Service Discovery
Продолжая разговор о микросервисной архитектуре, нельзя не упомянуть о Service Discovery. К сожалению, в русском языке до сих пор так и не появилось адекватного перевода этого термина. Дословное «обнаружение сервисов» звучит слишком топорно и неизящно, а «каталог сервисов» хоть и неплох, но имеет много других значений.
Русская википедия про Service Discovery (далее — sd) не знает ничего и дает вместо этого список протоколов для sd, английская, впрочем, тоже.
Что же, я попробую рассказать об этом простыми словами.
Во-первых, зачем нужен sd? Допустим, в вашем окружении (ландшафте) есть какое-то количество сервисов, которые должны знать друг о друге — адреса, порты и какую-то дополнительную информацию. Если таких сервисов немного, то несложно прописать эту информацию в конфигурации конкретных сервисов. Когда сервисов становится больше, они начинают чаще появляться, исчезать, переезжать, то поддерживать актуальной конфигурацию для разных окружений становится все сложнее. В какой-то момент вы понимаете, что вам необходимо динамически масштабировать количество экземпляров конкретных сервисов, и тут уже ручная работа становится просто невозможной — необходимо использовать sd. Я в очередной раз акцентирую внимание, что как только вы затаскиваете новую сущность в ваш проект, он становится от этого только сложнее, и sd в этом смысле не исключение. Как только вы понимаете, что не сможете жить без sd, вам необходимо мало того, что поддерживать сам сервис sd, но также надо допилить все ваши сервисы, чтобы они умели с этим sd взаимодействовать, желательно динамически и без перезапуска сервиса. С другой стороны, из всех конфигурации конкретного окружения вам теперь надо знать только адрес sd-сервиса.
Допустим у нас есть два сервиса — А и Б, и сервиса Б использует сервис А. Конкретный экземпляр сервиса А стартует, стучится к sd и говорит: «Я сервис А, нахожусь по такому-то адресу». После этого стартует экземпляр сервиса Б и говорит: «А где у нас запущен сервис А?». В ответ он получает список всех адресов экземпляров сервиса А. Соответственно, сервис Б подписывается на обновления от sd, и если сервис А меняет свое расположение, сервис Б практически мгновенно узнает об этом от sd.
Фактически, sd является непротиворечивым хранилищем информации об связях всех сервисов между собою. Именно поэтому, наверное, все системы sd являются распределенными, чтобы отказ оборудования не приводил к полной остановке всех сервисов (почитайте про CAP-теорему на досуге). Также это позволяет с помощью sd организовать HA и failover (переключение на резерв в случае отказа), но это тема для отдельного разговора.
Сейчас существует много реализаций sd, но я бы рекомендовал начать знакомство с Consul. Я могу заблуждаться (и очень глубоко), но, по моему скромного мнению, он является стандартом де-факто для Service Discovery.
И как всегда, даже здесь нас ожидает инженерный компромис — чтобы сделать систему проще в одном месте, нам надо сделать ее сложнее в другом.
И, конечно, микросервисная архитектура, где количество различных сервисов, а также динамика их изменения, просто огромны, немыслима без Service Discovery.
Service Discovery в распределенных системах на примере Consul. Александр Сигачев
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Я всех приветствую! Я Сигачев Александр, работаю в компании Inventos. И сегодня я вас познакомлю с таким понятием как Service Discovery. Рассмотрим мы Service Discovery на примере Consul.
Какие проблемы решает Service Discovery? Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
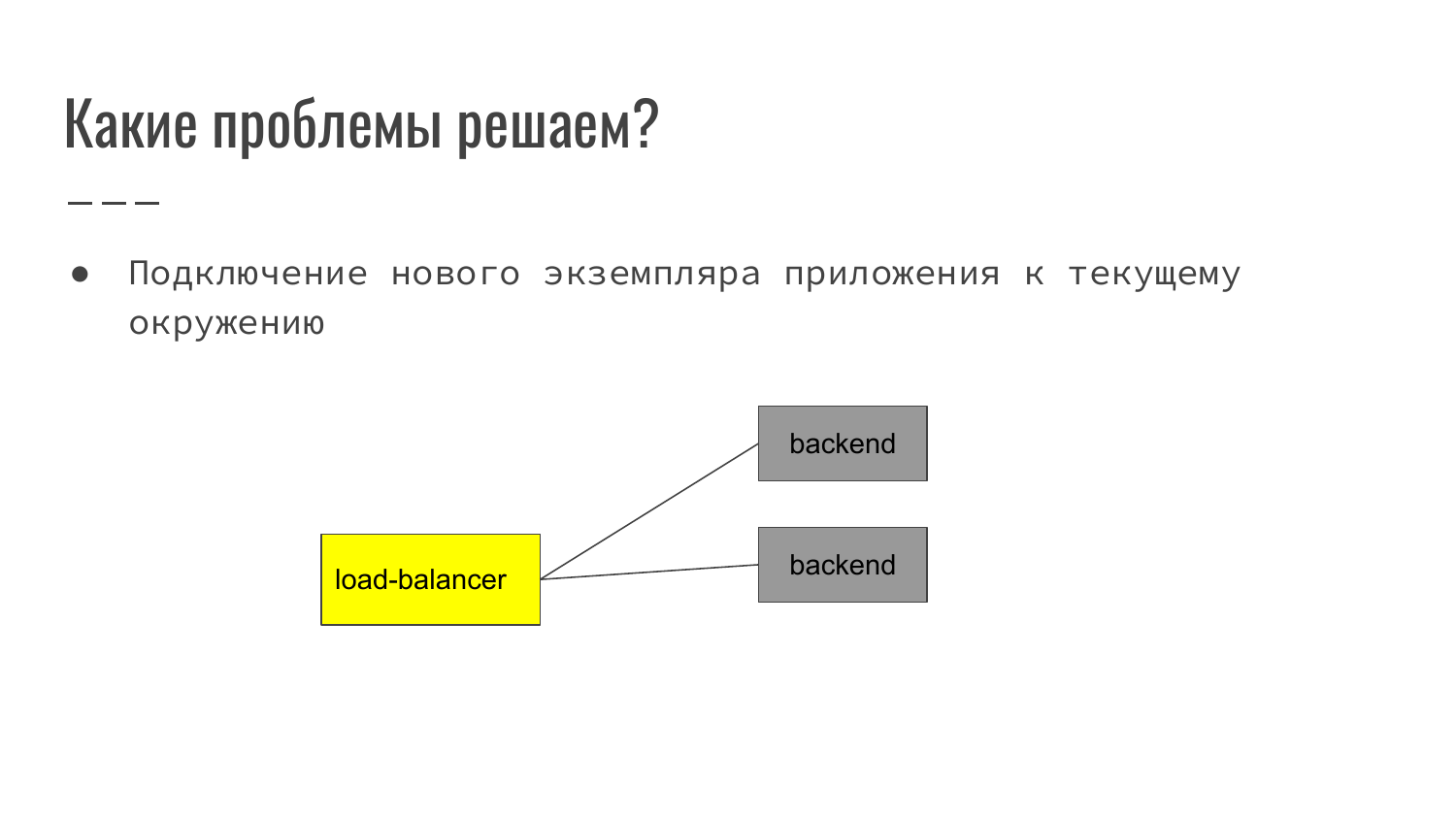
Как это выглядит? На классическом примере в вебе – это фронтенд, который принимает запрос пользователя. Дальше выполняет маршрутизацию его на backend. На данном примере – это load-balancer балансирует на два backend.
