Описание файловой системы OverlayFS
Не закончен, так как не хватает знаний. По мере изучения, постараюсь дополнить.
Данная файловая системы используется, например, в Docker. Часто её можно наблюдать на роутерах или других подобных устройствах, где оперативная запись информации ведётся во временную наложенную ФС, доступную до момента выключения устройства.
С помощью OverlayFS я объединяю домашние фото и видео каталоги для удобного просмотра. Так как архивы исходных фотографий доступны только для чтения, наложением рабочей папки, для сохранения временных или промежуточных файлов обработки, я добиваюсь удобства в обработке фоток.
Перед пониманием темы Overlay Filesystem, мне необходимо провентилировать Linux Virtual File System.
Overlay Filesystem
Этот документ описывает прототип нового подхода к обеспечению функциональности overlay filesystem (наложенная файловая система) в Линукс (некоторые предпочитают называть union-filesystems объединённая файловая система). Overlay filesystem пытается показать файловую систему так, как результат наложения одной ФС поверх другой ФС.
Overlay объекты
Метод наложения файловой системы является смешанным, так как объекты, которые видны в этой ФС не всегда ей принадлежат. Во многих случаях, доступ к объекту в объединении будет неразличимым от доступа к соответствующему объекту из обычной файловой системы. Это наиболее очевидно из поля ‘st_dev’ возвращаемого системным вызовом stat ( man 2 stat ).
Почитав stat(2), я выяснил, что поле ‘st_dev’ описывает устройство на котором находится файл. ‘st_ino’ — номер inode.
В то время как директории будут сообщать ‘st_dev’ из наложенной файловой системы, объекты, не являющиеся каталогами, могут сообщать ‘st_dev’ из нижней или верхней файловой системы, которая предоставляет объект. Аналогично ‘st_ino’ будет уникальным только в сочетании с ‘st_dev’, и оба они могут изменяться в течение всего времени жизни объекта не-каталога. Многие приложения и инструменты игнорируют эти значения.
В особом случае, когда все наложенные слои принадлежат одной подлежащей файловой системе, то все объекты будут сообщать ‘st_dev’ из наложенной файловой системы, а ‘st_ino’ из подлежащей файловой системы. Это делает монтирование наложения более совместимым со сканерами файловой системы, и оверлей-объекты будут отличаться от соответствующих объектов в оригинальной файловой системе.
On 64bit systems, even if all overlay layers are not on the same underlying filesystem, the same compliant behavior could be achieved with the “xino” feature. The “xino” feature composes a unique object identifier from the real object st_ino and an underlying fsid index. If all underlying filesystems support NFS file handles and export file handles with 32bit inode number encoding (e.g. ext4), overlay filesystem will use the high inode number bits for fsid. Even when the underlying filesystem uses 64bit inode numbers, users can still enable the “xino” feature with the “-o xino=on” overlay mount option. That is useful for the case of underlying filesystems like xfs and tmpfs, which use 64bit inode numbers, but are very unlikely to use the high inode number bit.
Верхний и нижний слои
Наложенная файловая система комбинируется из двух ФС — верхней и нижней. Когда имя объекта существует в обеих ФС, тогда объект из верхней ФС виден, а объект из нижней ФС скрыт. В случае с совпадением имён каталогов, их содержимое будет объединено.
Было бы правильней употреблять термин верхнее и нижнее дерево каталогов вместо термина файловая система, поскольку вполне возможно, что оба дерева каталогов могут находиться в одной и той же файловой системе, и здесь не требуется указывать корень файловой системы для верхней или нижней файловой системы.
Нижняя файловая система может быть любой файловой системой, поддерживаемой Linux, и для неё не требуется прав на запись. Нижняя файловая система может быть даже другим оверлеем. Верхняя файловая система обычно доступна для записи, и в таком случае она должна поддерживать создание расширенных атрибутов “trusted.*”, и также должна предоставлять допустимый ’d_type’ в ‘readdir’ ответах, так что NFS не подходит.
readdir — чтение директории описание поля “d_type”…
«d_type» Это поле содержит значение, обозначающее тип файла, что позволяет избежать затрат на вызов lstat(2), если дальнейшие действия зависят от типа файла.
When a suitable feature test macro is defined (_DEFAULT_SOURCE on glibc versions since 2.19, or _BSD_SOURCE on glibc versions 2.19 and earlier), glibc defines the following macro constants for the value returned in d_type: DT_BLK This is a block device. DT_CHR This is a character device. DT_DIR This is a directory. DT_FIFO This is a named pipe (FIFO). DT_LNK This is a symbolic link. DT_REG This is a regular file. DT_SOCK This is a UNIX domain socket. DT_UNKNOWN The file type could not be determined.
На данный момент только некоторые файловые системы (среди них, такие как: Btrfs, ext2, ext3, and ext4) умеют возвращать правильное значение типа файла в поде “d_type”. Все приложения обязаны должным образом обрабатывать возвращаемое значение DT_UNKNOWN.
