Метод последовательности index() в Python
Индекс первого появления элемента в последовательности
Синтаксис:
sequence.index(x[, i[, j]])
Параметры:
- sequence — последовательность. Могут быть list , str , tuple и т. д.
- x — произвольный объект, удовлетворяющий любым ограничениям типа и значения, наложенным на последовательности sequence .
- i и j — целые числа
Результат:
- целое число, индекс первого вхождения
Описание:
Метод позволяет узнать индекс первого вхождения указанного элемента в последовательность.Результатом будет индекс первого вхождения элемента x в последовательность sequence .
- Если задан индекс i то первое вхождение будет искаться после индекса i .
- Если заданы индексы i и j , то первое вхождение будет искаться после индекса i и перед индексом j .
Метод sequence.index() вызывает ValueError , когда элемент x не найден в последовательности s . Не все реализации языка Python поддерживают передачу дополнительных аргументов i и j . Эти аргументы позволяют эффективно искать в подразделах последовательности.
Эта операция поддерживаются большинством типов последовательностей, как изменяемых, так и неизменяемых.
Примечание: Множества set и frozenset не поддерживает индексирование элементов, т.к. это неупорядоченная коллекция без повторяющихся элементов.
Примеры получения индекса первого появления элемента.
>>> x = ['a', 'e', 'i', 'o', 'i', 'u'] >>> x.index('e') # 1 >>> x = 'HelloWorld' >>> x.index('l') # 2 >>> x.index('or') # 6 >>> x.index('l', 4) # 8 >>> x.index('l', 4, 8) # Traceback (most recent call last): # File "", line 1, in # ValueError: substring not found
Передача дополнительных аргументов i и j примерно эквивалентна использованию sequence[i: j].index(x) . Этот пример вернет индекс первого вхождения относительно начала среза sequence[i: j] , а не с начала последовательности sequence .
>>> x = ['a', 'e', 'i', 'o', 'i', 'u'] >>> x[2:].index('i') # 0
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Проверка существования значения в последовательности Python
- Конкатенация (сложение) последовательностей
- Увеличение последовательности в N раз
- Получение значения элемента по индексу sequence[i]
- Получение среза sequence[i:j]
- Получение среза с заданным шагом sequence[i:j:k]
- Вычисление длины последовательности
- Наименьшее значение последовательности Python
- Наибольшее значение в последовательности Python
- Метод последовательности index()
- Метод последовательности count()
Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
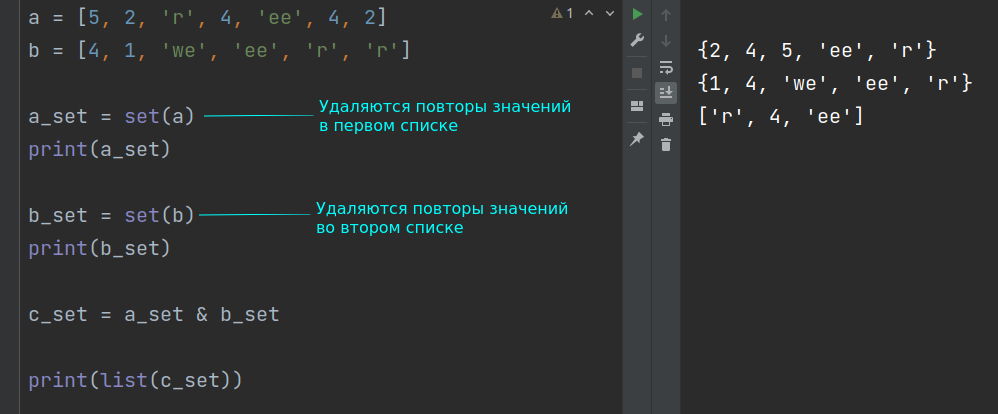
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
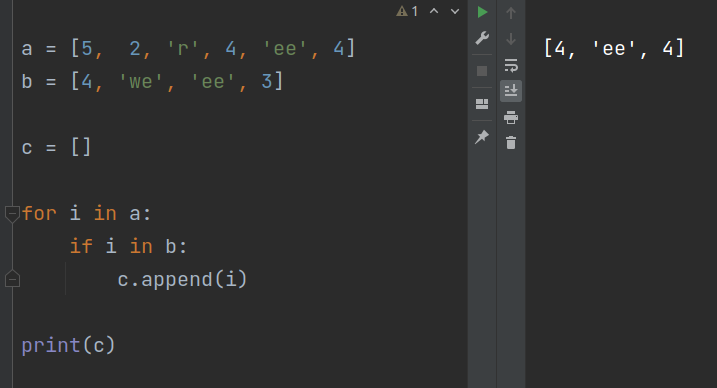
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python
Получение значения элемента по его индексу
Результатом будет значение i -го элемента последовательности sequence . Эту операцию еще называют «взятие элемента индексу».
