Google выпустила новый API для распознавания объектов при помощи TensorFlow
Google выпустила TensorFlow Object Detection API, предназначенный для распознавания объектов на изображениях. API получился одновременно простым и мощным.
Google выпустила TensorFlow Object Detection API, предназначенный для распознавания объектов на изображениях. Инструмент получился одновременно простым и мощным, и он уже хорошо зарекомендовал себя в бенчмарках.
Что может новый API?
Среди моделей, добавленных в API, есть как мощные свёрточные нейронные сети, так и оптимизированные, предназначенные для работы на менее производительных машинах, например, недавно представленные MobileNets.
На данный момент этот блок не поддерживается, но мы не забыли о нём! Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Современные смартфоны не обладают мощными вычислительными ресурсами по сравнению с настольными или серверными решениями. Поэтому у разработчиков есть два варианта. Первый — располагать модели машинного обучения в облаке, но это приводит к задержкам и требует подключения к Интернету. Второй подход — упрощать сами модели, делая ставку на массовое распространение.
Google, Facebook и Apple вкладывают немалые ресурсы в эти мобильные модели. Прошлой осенью Facebook выпустила фреймворк Caffe2Go для использования машинного обучения в режиме реального времени. Этой весной на I/O 2017 Google представила TensorFlow Lite, мобильную версию своего фреймворка. А на WWDC 2017 Apple показала CoreML, позволяющий встроить модели машинного обучения в приложение.
TensorFlow Object Detection API уже доступен, найти его можно на GitHub.
Обработка изображений: Tensorflow Object Detection API
Последние несколько лет в развитии глубоких нейронных сетей происходит настоящая революция: возникают новые архитектуры, совершенствуются фреймворки для разработчиков, а железо для экспериментов можно получить совершенно бесплатно — например, в рамках проекта Google colaboratory. Всем, кому интересно как применить предобученные модели из репозитория к решению своей задачи, используя мощности Colaboratory — добро пожаловать под кат.
Топовые GPU — для всех
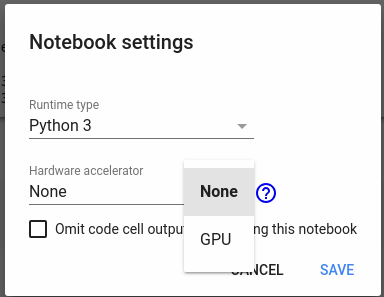
Для обучения нейросетей на больших объёмах данных лучше использовать GPU: скорость обучения и инференса будет выше, чем на CPU за счёт эффективного распараллеливания операций по тысячам ядер. До последнего времени применить карточки в своих расчётах можно было, например, с помощью облачных инстансов Amazon. Однако зачем платить за что-то, что можно получить бесплатно? Google Colaboratory предоставляет доступ к карточке Tesla K80.
Доступ к карте можно получить через меню Edit->Notebook setttings->Hardware accelerator:
С этой карточкой можно быстро проводить эксперименты с нейронными сетями — например пройти крутой курс по NLP от ребят из DeepPavlov. Единственный минус сервиса — карточка ваша всего на 12 часов, этому промежуточные результаты нужно куда-нибудь сохранять — если есть необходимость использовать их в дальнейшем.
В этой статье я расскажу как с помощью Colaboratory обучить модель и сохранить её для дальнейшего использования. В статье будет мало кода — весь код, обучающий модель и осуществляющий взаимодействие с Google Drive (для сохранения промежуточных результатов) доступен в моём репозитории. Поехали!
Датасет DeepFashion
Для экспериментов я буду использовать датасет Deep Fashion — это 800к изображений предметов одежды.

Изображения содержат теги, а так же на фото размечены bounding boxes. Мы будем обучать нейросеть детектировать изображения одежды на фото — рисовать bounding box и классифицировать один из трёх классов: upper-body, lower-body и full-body.
Подготовка данных
Вначале скопируйте DeepFashion себе на GoogleDrive датасет из директории Category and Attribute Prediction Benchmark в корневую директорию. Мы будем много работать с GoogleDrive как с файловым хранилищем — копировать оттуда данные и закачивать на Диск результаты работы (например, чекпоинт модели).
Для начала скопируем репозиторий с кодом и установим зависимости:
!rm -r TFFashionDetection !git clone https://github.com/Dju999/TFFashionDetection.git !pip install lxml !pip install -U -q PyDrive !pip install tqdm Ещё нужно создать вспомогательный объект для работы с файловой системой Google Drive
from TFFashionDetection.utils.colab_fs import GoogleColabFS fs = GoogleColabFS()Для более подробной информации можно посмотреть файл utils.colab_fs.py в репозитории.
