Статьи -> Как поменять кодировку текстового файла, .txt, .doc
Время от времени возникает потребность изменения кодировки текстового файла. Например, при создании сайтов или разработке программного обеспечения на PHP. К слову файл системный файл .htaccess, отвечающий за некоторые настройки веб-сервера должен иметь кодировку UTF-8.
Изменить кодировку текстового файла, создаваемого в Windows можно легко с помощью встроенной программы «Блокнот». Для этого достаточно открыть требуемый файл и нажать «Файл» -> «Сохранить как». В выпавшем меню выбрать требуемую кодировку и сохранить текстовой файл.
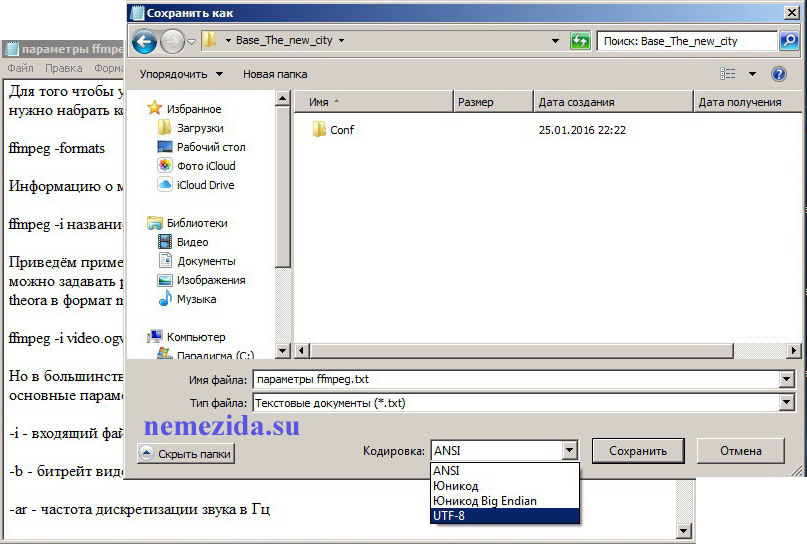
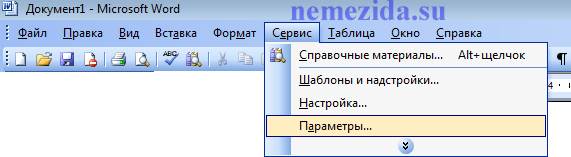
В Microsoft Word 2003 эта манипуляция несколько сложнее. Открываем требуемый .doc файл. Переходим на вкладку «Параметры». В открывшемся окне нажимаем кнопку «Параметры веб-документа». В следующем окне выбираем вкладку «Кодировка», где уже и может выбрать кодировку символов в сохраняемом файле.
В Linux Ubuntu все предсказуемо. Открываем редактируемый файл редактором gedit. Выбираем вкладку «Файл» -> «Сохранить как». В выпавшем окне открываем вкладку «Кодировка символов». Там же, кстати, можно добавить кодировку, если нужной не было в списке.
Инструкция по переходу на UTF-8
Вычислительная система кафедры перешла на использование многобайтовой кодировки UTF-8 для файловых систем и пользовательского окружения вместо однобайтовой кодировки KOI8-R. В данной инструкции рассматриваются типичные проблемы, которые могли возникнуть у пользователей в связи с данным переходом и предлагаются способы их решения (изменения настроек, команды и т.п.).
- 1 Основные понятия
- 2 Имена файлов
- 3 Содержимое файлов
- 4 Приложения
- 4.1 Текстовый терминал из Windows
- 4.2 Текстовый терминал из Linux
- 4.3 TEX
- 4.4 Bibtex
Основные понятия
Юнико́д, или Унико́д (англ. Unicode™) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Важно понимать, что один символ в кодировке UTF-8 может быть представлен более чем одним байтом. С этим связано, например, то, что файл, содержащий текст в кодировке UTF-8 будет иметь больший размер по сравнению с файлом, содержащим тот-же текст в кодировке KOI8-R.
Пример: команда wc имеет ключ -c для подсчета байтов и ключ -m для подсчета символов.
$ echo -n "Слово." | wc -c 11 $ echo -n "Слово." | wc -m 6
Имена файлов
Имена файлов были перекодированы автоматически с помощью утилиты convmv:
convmv -r -f koi8-r -t utf-8 —notest
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r
После проверки вывода команды повторить с ключем --notest. Ключ -r включает рекурсивный обход каталогов.
