Импорт и создание модулей
Питон включает в себя обширную библиотеку модулей, в которых реализовано множество полезных функций. Далее в этом курсе мы будем применять и другие полезные модули: re для регулярных выражений, collections , содержащий множество удобных структур данных, os и shutil для управления файлами и папками.
Для использования модуля его нужно импортировать — попросить питон загрузить его и сделать его функции доступными для использования. Импорт осуществляется с помощью оператора import . Например, модуль random используется для генерации “случайных” чисел.
>>> import random >>> # Теперь мы можем вызывать функции из модуля random, указав их имя после "random." с точкой >>> random.randint(0, 5) # выводит случайное целое число между 0 и 5 включительно 2 >>> random.choice('abcdef') # выберает случайный элемент коллекции 'c' >>> random.random() # Выводит случайное число на полуинтервале [0, 1) 0.9131300358342321 Ещё один пример: модуль math , содержащий различные математические функции и константы
>>> math.cos(0) # ошибка, модуль ещё не импортирован --------------------------------------------------------------------------- NameError Traceback (most recent call last) ipython-input-4-9cdcc157d079> in module>() ----> 1 math.cos(0) NameError: name 'math' is not defined >>> import math >>> math.cos(0) 1.0 >>> math.asin(1) 1.5707963267948966 >>> math.e 2.718281828459045 Использование псевдонимов
Если название модуля слишком длинное и вы не хотите его писать каждый раз, когда используете какую-то функцию, вы можете импортировать этот модуль под псевдонимом с помощью as:
>>> import math as m >>> m.factorial(5) 120 Импорт нескольких модулей
Модули можно импортировать в одну строчку через запятую, если требуется использовать несколько, либо можно писать каждый импорт на новой строчке.
>>> import random, math >>> math.sqrt(random.randint(0, 5)) 2.23606797749979 import random import math >>> math.sqrt(random.randint(0, 5)) 2.0 Инструкция from
Иногда в модуле бывает много разных функций, а вам нужно использовать только что-то одно (и, например, использовать много раз), тогда проще импортировать какую-то определенную функцию из этого модуля и (1) чуть-чуть сэкономить память, (2) короче синтаксис. Тогда синтаксис импорта будет следующий:
>>> from math import ceil, floor >>> ceil(145.3) 146 >>> floor(145.6) 145 Также можно импортировать из модуля всё. То есть все функции, переменные и классы. Тогда нам не нужно каждый раз писать название модуля.
>>> from math import * >>> sqrt(144) 12.0 >>> pi 3.141592653589793 Однако, это очень плохая практика так как в двух разных модулях могут быть одинаковые функции и при импорте вы просто не будете знать, какую используете.
Правило хорошего тона — импортировать модули вначале вашей программы, до любого другого кода и функций.
Создание своего модуля питон
Любой файл с исходным кодом на Python — модуль! Это значит, что любая программа может выступать в роли модуля для другой и импортироваться.
Давайте напишем скрипт с парой функций и импортируем эти функции в другую программу.
Создадим программу mymodule.py:
def avg(numbers): if not numbers: return 0 return sum(numbers) / len(numbers) def myfactorial(n): if n == 1: return n elif n 1: return ("NA") else: return n * myfactorial(n-1) В ней мы прописали две математические функции: среднее и факториал. Предположим теперь мы хотим воспользоваться ими в какой-нибудь другой программе myscript.py. Тогда мы положим эти два файла в одну директорию, чтобы импорт работал. И в результате мы сможем ипмортировать эти функции в новую программу.
