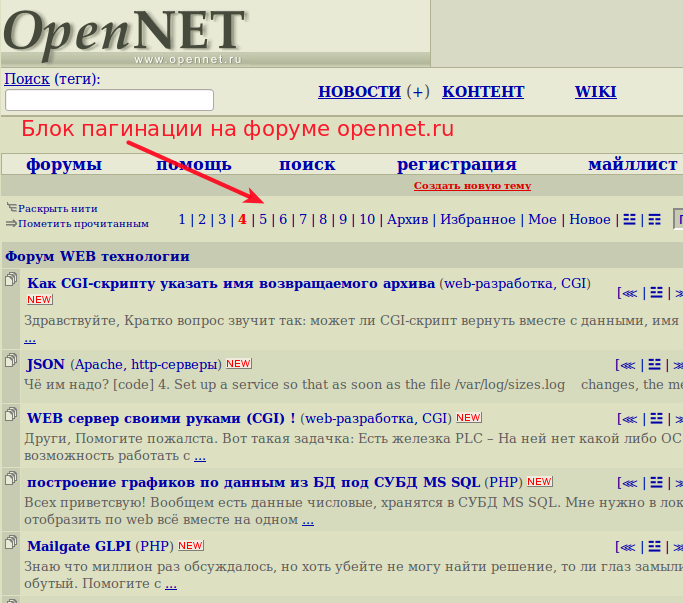
Пагинация¶
В Интернете под пагинацией понимают показ ограниченной части информации на одной веб-странице (например, 10 результатов поиска или 20 форумных трэдов). Она повсеместно используется в веб-приложениях для разбиения большого массива данных на страницы и включает в себя навигационный блок для перехода на другие страницы.
Paginate¶
- webhelpers.paginate
- https://github.com/Pylons/paginate
- https://v4-alpha.getbootstrap.com/components/pagination/
Модуль paginate делит список статей на страницы. Номер страницы передается методом GET , в параметре page . По умолчанию берется первая страница.
p = paginate.Page( items, page=1, items_per_page=42 )
Пример Mako шаблона, использующего Bootstrap4 для пагинации.
inherit file="base.mako"/> block name="content"> h2>$tag.title()>h2> br/> div class="row"> %for item in p: div class="col"> div class="row"> a href="$_static_prefix>/item/$item.id>.html"> �� a> div> br/> div class="row"> pre id='id-$item.id>' width=100%> $item.text> pre> div> div> %endfor div> # https://v4-alpha.getbootstrap.com/components/pagination/ div class="row"> nav aria-label="Page navigation example"> ul class="pagination"> $, link_tag=lambda page: 'li class="page-item <> <>">a class="page-link" href="<>"><>a>li>'.format( 'active' if page['type'] == 'current_page' else '', 'disabled' if not len(page['href'].strip()) else '', page['href'], page['value'] ) )> ul> nav> div> block>
Блог¶
Данные¶
Для начала наполним блог случайными статьями при помощи функции generate_lorem_ipsum из пакета jinja2.utils .
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
from jinja2.utils import generate_lorem_ipsum ARTICLES = [] for id, article in enumerate(range(100), start=1): title = generate_lorem_ipsum( n=1, # Одно предложение html=False, # В виде обычного текста min=2, # Минимум 2 слова max=5 # Максимум 5 ) content = generate_lorem_ipsum() ARTICLES.append( 'id': id, 'title': title, 'content': content> )
