Общие сведения о требованиях MDC
В этом руководстве описываются требования, необходимые для установки и настройки модульного центра обработки данных (MDC).
Цели этого руководства:
- Предоставьте контрольный список перед развертыванием, чтобы убедиться, что все предварительные требования выполнены перед установкой компонентов.
- Общие сведения о ключевых компонентах MDC.
- Проверьте развертывание клиента.
Для полного понимания содержимого этого руководства требуется технический опыт в области виртуализации, серверов, операционных систем, сетевых решений и решений хранилища.
В этом руководстве рассматриваются развертывание основных компонентов Microsoft Azure Stack Hub и особенности решения MDC. В этом руководстве не описываются процедуры работы Azure Stack Hub и не рассматриваются все функции, доступные в Azure Stack Hub.
Введение
MDC — это интегрированное предложение для Azure Stack Hub, упакованое в стандартный 40-футовый контейнер для доставки металла. Контейнер включает блок управления климатом, освещение и систему оповещений. Основные компоненты Azure Stack Hub устанавливаются в виде модулей pod.
Терминология
В следующей таблице перечислены некоторые термины, используемые в этом руководстве.
| Термин | Определение |
|---|---|
| Узел жизненного цикла оборудования (HLH) | HLH — это физический сервер, который используется для начальной начальной загрузки развертывания, а также для текущего управления оборудованием, поддержки и резервного копирования инфраструктуры Azure Stack Hub. HLH работает под управлением Windows Server 2019 с возможностями рабочего стола и ролью Hyper-V. Сервер используется для размещения средств управления оборудованием, средств управления коммутаторами, набора средств для партнеров Azure Stack Hub и виртуальной машины развертывания. |
| Развертывание виртуальной машины (DVM) | DVM — это виртуальная машина, созданная в HLH на время развертывания программного обеспечения Azure Stack Hub. DvM выполняет подсистему оркестрации программного обеспечения Azure Stack Hub, называемую Enterprise Cloud Engine (ECE), для установки и настройки программного обеспечения инфраструктуры структуры Azure Stack Hub на всех серверах единиц масштабирования Azure Stack Hub по сети. |
| Набор средств для партнеров Azure Stack Hub | Коллекция программных средств, используемых для сбора входных параметров конкретного клиента и запуска установки и настройки Azure Stack Hub. Он включает лист развертывания, который представляет собой средство графического пользовательского интерфейса (GUI), используемое для записи и хранения настраиваемых параметров для установки Azure Stack Hub. Он также включает средство генератора конфигурации сети, которое использует входные данные листа развертывания для создания файлов конфигурации сети для всех физических сетевых устройств в решении. |
| Пакет расширения OEM | Пакет встроенного ПО, драйверов устройств и средств управления оборудованием в специализированном формате, используемом Azure Stack Hub во время первоначального развертывания и обновления. |
| Концентратор последовательных портов | Физическое устройство, установленное в каждом модуле pod, которое предоставляет сетевой доступ к последовательным портам сетевых коммутаторов для развертывания и управления. |
| Единица масштабирования | Основной компонент Azure Stack Hub, предоставляющий вычислительные ресурсы и ресурсы хранилища для инфраструктуры структуры и рабочих нагрузок Azure Stack Hub. |
| Хранилище Isilon | Компонент Azure Stack Hub, относящееся к решению MDC. Isilon предоставляет дополнительное хранилище BLOB-объектов и файлов для рабочих нагрузок Azure Stack Hub. |
| Pod | В контексте MDC pod — это независимая логическая единица, состоящая из двух взаимосвязанных физических стоек. |
Рабочий процесс развертывания
На высоком уровне процесс развертывания MDC состоит из следующих этапов:
Планирование
- Планирование работы центра обработки данных.
- Планирование настройки логической сети Azure Stack Hub.
- Планирование сетевой интеграции центра обработки данных.
- Планирование интеграции удостоверений .
- Планирование интеграции безопасности .
- Планирование PKI-сертификатов.
Этап подготовки
- Сбор данных инвентаризации.
- Подключение питания и питания решения.
- Проверка работоспособности системы ОВКВ.
- Проверка мониторинга пожара и оповещения о работоспособности системы.
- Проверка работоспособности физического оборудования.
Этап выполнения — отдельно для каждого из трех модулей pod.
- Настройка узла жизненного цикла оборудования.
- Настройка сетевых коммутаторов.
- Интеграция сети центра обработки данных.
- Настройка параметров физического оборудования.
- Настройка хранилища Isilon.
- Развертывание инфраструктуры структуры Azure Stack Hub.
- Интеграция удостоверений центра обработки данных.
- Установка надстроек для расширенной функциональности.
Этап проверки — отдельно для каждого из трех модулей pod
- Проверка работоспособности после развертывания.
- Регистрация Azure Stack Hub в корпорации Майкрософт.
- Передача клиентов Azure Stack Hub.
Структурированный журнал приложений для Azure Spring Apps
Azure Spring Apps — это новое название службы Azure Spring Cloud. Старое название будет еще некоторое время встречаться в наших материалах, пока мы не обновим ресурсы, такие как снимки экрана, видео и схемы.
Эта статья относится к: ✔️ Basic/Standard ✔️ Enterprise
Из этой статьи вы узнаете, как создавать и собирать структурированные данные журнала приложений в Azure Spring Apps. Если правильно настроить Azure Spring Apps, вы сможете запрашивать журнал приложений и выполнять анализ посредством Log Analytics.
Требования к схеме журнала
Для должной работы журнал приложений должен быть в формате JSON и соответствовать заданной схеме. Azure Spring Apps использует эту схему, чтобы анализировать приложение и передавать данные в Log Analytics.
