Как парсить сайты с помощью Python? Основы работы с Requests и Selenium
Бывают ситуации, когда нужно автоматизировать сбор и анализ данных из разных источников. Для решения подобных задач применяют парсинг. В этой статье кратко рассказываем, как парсить данные веб-сайтов с помощью Python. Пособие подойдет новичкам и продолжающим — сохраняйте статью в закладки и задавайте вопросы в комментариях.
Дисклеймер: в статье рассмотрена только основная теория. На практике встречаются нюансы, когда нужно, например, декодировать спаршенные данные, настроить работу программы через xPath или даже задействовать компьютерное зрение. Обо всем этом — в следующих статьях, если тема окажется интересной.
Что такое пирсинг?
Парсинг — это процесс сбора, обработки и анализа данных. В качестве их источника может выступать веб-сайт.
Парсить веб-сайты можно несколькими способами — с помощью простых запросов сторонней программы и полноценной эмуляции работы браузера. Рассмотрим первый метод подробнее.
Парсинг с помощью HTTP-запросов
Суть метода в том, чтобы отправить запрос на нужный ресурс и получить в ответ веб-страницу. Ресурсом может быть как простой лендинг, так и полноценная, например, социальная сеть. В общем, все то, что умеет «отдавать» веб-сервер в ответ на HTTP-запросы.
Чтобы сымитировать запрос от реального пользователя, вместе с ним нужно отправить на веб-сервер специальные заголовки — User-Agent, Accept, Accept-Encoding, Accept-Language, Cache-Control и Connection. Их вы можете увидеть, если откроете веб-инспектор своего браузера.
Наиболее подробно о HTTP-запросах, заголовках и их классификации мы рассказали в отдельной статье.
Подготовка заголовков
На самом деле, необязательно отправлять с запросом все заголовки. В большинстве случаев достаточно User-Agent и Accept. Первый заголовок поможет сымитировать, что мы реальный пользователь, который работает из браузера. Второй — укажет, что мы хотим получить от веб-сервера гипертекстовую разметку.
st_accept = «text/html» # говорим веб-серверу, # что хотим получить html # имитируем подключение через браузер Mozilla на macOS st_useragent = «Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15» # формируем хеш заголовков headers = < "Accept": st_accept, "User-Agent": st_useragent >
После формирования заголовков нужно отправить запрос и сохранить страницу из ответа веб-сервера. Это можно сделать с помощью нескольких библиотек: Requests, ScraPy или PySpider.
Requests: получаем страницу по запросу
Для начала работы будет достаточно Requests — он удобнее и проще, чем привычный модуль urllib.
Requests — это библиотека на базе встроенного пакета urllib, которая позволяет легко отправлять различные веб-запросы, а также управлять кукисами и сессиями, авторизацией и автоматической организацией пула соединений.
Для примера попробуем спарсить страницу с курсами в Академии Selectel — это можно сделать за несколько действий:
# импортируем модуль import requests … # отправляем запрос с заголовками по нужному адресу req = requests.get(«https://selectel.ru/blog/courses/», headers) # считываем текст HTML-документа src = req.text print(src)
Пример: парсинг страницы с курсами в Академии Selectel.
Сервер вернет html-страницу, который можно прочитать с помощью атрибута text.
…
Супер — гипертекстовую разметку страницы с курсами получили. Но что делать дальше и как извлечь из этого многообразия полезные данные? Для этого нужно применить некий «парсер для выборки данных».
Интересен Python? Мы собрали самые интересные и популярные запросы разработчиков в одном файле!
Beautiful Soup: извлекаем данные из HTML
Извлечь полезные данные из полученной html-страницы можно с помощью библиотеки Beautiful Soup.
Beautiful Soup — это, по сути, анализатор и конвертер содержимого html- и xml-документов. С помощью него полученную гипертекстовую разметку можно преобразовать в полноценные объекты, атрибуты которых — теги в html.
# импортируем модуль from bs4 import BeautifulSoup … # инициализируем html-код страницы soup = BeautifulSoup(src, ‘lxml’) # считываем заголовок страницы title = soup.title.string print(title) # Программа выведет: Курсы — Блог компании Селектел
Готово. У нас получилось спарсить и напечатать заголовок страницы. Где это можно применить — решать только вам. Например, мы в Selecte на базе Requests и Beautiful Soup разработали парсер данных с Хабра. Он помогает собирать и анализировать статистику по выбранным хабраблогам. Подробнее о решении можно почитать в предыдущей статье.
Проблема парсинга с помощью HTTP-запросов
Бывают ситуации, когда с помощью простых веб-запросов не получается спарсить все данные со страницы. Например, если часть контента подгружается с помощью API и JavaScript. Тогда сайт можно спарсить только через эмуляцию работы браузера.
Парсинг с помощью эмулятора
Для эмуляции работы браузера необходимо написать программу, которая будет как человек открывать нужные веб-страницы, взаимодействовать с элементами с помощью курсора, искать и записывать ценные данные. Такой алгоритм можно организовать с помощью библиотеки Selenium.
Настройка рабочего окружения
1. Установите ChromeDriver — именно с ним будет взаимодействовать Selenium. Если вы хотите, чтобы актуальная версия ChromeDriver подтягивалась автоматически, воспользуйтесь webdriver-manager. Далее импортируйте Selenium и необходимые зависимости.
pip3 install selenium
from selenium import webdriver as wd
2. Инициализируйте ChromeDriver. В качестве executable_path укажите путь до установленного драйвера.
browser = wd.Chrome(«/usr/bin/chromedriver/»)
Теперь попробуем решить задачу: найдем в Академии Selectel статьи о Git.
Задача: работа с динамическим поиском
При переходе на страницу Академии встречает общая лента, в которой собраны материалы для технических специалистов. Они помогают прокачивать навыки и быть в курсе новинок из мира IT.
Но материалов много, а у нас задача — найти все статьи, связанные с Git. Подойдем к парсингу системно и разобьем его на два этапа.
Шаг 1. Планирование
Для начала нужно продумать, с какими элементами должна взаимодействовать наша программа, чтобы найти статьи. Но здесь все просто: в рамках задачи Selenium должен кликнуть на кнопку поиска, ввести поисковый запрос и отобрать полезные статьи.
Теперь скопируем названия классов html-элементов и напишем скрипт!
Шаг 2. Работа с полем ввода
Работа с html-элементами сводится к нескольким пунктам: регистрации объектов и запуску действий, которые будет имитировать Selenium.
. # регистрируем кнопку «Поиск» и имитируем нажатие open_search = browser.find_element_by_class_name(«header_search») open_search.click() # регистрируем текстовое поле и имитируем ввод строки «Git» search = browser.find_element_by_class_name(«search-modal_input») search.send_keys(«Git»)
Осталось запустить скрипт и проверить, как он отрабатывает:
Скрипт работает корректно — осталось вывести результат.
Шаг 3. Чтение ссылок и результат
Вне зависимости от того, какая у вас задача, если вы работаете с Requests и Selenium, Beautiful Soup станет серебряной пулей в обоих случаях. С помощью этой библиотеки мы извлечем полезные данные из полученной гипертекстовой разметки.
from bs4 import BeautifulSoup . # ставим на паузу, чтобы страница прогрузилась time.sleep(3) # загружаем страницу и извлекаем ссылки через атрибут rel soup = BeautifulSoup(browser.page_source, ‘lxml’) all_publications = \ soup.find_all(‘a’, <'rel': 'noreferrer noopener'>)[1:5] # форматируем результат for article in all_publications: print(article[‘href’])
Готово — программа работает и выводит ссылки на статьи о Git. При клике по ссылкам открываются соответветствующие страницы в Академии Selectel.
Какому инструменту для парсинга отдаете предпочтение вы? Поделитесь мнением в комментариях! И подпишитесь на блог Selectel, чтобы не пропустить новые обзоры, новости и кейсы из мира IT и технологий.