Только в варианте, когда наложенная ФС имеет атрибут “только для чтения” и составлена из двух “только для чтения” файловых систем, могут использоваться любые типы ФС.
Каталоги
В оверлее, в основном, участвуют каталоги. Если имя объекта ссылается не на каталог, и объект проявляется как в верхней, так и в нижней файловых системах, то нижний объект скрыт и имя относится только к верхнему объекту.
Если верхний и нижний объекты являются каталогами, то формируется объединенный каталог.
В момент монтирования две директории, указанные в опциях как “upperdir” и “lowerdir”, соединяются в одну объединённую директорию:
# mount -t overlay overlay -olowerdir=/lower,upperdir=/upper,workdir=/work /merged Опция “workdir” должна указывать на пустой каталог в той же файловой системе, где находится “upperdir”.
dentry — объект VFS, содержащий информацию о директориях ФС и существующий только в памяти файловой системы и не хранится на диске. Если я правильно понял, то предназначен для уменьшения обращений к ФС при перечитывании содержимого каталогов.
Тогда всякий раз, когда поиск запрашивается в такой объединенной директории, просмотр выполняется в каждой фактической директории и объединенный результат кэшируется в dentry, принадлежащем наложенной файловой системе. Если оба актуальных поиска находят каталоги, оба сохраняются и создается объединенный каталог, в противном случае сохраняется только один: верхний, если он существует, иначе нижний.
Объединяются только списки имён из директорий. Другое содержимое, такое как метаданные и расширенные атрибуты, отображается только для директорий из верхней ФС. Эти атрибуты для директории из нижней ФС скрыты.
“Выбеленные” и “непрозрачные” каталоги
Не уверен, что подобрал правильный перевод для “whiteouts and opaque directories”.
Чтобы выполнять rm и rmdir без изменения нижней файловой системы, наложенная файловая система должна записать в верхнюю файловую систему информацию о том, что файлы были удалены. Это делается с помощью “выбеленных” и “непрозрачных” каталогов (объекты не-каталоги всегда непрозрачны).
“Выбеленная” директория создаётся как символьное устройство с номером устройства 0/0. Когда в верхнем слое объединенного каталога обнаруживается “выбеленная” директория, любое совпадающее имя на нижнем уровне игнорируется, и сама “выбеленная” директория также скрывается.
Каталог объявляется “непрозрачным” установкой расширенного атрибута “trust.overlay.opaque” в значение “y”. Если верхний слой содержит “непрозрачный” каталог с именем совпадающим с именем каталога из нижнего слоя, тогда соответствующий каталог в нижнем слое игнорируется.
Системный запрос readdir (Чтение каталога)
Когда readdir запрашивается в объединенном каталоге, то каждый верхний и нижний каталог читается, а списки имён объединяются очевидным образом (сначала читается верхний, затем нижний, уже существующие имена не добавляются повторно). Этот объединенный список имён кэшируется в ‘struct file’ и таким остаётся так долго, пока файл остаётся открытым. Если директория открыта и одновременно читается двумя процессами, то каждый из них будет иметь отдельный кэш. A seekdir to the start of the directory (offset 0) followed by a readdir will cause the cache to be discarded and rebuilt.
Это означает, что изменения в объединённой директории не проявятся пока каталог читается. Вряд ли это будет замечено каким-либо программами.
seek offsets are assigned sequentially when the directories are read. Thus if
- read part of a directory
- remember an offset, and close the directory
- re-open the directory some time later
- seek to the remembered offset
there may be little correlation between the old and new locations in the list of filenames, particularly if anything has changed in the directory.
Readdir on directories that are not merged is simply handled by the underlying directory (upper or lower).
Переименование каталога
Когда переименовывается каталог, который является нижним или объединённым (то есть этот каталог не был создан на верхнем слое до начала операции), overlayfs может обработать его двумя различными способами:
- возврат EXDEV ошибки: эта ошибка возвращается вызовом rename , когда при попытке перемещения файла или директории нарушаются границы файловой системы. Приложение обычно готово обработать эту ошибку ( mv , для примера, рекурсивно копирует дерево директорий). Это поведение по умолчанию.
- Если свойство “redirect_dir” включено, тогда директория будет скопирована (без своего содержимого). Потом будет установлен расширенный атрибут “trusted.overlay.redirect” на путь оригинального местоположения от корня наложения. В заключении директория перемещается в новое место.
Есть несколько способов настроить “redirect_dir” свойство.
Kernel config options:
- OVERLAY_FS_REDIRECT_DIR:
- If this is enabled, then redirect_dir is turned on by default.
- If this is enabled, then redirects are always followed by default. Enabling this results in a less secure configuration. Enable this option only when worried about backward compatibility with kernels that have the redirect_dir feature and follow redirects even if turned off.
Module options (can also be changed through /sys/module/overlay/parameters/* ) :
- “redirect_dir=BOOL”:
- See OVERLAY_FS_REDIRECT_DIR kernel config option above.
