Как запустить одновременно две бесконечные функции?
Есть бот на aiogram, он работает на пулинге. Он обрабатывает некоторый инпут с юзера, но есть еще и основная функция, которая играет каждую минуту. Одна из функции не играет вообще, в зависимости от того какую первую вызвал.
Пытался разделить на потоки, 1 раз работают оба элемента, потом выключаются. Это если использовать thread.join(), а если на join() не разделять, то работает только один поток всегда. Подскажите как решить?
def main(): while True: db = downloadCSV() print("db downloaded") sticker_list = getAllWantedStickers(telegramId) notifyAboutSticker(db, sticker_list) if os.path.exists(db): os.remove(db) time.sleep(10) if __name__=="__main__": #while True: thread1 = Thread(target=main()) thread2 = Thread(target=executor.start_polling(dp)) thread1.start() thread2.start()- Вопрос задан более двух лет назад
- 486 просмотров
Способы реализации параллельных вычислений в программах на Python
Параллелизм дает возможность работать над несколькими вычислениями одновременно в одной программе. Такого поведения в Python можно добиться несколькими способами:
- Используя многопоточность threading , позволяя нескольким потокам работать по очереди.
- Используя несколько ядер процессора multiprocessing . Делать сразу несколько вычислений, используя несколько ядер процессора. Это и называется параллелизмом.
- Используя асинхронный ввод-вывод с модулем asyncio . Запуская какую то задачу, продолжать делать другие вычисления, вместо ожидания ответа от сетевого подключения или от операций чтения/записи.
Разница между потоками и процессами.
Поток threading — это независимая последовательность выполнения каких то вычислений. Поток thread делит выделенную память ядру процессора, а также его процессорное время со всеми другими потоками, которые создаются программой в рамках одного ядра процессора. Программы на языке Python имеют, по умолчанию, один основной поток. Можно создать их больше и позволить Python переключаться между ними. Это переключение происходит очень быстро и кажется, что они работают параллельно.
Понятие процесс в multiprocessing — представляет собой также независимую последовательность выполнения вычислений. В отличие от потоков threading , процесс имеет собственное ядро и следовательно выделенную ему память, которое не используется совместно с другими процессами. Процесс может клонировать себя, создавая два или более экземпляра в одном ядре процессора.
Асинхронный ввод-вывод не является ни потоковым ( threading ), ни многопроцессорным ( multiprocessing ). По сути, это однопоточная, однопроцессная парадигма и не относится к параллельным вычислениям.
У Python есть одна особенность, которая усложняет параллельное выполнение кода. Она называется GIL, сокращенно от Global Interpreter Lock. GIL гарантирует, что в любой момент времени работает только один поток. Из этого следует, что с потоками невозможно использовать несколько ядер процессора.
GIL был введен в Python потому, что управление памятью CPython не является потокобезопасным. Имея такую блокировку Python может быть уверен, что никогда не будет условий гонки.
Что такое условия гонки и потокобезопасность?
- Состояние гонки возникает, когда несколько потоков могут одновременно получать доступ к общей структуре данных или местоположению в памяти и изменять их, вследствии чего могут произойти непредсказуемые вещи. Пример из жизни: если два пользователя одновременно редактируют один и тот же документ онлайн и второй пользователь сохранит данные в базу, то перезапишет работу первого пользователя. Чтобы избежать условий гонки, необходимо заставить второго пользователя ждать, пока первый закончит работу с документом и только после этого разрешить второму пользователю открыть и начать редактировать документ.
- Потокобезопасность работает путем создания копии локального хранилища в каждом потоке, чтобы данные не сталкивались с другим потоком.
Алгоритм планирования доступа потоков к общим данным.
Как уже говорилось, потоки используют одну и ту же выделенную память. Когда несколько потоков работают одновременно, то нельзя угадать порядок, в котором потоки будут обращаются к общим данным. Результат доступа к совместно используемым данным зависит от алгоритма планирования. который решает, какой поток и когда запускать. Если такого алгоритма нет, то конечные данные могут быть не такими как ожидаешь.