Читайте также:
- 5 неприятных случаев при продаже гаджетов
- Как разработать персональный план развития для UX-дизайнера
- 8 багов Midjourney, которые мы нашли за время ее существования
Парсинг сайта вместе с Python и библиотекой Beautiful Soup: простая инструкция в три шага
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.

Иллюстрация: Катя Павловская для Skillbox Media

Антон Яценко
Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Что такое парсинг и зачем он нужен?
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP-запросы, XML и JSON
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
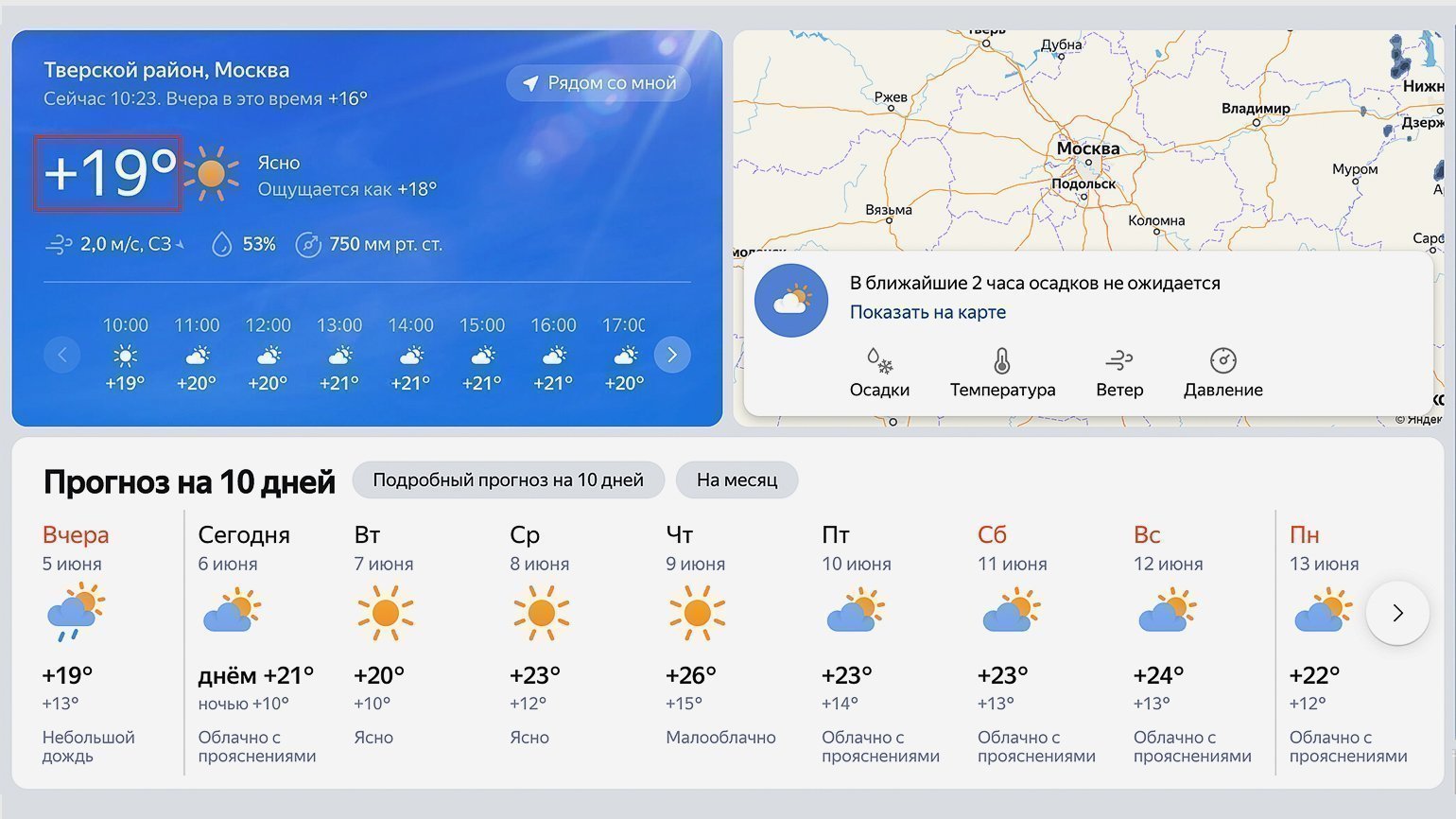
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
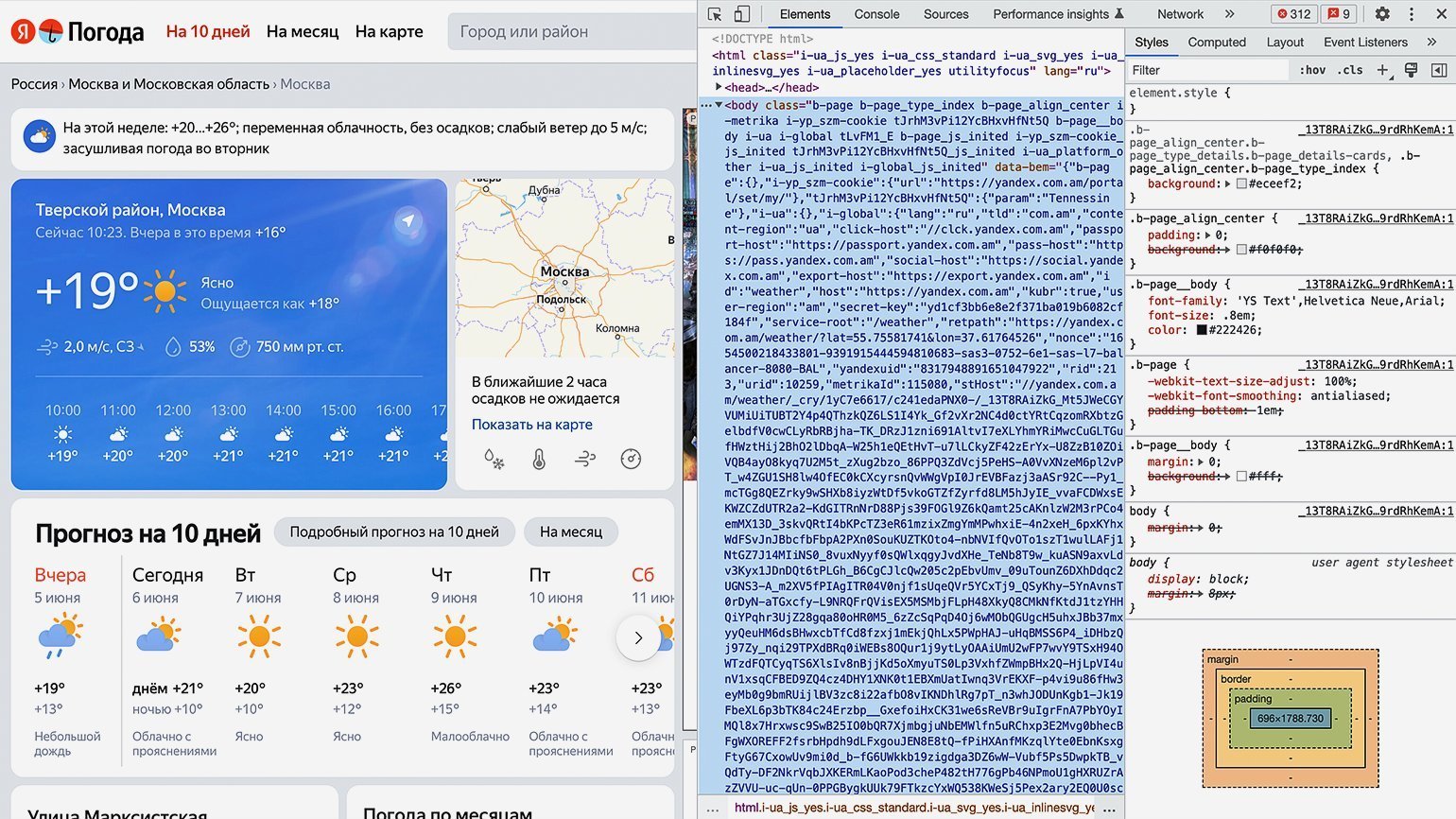
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега . Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
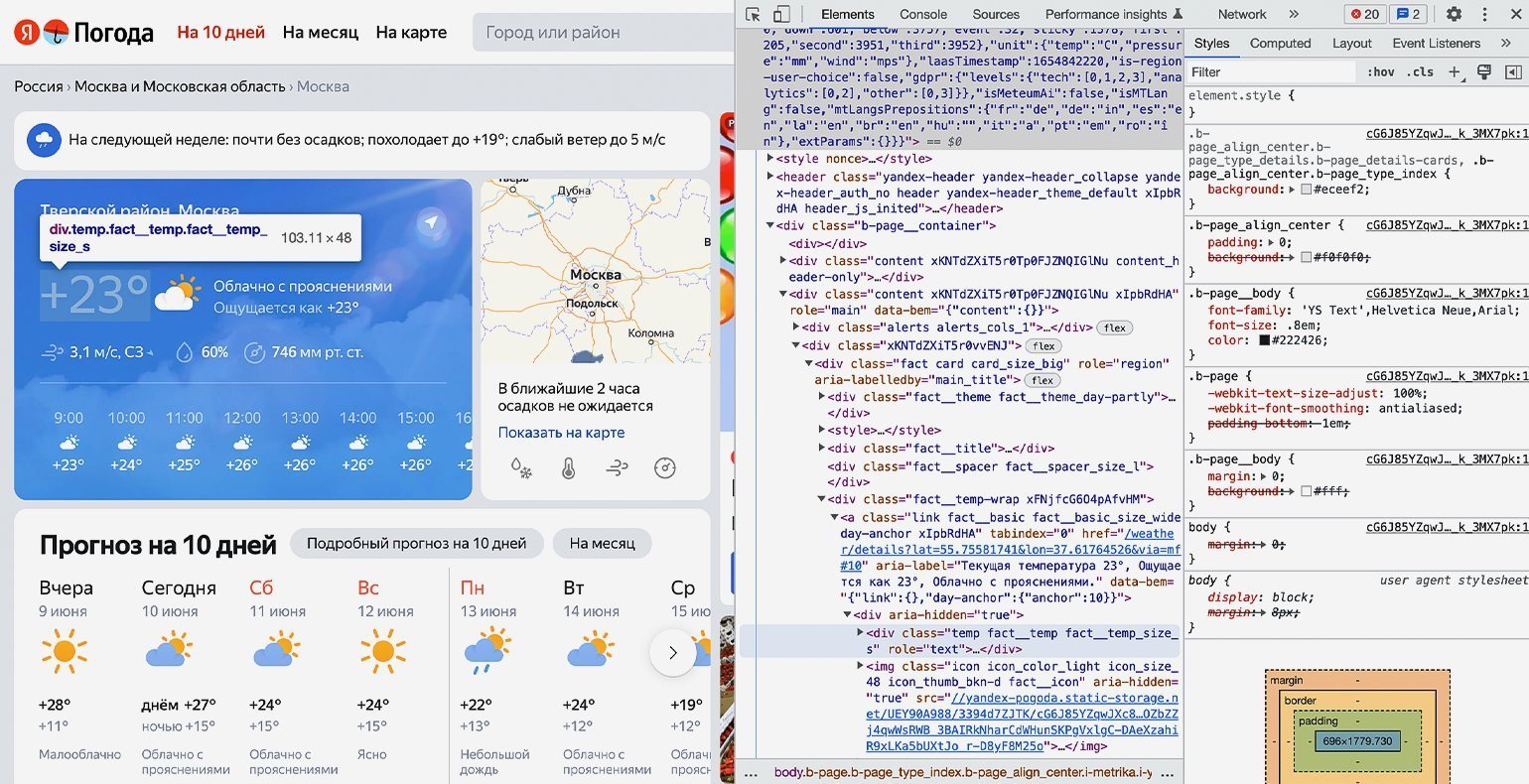
Шаг 3
Пишем код и получаем необходимую информацию
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента . Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это . Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
class="temp__value temp__value_with-unit">+17
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Скрапинг веб-сайтов с помощью Python — мастер-класс для новичков
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Запись вебинара по скрапингу сайтов с помощью Python и библиотеки Beautiful Soup
Парсинг динамических сайтов c помощью Python и библиотеки Selenium
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Запись вебинара по сбору данных с помощью библиотек Selenium и Beautiful Soup
Резюме
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.
Читайте также:
- 3 фреймворка для тестирования на Python: обзор конфигураций
- 5 шаблонов проектирования, которые должен освоить каждый разработчик
- Как происходит модульное тестирование в Python
Как парсить данные с сайта python

Парсинг полученных данных
Извлечь адрес ссылки можно 4 разными способами – с помощью:
- Методов строк.
- Регулярного выражения.
- Запроса XPath.
- Обработки BeautifulSoup.
Рассмотрим все эти способы по порядку.
Методы строк
