Что такое краулинг и как управлять роботами
Выдача ответов на поисковый запрос на странице поиска за долю секунды только верхушка айсберга. В «черном ящике» поисковых систем — просканированные и занесенные в специальную базу данных миллиарды страниц, которые отбираются для представления с учетом множества факторов.
Страница с результатами поиска формируется в результате трех процессов:
- сканирования;
- индексирования;
- предоставления результатов (состоит из поиска по индексу и ранжирования страниц).
В этом выпуске «Азбуки SEO» речь пойдет о сканировании или краулинге страниц сайта.
Как работает сканирование (краулинг) сайта?
Если кратко, краулинг (сканирование, crawling) — процесс обнаружения и сбора поисковым роботом (краулером) новых и обновленные страницы для добавления в индекс поисковых систем. Сканирование — начальный этап, данные собираются только для дальнейшей внутренней обработки (построения индекса) и не отображаются в результатах поиска. Просканированная страница не всегда оказывается проиндексированной.
Поисковый робот (он же crawler, краулер, паук, бот) — программа для сбора контента в интернете. Краулер состоит из множества компьютеров, запрашивающих и выбирающих страницы намного быстрее, чем пользователь с помощью своего веб-браузера. Фактически он может запрашивать тысячи разных страниц одновременно.
Что еще делает робот-краулер:
- Постоянно проверяет и сравнивает список URL-адресов для сканирования с URL-адресами, которые уже находятся в индексе Google.
- Убирает дубликаты в очереди, чтобы предотвратить повторное скачивание одной и той же страницы.
- Добавляет на переиндексацию измененные страницы для предоставления обновленных результатов.
При сканировании пауки просматривают страницы и выполняют переход по содержащимся на них ссылкам так же, как и обычные пользователи. При этом разный контент исследуется ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
Например, в Google существуют роботы для обработки разного типа контента:
- Googlebot — основной поисковый робот;
- Googlebot News — робот для сканирования новостей;
- Googlebot Images — робот для сканирования изображений;
- Googlebot Video — робот для сканирования видео.
В статье о robots.txt мы собрали полный перечень роботов-пауков. Знакомьтесь 🙂
Кстати, именно с robots.txt и начинается процесс сканирования сайта — краулер пытается обнаружить ограничения доступа к контенту и ссылку на карту сайта (Sitemap). В карте сайта должны находиться ссылки на важные страницы сайта. В некоторых случаях поисковый робот может проигнорировать этот документ и страницы попадут в индекс, поэтому конфиденциальную информацию нужно закрывать паролем непосредственно на сервере.

Просматривая сайты, бот находит на каждой странице ссылки и добавляет их в свою базу. Робот может обнаружить ваш сайт даже без размещения ссылок на него на сторонних ресурсах. Для этого нужно осуществить переход по ссылке с вашего сервера на другой. Заголовок HTTP-запроса клиента «referer» будет содержать URL источника запроса и, скорее всего, сохранится в журнале источников ссылок на целевом сервере. Следовательно, станет доступным для робота.
Как краулер видит сайт
Если хотите проверить, как робот-краулер видит страницу сайта, отключите обработку JavaScript при включенном отладчике в браузере. Рассмотрим на примере Google Chrome:
1. Нажимаем F12 — вызываем окно отладчика, переходим в настройки.
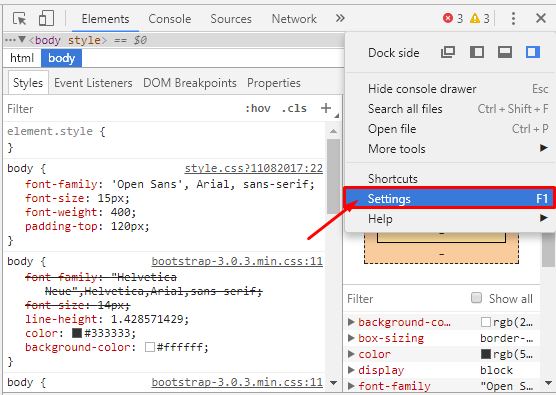
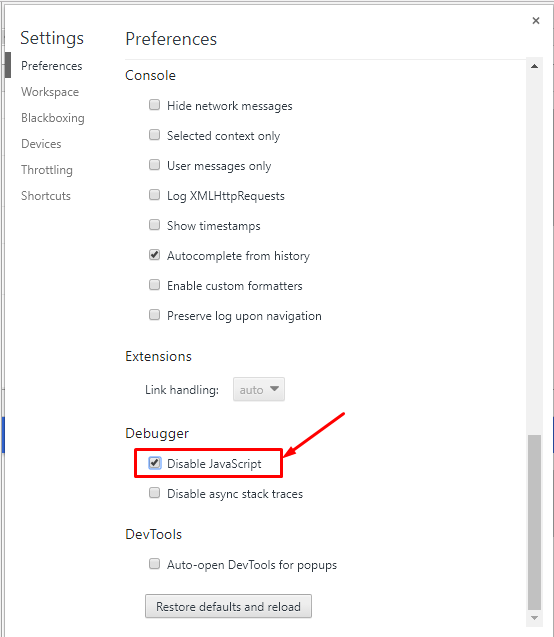
2. Отключаем JavaScript и перезагружаем страницу.
Если в целом на странице сохранилась основная информация, ссылки на другие страницы сайта и выглядит она примерно так же, как и с включенным JavaScript, проблем со сканированием не должно возникнуть.
Второй способ — использовать инструмент Google «Просмотреть как Googlebot» в Search Console.
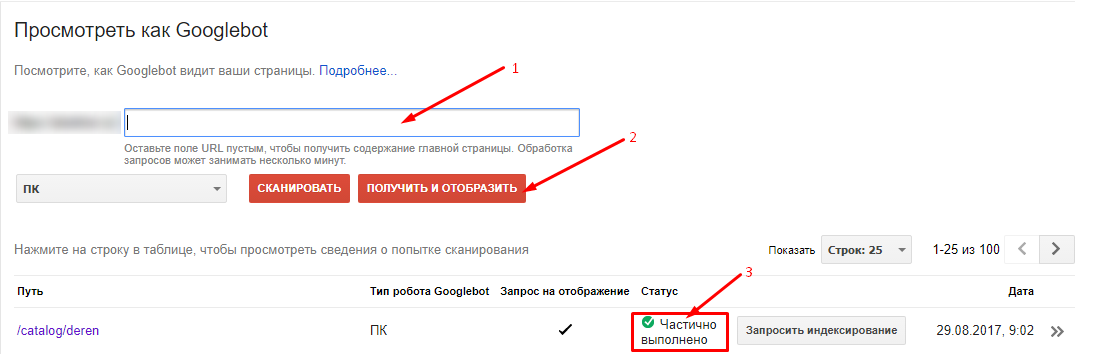
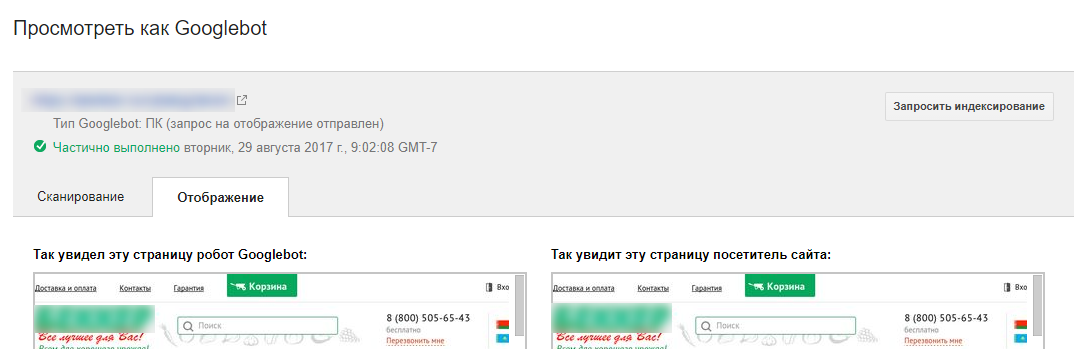
Если краулер видит вашу страницу так же, как и вы, проблем со сканированием не возникнет.
Третий метод — специальное программное обеспечение. Например, Netpeak Spider показывает более 50 разных видов ошибок, найденных при сканировании, и разделяет их по степени важности.
Если страница не отображается так, как вы ожидали, стоит проверить, доступна ли она для сканирования: не заблокирована ли она в robots.txt, в файле .htaccess.
Проблемы со сканированием могут возникать, если сайт создан с помощью технологий Javascript и Ajax , так как поисковые системы пока с трудом сканируют подобный контент.
Как управлять сканированием страниц
Запуск и оптимизация сканирования сайта
Существует несколько методов пригласить робота-паука к себе на сайт:
- Разрешить сканирование сайта, если он был запаролен на сервере, и передать информацию об URL c помощью HTTP-заголовка «referer» при переходе на другой ресурс.
- Разместить ссылку на ваш сайт на другом ресурсе, например, в соцсетях.
- Зарегистрироваться в панелях вебмастеров Google.
- Сообщить о сайте поисковой системе напрямую через кабинет вебмастеров Google.
- Использовать внутреннюю перелинковку страниц для улучшения навигации и сканирования ресурса, например, хлебные крошки.
- Создать карту сайта с нужным списком страниц и разместить ссылку на карту в robots.txt.
Запрет сканирования сайта
- Для ограничения сканирования контента следует защитить каталогов сервера паролем. Это простой и эффективный способ защиты конфиденциальной информации от ботов.
- Ставить ограничения в robots.txt.
- Использовать метатег . С помощью директивы “nofollow” стоит запретить переход по ссылкам на другие страницы.
- Использовать HTTP-заголовок X-Robots tag. Запрет на сканирование со стороны сервера осуществляется с помощью HTTP заголовка X-Robots-tag: nofollow. Директивы, которые применяются для robots.txt, подходят и для X-Robots tag.
Больше информации о использовании http-заголовка в справке для разработчиков.
Управление частотой сканирования сайта
Googlebot использует алгоритмический процесс для определения, какие сайты сканировать, как часто и сколько страниц извлекать. Вебмастер может предоставить вспомогательную информацию краулеру с помощью файла sitemap, то есть с помощью атрибутов:
- — дата последнего изменения файла;
- — вероятная частота изменений страницы;
- — приоритетность.
К сожалению, значения этих атрибутов рассматриваются роботами как подсказка, а не как команда, поэтому в Google Search Console и существует инструмент для ручной отправки запроса на сканирование.
Выводы
- Разный контент обрабатывается ботами в разной последовательности. Это позволяет одновременно обрабатывать огромные массивы данных.
- Для улучшения процесса сканирования нужно создавать карты сайтов и делать внутреннюю перелинковку — чтобы бот смог найти все важные страницы.
- Закрывать информацию от индексирования лучше с помощью метатега или http-заголовка X-Robot tag, так как файл robots.txt содержит лишь рекомендации по сканированию, а не прямые команды к действию.
