Узнать кодировку файла
Есть файл не понятно в какой кодировке, нужно определить кодировку, написал вот такой вариант, но уверен что есть способ определения кодировки на много проще, подскажите.
# какой то файл скачанный с интернета в неизвестной кодировке. open('test.txt', 'w', encoding='cp500').write('Hello\n') # сюда можно впихнуть все известные кодировки. encoding = [ 'utf-8', 'cp500', 'utf-16', 'GBK', 'windows-1251', 'ASCII', 'US-ASCII', 'Big5' ] correct_encoding = '' for enc in encoding: try: open('test.txt', encoding=enc).read() except (UnicodeDecodeError, LookupError): pass else: correct_encoding = enc print('Done!') break print(correct_encoding) Отслеживать
задан 1 авг 2017 в 15:17
Игорь Игоряныч Игорь Игоряныч
1,903 4 4 золотых знака 15 15 серебряных знаков 27 27 бронзовых знаков
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
from chardet.universaldetector import UniversalDetector detector = UniversalDetector() with open('test.txt', 'rb') as fh: for line in fh: detector.feed(line) if detector.done: break detector.close() print(detector.result) Отслеживать
ответ дан 1 авг 2017 в 16:27
Sergey Gornostaev Sergey Gornostaev
66.5k 6 6 золотых знаков 53 53 серебряных знака 112 112 бронзовых знаков
Еще мудренее чем у меня, и не все кодировки распознает, да еще и левый модуль нужно устанавливать, я так понял проще способа нет.
1 авг 2017 в 17:14
Проще способа нет. Но chardet в этой области признанный стандарт, используемый чуть ли не каждым вторым модулем из PyPI.
1 авг 2017 в 17:17
@ИгорьИгоряныч: способ в вопросе явно неверный: отсутствие исключения не говорит, что «правильную кодировку» нашли — вы таким образом кракозябры можете получить. В общем случае, не существует метода определения «правильной» кодировки. Но отдельные кодировки могут быть более вероятными нежели другие. chardet именно этим и занимается: гадает какие кодировки наибольшие шансы имеют.
Модуль chardet в Python, определение кодировки
Когда мы думаем о тексте, то представляем слова и буквы, которые видим на экране компьютера. Но компьютеры не работают с буквами и символами. Они имеют дело с битами и байтами. Каждый фрагмент текста, который выводится на экране, на самом деле хранится в определенной кодировке символов. Существует множество различных кодировок, некоторые из которых оптимизированы для определенных языков, таких как русский, китайский или английский, а другие могут использоваться для нескольких языков. Грубо говоря, кодировка символов обеспечивает соответствие между тем, что мы видим на экране, и тем, что компьютер фактически хранит в памяти и на диске.
Модуль chardet , это автоматический детектор кодировки текста и является портом кода автоопределения в Mozilla. Этот модуль поможет определить кодировку символов, если вдруг на экране появятся «кракозябры«.
Модуль chardet отлично поддерживает и определяет русские кодировки: KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251(Cyrillic)
Установка модуля chardet в виртуальное окружение.
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль chardet (VirtualEnv):~$ python -m pip install -U chardet
Примеры автоматического определения кодировки символов:
Самый простой способ автоматически определить кодировку — это использовать функцию обнаружения detect() модуля chardet .
>>> import urllib.request, chardet >>> rawdata = urllib.request.urlopen('http://yandex.ru/').read() >>> chardet.detect(rawdata) # >>> rawdata = urllib.request.urlopen('https://www.zeit.de/index').read() >>> chardet.detect(rawdata) #
Расширенное использование модуля chardet .
Если имеется большой объем текста/данных, то можно вызывать обнаружение кодировки постепенно. Как только модуль будет достаточно уверен в своих результатах, он остановится.
Для такого поведения необходимо создать объект UniversalDetector(), затем повторно вызывать его метод подачи .feed() с каждым блоком текста. Если созданный детектор достигнет минимального порога достоверности, он установит для Detector.done значение True.