- See OVERLAY_FS_REDIRECT_ALWAYS_FOLLOW kernel config option above.
- The maximum number of bytes in an absolute redirect (default is 256)
- “redirect_dir=on”: Redirects are enabled.
- “redirect_dir=follow”: Redirects are not created, but followed.
- “redirect_dir=off”: Redirects are not created and only followed if “redirect_always_follow” feature is enabled in the kernel/module config.
- “redirect_dir=nofollow”: Redirects are not created and not followed (equivalent to “redirect_dir=off” if “redirect_always_follow” feature is not enabled).
When the NFS export feature is enabled, every copied up directory is indexed by the file handle of the lower inode and a file handle of the upper directory is stored in a “trusted.overlay.upper” extended attribute on the index entry. On lookup of a merged directory, if the upper directory does not match the file handle stores in the index, that is an indication that multiple upper directories may be redirected to the same lower directory. In that case, lookup returns an error and warns about a possible inconsistency.
Because lower layer redirects cannot be verified with the index, enabling NFS export support on an overlay filesystem with no upper layer requires turning off redirect follow (e.g. “redirect_dir=nofollow”).
Прочие объекты не-Каталоги
Объекты, не являющиеся каталогами (файлы, симлинки, device-special files, и т.д.), представлены в объединённой ФС из верхней, либо из нижней файловой системы, по обстоятельствам. Когда требуется доступ на запись к файлу, представленному в нижней файловой системе, то сначала файл копируется из нижней ФС в верхнюю (copy_up). Обратите внимание, что создание жёсткой ссылки также требует copy_up, тогда как создание симлинка такой операции конечно не требует.
Если файл, открытый на запись, не был изменён, то операция copy_up выполнена не будет.
Процесс copy_up начинается с проверки наличия в верхней ФС соответствующих каталогов, которые создаются при необходимости. После чего в существующий или созданный каталог копируется объект с такими же метаданными (owner, mode, mtime, symlink-target etc.). Далее, в случае если объект это файл, то копируется содержимое нижнего файла в только что созданный файл в верхней ФС. В заключении копируются расширенные атрибуты.
После завершения процесса copy_up, overlay ФС предоставит прямой доступ к только что созданному файлу из верхней файловой системы. Последующие операции над файлом будут едва заметны для overlay ФС (тогда как операции над именем файла, вроде переименования или unlink, конечно будут замечены и обработаны).
Множество нижних слоёв
Множество нижних слоёв можно задать с помощью символа двоеточие («:»), используя его как разделитель между именами каталогово. Для примера:
mount -t overlay overlay -olowerdir=/lower1:/lower2:/lower3 /mergedКак видно в примере, опции “upperdir=” и “workdir=” могут не указываться. И в этом случае наложение будет доступно только для чтения.
Указанные нижние каталоги будут стекированы справа налево, то есть lower1 будет на самом верху, lower2 посередине, а lower3 на нижнем уровне.
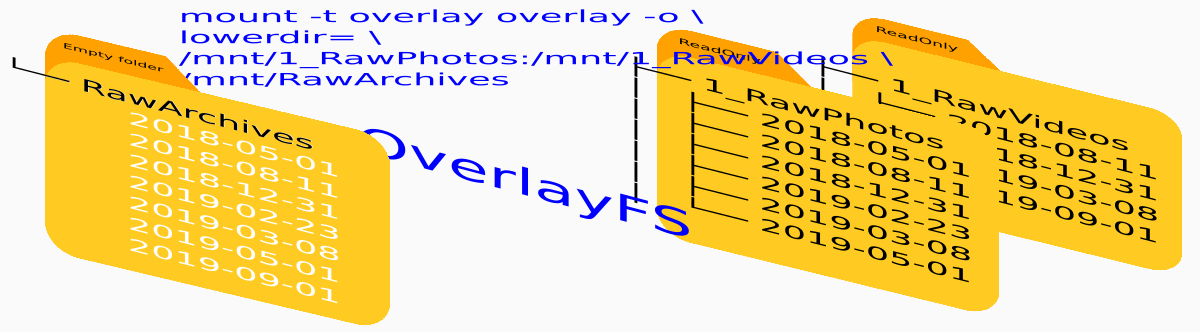
В пустом каталоге RawArchive , после монтирования доступном только для чтения, мы увидим объединённое отображение двух папок c исходниками фото- и видеоматериалов. Все каталоги, задействованные в этой схеме, могут находиться, как на одном носителе, так и на разных (даже сетевых?).
Копирование только метаданных
Когда включена опция копирования только метаданных, overlayfs скопирует только метаданные (в отличие от всего файла), в том случае когда выполняется определённая операция, типа chown/chmod . Полностью файл будет скопирован после того, как файл будет открыт для записи.
Другими словами, это операция с задержкой копирования данных. Данные будут скопированы в том случае, если понадобится их изменение.
Есть несколько способов включения/отключния этой опции. Опция CONFIG_OVERLAY_FS_METACOPY может быть установлена/снята для включения/отключения этой функции по умолчанию. Или можно включить/отключить эту опцию во время загрузки модуля с параметром metacopy=on/off. И наконец, использовать опцию metacopy=on/off во время монтирования.
Не стоит использовать metacopy=on с ненадёжными верхним/нижним каталогом. Otherwise it is possible that an attacker can create a handcrafted file with appropriate REDIRECT and METACOPY xattrs, and gain access to file on lower pointed by REDIRECT. This should not be possible on local system as setting “trusted.” xattrs will require CAP_SYS_ADMIN. But it should be possible for untrusted layers like from a pen drive.
Note: redirect_dir=
(*) redirect_dir=follow only conflicts with metacopy=on if upperdir=… is given.
Расшаривание и копирование слоёв
Нижние слои могут совместно использоваться при монтировании нескольких разных overlay-стеков, и это обычная практика. При монтировании какой-нибудь Overlay может использовать тот же путь до каталога нижнего слоя, что и другой overlay mount.
Overlay filesystem (Русский)
Состояние перевода: На этой странице представлен перевод статьи Overlay filesystem. Дата последней синхронизации: 27 мая 2020. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.
Overlayfs позволяет накладывать одно дерево каталогов (обычно доступное в режиме «чтение-запись») на другое, но с доступом только для чтения. Все изменения переходят на верхний слой с возможностью записи. Данная схема чаще всего используется с Live CD, но существует и множество других применений. Данная реализация отличается от других каскадно-объединённых файловых систем тем, что после открытия файла все операции направляются непосредственно в базовую, «нижнюю» или «верхнюю» файловую систему, что упрощает реализацию и не ухудшает производительность в данных случаях.
Overlayfs доступен в ядре Linux с версии 3.18.
Установка
Overlayfs включён в ядре по умолчанию, а модуль overlay автоматически подгружается после ввода команды монтирования.
Использование
Используйте следующие аргументы mount для монтирования overlay:
# mount -t overlay overlay -o lowerdir=/lower,upperdir=/upper,workdir=/work /merged
Примечание: Рабочий каталог ( workdir ) должен быть пустым и находиться в той же точке монтирования файловой системы, что и верхний каталог.
Нижняя директория может быть списком каталогов, разделённых : , все изменения в каталоге merged по-прежнему будут отражаться в upper .
# mount -t overlay overlay -o lowerdir=/lower1:/lower2:/lower3,upperdir=/upper,workdir=/work /merged
Примечание: Порядок монтирования папок lowerdir : слева-направо/сверху-вниз. То есть крайняя левая папка из списка будет смонтирована как самый верхний слой из lowerdir , а крайняя правая папка, соответственно, как самый нижний слой.
Таким образом порядок слоёв из вышеупомянутого примера будет следующим:
/upper /lower1 /lower2 /lower3
Используйте следующий формат, чтобы добавить запись overlayfs в /etc/fstab :
/etc/fstab
overlay /merged overlay noauto,x-systemd.automount,lowerdir=/lower,upperdir=/upper,workdir=/work 0 0
Параметры монтирования noauto и x-systemd.automount необходимы для предотвращения зависания systemd при загрузке, например, из-за ошибки монтирования overlay. Также overlay теперь будет монтироваться при первом обращении, а запросы будут буферизироваться до готовности самого overlay. Для получения дополнительной информации смотрите раздел Fstab (Русский)#Автоматическое монтирование с systemd.
Overlay только для чтения
Иногда необходимо создать представление из комбинации двух или более каталогов, доступное только для чтения. В этом случае его можно создать более простым способом, так как каталоги upper и work не обязательны:
# mount -t overlay overlay -o lowerdir=/lower1:/lower2 /merged
Когда upperdir не указан, overlay автоматически монтируется только для чтения.
Смотрите также
- Документация файловой системы Overlay
- Обзор OverlayFS — что она делает и как работает [устаревшая ссылка 2023-05-06 ⓘ]
- Wikipedia:OverlayFS
��️ Введение в OverlayFS

Псевдо-файловая система OverlayFS была впервые включена в релиз 3.18 ядра Linux: она позволяет объединять два дерева каталогов или файловых систем (“верхнее” и “нижнее”) совершенно прозрачно для пользователя, который может обращаться к файлам и каталогам на “объединенном” уровне точно так же, как и на стандартной файловой системе.
В этом руководстве мы изучим основные концепции OverlayFS и увидим демонстрацию ее использования.
В этом руководстве вы узнаете:
- Основные концепции OverlayFS
- Как объединить две файловые системы с помощью OverlayFS
Введение
Все мы должны быть знакомы со стандартным поведением ядра Linux при монтировании файловой системы: файлы и каталоги, существующие в каталоге, используемом в качестве точки монтирования, маскируются и становятся недоступными для пользователя, в то время как файлы, существующие в смонтированной файловой системе, отображаются.
Доступ к исходным файлам можно получить только после размонтирования файловой системы.
Это также происходит тогда, когда мы монтируем несколько файловых систем в одном каталоге.
Когда используется псевдо-файловая система OverlayFS, вместо этого файлы, существующие на разных слоях, объединяются, и результирующая файловая система может быть смонтирована самостоятельно.
OverlayFS обычно используется в системах, работающих на встроенных устройствах, таких как OpenWRT, где полезно сохранять базовый набор конфигураций и в то же время позволять пользователю выполнять модификации.
OverlayFS также лежит в основе драйверов хранения “overlay” и “overlay2” Docker.
Что происходит при удалении файла или каталога?
Если удаляемый файл принадлежит верхнему слою, то он удаляется на месте; если же он принадлежит нижнему слою, то удаление имитируется с помощью файла whiteout (или непрозрачного каталога – каталога с расширенным атрибутом trusted.overlay.opaque), который создается в слое с возможностью записи и заслоняет исходный элемент.
OverlayFS является основой драйверов Docker overlay и overlay2.
В такой реализации нижний, доступный только для чтения, слой представлен образами; верхний, доступный для записи, представлен контейнерами на их основе.
Образы неизменяемы: все изменения происходят внутри контейнеров и теряются при их удалении (именно поэтому для сохранения данных используются тома).
Использование OverlayFS
Давайте посмотрим, как использовать OverlayFS.
Для данного примера я предположу, что мы хотим объединить две файловые системы: нижнюю, существующую на разделе /dev/sda1, и ту, которая будет использоваться в режиме чтения-записи, на разделе /dev/sda2.
Первое, что мы хотим сделать, это создать каталоги, которые мы будем использовать в качестве точек монтирования:
$ sudo mkdir /lower /overlay
Теперь смонтируем файловую систему /dev/sda1 в каталоге /lower в режиме только для чтения:
$ sudo mount -o ro /dev/sda1 /lower
Команда ls показывает, что файловая система содержит только один файл:
$ ls -l /lower total 20 -rw-r--r--. 1 root root 23 Sep 1 10:43 file1.txt drwx------. 2 root root 16384 Sep 1 10:40 lost+foun
Файлы содержат всего одну строку:
$ cat /lower/file1.txt this is the first line
Теперь давайте продолжим.
В качестве следующего шага мы смонтируем файловую систему /dev/sda2 в каталог /overlay:
$ sudo mount /dev/sda2 /overlay
Когда файловая система смонтирована, мы создаем на ней две директории: upper и work.
В первой будут храниться файлы, являющиеся частью верхнего слоя, вторая будет использоваться для подготовки файлов при переходе с одного слоя на другой: она должна быть пустой и находиться в той же файловой системе, что и верхняя:
$ sudo mkdir /overlay/
Теперь мы можем “собрать” и смонтировать оверлей.
Для выполнения этой задачи мы используем следующую команду:
$ sudo mount overlay -t overlay -o lowerdir=/lower,upperdir=/overlay/upper,workdir=/overlay/work /media
Мы вызвали mount, передав “overlay” в качестве аргумента опции -t (сокращение от –types), тем самым указав тип файловой системы, которую мы хотим смонтировать (в данном случае псевдо-файловую систему), затем мы использовали флаг -o для перечисления опций монтирования: в данном случае “lowerdir”, “upperdir” и “workdir”, чтобы указать: каталог, в который монтируется файловая система только для чтения, каталог, содержащий файлы верхнего, записываемого слоя, и расположение “рабочего” каталога, соответственно. Наконец, мы указали точку монтирования для “объединенной” файловой системы: /media, в данном случае.
С помощью команды mount мы можем просмотреть сводную информацию о настройке оверлея:
$ mount | grep -i overlay overlay on /media type overlay (rw,relatime,seclabel,lowerdir=/lower,upperdir=/overlay/upper,workdir=/overlay/work)
Если мы перечислим файлы в каталоге /media, то увидим, что существует только файл file1.txt, который, как мы знаем, принадлежит нижнему уровню:
$ ls -l /media total 20 -rw-r--r--. 1 root root 23 Sep 1 10:43 file1.txt drwx------. 2 root root 16384 Sep 1 10:40 lost+found
Теперь давайте попробуем добавить строку в файл и посмотрим, что произойдет:
$ echo "this is the second line" | sudo tee -a /media/file1.txt
Если мы проверим содержимое файла, то увидим, что строка была добавлена успешно:
$ cat /media/file1.txt this is the first line this is the second line
Однако оригинальный файл file1.txt не был изменен:
$ cat /lower/file1.txt this is the first line
IВместо этого в верхний слой был добавлен файл с тем же именем:
$ ls -l /overlay/upper -rw-r--r--. 1 root root 47 Sep 1 14:36 file1.txt
Теперь, если мы удалим файл /media/file1.txt, /overlay/upper/file1.txt станет таким файлом whiteout :
$ sudo rm /media/file1.txt $ ls -l /overlay/upper c---------. 2 root root 0, 0 Sep 1 14:45 file1.txt
Как указано в официальной документации, файл whiteout является символьным устройством (это отражено в выводе ls – см. выделенную ведущую “c”) с номером устройства 0/0.
Заключение
В этом руководстве мы поговорили о OverlayFS: мы узнали основные концепции ее использования, увидели, как она может быть использована для объединения двух файловых систем или деревьев каталогов, и каковы некоторые из возможных случаев ее использования.
Наконец, мы увидели, как на самом деле создать установку OverlayFS на Linux.
- �� Что такое Docker без root (rootless)?
- Как найти эксплойты Linux по версии ядра
- �� Как анализировать и исследовать содержимое образов Docker
- �� 3 довольно неизвестных команды Docker, которые помогут вам в самых различных ситуациях
Полное погружение в Docker: файловая система OverlayFS

Изучаем внутреннюю работу OverlayFS — файловой системы, лежащей в основе образов и контейнеров Docker, вместе с сертифицированным специалистом по работе c Kubernetes, OpenShift, Docker и автором статьи на ITNEXT. В этой статье исследована одна из частей архитектуры Docker — файловая система для Linux. Всем поклонникам этой операционной системы на заметку.
Детям из Мариуполя нужно 120 ноутбуков для обучения — подари старое «железо», пусть оно работает на будущее Украины
Работать с Docker CLI довольно легко — вы просто создаете, запускаете, проверяете, извлекаете и отправляете контейнеры и образы. Но задумывались ли вы над тем, как на самом деле работают внутренние компоненты в Docker-интерфейсе?
Здесь скрывается множество интересных технологий, и в этой статье мы рассмотрим одну из них — union filesystem — файловую систему, лежащую в основе всех слоев контейнеров и образов.
Что такое Union Filesystem?
Union mount — это тип файловой системы, которая создает иллюзию слияния содержимого нескольких каталогов в один без изменения исходных (физических) данных в оригинальных источниках. Это может быть полезно, когда у нас есть наборы файлов, которые хранятся в разных местах и на разных носителях, и мы хотим их объединить. Например, пользовательские директории /home с удаленных NFS-серверов — все они объединены в один каталог или в один полный ISO-образ.
Union mount или объединенная файловая система — это не тип файловой системы, а скорее концепция с возможностью различных реализаций. Некоторые из них быстрее, некоторые проще, они могут достигать совершенно разных целей и уровней исполнения. Прежде чем мы начнем разбираться во всех деталях, давайте кратко рассмотрим некоторые из наиболее популярных реализаций:
Курс Англійської.
Онлайн-навчання англійської за методикою Кембриджу — вибір понад мільярда людей.- UnionFS — начнем с исходной объединенной файловой системы. Похоже, что разработчики UnionFS с августа 2014 года перестали ее развивать. Больше об этом можно узнать здесь .
- aufs — альтернативная версия UnionFS, которая располагала множеством новых функций, но была отклонена для слияния с основным ядром Linux. Aufs был дефолтным драйвером для Docker в Ubuntu/Debian, но его заменили на OverlayFS (для ядра Linux >4.0). Он имеет некоторые преимущества по сравнению с другими объединенными файловыми системами. Все они описаны в Docker docs page .
- OverlayFS — включена в ядро Linux с версии 3.18 (26 октября 2014 года). Это файловая система, использующая дефолтный драйвер Docker overlay2 (верифицировать можно с помощью docker system info | grep Storage ). OverlayFS имеет лучшую производительность, чем aufs, и располагает некоторыми приятными функциями, такими как совместное использование кеша страниц .
- ZFS — это объединенная файловая система, созданная Sun Microsystems (теперь Oracle). Имеет некоторые интересные функции, такие как иерархическое вычисление контрольных сумм, встроенная обработка снимков файловой системы и резервное копирование/репликация или сжатие и дедупликация данных. Но при поддержке Oracle ZFS не поддерживает лицензию CDDL и поэтому не может поставляться как часть ядра Linux. Однако можно использовать проект ZFS в Linux (ZoL), который описан в документации Docker, как годный и развивающийся, но не готовый для продакшена. Если хотите попробовать, необходимую информацию можно найти здесь .
Чтобы более подробно изучить эти драйверы для Docker, ознакомьтесь с документацией . Но если не уверены в своих действиях, просто используйте дефолтный overlay2 , который также будет использоваться в этой статье в качестве демо.
Почему Union Filesystem?
Выше была упомянута причина, по которой представленный тип файловой системы может быть полезен. Но почему именно он — хороший выбор для контейнеров и Docker в целом?
Многие образы, которые мы используем для контейнеров, имеют довольно большие размеры. К примеру, размер ubuntu 72 Мб или nginx — 133 Мб. Нецелесообразно выделять столько места каждый раз, когда мы хотим создать контейнер. Благодаря объединенной файловой системе, в Docker нужно создать только один слой поверх образа, а остальная его часть может использоваться всеми контейнерами. Это также дает дополнительное преимущество в виде сокращения времени запуска, поскольку нет необходимости копировать файлы образов и другие данные.
