Работа с коллекциями в Kotlin и Java
В этой статье хотелось бы сделать шпаргалку для тех, кто только начинает осваивать Kotlin. Этот язык предлагает широкий набор методов для работы с коллекциями. Многие начинают осваивать его, уже имея за плечами опыт на Java, поэтому мне хотелось бы привести также варианты кода и на Java.
Создаём класс-сущность
Для того, чтобы нам было от чего отталкиваться, создадим класс-сущность. Это класс, предназначенный для хранения данных. Часто в приложениях поля таких классов мапятся один к одному на поля таблицы в базе данных. Для примера рассмотрим сущность «Город», у которой есть два атрибута: название и количество проживающих в нём людей.
На старых версиях Java такой класс выглядел бы следующим образом:
public class City <
private final String name;
private final int population;
public City(String name, int population) this .name = name;
this .population = population;
>
public String getName() return name;
>
public int getPopulation() return population;
>
@Override
public String toString() return «City «name='» + name + ‘\» +
«, population=» + population +
‘>’ ;
>
>
Обратите внимание, что класс неизменяемый, то есть значения его полей можно установить только в момент создания объекта, а затем они доступны лишь для чтения. Это особенно важно при работе с коллекциями в функциональном стиле.
С появлением Java 16 для этих целей мы можем использовать класс типа record.
public record City(
String name,
int population
) >
Компилятор автоматически сгенерит для него конструктор, стандартные методы equals(), hashCode(), toString() и get-методы для каждого поля. record тоже является неизменямым. Значения полей можно установить только через конструктор в момент инициализации.
На kotlin аналогичный класс объявляется следующим образом:
data class City(
val name: String,
val population: Int
)
Все классы на kotlin полностью совместимы на уровне байт-кода с Java-классами.
Создание коллекции
Создадим список (List) из четырёх объектов типа City. На Java, начиная с 9-ой версии, мы можем сделать это с помощью метода List.of():
List
new City( «Париж» , 2_148_327 ),
new City( «Москва» , 12_678_079 ),
new City( «Берлин» , 3_644_826 ),
new City( «Мадрид» , 3_266_126 )
);
А на kotlin вот так (ключевое слово new не требуется):
val cities = listOf(
City( «Париж» , 2_148_327 ),
City( «Москва» , 12_678_079 ),
City( «Берлин» , 3_644_826 ),
City( «Мадрид» , 3_266_126 )
)
Метод расширения listOf() возвращает объект класса List. Причём это опять-таки неизменяемый объект, то есть в него нельзя добавлять или удалять элементы. Если же нам нужен изменяемый список, то мы могли бы воспользоваться методом mutableListOf(), который вернёт нам объект класса MutableList.
И Java, и kotlin позволяют разделять десятичные разряды в числах при помощи символа нижнего подчёркивания. Делается это исключительно для удобства чтения и на сами значения никак не влияет.
Перебор всех элементов коллекции
Помимо традиционного перебора элементов через цикл foreach (например, в целях логирования), Java позволяет сделать это в функциональном стиле через метод forEach():
cities.forEach(c -> System.out.println(c.name()));
Тут мы при помощи лямбда-выражения выводим в консоль название каждого города. В kotlin это делается аналогично:
cities.forEach < println(it.name) >
Имя переменной it представляет собой имя по умолчанию для единственного параметра ламбда-выражения. Вы также можете явно задать имя по аналогии с Java. Но если у вас окажется несколько вложенных лямбда-выражений, тогда явное именование их параметров становится обязательным.
Если вам помимо самого элемента нужен ещё и его индекс в коллекции, то используйте метод forEachIndexed(). Тогда в лямбде нужно будет в явном виде указывать два параметра вместо одного дефолтного it: индекс и элемент.
cities.forEachIndexed < index, city ->println( «$index: $
Здесь мы выводим индекс элемента, а затем после двоеточия название города. В kotlin символ доллара позволяет подставлять значение переменной прямо в строку. Если нужно встроить не объект целиком, а одно из его полей, тогда помимо доллара выражение нужно взять в фигурные скобки.
Преобразование элементов списка
Давайте теперь преобразуем созданный нами список городов в список их названий с сохранением порядка следования. На Java нам помогут стримы:
List
.map(City::name)
.toList();
Тут мы сначала преобразуем нашу коллекцию в стрим, затем делаем преобразование с помощью метода map() и затем преобразуем стрим в новый список с помощью метода toList(). На kotlin такое же преобразование выглядт следующим образом:
// более краткая запись: cities.map < it.name >
val cityNames = cities.map < c ->c.name >
Тут метод также называется map().
Фильтрация элементов списка
Давайте теперь создадим новый список, в котором будут только города с населением более трёх миллионов человек. Код на Java:
cities.stream()
.filter(c -> c.population() >= 3_000_000 )
.toList();
cities.filter < it.population >= 3_000_000 >
Как видите, в обоих случаях ключевым является метод filter(). Только в kotlin он уже возвращает готовую коллекцию, тогда как на Java возвращается стрим, который затем мы преобразуем с помощью toList().
Первый и последний элемент списка
По аналогии с фильтрацией можно сделать поиск первого элемента из списка. В Java 21 нам поможет метод getFirst(). Если же список пустой, то этот метод кидает исключение NoSuchElementException. Поэтому можно использовать более универсальный findFirst() из стримов:
// если список не пустой, начиная с Java 21
City first = cities.getFirst();
// список может быть пустой
Optional first = cities.stream().findFirst();
Он возвращает объект типа Optional, т.к. коллекция может быть пустой и тогда Optional также будет пустым. В kotlin нет Optional, а вместо этого используется nullable-тип, т.е. компилятор контролирует, может ли ваш тип когда-либо принять значение null или не может. Признаком допустимости null является знак вопроса после имени соответствующего типа. Ниже для наглядности тип возвращаемого значения указан в явном виде после двоеточия. Обычно компилятор kotlin сам выводит тип, поэтому явное указание излишне.
// кидает исключение для пустого списка
val nonNullableFirst: City = cities.first()
// возвращает null в случае пустого списка
val nullableFirst: City? = cities.firstOrNull()
В случае пустого списка firstOrNull() вернёт null, тогда как метод first() выбросит исключение. Поэтому метод firstOrNull() в общем случае использовать предпочтительнее.
Помимо получения самого первого элемента списка вы можете выбрать первый элемент, удовлетворяющий определённым условиям. Например, первый город, имя которого начинается на букву «М». На Java мы просто скомбинируем два уже известных нам метода:
cities.stream()
.filter(c -> c.name().startsWith( «М» ))
.findFirst();
А на kotlin метод firstOrNull() и другие ему подобные принимают в качестве параметра предикат (условие фильтрации):
cities.firstOrNull < it.name.startsWith( "М" ) >
Опять же, код получился более компактным.
Kotlin также предоставляет методы last() и lastOrNull(), которые возвращают не первый, а последний элемент списка. В остальном принцип их работы такой же, как и у выше рассмотренных методов.
Начиная с Java 21 нам также доступен метод getLast(), возвращающий последний элемент, если список не пустой.
Прямая и обратная сортировка элементов
Теперь давайте отсортируем наши города по названию в обратном алфавитном порядке. То есть от «Я» до «А». Код на Java:
List
.sorted(Comparator.comparing(City::name, Comparator.reverseOrder()))
.toList(); // Париж, Москва, Мадрид, Берлин
В метод sorted() мы передаём компаратор, который содержит в себе информацию, по какому полю сортируем (поле name) и каков порядок сортировки (обратный). Для прямой сортировки нужно использовать Comparator.naturalOrder() или же вообще не указывать второй параметр. Затем создаём новый отсортированный список. То же самое на kotlin записывается более компактно:
// Париж, Москва, Мадрид, Берлин
val sortedCities = cities.sortedByDescending < it.name >
Как видите, для удобства есть специальный метод расширения sortedByDescending(). В виде лямбды в него нужно лишь передать поле, по которому производится сортировка. Для прямой сортировки используйте метод sortedBy().
Объединение нескольких строк в одну
Очень полезно бывает объединить несколько строк в одну, поместив между ними запятую. Давайте объединим названия городов. В Java для этого есть метод String.join().
// «Париж, Москва, Берлин, Мадрид»
String citiesString = String.join( «, » , cityNames);
В kotlin есть похожий метод joinToString():
// «Париж, Москва, Берлин, Мадрид»
val citiesString = cityNames.joinToString(separator = «, » )
В параметрах можно указывать не только разделитель, но и префикс, постфикс, ограничение на максимальное количество элементов, которые будут включены в строку, а также специальную строку, которая будет сигнализировать о том, что в результат поместились не все элементы (например, многоточие). По умолчанию все эти параметры имеют подходящие значения, поэтому в явном виде их вообще можно не указывать.