Файл myscript.py:
import mymodule n = input("Введите число: ") my_list = [1] * (int(n)/2) + [2] * (int(n)/2) print(mymodule.avg(my_list)) print(mymodule.myfactorial(int(n))) Кстати, найдите баг в этом коде:
>>> [1] * (5/2) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) ipython-input-35-f37e9b720bb2> in module> ----> 1 [1] * (5/2) TypeError: can't multiply sequence by non-int of type 'float' >>> [1] * (5//2) [1, 1] Задача: составление анаграмм
В качестве примера использования функций и модуля стандартной библиотеки random рассмотрим задачу составления анаграмм. В качестве входного файла будем использовать любой текст, из которого мы выберем слова. Пусть текст находится в файле text.txt и имеет следующее содержание (из Яндекс.Рефератов):
Субъект вызывает мелодический импульс. Пласт параллельно понимает понимающий эриксоновский гипноз, следовательно тенденция к конформизму связана с менее низким интеллектом. Дифференциация, по определению, дает звукорядный бихевиоризм. Задача состоит в том, что необходимо составить файл формата TSV, состоящий из 4 колонок: слово из файла и три его случайных анаграммы. Для простоты анаграммы могут совпадать с самим словом или друг с другом. В итоге требуется получить файл table.tsv , который будет начинаться следующим образом:
субъект ъсукебт кутесъб кеубътс вызывает езтавыыв аыезыввт ывеаывзт мелодический скйчмеелидио диимечеслйок мкееийлчосид импульс млсупьи уьмипсл льмпиус пласт сатпл таслп тпалс . Полный код для решения этой задачи может выглядеть следующим образом:
"""Эта программа собирает слова из text.txt и составляет список анаграмм из них в таблице table.tsv""" # Здесь мы импортируем модуль стандартной библиотеки random, в котором # содержаться функции для работы с псевдослучайными числами. # Правило хорошего тона — делать все импорты в начале вашей программы. import random def words_from_file(filename): """Принимает имя файла, а точнее его системный путь, и возвращает список слов в нем """ with open(filename, encoding='utf-8') as f: # открвываем файл text = f.read() # прочитываем весь файл в строковую переменную text = text.replace('-', '') # удаляем дефисы text = text.replace(',', '').replace('.', '') # удаляем запятые и точки # Тут можно было почистить текст еще лучше text = text.lower() # заменяем все заглавные на строчные words = text.split() # получаем список слов return words # возвращаем список слов def anа(word): """Возвращает случайную анаграмму word""" # Функция random.sample(sequence, count) возвращает список из count # уникальных элементов последовательности (например списка или строки) # взятых в случайном порядке. Заметим, что каждый элемент не может быть # больше одного раза, а также напомним, что элементами строки являются # односимвольные строки. a = random.sample(word, len(word)) # получаем список перемешанных букв new_word = ''.join(a) # объединяем элементы списка из букв в одну строку return new_word # возвращаем анаграмму def create_tsv_table(table_filename, words, n_anа): """Создает TSV-файл с именем table_filename со строками типа слово→анаграмма→анаграмма. где список слов задается аргументом words, а число анаграмм — n_ana """ with open(table_filename, 'w', encoding='utf-8') as f: # открываем файл для записи for x in words: # перебираем слова в переменной x f.write(x) # запишем слово в файл for i in range(n_ana): # n_ana раз создадим и запишем анаграмму f.write('\t') # запишем разделитель f.write(ana(x)) # запишем случайную анаграмму f.write('\n') # не забудем поставить символ конца строки перед следующей строкой def main(): words = words_from_file('text.txt') # получаем список слов create_tsv_table('table.tsv', words, 3) # создаем таблицу с тремя анаграммами в каждой строке if __name__ == '__main__': main() Домашнее задание
Пусть какая-то функция получает на вход список из 30 случайных целых чисел от 0 до 100, сгенерированных с помощью модуля random. В вариантах описана функция.
+1 балл для всех: ответьте коротко на вопрос “Почему модуль random на самом деле НЕ генерирует случайные числа?”
- Функция берёт два случайных числа из этого списка (с помощью модуля random) и считает по ним количество всевозможных сочетаний этих чисел с точки зрения теории вероятности, С из n по k (использовать функцию из модуля math – factorial). Количество сочетаний (в формате float) печатается. k должно быть меньше n
- Функция возвращает произведение значений списка. Нужно пользоваться модулем math. Руководствоваться надо тем, что exp(log(a) + log(b)) = a * b
- Функция возвращает строку из 30 букв. Список, полученный на вход, задает порядок букв в строке по номеру буквы в алфавите.
