Функции потерь (Loss Function) для алгоритмов машинного обучения

Функция потерь – это функция, которая принимает два значения – истинное (y) и прогнозируемое (ŷ), и возвращает оценку сравнения, насколько прогнозируемое значение близко к истинному. Чем меньше эта оценка, тем лучше, и наоборот — большие значения оценки указывают на то, что модель нуждается в доработке. Основная задача в процессе обучения нейронной сети, сводить к минимуму разницу между истинным и прогнозируемым значением в готовой модели.
Решаемые нейронными сетями задачи сводятся к двум глобальным категориям — регрессия и классификация. Функции потерь тоже можно разделить на эти две категории.
Функции потерь для задач классификации
Hinge Loss (потеря шарнира)
Данная функция разработана для оценки модели опорных векторов (SVM). В данном случае, чтобы понять принцип работы функции, необходимо понимать принцип работы опорных векторов.
Границы работы функции проходят в промежутке [-1; 1], при правильной классификации размер штрафа минимален, тогда как на неправильной классификации размер будет огромным.
Штраф – в случае функций потерь, это величина, которая добавляется к весовым коэффициентам, в зависимости от предсказанного значения, которое является результатом функции активации. Чем больше разница между предсказанным и фактическим значением, тем больше значение штрафа для значений функции активации.
При появлении большого количества таких штрафов (увеличение потерь) в процессе обучения может образоваться градиентный взрыв.
Бинарная кросс-энтропия и логарифмическая функция
В задачах бинарной классификации, чаще всего используется именно эта функция. Функция возвращает вероятность принадлежности к одному из классов в диапазоне [0, 1]. При этом потеря кросс-энтропии уменьшается, по мере схождения прогнозируемого и фактического значения.
Для работы с классификацией, где количество классов больше 2, используется кросс-энтропия, но с добавлением логарифмов.
Функции потерь для задач регрессии
Среднеквадратическая ошибка (MSE)
$$MSE=\frac\sum_^n(y_-\widetilde)$$
Определяется как среднее квадрата разности между фактическим и прогнозируемым значениями. За счет возведения в квадрат значения потери, функция наказывает модель за большие ошибки, то есть значения признака можно исключить из модели, так как это может быть шумом или выбросом. Поэтому для функции важно минимизировать выбросы, если это возможно. В противном случае, функция не рекомендуется для применения.
Среднеквадратичная ошибка (RMSE)
$$RMSE=\sqrt^n(y_-\widetilde)^2>>$$
В данном случае вычисление происходит путем извлечения квадратного корня из MSE. Также известна как среднеквадратичное отклонение. При значении RMSE равным нулю, считается, что модель идеальна. Не дает больших штрафов за ошибки, как есть в MSE.
В минусы функции можно отнести следующее: как и MSE зависима от данных и выбросов, а также от размера тестовой выборки.
Средняя абсолютная ошибка (MAE)
$$MAE=\frac\sum_^n|y_-\widetilde|$$
Возвращает среднее всех абсолютных значений разницы между фактическим и прогнозируемым. Данная функция, наоборот, более предпочтительна для работы с большим количеством выбросов. Так как функция работает с абсолютом (модулем), то все отрицательные значения становятся положительными, и соответственно, будут налагаться меньшие штрафы за большую разницу.
Из минусов можно выделить следующее:
- Большие ошибки могут иметь то же влияние, что и маленькие.
- Вычисление градиентов может быть осложнено.
Средняя абсолютная ошибка в процентах (MAPE)
Отличием от MAE будет в том, что добавляется деление на фактическое значение, к которому применяется процент, а далее, как и в МАЕ – высчитывается среднее значение. Также известна как среднее абсолютное процентное отклонение – MAPD.
- Проблема деления на ноль, когда истинное может быть нулем.
- Предвзятое поведение в отношении отрицательных ошибок – налагается больший штраф, чем за положительные.
Средняя ошибка смещения (MBE)
Значение функции — это разница между прогнозируемым и фактическим значением. Функция фиксирует только смещение в прогнозе. Положительное смещение означает, что ошибка завышена, отрицательная – занижена. Похожа на функцию MAE, с единственным отличием – здесь нет абсолюта.
- Ошибки компенсируют друг друга, и процесс обучения выпадает в затухание или градиентный взрыв
- Часто ошибается, беря одно направление. Например, может предсказывать меньшее значение, чем наблюдается.