Например, есть общая переменная a = 2 . Теперь предположим, что есть два потока, thread_one и thread_two . Они выполняют следующие операции:
a = 2 # функция 1 потока def thread_one(): global a a = a + 2 # функция 2 потока def thread_two(): global a a = a * 3
Если поток thread_one получит доступ к общей переменной a первым и thread_two вторым, то результат будет 12:
или наоборот, сначала запустится thread_two , а затем thread_one , то мы получим другой результат:
Таким образом очевидно, что порядок выполнения операций потоками имеет значение
Без алгоритмов планирования доступа потоков к общим данным такие ошибки очень трудно найти и произвести отладку. Кроме того, они, как правило, происходят случайным образом, вызывая беспорядочное и непредсказуемое поведение.
Есть еще худший вариант развития событий, который может произойти без встроенной в Python блокировки потоков GIL . Например, если оба потока начинают читать глобальную переменную a одновременно, оба потока увидят, что a = 2 , а дальше, в зависимости от того какой поток произведет вычисления последним, в конечном итоге и будет равна переменная a (4 или 6). Не то, что ожидалось!
Исследование разных подходов к параллельным вычислениям в Python.
Определим функцию, которую будем использовать для сравнения различных вариантов вычислений. Во всех следующих примерах используется одна и та же функция, называемая heavy() :
def heavy(n): for x in range(1, n): for y in range(1, n): x**y
Функция heavy() представляет собой вложенный цикл, который выполняет возведение в степень. Это функция связана со скоростью ядра процессора производить математические вычисления. Если понаблюдать за операционной системой во время выполнения функции, то можно увидеть загрузку ЦП близкую к 100%.
Будем запускать эту функцию по-разному, тем самым исследуя различия между обычной однопоточной программой Python, многопоточностью и многопроцессорностью.
Однопоточный режим работы.
Каждая программа Python имеет по крайней мере один основной поток. Ниже представлен пример кода для запуска функции heavy() в одном основном потоке одного ядра процессора, который производит все операции последовательно и будет служить эталоном с точки зрения скорости выполнения:
import time def heavy(n): for x in range(1, n): for y in range(1, n): x**y def sequential(n): for i in range(n): heavy(500) print(f"n> циклов вычислений закончены") if __name__ == "__main__": start = time.time() sequential(80) end = time.time() print("Общее время работы: ", end - start) # 80 циклов вычислений закончены # Общее время работы: 23.573118925094604
Использование потоков threading .
В следующем примере будем использовать несколько потоков для выполнения функции heavy() . Также произведем 80 циклов вычислений. Для этого разделим вычисления на 4 потока, в каждом из которых запустим 20 циклов:
import threading import time def heavy(n, i, thead): for x in range(1, n): for y in range(1, n): x**y print(f"Цикл № i>. Поток thead>") def sequential(calc, thead): print(f"Запускаем поток № thead>") for i in range(calc): heavy(500, i, thead) print(f"calc> циклов вычислений закончены. Поток № thead>") def threaded(theads, calc): # theads - количество потоков # calc - количество операций на поток threads = [] # делим вычисления на `theads` потоков for thead in range(theads): t = threading.Thread(target=sequential, args=(calc, thead)) threads.append(t) t.start() # Подождем, пока все потоки # завершат свою работу. for t in threads: t.join() if __name__ == "__main__": start = time.time() # разделим вычисления на 4 потока # в каждом из которых по 20 циклов threaded(4, 20) end = time.time() print("Общее время работы: ", end - start) # Показано часть вывода # . # . # . # Общее время работы: 43.33752250671387
Однопоточный режим работы, оказался почти в 2 раза быстрее, потому что один поток не имеет накладных расходов на создание потоков (в нашем случае создается 4 потока) и переключение между ними.
Если бы у Python не было GIL, то вычисления функции heavy() происходили быстрее, а общее время выполнения программы стремилось к времени выполнения однопоточной программы. Причина, по которой многопоточный режим в данном примере не будет работать быстрее однопоточного — это вычисления, связанные с процессором и заключаются в GIL!
Если бы функция heavy() имела много блокирующих операций, таких как сетевые вызовы или операции с файловой системой, то применение многопоточного режима работы было бы оправдано и дало огромное увеличение скорости!