- Функция берёт из списка 4 случайных числа, условно принимает их за две точки в двумерном пространстве и возвращает евклидово расстояние между этими точками. Использовать модули random и math.
- Функция перемешивает список с помощью random.shuffle(), сравнивает его с исходным списком и возвращает количество индексов, значение элемента по которым поменялось. Запустите функцию в цикле 100 раз и напечатайте в скольки процентов случаев меняются все элементы списка.
- Функция возвращает среднее геометрическое списка. Вомпользуйтесь модулем math. Отдельно вне функции покажите, что ее результат лежит между минимальным и максимальным значениями списка для 20 случаев. (Для это нужно на каждой итерации генерировать подаваемый на вход список заново)
- Функция возвращает среднее арифметическое элементов списка, округлённое вверх. Используйте модуль math.
5 разных библиотек Python, которые сэкономят ваше время

В этой подборке, переводом которой мы решили поделиться к старту курса о машинном и глубоком обучении, по мнению автора, каждая библиотека заслуживает отдельной статьи. Всё начинается с самого начала: предлагается библиотека, которая сокращает шаблонный код импортирования; заканчивается статья пакетом удобной визуализации данных для исследовательского анализа. Автор также касается работы с картами Google, ускорения и упрощения работы с моделями ML и библиотеки, которая может повысить качество вашего проекта в области обработки естественного языка. Посвящённый подборке блокнот Jupyter вы найдёте в конце.
PyForest
Когда вы начинаете писать код для проекта, каков ваш первый шаг? Наверное, вы импортируете нужные библиотеки. Проблема в том, что заранее неизвестно, сколько библиотек нужно импортировать, пока они вам не понадобятся, то есть пока вы не получите ошибку.
Вот почему PyForest — это одна из самых удобных библиотек, которые я знаю. С её помощью в ваш блокнот Jupyter можно импортировать более 40 популярнейших библиотек (Pandas, Matplotlib, Seaborn, Tensorflow, Sklearn, NLTK, XGBoost, Plotly, Keras, Numpy и другие) при помощи всего одной строки кода.
Выполните pip install pyforest. Для импорта библиотек в ваш блокнот введите команду from pyforest import *, и можно начинать. Чтобы узнать, какие библиотеки импортированы, выполните lazy_imports().

При этом с библиотеками удобно работать. Технически они импортируются только тогда, когда вы упоминаете их в коде. Если библиотека не упоминается, она не импортируется.
Emot
Эта библиотека может повысить качество вашего проекта по обработке естественного языка. Она преобразует эмотиконы в их описание. Представьте, например, что кто-то оставил в Твиттере сообщение “I ️️[здесь в оригинале эмодзи «красное сердце», новый редактор Хабра вырезает его] Python”. Человек не написал слово “люблю”, вместо него вставив эмодзи. Если твит задействован в проекте, придётся удалить эмодзи, а значит, потерять часть информации.
Вот здесь и пригодится пакет emot, преобразующий эмодзи в слова. Для тех, кто не совсем понял, о чём речь, эмотиконы — это способ выражения через символы. Например, 🙂 означает улыбку, а 🙁 выражает грусть. Как же работать с библиотекой?
Чтобы установить Emot, выполните команду pip install emot, а затем командой import emot импортируйте её в свой блокнот. Нужно решить, с чем вы хотите работать, то есть с эмотиконами или с эмодзи. В случае эмодзи код будет таким: emot.emoji(your_text). Посмотрим на emot в деле.
