Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
- Общие сведения о кодировке текста
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Поиск кодировок, доступных в Word
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
- Откройте вкладку Файл.
- Нажмите кнопку Параметры.
- Нажмите кнопку Дополнительно.
- Перейдите к разделу Общие и установите флажокПодтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
- Нажмите кнопку Пуск и выберите пункт Панель управления.
- Выполните одно из указанных ниже действий. В Windows 7
- На панели управления выберите раздел Удаление программы.
- В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
- На панели управления выберите раздел Удаление программы.
- В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows XP
- На панели управления щелкните элемент Установка и удаление программ.
- В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
- Откройте вкладку Файл.
- Выберите пункт Сохранить как. Чтобы сохранить файл в другой папке, найдите и откройте ее.
- В поле Имя файла введите имя нового файла.
- В поле Тип файла выберите Обычный текст.
- Нажмите кнопку Сохранить.
- Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
- В диалоговом окне Преобразование файла выберите подходящую кодировку.
- Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
- Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
- Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Система письменности
Используемый шрифт
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Windows 1250, 1252-1254, 1257, ISO8859-x
Какая кодировка используется в windows
Иногда по неизвестным причинам некоторые команды русскоязычной версии Windows выводят русский текст в нечитаемой кодировке, кракозябрами.
Например, команда help выводит нормальный текст:
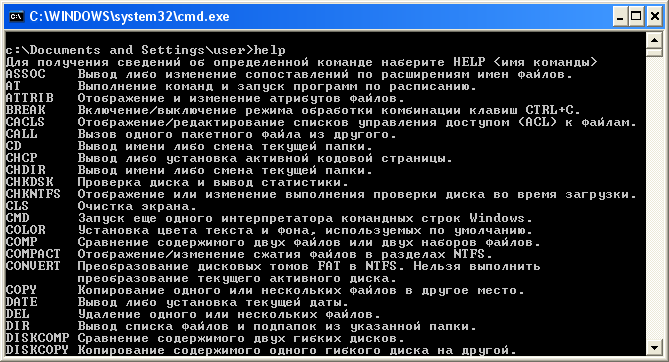
Но при этом подсказка telnet выводит в ответ кракозябры.
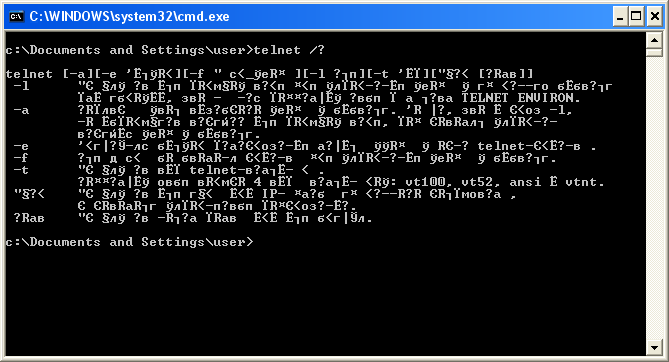
Так может происходить, к примеру, если текущая кодировка консоли 866, а утилита telnet.exe почему-то выводит текст в кодировке 1251. Вывести текст в нужной кодировке поможет команда chcp, которая устанавливает нужную кодировку.
Вот так можно посмотреть текущую кодировку консоли:
c:\Documents and Settings\user>chcp Текущая кодовая страница: 866 c:\Documents and Settings\user>
А вот так можно поменять кодировку на 1251, после чего вывод подсказки telnet будет отображаться нормально:
c:\Documents and Settings\user>chcp 1251 Текущая кодовая страница: 1251 c:\Documents and Settings\user>
К сожалению, заранее угадать, в какой кодировке выводится текст, невозможно, поэтому проще попробовать установить командой chcp разные кодировки, чтобы добиться правильного отображения русского текста. Обычно используются кодировки 866 (кодировка русского текста DOS), 1251 (кодировка русского текста Windows), 65001 (UTF-8).
[Шрифт cmd.exe]
Иногда кракозябры можно убрать, если выбрать в свойствах окна cmd.exe шрифт Lucida Console (по умолчанию там стоит «Точечные шрифты»).
[Ссылки]
Очередная причуда Win 10 — и как с ней бороться
Квалификацию надо иногда повышать, и вообще учиться для мозгов полезно. А потому пошел я недавно на курсы — поизучать Python и всякие его фреймворки. На днях вот до Django добрался. И тут мы в ходе обучения коллективно выловили не то чтобы баг, но дивный эффект на стыке Python 3, Sqlite 3, JSON и Win 10. Причем эффект был настолько дивен, что гугль нам не помог — пришлось собираться всей заинтересованной группой вместе с преподавателем и коллективным разумом его решать.
А дело вот в чем: изучали мы базу данных (а у Django предустановлена Sqlite 3) и, чтоб каждый раз заново руками данные не вбивать, прикрутили загрузку скриптом из json-файлов. А в файлы данные из базы штатно дампили питоновскими же методами:
python manage.py dumpdata -e contenttypes -o db.jsonВнезапно те, кто работал под виндой (за все версии не поручусь, у нас подобрались только обитатели Win 10), обнаружили, что дамп у них производится в кодировке windows-1251. Более того, джейсоны в этой кодировке отлично скармливаются базе. Но стоило только переформатировать их в штатную по документам для Sqlite 3, Python 3 и особенно для JSON кодировку UTF-8, как в лучшем случае кириллица в базе превращалась в тыкву, а в худшем ломался вообще весь процесс загрузки данных.
Ничего подобного найти не удалось ни в документации, ни во всем остальном гугле, считая и англоязычный. Что самое загадочное, ручная загрузка тех же самых данных через консоль или админку проекта работала как часы, хотя уж там-то кодировка была точно UTF-8. Более того, принудительное прописывание кодировки базе никакого эффекта не дало.
Мы предположили, что причиной эффекта было взаимодействие джейсона с операционной системой — каким-то образом при записи и чтении именно джейсонов система навязывала свою родную кодировку вместо нормальной. И действительно, когда при открытии файла принудительно устанавливалась кодировка UTF-8:
open(os.path.join(JSON_PATH, file_name + '.json'), 'r', encoding="utf-8")в базу попадали не кракозябры, а нормальные русские буквы. Но проблему с созданием дампа таким способом не решишь, а переделывать кодировку потом руками тоже как-то не по-нашему.
И тогда мы решили поискать способ укротить винду.
И такой способ нашелся. Вот он:
- открываем панель управления, но не новую красивую, а старую добрую:

- открываем (по стрелке) окошко региона:

- по стрелкам переключаем вкладку «Дополнительно» и открываем окошко «Изменить язык системы»:

- и в нем ставим галку по стрелке в чекбоксе «Бета-версия: Использовать Юникод (UTF-8) для поддержки языка во всем мире.
Система потребует перезагрузки, после чего проблема будет решена.
Не могу сказать, чтобы этот мелкий странный баг был так уж важен или интересен (питоновские проекты обычно живут под линуксами, где такого не бывает), но мозги он нам поломал изрядно — вследствие чего я и решил написать эту заметку. Мало ли кто еще из новичков как раз во время учебы попадется.
Какая кодировка используется в Windows 10?
Начал изучать кодировки, и возникло очень много вопросов. Какая кодировка в Windows 10? Какие процессы выполняются в этой кодировке, а какие нет? Я знаю что Python, например, использует кодировку UTF-32, и если эта кодировка отличается от кодировки в Windows 10, то как это вообще может правильно работать? Почему кодировка может быть другая и в Интернете? У кого может быть своя кодировка, а у кого нет, и каким образом все они кооперируются, если работают в разных кодировках?
Отслеживать
задан 2 янв в 19:52
holyDemon12 holyDemon12
23 4 4 бронзовых знака1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Никакие процессы ни в какой кодировке не выполняются. Кодировка применяется только при выводе текста на экран. Во все остальное время это такие же данные, как и числа, например.
Аналогия: Последовательность букв «pain» в кодировке «английский язык» означает «боль», а кодировке «французский язык» — «хлеб». Однако для пересылки этой последовательности или её сохранения это не имеет значения. Это важно только в момент чтения.
Так и с кодировкой символов. Кодировка при меняется только в момент вывода текста на экран или бумагу, от неё зависит как будет выглядеть та или иная последовательность чисел.