Union Filesystem также обеспечивает изоляцию, поскольку контейнеры имеют доступ только для чтения к слоям образов. Если им понадобится изменить какой-либо из общих файлов, доступных только для чтения, они используют копирование при записи — копирование контента на верхний доступный для записи уровень, где его можно безопасно изменить.
Курс UI/UX для геймдеву.
Під час навчання ви розробите проекти для портфоліо, що складається з 5 ключових аспектів UX/UI-дизайну, та отримаєш необхідні навички для професійного росту.
Как это работает?
Из всего описанного выше может показаться, что Union Filesystem обладает магическими способностями, но на самом деле это не так. Давайте начнем с объяснения того, как это работает в общем (неконтейнерном) случае. Представим, что мы хотели бы объединить две директории (верхний и нижний каталоги) в одну и ту же точку монтирования и получить их объединенное представление:
. ├── upper │ ├── code.py # Content: `print("Hello Overlay!")` │ └── script.py └── lower ├── code.py # Content: `print("This is some code. ")` └── config.yamlВ терминологии Union mount эти каталоги называются ветками. Каждой из этих веток назначается свой приоритет. Этот приоритет используется для определения того, какой файл будет отображаться в объединенном представлении в случае, если в нескольких ветках есть файлы с одинаковыми именами. Глядя на файлы и директории выше, становится ясно, что если мы попытаемся наложить их поверх, они буду конфликтовать ( файл code.py ):
~ $ mount -t overlay \ -o lowerdir=./lower,\ upperdir=./upper,\ workdir=./workdir \ overlay /mnt/merged ~ $ ls /mnt/merged code.py config.yaml script.py ~ $ cat /mnt/merged/code.py print("Hello Overlay!")В приведенном выше примере мы использовали команду mount с типом overlay , чтобы объединить lower (только для чтения, низкий приоритет) и upper (запись, высокий приоритет) каталоги в единое представление /mnt/merged . Также был включен параметр workdir=./workdir , который служит местом для подготовки объединенного представления lowerdir и upperdir перед его перемещением в /mnt/merged .
Глядя на вывод команды cat выше, можно увидеть, что содержимое файлов в upper (верхнем) каталоге имеет приоритет в объединенном представлении.
Теперь мы знаем, как объединить два каталога и что произойдет в случае конфликта. Но что произойдет, если мы попытаемся изменить некоторые файлы из объединенного представления?
Здесь в игру вступает функция копирования при записи (CoW) . Что это такое? CoW — это метод оптимизации, при котором создается общая копия ресурса при его запросах, осуществляемых одновременно. Копирование становится необходимым только тогда, когда один из вызывающих абонентов пытается записать свою «копию» . Отсюда и термин «копировать при (первой попытке) записи» .
В случае union mount это означает, что когда мы пытаемся изменить общий файл (или файл только для чтения), он сначала копируется в верхнюю доступную для записи ветку ( upperdir ), которая имеет более высокий приоритет, чем нижние ветки только для чтения ( lowerdir ). Когда файл находится в ветке с возможностью записи, его можно безопасно изменить. Его новый контент будет виден в объединенном представлении, потому что верхний слой имеет более высокий приоритет.
Последняя операция — это удаление файлов. При удалении в ветке с возможностью записи создается чистый файл. Файл, который мы хотим удалить, на самом деле не удаляется, а скорее скрывается в объединенном представлении.
Как же union mount связан с Docker и его контейнерами? Давайте посмотрим на многоуровневую архитектуру Docker. Песочница контейнера состоит из нескольких веток — или слоев. Слои доступны только для чтения ( lowerdir ) и являются частью объединенного представления, а слой контейнера — записываемой верхней частью ( upperdir ).
Слои образов, которые вы извлекаете из реестра, являются lowerdir (нижним) каталогом, а при запуске контейнера, upperdir (верхний) каталог приаттачивается к верхним слоям образов, чтобы обеспечить доступное для записи рабочее пространство для вашего контейнера. Звучит довольно просто, правда? Попробуем?
Курс Project Manager.
Впроваджуйте покроковий алгоритм управління проєктами вже зараз. У цьому вам допоможе Павло Харіков — Head of IoT у Veon Group (Kyivstar).
Как OverlayFS используется в Docker
Чтобы продемонстрировать, как OverlayFS используется в Docker, попробуем имитировать то, как Docker монтирует слои образов и контейнера.