- Индексирование последовательностей всегда начинается с 0 нуля, это означает, что бы получить значение первого элемента последовательности, например списка, нужно выполнить операцию sequence[0] .
- Если индекс i отрицателен, то индекс считается относительно конца последовательности sequence . В этом случае положительный индекс можно посчитать по формуле len(sequence) — i .
- Обратите внимание, что -0 по-прежнему будет 0 .
При попытке получить значение элемента с индексом, превышающим длину последовательности поднимается исключение IndexError .
Эта операция поддерживаются большинством типов последовательностей, как изменяемых, так и неизменяемых.
Примечание: Множества set не поддерживает индексирование элементов, т.к. это неупорядоченная коллекция без повторяющихся элементов. Но если все же необходимо получить значение элемента по индексу, то множество set необходимо преобразовать в список list или кортеж tuple . Например:
>>> mySet = set([1, 2, 3]) >>> list(mySet)[1] # 2
Примеры получения значения элемента по индексу.
>>> x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> x[0] # 1 >>> x[4] # 5 >>> x[-1] # 10 >>> x[-4] # 7 # Проверка формулы len(sequence) - i >>> y = len(x) - 4 >>> x[y] # 7 # Индекс превышает длину последовательности >>> x[15] # Traceback (most recent call last): # File "", line 1, in # IndexError: list index out of range
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Проверка существования значения в последовательности Python
- Конкатенация (сложение) последовательностей
- Увеличение последовательности в N раз
- Получение значения элемента по индексу sequence[i]
- Получение среза sequence[i:j]
- Получение среза с заданным шагом sequence[i:j:k]
- Вычисление длины последовательности
- Наименьшее значение последовательности Python
- Наибольшее значение в последовательности Python
- Метод последовательности index()
- Метод последовательности count()
Как узнать индекс двух одинаковых элементов в списке
Можно пройтись по списку циклом for и после совпадения удалять нужный элемент, а его индекс добавлять в новый список. Но не нужно забывать, что после каждого удаления числа из списка индекс смещается на 1, поэтому нужно добавить счетчик(count)
lis = [1, 2, 3, 4, 1, 5, 1] ind = [] count = 0 for f in lis: if f == 1: ind.append(lis.index(f) + count) lis.remove(f) count += 1 print(*ind) Ну или же просто вместо индекса элемента можно добавлять число, на которое ссылается переменная count
lis = [1, 2, 3, 4, 1, 5, 1, 1, 1] ind = [] count = 0 for f in lis: if f == 1: ind.append(count) count += 1 print(*ind) Поиск значений в списке в Python

Часто в процессе работы с Python возникает необходимость найти конкретное значение в списке. Учитывая, что в Python список является одной из основных структур данных, такая задача встречается довольно часто. Например, может возникнуть необходимость проверить, есть ли определенный элемент в списке чисел или строк.
my_list = [1, 2, 3, 4, 5] item = 3
Наиболее простым и «pythonic» способом проверить наличие элемента в списке является использование оператора in . Если элемент присутствует в списке, оператор in вернет True , в противном случае — False .
if item in my_list: print("Desired item is in list")
Однако, этот метод не подскажет о местоположении элемента в списке. Для определения индекса элемента можно использовать метод .index() . Если элемент присутствует в списке, метод вернет индекс первого вхождения элемента, в противном случае будет сгенерировано исключение ValueError .
try: index = my_list.index(item) print(f"Item is at index ") except ValueError: print("Item is not in the list")
Важно помнить, что оба этих метода ищут только первое вхождение элемента. Если в списке присутствует несколько одинаковых элементов и нужно найти все их индексы, потребуется более сложный код.
indexes = [i for i, x in enumerate(my_list) if x == item] print(f"Item is at indexes ")
В этом коде используется функция enumerate() , которая возвращает пары индекс-значение для элементов списка, и генератор списка для создания нового списка с индексами.
Таким образом, Python предоставляет различные способы для поиска элементов в списке, каждый из которых подходит для своих специфических задач.
Как узнать индекс двух одинаковых элементов в списке
Можно пройтись по списку циклом for и после совпадения удалять нужный элемент, а его индекс добавлять в новый список. Но не нужно забывать, что после каждого удаления числа из списка индекс смещается на 1, поэтому нужно добавить счетчик(count)
lis = [1, 2, 3, 4, 1, 5, 1] ind = [] count = 0 for f in lis: if f == 1: ind.append(lis.index(f) + count) lis.remove(f) count += 1 print(*ind) Ну или же просто вместо индекса элемента можно добавлять число, на которое ссылается переменная count
lis = [1, 2, 3, 4, 1, 5, 1, 1, 1] ind = [] count = 0 for f in lis: if f == 1: ind.append(count) count += 1 print(*ind) Находим повторяющиеся элементы в списке Python

Статьи
Автор Admin На чтение 3 мин Просмотров 3.6к. Опубликовано 21.04.2023
Введение
В данной статье разберём три способа нахождения повторяющихся элементов в неупорядоченном списке Python.