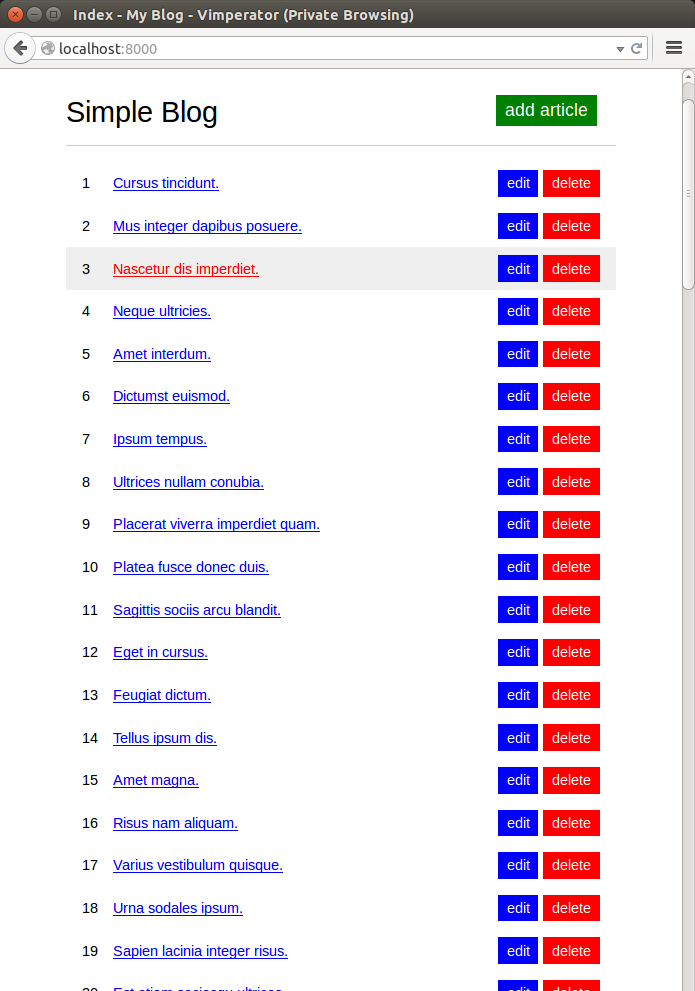
Много статей не помещаются на экран
Paginate¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
class BlogIndex(BaseBlog): def __iter__(self): self.start('200 OK', [('Content-Type', 'text/html')]) # Get page number from urllib.parse import parse_qs values = parse_qs(self.environ['QUERY_STRING']) # Wrap articles to paginated list from paginate import Page page = values.get('page', ['1', ]).pop() paged_articles = Page( ARTICLES, page=page, items_per_page=8, ) yield str.encode( env.get_template('index.html').render( articles=paged_articles ) )
templates/index.html ¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
extends "base.html" %> block title %>Index endblock %> block content %> div class="blog__title">Simple Blogdiv> a href="/article/add" class="blog__button">add articlea> div class="blog-list"> for article in articles %> div class="blog-list__item"> div class="blog-list__item-id"> <article.id >>div> a href="/article/ <article.id >>" class="blog-list__item-link"> <article.title >>a> div class="blog-list__item-action"> a href="/article/ <article.id >>/edit" class="blog-list__item-edit">edita> a href="/article/ <article.id >>/delete" onclick="return confirm_delete();" class="blog-list__item-delete">deletea> div> div> endfor %> div> div class="paginator"> <articles.pager(url="?page=$page") >> div> endblock %>
В результате на каждой странице отображаются только 8 статей.
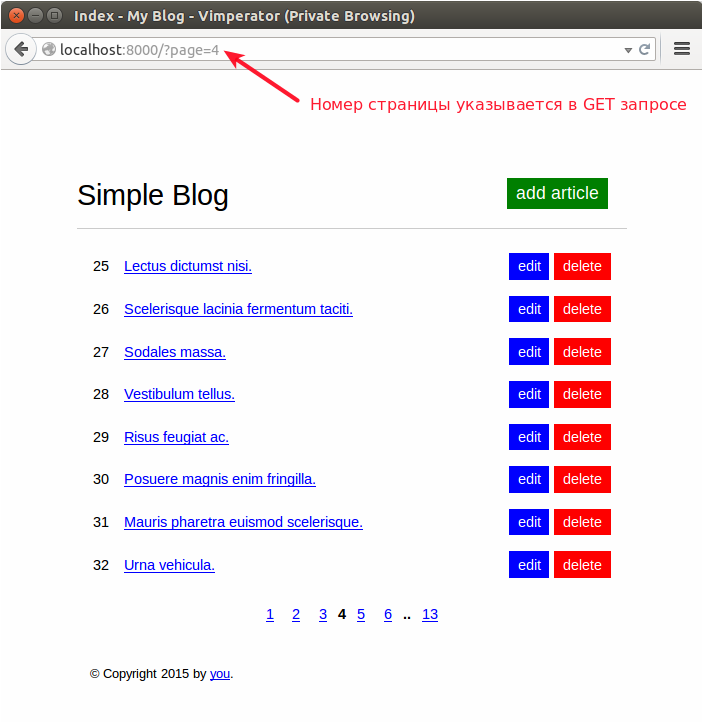
Блог со страницами
Previous: Статика Next: WebOb
© Copyright 2020, Кафедра Интеллектуальных Информационных Технологий ИнФО УрФУ. Created using Sphinx 1.7.6.
