его значение изменяется от –1 (рис. 4.1, ), что соответствует обратной связи, до +1 (рис. 4.2, ), соответствующее прямо пропорциональной связи (значение 0, означает отсутствие связи (рис. 4.3).
Значимость коэффициента корреляции. Поскольку мы имеем дело со случайными величинами, одной величины коэффициента парной корреляции для вывода недостаточно. Необходимо проверить, значимо ли он отличается от нуля. Это можно сделать с помощью критерия Стьюдента. Фактически проверяется гипотеза о равенстве коэффициента корреляции нулю. Для этого рассчитывается критериальное значение по формуле
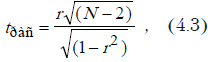
где r — значение коэффициента корреляции, а N — количество наблюдений.
Если расчетное значение t () больше табличного, взятого с N–2 степенями свободы, нулевая гипотеза отвергается. Это означает, что коэффициент корреляции значимо отличается от нуля (с выбранным уровнем значимости). Полуширина доверительного интервала для коэффициента корреляции определяется по формуле

где N — число наблюдений, по которым рассчитывается коэффициент корреляции; r — значение коэффициента корреляции; .— табличное значение критерия Стьюдента, взятого с N-2 степени свободы.
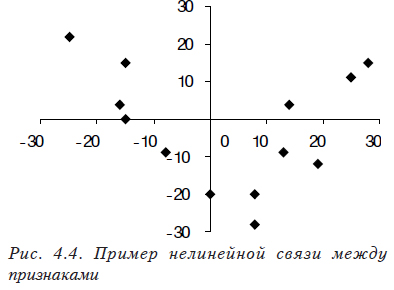
Примечание:
- При использовании корреляционного анализа следует помнить, что коэффициент корреляции показывает тесноту только линейной связи. Поэтому, в том случае, когда зависимости более сложные, чем линейные, коэффициент корреляции будет показывать отсутствие связи. Например, на рис. 4.4 хорошо видно, что между переменными существует зависимость второго порядка. Рассчитанный коэффициент корреляции будет близок к нулю, и проверка покажет, что он статистически незначим. Поэтому для определения сложных зависимостей между переменными используются другие статистические методы, наиболее часто и эффективно — регрессионный анализ, который будет рассмотрен в следующих разделах.
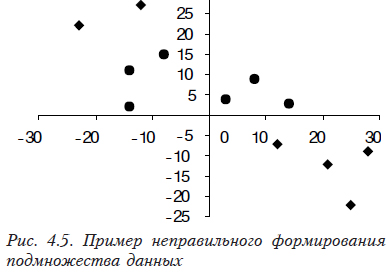
- Следует также помнить, что при наличии физической связи между переменными следствием обычно является наличие и корреляционной связи. Однако, если выборка нерепрезентативная, то есть содержит не те реализации случайной величины, которые позволяют определить зависимость, коэффициент корреляции будет близок к нулю и незначим. Например, рис.5 повторяет рис. 4.1, на котором присутствует обратная связь с коэффициентом корреляции близким к –1. В том случае, если выборка будет включать выделенные (круглые) точки, являющиеся подмножеством нашей выборки, то коэффициент парной корреляции будет близок к нулю.
- С другой стороны, наличие статистической связи необязательно означает наличие физической. Причиной может быть нерепрезентативность выборки, как в предыдущем случае, или же тот факт, что исследуемая переменная Х не зависит от переменной Y, но обе они зависят от переменной Z. В этом случае при проведении корреляционного анализа мы видим связь между Х и Y, которая в физическом смысле отсутствует. Рассмотрим известный пример такой ситуации[1]. В Стокгольме в 60-е годы подсчитали коэффициент корреляции между количеством прилетающих аистов и количеством рождающихся детей. Он оказался близок к единице и статистически значим. Дело в том, что количество аистов зависело от количества отдельных домохозяйств, а количество детей и домохозяйств — от количества семей. И еще пример: в одном из штатов США установили наличие положительной корреляционной связи между количеством церквей и количеством баров — чем больше церквей, тем больше баров [5]. На самом деле обе эти величины зависели от размера города. Следует помнить о возможности существования аистов, приносящих младенцев, так как в большинстве случаев, возникающих при решении практических задач, абсурдность наличия или отсутствия физической связи неочевидна.
- Из наличия корреляционной связи, которая служит отражением действительно существующей физической связи, следует делать правильные выводы. Ведь из наличия обратной корреляционной связи между температурой воздуха на улице и количеством топлива, расходуемым на обогрев помещения, вовсе не следует вывод: «чем больше топишь печь , тем холоднее становится на улице».
Пример[2]
Взаимосвязь между объемом циркулирующей крови (ОЦК), объемом циркулирующей плазмы (ОЦП) и гематокритом (Ht) выражается формулой
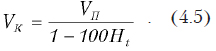
Получены экспериментальные данные — 21 наблюдение для этих величин. Нам необходимо определить степень зависимости между ними, используя коэффициент корреляции. Набрав исходные (столбцы А,В,С рис. 4.8) в меню выбираем Сервис, а затем Анализ данных. Появится окно выбора метода обработки (рис. 4.6).
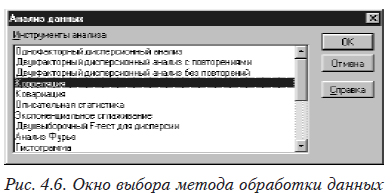
В этом окне выбираем Корреляция — появится окно задания исходных данных для корреляции (рис. 4.7).
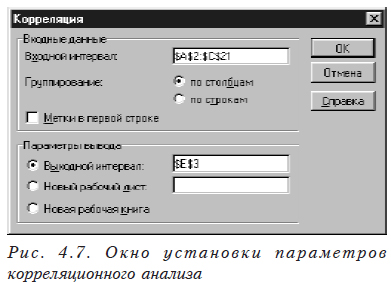
В нем необходимо задать исходные данные для корреляционного анализа.
Входной интервал — необходимо отметить таблицу, в которой размещены исходные данные (левая верхняя ячейка и правая нижняя).
Группирование — необходимо указать, в строках или столбцах находятся данные, относящиеся к одному уровню фактора (в данной ситуации по столбцам).
Выходной интервал — вводится ссылка на ячейку, расположенную в левом верхнем углу выходного диапазона (мета, куда вы хотите поместить результат). Размеры выходной области будут рассчитаны автоматически.
Новый рабочий лист — выбирается в случае, если вы хотите поместить результаты работы на другой лист; при этом в соответствующем окошке указывается диапазон размещения результатов аналогично предыдущему пункту.
Новая рабочая книга — выбирается в случае, когда вы хотите поместить результаты в новую книгу; результаты дисперсионного анализа при этом будут размещаться на первом листе новой книги, начиная с ячейки А1.
После установки параметров и нажатия ОК мы получаем матрицу коэффициентов парной корреляции (рис. 4.8).

Никакого анализа на самом деле эта функция не выполняет. Коэффициенты корреляции можно получить и другим способом. Если вы наберете вызовы функций =КОРРЕЛ(A2:A21;B2:B21); =КОРРЕЛ(A2:A21;C2:C21) и =КОРРЕЛ(B2:B21;C2:C21), то в ячейках, где они набраны, получите значения коэффициентов корреляции столбца А с В, А с С и В с С соответственно.
Для принятия решения о наличии значимой связи между переменными необходимо проверить значимость коэффициентов корреляции. Для этого для каждого коэффициента рассчитывается значение t-критерия. В ячейках А25, В25, С25 помещаем формулы =A23*КОРЕНЬ(ЧСТРОК(A2:A22))/КОРЕНЬ(1-A23*A23);
=B23*КОРЕНЬ(ЧСТРОК(B2:B22))/КОРЕНЬ(1-B23*B23) и =C23*КОРЕНЬ(ЧСТРОК(C2:C22))/КОРЕНЬ(1-C23*C23), которые рассчитывают эти значения для rab, rac и rbc соответственно. Критическое значение помещаем в ячейку А27 посредством вызова функции =СТЬЮДРАСПОБР(0,05;ЧСТРОК(A2:A22)-2). Здесь 0,05 — уровень значимости, а ЧСТРОК(A2:A22)-2 — число степеней свободы. Поскольку расчетное значение t-критерия больше критического только для коэффициента корреляции между ОЦП и ОЦК (4,785983 против 2,093025), то этот коэффициент является значимым (остальные два – незначимы).
В ряде случаев для оценки коэффициента корреляции необходимо рассчитывать доверительный интервал. Сначала по формуле (ячейка А27) определяем полуширину доверительного интервала, воспользовавшись формулой =A26*(1-A23*A23)/КОРЕНЬ(ЧСТРОК(A2:A22)). Затем можно найти его нижнюю и верхние границы (=A23-A27 и =A23+A27 соответственно для первого коэффициента корреляции). Результаты приведены на рис. 4.9.

4.2.2. Частная корреляция
Для того чтобы влияние корреляционной связи между двумя переменными «очистить» от возможного влияния третьей, введено понятие частной корреляции. По ней коэффициент корреляции между двумя переменными X и Z определяется по формуле
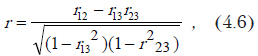
Здесь r12, r13 и r23 — коэффициенты парной корреляции между переменными X и Y, X и Z, Y и X соответственно. При использовании частного коэффициента корреляции необходимо помнить:
- взаимовлияющих переменных может быть не три, а сколь угодно много;
- вы можете не знать о всех взаимовлияющих переменных;
- некоторые авторы утверждают, что для корректного использования частного коэффициента корреляции необходимо наличие многомерного нормального закона распределения, однако проверить выполнение этой предпосылки практически нереально.
Пример
Рассмотрим пример из раздела 4.2.1. В этом примере коэффициент корреляции между ОЦП и ОЦК не очень большой, хотя между ними существует функциональная связь. Возможно это обусловлено влиянием на данные третьей переменной. Попробуем получить коэффициент корреляции между ОЦП и ОЦК, «очистив» его от влияния Ht. Для этого наберем формулу =(A23-B23*C23)/КОРЕНЬ((1-B23*B23)*(1-C23*C23)). В результате получим значение частного коэффициента корреляции между ОЦП и ОЦК — 0,984651. Это значение очень близко к 1 и отвечает нашему интуитивному представлению о функциональной связи.
4.2.3. Ранговая корреляция
Ранговая корреляция является аналогом парной корреляции для тех случаев, когда величины, наличие связи между которыми нужно проверить, представлены не в шкале отношений, а в какой-либо другой. Наиболее часто такая ситуация возникает, если мы имеем дело с субъективными оценками объективных явлений, которые нельзя измерить, то есть с экспертными оценками. Кроме того, ранговая корреляция используется также в случаях, когда закон распределения изучаемых переменных не является гаусовским (нормальным).
Коэффициенты корреляции называются ранговыми, так как перед вычислением значения переменных превращают в ранги. Для этого имеющиеся значения переменных располагают в ранжированном[3] ряду (значения могут в исходном состоянии являться таким ранжированным рядом). Затем каждому значению присваивается ранг от 1 до N, где N — количество анализируемых объектов. В том случае, если несколько элементов имеют один и тот же ранг, то каждому из них присваивается среднее от занимаемых ими мест (см. 3.3.1).
Допущения
- Все наблюдения взаимно независимы.
- Все значения наблюдений извлечены из одной и той же двумерной генеральной совокупности, то есть Х и У одинаково распределены.
Существует несколько различных способов вычисления коэффициентов ранговой корреляции. Наиболее часто используется коэффициент корреляции Спирмена (r, иногда обозначается rs) и коэффициент Кендалла (t).
Коэффициент ранговой корреляции Спирмена
Коэффициент Спирмена вычисляется по формуле
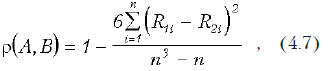
где R1i и R2i — ранги i-го объекта для каждой из сравниваемых переменных. Значение r не зависит от способа упорядочения рангов.
Очевидно, что этот коэффициент является полным аналогом коэффициента парной корреляции — после преобразования его можно представить в виде:
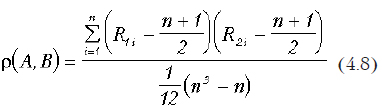
При наличии совпадающих значений (связок) знаменатель уменьшается на величину

где L1 и L2 — количество связок в T1i и T2j — размеры связок (количество элементов в них).
Для проверки значимости коэффициента ранговой корреляции Спирмена при n > 9 можно пользоваться критерием Стьюдента (как и для обычного коэффициента парной корреляции). Проверка значимости для общего случая выполняется с помощью специальных таблиц (см. приложение Е).
Пример
Допустим, нам необходимо проверить, существует ли статистически значимая связь между двумя факторами (признаками), которые являются параметрами гемостазу крови, полученной из локтевой вены у больных со стабильной стенокардией, или эти факторы являются независимыми. Возьмем два фактора, определяющих функциональную активность тромбоцитов: тромбопластиновый (ТФ3) и антигепариновый (ТФ4). Данные и результаты вычислений приведены в табл. 4.2.
Таблица 4.2
Результаты исследования крови у больных со стабильной стенокардией
| ТФ3 | ТФ4 | Ранги ТФ3 (R1) | Ранги ТФ4 (R2) | (R1i – R2i) 2 |
| 55 | 72 | 11 | 4 | 49 |
| 24 | 77 | 2 | 5,5 | 12,25 |
| 40 | 85 | 8 | 11 | 9 |
| 60 | 90 | 12 | 13 | 1 |
| 39 | 82 | 7 | 9 | 4 |
| 28 | 77 | 4 | 5,5 | 2,25 |
| 22 | 60 | 1 | 2 | 1 |
| 37 | 79 | 6 | 7 | 1 |
| 72 | 88 | 13 | 12 | 1 |
| 42 | 80 | 10 | 8 | 4 |
| 33 | 66 | 5 | 3 | 4 |
| 41 | 83 | 9 | 10 | 1 |
| 25 | 46 | 3 | 1 | 4 |
| Распределение не нормальное | Распределение нормальное | |||
| Значение суммы квадратов разностей рангов | 93,5 | |||
| Размер выборки | 13 | |||
| Вычисленное значение коэффициента ранговой корреляции Спирмена | 0,743132 | |||
| Уровень значимости a | 0,05 | |||
| Критическое значение по таблице (a = 0,05; N = 13) | 0,412 | |||
Для того, чтобы получить приведенные в табл. 4.2 результаты, необходимо выполнить следующие действия.

- Проверим обе выборки на соответствие их значений нормальному закону распределения. Так как мы располагаем количественными данными, то проверка необходима для того, чтобы определить, каким образом проверять статистическую независимость данных факторов (признаков). Применим пользовательскую функцию NORMSAMP_1(R_1). С этой целью в ячейки B16 и C16 введем соответственно функции =NORMSAMP_1(B3:B15) и =NORMSAMP_1(C3:C15). Результаты покажут, что значения первой выборки не соответствуют нормальному закону распределения (NO_NORM), а второй — соответствуют (NORM). Этот факт позволяет для определения независимости двух признаков (факторов) применить метод ранговой корреляции.
- Построим ранги для первой и второй выборок при помощи пользовательской функции Rank1(x; R_1, t) (см. 3.3.1). Для этого в ячейку D3 введем формулу =Rank1(B3;$B$3:$B$15;0), а в ячейку Е3 — =Rank1(C3;$C$3:$C$15;0). После этого согласованно размножим данные формулы по соответствующим столбцам. В результате этих действий получим ранги первой и второй выборок соответственно (см. рис. 4.10).
- В столбце F получим частичные квадраты разностей рангов первой и второй выборок построчно (R1i – R2i). Для этого в ячейку F3 введем формулу =(D3-E3)^2 и согласованно размножим ее по столбцу.
- Просуммируем квадраты разностей рангов по столбцу F. Для этого в ячейку F17 введем формулу =СУММ(F3:F15). В нашем случае сумма квадратов разностей рангов будет равна 93,5.
- Вычислим коэффициент ранговой корреляции Спирмена, введя в ячейку F19 формулу =1-(6*F17)/(F18^3-F18). Искомый коэффициент будет равен 0,743132.
- Проверим полученный коэффициент ранговой корреляции Спирмена (0,743132) на его статистическую значимость. Для этого, задав уровень значимости a = 0,05, сравним его с табличным значением (приложение Г), которое для такого уровня значимости и размера выборок равно 0,478. Так как вычисленный нами коэффициент ранговой корреляции больше критического (табличного) значения, то нулевая гипотеза о независимости этих двух выборок отвергается. То есть анализируемые нами выборки связаны и довольно тесно.
Коэффициент корреляции Кендалла
Вычисляется по формуле
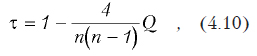
где n — количество наблюдений, а Q — число несогласованных пар (Xj,Yj) и (Xi,Yi) для всех комбинаций i и j. Пары называются несогласованными, если для них выполняется следующее условие:
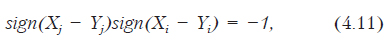
где sign — означает «знак». Это функция принимает значение +1 для положительного числа и –1 для отрицательного. Другими словами, приведенное условие означает, что увеличение Х приводит к уменьшению У, и наоборот.
Для проверки значимости коэффициента существуют специальные таблицы (см. приложение Ж).
Пример
Вычислим коэффициент ранговой корреляции Кэндалла, воспользовавшись данными из примера в 4.3.1 (табл. 4.2).
- Проверим обе выборки на соответствие их значений нормальному закону распределения. Так как мы располагаем количественными данными, то проверка необходима для того, чтобы определить, каким образом проверять статистическую независимость данных факторов (признаков). Применим пользовательскую функцию NORMSAMP_1(R_1). С этой целью в ячейки B16 и C16 введем соответственно функции =NORMSAMP_1(B3:B15) и =NORMSAMP_1(C3:C15). Результаты покажут, что значения первой выборки не соответствуют нормальному закону распределения (NO_NORM), а второй — соответствуют (NORM). Этот факт позволяет для определения независимости двух признаков (факторов) применить метод ранговой корреляции.
- Построим ранги для первой и второй выборок при помощи пользовательской функции Rank1(x; R_1, t) (см. 3.3.1). Для этого в ячейку D3 введем формулу =Rank1(B3;$B$3:$B$15;0), а в ячейку Е3 — =Rank1(C3;$C$3:$C$15;0). После этого согласованно размножим данные формулы по соответствующим столбцам. В результате этих действий получим ранги первой и второй выборок соответственно (см. рис. 4.11).
- Вычислим количество инверсий среди рангов второй выборки при условии, что ранги первой выборки согласовано с ней упорядочены. Это означает, что если бы вторая выборка состояла из значений , то в ней имелись бы такие инверсии. Для первого элемента: (4 раньше 3) — одна инверсия, (4 раньше 1) — вторая и (4 раньше 2) — третья. Для второго элемента: (3 раньше 1) — одна инверсия и (3 раньше 2) — вторая. Для третьего элемента: (1 раньше 2) — инверсия отсутствует. Таким образом, в этой маленькой выборке число инверсий (Q) равно 3+2 = 5.
В нашем примере вычислять подобным образом количество инверсий довольно неудобно, поэтому лучше определить пользовательскую функцию (см. 1.16) подсчета инверсий во второй выборке при условии, что первая согласованно с ней упорядочена. Это функция Candall_K(R_1; R_2), в которой R_1 — массив рангов первой выборки и R_2 — массив рангов второй выборки. Текст функции приведен ниже.
Function Candall_K(R_1 As Object, R_2 As Object) As Double
‘Вычисление количества инверсий во второй выборке
‘при условии, что первая выборка упорядочена
‘R_1 — 1-й массив (1-я анализируемая выборка)
‘R_2 — 2-й массив (2-я анализируемая выборка)
N_el = R_1.Count ‘вычисление количества элементов в выборке
‘Формированние временных массивов
For i = 1 To N_el
‘ранжирование первой выборки
‘с согласованной перестановкой второй
Counter = 1 ‘Инициализация индикатора перестановок.
While Counter = 1 ‘ Анализ значения индикатора перестановок.
Counter = 0 ‘Обнуление индикатора перестановок.
For i = 1 To N_el — 1
If R_t1(i) > R_t1(i + 1) Then
tp = R_t1(i): R_t1(i) = R_t1(i + 1): R_t1(i + 1) = tp
tp2 = R_t2(i): R_t2(i) = R_t2(i + 1): R_t2(i + 1) = tp2
‘Подсчет количества инверсий во второй выборке
For i = 1 To N_el — 1
For j = i To N_el — 1
После того, как функция Candall_K(R_1; R_2) будет определена, введите в ячейку Е18 формулу =Candall_K(D3:D15;E3:E15). В результате получим значение количества инверсий Q = 78 (см. рис. 4.11).

- Вычислим коэффициент ранговой корреляции Кендалла, введя в ячейку Е19 формулу =1-4*E18/(E18*(E17-1)). Искомый коэффициент будет равен 0,666667.
- Проверим полученный коэффициент ранговой корреляции Кендалла (0,666667) на его статистическую значимость. Для этого, задав уровень значимости a = 0,05, сравним его с табличным значением (приложение Д), которое для такого уровня значимости и размера выборок равно 0,359. Так как вычисленный нами коэффициент ранговой корреляции больше критического (табличного) значения, то нулевая гипотеза о независимости этих двух выборок отвергается. То есть анализируемые нами выборки связаны и довольно тесно.
Замечания к коэффициентам Кендалла и Спирмена
- Рассчитанные для одних и тех же данных значения коэффициентов Кендалла и Спирмена не совпадают, кроме крайних значений (–1,0,1).
- Асимптотически эти коэффициенты сходятся.
Конкордация
В том случае, когда необходимо сравнение не двух переменных, а большего количества (например, при выяснении согласованности мнений группы экспертов) используется коэффициент конкордации, предложенный Кендаллом:
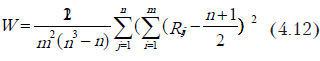
где n — количество анализируемых объектов, m — количество экспертов, Rij — ранг j-го объекта, который присвоен ему i-ым экспертом.
Следует обратить внимание на отличие в значениях коэффициента конкордации от коэффициента корреляции. Если мнения экспертов полностью противоположны, коэффициент конкордации равен нулю (W = 0), но коэффициент корреляции в этом случае будет равен –1.
При наличии связок (одинаковых значений) формула приобретает следующий вид
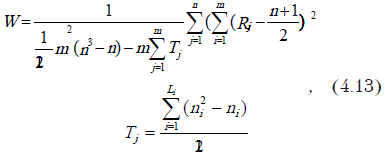
где , при этом Li – число связок, ni количество элементов в i-й связке для j-го эксперта.
Значимость коэффициента конкордации при малом количестве экспертов проверить затруднительно. Для малых значений существуют неполные таблицы, например таблица 6.10 в [1], фрагмент из которой приведен ниже.
| N=3;m=10 | N=5;m=3 | ||
| 50 | 0,092 | 56 | 0,096 |
| 62 | 0,046 | 62 | 0,056 |
| 104 | 0,0034 | 78 | 0,053 |
| 126 | 0,0008 | 86 | 0,0009 |
Для получения критического значения коэффициента конкордации необходимо взятое из таблицы значение подставить в формулу: 12*S/m 2 (n 3 –n).
Если же количество экспертов больше 7, то возможно сравнение значения выражения n(m-1)W с табличным значением, распределенным по c 2 с N-1 степенями свободы.
Пример
Есть 7 объектов, каждый из которых оценивается независимо тремя экспертами по десятибальной шкале (см. рис. 4.12, ячейки В2–Е9). Необходимо определить степень согласованности мнений экспертов – коэффициент конкордации.
- Рассчитываем столбцы для выражения . Для этого в ячейку G3 помещаем формулу =Rank1(C3;C$3:C$9;1)-(ЧСТРОК(C$3:C$9)-1)/2. Затем размножаем ее от G3 до I
- Формируем столбец построчных сумм квадратов. Для этого в ячейку J3 помещаем формулу =СУММ(G3:I3)*СУММ(G3:I3), которую затем размножаем перетягиванием до
- Находим сумму по столбцу, для чего в ячейку J10 вводим формулу =СУММ(J3:J9).
- В ячейки J11 и J12 вводим число экспертов m =ЧИСЛСТОЛБ(C3:E3) и число объектов n =ЧСТРОК(C3:C9).
- Рассчитываем значение коэффициента конкордации
Как видно из величины коэффициента конкордации (0,674603), согласованность между экспертами существует, хотя и не очень большая (см. рис. 4.12).

4.3. Дисперсионный анализ
В задачах, которые решаются дисперсионным анализом присутствует отклик числовой природы, на который воздействует несколько переменных, имеющих номинальную природу. Например, несколько видов рационов откорма скота или два способа их содержания и т.п. Считается, что мы можем рассматривать модель

то есть рассеивание равно изменению, зависящему от одного фактора , плюс рассеивание, зависящее от второго фактора , плюс случайная ошибка . Тогда общее рассеяние состоит из нескольких компонент: s 2 = s 2 a + s 2 b + s 2 . Выделив соответствующие компоненты, с помощью критерия Фишера можно определить их значимость.
4.3.1. Параметрический дисперсионный анализ
Однофакторная задача
Для простейшего случая таблица исходных данных имеет следующий вид:
Таблица 4.4
Общий вид исходных данных для однофакторного дисперсионного анализа
| Номера элементов совокупностей | 1 | 2 | … | j | … | n |
| Номера совокупностей | ||||||
| 1 | X11 | X12 | X1j | X1n | ||
| 2 | X21 | X22 | X2j | X2n | ||
| … | … | … | ||||
| I | Xi1 | Xi2 | Xij | Xjn | ||
| … | … | … | ||||
| m | Xm1 | Xm2 | Xmj | Xmn |
Это может быть, например, m партий сырья, и из каждой взято n образцов. Необходимо выяснить, изменяются ли показатели сырья от партии к партии. Мы можем также рассматривать какие-то характеристики лабораторных животных (m групп по n животных в каждой), чтобы выяснить, отличаются ли их характеристики от группы к группе. Смысл в том, чтобы сравнить дисперсию, обусловленную случайными причинами, с дисперсией, вызываемой наличием некоторого фактора. Если они значимо различаются, то фактор оказывает статистически значимое влияние на исследуемую переменную.
Отличие считается значимым, если расчетное значение критерия Фишера (отношение межгрупповой дисперсии к внутригрупповой) будет больше табличного, взятого с заданным уровнем значимости и степенями свободы (m-1) и m(n-1).
Межгрупповая дисперсия рассчитывается по формуле
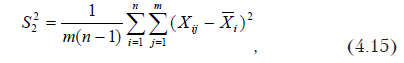
Внутригрупповая —

Здесь — общее среднее, а .
Для дисперсионного анализа в английском языке принято сокращение ANOVA (ANalys Of VAriances, что означает «дисперсионный анализ»), которое используется и в некоторых русскоязычных источниках.
Для однофакторного случая результаты расчетов принято представлять в следующем виде (см. табл. 4.5).
Таблица 4.5
Представление результатов расчета однофакторного дисперсионного анализа
Здесь внутригрупповая дисперсия характеризует влияние случайной составляющей, а межгрупповая — влияние изучаемого фактора.
Пример
Пример условный, но базируется на реальной задаче, приведенной в [6], в которой рассматривается влияние погоды на изменение продолжительности систолической остановки сердца при введении бария хлорида. Допустим (см. таблицу 4.6), у нас есть набор данных, которые характеризуют продолжительность реакции лабораторных животных на некоторый препарат при различных погодных условиях.
Таблица 4.6
Исходные данные примера однофакторного дисперсионного анализа
| Экспериментальные животные | ||||
| Погода | 1 | 2 | 3 | 4 |
| Тихая погода | 13,8 | 11 | 13,7 | 12,1 |
| Ветер и вьюга | 16 | 12,2 | 15,8 | 14,3 |
После того как наши данные набраны в электронной таблице (строки 2–4 и столбцы А — Е), входим в меню, выбирая последовательно Сервис, а затем Анализ данных, в результате чего появится окно (см. рис.4.13).
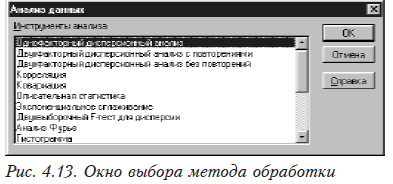
В этом окне необходимо выбрать «Однофакторный дисперсионный анализ». После чего откроется новое окно (см. рис. 4.14).
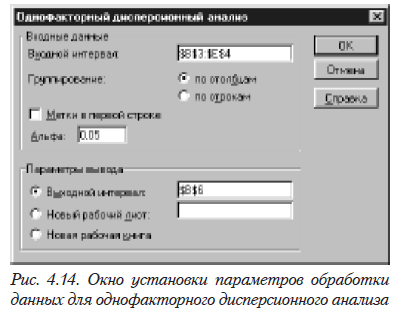
В этом окне необходимо задать исходные данные для дисперсионного анализа.
Входной интервал — необходимо отметить таблицу, в которой размещены исходные данные (левая верхняя ячейка и правая нижняя).
Группирование — необходимо указать, в строках или столбцах находятся данные, относящиеся к одному уровню фактора (в данной ситуации — в строках).
Альфа — требуемый уровень значимости.
Выходной интервал — вводится ссылка на ячейку, расположенную в левом верхнем углу выходного диапазона (мета, куда вы хотите поместить результат). Размеры выходной области будут рассчитаны автоматически.
Новый рабочий лист — выбирается в том случае, когда вы хотите поместить результаты работы на другой лист; при этом в соответствующем окошке указывается диапазон размещения результатов аналогично предыдущему пункту.
Новая рабочая книга — выбирается, если вы хотите поместить результаты в новую книгу; результаты дисперсионного анализа при этом будут размещаться на первом листе новой книги, начиная с ячейки А1.
Исходные данные и результаты для нашего примера приведены на рисунке 4.15.