Читайте больше об инструментах для парсинга сайта , необходимых SEO-специалисту в рутинной работе.
1.1.1. Компоненты поисковых машин
Информация в Сети не только пополняется, но и постоянно изменяется, но об этих изменениях никто никому не сообщает. Отсутствует единая система занесения информации, одновременно доступная для всех пользователей Интернета. Поэтому с целью структурирования информации, предоставления пользователям удобных средств поиска данных и были созданы поисковые машины.
Поисковые системы бывают разных видов. Одни из них выполняют поиск информации на основе того, что в них заложили люди. Это могут быть каталоги, куда сведения о сайтах, их краткое описание либо обзоры заносят редакторы. Поиск в них ведется среди этих описаний.
Вторые собирают информацию в Сети, используя специальные программы. Это поисковые машины, состоящие, как правило, из трех основных компонентов:
Агент, или более привычно — паук, робот (в англоязычной литературе — spider, crawler), в поисках информации обходит сеть или ее определенную часть. Этот робот хранит список адресов (URL), которые он может посетить и проиндексировать, с определенной для каждой поисковой машины периодичностью скачивает соответствующие ссылкам документы и анализирует их. Полученное содержимое страниц сохраняется роботом в более компактном виде и передается в Индекс. Если при анализе страницы (документа) будет обнаружена новая ссылка, робот добавит ее в свой список. Поэтому любой документ или сайт, на который есть ссылки, может быть найден роботом. И наоборот, если на сайт или любую его часть нет никаких внешних ссылок, робот может его не найти.
Робот — это не просто сборщик информации. Он обладает довольно развитым «интеллектом». Роботы могут искать сайты определенной тематики, формировать списки сайтов, отсортированных по посещаемости, извлекать и обрабатывать информацию из существующих баз данных, могут выполнять переходы по ссылкам различной глубины вложенности. Но в любом случае, всю найденную информацию они передают базе данных (Индексу) поисковой машины.
Поисковые роботы бывают различных типов:
? Spider (паук) — это программа, которая скачивает веб-страницы тем же способом, что и браузер пользователя. Отличие состоит в том, что браузер отображает информацию, содержащуюся на странице (текстовую, графическую и т. д.), паук же не имеет никаких визуальных компонентов и работает напрямую с HTML-текстом страницы (аналогично тому, что вы увидите, если включите просмотр HTML-кода в вашем браузере).
? Crawler (краулер, «путешествующий» паук) — выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Краулер, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
? Индексатор разбирает страницу на составные части и анализирует их. Выделяются и анализируются различные элементы страницы, такие как текст, заголовки, структурные и стилевые особенности, специальные служебные HTML-теги и т. д.
Индекс — это та часть поисковой машины, в которой осуществляется поиск информации. Индекс содержит все данные, которые были переданы ему роботами, поэтому размер индекса может достигать сотен гигабайт. Практически, в индексе находятся копии всех посещенных роботами страниц. В случае если робот обнаружил изменение на уже проиндексированной им странице, он передает в Индекс обновленную информацию. Она должна замещать имеющуюся, но в ряде случаев в Индексе появляется не только новая, но остается и старая страница.
Поисковый механизм — это тот самый интерфейс, с помощью которого посетитель взаимодействует с Индексом. Через интерфейс пользователи вводят свои запросы и получают ответы, а владельцы сайтов регистрируют их (и эта регистрация — еще один способ донести до робота адрес своего сайта). При обработке запроса поисковый механизм выполняет отбор соответствующих ему страниц и документов среди многих миллионов проиндексированных ресурсов и выстраивает их в порядке важности или соответствия запросу.
Названные выше компоненты не обязательно входят в состав поисковой машины так, как они здесь описаны. У разных поисковиков реализация может отличаться друг от друга. К примеру, связка Spider+Crawler+Индексатор может быть выполнена в виде единой программы, которая скачивает известные веб-страницы, анализирует их и ищет по ссылкам новые ресурсы.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Читайте также
Виды виртуальных машин
Виды виртуальных машин Система виртуальных машин может быть построена на базе различных платформ и при помощи разных технологий. Используемая схема виртуализации зависит как от аппаратной платформы, так и от особенностей «взаимоотношений» хостовой ОС и поддерживаемых
Консоль виртуальных машин
Консоль виртуальных машин Большую часть окна консоли занимает поле, в котором отображается перечень имеющихся ВМ. Если ни одной машины еще не создано, то это поле пустое (см. рис. 2.4), а в правой части окна доступна единственная кнопка — New (создать). Эта кнопка запускает
Окно виртуальных машин
Окно виртуальных машин Центральную часть окна виртуальных машин занимает поле, в котором отображаются значения основных параметров и текущая конфигурация запущенной ВМ (рис. 4.7). Рис. 4.7. Окно виртуальных машин Parallels WorkstationВ каждый момент времени могут быть представлены
Поиск по трекерам средствами поисковых машин
Поиск по трекерам средствами поисковых машин Если вы пользуетесь услугами пиринговой сети не часто, а от случая к случаю, то можете искать ссылки или так называемые торренты с помощью поисковой машины Google. Для этого достаточно ввести в поле ввода ключевых слов для поиска
Использование языка запросов поисковых машин
Использование языка запросов поисковых машин В строку запроса поисковой машины, помимо ключевых слов, можно вводить так называемые операторы – специальные служебные слова или символы, которые сообщают поисковой системе, каким образом нужно обращаться с теми или иными
Описание языков запросов различных поисковых машин
Описание языков запросов различных поисковых машин Умение искать информацию с помощью поисковых машин очень важно для создания и последующей раскрутки блога.Благодаря поисковым машинам можно своевременно собирать информацию, появляющуюся в Интернете по теме, которой
18.2. Инсталляция системы виртуальных машин
18.2. Инсталляция системы виртуальных машин Для установки необходимо сначала скачать ПО с сайта компании VMware, а также получить лицензию на его использование. Можно, конечно, купить лицензию (стоимость ее около 300 долларов), однако можно пользоваться и временной (30-дневной)
История развития поисковых машин
История развития поисковых машин История эволюции поисковых машин наиболее полно, на наш взгляд, представлена в книге признанных экспертов в области невидимого интернета Криса Шермана и Гарри Прайса «Невидимый Интернет».[2]До середины 1960-х годов компьютеров было
Ограничения возможностей поисковых машин
Ограничения возможностей поисковых машин 1. Физические ограничения скорости. Информационные системы имеют физические ограничения по скорости поиска новых страниц. Скажем так, скорость, с которой сегодня паук пытается найти новые страницы, оказывается ниже, чем
1.1.2. Характеристики поисковых машин
1.1.2. Характеристики поисковых машин В статье, посвященной поисковой машине Rambler (http://www.rambler.ru/ doc/architecture.shtml), называются основные характеристики, которые могут быть применены к любым поисковикам:? полнота;? точность;? актуальность;? скорость;? наглядность.Полнота поиска
5.4. Оптимизация сайта для поисковых машин
5.4. Оптимизация сайта для поисковых машин Какие задачи решает оптимизация для поисковых машин Поисковые машины сегодня являются важнейшим инструментом навигации в Интернете. С их помощью в Сети ищут информацию, сравнивают, анализируют, спрашивают совета, ищут
Какие задачи решает оптимизация для поисковых машин
Какие задачи решает оптимизация для поисковых машин Поисковые машины сегодня являются важнейшим инструментом навигации в Интернете. С их помощью в Сети ищут информацию, сравнивают, анализируют, спрашивают совета, ищут единомышленников, знакомых и даже смысл жизни. Если
13-я КОМНАТА: Этика машин и механизмов
13-я КОМНАТА: Этика машин и механизмов Автор: Леонид Левкович-МаслюкВ этом номере вы найдете статью о «биржевых роботах» — компьютерных программах, зарабатывающих для своих владельцев деньги на фондовом рынке. Соотношение квалификации электронных и живых трейдеров
История машин, мешавших обучению
История машин, мешавших обучению Несмотря на все факты, сведения и научные выводы, говорящие против этого, в настоящее время школы (и даже детские сады!) повсеместно оборудуются компьютерами — в целях обучения. Почему это не может дать положительных результатов, было
Адаптивный краулер для поиска и сбора внешних гиперссылок Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Печников Андрей Анатольевич, Чернобровкин Денис Игоревич
Описывается поисковый робот (краулер), предназначенный для сбора информации об исходящих гиперссылках с задаваемого множества сайтов, относящихся к одной тематике. Адап-тивное поведение краулера сформулировано в терминах задачи о многоруком бандите . Проведенные эксперименты показыва-ют, что выбор адаптивного алгоритма рационального поведе-ния краулера зависит от тематики множества сайтов.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Печников Андрей Анатольевич, Чернобровкин Денис Игоревич
Построение тематико-ориентированных веб-краулеров с использованием обобщенного ядра
Разработка программы сбора данных о структуре веб-сайтов
Разработка инструментов для вебометрических исследований гиперссылок научных сайтов
Применение вебометрических методов для исследования информационного веб-пространства научной организации (на примере Карельского научного центра РАН)
Модель университетского веба
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Adaptive crawler for external hyperlinks search and acquisition
We consider the web-crawler designed to find information about outgoing hyperlinks from a set of monothematic web-sites. Adaptive behavior of the crawler is formulated in terms of the multi-armed bandit problem . The experiments show that the choice of the adaptive algorithm of rational behavior depends on the subject of the considered set of web-sites.
Текст научной работы на тему «Адаптивный краулер для поиска и сбора внешних гиперссылок»
УДК 004.738.5:519.7 ББК 32.973-22.18
АДАПТИВНЫЙ КРАУЛЕР ДЛЯ ПОИСКА И СБОРА ВНЕШНИХ ГИПЕРССЫЛОК
(Учреждение Российской академии наук Институт прикладных математических исследований КарНЦ РАН, Петрозаводск)
Чернобровкин Д. И.2 (Факультет прикладной математики -процессов управления Санкт-Петербургского государственного университета, Санкт-Петербург)
Описывается поисковый робот (краулер), предназначенный для сбора информации об исходящих гиперссылках с задаваемого множества сайтов, относящихся к одной тематике. Адаптивное поведение краулера сформулировано в терминах задачи
о многоруком бандите. Проведенные эксперименты показывают, что выбор адаптивного алгоритма рационального поведения краулера зависит от тематики множества сайтов.
Ключевые слова: гиперссылка, поисковый робот, адаптивное поведение, задача о многоруком бандите, индексы Г иттинса.
Концептуальная модель фрагмента Веба [2] строится на основе задаваемого множества веб-сайтов, относящихся к одной тематике и являющихся регламентируемыми, т.е. создающихся и развивающихся по заранее сформулированным правилам, утвержденным в виде нормативных документов организаций-
1 Андрей Анатольевич Печников, доктор технических наук, доцент (pechnikov@krc. karelia. т).