Создаем кэшируемую пагинацию, которая не боится неожиданного добавления данных в БД
Если на вашем сайте присутствует большое количество контента, то для отображения пользователю его приходится так или иначе делить.
Все известные мне способы имеют недостатки и я попытался создать систему, которая сможет решить некоторые из них и при этом не будет слишком сложна для реализации.
Существующие методы
1. Пагинация (разделение на отдельные страницы)

Пагинация или разделение на отдельные страницы — достаточно старый способ разделения контента, который, в том числе используется на Хабре. Основным преимуществом является его универсальность и простота реализации как со стороны сервера так и клиентской части.
Код запроса данных из бд чаще всего ограничивается парой строк.
Тут и далее примеры на языке arangodb aql, я скрыл код сервера т.к там пока ничего интересного.
// Возврат по 20 элементов для каждой страницы. LET count = 20 LET offset = count * $ FOR post IN posts SORT post.date DESC // сортируем от новых к старым LIMIT offset, count RETURN postНа стороне клиента мы запрашиваем и выводим получившийся результат, я использую vuejs с nuxtjs для примера, но то же самое можно проделать на любом другом стеке, все специфичные для vue моменты я буду подписывать.
# https://example.com/posts?page=3 main.vue > Теперь у нас выводятся все посты на странице, но погодите, как пользователи будут переключаться между страницами? Добавим пару кнопок для перелистывания страниц.
> Минусы данного способа
- При достижении конца страницы пользователю нужно переключаться на следующую страницу вручную.
- Не получится кешировать результаты, т.к посты находящиеся на странице 2, при добавлении новых, непременно сместятся на страницу 3, 4 и так далее, т.е одна и та же операция GET возвращает разные результаты в зависимости от количества постов.
- Если в момент перелистывания добавятся новые посты, то мы повторно увидим просмотренные элементы на следующей странице и напротив, пропустим если будем листать в обратную сторону.
2. Бесконечный скроллинг
Этот способ решает первую проблему, теперь пользователю не нужно вручную переключаться между страницами.
Основная идея заключается в том, что мы получаем следующую страницу при достижении конца прошлой и добавляем новые элементы к существующим.
При таком подходе проблема №3 проявляются еще более явно, если раньше мы не могли увидеть 2 похожих элемента рядом, то теперь это станет обычной ситуацией, конечно можно воспользоваться грязным трюком и отфильтровывать элементы с совпадающим id прямо на клиенте, но что если добавится 40 новых элементов за раз? Мы потратим 3 запроса к серверу, чтобы достичь новых результатов, т.к прошлые сместятся на 2 страницы (при условии что на одной странице 20 элементов). Это не мой подход!
Как решают эту проблему люди из интернета:
- Используют описанный мной выше подход, я не искал подтверждение, но я практически уверен в этом, т.к это самое простое решение которое может прийти на ум, его можно использовать для быстрого прототипирования или создания mvp.
- Создают уникальный идентификатор при первом запросе, и сохраняют результаты запроса на сервере, а затем выдают порционно. Тут сразу напрашивается 2 минуса. Во-первых, это использование лишней памяти сервера для хранения результатов всех пользователей. Во-вторых, более сложная реализация, требующая и логики хранения результатов для каждого пользователя, и логики удаления устаревших запросов. Я уверен, что такие реализации существуют и возможно некоторым удалось решить проблему излишней памяти, но проще система от этого не стала, да и проблему кеширования это не решает, а лишь усугубляет ситуацию.
- Возможны и другие более или менее изобретательные решения, но то что я хочу вам предложить я пока не встречал. В свое время мне бы очень помогла подобная статья, поэтому я и решил её создать. Думаю что людям с похожей задачей она окажется полезной!
Моя реализация
Основная идея в том, что нам придется немного изменить логику запроса к базе, при этом не потребуется добавлять новые сущности или добавлять новые параметры в запрос.
Обновляем код на сервере
Для начала решим проблему кеширования, для этого просто всё перевернем.