Между группами — межгрупповая сумма квадратов;
Внутри групп — внутригрупповая сумма квадратов;
Итого — общая (полная) сумма квадратов;
df — число степеней свободы;
MS — средний квадрат (фактически дисперсия);
F — расчетное значение критерия Фишера;
P-Значение — расчетное значение минимальной значимости;
F критическое — критическое значение распределения Фишера.
В нашем примере расчетное значение критерия Фишера (3,026) меньше критического (5,99). Из этого следует, что мы принимаем гипотезу об отсутствии влияния погоды на фармакологические реакции при принятом уровне значимости 0,05.
P-Значение в нашем примере равно 0,133. Поскольку оно достаточно велико, нет оснований отвергать гипотезу о равенстве дисперсий.
Замечание к дисперсионному анализу в Excel
В функции дисперсионного анализа в Excel проверяется следующая альтернативная гипотеза: дисперсия числителя больше дисперсии знаменателя, то есть односторонняя гипотеза. При этом не учитывается возможность ситуации, когда F-расчетное меньше 1. В таком случае выполняемая в Excel односторонняя проверка с критическим значением распределения Фишера неправомочна (см. 3.2.1). Для корректной проверки необходимо или пересчитать расчетное и критическое значение критериев Фишера и после этого выполнить их сравнение или же рассчитать нижнюю критериальную границу.
Допустим, что подобная ситуация возникла в нашем примере (то есть расчетное значение критерия меньше 1). Тогда новое значение расчетного значения F-критерия определяется по формуле =1/F16, а соответствующее ему критическое значение — из функции = FРАСПОБР(0,05;D17;D16). Если новое расчетное значение больше нового критического, то гипотеза о равенстве дисперсий отклоняется и принимается гипотеза о том, что внутригрупповая дисперсия больше межгрупповой.
Для второго варианта проверки расчетное критическое значение не изменяется, но рассчитываются новые значения для критериальных границ: нижней =FРАСПОБР(0,972; D16;D17) и верхней = FРАСПОБР(0,972; D16;D17). Если расчетное критическое значение находится внутри этих границ, то гипотеза об отсутствии различия принимается. Если расчетное значение больше верхнего или меньше нижнего, тогда принимается альтернативная гипотеза, которая в данном случае звучит так: межгрупповая и внутригрупповая дисперсия различаются статистически значимо.
Однофакторная задача с неравномерным числом испытаний
Достаточно часто возникает ситуация, при которой число опытов для разных значений уровня фактора различно. Это может быть связано, например, с тем, что часть лабораторных животных во время эксперимента погибла или не проявила требуемой реакции и пр.
Тогда общая дисперсия определяется по формуле
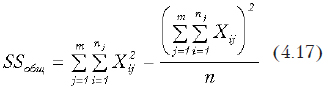
где Xij — значение соответствующего наблюдения аналогично указанному в предыдущем параграфе, nj — количество наблюдений для j-го уровня фактора; — общее количество наблюдений.
Межгрупповая (вызванная влиянием фактора) сумма квадратов определяется по формуле
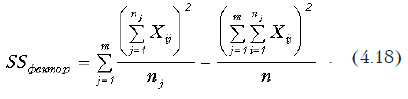
Остаточная сумма находится как разница между общей и факторной
Затем находятся остаточная (внутригрупповая) и факторная (межгрупповая) дисперсии , а также расчетное значение критерия Фишера .
Примечание:
- В однофакторном дисперсионном анализе Excel данный вариант не предусмотрен.
Пример
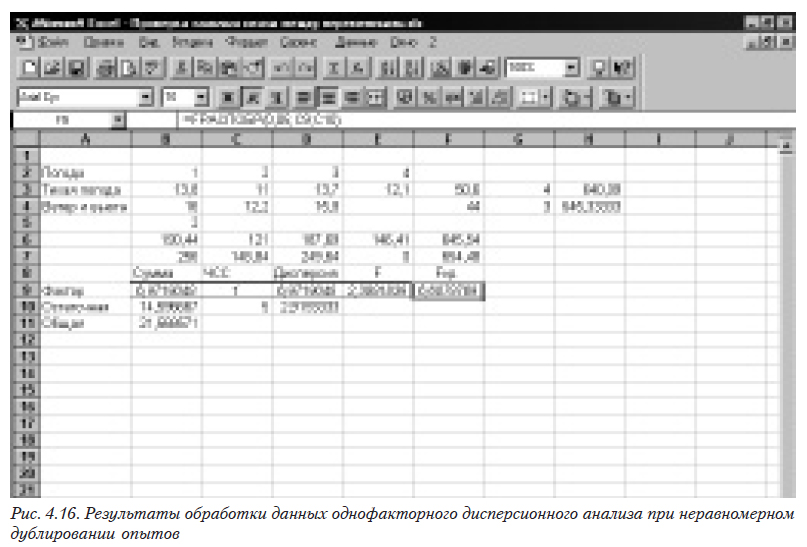
Рассмотрим пример, использованный в предыдущей задаче, но с меньшим количеством (равным трем) наблюдений для погоды.
Проведем вспомогательные вычисления.
Таблица 4.7
Формулы вспомогательных вычислений
| Ячейка | Содержание | Комментарий |
| В5 | =ЧСТРОК(B3:B4) | Число уровней варьирования фактора |
| от В6 до Е7 | =B3*B3 в В6, остальные размножаются | Квадраты значений наблюдений |
| от F3 до F4 | =СУММ(B3:E3) в F3, далее размножается | Сумма значений наблюдений |
| от G3 до G 4 | =ЧИСЛСТОЛБ(B3:E3) в G3, далее размножается | Количество наблюдений в каждой строке |
| от H3 до H4 | =F3*F3/G3 в H3, далее размножается | Квадраты сумм, деленные на число наблюдений |
После этого мы можем рассчитывать значения, которые непосредственно входят в таблицу дисперсионного анализа. В таблице 4.8 приведены формулы (с соответствием размещения по ячейкам), по которым и выполняется расчет всех необходимых промежуточных значений. Как обычно, однотипные формулы набираются один раз, а затем размножаются (см. раздел 1).
Таблица 4.8
Формулы для формирования вспомогательной таблицы
| A | B | C | D | E | |
| 9 | = СУММ(H3:H4)-СУММ(F3:F4)*СУММ(F3:F4)/СУММ(G3:G4) | =ЧСТРОК(B3:B4)-1 | =B9/C9 | =D9/D10 | =FРАСПОБР(0,05;C9;C10) |
| 10 | =B11-B9 | =СУММ(G3:G4)-B5 | =B10/C10 | =D9/D10 | |
| 11 | =СУММ(F6:F7)-СУММ(F3:F4)*СУММ(F3:F4)/СУММ(G3:G4 |
В табл. 4.9, соответствующей по размещению табл. 4.7, приведено описание содержания ячеек.
Таблица 4.9
Описание содержимого ячеек для таблицы 4.8
| A | B | C | D | E | |
| 9 | Сумма квадратов, обусловленная влиянием фактора | Число степеней свободы для дисперсии, обусловленной влиянием фактора | Дисперсия, обусловленная влиянием фактора | Расчетное значение критерия Фишера | Критическое значение распределения Фишера |
| 10 | Сумма квадратов, обусловленная влиянием случайной составляющей | Число степеней свободы для дисперсии, обусловленной влиянием случайной составляющей | Дисперсия, обуслов-ленная влиянием случайной составляющей | ||
| 11 | Общая сумма квадратов |
Результаты работы приведены на рис. 4.16. Из него видно, что, поскольку расчетное значение критерия Фишера меньше критического, следовательно влияние фактора отсутствует.
Двухфакторная задача с равномерным числом наблюдений в ячейке
В такой задаче есть два фактора, измеряемых в шкале наименований, которые влияют на отклик. Общий вид представления данных для такой задачи содержится в табл. 4.10.
Таблица 4.10
Общий вид представления данных для двухфакторного дисперсионного анализа
Здесь Х111, Х112,… Хmnk — наблюдавшиеся значения исследуемой переменной; — среднее значение в ячейке; — среднее значение по строке; — среднее по столбцу; — общее среднее. Результаты расчетов обычно представляются в таблице следующего вида.
Таблица 4.11
Форма представления результатов двухфакторного дисперсионного анализа
| Компонента дисперсии | Суммы квадратов | Число степеней свободы | Дисперсии |
| Между средними по строкам (по фактору А) | n-1 | ||
| Между средними по столбцам (по фактору В) | m-1 | ||
| Взаимодействие | (m-1)(n-1) | ||
| Остаточная | nm(k-1) | ||
| Полная | nmk-1 |
Здесь — характеризует влияние фактора А; — влияние фактора В; — совместное влияние обоих факторов; — влияние случайных факторов, которые невозможно отнести ни к А, ни к В. Необходимо проверить значимость различия дисперсий и , и , и .Для этого находят расчетные значения F критерия Фишера FA=/, FB=/, FAB=/. Если выполняются условия (каждое отдельно!) FA >Fa,n-1,nm(k-1), FB >Fa,m-1,nm(k-1), FAB >Fa,,(n-1)(m-1),nm(k-1) то влияние факторов А, В (или их взаимодействия соответственно) является значимым.
В Excel есть два варианта двухфакторного регрессионного анализа: с повторениями и без повторений. Двухфакторный дисперсионный анализ с повторениями соответствует описанному выше в данном параграфе. Двухфакторный дисперсионный анализ без повторений — такая его разновидность, в каждой ячейке которого содержится только одно наблюдение. Таблица исходных данных для такого анализа имеет вид, подобный таблице однофакторного, только вместо номера испытания — номер уровня второго фактора. Таблица результатов похожа на приведенную выше таблицу, только в ней отсутствует строка взаимодействия факторов.
К сожалению, функция двухфакторного дисперсионного анализа с повторениями в Excel работает неправильно и выполнять расчеты по ней невозможно.
Пример
Сначала рассмотрим пример двухфакторного дисперсионного анализа без повторений.
(Пример условный). Допустим, что необходимо выяснить, не оказывает ли значимое влияние на изучаемую характеристику личность экспериментатора и питомник, из которого получают животных для лабораторных исследований. A priori предполагается, что не оказывают.
Таблица 4.12
Исходные данные для двухфакторного дисперсионного анализа без повторений
| Экспериментатор | Питомник 1 | Питомник 2 | Питомник 3 |
| A | 75 | 67 | 78 |
| B | 68 | 65 | 59 |
| C | 56 | 69 | 65 |
Поместив данные в таблицу Excel выбираем в меню Сервис, Анализ данных. Появится окно (см. рис. 4.13), в котором выбираем «Двухфакторный дисперсионный анализ без повторений». После этого появляется окно установки параметров (рис. 4.17).
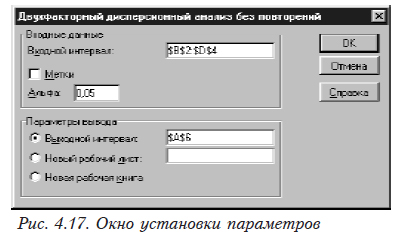
Входной интервал — ссылка на левую верхнюю и правую нижнюю ячейки таблицы, в которых находятся данные. Могут быть отмечены мышкой.
Альфа — требуемый уровень значимости.
Выходной интервал — вводится ссылка на ячейку, расположенную в левом верхнем углу выходного диапазона(мета, куда вы хотите поместить результат). Размеры выходной области будут рассчитаны автоматически.
Новый рабочий лист — выбирается в том случае, если вы хотите поместить результаты работы на другой лист (при этом в соответствующем окошке указывается диапазон размещения результатов аналогичный указанному в предыдущем пункте).
Новая рабочая книга — выбирается в том случае, когда вы хотите поместить результаты в новую книгу (результаты дисперсионного анализа при этом будут размещаться на первом листе новой книги, начиная с ячейки А1).
После установки всех необходимых параметров выбирается ОК. Результаты работы представлены на рис. 4.18.
Строки — сумма квадратов, обусловленная первым фактором (изменением по строкам);
Столбцы — сумма квадратов, обусловленная вторым фактором (изменением по столбцам);
Погрешность — остаточная сумма квадратов, обусловленная случайной ошибкой;
df — число степеней свободы;
MS — средний квадрат (фактически дисперсия);
F — расчетное значение критерия Фишера;
P-Значение — расчетное значение минимальной значимости;
F критическое — критическое значение распределения Фишера.
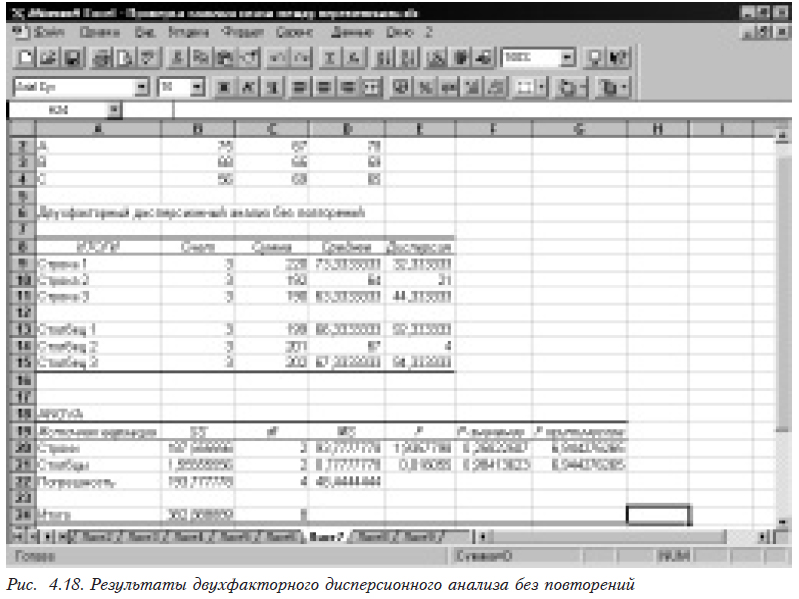
Для первого фактора (строки) F-расчетное (1,93578) меньше критического 6,944276. Это заставляет принять нас нулевую гипотезу о равенстве дисперсий, следовательно, первый фактор не влияет на изучаемый показатель. Что касается второго фактора (столбцы), то здесь расчетное значение критерия Фишера меньше 1 (0,016055), и проверка в том виде, который приведен в Excel, некорректна.
Проверка может быть осуществлена двумя способами.
Первый способ. Проверяется односторонний критерий: одна дисперсия больше другой. Для этого находим обратное значение к имеющемуся расчетному значению =1/E21 (получим 62,28571), а затем — новое критическое значение =FРАСПОБР(0,05;C22;C21), в котором степени свободы поменялись местами (получили 19,24673). Поскольку расчетное больше критического, то принимается гипотеза, что дисперсия погрешности больше дисперсии столбцов.
Второй способ. Не изменяя расчетное значение критерия Фишера, рассчитываем новые критические значения для проверки двухсторонней альтернативной гипотезы (дисперсии неравны). Нижнее критическое при этом вычисляется по формуле =FРАСПОБР(0,975;C21;C22) (результат равен 0,025475), а верхнее — по формуле =FРАСПОБР(0,025;C21;C22) (результат равен 10,64905). Поскольку 0,016055 меньше 0,025475, то гипотеза о неравенстве дисперсий принимается. При этом дисперсия, вызванная случайными факторами, больше.
Двухфакторный дисперсионный анализ с повторениями
Исходные данные для анализа представлены в табл. 4.13. Каждый опыт (для каждого экспериментатора) был сделан 3 раза.
Таблица 4.13
Исходные данные для двухфакторного дисперсионного анализа
| Экспериментатор | Питомник 1 | Питомник 2 | Питомник 3 |
| 75 | 67 | 78 | |
| А | 68 | 65 | 59 |
| 56 | 69 | 65 | |
| 66 | 76 | 55 | |
| Б | 67 | 87 | 57 |
| 78 | 67 | 69 | |
| 78 | 56 | 67 | |
| В | 56 | 78 | 67 |
| 58 | 80 | 67 | |
| 74 | 67 | 77 | |
| Г | 73 | 54 | 66 |
| 71 | 78 | 72 |
Исходные данные вводятся в Excel и содержатся в ячейках от А1 до D13 (см. рис. 4.19). Выполняем следующие действия.
- Вычисляем , которые размещаем в ячейках от В16 до D20.
- Вычисляем средние значения по строкам .
- Вычисляем средние значения по столбцам .
- Вычисляем общее среднее .
Формулы, использованные для вычислений, представлены в таблице 4.14
Таблица 4.14
Формулы для вычисления средних, набранные в Excel
| Ячейка | B | C | D | E |
| 16 | =СРЗНАЧ(B$2:B$4) | =СРЗНАЧ(C$2:C$4) | =СРЗНАЧ(D$2:D$4) | =СРЗНАЧ($B16:$D16) |
| 17 | =СРЗНАЧ(B$5:B$7) | =СРЗНАЧ(C$5:C$7) | =СРЗНАЧ(D$5:D$7) | =СРЗНАЧ($B17:$D17) |
| 18 | =СРЗНАЧ(B$8:B$10) | =СРЗНАЧ(C$8:C$10) | =СРЗНАЧ(D$8:D$10) | =СРЗНАЧ($B18:$D18) |
| 19 | =СРЗНАЧ(B$11:B$13) | =СРЗНАЧ(C$11:C$13) | =СРЗНАЧ(D$11:D$13) | =СРЗНАЧ($B19:$D19) |
| 20 | =СРЗНАЧ(B$16:B$19) | =СРЗНАЧ(C$16:C$19) | =СРЗНАЧ(D$16:D$19) | =СРЗНАЧ(E16:E19) |
Набрать можно не все формулы, а только часть — остальные получим путем размножения перетягиванием. Необходимо набрать формулы в столбец В от 16 до 20 строчки, а формулы в столбцах С и D получим построчным перетягиванием ячеек столбца В. В столбце Е набираем ячейку Е16, а ячейки Е17–Е19 получаем перетягиванием. Ячейка Е20 набирается вручную, причем безразлично получите ли вы в ней сумму по строкам или по столбцам. Это будет одно и то же значение.
- Находим квадраты разностей для каждой ячейки. Массив разностей размещен в ячейках с F2 по
Для этого размещаем формулы
| Ячейка | Содержимое |
| F2 | =(B2-B$16)*(B2-B$16) |
| F5 | =(B5-B$17)*(B5-B$17) |
| F8 | =(B8-B18)*(B8-B18) |
| F11 | =(B11-B$19)*(B11-B$19) |
В остальных ячейках формулы размножаются перетягиванием. При этом в столбце F ячейки размножаются сверху вниз, а столбцы G и H получаем построчным перетягиванием соответствующих ячеек столбца F.
- Находим квадраты построчных разностей . Для этого в ячейке G16 помещаем формулу =(E16-$E$20)*(E16-$E$20), которую затем размножаем на ячейки G17–G19 перетягиванием.
- Находим квадраты разностей по столбцам . Для этого в ячейку В22 помещаем формулу =(B20-$E$20)*(B20-$E$20), которую затем размножаем построчно на ячейки С и D.
- Находим квадраты разностей, необходимые для расчета дисперсии взаимодействия . Для этого в ячейку И25 помещаем формулу =(B16+$E$20-B$20-$E16)*(B16+$E$20-B$20-$E16), которую размножаем на все ячейки таблицы до D28 перетягиванием.
- Формируем таблицу дисперсионного анализа (ячейки от G21 до N25).
Таблица по содержанию в основном соответствует таблице 4.11. Отличие состоит в отсутствии строки для полной суммы квадратов. Дополнительно есть столбцы для расчетного значения критерия Фишера нижнего и верхнего критического значения для проверки гипотезы. Расчетные формулы, которые помещены в ячейки, представлены в табл. 4.15 и 4.16.
Таблица 4.15
| Ячейка | I | J | K | L |
| 22 | =СУММ(G16:G19)*ЧИСЛСТОЛБ(B2:D2)*ЧСТРОК(B2:B4) | =(ЧИСЛСТОЛБ(B2:D2)-1) | =I22/J22 | =K22/$K$25 |
| 23 | =СУММ(B22:D22)*4*ЧСТРОК(B2:B4) | =4-1 | =I23/J23 | =K23/$K$25 |
| 24 | =ЧСТРОК(B2:B4)*СУММ(B25:D28) | =(4-1)*(ЧИСЛСТОЛБ(B2:D2)-1) | =I24/J24 | =K24/$K$25 |
| 25 | =СУММ(F2:H13) | =4*ЧИСЛСТОЛБ(B2:D2)*(ЧСТРОК(B2:B4)-1) | =I25/J25 |
Таблица 4.16
| Ячейка | M | N |
| 22 | =FРАСПОБР(0,975;$J22;$K$25) | =FРАСПОБР(0,025;$J22;$K$25) |
| 23 | =FРАСПОБР(0,975;$J23;$K$25) | =FРАСПОБР(0,025;$J23;$K$25) |
| 24 | =FРАСПОБР(0,975;$J24;$K$25) | =FРАСПОБР(0,025;$J24;$K$25) |
Все три расчетных значения критерия Фишера меньше нижней критической границы. Поэтому принимается гипотеза о значимом превышении остаточной дисперсии над дисперсиями строк, столбцов и взаимодействий. Это значит, что в данном примере влияние экспериментатора и питомника значимо меньше влияния неизвестных нам случайных факторов. Если бы это были результаты реального эксперимента, то из статистического анализа вытекает вывод:

- Результаты экспериментов фальсифицированы, то есть рассеяние от влияющих факторов слишком мало. Или оно должно быть больше рассеяния случайных факторов (при наличии влияния факторов), или не должно отличаться от них (при отсутствии влияния). В данном случае результаты фальсифицированы.
- Эксперимент проведен некачественно. На результаты опытов влиял фактор (или несколько факторов), который мы не учитывали.
Примечание:
- Существуют более сложные схемы, учитывающие большее количество факторов, их взаимодействия и возможность повторных опытов, неравномерность числа наблюдений в ячейке и пр.
- Следует отметить, что с ростом количества компонент расчеты и анализ становятся более громоздкими. При числе факторов больше двух возможно использование (с некоторыми ограничениями) регрессионного анализа.
4.3.2. Непараметрический дисперсионный анализ Фридмана
Назначение. В том случае, когда закон распределения не является нормальным, используется непараметрический дисперсионный анализ Фридмана.
Нулевая гипотеза. Средние значения всех выборок равны.
- Все случайные величины взаимно независимы.
- Данные каждой выборки распределены по одному закону распределения. Обратите внимание: закон распределения каждой выборки может отличаться от закона распределения других.
Исходные данные представляются в следующем виде (табл. 4.17).
Таблица 4.17
Общий вид исходных данных для однофакторного дисперсионного анализа
| Номера элементов совокупностей | 1 | 2 | … | j | … | n |
| Номера совокупностей | ||||||
| 1 | X11 | X12 | X1j | X1n | ||
| 2 | X21 | X22 | X2j | X2n | ||
| … | … | … | ||||
| I | Xi1 | Xi2 | Xij | Xjn | ||
| … | … | … | ||||
| m | Xm1 | Xm2 | Xmj | Xmn |
Для этого в каждом столбце значения Х заменяют их рангами (другими словами, вместо значений переменных ставится их номер в ряду, упорядоченном по возрастанию). Затем рассчитывается значение критерия:

где Rij — соответствующие значения рангов.
Если расчетное значение c 2 будет больше критического, взятого с заданным уровнем значимости и (n-1) степенью свободы, гипотеза о различии между партиями принимается.
При расчетах можно проверить правильность расстановки рангов и расчетов, зная, что имеет место соотношение
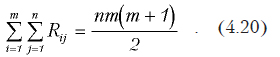
Прмечание:
- При малых значениях m и n критерий c 2 дает слишком грубое приближение, и при этом возможно принятие неправильного решения. Поэтому критерий c 2 применяется в том случае, когда выполняются следующие условия: m = 3 и n > 9 или m = 4 и n > 4 или m > 4 n ³ 9 (см. [4]). Если эти условия не выполняются, то проверка осуществляется по критерию Фридмана (см. табл. в приложении Б).
Пример.
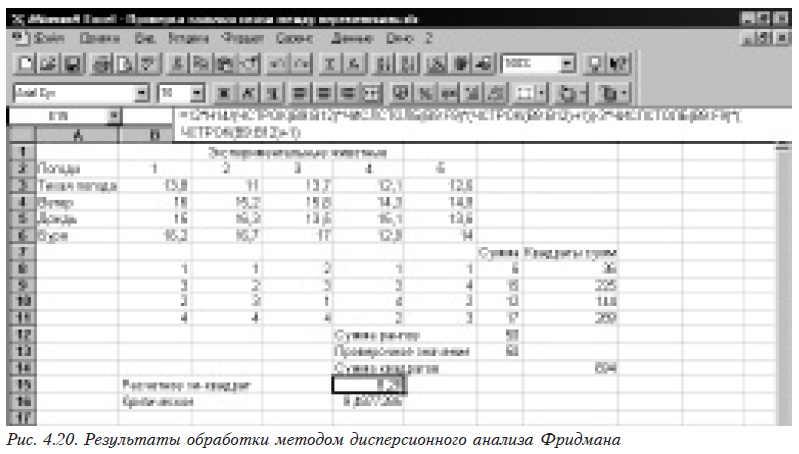
Рассмотрим вариант примера, использованного в 4.3.1 (данные изменены и расширены): у нас есть 4 вида погодных условий, для каждого из которых проведено 5 экспериментов. Необходимо выяснить, значимо ли влияет изменение погодных условий на результаты экспериментов. Все исходные данные и результаты работы приведены на рис. 4.20.
Сначала необходимо построить ранги по столбцам. Для этого в ячейке В8 набираем вызов функции построения рангов =Rank1(B3;B$3:B$6;1), а затем размножаем ее перетягиванием на ячейки от В8 до F11.
Находим суммы рангов по строкам и помещаем их в столбец G. Для этого в G8 набираем формулу =СУММ(B8:F8), а потом размножаем ее перетягиванием на остальные ячейки столбца. Здесь желательно выполнить проверку расстановки рангов. Для этого в ячейке G12 формируем сумму рангов (=СУММ(G8:G11)), а в ячейке G13 — проверочное значение, которое определяется по формуле
Если эти значения совпадают, то расчеты выполнены правильно.
Далее в столбце H формируем квадраты сумм рангов по строчкам. Для этого в ячейке H8 набираем формулу =G8*G8 и размножаем перетягиванием на остальные ячейки столбца.
Находим сумму квадратов =СУММ(H8:H11) и помещаем ее в ячейке H14.
Теперь мы можем рассчитать критериальное значение по формуле
=12*H14/(ЧСТРОК(B8:B11)*ЧИСЛСТОЛБ(B8:F8)*(ЧСТРОК(B8:B11)+1))-3*ЧИСЛСТОЛБ(B8:F8)*(ЧСТРОК(B8:B11)+1) и определить критическое значение критерия c2 вызовом функции
Поскольку расчетное критериальное (8,28) меньше критического (9,4877), то принимается гипотеза об отсутствии значимого влиянии погодных условий на результаты эксперимента.
4.4. Анализ таблиц сопряженности
–Анализ показывает, что Ежов и Бочаров ни разу не встречались вместе в одном ресторане, одном театре, одном санатории…но статистика показывает, что таких чисто официальных отношений между Ежовым и его подчиненными не бывает.
–Вы можете свою мысль выразить короче?
Виктор Суворов “Контроль”
В медико-биологических исследованиях большую роль играет анализ таблиц сопряженности.
Для этих методов применяют также название «анализ таблиц долей и пропорций». Предназначены методы для анализа данных, которые описывают объекты с некоторым количеством свойств, причем часто о свойстве можно лишь сказать есть оно или нет (например, см. таблицу из [21] — табл. 4.18).
Таблица 4.18
Показатели смертности от рака легких и ишемической болезни сердца (на 100000 человек в год)
| Заболевание | Курящие | Некурящие |
| Рак легких | 48,33 | 4,49 |
| Ишемическая болезнь сердца | 394,67 | 109,54 |
Нулевая гипотеза показатели смертности от указанных заболеваний не зависит от того, курит человек или нет. Если нулевая гипотеза будет отвергнута, то это означает, что между курением и смертностью от указанных заболеваний существует статистически значимая связь.
В общем виде четырехклеточная таблица (их еще называют таблицы 2Х2) имеет следующий вид (табл. 4.19).
Таблица 4.19
Общий вид четырехклеточной таблицы сопряженности
C
Нулевая гипотеза о принадлежности обеих выборок к одной генеральной совокупности выполняется с использованием критерия c 2 , который рассчитывается по формуле

Для малых выборок вместо n берут (n-1).
Расчетное значение сравнивается с критическим, взятым с одной степенью свободы и заданным уровнем значимости. Если расчетное значение больше критического, то гипотезу об однородности следует отбросить и принять гипотезу о наличии между изучаемыми признаками существенной связи.
Примечание:
- Правильность полученных выводов зависит от того, как были выбраны данные: выборка должна быть однородна по отношению к анализируемому признаку. Например, если в анализируемую выборку входят одновременно особи, на которых препарат оказывает положительное (улучшающее состояние здоровья) влияние, и особи, на которых он оказывает отрицательное влияние, то в результате анализа может быть принята гипотеза о том, что препарат не оказывает никакого влияния. А это не соответствует реальному положению вещей.
- Следует помнить, что объем выборок не должен быть слишком маленьким. Так, для уровня значимости 0,05 необходимо минимальное значение n1= n2 = 124 (n = 248).
Кроме четырехклеточных таблиц сопряженности существуют многоклеточные таблицы сопряженности. Использование каждого вида таблицы сопряженности в качестве данных для регрессионного анализа будет рассмотрено в соответствующих параграфах.
Пример
Рассмотрим анализ на примере задачи, представленной таблицей 4.16. На рис. 4.21 представлены исходные данные. Для решения задачи о проверки наличия связи между курением и смертностью от рака легких и ишемической болезни сердца выполним следующие действия.
- Найдем суммы по строчкам и по столбцам, для чего введем формулы суммирования в соответствующие ячейки.
| Строка/Столбец | C | D | E |
| 3 | 48,33 | 4,49 | =СУММ(C3:D3) |
| 4 | 394,67 | 109,54 | =СУММ(C4:D4) |
| 5 | =СУММ(C3:C4) | =СУММ(D3:D4) | =СУММ(E3:E4) |
- Определим расчетное значение, введя формулу =(E5*(C3*D4-D3*C4)*(C3*D4-D3*C4))/(E3*E4*C5*D5) в ячейку Е7.
- Определим табличное значение критерия хи-квадрат, введя в ячейку Е8 вызов функции =ХИ2ОБР(0,05;1).
- Выполним сравнение расчетного и табличного значений. Поскольку расчетное значение (5,135995) больше критического (3,841455), то с уровнем значимости 0,05 нулевая гипотеза отклоняется. Следовательно, существует статистически значимая связь между курением и смертностью от указанных заболеваний.
Результаты работы приведены на рис. 4.21.