Это самый трудоемкий способ – для извлечения каждого элемента нужно определить 2 индекса – начало и конец вхождения. При этом к индексу вхождения надо добавить длину стартового фрагмента:
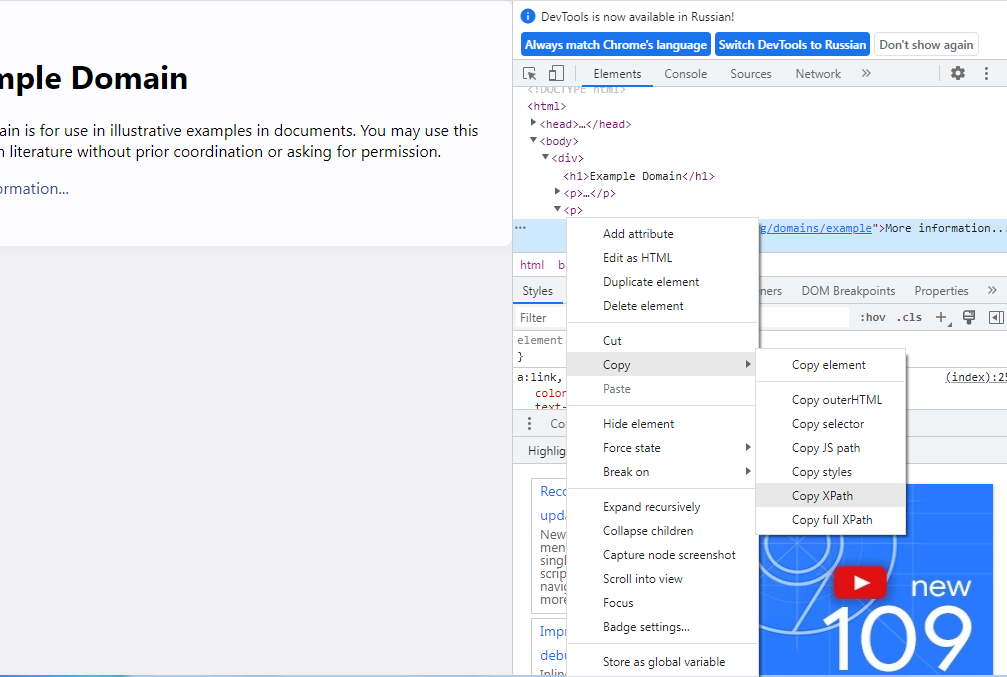
В приведенном выше примере для извлечения ссылки к пути /html/body/div/p[2]/a/ мы добавили указание для получения значения ссылки @href , и индекс [0] , поскольку результат возвращается в виде списка. Если @href заменить на text() , программа вернет текст ссылки, а не сам URL :
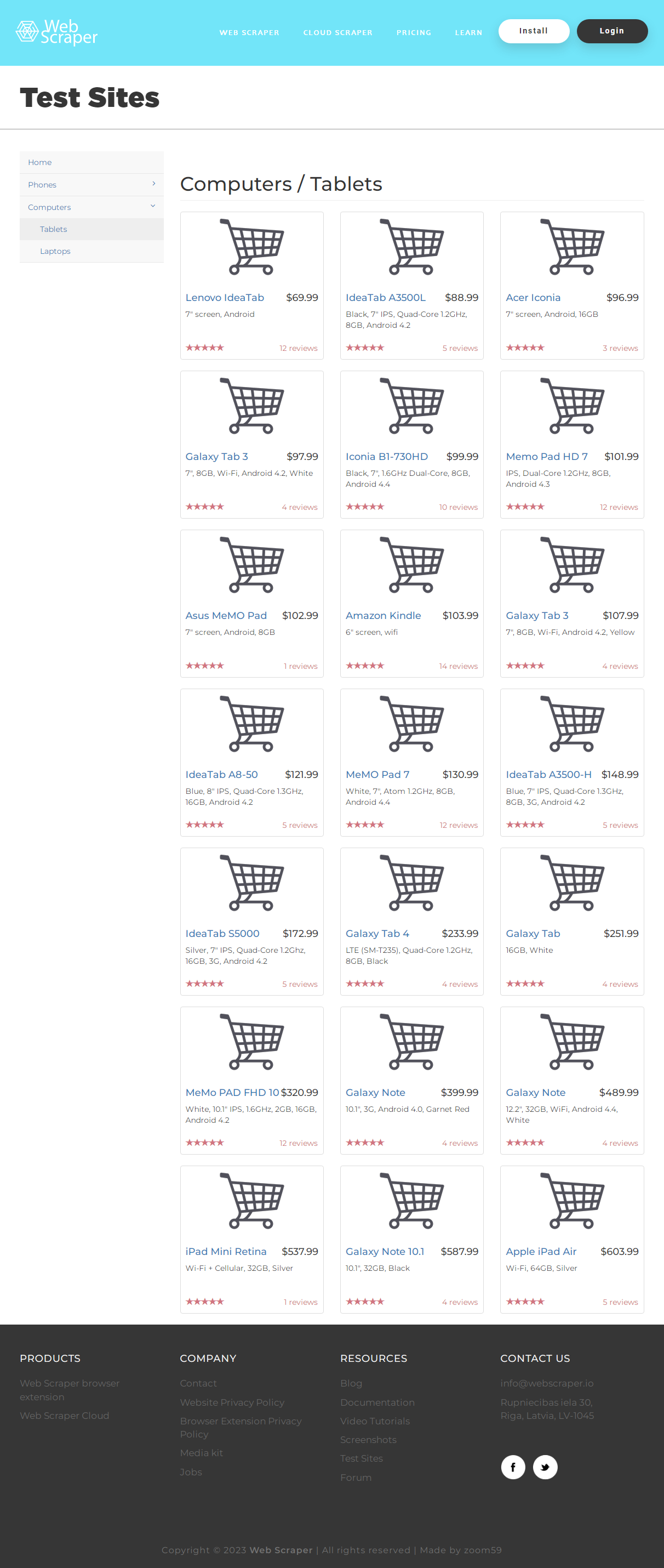
Пока страница не прокручена, полный HTML -код с информацией о планшетах получить невозможно. Для имитации прокрутки мы воспользуемся скриптом ‘window.scrollTo(0, document.body.scrollHeight);’ . Цены планшетов находятся в тегах h 4 класса pull-right price, а названия моделей – в тексте ссылок a класса title. Готовый код выглядит так :
Пример результата:
from bs4 import BeautifulSoup import requests import re url = 'https://www.livelib.ru/book/1002978643-ohotnik-za-tenyu-donato-karrizi' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,'html.parser') sp = soup.find('div', class_='bc-menu__image-wrapper') img_url = re.findall(r'(?:https\:)?//.*\.(?:jpeg)', str(sp))[0] response = requests.get(img_url, headers=headers) if response.status_code == 200: file_name = url.split('-', 1)[1] with open(file_name + '.jpeg', 'wb') as file: file.write(response.content) Задание 6
Напишите программу, которая составляет рейтинг топ-100 лучших триллеров на основе этого списка.
Пример результата:
1. "Побег из Шоушенка", Стивен Кинг - 4.60 2. "Заживо в темноте", Майк Омер - 4.50 3. "Молчание ягнят", Томас Харрис - 4.47 4. "Девушка с татуировкой дракона", Стиг Ларссон - 4.42 5. "Внутри убийцы", Майк Омер - 4.38 . 98. "Абсолютная память", Дэвид Болдаччи - 4.22 99. "Сломанные девочки", Симона Сент-Джеймс - 4.11 100. "Цифровая крепость", Дэн Браун - 3.98 from bs4 import BeautifulSoup import requests url = 'https://www.livelib.ru/genre/%D0%A2%D1%80%D0%B8%D0%BB%D0%BB%D0%B5%D1%80%D1%8B/top' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.content,'html.parser') titles = soup.find_all('a', class_='brow-book-name with-cycle') authors = soup.find_all('a', class_='brow-book-author') rating = soup.find_all('span', class_='rating-value stars-color-orange') i = 1 for t, a, r in zip(titles, authors, rating): print(f'. "", - ') i += 1 Задание 7