Включение формата журнала JSON затрудняет чтение потоковой передачи журналов из консоли. Чтобы получить результат в понятном для человека формате, добавьте аргумент —format-json в команду CLI az spring app logs . См. статью Форматирование структурированных журналов JSON.
Требования к схеме JSON:
| Ключ JSON | Тип значения JSON | Обязательное поле | Столбец в Log Analytics | Description |
|---|---|---|---|---|
| TIMESTAMP | строка | Да | AppTimestamp | Метка времени в формате UTC |
| logger | строка | Нет | Ведение журнала | logger |
| level | строка | Нет | CustomLevel | log level |
| среды | строка | Нет | Дискуссия | среды |
| message | строка | Нет | Message | Сообщение журнала |
| stackTrace | строка | Нет | StackTrace | Трассировка стека исключений |
| exceptionClass | строка | Нет | ExceptionClass | Название класса исключений |
| mdc | Вложенный массив JSON | Нет | Сопоставленный контекст диагностики | |
| mdc.traceId | строка | Нет | TraceId | Идентификатор трассировки для распределенной трассировки |
| mdc.spanId | строка | Нет | SpanId | Идентификатор диапазона для распределенной трассировки |
- Поле timestamp является обязательным и должно быть в формате UTC, все остальные поля необязательны.
- traceId и spanId в поле mdc используются в целях трассировки.
- Каждую запись JSON необходимо вносить отдельной строкой.
Пример записи журнала
,"stackTrace":"java.lang.RuntimeException: get an exception\r\n\tat com.example.demo.HelloController.throwEx(HelloController.java:54)\r\n\","message":"Got an exception","exceptionClass":"RuntimeException"> Ограничения
Каждая строка журналов JSON имеет не более 16 байт. Если выходные данные JSON одной записи журнала превышают это ограничение, он разбивается на несколько строк, и каждая необработанную строку собирается в Log столбец без анализа структурно.
Как правило, эта ситуация возникает при ведении журнала исключений с глубоким стеком, особенно если приложение Аналитика включен агент in-Process. Примените параметры ограничения к результату трассировки стека (см. приведенные ниже примеры конфигурации), чтобы гарантировать его надлежащий анализ.
Создание журнала JSON в соответствии со схемой
Для приложений Spring можно создать ожидаемый формат журнала JSON с помощью общих платформ ведения журнала, таких как Logback и Log4j2.
Ведение журнала с помощью logback
При использовании начальных средств Spring Boot по умолчанию используется logback. Для приложений Logback используйте кодировщик logstash-encoder для создания форматированного журнала JSON. Этот метод поддерживается в Spring Boot версии 2.1 или более поздней.
-
Добавьте зависимость logstash в файл pom.xml .
net.logstash.logback logstash-logback-encoder 6.5 timestamp UTC logger level thread mdc stackTrace 200 14000 true exceptionClass Ведение журнала с помощью log4j2
Если речь идет о приложениях log4j2, создать журнал в формате JSON можно с помощью json-template-layout. Этот метод поддерживается в Spring Boot 2.1 и более поздних версиях.
-
Исключите spring-boot-starter-logging из spring-boot-starter , добавьте зависимости spring-boot-starter-log4j2 , log4j-layout-template-json в файл pom.xml .
org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-logging org.springframework.boot spring-boot-starter-log4j2 org.apache.logging.log4j log4j-layout-template-json 2.14.0 < "mdc": < "$resolver": "mdc" >, "exceptionClass": < "$resolver": "exception", "field": "className" >, "stackTrace": < "$resolver": "exception", "field": "stackTrace", "stringified": true >, "message": < "$resolver": "message", "stringified": true >, "thread": < "$resolver": "thread", "field": "name" >, "timestamp": < "$resolver": "timestamp", "pattern": < "format": "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'", "timeZone": "UTC" >>, "level": < "$resolver": "level", "field": "name" >, "logger": < "$resolver": "logger", "field": "name" >> Анализ журналов в Log Analytics
После правильной настройки приложения журнал консоли приложения передается в Log Analytics. Такая структура обеспечивает эффективную обработку запросов в Log Analytics.
Проверка структуры журнала в Log Analytics
Это можно сделать следующим образом:
- Перейдите на страницу обзора своего экземпляра службы.
- Щелкните Журналы в разделе Мониторинг.
- Выполните этот запрос.
AppPlatformLogsforSpring | where TimeGenerated > ago(1h) | project AppTimestamp, Logger, CustomLevel, Thread, Message, ExceptionClass, StackTrace, TraceId, SpanId 
Отобразите записи журнала, содержащие ошибки.
Чтобы проверить записи журнала с ошибкой, выполните следующий запрос:
AppPlatformLogsforSpring | where TimeGenerated > ago(1h) and CustomLevel == "ERROR" | project AppTimestamp, Logger, ExceptionClass, StackTrace, Message, AppName | sort by AppTimestamp Этот запрос позволяет искать ошибки или менять условия запроса таким образом, чтобы находить конкретные классы исключения или коды ошибки.
Отображение записей журнала по определенному идентификатору трассировки
Чтобы изучить записи журнала по конкретному идентификатору трассировки trace_id, выполните следующий запрос:
AppPlatformLogsforSpring | where TimeGenerated > ago(1h) | where TraceId == "trace_id" | project AppTimestamp, Logger, TraceId, SpanId, StackTrace, Message, AppName | sort by AppTimestamp Следующие шаги
- Подробнее о запросах к журналу см. в статье Начало работы с запросами к журналу в Azure Monitor.