4.4.2. Таблицы вида 2´К
Таблица сопряженности типа 2´К имеет общий вид как табл. 4.20.
Для проверки нулевой гипотезы об однородности k выборок используется формула, предложенная Брандтом и Снедекором:
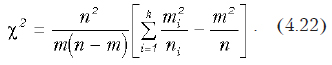
Расчетное значение сравнивается с критическим, взятым с (k-1) степенью свободы и заданным уровнем значимости. Если расчетное значение больше критического, то гипотезу об однородности следует отбросить и принять гипотезу о наличии между изучаемыми признаками существенной связи.
Таблица 4.20
Общий вид таблицы сопряженности вида 2´К
| № выборки или № уровня | Признак 1 | S | |||
| 2-го признака | Имеется | Отсутствует | |||
| 1 | m1 | n1 – m1 | n1 | ||
| 2 | m2 | n2 – m2 | n2 | ||
| .. | … | … | … | ||
| I | mi | ni – mi | ni | ||
| .. | … | … | … | ||
| k | mk | nk – mk | nk | ||
| S | m | n – m | N | ||
Пример
В примере, приведенном в 3.3.7, фактически выполняется анализ таблиц сопряженности данного вида. Отличие (чисто внешнее) в том, что табл. 4.20 является транспонированной по сравнению с табл. 3.19 (строки и столбцы менялись местами).
Для полноты картины данные, в которых представлена зависимость зараженности населения бруцеллезом типа Suis от частоты контактов с животными[4].
Таблица 4.21
Зараженность населения бруцеллезом типа Suis в зависимости от частоты контактов с животными
| Группа | Количество обследованных | ||
| обследованных | с положительной реакцией | с отрицательной реакцией | Всего |
| Работавшие в свинарнике | 19 | 42 | 61 |
| Имевшие эпизодические контакты с животными | 23 | 71 | 94 |
| Без контактов с животными | 23 | 227 | 250 |
| Итого | 65 | 340 | 405 |
Необходимо установить, имеется ли связь между уровнем зараженности бруцеллезом и степенью контактов населения с животными. В табл. 4.22 показано, как с помощью операций и функций Excel рассчитать предварительные данные, необходимые для расчета значения критерия c 2 .
Таблица 4.22
| Строка / столбец | C | D | E | F |
| 3 | 19 | 42 | =СУММ(C3:D3) | =C3*C3/E3 |
| 4 | 23 | 71 | =СУММ(C4:D4) | =C4*C4/E4 |
| 5 | 23 | 227 | =СУММ(C5:D5) | =C5*C5/E5 |
| 6 | =СУММ(C3:C5) | =СУММ(D3:D5) | =СУММ(C6:D6) | =СУММ(F3:F5) |
После выполнения всех перечисленных действий мы имеем необходимую информацию для вычисления критериального значения. Для этого помещаем в ячейку Е8 формулу =E5*E5*(F6-C6*C6/E6)/(C6*(E6-C6)). Теперь необходимо получить критическое значение (процентную точку) распределения c 2 для сравнения. В ячейку Е9 помещаем вызов функции =ХИ2ОБР(0,05;3-1). Здесь 0,05 — уровень значимости, а 3 — количество различных выборок. Поскольку 9,133466 > 5,991476, то нулевая гипотеза об отсутствии связи отклоняется. Таким образом, мы можем утверждать, что между степенью контактов населения с животными и заболеваемосью бруцеллезом существует статистически значимая связь.

4.4.3. Таблицы вида К´L
Таблицы вида К´L (см. табл. 4.2.1) являются наиболее общим видом таблиц сопряженности. В этом случае значениями признака 1 могут быть, например, различные виды лечения: симптоматическое, специфическое с нормальными дозами, специфическое с повышенными дозами или специфическое с добавлением других препаратов и пр. Значениями признака 2 могут быть, например, выздоровление за 2 недели, выздоровление за 4 недели, летальный исход.
Признак 2 может быть также совокупностью различных выборок. В этом случае применяется один критерий для проверки гипотез о независимости признаков и об однородности выборок. Для случая, когда первый столбец табл. 4.23 представляет собой К значения уровня второго признака, проверяется гипотеза о независимости первого и второго признаков. Если же первый столбец содержит k различных выборок, то проверяется гипотеза об однородности этих выборок (то есть, можно ли считать, что эти выборки извлечены из одной генеральной совокупности).
Значение критерия рассчитывается по формуле:
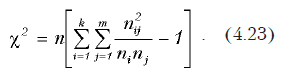
Расчетное значение сравнивается с критическим, взятым с (k–1)(m–1) степенями свободы и заданным уровнем значимости. Если расчетное значение больше критического, то гипотезу об однородности следует отбросить и принять гипотезу о наличии между изучаемыми признаками существенной связи.
Таблица 4.23
Общий вид таблицы сопряженности вида К´L
| Признак 2 | Признак 1 (m значений уровней) | Суммы | ||||||||
| (k значений уровней) | 1 | 2 | j | m | по строкам | |||||
| 1 | n11 | n12 | .. | n1j | … | n1m | n1 | |||
| 2 | n21 | n22 | … | n2j | … | n2m | n2 | |||
| … | … | … | … | … | … | … | … | |||
| i | ni1 | ni2 | … | nij | … | nim | ni | |||
| … | … | … | … | … | … | … | … | |||
| k | nk1 | nk2 | … | nkj | … | nkm | nk | |||
| Суммы по столбцам | n.k | n.2 | … | n.j | … | n.m | n..= n | |||
Пример
Рассмотрим задачу о распределении фракций ПВП (поливинилпирролидона в гемодезе различных производителей[5]. Исходные данные приведены в табл. 4.24.
Таблица 4.24
Распределении фракций ПВП (поливинилпиролидона в гемодезе различных производителей
| Производитель | Площадь пиков фракций ПВП | ||
| Препарата | высокомолекуляные с М,М>160000 | c номинальной М,М>8000+2000 | низкомолекулярные с М,М>4500 |
| АТ «Биохимик» | 15,4 | 80,1 | 4,5 |
| АТ «Биосинтез» | 16,7 | 78,3 | 4,8 |
| Днепропетровский ХФЗ | 31,9 | 65,1 | 2,5 |
| «Биолек» | 32,4 | 64,3 | 3,3 |
| АТ «Черкасымясо» з-д медпрепаратов | 20,7 | 77 | 2.4 |
| Пензенский з-д медпрепаратов | 37,9 | 58,4 | 3 |
| Несвижский з-д медпрепаратов | 29,6 | 67,8 | 2,4 |
Набираем приведенные выше данные в Excel (см. рис. 4.25). Для удобства при дальнейшем использовании таблица транспонирована (строки и столбцы поменялись местами). Сначала вычисляем суммы по строкам и столбцам, для чего набираем следующие вызовы функций.
Таблица 4.25
| Номер ячейки | Содержание |
| L5 | =СУММ(L2:L4) |
| M5 | =СУММ(M2:M4) |
| N5 | =СУММ(N2:N4) |
| O5 | =СУММ(O2:O4) |
| P5 | =СУММ(P2:P4) |
| Q5 | =СУММ(Q2:Q4) |
| R5 | =СУММ(R2:R4) |
| S2 | =СУММ(L2:R2) |
| S3 | =СУММ(L3:R3) |
| S4 | =СУММ(L4:R4) |
| S5 | =СУММ(L5:R5) |

После этого формируем вспомогательную таблицу такого же размера как исходная.
Таблица 4.26
Формирование вспомогательной таблицы
| Cтолбец / Строка | 2 | 3 | 4 |
| T | =L2*L2/($L$5*$S2) | =L3*L3/($L$5*$S3) | =L4*L4/($L$5*$S4) |
| U | =M2*M2/($M$5*$S2) | =M3*M3/($M$5*$S3) | =M4*M4/($M$5*$S4) |
| V | =N2*N2/($N$5*$S2) | =N3*N3/($N$5*$S3) | =N4*N4/($N$5*$S4) |
| W | =O2*O2/($O$5*$S2) | =O3*O3/($O$5*$S3) | =O4*O4/($O$5*$S4) |
| X | =P2*P2/($P$5*$S2) | =P3*P3/($P$5*$S3) | =P4*P4/($P$5*$S4) |
| Y | =Q2*Q2/($Q$5*$S2) | =Q3*Q3/($Q$5*$S3) | =Q4*Q4/($Q$5*$S4) |
| Z | =R2*R2/($R$5*$S2) | =R3*R3/($R$5*$S3) | =R4*R4/($R$5*$S4) |
Не стоит пугаться — на самом деле набирается только формула =L2*L2/($L$5*$S2). Обратите внимание на размещение в формуле знаков $. Во все остальные ячейки формула размножается перетягиванием (см. раздел 1).
После этой предварительной работы можно получить расчетное значение для критерия c 2 . Для этого в ячейку W10 помещаем формулу =S5*(СУММ(T2:Z4)-1). Затем определяем критическое значение посредством вызова в ячейке W12 функции =ХИ2ОБР(0,05;(3-1)*(7-1)). Здесь 0,05 — уровень значимости, 3 и 7 — количество уровней варьирования (разных значений) первого и второго признаков. Поскольку расчетное значение (25,06148) больше критического (21,02606), то нулевая гипотеза отклоняется. Это значит, что по качеству препарата представленных производителей существуют статистически значимые различия. Результаты представлены на рис. 4.24.
4.4.4. Размер выборки и рандомизация
[Рандомизация] обеспечивает три вещи: она гарантирует, что наши наклонности и предпочтения не повлияют на формирование групп с различными обработками; она предотвращает опасность, связанную с выбором на основе личных суждений, — считая, что наши суждения могут быть пристрастными, мы стараемся учесть и устранить пристрастность и при этом можем перестараться, ударяясь в другую крайность; наконец, при случайном распределении обработок самый строгий критик не сможет сказать, что группы рассматривались по-разному вследствие наших предпочтений или нашей глупости.
Проблема рандомизации возникает когда данные, которые мы собираемся анализировать, получаются как некоторая выборка из генеральной совокупности. В этом случае возникает два вопроса:
- Сколько необходимо данных для принятия правильного решения?
- Как формировать выборку?
Количество данных, необходимых для анализа, зависит от следующих факторов:
- допустимой ошибки первого рода, то есть вероятности установить значимую зависимость, когда ее нет; обеспечивается за счет установки уровня значимости a;
- допустимой ошибки второго рода, то есть вероятности установить отсутствие связи, когда на самом деле она есть. Обычно задается через вероятность ошибки второго рода b или мощность критерия 1-b;
- от того, начиная с какой разницы частот мы будем считать их различие значимым.
Проблема в том, что уменьшение размера выборки ведет к уменьшению вероятности обнаружения значимого различия, а увеличение ее (выборки) — к увеличению вероятности признания значимыми несущественных различий.
Расчет размера выборки для случая подвыборок равных размеров
Сначала задаются уровень значимости a и мощность критерия 1-b. Затем необходимо установить частоты, которые мы будем считать различающимися. Обычно выбирается одна частота и устанавливается доля различия. После этого рассчитывается вторая частота по формуле

Здесь, Р1 — первая частота, а f — доля, с которой мы считаем различие значимым. Например, если Р1 = 0,6 и при этом f = 0,25 то P2 = 0,6 + 0,25(1-0,6) = 0,7. Это означает, что частоты 0,6 и 0,7 мы решили считать значимо различающимися.
Тогда размер каждой из двух подвыборок рассчитывается по формуле

При этом n — находится по формуле
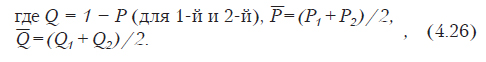
где Q = 1 – P (для 1-й и 2-й), , .
С помощью Excel эти формулы можно вычислить следующим образом. Допустим, что исходные данные находятся в следующих ячейках (см. табл. 4.27)
Таблица 4.27
Размещение исходных данных для расчета размера выборки при равных подвыборках
| Ячейка | Содержимое | Комментарий |
| А1 | 0,05 | a |
| В1 | 0,01 | b |
| С1 | 0,6 | P1 |
| D1 | 0,7 | P2 |
| B2 | =1-В1 | 1-b |
| C2 | =1-С1 | Q1 |
| D2 | =1- D1 | Q2 |
| C3 | =(С1+D1)/2 | |
| D3 | =(С2+D2)/2 |
Теперь можно рассчитать n` по формуле, которая помещена в ячейку C5:
После этого вычисляем размер выборки по формуле =ОКРВВЕРХ((C5/4)*(1+КОРЕНЬ(1+4/(C5*ABS(C1-D1))));1). В результате получаем значение размера выборки (359), удовлетворяющее поставленным условиям.
Расчет размера выборки для случая подвыборок разных размеров
Достаточно распространены ситуации, когда размеры выборок отличаются. В таком случае считаем, что размер одной выборки равен m, а второй N = (r + 1)m, где r в общем случае не равно 1. Тогда размер m вычисляется по формуле

а Q = 1 – P (для 1-й и 2-й), , как и в предыдущем случае.
С помощью Excel эти формулы можно вычислить следующим образом. Допустим, что исходные данные находятся в ячейках (см. табл. 4.26)
Таблица 4.26
Размещение исходных данных для расчета размера выборки при неравных подвыборках
| Ячейка | Содержимое | Комментарий |
| А1 | 0,05 | a |
| В1 | 0,01 | b |
| С1 | 0,6 | P1 |
| D1 | 0,7 | P2 |
| А2 | 2 | r |
| B2 | =1-В1 | 1-b |
| C2 | =1-С1 | Q1 |
| D2 | =1- D1 | Q2 |
| C3 | =(С1+D1)/2 | |
| D3 | =(С2+D2)/2 |
Теперь можно рассчитать m` по формуле, которая помещена в ячейку C5:
После этого вычисляем размер выборки по формуле =ОКРВВЕРХ((C5/4)*(1+КОРЕНЬ((2*(A2+1)/(1+A2*C5*ABS(C1-D1))));1).
После этого рассчитывается размер второй выборки по формуле =(А2+1)*В6. В В6 находится значение m.
Рандомизация
Если не делать рандомизацию, то выводы будут некорректны по причине с неслучайного формирования выборок вследствие нарушение исходных предпосылок случайности и независимости наблюдений. Осуществляется она следующим образом. Назначение пациентов в одну или другую группу выполняется с использованием таблиц случайных чисел [21]. Например, планируется подвергнуть испытанию 100 человек, 50 из которых назначают лекарственный препарат, а остальным плацебо. Для этого пациентам дают номера от 1 до 100. Затем выбирают 50 случайных чисел, равномерно распределенных в интервале 1..100. Пациентам, номера которых совпали с выбранными, назначают препарат, остальным — плацебо. Например, таблица 7.1а [1] содержит равномерно распределенные случайные числа. Если из этой таблицы взять ряд чисел 10, 09, 73, 25, 33, 76 и т.д. — это и будут необходимые нам номера.
Во многих случаях общее количество пациентов, которые будут подвергнуты испытанию может быть неизвестно (или таковых нет в наличии), а испытания проводят по мере поступления пациентов в клинику. В таком случае каждому новому поступившему назначают или препарат или плацебо. Для этого из таблицы случайных чисел выбирают последовательность, и если очередное число нечетное, то назначается препарат, если четное — плацебо. Например, если мы возьмем тот же ряд цифр 1, 0, 0, 9, 7, 3, 2, 5, 3, 3, 7, 6, то первому, четвертому, пятому, шестому, восьмому, девятому, десятому и одиннадцатому назначается препарат, а второму, третьему, седьмому и двенадцатому — плацебо. Более сложные ситуации с рандомизацией подробно изложены в [21].
Литература, рекомендуемая для изучения
- Большев Л.Н., Смирнов Н.В. Таблицы математической статистики.— 3-е изд.— М.: Наука, 1983.— 416 с.
- Браунли К.А. Статистическая теория и методология в науке и технике.— М.: Наука, — 407 с.
- Гмурман В.Е. Теория вероятностей и математическая статистика. Учеб. пособие для втузов. — М.: Высш. Шк., 1977. — 479 с.
- Закс Л. Статистическое оценивание.— М.: Статистика, 1976. — 598 с.
- Кимбл Г. Как правильно пользоваться статистикой. — М.: Финансы и статистика, 1982. — 294 с.
- Кудрин А.Н., Пономарева Г.Т. Применение математики в экспериментальной и клинической медицине. — М.: Медицина, — 356 с.
- Лапач С.Н., Пасечник М.Ф., Чубенко А.В. Статистические методы в фармакологии и маркетинге фармацевтического рынка — К.: ЗАO «Укрспецмонтажпроект», 1999. —312 с.
- Ликеш И., Ляга Й. Основные таблицы математической статистики.— М.: Финансы и статистика, 1985.— 356 с.
- Мисюк Н.С., Мастыркин А.С., Кузнецов Г.П. Корреляционно-регрессионный анализ в клинической медицине. — М.: Медицина, 1975. — 192 с.
- Мюллер П., Нойман П., Шторм Р. Таблицы по математической статистике. — М.: Финансы и статистика, 1982.— 278 с.
- Плохинский Н.А. Алгоритмы биометрии. — М.: МГУ, 1980. — 150 с.
- Поллард Дж. Справочник по вычислительным методам статистики. — М.: Финансы и статистика, 1982. — 344 с.
- Рунион Р. Справочник по непараметрической статистике: Современный подход / Пер. с англ. Е.З. Демиденко; Предисл. Ю.Н. Тюрина. — М.: Финансы и статистика, 1982. — 198 с.
- Справочник по прикладной статистике. В 2 т. Т. 1: Пер. с англ. / Под ред. Э. Ллойда, У. Ледермана, Ю.Н. Тюрина. — М.: Финансы и статистика, 1989. — 510 с.
- Справочник по прикладной статистике В 2 т. Т. 2: Пер. с англ.— М.: Финансы и статистика, 1990.— 526 с.
- Спрент П. Как обращаться с цифрами, или статистика в действии / Пер. с англ. А.Ф. Якубова.— Мн.: Выcш. шк., 1983.— 271 с.
- Терентьев П.В., Ростова Н.С. Практимум по биометрии. — Л.: ЛГУ, 1977. — 152 с.
- Тюрин Ю.Н. Непараметрические методы статистики.— М.: Знание, 1978.— 64 с.
- Тюрин Ю.Н. , Макаров А.А. Статистический анализ данных на компьютере. — М.: ИНФРА-М, 1998.— 528 с.
- Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа. Руководство для экономистов / Пер. с нем. и предисл. В.М.Ивановой.— М.: Финансы и статистика, 1983.— 304 с.
- Флейс Дж. Статистические методы для изучения таблиц долей и пропорций.— М.: Финансы и статистика, 1989. — 319с.
- Хеттманспертер Т. Статистические выводы, основанные на рангах. — М.: Финансы и статистика, 1987. — 334 с.
- Хилл А. Основы медицинской статистики. — М.: Медгиз, 1958. — 306 с.
- Холлендер М., Вулф Д.А. Непараметрические методы статистики. — М.: Финансы и статистика, 1983.— 518 с.
[1] Адлер Ю.П., Маркова Е.В., Грановский Ю.В. Планирование эксперимента при поиске оптимальных условий.–М.: Наука, 1976.–280с.
[2] Данные для примера взяты из [9].
[3] Упорядоченном по величине.
[4] Дранкин Д.И., Заметин Б.А., Коржева В.С. // Микробиология. — 1960. — № 2.
[5] Сур С.В., Матюшова В.М., Нигматулин Р.Р. // Ліки України. — 1998. —.№ 3.
Описательная статистика в EXCEL
Задача описательной статистики (descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений выборки к нескольким итоговым показателям, которые дают представление о выборке .В качестве таких статистических показателей используются: среднее , медиана , мода , дисперсия, стандартное отклонение и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные статистические выводы о распределении , из которого была взята выборка . Например, если у нас есть выборка значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой выборки мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных выборок , используем надстройку Пакет анализа . Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ : Подробнее о других инструментах надстройки Пакет анализа и ее подключении – читайте в статье Надстройка Пакет анализа MS EXCEL .
Выборку разместим на листе Пример в файле примера в диапазоне А6:А55 (50 значений).
Примечание : Для удобства написания формул для диапазона А6:А55 создан Именованный диапазон Выборка.
В диалоговом окне Анализ данных выберите инструмент Описательная статистика .

После нажатия кнопки ОК будет выведено другое диалоговое окно,
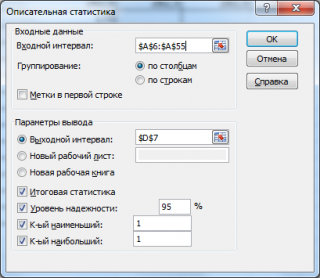
в котором нужно указать:
- входной интервал (Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле Метки в первой строке (Labelsinfirstrow). В этом случае заголовок будет выведен в Выходном интервале. Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
- выходной интервал (Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
- Итоговая статистика (SummaryStatistics) . Поставьте галочку напротив этого поля – будут выведены основные показатели выборки: среднее, медиана, мода, стандартное отклонение и др.;
- Также можно поставить галочки напротив полей Уровень надежности (ConfidenceLevelforMean) , К-й наименьший (Kth Largest) и К-й наибольший (Kth Smallest).
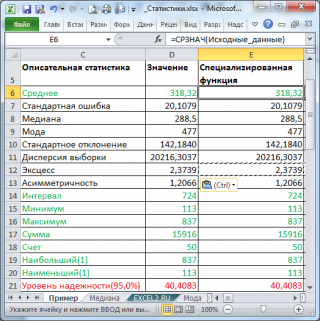
В результате будут выведены следующие статистические показатели:
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во входном интервале указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во Входной интервал и установите галочку в поле Метки в первой строке ). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в файле примера выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
- Интервал (Range) — разница между максимальным и минимальным значениями;
- Минимум (Minimum) – минимальное значение в диапазоне ячеек, указанном во Входном интервале (см. статью про функцию МИН() );
- Максимум (Maximum)– максимальное значение (см. статью про функцию МАКС() );
- Сумма (Sum) – сумма всех значений (см. статью про функцию СУММ() );
- Счет (Count) – количество значений во Входном интервале (пустые ячейки игнорируются, см. статью про функцию СЧЁТ() );
- Наибольший (Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см. статью про функцию НАИБОЛЬШИЙ() );
- Наименьший (Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см. статью про функцию НАИМЕНЬШИЙ() ).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее (mean, average) или выборочное среднее или среднее выборки (sample average) представляет собой арифметическое среднее всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция СРЗНАЧ() . Выборочное среднее является «хорошей» (несмещенной и эффективной) оценкой математического ожидания случайной величины (подробнее см. статью Среднее и Математическое ожидание в MS EXCEL ).
Медиана выборки
Медиана (Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем медиана , а половина чисел меньше, чем медиана . Для определения медианы необходимо сначала отсортировать множество чисел . Например, медианой для чисел 2, 3, 3, 4 , 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется среднее для двух чисел, находящихся в середине множества. Например, медианой для чисел 2, 3, 3 , 5 , 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то Медиана лучше, чем среднее значение , отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что как минимум у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения медианы в MS EXCEL существует одноименная функция МЕДИАНА() , английский вариант — MEDIAN().
Медиану также можно вычислить с помощью формул
Подробнее о медиане см. специальную статью Медиана в MS EXCEL .
СОВЕТ : Подробнее про квартили см. статью, про перцентили (процентили) см. статью.
Мода выборки
Мода (Mode) – это наиболее часто встречающееся (повторяющееся) значение в выборке . Например, в массиве (1; 1; 2 ; 2 ; 2 ; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это мода . Для вычисления моды используется функция МОДА() , английский вариант MODE().
Примечание : Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье Есть ли повторы в списке?
Начиная с MS EXCEL 2010 вместо функции МОДА() рекомендуется использовать функцию МОДА.ОДН() , которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция МОДА.НСК() , которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1; 2 ; 2 ; 2 ; 3; 4 ; 4 ; 4 ; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются модами . Функции МОДА.ОДН() и МОДА() вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см. файл примера , лист Мода ).
Чтобы исправить эту несправедливость и была введена функция МОДА.НСК() , которая выводит все моды . Для этого ее нужно ввести как формулу массива .
Как видно из картинки выше, функция МОДА.НСК() вернула все три моды из массива чисел в диапазоне A2:A11 : 1; 3 и 7. Для этого, выделите диапазон C6:C9 , в Строку формул введите формулу =МОДА.НСК(A2:A11) и нажмите CTRL+SHIFT+ENTER . Диапазон C 6: C 9 охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству мод . Если ячеек больше чем м о д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если мода только одна, то все выделенные ячейки будут заполнены значением этой моды .
Теперь вспомним, что мы определили моду для выборки, т.е. для конечного множества значений, взятых из генеральной совокупности . Для непрерывных случайных величин вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция МОДА() вернет ошибку.
Даже в нашем массиве с модой , которая была определена с помощью надстройки Пакет анализа , творится, что-то не то. Действительно, модой нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на гистограмму распределения , построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
Проблема в том, что мы определили моду как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому, моду в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для логнормального распределения мода (наиболее вероятное значение непрерывной случайной величины х), вычисляется как exp ( m — s 2 ) , где m и s параметры этого распределения.
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для моды распределения, из которого взята выборка (наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку моды распределения, из генеральной совокупности которого взята выборка , можно, например, построить гистограмму . Оценкой для моды может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод : Значение моды для выборки , рассчитанное с помощью функции МОДА() , может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер выборки существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане), модой является число 15 (17 значений из 51, т.е. 33%). В этом случае функция МОДА() дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание : Строго говоря, в примере с зарплатой мы имеем дело скорее с генеральной совокупностью , чем с выборкой . Т.к. других зарплат в компании просто нет.
О вычислении моды для распределения непрерывной случайной величины читайте статью Мода в MS EXCEL .
Мода и среднее значение
Не смотря на то, что мода – это наиболее вероятное значение случайной величины (вероятность выбрать это значение из Генеральной совокупности максимальна), не следует ожидать, что среднее значение обязательно будет близко к моде .
Примечание : Мода и среднее симметричных распределений совпадает (имеется ввиду симметричность плотности распределения ).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6. Модой является 6, а среднее значение – 3,6666.
Другой пример. Для Логнормального распределения LnN(0;1) мода равна =EXP(m-s2)= EXP(0-1*1)=0,368, а среднее значение 1,649.
Дисперсия выборки
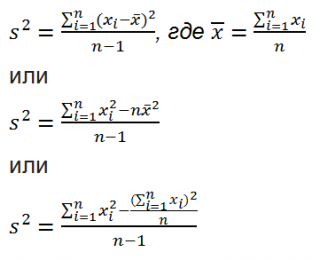
Дисперсия выборки или выборочная дисперсия ( sample variance ) характеризует разброс значений в массиве, отклонение от среднего .
Из формулы №1 видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления дисперсии выборки используется функция ДИСП() . С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию ДИСП.В() .
Дисперсию можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ): =КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1) – обычная формула =СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1) – формула массива
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению .
Чем больше величина дисперсии , тем больше разброс значений в массиве относительно среднего .
Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Стандартное отклонение выборки
Стандартное отклонение выборки (Standard Deviation), как и дисперсия , — это мера того, насколько широко разбросаны значения в выборке относительно их среднего .
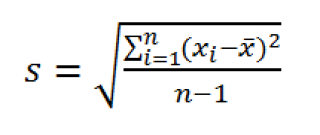
По определению, стандартное отклонение равно квадратному корню из дисперсии :
Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок : (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция СТАНДОТКЛОН() . С версии MS EXCEL 2010 рекомендуется использовать ее аналог СТАНДОТКЛОН.В() .
Стандартное отклонение можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ): =КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Стандартная ошибка
В Пакете анализа под термином стандартная ошибка имеется ввиду Стандартная ошибка среднего (Standard Error of the Mean, SEM). Стандартная ошибка среднего — это оценка стандартного отклонения распределения выборочного среднего .
Примечание : Чтобы разобраться с понятием Стандартная ошибка среднего необходимо прочитать о выборочном распределении (см. статью Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL ) и статью про Центральную предельную теорему .
Стандартное отклонение распределения выборочного среднего вычисляется по формуле σ/√n, где n — объём выборки, σ — стандартное отклонение исходного распределения, из которого взята выборка . Т.к. обычно стандартное отклонение исходного распределения неизвестно, то в расчетах вместо σ используют ее оценку s — стандартное отклонение выборки . А соответствующая величина s/√n имеет специальное название — Стандартная ошибка среднего. Именно эта величина вычисляется в Пакете анализа.
В MS EXCEL стандартную ошибку среднего можно также вычислить по формуле =СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность или коэффициент асимметрии (skewness) характеризует степень несимметричности распределения ( плотности распределения ) относительно его среднего .