Это утверждение можно проверить смоделировав операции ввода-вывода при помощи функции time.sleep() .
import threading import time def heavy(): # имитации операций ввода-вывода time.sleep(2) def threaded(theads): threads = [] # делим операции на `theads` потоков for thead in range(theads): t = threading.Thread(target=heavy) threads.append(t) t.start() # Подождем, пока все потоки # завершат свою работу. for t in threads: t.join() print(f"theads> циклов имитации операций ввода-вывода закончены") if __name__ == "__main__": start = time.time() # 80 потоков - это неправильно и показано # чисто в демонстрационных целях threaded(80) end = time.time() print("Общее время работы: ", end - start) # 80 циклов имитации операций ввода-вывода закончены # Общее время работы: 2.008725881576538
Даже если воображаемый ввод-вывод делится на 80 потоков и все они будут спать в течение двух секунд, то код все равно завершится чуть более чем за две секунды, т. к. многопоточной программе нужно время на планирование и запуск потоков.
Примечание! Каждый процессор поддерживает определенное количество потоков на ядро, заложенное производителем, при которых он работает оптимально быстро. Нельзя создавать безгранично много потоков. При увеличении числа потоков на величину, большую, чем заложил производитель, программа будет выполняться дольше или вообще поведет себя непредсказуемым образом (вплоть до зависания).
Использование многопроцессорной обработки multiprocessing .
Теперь попробуем настоящую параллельную обработку с использованием модуля multiprocessing . Модуль multiprocessing во многом повторяет API модуля threading , поэтому изменения в коде будут незначительны.
Для того, чтобы произвести 80 циклов вычислений функции heavy() , узнаем сколько процессор имеет ядер, а потом поделим циклы вычислений на количество ядер.
import multiprocessing import time def heavy(n, i, proc): for x in range(1, n): for y in range(1, n): x**y print(f"Цикл № i> ядро proc>") def sequential(calc, proc): print(f"Запускаем поток № proc>") for i in range(calc): heavy(500, i, proc) print(f"calc> циклов вычислений закончены. Процессор № proc>") def processesed(procs, calc): # procs - количество ядер # calc - количество операций на ядро processes = [] # делим вычисления на количество ядер for proc in range(procs): p = multiprocessing.Process(target=sequential, args=(calc, proc)) processes.append(p) p.start() # Ждем, пока все ядра # завершат свою работу. for p in processes: p.join() if __name__ == "__main__": start = time.time() # узнаем количество ядер у процессора n_proc = multiprocessing.cpu_count() # вычисляем сколько циклов вычислений будет приходится # на 1 ядро, что бы в сумме получилось 80 или чуть больше calc = 80 // n_proc + 1 processesed(n_proc, calc) end = time.time() print(f"Всего n_proc> ядер в процессоре") print(f"На каждом ядре произведено calc> циклов вычислений") print(f"Итого n_proc*calc> циклов за: ", end - start) # Весь вывод показывать не будем # . # . # . # Всего 6 ядер в процессоре # На каждом ядре произведено 14 циклов вычислений # Итого 84 циклов вычислений за: 5.0251686573028564
Код выполнился почти в 5 раз быстрее. Это прекрасно демонстрирует линейное увеличение скорости вычислений от количества ядер процессора.
Использование многопроцессорной обработки с пулом.
Можно сделать предыдущую версию программы немного более элегантной, используя multiprocessing.Pool() . Объект пула, управляет пулом рабочих процессов, в который могут быть отправлены задания. Используя метод Pool.starmap() , можно произвести инициализацию функции sequential () для каждого процесса.