Поиск одинаковых элементов в списке с помощью словаря
Для начала создадим неупорядоченный список с числами и пустой словарь:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] duplicate_elements = <>Теперь пройдёмся по нашему неупорядоченному списку при помощи цикла for. Внутри цикла добавим условие, что если итерабельный элемент присутствует в словаре duplicate_elements, то прибавляем к значению ключа единицу, т.к. этот элемент уже присутствует в словаре, и был найден его дубликат. Если же условие оказалось ложным, то сработает else, где в словарь будет добавляться новый ключ, которого в нём ранее не было:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] duplicate_elements = <> for item in unordered_list: if item in duplicate_elements: duplicate_elements[item] += 1 else: duplicate_elements[item] = 1unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] duplicate_elements = <> for item in unordered_list: if item in duplicate_elements: duplicate_elements[item] += 1 else: duplicate_elements[item] = 1 print(duplicate_elements) # Вывод:
В выводе мы видим, что было найдено две шестёрки, одна восьмёрка, две семёрки, две пятёрки, одна единица и две четвёрки.
Поиск одинаковых элементов в списке с помощью модуля collections
В данном способе для поиска одинаковых элементов в неупорядоченном списке мы будем использовать модуль collections, а точнее класс Counter из него. Сам модуль входит в стандартную библиотеку Python, поэтому устанавливать его не придётся.
Для начала импортируем сам модуль collections и добавим неупорядоченный список:
import collections unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]Далее при помощи класса Counter из модуля collections подсчитаем количество повторяющихся элементов:
import collections unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] count_frequency = collections.Counter(unordered_list)Выведем результат в виде словаря:
import collections unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] count_frequency = collections.Counter(unordered_list) print(dict(count_frequency)) # Вывод:
Поиск одинаковых элементов в списке с помощью функции filter()
В данном способе мы просто будем выводить повторяющиеся элементы в списке, но не указывать количество их повторений.
При помощи функции filter() отфильтруем наш список. Внутри неё анонимной функцией lambda будем производить проверку поэлементно, и если определённый элемент встречается больше одного раза, мы добавляем его в count_frequency:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list)При помощи функции set() преобразуем полученные данные в count_frequency в множество, а множество в список:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list) count_frequency = list(set(count_frequency))Выведем полученный результат:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7] count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list) count_frequency = list(set(count_frequency)) print(count_frequency) # Вывод: [4, 5, 6, 7]Т.е. в неупорядоченном списке повторяются четвёрки, пятёрки, шестёрки и семёрки.
Заключение
В ходе статьи мы с Вами разобрали целых три способа нахождения повторяющихся элементов в списке Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! ��
Нахождение индекса элемента в списке Python
Иногда при работе с различными структурами данных в Python возникает необходимость найти индекс определенного элемента в списке. Это становится особенно актуально при работе со списками, где порядок элементов имеет значение.
Пример
Допустим, есть список со следующими элементами:
fruits = ["apple", "banana", "cherry", "date", "elderberry"]
И задача состоит в том, чтобы найти позицию элемента «cherry» в этом списке.
Решение
Для решения этой задачи в Python предусмотрен встроенный метод списков под названием index() . Этот метод принимает один аргумент — элемент, индекс которого нужно найти, и возвращает первый индекс этого элемента в списке.
Код для решения этой задачи будет выглядеть следующим образом:
fruits = ["apple", "banana", "cherry", "date", "elderberry"] index = fruits.index("cherry") print(index)
В результате выполнения этого кода будет выведено число 2, что соответствует индексу элемента «cherry» в списке fruits .
Ограничения метода index()
Однако стоит учесть, что метод index() выбросит исключение ValueError , если элемент, индекс которого пытаются найти, отсутствует в списке. Чтобы избежать этого, можно предварительно проверить наличие элемента в списке с помощью оператора in . Если элемент присутствует в списке, то можно безопасно вызывать метод index() .
fruits = ["apple", "banana", "cherry", "date", "elderberry"] if "cherry" in fruits: index = fruits.index("cherry") print(index) else: print("Элемент не найден в списке.")
В этом случае, если элемента «cherry» не будет в списке fruits , программа выведет сообщение «Элемент не найден в списке.»