Eclair — Java Spring библиотека декларативного логирования

2018-06-08 в 13:55, admin , рубрики: java, logging, open source, spring, spring boot, Блог компании Tinkoff.ru

Вопросов о работе сервисов на этапах разработки, тестирования и поддержки очень много и все они на первый взгляд непохожи: «Что произошло?», «Был ли запрос?», «Какой формат даты?», «Почему сервис не отвечает?» и т.д.
Корректно составленный лог сможет подробно ответить на эти и многие другие вопросы абсолютно автономно без участия разработчиков. В стремлении к такой заманчивой цели родилась библиотека логирования Eclair, призванная вести диалог со всеми участниками процесса, не перетягивая на себя слишком много одеяла.
Об одеяле и особенностях решения — далее.
В чём проблема логирования
Если вам не очень интересно разбираться в предпосылках, можете сразу перейти к описанию нашего решения.
- Лог приложения — его алиби.
Доказать успешность работы приложения может, чаще всего, только он. Состояния у микросервиса нет, смежные системы подвижны и привередливы. «Повторить», «воссоздать», «перепроверить» – всё это трудно и/или невыполнимо. Лог должен быть достаточно информативен, чтобы в любой момент времени ответить на вопрос: «Что произошло?». Лог должен быть понятен всем: разработчику, тестировщику, иногда аналитику, иногда администратору, иногда первой линии поддержки – всякое случается. - Микросервисы — это про многопоточку.
Приходящие в сервис запросы (или запрашиваемые сервисом данные) чаще всего обрабатываются несколькими потоками. Лог всех потоков, как правило, перемешан. Вы хотите отличать параллельные потоки и отличать «последовательные» потоки? Один и тот же поток переиспользуется для последовательной обработки запросов, раз за разом выполняя свою логику для разных наборов данных. Эти «последовательные» потоки из другой плоскости, но их границы должны быть чёткими для читателя. - Лог должен сохранять оригинальный формат данных.
Если в действительности сервисы перекидываются XML’ем, то соответствующий лог должен хранить XML. Это не всегда компактно и не всегда красиво (зато удобно). Проще убедиться в успехе, проще проанализировать неудачу. В отдельных случаях, лог может использоваться для ручного воспроизведения или повторной обработки запроса. - Часть данных в логе требует особого отношения.
Входящие данные (запросы), исходящие данные (ответы), запросы к сторонним системам и ответы от них часто требуется хранить отдельно. К ним предъявляются особые требования: по сроку хранения или надёжности. Кроме того, эти данные могут иметь внушительный объём по сравнению с типичной строкой лога. - Часть данных не для лога.
Из регулярного лога обычно должны быть исключены: бинарные данные (массивы байт, base64, ..), персональные данные клиентов / партнеров / прочих физических и юридических лиц. Это всегда индивидуальная история, но систематическая и ручному контролю не поддаётся.
Почему не руками
- Объём кода необоснованно (необыкновенно) растёт. На первых порах это не сильно бросается в глаза, если логировать только самое основное (удачной поддержки, кстати, при таком подходе).
- Вызывать руками логгер быстро становится лень. Объявлять static поле с логгером тоже лень (ладно, это может сделать за нас Lombok). Мы, разработчики, ленивы. И мы прислушиваемся к своей лени, это благородная лень: она настойчиво меняет мир к лучшему.
- Микросервисы оказываются не со всех сторон хороши. Да, они маленькие и миленькие, но есть обратная сторона: их много! Отдельное приложение от начала и до конца зачастую пишет один разработчик. У него перед глазами не маячит legacy. Счастливый, не обремененный навязанными правилами, разработчик считает долгом изобрести свой формат лога, свой принцип и свои правила. Затем, блестяще реализует изобретение. В каждом классе по-разному. Это проблема? Колоссальная.
- Рефакторинг сломает ваш лог. Даже всемогущая Idea его не спасёт. Актуализировать лог в той же степени невозможно, как невозможно актуализировать Javadoc. Javadoc при этом хотя бы читают только разработчики (нет, никто не читает), но аудитория логов гораздо шире и командой разработки не ограничивается.
- MDC (Mapped Diagnostic Context) — неотъемлемая часть многопоточного приложения. Ручное заполнение MDC требует своевременной его очистки по окончанию выполнения работы в потоке. Иначе вы рискуете связать одним ThreadLocal – не относящиеся друг к другу данные. Руками и глазами это проконтролировать, осмелюсь утверждать, невозможно.
И вот как мы решаем эти проблемы в своих приложениях.
Что такое Eclair, и что он умеет
Eclair – это инструмент, упрощающий написание логируемого кода. Он помогает собрать нужную meta-информацию об исходном коде, связать ее с данными, летящими в приложении в runtime и направить их в привычное вам хранилище лога, породив при этом минимум кода.
Основная цель — сделать лог понятным всем участникам процесса разработки. Поэтому, удобством написания кода польза от Eclair не заканчивается, а только начинается.