Теперь нужно скачать датасет DeepFashion:
!python3 /content/TFFashionDetection/utils/dataset_download.py
В наборе данных присутствуют три директории
- Img — с изображениями предметов одежды
- Eval — содержит текстовый файл с разбиением датасета на train, test, valid
- Anno — тут файлы с тегами, баундинг боксами и прочей служебной информацией
Наша задача — подготовить эти данные для скармливания нейросети: описание файлов в специальном формате, разбиение на train и test.
Детекция изображений на Tensorflow
Google в 2017 году зарелизил Object Detection API — набор моделей и инструментов для детекции изображений. В репозитории очень много скриптов для подготовки обучающих данных, обучения моделей и визуализации результатов — например, отрисовки bounding boxes.
Код ниже устанавливает TF Object Detection API из github-репозитория в среду GoogleColaboratory.
! cd /content; git clone https://github.com/tensorflow/models.git # установка зависимостей для object detection тут # https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md !apt-get install protobuf-compiler python-pil python-lxml python-tk !pip install Cython !cd /content; git clone https://github.com/cocodataset/cocoapi.git; cd cocoapi/PythonAPI; make; cp -r pycocotools /content/models/research/ !cd /content/models/research; protoc object_detection/protos/*.proto --python_out=. # проверка - запускаем тесты !cd /content/models/research; export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim; python object_detection/builders/model_builder_test.py Теперь нужно подготовить данные. В Img сложная структура поддиректорий, где каждому классу одежды соответствует своя категория. Код ниже копирует все фотографии в одну директорию, а так же готовит для каждого файла описание в виде tf.train.Example — на всём этом добре будет обучаться модель детекции
В коде есть название модели ssd_mobilenet_v2_coco_2018_03_29 — подходящую модельку можно скачать в Detection Zoo. Модельку можно скачать другую — но тогда нужно будет переписать файл /content/data_dir/tf_api.config.
import sys import os import numpy as np API_PATH = os.path.join('/content', 'models/research') sys.path.append(API_PATH) DETECTOR_PATH = os.path.join('/content', 'TFFashionDetection') sys.path.append(DETECTOR_PATH) from TFFashionDetection.data_preparator import DataPreparator from TFFashionDetection.utils.ssd_config import write_config data_preparator = DataPreparator() data_preparator.build() write_config('ssd_mobilenet_v2_coco_2018_03_29')
После того, как выполнение ячейки закончится — можно скачать предобученную модель и запускать обучение модели. Frozen inference graph из репы Object Detetetion позволит быстрее обучить свой детектор. Путь до директории с графом модели нужно будет передать в скрипт обучения /object_detection/train.py.
# скачиваем модель (предобученную) !python /content/TFFashionDetection/utils/download_tf_zoo_model.py --name ssd_mobilenet_v2_coco_2018_03_29 --dir /content # запускаем обучение модели !export PYTHONPATH=$PYTHONPATH:/content/models/research/slim:/content/models/research/;python /content/models/research/object_detection/train.py --logtostderr --pipeline_config_path=/content/data_dir/tf_api.config --train_dir=/content/data_dir/checkpoints Если всё сделали правильно — увидим, как побегут логи и loss будет уменьшаться на каждой итерации. Когда вы видите, что функция потерь перестала уменьшаться — можно останавливать обучение. Граф модели сохраняется в директорию /content/data_dir/checkpoints — его нужно будет сохранить для дальнейших экспериментов. Обучение модели нужно провести один раз, после этого использовать полученный граф для инференса.