Поиск максимальных и минимальных значений
Давайте найдём город с самым большим населением. Нетрудно догадаться, что среди наших исходных данных это Москва. В Java мы воспользуемся методом max() и методом Comparator.comparing() для указания того поля, по которому происходит сравнение:
Optional
.max(Comparator.comparing(City::population)); // Москва
В kotlin такая же выборка делается c помощью метода maxByOrNull():
val mostPopulatedCity = cities.maxByOrNull < it.population >// Москва
Для поиска минимального элемента в обоих случаях нужно поменять «max» на «min», то есть воспользоваться методами min() и minByOrNull() соответственно. Тогда в нашей выборке самым маленьким городом окажется Париж.
Вычисление суммы и среднего значения
Теперь давайте посчитаем сколько всего людей живёт в наших городах вместе взятых. То есть посчитаем сумму по полю population. В Java нам нужно будет получить IntStream при помощи метода mapToInt():
int totalPopulation = cities.stream()
.mapToInt(City::population)
.sum();
Метод IntStream.sum() всегда возвращает целочисленное значение, т.к. даже в случае пустой коллекции сумма просто будет равна нулю.
Теперь давайте вычислим среднее значение населения. Тут уже чуть сложнее, потому что во-первых, среднее значение имеет тип Double, а во-вторых, его может и не быть в случае, если коллекция пуста:
OptionalDouble averagePopulation = cities.stream()
.mapToInt(City::population)
.average();
Также класс IntStream предлагает метод summaryStatistics(), который позволяет получить все основные статистические параметры разом:
IntSummaryStatistics statistics = cities.stream()
.mapToInt(City::population).summaryStatistics();
// count=4, sum=21737358, min=2148327, average=5434339.500000, max=12678079
Объект IntSummaryStatistics содержит пять полей:
- количество элементов
- сумма
- минимум
- максимум
- среднее значение.
Теперь давайте найдём вычислим суммарное и среднее население с использованием kotlin:
val totalPopulation = cities.sumOf < it.population >// или cities.map < it.population >.sum()
val averagePopulation = cities.map < it.population >.average() // среднее значение
Метод sumOf() принимает в качестве параметра поле, по которому нужно выполнить суммирование и возвращает целочисленную сумму. Этот метод равносилен комбинации методов map() и sum(). Метод average() возвращает среднее значение в виде Double, причём в случае пустого списка метод вернёт специальное значение Double.NAN («not a number»).
Преобразование List в Map
Теперь давайте превратим наш список городов в мапу, где ключом будет название города. После этого мы сможем быстро находить нужный город в нашей коллекции по его имени. На Java это делается через метод Collectors.toMap():
Map
.collect(Collectors.toMap(City::name, Function.identity()));
В первом параметре мы указываем, какое поле должно стать ключом, а во втором – что брать в качестве значения. Function.identity() возвращает элемент списка целиком. На kotlin для этого есть специальный метод associateBy():
val citiesByName = cities.associateBy < it.name >
Если же мы хотим, чтобы ключом мапы было название города, а значением – кол-во его жителей, тогда на Java код будет выглядеть так:
Map
.collect(Collectors.toMap(City::name, City::population));
А на kotlin вот так:
val nameToPopulation = cities.associate < it.name to it.population >
Обратите внимание, что to в данном случае не ключевое слово языка, а лишь обычная функция, помеченная ключевым словом infix. Этот модификатор позволяет записывать вызов функций в таком красивом виде, а по факту данный вызов полностью эвивалентен вызову it.name.to(it.population). Механизм инфиксной записи открывает довольно широкие возможности для создания синтаксисов, ориентированных на конкретную предметную область.
В итоге функция to() возвращает объект Pair, который состоит из двух полей first и second. Затем метод associate() преобразует список таких объектов в мапу.
Группировка элементов
Теперь давайте создадим не просто мапу, а такую мапу, в которой ключом будет первая буква имени города, а значением – список всех городов, начинающихся на эту букву. Иными словами, сделаем группировку по первой букве имени города. В наших исходных данных есть два города, начинающихся на одну букву, следовательно по ключу «М» у нас должен быть список из двух элементов.
Map
.collect(Collectors.groupingBy(c -> c.name().charAt( 0 )));
В Java мы используем метод Collectors.groupingBy(), в который указываем правило формирования ключа будущей мапы. Логика его заключается в том, чтобы брать первый символ в названии города. На kotlin это записывается с помощью метода groupBy():
val citiesByFirstLetter = cities.groupBy < it.name.first() >
Уже знакомый нам метод first(), применённый к строке, возвращает её первый символ.
Преобразование двумерного списка в одномерный
Теперь выполним обратную задачу: объединим несколько списков разного размера в один общий список. Предположим, у нас имеется список, каждый элемент которого является списком строк. Тогда мы можем получить один «плоский» список с помощью метода flatMap(). Код на Java:
List Каждый элемент, являющийся вложенным списком, мы преобразуем в стрим. Эти стримы объединяются в один общий и затем результирующий стрим преобразуется в новый список. В kotlin также есть метод flatMap(), но если нам не требуется выполнять дополнительных преобразований над элементами, то воспользуемся его более кратким эквивалентом flatten(): val letterLists = listOf( Коллекция типа «множество» (set) отличается от простого списка тем, что в нём содержатся только уникальные значения. Если мы сначала создадим список с дублями, а затем преобразуем его в Set, то в результате получим новую коллекцию с меньшим количеством элементов и все они будут уникальными. Давайте создадим сначала список из дней недели, в котором будут дубли. Затем преобразуем его в множество с уникальными элементами (множество дней недели, которые считаются выходными). В Java это можно сделать так: // список с дублями // быстрый поиск // сохранение порядка элементов Как я рассказывал в статье Коллекции: list, set, map, в Java (а, значит, и в Kotlin) есть несколько реализаций интерфейса Set. В данном случае я привёл две из них: HashSet и LinkedHashSet. Первую следует использовать тогда, когда нам требуется искать в ней элементы и порядок нам не важен, а вторую – когда мы будем где-либо показывать это множество, т.к. в нём сохранится порядок следования элементов из исходной коллекции. На kotlin создание этих множеств будет выглядеть следующим образом: val days = listOf( «суббота» , «воскресенье» , «суббота» ) // список с дублями Метод toHashSet() ожидаемо возвращает именно HashSet, оптимизированный для поиска значений. А метод toSet() по факту возвращает именно LinkedHashSet, если в исходной коллекции больше одного элемента. То есть он возвращает множество, которое сохранит порядок следования элементов из исходной коллекции. Поиск элементов по значению можно выполнять в любом виде коллекций (list, set, map), но лучше всего для этого подходят именно множества (set). Сказанное далее технически применимо к любой коллекции, но быстрее всего будет работать именно в HashSet. Поэтому возьмём коллекцию fastHolidays из предыдущего примера и проверим, является ли понедельник выходным днём. В Java для таких проверок используется метод contains(): boolean isHoliday = fastHolidays.contains( «понедельник» ); // false В результате мы ожидаемо получим false, т.к. «понедельник – день тяжёлый» и выходным не является. В kotlin эквивалентная проверка выглядит следующим образом: val isHoliday = fastHolidays.contains( «понедельник» ) Вторая форма использует выражение in, но это не более чем синтаксический сахар, т.к. благодаря соглашениям об именовании методов kotlin всегда будет вызывать метод contains(), когда встречает выражение in. На мой взгляд, второй вариант гораздо более читаемый и понятный. Иногда бывает необходимо проверить какое-то условие над всеми элементами коллекции сразу. Например, у нас есть множество целых чисел и мы хотим узнать, есть ли среди них положительные числа? Все ли они положительны? И наконец, мы хотим убедиться, что среди них нет нуля. Пример на Java: Set В этом нам помогают методы стримов anyMatch(), allMatch() и noneMatch(), которые принимают условия проверки в виде лямбды. В результате этих проверок мы узнаём, что среди наших чисел есть положительные, однако не все, и среди них действительно нет нуля. То же самое можно написать и на kotlin с использованием методов any(), all() и none() соответственно: val numbers = setOf(- 2 , — 1 , 3 , 4 , 5 ) Важно также отметить, что и в случае метода allMatch(), и в случае метода all(), вызов на пустой коллекции с любым предикатом всегда вернёт true. Как видите, с точки зрения синтаксиса, операции над коллекциями в kotlin всегда более компактны и читаемы, нежели на Java. Важно заметить, что при этом нет накладных расходов в плане производительности, т.