Eclair логирует аннотированные методы и параметры:
- логирует вход в метод / выход из метода / исключения / аргументы / возвращаемые методом значения
- фильтрует исключения, чтобы логировать их специфично типам: только там, где это нужно
- варьирует «подробность» лога, исходя из настроек приложения для текущей локации: например, в самом подробном случае печатает значения аргументов (всех или некоторых), в самом кратком варианте — только факт входа в метод
- печатает данные как JSON / XML / в любом другом формате (из коробки готов работать с Jackson, JAXB): понимает, какой формат наиболее предпочтителен для определённого параметра
- понимает SpEL (Spring Expression Language) для декларативной установки и авто-очистки MDC
- пишет в N логгеров, «логгер» в понимании Eclair — это bean в контексте, реализующий interface EclairLogger : указать логгер, который должен обработать аннотацию, можно по имени, по алиасу или по умолчанию
- подсказывает программисту о некоторых ошибках в использовании аннотаций: например, Eclair знает, что работает на динамических прокси (со всеми вытекающими особенностями), поэтому может подсказать, что аннотация на private методе никогда не сработает
- воспринимает мета-аннотации (как их называет Spring): можно определять свои аннотации для логирования, пользуясь немногочисленными базовыми аннотациями — для сокращения кода
- умеет маскировать «чувствительные» данные при распечатке: из коробки XPath-экранирование XML’я
- пишет лог в «ручном» режиме, определяет invoker’а и «разворачивает» аргументы, реализующие Supplier : давая возможность инициализировать аргументы «лениво»
Как подключить Eclair
Исходный код опубликован у нас в GitHub’е под лицензией Apache 2.0:
github.com/TinkoffCreditSystems/eclair
Для подключения вам потребуется Java 8, Maven и Spring Boot 1.5+. Артефакт размещён в Maven Central Repository:
ru.tinkoff eclair-spring-boot-starter 0.8.3 Стартер содержит стандартную реализацию EclairLogger , использующую инициализированную Spring Boot’ом систему логирования с некоторым выверенным набором настроек.
Примеры
Здесь приведены некоторые примеры типичного использования библиотеки. Сначала даётся фрагмент кода, затем соответствующий ему лог в зависимости от доступности определенного уровня логирования. Более полный набор примеров можно найти на Wiki проекта в разделе Examples.
Самый простой пример
По умолчанию применяется уровень DEBUG.
@Log void simple()
| Если доступен уровень | … то лог будет таким |
|---|---|
| TRACE DEBUG |
DEBUG [] r.t.e.e.Example.simple > DEBUG [] r.t.e.e.Example.simple |
| INFO WARN ERROR |
— |
Подробность лога зависит от доступного уровня логирования
Доступный в текущей локации уровень логирования влияет на подробность лога. Чем «ниже» доступный уровень (т.е. чем ближе к TRACE), тем лог подробнее.
@Log(INFO) boolean verbose(String s, Integer i, Double d)
| Уровень | Лог |
|---|---|
| TRACE DEBUG |
INFO [] r.t.e.e.Example.verbose > s=»s», i=4, d=5.6 INFO [] r.t.e.e.Example.verbose < false |
| INFO | INFO [] r.t.e.e.Example.verbose > INFO [] r.t.e.e.Example.verbose |
| WARN ERROR |
— |
Тонкая настройка логирования исключений
Типы логируемых исключений могут быть отфильтрованы. Залогированы будут отобранные исключения и их потомки. В этом примере NullPointerException будет залогирован на уровне WARN, Exception на уровне ERROR (по умолчанию), а Error не будет залогирован совсем (потому что Error не включён в фильтр первой аннотации @Log.error и явно исключён из фильтра второй аннотации).
@Log.error(level = WARN, ofType = ) @Log.error(exclude = Error.class) void filterErrors(Throwable throwable) throws Throwable < throw throwable; >// рассмотрен лог вызовов с разными аргументами filterErrors(new NullPointerException()); filterErrors(new Exception()); filterErrors(new Error()); | Уровень | Лог |
|---|---|
| TRACE DEBUG INFO WARN |
WARN [] r.t.e.e.Example.filterErrors ! java.lang.NullPointerException java.lang.NullPointerException: null at r.t.e.e.ExampleTest.filterErrors(ExampleTest.java:0) .. ERROR [] r.t.e.e.Example.filterErrors ! java.lang.Exception java.lang.Exception: null at r.t.e.e.ExampleTest.filterErrors(ExampleTest.java:0) .. |
| ERROR | ERROR [] r.t.e.e.Example.filterErrors ! java.lang.Exception java.lang.Exception: null at r.t.e.e.ExampleTest.filterErrors(ExampleTest.java:0) .. |
Настроить каждый параметр отдельно
@Log.in(INFO) void parameterLevels(@Log(INFO) Double d, @Log(DEBUG) String s, @Log(TRACE) Integer i)
| Уровень | Лог |
|---|---|
| TRACE | INFO [] r.t.e.e.Example.parameterLevels > d=9.4, s=»v», i=7 |
| DEBUG | INFO [] r.t.e.e.Example.parameterLevels > d=9.4, s=»v» |
| INFO | INFO [] r.t.e.e.Example.parameterLevels > 9.4 |
| WARN ERROR |
— |
Выбрать и настроить формат распечатки
«Принтеры», отвечающие за формат распечатки, могут конфигурироваться pre- и post-процессорами. В приведённом примере maskJaxb2Printer сконфигурирован так, что элементы, соответствующие XPath-выражению «//s» , маскируются при помощи «********» . В то же время jacksonPrinter печатает Dto «as is».
@Log.out(printer = "maskJaxb2Printer") Dto printers(@Log(printer = "maskJaxb2Printer") Dto xml, @Log(printer = "jacksonPrinter") Dto json, Integer i)
| Уровень | Лог |
|---|---|
| TRACE DEBUG |
DEBUG [] r.t.e.e.Example.printers > xml= DEBUG [] r.t.e.e.Example.printers |
| INFO WARN ERROR |
— |
Несколько логгеров в контексте
Метод логируется при помощи нескольких логгеров одновременно: логгером по умолчанию (аннотированным при помощи @Primary ) и логгером auditLogger . Определить несколько логгеров можно, если вы хотите разделить логируемые события не только по уровням (TRACE — ERROR), но и направить их в разные хранилища. Например, основной логгер может писать лог в файл на диск при помощи slf4j, а auditLogger может писать особый срез данных в отличное хранилище (например в Kafka) в своём специфичном формате.