В целях эксперимента в функции запуска пула процессов pooled(core) предусмотрено ручное указание количества ядер процессора. Если не указывать значение core , то по умолчанию будет использоваться количество ядер процессора вашей системы, что является разумным выбором:
import multiprocessing import time def heavy(n, i, proc): for x in range(1, n): for y in range(1, n): x**y print(f"Вычисление № i> процессор proc>") def sequential(calc, proc): print(f"Запускаем поток № proc>") for i in range(calc): heavy(500, i, proc) print(f"calc> циклов вычислений закончены. Процессор № proc>") def pooled(core=None): # вычисляем количество ядер процессора n_proc = multiprocessing.cpu_count() if core is None else core # вычисляем количество операций на процесс calc = int(80 / n_proc) if 80 % n_proc == 0 else int(80 // n_proc + 1) # создаем список инициализации функции # sequential(calc, proc) для каждого процесса init = map(lambda x: (calc, x), range(n_proc)) with multiprocessing.Pool() as pool: pool.starmap(sequential, init) print (calc, n_proc, core) return (calc, n_proc, core) if __name__ == "__main__": start = time.time() # в целях эксперемента, укажем количество # ядер больше чем есть на самом деле calc, n_proc, n = pooled(20) end = time.time() text = '' if n is None else 'задано ' print(f"Всего text>n_proc> ядер процессора") print(f"На каждом ядре произведено calc> циклов вычислений") print(f"Итого n_proc*calc> циклов за: ", end - start) # Весь вывод показывать не будем # . # . # . # Всего задано 20 ядер процессора # На каждом ядре произведено 4 циклов вычислений # Итого 80 циклов за: 5.422096252441406
Из результатов работы видно, что время работы незначительно увеличилось.
Если запустить этот код, то можно проследить, что вычисления все равно происходят на том количестве ядер, которые имеются в процессоре. Только вычисления происходят поочередно — из за этого незначительное увеличение времени работы программы.
Выводы:
- Используйте модули threading или asyncio для программ, связанных с сетевым вводом-выводом, чтобы значительно повысить производительность.
- Используйте модуль multiprocessing для решения проблем, связанных с операциями ЦП. Этот модуль использует весь потенциал всех ядер в процессоре.
- КРАТКИЙ ОБЗОР МАТЕРИАЛА.
- Global Interpreter Lock (GIL)
Python: как сделать многопоточную программу
Когда-то давно мы делали простой таймер с напоминанием на Python. Он работал так:
- Мы спрашивали пользователя, о чём ему напомнить и через сколько минут.
- Программа на это время засыпала и ничего не делала.
- Как только время сна заканчивалось, программа просыпалась и выводила напоминание.
У такой схемы есть минус: мы не можем пользоваться программой и выделенными на неё ресурсами до тех пор, пока она не проснётся. Процессор по кругу гоняет пустые команды и ждёт, когда можно будет продолжить полезную работу. Чтобы процессор и программа могли во время работы таймера делать что-то ещё, используют потоки.
Что такое поток
В упрощённом виде потоки — это параллельно выполняемые задачи. По умолчанию используется один поток — это значит, что программа делает всё по очереди, линейно, без возможности делать несколько дел одновременно.
Но если мы сделаем в программе два потока задач, то они будут работать параллельно и независимо друг от друга. Одному потоку не нужно будет становиться на паузу, когда в другом что-то происходит.
�� Важно понимать, что поток — это высокоуровневое понятие из области программирования. На уровне вашего «железа» эти потоки всё ещё могут обсчитываться последовательно. Но благодаря тому, что они будут обсчитываться быстро, вам может показаться, что они работают параллельно.
Многопоточность
Представим такую ситуацию:
- У вас на руке смарт-часы, которые собирают данные о вашем пульсе, УФ-излучении и движениях. На смарт-часах работает программа, которая обрабатывает эти данные.
- Программа состоит из четырёх функций. Первая собирает данные с датчиков. Три другие обрабатывают эти данные и делают выводы.
- Пока первая функция не собрала нужные данные, ничего другого не происходит.
- Как только данные введены, запускаются три оставшиеся функции. Они не зависят друг от друга и каждая считает своё.
- Как только все три функции закончат работу, программа выдаёт нужный результат.