к. в kotlin используются те же классы коллекций из Java, но при этом они дополнены большим количеством вспомогательных методов расширения. В результате работать с коллекциями в kotlin всегда легко и приятно. Kotlin быстро становится предпочтительным языком для разработки современных приложений для Android благодаря лаконичному синтаксису и мощным функциям. Одной из функций, которая значительно расширяет возможности разработки, является сериализация Kotlin, процесс перевода объектов Kotlin в формат, который можно удобно хранить или передавать, а затем реконструировать в исходные объекты. Эта способность эффективно кодировать и декодировать структуры данных имеет решающее значение в мире, где приложения часто взаимодействуют с веб-сервисами, требуют постоянного хранения данных и полагаются на сложный обмен данными. Сериализация — это не только техническая необходимость для таких задач, но и практическое решение проблем, связанных с различными форматами данных и необходимостью взаимодействия. Сериализация Kotlin, по сути, представляет собой официальную библиотеку Kotlin, предназначенную для плавного преобразования классов данных Kotlin в JSON, фактический стандарт для обмена данными в сети и обратно. Однако на этом его возможности не заканчиваются; библиотеку можно расширить для поддержки множества других форматов, таких как XML , Protobuf или CBOR. Являясь неотъемлемой частью мультиплатформенной экосистемы Kotlin, он предлагает сообществу разработчиков единый подход к обработке данных на нескольких платформах, таких как JVM, JavaScript и Native, что еще больше укрепляет позиции Kotlin как универсального игрока в разработке программного обеспечения . Сегодняшние требования к разработке приложений подчеркивают необходимость эффективной среды сериализации в Kotlin. Данные необходимо сериализовать при сохранении в базе данных, отправке по сети или локальном хранении на устройстве. В экосистеме Android сериализованные данные обычно используются для передачи между действиями и фрагментами. Библиотека сериализации Kotlin не только оптимизирует эти процессы, но также гарантирует, что они выполняются безопасно и с учетом типов, снижая вероятность ошибок во время выполнения и повышая устойчивость приложений. Библиотека отличается несколькими краеугольными функциями, такими как: Разбираясь в нюансах сериализации Kotlin, мы рассмотрим, почему эта библиотека является не просто удобным инструментом, но и важным аспектом программирования Kotlin, который позволяет разработчикам эффективно управлять данными в своих приложениях. Это путешествие в сериализацию Kotlin особенно актуально для тех, кто стремится использовать весь потенциал Kotlin, а также для тех, кто хочет и дальше совершенствовать свои методы обработки данных в приложениях на основе Kotlin. Для разработчиков, использующих такие платформы, как AppMaster , предлагающий мощное no-code решение для создания серверных, веб- и мобильных приложений, сериализация Kotlin может стать ключевым компонентом, помогающим в быстрой обработке и хранении данных, плавно интегрируясь с создаваемыми серверными процессами. у платформы. Сериализация преобразует объект в формат, который можно сохранить или передать, а затем реконструировать. В Kotlin эта концепция имеет решающее значение для многих приложений: от сохранения пользовательских настроек до отправки объектов по сети. Библиотека сериализации Kotlin упрощает этот процесс за счет непосредственной интеграции с языком и его системой типов времени компиляции. Первым шагом к эффективному использованию сериализации Kotlin является настройка среды разработки. Независимо от того, работаете ли вы над мультиплатформенным проектом или ориентируетесь на JVM или Native, процесс установки требует включения библиотеки сериализации Kotlin и плагина сериализации. Вот как вы можете подготовить свой проект к сериализации Kotlin: letterLists = List.of(
List.of( «a» , «b» , «c» ),
List.of( «d» ),
List.of( «e» , «f» )
);
List plainLetters = letterLists.stream()
.flatMap(Collection::stream)
.toList(); // [a, b, c, d, e, f]
listOf( «a» , «b» , «c» ),
listOf( «d» ),
listOf( «e» , «f» )
)
val plainLetters = letterLists.flatten() // [a, b, c, d, e, f]Преобразование List в Set
List days = List.of( «суббота» , «воскресенье» , «суббота» );
Set fastHolidays = new HashSet<>(days);
Set orderedHolidays = new LinkedHashSet<>(days);
val fastHolidays = days.toHashSet() // быстрый поиск
val orderedHolidays = days.toSet() // сохранение порядка элементовПоиск элементов в коллекции
// или более краткая форма
val isHoliday = «понедельник» in fastHolidaysГрупповая проверка условий
boolean hasPositive = numbers.stream().anyMatch(n -> n > 0 ); // true
boolean allPositive = numbers.stream().allMatch(n -> n > 0 ); // false
boolean withoutZero = numbers.stream().noneMatch(n -> n == 0 ); // true
val hasPositive = numbers.any < it >0 > // true
val allPositive = numbers.all < it >0 > // false
val withoutZero = numbers.none < it == 0 >// trueВыводы
Обработка данных с помощью сериализации Kotlin
Сериализация в Kotlin: основы и настройка
Включите плагин сериализации Kotlin: Сначала вы должны добавить плагин сериализации Kotlin в свой скрипт сборки. Если вы используете Gradle, вы должны включить его в свой файл build.gradle.kts (Kotlin DSL) или build.gradle (Groovy DSL) в блоке плагинов:
Kotlin DSL:plugins < kotlin("multiplatform") kotlin("plugin.serialization") version "1.5.0">Groovy DSL:plugins
// For JVMimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json:1.2.2'// For JavaScriptimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-jsLegacy:1.2.2'// For Native or Multiplatformimplementation 'org.jetbrains.kotlinx:kotlinx-serialization-json-native:1.2.2'@Serializabledata class User(val name: String, val age: Int)Более того, правильно настроив сериализацию Kotlin в своем проекте, вы гарантируете, что ваши классы можно будет легко сериализовать в JSON или любой другой поддерживаемый формат, а также беспрепятственно взаимодействовать с другими системами. Эта настройка не ограничивается простыми объектами данных. Тем не менее, его также можно распространить на более сложные пользовательские сценарии сериализации, с которыми вы можете столкнуться по мере усложнения вашего проекта.
Инициализация сериализатора
После завершения настройки вы можете приступить к сериализации и десериализации объектов. Например:
val user = User("John Doe", 30)val jsonString = Json.encodeToString(User.serializer(), user)val userObject = Json.decodeFromString(User.serializer(), jsonString)Здесь мы использовали объект Json для кодирования экземпляра User в строку JSON и декодирования его обратно в объект User . Сериализация Kotlin берет на себя все тонкости преобразования сложных структур данных в их представления JSON и наоборот.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Освоение основ настройки сериализации Kotlin закладывает прочную основу для создания приложений, требующих постоянного хранения данных, связи через API или поддержки мультиплатформенности. Познакомившись с библиотекой поближе, вы оцените ее тонкие функции и оптимизации для эффективной обработки данных.
Источник изображения: Kodeco
Работа с JSON в сериализации Kotlin
Kotlin, будучи современным и универсальным языком программирования, предлагает различные способы работы с данными JSON. JSON означает «Нотация объектов JavaScript» и является широко распространенным стандартом обмена данными в Интернете. Библиотека сериализации Kotlin играет ключевую роль в анализе данных JSON в объекты Kotlin и наоборот. Это упрощает процесс обработки данных в приложениях, поскольку разработчикам не нужно вручную анализировать строки JSON или компилировать объекты JSON.
Во-первых, чтобы сериализовать объекты в JSON, вам необходимо определить класс данных Kotlin с аннотацией @Serializable. Это сообщает библиотеке сериализации Kotlin, что класс сериализуем. Например:
import kotlinx.serialization.* import kotlinx.serialization.json.* @Serializable data class User(val name: String, val age: Int)Как только ваш класс будет готов, вы можете использовать объект Json для сериализации и десериализации данных:
val user = User(name = "John Doe", age = 30) // Serialize to JSON val jsonString = Json.encodeToString(user) // Deserialize from JSON val userObj = Json.decodeFromString(jsonString)Библиотека сериализации Kotlin предлагает методы encodeToString и decodeFromString для этих операций. В процессе десериализации важно обрабатывать исключения, возникающие из-за недопустимых строк JSON или несовпадающих типов данных.
В некоторых случаях вам может потребоваться настроить вывод JSON. Сериализация Kotlin предоставляет конфигурации через объект Json, которые можно изменить для достижения требуемого поведения, например, красивую печать JSON или игнорирование нулевых значений:
val json = Json < prettyPrint = true; ignoreUnknownKeys = true >val jsonString = json.encodeToString(user)Для взаимодействия с API или любым внешним источником данных JSON можно эффективно использовать сериализацию Kotlin для сопоставления данных. Вы можете определить класс, представляющий структуру JSON, и библиотека преобразует входящий JSON в объекты Kotlin, с которыми ваше приложение сможет беспрепятственно работать.