@Log @Log(logger = "auditLogger") void twoLoggers()
Управление MDC
MDC, установленные при помощи аннотации, автоматически удаляются после выхода из аннотированного метода. Значение записи в MDC может вычисляться динамически при помощи SpEL. В примере приведены: статичная строка, воспринимаемая константой, вычисление выражения 1 + 1 , обращение к бину jacksonPrinter , вызов static метода randomUUID .
MDC с атрибутом global = true не удаляются после выхода из метода: как видно единственная запись, оставшаяся в MDC до конца лога, — это sum .
@Log void outer() < self.mdc(); >@Mdc(key = "static", value = "string") @Mdc(key = "sum", value = "1 + 1", global = true) @Mdc(key = "beanReference", value = "@jacksonPrinter.print(new ru.tinkoff.eclair.example.Dto())") @Mdc(key = "staticMethod", value = "T(java.util.UUID).randomUUID()") @Log void mdc() < self.inner(); >@Log.in void inner()
Лог при выполнении приведённого выше кода:
DEBUG [] r.t.e.e.Example.outer >
DEBUG [beanReference=, sum=2, static=string, staticMethod=01234567-89ab-cdef-ghij-klmnopqrstuv] r.t.e.e.Example.mdc >
DEBUG [beanReference=, sum=2, static=string, staticMethod=01234567-89ab-cdef-ghij-klmnopqrstuv] r.t.e.e.Example.inner >
DEBUG [beanReference=, sum=2, static=string, staticMethod=01234567-89ab-cdef-ghij-klmnopqrstuv] r.t.e.e.Example.mdc DEBUG [sum=2] r.t.e.e.Example.outer
Установка MDC на основе параметров
Если задавать MDC при помощи аннотации на параметре, то аннотированный параметр доступен как корневой объект evaluation-контекста. Здесь «s» — это поле класса Dto с типом String .
@Log.in void mdcByArgument(@Mdc(key = "dto", value = "#this") @Mdc(key = "length", value = "s.length()") Dto dto)
Лог при выполнении приведённого выше кода:
DEBUG [length=8, dto=Dto] r.t.e.e.Example.mdcByArgument > dto=Dto
Ручное логирование
Для «ручного» логирования достаточно внедрить реализацию ManualLogger . Передаваемые аргументы, реализующие interface Supplier , будут «развёрнуты» только при необходимости.
@Autowired private ManualLogger logger; @Log void manual() < logger.info("Eager logging: <>", Math.PI); logger.debug("Lazy logging: <>", (Supplier) () -> Math.PI); > | Уровень | Лог |
|---|---|
| TRACE DEBUG |
DEBUG [] r.t.e.e.Example.manual > INFO [] r.t.e.e.Example.manual — Eager logging: 3.141592653589793 DEBUG [] r.t.e.e.Example.manual — Lazy logging: 3.141592653589793 DEBUG [] r.t.e.e.Example.manual |
| INFO | INFO [] r.t.e.e.Example.manual — Eager logging: 3.141592653589793 |
| WARN ERROR |
— |
Чего не делает Eclair
Eclair не знает о том, где вы будете хранить свои логи, насколько подробно и долго. Eclair не знает, как вы планируете пользоваться своим логом. Eclair аккуратно достаёт из вашего приложения всю необходимую вам информацию и перенаправляет её в сконфигурированное вами хранилище.
Пример конфигурации EclairLogger , направляющего лог в Logback-логгер со специфичным Appender’ом:
@Bean public EclairLogger eclairLogger() < LoggerFacadeFactory factory = loggerName -> < ch.qos.logback.classic.LoggerContext context = (LoggerContext) LoggerFactory.getILoggerFactory(); ch.qos.logback.classic.Logger logger = context.getLogger(loggerName); // Appenderappender = ? // logger.addAppender(appender); return new Slf4JLoggerFacade(logger); >; return new SimpleLogger(factory, LoggingSystem.get(SimpleLogger.class.getClassLoader())); > Это решение не для всех
Перед тем, как начать пользоваться Eclair как основным инструментом для логирования, стоит ознакомиться с рядом особенностей этого решения. Эти «особенности» обусловлены тем, что в основе Eclair лежит стандартный для Spring механизм проксирования.
— Скорость выполнения кода, завёрнутого в очередной прокси, незначительно, но упадёт. Для нас эти потери редко бывают существенны. Если встает вопрос о сокращении времени выполнения, есть множество действенных мер по оптимизации. Отказ от удобного информативного лога может быть рассмотрен в качестве одной из мер, но не в первую очередь.
— StackTrace «раздуется» ещё чуть больше. Если вы не привыкли к длинным stackTrace’ам от Spring’овых прокси, для вас это может стать неприятностью. По столь же очевидной причине затруднится отладка проксированных классов.
— Не всякий класс и не всякий метод может быть проксирован: private методы проксировать не удастся, для логирования цепочки методов в одном bean’е потребуется self, проксировать что-либо, не являющееся bean’ом, вы не сможете и т.д.
Напоследок
Совершенно ясно, что этот инструмент, как и любой другой, нужно уметь применить, чтобы извлечь из него пользу. А этот материал лишь поверхностно освещает сторону, в которую мы решили двигаться в поисках идеального решения.