Теперь последняя страница станет страницей номер 0, а предпоследняя страница номером 1, слово страница (page) сюда уже не вписывается, т.к мы с детства привыкли что в книжках страницы идут с начала, поэтому используем более нейтральное слово offset (смещение).
LET count = 20 LET offset = $ FOR post IN posts SORT post.date ASC // для этого отсортируем всё в обратном порядке LIMIT offset, count RETURN postТеперь сколько постов мы бы ни добавили, GET «/?offset=0» всегда будет возвращать один и тот же результат.
Получать первую страницу стало немного сложнее, поэтому совместим оба выше приведенных способа, для этого перейдем с уровня запроса к базе на уровень сервера (язык nodejs):
async getPosts() < const isOffset = offset !== undefined if (isOffset && isNaN(+offset)) throw new BadRequestException() const count = 20 // Смещение должно быть кратно количеству элементов, чтобы результаты не пересекались if (offset % count !== 0) throw new BadRequestException() const sort = isOffset ? ` SORT post.date DESC LIMIT $, $ ` : ` SORT post.date ASC LIMIT 0, $ // Возвращаем больше чем нужно если это первая страница* ` const q = < query: ` FOR post IN posts $RETURN post `, bindVars: <> > // получаем результат запроса вместе с общим количеством найденных элементов const cursor = await this.db.query(q, ) const fullCount = cursor.extra.stats.fullCount /* *Если общее число элементов в базе не кратно count то в начальном запросе приходит 2 страницы [21-39] элементов В таком случае вторую страницу нужно пропустить т.к она уже входит в первую Если общее число делится на 20 то в первом запросе приходит 1-я страница c count элементов */ let data; if (isOffset) < // отсекаем попытку получить вторую страницу если она встроена в первую const allow = offset else < const all = await cursor.all() if (fullCount % count === 0) < // отрезаем лишние 20 элементов, это можно сделать как тут, так и в запросе к бд, вопрос лишь в оптимизации data = all.slice(0, count) >else < /* Тут посложней, если ранее мы могли иметь на последней странице 0-20 элементов, то теперь там нам всегда возвращается 20 элементов и недостачу нужно компенсировать, для этого на первую страницу добавляются дополнительные 0-20 элементов к имеющимся, в запросе к бд для первой страницы мы возвращаем с запасом 40 элементов и затем здесь отрезаем лишние */ const pagesCountUp = Math.ceil(fullCount / count) const resultCount = fullCount - pagesCountUp * count + count * 2 data = all.slice(0, resultCount) >> if (!data.length) throw new NotFoundException() return < fullCount, count: data.length, data >>Чего мы этим добились:
- Теперь перекрытия id после добавления новых элементов стали невозможны.
- Запросы теперь статичны и легко поддаются кешированию, единственным плавающим по количеству элементов и их id остался запрос без параметра offset.
- Наш код на клиенте теперь не работает(
Минусы моего способа:
- Вопрос что делать при удалении все ещё открыт, это не частая операция, поэтому можно каждый раз полностью сбрасывать кэш, либо возвращать null вместо отсутствующего элемента, это неплохое решение, т.к. зачастую реального удаления с сервера не происходит, элемент лишь помечается как удаленный, если таких «null-зомби» станет много, то можно удалить все null-зомби из выдачи и сбросить кэш для всех запросов.
- Если новый элемент оказывается не в начале после сортировки по выбранному полю (например по названию), то данный алгоритм не сработает. Поэтому подходит только сортировка по возрастающим или убывающим полям (например по дате или по id).
Обновляем код на клиенте
Заодно я покажу как сделать бесконечную прокрутку из пункта №2.
> Теперь у нас есть полностью лишенная обозначенных недостатков реализация. Несомненно присутствуют моменты которые можно сделать лучше, я хотел показать сам подход, реализация может быть у каждого разной.
Бонус: Добавляем гибкую систему перехода по страницам
В данный момент мы можем перемещаться лишь на 1 страницу вперед или назад, добавим возможность перейти на любую страницу, элемент управления может выглядеть примерно так (в квадратных скобках текущая страница):
Основа метода для генерации пагинации взята из этого обсуждения: https://gist.github.com/kottenator/9d936eb3e4e3c3e02598#gistcomment-3238804 и скрещена с моим решением.