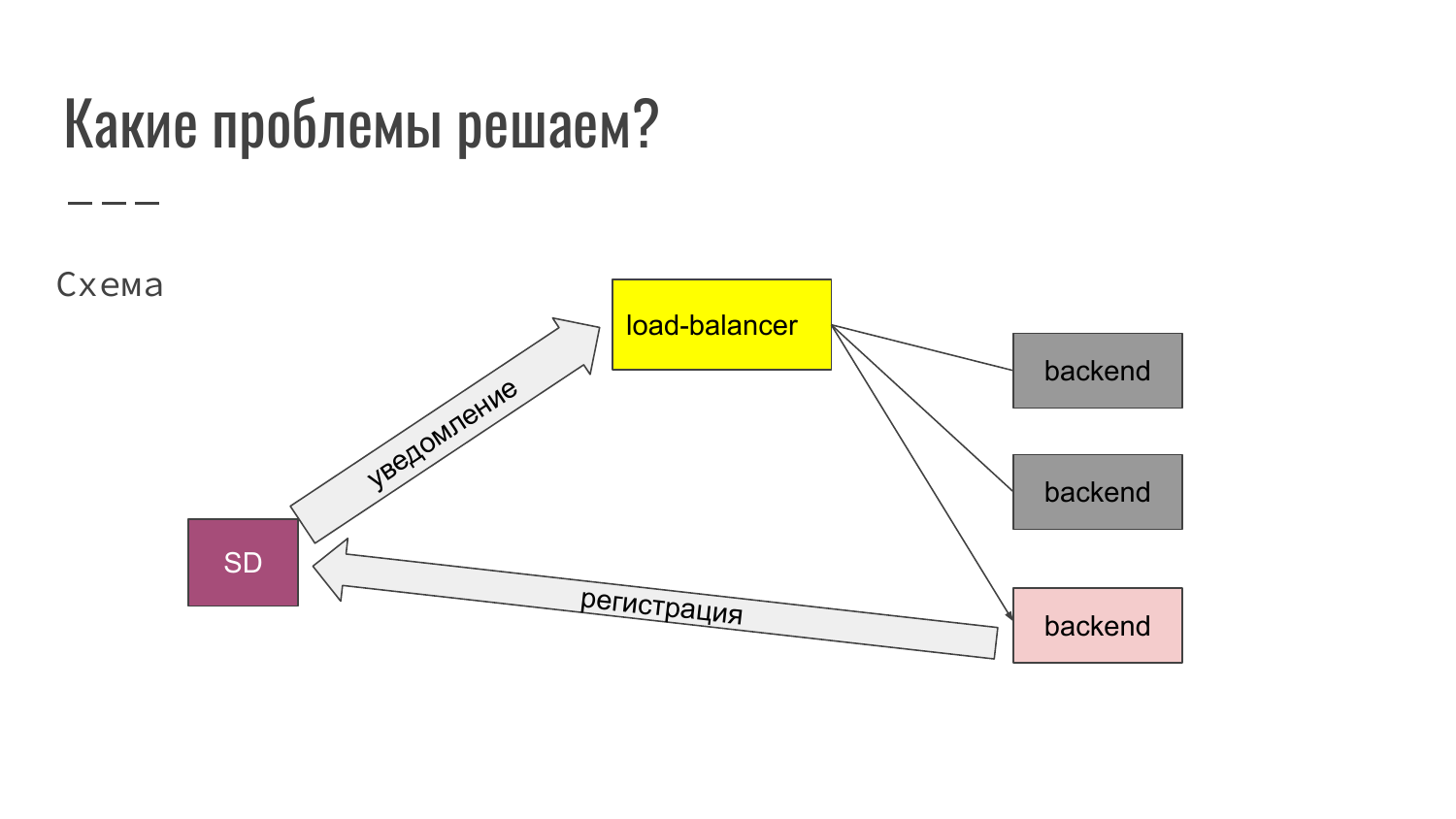
Здесь мы видим, что мы запускаем третий экземпляр приложения. Соответственно, когда приложение запускается, оно производит регистрацию в Service Discovery. Service Discovery уведомляет load-balancer. Load-balancer меняет свой конфиг автоматически и уже новый backend подключается в работу. Таким образом могут добавляться backend, либо, наоборот, исключаться из работы.

Что еще удобно делать при помощи Service Discovery? В Service Discovery могут храниться конфиги nginx, сертификаты и список активных backend-серверов.