Содержимое файлов
Для того, чтобы преобразовать содержимое файлов из кодировки KOI8-R в кодировку UTF-8 можно воспользоваться командой:
recode koi8-r..utf-8
Для потокового перекодирования используется команда:
iconv -f koi8-r
Редактор Emacs может автоматически распознать кодировку текста при открытии файла. Принудительно задать кодировку открытия или сохранения файла в редакторе Emacs можно следующим образом:
- Ввести комбинацию клавиш C-x RET c .
- Внизу экрана будет запрошена кодировка, которую вы хотите применить для следующей команды.
- Введите команду, которая будет выполнена с применением введенной на предыдущем шаге кодировки, например:
- комбинацию клавиш для открытия файла: C-x C-f ;
- комбинацию клавиш для сохранения файла: C-x C-s .
Приложения
Текстовый терминал из Windows
Для корректного отображения русского текста при входе на серверы кафедры с помощью терминального клиента PuTTY нужно указать в настройках:
- Раздел Window/Translation
- Character set translation on recieved data: UTF-8
Текстовый терминал из Linux
Если системная локаль не UTF-8, то необходимо запустить X-терминал с поддержкой UTF-8 и выполнить вход по ssh из него.
Если системная локаль UTF-8, то никаких дополнительных действий предпринимать не надо.
Если по какой-то причине при входе по ssh не установились правильно переменные окружения локали (вывод команды locale не содержит строки LANG=ru_RU.UTF-8 ), то необходимо выполнить команду:
export LANG=ru_RU.UTF-8
WinSCP
Для корректного отображения русских имен файлов:
- Раздел Environment
- UTF-8 encoding for filenames: On
TEX
- После выполнения перекодировки содержимого tex-файла (см. Содержимое файлов) необходимо сменить кодировку в преамбуле:
\usepackage[koi8-r]
\usepackage[utf8x]- Также необходимо подключить пакет ucs:
\usepackage
- Для установки диакритических знаков (ударений) нужно использовать полную форму стандартной записи \', т.е.:
Б\'льшую
Bibtex
Bib-файлы, содержащие описание литературы, хранятся в кодировке KOI8-R. После выполнения команды bibtex необходимо сначала перекодировать получившийся bbl-файл в кодировку UTF-8 (см. Содержимое файлов), а затем выполнять трансляцию tex-файлов, подключающих этот список литературы.
Замечания по работе сервера: webmaster@cs.karelia.ru
Вопросы по содержимому страницы: Александр Колосов
Последние изменения: Чт 10 сен 2009 08:10:07 UTCКонвертация текста в кодировку utf8 Python
Даже после использования decode в коде страницы есть элементы которые выдаются в unicode кодировке, как пример:
u041a\u043e\u0440\u0435\u043d\u043d\u0430\u044f \u0410\u043d\u043d\u0430 \u0415\u0432\u0433\u0435\u043d\u044c\u0435\u0432\u043d\u0430Как можно перекодировать данный текст если он уже имеет тип данных str
Отслеживать
задан 16 апр 2022 в 17:16
406 2 2 серебряных знака 13 13 бронзовых знаков1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Вопрос решен. К переменной в которой лежала строка в юникоде с типом данных str нужно было применить:
text = 'u041a\u043e\u0440\u0435\u043d\u043d\u0430\u044f \u0410\u043d\u043d\u0430 \u0415\u0432\u0433\u0435\u043d\u044c\u0435\u0432\u043d\u0430' text = bytes(text, encoding='utf8') text = text.decode("unicode_escape")В таком случае текст переходит в читабельный вид utf8 кодировки
Как сохранить файл в кодировке UTF-8
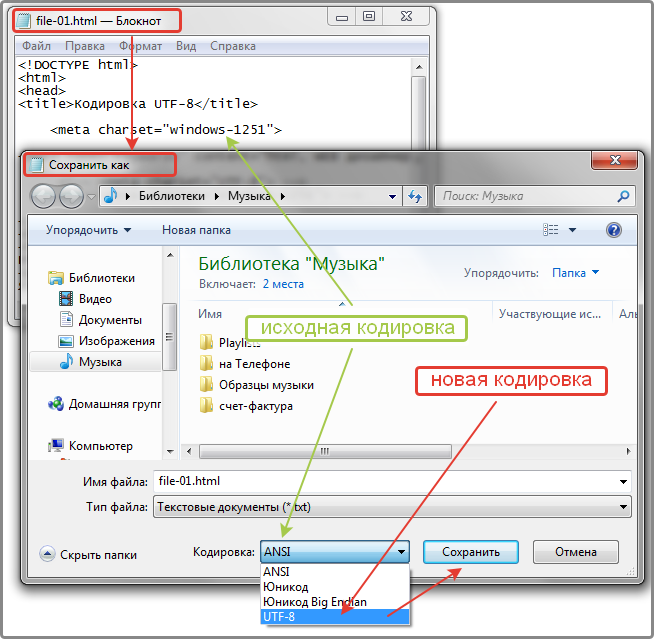
Решение 1.
- Открываеем file-01.html в текстовом редакторе Блокнот.
- Выбикаем «Сохранить как…».
- Выбираем кодировку UTF-8.
- Жмем кнопку — Сохранить.
- Открываем file-01.html в текстовом редакторе Notepad++
- Меню -> Кодировки.
Здесь видим, что Notepad++ определяет сам известную кодировку открытого файла.
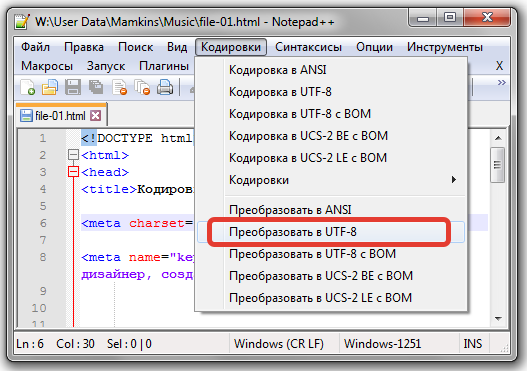
- Меню -> Файл -> Сохранить (не забывать).
Как браузер определяет кодировку?
Мы сами сообщаем браузеру о том, какая кодировка установлена для данного HTML файла.
Делается это посредством META-тега и атрибут charset1) charset="utf-8">
2) charset="windows-1251">
3) charset=koi8-r>
Атрибут charset указывает браузеру в какой кодировке отображать страницу сайта.
Важно!
При перекодировке файлов не забывать изменять директивы в META-теге на актуальные.
Если в META-теге указана одна кодировка, а файл сохранен в другой кодировке, то на экране мы увидем «абракадабру». Браузер в первую очередь открывает страницу в кодировке указанной в META-теге на странице.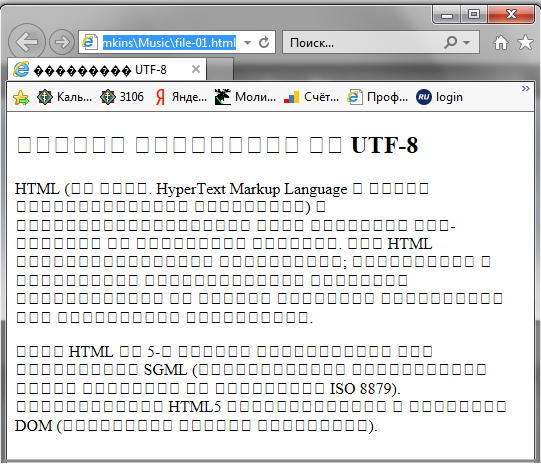
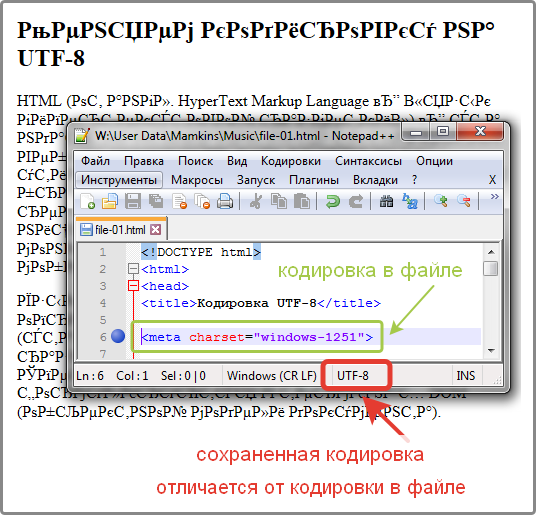
4) В случае
Если в META-теге указана нужная кодировка, а сайт все равно отображает «абракадабру», то нужно проверить настройку сайта на хостинге (веб-сервере).
Обычно на хостингне в настройках сайта указана кодировка utf-8.
Если в настройках хостинга указана кодировка windows-1251, то нужно сменить настройку на utf-8.