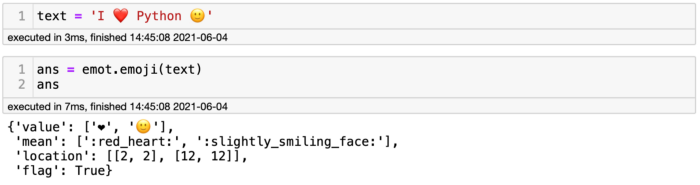
Выше видно предложение I ️ ️️[эмодзи «красное сердце»] Python, обёрнутое в метод Emot, чтобы разобраться со значениями. Код выводит словарь со значением, описанием и расположением символов. Как всегда, из словаря можно получить слайс и сосредоточиться на необходимой информации, например, если я напишу ans[‘mean’], вернётся только описание эмодзи.

Geemap
Говоря коротко, с её помощью можно интерактивно отображать данные Google Earth Engine. Наверное, вы знакомы с Google Earth Engine и всей его мощью, так почему не задействовать его в вашем проекте? За следующие несколько недель я хочу создать проект, раскрывающий всю функциональность пакета geemap, а ниже расскажу, как можно начать с ним работать.
Установите geemap командой pip install geemap из терминала, затем импортируйте в блокнот командой import geemap. Для демонстрации я создам интерактивную карту на основе folium:
import geemap.eefolium as geemap Map = geemap.Map(center=[40,-100], zoom=4) MapКак я уже сказал, я не изучил эту библиотеку настолько, насколько она того заслуживает. Но у неё есть исчерпывающий Readme о том, как она работает и что можно делать с её помощью.
Dabl
Позвольте мне рассказать об основах. Dabl создан, чтобы упростить работу с моделями ML для новичков. Чтобы установить её, выполните pip install dabl, импортируйте пакет командой import dabl — и можно начинать. Выполните также строчку dabl.clean(data), чтобы получить информацию о признаках, например о том, есть ли какие-то бесполезные признаки. Она также показывает непрерывные, категориальные признаки и признаки с высокой кардинальностью.
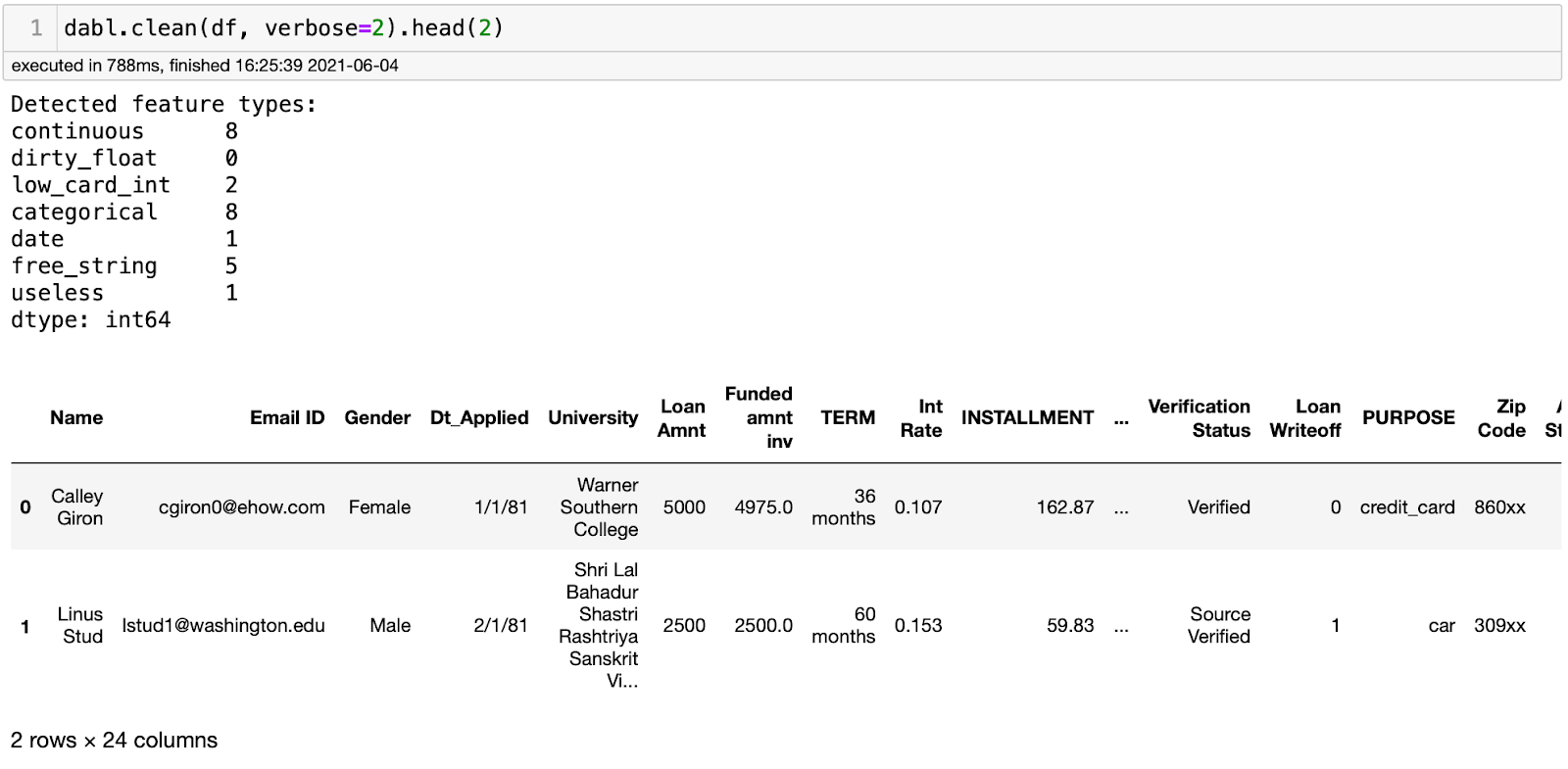
Чтобы визуализировать конкретный признак, можно выполнить dabl.plot(data).
Наконец, одной строчкой кода вы можете создать несколько моделей вот так: dabl.AnyClassifier, или так: dabl.Simplefier(), как это делается в scikit-learn. Но на этом шаге придётся предпринять некоторые обычные шаги, такие как создание тренировочного и тестового набора данных, вызов, обучение модели и вывод её прогноза.