Еще одна важная функция — обработка значений по умолчанию. Когда в данных JSON отсутствуют определенные поля, сериализация Kotlin может использовать значения по умолчанию, указанные в классе данных:
@Serializable data class Product(val id: Int, val name: String, val stock: Int = 0)Если поле «stock» опущено во входных данных JSON, сериализация Kotlin будет использовать значение по умолчанию, равное 0.
Анализ списков и других коллекций выполняется так же просто. Определяя соответствующий класс данных и используя сериализаторы типов коллекций, сериализация Kotlin автоматизирует процесс привязки данных:
val userListJson = "[,]" val users: List = Json.decodeFromString(userListJson)В приведенном выше примере строка JSON, представляющая список пользователей, легко преобразуется в объект списка Kotlin.
Взаимодействие с AppMaster может еще больше расширить возможности сериализации Kotlin. Используя библиотеку в проектах, созданных с помощью платформы no-code , разработчики могут обрабатывать модели данных и выполнять задачи быстрой сериализации и десериализации, которые дополняют рабочий процесс визуальной разработки, поддерживая эффективный мост между сгенерированной базой кода и структурами данных.
Включение сериализации JSON Kotlin в ваш проект обеспечивает уровень безопасности типов и выразительности, сокращая количество шаблонного кода, обычно связанного с такими операциями. Он поддерживает быструю разработку приложений, которые в значительной степени полагаются на манипулирование данными JSON, и закладывает основу для создания приложений Kotlin, управляемых данными.
Пользовательская сериализация с помощью Kotlin
Хотя библиотека сериализации Kotlin отлично справляется с общими потребностями сериализации, бывают случаи, когда разработчики сталкиваются с необходимостью настройки этого процесса для уникальных типов данных или сложной логики сериализации. Пользовательская сериализация в Kotlin предлагает огромную гибкость, позволяя вам формировать процесс в соответствии с точными спецификациями, гарантируя, что ваши данные не только надежно сохраняются, но и сохраняют целостность при переходе между сериализованной формой и объектами Kotlin.
Чтобы реализовать пользовательскую сериализацию, разработчикам необходимо углубиться во внутреннюю работу библиотеки сериализации и использовать некоторые из ее основных компонентов. В основе пользовательской сериализации лежат интерфейс KSerializer и аннотация @Serializer . Пользовательский сериализатор должен переопределять методы serialize и deserialize , предоставляемые интерфейсом KSerializer , чтобы точно определять, как объект записывается и реконструируется.
Создание пользовательских сериализаторов
Чтобы начать настраиваемую сериализацию, необходимо создать класс, реализующий интерфейс KSerializer , где T — тип данных, требующий настраиваемой обработки. Внутри класса вы переопределите методы serialize и deserialize для определения своей логики.
После написания собственного сериализатора вы можете вызвать его, аннотировав класс данных с помощью @Serializable или используя его непосредственно в объекте JSON для специальных задач сериализации.
Обработка сложных сценариев
Более сложные сценарии сериализации могут включать в себя работу с полиморфизмом или необходимость сериализации сторонних классов, которые нельзя аннотировать напрямую. В случае полиморфизма сериализация Kotlin обеспечивает поддержку иерархий классов «из коробки» с помощью аннотации @Polymorphic или регистрации подклассов в модуле. Тем не менее, для сторонних классов разработчики должны создать собственный сериализатор и вручную применять его всякий раз, когда требуется сериализация или десериализация этих типов.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Преимущества пользовательской сериализации
Возможность определять собственное поведение сериализации особенно полезна для:
- Работа с устаревшими системами, форматы данных которых не соответствуют современным стандартам.
- Взаимодействие с внешними сервисами, которые могут использовать нестандартные форматы или требовать определенных структур данных.
- Оптимизация производительности за счет настройки сериализованного вывода для повышения эффективности по размеру и скорости.
Пользовательская сериализация гарантирует, что вы сможете эффективно работать с любым типом структуры данных или требованиями, обеспечивая высокую точность и контроль над процессом сериализации. Благодаря фундаментальному пониманию механизмов сериализации в Kotlin вы можете решить практически любую задачу обработки данных типобезопасным и автономным образом.
Интеграция пользовательских сериализаторов
Интеграция пользовательских сериализаторов в рабочий процесс вашего проекта становится простой задачей после реализации. Учитывая ориентацию Kotlin на совместимость и лаконичный синтаксис, пользовательская сериализация естественным образом вписывается в код. Дополнительным преимуществом является то, что определения сериализации могут быть модульными и использоваться в разных модулях или даже проектах, что улучшает повторное использование кода и удобство сопровождения.
Возможности сериализации Kotlin в сочетании с гибкостью пользовательских сериализаторов открывают новые уровни эффективности и надежности для разработчиков, работающих с различными формами данных. А для тех, кто использует такие платформы, как AppMaster , которые ускоряют разработку серверной части и приложений за счет подхода no-code , сериализация Kotlin расширяет возможности серверной части, обеспечивая эффективные стратегии обмена и хранения данных, адаптированные к конкретным потребностям службы.
Пользовательская сериализация с помощью Kotlin — мощная функция для разработчиков, которым необходимо выйти за рамки традиционных решений сериализации. Будь то специализированные форматы данных, оптимизация или совместимость с устаревшими системами, гибкость, предлагаемая Kotlin, гарантирует, что ваша обработка данных будет эффективной и будет соответствовать уникальным требованиям вашего приложения.
Обработка сложных структур данных
Разработчикам часто приходится управлять сложными структурами данных при работе с современными приложениями. Они могут варьироваться от вложенных объектов и коллекций до пользовательских типов данных со сложной логикой сериализации. Сериализация Kotlin предоставляет инструменты и аннотации, которые позволяют нам легко сериализовать даже самые сложные модели данных.
Во-первых, рассмотрим вложенные классы. Когда класс данных содержит другой класс или список классов, сериализация Kotlin автоматически обрабатывает их при условии, что все задействованные классы сериализуемы. Вы просто аннотируете родительский и дочерний классы с помощью @Serializable , а библиотека сериализации позаботится обо всем остальном. Но если вы имеете дело со свойством, с которым сериализация Kotlin не умеет обращаться, вам может потребоваться предоставить собственный сериализатор.
Что касается коллекций, сериализация Kotlin работает «из коробки» для коллекций стандартных библиотек, таких как списки, наборы и карты. Каждый элемент или пара ключ-значение в коллекции сериализуется в соответствии со своим сериализатором. Эта бесшовная интеграция гарантирует, что коллекции обрабатываются эффективно и интуитивно без дополнительных затрат.
Однако работа с пользовательскими коллекциями или типами данных становится более сложной. В таких сценариях вы определяете собственный сериализатор, реализуя интерфейс KSerializer для вашего типа. Здесь вы имеете полный контроль над процессом сериализации и десериализации, что позволяет использовать индивидуальный подход, соответствующий вашему конкретному случаю использования. Примером может служить тип данных, который необходимо сериализовать в формате, отличном от формата по умолчанию, или когда вам необходимо обеспечить соблюдение определенных правил проверки во время процесса.
Полиморфная сериализация — еще одна функция, повышающая гибкость при работе со сложными иерархиями. Если у вас есть суперкласс с несколькими подклассами и вы хотите сериализовать объект, который может быть любым из этих подклассов, сериализация Kotlin предоставляет аннотацию @Polymorphic . Благодаря этому вы можете обрабатывать коллекцию различных подклассов, сохраняя при этом их конкретные типы и свойства при сериализации и десериализации.
Также стоит упомянуть контекстную сериализацию. С помощью аннотации @Contextual поведение сериализации можно изменить в зависимости от контекста без необходимости писать собственные сериализаторы для каждого случая. Эта мощная функция позволяет разработчикам абстрагировать повторяющуюся логику сериализации и повторно использовать ее в различных структурах данных, обеспечивая тем самым чистоту и удобство обслуживания кода.
Библиотека сериализации Kotlin способна справляться со сложными сценариями обработки данных с помощью различных аннотаций и пользовательских сериализаторов. Эти функции позволяют разработчикам уверенно решать сложные задачи сериализации, гарантируя, что все аспекты их модели данных будут надлежащим образом сохранены и переданы. В результате, независимо от того, насколько сложны структуры данных, с которыми вы можете столкнуться, сериализация Kotlin обеспечивает необходимую гибкость и мощность для умелого управления ими.