В конце работы детектора необходимо вызвать Detector.close() , который выполнит некоторые окончательные вычисления в случае, если детектор не достиг минимального порога достоверности.
import urllib.request from chardet.universaldetector import UniversalDetector usock = urllib.request.urlopen('https://www.zeit.de/index') # создаем детектор detector = UniversalDetector() for line in usock.readlines(): # скармливаем детектору строки detector.feed(line) if detector.done: # если детектор определил # кодировку, то прерываем цикл break # закрываем детектор detector.close() # закрываем соединение с сайтом usock.close() print(detector.result) #
Пример определения кодировки нескольких файлов.
Для определения кодировки текстовых файлов, их необходимо открывать в режиме чтения байтов: more=’rb’
import glob from chardet.universaldetector import UniversalDetector # создаем детектор detector = UniversalDetector() for filename in glob.glob('*.xml'): print(filename.ljust(60), end='') # сбрасываем детектор # в исходное состояние detector.reset() # проходимся по строкам очередного # файла в режиме 'rb' for line in open(filename, 'rb'): detector.feed(line) if detector.done: break detector.close() print(detector.result)
Python3 декодирование/чтение Dat файла. Как определить кодировку файла?

Здравствуйте!
Передо мной стоит задача прочитать .Dat файл но проблема в том что он имеет какую-то странную кодировку и при попытке его прочитать редактором(В моем случае Nano) я вижу следующее:
Так-же я пробовал прочитать его посредствам python3 через
f = open('file_name.dat', 'r', encoding="utf-8") print(f.read())Вместо utf-8 я пробовал подставить другую кодировку из этого сайта, был еще один с кодировками Cyrillic но его я уже не найду.
Я перепробовал их все, большинство не подошли и я просто получал ошибку по типу такой:
UnicodeDecodeError: 'utf-32-le' codec can't decode bytes in position 0-3: code point not in range(0x110000)- Python3.10.4
- OS: Ubuntu 22.04.1 LTS
- Вопрос задан более года назад
- 505 просмотров
Комментировать
Решения вопроса 1
никого не трогаю, починяю примус
это не кодировка. это файл с данными какого-то формата. быстрое гугление по заголовку «Crofile» выдало что это вероятно «база Cronos».
Ответ написан более года назад
Комментировать
Нравится 1 Комментировать
Ответы на вопрос 2
Тут имхо сразу понятно, что это не текст в кодировке.
Но вообще выяснение кодировки текстового файла это перебор по списку кодировок или использование модулей, которые, однако, всё равно определяют не точную кодировку, а наиболее вероятную.
Когда искал ответ на этот вопрос, тут
https://stackoverflow.com/questions/436220/how-to-.
нашёл chardet
https://pypi.org/project/chardet/
Ответ написан более года назад
Комментировать
Нравится Комментировать
mayton2019 @mayton2019
Bigdata Engineer
Лет 10 назад мне попала в руки база абонентов мобильного оператора. Как раз в формате Cronos. Но открыть я ее не смог приложением. Дело в том что этот формат использует симметричное шифрование данных. Как архиватор RAR. Без знания пароля — безнадёжное дело.
Поэтому Python здесь не поможет. Надо первым делом понять с чем мы имеем дело. Открыть файл приложением клиентом и убедится что он хотя-бы не шифрован.
Ответ написан более года назад
Комментировать
Нравится Комментировать
Ваш ответ на вопрос
Войдите, чтобы написать ответ

- Python
- +3 ещё
Как сделать так, чтобы при регистрации пользователя в телеграмм боте его ID сохранялся в файле только один раз?
- 2 подписчика
- 40 минут назад
- 25 просмотров
Как узнать кодировку файла python
Этот документ (PEP 263 [1]) представляет синтаксис для декларации кодировки текста в файле исходного кода на языке Python. Информация о кодировке затем используется парсером Python для интерпретации файла на указанной кодировке. Прежде всего это улучшает интерпретацию литералов Unicode в исходном коде, и делает возможным писать в литералах Unicode с использованием например UTF-8 напрямую в редакторе, поддерживающем Unicode.