Критика, мысли, подсказки, ссылки – любое ваше участие в жизни проекта я горячо приветствую! Буду рад, если сочтёте Eclair полезным для своих проектов.
тут блог

Общественные обязательства интроверта.
Сообщения на ИТ тематику, но не обязательно.
О логах
Логгирование. Журналирование. Логи. Журналы. Файлы логов. Вроде всё знакомо.
Почему вообще «log»? Это же «бревно». А «logging» — это «cutting down trees for logs».
Если верить вики-словарю, наш программистский «log» происходит от «logbook», то есть от судового журнала. Туда, в том числе, регулярно записывались показания лага, то есть «chip log». Типичный старый добрый лаг — это дощечка на верёвочке. Её бросали за кормой. Сколько верёвочки за единицу времени отмоталось — такова скорость судна. В узлах, которые на верёвочке завязаны. По сути, бревно на верёвке, ага.

Логи чаще всего пишут в файлы.
Эти файлы ещё ротируют, но есть заменяют новыми, а старые удаляют, чтобы логи не разрослись и не заполнили весь диск. Как правило, ротация происходит по времени (файлы подменяются раз в сутки, например) или по размеру файлов (по 10 мегабайт, например). Для ротации произвольных файлов в юниксах даже есть своя специальная программка logrotate. Её обычно запускают по крону.
В файлы могут писаться и бинарные данные. Например, в журнал транзакций пишут все события изменения состояния системы. Это используется в СУБД и журналируемых файловых системах. Смысл в том, что запись в журнал — относительно дешёвая операция. Это лишь дополнение одного файла. Эту запись можно быстро и гарантированно сбросить на диск через все кэши. И начиная с этого момента считать, что, мол, данные действительно записаны. А уже потом взяться за значительно более сложные изменения настоящих структур данных. Которые могут оборваться. Но у нас уже есть журнал, из которого можно всё восстановить.
Дальше будем говорить про журналы (текстовых) сообщений, в которых программы сообщают о своих действиях.
Самая стандартизированная версия таких логов — то, что часто называют access log. Это журнал доступа к веб серверу в Common Log Format. Так уж исторически сложилось, что первые http сервера писали логи именно в таком формате. И развелась куча инструментов, которые анализировали файлы именно в таком формате. Красивые графики нагрузки веб сервера рисовали. Сейчас, конечно, любой веб сервер можно настроить на логирование запросов в любом формате.
127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 
Очень часто и до сих пор программы пишут свои файлы логов самостоятельно. Но ещё у нас есть syslog.
Syslog существует аж с 80-х. У syslog клиент-серверная архитектура. Впервые мы разделяем то место, где порождаются сообщения (приложение), от того места, где сообщения записываются в те самые файлы (syslog демон). Передача сообщений происходит по сети. Когда-то давно даже по UDP.
Клиентов, порождающих сообщения, много. А syslog демон один. Поэтому в формате сообщений syslog появились дополнительные поля, чтобы как-то сообщения различать. Как минимум распихивать их по разным файлам.
Facility. Плохо переводимый термин. В данном случае означает субъекта, который прислал сообщения. Есть полтора десятка стандартных кодов: kern , user , mail , daemon , auth и тому подобные. Собственно, именно файлы с примерно такими именами вы можете найти в /var/log типичного дистрибутива Linux. Многие коды (например, uucp ) уже устарели и никому не нужны. А новых кодов (например, docker ) никто вводить не собирается.
Severity level. Уровень серьёзности. В syslog определены такие: emerg (Emergency, или panic ), alert , crit (Critical), err (или error ), warning (или warn ), notice , info (Informational), debug . Эти уровни вполне живы и вовсю используются.
Message. Сообщение. Содержимое сообщения ( CONTENT ) — это просто строка. Но выделяют также TAG , куда обычно записывают имя приложения, отправившего сообщение. А в более поздних версиях стандарта есть более отдельные поля для имени приложения, его PID, идентификатора сообщения и тому подобного. Ну и syslog демон ещё знает имя хоста, приславшего ему сообщение. Также присутствует момент времени (timestamp) создания сообщения. Налицо всё большая структурированность сообщения, по мере эволюции стандарта.
В современных линуксах вместо демона syslog у нас присутствует journald, который часть systemd. Будем считать, что кроме загадочного бинарного формата хранения логов и новых команд, ничего для приложений не меняется. В современном Debian/Ubuntu работает и journalctl -f , и tail -f /var/log/syslog .

Перейдём на клиентскую сторону. Как писать логи.
Конечно, писать прямо в stdout и stderr никто не отменял. А всякие докеры даже могут это выхлоп забрать и куда-нибудь передать для анализа. Но в настоящих API для логирования есть много других интересных вещей.
Для логов из ядра есть специальный printk() . Всё правильно, ведь stdout / stderr в ядре ещё нет. И никакого syslog ещё нет. Поэтому нужна специальная функция, которая пишет сообщения в специальный буфер в ядре. А прочитать сообщения можно с помощью команды dmesg .
Даже у простого printk() есть log level. Те самые уровни важности по syslog. От emerg до debug . Плюс специальный псевдоуровень cont , чтобы записать несколько сообщений в одну строку.
printk(KERN_INFO "Message: %s\n", arg); Зачем нужен log level? Чтобы фильтровать сообщения при выводе. Скажем, писать в консоль при загрузке только критические ошибки, но не debug выхлоп.