Вопросы производительности при сериализации Kotlin
Производительность — это ключевой аспект функциональности любого приложения, который ничем не отличается от сериализации Kotlin. Эффективность, с которой приложение обрабатывает сериализацию и десериализацию данных, может существенно повлиять на его скорость и скорость реагирования. Разработчики должны знать различные факторы, влияющие на производительность сериализации в их приложениях Kotlin.
Размер и сложность сериализуемых объектов данных могут существенно повлиять на производительность. Обработка более крупных объектов с множеством полей или вложенных структур занимает больше времени, чем более простые и меньшие объекты. Аналогично, сложности структуры данных, такие как рекурсивные отношения или сложные иерархии, могут привести к дополнительным накладным расходам на сериализацию.
Формат данных является еще одним фактором. JSON — это текстовый формат, и хотя он удобен для чтения и широко совместим, он не всегда наиболее эффективен с точки зрения производительности, особенно для больших наборов данных или в приложениях, где производительность критична. Двоичные форматы, такие как протокольные буферы или CBOR, могут обеспечить более высокую производительность, поскольку они более компактны и разработаны с учетом эффективности, хотя и жертвуют удобочитаемостью для человека.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Частота операций сериализации также может играть роль. Совокупное влияние на производительность может быть существенным, если приложение часто сериализует данные в рамках своей основной функциональности. В таких случаях могут оказаться полезными такие стратегии, как кэширование сериализованных данных или использование другой стратегии сериализации для временных объектов.
Выбор правильных сериализаторов имеет решающее значение. Сериализация Kotlin предоставляет ряд встроенных сериализаторов, но могут быть сценарии, когда потребуются собственные сериализаторы. Пользовательские сериализаторы можно оптимизировать для конкретных типов данных, что приводит к повышению производительности, но они также требуют тщательного проектирования, чтобы избежать плохо масштабируемых решений.
Обработка ошибок в операциях сериализации может привести к дополнительным затратам производительности, особенно если в логике сериализации часто возникают исключения. Надежный механизм проверки и обнаружения ошибок может снизить влияние на производительность.
Наконец, платформа и среда, в которой выполняется сериализация, могут влиять на производительность. В разных средах могут быть разные оптимизации или ограничения для процессов сериализации, и их учет может помочь точно настроить производительность.
Когда мы рассматриваем интеграцию сериализации Kotlin в такие платформы, как AppMaster , которая облегчает быструю разработку приложений в различных сегментах, последствия производительности сериализации становятся еще более заметными. Учитывая, что AppMaster создает приложения, уделяя особое внимание масштабируемости и эффективности, обеспечение эффективной обработки сериализации способствует обещанию платформы предоставлять высокопроизводительные приложения.
Напомним, что рассмотрение размера и структуры данных, выбор правильного формата данных и сериализатора, оптимизация частоты и механизма операций сериализации, эффективная обработка ошибок и понимание среды выполнения необходимы для достижения оптимальной производительности в процессах сериализации Kotlin.
Сериализация Kotlin в мультиплатформенных проектах
Способность Kotlin работать на нескольких платформах — одна из его самых знаменитых особенностей, а сериализация играет фундаментальную роль в обеспечении согласованной обработки данных на всех этих платформах. Мультиплатформенные проекты на Kotlin направлены на совместное использование кода между различными модулями (например, JVM для серверной части, Kotlin/JS для Интернета и Kotlin/Native для настольных или мобильных приложений), что требует общего подхода к моделям данных и бизнес-логике.
Сериализация Kotlin обеспечивает столь необходимое единообразие, предоставляя единый и последовательный способ сериализации и десериализации объектов. Он абстрагирует особенности платформы, гарантируя, что сериализованные данные из одного модуля могут быть поняты другим независимо от целевой платформы. Эта важная характеристика становится важным помощником для разработчиков, которые хотят поддерживать общую базу кода для различных сред.
Реализация сериализации в многоплатформенном контексте
В мультиплатформенном проекте вы обычно определяете общие ожидания в общем модуле, тогда как фактические реализации для конкретной платформы находятся в соответствующих модулях платформы. Сериализация Kotlin легко согласуется с этой моделью, предлагая интерфейсы и аннотации KSerializer , которые понятны каждому. Это означает, что вы можете определить стратегии сериализации в своем общем коде, которые будут применяться на всех платформах.
Более того, сериализация Kotlin интегрируется с многоплатформенными инструментами Kotlin, что позволяет при необходимости указывать форматы сериализации для конкретной платформы. Например, хотя JSON используется повсеместно, при работе с Kotlin/Native для повышения производительности вы можете использовать более компактные двоичные форматы, такие как ProtoBuf или CBOR.
Проблемы и решения
Несмотря на свои удобства, многоплатформенная сериализация не лишена проблем. Ограничения, специфичные для платформы, могут накладывать ограничения на то, как структурируются или обрабатываются данные. Тем не менее, сериализация Kotlin разработана с учетом расширяемости. Разработчики могут решить эти проблемы, написав собственные сериализаторы или используя альтернативные библиотеки в сочетании со стандартной платформой сериализации для удовлетворения конкретных потребностей каждой платформы.
Одной из распространенных проблем является обработка типов, специфичных для конкретной платформы, которые не имеют прямых эквивалентов на других платформах. В таких случаях возникает общий ожидаемый тип с фактическими реализациями, использующими типы, специфичные для платформы, что позволяет сериализовать и десериализовать независимо от платформы.
Тематические исследования и примеры
Репозитории проектов Kotlin с открытым исходным кодом на GitHub предоставляют реальные примеры использования сериализации Kotlin в мультиплатформенных настройках. Эти проекты выигрывают от унифицированного подхода к обработке данных, снижения сложности кодовой базы и снижения вероятности ошибок.
Глядя на собственную библиотеку Kotlinx.serialization, вы можете найти примеры и тесты, которые дополнительно иллюстрируют, как реализовать многоплатформенную сериализацию. В библиотеке демонстрируются методы решения проблем сериализации, которые могут возникнуть в проектах, ориентированных на JVM, JS и собственные двоичные файлы.
Будучи важнейшим инструментом для мультиплатформенных проектов, сериализация Kotlin делает больше, чем просто упрощает обработку данных. Это позволяет разработчикам сосредоточиться на бизнес-логике, а не увязнуть в тонкостях совместимости форматов данных — утопия разработки, к которой стремится Kotlin.
Роль сериализации Kotlin в движении No-code
Такие платформы, как AppMaster часто стирают грань между традиционным программированием и разработкой no-code . Хотя Kotlin сам по себе является полноценным языком программирования, лежащая в его основе философия повышения доступности разработки перекликается с движением no-code . Упрощая сериализацию данных на нескольких платформах, Kotlin предоставляет серверное решение, которое может сосуществовать и дополнять инструменты no-code .
Например, с помощью AppMaster ускорение процесса разработки идеально сочетается с сериализацией Kotlin. Разработчики могут создавать модели данных и бизнес-логику для серверной части своего приложения на Kotlin, а компоненты внешнего интерфейса и пользовательского интерфейса могут создаваться с использованием визуальных конструкторов AppMaster для веб-приложений или мобильных приложений. Такая интеграция инструментов с кодом и no-code в процессе разработки программного обеспечения является свидетельством гибкости и ориентированности на будущее, заложенных в сериализации Kotlin.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Сериализация и безопасность Kotlin
Безопасность — важнейший аспект любого процесса разработки приложений, особенно при сериализации и десериализации данных. По сути, сериализация — это преобразование состояния объекта в формат, который можно хранить или передавать, а десериализация преобразует эти данные обратно в объект. В Kotlin библиотека Kotlinx.serialization делает это эффективно и результативно, но, как и при любой операции обработки данных, здесь необходимо помнить о важных соображениях безопасности. Что касается безопасности, процессы сериализации могут представлять несколько рисков, особенно при работе с ненадежными данными или раскрытии сериализованных данных внешним объектам. Вот некоторые ключевые аспекты безопасности, связанные с сериализацией Kotlin, к которым разработчикам следует проявлять бдительность:
- Подделка данных Сериализация может предоставить злоумышленникам возможность изменить сериализованные данные при передаче, что потенциально может привести к повреждению данных, несанкционированному доступу или непреднамеренному поведению при десериализации. Очень важно использовать контрольные суммы, цифровые подписи или шифрование для проверки целостности и подлинности данных до и после сериализации.