А теперь давайте посмотрим, как это выглядит в однопоточной и многопоточной системе. Видно, что если процессор позволяет делать несколько дел одновременно, в многопоточном режиме программа будет работать быстрее:
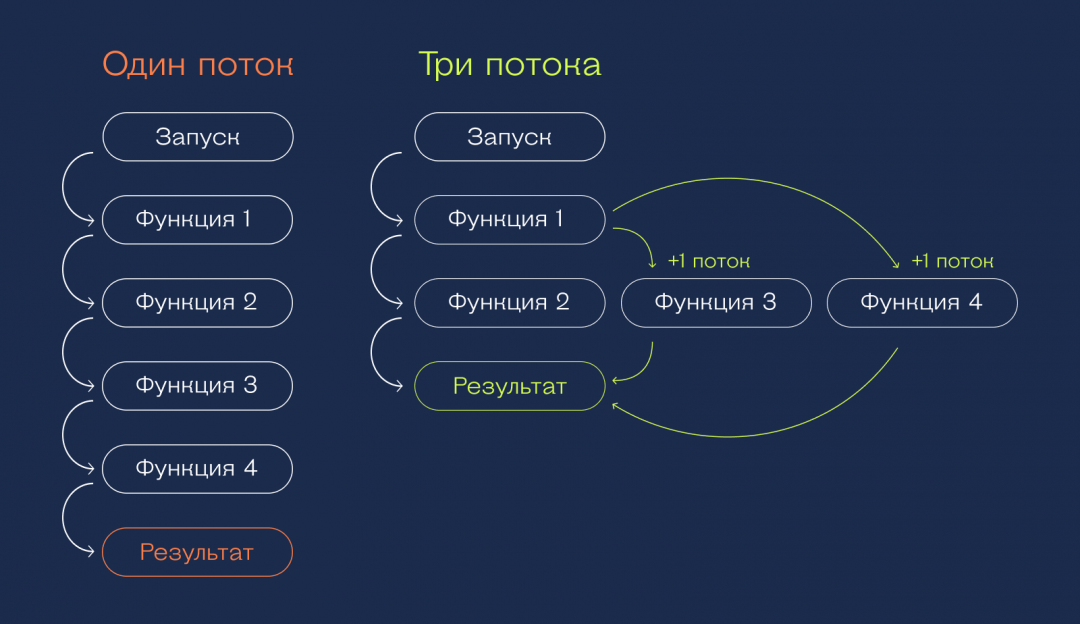
Многопоточность на Python
За потоки в Python отвечает модуль threading, а сам поток можно создать с помощью класса Thread из этого модуля. Подключается он так:
from threading import Thread
После этого с помощью функции Thread() мы сможем создать столько потоков, сколько нам нужно. Логика работы такая:
- Подключаем нужный модуль и класс Thread.
- Пишем функции, которые нам нужно выполнять в потоках.
- Создаём новую переменную — поток, и передаём в неё название функции и её аргументы. Один поток = одна функция на входе.
- Делаем так столько потоков, сколько требует логика программы.
- Потоки сами следят за тем, закончилась в них функция или нет. Пока работает функция — работает и поток.
- Всё это работает параллельно и (в теории) не мешает друг другу.