Относительная абсолютная ошибка (RAE)
Вычисляется путем деления общей абсолютной ошибки на абсолютную разницу между средним и фактическим значением. Работает в диапазоне [0; 1], при этом обученная модель будет хорошей в том случае, если значения ошибок будут стремиться к нулю.
Функцию можно использовать для сравнения моделей, где используются разные loss-функции, и функция не подвержена влиянию выбросов.
Функция потерь Хьюбера (Huber loss)
Является комбинацией MAE и MSE, на больших значениях принимает абсолютные значения, а для малых — квадратичное. Граница, по которой будет проходить разделение, задается гиперпатаметром дельта, который может задаваться вручную, и он имеет решающее значение, поскольку именно дельта определяет, что именно считать выбросами. Возможен вариант, когда дельта гипермараметров обучается отдельно.
Логарифм гиперболического косинуса
Принцип работы схож с MSE, но не зависим от больших значений потерь. Вторым отличием функции является то, что у функции две производных, а это положительно влияет на процесс обучения – требует меньшего количества вычислений для сведения модели.
Впрочем, несмотря на то что на функцию не оказывают особого влияния большие значения, на очень больших выбросах она показывает себя неудовлетворительно.
Квантиль
А именно квантиль потерь и квантиль регрессии. Чаще всего применяется для прогноза интервалов в нейронных сетях и древовидных моделях. Основной принцип заключается в том, что необходимо определить значение квантиля, где функция будет штрафовать за переоценку или недостаточную оценку. В случае, если квантиль определен 50 перцентилем, то получается MAE.
Функция устойчива к выбросам, но требует больших вычислительных ресурсов.
В качестве заключения
Единой, универсальной функции для всех типов данных и решаемых задач не существует. Выбор функции потерь зависит от множества факторов, таких как наличие выбросов и их важность, алгоритм машинного обучения, достоверность прогнозов и задачи, которую необходимо решить.
Удачи в познании мира нейронных сетей!
© 2024. При использовании материалов ссылка на источник будет плюсом в карму
Функция потерь (Loss function)
В математической статистике и машинном обучении функция потерь — это функция, которая отображает некоторое событие в виде действительного числа, интуитивно представляя некоторую «стоимость», связанную с событием. Например, таким событием может быть допущение или не допущение клиентом просрочки по кредиту, а соответствующая функция потерь будет принимать два значения: 0 или 1.
В статистике функция потерь обычно используется для оценки параметров моделей, а рассматриваемое событие является разностью между оцененным и истинным значениями для каждого наблюдения набора данных.
Например, в контексте экономики это обычно экономические издержки или потери. В классификации это «штраф» модели за неправильное распознавание примера. В управлении потери могут быть издержками из-за неспособности достичь желаемого значения управляемых параметров. В управлении финансовыми рисками функция сопоставляется с денежными потерями.
Наиболее часто используемой является квадратичная функция потерь:
λ ( y ) = C ( y − y ′ ) 2 ,
где C — константа, y — истинное значение выхода модели (которое должно быть получено в идеальном случае), y ′ — фактический выход модели.
Преимуществом квадратичной функции потерь являются инвариантность к знаку — значение функции всегда положительно. Т.е. независимо от знака ошибки результат будет один и тот же. Квадратичная функция потерь используется в моделях, параметры которых оцениваются на основе метода наименьших квадратов, например, линейной регрессии.
В бинарной классификации используется двоичная функция потерь (0-1 loss function), которая определяется следующим образом:
L ( ^ y , y ) = f ( ^ y ≠ y ) .
Как видно, потери определяются появлением двух взаимоисключающих состояний выхода модели.
Используется также и простая функция потерь, равная разности истинного и фактического выходов модели:
L ( ^ y , y ) = f ( ^ y − y ) .
Она используется в тех случаях, где важен знак ошибки, например, при обучении нейронных сетей.
Что такое функция потерь (loss function) в нейросетях?

Обучение нейронных сетей является процессом, в котором сеть обучается на основе предоставленных данных с целью выполнения определенной задачи. В процессе обучения важную роль играет функция потерь (loss function), которая измеряет, насколько хорошо модель выполняет задачу на каждом шаге обучения. В данной статье мы рассмотрим, что представляет собой функция потерь, почему она важна для обучения нейросетей и какие виды функций потерь существуют.