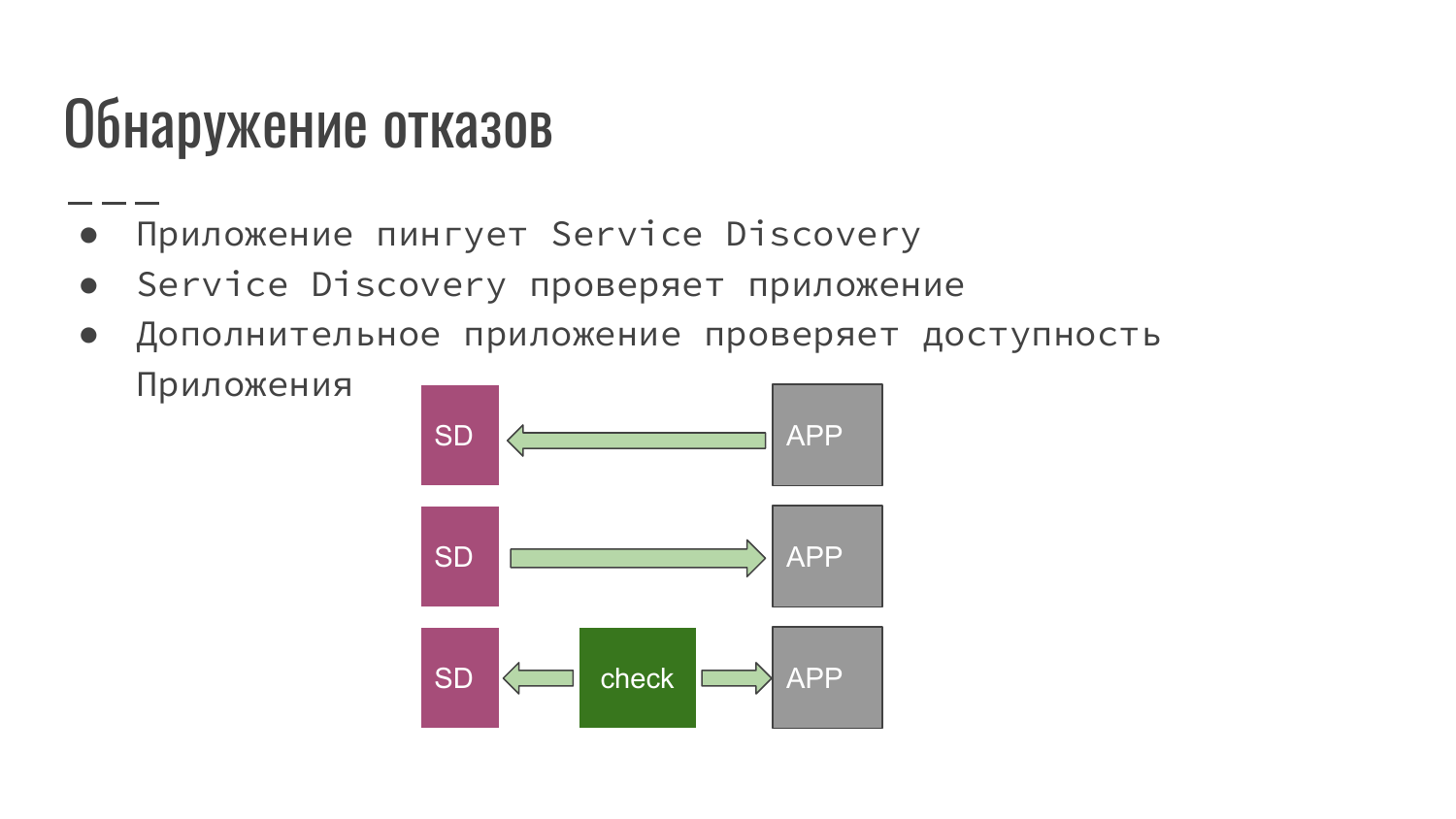
Также Service Discovery позволяет обнаружить сбой, обнаружить отказы. Какие возможны схемы при обнаружении отказов?
- Это приложение, которое мы разработали, само уведомляет Service Discovery, что оно еще до сих пор работоспособно.
- Service Discovery со своей стороны опрашивает приложение на факт доступности.
- Или же используется сторонний скрипт или приложение, которое проверяет наше приложение на доступность и уведомляет Service Discovery, что все хорошо и можно работать, или, наоборот, что все плохо и необходимо этот экземпляр приложения исключить из балансировки.
Каждая из схем может применяться в зависимости от того, какое ПО мы используем. Например, мы только начали разрабатывать новый проект, то мы без проблем можем обеспечить схему, когда наше приложение уведомляет Service Discovery. Либо можем подключить, что Service Discovery проводит проверку.
Если же приложение досталось нам в наследство или разработано кем-то сторонним, то здесь подходит третий вариант, когда мы пишем обработчик, и все это встает в нашу работу автоматически.

Это один из примеров. Load-balancer в виде nginx перезагружается. Это дополнительная утилита, которая предоставляется вместе с Consul. Это consul-template. Мы описываем правило. Говорим, что используем шаблон (Шаблонизатор Golang). При совершении событий, при уведомлениях, что произошли изменения, он перегенерируется и Service Discovery присылается команда «reload». Простейший пример, когда по событию переконфигурируется nginx и перезапускается.

Что такое Consul?
- Прежде всего – это Service Discovery.
- Он имеет механизм проверки доступности – Health Checking.
- Также он имеет KV Store.
- И в его основу заложено возможность использовать Multi Datacenter.
Для чего все это можно использовать? В KV Store мы можем хранить примеры конфигов. Health Checking мы можем проводить проверку локального сервиса и уведомлять. Multi Datacenter используется для того, чтобы можно было построить карту сервисов. Например, Amazon имеет несколько зон и маршрутизирует трафик наиболее оптимально, чтобы не было лишних запросов между дата-центрами, которые тарифицируются отдельно от локального трафика, и, соответственно, имеют меньшую задержку.

Немножко разберемся с терминами, которые в Consul используются.
- Consul – сервис, написанный на Go. Одним из преимуществ программы на Go – это 1 бинарный файл, который ты просто скачал. Запустил из любого места и у тебя никаких зависимостей нет.
- Дальше при помощи ключей мы можем запустить этот сервис либо в режиме клиента, либо в режиме сервера.
- Также атрибут «datacenter» позволяет поставить флаг к какому дата-центру принадлежит данный сервер.
- Consensus – базируется на протоколе raft. Если кому интересно, то об этом можно прочитать поподробнее на сайте Consul. Это протокол, который позволяет определить лидера и определить какие денные считать валидными и доступными.
- Gossip – это протокол, который обеспечивает взаимодействие между нодами. Причем эта система является децентрализованной. В рамках одного дата-центра все ноды общаются с соседями. И, соответственно, передается друг другу информация об актуальном состоянии. Можно сказать, что это сплетни между соседями.
- LAN Gossip – локальный обмен данных между соседями в рамках одного дата-центра.
- WAN Gossip – используется, когда нам необходимо синхронизировать информацию между двумя дата-центрами. Информация идет между нодами, которые помечены как сервер.
- RPC – позволяет выполнять запросы через клиента на сервере.