Напишите программу, которая составляет топ-20 языков программирования на основе рейтинга популярности TIOBE .
Пример результата:
1. Python: 14.83% 2. C: 14.73% 3. Java: 13.56% 4. C++: 13.29% 5. C#: 7.17% 6. Visual Basic: 4.75% 7. JavaScript: 2.17% 8. SQL: 1.95% 9. PHP: 1.61% 10. Go: 1.24% 11. Assembly language: 1.11% 12. MATLAB: 1.08% 13. Delphi/Object Pascal: 1.06% 14. Scratch: 1.00% 15. Classic Visual Basic: 0.98% 16. R: 0.93% 17. Fortran: 0.79% 18. Ruby: 0.76% 19. Rust: 0.73% 20. Swift: 0.71% import requests from lxml import html url = 'https://www.tiobe.com/tiobe-index/' headers = page = requests.get(url, headers=headers) tree = html.fromstring(page.content) languages, rating = [], [] for i in range(1, 21): languages.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[]/td[5]/text()')[0]) rating.append(tree.xpath(f'//*[@id="top20"]/tbody/tr[]/td[6]/text()')[0]) i = 1 for l, r in zip(languages, rating): print(f'. : ') i += 1 Задание 8
Напишите программу для получения рейтинга 250 лучших фильмов по версии IMDb. Названия должны быть на русском языке.
Пример результата:
1. Побег из Шоушенка, (1994), 9,2 2. Крестный отец, (1972), 9,2 3. Темный рыцарь, (2008), 9,0 . 248. Аладдин, (1992), 8,0 249. Ганди, (1982), 8,0 250. Танцующий с волками, (1990), 8,0 import requests from lxml import html url = 'https://www.imdb.com/chart/top/' headers = page = requests.get(url, headers=headers) tree = html.fromstring(page.content) movies, year, rating = [], [], [] for i in range(1, 251): movies.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[2]/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[2]/span/text()')[0]) rating.append(tree.xpath(f'//*[@id="main"]/div/span/div/div/div[3]/table/tbody/tr[]/td[3]/strong/text()')[0]) i = 1 for m, y, r in zip(movies, year, rating): print(f'. , , ') i += 1 Задание 9
Напишите программу, которая сохраняет в текстовый файл данные о фэнтези фильмах с 10 первых страниц соответствующего раздела IMDb . Если у фильма/сериала еще нет рейтинга, следует указать N / A .