Роль функции потерь в обучении нейронных сетей
Функция потерь является ключевым компонентом в процессе обучения нейронных сетей. Она используется для оценки того, насколько хорошо модель сети выполняет поставленную задачу. На каждом шаге обучения, сеть делает предсказания на основе входных данных, и функция потерь измеряет расхождение между предсказаниями и фактическими значениями. Затем это расхождение используется для корректировки параметров сети с помощью алгоритмов оптимизации, таких как градиентный спуск, с целью улучшения качества предсказаний.
Виды функций потерь
Существует множество различных функций потерь, каждая из которых подходит для определенного типа задачи или типа данных. Например, для задачи классификации, где предсказания модели должны относиться к определенным классам, часто используется категориальная кросс-энтропия. Для задач регрессии, где необходимо предсказать непрерывное значение, часто применяется среднеквадратичная ошибка. Кроме того, существуют специализированные функции потерь для задач с несбалансированными классами, для задач генерации изображений и многих других.
Свойства функций потерь

Хорошая функция потерь должна обладать несколькими важными свойствами. Во-первых, она должна быть дифференцируемой, чтобы ее можно было оптимизировать с помощью методов градиентного спуска. Во-вторых, она должна быть чувствительной к ошибкам и штрафовать большие расхождения между предсказаниями и фактическими значениями. Также важно, чтобы функция потерь была устойчива к выбросам и шуму в данных, чтобы не приводила к слишком большим изменениям параметров модели из-за непредставительных данных.
Примеры функций потерь
Одним из наиболее распространенных примеров функции потерь является среднеквадратичная ошибка (MSE), которая используется в задачах регрессии. Эта функция измеряет среднеквадратичное отклонение между предсказаниями модели и фактическими значениями. Еще одним примером является кросс-энтропия, которая штрафует модель за неправильные предсказания в задачах классификации. Для задачи обнаружения объектов на изображениях часто используется функция потерь, основанная на IoU (Intersection over Union), которая измеряет степень перекрытия между предсказанными и фактическими областями объектов.
Выбор функции потерь
Выбор подходящей функции потерь зависит от конкретной задачи, типа данных и особенностей модели. При выборе функции потерь необходимо учитывать, какие типы ошибок являются наиболее критическими для данной задачи, и какие свойства данных необходимо учесть. Например, если задача связана с классификацией изображений и классы несбалансированы, то целесообразно использовать функцию потерь, учитывающую этот факт. При этом также важно экспериментировать с различными функциями потерь и оценивать их влияние на качество модели, чтобы выбрать наиболее подходящую.
Функция потерь является ключевым аспектом в обучении нейронных сетей, определяя то, как модель оценивает свои предсказания и каким образом корректируются параметры сети в процессе обучения. Различные виды функций потерь подходят для различных задач и типов данных, и их выбор играет важную роль в достижении высокого качества модели. Понимание роли и свойств функций потерь является важным для успешного применения нейронных сетей в различных областях.
Вам также может быть интересно
Нейронные сети – это мощный инструмент в области искусственного интеллекта, который находит все большее применение в различных сферах: от распознавания образов до управления производственными процессами. Однако одним из основных вопросов, которые возникают.
Нейронные сети, как один из основных инструментов машинного обучения, позволяют решать широкий спектр задач, от распознавания образов до автоматического управления. Однако при работе с нейросетями возникает ряд проблем, одной из которых является переобучение.
Зачем важен правильный выбор данных? Правильный выбор данных для обучения нейросети является одним из ключевых моментов в процессе создания эффективной модели. Данные, на которых обучается нейронная сеть, определяют ее способность к обобщению и точность.
Обучение нейронных сетей стало широко распространенным методом для решения различных задач в области искусственного интеллекта. Однако, одной из основных проблем при работе с нейронными сетями является измерение качества обучения. Измерение качества.
Проблемы нейронных сетей
Нейронные сети считаются универсальными моделями в машинном обучении, поскольку позволяют решать широкий класс задач. Однако, при их использовании могут возникать различные проблемы.
Взрывающийся и затухающий градиент
Определение
Напомним, что градиентом в нейронных сетях называется вектор частных производных функции потерь по весам нейронной сети. Таким образом, он указывает на направление наибольшего роста этой функции для всех весов по совокупности. Градиент считается в процессе тренировки нейронной сети и используется в оптимизаторе весов для улучшения качества модели.