Описание RPC. Допустим, на виртуальной машине или физическом сервере запущен Consul в виде клиента. К нему локально обращаемся. А дальше локальный клиент запрашивает информацию у сервера и синхронизируется. Информация в зависимости от настроек может выдаваться из локального кэша, либо может быть синхронизирована с лидером, с мастером сервера.
У этих двух схем есть как плюсы, так и минусы. Если мы работаем с локальным кэшем, то это быстро. Если мы работаем с данными, которые хранятся на сервере, то это дольше, но получаем более актуальную информацию.
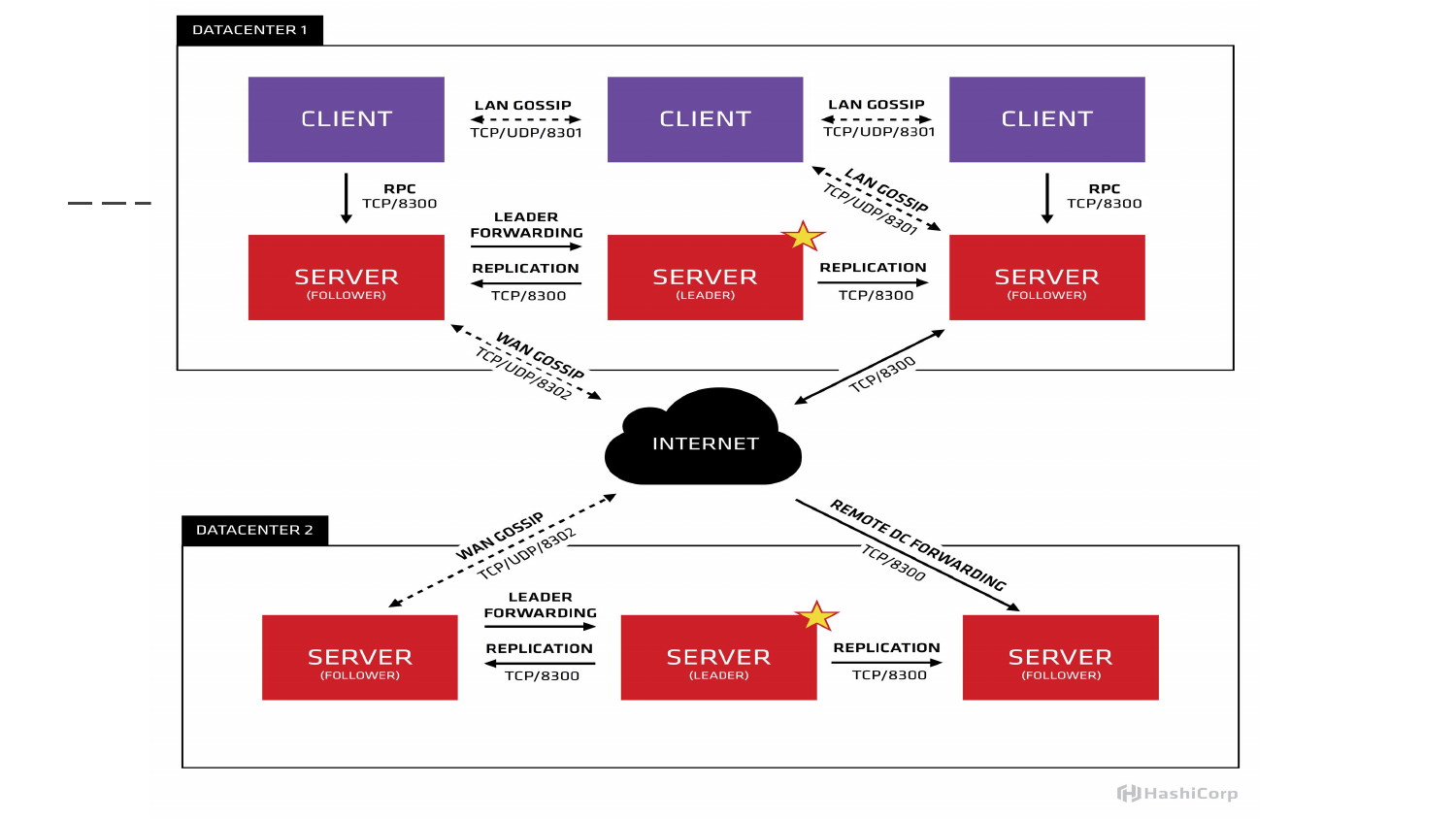
Если это изобразить графически, то вот такая картинка сайта. Мы видим, что у нас запущено три мастера. Один звездочкой помечен как лидер. В данном примере три клиента, которые между собой обмениваются локально информацией по UDP/TCP. А информация между дата-центрами передается между серверами. Здесь клиенты взаимодействуют между собой локально.

Какой API предоставляет Consul? Для того чтобы получить информацию, есть два вида API у Consul.
Это DNS API. По умолчанию Consul запускается на 8600 порту. Мы можем настроить проксирование запроса и обеспечить доступ через локальный резолвинг, через локальный DNS. Мы можем запросить по домену и получим в ответ информацию об IP-адресе.
HTTP API – либо мы можем локально на 8500 порту запросить информацию о конкретном сервисе и получим JSON ответ, какой IP имеет сервер, какой host, какой порт зарегистрирован. И дополнительная информация может быть передана через token.

Что нужно, чтобы запустить Consul?
В первом варианте мы в режиме разработчика указываем флаг, что это режим разработчика. Agent стартует как сервер. И всю функцию выполняет уже самостоятельно на одной машине. Удобно, быстро и никаких практически дополнительных настроек для первого старта не требуется.
Второй режим – это запуск в production. Здесь запуск немного усложняется. Если у нас нет ни одной версии консула, то мы должны привести в bootstrap первую машину, т. е. эта машина, которая возьмет на себя обязанности лидера. Мы поднимаем ее, затем мы поднимаем второй экземпляр сервера, передавая ему информацию, где у нас находится мастер. Третий поднимаем. После того, как у нас поднято три машины, мы на первой машине из запущенного bootstrap, перезапускаем ее в обычном режиме. Данные синхронизируются, и начальный кластер уже поднят.
Рекомендуется запускать от трех до семи экземпляров в режиме сервера. Это обуславливается тем, что если количество серверов растет, то увеличивается время на синхронизацию информации между ними. Количество нод должно быть нечетным, чтобы обеспечить кворум.

Как обеспечиваются Health Checks? В директорию для конфигурации Consul мы в виде Json пишем правило проверки. Первый вариант – это доступность в данном примере домена google.com. И говорим, что через интервал в 30 секунд нужно выполнять эту проверку. Таким образом мы проверяем, что наша нода имеет доступ во внешнюю сеть.