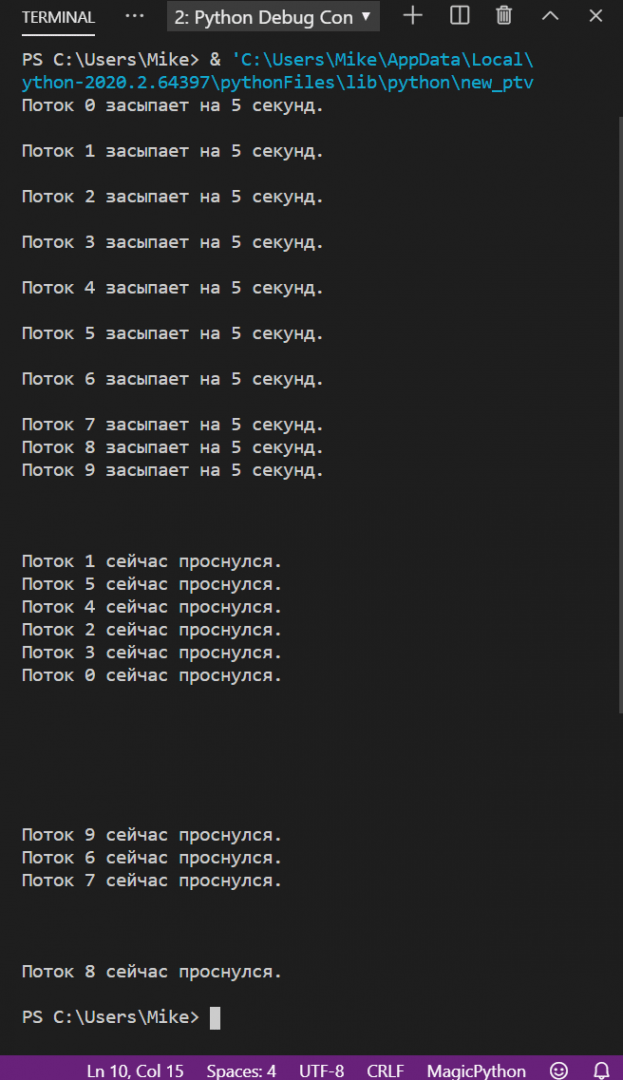
Для иллюстрации запустим такой код:
import time from threading import Thread def sleepMe(i): print("Поток %i засыпает на 5 секунд.\n" % i) time.sleep(5) print("Поток %i сейчас проснулся.\n" % i) for i in range(10): th = Thread(target=sleepMe, args=(i, )) th.start()А вот как выглядит результат. Обратите внимание — потоки просыпаются не в той последовательности, как мы их запустили, а в той, в какой их выполнил процессор. Иногда это может помешать работе программы, но про это мы поговорим отдельно в другой статье.
Добавляем потоки в таймер
Первое, что нам нужно сделать, — вынести код таймера-напоминания в отдельную функцию, чтобы создать с ней поток. Для этого используем команду def :
# Делаем отдельную функцию с напоминанием def remind(): # Спрашиваем текст напоминания, который нужно потом показать пользователю print("О чём вам напомнить?") # Ждём ответа пользователя и результат помещаем в строковую переменную text text = str(input()) # Спрашиваем про время print("Через сколько минут?") # Тут будем хранить время, через которое нужно показать напоминание local_time = float(input()) # Переводим минуты в секунды local_time = local_time * 60 # Ждём нужное количество секунд, программа в это время ничего не делает time.sleep(local_time) # Показываем текст напоминания print(text)Теперь сделаем новый поток, в который отправим выполняться нашу новую функцию. Так как аргументов у нас нет, то и аргументы передавать не будем, а напишем args=().
# Создаём новый поток
th = Thread(target=remind, args=())
# И запускаем его
th.start()
Нам осталось убедиться в том, что пока поток работает, мы можем выполнять в программе что-то ещё и наше засыпание в потоке на это не повлияет. Для этого мы через 20 секунд после запуска выведем сообщение на экран. За 20 секунд пользователь успеет ввести напоминание и время, после чего таймер уйдёт в новый поток и там уснёт на нужное количество минут. Но это не помешает работе основной программы — она тоже будет выполнять свои команды параллельно с потоком.