Ожидаемый результат в файле fantasy . txt – 500 записей:
Мандалорец, (2019– ), 8,7 Всё везде и сразу, (2022), 8,0 Атака титанов, (2013–2023), 9,0 Peter Pan & Wendy, (2023), N/A Игра престолов, (2011–2019), 9,2 . Шрэк 3, (2007), 6,1 Кунг-фу Панда 3, (2016), 7,1 Смерть ей к лицу, (1992), 6,6 Исход: Цари и боги, (2014), 6,0 Кошмар на улице Вязов 3: Воины сна, (1987), 6,6 import requests import mechanicalsoup from lxml import html import time url = 'https://www.imdb.com/search/title/?genres=fantasy' headers = browser = mechanicalsoup.StatefulBrowser() j = 51 for _ in range(10): browser.open(url) page = requests.get(url, headers=headers) tree = html.fromstring(page.content) titles, year, rating = [], [], [] for i in range(1, 51): if tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/p[1]/b/text()') != []: titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/span[2]/text()')[0]) rating.append('N/A') else: titles.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/a/text()')[0]) year.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/h3/span[2]/text()')[0]) rating.append(tree.xpath(f'//*[@id="main"]/div/div[3]/div/div[]/div[3]/div/div[1]/strong/text()')[0]) with open('fantasy.txt', 'a', encoding='utf-8') as file: for t, y, r in zip(titles, year, rating): file.write(f', , \n') time.sleep(2) lnk = browser.follow_link('start=' + str(j)) url = browser.url j += 50 Задание 10
Напишите программу для получения главных новостей (на русском) с портала Habr. Каждый заголовок должен сопровождаться ссылкой на полный текст новости.
Пример вывода:
Bethesda назвала дату релиза Starfield на ПК, Xbox Series и Xbox Game Pass — 6 сентября 2023 года https://habr.com/ru/news/t/721148/ Honda запатентовала съёмные подушки безопасности для мотоциклистов https://habr.com/ru/news/t/721142/ . Microsoft увольняет 689 сотрудников из своих офисов в Сиэтле https://habr.com/ru/news/t/721010/ «Ъ»: в России образовались большие запасы бытовой техники из-за низкого спроса https://habr.com/ru/news/t/721006/ from bs4 import BeautifulSoup import requests url = 'https://habr.com/ru/news/' headers = res = requests.get(url, headers=headers) soup = BeautifulSoup(res.content,'html.parser') articles = soup.find_all('a', class_='tm-article-snippet__title-link') for a in articles: print(f'\nhttps://habr.com') Заключение
Мы рассмотрели основные приемы работы с главными Python -инструментами для скрапинга и парсинга. Способы извлечения и обработки данных варьируются от сайта к сайту – в некоторых случаях эффективнее использование XPath , в других – разбор с BeautifulSoup , а иногда может потребоваться применение регулярных выражений.
В следующей главе приступим к изучению основ ООП (объектно-ориентированного программирования).
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
- Регулярные выражения
- Основы скрапинга и парсинга
- Основы ООП – инкапсуляция и наследование
- Основы ООП – абстракция и полиморфизм
- Графический интерфейс на Tkinter
- Основы разработки игр на Pygame
- Основы работы с SQLite
- Основы веб-разработки на Flask
- Основы работы с NumPy
- Основы анализа данных с Pandas
Скрапинг веб-сайтов на Python — пошаговое руководство
Научитесь парсить веб-страницы с помощью Python, чтобы быстро собирать данные с нескольких сайтов с экономией времени и усилий.
3 min read
Antonello Zanini

Узнайте, как выполнять веб-скрапинг с помощью Python, чтобы быстро собирать данные с различных сайтов, экономя время и силы.
Веб-скрапинг — извлечение данных с сайтов в интернете. В частности, парсер —инструмент, позволяющий осуществлять веб-скрапинг. Python является одним из самых простых языков программирования и содержит большое количество библиотек для веб-скрапинга. Это делает его идеальным вариантом для парсинга сайтов. Скрипт для веб-скрапинга на Python требует относительно небольшого количества кода!
В этом пошаговом руководстве вы узнаете, как создать простой парсер на языке Python. Это приложение будет обходить весь сайт, извлекать данные с каждой его страницы и экспортировать их в CSV-файл. Данное руководство поможет вам понять, какие библиотеки для сбора данных на языке Python являются лучшими, какие из них следует взять на вооружение и как именно их использовать. Следуйте этому пошаговому руководству и узнайте, как создать Python-скрипт для веб-скрапинга.
Требования
Чтобы создать парсер Python, вам необходимы:
Обратите внимание, что pip по умолчанию включен в состав Python версии 3.4 и выше. Поэтому устанавливать его вручную не требуется. Если на вашем компьютере нет Python, следуйте приведенному ниже руководству для вашей операционной системы
macOS
Раньше компьютеры Mac поставлялись с предустановленным Python 2.7, но теперь это уже не так, поскольку эта версия устарела.
Если вам нужна последняя версия Python, ее необходимо установить вручную. Для этого загрузите программу установки, дважды щелкните по ней, чтобы запустить, и следуйте указаниям мастера установки.
Windows
Загрузите программу установки Python и запустите ее. Во время работы мастера установки убедитесь, что отмечен флажок «Добавить python.exe в PATH», как показано ниже:
Таким образом, Windows будет автоматически распознавать команды python и pip в терминале. Напомним, что pip — менеджер пакетов для Python.
Linux
В большинстве дистрибутивов Linux Python уже предустановлен, однако речь может идти не о самой последней версии. Команда для установки или обновления Python в Linux зависит от менеджера пакетов. В дистрибутивах Linux на базе Debian выполните команду:
sudo apt-get install python3
Независимо от используемой ОС, откройте терминал и убедитесь, что Python успешно установлен:
python --version
В результате должно получиться что-то вроде этого:
Python 3.11.0
Теперь все готово для создания вашего первого парсера Python. Но сначала вам нужна библиотека веб-скрапинга Python!
Лучшие библиотеки веб-скрапинга Python
Можно создать скрипт веб-парсера с нуля с помощью ванильного Python, но это не идеальное решение. В конце концов, Python известен своим обширным выбором пакетов и, в частности, есть масса библиотек для веб-скрапинга. Пришло время рассмотреть наиболее важные из них!
Requests
Библиотека Requests позволяет выполнять HTTP-запросы на языке Python. Она упрощает отправку HTTP-запросов, особенно по сравнению со стандартной библиотекой Python HTTP. Requests играет ключевую роль в проекте для веб-скрапинга на Python. Это связано с тем, что для сбора данных, содержащихся на странице, необходимо сначала получить их с помощью HTTP-запроса GET. Кроме того, возможно, придется выполнить и другие HTTP-запросы к серверу целевого сайта.
Установить Requests можно с помощью следующей команды pip:
pip install requestsBeautiful Soup
Python-библиотека Beautiful Soup упрощает сбор информации со страниц. В частности, Beautiful Soup работает с любым HTML- или XML-парсером и предоставляет все необходимое для итерации, поиска и модификации абстрактного синтаксического дерева. Обратите внимание, что Beautiful Soup можно использовать вместе с html.parser — парсером, входящим в стандартную библиотеку Python и позволяющим парсить текстовые HTM-файлы. В частности, Beautiful Soup помогает обходить DOM и извлекать из него нужные данные.
Установить Beautiful Soup с помощью программы pip можно следующим образом:
pip install beautifulsoup4Selenium
Selenium — современная система автоматизированного тестирования с открытым исходным кодом, позволяющая выполнять операции на странице в браузере. Другими словами, с его помощью можно поручить браузеру выполнение определенных задач. Обратите внимание, что Selenium также можно использовать в качестве библиотеки для веб-скрапинга благодаря его возможностям «безголового» браузера. Если вы не знакомы с этим понятием, то речь идет о веб-браузере, работающем без графического интерфейса пользователя (GUI). Если Selenium настроен в безголовом режиме, он будет запускать управляемый браузер, образно говоря «закулисно».