Положительное значение коэффициента асимметрии указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого. Коэффициент асимметрии идеально симметричного распределения или выборки равно 0.
Примечание : Асимметрия выборки может отличаться расчетного значения асимметрии теоретического распределения. Например, Нормальное распределение является симметричным распределением ( плотность его распределения симметрична относительно среднего ) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в выборке из соответствующей генеральной совокупности не обязательно должны располагаться совершенно симметрично относительно среднего . Поэтому, асимметрия выборки , являющейся оценкой асимметрии распределения , может отличаться от 0.
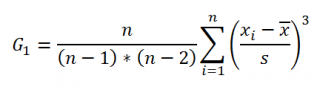
Функция СКОС() , английский вариант SKEW(), возвращает коэффициент асимметрии выборки , являющейся оценкой асимметрии соответствующего распределения, и определяется следующим образом:
где n – размер выборки , s – стандартное отклонение выборки .
В файле примера на листе СКОС приведен расчет коэффициента асимметрии на примере случайной выборки из распределения Вейбулла , которое имеет значительную положительную асимметрию при параметрах распределения W(1,5; 1).
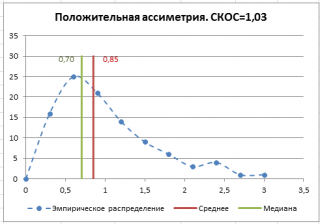
Эксцесс выборки
Эксцесс показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/- σ .
Примечание : Не смотря на старания профессиональных статистиков, в литературе еще попадается определение Эксцесса как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение Эксцесса ничего не говорит о форме пика распределения.
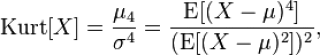
Согласно определения, Эксцесс равен четвертому стандартизированному моменту:
Для нормального распределения четвертый момент равен 3*σ 4 , следовательно, Эксцесс равен 3. Многие компьютерные программы используют для расчетов не сам Эксцесс , а так называемый Kurtosis excess, который меньше на 3. Т.е. для нормального распределения Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание : Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как Эксцесс (от англ. excess — «излишек»). Например, функция MS EXCEL ЭКСЦЕСС() на самом деле вычисляет Kurtosis excess.
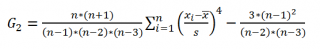
Функция ЭКСЦЕСС() , английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку эксцесса распределения случайной величины и определяется следующим образом:
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из нормального распределения формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция ЭКСЦЕСС() возвращает значение ошибки #ДЕЛ/0!
Вернемся к распределениям случайной величины . Эксцесс (Kurtosis excess) для нормального распределения всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений Эксцесс зависит от параметров распределения: см., например, распределение Вейбулла или распределение Пуассона , для котрого Эксцесс = 1/λ.
Уровень надежности
Уровень надежности — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Вместо термина Уровень надежности часто используется термин Уровень доверия . Про Уровень надежности (Confidence Level for Mean) читайте статью Уровень значимости и уровень надежности в MS EXCEL .
Задав значение Уровня надежности в окне надстройки Пакет анализа , MS EXCEL вычислит половину ширины доверительного интервала для оценки среднего (дисперсия неизвестна) .
Тот же результат можно получить по формуле (см. файл примера ): =ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n) s — стандартное отклонение выборки , n – объем выборки .
Документация по СУБД «Квант-Гибрид» 1.2.0
Системные каталоги — это место, где система управления реляционными базами данных хранит метаданные схемы, такие как сведения о таблицах и столбцах, а также информацию о внутреннем бухгалтерском учете. Системные каталоги QHB-это обычные таблицы. Вы можете удалить и пересоздать таблицы, добавить столбцы, вставить и обновить значения и сильно испортить свою систему таким образом. Как правило, не следует изменять системные каталоги вручную, для этого обычно существуют команды SQL. (Например, CREATE DATABASE вставляет строку в каталог pg_database и фактически создает базу данных на диске.) Есть некоторые исключения для особенных операций, но многие из них становятся доступны в виде команд SQL с течением времени, и поэтому необходимость в прямом манипулировании системными каталогами постоянно уменьшается.
- Обзор
- pg_aggregate
- pg_am
- pg_amop
- pg_amproc
- pg_attrdef
- pg_attribute
- pg_authid
- pg_auth_members
- pg_cast
- pg_class
- pg_collation
- pg_constraint
- pg_conversion
- pg_database
- pg_db_role_setting
- pg_default_acl
- pg_depend
- pg_description
- pg_enum
- pg_event_trigger
- pg_extension
- pg_foreign_data_wrapper
- pg_foreign_server
- pg_foreign_table
- pg_index
- pg_inherits
- pg_init_privs
- pg_language
- pg_largeobject
- pg_largeobject_metadata
- pg_namespace
- pg_opclass
- pg_operator
- pg_opfamily
- pg_partitioned_table
- pg_pltemplate
- pg_policy
- pg_proc
- pg_publication
- pg_publication_rel
- pg_range
- pg_replication_origin
- pg_rewrite
- pg_seclabel
- pg_sequence
- pg_shdepend
- pg_shdescription
- pg_shseclabel
- pg_statistic
- pg_statistic_ext
- pg_statistic_ext_data
- pg_subscription
- pg_subscription_rel
- pg_tablespace
- pg_transform
- pg_trigger
- pg_ts_config
- pg_ts_config_map
- pg_ts_dict
- pg_ts_parser
- pg_ts_template
- pg_type
- pg_user_mapping
- Системные представления
- pg_available_extensions
- pg_available_extensions_versions
- pg_config
- pg_cursors
- pg_file_settings
- pg_group
- pg_hba_file_rules
- pg_indexes
- pg_locks
- pg_matviews
- pg_policies
- pg_prepared_statements
- pg_prepared_xacts
- pg_publication_tables
- pg_replication_origin_status
- pg_replication_slots
- pg_roles
- pg_rules
- pg_seclabels
- pg_sequences
- pg_settings
- pg_shadow
- pg_stats
- pg_stats_ext
- pg_tables
- pg_timezone_abbrevs
- pg_timezone_names
- pg_user
- pg_user_mappings
- pg_views
Обзор
В таблице «Системный каталог» перечислены системные каталоги. Более подробная документация по каждому каталогу приводится ниже.
Большинство системных каталогов копируются из шаблона базы данных во время создания базы данных и затем зависят от конкретной базы данных. Несколько каталогов физически совместно используются во всех базах данных в кластере — они отмечаются в описаниях отдельных каталогов.
Системный каталог
имя каталога Цель pg_aggregate агрегатные функции pg_am методы доступа pg_amop операторы метода доступа pg_amproc функции поддержки метода доступа pg_attrdef значения столбца по умолчанию pg_attribute столбцы таблицы pg_authid идентификаторы авторизации (роли) pg_auth_members отношения членства идентификатора авторизации pg_cast приведения (преобразование типов данных) pg_class таблицы, индексы, последовательности, представления (все «отношения”) pg_collation параметры сортировки (сведения о локали) pg_constraint проверочные ограничения, ограничения уникальности, ограничения первичного ключа, ограничения внешнего ключа pg_conversion кодирование информация о преобразовании pg_database базы данных в этом кластере pg_db_role_setting параметры для каждой роли и базы данных pg_default_acl права доступа по умолчанию для типов объектов pg_depend зависимости между объектами базы данных pg_description описания или комментарии объектов базы данных pg_enum перечисление — метка и значения pg_event_trigger триггер события pg_extension установленные расширения pg_foreign_data_wrapper определения внешних данных pg_foreign_server определения внешних серверов pg_foreign_table дополнительная информация по внешней таблице pg_index дополнительная индексная информация pg_inherits иерархия наследования таблиц pg_init_privs начальные привилегии объекта pg_language языки для написания функций pg_largeobject страницы данных для больших объектов pg_largeobject_metadata метаданные для больших объектов pg_namespace схемы pg_opclass классы операторов метода доступа pg_operator операторы pg_opfamily семейства операторов метода доступа pg_partitioned_table информация о ключе партиционирования таблиц pg_pltemplate шаблонные данные для процедурных языков pg_policy строки-политики безопасности pg_proc функции и процедуры pg_publication публикации для логической репликации pg_publication_rel связь-сопоставление с публикаций pg_range информация о типах диапазона pg_replication_origin зарегистрированные источники репликации pg_rewrite правила перезаписи запроса pg_seclabel метки безопасности для объектов базы данных pg_sequence информация о последовательностях pg_shdepend зависимости от общих объектов pg_shdescription комментарии к общим объектам pg_shseclabel метки безопасности для объектов общей базы данных pg_statistic статистика планировщика pg_statistic_ext расширенная статистика планировщика (определения) pg_statistic_ext_data расширенная статистика планировщика (данные) pg_subscription подписки на логическую репликацию pg_subscription_rel состояние связи для подписок pg_tablespace табличные пространства в кластере баз данных pg_transform преобразования (преобразование типа данных в процедурный язык) pg_trigger триггера pg_ts_config конфигурации текстового поиска pg_ts_config_map сопоставления маркеров конфигураций текстового поиска pg_ts_dict словари текстового поиска pg_ts_parser парсеры для текстового поиска pg_ts_template шаблоны текстового поиска pg_type типы данных pg_user_mapping сопоставления пользователей с внешними серверами pg_aggregate
Каталог pg_aggregate хранит информацию о агрегатных функциях. Агрегатная функция-это функция, которая работает с набором значений (как правило, один столбец из каждой строки, которая соответствует условию запроса) и возвращает одно значение, вычисленное из всех этих значений. Типичными агрегатными функциями являются сумма, среднее, и максимум. Каждая запись внутри pg_aggregate это расширение записи в pg_proc. pg_proc запись содержит имя агрегата, типы входных и выходных данных, а также другую информацию, аналогичную обычным функциям.
pg_aggregate столбцы
Имя Тип Ссылки Описание aggfnoid regproc pg_proc.oid OID из pg_proc для агрегатной функции aggkind char Агрегатный вид: n для «нормальных» агрегатов, o для агрегатов «упорядоченный набор», или h для агрегатов «гипотетический набор» aggnumdirectargs int2 Число прямых (неагрегированных) аргументов агрегата с упорядоченным набором или гипотетическим набором, считая массив переменной длинны в качестве одного аргумента. Если равны pronargs, агрегат должен быть с переменным числом аргументов, и соот. массив описывает агрегированные аргументы, а также конечные прямые аргументы. Всегда ноль для нормальных агрегатов. aggtransfn regproc pg_proc.oid Переходная функция aggfinalfn regproc pg_proc.oid Конечная функция (ноль, если нет) aggcombinefn regproc pg_proc.oid Функция объединения (ноль, если нет) aggserialfn regproc pg_proc.oid Функция сериализации (ноль, если нет) aggdeserialfn regproc pg_proc.oid Функция десериализации (ноль, если нет) aggmtransfn regproc pg_proc.oid Функция прямого перехода для режима перемещения агрегата (ноль, если нет) agminvtransfn regproc pg_proc.oid Обратная переходная функция для режима перемещения агрегата (ноль, если нет) aggmfinalfn regproc pg_proc.oid Конечная функция для режима перемещения-aggregate (ноль, если нет) aggfinalextra bool True для передачи дополнительных фиктивных аргументов в aggfinalfn aggmfinalextra bool True для передачи дополнительных фиктивных аргументов в aggmfinalfn aggfinalmodify char aggfinalfn изменяет значение состояния перехода: r если он доступен только для чтения, s если aggtransfn не может быть применен после выполнения aggfinalfn, или w если он пишет на значение aggmfinalmodify char Также как aggfinalmodify, но для самого aggmfinalfn aggsortop oid pg_operator.oid Связанный оператор сортировки (ноль, если нет) aggtranstype oid pg_type.oid Тип данных данных внутреннего перехода (состояния) агрегатной функции aggtransspace int4 Приблизительный средний размер (в байтах) данных о состоянии перехода или ноль для использования оценки по умолчанию aggmtranstype oid pg_type.oid Тип данных внутреннего перехода (состояния) агрегатной функции для режима перемещения moving-aggregate (ноль, если нет) aggmtransspace int4 Приблизительный средний размер (в байтах) данных о состоянии перехода для режима перемещения moving-aggregate, или ноль для использования оценки по умолчанию agginitval text Начальное значение переходного состояния. Это текстовое поле, содержащее начальное значение во внешнем строковом представлении. Если это поле имеет значение null, то значение состояния перехода начинается с null. agginitval text Начальное значение переходного состояния для режима перемещения агрегата. Это текстовое поле, содержащее начальное значение во внешнем строковом представлении. Если это поле имеет значение null, то значение состояния перехода начинается с null. Новые агрегатные функции регистрируются с помощью команды CREATE AGGREGATE. Дополнительную информацию о написании агрегатных функций и значении переходных функций смотрите в Пользовательские агрегаты.
pg_am
Каталог pg_am хранит информацию о методах доступа к отношениям. Существует одна строка для каждого метода доступа, поддерживаемого системой. В настоящее время только таблицы и индексы имеют методы доступа. Требования к методам доступа к таблицам и индексам подробно рассматриваются соответственно в главах Интерфейс доступа к таблице и Интерфейс доступа индекса.
pg_am столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки amname name Имя метода доступа amhandler regproc pg_proc.oid OID функции обработчика, ответственного за предоставление информации о методе доступа amtype char t = таблица (включая материализованные представления), i = индекс. pg_amop
Каталог pg_amop хранит информацию об операторах, связанных с семействами операторов метода доступа. Существует одна строка для каждого оператора, который является членом семейства операторов. Членом семейства может быть либо оператор поиска, либо оператор сравнения. Оператор может отображаться в нескольких семействах, но не может отображаться более чем в одной позиции поиска или более чем в одной позиции в пределах одного семейства. (Это разрешено, хотя и маловероятно, для оператора, который будет использоваться как для поиска, так и для сравнения.)
pg_amop столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки amopfamily oid pg_opfamily.oid Семейство операторов для которых эта запись предназначена amoplefttype oid pg_type.oid Левый тип входных данных оператора amoprighttype oid pg_type.oid Правый тип входных данных оператора amopstrategy int2 Номер стратегии оператора amoppurpose char Назначение оператора, либо s для поиска или о для сравнения amopopr oid pg_operator.oid OID оператора amopmethod oid pg_am.oid Семейство операторов метода индексного доступа amopsortfamily oid pg_opfamily.oid Семейство операторов B-дерева для которого запись сортируется если оператор сравнения — ноль, если оператор поиска Запись оператора «поиск” указывает, что индекс этого семейства операторов может быть использован для поиска всех строк, удовлетворяющих требованиям WHERE indexed_column operator constant. Очевидно, что такой оператор должен вернуть boolean, и его левый тип ввода должен соответствовать типу данных столбца индекса.
Запись оператора ordering указывает, что индекс этого семейства операторов может быть отсканирован для возврата строк в порядке, представленном ORDER BY indexed_column operator constant. Такой оператор может возвращать любой сортируемый тип данных, хотя опять же его левый входной тип должен соответствовать типу данных столбца индекса. Точная семантика выражения ORDER BY определяются по формуле: amopsortfamily столбец, который должен ссылаться на семейство операторов B-tree для типа результата оператора.
Примечание.
В настоящее время предполагается, что порядок сортировки для оператора ordering является значением по умолчанию для указанного семейства операторов, т. е., ASC NULLS LAST. Это может быть когда-нибудь изменено путем добавления дополнительных столбцов, чтобы явно указать параметры сортировки.Вход amopmethod должен соответствовать opfmethod содержащего его семейства операторов (это преднамеренная денормализация структуры каталога по причинам производительности). Также, amoplefttype и amoprighttype должны соответствовать oprleft и oprright поля ссылки pg_operator.
pg_amproc
Каталог pg_amproc хранит информацию о функциях поддерживаемых оператором и связанных с семействами операторов метода доступа. Существует одна строка для каждой опорной функции, принадлежащей семейству операторов.
pg_amproc столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки amprocfamily oid pg_opfamily.oid Семейство операторов для которых предназначается эта запись amproclefttype oid pg_type.oid Левый тип входных данных ассоциированного оператора amprocrighttype oid pg_type.oid Правый тип входных данных ассоциированного оператора amprocnum int2 Номер поддерживаемой функции amproc regproc pg_proc.oid OID функции Пояснить эту структуру можно так amproclefttype и amprocrighttype поля — которые идентифицируют левый и правый типы входных данных оператора(ов), поддерживающие определенную функцию. Для некоторых методов доступа они соответствуют типам входных данных самой функции, для других-нет. Существует понятие функции для индекса ”по умолчанию» это такая функция,для которой amproclefttype и amprocrighttype оба равны классу оператора индекса opcintype.
pg_attrdef
Каталог pg_attrdef сохраняет значения столбца по умолчанию. Основная информация о столбцах хранится в каталоге pg_attribute. Только столбцы, для которых значение по умолчанию было явно установлено, хранятся в этом каталоге.
pg_attrdef столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки adrelid oid pg_class.oid Таблица, к которой принадлежит этот столбец adnum int2 pg_attribute.attnum Номер столбца: adbin pg_node_tree Значение столбца по умолчанию, в nodeToString() представлении. Воспользуйтесь pg_get_expr(adbin, adrelid) чтобы преобразовать его в выражение SQL. pg_attribute
Каталог pg_attribute хранит информацию о столбцах таблицы. Хранится ровно одна строка для каждого столбца в каждой таблице базы данных. (Также хранятся записи атрибутов для индексов, и всех объектов, которые имеют записи в pg_class).
Термин атрибут эквивалентен столбцу и используется по историческим причинам.
pg_attribute столбцы
Имя Тип Ссылки Описание attrelid oid pg_class.oid Таблица, к которой принадлежит этот столбец attname name Имя столбца atttypid oid pg_type.oid Тип данных этого столбца attstattarget int4 attstattarget управляет уровнем детализации статистики, накопленной для данного столбца методом ANALYZE. Нулевое значение указывает на то, что статистика не должна собираться. Отрицательное значение указывает на использование статистики по умолчанию. Точное значение положительных значений зависит от типа данных. Для скалярных типов данных, attstattarget является как числом «наиболее распространенных значений» для сбора, так и числом ячеек гистограммы для создания. attlen int2 Копия pg_type.typlen типа этого столбца attnum int2 Номер столбца. Обычные столбцы пронумерованы от 1 и выше. Системные столбцы, такие как ctid, имеют (произвольные) отрицательные числа. attndims int4 Число измерений, если столбец имеет тип массива; в противном случае 0. (В настоящее время число измерений массива не обязательно, поэтому любое ненулевое значение означает “это массив”.) attcacheof int4 Всегда -1 в хранилище, но при загрузке в дескриптор строки в памяти он может быть обновлен для кэширования смещения атрибута в строке atttypmod int4 atttypmod записи специфичные для типа данных, предоставляемых во время создания таблицы (например, максимальная длина для varchar) Передается в функции ввода определенного типа и функции ограничения длины. Значение обычно будет равно -1 для типов, которые не нуждаются в atttypmod. attbyval bool Копия pg_type.typbyval типа этого столбца attstorage char Обычно это копия pg_type.typsize типа этого столбца. Для TOAST типов данных этот атрибут можно изменить после создания столбца для управления политикой хранения. attalign char Копия pg_type.typalign типа этого столбца attnotnull bool Ограничение not-null. atthasdef bool Показывает, что столбец имеет выражение по умолчанию или выражение генерации, в этом случае будет соответствующая запись в поле pg_attrdef из каталога, который фактически определяет выражение. (Необходимо проверять attgenerated чтобы определить, является ли это выражение по умолчанию или значение.) atthasmissing bool Показывает, что столбец имеет значение, которое используется, когда столбец полностью отсутствует в строке, это происходит, когда столбец добавляется с значением ПО УМОЛЧАНИЮ после создания строки. Используемое фактическое значение хранится в колонке attmissingval . attidentity char Если пусто (”), то столбец идентификаторов отсутствует. Иначе, a = генерируется всегда, d = генерируется по умолчанию. attgenerated char Если пусто (”), то столбец не сгенерированный. Иначе, с = на хранении. (В будущем могут быть добавлены и другие значения.) attisdropped bool Этот столбец был удален и больше не является допустимым. Удалённый столбец все еще физически присутствует в таблице, но игнорируется синтаксическим анализатором и поэтому не может быть доступен через SQL. attislocal bool Этот столбец определяется локально в отношении. Обратите внимание, что столбец может быть локально определен и унаследован одновременно. attinhcount int4 Число прямых предков, которые есть в этой колонке. Столбец с ненулевым числом предков нельзя удалить или переименовать. attcollation oid pg_collation.oid Заданные параметры сортировки столбца или ноль, если столбец не является типом данных с возможностью сортировки. attacl aclitem[] Права доступа на уровне столбца, если они были предоставлены специально для этого столбца attoptions text[] Параметры уровня атрибута, в виде строки «ключ=значение» attfdwoptions text[] Параметры внешней оболочки данных уровня атрибута, в виде строки «ключ=значение» attmissingval anyarray Этот столбец имеет массив из одного элемента, содержащий значение, используемое, когда столбец полностью отсутствует в строке, как это происходит, когда в столбец добавляется значение по умолчанию после создания строки. Значение используется только тогда, когда atthasmissing установлен в true. Если значение отсутствует, столбец имеет значение null. Для удалённого(ых) столбца(ов) в pg_attribute, atttypid колонка сбрасывается в null, но attlen а остальные поля скопированые из pg_type все еще действительны. Это необходимо, чтобы справиться с ситуацией, когда тип данных удалённого столбца был позже удалён, и поэтому несуществует соот. pg_type и не возникает конфликта при повторном использовании OID, а attlen а другие поля можно использовать для интерпретации содержимого строки таблицы.
pg_authid
Каталог pg_authid содержит информацию об идентификаторах авторизации базы данных (ролях). Роль включает в себя понятия “пользователи” и “группы”. Пользователь-это просто роль с установленным флагом rolcanlogin. Любая роль (С или без rolcanlogin) может иметь другие роли в качестве членов — см. pg_auth_members.
Поскольку этот каталог содержит пароли, он не должен быть общедоступным для чтения. pg_roles-это публично доступное представление (VIEW) для pg_authid для того чтобы скрыть поле пароля.
В Роли в базе данных содержатся подробные сведения об управлении правами пользователей и привилегиями.
Поскольку аутентификация пользователей проводится для всего кластера, pg_authid является общим каталогом для всех баз данных кластера: существует только одна копия pg_authid на кластер, а не собственная для каждой базы данных.
pg_authid столбцы
Имя Тип Описание oid oid Идентификатор строки rolname name Имя роли rolsuper bool Роль имеет привилегии суперпользователя rolinherit bool Роль автоматически наследует привилегии ролей, членом которых она является rolcreaterole bool Роль может создавать другие роли rolcreatedb bool Роль может создавать базы данных rolcanlogin bool Роль может войти в систему. То есть эта роль может быть задана в качестве идентификатора авторизации начального сеанса rolreplication bool Роль — это роль репликации. Роль репликации может инициировать подключения репликации и создавать и удалять слоты репликации. rolbypassrls bool Роль обходит политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. rolconnlimit int4 Для ролей, которые могут войти в систему, задает максимальное число одновременных подключений, которые может создать эта роль. -1 означает отсутствие ограничений. rolpassword text Пароль (возможно зашифрованный), null, если нет. Формат зависит от используемой формы шифрования. rolvaliduntil timestamptz Срок действия пароля (используется только для аутентификации по паролю); null, если нет срока действия Для зашифрованного пароля MD5, rolpassword столбец будет начинаться со строки md5 далее следует 32-символьный шестнадцатеричный хэш MD5. Хэш MD5 будет содержать пароль пользователя, связанный с его именем. Например, если пользователь Джо имеет пароль xyzzy, QHB будет хранить хэш md5 из xyzzyjoe.
Если пароль зашифрован с помощью SCRAM-SHA-256, он имеет следующий формат:
SCRAM-SHA-256$:$:
где salt, StoredKey и ServerKey строки в формате Base64. Этот формат совпадает с форматом, указанным в документе RFC5803.
Пароль, который не соответствует ни одному из этих форматов, считается незашифрованным.
pg_auth_members
Каталог pg_auth_members содержит отношения членства между ролями. Допускается любой нециклический набор отношений.
Поскольку авторизация пользователей является кластерной, pg_auth_members является общим каталогом для всех баз данных кластера: существует только одна копия pg_auth_members на кластер, а не для каждой базы данных.
pg_auth_members столбцы
Имя Тип Ссылки Описание roleid oid pg_authid.oid Идентификатор роли, имеющей участника member oid pg_authid.oid Идентификатор роли, которая является членом roleid grantor oid pg_authid.oid Идентификатор роли, предоставившей это членство admin_option bool True, если member может предоставить членство в компании roleid для других pg_cast
Каталог pg_cast хранит пути преобразования типов данных, как встроенные, так и определяемые пользователем.
Следует отметить, что pg_cast не содержит все преобразования типов, которые система умеет выполнять, а только те, которые не могут быть выведены из некоторого общего правила. Например, приведение между доменом и его базовым типом явно не представлено в виде pg_cast. Еще одним важным исключением является то, что каталог pg_cast не содержит «автоматическое преобразование ввода-вывода», те преобразования, которые выполняются с использованием собственных функций ввода-вывода типа данных для преобразования в или из текст или другие строковые типы, явно не представленные в pg_cast.
pg_cast столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки castsource oid pg_type.oid OID типа исходных данных casttarget oid pg_type.oid OID целевого типа данных castfunc oid pg_proc.oid OID функции, которая будет использоваться для выполнения этого приведения. Null, если метод cast не требует функции. castcontext char Указывает, в каких контекстах приведение может быть вызвано — e означает только явное приведение (использование синтаксиса CAST или :: ) а означает неявно при присвоении целевому столбцу, а также явно, i означает неявно в выражениях, а также в других случаях. castmethod char Указывает, как выполняется приведение. а означает, что используется функция, указанная в столбце castfunc, i означает, что используются функции ввода/вывода. b означает, что типы являются двоично-совместимыми, поэтому преобразование не требуется. Функции, перечисленные в pg_cast должны всегда использовать тип источника приведения в качестве первого аргумента и возвращать тип назначения приведения в качестве типа результата. Приведенная функция может иметь до трех аргументов. Второй аргумент, если он присутствует, должен быть типом integer; он получает модификатор типа, связанный с целевым типом, или -1, если его нет. Третий аргумент, если он присутствует, должен быть логическим типом — он получает значение true если приведение является явным приведением, иначе false.
Возможно создать в pg_cast запись, в которой исходные и целевые типы совпадают, если связанная функция принимает более одного аргумента. Такие функции представляют собой «функции приведения длины», которые принуждают значения типа быть приемлимым для определенного значения модификатора типа.
Когда a pg_cast запись имеет различные исходные и целевые типы, а функция, принимающая более одного аргумента, представляет собой преобразование из одного типа в другой и применение приведения длины за один шаг. Если такая запись недоступна, приведение к типу, использующему модификатор типа, включает два шага: один для преобразования между типами данных и второй для применения модификатора.
pg_class
Каталог pg_class содержит информацию о таблицах и всех других объектах, которые имеет столбцы или иным образом похожи на таблицу. Этот каталог включает в себя индексы (см. также pg_index), последовательности (см. также pg_sequence), представления, материализованные представления, составные типы и таблицы TOAST (см. relkind). Когда мы имеем в виду все эти виды объектов, мы говорим об “отношениях”. Не все столбцы в каталоге имеют значение для всех типов отношений.
pg_class столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки relname name Имя таблицы, индекса, представления и т.д. relnamespace oid pg_namespace.oid OID пространства имен, содержащего это отношение reltype oid pg_type.oid OID типа данных, который соответствует типу строки этой таблицы, если таковой имеется (ноль для индексов, у которых нет pg_type вход) reloftype oid pg_type.oid Для типизированных таблиц OID базового составного типа NULL для всех других отношений relowner oid pg_authid.oid Владелец отношения relam oid pg_am.oid Если это таблица или индекс, то используется метод доступа (куча, B-дерево, хэш и т. д.) relfilenode oid Имя файла на диске для этого отношения — NULL означает, что это “сопоставленное” отношение, имя файла на диске для которого определяется низкоуровневым состоянием reltablespace oid pg_tablespace.oid Табличное пространство, в котором хранится это отношение. Если NULL, подразумевается табличное пространство базы данных по умолчанию . (Не имеет смысла, если отношение не имеет файла на диске.) relpages int4 Размер представления этой таблицы на диске в страницах (размера BLCKSZ). Это только оценка, используемая планировщиком, столбец обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. reltuples float4 Количество «живых» строк в таблице. Это только оценка, используемая планировщиком. Она обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. relallvisible int4 Количество страниц, отмеченных как все видимые на карте видимости таблицы. Это только оценка, используемая планировщиком. Она обновляется с помощью VACUUM, ANALYZE и нескольких команд DDL, таких как CREATE INDEX. reltoastrelid oid pg_class.oid OID таблицы TOAST, связанной с этой таблицей, 0, если нет. Таблица TOAST хранит большие атрибуты «вне строки» во вторичной таблице. relhasindex bool True, если это таблица и она имеет (или недавно имела) какие-либо индексы relisshared bool True, если эта таблица является общей для всех баз данных в кластере. Только определенные системные каталоги (такие как pg_database) разделяемы. relpersistence char p = постоянная таблица, u = незарегистрированная таблица, t = временная таблица relkind char r = Обычная таблица, i = индекс, s = последовательность, t = Таблица TOAST, v = представление, m = материализованное представление, c = составной тип, f = внешняя таблица, p = партиционированная таблица, I = партиционированный индекс relnatts int2 Количество пользовательских столбцов в связи (системные столбцы не учитываются). Должно быть такое количество соответствующих записей в pg_attribute. См. также pg_attribute.attnum. relchecks int2 Количество CHECK (порверок) ограничений для таблицы; см. каталог pg_constraint relhasrules bool True, если таблица имеет (или когда-то имела) правила; см. каталог pg_rewrite relhastriggers bool True, если таблица имеет (или когда-то имела) триггеры; см. каталог pg_trigger relhassubclass bool True, если у таблицы или индекса есть (или когда-то были) «дети» в результате наследования relrowsecurity bool True, если в таблице включена защита на уровне строк; см. каталог pg_policy relforcerowsecurity bool True, если безопасность на уровне строк (если она включена) будет также применяться к владельцу таблицы; см. каталог pg_policy relispopulated bool True, если отношение заполнено (это справедливо для всех отношений, кроме некоторых материализованных представлений) relreplident char Столбцы, используемые для формирования «идентичности реплики» для строк: d = по умолчанию (первичный ключ, если есть), n = ничего, f = все столбцы i = индекс с indisreplident или по умолчанию relispartition bool True, если таблица или индекс является партицией relrewrite oid pg_class.oid Для новых отношений, записываемых во время операции DDL, которая требует перезаписи таблицы, это содержит OID исходного отношения; в противном случае 0. Это состояние является видимым только dyenhb — это поле никогда не должно содержать ничего, кроме 0 для отношения пользователя. relfrozenxid xid Все идентификаторы транзакций до этого были заменены на постоянный (”замороженный») идентификатор транзакции в этой таблице. Используется для отслеживания того, нужно ли очистить таблицу, чтобы предотвратить «оборачивание» идентификатора транзакции или разрешить уменьшение pg_xact. NULL (InvalidTransactionId) если отношение не является таблицей. relminmxid xid Все идентификаторы multixact перед этим были заменены на постоянный (”замороженный») идентификатор транзакции в этой таблице. Это используется для отслеживания того, нужно ли вакуумировать таблицу, чтобы предотвратить «оборачивание» multixact ID или разрешить уменьшение pg_multixact. Ноль (InvalidMultiXactId) если отношение не является таблицей. relacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации reloptions text[] Параметры, зависящие от метода доступа, в виде строки «ключ=значение» relpartbound pg_node_tree Если таблица является партицией (см. relispartition), внутреннее представление связанной партиции Несколько логических флагов внутри pg_class поддерживаются «лениво» : они гарантированно будут истинными, если это правильное состояние, но не сбрасываются на false сразу же, когда условие больше не является истинным. Например, relhasindex устанавливается с помощью CREATE INDEX, но никогда не очищается с помощью DROP INDEX. Вместо этого, вакуум очищает relhasindex если он обнаружит, что таблица не имеет индексов. Это расположение позволяет избежать условий гонки и улучшает параллелизм.