В процессе обратного распространения ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это в свою очередь может сделать нестабильным алгоритм обучения нейронной сети. В таком случае элементы градиента могут переполнить тип данных, в котором они хранятся. Такое явление называется взрывающимся градиентом (англ. exploding gradient).
Существует аналогичная обратная проблема, когда в процессе обучения при обратном распространении ошибки через слои нейронной сети градиент становится все меньше. Это приводит к тому, что веса при обновлении изменяются на слишком малые значения, и обучение проходит неэффективно или останавливается, то есть алгоритм обучения не сходится. Это явление называется затухающим градиентом (англ. vanishing gradient).
Таким образом, увеличение числа слоев нейронной сети с одной стороны увеличивает ее способности к обучению и расширяет ее возможности, но с другой стороны может порождать данную проблему. Поэтому для решения сложных задач с помощью нейронных сетей необходимо уметь определять и устранять ее.
Причины
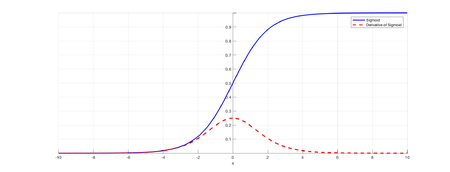
Рисунок 1. График сигмоиды и ее производной [1]
Такая проблема может возникнуть при использовании нейронных сетях классической функцией активации (англ. activation function) сигмоиды (англ. sigmoid):
Эта функция часто используется, поскольку множество ее возможных значений — отрезок $[0, 1]$ — совпадает с возможными значениями вероятностной меры, что делает более удобным ее предсказание. Также график сигмоиды соответствует многим естественным процессам, показывающим рост с малых значений, который ускоряется с течением времени, и достигающим своего предела [2] (например, рост популяции).
Пусть сеть состоит из подряд идущих нейронов с функцией активации $\sigma(x)$; функция потерть (англ. loss function) $L(y) = MSE(y, \hat) = (y — \hat)^2$ (англ. MSE — Mean Square Error); $u_d$ — значение, поступающее на вход нейрону на слое $d$; $w_d$ — вес нейрона на слое $d$; $y$ — выход из последнего слоя. Оценим частные производные по весам такой нейронной сети на каждом слое. Оценка для производной сигмоиды видна из рисунка 1.
Откуда видно, что оценка элементов градиента растет экспоненциально при рассмотрении частных производных по весам слоев в направлении входа в нейронную сеть (уменьшения номера слоя). Это в свою очередь может приводить либо к экспоненциальному росту градиента от слоя к слою, когда входные значения нейронов — числа, по модулю большие $1$, либо к затуханию, когда эти значения — числа, по модулю меньшие $1$.
Однако, входные значения скрытых слоев есть выходные значения функций активаций предшествующих им слоев. В частности, сигмоида насыщается (англ. saturates) при стремлении аргумента к $+\infty$ или $-\infty$, то есть имеет там конечный предел. Это приводит к тому, что более отдаленные слои обучаются медленнее, так как увеличение или уменьшение аргумента насыщенной функции вносит малые изменения, и градиент становится все меньше. Это и есть проблема затухающего градиента.
Способы определения
Взрывающийся градиент
Возникновение проблемы взрывающегося градиента можно определить по следующим признакам:
- Модель плохо обучается на данных, что отражается в высоком значении функции потерь.
- Модель нестабильна, что отражается в значительных скачках значения функции потерь.
- Значение функции потерь принимает значение NaN .
Более непрозрачные признаки, которые могут подтвердить возникновение проблемы:
- Веса модели растут экспоненциально.
- Веса модели принимают значение NaN .
Затухающий градиент
Признаки проблемы затухающего градиента:
- Точность модели растет медленно, при этом возможно раннее срабатывание критерия останова, так как алгоритм может решить, что дальнейшее обучение не будет оказывать существенного влияния.
- Градиент ближе к концу показывает более сильные изменения, в то время как градиент ближе к началу почти не показывает никакие изменения.
- Веса модели уменьшаются экспоненциально во время обучения.
- Веса модели стремятся к $0$ во время обучения.