- Небезопасная десериализация Небезопасная десериализация может позволить злоумышленнику использовать логику приложения, выполнять атаки типа «отказ в обслуживании» или выполнять произвольный код, когда данные объекта не проверены должным образом. Разработчикам никогда не следует десериализовать данные из ненадежных источников без тщательной проверки и следует избегать использования форматов сериализации, которые могут привести к появлению уязвимостей, таких как опасные типы в графе сериализованных объектов.
- Раскрытие информации Сериализованные объекты могут случайно раскрыть конфиденциальную информацию, если не будут обработаны правильно. Разработчикам следует помечать конфиденциальные поля в классах Kotlin аннотацией @Transient , чтобы исключить их из сериализации, тем самым снижая риск раскрытия личных данных.
- Управление версиями и совместимость. Поддержание совместимости между различными версиями объекта может быть сложной задачей и может привести к дырам в безопасности, если им не управлять правильно. Сериализация Kotlin предоставляет механизмы для развития схемы, такие как значения параметров по умолчанию и необязательные поля, которые следует применять осторожно, чтобы предотвратить проблемы совместимости, которые могут привести к уязвимостям безопасности.
- Выбор формата Библиотека Kotlinx.serialization поддерживает различные форматы, включая JSON, Protobuf и CBOR. Каждый формат имеет свои характеристики и потенциальные последствия для безопасности. Например, JSON удобен для чтения и широко используется, но его многословный характер может привести к дополнительным затратам. В то же время Protobuf предлагает компактный двоичный формат, который может быть более непрозрачным, но эффективным с точки зрения производительности и уменьшения поверхности атаки.
Чтобы защититься от этих рисков и обеспечить безопасность сериализации Kotlin, разработчикам следует следовать нескольким рекомендациям:
- Используйте последнюю стабильную версию библиотеки Kotlinx.serialization, чтобы воспользоваться исправлениями и улучшениями безопасности.
- Применяйте правильные методы проверки ввода при десериализации данных, включая строгую проверку типов и проверку содержимого.
- Рассмотрите возможность шифрования сериализованных данных при работе с конфиденциальной информацией или когда данные необходимо безопасно передавать по сети.
- Выполняйте регулярные проверки кода и аудиты безопасности, чтобы выявлять и устранять потенциальные проблемы безопасности, связанные с сериализацией.
- Внедрите комплексную обработку ошибок и ведение журнала для быстрого обнаружения и реагирования на события безопасности, связанные с сериализацией.
В дополнение к этим мерам предосторожности интеграция с такими решениями, как AppMaster , может упростить обработку данных, соблюдая при этом лучшие практики безопасности. Платформы AppMaster no-code создают серверные приложения , включая процессы сериализации и десериализации, которые работают эффективно и безопасно, не углубляясь в детали реализации низкого уровня. Ключевой вывод — рассматривать безопасность как непрерывный процесс, а не как разовый контрольный список. Правильная защита сериализации Kotlin предполагает постоянную бдительность, актуальные знания методов обеспечения безопасности и упреждающий подход к защите на протяжении всего жизненного цикла приложения.
Лучшие практики сериализации Kotlin
При работе с любой библиотекой или платформой следование установленным рекомендациям может значительно повысить эффективность и надежность вашего кода. Сериализация Kotlin не является исключением. Независимо от того, имеете ли вы дело с небольшим проектом или приложением корпоративного уровня, соблюдение рекомендаций гарантирует правильную обработку сериализованных данных, что делает ваши системы совместимыми и простыми в обслуживании. Вот несколько лучших практик использования сериализации Kotlin в ваших проектах:
Используйте сериализацию на основе аннотаций
Возможно, самая простая и важная практика — эффективное использование встроенных аннотаций Котлина:
- @Serializable : аннотируйте свой класс данных с помощью @Serializable , чтобы сообщить Kotlin, что этот класс может быть сериализован автоматически.
- @Transient : поля, которые не следует сериализовать, можно пометить @Transient , что автоматически исключает их из процесса сериализации.
- @SerialName : если вам нужно изменить имя поля в сериализованной форме, используйте @SerialName чтобы определить собственное имя.
- @Required : вы можете пометить поля, не допускающие значения NULL, которые всегда должны присутствовать в данных JSON, используя @Required ; это гарантирует, что поле по умолчанию не будет иметь значение null , если оно отсутствует.
Аннотации — это мощные инструменты, которые предоставляет сериализация Kotlin, чтобы сделать процессы сериализации и десериализации понятными и интуитивно понятными.
Попробуйте no-code платформу AppMaster
AppMaster поможет создать любое веб, мобильное или серверное приложение в 10 раз быстрее и 3 раза дешевле
Придерживайтесь стандартов кодирования Kotlin
Используйте сильные стороны Kotlin как языка:
- Предпочитайте классы данных для сериализации, поскольку они обладают внутренней совместимостью с процессами сериализации.
- По возможности используйте неизменяемость, используя val вместо var для сериализованных свойств. Это способствует безопасности потоков и предсказуемости в сериализованных состояниях.
- Воспользуйтесь преимуществами вывода типов, чтобы сделать код кратким и читаемым.
Держите модели сериализации хорошо документированными
Тщательно документируйте свои модели данных:
- Используйте комментарии для описания назначения каждого свойства, особенно если имя в сериализованной форме не отражает четко его использование.
- Задокументируйте любую пользовательскую логику сериализации или причины, по которым определенные поля могут быть помечены как временные.
Эта практика особенно важна для команд и для поддержки долгосрочных проектов, где другим может потребоваться понять причины вашего выбора дизайна сериализации.
Грамотно обрабатывайте исключения
Сериализация может завершиться неудачей по многим причинам. Крайне важно корректно обрабатывать эти сценарии:
- Используйте блоки try-catch Котлина для обработки исключений, возникающих во время процессов сериализации или десериализации.
- Предоставляйте четкие сообщения об ошибках, чтобы облегчить отладку и информировать пользователей о том, что пошло не так.
- Рассмотрите резервные механизмы или значения по умолчанию, если ошибки сериализации можно устранить некритическим способом.
При необходимости используйте универсальные и пользовательские сериализаторы
Хотя сериализация Kotlin автоматически обрабатывает многие случаи, иногда вам может потребоваться больше контроля:
- Для универсальных классов используйте сериализаторы контекста, чтобы предоставить сериализации Kotlin информацию, необходимую для сериализации этих структур.
- При работе с типом, который не имеет прямого сериализованного представления, или при взаимодействии с внешними системами с уникальными требованиями вам может потребоваться реализовать собственный сериализатор.
Пользовательские сериализаторы могут дать вам детальный контроль над процессом, но их следует использовать только при необходимости, поскольку они могут усложнить вашу кодовую базу.
Будьте в курсе последних версий
Как и любая активная библиотека, сериализация Kotlin постоянно совершенствуется:
- Регулярно обновляйте свои зависимости, чтобы воспользоваться преимуществами оптимизации, новыми функциями и важными исправлениями ошибок.
- Следите за изменениями в примечаниях к выпуску, чтобы корректировать свой код в соответствии с критическими изменениями или устареваниями.
Оптимизация конфигурации плагина компилятора
Плагин сериализации Kotlin имеет несколько вариантов конфигурации:
- Настройте эти параметры в файле build.gradle вашего модуля, чтобы адаптировать поведение плагина к потребностям вашего проекта.
Следуя этим рекомендациям, вы обеспечите эффективность и оптимизацию использования сериализации Kotlin для будущего развития. Когда эти методы применяются на платформе no-code такой как AppMaster , вы можете еще больше повысить производительность и использовать весь потенциал Kotlin синхронно с мощными функциями платформы для разработки приложений.
Интеграция сериализации Kotlin с AppMaster
Бесшовная интеграция сложных технологий имеет решающее значение для развития современной разработки программного обеспечения. Сериализация Kotlin, являющаяся мощным набором инструментов для обработки данных, исключительно хорошо взаимодействует с платформами, предназначенными для ускорения процесса разработки, такими как AppMaster . Эти синергетические отношения лежат в основе динамического характера приложений, ориентированных на данные.
В основе AppMaster , передовой платформы no-code , которая генерирует реальный исходный код для серверных, веб- и мобильных приложений, лежит необходимость эффективной сериализации данных. Благодаря своей лаконичности и совместимости Kotlin является предпочтительным выбором для серверной разработки во многих сценариях, а для обмена данными в AppMaster сериализация Kotlin является незаменимым инструментом.
Сериализация является важнейшим аспектом серверных генераторов AppMaster , использующих Go , и создания мобильных приложений, основанных на Kotlin и Swift . Хотя в бэкэнде в основном используется Go, роль Kotlin играет при соединении мобильных приложений с различными бэкэнд-сервисами. Здесь сериализация Kotlin упрощает преобразование объектов Kotlin в строки в формате JSON, обеспечивая тем самым плавную обработку данных и обмен между мобильным приложением и серверными службами.