# Setting X and y variables X, y = load_digits(return_X_y=True) # Splitting the dataset into train and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1) # Calling the model sc = dabl.SimpleClassifier().fit(X_train, y_train) # Evaluating accuracy score print(“Accuracy score”, sc.score(X_test, y_test))Как видите, Dabl итеративно проходит через множество моделей, включая Dummy Classifier (фиктивный классификатор), GaussianNB (гауссовский наивный Байес), деревья решений различной глубины и логистическую регрессию. В конце библиотека показывает лучшую модель. Все модели отрабатывают примерно за 10 секунд. Круто, правда? Я решил протестировать последнюю модель при помощи scikit-learn, чтобы больше доверять результату:

Я получил точность 0,968 с обычным подходом к прогнозированию и 0,971 — с помощью Dabl. Для меня это достаточно близко! Обратите внимание, что я не импортировал модель логистической регрессии из scikit-learn, поскольку это уже сделано через PyForest. Должен признаться, что предпочитаю LazyPredict, но Dabl стоит попробовать.
SweetViz
Это low-code библиотека, которая генерирует прекрасные визуализации, чтобы вывести ваш исследовательский анализ данных на новый уровень при помощи всего двух строк кода. Вывод библиотеки — интерактивный файл HTML. Давайте посмотрим на неё в общем и целом. Установить её можно так: pip install sweetviz, а импортировать в блокнот — строкой import sweetviz as sv. И вот пример кода:
my_report = sv.analyze(dataframe) my_report.show_html()Вы видите это? Библиотека создаёт HTML-файл с исследовательским анализом данных на весь набор данных и разбивает его таким образом, что каждый признак вы можете проанализировать отдельно. Возможно также получить численные или категориальные ассоциации с другими признаками; малые, большие и часто встречающиеся значения. Также визуализация изменяется в зависимости от типа данных. При помощи SweetViz можно сделать так много, что я даже напишу о ней отдельный пост, а пока настоятельно рекомендую попробовать её.