pg_collation
Каталог pg_collation описывает доступные параметры сортировки, которые представляют собой сопоставления между именем SQL и категориями локали операционной системы.
pg_collation столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки collname name Имя сортировки (уникальное для каждого пространства имен и кодировки) collnamespace oid pg_namespace.oid OID пространства имен, содержащего эту сортировку collowner oid pg_authid.oid Владелец сортировки collprovider char Поставщик сортировки: d = database по умолчанию, c = libc, i = icu collisdeterministic bool Является ли сортировка детерминированной? collencoding int4 Кодировка, в которой применяется сортировка, или -1, если она работает для любой кодировки collcollate name LC_COLLATE для этого объекта сортировки collctype name LC_CTYPE для этого объекта сортировки collversion text Версия параметров сортировки для конкретного поставщика. Записывается при создании параметров сортировки, а затем проверяется при их использовании для обнаружения изменений в определении параметров сортировки, которые могут привести к повреждению данных. Обратите внимание, что уникальным ключем в этом каталоге является (collname, collencoding, collnamespace) а не только (collname, collnamespace). QHB обычно игнорирует все параметры сортировки, которые не имеют collencoding равным либо кодировке текущей базы данных, либо -1, кроме того, создание новых записей с тем же именем, что и запись с collencoding = -1 запрещено. Поэтому достаточно использовать полное имя SQL (schema.name) для определения параметров сортировки, даже если оно не является уникальным в соответствии с определением каталога. Причина определения каталога таким образом заключается в том, что qhb_bootstrap заполняет его во время инициализации кластера записями для всех локалей, доступных в системе, поэтому он должен иметь возможность хранить записи для всех кодировок, которые могут когда-либо использоваться в кластере.
В шаблоне template0 может быть полезно для создать параметры сортировки, кодировка которых не соответствует кодировке базы данных, так как они могут соответствовать кодировкам баз данных, клонированных позже из template0. В настоящее время это можно сделать вручную.
pg_constraint
Каталог pg_constraint хранит ограничения check, primary key, unique, foreign key и exclusion для таблиц. (Ограничения столбцов не обрабатываются специально. Каждое ограничение столбца эквивалентно некоторому ограничению таблицы.) Ограничения Not-null представлены не здесь а в каталоге pg_attribute.
Определяемые пользователем триггеры ограничений (созданные с помощью триггера CREATE CONSTRAINT ) также приводят к появлению записи в этой таблице.
Здесь также хранятся проверочные ограничения для доменов.
pg_constraint столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки conname name Имя ограничения (не обязательно уникальное!) connamespace oid pg_namespace.oid OID пространства имен, содержащего это ограничение contype char c = проверочное ограничение, f = ограничение внешнего ключа, p = ограничение первичного ключа, u = ограничение уникальности, t = триггер ограничения, x = ограничение на исключение condeferrable bool Может ли это ограничение быть отложенным? condeferred bool Является ли ограничение отложенным по умолчанию? convalidated bool Было ли это ограничение проверено? В настоящее время может быть false только для внешних ключей и проверочных ограничений conrelid oid pg_class.oid Таблица, на которую наложено это ограничение; 0 если нет ограничения таблицы contypid oid pg_type.oid Домен, на который наложено это ограничение; 0 если нет ограничения домена conindid oid pg_class.oid Индекс, поддерживающий это ограничение, если это уникальный, первичный ключ, внешний ключ или ограничение исключения — в противном случае 0 conparentid oid pg_constraint.oid Соответствующее ограничение в родительской партиционированной таблице, если это ограничение для партиции в противном случае 0 confrelid oid pg_class.oid Если это внешний ключ, то ссылочная таблица (на которую ссылается ключ) — в противном случае 0 confupdtype char Код действия при обновлении внешнего ключа: a = нет действия, r = ограничивать, c = каскад, n = установить значение null, d = установить по умолчанию confdeltype char Код действия при удалении внешнего ключа: a = нет действия, r = ограничивать, c = каскад, n = установить значение null, d = установить по умолчанию confmatchtype char Тип соответствия для внешнего ключа: f = полный, p = частичный, s = простой conislocal bool Определяется ли ограничение локально для отношения. Обратите внимание, что ограничение может быть локально определено и унаследовано одновременно. coninhcount int4 Число предков прямого наследованият ограничения. Ограничение с ненулевым числом предков не может быть удалено или переименовано. connoinherit bool True если не наследуемое ограничение (определяется локально для отношения). conkey int2[] pg_attribute.attnum Если ограничение таблицы (включая внешние ключи, но не триггеры ограничений), то список ограниченных столбцов confkey int2[] pg_attribute.attnum Если это внешний ключ, то список ссылочных столбцов conpfeqop oid[] pg_operator.oid Если ограничение — внешний ключ, то список операторов равенства для сравнений PK = FK conppeqop oid[] pg_operator.oid Если ограничение — внешний ключ, то список операторов равенства для сравнений PK = PK conffeqop oid[] pg_operator.oid Если ограничение — внешний ключ, то список операторов равенства для сравнений FK = FK conexclop oid[] pg_operator.oid Если ограничение исключения, то список операторов исключения для каждого столбца conbin pg_node_tree Если это проверочное ограничение (CHECK), то внутреннее представление выражения. (Чтобы извлечь определение проверочного ограничения рекомендуется использовать pg_get_constraintdef()) В случае ограничения исключения, столбец conkey полезен только для элементов ограничений, которые являются простыми ссылками на столбец. Для других случаев, значение conkey будет NULL и необходимо просмотретьсвязный индекс, чтобы обнаружить выражение ограничения (conkey таким образом, имеет то же содержание, что и pg_index.indkey для индекса.)
Примечание.
pg_class.relchecks необходимо согласовать с количеством записей check-constraint, найденных в этой таблице для каждого отношения.pg_conversion
Каталог pg_conversion описывает функции преобразования кодировки. Дополнительную информацию смотрите в разделе CREATE CONVERSION.
pg_conversion столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки conname name Имя преобразования (уникальное в пределах пространства имен) connamespace oid pg_namespace.oid OID пространства имен, содержащего это преобразование conowner oid pg_authid.oid Владелец преобразования conforencoding int4 ID кодировки источника contoencoding int4 ID кодировки назначения conproc regproc pg_proc.oid Функция преобразования condefault bool True, если это преобразование по умолчанию pg_database
Каталог pg_database хранит информацию о доступных базах данных. Базы данных создаются с помощью команды CREATE DATABASE. Дополнительную информацию о значении некоторых параметров см. в главе Управление базами данных.
В отличие от большинства системных каталогов, pg_database является общим для всех баз данных кластера: существует только одна копия pg_database на кластер, а не по одному на каждую базу данных.
pg_database столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки datname name Имя базы данных datdba oid pg_authid.oid Владелец базы данных, как правило, пользователь, который ее создал encoding int4 Кодировка символов для этой базы данных (при помощи pg_encoding_to_char() можно перевести число в имя кодировки) datcollate name LC_COLLATE для этой базы данных datctype name LC_CTYPE для этой базы данных datistemplate bool Если true, то эта база данных может быть клонирована любым пользователем обладающим привелегией CREATEDB, если значение false, то клонировать его могут только суперпользователи или владелец базы данных. datallowconn bool Если false, то никто не может подключиться к этой базе данных. Используется для защиты базы данных template0 от изменения. datconnlimit int4 Задает максимальное число одновременных подключений, которые могут быть выполнены для этой базы данных. -1 означает отсутствие ограничений. datlastsysoid oid Последний системный OID в базе данных — необходимо, в частности, для qhb_dump datfrozenxid xid Все идентификаторы транзакций до этого были заменены на постоянный (”замороженный») идентификатор транзакции в этой базе данных. Используется для отслеживания того, должна ли база данных быть очищена для предотвращения «оборачивания» идентификатора транзакции или для разрешения уменьшения pg_xact. Это минимальное значение pg_class.relfrozenxid для каждой таблицы. datminmxid xid Все идентификаторы multixact перед этим были заменены на постоянный (”замороженный») идентификатор транзакции в этой базе данных. Используется для отслеживания того, должна ли база данных быть очищена для предотвращения «оборачивания» multixact или для разрешения уменьшенния pg_multixact. Это минимальное значение pg_class.relminmxid для каждой таблицы. dattablespace oid pg_tablespace.oid Табличное пространство по умолчанию для этой базы данных. Если в пределах этой базы данных pg_class.reltablespace — NULL там будут находиться все общие системные каталоги datacl aclitem[] Права доступа- смотрите раздел Привилегии для получения дополнительной информации pg_db_role_setting
Каталог pg_db_role_setting хранит значения по умолчанию, заданные для переменных конфигурации времени выполнения, для каждой комбинации роли и базы данных.
В отличие от большинства системных каталогов, pg_db_role_setting является общим для всех баз данных кластера: существует только одна копия pg_db_role_setting на кластер, а не по одному на каждую базу данных.
pg_db_role_setting столбцы
Имя Тип Ссылки Описание setdatabase oid pg_database.oid OID базы данных, к которой применяется этот параметр, или NULL, если он не относится к конкретной базе данных setrole oid pg_authid.oid OID роли, к которой применяется этот параметр, или NULL, если он не относится к конкретной роли setconfig text[] Значения по умолчанию для переменных конфигурации времени выполнения pg_default_acl
Каталог pg_default_acl сохраняет начальные привилегии, назначаемые вновь созданным объектам.
pg_default_acl столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки defaclrole oid pg_authid.oid OID роли, связанной с этой записью defaclnamespace oid pg_namespace.oid OID пространства имен, связанного с этой записью, или 0 для глобальной записи defaclobjtype char Тип объекта для которого эта запись предназначена для: r = отношение (таблица, представление), S = последовательность, f = функция, T = тип, n = схема defaclacl aclitem[] Права доступа, которые этот тип объекта должен иметь при создании Одна запись в pg_default_acl показывает начальные привилегии, которые должны быть назначены объекту, принадлежащему указанному пользователю. В настоящее время существует два типа записей: «глобальные» записи с defaclnamespace = 0 и записи «схемы», ссылающиеся на конкретную схему. Если глобальная запись присутствует, то она переопределяет обычные жесткие привилегии задаваемые по умолчанию для типа объекта. Запись для каждой схемы, если она присутствует, представляет привилегии, которые должны быть добавлены к глобальным или жестко привязанным привилегиям по умолчанию.
Обратите внимание, что если запись ACL в другом каталоге имеет значение NULL, то она используется для представления жестко привязанных привилегий по умолчанию для ее объекта, а не того, что может быть внутри pg_default_acl в данный момент. pg_default_acl считывается только во время создания объекта.
pg_depend
Каталог pg_depend записывает отношения зависимости между объектами базы данных. Эта информация позволяет командам DROP находить, какие другие объекты должны быть удалены с помощью DROP CASCADE, или предотвращать удаление в случае DROP RESTRICT.
Смотрите также раздел pg_shdepend, который выполняет аналогичную функцию для зависимостей, включающих объекты, совместно используемые в кластере баз данных.
pg_depend столбцы
Имя Тип Ссылки Описание classid oid pg_class.oid OID системного каталога, в котором находится зависимый объект objid oid OID для любого столбца OID конкретного зависимого объекта objsubid int4 Для столбца таблицы это номер столбца (objid и classid задают саму таблицу). Для всех других типов объектов этот столбец равен нулю. refclassid oid pg_class.oid OID системного каталога, в котором находится объект ссылки refobjid oid OID для любого столбца OID конкретного объекта ссылки refobjsubid int4 Для столбца таблицы это номер столбца (refobjid и refclassid задают саму таблицу). Для всех других типов объектов этот столбец равен нулю. deptype char Код, определяющий конкретную семантику этого отношения зависимости Во всех случаях a pg_depend запись указывает, что объект ссылки не может быть удален без удаления также зависимого объекта. Тем не менее, есть несколько подвидов зависимостей, задаваемых с помощью deptype:
DEPENDENCY_NORMAL (n)
Обычное отношение между раздельно созданными объектами. Зависимый объект можно удалить, не затрагивая объект который на него ссылается. Объект который ссылается может быть удален только путем указания CASCADE и в этом случае зависимый объект также удаляется. Пример: столбец таблицы имеет нормальную зависимость от своего типа данных.
DEPENDENCY_AUTO (a)
Зависимый объект может быть удален отдельно от объекта который на него ссылается и должен быть автоматически удален (независимо от того выбран режим, RESTRICT или CASCADE). Пример: именованное ограничение из таблицы становится автоматически зависимым от таблицы, так что оно исчезнет автоматически , если таблица будет удалена.
DEPENDENCY_INTERNAL (i)
Зависимый объект был создан как часть другого объекта, и на самом деле является только частью его внутренней реализации. Удаление при помощи DROP такого зависимого объекта будет запрещено (вместо этого пользователю будет выдано сообщение о том что необходимо вызвать DROP для основного объекта). Удаление объекта который ссылается на данный приведет к автоматическому удалению зависимого объекта вне зависимости от тогоуказывается CASCADE при удалении или нет. Если зависимый объект должен быть удален из-за зависимости от какого-либо другого удаляемого объекта, его удаление преобразуется в удаление объекта который создал ссылки, так что зависимости NORMAL и AUTO зависимого объекта ведут себя так же, как и зависимости объекта который ссылается на данный. Пример: Правило ON SELECT для представления (VIEW) становится внутренне зависимым от представления, предотвращая его удаление, пока представление остается в системе. Зависимости для этого правила (например, таблицы, на которые оно ссылается) действуют так, как если бы они были зависимостями представления (VIEW).
DEPENDENCY_PARTITION_PRI (P) и DEPENDENCY_PARTITION_SEC (S)
Зависимый объект был создан как часть создания партиции и на самом деле является только частью его внутренней реализации — однако, в отличие от INTERNAL, существует более одного объекта ссылающегося на данный. Зависимый объект не должен быть удален, пока не будет удален хотя бы один из этих объектов — если какой-либо из них удаляется, зависимый объект должен быть удален вне зависимости от указания CASCADE. Также в отличие от INTERNAL, удаление некоторого другого объекта, от которого зависит объект, не приводит к автоматическому удалению какого-либо объекта, на который он ссылается. Следовательно, если удаление не касается хотя бы одного из этих объектов каким либо способом, оно не будет затрагивать зависимый объект. (В большинстве случаев зависимый объект совместно использует все свои зависимости связанные с партициями по крайней мере с одним объектом, на который ссылается партиция, так что это ограничение не приводит к блокированию каскадного удаления.) Первичные и вторичные зависимости партиций ведут себя одинаково, за исключением того, что первичная зависимость предпочтительна для использования в сообщениях об ошибках — следовательно, объект, зависящий от партиции, должен иметь одну первичную зависимость партиции и одну или несколько вторичных зависимостей партиции. Обратите внимание, что зависимости партиций создаются в дополнение к любым зависимостям, которые обычно имеются у объекта, а не вместо них. Это упрощает задачу Операции присоединения / отсоединения партиций: необходимо только добавить или удалить зависимости. Пример: дочерний партиционированный индекс становится зависимым от партиционирования как таблицы, в которой он находится, так и от родительского партиционированного индекса, так что он удаляется, если любой из этих объектов удаляется, но не иначе. Зависимость от родительского индекса является основной, так что если пользователь пытается удалить дочерний партиционированный индекс, сообщение об ошибке будет предлагать вместо этого удалить родительский индекс (а не таблицу).
DEPENDENCY_EXTENSION (е)
Зависимый объект является элементом расширения, на которое ссылается объект (см. раздел pg_extension). Зависимый объект можно удалить только с помощью DROP EXTENSION для объекта который ссылается. Функционально этот тип зависимости действует так же, как и INTERNAL зависимость, но она хранится отдельно для ясности и упрощения qhb_dump.
DEPENDENCY_AUTO_EXTENSION (x)
Зависимый объект не является элементом расширения, на которое ссылается объект (и поэтому он не должен игнорироваться qhb_dump), но он не может функционировать без расширения и должен автоматически удаляться, если расширение удаляется. Зависимый объект также может быть удалён сам по себе. Функционально этот тип зависимости действует так же, как и AUTO зависимость, но она хранится отдельно для ясности и упрощения qhb_dump.
DEPENDENCY_PIN (p)
Зависимого объекта нет — этот тип записи означает, что сама система зависит от объекта, и поэтому этот объект никогда не должен быть удален. Записи этого типа создаются только вкоманде qhb_bootstrap. Столбцы для зависимого объекта содержат нули.
Обратите внимание, что вполне возможно, что два объекта будут связаны более чем одной зависимостью в pg_depend. Например, дочерний партиционированный индекс будет иметь зависимость от партиции связанной таблицы, и автозависимость от каждого столбца той таблицы, которую он индексирует. Такая ситуация нужна для выражения семантики множественной зависимости. Зависимый объект можно удалить без CASCADE если какая-либо из его зависимостей удовлетворяет его условию автоматического сброса. И наоборот, должны быть выполнены все ограничения зависимостей, относительно которых объекты должны быть удалены вместе.
pg_description
Каталог pg_description хранит комментарий для каждого объекта базы данных. Описаниями можно манипулировать с помощью команды COMMENT и просматривать с помощью qsql \d команды.
Смотрите также раздел pg_shdescription, который выполняет аналогичную функцию для описаний объектов, совместно используемых в кластере баз данных.
pg_description столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID объекта, к которому относится данное описание classoid oid pg_class.oid Идентификатор OID системного каталога, в котором отображается этот объект objsubid int4 Для комментария к столбцу таблицы это номер столбца (objoid и classoid задают таблицу). Для всех других типов объектов этот столбец равен нулю. description text Произвольный текст, который служит необязательным описанием (комментарием) данного объекта pg_enum
Каталог pg_enum содержит записи, показывающие значения и текстовые метки для каждого типа enum. Внутренним представлением значения enum фактически является OID связанной строки в pg_enum.
pg_enum столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки enumtypid oid pg_type.oid OID записи в pg_type владеющей этим значением enum enumsortorder float4 Положение сортировки этого значения enum в пределах его типа enum enumlabel name Текстовая метка для этого перечисления значения OIDs для pg_enum строки следуют специальному правилу: четные OID гарантированно упорядочиваются таким же образом, как и порядок сортировки их типа enum. То есть, если два четных OID принадлежат к одному и тому же типу перечисления, меньший OID должен иметь меньший размер enumsortorder значение. Нечетные значения OID не должны иметь никакого отношения к порядку сортировки. Это правило позволяет подпрограммам сравнения перечислений избегать поиска в каталоге во многих распространенных случаях. Подпрограммы, которые создают и изменяют типы перечислений, пытаются назначить чётный OID для значений перечисления, когда это возможно.
При создании типа перечисления его членам присваиваются позиции порядка сортировки 1..n. Но элементы, добавленные позже, могут иметь отрицательные или дробные значения enumsortorder. Единственное требование к этим значениям состоит в том, чтобы они были правильно упорядочены и уникальны в каждом типе перечисления.
pg_event_trigger
Каталог pg_event_trigger хранит триггеры событий БД.
pg_event_trigger столбцы
Имя Тип Ссылки Описание evtname name Имя триггера (должно быть уникальным) evtevent name Определяет событие, для которого срабатывает этот триггер evtowner oid pg_authid.oid Владелец триггера события evtfoid oid pg_proc.oid Вызываемая функция evtenabled char Задаёт режимы session_replication_role в которых срабатывает триггер события. О = триггер срабатывает в режимах origin и local, D = триггер отключен, R = триггер срабатывает в режиме replica, A = триггер срабатывает всегда. evttags text[] Метки команд, для которых этот триггер будет срабатывать. Если NULL, то запуск этого триггера не ограничен тегом команды. pg_extension
Каталог pg_extension сохраняет информацию об установленных расширениях. Смотрите раздел Упаковка связанных объектов в расширение для получения подробной информации о расширениях.
pg_extension столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки extname name Имя расширения extowner oid pg_authid.oid Владелец расширения extnamespace oid pg_namespace.oid Схема, содержащая экспортируемые объекты расширения extrelocatable bool True, если расширение можно переместить в другую схему extversion text Имя версии для расширения extconfig oid[] pg_class.oid Массив из regclass OID для таблиц конфигурации расширения, или NULL если у расширения нет таблиц extcondition text[] Массив для условия фильтра WHERE предложений для таблиц конфигурации расширения, или NULL если условий нет Обратите внимание, что в отличие от большинства каталогов со столбцами namespace, extnamespace их наличие в этом каталоге не означает, что расширение принадлежит к этой схеме. Имена расширений никогда не определяются схемой. Скорее, extnamespace указывает схему, содержащую большинство или все объекты расширения. Если extrelocatable true, тогда эта схема должна содержать все объекты, принадлежащие расширению.
pg_foreign_data_wrapper
Каталог pg_foreign_data_wrapper сохраняет определения внешних данных. Внешние данные — это механизм, с помощью которого осуществляется доступ к данным находящимся на внешних серверах.
pg_foreign_data_wrapper столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки fdwname name Имя источника внешних данных fdwowner oid pg_authid.oid Владелец источника внешних данных fdwhandler oid pg_proc.oid Ссылается на функцию обработчика, которая отвечает за предоставление подпрограмм для обработки внешних данных. Ноль, если обработчик не предусмотрен fdwvalidator oid pg_proc.oid Ссылается на функцию валидатора, которая отвечает за проверку правильности параметров, заданных вне СУБД, а также параметров для внешних серверов и сопоставлений пользователей, использующих внешние данные. Ноль, если валидатор не предусмотрен fdwacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации fdwoptions text[] Конкретные параметры внешних данных, в виде строки «ключ=значение» pg_foreign_server
Каталог pg_foreign_server сохраняет определения внешних серверов. Внешний сервер описывает источник внешних данных, например удаленный сервер. Доступ к внешним серверам осуществляется через foreign_data_wrapper.
pg_foreign_server столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки srvname name Имя внешнего сервера srvowner oid pg_authid.oid Владелец внешнего сервера srvfdw oid pg_foreign_data_wrapper.oid OID foreign_data_wrapper этого внешнего сервера srvtype text Тип сервера (необязательно) srvversion text Версия сервера (необязательно) srvacl aclitem[] Права доступа — смотрите раздел Привилегии для получения дополнительной информации srvoptions text[] Конкретные параметры внешнего сервера, в виде строки «ключ=значение» pg_foreign_table
Каталог pg_foreign_table содержит дополнительную информацию о внешних таблицах. Внешняя таблица в основном представлена в каталоге pg_class, как обычная таблица. Запись соответствующая ей в pg_foreign_table содержит информацию, относящуюся только к внешним таблицам, а не к какому-либо другому виду связи.
pg_foreign_table столбцы
Имя Тип Ссылки Описание ftrelid oid pg_class.oid OID записи из pg_class для этой внешней таблицы ftserver oid pg_foreign_server.oid OID внешнего сервера для этой внешней таблицы ftoptions text[] Параметры внешней таблицы, в виде строки «ключ=значение» pg_index
Каталог pg_index содержит часть информации об индексах. Остальное — в основном каталоге pg_class.
pg_index столбцы
Имя Тип Ссылки Описание indexrelid oid pg_class.oid OID записи из pg_class для этого индекса indrelid oid pg_class.oid OID записи pg_class таблицы для которой индекс предназначен indnatts int2 Общее количество столбцов в индексе (повторяет pg_class.relnatts) это число включает в себя как ключевые, так и включенные атрибуты indnkeyatts int2 Количество ключевых столбцов в индексе, не считая каких-либо включенных столбцов, которые просто хранятся и не участвуют в семантике индекса indisunique bool Если true, то это уникальный индекс indisprimary bool Если true, то этот индекс представляет собой первичный ключ таблицы (indisunique в этом случае должно быть true) indisexclusion bool Если значение true, то этот индекс поддерживает ограничение исключения indimmediate bool Если true, то проверка уникальности применяется сразу после вставки (не имеет значения, если indisunique false) indisclustered bool Если true, то таблица была кластеризованной по этому индексу indisvalid bool Если значение true, то индекс в настоящее время является допустимым для запросов. False означает, что индекс может быть неполным: и еще должен быть изменен с помощью операций вставки / обновления, но он не может безопасно использоваться для запросов. Если он обозначен как уникальный, свойство уникальности также не гарантируется. indcheckxmin bool Если значение true, запросы не должны использовать индекс до тех пор, пока поле xmin находится ниже их горизонта событий (TransactionXmin) , поскольку таблица может содержать разорванные HOT цепочки с несовместимыми строками, которые запросы могут видеть indisready bool Если true, то индекс в настоящее время готов к вставкам. False означает, что индекс должен быть проигнорирован операциями вставки / обновления. indislive bool Если значение false, индекс находится в процессе удаления и должен игнорироваться при любой попытке использования (включая использования в HOT цепочках) indisreplident bool Если true, то этот индекс был выбран в качестве «идентификатора реплики» с помощью команд ALTER TABLE . REPLICA IDENTITY USING INDEX . indkey int2vector pg_attribute.attnum Массив из значений indnatts, указывающий, на столбцы таблицы которые этот индекс обрабатывает. Например, значение параметра 1 3 означает, что первый и третий столбцы таблицы составляют записи индекса. Ключевые столбцы предшествуют неключевым (включенным) столбцам. Ноль в этом массиве указывает, что соответствующий атрибут индекса является выражением над столбцами таблицы, а не просто ссылкой на столбец. indcollation oidvector pg_collation.oid Для каждого столбца в ключе индекса (indnkeyatts values),содержит OID параметров сортировки, используемых для индекса,или ноль, если столбец не является типом данных с возможностью сортировки. indclass oidvector pg_opclass.oid Для каждого столбца в ключе индекса (indnkeyatts values), содержит OID класса оператора для использования. Смотрите дополнительную информацию в разделе pg_opclass. indoption int2vector Массив из indnkeyatts значений, хранящие биты флагов для каждого столбца. Значение битов определяется методом доступа индекса. indexprs pg_node_tree Деревья выражений (nodeToString() представление) для атрибутов индекса, которые не являются простыми ссылками на столбец. Это список с одним элементом для каждой нулевой записи в indkey. Null, если все атрибуты индекса являются простыми ссылками. indpred pg_node_tree Дерево выражений (nodeToString() представление) для частичного индексного предиката. Null, если не является частичным индексом. pg_inherits
Каталог pg_inherits записывает информацию об иерархиях наследования таблиц. Существует одна запись для каждой прямой связи родительской и дочерней таблиц в базе данных. (Косвенное наследование может быть определено цепочками записей.)
pg_inherits столбцы
Имя Тип Ссылки Описание inhrelid oid pg_class.oid OID дочерней таблицы inparent oid pg_class.oid OID родительской таблицы inhseqno int4 Если для дочерней таблицы существует более одного прямого родителя (множественное наследование), это число указывает порядок, в котором должны быть упорядочены наследуемые столбцы. Отсчет начинается с 1. pg_init_privs
Каталог pg_init_privs записывает информацию о начальных привилегиях объектов в системе. Существует одна запись для каждого объекта в базе данных, имеющего начальный набор привилегий отличных от привелегий по умолчанию (не-NULL) .
Объекты могут иметь начальные привилегии, задавая эти привилегии при инициализации системы (с помощью qhb_bootstrap) или при создании объекта при выполнении CREATE EXTENSION, а сценарий расширения устанавливает начальные привилегии с помощью системы предоставления привелегий (GRANT). Обратите внимание, что система автоматически обрабатывает запись привилегий во время сценария расширения и что авторам расширения нужно только использовать инструкции GRANT и REVOKE в своем сценарии, чтобы иметь записанные привилегии. Cтолбец privtype указывает, была ли начальная привилегия установлена qhb_bootstrap или во время выполнения команды CREATE EXTENSION.