Второй вариант – это проверка себя. Мы обычным curl дергаем localhost по указанному порту с интервалом в 10 секунд.
Эти проверки суммируются и поступают в Service Discovery. На основании доступности эти ноды либо исключаются, либо появляются в списке доступных и корректно работающих машинок.

Также Consul предоставляет UI-интерфейс, который с отдельным флагом запускается и будет доступен на машинке. Это позволяет просматривать информацию, а также можно вносить некоторые изменения.
В данном примере открыта вкладка «Сервис». Показано, что запущено три сервиса, один из них Consul. Количество выполненных проверок. И имеются три дата-центра, в которых находятся машинки.
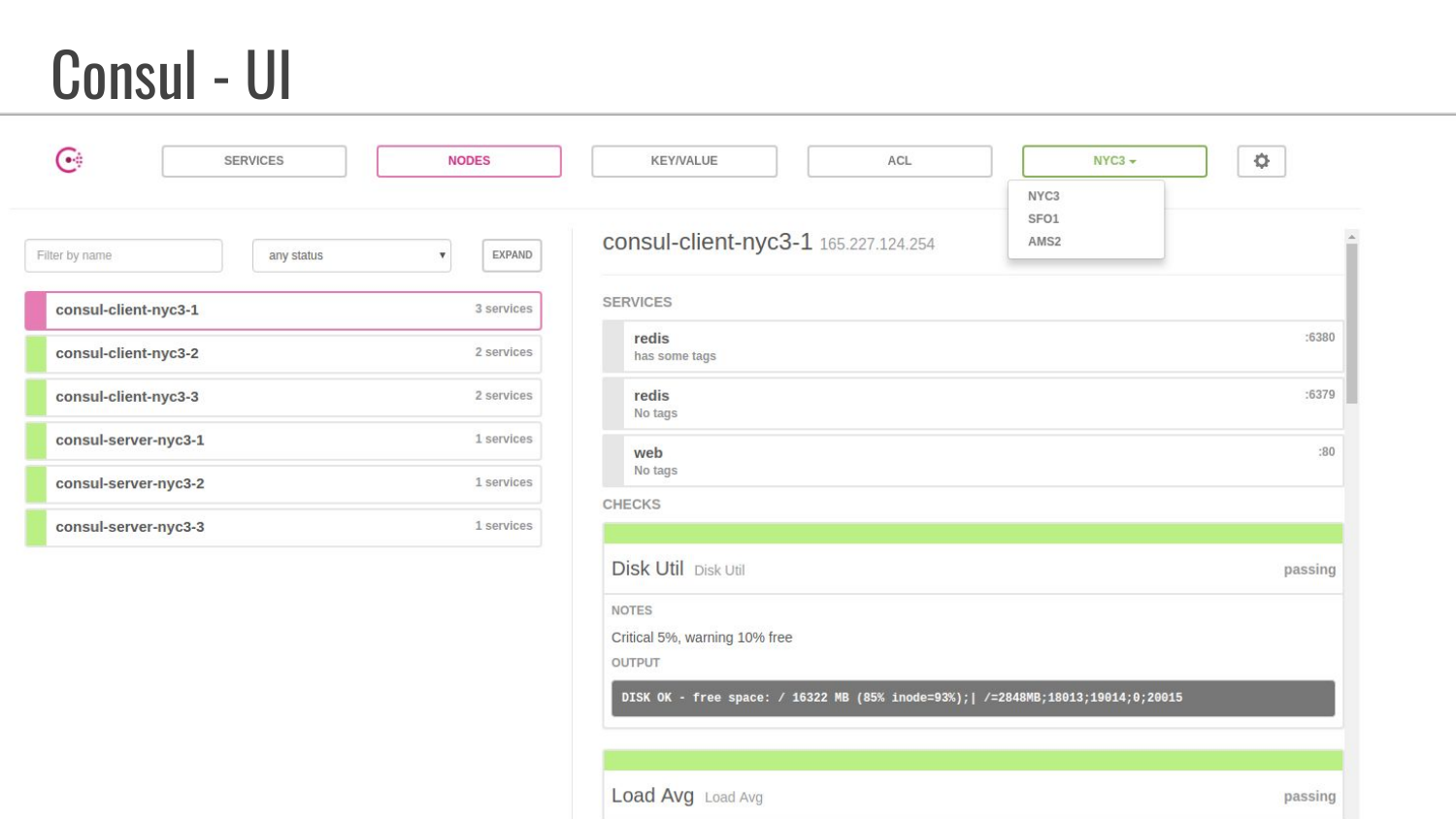
Это пример вкладки «Nodes». Видим, что у них составные имена с участием дата-центров. Здесь также показано, какие сервисы запущены, т. е. мы видим, что теги не заданы. В этих дополнительных тегах можно задать какую-то информацию, которую разработчик может использовать для указания дополнительных параметров.
Также можно передавать информацию в Consul о состоянии дисков, о средней загрузке.
Вопрос: У нас есть докер-контейнер, как его использовать с Consul ?
Ответ: Для докер-контейнера есть несколько подходов. Один из самых распространенных – это использовать сторонний докер-контейнер, отвечающий за регистрацию. При запуске ему прокидывается сокет докера. Все события по регистрации и депубликации контейнера заносятся в Consul.
Вопрос: Т. е. Consul сам запускает докер-контейнер?
Ответ: Нет. Мы запускаем докер-контейнер. И при конфигурации указываем – слушай такой-то сокет. Это примерно так же, как идет работа с сертификатом, когда мы прокидываем информацию, где и что у нас лежит.
Вопрос: Получается, что внутри докер-контейнера, который мы пытаемся подключить к Service Discovery должна быть какая-то логика, которая умеет отдавать данные Consul?
Ответ: Не совсем. Когда он стартует, то мы через переменное окружение передаем переменные. Допустим, сервис name, сервис порт. В регистре слушает эту информацию и заносит в Consul.
Вопрос: У меня еще по UI вопрос. Мы развернули UI, допустим, на production-сервере. Что с безопасностью? Где хранятся данные? Можно ли как-то аккумулировать данные?
Ответ: В UI как раз данные из базы и из Service Discovery. Пароли мы ставим в настройках самостоятельно.
Вопрос: Это можно публиковать в интернет?