2 Денис Игоревич Чернобровкин, аспирант (denis_univer@mail.com).
владельцев ресурсов. Примерами тематических целевых множеств служат официальные веб-сайты институтов Санкт-Петербургского научного центра РАН и официальные веб-сайты высших учебных заведений Санкт-Петербурга. Анализ внешних гиперссылок, сделанных с веб-сайтов целевого множества, позволяет построить так называемое «сопутствующее множество» — множество сайтов, не входящих в целевое множество, на которые имеются гиперссылки с целевого множества. Сопутствующее множество разбивается на несколько непересекающихся подмножеств, в зависимости от степени связности входящих в них сайтов с сайтами целевого множества. Концептуальная модель фрагмента Веба представляет собой набор множеств, состоящий из целевого множества и подмножеств сопутствующего множества, заданных на них отношениях, определяющих структуру фрагмента Веба, а также атрибутов множеств и отношений, задающих их характеристики (термин «концептуальная модель» понимается в смысле работы [5]). Реализация концептуальных моделей для различных фрагментов российского Веба [1, 3, 4] позволяет сделать выводы об их организации и предложить решение ряда задач по улучшению их присутствия в Вебе.
В более широком контексте построение и исследование концептуальных моделей фрагментов Веба относится к такому направлению вебометрики, как гиперссылочный анализ (link analysis) [12], существенное место в котором отводится краулерам (поисковым роботам), — специализированным программам, использующим графовую структуру Веба для перемещения по страницам вебсайтов с целью сбора требуемой информации. В общем случае задача краулинга может рассматриваться как многоцелевая задача поиска с ограничениями, где большое разнообразие целевых функций вместе с нехваткой соответствующих знаний о месте поиска делает задачу весьма сложной [9].
Возвращаясь к теме построения концептуальной модели фрагмента Веба для заданного тематического целевого множества, заметим, что её основой является база данных внешних гиперссылок, связывающих веб-сайты модели. Краулер, формирующий в процессе сканирования веб-сайтов такую базу дан-
ных, очевидно, должен быть избирательным и адаптивным [9]. Избирательность краулера в нашем случае определяется его направленностью на поиск внешних гиперссылок (с некоторой дополнительной информацией о них, например, контекстом гиперссылки). Адаптивность краулера заключается в том, что за заданное (ограниченное) время должно быть найдено максимально возможное количество внешних гиперссылок, что обеспечивает более полный охват веб-сайтов, входящих в сопутствующее множество.
В статье описана структура и базовые функции разработанного краулера BeeBot («робот-пчела»), предназначенного для сбора внешних гиперссылок с веб-сайтов заданного целевого множества. Задача о нахождении максимального количества внешних гиперссылок за конечный период времени сформулирована как задача о многоруком бандите [6] и предложены три алгоритма её решения. Были проведены сравнительные эксперименты на множестве официальных веб-сайтов университетов и научных институтов Санкт-Петербурга, показывающие, что выбор алгоритма рационального поведения краулера во многом зависит от тематики сканируемого множества сайтов. Этот результат затем используется для управления процессом сканирования BeeBot: для официальных веб-сайтов университетов и для веб-сайтов научных институтов используются различные алгоритмы адаптивного поведения.
2. BeeBot — краулер для сбора внешних гиперссылок
Работу краулера можно описать следующим образом [9]: сканирование сайта начинается с начальной страницы и затем робот использует ссылки, размещенные на ней, для перехода на другие страницы. Каждая страница сайта анализируется на наличие требуемой информации, которая копируется в соответствующее хранилище в случае обнаружения. Процесс повторяется до тех пор, пока не будет проанализировано требуемое число страниц либо пока не будет достигнута некая цель. Такое описание работы краулера является слишком общим, и далее мы
конкретизируем его для специфических моментов, связанных с разработкой и реализацией BeeBot.
Далее нам понадобится следующее определение уровня страницы веб-сайта: считаем, что начальная страница сайта имеет уровень 0, а уровень любой другой страницы сайта — это минимальное количество внутренних гиперссылок, ведущих от начальной страницы к данной.
BeeBot состоит из трех основных частей: база данных, блок управления краулером (включая интерфейс пользователя и представление результатов) и блок сканирования и обработки данных. В качестве основы для базы данных была выбрана бесплатная версия СУБД Microsoft SQL Server 2008 R2 Express Edition, поскольку с ней легко интегрируются приложения платформы .NET. В частности, используется технология Entity Framework, позволяющая представлять данные в виде объектов, что упрощает работу с БД.
Для хранения информации используется 5 таблиц: Crawler Settings, Seeds, External Link, Internal Links, Bad Links. В таблице Crawler Settings хранятся настройки для краулера. Например, значение одной из настроек ограничивает максимальный уровень страниц, до которого может дойти краулер в процессе сканировании веб-сайта. Это значение устанавливается по умолчанию и распространяется на все сканируемые сайты.
Таблица Seeds содержит начальную информацию обо всех сканируемых веб-сайтах. Начальная информация о каждом вебсайте задается пользователем и представляет собой номер сайта, полное название сайта, его краткое название и начальный адрес — доменное имя сайта, с которого начинается сканирование. В таблице Internal Links хранятся сведения о внутренних ссылках, найденных на сканируемых сайтах. Они описываются собственно самой ссылкой, начальным адресом, страницей, на которой найдена внутренняя ссылка, уровнем этой страницы и её статусом, показывающим, обработана ли страница, соответствующая внутренней ссылке, краулером или нет. Таблица External Links содержит информацию обо всех найденных внешних гиперссылках. В этой таблице поля во многом анало-
гичны таблице Internal Links, за исключением того, что у внешней ссылки нет статуса обработки. Кроме того, добавлено поле, содержащее контекст гиперссылки (в частном случае — её ан-кор). Таблица Bad Links содержит так называемые «плохие ссылки». Например, это ссылка, которую краулер не смог воспринять, как корректную ссылку, хотя этот элемент был под тегом href Также сюда могут попасть фрагменты javascript-кода, так как иногда веб-мастера вставляют его прямо в тело ссылки.
Рассмотрим блок управления BeeBot и пользовательский интерфейс. Пользователю предоставляются следующие возможности по управлению краулером: пуск/остановка работы краулера (надо отметить, что в случае прерывания краулер продолжит с места остановки, не потеряв ссылок), просмотр текущего списка сайтов, добавление новых и удаление ненужных сайтов. Также пользователю дается возможность просматривать собранные ссылки. Для этого разработано специальное окно, содержащее две отдельные страницы, где можно просматривать все собранные внешние и внутренние ссылки, фильтровать результаты и удалять выбранные ссылки. Просмотр результатов проходит в режиме «реального времени», т.е. прямо во время работы краулера: при нажатии на кнопку «Refresh» результаты будут обновлены.
Для управления последовательностью сканирования сайтов в состав блока управления входит модуль-планировщик, который в простейшем варианте работает следующим образом: после завершения сканирования очередного сайта из текущего списка выбирается следующий сайт. (Естественное завершение сканирования каждого сайта в этом случае возможно по двум причинам: сайт отсканирован полностью или отсканированы все его страницы до установленного максимального уровня).
Перейдем к блоку сканирования. Процесс сбора ссылок происходит следующим способом: из базы данных берутся начальные адреса всех сайтов и для каждого из них последовательно запускается процесс сканирования по обработке опреде-
ленного количества страниц с целью нахождения внешних гиперссылок.
Обработка страницы начинается с того, что краулер предпринимает попытку загрузки страницы и преобразует её в XML-документ с помощью библиотеки HTMLAgilityPack. Если в процессе стандартной процедуры загрузки произошел сбой или автоматически была выбрана неправильная кодировка, то страница загружается альтернативным методом, а именно, скачивается в бинарном формате и затем преобразуется в текстовый формат с уже определенной краулером кодировкой. Альтернативная загрузка нужна и в том случае, когда веб-сервер поддерживает кусочную (chunked) передачу данных [7, п. 3.6.1], поскольку стандартный загрузчик в данном случае скачивает только первый фрагмент данных, в котором может оказаться не весь XML -документ и неполная информация о странице.
Если процедура загрузки не выполняется, то сайт помечается в базе данных как Not Available и далее не обрабатывается. В случае если процедура загрузки прошла успешно, краулер считывает полученный XML-документ и собирает все доступные фреймы со страницы. Адреса фреймов, в свою очередь, также рассматриваются как внутренние ссылки и сохраняются в базе данных для будущей обработки.
После сбора фреймов краулер собирает все возможные ссылки со страницы (элементы с тегом «href»). Перед занесением в базу данных ссылка нормализуется. Как показано в [10], нормализация ссылки в виде приведения её как строки текста к нижнему регистру, а также удаления символа «\» в конце ссылки, приводит к потере менее процента уникальных ссылок, но при этом ведет к избавлению от 50% «семантических дубликатов» (ссылок, которые синтаксически не равны друг другу, но указывают на один и тот же ресурс). Такая нормализация используется в BeeBot, поскольку она не изменяет функционала гиперссылки.
Далее, в зависимости от того, к какому типу относится ссылка, она помещается в одну из таблиц Internal Links или External Links (есть и третий случай, когда «плохая» ссылка
помещается в таблицу Bad Links). Решение о том, в какую именно таблицу занести ссылку, краулер принимает на основе доменного имени, которое он извлекает из ссылки. Если доменное имя извлеченной ссылки совпадает с доменным именем сканируемого сейчас сайта, значит ссылка внутренняя, если нет, то внешняя. После завершения обработки страницы краулер извлекает из базы данных следующую необработанную внутреннюю ссылку с самым высоким уровнем для данного сайта. Таким образом, сканирование сайта можно представить как обход виртуального дерева сайта по принципу «вначале вширь».
В идеальном случае работа краулера завершается в том случае, когда будут полностью отсканированы все сайты из заданного списка. В реальности работа может быть завершена по истечении выделенного процессорного времени. На практике такой вариант завершения работы имеет недостатки. Например, если в списке сканируемых сайтов первым окажется сайт РАН (www.ras.ru), есть опасность затратить на него всё отведенное время. Естественным развитием модуля-планировщика является процедура управления последовательностью сканирования сайтов, последовательно выделяющая каждому сайту из текущего списка определенный квант времени для его сканирования. В этом случае даже по истечении выделенного процессорного времени будут частично (или полностью) отсканированы все сайты из списка.
3. Адаптивные алгоритмы
Вернемся к задаче, сформулированной во Введении: за ограниченное время необходимо найти максимально возможное количество внешних гиперссылок с веб-сайтов из заданного списка. Мы уже исключили из рассмотрения случай полного сканирования всех сайтов. Понятно также, что поведение краулера типа «на каждом сайте из целевого множества обрабатывается одинаковое количество страниц» вряд ли приводит к решению этой задачи. Количество внешних гиперссылок, находящихся на странице становится известным только после её обработки, поэтому выбор того или иного веб-сайта для скани-
рования его очередных страниц должен осуществляться на основе текущей (накапливаемой) информации. Таким образом, мы приходим к задаче, известной как задача о «многоруком бандите». Сформулируем её применительно к нашему случаю, используя обозначения и терминологию работ [6, 8].