Объекты, которые имеют начальные привилегии, установленные qhb_bootstrap, будут иметь записи, где privtype помечается как i, в то время как объекты, которые имеют начальные привилегии, установленные при помощи CREATE EXTENSION, будут помечатся как e.
pg_init_privs столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID конкретного объекта classoid oid pg_class.oid OID системного каталога, в котором находится объект objsubid int4 Для столбца таблицы это номер столбца (objoid и classoid заданы от самой таблицы). Для всех других типов объектов этот столбец равен нулю. privtype char Код, определяющий тип начальной привилегии этого объекта — i или e initprivs aclitem[] Начальные права доступа — смотрите раздел Привилегии для получения дополнительной информации pg_language
Каталог pg_language регистрирует языки, на которых можно писать функции или хранимые процедуры. Дополнительную информацию о обработчиках языка смотрите в разделе CREATE LANGUAGE.
pg_language столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки lanname name Название языка lanowner oid pg_authid.oid Владелец языка lanispl bool Это значение false для внутренних языков (таких как SQL) и true для пользовательских языков. В настоящее время qhb_dump все еще использует это, чтобы определить, какие языки должны быть сохранены, Но это может быть заменено другим механизмом в будущем. lanplusted bool True, если это доверенный язык, пердполагается, что он, не предоставляет доступ к чему-либо за пределами обычной среды выполнения SQL. Только суперпользователи могут создавать функции на ненадежных языках. lanplcallfoid oid pg_proc.oid Для языков не использующих внутренние механизмы это ссылка на обработчик языка — специальную функцию, ответственную за выполнение всех предложений, написанных на определенном языке laninline oid pg_proc.oid Ссылка на функцию, которая отвечает за выполнение “встроенных” анонимных блоков кода ( DO блоков). Ноль, если анонимные блоки не поддерживаются. lanvalidator oid pg_proc.oid Ссылка на функцию-валидатор языка, которая отвечает за проверку синтаксиса и валидности новых функций при их создании. Ноль, если валидатор не предусмотрен. lanacl aclitem[] Права доступа — смотрите раздел Привилегии для получения дополнительной информации pg_largeobject
Каталог pg_largeobject содержит данные, составляющие “большие объекты». Большой объект идентифицируется OID, назначенным при его создании. Каждый большой объект разбивается на сегменты или «страницы» достаточно маленькие, чтобы удобно хранить их в виде строк внутри pg_largeobject. Количество данных на странице определяется как LOBLKSIZE (который в настоящее время BLCKSZ / 4, или обычно 2 кб).
Для получения списка OID больших объектов используйте pg_largeobject_metadata.
pg_largeobject столбцы
Имя Тип Ссылки Описание loid oid pg_largeobject_metadata.oid Идентификатор большого объекта, включающий страницу pageno int4 Номер страницы в пределах ее большого объекта (отсчет от нуля) data bytea Фактические данные, хранящиеся в большом объекте. Никогда не будет больше, чем LOBLKSIZE байт а может быть и меньше. Каждая строка из pg_largeobject содержит данные для одной страницы большого объекта, начиная со смещения в байтах (pageno * LOBLKSIZE) внутри объекта. Реализация позволяет использовать разреженное хранилище: страницы могут отсутствовать и быть короче, чем LOBLKSIZE байты, даже если они не являются последней страницей объекта. Отсутствующие области внутри большого объекта считываются как нули.
pg_largeobject_metadata
Каталог pg_largeobject_metadata содержит метаданные, связанные с большими объектами. Фактические данные большого объекта хранятся в pg_largeobject.
pg_largeobject_metadata столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки lomowner oid pg_authid.oid Владелец большого объекта lomacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации pg_namespace
Каталог pg_namespace хранит пространства имен. Пространство имен-это структура, лежащая в основе схем SQL — каждое пространство имен может иметь отдельную коллекцию отношений, типов и т. д.
pg_namespace столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки nspname name Имя пространства имен nspowner oid pg_authid.oid Владелец пространства имен nspacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации pg_opclass
Каталог pg_opclass определяет классы операторов метода доступа к индексу. Каждый класс операторов определяет семантику для индексных столбцов определенного типа данных и конкретного метода доступа к индексам. Класс оператора по существу определяет, что определенное семейство операторов применимо к определенному типу данных индексируемого столбца. Набор операторов из семейства, которые фактически используются с индексированным столбцом, являются теми, которые принимают тип данных столбца в качестве их аргумента.
Классы операторов подробно описаны в разделе Расширения для индексов .
pg_opclass столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки opcmethod oid pg_am.oid Класс оператора для метода индексного доступа opcname name Имя класса оператора opcnamespace oid pg_namespace.oid Пространство имен класса оператора opcowner oid pg_authid.oid Владелец класса оператора opcfamily oid pg_opfamily.oid Семейство операторов, содержащее класс оператора opcintype oid pg_type.oid Тип данных, который индексирует класс оператора opcdefault bool True, если этот класс оператора является значением по умолчанию для opcintype opckeytype oid pg_type.oid Тип данных, хранящихся в индексе, или ноль, если он совпадает с opcintype Класс оператора должен соответствовать opfmethod содержащего его семейства операторов. Кроме того, должно быть не более одной строки в pg_opclass у которой opcdefault true для любой заданной комбинации opcmethod и opcintype.
pg_operator
Каталог pg_operator хранит информацию об операторах. Дополнительную информацию смотрите в разделах CREATE OPERATOR и Пользовательские операторы.
pg_operator столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки oprname name Наименование оператора oprnamespace oid pg_namespace.oid OID пространства имен, содержащего этот оператор oprowner oid pg_authid.oid Владелец оператора oprkind char b = инфикс («оба”), l = префикс («слева”), r = постфикс («справа”) oprcanmerge bool Этот оператор поддерживает объединения слиянием oprcanhash bool Этот оператор поддерживает хэш-соединения oprleft oid pg_type.oid Тип левого операнда oprright oid pg_type.oid Тип правого операнда oprresult oid pg_type.oid Тип результата oprcom oid pg_operator.oid Коммутатор оператора этого типа, если таковой имеется oprnegate oid pg_operator.oid Отрицание оператора этого типа, если таковое имеется oprcode regproc pg_proc.oid Функция, реализующая этот оператор oprrest regproc pg_proc.oid Функция оценки селективности ограничения для данного оператора oprjoin regproc pg_proc.oid Функция оценки селективности соединения для этого оператора Неиспользуемые столбцы содержат нули. Например, oprleft равно нулю для префиксного оператора.
pg_opfamily
Каталог pg_opfamily определяет семейства операторов. Каждое семейство операторов представляет собой набор операторов и связанных с ними основных процедур, реализующих семантику, заданную для конкретного метода доступа к индексу. Кроме того, операторы в семействе все “совместимы”, тем способом, который определяет метод доступа. Концепция семейства операторов позволяет использовать операторы разного типа с индексами и использовать знания о семантике метода доступа.
Семейства операторов подробно описаны в разделе Расширения для индексов.
pg_opfamily столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки opfmethod oid pg_am.oid Метода индексного доступа для которго предназначено семейство операторов opfname name Имя этого семейства операторов opfnamespace oid pg_namespace.oid Пространство имен этого семейства операторов opfowner oid pg_authid.oid Владелец семейства операторов Большая часть информации, определяющей семейство операторов, не входит в pg_opfamily, а находится в связанных строках в pg_amop, pg_amproc и pg_opclass.
pg_partitioned_table
Каталог pg_partitioned_table хранит информацию о способе партиционирования таблиц.
pg_partitioned_table столбцы
Имя Тип Ссылки Описание partrelid oid pg_class.oid OID партиционированой таблицы, запись из pg_class partstrat char Стратегия партиционирования; h = хэш партиционирование, l = партиционирование по списку, r = партиционирование по диапазону partnatts int2 Количество столбцов в ключе партиции partdefid oid pg_class.oid OID из pg_class для партиции по умолчанию этой партиционированой таблицы или ноль, если эта партиционированная таблица не имеет партиции по умолчанию. partattrs int2vector pg_attribute.attnum Массив из значений partnatts , указывающий, какие столбцы таблицы являются частью ключа партиции. Например, значение параметра 1 3 означает, что первый и третий столбцы таблицы составляют ключ партиции. Ноль в этом массиве указывает, что соответствующий столбец ключа партиции является выражением, а не простой ссылкой на столбец. partclass oidvector pg_opclass.oid Для каждого столбца в ключе партиционирования содержит OID класса оператора для использования. Смотрите дополнительную информацию в разделе pg_opclass. partcollation oidvector pg_opclass.oid Для каждого столбца в ключе партиционирования содержит OID параметров сортировки, используемых для партиционирования, или ноль, если столбец не является типом данных с возможностью сортировки. partexprs pg_node_tree Деревья выражений (nodeToString() представление) для столбцов ключа партиции, которые не являются простыми ссылками на столбцы. Это список с одним элементом для каждой нулевой записи в partattrs. Null, если все столбцы ключа партиции являются простыми ссылками. pg_pltemplate
Каталог pg_pltemplate хранит информацию о «шаблоне» для процедурных языков. Шаблон для языка позволяет создать язык в конкретной базе данных с помощью простой команды CREATE LANGUAGE, без необходимости указывать детали реализации.
В отличие от большинства системных каталогов, pg_pltemplate является общим для всех баз данных кластера: существует только одна копия pg_pltemplate на кластер, а не по одному на каждую базу данных. Это позволяет получить доступ к информации в каждой базе данных по мере необходимости.
pg_pltemplate столбцы
Имя Тип Описание tmplname name Название языка для которого предназначен данный шаблон tmpltrusted boolean True, если язык считается доверенным tmpldbacreate boolean True, если язык может быть создан владельцем базы данных tmplhandler text Имя функции обработчика вызовов tmplinline text Имя функции обработчика анонимных блоков или null, если анонимных блоков нет tmplvalidator text Имя функции валидатора, или null, если валидатора нет tmpllibrary text Путь к разделяемой библиотеке, реализующей язык tmplacl aclitem[] Права доступа для шаблона (фактически не используется) В настоящее время нет никаких команд, которые управляют шаблонами процедурного языка; чтобы изменить встроенную информацию , суперпользователь должен изменить таблицу с помощью обычных команд INSERT, DELETE или UPDATE.
Примечание.
Вполне вероятно, что pg_pltemplate будет удален в некоторых будущих выпусках QHB, в пользу сохранения этих знаний о процедурных языках в их соответствующих сценариях установки расширений.pg_policy
Каталог pg_policy сохраняет политики безопасности на уровне строк для таблиц. Политика включает тип команды, к которой она применяется (возможно, все команды), роли, к которым она применяется, выражение, которое должно быть добавлено в качестве квалификацтонного барьера безопасности к запросам, включающим таблицу, и выражение, которое должно быть добавлено в опцию WITH CHECK для запросов, которые пытаются добавить новые записи в таблицу.
pg_policy столбцы
Имя Тип Ссылки Описание polname name Название политики polrelid oid pg_class.oid Таблица, к которой применяется политика polcmd char Тип команды, к которой применяется политика: r для SELECT, a для INSERT, w для UPDATE, d для DELETE, или * для всех polpermissive boolean Является ли эта политика разрешительной или ограничительной? polroles oid[] pg_authid.oid Роли, к которым применяется политика polqual pg_node_tree Дерево выражений, добавляемое к квалификациям барьеров безопасности для запросов, использующих таблицу polwithcheck pg_node_tree Дерево выражений, которое будет добавлено в квалификацию WITH CHECK для запросов, пытающихся добавить строки в таблицу Примечание.
Политики, хранящиеся в pg_policy применяются только тогда, когда pg_class.relrowsecurity установлено для соот. таблицы.pg_proc
Каталог pg_proc хранит информацию о функциях, процедурах, агрегатных функциях и оконных функциях (в совокупности также известных как подпрограммы). Дополнительную информацию смотрите в разделах CREATE FUNCTION, CREATE PROCEDURE и Пользовательские функции.
Если prokind указывает, что запись предназначена для агрегатной функции, в ней должна быть соответствующая строка из pg_aggregate.
pg_proc столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки proname name Имя функции pronamespace oid pg_namespace.oid OID пространства имен, содержащего эту функцию proowner oid pg_authid.oid Владелец функции prolang oid pg_language.oid Язык реализации или интерфейс вызова этой функции procost float4 Расчетная стоимость исполнения (в единицах cpu_operator_cost ), если установлен признак proretset, это стоимость за одну возвращенную строку prorows float4 Предполагаемое количество строк результатов (ноль, если не задан proretset) provariadic oid pg_type.oid Тип данных элементов масива параметров переменной длинны, либо ноль, если функция не имеет переменного числа параметров prosupport regproc pg_proc.oid Дополнительная функция поддержки планировщика для этой функции (см. раздел Оптимизация функций) prokind char f для нормальной функции, p для процедуры, a для агрегатной функции, или w для оконной функции prosecdef bool Функция- определитель контекста безопасности (т. е. функция «setuid») proleakproof bool Функция не имеет никаких побочных эффектов. Никакая информация о аргументах не передается, иначе чем через возвращаемое значение. Любая функция, которая может вызвать ошибку в зависимости от значений ее аргументов, не является герметичной. proisstrict bool Функция возвращает значение null, если любой аргумент вызова имеет значение null. В этом случае функция по факту не будет вызвана вообще. Функции, которые не являются «строгими»(strict), должны быть подготовлены для обработки нулевых входных данных. proretset bool Функция возвращает набор (т. е. несколько значений указанного типа данных) provolatile char provolatile указывает, зависит ли результат функции только от ее входных аргументов или на него влияют внешние факторы. Для «неизменяемых» функций , которые всегда дают один и тот же результат для одних и тех же входных данных устанавливается значение i. Для «стабильных» функций, результаты которых (для фиксированных входных аргументов) не изменяются в пределах сканирования устанавливается значение s. Для «изменчивых» (volatile) функций, результаты которых могут измениться в любое время устанавливается значение v. (Также v используется для функций с побочными эффектами, так их вызовы не могут быть исключены в процессе оптимизации.) proparallel char Указывает, можно ли безопасно запускать функцию в параллельном режиме. Для функций, которые безопасно запускать в параллельном режиме без ограничений устанавливается значение s.Для функций, которые могут выполняться в параллельном режиме, но их выполнение ограничено процессом — параллельные рабочие процессы не могут вызывать эти функции устанавливается значение r. Для функций, которые небезопасны в параллельном режиме устанавливается значение u — наличие такой функции заставляет оптимизатор строить план последовательного выполнения. pronargs int2 Количество входных аргументов pronargdefaults int2 Количество аргументов, имеющих значения по умолчанию prorettype oid pg_type.oid Тип данных возвращаемого значения proargtypes oidvector pg_type.oid Массив с типами данных аргументов функции. Включает только входные аргументы (включая INOUT и VARIADIC Аргументы), и таким образом представляет сигнатуру вызова функции. proallargtypes oid[] pg_type.oid Массив с типами данных аргументов функции. Включает в себя все аргументы (в том числе IN и INOUT аргументы), однако, если все аргументы являются IN, это поле будет иметь значение null. Обратите внимание, что индексация массива обычно начинается с 1, тогда как по историческим причинам proargtypes индексируется от 0. proargmodes char[] Массив с режимами аргументов функции, закодированными как i для IN аргументов, о для OUT аргументы, b для INOUT аргументов, v для VARIADIC аргументов, t для TABLE аргументов. Если все аргументы это IN аргументы, это поле будет иметь значение null. Обратите внимание, что индексы соответствуют позициям proallargtypes нет proargtypes. proargnames text[] Массив с именами аргументов функции. Аргументы без имени представляют собой пустые строки в массиве. Если ни один из аргументов не имеет имени, это поле будет иметь значение null. Обратите внимание, что индексы соответствуют позициям proallargtypes но не proargtypes. proargdefaults pg_node_tree Деревья выражений (nodeToString() представление) для значений по умолчанию. Это список pronargdefaults элементов, соответствующих последнему N входным аргументам (т. е. последним N позициям в proargtypes). Если ни один из аргументов не имеет значений по умолчанию, это поле будет иметь значение null. protrftypes oid[] Типы OID данных, для которых необходимо применить преобразования. prosrc text Способ вызвать функцию. Может быть фактический исходный код функции для интерпретируемых языков, символ ссылки, имя файла или почти все остальное, в зависимости от языка и реализации/соглашения о вызове. probin text Дополнительная информация о том, как вызвать эту функцию. Интерпретация зависит от языка. proconfig text[] Локальные настройки функции для переменных конфигурации времени выполнения proacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации Для скомпилированных функций, как встроенных, так и динамически загружаемых, prosrc содержит имя функции на языке C (объектную ссылку). Для всех других известных на данный момент типов языков, prosrc содержит исходный текст функции. probin не используется, за исключением динамически загружаемых функций C/RUST, для которых он дает имя файла общей библиотеки, содержащего функцию.
pg_publication
Каталог pg_publication содержит все публикации для логической репликации, созданные в базе данных.
pg_publication столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки pubname name Название публикации pubname oid pg_authid.oid Владелец публикации puballtables bool Если задано значение true, эта публикация автоматически включает все таблицы в базе данных включая те которые созданы в будущем. pubinsert bool При значении true операции вставки реплицируются для таблиц в публикации. pubupdate bool При значении true операции обновления реплицируются для таблиц в публикации. pubdelete bool При значении true операции удаления реплицируются для таблиц в публикации. pubtruncate bool Если задано значение true, то операции truncate реплицируются для таблиц в публикации. pg_publication_rel
Каталог pg_publication_rel содержит сопоставление между отношениями и публикациями в базе данных в виде отображение многие-ко-многим . Смотрите также раздел pg_publication_tables для более удобного просмотра этой информации.
pg_publication_rel столбцы
Имя Тип Ссылки Описание prpubid oid pg_publication.oid Ссылка на публикацию prrelid oid pg_class.oid Ссылка на связь pg_range
Каталог pg_range хранит информацию о типах диапазона в дополнение к записям типов в pg_type .
pg_range столбцы
Имя Тип Ссылки Описание rngtypid oid pg_type.oid OID типа диапазона rngsubtype oid pg_type.oid OID типа элемента (подтипа) данного типа диапазона rngcollation oid pg_collation.oid OID параметров сортировки, используемых для сравнения диапазонов, или 0, если нет rngsubopc oid pg_opclass.oid OID класса оператора подтипа, используемого для сравнения диапазонов rngcanonic regproc pg_proc.oid OID функции для преобразования значения диапазона в каноническую форму или 0, если нет rngsubdiff regproc pg_proc.oid OID функции для возврата разницы между двумя значениями элементов в виде двойная точность, или 0, если нет rngsubopc (плюс rngcollation, если тип элемента является collatable) определяет порядок сортировки, используемый типом диапазона. rngcanonic используется, когда тип элемента является дискретным. rngsubdiff является необязательным, но может задаваться для повышения производительности индексов GiST по типу диапазона.
pg_replication_origin
Каталог pg_replication_origin содержит все созданные источники репликации. Дополнительные сведения об источниках репликации.
В отличие от большинства системных каталогов, pg_replication_origin является общим для всех баз данных кластера: существует только одна копия pg_replication_origin на кластер, а не по одному на каждую базу данных.
pg_replication_origin столбцы
Имя Тип Ссылки Описание roident oid Уникальный кластерный идентификатор источника репликации. Никогда должен выходить за границы системы. roname text Внешнее, определяемое пользователем, имя источника репликации. pg_rewrite
Каталог pg_rewrite хранит правила перезаписи для таблиц и представлений.
pg_rewrite столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки rulename name Имя правила ev_class oid pg_class.oid Таблица для которой предназначено это правило ev_type char Тип события, для которого используется правило: 1 = SELECT, 2 = UPDATE, 3 = INSERT, 4 = DELETE ev_enabled char Элементы управления, в которых срабатывает правило режимы session_replication_role. О = правило срабатывает в режимах origin и local, D = правило отключено, R = правило срабатывает в режиме replica, A = правило срабатывает всегда. is_instead bool True, если правило INSTEAD ev_qual pg_node_tree Дерево выражений (nodeToString() представление) для квалификационного условия правила ev_action pg_node_tree Дерево запросов (nodeToString() представление) для действия правила Примечание.
pg_class.relhasrules должно быть true, если таблица имеет какие-либо правила в этом каталоге.pg_seclabel
Каталог pg_seclabel сохраняет метки безопасности на объектах базы данных. Метками безопасности можно управлять с помощью команды SECURITY LABEL. Для более простого способа просмотра меток безопасности см. раздел pg_seclabels, а также раздел pg_shseclabel, который содержит аналогичную информацию для меток безопасности объектов базы данных, совместно используемых в кластере баз данных.
pg_seclabel столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID объекта, к которому относится эта метка безопасности classoid oid pg_class.oid Идентификатор OID системного каталога, в котором отображается этот объект objsubid int4 Для метки безопасности в столбце таблицы это номер столбца (в этом случае objoid и classoid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. provider text Поставщик меток безопасности, связанный с этой меткой. label text Метка безопасности, применяемая к этому объекту. pg_sequence
Каталог pg_sequence содержит информацию о последовательностях (sequence). Некоторые сведения о последовательностях, такие как имя и схема, находятся в разделе pg_class.
pg_sequence столбцы
Имя Тип Ссылки Описание seqrelid oid pg_class.oid OID в pg_class для этой последовательности seqtypid oid pg_type.oid Тип данных последовательности seqstart int8 Начальное значение последовательности seqincrement int8 Значение приращения последовательности seqmax int8 Максимальное значение последовательности seqmin int8 Минимальное значение последовательности seqcache int8 Размер кэша последовательности seqcycle bool Циклы последовательности pg_shdepend
Каталог pg_shdepend содержит зависимости между объектами базы данных и общими объектами, такими как роли. Эта информация позволяет QHB убедиться в том, что эти объекты не используются перед попыткой их удаления.
См. также раздел pg_depend, который содержит аналогичную информацию для зависимостей, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shdepend является общим для всех баз данных кластера: существует только одна копия pg_shdepend на кластер, а не по одному на каждую базу данных.
pg_shdepend столбцы
Имя Тип Ссылки Описание dbid oid pg_database.oid Идентификатор OID базы данных, в которой находится зависимый объект, или ноль для общего объекта classid oid pg_class.oid OID системного каталога, в котором находится зависимый объект objid oid OID для любого столбца OID конкретного зависимого объекта objsubid int4 Для столбца таблицы это номер столбца (objid и classid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. refclassid oid pg_class.oid OID системного каталога, в котором находится объект ссылки (должен быть общим каталогом) refobjid oid OID для любого столбца OID конкретного ссылки на объект deptype char Код, определяющий конкретную семантику этого отношения зависимости — см. ниже детальное описание Во всех случаях запись в pg_shdepend указывает, что объект ссылки не может быть удален без удаления также зависимого объекта. Тем не менее, есть несколько подвидов, которые задаются с помощью deptype:
SHARED_DEPENDENCY_OWNER (о)
Объект на который ссылаются (должен быть ролью) является владельцем зависимого объекта.
SHARED_DEPENDENCY_ACL (a)
Объект на который ссылаются (должен быть ролью) упоминается в списке ACL (access control list, т. е. список привилегий) зависимого объекта. (Запись SHARED_DEPENDENCY_ACL не создаётся для владельца объекта, так как у владельца в любом случае будет SHARED_DEPENDENCY_OWNER .)
SHARED_DEPENDENCY_POLICY (r)
Объект на который ссылаются (должен быть ролью) является целью для зависимого объекта политики.
SHARED_DEPENDENCY_PIN (p)
Не зависимого объекта — этот тип записи означает то, что сама система зависит от объекта на который ссылается, и поэтому этот объект никогда не должен быть удален. Записи этого типа создаются только в команде qhb_bootstrap. Столбцы для зависимого объекта у этой записи содержат нули.
В будущем могут потребоваться и другие виды зависимостей. Обратите внимание, сейчас для объекта на который ссылаются поддерживаются только роли.
pg_shdescription
Каталог pg_shdescription хранит необязательные описания (комментарии) для общих объектов базы данных. Описаниями можно манипулировать с помощью команды COMMENT и просматривать с помощью qsql \d команды.
См. также раздел pg_description, который содержит аналогичную информацию для описаний, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shdescription является общим для всех баз данных кластера: существует только одна копия pg_shdescription на кластер, а не по одному на каждую базу данных.
pg_shdescription столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID объекта, к которому относится данное описание classoid oid pg_class.oid Идентификатор OID системного каталога, в котором отображается этот объект description text Произвольный текст, который служит описанием данного объекта pg_shseclabel
Каталог pg_shseclabel сохраняет метки безопасности на общих объектах базы данных. Метками безопасности можно управлять с помощью команды SECURITY LABEL. Для простого способа просмотра меток безопасности см. раздел pg_seclabels.
Смотрите также раздел pg_seclabel, который выполняет аналогичную функцию для меток безопасности, включающих объекты в пределах одной базы данных.
В отличие от большинства системных каталогов, pg_shseclabel является общим для всех баз данных кластера: существует только одна копия pg_shseclabel на кластер, а не по одному на каждую базу данных.
pg_shseclabel столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID объекта, к которому относится эта метка безопасности classoid oid pg_class.oid Идентификатор OID системного каталога, в котором отображается этот объект provider text Поставщик, связанный с этой меткой. label text Метка безопасности, применяемая к этому объекту. pg_statistic
Каталог pg_statistic хранит статистические данные о содержимом базы данных. Записи создаются при помощи команды ANALYZE и впоследствии используются планировщиком запросов. Обратите внимание, что все статистические данные по своей сути являются приблизительными, даже если они являются актуальными.
Обычно есть одна запись, с stainherit = false, для каждого столбца таблицы, который был проанализирован. Если таблица имеет дочерние элементы наследования, тотакже создается вторая запись с stainherit = true . Эта строка представляет статистику для столбца по всему дереву наследования, т. е. статистику для данных, которые вы видите с помощью SELECT column FROM table*, в то время как stainherit = false строка представляет собой результаты выполнения SELECT column FROM ONLY table.
В pg_statistic также хранятся статистические данные о значениях индексных выражений. Они описываются так, как если бы они были реальными столбцами данных — в частности, starelid ссылается на индекс. Однако для обычного столбца индекса, не содержащего выражения, запись не производится, поскольку она была бы избыточной для записи для базового столбца таблицы. В настоящее время записи для выражений индекса всегда имеют stainherit = false.
Поскольку различные виды статистики подходят для различных видов данных, pg_statistic предназначен не для того, чтобы строитьь очень много предположений о том, какую статистику он хранит. Только очень общие статистические данные (такие как nullness) приведены в отдельных столбцах в pg_statistic. Все остальное хранится в «слотах», которые представляют собой группы связанных столбцов, содержимое которых определяется кодовым номером в одном из слотов.
pg_statistic она не должна быть доступной для чтения любым пользователем, поскольку даже статистическая информация о содержании таблицы может считаться конфиденциальной. (Например: минимальные и максимальные значения столбца зарплаты могут представлять интерес.) pg_stats-это доступнаое для читениявсем пользователям представление для pg_statistic оно предоставляет только информацию о тех таблицах, которые доступны на чтение текущему пользователю.
pg_statistic столбцы
Имя Тип Ссылки Описание starelid oid pg_class.oid Таблица или индекс, к которому принадлежит описываемый столбец staattnum int2 pg_attribute.attnum Номер описываемой колонки stainherit bool Если значение true, то статистика включает дочерние столбцы наследования, а не только значения в указанном отношении stanullfrac float4 Доля записей в которых столбец не заполнен stawidth int4 Средняя сохраненная ширина записей для ненулевых столбцов в байтах stadistinct float4 Число различных значений данных в ненулевом в столбце. Значение больше нуля-это фактическое число различных значений. Значение меньше нуля- взятое по модулю это количество строк в таблице; например, столбец, в котором около 80% значений не имеют значения NULL и каждое ненулевое значение появляется в среднем примерно два раза , может быть представлен следующим образом: stadistinct = -0.4. Нулевое значение означает, что число различных значений неизвестно. stakindN int2 Кодовый номер, указывающий вид статистики, хранящейся в N-м «слоте» строки из pg_statistic. staopN oid pg_operator.oid Оператор, используемый для получения статистики, хранящейся в N-м «слоте». Например, для «слота гистограммы» это будет оператор , определяющий порядок сортировки данных. stacollN oid pg_collation.oid Параметры сортировки, используемые для получения статистики, хранящейся в N-м «слоте». Например, «слот гистограммы» для столбца с возможностью сортировки будет отображать параметры сортировки, определяющие порядок сортировки данных. Ноль для непроверяемых данных. stanumbersN float4[] Числовая статистика соответствующего вида для N-го «слота», или null, если вид «слот» не содержит числовых значений stavaluesN anyarray Значения данных столбца соответствующего вида длядля N-го «слота», или null, если этот вид «слота» не хранит никаких значений для данных. Значения каждого элемента массива фактически относятся к определенному типу данных столбца или связанному типу, такому как тип элемента массива, поэтому нет способа определить тип этих столбцов более конкретно, чем anyarray. pg_statistic_ext
Каталог pg_statistic_ext содержит определения расширенной статистики планировщика. Каждая строка в этом каталоге соответствует объекту статистики, созданному с помощью команды CREATE STATISTICS.