# Пока работает поток, выведем что-то на экран через 20 секунд после запуска
time.sleep(20)
print(«Пока поток работает, мы можем сделать что-нибудь ещё.\n»)
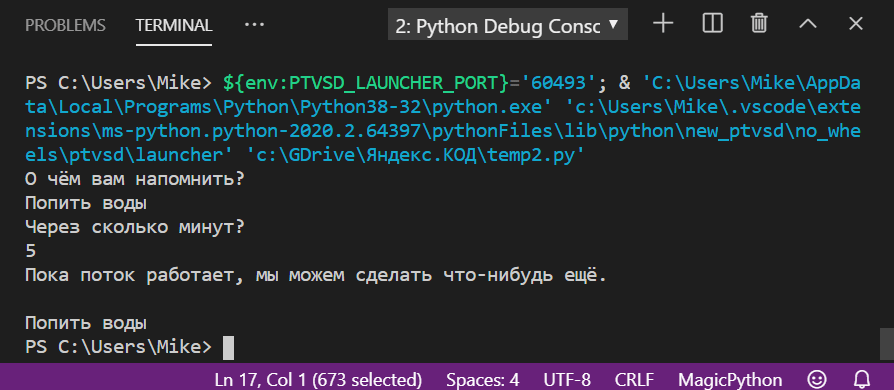
Готовый код
# Подключаем модуль для работы со временем import time # Подключаем потоки from threading import Thread # Делаем отдельную функцию с напоминанием def remind(): # Спрашиваем текст напоминания, который нужно потом показать пользователю print("О чём вам напомнить?") # Ждём ответа пользователя и результат помещаем в строковую переменную text text = str(input()) # Спрашиваем про время print("Через сколько минут?") # Тут будем хранить время, через которое нужно показать напоминание local_time = float(input()) # Переводим минуты в секунды local_time = local_time * 60 # Ждём нужное количество секунд, программа в это время ничего не делает time.sleep(local_time) # Показываем текст напоминания print(text) # Создаём новый поток th = Thread(target=remind, args=()) # И запускаем его th.start() # Пока работает поток, выведем что-то на экран через 20 секунд после запуска time.sleep(20) print("Пока поток работает, мы можем сделать что-нибудь ещё.\n")Потоки — это ещё не всё
В Python кроме потоков есть ещё очереди (queue) и управление процессами (multiprocessing). Про них мы поговорим отдельно.
Как работать с многопоточностью в Python
Освойте многопоточность в Python с примерами кода: создание потоков, синхронизация данных и использование ThreadPoolExecutor.
Алексей Кодов
Автор статьи
10 июля 2023 в 17:48
Многопоточность — это одновременное выполнение нескольких потоков в одном процессе. В Python для работы с многопоточностью используется модуль threading . В данной статье мы рассмотрим основы работы с многопоточностью и покажем примеры кода.
Создание потоков
Для создания потока вы можете использовать класс Thread из модуля threading . Вот пример создания и запуска двух потоков:
import threading def print_numbers(): for i in range(10): print(i) def print_letters(): for letter in 'abcdefghij': print(letter) # Создаем потоки thread1 = threading.Thread(target=print_numbers) thread2 = threading.Thread(target=print_letters) # Запускаем потоки thread1.start() thread2.start() # Ждем завершения потоков thread1.join() thread2.join()
В этом примере два потока выполняют функции print_numbers и print_letters одновременно. Вызов метода start() запускает поток, а метод join() блокирует выполнение основного потока до завершения вызываемого потока.
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Синхронизация потоков
При работе с многопоточностью важно обеспечить синхронизацию данных между потоками. Для этого в Python используются блокировки (Locks). Вот пример использования блокировок:
import threading # Создаем блокировку lock = threading.Lock() def safe_print(item): with lock: print(item) def print_numbers(): for i in range(10): safe_print(i) def print_letters(): for letter in 'abcdefghij': safe_print(letter) # Создаем потоки thread1 = threading.Thread(target=print_numbers) thread2 = threading.Thread(target=print_letters) # Запускаем потоки thread1.start() thread2.start() # Ждем завершения потоков thread1.join() thread2.join()
В этом примере мы создали блокировку lock и использовали ее в функции safe_print() для синхронизации доступа к функции print() . Таким образом, потоки не будут конфликтовать при выводе данных.
Работа с ThreadPoolExecutor
Для упрощения работы с потоками вы можете использовать класс ThreadPoolExecutor из модуля concurrent.futures . Вот пример использования ThreadPoolExecutor для выполнения задач параллельно:
from concurrent.futures import ThreadPoolExecutor def square(x): return x * x # Создаем ThreadPoolExecutor с 4-мя потоками with ThreadPoolExecutor(max_workers=4) as executor: # Запускаем задачи и получаем результаты results = list(executor.map(square, range(10))) print(results)
В этом примере мы создали ThreadPoolExecutor с 4 потоками и использовали метод map() для выполнения функции square() с аргументами от 0 до 9. Результаты выполнения функции собираются в список.
Теперь вы знаете основы работы с многопоточностью в Python и можете применять эти знания на практике. Удачного кодирования! ��