Pandas
Pandas — это библиотека Python для обработки и анализа структурированных данных, её название происходит от «panel data» («панельные данные»). Панельными данными называют информацию, полученную в результате исследований и структурированную в виде таблиц. Для работы с такими массивами данных и создан Pandas.

Освойте профессию «Аналитик данных»
Работа с открытым кодом
Pandas — это opensource-библиотека, то есть ее исходный код в открытом доступе размещен на GitHub. Пользователи могут добавлять туда свой код: вносить пояснения, дополнять методы работы и обновлять разделы. Для работы потребуется компилятор (программа, которая переводит текст с языка программирования в машинный код) C/C++ и среда разработки Python. Подробный процесс установки компилятора С для разных операционных систем можно найти в документации Pandas.
Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

В каких профессиях понадобится библиотека?
Навык работы с этой библиотекой пригодится дата-сайентистам или аналитикам данных. С помощью Pandas эти специалисты могут группировать и визуализировать данные, создавать сводные таблицы и делать выборку по определенным признакам.
Как установить Pandas
Пошаговая инструкция по установке библиотеки Pandas
-
Скачать библиотеку На официальном сайте Pandas указан самый простой способ начать работу с библиотекой. Для этого потребуется установить Anaconda — дистрибутив (форма распространения программного обеспечения, набор библиотек или программного кода для установки программы) для Python с набором библиотек. Безопасно скачать его можно на официальном сайте.
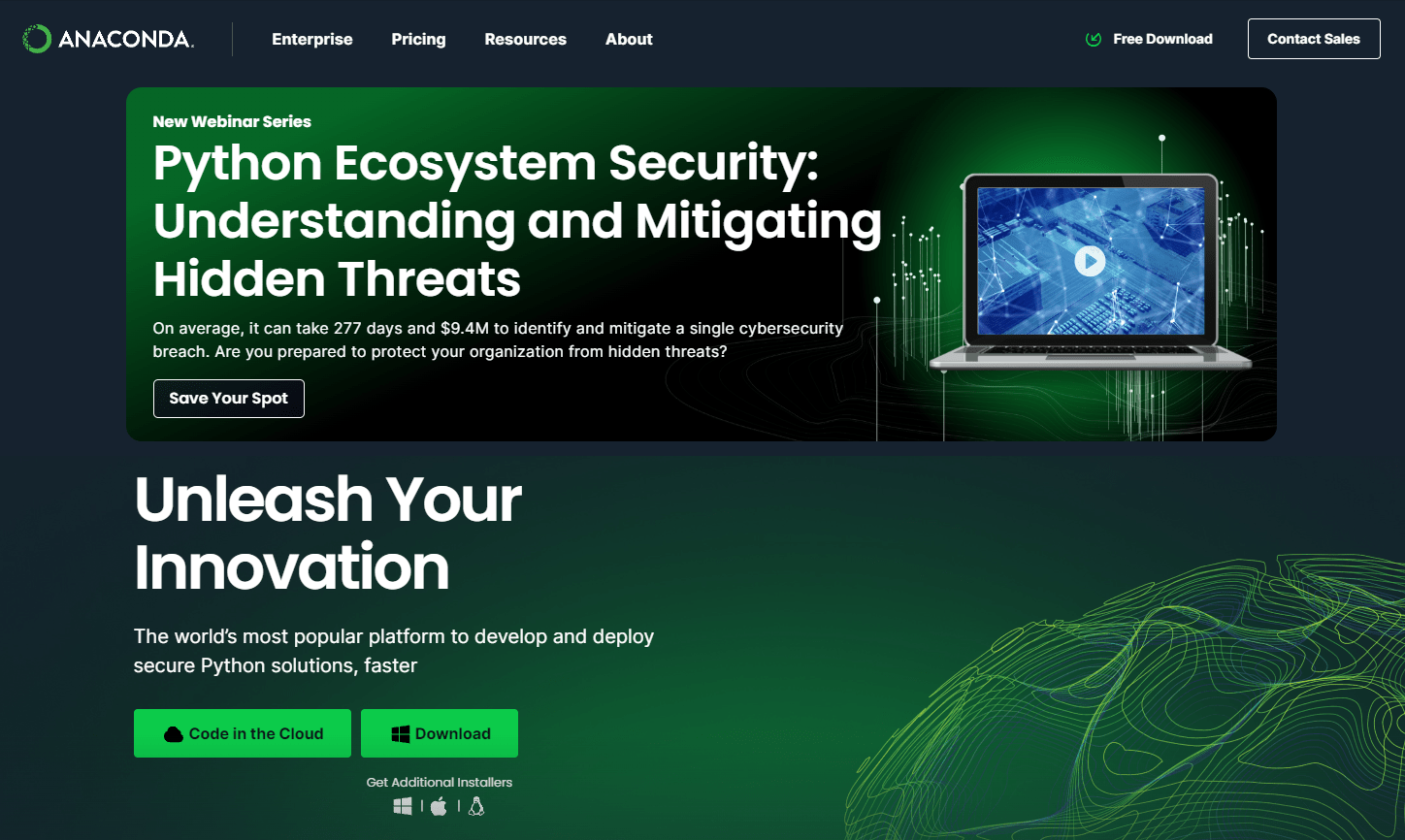
Настройка установки Вот несколько советов по установке Anaconda для новичков:
— Выбирайте рекомендованные настройки, на первое время этого будет достаточно. Например, Install for: Just me (recommended).
— Но если не поставить галочку «Add Anaconda to my PATH environment variable», то Anaconda не будет запускаться по умолчанию, каждый раз ее нужно будет запускать отдельно.
— На вопрос: «Do you wish to initialize Anaconda3?» (Хотите ли вы инициализировать Anaconda3?) отвечайте «Да».
— После завершения установки перезагрузите компьютер.
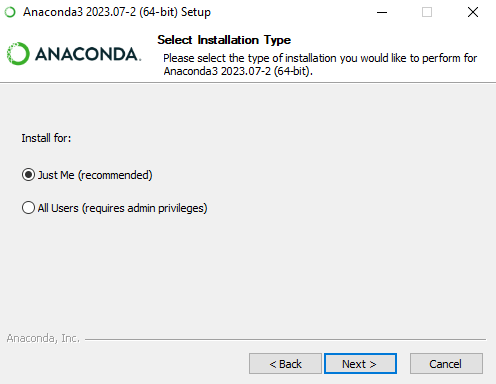
Запуск JupyterLab В командной строке Anaconda запустите JupyterLab — это интерактивная среда для работы с кодом, данными и блокнотами, которая входит в пакет дистрибутива. Для этого введите jupyter-lab .