Ответ: По умолчанию Consul стартует на localhost. Чтобы публиковать в это интернет, надо будет поставить какой-то proxy. За правила безопасности мы отвечаем сами.
Вопрос: Исторические данные из коробки выдает? Интересно посмотреть статистику по Health Checks. Можно же диагностировать проблемы, если сервер часто выходит из строя.
Ответ: Я не уверен, что там есть детали проверок.
Вопрос: Не столько важно текущее состояние, сколько важна динамика.
Ответ: Для анализа – да.
Вопрос: Service Discovery для докера Consul лучше не использовать?
Ответ: Я бы не рекомендовал его использовать. Цель доклада – познакомить, что есть такое понятие. Исторически он проделал путь, по-моему, до 1-ой версии. Сейчас уже есть более полноценные решения, например, Kubernetes, который все это имеет под капотом. В составе Kubernetes Service Discovery уступает Etcd. Но я с ним не так плотно знаком, как с Consul. Поэтому Service Discovery я решил сделать на примере Consul.
Вопрос: Схема с сервером лидером не тормозит старт приложения в целом? И как Consul определяет нового лидера, если этот лежит?
Ответ: У них описан целый протокол. Если интересно, то можно почитать.
Вопрос: Consul у нас выступает полноценным сервером и все запросы летают через него?
Ответ: Он выступает не полноценным сервером, а берет определенную зону. Она, как правило, оканчивается service.consul. И дальше мы уже по логике идем. Мы не используем в production доменные имена, а именно внутреннюю инфраструктуру, которая обычно прячется за кэширование сервера, если мы работаем по DNS.
Вопрос: Т. е. если мы хотим обратиться к базе данных, то мы в любом случае будем дергать Consul, чтобы найти эту базу сперва, правильно?
Ответ: Да. Если работаем по DNS, то это работает как без Consul, когда используем DNS имена. Обычно современные приложения не в каждом запросе дергают доменное имя, потому что мы connect установили, все работает и в ближайшее время мы практически не используем. Если connect разорвался, то – да, мы опять спрашиваем, где у нас лежит база и идем к ней.
Чат по продуктам hashicorp — Чат пользователей Hashicorp: Consul, Nomad, Terraform
Service-discovery — DevOps: Управление инфраструктурой
Пример файла ansible/common/register_consul_server_ip.yml
- name: Gather facts from consul_server ansible.builtin.setup: delegate_to: "server1" delegate_facts: true register: consul_server_facts - set_fact: # Регистрируем в переменную IP адрес в приватной подсети consul_server_ip: ". " - debug: var: consul_server_ip Пример файла ansible/files/devops.json
"service": "name": "devops", "tags": ["hexlet"], "port": 5000 > > Самостоятельная работа
Вы на опыте познакомитесь с Consul. В данной практике мы описали небольшую инфраструктуру из нескольких серверов. Представим, что эти сервера периодически добавляются в инфраструктуру и убираются из нее (например, для обновления), а перед нами стоит задача понять, какие из серверов доступны. Допустим, у нас есть приложение, которое делает некие вычисления на этих серверах. Для того чтобы сделать эти вычисления, нужно знать ip адрес сервера и убедиться, что он готов к нужной нам работе (например, на нем запущен docker или любая другая программа необходимая для вычислений). Эта задача может быть решена следующими способами:
- После добавления очередного сервера, копируем его ip адрес в конфиг нашего приложения и перезапускаем его. При удалении сервера делаем все то же самое. Минусы — ручные операции, перезагрузка приложения и тд.
- Устанавливаем consul и настраиваем service discovery. На каждом сервере устанавливается consul agent, который подключается к другим агентам в известной ему сети. После этого, он начинает передавать всю известную ему информацию остальным агентам в сети. Таким образом происходит быстрый обмен информацией, а при остановке сервера или появлении нового, другие агенты об этом узнают практически мгновенно. Когда мы хотим узнать ip адреса доступных серверов в нашей сети, мы делаем http запрос в Consul агент (О котором мы знаем. Например, в локальный агент.) и получаем список живых серверов вместе с ip адресами. Минусы такого подхода тоже есть. Самый значимый для нас на этом этапе — сложность настройки и обилие новых концепций.
В этой практике сервера и консул агенты на них практически полностью настроены за вас. Ваша задача заключается в том, чтобы установить инфраструктуру и увидеть, как это все работает. В практике нет сложного сервиса, которому требуется знать ip адреса других серверов в сети. Вместо этого вы являетесь этим сервисом, а тестирование происходит через утилиту curl. Поэтому успехом будет считаться получение списка серверов после выполнения всех действий, а так же обзор инфраструктуры и понимание роли consul в ней.
Подготовка
- Форкните или склонируйте репозиторий с примером инфраструктуры
- Выполните инициализацию Terraform в директории terraform и создайте инфраструктуру.
- Скопируйте IP адреса серверов в ansible/hosts из вывода Terraform. В каждой группе должно быть по одному хосту. В группе серверов с алиас хоста — server1 , в группе клиентов — client1 .
- Выполните подготовку серверов командой make setup-servers. Команда выполнит подготовку серверов: установит необходимые модули для Docker и отключит фаервол (Для простоты тестирования данной практики — в реальном проекте не отключайте, а настраивайте фаервол. Подробнее это разбиралось в уроке Безопасность).
Подготовка окружения завершена, теперь необходимо связать клиент Consul с сервером. Агенты Consul будут запускаться внутри Docker контейнеров. Для того чтобы они могли между собой общаться, им необходимо указать IP адреса из приватной подсети. В качестве такой сети будем использовать VPC которая предоставляется Digital Ocean.
Настройка Service Discovery
- В файле ansible/group_vars/all.yml опишите переменную advertise_ip , в которой будет храниться IP адрес из предоставляемой VPC. Чтобы это сделать, вам необходимо собрать факты о сервере и отфильтровать IP адреса по верной подсети. Этот IP адрес будет выставлять агент Consul, чтобы его могли найти другие агенты.