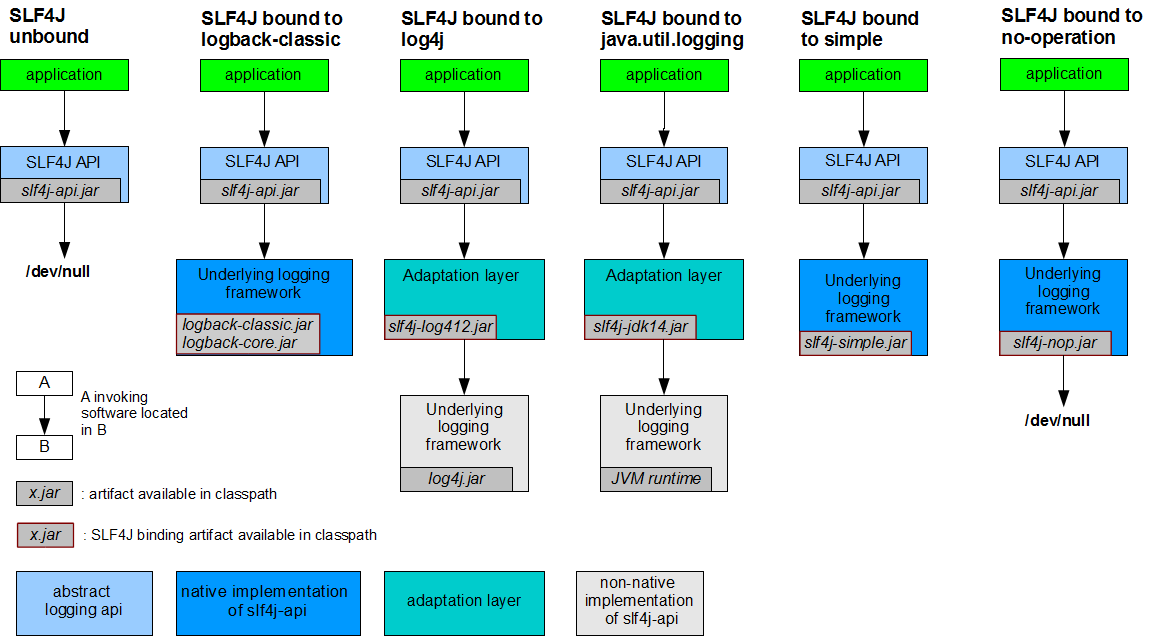
Посмотрим на типичную архитектуру логирования на примере SLF4J. Simple Logging Facade for Java, ага. Это самое популярное API для ведения логов в Java. И активно вытесняет Log4j.
Здесь у нас тоже есть уровни логирования. Они выбираются соответствующим методом у Logger . error , warn , info , debug , trace . В Log4j есть ещё уровень fatal .
Уровней поменьше, чем у syslog. Зато они понятнее. error — для ошибок, которые не могут быть исправлены и прерывают текущую обработку. warn — для ошибок, которые могут быть исправлены или не критичны для последующей работы. info — для информационных сообщений, которые (как правило) всегда должны быть видны в логах. debug — для отладочных сообщений, которые обычно не видны, но при необходимости можно включить. trace — можно втыкать в начало и конец каждого метода, чтобы, при необходимости, увидеть всю последовательность вызовов.
Уровни логирования упорядочены (на то они и уровни). От самого высокого error до самого низкого trace . Всегда можно ограничить вывод только сообщений от выбранного уровня и более приоритетных. По умолчанию выводятся info , warn и error .
Logger logger = LoggerFactory.getLogger(HelloWorld.class); logger.info("Hello World"); Здесь у нас также есть иерархия логеров. В Java так принято, что в каждом классе заводится свой логер, с именем, совпадающим с полным именем класса. А класс объявлен в пакете. А пакет в пакете. Получается развесистое такое дерево логеров, совпадающее с деревом пакетов, с классами-листиками. В Python, в стандартном logging тоже так можно, только иерархии обычно менее развесистые получаются. Так принято.
Иерархия логеров очень полезна. Для любой веточки этой иерархии можно задать уровень логирования. Или даже совсем отключить вывод каких-либо логов. В результате можно, например, выводить только ошибки, но для какой-нибудь подсистемы включить дебаг.
В этом основной фокус. Формирование сообщений логов — это одно. Тут можно не лениться и выдавать максимально подробные сообщения. А вывод этих сообщений в файлы или ещё куда — это другое. Тут можно задать и сообщения какого уровня будут выводиться, и в какие файлы какие логеры будут писаться. И, даже, как эти файлы будут ротироваться.
Более того, SLF4 — это только API для отправки сообщений. А к нему прилагается несколько бэкендов для, собственно, записи сообщений. От простых, которые либо просто ничего никуда не пишут, либо всё выплёвывают в stderr. До сложных и навороченных, вроде целой отдельной библиотеки logback.
Более того, бэкенд системы логирования можно дополнить отправкой сообщений в любимый мною Sentry. Чтобы сообщения писались не в файл, а отправлялись в Sentry. Установленный вами или облачный (и платный) sentry.io. Как правило, в Sentry нужно отправлять только ошибки или ворнинги.
Sentry не просто собирает сообщения логов. Он их группирует в задачи и собирает статистику. Если данное сообщение вызвано ошибкой, можно увидеть, как часто эта ошибка происходит. Когда ошибка починилась, можно пометить, что больше такого быть не должно. Если ошибка вернётся или появится новая, Sentry пришлёт вам уведомление. Это гораздо удобнее, чем шерстить логи вручную.
Логи можно засылать и в Logstash, которое проиндексирует их в Elasticsearch. По этим данным можно нарисовать какие-нибудь уведомления. Или построить красивые графики в Kibana. Всё вместе это называется Elastic Stack (раньше называли ELK Stack).