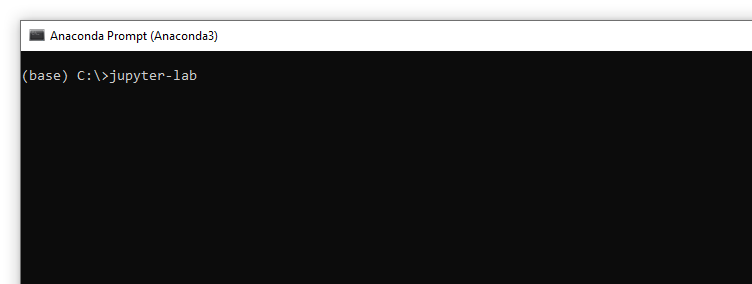
Открытие блокнота Создайте в JupyterLab новый блокнот Python3. Для его создания надо щелкнуть на значке «+», расположенном в верхней левой части интерфейса. В появившемся меню выбрать «Python 3» для создания блокнота.
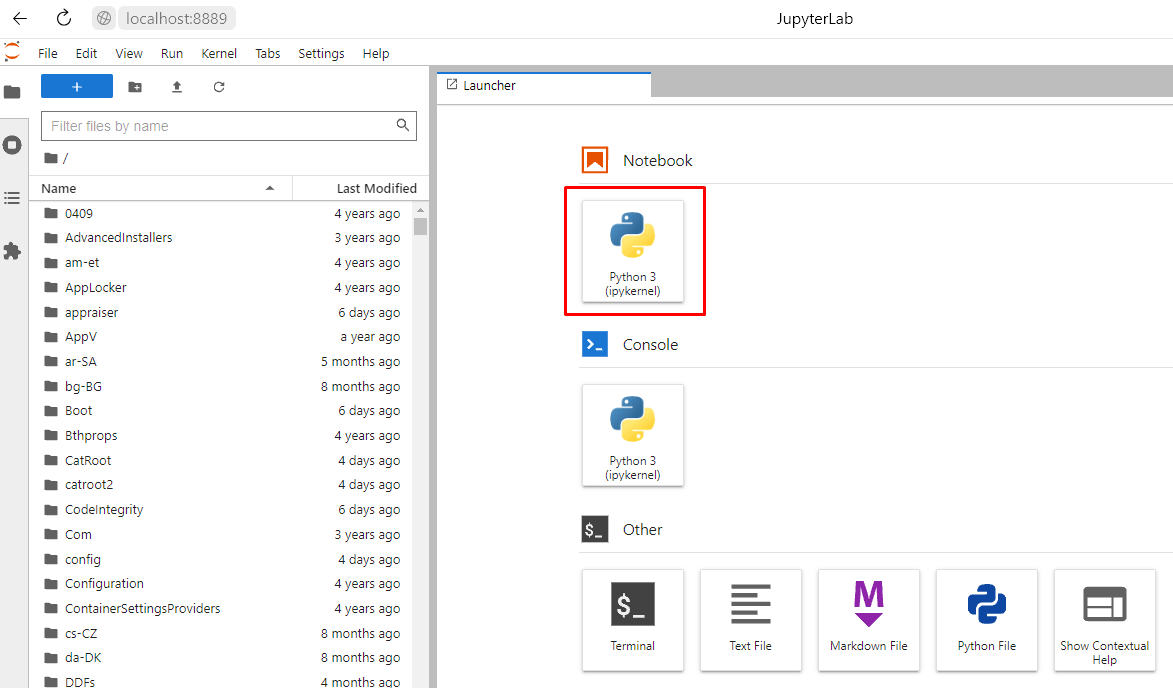
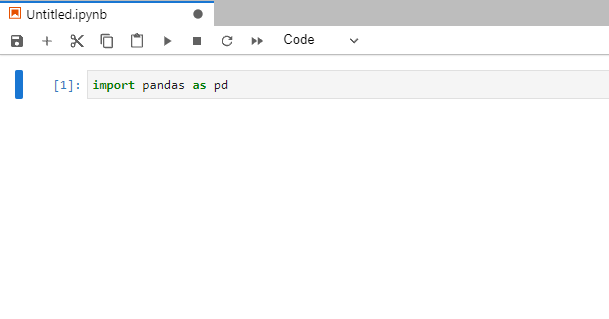
Импорт библиотеки В первой ячейке пропишите: import pandas as pd , после этого в следующих ячейках можно писать код.
Читайте также Как выбрать IT-специальность в новых реалиях?
DataFrame и Series
Чтобы анализировать данные с помощью Pandas, нужно понять, как устроены структуры этих данных внутри библиотеки. В первую очередь разберем, что такое DataFrame и Series.
Series
Pandas Series (серия) — это одномерный массив. Визуально он похож на пронумерованный список: слева в колонке находятся индексы элементов, а справа — сами элементы.
my_series = pd.Series([5, 6, 7, 8, 9, 10])
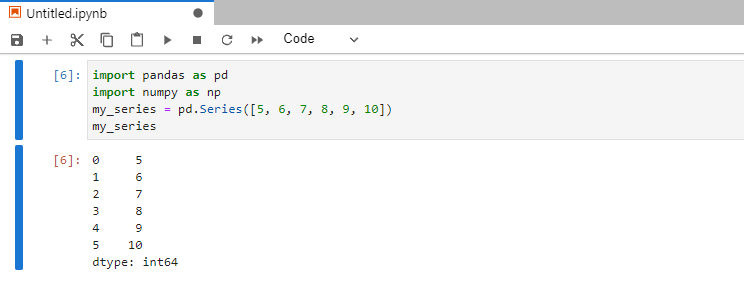
Индексом может быть числовой показатель (0, 1, 2…), буквенные значения (a, b, c…) или другие данные, выбранные программистом. Если особое значение не задано, то числовые индексы проставляются автоматически. Например, от 0 до 5 как в примере выше.
Такая нумерация называется RangeIndex, в ней всегда содержатся числа от 0 до определенного числа N, которое обозначает количество элементов в серии. Собственные значения индексов задаются в квадратных скобках через index, как в примере ниже:
my_series2 = pd.Series([5, 6, 7, 8, 9, 10]), index=['a', 'b', 'c', 'd', 'e', 'f'])

Индексы помогают обращаться к элементам серии и менять их значения. Например, чтобы в нашей серии [5, 6, 7, 8, 9, 10] заменить значения некоторых элементов на 0, мы прописываем индексы нужных элементов и указываем, что они равны нулю:
my_series2[['a', 'b', 'f']] = 0
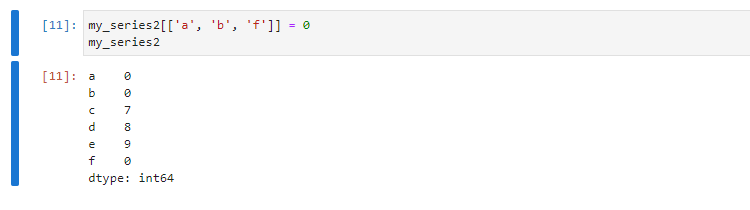
Можно сделать выборку по нескольким индексам, чтобы ненужные элементы в серии не отображались:
my_series2[['a', 'b', 'f']]
a 5 b 6 f 10 dtype: int64DataFrame
Pandas DataFrame — это двумерный массив, похожий на таблицу/лист Excel (кстати, данные из Excel можно читать с помощью команды pandas.read_excel(‘file.xls’)) . В нем можно проводить такие же манипуляции с данными: объединять в группы, сортировать по определенному признаку, производить вычисления. Как любая таблица, датафрейм состоит из столбцов и строк, причем столбцами будут уже известные объекты — Series.