- В файле ansible/common/register_consul_server_ip.yml опишите задачу, которая зарегистрирует в переменную consul_server_ip IP адрес в приватной подсети. Принцип такой же, как и на предыдущем шаге, только данные нужно взять из consul_server_facts
- Выполните команду make setup-consul-server . Откройте в браузере http://<server_ip>:8500 . По этому адресу открывается страница с дашбордом Consul. Убедитесь, что отображается запущенный сервер Consul и других нод нет
- Зайдите по ssh на сервер с сервером Consul. Выполните docker exec consul-server consul members и убедитесь, что запущена одна нода
- Выполните запрос с помощью curl по адресу http://<server_ip>:8500/v1/catalog/nodes Убедитесь, что в списке только нода сервера
- Выполните команду make setup-consul-client . Команда запустит на втором сервере Consul, который будет клиентом. Выполните предыдущие действия: посмотрите изменения в дашборде Consul, выполните consul members (выполните эту команду в контейнере на сервере и с клиентом), выполните запрос к API сервера Consul.
- Выполните команду make register-consul-service . Команда запустит контейнер с приложением, скопирует конфиг и перезапустит контейнер с клиентом Consul. Теперь наше приложение будет доступно в дашборде и по api сервера Consul по адресу http://<server_ip>:8500/v1/catalog/service/devops
Дополнительные материалы
- Документация Consul
- Consul with Containers
![]()
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты
Об обучении на Хекслете
- Статья «Как учиться и справляться с негативными мыслями»
- Статья «Ловушки обучения»
- Статья «Сложные простые задачи по программированию»
- Вебинар « Как самостоятельно учиться »
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Service Discovery в распределенных системах на примере Consul. Александр Сигачев
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Я всех приветствую! Я Сигачев Александр, работаю в компании Inventos. И сегодня я вас познакомлю с таким понятием как Service Discovery. Рассмотрим мы Service Discovery на примере Consul.
Какие проблемы решает Service Discovery?
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Как это выглядит? На классическом примере в вебе – это фронтенд, который принимает запрос пользователя. Дальше выполняет маршрутизацию его на backend. На данном примере – это load-balancer балансирует на два backend.
Здесь мы видим, что мы запускаем третий экземпляр приложения. Соответственно, когда приложение запускается, оно производит регистрацию в Service Discovery. Service Discovery уведомляет load-balancer. Load-balancer меняет свой конфиг автоматически и уже новый backend подключается в работу. Таким образом могут добавляться backend, либо, наоборот, исключаться из работы.
Что еще удобно делать при помощи Service Discovery?
В Service Discovery могут храниться конфиги nginx, сертификаты и список активных backend-серверов.
Также Service Discovery позволяет обнаружить сбой, обнаружить отказы.
Какие возможны схемы при обнаружении отказов?
- Это приложение, которое мы разработали, само уведомляет Service Discovery, что оно еще до сих пор работоспособно.
- Service Discovery со своей стороны опрашивает приложение на факт доступности.
- Или же используется сторонний скрипт или приложение, которое проверяет наше приложение на доступность и уведомляет Service Discovery, что все хорошо и можно работать, или, наоборот, что все плохо и необходимо этот экземпляр приложения исключить из балансировки.
Каждая из схем может применяться в зависимости от того, какое ПО мы используем. Например, мы только начали разрабатывать новый проект, то мы без проблем можем обеспечить схему, когда наше приложение уведомляет Service Discovery. Либо можем подключить, что Service Discovery проводит проверку.
Если же приложение досталось нам в наследство или разработано кем-то сторонним, то здесь подходит третий вариант, когда мы пишем обработчик, и все это встает в нашу работу автоматически.
Это один из примеров. Load-balancer в виде nginx перезагружается. Это дополнительная утилита, которая предоставляется вместе с Consul. Это consul-template. Мы описываем правило. Говорим, что используем шаблон (Шаблонизатор Golang). При совершении событий, при уведомлениях, что произошли изменения, он перегенерируется и Service Discovery присылается команда «reload». Простейший пример, когда по событию переконфигурируется nginx и перезапускается.
Что такое Consul?
- Прежде всего – это Service Discovery.
- Он имеет механизм проверки доступности – Health Checking.
- Также он имеет KV Store.
- И в его основу заложено возможность использовать Multi Datacenter.
Для чего все это можно использовать? В KV Store мы можем хранить примеры конфигов. Health Checking мы можем проводить проверку локального сервиса и уведомлять. Multi Datacenter используется для того, чтобы можно было построить карту сервисов. Например, Amazon имеет несколько зон и маршрутизирует трафик наиболее оптимально, чтобы не было лишних запросов между дата-центрами, которые тарифицируются отдельно от локального трафика, и, соответственно, имеют меньшую задержку.
Немножко разберемся с терминами, которые в Consul используются.
- Consul – сервис, написанный на Go. Одним из преимуществ программы на Go – это 1 бинарный файл, который ты просто скачал. Запустил из любого места и у тебя никаких зависимостей нет.
- Дальше при помощи ключей мы можем запустить этот сервис либо в режиме клиента, либо в режиме сервера.
- Также атрибут «datacenter» позволяет поставить флаг к какому дата-центру принадлежит данный сервер.
- Consensus – базируется на протоколе raft. Если кому интересно, то об этом можно прочитать поподробнее на сайте Consul. Это протокол, который позволяет определить лидера и определить какие денные считать валидными и доступными.
- Gossip – это протокол, который обеспечивает взаимодействие между нодами. Причем эта система является децентрализованной. В рамках одного дата-центра все ноды общаются с соседями. И, соответственно, передается друг другу информация об актуальном состоянии. Можно сказать, что это сплетни между соседями.
- LAN Gossip – локальный обмен данных между соседями в рамках одного дата-центра.
- WAN Gossip – используется, когда нам необходимо синхронизировать информацию между двумя дата-центрами. Информация идет между нодами, которые помечены как сервер.
- RPC – позволяет выполнять запросы через клиента на сервере.
Описание RPC. Допустим, на виртуальной машине или физическом сервере запущен Consul в виде клиента. К нему локально обращаемся. А дальше локальный клиент запрашивает информацию у сервера и синхронизируется. Информация в зависимости от настроек может выдаваться из локального кэша, либо может быть синхронизирована с лидером, с мастером сервера.
У этих двух схем есть как плюсы, так и минусы. Если мы работаем с локальным кэшем, то это быстро. Если мы работаем с данными, которые хранятся на сервере, то это дольше, но получаем более актуальную информацию.
Если это изобразить графически, то вот такая картинка сайта. Мы видим, что у нас запущено три мастера. Один звездочкой помечен как лидер. В данном примере три клиента, которые между собой обмениваются локально информацией по UDP/TCP. А информация между дата-центрами передается между серверами. Здесь клиенты взаимодействуют между собой локально.
Какой API предоставляет Consul?
Для того чтобы получить информацию, есть два вида API у Consul.