pg_statistic_ext столбцы
Имя Тип Ссылки Описание stxrelid oid pg_class.oid Таблица, содержащая столбцы, описываемые данным объектом stxname name Имя объекта статистики stxnamespace oid pg_namespace.oid OID пространства имен, содержащего этот объект статистики stxowner oid pg_authid.oid Владелец объекта статистики stxkeys int2vector pg_attribute.attnum Массив номеров атрибутов, указывающих, какие столбцы таблицы покрываются этим объектом статистики; например, значение 1 3 это означает, что будут покрыты первый и третий столбцы таблицы stxkind char[] Массив, содержащий коды для включенных типов статистики; допустимыми значениями являются: d для n-различных статистических данных, f для статистики функциональной зависимости, а также m для статистики списка наиболее часто встречающихся значений (MCV) pg_statistic_ext запись полностью заполняется при выполнении команды CREATE STATISTICS, но фактические статистические значения не вычисляются. Последующие команды ANALYZE вычисляют требуемые значения и заполняют запись в каталоге pg_statistic_ext_data.
pg_statistic_ext_data
Каталог pg_statistic_ext_data содержит данные для расширенной статистики планировщика, определенной в pg_statistic_ext. Каждая строка в этом каталоге соответствует объекту статистики, созданному с помощью команды CREATE STATISTICS.
Также как pg_statistic, pg_statistic_ext_data этот каталог не должен быть доступен для чтения всем пользователям, поскольку его содержимое может считаться конфиденциальным. (Пример: наиболее распространенные комбинации значений в столбцахбазы данных могут предоставлять определённый интерес.) pg_stats_ext-это доступное для чтения представление (view) bp pg_statistic_ext_data (после соединения с pg_statistic_ext) которое предоставляет только информацию о тех таблицах и столбцах, которые могут быть прочитаны текущим пользователем.
pg_statistic_ext_data столбцы
Имя Тип Ссылки Описание stxoid oid pg_statistic_ext.oid Расширенный статистический объект, содержащий определение для данных stxdndistinct pg_ndistinct количество значений сохранённая как тип pg_ndistinct stxddependencies pg_dependencies Статистика функциональных зависимостей, сохранённая как тип pg_dependenciesп stxdmcv pg_mcv_list Статистика списка MCV (most-common values), ссохранённая как тип pg_mcv_list Тип pg_subscription
Каталог pg_subscription содержит все существующие подписки на логическую репликацию.
В отличие от большинства системных каталогов, pg_subscription является общим для всех баз данных кластера: существует только одна копия pg_subscription на кластер, а не по одному на каждую базу данных.
Доступ к колонке subconninfo отзывается у обычных пользователей, поскольку он может содержать простые текстовые пароли.
pg_subscription столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки subdbid oid pg_database.oid OID базы данных, в которой находится подписка subname name Название подписки subowner oid pg_authid.oid Владелец подписки subenabled bool Если задано значение true, подписка включена и должна реплицироваться. subsynccommit text Содержит значение параметра настройка synchronous_commit для процессов подписки. subconninfo text Строка подключения к вышестоящей базе данных subslotname name Имя слота репликации в вышестоящей базе данных. Также используется при локальной репликации имя источника. subpublications text[] Массив подписанных имен публикаций которые ссылаются на публикации на сервере. pg_subscription_rel
Каталог pg_subscription_rel содержит состояние для каждого реплицируемого отношения в каждой подписке. Это отображение хранится как многие-ко-многим.
Этот каталог содержит только таблицы, известные подписке после выполнения команды CREATE SUBSCRIPTION или ALTER SUBSCRIPTION или REFRESH PUBLICATION.
pg_subscription_rel столбцы
Имя Тип Ссылки Описание srsubid oid pg_subscription.oid Ссылка на подписку srrelid oid pg_class.oid Ссылка на связь srsubstate char Код состояния: i = инициализация, d = данные копируются, s = синхронизированно, r = готов (нормальная репликация) srsublsn pg_lsn LSN принимающей стороны для состояния s и r. pg_tablespace
Каталог pg_tablespace хранит информацию о доступных табличных пространствах. Таблицы могут быть размещены в определенных табличных пространствах для облегчения администрирования хранилища.
В отличие от большинства системных каталогов, pg_tablespace является общим для всех баз данных кластера — существует только одна копия pg_tablespace на кластер, а не по одному на каждую базу данных.
pg_tablespace столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки spcname name Имя табличного пространства spcowner oid pg_authid.oid Владелец табличного пространства, обычно пользователь, который его создал spcacl aclitem[] Права доступа; смотрите раздел Привилегии для получения дополнительной информации spcoptions text[] Параметры табличного пространства, в виде строки «ключ=значение» pg_transform
Каталог pg_transform хранит информацию о преобразованиях, которые являются механизмом для адаптации типов данных к процедурным языкам.
pg_transform столбцы
Имя Тип Ссылки Описание trftype oid pg_type.oid OID типа данных, для которого предназначено это преобразование trflang oid pg_language.oid OID языка, для которого это преобразование предназначено trffromsql regproc pg_proc.oid OID функции, используемый при преобразовании типа данных для передачи в процедурный язык (например, параметры функции). Ноль — если эта операция не поддерживается. trftosql regproc pg_proc.oid OID функции, используемый при преобразовании полученых из процедурного языка (например, возвращаемых значений) в тип данных. Ноль — если эта операция не поддерживается. pg_trigger
Каталог pg_trigger содержит иноформацию о триггерах в таблицах и представлениях.
pg_trigger столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки tgrelid oid pg_class.oid Таблица, в которой находится этот триггер tgname name Имя триггера (должно быть уникальным среди триггеров одной таблицы) tgfoid oid pg_proc.oid Вызываемая функция tgtype int2 Битовая маска, идентифицирующая условия срабатывания триггера tgenabled char Элементы управления, для которых срабатывает триггер в режиму session_replication_role . О = триггер срабатывает в режимах origin и local, D = триггер отключен, R = триггер срабатывает в режиме replica, A = триггер срабатывает всегда. tgisinternal bool True, если триггер генерируется внутри системы (обычно для принудительного применения ограничения, определенного tgconstraint) tgconstrrelid oid pg_class.oid Таблица, на которую ссылается ограничение ссылочной целостности tgconstrindid oid pg_class.oid Индекс, поддерживающий ограничение уникальности, первичного ключа, ссылочной целостности или исключения tgconstraint oid pg_constraint.oid pg_constraint запись, связанная с триггером, если таковая имеется tgdeferrable bool True, если триггер ограничения является отложенным tginitdeferred bool True, если триггер ограничения изначально отложен tgnargs int2 Количество строк аргументов, переданных в функцию trigger tgattr int2vector pg_attribute.attnum Номера столбцов, если триггер является специфичным для столбца — в противном случае пустой массив tgargs bytea Строки аргументов для передачи триггеру, завершается NULL tgqual pg_node_tree Дерево выражений (nodeToString() представление) для условие триггера WHEN, или NULL, если условия нет tgoldtable name имя предложения REFERENCING для СТАРОЙ ТАБЛИЦЫ, или NULL, если нет tgnewtable name имя предложения REFERENCING для НОВОЙ ТАБЛИЦЫ, или NULL, если условия нет В настоящее время специфичный для столбца запуск триггера поддерживается только для UPDATE события, соот. tgattr актуально только для этого типа событий. tgtype может также содержать биты для других типов событий, но они считаются независимы от того, что находится внутри tgattr.
Примечание.
Когда tgconstraint ненулевое значение оно ссылается на строки из pg_constraint, т.о. tgconstrrelid, tgconstrindid, tgdeferrable, и tginitdeferred избыточны . Тем не менее, возможно, что не отложенный триггер будет связан с ограничением deferrable — ограничения внешнего ключа могут иметь некоторые отложенные и некоторые не отложенные триггеры.Примечание.
pg_class.relhastriggers должно быть true, если отношение имеет какие-либо триггеры в этом каталоге.pg_ts_config
Каталог *pg_ts_config содержит записи конфигурации полнотекстового поиска. Конфигурация задает определенный синтаксический анализатор полнотекстового поиска и список словарей, которые будут использоваться для каждого из типов выходных маркеров синтаксического анализатора. Синтаксический анализатор хранится в записи pg_ts_config, но сопоставление токен-словарь определяется дочерними записями в pg_ts_config_map.
pg_ts_config столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки cfgname name Имя конфигурации текстового поиска cfgnamespace oid pg_namespace.oid OID пространства имен, содержащего эту конфигурацию cfgowner oid pg_authid.oid Владелец конфигурации cfgparser oid pg_ts_parser.oid OID синтаксического анализатора текстового поиска для этой конфигурации pg_ts_config_map
Каталог pg_ts_config_map содержит записи, показывающие, с какими словарями текстового поиска следует обращаться и в каком порядке, для каждого типа выходного токена синтаксического анализатора каждой конфигурации текстового поиска.
pg_ts_config_map столбцы
Имя Тип Ссылки Описание mapcfg oid pg_ts_config.oid OID записи из pg_ts_config, владеющий этим отображением maptokentype integer Тип маркера, создаваемого синтаксическим анализатором конфигурации mapseqno integer Порядок, в котором следует ознакомиться с этой записью (ниже mapseqnos первый) mapdict oid pg_ts_dict.oid OID словаря текстового поиска для консультации pg_ts_dict
Каталог pg_ts_dict содержит записи, определяющие словари текстового поиска. Словарь зависит от шаблона текстового поиска, который задает все необходимые функции реализации — сам словарь предоставляет значения для настраиваемых пользователем параметров, поддерживаемых шаблоном. Такое разделение позволяет создавать словари непривилегированным пользователям. Параметры задаются текстовой строкой dictinitoption, формат и значение которой различаются в зависимости от шаблона.
pg_ts_dict столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки dictname name Название словаря текстового поиска dictnamespace oid pg_namespace.oid OID пространства имен, содержащего этот словарь dictowner oid pg_authid.oid Владелец словаря dicttemplate oid pg_ts_template.oid OID шаблона текстового поиска для этого справочника dictinitoption text Строка параметра инициализации для шаблона pg_ts_parser
Каталог pg_ts_parser содержит записи, определяющие синтаксические анализаторы текстового поиска. Синтаксический анализатор отвечает за разбиение входного текста на лексемы и присвоение каждой лексеме типа токена. Поскольку синтаксический анализатор должен быть реализован с помощью функций на языке C\RUST, создание новых синтаксических анализаторов возможно только для суперпользователей базы данных.
pg_ts_parser столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки prsname name Имя синтаксического анализатора для поиска текста prsnamespace oid pg_namespace.oid OID пространства имен, содержащего этот синтаксический анализатор prsstart regproc pg_proc.oid OID функции запуска синтаксического анализатора prstoken regproc pg_proc.oid OID функции поиска следующего маркера синтаксического анализатора prsend regproc pg_proc.oid OID функции завершения работы синтаксического анализатора prsheadline regproc pg_proc.oid OID функции заголовка синтаксического анализатора prslextype regproc pg_proc.oid OID функции анализатора лексического типа pg_ts_template
Каталог pg_ts_template содержит записи, определяющие шаблоны текстового поиска. Шаблон-это скелет реализации для класса словарей текстового поиска. Поскольку шаблон должен быть реализован с помощью функций на языке C\RUST, создание новых шаблонов возможно только для суперпользователей базы данных.
pg_ts_template столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки tmplname name Имя шаблона текстового поиска tmplnamespace oid pg_namespace.oid OID пространства имен, содержащего этот шаблон tmplinit regproc pg_proc.oid OID функции инициализации шаблона tmpllexize regproc pg_proc.oid OID функции лексера pg_type
Каталог pg_type хранит информацию о типах данных. Базовые типы и типы перечислений (скалярные типы) создаются с помощью CREATE TYPE, а домены-с помощью CREATE DOMAIN. Составной тип автоматически создается для каждой таблицы в базе данных, чтобы представить структуру строк таблицы. Кроме того, можно создать составные типы с помощью CREATE TYPE AS.
pg_type столбцы
Показывает требуется ли выравнивание при хранении значения этого типа. Это относится к хранилищу на диске, а также к большинству представлений значения внутри QHB. Когда несколько значений хранятся последовательно, например в представлении строки данных на диске, заполнение числами вставляется перед Datum для этого типа так, чтобы он начинался на указанной границе. Ссылка на выравнивание является началом первого Datum в последовательности.
- c = посимвольное выравнивание (char alignment), т. е. выравнивание не требуется.
- s = выравнивание по границе слова (short alignment) 2 байта на большинстве процессоров.
- i = выравнивание по границе целого (int alignment) 4 байта на большинстве процессоров.
- d = выравнивание по границе двойного слова (double alignment) 8 байт на многих процессорах, но далеко не на всех.
Примечание
Для типов, используемых в системных таблицах, очень важно, чтобы размер и выравнивание определённые в pg_type были согласованы с тем, как компилятор будет упаковывать столбец в структуру, представляющую строку таблицы.
typstorage сообщает о типах varlena (те с typlen = -1) подготовлен ли тип к TOAST и какова должна быть стратегия по умолчанию для атрибутов этого типа. Возможные значения:
- p: Значение всегда должно храниться в обычном виде.
- e: Значение может быть сохранено в «вторичном» отношении (если отношение имеет один, см. pg_class.reltoastrelid).
- m: Значение может быть сохранено сжатым в строке.
- x: Значение может быть сохранено сжатым в строке или сохранено в «вторичном» хранилище.
Обратите внимание, что столбцы «m» также можно переместить во вторичное хранилище, но только в крайнем случае («e» и «x» столбцы перемещаются первыми).
В таблице pg_type столбцы перечислены определяемые системой значения следующих параметров: typcategory. Любые будущие дополнения к этому списку также будут прописными буквами ASCII. Все остальные символы ASCII зарезервированы для пользовательских категорий.
typcategory Коды
Код Категория A Массив B Булевый тип C Составной тип D Типы даты / времени E Тип enum G Геометрические типы I Типы сетевых адресов N Числовой тип P Псевдо-типы R Тип диапазон S Строковый тип T Типы Timespan U Определяемые пользователем типы V Типы битовых строк X Неизвестный тип pg_user_mapping
Каталог pg_user_mapping содержит сопоставления для локального и удаленного пользователя. Доступ к этому каталогу ограничен для обычных пользователей, используйте вместо этого представление pg_user_mappings.
pg_user_mapping столбцы
Имя Тип Ссылки Описание oid oid Идентификатор строки umuser oid pg_authid.oid OID сопоставляемой локальной роли, 0, если пользовательское сопоставление является общедоступным umserver oid pg_foreign_server.oid OID внешнего сервера, содержащий это сопоставление umoptions text[] Параметры сопоставления, в виде строки «ключ=значение» Системные представления
Помимо системных каталогов, QHB предоставляет ряд встроенных представлений. Некоторые системные представления обеспечивают удобный доступ к некоторым часто используемым запросам в системных каталогах. Другие представления предоставляют доступ к внутреннему состоянию сервера.
Информационная схема (information_schema) предоставляет альтернативный набор представлений, которые перекрывают функциональные возможности системных представлений. Поскольку информационная схема является частью стандарта SQL, а представления, описанные здесь, являются специфичными для QHB, обычно лучше использовать информационную схему, если она предоставляет всю необходимую информацию.
В таблице «системные представления» перечислены системные представления, описанные в этом разделе. Более подробная документация по каждому представлению приведена ниже. Существуют некоторые дополнительные представления, обеспечивающие доступ к результатам работы сборщика статистических данных; они описаны в разделе Сборщик статистики
За исключением тех случаев, когда это отмечено, все представления, описанные здесь, доступны только для чтения.
системные представление
имя представления Цель pg_available_extensions доступные расширения pg_available_extension_versions доступные версии расширений pg_config параметры конфигурации во время компиляции pg_cursors открытый курсор pg_file_settings сводка содержимого файла конфигурации pg_group группы пользователей баз данных pg_hba_file_rules сводка содержимого файла конфигурации проверки подлинности клиента pg_indexes индексы pg_locks замки в настоящее время удерживаются или ожидаются pg_matviews материализованное представление pg_policies политики pg_prepared_statements подготовленное заявление pg_prepared_xacts подготовленные сделки pg_publication_tables публикации и связанные с ними таблицы pg_replication_origin_status сведения об источниках репликации, включая ход выполнения репликации pg_replication_slots сведения о слоте репликации pg_roles роль базы данных pg_rules правила pg_seclabels метка безопасности pg_sequences последовательности pg_settings настройка параметров pg_shadow пользователь базы данных pg_stats статистика планировщика pg_stats_ext расширенная статистика планировщика pg_tables таблицы pg_timezone_abbrevs сокращения часовых поясов pg_timezone_names названия часовых поясов pg_user пользователь базы данных pg_user_mappings сопоставление пользователей pg_views число просмотров pg_available_extensions
Представление pg_available_extensions содержит список расширений, доступных для установки. См. также каталог pg_extension, в котором отображаются установленные в данный момент расширения.
pg_available_extensions столбцы
Имя Тип Описание name name Имя расширения default_version text Имя версии по умолчанию, или NULL если версия не указана installed_version text Версия расширения установленного сейчас, или NULL если расширение не установлено comment text Строка комментария из управляющего файла расширения Представление pg_available_extensions доступно только для чтения.
pg_available_extensions_versions
Представление pg_available_extension_versions содержит список конкретных версий расширений, доступных для установки. См. также каталог pg_extension, в котором отображаются установленные в данный момент расширения.
pg_available_extension_versions столбцы
Имя Тип Описание name name Имя расширения version text Версия installed bool True, если эта версия данного расширения уже установлена superuser bool True, если только суперпользователям разрешено устанавливать это расширение relocatable bool True, если расширение можно переместить в другую схему schema name Имя схемы, в которую необходимо установить расширение, или NULL при частичном или полном перемещении requires name[] Имена необходимых для работы расширений (зависимости), или NULL если зависимостей нет comment text Строка комментария из управляющего файла расширения Представление pg_available_extension_versions доступно только для чтения.
pg_config
Представление pg_config описывает параметры конфигурации во время компиляции текущей установленной версии QHB. Оно предназначено, например, для использования программными пакетами, которые хотят взаимодействовать с QHB, чтобы облегчить поиск необходимых заголовочных файлов и библиотек. Оно предоставляет ту же основную информацию, что и утилита qhb_config из поставки QHB.
По умолчанию, представление pg_config может быть прочитано только суперпользователями.
pg_config столбцы
Имя Тип Описание name text Имя параметра setting text Значение параметра pg_cursors
Представление pg_cursors — список курсоров, которые в настоящее время доступны. Курсоры могут быть определены несколькими способами:
- через оператор DECLARE в SQL
- через сообщение привязки в сетевом протоколе QHB
- через интерфейс программирования сервера (SPI), как описано в соот. разделе документации SPI
Представление pg_cursors отображает курсоры, созданные любым из этих средств. Курсоры существуют только в течение транзакции, которая их определяет, если они не были объявлены WITH HOLD. Таким образом, не удерживаемые курсоры присутствуют в представлении только до конца транзакции их создавшей.
Примечание.
Курсоры используются в системе для реализации некоторых компонентов QHB, таких как процедурные языки. Поэтому представление pg_cursors может содержать курсоры, которые не были явно созданы пользователем.pg_cursors столбцы
Имя Тип Описание name text Имя курсора statement text Строка запроса (полностью), отправленная для объявления этого курсора is_holdable boolean True если курсор является удерживаемым (то есть он может быть доступен после транзакции, объявшей курсор) — иначе false is_binary boolean True если курсор был объявлен BINARY — иначе false is_scrollable boolean True если курсор двунаправленный (то есть он позволяет извлекать строки непоследовательным образом)- иначе false creation_time timestamptz Время когда был объявлен курсор Представление pg_cursors доступно только для чтения.
pg_file_settings
Представление pg_file_settings предоставляет сводку содержимого файла(ов) конфигурации сервера. В этом представлении отображается строка для каждой записи «имя = значение», появляющейся в файлах, с примечаниями, указывающими, может ли это значение быть успешно применено. Дополнительные строки могут отображаться для проблем, не связанных с записью «имя = значение», например синтаксических ошибок в файлах.
Это представление полезно для проверки того, будут ли работать запланированные изменения в файлах конфигурации, или для диагностики предыдущего сбоя. Обратите внимание, что это представление сообщает о текущем содержимом файлов, а не о том, что было применено сервером в последний раз. (Для этого обычно достаточно представления pg_settings).
По умолчанию, представление pg_file_settings может быть прочитано только суперпользователями.
pg_file_settings столбцы
Имя Тип Описание sourcefile text Полный путь к файлу конфигурации sourceline integer Номер строки в файле конфигурации, где появляется запись seqno integer Порядок, в котором обрабатываются операции (1..N) name text Имя параметра конфигурации setting text Значение, которое будет присвоено параметру applied boolean True, если значение может быть применено успешно error text Если не null — в столбце содержится сообщение об ошибке, указывающее, почему эта запись не может быть применена Если файл конфигурации содержит синтаксические ошибки или недопустимые имена параметров, сервер не будет пытаться применить какие-либо параметры из файла, а следовательно, все значения поля applied будут false. В таком случае в представлении будет одна или несколько строк с ненулевым значением error, указывающие на проблему(ы). В противном случае, если это возможно, будут применены отдельные настройки. Если индивидуальный параметр не может быть применен (например, недопустимое значение или параметр не может быть изменен после запуска сервера), он будет иметь соответствующее сообщение в поле error. Другой способ, при ктотром applied = false означает, что параметр переопределяется более поздней записью для того же имени параметра; этот случай не считается ошибкой, поэтому ничто не появляется в поле error.
Дополнительную информацию о различных способах изменения параметров времени выполнения см. в разделе Настройка параметров
pg_group
Представление pg_group показывает имена и члены всех ролей, которые помечены как not rolcanlogin, т.е. отображает роли как группы.
pg_group столбцы
Имя Тип Ссылки Описание groname name pg_authid.rolname Название группы grosysid oid pg_authid.oid ID этой группы grolist oid[] pg_authid.oid Массив, содержащий идентификаторы ролей в этой группе pg_hba_file_rules
Представление pg_hba_file_rules предоставляет сводку содержимого файла конфигурации проверки подлинности клиента, qhb_hba.conf. В этом представлении отображается строка для каждой непустой строки файла, не содержащей комментариев, с примечаниями, указывающими на возможность успешного применения правила.
Это представление может быть полезно для проверки того, будут ли работать запланированные изменения в файле конфигурации проверки подлинности, или для диагностики предыдущего сбоя. Обратите внимание, что это представление сообщает о текущем содержимом файла, а не о том, что было загружено последним сервером.
По умолчанию, представление pg_hba_file_rules может быть прочитано только суперпользователями.
pg_hba_file_rules столбцы
Имя Тип Описание line_number integer Номер строки этого правила в qhb_hba.conf type text Тип соединения database text[] Список имен баз данных, к которым применяется данное правило user_name text[] Список имен пользователей и ролей, к которым применяется данное правило address text Имя хоста или IP-адрес, либо одно из значений all, samehost, или samenet, или null для локальных соединений netmask text Маска IP-адреса, или null, если не применимо auth_method text Способ аутентификации options text[] Параметры, указанные для метода аутентификации, если таковые имеются error text Если не null, то сообщение об ошибке, указывающее, почему эта строка не может быть обработана Обычно строка, отражающая неверную запись, будет иметь значения только для line_number и error.
pg_indexes
Представление pg_indexes предоставляет доступ к полезной информации о каждом индексе в базе данных.
pg_indexes столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу и индекс tablename name pg_class.relname Имя таблицы, для которой используется индекс indexname name pg_class.relname Имя индекса tablespace name pg_tablespace.spcname Имя табличного пространства, содержащего индекс (null, если пространство по умолчанию для базы данных) indexdef text Определение индекса (восстановленная команда CREATE INDEX) pg_locks
Представление pg_locks предоставляет доступ к информации о блокировках, удерживаемых активными процессами на сервере базы данных. Дополнительную информацию о блокировке смотрите в разделе посвященном блокировкам
pg_locks содержит одну строку на активный блокируемый объект, запрошенный режим блокировки и соответствующий процесс. Таким образом, один и тот же блокируемый объект может появляться много раз, если несколько процессов удерживают или ожидают блокировки на нем. Однако объект, который в настоящее время не имеет блокировок не будет отображаться вообще.
Существует несколько различных типов блокируемых объектов: отношения целиком (например, таблицы), отдельные страницы отношений, отдельные кортежи отношений, идентификаторы транзакций (как виртуальные, так и постоянные идентификаторы) и общие объекты базы данных (идентифицируемые классом OID и объектным OID, таким же образом, как и в pg_description или pg_depend). Также запрос на расширение отношения представляется в виде отдельного блокируемого объекта. Кроме того, «необязательные» блокировки могут быть иметь номера, значения которых определет пользователь.
pg_locks столбцы
Имя Тип Ссылки Описание locktype text Тип блокируемого объекта: отношение (relation), расширение (extend), Страница (page), кортеж (tuple), транзакция ( transactionid, virtualxid), объект (object), userlock, или необязательная (advisory) database oid pg_database.oid OID базы данных, в которой существует цель блокировки, или ноль, если цель является общим объектом, или null, если цель является идентификатором транзакции relation oid pg_class.oid OID отношения, на которое направлена блокировка, или null, если цель не является отношением или частью отношения page integer Номер страницы, на которую направлена блокировка в пределах отношения, или значение null, если цель не является страницей отношения или кортежем tuple smallint Номер кортежа, на который направлена блокировка внутри страницы, или значение null, если цель не является кортежем virtualxid text Виртуальный идентификатор транзакции, на которую направлена блокировка, или значение null, если цель не является виртуальным идентификатором транзакции transactionid xid Идентификатор транзакции, на которую направлена блокировка, или значение null, если цель не является идентификатором транзакции classid oid pg_class.oid OID системного каталога, содержащего целевой объект блокировки, или значение null, если целевой объект не является общим объектом базы данных objid oid OID для любого столбца OID целевого объекта блокировки в системном каталоге или значение null, если целевой объект не является общим объектом базы данных objsubid smallint Номер столбца, на который направлена блокировка (classid и objid определяет саму таблицу), или ноль, если целевой объект является каким-либо другим общим объектом базы данных, или null, если целевой объект не является общим объектом базы данных virtualtransaction text Виртуальный идентификатор транзакции, которая удерживает или ожидает эту блокировку pid integer Идентификатор серверного процесса (PID), удерживающего или ожидающего эту блокировку, или значение null, если блокировка удерживается подготовленной транзакцией mode text Название режима блокировки, удерживаемого или ожидаемого этим процессом (см. раздел Блокировки на уровне таблицы и раздел Уровень изоляции Serializable) granted boolean True, если блокировка удерживается, false, если блокировка ожидается fastpath boolean True, если блокировка была получена через fastpath, false, если получена через главную таблицу блокировки granted имеет значение true в строке, представляющей блокировку, удерживаемую указанным процессом. Значение False указывает, что этот процесс в настоящее время ожидает получения этой блокировки, что означает, что по крайней мере один другой процесс удерживает или ожидает разрешения конфликтного режима блокировки на том же самом заблокированном объекте. Процесс ожидания будет находиться в спящем режиме до тех пор, пока не будет снята другая блокировка (или обнаружена ситуация взаимоблокировки). Один процесс может ожидать получения не более одной блокировки за один раз.
Во время выполнения транзакции серверный процесс удерживает монопольную блокировку виртуального идентификатора транзакции. Если постоянному идентификатору присваивается транзакция (что обычно происходит только в том случае, если транзакция изменяет состояние базы данных), он также удерживает монопольную блокировку на постоянном идентификаторе транзакции до ее завершения. Когда процесс считает необходимым специально дождаться окончания другой транзакции, он делает это, пытаясь получить общую блокировку идентификатора другой транзакции (виртуальный или постоянный идентификатор в зависимости от ситуации). Это произойдет только тогда, когда другая транзакция завершится и освободит свои блокировки.
Хотя кортежи являются блокируемым типом объекта, информация о блокировках на уровне строк хранится на диске, а не в памяти, и поэтому блокировки на уровне строк обычно не отображаются в этом представлении. Если процесс ожидает блокировки уровня строки, он обычно отображается в представлении как Ожидание постоянного идентификатора транзакции текущего держателя блокировки этой строки.
Необязательные блокировки можно приобрести для ключей состоящих из любого одиночного значения bigint или двух integer. Старшая часть отображается в колонке classid, младшая в objid, а objsubid равно 1. Оригинал значения bigint можно собрать заново с помощью выражения (classid::bigint classid колонка, второй в столбце objid, а objsubid равно 2. Фактическое значение ключей зависит от пользователя. Необязательные блокировки являются локальными для каждой базы данных, поэтому столбец database имеет значение для необязательной блокировки.
pg_locks обеспечивает глобальное представление всех блокировок в кластере баз данных, а не только тех, которые относятся к текущей базе данных. Хотя через соединение по столбцу relation с pg_class.oid можно определить заблокированные отношения, это будет правильно работать только для отношений в текущей базе данных (те, для которых столбец database — это либо OID текущей базы данных, либо ноль).