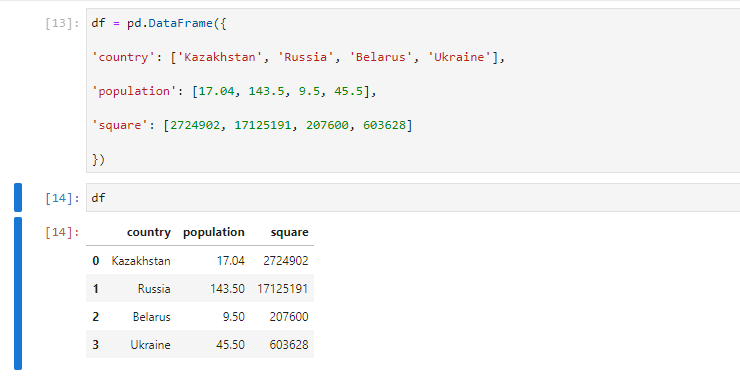
Чтобы проверить, действительно ли серии — это части датафрейма, можно извлечь любую колонку из таблицы. Возьмем набор данных о нескольких странах СНГ, их площади и населении и выберем колонку country:
df = pd.DataFrame(< 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], 'population': [17.04, 143.5, 9.5, 45.5], 'square': [2724902, 17125191, 207600, 603628] >)
В итоге получится простая серия, в которой сохранятся те же индексы по строкам, что и в исходном датафрейме:
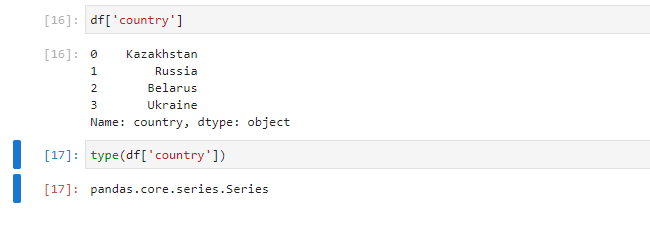
df['country']
type(df['country'])

Станьте аналитиком данных и получите востребованную специальность
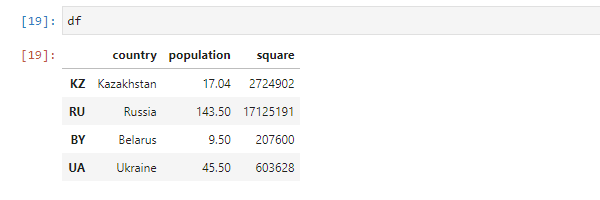
Кроме этого, у датафрейма есть индексы по столбцам, которые задаются вручную. Для простоты написания кода обозначим страны индексами из двух символов: Kazakhstan — KZ, Russia — RU и так далее:
# Создаем датафрейм с заданными индексами df = pd.DataFrame(< 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], 'population': [17.04, 143.5, 9.5, 45.5], 'square': [2724902, 17125191, 207600, 603628] >, index=['KZ', 'RU', 'BY', 'UA'])
# Изменяем индексы df.index = ['KZ', 'RU', 'BY', 'UA'] df.index.name = 'Country Code'
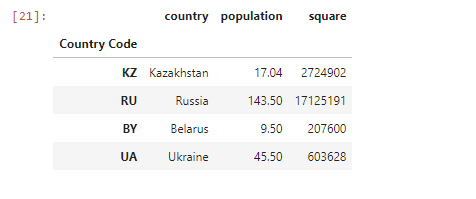
По индексам можно искать объекты и делать выборку, как в Series . Возьмем тот же датафрейм и сделаем выборку по индексам KZ, RU и колонке population методом .loc (в случае .loc мы используем квадратные скобки, а не круглые, как с другими методами), чтобы сравнить население двух стран:
df.loc[['KZ', 'RU'], 'population']
Anaconda выведет следующее:
Country Code
KZ 17.04
RU 143.50
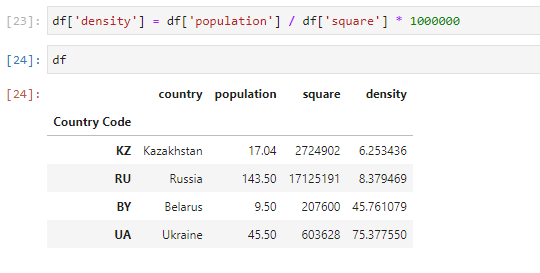
Name: population, dtype: float64Также в DataFrame производят математические вычисления. Например, рассчитаем плотность населения каждой страны в нашем датафрейме. Данные в колонке population (численность населения) делим на square (площадь) и получаем новые данные в колонке density, которые показывают плотность населения:
# Вычисление плотности населения df['density'] = df['population'] / df['square'] * 1000000
Станьте аналитиком данных и получите востребованную специальность
Чтение и запись данных
В Pandas работают с форматами csv, excel, sql, html, hdf и другими. Полный список можно посмотреть с помощью метода .read, где через нижнее подчеркивание «_» будут указаны все доступные форматы.
Ниже представлены примеры чтения и записи данных на Python с использованием Pandas:
Чтение данных:
- Чтение данных из CSV файла:
import pandas as pd # Чтение CSV файла data = pd.read_csv('data.csv') # Вывод первых нескольких строк датафрейма print(data.head())
- Чтение данных из Excel файла:
# Чтение данных из Excel файла data = pd.read_excel('data.xlsx') # Вывод первых нескольких строк датафрейма print(data.head())
- Чтение данных из SQL базы данных:
from sqlalchemy import create_engine # Создание подключения к базе данных engine = create_engine('sqlite:///database.db') # Чтение данных с помощью SQL запроса query = "SELECT * FROM table_name" data = pd.read_sql(query, engine) # Вывод первых нескольких строк датафрейма print(data.head())
Запись данных:
- Запись данных в CSV или Exсel файл:
# Создание датафрейма data = pd.DataFrame(< 'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 22] >) # Запись в CSV файл (или Exсel, нужно будет поменять расширение ниже) data.to_csv('output.csv', index=False)
- Запись данных в SQL базу данных:
import pandas as pd from sqlalchemy import create_engine # Создание датафрейма data = pd.DataFrame(< 'name': ['Alice', 'Bob', 'Charlie'], 'age': [25, 30, 22] >) # Создание подключения к базе данных engine = create_engine('sqlite:///new_database.db') # Запись данных в базу данных data.to_sql('new_table', engine, index=False, if_exists='replace')
Доступ по индексу в DataFrame
Для поиска данных в библиотеке Pandas используются два метода: .loc и .iloc . Рассмотрим их функциональность и применение.