Заключение
Все эти библиотеки заслуживают отдельной статьи и того, чтобы вы узнали о них, потому что они превращают сложные задачи в прямолинейно простые. Работая с этими библиотеками, вы сохраняете драгоценное время для действительно важных задач. Я рекомендую попробовать их, а также исследовать не упомянутую здесь функциональность. На Github вы найдёте блокнот Jupyter, который я написал, чтобы посмотреть на эти библиотеки в деле.
Этот материал не только даёт представление о полезных пакетах экосистемы Python, но и напоминает о широте и разнообразии проектов, в которых можно работать на этом языке. Python предельно лаконичен, он позволяет экономить время и в процессе написания кода, выражать идеи максимально быстро и эффективно, то есть беречь силы, чтобы придумывать новые подходы и решения задач, в том числе в области искусственного интеллекта, получить широкое и глубокое представление о котором вы можете на нашем курсе «Machine Learning и Deep Learning».

Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
- Профессия Data Scientist
- Профессия Data Analyst
- Курс по Data Engineering
ПРОФЕССИИ
- Профессия Fullstack-разработчик на Python
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по Machine Learning
- Курс «Machine Learning и Deep Learning»
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс «Python для веб-разработки»
- Курс «Алгоритмы и структуры данных»
- Курс по аналитике данных
- Курс по DevOps
Тест по дисциплине «Алгоритмизация и программирование»

Председатель цикловой комиссии __________Мукушева Л.А.
Тест по дисциплине «Алгоритмизация и программирование»
- Язык программирования Python подходит для разработки:
- Компьютерных и мобильных приложений
- Аналитика и машинное обучение
- Игр
- Ничего из этого.
- Аккумулятор
- Назовите тип алгоритма:
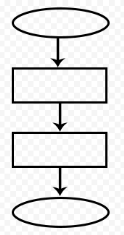
- Разветвляющийся
- Линейный
- Циклический
- Смешанный
- Комбинированный
- Назовите тип алгоритма:
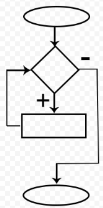
- Линейный
- Разветвляющийся
- Циклический
- Смешанный
- Комбинированный
- Назовите тип алгоритма:
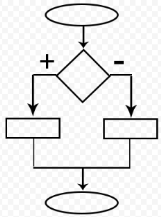
- Разветвляющийся
- Линейный
- Смешанный
- Циклический
- Комбинированный
- Что хранит в себе переменная?
- Имя
- Значение
- Тип
- Длину своего значения
- Периметр
- Что обозначает тип данных int?
- Целочисленное
- Вещественное
- Строковое
- Булевое
- Логическое
- Выберите правильную запись оператора присваивания:
- 10 = х
- у = 7,8
- а = 5
- а == b + x
- а — b
- Укажите оператор ввода:
- input()
- print()
- int()
- random()
- cout()
- Сколько возможных значений у переменной типа bool?
- 2
- 4
- 10
- Сколько угодно
- 15
- Какой оператор здесь используется?
If n b = n + a
- Условный оператор
- Оператор присваивания
- Оператор сложения
- Оператор умножения
- Оператор цикла
- Что лучше использовать для множественного ветвления?
- if – elif –else
- Много if
- if – else – elif
- while
- for
- Оператор цикла в языке Python:
- while
- for
- if
- real
- Сколько раз произойдет итерация цикла? (Итерация – единичное выполнение тела цикла)
print(“Осталось”, total) total = 100 i = 0 while i n = int(input()) total = total – n i = i + 1
- 4
- 5
- 6
- 0
- 8
- Для чего нужен оператор break?