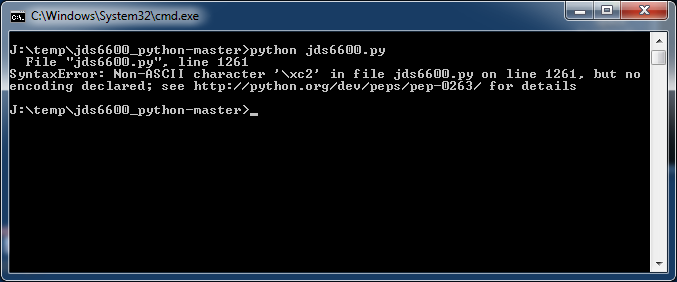
Описываемый ниже метод позволяет избежать ошибок наподобие:
SyntaxError: Non-ASCII character '\xc2' in file имя_модуля.py on line 1261, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
Источник проблемы. В Python 2.1 литералы Unicode могут быть написаны только с использованием кодировки на основе Latin-1 («unicode-escape»). Это делает рабочее окружение программиста не дружественным для пользователей Python, кто живет и работает в странах, где используется не-Latin-1 локаль, как например многие из стран Азии. Программисты могут писать свои тексты своими 8-битными строками в любимой кодировке, но ограничены кодировкой «unicode-escape» для литералов Unicode.
Чаще всего ошибка «SyntaxError: Non-ASCII character» возникает из-за попытки использовать русскоязычные комментарии в файле, кодировка которого не UTF-8. Чтобы быстро исправить проблему, нужно сохранить текст проблемного модуля *.py в кодировке UTF-8, и сообщить об этом интерпретатору Python.
Процесс по шагам:
1. Проверьте, что текст модуля Python сохранен в кодировке UTF-8. В редакторе Notepad2 это делается через меню File -> Encoding. Этот же пункт меню позволяет перекодировать файл в кодировку UTF-8.
2. Добавьте в начало модуля строку:
# -*- coding: utf-8 -*-
После этого ошибка исчезнет.
Рекомендуемое решение. Рекомендуется сделать кодирование исходного кода Python как видимым, так и изменяемым на уровне исходного файла, применяя в каждом модуле файла исходного кода специальный комментарий в начале файла, чтобы декларировать в нем кодировку.
Чтобы настроить Python для распознавания этой декларации кодировки, необходимо ознакомиться о принципах обработки данных исходного кода Python.
[Определение кодировки]
По умолчанию Python подразумевает, что в файле принят стандарт кодирования ASCII, если не дано никаких других подсказывающих указаний. Чтобы определить кодировку исходного кода, во все исходные файлы нужно добавить «магический» комментарий в первой или второй строке исходного файла:
# coding=
или (используя форматы, распознаваемые популярными редакторами):
#!/usr/bin/python
# -*- coding: < имя_кодировки>-*-
#!/usr/bin/python
# vim: set fileencoding= < имя_кодировки>:
Если быть более точным, то первая или вторая строка должна попадать под фильтр следующего регулярного выражения:
^[ \t\v]*#.*?coding[:=][ \t]*([-_.a-zA-Z0-9]+)
Первая группа этого выражения интерпретируется как имя кодировки. Если эта кодировка не известна для Python, то во время попытки компиляции произойдет ошибка. Не должно быть никакого любого оператора Python в строке, в этой строке, где содержится декларация о кодировке. Если на первую строку регулярное выражение сработает, то вторая строка на предмет поиска кодировки игнорируется.
Чтобы обработать такие платформы, как Windows, которые добавляют маркеры Unicode BOM в начало файла Unicode, UTF-8 сигнатура \xef\xbb\xbf будет также интерпретироваться как кодировка ‘utf-8’ (даже если в файл не добавлен описанный магический комментарий).
Если исходный файл использует одновременно сигнатуру маркера UTF-8 BOM, и магический комментарий, то разрешенной кодировкой для комментария будет только ‘utf-8’. Любая другая кодировка в этом случае приведет к ошибке.
[Примеры]
Ниже приведено несколько примеров, показывающих разные стили определения кодировки исходного кода в начале файла Python.