В базовой формулировке задача о многоруком бандите определяется через случайные величины Х(/’, у) для 1 < < К и у >1, где каждый индекс i соответствует игровому автомату, у — порядковому номеру игры с этим автоматом. Последовательная игра на автомате i приносит игроку доходы Х(/’, 1), Х(/’, 2), . которые представляют независимые одинаково распределенные величины с неизвестным законом распределения и неизвестным математическим ожиданием. Независимость справедлива также и для выигрышей на различных машинах, т.е. Х(/’, 5) и Х(1, О являются независимыми величинами (и обычно с различными распределениями) для любых 1 < i < I < К и 5, t >1. В нашем случае «игроком» является краулер, а переменные Х(/’, 1), Х(/’, 2), . Х(/’,у), . обозначают количество найденных на i-м сайте внешних гиперссылок на 1-й, 2-й, у-й и т.д. сканируемой странице (в порядке обхода «вначале вширь», как говорилось ранее), а К соответствует мощности сканируемого целевого множества. В такой постановке мы делаем допущение о том, что время сканирования любой страницы любого сайта одинаково, поэтому вместо суммарных затрат времени, выделяемых на сканирование всех сайтов, можно ввести суммарное количество планируемых для сканирования страниц, которое обозначим N. Из содержательной постановки следует, что N >> К. Доход на одном шаге в этом случае равен количеству внешних гиперссылок, найденных на странице, поэтому Х(/’, у) > 0 для 1 < i < К и
Решающее правило R — это алгоритм, который выбирает следующий сайт для сканирования, основываясь на последовательности предыдущих сканирований и полученного количества гиперссылок.
Пусть Т^, п) означает количество страниц, отсканированных на сайте i за п сканирований на всех сайтах с использова-
нием правила R. Тогда суммарное количество внешних гиперссылок, найденных за п сканирований при использовании правила R, равно
Задача заключается в разработке такого правила R*, которое максимизирует значение функции &1(п) для заданного конечного горизонта сканирования N.
Известно, что в общем случае задача о многоруком бандите является Л’ї-полной задачей [12], поэтому для её решения предложены различные подходы с целью получения хороших результатов при относительно небольших затратах ресурсов. Далее мы описываем и сравниваем три решающих правила R1, R2 и R3, первое из которых является тривиальным, второе построено с использованием индексов Гиттинса [8], а третье основано на алгоритме иСВ1, предложенном в работе [6].
Правило («тривиальное правило»).
1. На каждом из К сайтов целевого множества последовательно сканировать первые [ШК] страниц ([*] — округление до ближайшего целого).
2. Оставшиеся N — [ШК] страниц сканировать на сайте с но-
мером і , для которого і = а^тах £Х(і, у).
Правило R2 (индекс Гиттинса).
1. Задать шаг сканирования п; п
Для всех і: s(i) := 0 ^(і) — промежуточные суммы, вспомогательные переменные).
2. На каждом сайте отсканировать п страниц.
3. Для всех г. s(i) := s(i) + Ъх(/’, у).
4. Для всех г. 1^(7′) := s(i)/n; ^) := п (^nd(/) — текущие значения индексов Гиттинса для каждого сайта; ф’) — количество отсканированных страниц на каждом сайте).
5. Найти Г .= а^тах 1пй(i).
6. Отсканировать п страниц на сайте i .
7. s(i*) := s(i*) + Тх(/*,у); К* := ф*) + п; 1Ы(1*) := s(i*)/t(i*).
Правило ^3 (алгоритм ССШ).
1. Задать начальный шаг сканирования т; т
Для всех г. s(i) := 0 ^(!) — промежуточные суммы, вспомогательные переменные).
2. На каждом сайте отсканировать т страниц.
3. Для всех г. s(i) := s(i) + Ъх(/’, у), t(i) := т.
4. Для всех г. X(!):= s(i)/1(!) (X(!) — промежуточные средние значения количества ссылок, собранных со страницы сайта).
5. п .= Ъ(i) , Хтах := тах х(i, 3).
6. Найти /■* := а^тах(^^ + /21п(П).
8. Сканировать страницу ^ ) сайта i .
9. s(i ) := s(i ) + Х(1 , ^ )), X(/’ ) := s(i )/1(/’ ), п := п + 1.
4. Некоторые результаты
Для проведения эксперимента с целью апробации и сравнения трех решающих правил Rl, R2 и R3 было взято 10 официальных веб-сайтов институтов Санкт-Петербургского научного центра РАН и 10 официальных веб-сайтов высших учебных заведений Санкт-Петербурга. Веб-сайты сканировались в период с 20 по 25 ноября 2011 г. на глубину до 5-го уровня включительно, общее количество обработанных ^т1-страниц равняется 105711, а общее количество собранных внешних гиперссылок -8990. В таблице 1 приведены сведения о некоторых сайтах (так называемое «выборочное множество», содержащее 5 научных и 5 вузовских сайтов), а в таблице 2 — итоговые результаты эксперимента.
В частности, из таблицы 1 можно увидеть, что веб-сайты существенно различаются по количеству ^т1-страниц и внешних гиперссылок, причём это различие характерно как для научных, так и для вузовских сайтов.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Таблица 1. Выборочное множество
Название Веб-сайт Кол-во Ыт1-стр. Кол-во внешних ссылок
Ботанический институт РАН www.binran.ru 1298 29
Зоологический институт РАН www.zin.ru 1100 69
Институт восточных рукописей РАН orientalstudies.r и 2411 48
Таблица 1 (продолжение)
Институт русской литературы РАН (Пушкинский дом) www.pushkinskijdom.ru 39292 3192
Институт лингвистических исследований РАН www.iling.spb.ru 3523 129
Петербургский госуниверситет путей сообщения www.pgups.ru 431 19
Российский государственный гидрометеоро- логический университет www.rshu.ru 1766 409
Санкт- Петербургский государственный политехнический университет www.spbstu.ru 1471 214
Санкт- Петербургский госуниверситет www.spbu.ru 12935 903
Санкт- Петербургский госуниверситет экономики и финансов www.finec.ru 7253 1048
Таблица 2. Результаты эксперимента
Множество Количество сайтов N 5й1 5й2 5й3
Институты РАН 10 2000 417 816 457
Вузы 10 2000 1337 774 1447
Выборочное множество 10 2000 949 994 1078
5. Выводы и заключение
Следует сказать, что как вузовские, так и научные сайты в целом характеризуются достаточно большим разбросом значений как количества страниц, так и количества исходящих гиперссылок. При этом характер расположения внешних ссылок на страницах весьма различен: для официальных вузовских сайтов характерно небольшое количество гиперссылок, сделанных с большого количества страниц, а для официальных сайтов научных учреждений РАН сайтов отмечается большое количество страниц, не имеющих внешних гиперссылок вообще, и небольшое количество страниц, имеющих очень много ссылок. Сказанное может служить объяснением плохого результата алгоритма R2, основанного на индексах Г иттинса, применительно к вузовским сайтам. Этот алгоритм выбирает самые «привлекательные» сайты, и краулер сканирует их достаточно долго. Если же на первых страницах сайта очень мало внешних ссылок, то очередь до него дойдёт нескоро. Более того, если на первых п страницах внешних ссылок нет, то краулер не дойдет до этого сайта никогда. Если за базовый результат принять количество гиперссылок, найденных по варианту Rl, то в случае научных институтов мы получаем почти двукратный рост найденных гиперссылок при использовании варианта R2, а для вузов — рост 10% при использовании варианта R3. Для выборочного множества также предпочтительнее вариант R3.
Полученные результаты используются в модуле-планировщике блока управления BeeBot следующим образом: если пользователь указывает, что сканируемое множество является множеством официальных вузовских сайтов, то используется правило R3, а для официальных сайтов РАН используется правило R2. Если пользователь не указывает информации о целевом множестве, то каждому сайту целевого множества последовательно выделяется определенный квант времени для его сканирования.
Таким образом, в статье описан адаптивный краулер, предназначенный для сбора исходящих гиперссылок с заданного целевого множества веб-сайтов. Адаптивное поведение крауле-
ра, заключающееся в том, что за ограниченное время он должен находить максимально возможное суммарное количество гиперссылок, моделируется как задача о многоруком бандите. Такая постановка задачи позволила применить для её решения известные алгоритмы, эксперименты с которыми показали их зависимость от тематики целевого множества.
Очевидно, что задача разработка «хороших» адаптивных алгоритмов рационального поведения краулера имеет много направлений для развития, начиная от эвристических подходов до статистического анализа размещения внешних гиперссылок на сайтах заданной тематики.
1. ВОРОНИН А.В., ПЕЧНИКОВ А.А. Исследования сайтов органов власти Республики Карелия // Век качества. — 2010.
2. ПЕЧНИКОВ А.А. Методы исследования регламентируемых тематических фрагментов Web // Труды Института системного анализа Российской академии наук. Серия: Прикладные проблемы управления макросистемами. — 2010. -Том59. — С. 134-145.
3. ПЕЧНИКОВ А.А. Модель университетского Веба // Вестник Нижегородского университета им. Н.И. Лобачевского. -2010. — №6. — С. 208-214.
4. ПЕЧНИКОВ А.А. Исследование взаимосвязей между вебсайтами научных библиотек университетов России // Дистанционное и виртуальное обучение. — 2011. — №7. — С. 13-24.
5. СОВЕТОВ Б.Я., ЯКОВЛЕВ С.А. Моделирование систем. -М.: Высшая школа, 2001. — 344 с.
6. AUER P., CESA-BIANCHI N., FISHER P. Finite-time Analysis of the Multiarmed Bandit Problem // Machine Learning. — 2002.
7. FIELDING R., GETTYS J., MOGUL J., NIELSEN H., MASINTER L., LEACH P., BERNERS-LEE T. RFC 2616: Hypertext Transfer Protocol — HTTP/1.1. June 1999. — URL: http://www.ietf.org/rfc/rfc2616.txt (07.12.2011).
S. MAHAJAN A., TENEKETZIS T. Multi-armed bandit problems // In Foundations and Applications of Sensor Management.
— A. Hero, D. Castanon, D. Cochran, K. Rastella, eds. — Springer, 200S. — P. 121-151.
9. PANT G., SRINIVASAN P., MENCZER F. Crawling the Web // In “Web Dynamics”. — M. Levene, Poulovassilis, eds. -Springer, 2004. — P.153-17S.
10. SANG HO LEE, SUNG JIN KIM On URL Normalization // Lecture Notes in Computer Science. — 2005. — Vol. 47. -P.1076-10S5.