Способы устранения
Использование другой функции активации
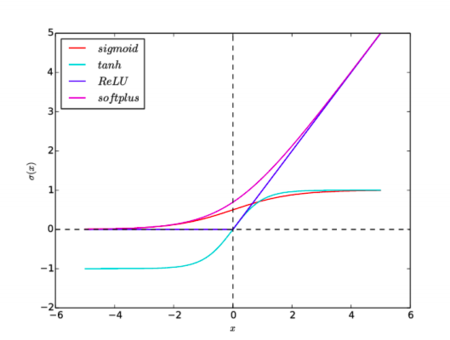
Рисунок 2. Графики функций активации: sigmoid, tanh, ReLU, softplus
Как уже упоминалось выше, подверженность нейронной сети проблемам взрывающегося или затухающего градиента во многом зависит от свойств используемых функций активации. Поэтому правильный их подбор важен для предотвращения описываемых проблем.
Tanh
Функция аналогична сигмоиде, но множество возможных значений: $[-1, 1]$. Градиенты при этом сосредоточены около $0$,. Однако, эта функция также насыщается в обоих направлениях, поэтому также может приводить к проблеме затухающего градиента.
ReLU
Функция проста для вычисления и имеет производную, равную либо $1$, либо $0$. Также есть мнение, что именно эта функция используется в биологических нейронных сетях. При этом функция не насыщается на любых положительных значениях, что делает градиент более чувствительным к отдаленным слоям.
Недостатком функции является отсутствие производной в нуле, что можно устранить доопределением производной в нуле слева или справа. Также эту проблему устраняет использование гладкой аппроксимации, Softplus.
Существуют модификации ReLU:
- Noisy ReLU: $h(x) = \max(0, x + \varepsilon), \varepsilon \sim N(0, \sigma(x))$.
- Parametric ReLU: $h(x) = \begin x & x > 0 \\ \beta x & \text \end$.
- Leaky ReLU: Paramtetric ReLU со значением $\beta = 0.01$.
Softplus
Гладкий, везде дифференцируемый аналог функции ReLU, следовательно, наследует все ее преимущества. Однако, эта функция более сложна для вычисления. Эмпирически было выявлено, что по качеству не превосходит ReLU.
Графики всех функций активации приведены на рисунок 2.
Изменение модели
Для решения проблемы может оказаться достаточным сокращение числа слоев. Это связано с тем, что частные производные по весам растут экспоненциально в зависимости от глубины слоя.
В рекуррентных нейронных сетях можно воспользоваться техникой обрезания обратного распространения ошибки по времени, которая заключается в обновлении весов с определенной периодичностью.
Использование Residual blocks
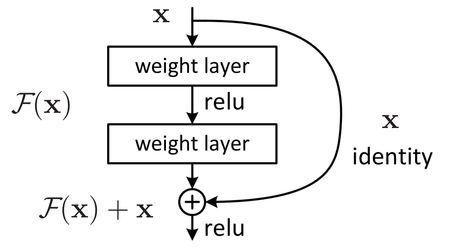
Рисунок 3. Устройство residual block [3]
В данной конструкции вывод нейрона подается как следующему нейрону, так и нейрону на расстоянии 2-3 слоев впереди, который суммирует его с выходом предшествующего нейрона, а функция активации в нем — ReLU (см. рисунок 3). Такая связка называется shortcut. Это позволяет при обратном распространении ошибки значениям градиента в слоях быть более чувствительным к градиенту в слоях, с которыми связаны с помощью shortcut, то есть расположенными несколько дальше следующего слоя.
Регуляризация весов
Регуляризация заключается в том, что слишком большие значения весов будут увеличивать функцию потерь. Таким образом, в процессе обучения нейронная сеть помимо оптимизации ответа будет также минимизировать веса, не позволяя им становиться слишком большими.
Обрезание градиента
Образание заключается в ограничении нормы градиента. То есть если норма градиента превышает заранее выбранную величину $T$, то следует масштабировать его так, чтобы его норма равнялась этой величине:
См. также
- Нейронные сети, перцептрон
- Обратное распространение ошибки
- Регуляризация
- Глубокое обучение
- Сверточные нейронные сети
Примечания
- ↑towardsdatascience.com — Derivative of the sigmoid function
- ↑wikipedia.org — Sigmoid function, Applications
- ↑wikipedia.org — Residual neural network
Источники
- Курс Machine Learning, ИТМО, 2020;
- towardsdatascience.com — The vanishing exploding gradient problem in deep neural networks;
- machinelearningmastery.com — Exploding gradients in neural networks.