Когда пользователь разрабатывает модель данных или настраивает бизнес-логику с помощью AppMaster , платформа может использовать сериализацию Kotlin для мобильных endpoints . Циклический процесс сериализации (преобразование объектов в JSON) и десериализации (обратно JSON в объекты Kotlin) часто автоматизируется, что повышает эффективность разработки и сводит к минимуму вероятность человеческой ошибки.
Более того, благодаря способности обрабатывать сложные структуры данных, включая вложенные классы и коллекции, сериализация Kotlin прекрасно дополняет возможности моделирования данных AppMaster . Будь то простая операция CRUD или сложная транзакция, структурированные данные можно легко сериализовать и десериализовать, гарантируя сохранение целостности данных на протяжении всего жизненного цикла приложения.
Интеграция с платформой AppMaster также позволяет использовать сериализацию Kotlin в единой системе непрерывной доставки. По мере того как приложения развиваются в соответствии с меняющимися требованиями, AppMaster восстанавливает приложения с нуля. Этот процесс позволяет сериализации Kotlin повторно связывать объекты и схемы данных без накопления технического долга .
Что касается мультиплатформенных возможностей, сериализация Kotlin является достойным союзником. В то время как AppMaster способствует быстрой разработке кросс-платформенных приложений, сериализация Kotlin обеспечивает гибкость и надежность, необходимые для согласованной обработки данных на этих платформах. Это делает путь от концептуализации к развертыванию существенно менее сложным и более согласованным с современными протоколами разработки, которые отдают предпочтение многоплатформенным стратегиям.
Интеграция сериализации Kotlin в экосистему AppMaster усиливает стремление платформы предоставить среду, в которой даже те, у кого нет традиционного опыта программирования, могут создавать производительные, масштабируемые и сложные приложения. Это свидетельство того, насколько эффективно сочетание возможностей современных методов сериализации с инновационными платформами разработки позволяет по-настоящему демократизировать процесс создания приложений.
Как интегрируются сериализация Kotlin и AppMaster?
Сериализация Kotlin может интегрироваться с такими платформами, как AppMaster при разработке серверных сервисов, повышая эффективность создания веб-, мобильных и серверных приложений. Модели данных можно сериализовать и десериализовать с помощью Kotlin, что способствует эффективной обработке и хранению данных.
Что такое сериализация Kotlin?
Сериализация Kotlin — это библиотека, которая позволяет преобразовывать объекты Kotlin в строковый формат, например JSON, чтобы их можно было легко хранить или передавать, а затем восстанавливать обратно в объекты.
Может ли сериализация Kotlin обрабатывать сложные структуры данных?
Да, сериализация Kotlin может управлять сложными структурами данных, включая вложенные классы, коллекции и пользовательские типы, используя при необходимости различные аннотации и пользовательские сериализаторы.
Каковы наилучшие методы использования сериализации Kotlin?
Лучшие практики сериализации Kotlin включают использование последней версии библиотеки, соблюдение идиоматического кода Kotlin, использование встроенных сериализаторов, написание пользовательских сериализаторов при необходимости и обеспечение правильной обработки ошибок.
Почему сериализация данных важна?
Сериализация данных важна, поскольку она позволяет преобразовывать данные в формат, который можно легко хранить, передавать и реконструировать, обеспечивая эффективную связь между различными системами или частями приложения.
Поддерживает ли сериализация Kotlin XML или другие форматы?
Хотя сериализация Kotlin в первую очередь ориентирована на JSON, ее можно расширить для поддержки других форматов, таких как Protobuf, CBOR или даже XML, с помощью пользовательских сериализаторов и реализаций формата.
Как мне настроить сериализацию Kotlin в моем проекте?
Чтобы настроить сериализацию Kotlin, вам необходимо добавить соответствующий плагин и зависимость в файл build.gradle. После синхронизации проекта вы можете использовать библиотеку для сериализации и десериализации объектов.
Подходит ли сериализация Kotlin для мультиплатформенных проектов?
Сериализация Kotlin разработана с учетом поддержки мультиплатформенности. Его можно использовать на разных платформах, таких как JVM, JavaScript, Native, и он поддерживает на этих платформах общие форматы, такие как JSON.
Как в Kotlin обрабатывается пользовательская сериализация?
Пользовательская сериализация осуществляется путем определения собственных сериализаторов для сложных или нестандартных типов, что обеспечивает гибкость управления сериализацией и десериализацией данных с помощью аннотаций и реализации интерфейса KSerializer.
Какие соображения по производительности следует учитывать при сериализации Kotlin?
При этом учитываются размер и сложность сериализуемых данных, количество объектов и используемые форматы. Важно профилировать и оптимизировать процессы сериализации, чтобы предотвратить возникновение узких мест в приложении.
Функциональное программирование
Одним из строительных блоков программы являются функции. Функция определяет некоторое действие. В Kotlin функция объявляется с помощью ключевого слова fun , после которого идет название функции. Затем после названия в скобках указывается список параметров. Если функция возвращает какое-либо значение, то после списка параметров через запятую можно указать тип возвращаемого значения. И далее в фигурных скобках идет тело функции.
fun имя_функции (параметры) : возвращаемый_тип
Например, определим и вызовем функцию, которая просто выводит некоторую строку на консоль:
fun main() < hello() // вызов функции hello hello() // вызов функции hello hello() // вызов функции hello >// определение функции hello fun hello()
Функции можно определять в файле вне других функций или классов, сами по себе, как например, определяется функция main. Такие функции еще называют функциями верхнего уровня (top-level functions).
Здесь кроме главной функции main также определена функция hello, которая не принимает никаких параметров и ничего не возвращает. Она просто выводит строку на консоль.
Функция hello (и любая другая определенная функция, кроме main) сама по себе не выполняется. Чтобы ее выполнить, ее надо вызвать. Для вызова функции указывается ее имя (в данном случае «hello»), после которого идут пустые скобки.
Таким образом, если необходимо в разных частях программы выполнить одни и те же действия, то можно эти действия вынести в функцию, и затем вызывать эту функцию.
Предача параметров
Через параметры функция может получать некоторые значения извне. Параметры указываются после имени функции в скобках через запятую в формате имя_параметра : тип_параметра . Например, определим функцию, которая просто выводит сообшение на консоль:
fun main() < showMessage("Hello Kotlin") showMessage("Привет Kotlin") showMessage("Salut Kotlin") >fun showMessage(message: String)
Функция showMessage() принимает один параметр типа String . Поэтому при вызове функции в скобках необходимо передать значение для этого параметра: showMessage(«Hello Kotlin») . Причем это значение должно представлять тип String, то есть строку. Значения, которые передаются параметрам функции, еще назвают аргументами.
Консольный вывод программы:
Hello Kotlin Привет Kotlin Salut Kotlin
Другой пример — функция, которая выводит данные о пользователе на консоль:
fun main() < displayUser("Tom", 23) displayUser("Alice", 19) displayUser("Kate", 25) >fun displayUser(name: String, age: Int)
Функция displayUser() принимает два параметра — name и age. При вызове функции в скобках ей передаются значения для этих параметров. При этом значения передаются параметрам по позиции и должны соответствовать параметрам по типу. Так как вначале идет параметр типа String , а потом параметр типа Int , то при вызове функции в скобках вначале передается строка, а потом число.
Аргументы по умолчанию
В примере выше при вызове функций showMessage и displayUser мы обязательно должны предоставить для каждого их параметра какое-то определенное значение, которое соответствует типу параметра. Мы не можем, к примеру, вызвать функцию displayUser, не передав ей аргументы для параметров, это будет ошибка:
displayUser()
Однако мы можем определить какие-то параметры функции как необязательные и установить для них значения по умолчанию:
fun displayUser(name: String, age: Int = 18, position: String=»unemployed») < println("Name: $name Age: $age Position: $position") >fun main()
В данном случае функция displayUser имеет три параметра для передачи имени, возраста и должности. Для первого параметр name значение по умолчанию не установлено, поэтому для него значение по-прежнему обязательно передавать значение. Два последующих — age и position являются необязательными, и для них установлено значение по умолчанию. Если для этих параметров не передаются значения, тогда параметры используют значения по умолчанию. Поэтому для этих параметров в принципе нам необязательно передавать аргументы. Но если для какого-то параметра определено значение по умолчанию, то для всех последующих параметров тоже должно быть установлено значение по умолчанию.