11. TACKSEUNG J. A survey on the bandit problem with switching costs // De Economist. — 2004. — Vol. 152. — P. 513-541.
12. THELWALL M. Link Analysis: An Information Science Approach. — Amsterdam: Elsevier Academic Press, 2004. — 269 p.
ADAPTIVE CRAWLER FOR EXTERNAL HYPERLINKS SEARCH AND ACQUISITION
Andrey Pechnikov, Institute of Applied Mathematical Research Karelian Research Center of RAS, Petrozavodsk, Doctor of Science, assistant professor (pechnikov@krc.karelia.ru).
Denis Chernobrovkin, Faculty of applied mathematics and control processes Saint-Petersburg State University, graduate, Saint-Petersburg (Sezhikov@gmail.com).
Abstract: We consider the web-crawler designed to find information about outgoing hyperlinks from a set of monothematic web-sites. Adaptive behavior of the crawler is formulated in terms of the multiarmed bandit problem. The experiments show that the choice of the adaptive algorithm of rational behavior depends on the subject of the considered set of web-sites.
Keywords: hyperlink, crawler, adaptive behavior, multi-armed bandit problem, Gittins index.
Статья представлена к публикации членом редакционной коллегии В. В. Мазаловым
Подробная настройка программы Screaming Frog SEO Spider
Screaming Frog SEO spider — незаменимый помощник SEO-оптимизатора при внутреннем техническом анализе веб-сайтов. В программе есть множество функций, о которых мы расскажем в этой статье. Также в конце приведем конкретные примеры, как можно применять разные опции в работе.
Прочитав инструкцию, вы научитесь использовать нужные инструменты, предоставляемые сервисом, для технического аудита сайтов. В будущем это может пригодиться при выявлении технических ошибок и составлений ТЗ на доработку сайта.
Для начала рассмотрим по порядку все вкладки интерфейса программы.
File
Раздел, предназначенный для работы с файлами — загрузкой проектов и конфигураций, планирования будущих проверок и т.д.
Доступные опции:
- Open — используется для загрузки и открытия файла с ранее проводившимся парсингом.
- Open Recent — похожая функция, но открывает последний проведенный парсинг. То есть, Open можно использовать для открытия любых файлов, а Open Recent — для последнего файла.
- Save — сохранение парсинга.
- Configuration — важный параметр, позволяющий загружать и/или сохранять конфигурации — специальные предварительно заданные настройки с параметрами парсинга. Подробнее расскажем в разделе про Configuration.
- Crawl Recent — используется для повторного парсинга последнего сайта, который ранее проверялся. Удобно, если нужно быстро провести второй технический аудит.
- Scheduling — применяется для планирования будущих парсингов и других задач программы.
- Exit — очевидный выход.
Mode
Устанавливает режим, в котором будет проводиться парсинг. Можно выбрать 1 из 3 опций:
- Spider — режим по-умолчанию. Парсинг будет проводиться по внутренним линкам. Для старта достаточно ввести в адресную строку приложения нужный домен.
- List — парсинг предварительно собранных URL. Сами веб-адреса можно загрузить из файла (опция From a file), указать вручную (Enter Manually) или воспользоваться картой сайта (Download Sitemap).
- SERP Mode — позволяет загрузить мета-данные с сайта и редактировать их, посмотреть, как они будут отображаться в браузере. Сканирование при этом не проводится.
Configuration
Одна из самых обширных вкладок — в ней расположены основные настройки «паука» и опции по парсингу сайтов. Всего в ней доступно 13 пунктов подменю. Рассмотрим каждый подробнее.
Spider
В этом подпункте расположены основные настройки парсингов сайта. Включает в себя 5 вкладок: Crawl, Limits, Rendering, Advanced и Preferences.
Crawl
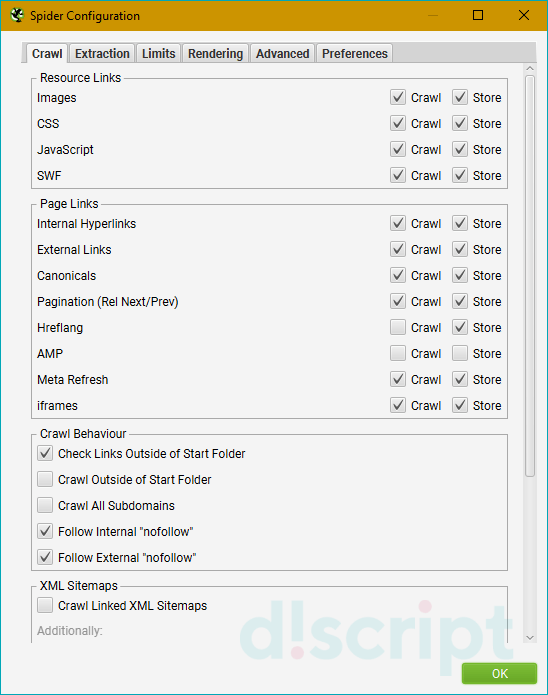
Позволяет выбрать, что именно и как вы хотите парсить. Основные опции вкладки разделены на 4 блока:
Resource Links — определяют, какие файлы и элементы будут парситься. Включают в себя 4 опции:
- Check Images — парсит картинки.
- Check CSS — парсит подключенные к сайту файлы CSS.
- Check JavaScript — парсит JS-скрипты.
- Check SWF — применяется, когда нужно включить в отчет анализ Flash-анимаций.
Page Links — определяют, какие ссылки будут парситься. В этом разделе доступны следующие опции:
- Internal Hyperlinks — добавляет в отчет внутренние ссылки.
- External Links — добавляет в отчет внешние ссылки.
- Canonicals — при сканировании веб-страниц будут анализироваться канонические (canonical) параметры.
- Pagination (Rel Next/Prev) — используется для анализа страниц с атрибутами rel = next и rel = prev.
- Hreflang — извлекает атрибут hreflang.
- AMP — извлекает с сайта и добавляет в отчет AMP-ссылки.
- Meta Refresh — сканирует и сохраняет URL-адреса, содержащиеся в мета-обновлениях (например, такие: https://example.com/" />.).
- iframes — сканирует и сохраняет адреса, содержащиеся в теге (например, такие: .
Crawl Behaviour — определяет поведение краулера. Доступные опции:
- Check Links Outside of Start Folder — активируйте эту опцию, если хотите получить анализ всех линков, а не только тех, что расположены в стартовой папке.
- Crawl Outside of Start Folder — стандартно программа будет сканировать только указанную пользователем подпапку. Включение этой опции позволяет сканировать весь сайт. При этом парсинг все равно начнется с поддомена.
- Crawl All Subdomains — активируйте эту опцию, если хотите сканировать все поддомены веб-сайта.
- Follow internal «nofollow» — позволяет сканировать ссылки с тегом nofollow.
- Follow external «nofollow» — по принципу действия почти та же опция, что и предыдущая, но вместо внутренних ссылок анализирует внешние.
XML Sitemaps — отвечает за сканирование карты сайта. Здесь доступна всего 1 опция и 2 подпункта для неё:
- Crawl Linked XML Sitemap — сканирует карту сайта. Поисковый робот может либо взять ее из файла robots.txt (опция Auto Discover SML Sitemaps via robots.txt), либо по ручному пути, указанному пользователем — тогда вам нужно будет выбрать опцию «Crawl These Sitemaps» и указать нужные.
Также все опции имеют 2 опции — «Crawl» и «Store». Первая отвечает за сканирование. Если отключить ее в каком-либо элементе, он не будет анализироваться пауком. Например, сняв флажок со сканирования ссылок, вы позволите поисковому роботу обнаруживать их и хранить, но не переходить по ним и не получать коды ответов сервера.
Поначалу может показаться, что опций слишком много, но главное в освоении этой программы — практика и умеренность. Выбирайте те, которые могут пригодиться вам в работе, а с остальными познакомитесь по ходу использования приложения.
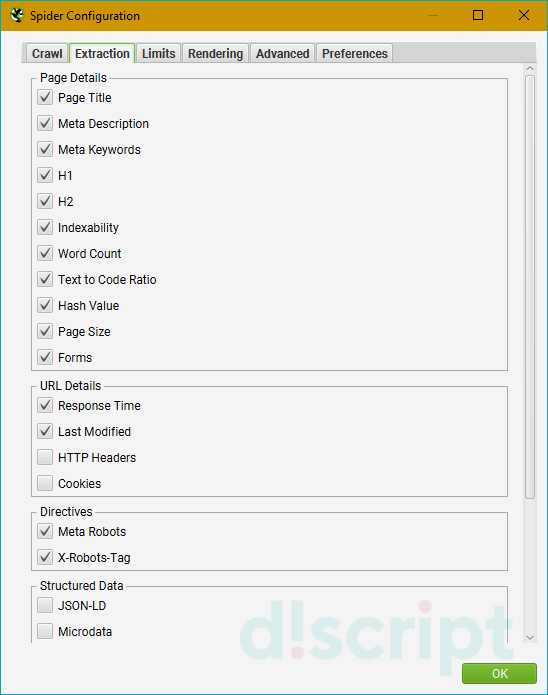
Extraction
Вкладка отвечает за то, какие элементы будут извлекаться парсером и добавляться в отчет. Разделена на 5 секций:
Page Details
Отвечает за извлечение следующих элементов:
- Page Title — метатег title.
- Meta Description — метатег description.
- Meta Keywords — метатег keywords.
- H1 — заголовок 1 уровня.
- H2 — заголовок 2 уровня.
- Indexability — статус индексируемости.
- Word Count — количество слов.
- Text to Code Ratio — соотношение текста к коду.
- Hash Value — хэш-значение.
- Page Size — размер страницы.
- Forms — формы.
URL details
- Response Time — время в секундах для загрузки URL-адреса.
- Last Modified — чтение из заголовка Last-Modified в HTTP-ответе сервера. Если сервер не предоставит ответ, поле останется пустым.
- HTTP Headers — полные заголовки запросов и ответов HTTP.
- Cookies — файлы cookie, найденные во время сканирования. Будут храниться на нижней вкладке отчета «Cookies files».
- Meta Robots — сохраняет директиву мета-роботов.
- X-Robots Tag — добавляет в отчет директиву X-Robots-Tag.
Structred Data
- JSON-LD — используется для извлечения микроразметки JSON-LD.
- Microdata — извлекает микроразметку сайта Microdata.
- RDFa — извлекает RDF микроразметку.
- Schema.org Validation —настраивает проверку микроразметки по механизму Schema Validation.
- Google Rich Result Feature Validation — включает проверку по Google Validation.
- Case-Sensitive — активирует проверку по Case-Sensitive методу.
- Store HTML — позволяет хранить статический HTML каждого URL, просканированного парсером. Полезно, если нужно изучить его до того, как будет подключен JavaScript.