- Для завершения программы
- Для выхода из цикла
- Для поломки компьютера
- Для удаления программы
- Для возврата программы
- Где находятся параметры, а где аргументы функции?
- Параметры пишутся при объявлении функции, аргументы при вызове
- Аргументы пишутся при объявлении функции, параметры при вызове
- Это одно и то же!
- У функции есть только параметры
- У функции нет параметров
- Что делает функция len()?
- Возвращает длину строки
- Возвращает случайное число
- Возвращает номер символа
- Возвращает модуль числа
- Возвращает значение
- Как добавить модуль в программу?
- import math
- import math()
- import (math)
- import.math
- import.**math
- На каких операционных системах может работать Python?
- Windows
- Linux
- macOS
- Ничего из этого
- Yandex
- От чего язык программирования называется «Питон»?
- В честь змеи
- В честь ТВ-шоу
- В честь игры
- В честь блюда
- В честь собаки
- Создатель языка программирования Python
- Гвидо Ван Россум
- Дэвид Паттерсон
- Эрвин Дональд Кнут
- Джеймс Артур Гослинг
- Никлаус Вирт
- а = 345. Что выведет команда print(//100)
- 3
- 5
- 4
- 34
- 95
- Выберите циклический алгоритм
- k = 0
- a = int(input())
- a = int(input())
- В какой строке правильно записан ввод числа с клавиатуры?
- a = int(input))
- b=input(int())
- c=int(input())
- s=a+b+c
- print(s)
- 1
- 2
- 5
- 4
- 6
- Что такое «else»?
- Так как
- Иначе
- Если
- Потому что
- Начало
- Сколько раз программа напишет слово «Пока»?
- 9
- 0
- 10
- Бесконечно
- -5
- Как получить данные от пользователя?
- Использовать метод get()
- Использовать метод cin()
- Использовать метод read()
- Использовать метод readLine()
- Использовать метод input()
- Что покажет этот код?
- Ошибку в коде
- «Найдено» и «Готово»
- «Готово»
- «Найдено»
- Нет правильного ответа
- Что будет результатом этого кода?
- 23
- 10
- 11
- Ошибка
- 0
- Какие ошибки допущены в коде ниже?
- Функция не может вызывать сама себя
- Необходимо указать тип возвращаемого значения
- Функция всегда будет возвращать 1
- В коде нет никаких ошибок
- Нет правильного ответа
- Где правильно создана переменная?
- int num = 2
- Нет подходящего варианта
- var num = 2
- $num = 2
- num = float(2)
- Что будет показано в результате?
- «Hi, name»
- «Hi, «
- Ошибка
- «Hi, John»
- «John»
- Какая функция выводит что-либо в консоль?
- write();
- log();
- out();
- print();
- cin();
- Какая библиотека отвечает за время?
- localtime
- clock
- Time
- time
- Date
- Что покажет этот код?
- Ошибку, так как i не присвоена
- Ошибку из-за неверного вывода
- Числа: 1, 3 и 5
- Числа: 0, 2 и 4
- Числа: 1 и 3
- Сколько библиотек можно импортировать в один проект?
- Не более 3
- Не более 10
- Не более 5
- Не более 23
- Неограниченное количество
- Что будет получено в результате вычисления следующего выражения:
- 0
- 1
- 3
- None
- синтаксическая ошибка
- Какого типа значение получится в результате вычисления следующего выражения:
- str (строка)
- tuple (кортеж)
- это синтаксическая ошибка
- unicode (Unicode-строка)
- list (список)
- Какого типа значение получится в результате вычисления следующего выражения:
- str (строка)
- tuple (кортеж)
- это синтаксическая ошибка
- unicode (Unicode-строка)
- list (список)
- Что будет выведено следующей программой:
- 212
- 121
- 111
- 11 11 21
- 2211
1 A, B, C 11 A 21 A 31 E 2 B 12 A, B 22 A 32 D 3 C 13 B 23 C 33 D 4 A 14 B 24 C, D 34 D 5 B 15 A 25 B 35 E 6 A 16 A 26 B 36 E 7 C 17 A 27 E 37 D 8 A 18 A, B, C 28 D 38 C 9 A 19 B 29 E 39 E 10 A, B, C 20 A 30 D 40 A Python import, как и для чего?