Показать продолжение бонуса
В начале вам нужно добавить этот вспомогательный метод внутрь тега
const getRange = (start, end) => Array(end - start + 1).fill().map((v, i) => i + start) const pagination = (currentPage, pagesCount, count = 4) => < const isFirst = currentPage === 1 const isLast = currentPage === pagesCount let delta if (pagesCount else < // delta === 2: [1 . 4 5 6 . 10] // delta === 4: [1 2 3 4 5 . 10] delta = currentPage >count + 1 && currentPage < pagesCount - (count - 1) ? 2 : 4 delta += count delta -= (!isFirst + !isLast) >const range = < start: Math.round(currentPage - delta / 2), end: Math.round(currentPage + delta / 2) >if (range.start - 1 === 1 || range.end + 1 === pagesCount) < range.start += 1 range.end += 1 >let pages = currentPage > delta ? getRange(Math.min(range.start, pagesCount - delta), Math.min(range.end, pagesCount)) : getRange(1, Math.min(pagesCount, delta + 1)) const withDots = (value, pair) => (pages.length + 1 !== pagesCount ? pair : [value]) if (pages[0] !== 1) < pages = withDots(1, [1, '. ']).concat(pages) >if (pages[pages.length - 1] < pagesCount) < pages = pages.concat(withDots(pagesCount, ['. ', pagesCount])) >if (!isFirst) pages.unshift('<') if (!isLast) pages.push('>') return pages >Добавляем недостающие методы
> Теперь, при необходимости, можно перейти на нужную страницу.
Что такое пагинация

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Пагинация на сайте — это навигационный ссылочный блок, который облегчает для пользователей переход и просмотр товарных позиций, страниц каталога, публикаций и так далее
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Пагинация — это ограничение показа информации, который используется для разбиения солидного массива данных на отдельные веб-страницы.
Чтобы понять, что из себя представляет пагинация, разберем простую аналогию. Когда мы используем справочную литературу или печатный каталог, мы видим, что информация в нем представлена в упорядоченном виде. Товарные позиции или профессиональная информация не представлены сплошным перечнем. Это позволяет облегчить использование издания и быстро найти то, что нужно. Пагинация решает аналогичные задачи: упростить просмотр товаров, сделать его удобнее.
Сегодня пагинации бывают нескольких типов:
- Прямая нумерация («1», «2», «3». ).
- Прямая с указанием позиций в списке («1-10», «10-20» . ).
- Обратная с позициями («40-30», «30-20», «20-10» . ).
Зачем нужна пагинация
Сегодня ведущие интернет магазины применяют пагинацию. Она значительно упрощает использование сайта. Представьте, что на одной странице размещен весь ассортимент, несколько тысяч изделий. Это определенно можно сделать, ведь интернет-страница безгранична, чего нельзя сказать о бумажной. Но нельзя забывать, что скорость соединения лимитирована, следовательно: чем больше товарных позиций на странице, тем дольше она загружается.
Таким образом, постраничная навигация используется для улучшения юзабилити сайта и увеличения скорости загрузки страниц.
Как сделать пагинацию
Разберем, как сделать пагинацию на скриптовом языке PHP, так как он сегодня чаще всего используется для разработки веб-приложений.
Итак, у нас есть много контента (перечень товарных позиций, различные заметки и так далее). Нам нужно организовать его для удобного представления на страницах сайта, то есть разбить его.
Для начала определяем, сколько у нас будет страниц, сколько из них будет отображаться в пагинации и какова текущая. Возьмем 45 страниц, текущую возьмем с $_GET’а (если ее нет, она равна 1). Число страниц, отображаемых в пагинации, оставляем гибким, чтобы корректировать число ссылок справа и слева от текущей.

Мы прописали сами данные, приступим к разработке пагинации. Она реализуется с помощью специальной функции — makePage, которая задается 4 параметрами: $iCurr (текущая страница), $iLastPage (последняя страница), $iLeftLimit (лимит слева), $iRightLimit (лимит справа).

Вывод при этом может иметь следующий вид:

Рассмотрим написанный код. Наиболее простым вариантом из возможных является ситуация, когда мы в центре (к примеру, на странице 8), справа и слева свободно отображаются страницы.

Если мы находимся в начале, используем другой код:

При этом $iSlice — это число элементов, которые не показываются с левой стороны, их нужно добавить с правой стороны.