~ $ docker image prune -af . Total reclaimed space: . MB ~ $ docker pull nginx Using default tag: latest latest: Pulling from library/nginx a076a628af6f: Pull complete 0732ab25fa22: Pull complete d7f36f6fe38f: Pull complete f72584a26f32: Pull complete 7125e4df9063: Pull complete Digest: sha256:10b8cc432d56da8b61b070f4c7d2543a9ed17c2b23010b43af434fd40e2ca4aa Status: Downloaded newer image for nginx:latest docker.io/library/nginx:latest
Итак, у нас есть nginx , теперь давайте проверим его слои. Мы можем проверить слои образов, запустив docker inspect и просмотрев поля GraphDriver , или отправиться в каталог /var/lib/docker/overlay2 , где хранятся все слои образов. Давайте воспользуемся двумя способами и посмотрим, что внутри:
~ $ cd /var/lib/docker/overlay2 ~ $ ls -l total 0 drwx------. 4 root root 55 Feb 6 19:19 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd drwx------. 3 root root 47 Feb 6 19:19 410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46 drwx------. 4 root root 72 Feb 6 19:19 685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e brw-------. 1 root root 253, 0 Jan 31 18:15 backingFsBlockDev drwx------. 4 root root 72 Feb 6 19:19 d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e drwx------. 4 root root 72 Feb 6 19:19 fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505 drwx------. 2 root root 176 Feb 6 19:19 l ~ $ tree 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/ 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/ ├── diff │ └── docker-entrypoint.d │ └── 20-envsubst-on-templates.sh ├── link ├── lower └── work ~ $ docker inspect nginx | jq .[0].GraphDriver.Data < "LowerDir": "/var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff:/var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff:/var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff:/var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff", "MergedDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/merged", "UpperDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff", "WorkDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/work" >
Очень похоже на то, что мы видели с командой mount , правда? Более конкретно:
-
LowerDir : каталог со слоями образов, доступных только для чтения, разделенными двоеточиями.
Теперь давайте запустим контейнер и проверим слои:
~ $ docker run -d --name container nginx ~ $ docker inspect container | jq .[0].GraphDriver.Data < "LowerDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4-init/diff:/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff:/var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff:/var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff:/var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff:/var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff", "MergedDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/merged", "UpperDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff", "WorkDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/work" >~ $ tree -l 3 /var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff # The UpperDir /var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff ├── etc │ └── nginx │ └── conf.d │ └── default.conf ├── run │ └── nginx.pid └── var └── cache └── nginx ├── client_temp ├── fastcgi_temp ├── proxy_temp ├── scgi_temp └── uwsgi_temp
Приведенный выше пример показывает, что те же каталоги, которые были выведены в docker inspect nginx ранее, как MergedDir , UpperDir и WorkDir (с ID 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd) теперь являются частью LowerDir- контейнера. Здесь LowerDir состоит из всех слоев образов nginx, наложенных друг на друга. Поверх них находится доступный для записи слой в UpperDir , который содержит /etc , /run и /var . В MergedDir находится вся файловая система, доступная для контейнера, включая все содержимое из UpperDir и LowerDir .
Чтобы имитировать поведение Docker, мы можем использовать эти же каталоги для ручного создания нашего собственного объединенного представления:
~ $ mount -t overlay -o \ lowerdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4-init/diff:/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff:/var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff:/var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff:/var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff:/var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff,\ upperdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff,\ workdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/work \ overlay /mnt/merged ~ $ ls /mnt/merged bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var boot docker-entrypoint.d etc lib media opt root sbin sys usr ~ $ umount overlay
Здесь мы просто взяли значения из предыдущего фрагмента и добавили их в соответствующие аргументы в команде mount с той лишь разницей, что для объединенного представления были использованы /mnt/merged вместо /var/lib/docker/overlay2/…/merged .
OverlayFS в Docker в итоге сводится единой mount команде на многих наложенных друг на друга слоях. Ниже приведена часть кода Docker, отвечающая за: подстановку значений lowerdir = … , upperdir = … , workdir = … и отслеживание unix.Mount .
// https://github.com/moby/moby/blob/1ef1cc8388165b2b848f9b3f53ec91c87de09f63/daemon/graphdriver/overlay2/overlay.go#L580 opts := fmt.Sprintf("lowerdir=%s,upperdir=%s,workdir=%s", strings.Join(absLowers, ":"), path.Join(dir, "diff"), path.Join(dir, "work")) mountData := label.FormatMountLabel(opts, mountLabel) mount := unix.Mount mountTarget := mergedDir rootUID, rootGID, err := idtools.GetRootUIDGID(d.uidMaps, d.gidMaps) // .Заключение
Интерфейс Docker поначалу кажется черным ящиком с множеством непонятных технологий внутри. Эти технологии довольно интересны и полезны. И хотя, чтобы эффективно использовать Docker, вам совсем не нужно уметь в них разбираться, все же стоит немного углубиться в эту тему и понять их предназначение.
Более глубокое понимание инструмента помогает принимать правильные решения, касающиеся в данном случае оптимизации производительности и последствий для безопасности. Вы откроете для себя некоторые крутые технологии, которые в будущем могут иметь для вас много вариантов использования.
Текст для Highload перевела Ольга Змерзлая.
Курс Аналітик даних.
Протягом 4 місяців ви вивчите повний набір інструментів для аналізу даних та отримаєте можливість працевлаштування в Laba Group.