В языке программирования Python подключение пакетов и модулей осуществляется с помощью import. Это позволяет распределять код по логическим «узлам» приложения(модели данных, обработчики, и тп.), что позволяет получить менее нагруженные кодом файлы.
- Повышается читаемость кода.
- Код логически разбит по «узлам», его поиск и дальнейший отлов ошибок становится понятнее и проще.
- Для разработки в команде это дает более четкое понимание, что и где делает каждый при выполнении «задания».
- Нужно понимать, что делается и для чего.
Как использовать import?
Синтаксис import в Python достаточно прост и интуитивно понятен:
# В данной строке импортируется something_we_want import something_we_want # В данной строке импортируется something_we_want, как aww(логично и просто) import something_we_want as aww # В данной строке импортируется из something_we_want something(логично и просто) from something_we_want import something # В данной строке импортируется из something_we_want something, как s(логично и просто) from something_we_want import something as s # Синтаксис as позволяет обращаться к импортируемому по новому нами описанному # далее имени(это работает только в рамках нашего файла)Что можно импортировать?
Для более глубокого понимания import стоит рассмотреть пример, представленный ниже.
def something(): pass somedata = 5# 1 случай import something_we_want something_we_want.something() import something_we_want print(something_we_want.somedata) # 2 случай import something_we_want as aww aww.something() import something_we_want as aww print(aww.somedata) # 3 случай from something_we_want import something something() from something_we_want import somedata print(somedata) # 4 случай from something_we_want import something as s s() from something_we_want import somedata as sd print(sd) # Классы импортируются по аналогии с функциямиКрасиво, читаемо и понятно.
В чем же подвох?
Но даже в таком простом примере есть подвох, о котором многие не догадываются(если вы начинающий программист, то лучше перейдите к следующему оглавлению).
Идеология Python достаточно интересна, что позволяет ему иметь низкий порог вхождения, низкое время написания кода, высокую читаемость, но именно в ней и кроется подвох.
По своему опыту использования данного языка, сложилось отчетливое ощущение главной идеи ООП(все есть объект). Что же в этом плохого?
Все файлы, функции и тд. это объект. Но что это за объект и класс стоят за файлами(модулями)?
Все просто, это любимый всеми программистами класс, использующий паттерн проектирования Singleton.
Поэтому при достаточно ветвистой структуре, импорт переменной и дальнейшая ее модификация может порождать достаточно не простые в понимании баги(переменная в своем цикле жизни может иметь любое значение и никаких гарантий нет).
Ветвистая структура приложения и существующие подходы импортирования
Часто в разработке приложений программисты пытаются разбить программу по логическим «узлам». Данный подход повышает читаемость и позволяет вести разработку в команде(один человек занимается реализацией одного «узла», второй другого). Так порождается структура приложения, которая зачастую виду сложности функционала является достаточно обширной(ветвистой, потому что имея одну точку входа откуда уже обрастая функционалом это становится похожим на дерево).
Пример ветвистой структуры:
Существует 2 подхода импортирования(лучше выбрать один и придерживаться его весь проект):
- Именованный(абсолютный)
- Неименованный(относительный)
Пример именованного импорта из models.py в auth.py:
# auth.py from app.models import UserПример неименованного импорта из models.py в auth.py:
# auth.py from ..models import User # Количество точек указывает на сколько (обьектов) мы поднимаемся от исходного. # В данном примере первая точка поднимает нас на уровень обьекта handlers, # А вторая точка поднимает нас на уровень обьекта appЭто два абсолютно разных подхода. В первом случае мы «идем» из «корня»(входной точки нашего приложения). Во втором случае мы «идем» от «листа»(нашего файла).
Плюсы и минусы подходов импорта: