Узнать кодировку файла
Есть файл не понятно в какой кодировке, нужно определить кодировку, написал вот такой вариант, но уверен что есть способ определения кодировки на много проще, подскажите.
# какой то файл скачанный с интернета в неизвестной кодировке. open('test.txt', 'w', encoding='cp500').write('Hello\n') # сюда можно впихнуть все известные кодировки. encoding = [ 'utf-8', 'cp500', 'utf-16', 'GBK', 'windows-1251', 'ASCII', 'US-ASCII', 'Big5' ] correct_encoding = '' for enc in encoding: try: open('test.txt', encoding=enc).read() except (UnicodeDecodeError, LookupError): pass else: correct_encoding = enc print('Done!') break print(correct_encoding) Отслеживать
задан 1 авг 2017 в 15:17
Игорь Игоряныч Игорь Игоряныч
1,903 4 4 золотых знака 15 15 серебряных знаков 27 27 бронзовых знаков
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
from chardet.universaldetector import UniversalDetector detector = UniversalDetector() with open('test.txt', 'rb') as fh: for line in fh: detector.feed(line) if detector.done: break detector.close() print(detector.result) Отслеживать
ответ дан 1 авг 2017 в 16:27
Sergey Gornostaev Sergey Gornostaev
66.5k 6 6 золотых знаков 53 53 серебряных знака 112 112 бронзовых знаков
Еще мудренее чем у меня, и не все кодировки распознает, да еще и левый модуль нужно устанавливать, я так понял проще способа нет.
1 авг 2017 в 17:14
Проще способа нет. Но chardet в этой области признанный стандарт, используемый чуть ли не каждым вторым модулем из PyPI.
1 авг 2017 в 17:17
@ИгорьИгоряныч: способ в вопросе явно неверный: отсутствие исключения не говорит, что «правильную кодировку» нашли — вы таким образом кракозябры можете получить. В общем случае, не существует метода определения «правильной» кодировки. Но отдельные кодировки могут быть более вероятными нежели другие. chardet именно этим и занимается: гадает какие кодировки наибольшие шансы имеют.
Как узнать кодировку текста онлайн?
Существует ряд сервисов, которые способны определить кодировку текста онлайн. Они все делают автоматически, в том числе позволяют конвертировать слова в правильный формат. Хотя подобных сервисов много, не все они одинаково хорошо подходят для определения кодировки онлайн. Мы подобрали несколько лучших вариантов.
Online Decoder
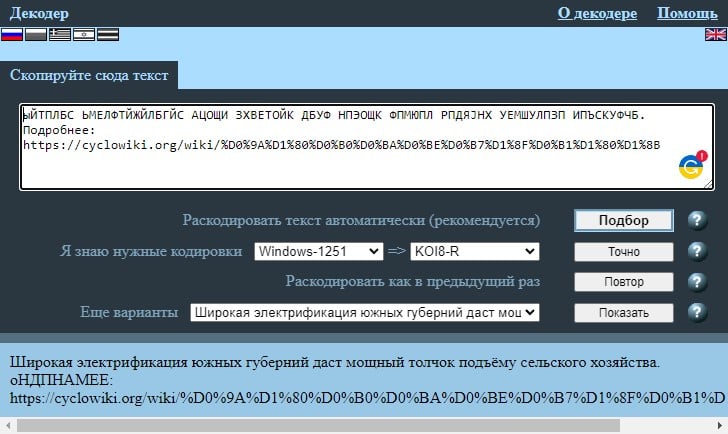
Помимо того, что сервис позволит узнать кодировку онлайн для любого фрагмента текста, он также способен конвертировать его. Поддерживает практически все кодировки. Работает быстро, просто и эффективно. Если нужен также конвертер кодировок онлайн, этот вариант окажется одним из лучших. Все необходимые действия можно выполнить в рамках 1 минуты и это в первый раз.
Что нужно сделать:
- Открывать сайт Online Decoder.
- Вставляем в пустое поле наш текст с неправильной кодировкой.
- В строке «Раскодировать текст автоматически (рекомендуется)» нажимаем на кнопку «Подбор».
- Немного ниже, в строке «Я знаю нужные кодировки» обращаем внимание на первую часть. Там указана кодировка вставленного текста, а во втором поле – та, в которую конвертирован фрагмент.
2cyr
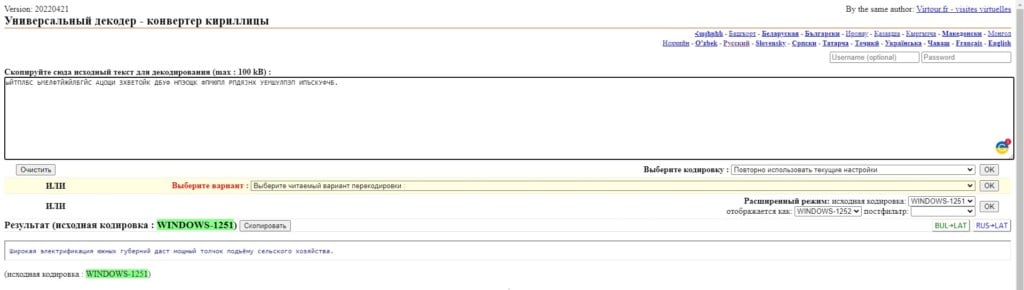
Сервис создан для декодирования различного текста, в том числе он способен преобразовывать строки между различными кодировками. Он довольно прост и не требует никаких особенных знаний. Вам достаточно открыть сайт 2cyr, вставить текст и нажать на кнопку «Ок» справа под пустым полем. После непродолжительного анализа система выдаст информацию о родной кодировке текста и той, что была установлена после преобразования.
FoxTools
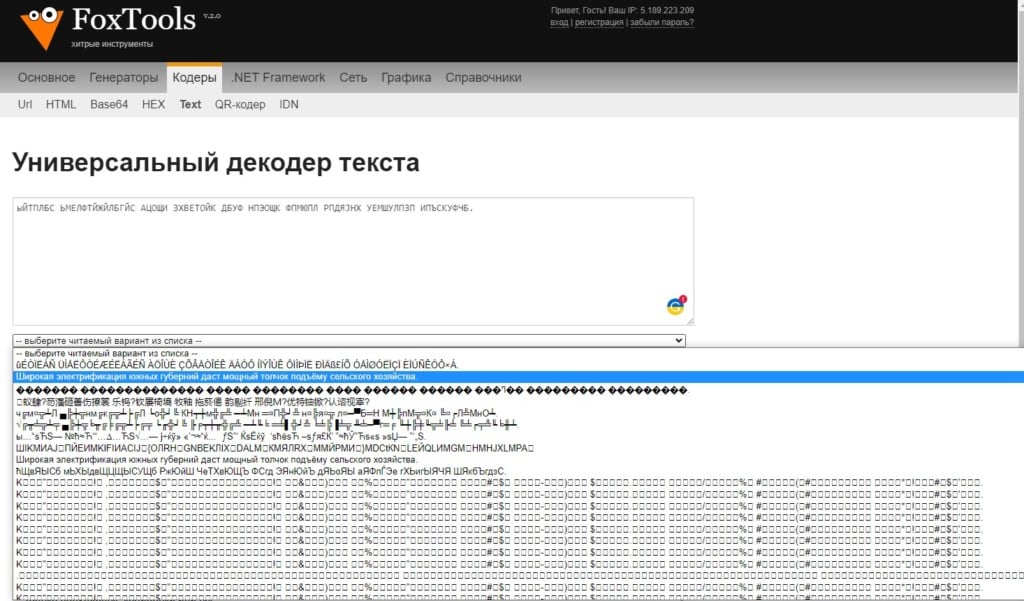
Принцип работы подобен описанным выше сервисам, но есть и одно отличие. Сайт предоставляет большой выбор вариантов текста на выходе. Он предлагает вам самостоятельно найти ту кодировку, в которой текст будет читаться правильно. Это положительная особенность, так как некоторые форматы пересекаются между собой и могут неправильно определяться автоматическими сервисами.
Как это работает:
- Переходим на целевую страницу FoxTools.
- Вставляем в пустое поле текст и жмем по кнопке «Отправить».
- Нажимаем по выпадающему списку с названием «Выберите читаемый вариант из списка» и ищем тот текст, который мы можем без проблем прочитать.
Определение кодировки онлайн – простая задача, особенно с помощью хороших веб-сервисов. Все они бесплатные, простые в использовании и достаточно точны.
FAQ: Как проверить кодировку в текстовом файле?

Программный комплекс SocialKit корректно работает с кириллицей в текстовых файлах, кодировка которых соответствует стандарту Windows-1251 (кратко может быть записано как CP1251 или ANSI). В этой связи в задачах, поддерживающих указание внешнего файла с перечнем комментариев, сообщений, описаний и прочей информации, которая может содержать кириллицу, нужно указывать текстовые файлы, где русский текст задан в кодировке по стандарту Windows-1251 или же просто ANSI, или CP1251 — всё это, по сути, одно и то же.
Учитывая, что многие инструменты по работе с текстом не отображают, в какой именно кодировке задан текст в текстовом файле и/или не поддерживают преобразование кодировок, то у новичков часто возникает вопрос о том, как именно привести кодировку текстового файла с русским текстом к понятному для SocialKit формату CP1251.
Следует сразу отметить, что большинство текстовых редакторов для ОС Windows (например, встроенный Блокнот и Wordpad) по умолчанию создают текстовые файлы именно с кодировкой по стандарту Windows-1251. Однако, эта кодировка по умолчанию может быть изменена в следствие тех или иных действий.
Если вы не уверены в том, в какой именно кодировке задан текст, то проще всего этот текст пересохранить через стандартный Блокнот Windows. При пересохранении Блокнот также покажет, в каком формате текст сейчас.
Опишем эту простую процедуру по шагам.
1. Открыть искомый текстовый файл в Блокноте Windows и выбрать пункт меню «Файл» -> «Сохранить как. «.
Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии.
2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Диалоговое окно пересохранения текстового файла, в котором можно сразу изменить кодировку.
Как видно, в примере текст в текстовом файле был ранее сохранён в кодировке UTF-8. Для изменения кодировке достаточно выбрать в выпадающем списке кодировку ANSI и нажать кнопку «Сохранить«.
При этом зрительно для вас ничего не изменится, но многое изменится для программы и алгоритмов, занимающихся обработкой текста в процессе отправки. Корректно Instagram’у будет отправлен только ANSI-текст.
Автоопределение кодировки текста

Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Сравнение найденных решений на автоопределение кодировки
Подготовил каталог softlandia\cpd тестовые данные с файлами в разных кодировках. Содержимое файлов очень короткое и одинаковое. Одна строка “Русский в кодировке CodePageName”. Дополнил файлами со смешением кодировок и некоторыми сложными случаями и попробовал определить.
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица CP 1251
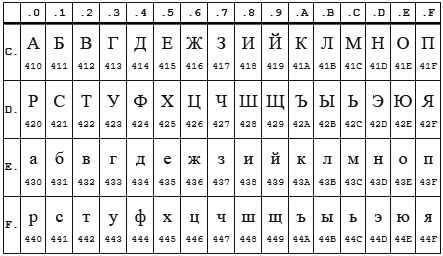
Таблица KOI8-r

В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Наблюдение 3
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true.
Собственный велосипед

Автоопределение кодировки возможно только эвристическими методами, неточно. Если мы не знаем, на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении, что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Критерии соответствия
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы. Для CP1251 использовал а, и, н, с, р, в, л, к, я. Для KOI8-r — о, а, и, т, с, в, л, к, м.
Второй критерий
К сожалению, для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Особенности, с которыми я столкнулся
Чуть коснусь прелестей и проблем, связанных с golang. Раздел может быть интересен только начинающим писать на golang.
Проблемы
Лично походил по некоторым подводным камушкам из 50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков.
Излишне переживая и пытаясь дуть на воду, прослышав от других о страшных ожогах от молока, переборщил с проверкой входного параметра типа io.Reader. Я проверял переменную типа io.Reader с помощью рефлексии.
//CodePageDetect - detect code page of ascii data from reader 'r' func CodePageDetect(r io.Reader, stopStr . string) (IDCodePage, error) < if !reflect.ValueOf(r).IsValid() < return ASCII, fmt.Errorf("input reader is nil") >. Но как оказалось в моём случае достаточно проверить на nil. Теперь всё стало проще
func CodePageDetect(r io.Reader, stopStr . string) (IDCodePage, error) < //test input interfase if r == nil < return ASCII, nil >//make slice of byte from input reader buf, err := bufio.NewReader(r).Peek(ReadBufSize) if (err != nil) && (err != io.EOF) < return ASCII, err >. вызов bufio.NewReader( r ).Peek(ReadBufSize) спокойно проходит следующий тест:
var data *os.File res, err := CodePageDetect(data)
В этом случае Peek() возвращает ошибку.
Разок наступил на грабли с передачей массивов по значению. Немного тупанул на попытке изменять элементы, хранящиеся в map, пробегая по ним в range…
Прелести
Сложно сказать что конкретно, постоянное ли битьё по рукам от линтера и компилятора или активное использование range, или всё вместе, но практически отсутствуют залёты по выходу индекса за пределы.
Конечно, очень приятно жить со сборщиком мусора. Полагаю мне ещё предстоит освоить грабли автоматизации выделения/освобождения памяти, но пока дебильная улыбка не покидает лица.
Строгая типизация — тоже кусочек счастья.
Переменные, имеющие тип функции — соответственно лёгкая реализация различного поведения у однотипных объектов.
Странно мало пришлось сидеть в отладчике, перечитывание кода обычно даёт результат.
Щенячий восторг от наличия массы инструментов из коробки, это чудное ощущение, когда компилятор, язык, библиотека и IDE Visual Studio Code работают на тебя вместе, слаженно.
Спасибо falconandy за конструктивные и полезные советы
Благодаря ему
- перевёл тесты на testify и они действительно стали более читабельны
- исправил в тестах пути к файлам данных для совместимости с Linux
- прошёлся линтером — таки он нашёл одну реальную ошибку (проклятущий copy/past)
Продолжаю добавлять тесты, выявился случай не определения UTF16. Обновил. Теперь UTF16 и LE и BE определяются даже в случае отсутствия русских букв