Интернет-страницы, посещаемые в Selenium, отображаются в реальном браузере. Таким образом, Selenium поддерживает веб-парсинг страниц, которые используют JavaScript для рендеринга или получения данных. Selenium предоставляет все необходимое для создания парсера, не требуя использования других библиотек. Установить его можно с помощью следующей команды pip:
pip install seleniumСоздание парсера на Python
Теперь давайте узнаем, как создать веб-парсер на языке Python. Вот как выглядит целевой сайт:
Это сайт Quotes to Scrape — «песочница» для веб-скрапинга, содержащая постраничный список цитат.
Цель этого урока — научиться извлекать из него данные: текст, автора и список тегов для каждой цитаты. Затем полученная информация будет преобразована в CSV-формат.
Как видите, Quotes to Scrape — это не что иное, как песочница для парсинга веб-страниц. Сайт содержит разбитый на страницы список цитат. Парсер Python, который вы собираетесь создать, извлечет все цитаты на каждой странице, и предоставит их в виде данных CSV.
Шаг 1: Выбор правильных библиотек для веб-скрапинга на языке Python
Прежде всего, необходимо понять, какие библиотеки для веб-скрапинга на языке Python лучше всего подходят для достижения поставленной цели. Для этого посетите целевой сайт в браузере. Щелкните правой кнопкой мыши по странице и выберите «Просмотреть код». Откроется окно браузера DevTools. Перейдите на вкладку «Сеть» и перезагрузите страницу.
Как вы заметили, целевой сайт не выполняет никаких Fetch/XHR-запросов.
Это означает, что Quotes to Scrape не использует JavaScript для динамического извлечения данных. Другими словами, страницы, возвращаемые сервером, уже содержат интересующие данные. Именно так происходит на сайтах со статическим контентом.
Поскольку целевой сайт не использует JavaScript для вывода страницы или получения данных, Selenium для его сканирования не нужен. Вы можете использовать его, но это не обязательно. Причина в том, что Selenium открывает страницы в браузере. Поскольку это требует времени и ресурсов, Selenium снижает производительность. Этого можно избежать, используя Beautiful Soup вместе с Requests.
Теперь, когда вы поняли, какие библиотеки для веб-скрапинга на Python следует использовать, узнайте, как создать простой парсер с помощью Beautiful Soup!
Шаг 2: Инициализация проекта Python
Прежде чем написать первую строку кода, необходимо настроить проект для веб-скрапинга на языке Python. Технически для этого достаточно одного файла .py. Однако использование продвинутой IDE (Integrated Development Environment) облегчит вам работу c кодом. Здесь мы рассмотрим настройку Python-проекта в PyCharm, но подойдет и любая другая IDE для Python.
Откройте PyCharm и выберите «File > New Project… ». Во всплывающем окне «Новый проект» выберите «Чистый Python» и создайте новый проект.
Например, вы можете назвать свой проект python-web-scraper. Нажмите кнопку «Создать», и вы получите доступ к своему пустому Python-проекту. По умолчанию PyCharm инициализирует файл main.py. Для наглядности переименуйте его в scraper.py. Вот как теперь будет выглядеть ваш проект:
PyCharm автоматически инициализирует Python-файл со стандартным кодом. Удалите его, чтобы начать писать код с нуля.
Далее необходимо установить зависимости проекта. Установить Requests и Beautiful Soup можно, выполнив в терминале следующую команду:
pip install requests beautifulsoup4Это приведет к одновременной установке двух библиотек. Дождитесь завершения процесса установки. Теперь вы готовы использовать Beautiful Soup и Requests для создания веб-краулера и парсера на Python. Убедитесь в импорте двух библиотек, добавив следующие строки в верхнюю часть файла сценария scraper.py:
import requests from bs4 import BeautifulSoupPyCharm подсветит эти две строки серым цветом, потому что библиотеки не используются в коде. Если он подчеркнет их красным цветом, значит, что-то пошло не так в процессе установки. В этом случае попробуйте установить их снова.
Теперь вы готовы приступить к написанию логики веб-скрапинга на языке Python.
Шаг 2: Подключение к целевому URL
Первое, что необходимо сделать в веб-парсере — подключиться к целевому сайту. Для этого необходимо получить полный URL-адрес страницы из браузера. Обязательно скопируйте также секцию http:// или https:// HTTP-протокола. В данном случае это полный URL целевого сайта:
https://quotes.toscrape.comТеперь вы можете использовать запросы для загрузки страницы с помощью следующей строки кода:
page = requests.get('https://quotes.toscrape.com')Эта строка просто присваивает результат работы метода request.get() переменной page. Закулисно request.get() выполняет GET-запрос с использованием URL, переданного в качестве параметра. Затем он возвращает объект Response, содержащий ответ сервера на HTTP-запрос.
Если HTTP-запрос выполнен успешно, page.status_code будет содержать статус 200. Код ответа HTTP 200 OK означает, что HTTP-запрос был выполнен успешно. Статус HTTP 4xx или 5xx означает ошибку. Она может произойти по целому ряду причин, но следует помнить, что большинство сайтов блокируют запросы, не содержащие корректного User-Agent. Этот специальный заголовок представляет собой строку, характеризующую версию приложения и операционной системы, с которой поступил запрос. Подробнее о User-Agent для веб-скрапинга.
Задать допустимый заголовок User-Agent в запросах можно следующим образом:
headers = < 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' >page = requests.get('https://quotes.toscrape.com', headers=headers
Requests теперь будет выполнять HTTP-запрос с заголовками, переданными в качестве параметра.
На что следует обратить внимание, так это на свойство page.text . В нем будет содержаться HTML-документ, возвращенный сервером в строковом формате. Передайте свойство text в программу Beautiful Soup, чтобы извлечь данные со страницы. Давайте узнаем, как это сделать.
На что следует обратить внимание, так это на свойство page.text. В нем будет содержаться HTML-документ, возвращенный сервером в строковом формате. Передайте свойство text в программу Beautiful Soup для парсинга страницы. Как это сделать, узнаем на следующем шаге!
Шаг 3: Парсинг содержимого HTML-документа
Чтобы выполнить парсинг HTML-документа, возвращенного сервером после GET-запроса, передайте конструктору BeautifulSoup() файл page.text:
soup = BeautifulSoup(page.text, 'html.parser')Второй параметр задает парсер, который будет использовать Beautiful Soup.
Теперь переменная soup содержит объект BeautifulSoup. Это древовидная структура, созданная в результате разбора HTML-документа, содержащегося в page.text, с помощью встроенного в Python парсера html.parser.
Теперь вы можете использовать его для выбора нужного HTML-элемента на странице. Смотрите, как!
Шаг 4: Выделение HTML-элементов с помощью Beautiful Soup
Beautiful Soup предлагает несколько подходов к выбору элементов в DOM. Отправными точками являются:
- find(): Возвращает первый HTML-элемент, соответствующий введенному селектору, если таковой вообще имеется.
- find_all(): Возвращает список HTML-элементов, удовлетворяющих условию селектора, переданному в качестве параметра.
В зависимости от параметров, передаваемых этим двум методам, они будут искать элементы на странице по-разному. В частности, можно выбрать элементы HTML:
# get all elements # on the page h1_elements = soup.find_all('h1')
# get the element with main_title_element = soup.find(id='main-title')
# find the footer element # based on the text it contains footer_element = soup.find(text=)
# find the email input element # through its "name" attribute email_element = soup.find(attrs=)
# find all the centered elements # on the page centered_element = soup.find_all(class_='text-center')
Объединение этих методов позволяет извлекать данные из любого HTML-элемента на странице. Обратите внимание на приведенный ниже пример:
# get all "li" elements # in the ".navbar" element soup.find(class_='navbar').find_all('li')
Чтобы упростить работу, в Beautiful Soup можно также использовать метод select(). Он позволяет применять CSS-селектор напрямую:
# get all "li" elements # in the ".navbar" element soup.select('.navbar > li')
Обратите внимание, что на момент написания статьи селекторы XPath не поддерживаются.