Это DNS API. По умолчанию Consul запускается на 8600 порту. Мы можем настроить проксирование запроса и обеспечить доступ через локальный резолвинг, через локальный DNS. Мы можем запросить по домену и получим в ответ информацию об IP-адресе.
HTTP API – либо мы можем локально на 8500 порту запросить информацию о конкретном сервисе и получим JSON ответ, какой IP имеет сервер, какой host, какой порт зарегистрирован. И дополнительная информация может быть передана через token.
Что нужно, чтобы запустить Consul?
В первом варианте мы в режиме разработчика указываем флаг, что это режим разработчика. Agent стартует как сервер. И всю функцию выполняет уже самостоятельно на одной машине. Удобно, быстро и никаких практически дополнительных настроек для первого старта не требуется.
Второй режим – это запуск в production. Здесь запуск немного усложняется. Если у нас нет ни одной версии консула, то мы должны привести в bootstrap первую машину, т. е. эта машина, которая возьмет на себя обязанности лидера. Мы поднимаем ее, затем мы поднимаем второй экземпляр сервера, передавая ему информацию, где у нас находится мастер. Третий поднимаем. После того, как у нас поднято три машины, мы на первой машине из запущенного bootstrap, перезапускаем ее в обычном режиме. Данные синхронизируются, и начальный кластер уже поднят.
Рекомендуется запускать от трех до семи экземпляров в режиме сервера. Это обуславливается тем, что если количество серверов растет, то увеличивается время на синхронизацию информации между ними. Количество нод должно быть нечетным, чтобы обеспечить кворум.
Как обеспечиваются Health Checks?
В директорию для конфигурации Consul мы в виде Json пишем правило проверки. Первый вариант – это доступность в данном примере домена google.com. И говорим, что через интервал в 30 секунд нужно выполнять эту проверку. Таким образом мы проверяем, что наша нода имеет доступ во внешнюю сеть.
Второй вариант – это проверка себя. Мы обычным curl дергаем localhost по указанному порту с интервалом в 10 секунд.
Эти проверки суммируются и поступают в Service Discovery. На основании доступности эти ноды либо исключаются, либо появляются в списке доступных и корректно работающих машинок.
Также Consul предоставляет UI-интерфейс, который с отдельным флагом запускается и будет доступен на машинке. Это позволяет просматривать информацию, а также можно вносить некоторые изменения.
В данном примере открыта вкладка «Сервис». Показано, что запущено три сервиса, один из них Consul. Количество выполненных проверок. И имеются три дата-центра, в которых находятся машинки.
Это пример вкладки «Nodes». Видим, что у них составные имена с участием дата-центров. Здесь также показано, какие сервисы запущены, т. е. мы видим, что теги не заданы. В этих дополнительных тегах можно задать какую-то информацию, которую разработчик может использовать для указания дополнительных параметров.
Также можно передавать информацию в Consul о состоянии дисков, о средней загрузке.
Вопросы
Вопрос: У нас есть докер-контейнер, как его использовать с Consul ?
Ответ: Для докер-контейнера есть несколько подходов. Один из самых распространенных – это использовать сторонний докер-контейнер, отвечающий за регистрацию. При запуске ему прокидывается сокет докера. Все события по регистрации и депубликации контейнера заносятся в Consul.
Вопрос: Т. е. Consul сам запускает докер-контейнер?
Ответ: Нет. Мы запускаем докер-контейнер. И при конфигурации указываем – слушай такой-то сокет. Это примерно так же, как идет работа с сертификатом, когда мы прокидываем информацию, где и что у нас лежит.
Вопрос: Получается, что внутри докер-контейнера, который мы пытаемся подключить к Service Discovery должна быть какая-то логика, которая умеет отдавать данные Consul?
Ответ: Не совсем. Когда он стартует, то мы через переменное окружение передаем переменные. Допустим, сервис name, сервис порт. В регистре слушает эту информацию и заносит в Consul.
Вопрос: У меня еще по UI вопрос. Мы развернули UI, допустим, на production-сервере. Что с безопасностью? Где хранятся данные? Можно ли как-то аккумулировать данные?
Ответ: В UI как раз данные из базы и из Service Discovery. Пароли мы ставим в настройках самостоятельно.
Вопрос: Это можно публиковать в интернет?
Ответ: По умолчанию Consul стартует на localhost. Чтобы публиковать в это интернет, надо будет поставить какой-то proxy. За правила безопасности мы отвечаем сами.
Вопрос: Исторические данные из коробки выдает? Интересно посмотреть статистику по Health Checks. Можно же диагностировать проблемы, если сервер часто выходит из строя.
Ответ: Я не уверен, что там есть детали проверок.
Вопрос: Не столько важно текущее состояние, сколько важна динамика.
Ответ: Для анализа – да.
Вопрос: Service Discovery для докера Consul лучше не использовать?
Ответ: Я бы не рекомендовал его использовать. Цель доклада – познакомить, что есть такое понятие. Исторически он проделал путь, по-моему, до 1-ой версии. Сейчас уже есть более полноценные решения, например, Kubernetes, который все это имеет под капотом. В составе Kubernetes Service Discovery уступает Etcd. Но я с ним не так плотно знаком, как с Consul. Поэтому Service Discovery я решил сделать на примере Consul.
Вопрос: Схема с сервером лидером не тормозит старт приложения в целом? И как Consul определяет нового лидера, если этот лежит?
Ответ: У них описан целый протокол. Если интересно, то можно почитать.
Вопрос: Consul у нас выступает полноценным сервером и все запросы летают через него?
Ответ: Он выступает не полноценным сервером, а берет определенную зону. Она, как правило, оканчивается service.consul. И дальше мы уже по логике идем. Мы не используем в production доменные имена, а именно внутреннюю инфраструктуру, которая обычно прячется за кэширование сервера, если мы работаем по DNS.
Вопрос: Т. е. если мы хотим обратиться к базе данных, то мы в любом случае будем дергать Consul, чтобы найти эту базу сперва, правильно?
Ответ: Да. Если работаем по DNS, то это работает как без Consul, когда используем DNS имена. Обычно современные приложения не в каждом запросе дергают доменное имя, потому что мы connect установили, все работает и в ближайшее время мы практически не используем. Если connect разорвался, то – да, мы опять спрашиваем, где у нас лежит база и идем к ней.
- Децентрализованные сети
- IT-инфраструктура
- DevOps
- Распределённые системы
- Микросервисы