Метод .loc:
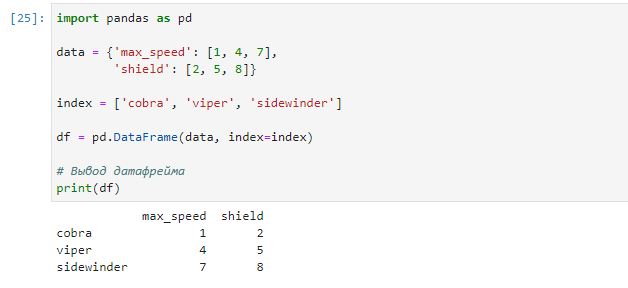
Метод .loc предоставляет доступ к данным по заданному имени строки (индексу) в DataFrame. Рассмотрим пример с набором данных о скорости и ядовитости нескольких видов змей:
data = index = ['cobra', 'viper', 'sidewinder'] df = pd.DataFrame(data, index=index) # Вывод датафрейма print(df)
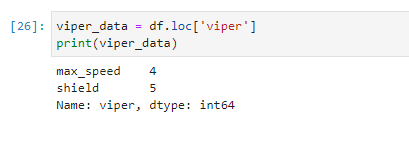
Используя метод .loc , мы можем получить информацию о конкретном виде змеи, например, гадюке (viper):
# Получение данных о гадюке (viper) viper_data = df.loc['viper'] print(viper_data)
Метод .iloc:
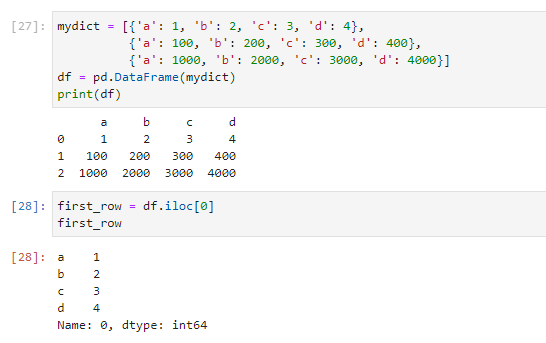
Метод .iloc позволяет осуществлять доступ к данным по порядковому номеру строки в DataFrame. Рассмотрим пример с набором данных, имеющим числовые индексы:
mydict = [, , ] df = pd.DataFrame(mydict) # Вывод датафрейма print(df)
a b c d 0 1 2 3 4 1 100 200 300 400 2 1000 2000 3000 4000
Используя метод .iloc , можно получить данные из первой строки с индексом 0:
first_row = df.iloc[0] first_row
Читайте также Что нужно знать, чтобы стать дата-сайентистом?
Группировка и агрегирование данных
Для этого используется метод .groupby , он позволяет анализировать отдельные группы данных и сравнивать показатели. Например, у нас есть несколько обучающих курсов, информация о которых хранится в одной таблице. Нужно проанализировать, какой доход приносит каждый из них:
Используем .groupby и указываем название колонки title, на основе которой Pandas объединит все данные. После этого используем метод .agregate – он поможет провести математические вычисления, то есть суммировать стоимость внутри каждой группы.
import pandas as pd # Создание DataFrame с данными о курсах data = < 'title': ['Курс A', 'Курс B', 'Курс C', 'Курс D', 'Курс E'], 'income': [100, 150, 200, 120, 180] >df = pd.DataFrame(data) # Группировка данных по названию курса и агрегирование дохода grouped = df.groupby('title', as_index=False).aggregate() grouped
Обратите внимание на as_index=False , эта часть кода отвечает за то, чтобы сохранить числовые индексы в результатах группировки и вычисления.

Сводные таблицы в Pandas
Их используют для обобщения информации, собранной об объекте исследования. Когда исходных данных много и все они разного типа, составление таблиц помогает упорядочить информацию. Чтобы создавать на Python сводные таблицы, тоже используют библиотеку Pandas, а именно — метод .pivot_table .
Для примера возьмем условный набор данных с простыми категориями one / two, small / large и числовыми значениями. В столбце A две категории foo / bar складываются в слово foobar — текст, который используется в программировании для условного обозначения. В этом случае он указывает, что мы делим данные на две группы по неопределенному признаку.
df = pd.DataFrame() df
Результат выполнения кода:

С помощью метода .pivot_table преобразуем эти данные в таблицу, а в скобках прописываем условия.
table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) table
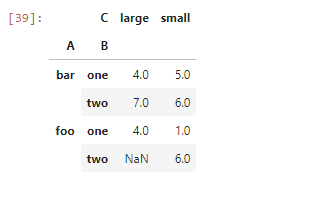
Мы разбиваем данные на две категории: bar и foo, в каждой из них будут подгруппы со значениями one и two, которые в свою очередь делятся на small и large. В сводной таблице мы вычисляем, сколько объектов будет в каждой группе. Для этого используем методы values, index, columns и aggfunc:
- values — метод для агрегации, объединяет элементы в одну систему;
- index и columns — методы, отвечающие за группировку столбцов;
- aggfunc — метод, который передает список функций, необходимых для расчета.
Визуализация данных в Pandas
Дата-аналитики составляют наглядные графики с помощью Pandas и библиотеки Matplotlib. В этой связке Pandas отвечает за вычислительную часть работы, а вспомогательная библиотека «создает» картинку.
Посмотрим на данные о продажах в одной из компаний:
| Число покупок на одного покупателя | Количество покупателей |
|---|---|
| 7000 | 4 |
| 3755 | 6 |
| 2523 | 13 |
| 541 | 16 |
| 251 | 21 |
| 1 | 31 |
В таблице видно, что одни пользователи совершили уже более 7 000 покупок, а некоторые — сделали первую. Чтобы увидеть подробную картину, составляем график sns.distplot. На горизонтальной оси будет отображаться число покупок на одного покупателя, а на вертикальной — количество покупателей, которые совершили именно столько покупок в этой компании. Так по графику можно определить, что самой многочисленной оказалась группа клиентов, которая совершила всего несколько покупок, а группа постоянных клиентов немногочисленная.
import seaborn as sns import matplotlib.pyplot as plt # Создание данных purchase_counts = [7000, 3755, 2523, 541, 251, 1] customer_counts = [4, 6, 13, 16, 21, 31] # Создание графика sns.set(style="whitegrid") sns.distplot(purchase_counts, bins=20, kde=False, hist_kws=) plt.xlabel('Число покупок на одного покупателя') plt.ylabel('Количество покупателей') plt.title('Распределение числа покупок') plt.show()
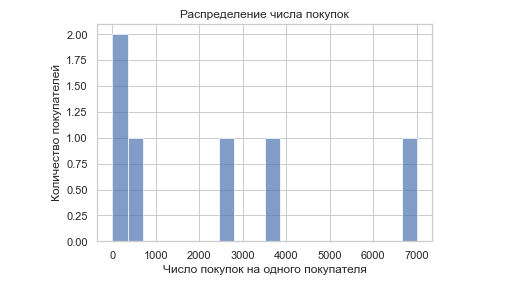
distplot — это график, который визуализирует гистограммы, то есть распределяет данные по столбцам. Каждому столбцу соответствует доля количества объектов в данной группе. Также distplot показывает плотность распределения — плавный линейный график, в котором самая высокая точка указывает на наибольшее количество объектов.