Важно усвоить, что для извлечения данных с интернет-страницы необходимо сначала определить интересующие вас HTML-элементы. В частности, важно определить стратегию выбора тех, которые содержат требующие извлечения данные.
Для этого можно воспользоваться предлагаемыми браузером инструментами для разработчиков. В браузере Chrome щелкните правой кнопкой мыши на интересующем вас HTML-элементе и выберите опцию «Просмотреть код». В данном случае это нужно сделать на элементе цитаты.
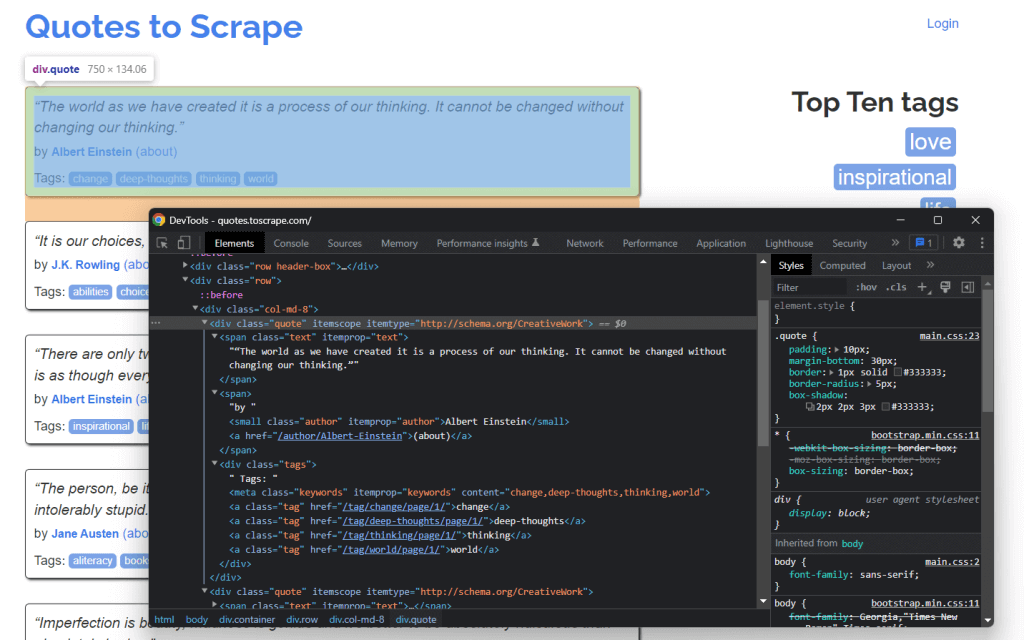
- Текст цитаты в HTML-элементе
- Автор цитаты в HTML-элементе
- Список тегов в элементе , каждый из которых содержится в HTML-элементе .
В частности, вы можете извлечь эти данные, используя следующие селекторы CSS в .quote:
Шаг 5: Извлечение данных из элементов
Во-первых, необходима структура данных, в которой будет храниться полученная благодаря парсингу информация. Для этого инициализируем переменную массива.
quotes = []Затем с помощью Soup извлекаем из DOM элементы цитаты, применив определенный ранее CSS-селектор .quote:
quote_elements = soup.find_all('div', class_='quote')Метод find_all() вернет список всех HTML-элементов
, идентифицированных классом quote. Итерация по списку цитат для получения данных о них приведена ниже:
for quote_element in quote_elements: # extract the text of the quote text = quote_element.find('span', class_='text').text # extract the author of the quote author = quote_element.find('small', class_='author').text # extract the tag HTML elements related to the quote tag_elements = quote_element.select('.tags .tag') # store the list of tag strings in a list tags = [] for tag_element in tag_elements: tags.append(tag_element.text)
Метод Beautiful Soup find() получит единственный интересующий элемент HTML. Поскольку строк тегов, которые связанны с цитатой, несколько, их следует хранить в списке.
Затем можно преобразовать полученные данные в словарь и добавить его в список цитат следующим образом:
quotes.append( < 'text': text, 'author': author, 'tags': ', '.join(tags) # merge the tags into a "A, B, . Z" string >)
Хранение данных в структурированном словаре облегчает доступ к ним и их понимание.
Отлично! Вы только что увидели, как извлечь все данные с одной страницы! Однако не забывайте, что у целевого сайта их гораздо больше. Пришло время научиться обходить весь сайт!
Шаг 6: Реализация логики поиска данных
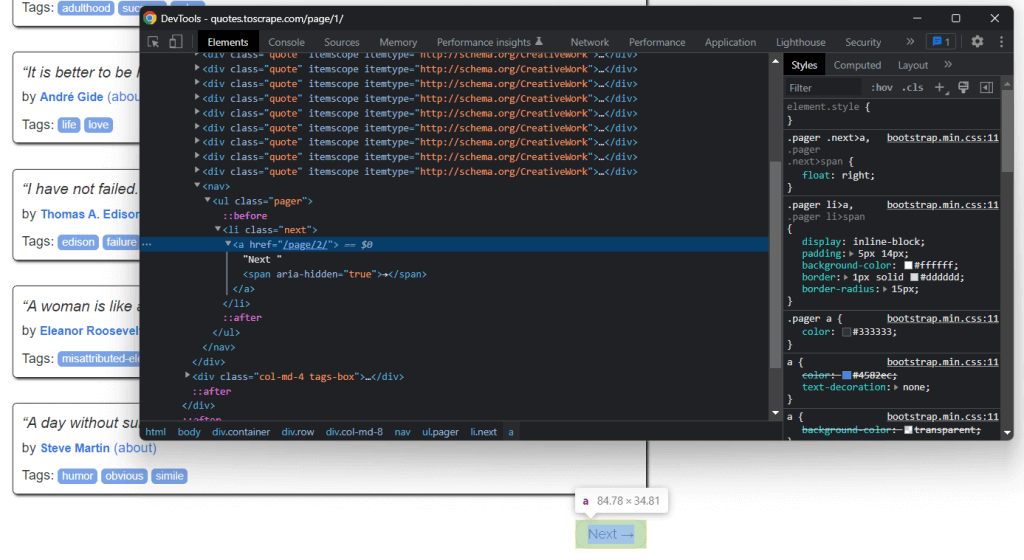
Переходя по ссылке, содержащейся в этом HTML-элементе, можно легко перемещаться по всему сайту. Итак, начните с главной страницы и посмотрите, как перейти на каждую страницу, из которых состоит целевой сайт. Для этого достаточно найти HTML-элемент .next и извлечь из него относительную ссылку на следующую страницу.
Реализовать логику по обходу всего сайта можно следующим образом:
# the URL of the home page of the target website base_url = 'https://quotes.toscrape.com' # retrieve the page and initializing soup. # get the "Next →" HTML element next_li_element = soup.find('li', class_='next') # if there is a next page to scrape while next_li_element is not None: next_page_relative_url = next_li_element.find('a', href=True)['href'] # get the new page page = requests.get(base_url + next_page_relative_url, headers=headers) # parse the new page soup = BeautifulSoup(page.text, 'html.parser') # scraping logic. # look for the "Next →" HTML element in the new page next_li_element = soup.find('li', class_='next')Цикл where выполняет итерацию по каждой странице до тех пор, пока не окажется на последней странице. Он извлекает относительный URL следующей страницы и использует его для создания полноценного URL-адреса для дальнейшего парсинга. Новая страница загружается, выполняется ее веб-скрапинг и та же логика повторяется снова.
