Атомарность
Атомарность (в программировании) — свойство непрерывности операции. Атомарная операция выполняется полностью (или происходит отказ в выполнении), без прерываний. Атомарность имеет особое значение в многопроцессорных компьютерах (и многозадачных операционных системах), так как доступ к неразделяемым ресурсам должен быть обязательно атомарным.
Атомарная операция открыта влиянию только одного потока.
Атомарность бывает аппаратная (когда непрерывность обеспечивается аппаратурой) и программной, когда используются специальные средства межпрограммного взаимодействия (мьютекс, семафор). По своей сути программные средства обеспечения атомарности представляют собой два этапа — блокировка ресурса и выполнение самой операции. Блокировка представляет собой атомарную операцию, которая либо успешна, либо возвращает сообщение о занятости.
См. также
- Сериализуемость
- Линеаризуемость
- Последовательная консистентность
Wikimedia Foundation . 2010 .
Синонимы:
- Сражение при Гренгаме
- Улица Щипок
Смотреть что такое «Атомарность» в других словарях:
- атомарность — элементарность; нецелостность, дробность Словарь русских синонимов. атомарность сущ., кол во синонимов: 3 • дробность (9) • … Словарь синонимов
- атомарность — АТОМАРНЫЙ, ая, ое. Толковый словарь Ожегова. С.И. Ожегов, Н.Ю. Шведова. 1949 1992 … Толковый словарь Ожегова
- атомарность — Свойство транзакций (см. ACID). Транзакция рассматривается как единая логическая единица, все изменения в базе данных, произведенные во время ее выполнения, или сохраняются целиком, или полностью откатываются. [http://www.morepc.ru/dict/]… … Справочник технического переводчика
- атомарность, непротиворечивость, изолированность, долговечность — Свойства, присущие транзакции. атомарность Свойство атомарности (atomicity) обозначает, что входящие в транзакцию операции выступают вместе как неделимая единица работы, т.е. либо все операции успешно завершаются, либо отменяются. Это делает… … Справочник технического переводчика
- атомарность — сложность … Словарь антонимов
- атомарность — Syn: элементарность … Тезаурус русской деловой лексики
- ароматность — атомарность … Краткий словарь анаграмм
- ACID — У этого термина существуют и другие значения, см. Acid. В информатике акроним ACID описывает требования к транзакционной системе (например, к СУБД), обеспечивающие наиболее надёжную и предсказуемую её работу. Требования ACID были в основном… … Википедия
- Атомарные операции — Атомарные операции операции, выполняющиеся как единое целое либо не выполняющиеся вовсе. Атомарность операций имеет особое значение в многопроцессорных компьютерах (и многозадачных операционных системах), так как доступ к неразделяемым… … Википедия
- Атомарная операция — Атомарные операции операции, выполняющиеся как единое целое либо не выполняющиеся вовсе. Атомарность операций имеет особое значение в многопроцессорных компьютерах (и многозадачных операционных системах), так как доступ к неразделяемым… … Википедия
- Обратная связь: Техподдержка, Реклама на сайте
- �� Путешествия
Экспорт словарей на сайты, сделанные на PHP,
WordPress, MODx.
- Пометить текст и поделитьсяИскать в этом же словареИскать синонимы
- Искать во всех словарях
- Искать в переводах
- Искать в ИнтернетеИскать в этой же категории
Атомарные и неатомарные операции (java)
Операция в общей области памяти называется атомарной, если она завершается в один шаг относительно других потоков, имеющих доступ к этой памяти. Во время выполнения такой операции над переменной, ни один поток не может наблюдать изменение наполовину завершенным. Атомарная загрузка гарантирует, что переменная будет загружена целиком в один момент времени. Неатомарные операции не дают такой гарантии.
Т.е. как я поняла, атомарные операции — это достаточно мелкие, выполняющиеся «за один шаг относительно других потоков». Но что значит этот «шаг»? Один шаг == одной машинной операции? Или чему-то другому? Как определить точно, какие операции относятся к атомарным, а какие к неатомарным? P.S.: Я нашла похожий вопрос, но там речь идёт о C#.
Отслеживать
задан 18 янв 2017 в 10:01
10.7k 6 6 золотых знаков 47 47 серебряных знаков 99 99 бронзовых знаков
@Ksenia я не обладаю достаточной квалификацией для того, чтобы дать ее самостоятельно, но в википедии приводится следующая формулировка (хоть она и туманна): an operation (or set of operations) is atomic, linearizable, indivisible or uninterruptible if it appears to the rest of the system to occur instantaneously.. Попробую не забыть накатать вечером свой ответ.
18 янв 2017 в 10:38
Комментарии не предназначены для расширенной дискуссии; разговор перемещён в чат.
29 янв 2017 в 8:34
3 ответа 3
Сортировка: Сброс на вариант по умолчанию
Как можно определить атомарность?
Атомарность операции чаще всего принято обозначать через ее признак неделимости: операция может либо примениться полностью, либо не примениться вообще. Хорошим примером будет запись значений в массив:
public class Curiousity < public volatile int[] array; public void nonAtomic() < array = new int[1]; array[0] = 1; >public void probablyAtomic() < array = new int[] < 1 >; > > При использовании метода nonAtomic существует вероятность того, что какой-то поток обратится к array[0] в тот момент, когда array[0] не проинициализирован, и получит неожиданное значение. При использовании probablyAtomic (при том условии, что массив сначала заполняется, а уже потом присваивается — я сейчас не могу гарантировать, что в java это именно так, но представим, что это правило действует в рамках примера) такого быть не должно: array всегда содержит либо null, либо проинициализированный массив, но в array[0] не может содержаться что-то, кроме 1. Эта операция неделима, и она не может примениться наполовину, как это было с nonAtomic — только либо полностью, либо никак, и весь остальной код может спокойно ожидать, что в array будет либо null, либо значения, не прибегая к дополнительным проверкам.
Кроме того, под атомарностью операции зачастую подразумевают видимость ее результата всем участникам системы, к которой это относится (в данном случае — потокам); это логично, но, на мой взгляд, не является обязательным признаком атомарности.
Почему это важно?
Атомарность зачастую проистекает из бизнес-требований приложений: банковские транзакции должны применяться целиком, билеты на концерты заказываться сразу в том количестве, в котором были указаны, и т.д. Конкретно в том контексте, который разбирается (многопоточность в java), задачи более примитивны, но произрастают из тех же требований: например, если пишется веб-приложение, то разбирающий HTTP-запросы сервер должен иметь очередь входящих запросов с атомарным добавлением, иначе есть риск потери входящих запросов, а, следовательно, и деградация качества сервиса. Атомарные операции предоставляют гарантии (неделимости), и к ним нужно прибегать, когда эти гарантии необходимы.
Кроме того, атомарные операции линеаризуемы — грубо говоря, их выполнение можно разложить в одну линейную историю, в то время как просто операции могут производить граф историй, что в ряде случаев неприемлимо.
Почему примитивные операции не являются атомарными сами по себе? Так же было бы проще для всех.
Современные среды исполнения очень сложны и имеют на борту некислый ворох оптимизаций, которые можно сделать с кодом, но, в большинстве случаев, эти оптимизации нарушают гарантии. Так как большинство кода этих гарантий на самом деле не требует, оказалось проще выделить операции с конкретными гарантиями в отдельный класс, нежели наоборот. Чаще всего в пример приводят изменение порядка выражений — процессор и JVM имеют право выполнять выражения не в том порядке, в котором они были описаны в коде, до тех пор, пока программист не будет форсировать определенный порядок выполнения с помощью операций с конкретными гарантиями. Также можно привести пример (не уверен, правда, что формально корректный) с чтением значения из памяти:
thread #1: set x = 2 processor #1: save_cache(x, 2) processor #1: save_memory(x, 2) thread #2: set x = 1 processor #2: save_cache(x, 1) processor #2: save_memory(x, 1) thread #1: read x processor #1: read_cache(x) = 2 // в то время как х уже был обновлен значением 1 в thread #2 Здесь не используется т.н. single source of truth для того, чтобы управлять значением Х, поэтому возможны такие аномалии. Насколько понимаю, чтение и запись напрямую в память (или в память и в общий кэш процессоров) — это как раз то, что форсирует модификатор volatile (здесь могу быть неправ).
Конечно, оптимизированный код выполняется быстрее, но необходимые гарантии никогда не должны приноситься в жертву производительности кода.
Это относится только к операциям связанным с установкой переменных и прочей процессорной сфере деятельности?
Нет. Любая операция может быть атомарной или неатомарной, например, классические реляционные базы данных гарантируют, что транзакция — которая может состоять из изменений данных на мегабайты — либо применится полностью, либо не будет применена. Процессорные инструкции здесь не имеют никакого отношения; операция может быть атомарной до тех пор, пока она является атомарной сама по себе или ее результат проявляется в виде другой атомарной операции (например, результат транзакции базы данных проявляется в записи в файл).
Кроме того, насколько понимаю, утверждение «инструкция не успела за один цикл — операция неатомарна» тоже неверно, потому что есть некоторые специализированные инструкции, и никто не мешает атомарно устанавливать какое-либо значение в памяти на входе в защищенный блок и снимать его по выходу.
Любая ли операция может быть атомарной?
Нет. Мне очень сильно не хватает квалификации для корректных формулировок, но, насколько понимаю, любая операция, подразумевающая два и более внешних эффекта (сайд-эффекта), не может быть атомарной по определению. Под сайд-эффектом в первую очередь подразумевается взаимодействие с какой-то внешней системой (будь то файловая система или внешнее API), но даже два выражения установки переменных внутри synchronized-блока нельзя признать атомарной операцией, пока одно из них может выкинуть исключение — а это, с учетом OutOfMemoryError и прочих возможных исходов, может быть вообще невозможно.
У меня операция с двумя и более сайд-эффектами. Могу ли я все-таки что-нибудь с этим сделать?
Да, можно создать систему с гарантией применения всех операций, но с условием, что любой сайд-эффект может быть вызван неограниченное число раз. Вы можете создать журналируемую систему, которая атомарно записывает запланированные операции, регулярно сверяется с журналом и выполняет то, что еще не применено. Это можно представить следующим образом:
client: journal.push , reserveTicket , sendEmail > client: journal: process withdrawMoney journal: markCompleted withdrawMoney journal: process reserveTicket journal: journal: journal: process reserveTicket # сайд-эффект вызывается еще раз, но только в случае некорректной работы journal: markCompleted reserveTicket journal: process sendEmail journal: markCompleted sendEmail Это обеспечивает прогресс алгоритма, но снимает все обязательства по временным рамкам (с которыми, формально говоря, и без того не все в порядке). В случае, если операции идемпотентны, подобная система будет рано или поздно приходить к требуемому состоянию без каких-либо заметных отличий от ожидаемого (за исключением времени выполнения).
Как все-таки определить атомарность операций в java?
Первичный источник правды в этом случае — это Java Memory Model, которая определяет, какие допущения и гарантии применяются к коду в JVM. Java Memory Model, впрочем, довольно сложна для понимания и покрывает значительно большую сферу операций, нежели сфера атомарных операций, поэтому в контексте этого вопроса достаточно знать, что модификатор volatile обеспечивает атомарное чтение и запись, а классы Atomic* позволяют производить compare-and-swap операции, чтобы атомарно менять значения, не боясь, что между чтением и записью придет еще одна чья-то запись, а в комментариях ниже на момент прочтения наверняка добавили еще что-то, что я забыл.
Атомарные и неатомарные операции
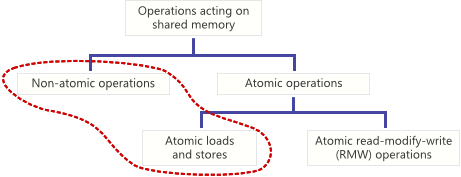
В Сети уже очень много написано об атомарных операциях, но в основном авторы рассматривают операции чтения-модификации-записи. Однако, существуют и другие атомарные операции, например, атомарные операции загрузки (load) и сохранения (store), которые не менее важны. В этой статье я сравню атомарные загрузки и сохранения с их неатомарными аналогами на уровне процессора и компилятора C/C++. По ходу статьи мы также разберемся с концепцией «состояния гонок» с точки зрения стандарта C++11.
Операция в общей области памяти называется атомарной, если она завершается в один шаг относительно других потоков, имеющих доступ к этой памяти. Во время выполнения такой операции над переменной, ни один поток не может наблюдать изменение наполовину завершенным. Атомарная загрузка гарантирует, что переменная будет загружена целиком в один момент времени. Неатомарные операции не дают такой гарантии.
Без подобных гарантии неблокирующее программирование было бы невозможно, поскольку было бы нельзя разрешить нескольким потокам оперировать одновременно одной переменной. Мы можем сформулировать правило:
В любой момент времени когда два потока одновременно оперируют общей переменной, и один из них производит запись, оба потока обязаны использовать атомарные операции.
Если вы нарушаете это правило, и каждый поток использует неатомарные операции, вы оказываетесь в ситауции, которую стандарт C++11 называет состояние гонок по данным (data race) (не путайте с похожей концепцией из Java, или более общим понятием состояния гонок (race condition)). Стандарт C++11 не объясняет, почему состояние гонок плохо, однако утверждает, что в таком состоянии вы получите неопределенное поведение (§1.10.21). Причина опасности таких состояний гонок, однако, очень проста: в них операции чтения и записи разорваны (torn read/write).
Операция с памятью может быть неатомарной даже на одноядерном процессоре только потому, что она использует несколько инструкций процессора. Однако и одна инструкция процессора на некоторых платформах также может быть неатомарной. Поэтому, если вы пишите переносимый код для другой платформы, вы никак не можете опираться на предположение об атомарности отдельной инструкции. Давайте рассмотрим несколько примеров.
Неатомарные операции из нескольких инструкций
Допустим, у нас есть 64-битная глобальная переменная, инициализированная нулем.
uint64_t sharedValue = 0; В какой-то момент времени мы присвоим ей значение:
void storeValue()
Если мы скомпилируем этот код с помощью 32-битного компилятора GCC, мы получим такой машинный код:
$ gcc -O2 -S -masm=intel test.c $ cat test.s . mov DWORD PTR sharedValue, 2 mov DWORD PTR sharedValue+4, 1 ret . Видно, что компилятор реализовал 64-битное присваивание с помощью двух процессорных инструкций. Первая инструкция присваивае нижним 32 битам значение 0x00000002, и вторая заносит в верхние биты значение 0x00000001. Очевидно, что такое присваивание неатомарно. Если к переменной sharedValue одновременно пытаются получить доступ различные потоки, можно получить несколько ошибочных ситуаций:
- Если поток, вызывающий storeValue, будет прерван между двумя инструкциями записи, то он оставит в памяти значение 0x0000000000000002 — это разорванная операция записи. Если в этот момент другой поток попытается прочитать sharedValue, он получит неправильное значение, которое никто и не собирался сохранять.
- Более того, если записывающий поток был остановлен между инструкциями записи, а другой поток поменяет значение sharedValue перед тем, как первый поток возобновит работу, мы получим постоянно разорванную запись: верхняя половина значения переменной будет установлена одним потоком, а нижняя — вторым.
- Чтобы получить разорванную запись на мультиядерных процессорах потоки даже не нужно прерывать: любой поток, выполняющийся на другом ядре, может прочитать значение переменной в момент, когда только половина нового значения записана в память.
Параллельное чтение из sharedVariable также имеет свои проблемы:
uint64_t loadValue()
$ gcc -O2 -S -masm=intel test.c $ cat test.s . mov eax, DWORD PTR sharedValue mov edx, DWORD PTR sharedValue+4 ret . Здесь таким же образом компилятор реализует чтение двумя инструкциями: сначала нижние 32 бита считываются в регистр EAX, а потом верхние 32 бита считываются в EDX. В этом случае, если параллельная запись будет произведена между этими двумя инструкциями, мы получим разорванную операцию считывания, даже если запись была атомарной.
Эти проблемы отнюдь не теоретические. Тесты библиотеки Mintomic включает тест test_load_store_64_fail, в котором один поток сохраняет набор 64-битных значений в переменную используя обычный оператор присваивания, а другой поток производит обычную загрузку из той же самой переменной, проверяя результат каждой операции. В многопоточном режиме x86 этот тест ожидаемо падает.

Неатомарные инструкции процессора
Операция с памятью может быть неатомарной даже если она выполняется одной инструкцией процессора. Например, в наборе инструкций ARMv7 есть инструкция strd, которая сохраняет содержимое двух 32-битных регистров в 64-битной переменной в памяти.
strd r0, r1, [r2] На некоторых ARMv7 процессорах эта инструкция не является атомарной. Когда процессор видит такую инструкцию, он на самом деле выполняет две отдельные операции (§A3.5.3). Как и в предыдущем примере, другой поток, выполняющийся на другом ядре, может попасть в ситуацию разорванной записи. Интересно, что ситуация разорванной записи может возникнуть и на одном ядре: системное прерывание — скажем, для запланированной смены контекста потока — может возникнуть между внутренними операциями 32-битного сохранения! В этом случае, когда поток возобновит свою работу, он начнет выполнять инструкцию strd заново.
Другой пример, всем известная операция архитектуры x86, 32-битная операция mov атомарна в том случае, когда операнд в памяти выровнен, и не атомарна в противном случае. То есть, атомарность гарантируется только в случае, когда 32-битное целое число находится по адресу, который делится на 4. Mintimoc содержит тестовый пример test_load_store_32_fail, который проверяет это условие. Этот тест всегда выполняется успешно на x86, но если его модифицировать так, чтобы переменная sharedInt находилась по невыровненному адресу, тест упадет. На моем Core 2 Quad 6600 тест падает, когда sharedInt разделен между различными линиями кеша:
// Force sharedInt to cross a cache line boundary: #pragma pack(2) MINT_DECL_ALIGNED(static struct, 64) < char padding[62]; mint_atomic32_t sharedInt; >g_wrapper; 
Думаю, мы рассмотрели достаточно нюансов процессорного выполнения. Давайте взглянем на атомарность на уровне C/C++.
Все операции C/C++ считаются неатомарными
В C/C++ каждая операция считается неатомарной до тех пор, пока другое не будет явно указано прозводителем компилятора или аппаратной платформы — даже обычное 32-битное присваивание.
uint32_t foo = 0; void storeFoo()
Стандарты языка ничего не говорят по поводу атомарности в этом случае. Возможно, целочисленное присваивание атомарно, может быть нет. Поскольку неатомарные операции не дают никаких гарантий, обычное целочисленное присваивание в C является неатомарным по определению.
На практике мы обычно обладаем некоторой информацией о платформах, для которых создается код. Например, мы обычно знаем, что на всех современных процессорах x86, x64, Itanium, SPARC, ARM и PowerPC обычное 32-битное присваивание атомарно в том случае, если переменная назначения выровнена. В этом можно убедиться, перечитав соответствующий раздел документации процессора и/или компилятора. Я могу сказать, что в игровой индустрии атомарность очень многих 32-битных присваиваний гарантируется этим конкретным свойством.
Как бы там ни было, при написании действительно переносимого кода C и C++, мы следуем давно установившейся традиции считать, что мы не знаем ничего более того, что нам говорят стандарты языка. Переносимые C и C++ спроектированы так, чтобы выполнятся на любом возможном вычислительном устройстве прошлого, настоящего и будущего. Я, например, люблю представлять устройство, память которого можно менять только предварительно заполнив ее случайным мусором:

На таком устройстве вы уж точно не захотите произвести параллальное считывание, так же как и обычное присваивание, потому что слишком высок риск получить в результате случайное значение.
В C++11 наконец-то появился способ выполнять действительно переносимые атомарные сохранения и загрузки. Эти операции, произведенные с помощью атомарной библиотеки C++11 будут работать даже на условном устройстве, описанном ранее: даже если это будет означать, что библиотеке прийдется блокировать мьютекс для того, чтобы сделать каждую операцию атомарной. Моя библиотека Mintomic которую я выпустил недавно, не поддерживает такое количество различных платформ, но работает на некоторых старых компьютерах, оптимизирована вручную и гарантировано неблокирующая.
Расслабленные (relaxed) атомарные операции
Давайте вернемся к примеру с sharedValuem который мы рассматривали в начале. Давайте перепишем его с использованием Mintomic так, чтобы все операции выполнялись атомарно на каждой платформе, которую поддерживает Mintomic. Для начала мы объявим sharedValue как один из атомарных типов Mintomic:
#include mint_atomic64_t sharedValue = < 0 >; Тип mint_atomic64_t гарантирует корректное выравнивание в памяти для атомарного доступа на каждой платформе. Это важно, поскольку, например, компилятор gcc 4.2 для ARM в среде разработки Xcode 3.2.5 не гарантирует, что тип uint64_t будет выровнен на 8 байтов.
В функции storeValue вместо выполнения обычного неатомарного присваивания, мы должны выполнить mint_store_64_relaxed.
void storeValue()
Аналогично, в loadValue мы вызываем mint_load_64_relaxed.
uint64_t loadValue()
Если использовать терминологию C++11, то эти функции сейчас свободны от состояний гонок по данным (data race free). Если они будут вызваны одновременно, абсолютно невозможно оказаться в ситуации разорванного чтения или записи, независимо от того, на какой платформе выполняется код: ARMv6/ARMv7(режимы Thumb или ARM), x86, x64 или PowerPC. Если вам интересно как работают mint_load_64_relaxed и mint_store_64_relaxed, то обе функции используют инструкцию cmpxchg8b на платформе x86. Подробности реализации для других платформ можно найти в реализации Mintomic.
Вот такой же код с использованием стандартной библиотеки C++11:
#include std::atomic sharedValue(0); void storeValue() < sharedValue.store(0x100000002, std::memory_order_relaxed); >uint64_t loadValue() < return sharedValue.load(std::memory_order_relaxed); >uint64_t loadValue()
Вы должны были заметить, что оба примера используют расслабленные атомарные операции, что подтверждается суффиксом _relaxed в идентификаторах. Этот суффикс напоминает об определенных гарантиях относительно упорядочивания памяти (memory ordering).
В частности, для таких операций допукается переупорядочивание операций с памятью в соответствии с переупорядочиванием компилятором либо с переупорядочиванием памяти процессором. Компилятор даже может оптимизировать избыточные атомарные операции, так же как и неатомарные. Но во всех этих случаях атомарность оперций сохраняется.
Я думаю, что в случае выполнения параллельных операций с памятью, использование функций атомарных библиотек Mintomic или C++11 является хорошей практикой, даже если вы уверены, что обычные операции чтения либо записи будут атомарны на спользуемой вами платформе. Использование атомарных библиотек будет служить лишним напоминанием, что переменные могут быть использованы в конкурентной среде.
Надеюсь, теперь вам стало понятнее, почему Самая простая в мире неблокирующая хэш-таблица использует Mintomic для манипуляции общей памятью одновременно с другими потоками.
Об авторе. Джефф Прешинг работает архитектором ПО в игровой компании Ubisoft и специализируется на многопоточном программировании и неблокирующих алгоритмах. В этом году он делал доклад о многопоточной разработке игр в соответствии со стандартом С++11 на конференции CppCon, видео этого доклада было и на Хабре. Он ведет интересный блог Preshing on Programming, посвященный в том числе и тонкостям неблокирующего программирования и связанных с ним нюансов C++.
Я бы хотел много статей из его блога перевести для сообщества, но поскольку его записи часто ссылаются одна на другую, выбрать статью для первого перевода достаточно сложно. Я попытался выбрать такую статью, которая бы минимально базировалась на других. Хотя рассматриваемый вопрос достаточно прост, я надеюсь, он все же будет интересен многим, кто начинает знакомиться с многопоточным программированием в C++.
- c
- c++
- c++11
- std::atomic
- параллельное программирование
- многопоточное программирование
- перевод
- C++
- C
- Параллельное программирование
Понимание атомарности в программировании

Атомарность — одно из ключевых понятий в программировании, особенно в контексте многопоточности.
Часто возникают ситуации, когда несколько потоков пытаются одновременно изменить значение одной и той же переменной. Если это происходит без какого-либо контроля, результат может быть непредсказуемым и привести к ошибкам. Например, один поток может прочитать значение переменной, затем другой поток может изменить это значение, а затем первый поток может записать обратно старое значение, тем самым перезаписывая изменения, сделанные вторым потоком.
Вот пример такой ситуации на псевдокоде:
thread1: x = read(variable) x = x + 1 write(variable, x) thread2: y = read(variable) y = y * 2 write(variable, y) Если эти два потока выполняются одновременно и без синхронизации, исходное значение переменной может быть случайно перезаписано одним из потоков, что приведет к неверному итоговому значению.
Здесь и вступает в игру понятие атомарности. Операция считается атомарной, если она выполняется как единое целое без возможности прерывания. Это означает, что если операция является атомарной, она либо полностью выполняется, либо не выполняется вовсе, и никакие другие операции не могут вмешаться в ее выполнение.
В контексте Java, чтение или запись переменной является атомарной операцией, за исключением переменных типа long или double . Это означает, что когда поток читает или записывает значение такой переменной, никакой другой поток не может вмешаться в эту операцию. Это помогает предотвратить вышеупомянутые проблемы с многопоточностью.
Однако стоит помнить, что атомарность операции чтения или записи не гарантирует атомарность более сложных операций, таких как инкрементирование. Для обеспечения атомарности таких операций необходимо использовать специальные синхронизационные механизмы, такие как блокировки или атомарные переменные.