Кроме этого, в Pandas есть другие виды графиков:
- kdeplot — график плотности распределения, который останется, если убрать гистограммы из distplot;
- jointplot — график, показывающий распределение данных между двумя переменными. Каждая строка из набора данных в исходном файле отображается на графике как точка внутри системы координат. У точек на графике jointplot будет два заданных значения: одно по оси X, другое по оси Y.
Например, можно отследить взаимосвязь между тем, сколько минут посетитель проводит в торговом центре и сколько магазинов успевает посетить за это время: кто-то за 30 минут успеет зайти в 5 бутиков, а кто-то обойдет 16. При этом каждый посетитель на графике будет отображаться отдельной точкой.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.

Статьи по теме:
Pandas как эффективный инструмент для анализа данных
Что такое? Pandas – это программная библиотека, написанная на Python. Ее задачи – сбор, первичная оценка сведений и их статистический учет. В целом создана для облегчения работы с большими объемами данных.
Каковы преимущества? Хорошие показатели скорости, интуитивно понятный интерфейс, интеграция с другими библиотеками для расширения функционала – все это делает Pandas одной из лучших программ для работы с данными.
В статье рассказывается:
- Что собой представляет библиотека Рandas
- Для чего нужна библиотека Рandas
- Ключевые возможности
- Преимущества Pandas
- Пошаговая установка Pandas
- Класс Series
- Data Frame
- Как считывать данные в DataFramepandas
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.
Бесплатно от Geekbrains
Что собой представляет библиотека Рandas
Название библиотеки образовано сочетанием двух слов – PANel DAta. Она используется для анализа структурированных данных, размещенных в таблицах (панелях). Рandas упрощает анализ информации, тестирование приложений и другие действия, предоставляя разработчику готовые алгоритмы.
Инструмент базируется на языке Python и применяется для предварительного преобразования, обработки и очистки структурированных данных, представленных в форматах, не подходящих для машинного обучения, например, в виде таблиц Excel.
Основные направления использования Pandas Python:
- Группировка данных по заданным параметрам.
- Объединение нескольких таблиц в одну сводную.
- Очищение данных от дубликатов и невалидных строк или столбцов.
- Вывод определенных значений по фильтрам или уникальности.
- Использование агрегирующих функций, включая подсчет значений, суммы элементов, определение среднего значения.
- Визуализация собранных данных.
Рandas – один из многочисленных инструментов для анализа данных, обращение с которыми входит в программу обучения по специальности «Аналитик данных».
Библиотека Рandas не входит в число встроенных функций Python. Она устанавливается по инструкции, размещенной на официальном сайте. Для начала стоит установить программу Anaconda для управления пакетами для работы данными, содержащую Pandas. После скачивания функции, доступные в этой библиотеки, используются при написании кода на Python.
Для работы с данными, как правило, применяют Jupyter Notebook. Это специальная среда разработки, подходящая для кодирования на Python с использованием возможностей библиотеки Рandas, а также для итерационного выполнения программ и анализа результатов выполнения отдельных операций, в том числе выборки из таблиц
Для чего нужна библиотека Рandas
Сфера применения Рandas настолько широка, что проще перечислить функции, с которыми она не справится.
Библиотека представляет собой комфортное место, в котором вы можете проделывать с вашими данными любые действия: собирать, очищать, преобразовывать и анализировать.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 25513
Предположим, что вам необходимо изучить набор данных с вашего компьютера в формате CSV. С помощью Pandas информация будет извлечена из CSV в DataFrame, то есть представлена в виде таблицы, а затем вы сможете:
- Рассчитать статистику и получить ответы на следующие вопросы:
- Каково среднее значение, медиана, максимум или минимум для каждого столбца?
- Коррелирует ли столбец A со столбцом B?
- Как выглядит распределение данных в столбце C?
Рandas – лучший инструмент, позволяющий разобраться в природе вашего набора данных. После этого их моделирование или сложная визуализация не составит труда.
Ключевые возможности
Набор функций библиотеки Рandas весьма обширен. Разработчики ценят этот продукт за следующие компоненты, упрощающие анализ данных и другие действия с ними:
- объекты data frame, позволяющие управлять индексированными массивами двумерной информации;
- встроенные инструменты совмещения данных, а также обработки сопутствующих сведений;
- функция обмена электронными материалами между структурами памяти, а также различными файлами и документами;
- срезы по значениям индексов;
- расширенные возможности при индексировании;
- наличие выборки из больших объемов наборов информации;
- вставка и удаление столбцов в массиве;
- встроенные средства совмещения информации;
- обработка отсутствующих сведений;
- слияние имеющихся информационных наборов;
- иерархическое индексирование, помогающее обрабатывать материалы высокой размерности в структурах с меньшей размерностью;
- группировка, делающая доступными одновременные трехэтапные операции типа «разделение, изменение и объединение».
Полезными функциями библиотеки Pandas являются поддержка временных рядов, формирование периодов, изменение интервалов. Как и другие возможности, они предназначены для повышения производительности при работе с данными.
Преимущества Pandas
- Высокая скорость благодаря оптимизации кода.
- Интуитивно понятный интерфейс.
- Расширенные возможности за счет интеграции с другим библиотеками на Python, в частности, с NumPy, Matplotlib и Scikit-learn.
- Сильное мировое комьюнити, силами которого продукт постоянно совершенствуется.
Пошаговая установка Pandas
Шаг 1. Самый простой способ приступить к работе с библиотекой описан на официальном сайте продукта. В первую очередь устанавливается размещенный на этом же ресурсе дистрибутив для Python с набором библиотек – Anaconda.
Новичкам помогут успешно справиться с этой задачей несколько советов:
- Становитесь на рекомендованных настройках, например, Install for: Just me (recommended). Изменения можно вносить по мере освоения программы.
- Запуск по умолчанию активируется галочкой «Add Anaconda to my PATH environment variable», иначе каждый раз придется включать Anaconda вручную.
- Вопрос: «Do you wish to initialize Anaconda3?» (Хотите ли вы инициализировать Anaconda3?) предполагает ответ «Да».
Завершив установку программы, перезагрузите компьютер.
Для вас подарок! В свободном доступе до 14.01 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окнеШаг 2. В командной строке Anaconda напишите JupyterLab: так вы запустите интерактивную среду для работы с кодом, данными и блокнотами, входящую в пакет дистрибутива.
Шаг 3. В JupyterLab необходимо создать новый блокнот Python3.
Шаг 4. В первой ячейке пропишите: import pandas as pd, после этого можно приступать к написанию кода в следующих ячейках.
Класс Series
Series – объект, по виду напоминающий одномерный массив. В него могут входить любые типы данных. Как правило, представляет собой столбец таблицы с последовательностями тех или иных значений, каждое из которых наделено индексом – номером строки.