Консольный вывод программы
Name: Tom Age: 23 Position: Manager Name: Alice Age: 21 Position: unemployed Name: Kate Age: 18 Position: unemployed
Именованные аргументы
По умолчанию значения передаются параметрам по позиции: первое значение — первому параметру, второе значение — второму параметру и так далее. Однако, используя именованные аргументы, мы можем переопределить порядок их передачи параметрам:
fun main()
При вызове функции в скобках мы можем указать название параметра и с помощью знака равно передать ему нужное значение.
При этом, как видно из последнего случае, необязательно все аргументы передавать по имени. Часть аргументов могут передаваться параметрам по позиции. Но если какой-то аргумент передан по имени, то остальные аргументы после него также должны передаваться по имени соответствующих параметров.
Также если до обязательного параметра функции идут необязательные параметры, то для обязательного параметра значение передается по имени:
fun displayUser(age: Int = 18, name: String) < println("Name: $name Age: $age") >fun main()
Изменение параметров
По умолчанию все параметры функции равносильны val-переменным, поэтому их значение нельзя изменить. Например, в случае следующей функции при компиляции мы получим ошибку:
fun double(n: Int) < n = n * 2 // !Ошибка - значение параметра нельзя изменить println("Значение в функции double: $n") >
Однако если параметр предствляет какой-то сложный объект, то можно изменять отдельные значения в этом объекте. Например, возьмем функцию, которая в качестве параметра принимает массив:
fun double(numbers: IntArray)< numbers[0] = numbers[0] * 2 println("Значение в функции double: $") > fun main() < var nums = intArrayOf(4, 5, 6) double(nums) println("Значение в функции main: $") >
Здесь функция double принимает числовой массив и увеличивает значение его первого элемента в два раза. Причем изменение элемента массива внутри функции приведет к тому, что также будет изменено значение элемента в том массиве, который передается в качестве аргумента в функцию, так как этот один и тот же массив. Консольный вывод:
Значение в функции double: 8 Значение в функции main: 8
Работа с файловой системой
Работа с настройками уровня activity и приложения позволяет сохранить небольшие данные отдельных типов (string, int), но для работы с большими массивами данных, такими как графически файлы, файлы мультимедиа и т.д., нам придется обращаться к файловой системе.
ОС Android построена на основе Linux. Этот факт находит свое отражение в работе с файлами. Так, в путях к файлам в качестве разграничителя в Linux использует слеш «/», а не обратный слеш «\» (как в Windows). А все названия файлов и каталогов являются регистрозависимыми, то есть «data» это не то же самое, что и «Data».
Приложение Android сохраняет свои данные в каталоге /data/data// и, как правило, относительно этого каталога будет идти работа.
Для работы с файлами абстрактный класс android.content.Context определяет ряд методов:
- boolean deleteFile (String name) : удаляет определенный файл
- String[] fileList () : получает все файлы, которые содержатся в подкаталоге /files в каталоге приложения
- File getCacheDir() : получает ссылку на подкаталог cache в каталоге приложения
- File getDir(String dirName, int mode) : получает ссылку на подкаталог в каталоге приложения, если такого подкаталога нет, то он создается
- File getExternalCacheDir() : получает ссылку на папку /cache внешней файловой системы устройства
- File getExternalFilesDir(String type) : получает ссылку на каталог /files внешней файловой системы устройства
- File getFileStreamPath(String filename) : возвращает абсолютный путь к файлу в файловой системе
- FileInputStream openFileInput(String filename) : открывает файл для чтения
- FileOutputStream openFileOutput (String name, int mode) : открывает файл для записи
Все файлы, которые создаются и редактируются в приложении, как правило, хранятся в подкаталоге /files в каталоге приложения.
Для непосредственного чтения и записи файлов применяются также стандартные классы Java из пакета java.io.
Итак, применим функционал чтения-записи файлов в приложении. Пусть у нас будет следующая примитивная разметка layout:
Поле EditText предназначено для ввода текста, а TextView — для вывода ранее сохраненного текста. Для сохранения и восстановления текста добавлены две кнопки.
Теперь в коде Activity пропишем обработчики кнопок с сохранением и чтением файла:
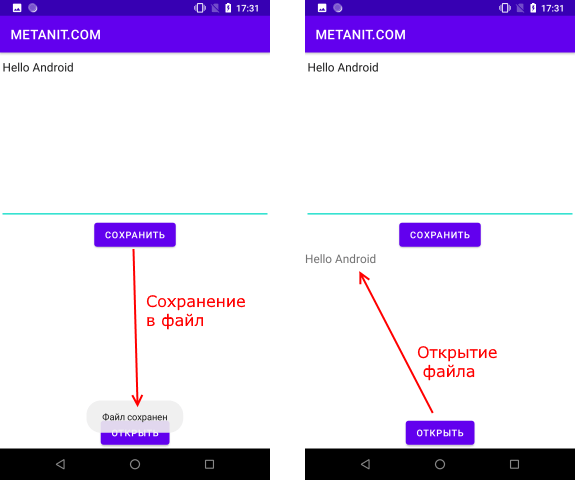
package com.example.filesapp; import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.view.View; import android.widget.EditText; import android.widget.TextView; import android.widget.Toast; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; public class MainActivity extends AppCompatActivity < private final static String FILE_NAME = "content.txt"; @Override protected void onCreate(Bundle savedInstanceState) < super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); >// сохранение файла public void saveText(View view) < FileOutputStream fos = null; try < EditText textBox = findViewById(R.id.editor); String text = textBox.getText().toString(); fos = openFileOutput(FILE_NAME, MODE_PRIVATE); fos.write(text.getBytes()); Toast.makeText(this, "Файл сохранен", Toast.LENGTH_SHORT).show(); >catch(IOException ex) < Toast.makeText(this, ex.getMessage(), Toast.LENGTH_SHORT).show(); >finally < try< if(fos!=null) fos.close(); >catch(IOException ex) < Toast.makeText(this, ex.getMessage(), Toast.LENGTH_SHORT).show(); >> > // открытие файла public void openText(View view) < FileInputStream fin = null; TextView textView = findViewById(R.id.text); try < fin = openFileInput(FILE_NAME); byte[] bytes = new byte[fin.available()]; fin.read(bytes); String text = new String (bytes); textView.setText(text); >catch(IOException ex) < Toast.makeText(this, ex.getMessage(), Toast.LENGTH_SHORT).show(); >finally < try< if(fin!=null) fin.close(); >catch(IOException ex) < Toast.makeText(this, ex.getMessage(), Toast.LENGTH_SHORT).show(); >> > >
При нажатии на кнопку сохранения будет создаваться поток вывода FileOutputStream fos = openFileOutput(FILE_NAME, MODE_PRIVATE)
В данном случае введенный текст будет сохраняться в файл «content.txt». При этом будет использоваться режим MODE_PRIVATE
Система позволяет создавать файлы с двумя разными режимами:
- MODE_PRIVATE : файлы могут быть доступны только владельцу приложения (режим по умолчанию)
- MODE_APPEND : данные могут быть добавлены в конец файла
Поэтому в данном случае если файл «content.txt» уже существует, то он будет перезаписан. Если же нам надо было дописать файл, тогда надо было бы использовать режим MODE_APPEND:
FileOutputStream fos = openFileOutput(FILE_NAME, MODE_APPEND);
Для чтения файла применяется поток ввода FileInputStream :
FileInputStream fin = openFileInput(FILE_NAME);
Подробнее про использование потоков ввода-вывода можно прочитать в руководстве по Java: https://metanit.com/java/tutorial/6.3.php
В итоге после нажатия кнопки сохранения весь текст будет сохранен в файле /data/data/название_пакета/files/content.txt
Где физически находится созданный файл? Чтобы увидеть его на подключенном устройстве перейдем в Android Stud в меню к пункту View -> Tool Windows -> Device File Explorer
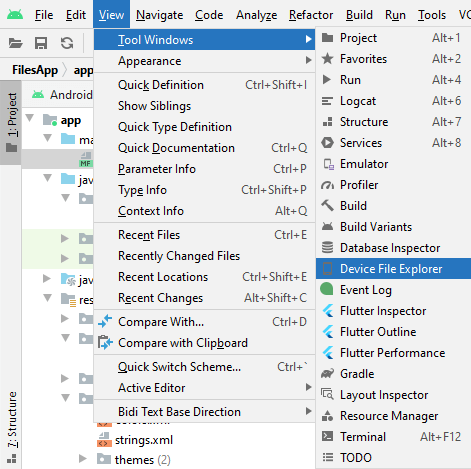
После этого откроектся окно Device File Explorer для просмотра файловой системы устройства. И в папке data/data/[название_пакета_приложения]/files мы сможем найти сохраненный файл.