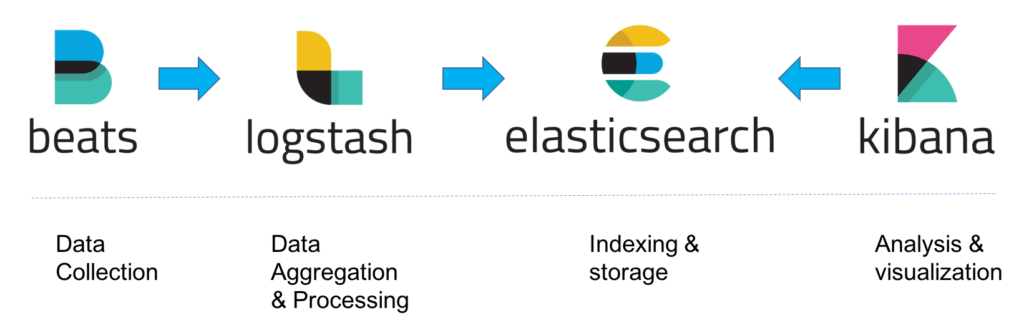
Log level. Logger. Ещё что-нибудь есть? Ведь сообщение — это всё ещё просто строка. Потому и понадобился целый движок полнотекстового поиска Elasticsearch. И целый Logstash, чтобы сообщения парсить. Как-то странно сначала формировать строку, а потом её парсить.
В SLF4J строку сообщения можно форматировать. Отдельно передавая аргументы. В основном это сделано для того, чтобы сэкономить на формировании сообщения, если данный уровень логирования отключен.
logger.debug("Temperature set to <>. Old temperature was <>.", newT, oldT); В питоновом logging тоже так можно. И Sentry, который сам написан на Python, умеет распознавать одно и то же сообщение с разными переданными аргументами, и отдельно показывать значения аргументов.
logging.warning('%s before you %s', 'Look', 'leap!') К сообщению можно прилеплять исключение. В SLF4J это делается прямо явно, исключение передается ещё одним аргументом в метод логирования. И по умолчанию при этом печатается полный стэктрейс исключения. Именно поэтому логи в Java, как правило, полны этих длиннющих стэктрейсов. В Python так не принято.
Goшная библиотека логирования logrus добавляет в сообщение ещё набор полей.
log.WithFields(log.Fields "animal": "walrus", "number": 1, "size": 10, >).Info("A walrus appears") time="2015-09-07T08:48:33Z" level=info msg="A walrus appears" animal=walrus number=1 size=10 Красиво расцвеченное, если вывод в терминал:

Или даже сразу в JSON:
"animal":"walrus","level":"info","msg":"A walrus appears","size":1,"time":"2014-03-10 19:57:38.562264131 -0400 EDT"> В общем-то, этот JSON уже вполне пригоден для правильного индексирования в том же Logstash. Это называется «structured logging». Ссылку не дам, ибо пока это довольно общее понятие, но никоим образом не стандарт.
Идея в том, чтобы все переменные параметры в сообщении передавать именно как именованные параметры, а не как часть текста сообщения. Сам текст сообщения лишь сообщает, что вообще происходит.
Должно быть не Item 123 is processing а Processing item=123 .
От себя добавлю, что само сообщение в этом случае должно быть максимально кратким и начинаться с глагола. Не обязательно точно соблюдать грамматику, главное, чтобы было понятно, действие ещё только собирается совершиться или уже совершилось, или же произошла ошибка. Различать «до» и «после» особенно важно при обращении к сторонним сетевым сервисам.
Processing item=123 — перед началом обработки. Processed item=123 — после успешного завершения обработки. «Completed» — тоже отличный глагол. Failed to process item=123 — если произошла ошибка. Тут нужно приложить исключение или другой какой error (в Go). Только ни в коем случае не «Can’t. » или даже «Cant. «. Что значит, пытался, но не смог? Пытался, но всё failed.
Какой уровень логирования при этом нужен, решайте сами. Это зависит от критичности этих действий с точки зрения пресловутой бизнес-логики. Хорошо, когда результат каждого явного действия пользователя отражается одной записью в логе. Как в access log. Хорошо также видеть в логах все критичные ошибки, которые мешают работе.
В питоновом logging тоже есть некий аналог полей структурированного логирования. Хотя это больше похоже на прямую передачу параметров форматеру.
FORMAT = '%(asctime)-15s %(clientip)s %(user)-8s %(message)s' logging.basicConfig(format=FORMAT) d = 'clientip': '192.168.0.1', 'user': 'fbloggs'> logging.warning('Protocol problem: %s', 'connection reset', extra=d) Напечатает что-то вроде:
2006-02-08 22:20:02,165 192.168.0.1 fbloggs Protocol problem: connection reset В SLF4J тоже можно передавать произвольные ключи-значения при логировании. Но сделано это через жопу. Называется это MDC (Mapped Diagnostic Context) и работает примерно как в Python.
Вот так используется MDC:
MDC.put("first", "Richard"); MDC.put("last", "Nixon"); logger.info("I am not a crook."); И если сконфигурировать logback правильно:
name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"> %X %X - %m%n То будет напечатано что-то вроде:
Richard Nixon - I am not a crook. Опять-таки, как будут интерпретироваться эти значения, полностью определяется бэкендом, конфигурацией апендера в данном случае. И далеко не все популярные бэкенды вообще знают про какой-то MDC.
Кажется, я хочу в Java новую библиотеку логирования. Как будто в истории Java их было мало. С синтаксисом вызова поближе к logrus. Чтобы сразу красиво и удобно иметь структурированные логи.