- Store Rendered HTML — похожая опция, но хранится уже отображенный HTML после обработки JS.
Limits
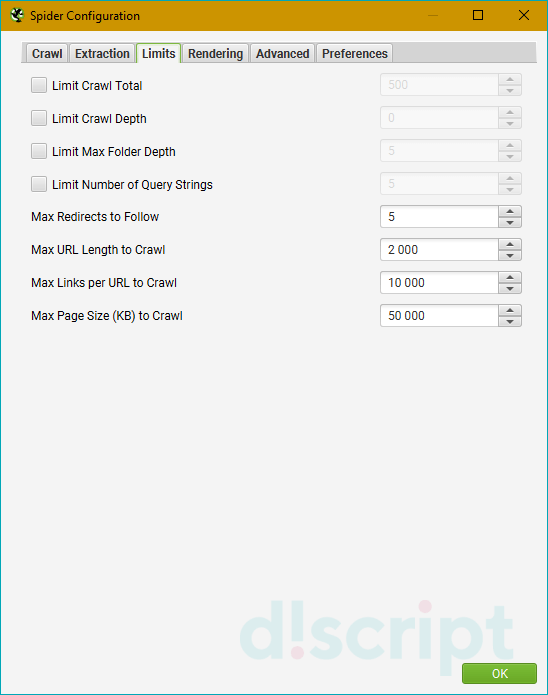
Применяется для установки лимитов парсинга. Содержит пункты:
- Limit Crawl Total — задает общий лимит веб-страниц для сканирования. С помощью этой опции можно установить точное количество страниц, которые будут выгружены в отчет.
- Limit Crawl Depth — определяет, насколько глубоко может зайти поисковый робот во время сканирования. Например, если указать число «0», краулер просканирует только указанный документ и остановится. Если указать «1», паук проанализирует документ, перейдет по ссылкам из него и остановится на следующей странице. Указав «2», робот продвинется на 3 страницы (первичный документ > переход на следующую страницу по ссылкам > переход на последующую веб-страницу по ссылкам из предыдущей).
- Limit Max Folder Depth — более специфический параметр, в котором можно установить глубину до конкретной папки. Работает по принципу, схожему с предыдущим пунктом, только указывать нужно конкретные папки. Пример: URL site.com/folder-1/folder-2/folder-3. Где цифры — глубина проверки.
- Limit Number of Query Strings — задает глубину парсинга для страниц с параметрами. Может быть полезно, если у вас на статической странице есть пара фильтров, которые могут создать большое количество динамических веб-страниц. Если не задать этот лимит, парсер будет сканировать все страницы, что увеличит время проверки, при этом полезной информации вы получите по-минимуму.
- Max Redirects to Follow — используется, чтобы задать максимальное количество редиректов с 1 веб-адреса.
- Max URL Length to Crawl — устанавливает максимальную длину URL в символах.
- Max Links per URL to Crawl — определяет максимальное количество ссылок в сканируемых страницах. Например, если на странице 5 ссылок, но параметр установлен на «4», то робот проанализирует 4 ссылки и добавит их в отчет.
- Max Page Size (KB) to Crawl — максимальный размер страницы для сканирования, указывается в килобайтах.
Rendering
Эта вкладка понадобится вам, если вы включили сканирование JavaScript в отчет и хотите настроить параметры рендеринга. На выбор доступно 3 режима:
- Text Only — анализ только текста страницы, без учета JS/AJAX.
- Old AJAX Crawling Scheme — использование устаревшей схемы сканирования AJAX.
- JavaScript — учитывает JS-скрипты при рендеринге.
Последний режим также имеет несколько дополнительных опций:
- Enable Rendered Page Screen Shots — позволяет включить сохранение скриншотов анализируемых страниц в папку на вашем компьютере.
- AJAX Timeout (secs) — устанавливает лимиты таймаута.
- Window Size — выбирает размер окна. На выбор их представлено много, от больших экранов (Large Desktop) до iPhone старых и новых версий.
- Sample — показывает пример окна, выбранный в пункте Window Size.
- Rotate — позволяет повернуть демонстрацию окна из Sample.
Advanced
Позволяет настроить продвинутые опции парсинга. Доступные опции:
- Cookie Storage — выбирает, где будут храниться куки-файлы во время сканирования.
- Ignore Paignated URL for Duplicate Filters
- Always Follow Redirects — разрешает поисковому роботу всегда следовать по редиректам вплоть до финальной страницы с учетом всех ответов сервера.
- Always Follow Canonicals — позволяет краулеру учитывать все атрибуты canonical. Может пригодиться, если вы несколько раз переезжали и еще не навели порядок с этим атрибутом.
- Respect noindex — запрещает сканировать страницы, обернутые в тег noindex.
- Respect Canonical — исключает канонические страницы из отчета. Полезная опция, если нужно убрать дубли по метаданным.
- Respect Next/Prev — исключает страницы с rel=”next/prev” из отчета. Так же, как и предыдущий пункт, позволяет убрать дубли по метаданным.
- Respect HSTS Policy — указывает поисковому боту, что все запросы должны выполняться через протокол HTTPS.
- Respect Self Referencing Meta Refresh — позволяет учитывать принудительную переадресацию на ту же страницу по метатегу Refresh.
- Extract Images from img srcset Attribute — извлекает и добавляет в отчет изображения из атрибута srscet, который прописывается в теге .
- Crawl Fragment Identifiers — позволяет сканировать URL-адреса с хэш-фрагментами и считать их за уникальные URL.
- Response Timeout — устанавливает время ожидания ответа страницы перед тем, как краулер перейдет к анализу следующего URL. Для медленных сайтов рекомендуем устанавливать большее число.
- 5xx Response Retries — определяет, сколько раз парсер будет пытаться проанализировать страницы с ответом сервера 5хх. Например, если установлен параметр «5», то поисковый робот будет посылать запросы веб-странице 5 раз, после чего остановится.
Preferences
Позволяет задать предпочтения для сканируемых мета-тегов и тегов (title, description, URL, H1-H2, alt и размеры картинок). Если размеры будут не соответствовать заданным в этой вкладке, Screaming Frog об этом сообщит.
- Page Title Width — ширина заголовка страницы. Можно указать в пикселях или символах.
- Meta Description Width — аналогично предыдущему пункту, только вместо заголовка указывается метатег title.
- Other — все остальные пункты, включая URL, заголовки 1 и 2 уровней, изображения и атрибуты alt к ним.
Не обязательная вкладка, в ней можно оставить параметры по умолчанию.
Content
Подпункт меню, отвечающий за поведение краулера при сканировании контента. Имеет 3 вкладки:
-
Area — отвечает за область контента, которая будет учитываться при сканировании. Используйте эту функцию, если хотите сфокусировать анализ на какой-либо конкретной области страницы.
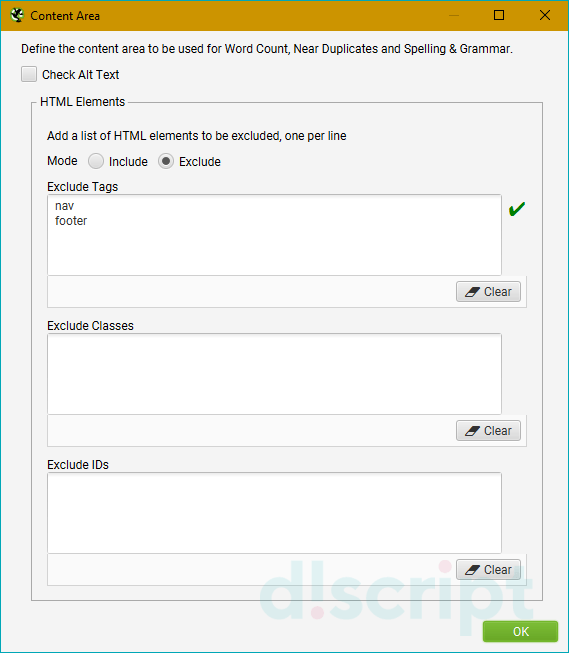
Robots.txt
Позволяет определить, каким правилам должен следовать краулер при парсинге. Имеет 2 вкладки: Settings и Custom.
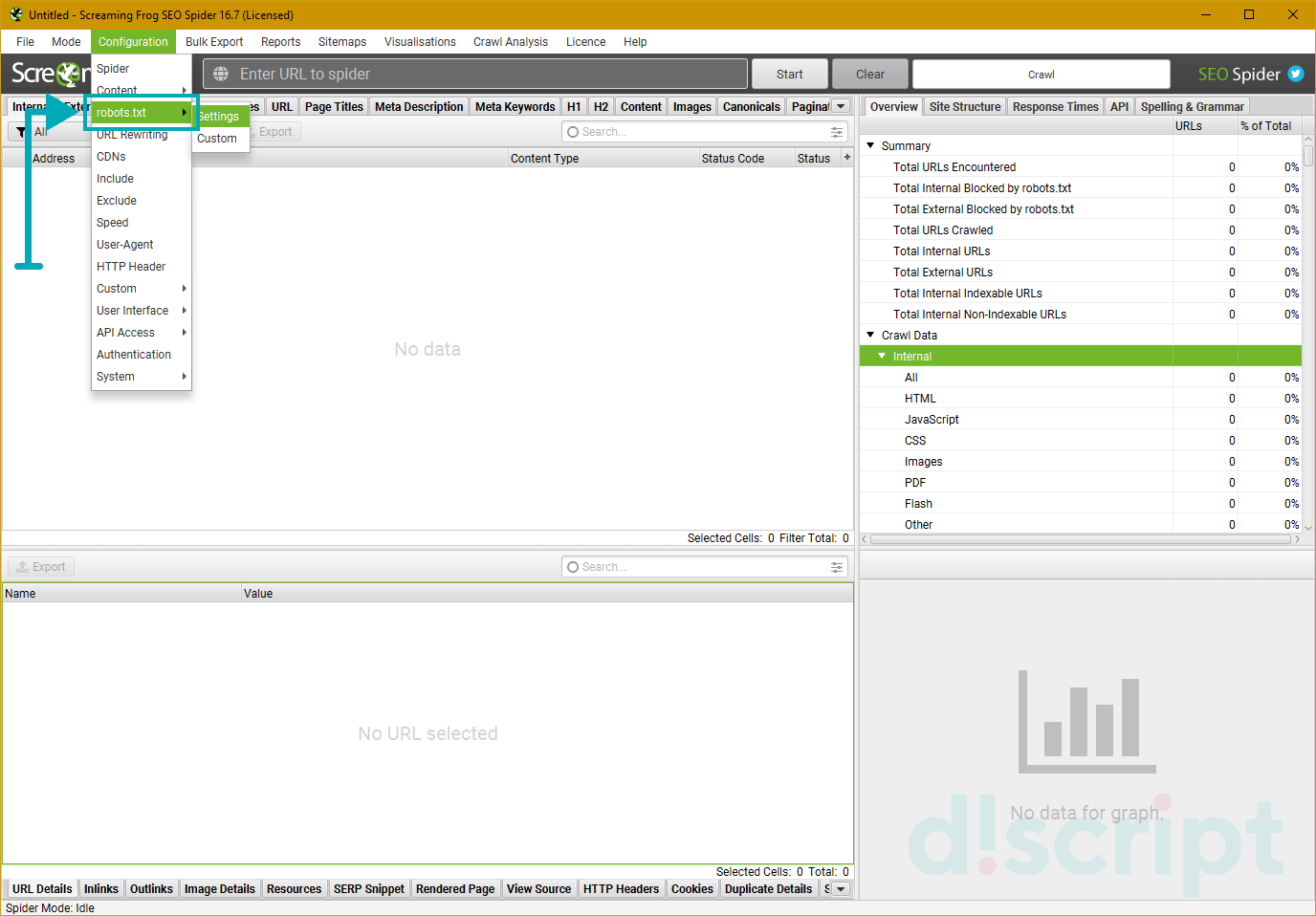
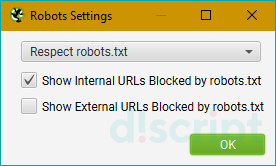
Settings — используется для настройки парсинга с учетом (или игнорированием) правил Robots.txt. На выбор предоставляется 3 режима:
- Respect robots.txt — парсер будет полностью следовать правилам, прописанным в файле для роботов, и учитывать только те папки и файлы, которые были открыты.