Обработка соответствующего кода завершается появлением на экране такой записи:
Series выглядит как таблица с индексами компонентов. В первом столбце выводится соответствующая информация, во второй размещаются заданные значения.
Data Frame
DataFrame – основной тип информации в Pandas. Это двумерная информационная структура в виде таблицы с разными типами столбцов. Вся дальнейшая работа ведется на основе DataFrame.
Объект данных может выглядеть как обычная таблица, например, в Excel, и включать любое количество столбцов и строк. Содержимое ячеек представляет сведения разных типов:
- числовые;
- булевы;
- строковые и так далее.
В DataFrame индексы присваиваются не только столбцам, но и строкам. Такая особенность позволяет сортировать и фильтровать данные, а также ускоряет и упрощает процесс поиска нужных значений.
В DataFrame поддерживается жесткое кодирование, а также импорт:
- CSV.
- TSV.
- Excel-документов.
- SQL-таблиц.
Соответствующий компонент может создаваться при помощи команды:
- data – это создание объекта из входных сведений (NumPy, series, dict и аналогичные им);
- index – строковые метки;
- columns – создание подписей столбцов;
- dtype – ссылка на тип сведений, содержащихся в каждом столбце (факультативный параметр);
- copy – копирование сведений, если они предусмотрены изначально.
Только до 11.01
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Создавать DataFrame можно по-разному, например, формируя объект из словаря или списков, кортежей, файла Excel.
Так выглядит код для создания DataFrame на базе списка словарей:
Обработка предложенного фрагмента завершится выводом на экран устройства следующей информации:
Принцип работы кода достаточно прост: после создания словаря в него передается метод DataFrame() в качестве аргумента. Получив те или иные значения, система выводит объект на печать.
Индекс с метками строк отображается в крайнем левом столбце. Сама таблица – это заголовки и электронные материалы. Используя настройки индексных параметров, возможно создать индексированные DataFrames.
Как считывать данные в DataFrame pandas
Процесс загрузки данных в DataFrame из файлов различных форматов несложен.
Чтение данных из CSV-файлов
Чтобы загрузить данные из файлов CSV, прописывается строка:
df = pd.read_csv(‘purchases.csv’)
У CSV нет индексов, как у DataFrames, поэтому достаточно определить index_col при чтении:
df = pd.read_csv(‘purchases.csv’, index_col=0)
Так мы устанавливаем, что индексом будет нулевой столбец.
У большинства CSV индексного столбца нет, поэтому этот шаг вас не должен волновать.
Чтение данных из JSON
Файл JSON представляет собой хранимый словарь Python, а значит, для pandas не составит труда прочитать его:
df = pd.read_json(‘purchases.json’)
Использование JSON делает возможной работу через вложенность, поэтому на этот раз нами получен правильный индекс. Чтобы посмотреть, как работает файл data_file.json, откройте его в блокноте.
В процессе анализа структуры вашего JSON Pandas пытается разобраться, как создать DataFrame, и иногда добивается успеха. Будьте готовы часто задавать именованный аргумент orient, который зависит от формата строки JSON.
Чтение данных из базы данных SQL
При работе с базой данных SQL для начала используйте соответствующую библиотеку Python для установки соединения и последующей передачи запроса в Pandas. Продемонстрируем этот процесс с использованием SQLite.
В первую очередь устанавливаем pysqlite3. Выполняем в терминале следующую команду:
pip install pysqlite3
Если вы в Jupyter Notebook, запускаете эту ячейку:
!pip install pysqlite3
sqlite3 нужен, чтобы соединиться с базой данных, которая впоследствии будет использоваться для создания DataFrame с помощью запроса SELECT.
Создаем соединение с файлом базы данных SQLite:
import sqlite3
con = sqlite3.connect(«database.db»)
Введение в pandas: анализ данных на Python

4 Март 2017 , Python, 750955 просмотров, Introduction to pandas: data analytics in Python
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
>>> import pandas as pd >>> my_series = pd.Series([5, 6, 7, 8, 9, 10]) >>> my_series 0 5 1 6 2 7 3 8 4 9 5 10 dtype: int64 >>>В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
>>> my_series.index RangeIndex(start=0, stop=6, step=1) >>> my_series.values array([ 5, 6, 7, 8, 9, 10], dtype=int64)Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
>>> my_series[4] 9Индексы можно задавать явно:
>>> my_series2 = pd.Series([5, 6, 7, 8, 9, 10], index=['a', 'b', 'c', 'd', 'e', 'f']) >>> my_series2['f'] 10Делать выборку по нескольким индексам и осуществлять групповое присваивание:
>>> my_series2[['a', 'b', 'f']] a 5 b 6 f 10 dtype: int64 >>> my_series2[['a', 'b', 'f']] = 0 >>> my_series2 a 0 b 0 c 7 d 8 e 9 f 0 dtype: int64Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
>>> my_series2[my_series2 > 0] c 7 d 8 e 9 dtype: int64 >>> my_series2[my_series2 > 0] * 2 c 14 d 16 e 18 dtype: int64Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
>>> my_series3 = pd.Series() >>> my_series3 a 5 b 6 c 7 d 8 dtype: int64 >>> 'd' in my_series3 TrueУ объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
>>> my_series3.name = 'numbers' >>> my_series3.index.name = 'letters' >>> my_series3 letters a 5 b 6 c 7 d 8 Name: numbers, dtype: int64Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
>>> my_series3.index = ['A', 'B', 'C', 'D'] >>> my_series3 A 5 B 6 C 7 D 8 Name: numbers, dtype: int64Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >) >>> df country population square 0 Kazakhstan 17.04 2724902 1 Russia 143.50 17125191 2 Belarus 9.50 207600 3 Ukraine 45.50 603628Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
>>> df['country'] 0 Kazakhstan 1 Russia 2 Belarus 3 Ukraine Name: country, dtype: object >>> type(df['country'])
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
>>> df.columns Index([u'country', u'population', u'square'], dtype='object') >>> df.index RangeIndex(start=0, stop=4, step=1)В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
>>> df = pd.DataFrame(< . 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'], . 'population': [17.04, 143.5, 9.5, 45.5], . 'square': [2724902, 17125191, 207600, 603628] . >, index=['KZ', 'RU', 'BY', 'UA']) >>> df country population square KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628 >>> df.index = ['KZ', 'RU', 'BY', 'UA'] >>> df.index.name = 'Country Code' >>> df country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628Как видно, индексу было задано имя — Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