Когда модель обучена — нужно сохранить её на гугл-диск
!cd /content/data_dir; zip -r checkpoint_save_20180514.zip checkpoints/* import os fs = GoogleColabFS() file_name = os.path.join('/content/data_dir', 'checkpoint_save_20180514.zip') fs.load_to_drive(file_name)
Скачивать с гугл-диска таким же образом
import os fs.load_file_from_drive('/content', 'checkpoint_save_20180514.zip') fs.unzip_file('/content', 'checkpoint_save_20180514.zip') !mkdir /content/deep_detection_model # экспортируем модель !export PYTHONPATH=$PYTHONPATH:/content/models/research/slim:/content/models/research/;python /content/models/research/object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path=/content/data_dir/tf_api.config --trained_checkpoint_prefix=/content/checkpoints/model.ckpt-2108 --output_directory inference_graph
Для примера выберем случайную фотку и скормим её нашей сети для детекции:
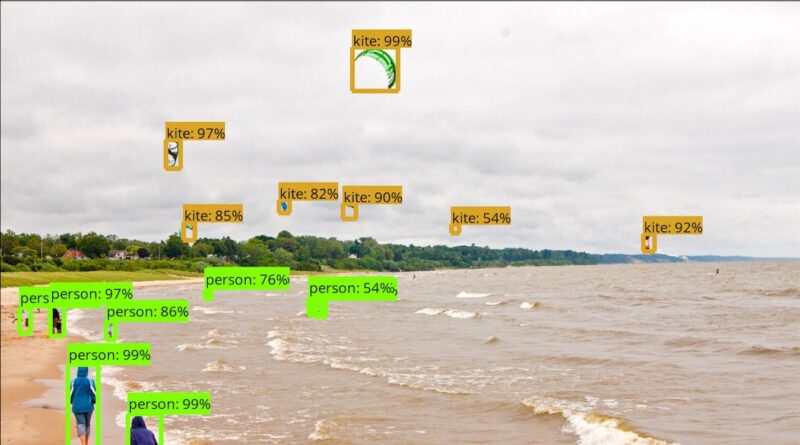
import sys import os import matplotlib.pyplot as plt plt.switch_backend('agg') sys.path.append(os.path.join('/content', 'models/research')) from object_detection.utils import visualization_utils as vis_util from PIL import Image as Pil_image %matplotlib inline boxes = np.array([oject_detector.img_detections[3]['category_box']]) def load_image_into_numpy_array(image): (im_width, im_height) = image.size return np.array(image.getdata()).reshape( (im_height, im_width, 3)).astype(np.uint8) # загружаем картинку и превращаем в массив image = Pil_image.open(file_path) image_np = load_image_into_numpy_array(image) # накладываем на массив bounding boxes vis_util.draw_bounding_boxes_on_image_array(image_np, boxes) # сохраняем картинку на диск result_file_path = os.path.join('/content', 'test.png') vis_util.save_image_array_as_png(image_np, result_file_path) # виуализируем картинку, которую сохранили from IPython.display import Image Image(result_file_path)
Видим результаты детекции — lower_body предмет одежды

Заключение
TF Object Detection API — крутая технология, которая позволяет использовать в своих моделях State-of-the-Art архитектуры сеток. А Google Colaboratory — отличная площадка для экспериментов, которая позволяет тренировать сети на мощном железе.
Как мы можем реализовать простую систему наблюдения сами?
Итак, теперь, когда мы знаем, что наблюдение, по большей части, может быть автоматизировано с помощью машинного обучения, мы можем задаться вопросом, как мы можем построить нашу собственную простую систему наблюдения.
Построить «маленькую» систему наблюдения довольно просто. Нам нужно только обучить модель обнаружения объекта классам, которые мы хотим обнаружить, и затем реагировать на обнаружение объекта.
В этой статье мы просто сохраним изображение обнаруженного объекта и запишем время его обнаружения в CSV-файл.
Для создания модели обнаружения объектов мы будем использовать API обнаружения объектов Tensorflow.
Tensorflow Object Detection API — это инфраструктура с открытым исходным кодом, которая позволяет вам использовать предварительно обнаруженные модели обнаружения объектов или создавать и обучать новые модели, используя передачу обучения. Это чрезвычайно полезно, потому что построение модели обнаружения объекта с нуля может быть трудным и может занять очень много времени для обучения.
Если вы еще не установили API Tensorflow Object Detection, вы можете проверить моя статья охватывающий, как это сделать.
Напомним, как использовать API обнаружения объектов Tensorflow для обнаружения живых объектов
В моей статье под названием « Обнаружение живых объектов Я рассказал, как переписать Демонстрационный скрипт Tensorflow Object Detection работать с прямой эфир, Для этого мы переписали run_inference_for_single_image метод включает только код, который должен быть выполнен один раз, и перемещает весь другой код за пределы метода.
Этот код является полезной отправной точкой, но у нас пока нет доступа к отдельным объектам. Кроме того, поскольку я просто буду использовать модель, обученную на наборе данных кокосов, я также создам переменную, которая указывает, какие объекты мы ищем, чтобы мы могли проверить, есть ли у объекта этот класс.
Получить координаты и метки для каждой коробки
Мы можем получить доступ к метке и координатам объектов, используя detection_classes а также detection_boxes ключи для output_dict толковый словарь.
В приведенном выше коде мы перебираем все оценки для обнаруженных объектов. Если оценка объекта выше указанного порога, мы получим метку и координаты и добавим их в наш выходной массив. Если оценка ниже порога, мы просто пропустим объект.
Проверьте, содержит ли коробка человека
Чтобы теперь реагировать на некоторые классы, мы можем просто пройти через выходной массив и проверить, соответствует ли метка классу, который мы ищем.
Если метка соответствует классу, мы вырежем часть изображения, которая содержит класс, и сохраним его в формате jpg. Мы также сохраним datetime и filepath в csv, чтобы мы знали время, когда было сделано изображение.