Столбец pid можно соединить cо столбцом pid представления pg_stat_activity, что позволяет получить дополнительную информацию о сессии для каждой блокировки, например
SELECT * FROM pg_locks pl LEFT JOIN pg_stat_activity psa ON pl.pid = psa.pid;Кроме того, если вы используете подготовленные транзакции, то virtualtransaction столбец можно соединить со столбцом transaction представления pg_prepared_xacts, что позволяет получить дополнительную информацию о подготовленных транзакциях, содержащих блокировки. (Подготовленная транзакция никогда не может ждать блокировки, но она продолжает удерживать блокировки, полученные во время выполнения)
SELECT * FROM pg_locks pl LEFT JOIN pg_prepared_xacts ppx ON pl.virtualtransaction = '-1/' || ppx.transaction;При этом можно получить информацию о том, какие процессы блокируют какие другие процессы путем присоединения pg_locks с самим собой, но у такого соединения много сложных деталей — такой запрос должен был бы кодировать знания о том, какие режимы блокировки конфликтуют с другими. Хуже того, чем pg_locks представление не предоставляет сведения о том, какие процессы опережают другие в очереди ожидания блокировки, а также сведения о том, какие процессы являются параллельными рабочими (workers), выполняющимися от имени каких других сеансов клиента. Это лучше всего использовать при помощи функции pg_blocking_pids() (см. раздел Системные информационные функции и операторы) для определения того, какой процесс (ы) процесс ожидают каких блокировок.
Представление pg_locks отображает данные как из обычного диспетчера блокировки, так и из диспетчера блокировки предикатов, которые являются отдельными системами, кроме того, обычный менеджер блокировки подразделяет свои блокировки на регулярные и быстрые блокировки (fastpath). Т.о. данные в pg_locks не гарантируют полной согласованности. Когда представление запрашивает, данные о блокировках быстрого доступа (с fastpath = true) данные собираются с каждого бэкенда последовательно, не «замораживая» состояние всего менеджера блокировок, поэтому можно устанвить или снять блокировки во время сбора информации. Обратите внимание, что эти блокировки, как известно, не конфликтуют с любой другой блокировкой во время получения информации. После того, как все бэкенды были опрошены для получения быстрых блокировок, оставшаяся часть обычного менеджера блокировок блокируется как единое целое, и согласованный снимок всех оставшихся блокировок собирается атомарно. После разблокировки обычного диспетчера блокировки диспетчер блокировки предикатов точно также блокируется, и все блокировки предикатов собираются как атомарно. Таким образом, за исключением быстрых блокировок, каждый менеджер блокировок будет выдавать последовательные наборы результатов, но поскольку мы не блокируем оба менеджера блокировок одновременно, возможно, что блокировки будут захвачены или освобождены после опроса обычного менеджера блокировок и до опроса менеджера блокировки предикатов.
Блокировка обычного и / или диспетчера блокировки и / или диспетчера предикатов может оказать некоторое влияние на производительность базы данных, если к этому представлению очень часто обращаются. Блокировки удерживаются только в течение минимального количества времени, необходимого для получения данных от менеджеров блокировки, но это полностью не исключает возможность влияния на производительность.
pg_matviews
Представление pg_matviews предоставляет доступ к полезной информации о каждом материализованном представлении в базе данных.
pg_matviews столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей материализованное представление matviewname name pg_class.relname Имя материализованного представления matviewowner name pg_authid.rolname Имя владельца материализованного представления tablespace name pg_tablespace.spcname Имя табличного пространства, содержащего материализованное представление (null, если пространство по умолчанию для базы данных) hasindexes boolean True, если материализованное представление имеет (или недавно имело) какие-либо индексы ISP populated boolean True, если материализованное представление заполнено в данный момент definition text Определение материализованного представления (реконструированный запрос SELECT) pg_policies
Представление pg_policies предоставляет доступ к полезной информации о каждой политике безопасности на уровне строк в базе данных.
pg_policies столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей табличную политику включено tablename name pg_class.relname Имя таблицы с включённой политикой policyname name pg_policy.polname Название политики polpermissive text Является ли эта политика разрешительной или ограничительной? roles name[] Роли, к которым применяется эта политика cmd text Тип команды, к которой применяется политика qual text Выражение, добавленное к условиям барьеров безопасности для запросов, к которым применяется эта политика with_check text Выражение, добавленное в условие WITH CHECK для запросов, которые пытаются добавить строки в эту таблицу pg_prepared_statements
Представление pg_prepared_statements отображает все подготовленные инструкции, доступные в текущем сеансе.
pg_prepared_statements содержит одну строку для каждого подготовленного оператора. Строки добавляются в представление при создании нового подготовленного оператора и удаляются при освобождении подготовленного оператора (например, с помощью команды DEALLOCATE).
pg_prepared_statements столбцы
Имя Тип Описание name text Идентификатор подготовленного заявления statement text Строка запроса, отправленная клиентом для создания этого подготовленного оператора. Для подготовленных операторов, созданных с помощью SQL, это оператор PREPARE, представленный клиентом. Для подготовленных операторов, созданных с помощью сетевого протокола, это текст самого подготовленного оператора. prepare_time timestamptz Время, в которое был создан prepared оператор parameter_types regtype[] Ожидаемые типы параметров для подготовленного оператора в виде массива regtype. OID, соответствующий элементу этого массива, может быть получен путем приведения regtype значение к oid. from_sql boolean True, если подготовленный оператор был создан с помощью SQL команды PREPARE — False если оператор было подготовлен через сетевой протокол Представление pg_prepared_statements доступно только для чтения.
pg_prepared_xacts
Представление pg_prepared_xacts отображает информацию о транзакциях, которые в настоящее время подготовлены для двухфазной фиксации (см. раздел PREPARE TRANSACTION для получения подробной информации).
pg_prepared_xacts содержит одну строку на подготовленную транзакцию. Запись удаляется при фиксации или откате транзакции.
pg_prepared_xacts столбцы
Имя Тип Ссылки Описание transaction xid Числовой идентификатор подготовленной транзакции gid text Глобальный идентификатор, присвоенный транзакции prepared timestamp with time zone Время, в которое транзакция была подготовлена к фиксации owner name pg_authid.rolname Имя пользователя, выполнившего транзакцию database name pg_database.datname Имя базы данных, в которой была выполнена транзакция Когда осуществляется доступ к представлению pg_prepared_xacts, внутренние структуры данных диспетчера транзакций на мгновение блокируются, а для отображения d представлении создается копия. Это гарантирует, что представление создает согласованный набор результатов, не блокируя при этом обычные операции дольше, чем это необходимо. Тем не менее, если к этому представлению часто обращаться, это может оказать определенное влияние на производительность базы данных.
pg_publication_tables
Представление pg_publication_tables предоставляет информацию о сопоставлении публикаций и таблиц, которые они содержат. В отличие от базового каталога pg_publication_rel, это представление расширяет список публикаций, определённых как FOR ALL TABLES, таким образом, для таких публикаций будет строка для каждой подходящей таблицы.
pg_publication_tables столбцы
Имя Тип Ссылки Описание pubname name pg_publication.pubname Название публикации schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу tablename name pg_class.relname Имя таблицы pg_replication_origin_status
Представление pg_replication_origin_status содержит информацию о том, как далеко продвинулось воспроизведение изменений для определенного источника.
pg_replication_origin_status столбцы
Имя Тип Ссылки Описание local_id oid pg_replication_origin.roident внутренний идентификатор узла external_id text pg_replication_origin.roname идентификатор внешнего узла remote_lsn pg_lsn Номер LSN исходного узла, до которого были реплицированы данные. local_lsn pg_lsn Номер LSN этого узла, в котором remote_lsn был реплицирован. Используется для очистки записей фиксации транзакции (COMMIT) перед сохранением данных на диске при использовании асинхронных commit. pg_replication_slots
Представление pg_replication_slots предоставляет список всех слотов репликации, которые в настоящее время существуют в кластере баз данных, а также их текущее состояние.
pg_replication_slots столбцы
Имя Тип Ссылки Описание slot_name name Уникальный кластерный идентификатор для слота репликации plugin name Базовое имя разделяемого объекта, содержащего модуль вывода, который использует этот логический слот, или null для физических слотов. slot_type text Тип слота — физический или логический datoid oid pg_database.oid Идентификатор OID базы данных, с которой связан этот слот, или значение null. Только логические слоты имеют связанную базу данных. database text pg_database.datname Имя базы данных, с которой связан этот слот, или null. Только логические слоты имеют связанную базу данных. temporary boolean True, если это слот временной репликации. Временные слоты не сохраняются на диске и автоматически сбрасываются при ошибке или по завершении сеанса. active boolean True, если этот слот в настоящее время активно используется active_pid integer Идентификатор процесса сеанса, использующего этот слот, если слот в настоящее время активно используется. NULL если неактивен. xmin xid Самая старая транзакция, которую этот слот должен сохранить в базе данных. VACUUM не сможет удалить кортежи, удаленные любой более поздней транзакцией. catalog_xmin xid Самая старая транзакция, влияющая на системные каталоги, которые этот слот должен сохранить в базе данных. VACUUM не сможет удалить кортежи каталога, удаленные любой более поздней транзакцией. restart_lsn pg_lsn Адрес (номер LSN) самого старого WAL, который все еще может потребоваться потребителю этого слота и, следовательно, не будет автоматически удален во время контрольных точек. NULL если номер LSN этого слота никогда не был зарезервирован. confirmed_flush_lsn pg_lsn Адрес (номер LSN) до которого потребитель логического слота подтвердил получение данных. Данные старше этого больше не доступны. NULL для физических слотов. pg_roles
Представление pg_roles предоставляет доступ к информации о ролях базы данных. Это просто общедоступное представление pg_authid, которое скрывает поле пароля.
pg_roles столбцы
Имя Тип Ссылки Описание rolname name Имя роли rolsuper bool Роль имеет привилегии суперпользователя rolinherit bool Роль автоматически наследует привилегии ролей, членом которых она является rolcreaterole bool Роль может создавать другие роли rolcreatedb bool Роль может создавать базы данных rolcanlogin bool Роль может войти в систему. То есть эта роль может быть задана в качестве идентификатора авторизации начального сеанса rolreplication bool Роль — это роль репликации. Роль репликации может инициировать подключения репликации и создавать и удалять слоты репликации. rolconnlimit int4 Для ролей, которые могут войти в систему, задает максимальное число одновременных подключений, которые может создать эта роль. -1 означает отсутствие ограничений. rolpassword text Скрытый пароль (всегда читается как ********) rolvaliduntil timestamptz Срок действия пароля (используется только для парольной аутентификации — null, если нет срока действия rolbypassrls bool Роль обходит любую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. rolconfig text[] Значения в роли по умолчанию для переменных конфигурации времени выполнения oid oid pg_authid.oid Идентификатор роли pg_rules
Вид pg_rules предоставляет доступ к полезной информации о правилах перезаписи запросов.
pg_rules столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу tablename name pg_class.relname Имя таблицы, для которой используется правило rulename name pg_rewrite.rulename Название правила definition text Определение правила (восстановленная команда создания) Из представления pg_rules исключены возможности правил ON SELECT для представлений и материализованных представлений те, которые можно увидеть в pg_views и pg_matviews.
pg_seclabels
Представление pg_seclabels предоставляет информацию о метках безопасности. Это как более простая для запроса версия каталога pg_seclabel.
pg_seclabels столбцы
Имя Тип Ссылки Описание objoid oid OID для любого столбца OID объекта, к которому относится эта метка безопасности classoid oid pg_class.oid Идентификатор OID системного каталога, в котором отображается этот объект objsubid int4 Для метки безопасности в столбце таблицы это номер столбца (objoid и classoid определяют саму таблицу). Для всех других типов объектов этот столбец равен нулю. objtype text Тип объекта, к которому применяется эта метка (текст). objnamespace oid pg_namespace.oid OID пространства имен для этого объекта, если применимо; в противном случае значение NULL. objname text Имя объекта, к которому применяется эта метка (текст). provider text pg_seclabel.provider Поставщик меток, связанный с этой меткой. label text pg_seclabel.label Метка безопасности, применяемая к этому объекту. pg_sequences
Представление pg_sequences предоставляет доступ к полезной информации о каждой последовательности в базе данных.
pg_sequences столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей последовательность sequencename name pg_class.relname Имя последовательности sequenceowner name pg_authid.rolname Имя владельца последовательности data_type regtype pg_type.oid Тип данных последовательности start_value bigint Начальное значение последовательности min_value bigint Минимальное значение последовательности max_value bigint Максимальное значение последовательности increment_by bigint Значение приращения последовательности cycle boolean Цикличность последовательности (возможность) cache_size bigint Размер кэша последовательности last_value bigint Последнее значение последовательности, записанное на диск. Если используется кэширование, это значение может быть больше, чем последнее значение, выдаваемое из последовательности. Значение Null, если последовательность еще не была прочитана. Кроме того, если текущий пользователь не имеет прав USAGE или SELECT на последовательность, значение равно null. pg_settings
Представление pg_settings предоставляет доступ к параметрам времени выполнения сервера. Это по существу альтернативный интерфейс к командам SHOW и SET. Оно также предоставляет доступ к некоторым фактам о каждом параметре, которые непосредственно не доступны из SHOW, таким как минимальные и максимальные значения.
pg_settings столбцы
Имя Тип Описание name text Имя параметра конфигурации времени выполнения setting text Текущее значение параметра unit text Неявная единица измерения параметра category text Логическая группа параметра short_desc text Краткое описание параметра extra_desc text Дополнительное, более детальное, описание параметра context text Контекст, необходимый для установки значения параметра (см. ниже) vartype text Тип параметра (bool, перечисление, integer, real, или строка) source text Источник текущего значения параметра min_val text Минимальное допустимое значение параметра (null для нечисловых значений) max_val text Максимально допустимое значение параметра (null для нечисловых значений) enumvals text[] Допустимые значения параметра enum (null для значений, отличных от enum) boot_val text Значение параметра принимается при запуске сервера, если параметр не задан иным образом reset_val text Значение, которое будет сброшено для параметра в текущем сеансе sourcefile text Файл конфигурации в котором текущее значение было установлено (null для значений, заданных из источников, отличных от файлов конфигурации, или при проверке пользователем, который не является ни суперпользователем, ни членом pg_read_all_settings); полезно при использовании использовать директивы include в файлах конфигурации sourceline integer Номер строки в файле конфигурации в котором текущее значение было установлено (null для значений, заданных из источников, отличных от файлов конфигурации, или при проверке пользователем, который не является ни суперпользователем, ни членом pg_read_all_settings). pending_restart boolean True если значение было изменено в файле конфигурации, но нуждается в перезапуске; иначе False. Существует несколько возможных значений: контекста. В порядке уменьшения сложности изменения настроек, ими являются:
internal
Эти параметры не могут быть изменены непосредственно; они отражают внутренне определенные значения. Некоторые из них могут быть изменены через изменения параметров, предоставляемых в qhb_bootstrap .
postmaster
Эти параметры могут применяться только при запуске сервера, поэтому любое изменение требует перезагрузки сервера. Значения для этих параметров обычно хранятся в qhb.conf файл, либо передаются в командной строке при запуске сервера. Конечно же, настройки с любым из нижниеследующих контекстов типы также могут быть установлены во время запуска сервера.
sighup
Изменения в этих настройках могут быть внесены в qhb.conf без перезагрузки сервера. Пошлите сигнал SIGHUP к qhbmaster для того чтобы причинить его перечитывать qhb.conf и применить изменения. Qhbmaster также переадресует сигнал SIGHUP своим дочерним процессам, чтобы все они приняли новое значение.
superuser-backend
Изменения в этих настройках могут быть внесены в qhb.conf без перезагрузки сервера. Они также могут быть установлены для определенного сеанса в пакете запроса на подключение (например, через переменную окружения PGOPTIONS), но только если подключающийся пользователь является суперпользователем. Однако эти параметры никогда не изменяются в сеансе после его запуска. Если вы измените их внутри qhb.conf, необходимо отправить сигнал SIGHUP к qhbmaster для того чтобы инициировать перечитывание qhb.conf. Новые значения будут влиять только на последующие запущенные сеансы.
backend
Изменения в этих настройках могут быть внесены в qhb.conf без перезагрузки сервера. Они также могут быть установлены для определенного сеанса в пакете запроса на подключение (например, через переменную окружения PGOPTIONS); любой пользователь может внести такое изменение для своей сессии. Однако эти параметры никогда не изменяются в сеансе после его запуска. Если вы измените их внутри qhb.conf, пошлите сигнал SIGHUP к qhbmaster для того чтобы инициировать перечитывание qhb.conf. Новые значения будут влиять только на последующие запущенные сеансы.
superuser
Эти настройки можно установить из qhb.conf, или в течение сеанса с помощью команды SET; но только суперпользователи могут изменить их с помощью SET. Изменения в составе qhb.conf будет влиять на существующие сеансы только в том случае, если не было установлено значение session-local с WITH SET .
user
Эти настройки можно установить из qhb.conf, или в течение сеанса с помощью команды SET. Любой пользователь может изменить свое локальное значение сеанса. Изменения в составе qhb.conf будет влиять на существующие сеансы только в том случае, если не было установлено значение session-local с WITH SET .
Представление pg_settings не может быть вставленj или удаленj, но его можно обновить. UPDATE, для pg_settings эквивалентен выполнению команды SET для этого именованного параметра. Это изменение влияет только на значение, используемое в текущем сеансе. Если обновление выполняется в рамках транзакции, которая позже прерывается, последствия команды UPDATE исчезают при откате транзакции. После фиксации окружающей транзакции эффекты будут сохраняться до конца сеанса, если только они не будут переопределены другим UPDATE или SET .
pg_shadow
Представление pg_shadow показывает свойства всех ролей, которые помечены как rolcanlogin в pg_authid.
Это имя связано с тем, что эта таблица не должна быть доступна для чтения любыми пользователями, поскольку она содержит пароли. pg_user-это доступное всем представление для pg_shadow но со скрытым полем пароля.
pg_shadow столбцы
Имя Тип Ссылки Описание usename name pg_authid.rolname Имя пользователя usesysid oid pg_authid.oid ID этого пользователя usecreatedb bool Пользователь может создавать базы данных usesuper bool Пользователь является суперпользователем userepl bool Пользователь может инициировать потоковую репликацию и вывести систему из режима резервного копирования. usebypassrls bool Пользователь игнорирует любую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. passwd text Пароль (возможно зашифрованный); null, если нет. Смотрите pg_authid для получения подробной информации о том, как хранятся зашифрованные пароли. valuntil timestamptz Срок действия пароля (используется только для аутентификации пароля) useconfig text[] Значения по умолчанию сеанса для переменных конфигурации времени выполнения pg_stats
Представление pg_stats предоставляет доступ к информации, хранящейся в каталоге pg_statistic. Это представление позволяет получить доступ только к строкам pg_statistic это соответствует таблицам, на которые у пользователь имеет разрешение для чтения, и поэтому безопасно разрешать публичный доступ для чтения к этому представлению.
pg_stats также предназначена для представления информации в более удобочитаемом формате, чем базовый каталог — за счет того, что его схема должна быть расширена всякий раз, когда определяются новые типы слотов для pg_statistic.
pg_stats столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу tablename name pg_class.relname Имя таблицы attname name pg_attribute.attname Имя столбца, описываемого этой строкой inherited bool Если true, то эта строка содержит дочерние столбцы наследования, а не только значения в указанной таблице null_frac real Доля записей столбцов, имеющих значение null avg_width integer Средняя ширина в байтах записей столбца n_distinct real Если больше нуля, то показывает примерное число различных значений в столбце. Если меньше нуля, то модуль числа показывает количество различных значений разделённое на число строк. (Отрицательная форма используется, когда ANALYZE считает, что число различных значений, вероятно, будет увеличиваться по мере роста таблицы; положительная форма используется, когда считается, что столбец имеет фиксированное число возможных значений.) Например, значение -1 указывает на уникальный столбец, в котором число различных значений совпадает с числом строк. most_common_vals anyarray Список наиболее распространенных значений в столбце. (Null, если никакие значения не более распространенны, чем любые другие.) most_common_freqs real[] Список частот наиболее частых значений, т. е. количество вхождений каждого значения делится на общее количество строк. (Null, если most_common_vals тоже null.) histogram_bounds anyarray Список значений, разделяющих значения столбца на группы примерно одинаковой наборы называемые «популяции». Значения внутри most_common_vals, если они присутствует, то они исключаются из этого расчета гистограммы. (Столбец имеет значение null, если тип данных столбца не имеет оператора < или если most_common_vals список охватывает все популяции.) correlation real Статистическая корреляция между физическим упорядочением строк и логическим упорядочением значений столбцов. Значение колеблется от -1 до +1. Когда значение близко к -1 или +1, сканирование индекса по столбцу будет оценено как более дешевое, чем когда оно близко к нулю, из-за уменьшения случайного доступа к диску. (Столбец имеет значение null, если тип данных столбца не имеет оператора <.) most_common_elems anyarray Список ненулевых значений элементов, наиболее часто появляющихся в пределах значений столбца. (Null для скалярных типов.) most_common_elem_freqs real[] Список частот наиболее распространенных значений элементов, т. е. доля строк, содержащих хотя бы один экземпляр данного значения. Два или три дополнительных значения следуют за частотами каждого элемента; это минимум и максимум предыдущих частот каждого элемента и, возможно, частота нулевых элементов. (Null, когда заполнен most_common_elems.) elem_count_histogram real[] Гистограмма подсчетов различных ненулевых значений элементов в пределах значений столбца, за которыми следует среднее число различных ненулевых элементов. (Null для скалярных типов.) Максимальное число записей в полях массива можно контролировать по столбцам с помощью команды ALTER TABLE SET STATISTICS или глобально, задавая параметр времени выполнения default_statistics_target.
pg_stats_ext
Представление pg_stats_ext предоставляет доступ к информации, хранящейся в каталогах pg_statistic_ext и pg_statistic_ext_data. Это представление позволяет получить доступ к строкам pg_statistic_ext и pg_statistic_ext_data которые соответствует таблицам, для которые у пользователя есть разрешение на чтение, и поэтому безопасно разрешить доступ на чтение к этому представлению.
pg_stats_ext также предназначена для представления информации в более удобочитаемом формате, чем базовые каталоги — и потому должна быть расширена всякий раз, когда добавляются новые типы расширенной статистики pg_statistic_ext.
pg_stats_ext столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу tablename name pg_class.relname Имя таблицы statistics_schemaname name pg_namespace.nspname Имя схемы, содержащей расширенную статистику statistics_name name pg_statistic_ext.stxname Наименование расширенной статистики statistics_owner oid pg_authid.oid Владелец расширенной статистики attnames name[] pg_attribute.attname Имена столбцов, на которых определяется расширенная статистика kinds text[] Типы расширенной статистики, включенной для этой записи n_distinct pg_ndistinct Если больше нуля, то показывает примерное число различных значений в столбце. Если меньше нуля, то модуль числа показывает количество различных значений разделённое на число строк. (Отрицательная форма используется, когда ANALYZE считает, что число различных значений, вероятно, будет увеличиваться по мере роста таблицы; положительная форма используется, когда считается, что столбец имеет фиксированное число возможных значений.) Например, значение -1 указывает на уникальный столбец, в котором число различных значений совпадает с числом строк. dependencies pg_dependencies Статистика для функциональной зависимости most_common_vals anyarray Список наиболее распространенных комбинаций значений в столбцах. (Null, если никакие комбинации не считаются более распространенными, чем любые другие.) most_common_val_nulls anyarray Список нулевых флагов для наиболее распространенных комбинаций значений. (Null, если задан most_common_vals) most_common_freqs real[] Список частот наиболее распространенных комбинаций, т. е. количество вхождений каждой делится на общее количество строк. (Null, если задан most_common_vals) most_common_base_freqs real[] Список базовых частот наиболее распространенных комбинаций, т. е. произведение частот на значение. (Null, если задан most_common_vals) Максимальное число записей в полях массива можно контролировать для столбцов с помощью команды ALTER TABLE SET STATISTICS или глобально, задавая параметр времени выполнения default_statistics_target.
pg_tables
Представление pg_tables предоставляет доступ к полезной информации о каждой таблице в базе данных.
pg_tables столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей таблицу tablename name pg_class.relname Имя таблицы tableowner name pg_authid.rolname Имя владельца таблицы tablespace name pg_tablespace.spcname Имя табличного пространства, содержащего таблицу (null, если пространство по умолчанию для базы данных) hasindexes boolean pg_class.relhasindex True, если таблица имеет (или недавно имела) какие-либо индексы hasrules boolean pg_class.relhasrules True, если таблица имеет (или когда-то имела) правила hastriggers boolean pg_class.реластриггеры True, если таблица имеет (или когда-то имела) триггеры rowsecurity boolean pg_class.relrowsecurity True, если в таблице включена защита строк pg_timezone_abbrevs
Представление pg_timezone_abbrevs предоставляет список сокращений часовых поясов, которые в настоящее время распознаются как корректные для функций datetime. Содержание этого представления изменяется при изменении параметра времени выполнения timezone_abbreviations.
pg_timezone_abbrevs столбцы
Имя Тип Описание abbrev text Аббревиатура часового пояса utc_offset интервал Смещение от UTC (положительное значение означает на восток от Гринвича) is_dst boolean True, если это аббревиатура необходима для перехода на летнее время Хотя большинство сокращений часовых поясов представляют собой фиксированные смещения от UTC, есть некоторые, которые исторически менялись в таких случаях этот представление содержит их текущее значение.
pg_timezone_names
Представление pg_timezone_names предоставляет список имен часовых поясов, которые распознаются командой SET TIMEZONE, а также связанные с ними сокращения, смещения UTC и состояние летнего времени. (Технически QHB не использует UTC, потому что координация для високосных секунд не обрабатываются). В отличие от сокращений, показанных в pg_timezone_abbrevs, многие из этих имен подразумевают набор правил перехода на летнее время. Таким образом, связанная информация изменяется через локальные границы для летнего времени. Отображаемая информация вычисляется на основе текущего значения параметра CURRENT_TIMESTAMP.
pg_timezone_names столбцы
Имя Тип Описание name text Название часового пояса abbrev text Аббревиатура часового пояса utc_offset интервал Смещение от UTC (положительное значение означает восток от Гринвича) is_dst boolean True, если в настоящее время наблюдается переход на летнее время pg_user
Представление pg_user доступ к информации о пользователях базы данных. Это просто общедоступное представление pg_shadow которое скрывает поле пароля.
pg_user столбцы
Имя Тип Описание usename name Имя пользователя usesysid oid ID этого пользователя usecreatedb bool Пользователь может создавать базы данных usesuper bool Пользователь является суперпользователем userepl bool Пользователь может инициировать потоковую репликацию и вывести систему из режима резервного копирования. usebypassrls bool Пользователь обходит каждую политику безопасности уровня строки, см. раздел Политики безопасности строк для получения дополнительной информации. passwd text Не пароль (всегда читается как ********) valuntil timestamptz Срок действия пароля (используется только для парольной аутентификации) useconfig text[] Значения по умолчанию сеанса для переменных конфигурации времени выполнения pg_user_mappings
Представление pg_user_mappings доступ к информации о сопоставлениях пользователей. Это по существу общедоступное представление pg_user_mapping, которое оставляет столбец umoptions, если у пользователя нет прав на его использование.
pg_user_mappings столбцы
Имя Тип Ссылки Описание umid oid pg_user_mapping.oid OID сопоставления пользователей srvid oid pg_foreign_server.oid OID внешнего сервера, содержащий это сопоставление srvname name pg_foreign_server.srvname Имя внешнего сервера umuser oid pg_authid.oid OID сопоставляемой локальной роли, 0, если пользовательское сопоставление является общедоступным usename name Имя локального пользователя для сопоставления umoptions text[] Пользователь сопоставляет определенные параметры, в виде строки «ключ=значение» Чтобы защитить информацию о пароле, сохраненную в качестве параметра сопоставления пользователей, umoptions столбец будет считываться как null, если не применяется одно из следующих условий:
- текущий пользователь-это сопоставляемый пользователь, который владеет сервером или имеет USAGE для него
- текущий пользователь является владельцем сервера и сопоставление для PUBLIC
- текущий пользователь является суперпользователем
pg_views
Представление pg_views предоставляет доступ к полезной информации о каждом представлении (view) в базе данных.
pg_views столбцы
Имя Тип Ссылки Описание schemaname name pg_namespace.nspname Имя схемы, содержащей представление viewname name pg_class.relname Имя представления viewowner name pg_authid.rolname Имя владельца объекта (view) определение text Определение представления (реконструированный запрос SELECT)