- Ignore robots.txt — позволяет игнорировать правила, прописанные в robots. В таком случае, в отчет попадут все папки и файлы сайта.
- Ignore robots.txt but report status — игнорирует правила, но выводит статус страницы (индексируемая или закрытая от индексации).
Также можно указать, хотите ли вы видеть в итоговом отчете внутренние и внешние ссылки, закрытые от индексации. Эти опции будут работать, только если вы выбрали 1-й режим парсинга (respect robots.txt).
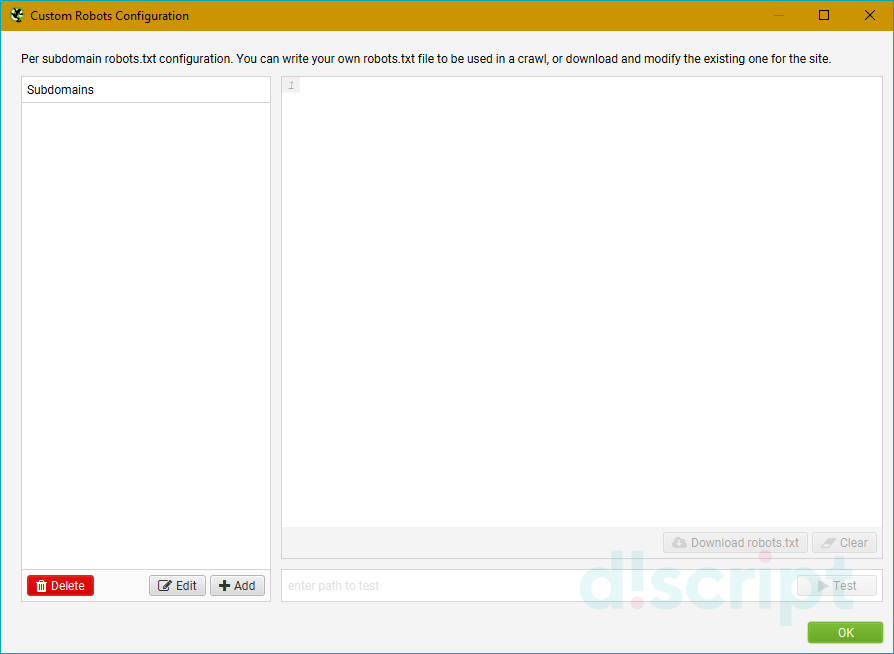
Custom — позволяет вручную отредактировать robots.txt для текущего парсинга. Удобно, если нужно добавить или исключить только конкретные папки, или добавить дополнительные правила для поддоменов сайта. Также с помощью этого режима можно сформировать собственный файл robots.txt, проверить его и потом при необходимости загрузить на веб-сайт.
Чтобы добавить собственный файл, нажмите кнопку «Add» в нижнем меню. Для проверки используйте кнопку «Test», расположенную справа внизу.
URL Rewriting
Используется для перезаписи сканируемых URL во время парсинга. Если вам надо изменить какие-либо URL во время работы, этот раздел может пригодиться.
Имеет 4 вкладки:
-
Remove Parameters — позволяет указать параметры, которые будут удаляться из URL при анализе сайта. Также можно исключить сразу все, если поставить галочку в чекбоксе «Remove all».
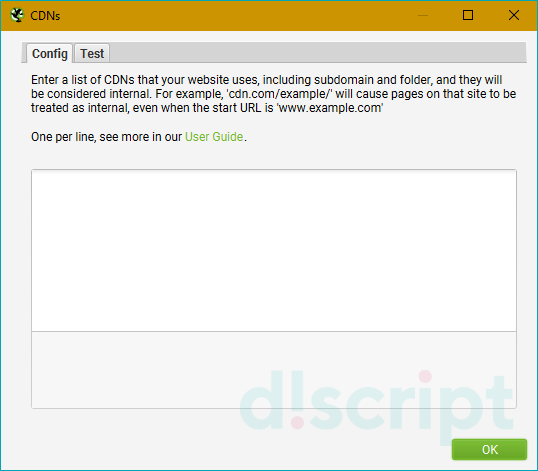
CDNs
В этой вкладке можно включать дополнительные домены и папки в процесс парсинга. Они будут считаться за внутренние ссылки. Также можно указать только конкретные папки для сканирования. Указывать нужные папки и файлы необходимо во вкладке «Config»:
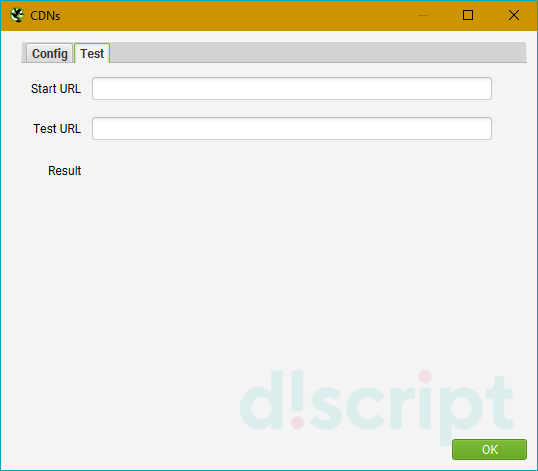
Последняя вкладка «Test» позволяет увидеть, как будут изменяться URL. Итог будет выводиться в виде параметра Internal или External. Если, например, в результате показывает External, то ссылка будет считаться внешней:
Include/Exclude
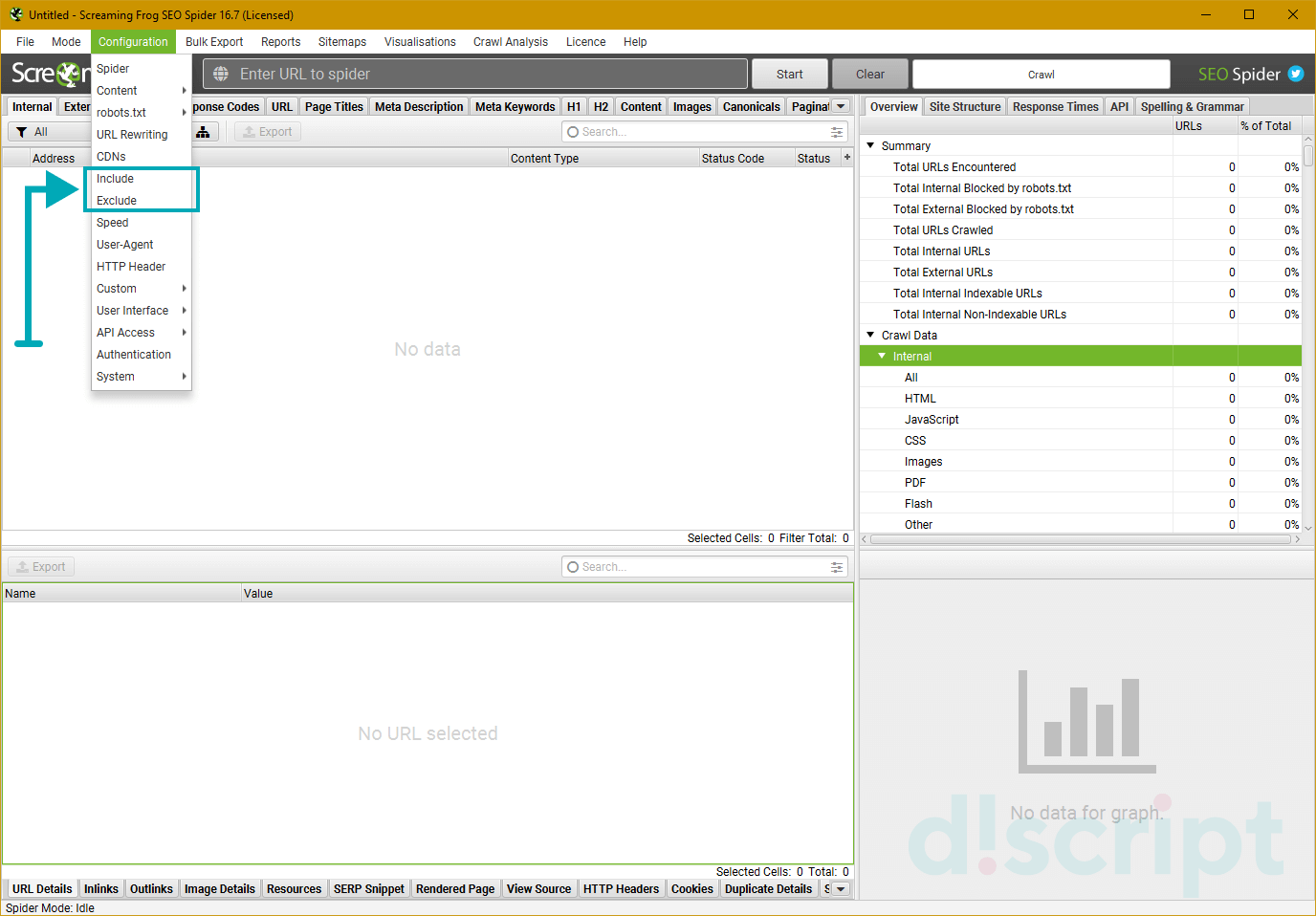
Используется для включения или исключения конкретных папок, ссылок, файлов или страниц при парсинге. Например, во вкладке Exclude будут указаны исключения парсинга для всех папок, кроме указанных.