Собираем вещи вместе
Теперь остается только собрать все части вместе. Мы также создадим метод для загрузки в наборе данных и будем использовать библиотека argparse таким образом, мы можем передать путь модели, метку карты, порог, выходной каталог и класс, который мы хотим найти.
Мы можем проверить этот скрипт, набрав
python simple_surveillance_system.py -m -l
Вы также можете указать любые другие параметры, но вам это не нужно, поскольку все они имеют предустановленные значения.
Используйте ImUtils для поддержки Raspberry Camera
Еще одна вещь, которую мы можем сделать, это добавить поддержку Raspberry Camera. Мы можем так с помощью библиотека имутилс,
Imutils построен на основе OpenCV и предлагает множество удобных функций, облегчающих базовую обработку изображений. Он включает в себя функции для перевода, поворота, изменения размера изображений, а также многие другие
Чтобы включить ImUtils в наш скрипт, нам нужно только изменить инициализацию камеры, чтение кадра, а также закрытие камеры при выходе из скрипта.
Можем ли мы доверять нашей модели
Возможность доверять модели очень важна, особенно когда модель используется для принятия важных решений, например, разрешать ли кому-либо одалживать деньги.
Чтобы быть уверенным, что наша модель обнаруживает людей только тогда, когда они действительно изображены на снимке, нам нужно проверить. Мы можем сделать это, просто запустив нашу модель и наблюдая, правильно ли она работает, но мы также можем использовать инструменты интерпретации модели, чтобы помочь нам понять нашу модель.
Если вы хотите узнать больше о интерпретации модели и почему это важно, вы можете проверить моя серия статей о модельной интерпретации,
Резюме
Сегодня модели машинного обучения способны автоматизировать повторяющиеся тривиальные задачи, такие как классификация изображений или обнаружение объектов. Единственное, что им нужно сделать, это много данных.
Система наблюдения может быть построена с использованием модели обнаружения объектов, которая отслеживает требуемые классы.
Что дальше?
В ближайшие месяцы я буду вести блог о различных применениях машинного обучения и науки о данных, а также о некоторых новых технологиях и библиотеках. Кроме того, я сосредоточусь больше на углубленном изучении теории машинного обучения.
Это все из этой статьи. Если у вас есть какие-либо вопросы или вы просто хотите пообщаться со мной, не стесняйтесь оставлять комментарии ниже или связываться со мной в социальных сетях. Если вы хотите получать постоянные обновления о моем блоге, следите за мной на Среднем и присоединиться к моей рассылке,
TensorFlow 2 Object Detection
Создание точных моделей машинного обучения, способных локализовать и идентифицировать несколько объектов на одном изображении, остается основной проблемой компьютерного зрения. API обнаружения объектов TensorFlow — это платформа с открытым исходным кодом, построенная на основе TensorFlow, которая упрощает создание, обучение и развертывание моделей обнаружения объектов. Детектирование объектов в TensorFlow 2 является мощнейшим средством, предназначенным для распознавания объектов на изображениях. Ссылка: https://github.com/tensorflow/models/tree/master/research/object_detection
Установка имеет свои особенности, в данной статье установка производится с учетом среды Kaggle
Установка Object Detection
Саму процедуру установки можно найти по следующим ссылкам:
- https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2.md
- https://www.kaggle.com/bhallaakshit/dicom-training-prediction-and-evaluation
Выглядит это примерно так:
!# Download models !git clone --depth 1 https://github.com/tensorflow/models !# Compile proto files ! # sudo apt install -y protobuf-compiler # Already present %cd models/research !protoc object_detection/protos/*.proto --python_out=. %cd .. %cd .. !# Install cocoapi !pip install cython !git clone https://github.com/cocodataset/cocoapi.git %cd cocoapi/PythonAPI !make %cd .. %cd .. !cp -r cocoapi/PythonAPI/pycocotools models/research/ !# Install object detection api %cd models/research !cp object_detection/packages/tf2/setup.py . !python -m pip install . %cd .. %cd ..
Подготовка данных
Про подготовку данных для обучения написано тут:
Данные лучше засовывать в tfrecord, чтобы можно было обучать и на TPU. По указанной ссылке показано, как это сделать. Для каждого изображения вызывается функция, которая создает порцию данных (Example). В данном случае она простая:
def create_cat_tf_example( encoded_cat_image_data ):
«»»Creates a tf.Example proto from sample cat image.
encoded_cat_image_data: The jpg encoded data of the cat image.
example: The created tf.Example.
xmins = [322.0 / 1200.0]
xmaxs = [1062.0 / 1200.0]
ymins = [174.0 / 1032.0]
ymaxs = [761.0 / 1032.0]