И последний вариант. Представим, что мы находимся в конце пагинации. Прописываем другой код:

Проблемы с пагинацией при SEO
Как вы выяснили, для юзабилити ресурса, пагинация — это всегда большой плюс. А вот для успешного СЕО продвижения пагинация может стать препятствием. Необходима правильная пагинация, в противном случае ресурс рискует потерять позиции в результатах поисковиков:
- Поисковики могут применить штрафные санкции за повторение контента.
- Товарные позиции долго индексируются, их трудно или вовсе нельзя найти через поиск.
Робот поисковиков находится на сайте ограниченное время. Представим, что бот зашел в интернет-магазин мужской одежды, где на каждой странице представлено 30-40 позиций, отличие позиций заключается лишь в наименовании брендов. Робот может просто не дойти до нужной позиции, потому что она находится на нижнем уровне. Однако владельцу интернет-ресурса нужно обратное, чтобы страницы были проиндексированы.
Если говорить о повторяющемся контенте, позиция поисковиков к нему резко отрицательная. Объясняется это просто: каждой странице должен соответствовать релевантный контент. Если контент схож, например, список товаров + описание групп одинаковые либо похожи, поисковику трудно определить релевантную страницу из представленных.Значимость страниц распыляется и теряется, главная страница уже не выделяется на фоне остальных. Следовательно, в выдаче поисковика сайт теряет позиции.
SEO и пагинация
Наша задача составить пагинацию таким образом, чтобы она нВ худшем раскладе не вредила СЕО, а в лучшем — улучшала позиции сайта в результатах выдачи поисковиков. Сделать это можно несколькими способами.
Закрыть пагинацию для индексации
Многие задаются вопросом, как закрыть страницы пагинации от индексации. Для этого есть несколько решений.
- Использовать мета-тег NOINDEX.
Здесь в «головную» секцию каждой страницы, кроме первой, мы вставляем строчку: . Таким образом мы не разрешаем роботу индексировать данную страничку, но позволяем проходить по ее ссылкам.
Здесь важно проработать XML карту ресурса. Если страницы ресурса динамичные, то есть можно использовать фильтры, ссылка первой веб-страницы должна выглядеть так: название домена/catalog. Со страниц «название домена/catalog?page=1» делаем редирект 301 на веб-страницу «название домена/catalog».
Важно учитывать ряд нюансов. Тег NOINDEX воспринимается индексом, однако Google его не читает. Если сайт обладает внушительном количеством динамичных страниц, на каждый из них нужно прописать NOINDEX. Весь контент при этом исключается из пагинации, кроме контента первой страницы.
- Использовать файл robots.txt.
Страницы пагинации имеют определенный вид «вид http://название домена/category/page/n», в которых n— номер страниц. Необходимо прописать robots.txt, присвоить ему определенную команду: «Disallow: /category/page». Данный способ универсален и подходит для любых поисковиков. Однако нюанс сохраняется: весь контент со страниц пагинации, кроме контента первой, будет исключен.
Применять страницу «Смотреть все» и тег CANONICAL
Смысл в следующем: создается веб-страница, где будут отображаться все имеющиеся товары. Для поисковиков данная страница указывается как каноническая через тег CANONICAL.
Здесь также не обойтись без нюансов: если товаров много, такая страница будет загружаться долго. Зато тег распознается всеми поисковиками (Google считает его приоритетным) и контент будет полностью проиндексирован.
Есть и минусы: имеются ограничения объема и качества контента, а при большом количестве товарных позиций и фильтров, необходимо прописать CANONICAL для каждой динамической страницы.
На сайте компании SEMANTICA вы можете заказать продвижение кадрового агентства. Оставьте заявку, и мы вам перезвоним в ближайшее время.
О метке
Пагинация в программировании — это показ ограниченной части информации на одной веб-странице. Она повсеместно используется в веб-приложениях для разбиения большого массива данных на страницы и включает в себя навигационный блок для перехода на другие страницы. Используйте эту метку только в том случае, если вопрос связан с ней.
Для этой метки до сих пор нет описания.
Описание помогает новичкам глубже понять тематику метки, содержит обзор темы, которую представляет метка, а также инструкции по её использованию.
Все зарегистрированные пользователи могут предлагать новые описания меток.
(Обратите внимание: если у вас меньше 20000 баллов репутации, то перед публикацией ваши изменения в описании метки должны будут пройти проверку).