>>> df['country'] Country Code KZ Kazakhstan RU Russia BY Belarus UA Ukraine Name: country, dtype: objectДоступ к строкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке
- .iloc — используется для доступа по числовому значению (начиная от 0)
>>> df.loc['KZ'] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: object >>> df.iloc[0] country Kazakhstan population 17.04 square 2724902 Name: KZ, dtype: objectМожно делать выборку по индексу и интересующим колонкам:
>>> df.loc[['KZ', 'RU'], 'population'] Country Code KZ 17.04 RU 143.50 Name: population, dtype: float64Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
>>> df.loc['KZ':'BY', :] country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600Фильтровать DataFrame с помощью т.н. булевых массивов:
>>> df[df.population > 10][['country', 'square']] country square Country Code KZ Kazakhstan 2724902 RU Russia 17125191 UA Ukraine 603628Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
>>> df.reset_index() Country Code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
>>> df['density'] = df['population'] / df['square'] * 1000000 >>> df country population square density Country Code KZ Kazakhstan 17.04 2724902 6.253436 RU Russia 143.50 17125191 8.379469 BY Belarus 9.50 207600 45.761079 UA Ukraine 45.50 603628 75.377550Не нравится новый столбец? Не проблема, удалим его:
>>> df.drop(['density'], axis='columns') country population square Country Code KZ Kazakhstan 17.04 2724902 RU Russia 143.50 17125191 BY Belarus 9.50 207600 UA Ukraine 45.50 603628Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
>>> df = df.rename(columns=) >>> df country_code country population square 0 KZ Kazakhstan 17.04 2724902 1 RU Russia 143.50 17125191 2 BY Belarus 9.50 207600 3 UA Ukraine 45.50 603628В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
>>> df.to_csv('filename.csv')Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
>>> df = pd.read_csv('filename.csv', sep=',')Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
>>> titanic_df = pd.read_csv('titanic.csv') >>> print(titanic_df.head()) PassengerID Name PClass Age \ 0 1 Allen, Miss Elisabeth Walton 1st 29.00 1 2 Allison, Miss Helen Loraine 1st 2.00 2 3 Allison, Mr Hudson Joshua Creighton 1st 30.00 3 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.00 4 5 Allison, Master Hudson Trevor 1st 0.92 Sex Survived SexCode 0 female 1 1 1 female 0 1 2 male 0 0 3 female 0 1 4 male 1 0Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
>>> print(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count()) Sex Survived female 0 154 1 308 male 0 709 1 142 Name: PassengerID, dtype: int64А теперь проанализируем в разрезе класса кабины:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count()) PClass Survived * 0 1 1st 0 129 1 193 2nd 0 160 1 119 3rd 0 573 1 138 Name: PassengerID, dtype: int64Сводные таблицы в pandas
Термин «сводная таблица» хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
>>> titanic_df = pd.read_csv('titanic.csv') >>> pvt = titanic_df.pivot_table(index=['Sex'], columns=['PClass'], values='Name', aggfunc='count')В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
>>> print(pvt.loc['female', ['1st', '2nd', '3rd']]) PClass 1st 143.0 2nd 107.0 3rd 212.0 Name: female, dtype: float64Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
>>> import pandas as pd >>> df = pd.read_csv('apple.csv', index_col='Date', parse_dates=True) >>> df = df.sort_index() >>> print(df.info()) DatetimeIndex: 1258 entries, 2017-02-22 to 2012-02-23 Data columns (total 6 columns): Open 1258 non-null float64 High 1258 non-null float64 Low 1258 non-null float64 Close 1258 non-null float64 Volume 1258 non-null int64 Adj Close 1258 non-null float64 dtypes: float64(5), int64(1) memory usage: 68.8 KBЗдесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
>>> df.loc['2012-Feb', 'Close'].mean() 528.4820021999999А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
>>> df.loc['2012-Feb':'2015-Feb', 'Close'].mean() 430.43968317018414А что если нам нужно узнать среднюю цену закрытия по неделям?!
>>> df.resample('W')['Close'].mean() Date 2012-02-26 519.399979 2012-03-04 538.652008 2012-03-11 536.254004 2012-03-18 576.161993 2012-03-25 600.990001 2012-04-01 609.698003 2012-04-08 626.484993 2012-04-15 623.773999 2012-04-22 591.718002 2012-04-29 590.536005 2012-05-06 579.831995 2012-05-13 568.814001 2012-05-20 543.593996 2012-05-27 563.283995 2012-06-03 572.539994 2012-06-10 570.124002 2012-06-17 573.029991 2012-06-24 583.739993 2012-07-01 574.070004 2012-07-08 601.937489 2012-07-15 606.080008 2012-07-22 607.746011 2012-07-29 587.951999 2012-08-05 607.217999 2012-08-12 621.150003 2012-08-19 635.394003 2012-08-26 663.185999 2012-09-02 670.611995 2012-09-09 675.477503 2012-09-16 673.476007 . 2016-08-07 105.934003 2016-08-14 108.258000 2016-08-21 109.304001 2016-08-28 107.980000 2016-09-04 106.676001 2016-09-11 106.177498 2016-09-18 111.129999 2016-09-25 113.606001 2016-10-02 113.029999 2016-10-09 113.303999 2016-10-16 116.860000 2016-10-23 117.160001 2016-10-30 115.938000 2016-11-06 111.057999 2016-11-13 109.714000 2016-11-20 108.563999 2016-11-27 111.637503 2016-12-04 110.587999 2016-12-11 111.231999 2016-12-18 115.094002 2016-12-25 116.691998 2017-01-01 116.642502 2017-01-08 116.672501 2017-01-15 119.228000 2017-01-22 119.942499 2017-01-29 121.164000 2017-02-05 125.867999 2017-02-12 131.679996 2017-02-19 134.978000 2017-02-26 136.904999 Freq: W-SUN, Name: Close, dtype: float64Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
>>> import matplotlib.pyplot as plt >>> new_sample_df = df.loc['2012-Feb':'2017-Feb', ['Close']] >>> new_sample_df.plot() >>> plt.show()И видим вот такую картину:
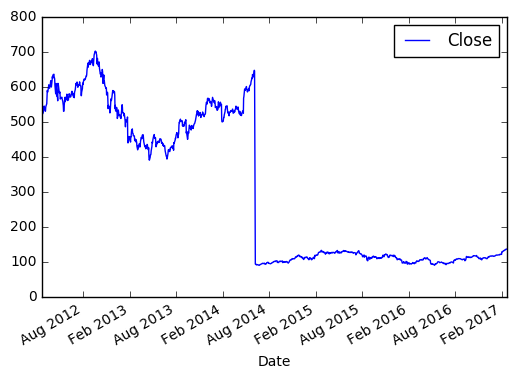
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 😉
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
- pandas cheatsheet
- Официальная документация pandas
- Почему Python
- Python Data Science Handbook
Интересные записи:
- Django Channels: работа с WebSocket и не только
- Pyenv: удобный менеджер версий python
- Работа с MySQL в Python
- Что нового появилось в Django Channels?
- Руководство по работе с HTTP в Python. Библиотека requests
- Celery: начинаем правильно
- FastAPI, asyncio и multiprocessing
- Введение в logging на Python
- Обзор Python 3.9
- Почему Python?