1. Двоичный интерпретатор и использование файла стиля Emacs:
#!/usr/bin/python
# -*- coding: latin-1 -*-
import os, sys
#!/usr/bin/python
# -*- coding: iso-8859-15 -*-
import os, sys
#!/usr/bin/python
# -*- coding: ascii -*-
import os, sys
2. Без строки интерпретатора, используя чистый текст:
# This Python file uses the following encoding: utf-8
import os, sys
3. Текстовые редакторы могут иметь разные способы определения кодировки файла, например:
#!/usr/local/bin/python
# coding: latin-1
import os, sys
4. Без комментария кодировки парсер Python подразумевает, что это текст ASCII:
#!/usr/local/bin/python
import os, sys
[Плохие примеры]
Ниже для полноты приведены ошибочные комментарии для указания кодировки, которые не будут работать.
A. Пропущенный префикс «coding:»:
#!/usr/local/bin/python
# latin-1
import os, sys
B. Комментарий кодировки не находится на строке 1 или 2:
#!/usr/local/bin/python
# -*- coding: latin-1 -*-
import os, sys
C. Не поддерживаемая кодировка:
#!/usr/local/bin/python
# -*- coding: utf-42 -*-
import os, sys
PEP [1] основывается на следующих концепциях, которые должны быть реализованы, чтобы включить использование такого «магического» комментария:
1. Во всем исходном файле Python должна использоваться одинаковая кодировка. Встраивание по-другому закодированных данных приведет к ошибке декодирования на этапе компиляции исходного файла кода Python.
Можно использовать в исходном коде любое кодирование, которое позволяет обработать две первые строки способом, показанным выше, включая ASCII-совместимое кодирование, а также определенные многобайтовые кодировки, такие как Shift_JIS. Это не включает кодировки наподобие UTF-16, которые используют два или большее количество байтов для всех символов. Причина в том, что требуется сохранять простым алгоритм декодирования кодировки в парсере ключевых слов (токенизатор).
2. Обработка escape-последовательностей должна продолжать работать, как она это уже делает, но со всеми возможными кодировками исходного кода, являющимися стандартными строковыми литералами (как 8-битными, так и Unicode). Расширение escape-последовательностей поддерживает только очень малое подмножество возможных вариантов.
3. Комбинация токенизатор/компилятор Python должна быть обновлена, чтобы работать следующим образом:
A. Чтение файла.
B. Декодирование текста файла в Unicode, подразумевая фиксацию кодировки на весь файл. Т. е. файле должна использоваться единая, не изменяемая в пределах файла кодировка (разные файлы могут иметь разные кодировки).
C. Преобразование текста в байтовую строку UTF-8.
D. Разбитие на ключевые слова (токенизация) содержимого UTF-8.
E. Компиляция кода, создание Unicode-объектов из данных Unicode и создание строковых объектов из литеральных данных Unicode. При этом сначала перекодируются данных UTF-8 в 8-битные строковые данные с использованием имеющейся кодировки файла.
Обратите внимание, что идентификаторы Python ограничены подмножеством кодирования ASCII, так что других преобразований не потребуется.
Для обратной совместимости с существующим кодом, который в нестоящее время использует не-ASCII кодировку в строковых литералах без декларации кодирования, реализация будет представлена двумя фразами:
1. Разрешается использование не-ASCII кодировки в строковых литералах и комментариях, при этом внутренне будет рассматриваться отсутствие объявление кодировки как декларация «iso-8859-1». В результате произвольная строка байт будет корректно обработана с предоставлением совместимости с Python 2.2 для литералов Unicode, которые содержат байты, не попадающие в кодировку ASCII.
Будут выдаваться предупреждения по мере появления non-ASCII байтов на входе, один раз на неправильно закодированный входной файл.
2. Удаление предупреждения, и изменение кодировки по умолчанию на «ascii».
Встроенное compile() API будет расширено, чтобы принимать на входе Unicode. 8-битные входные строки являются субъектами стандартной процедуры детектирования кодировки, как это описано выше.
Если строка Unicode с декларацией кодирования будет передана в compile(), будет сгенерировано событие SyntaxError.
[Ссылки]
1. PEP 263 — Defining Python Source Code Encodings site:python.org.