Теперь вы знаете, как парсить многостраничный сайт. Осталось научиться преобразовывать извлеченные данные в более удобный формат, например CSV.
Шаг 7: Извлечение полученных данных в CSV-файл
Рассмотрим, как экспортировать список словарей, содержащих извлеченные данные, в CSV-файл. Для этого понадобится следующий код:
import csv # scraping logic. # reading the "quotes.csv" file and creating it # if not present csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='') # initializing the writer object to insert data # in the CSV file writer = csv.writer(csv_file) # writing the header of the CSV file writer.writerow(['Text', 'Author', 'Tags']) # writing each row of the CSV for quote in quotes: writer.writerow(quote.values()) # terminating the operation and releasing the resources csv_file.close()Этот фрагмент записывает данные о цитатах, содержащиеся в списке словарей, в файл quotes.csv . Обратите внимание, что csv является частью стандартной библиотеки Python. Поэтому его можно импортировать и использовать без установки каких-либо дополнительных зависимостей.
По сути, необходимо просто создать CSV-файл с помощью функции open(). Затем заполнить его функцией writerow() из объекта Writer библиотеки csv. В результате каждый словарь цитат будет записан в виде строки в CSV-формате.
Вы перешли от необработанных данных, содержащихся на сайте, к полуструктурированным данным, хранящимся в CSV-файле. Процесс извлечения данных завершен, и теперь вы можете взглянуть на свой полноценный Python-парсер.
Шаг 8: Собираем все вместе
Вот как выглядит готовый скрипт на Python для сбора данных:
import requests from bs4 import BeautifulSoup import csv def scrape_page(soup, quotes): # retrieving all the quote HTML element on the page quote_elements = soup.find_all('div', class_='quote') # iterating over the list of quote elements # to extract the data of interest and store it # in quotes for quote_element in quote_elements: # extracting the text of the quote text = quote_element.find('span', class_='text').text # extracting the author of the quote author = quote_element.find('small', class_='author').text # extracting the tag HTML elements related to the quote tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag') # storing the list of tag strings in a list tags = [] for tag_element in tag_elements: tags.append(tag_element.text) # appending a dictionary containing the quote data # in a new format in the quote list quotes.append( < 'text': text, 'author': author, 'tags': ', '.join(tags) # merging the tags into a "A, B, . Z" string >) # the url of the home page of the target website base_url = 'https://quotes.toscrape.com' # defining the User-Agent header to use in the GET request below headers = < 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' ># retrieving the target web page page = requests.get(base_url, headers=headers) # parsing the target web page with Beautiful Soup soup = BeautifulSoup(page.text, 'html.parser') # initializing the variable that will contain # the list of all quote data quotes = [] # scraping the home page scrape_page(soup, quotes) # getting the "Next →" HTML element next_li_element = soup.find('li', class_='next') # if there is a next page to scrape while next_li_element is not None: next_page_relative_url = next_li_element.find('a', href=True)['href'] # getting the new page page = requests.get(base_url + next_page_relative_url, headers=headers) # parsing the new page soup = BeautifulSoup(page.text, 'html.parser') # scraping the new page scrape_page(soup, quotes) # looking for the "Next →" HTML element in the new page next_li_element = soup.find('li', class_='next') # reading the "quotes.csv" file and creating it # if not present csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='') # initializing the writer object to insert data # in the CSV file writer = csv.writer(csv_file) # writing the header of the CSV file writer.writerow(['Text', 'Author', 'Tags']) # writing each row of the CSV for quote in quotes: writer.writerow(quote.values()) # terminating the operation and releasing the resources csv_file.close()Как здесь показано, веб-парсер можно создать менее чем за 100 строк кода. Этот скрипт Python способен обойти весь сайт, автоматически извлечь его данные и экспортировать их в CSV-файл.
Поздравляем! Вы только что узнали, как создать веб-парсер на Python с помощью Requests и Beautiful Soup!
Шаг 9: Запуск скрипта для веб-скрапинга на языке Python
Если вы являетесь пользователем PyCharm, запустите скрипт, нажав кнопку ниже:

Или запустите следующую команду Python в терминале внутри каталога проекта:
python scraper.pyДождитесь окончания процесса, и вы получите доступ к файлу quotes.csv. Откройте его. Он должен содержать следующие данные:
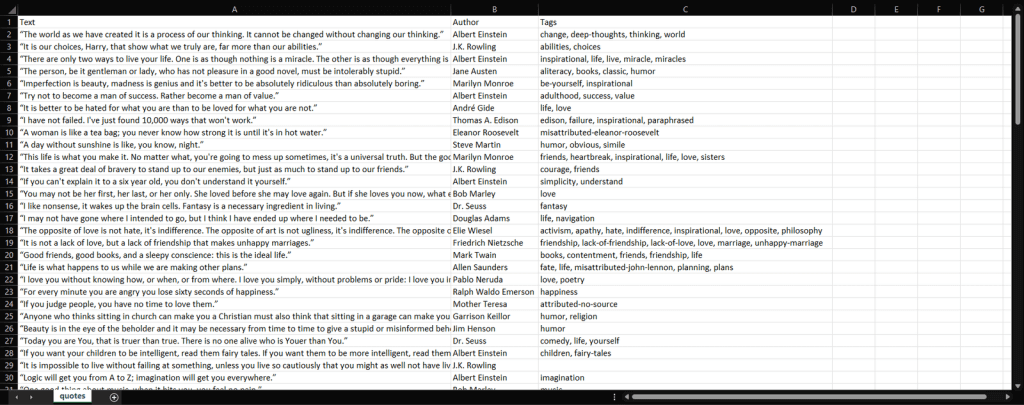
Теперь у вас есть все 100 цитат, содержащихся на целевом сайте, в одном файле и в удобном для чтения формате!
Вывод
Из этого руководства вы узнали, как выполнять веб-скрапинг с помощью Python, что в этом случае необходимо для начала работы и какие библиотеки Python для парсинга являются лучшими. Затем на реальном примере мы показали, как использовать Beautiful Soup и Requests для создания приложения для веб-скрапинга. Как вы могли убедиться, для создания скрипта для парсинга на языке Python нужно не так уж и много кода.
Однако веб-скрапинг сопряжен с целым рядом проблем. В частности, все большую популярность приобретают технологии защиты от ботов и парсинга. Именно поэтому вам необходим современный инструмент для веб-скрапинга, который предлагает компания Bright Data.
Чтобы избежать проблем с блокировками, мы также рекомендуем выбрать прокси с учетом ваших потребностей из большого ассортимента прокси-сервисов Bright Data.
FAQ
Является ли Python подходящим языком для веб-скрапинга? Python не только отлично подходит для веб-скрапинга, но и считается одним из лучших для этого языков. Это объясняется его удобочитаемостью и относительной простотой. Кроме того, он имеет одно из самых больших сообществ в мире IT и предлагает широкий выбор библиотек и инструментов, предназначенных для парсинга. Является ли веб-скрапинг и краулинг частью науки о данных? Да, веб-скрапинг и краулинг являются частью большой области науки о данных. Скрапинг/кроулинг служит основой для всех других побочных продуктов, которые могут быть получены из структурированных и неструктурированных данных. К ним относятся аналитика, алгоритмические модели/результаты, инсайты и «применимые знания». Как с помощью Python получить с сайта конкретные данные? Веб-скрапинг данных с сайта с помощью Python подразумевает изучение страницы целевого URL, определение данных, которые необходимо извлечь, написание и выполнение кода извлечения данных, а также сохранение полученной информации в нужном формате. Как создать веб-парсер на Python? Первым шагом в создании веб-парсера с помощью Python является использование строковых методов для анализа сайта, затем сбор данных с него с использованием HTML-парсера и, наконец, взаимодействие с необходимыми формами и компонентами интернет-ресурса.