К примеру, вы можете запретить парсинг конкретного домена. Проверить результат можно во вкладке Test — вместо указанного URL там будет указано, что этот веб-адрес был исключен из парсинга. Также эта опция поддерживает регулярные выражения.
Speed
Используется для установки лимитов на количество потоков и одновременно сканируемых адресов. Меняйте параметры аккуратно — если установить слишком низкие лимиты, поискового бота могут забанить, даже если скорость парсинга существенно повысится.
User-Agent
В этой вкладке можно задать тип поискового бота, который будет использоваться для сканирования. Может пригодиться, если, например, в настройках сайта запрещена индексация Yandex-ботам.
Также можно указать версии ботов для смартфонов, чтобы найти технические ошибки в мобильных версиях.
HTTP Header
Позволяет указать реакции краулера на HTTP-заголовки, если таковые будут найдены на сайте. Можно указать, будет ли учитываться контент и cookie-файлы, как именно они будут обрабатываться и т.д.
Custom
Включает в себя 2 вкладки: Search и Extraction. В них можно указать с помощью собственного кода дополнительные правила для парсинга. Например, если у вас на какой-то странице используется тег вместо тега , вы можете указать это в Custom Search.
Во вкладке Extraction можно указывать пользовательские настройки для извлечения любой информации из HTML-кода.
User Interface
Довольно простой раздел, с помощью которого можно сбросить сортировку столбцов и вкладок программы. Также в нем можно изменить тему со светлой на темную. На этом функции заканчиваются.
API Access
Позволяет подключить сторонние сервисы типа Google Analytics или Majestic. Вам потребуется войти в свою учетную запись в приложении. Для каждого варианта будут свои отдельные настройки по выгрузки данных, которые будут различаться от приложения к приложению.
Authentication
Если сайт будет запрашивать аутентификацию, вы можете указать настройки для них тут. Во вкладке есть 2 подпункта — Standards Based и Forms Based. Стандартно используется первый вариант — если придет запрос, он отобразится в соответствующем окне в программном обеспечении.
Если вам нужен встроенный браузер для указания данных, используйте опцию Forms Based. С ее помощью можно, например, пройти капчу, указав логин и пароль.
System
Позволяет задать настройки самой программе. Насчитывает 5 пунктов:
- Memory — указание лимитов оперативной памяти для парсинга. Стандартно стоит 2ГБ.
- Storage — выбирает режим сохранения информации. Ее можно хранить либо в оперативной памяти, либо в указанной пользователем папки.
- Proxy — при использовании позволяет указать данные подключенного прокси-сервера для парсинга.
- Embedded Browser — включает или выключает встроенный браузер приложения.
- Language — выбор языка. Русский не поддерживается.
Bulk Export
Здесь можно настроить массовый экспорт данных из отчетов. В целом, этот раздел можно использовать, чтобы вытягивать нужную информацию и затем составить ТЗ для доработок сайта.
Доступные подпункты меню экспорта:
- Queued URLs — все ссылки, которые были обнаружены и находятся в очереди на сканирование.
- Пункт Links
- All Inlinks — все входящие ссылки на URL-адреса, зафиксированные поисковым роботом во время парсинга.
- All Outlinks — все исходящие ссылки.
- All Anchor Text — экспорт анкоров со всех ссылок
- External Links — все внешние ссылки
- Screenshots — все сделанные скриншоты.
- All Page Source — статистический или визуализированный (rendered) HTML код просканированных страниц.
- All HTTP Headers
- All Cookies
Reports
Вкладка, отвечающая за отчеты. Доступные подпункты меню:
- Crawl Overview — содержит всю сводку сканирования, включая обнаруженные URL-адреса, заблокированные файлом robots.txt, количество просканированных ссылок, типы контента, коды ответов и т.д.
- Redirects — описывает найденные перенаправления и URL-адреса, через которые удалось найти редиректы. Также здесь отображаются канонические цепочки перенаправлений и канонические символы, указывается количество переходов и цикличность (если она присутствует).
- Canonicals — в этом разделе показываются ошибки и проблемы, найденные с каноническими цепочками или элементами. В ответе канонических цепочек отображаются все URL, имеющие больше 2 канонических линков.
- Pagination — отображает ошибки и проблемы, связанные с атрибутами rel=next/prev, которые применяются для обозначения содержимого, разбитого на страницы.
- Hreflang — сообщает о возможных проблемах с атрибутами hreflang, например: некорректных ответах серверов, страниц без гиперссылок, разных кодах языка на 1 веб-странице и т.п.
- Insecure Content — содержит HTTPS URL-адреса, на которых были обнаружены небезопасные элементы. Например, внутренние ссылки без SSL-сертификата.
- SERP summary — позволяет быстро выгрузить URL-адреса, title и description страниц. Их длина будет указываться в символах, а ширина в пикселях.
- Orphan Pages — отображает список потерянных страниц, собранных при помощи Google Analytics API и Search Console, а также XML Sitemap, которые не были сопоставлены с URL, обнаруженными во время сканирования.
- Structured Data — показывает отчет об обнаруженных ошибках валидации микроразметки веб-страниц.
- PageSpeed — содержит отчет о скорости загрузки каждой страницы. Работает, только если была подключена интеграция PageSpeed Insights.
- HTTP Headers — содержит отчет по заголовкам HTTP, обнаруженных во время сканирования. Показывает каждый уникальный заголовок и количество URL, ответивших этим заголовком.
- Cookies — содержит отчет о файлах cookie, обнаруженных во время сканирования, с указанием имени, домена, срока действия, безопасности и значения HttpOnly.
Sitemaps
Через этот пункт меню можно создавать свои карты сайта в формате XML. На выбор предлагается 2 пункта:
- XML Sitemap — генерация XML-карты сайта
- Images Sitemap — генерация XML-карты сайта для определенного изображения.
После выбора нужного варианта откроется всплывающее окно, в котором можно будет задать нужные параметры — например, создание карты для закрытых от индексации страниц, URL, разбитых на пагинацию и т.п.
Страница имеет 6 вкладок.
Pages — отвечает за тип страниц, которые будут включены в карту сайта.
- Noindex Pages — закрытые от индексации страницы.
- Canonicalised — каноникализированные страницы, говоря простым языком с атрибутом rel=canonical.
- Paginated URLs — страницы пагинации.
- PDFs — PDF-файлы.
- No response — не отвечающие страницы.
- Blocked by robots.txt — страницы, закрытые от индексации файлом robots.txt.
- 2xx — страницы с кодом ответа сервера 2хх (работающие страницы).
- 3xx — страницы с редиректами.
- 4xx — битые ссылки.
- 5xx — страницы с проблемами сервера при загрузке.
Last Modified — необязательная опция, позволяет выставить дату последнего обновления карты. Можно установить использование тега lastmod, либо применять ответ сервера при создании карты. Также возможно ручное указание даты.
Priority — используется для выставления приоритета ссылки в зависимости от глубины страницы.
Change Frequency — используется для выставления вероятной частоты обновления веб-страниц с помощью тега changefreq. Рассчитать тег можно либо по последнему измененному заголовку, либо по глубине страницы.
Images — позволяет добавить картинки в карту сайта, включая закрытые от индексации картинки или изображения с конкретным числом входящих ссылок.
Hreflang — отвечает за использование или не использование атрибута hreflang в карте сайта.
Visualisations
С помощью этого пункта меню можно получить визуализированную структуру сайта, которая будет отображаться в программе.
Пользователю на выбор предоставляется несколько вариантов визуализации, которые отображаются во встроенном браузере — это повышает эффективность работы с ними. Например, их можно масштабировать прямо в Screaming Frog.
- Crawl Tree Graph — визуализирует структуру сайта на основании сканирования в виде дерева каталогов.
- Directory Tree Graph — показывает все каталоги, найденные после сканирования. В отличие от первого режима, показывает даже папки, закрытые от индексации
- Force Directed Crawl-Diagram — похожий вариант на 2 других, только оформленный в виде кружков.
- Force Directed Tree-Diagram — похожий, но более масштабный способ визуализации.
- Inlink Anchor Text Word Cloud — визуализирует анкоры внутренних ссылок. Каждая страница отображается по отдельности. Помогает в анализе анкоров.
- Body Text Word Cloud — визуализирует плотность слов на веб-странице. Помогает понять, какие слова встречаются чаще других и нет ли переспама ими на странице.
Crawl Analysis
Помогает проанализировать и включить в отчет данные, которые не попадают в основную статистику в ходе сканирования. Это могут быть параметры Link Score, Orphan URLs (потерянные URL) и , и т.п.
Дополнительное сканирование запускается после основного парсинга. Во вкладке Configure можно настроить, какие данные будут добавляться в отчет.
- Link Score — присваивает оценки всем внутренним линкам веб-сайта.
- Pagination — показывает неправильно настроенные пагинации и страницы, которые были найдены только благодаря атрибуту rel next/prev.
- Hreflang — отображает URL с атрибутом hreflang без гиперссылок.
- AMP — показывает страницы без тегов HTML amp.
- Sitemaps — вносит в отчет неидексируемые страницы, найденные в карте сайта, дубли URL в нескольких sitemap, потерянные страницы.
- Analytics — потерянные страницы, найденные в аналитике.
- Search Console — потерянные страницы, найденные в консоли веб-мастера.
Licence
Раздел, в котором можно купить лицензию и ввести лицензионный ключ.
Help
Пункт меню, в котором собрана информация, полезная пользователю.
- User Guide — супер-подробное руководство по работе с программой.
- FAQ — часто задаваемые вопросы.
- Support — техническая поддержка.
- Feedback — предложения по работе или новым функциям.
- Check for Updates — ручная проверка на наличие обновлений.
- Auto Check for Updates — автоматическая проверка на наличие обновлений.
- Debug — сообщить о каком-либо баге разработчику.
- About — краткая информация о программе.
FAQ
Как включить русский язык?
К сожалению, официально это сделать никак нельзя — программа не поддерживает русскоязычную локализацию. Но вы можете поискать русификаторы в интернете. Мы не рекомендуем их использовать. Помните, что вы устанавливаете на свой страх и риск.
Как посмотреть структуру сайта?
Воспользуйтесь вкладкой «Visualisations» — в ней наглядно можно будет посмотреть примерную структуру сайта, основываясь на отчете. Программа предлагает несколько видов графиков, например, древовидный и в виде «кружков».
Как включить rendering?
Воспользуйтесь следующим путем: configuration > spider > rendering > выбрать нужный пункт (например, Rendered Page Screenshots).
Как игнорировать Robots.txt?
Во вкладке configuration перейдите в подпункт меню robots.txt и выберите режим «Ignore robots.txt».
Как ограничить скорость сканирования?Если вы хотите ограничить скорость сканирования, рекомендуем воспользоваться пунктом Limits во вкладке Configuration > Spider. Также можно выделить меньше RAM для программы — тогда сканирование будет идти медленнее.