- Работа с PostgreSQL в Python
- Как написать Telegram бота: практическое руководство
- Python-RQ: очередь задач на базе Redis
- Разворачиваем Django приложение в production на примере Telegram бота
- Авторизация через Telegram в Django и Python
- Django, RQ и FakeRedis
- Обзор Python 3.8
- Итоги первой встречи Python программистов в Алматы
- Интеграция Trix editor в Django
- Участие в подкасте TalkPython
- Строим Data Pipeline на Python и Luigi
- Видео презентации ETL на Python
- Авторизация через Telegram в Django приложении
Введение — Python: Pandas
В этом курсе мы разберем библиотеку Pandas. Это один из наиболее популярных инструментов для обработки и анализа табличных данных на языке Python. После обучения вы сможете использовать инструментарий библиотеки Pandas в подготовке и анализе данных.
В этом вводном уроке мы разберем, по каким причинам аналитики используют эту библиотеку, и как выглядит типичный порядок работы с Pandas.
Причины появления библиотеки Pandas
Чтобы организовать работу компаний и интернет-сервисов, нужны хранилища данных. Их организовывают по-разному:
- Записки на бумажном носителе
- Набор текстовых файлов
- Электронные таблицы
- Базы данных
Табличные варианты хранения информации используются чаще, поскольку информация в них структурирована. Это удобно, когда требуется проводить анализ, расследовать инциденты, периодически подводить итоги и искать нужные данные.
Для проектов с небольшим объемом производимых транзакций достаточно популярных средств работы с электронными таблицами. Это могут быть:
- Десктопные приложения: Microsoft Excel, LibreOffice, OfficeSuite
- Облачные решения: Google Sheets
В последнее время количество производимых операций и число пользователей или клиентов растет. Поэтому хранить данные в электронных таблицах становится накладным по следующим причинам:
- Увеличение объема необходимой памяти для хранения
- Недостаточная скорость записи данных
- Увеличение времени на чтение и обработку данных
В таких случаях на практике используют реляционные системы управления базами данных — СУБД. Часто их называют просто базами данных. Наиболее популярные из них: PostgreSQL, MySQL, SQL Server.
Для аналитика базы данных — это инструмент хранения большого количества данных в виде набора таблиц. Многие операции с электронными таблицами также реализуемы в базах данных, но с использованием особого языка — SQL.
Рост технологий анализа данных и машинного обучения подтолкнул многие компании к пересмотру подходов к хранению данных. Некоторые из них полностью перешли на базы данных, в некоторых часть данных осталась в виде электронных таблиц и документов. В последнем случае для анализа требуется широкий спектр инструментов.
Попытки создания универсального способа для анализа табличных данных привели к созданию библиотеки Pandas.
Широкое распространение библиотека Pandas получила по ряду причин:
- Написана на популярном языке для анализа данных и машинного обучения — Python
- Использует в основе библиотеку научных и быстрых вычислений — Numpy
- Работает с широким спектром типов входных данных: csv, xsl, xslx, json
- Подключается напрямую к базам данных
- Имеет высокоуровневый интерфейс для преобразований данных и аналитики
Типичный порядок работы с библиотекой Pandas
Рассмотрим последовательность действий аналитика при работе с данными. Она содержит несколько ключевых шагов:
- Чтение исходных данных
- Анализ данных
- Обработка данных
- Сохранение результатов анализа и обработки исходных данных
Одним из распространенных типов данных является csv — comma separated values. Это текстовые данные, в которых названия и значения разделяются запятой, точкой с запятой или табуляцией.
Для примера рассмотрим файл data/Shop_orders.csv со значениями продаж четырех магазинов за одну неделю. Значения разделены запятой:
Для работы с данными импортируем модуль Pandas и воспользуемся нужным методом чтения:
# Общепринятое сокращение для Pandas import pandas as pd df_orders = pd.read_csv('data/Shop_orders.csv', index_col=0)Помимо пути к файлу необходимо указать колонку, которую считаем за индекс. В нашем случае это нулевая колонка — Weekday.
Для обзора считанных данных воспользуемся методом head() , который покажет первые пять строк данных:
print(df_orders.head()) # => Shop_1 Shop_2 Shop_3 Shop_4 # Weekday # mon 7 1 7 8 # tue 4 2 4 5 # wed 3 5 2 3 # thu 8 12 8 7 # fri 15 11 13 9Посмотрим на основные статистические показатели:
print(df_orders.describe()) # => Shop_1 Shop_2 Shop_3 Shop_4 # count 7.000000 7.000000 7.000000 7.000000 # mean 11.857143 9.285714 10.857143 10.000000 # std 8.610625 6.725927 8.071113 6.557439 # min 3.000000 1.000000 2.000000 3.000000 # 25% 5.500000 3.500000 5.500000 6.000000 # 50% 8.000000 11.000000 8.000000 8.000000 # 75% 18.000000 14.000000 15.000000 13.000000 # max 25.000000 18.000000 25.000000 21.000000Одним методом удалось посмотреть среднее значение и отклонение от него, минимальное и максимальное значения и ряд персентильных значений.
Также одним методом можно достать средние значения по каждому магазину:
print(df_orders.mean()) # => Shop_1 11.857143 # Shop_2 9.285714 # Shop_3 10.857143 # Shop_4 10.000000 # dtype: float64Остановимся в подготовке данных на центрировании значений продаж по каждому магазину. Вычтем из значений продаж среднее для данного магазина:
df_orders_centered = df_orders - df_orders.mean() print(df_orders_centered) # => Shop_1 Shop_2 Shop_3 Shop_4 # Weekday # mon -4.857143 -8.285714 -3.857143 -2.0 # tue -7.857143 -7.285714 -6.857143 -5.0 # wed -8.857143 -4.285714 -8.857143 -7.0 # thu -3.857143 2.714286 -2.857143 -3.0 # fri 3.142857 1.714286 2.142857 -1.0 # sat 9.142857 8.714286 6.142857 11.0 # sun 13.142857 6.714286 14.142857 7.0Остается сохранить полученный результат:
df_orders_centered.to_csv('data/Shop_orders_centered.csv')В директории с исходным файлом теперь лежит преобразованный вариант с подготовленными данными. Работа аналитика завершена.
Выводы
В рамках данного курса рассматривается библиотека Pandas. Это один из наиболее популярных инструментов для обработки и анализа табличных данных на языке Python. Большое количество поддерживаемых типов данных и функций для их обработки, высокая скорость работы и дружелюбный интерфейс выделяют ее среди конкурентов.
Чтобы освоить основные навыки работы с данной библиотекой, предлагаем пройти несколько шагов:
- Понять основной порядок работы с данными
- Узнать про интерфейсы чтения и записи данных
- Поработать с индексированием
- Научиться фильтровать значения в таблицах
- Применить функции для обработки строк и столбцов
- Построить сложные агрегации и сводные таблицы
- Объединить несколько таблиц в одну
После этих тем вы сможете уверенно использовать инструментарий библиотеки Pandas в подготовке и анализе данных.
Подготовка к курсу
Данный курс предполагает, что у вас есть предварительная подготовка по Python. Если это не так, то обратитесь к курсам:
- Основы Python
- Python: Списки
- Python: Словари и Множества
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях: