Polybase в SQL Server 2016
Выпуск Microsoft SQL Server 2016 сделал большой шаг к еще лучшему управлению большими объемами данных и аналитике в реальном времени для предприятия. Несмотря на то, что в версии 2016 года улучшена скорость и безопасность данных, расширенные возможности аналитики являются одними из главных причин, побуждающих к обновелнию на новую версию.
Tech Republic Mark Kaelin описывает улучшения как важный шаг к эффективному, быстрому анализу транзакционных потоков в реальном времени без использования отдельного приложения для аналитики. Благодаря собственной интеграции с пакетом Business Intelligence (BI) Microsoft, новейшая итерация SQL Server может значительно расширить возможности анализа данных (data science), не нанимая дорогостоящих и высокопрофессиональных экспертов Hadoop.
Если еще не было достаточных оснований для обновления до SQL 2016 Enterprise Addition, Polybase — это встроенная функция для большого управления данными, которая по праву получает много внимания. Хотя эта функция ранее была частью служб Analytics Platform Services (APS), она впервые выпущена в составе корпоративного пакета. Читайте дальше, чтобы узнать, как работает Polybase и как он может управлять анализом большых данных (BigData) в вашей организации.
Что такое полибаза?
Polybase — это функция, которая позволяет организациям эффективно связывать SQL и хранилища данных, включая кластеры Hadoop. Администраторы SQL могут создавать стандартные SQL-запросы, которые передаются во внешнее озеро данных и возвращают результаты. Это устраняет необходимость использования Java или MapReduce, которые исторически сделали анализ больших данных значительно более сложным для организаций.
Существует несколько способов объединения внешних источников данных с данными, хранящимися на SQL-сервере. К ним относятся HDFS на Hadoop и Windows Azure Blob. Polybase имеет встроенную возможность доступа к внешним источникам хранения с помощью запросов T-SQL, написанных в SQL Server.
Что может сделать для вас Полибаза
Для многих организаций отсутствие навыков работы с Hadoop является препятствием для анализа внешних источников больших данных. Разрыв в навыках является одним из основных препятствий для больших данных во многих организациях, и Hadoop и связанные с ним знания в области программирования Java считаются одним из критических в области технологий сегодня. Полибаза позволяет организациям проводить анализ Hadoop без знаний Hadoop и не требует дополнительных дополнений к программному обеспечению Hadoop. Polybase выполняет всю работу, необходимую для выполнения нескольких действий, в том числе:
— Запрос данных Hadoop с использованием T-SQL
— Запрос данных хранилища Azure Blob с использованием T-SQL
— Импорт данных из Hadoop, Azure Blog Storage или Azure Data Lake Storage без отдельного инструмента импорта или извлечения, преобразования, загрузки (ETL)
— Экспорт данных в Hadoop, Azure Blog или Azure Data Lake
— Интеграция с стеком Microsoft BI или другими сторонними инструментами аналитики
3 случая использования полибазы для организаций любой отрасли
Полибаза работает как мост между SQL Server и внешними базами данных, которые предназначены для хранения массивных наборов данных. Наиболее интересные варианты использования Polybase связаны с улучшенной мобильностью данных, включая беспрепятственный доступ к большим данным. В то время как потенциал Polybase не ограничивается примерами использования ниже, они иллюстрируют некоторые способы, которыми это могло бы помочь организациям в разных отраслях.
1. Перемещение редко используемых данных в Hadoop или Azure
Hadoop, Azure Blob Storage и Azure Data Lake — все решения, предназначенные для эффективного хранения больших наборов данных. С помощью Polybase, администраторы баз данных, которые имеют опыт работы с T-SQL, но не имеют навыков Hadoop, могут снизить издержки путем перемещения данных с сервера SQL в Hadoop или Azure, если спрос на эти данные минимален.
2. Потоковая аналитика
Hadoop позволяет организациям собирать, хранить и анализировать быстро движущиеся потоки данных, включая информацию от устройств, подключенных к Интернету вещей (IoT), мобильных устройств и других датчиков. С помощью Polybase организации могут увеличить возможности передачи данных в режиме реального времени, используя Polybase для доступа к потоковым наборам данных для анализа и отчетности в режиме реального времени.
3. Расширяемая, быстрая передача данных на SQL
До Polybase перемещение данных с Hadoop на SQL Server было возможным, но часто сложным из-за ограниченной доступности инструмента и ограничений форматирования данных. Polybase упрощает и ускоряет перемещение данных в SQL для бизнес-аналитики. Microsoft SQL Server 2016 предлагает расширяемость для перемещения данных высокого спроса, в том числе Polybase Scale-Out Group, которая позволяет перемещать большие данные с Hadoop на SQL Server.
Полибаза делает большие данные более действенными
Для многих организаций функция Polybase имеет потенциал для превращения информации транзакций, хранящейся в Hadoop или Azure blob, в оперативный интеллект, позволяя выполнять аналитику на основе простых быстрых запросов, написанных на SQL-сервере. Microsoft предлагает бесплатную 180-дневную пробную версию SQL Server 2016, позволяющую организациям тестировать Polybase и другие новые функции при минимальных затратах.
В сочетании с другими улучшениями в SQL Server 2016, Polybase может сделать данные более полезными для пользователей по всему предприятию. Улучшая связь между движком SQL Server и внешними источниками хранения данных, ваша организация может предотвратить утопание в больших данных и улучшить аналитические возможности.
Масштабируемые группы PolyBase
Обработка больших наборов данных в Hadoop или хранилище BLOB-объектов Azure автономным экземпляром SQL Server с PolyBase может сопровождаться снижением производительности. Группы PolyBase позволяют создавать кластеры экземпляров SQL Server для обработки больших наборов данных из внешних источников данных (например, Hadoop или хранилища BLOB-объектов Azure), используя возможности масштабирования. Это помогает повысить производительность запросов. Теперь можно масштабировать вычисления SQL Server в соответствии с требованиями производительности рабочей нагрузки. Масштабируемая группа PolyBase — это группа экземпляров SQL Server, позволяющая обрабатывать большие наборы внешних данных в архитектуре параллельной обработки. Производительность загрузки данных и запросов может увеличиваться линейно по мере добавления дополнительных экземпляров SQL Server в группу.
Поддержка для групп горизонтального увеличения масштаба Microsoft SQL Server PolyBase будет прекращена. Функции группы горизонтального масштабирования будут удалены из продукта в SQL Server 2022 (16.x). Виртуализация данных PolyBase будет по-прежнему полностью поддерживаться как функция вертикального увеличения масштаба в SQL Server. Дополнительные сведения см. в разделе Параметры больших данных на платформе Microsoft SQL Server.
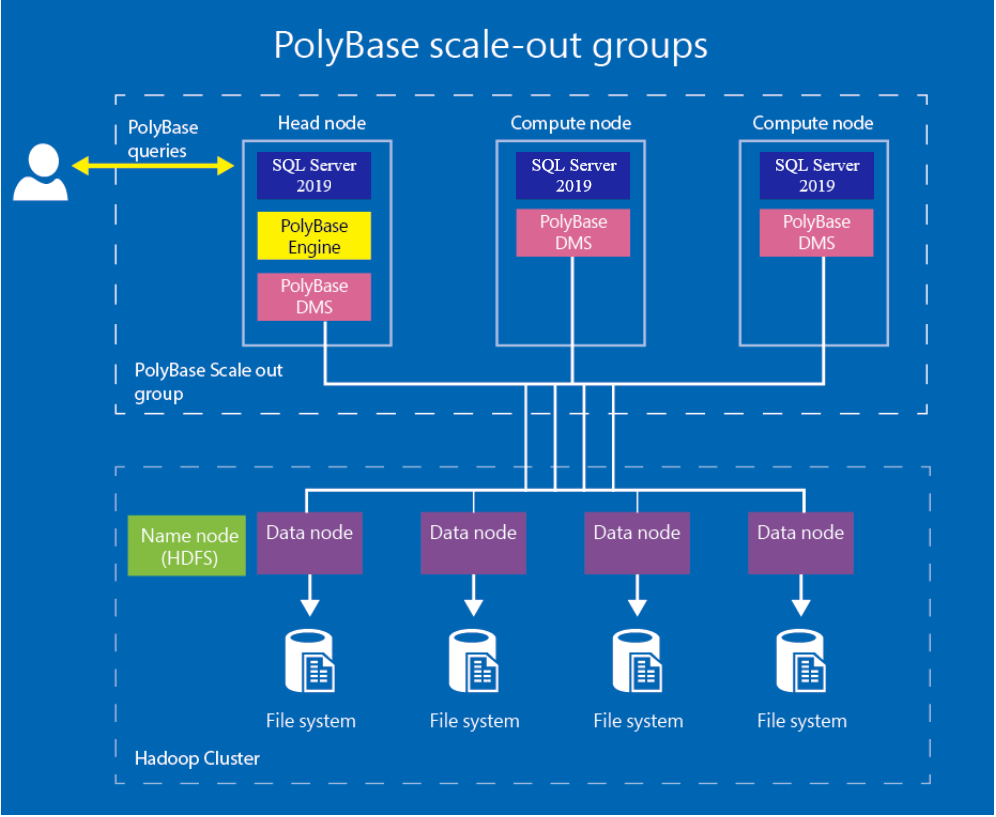
Головной узел
Головной узел содержит экземпляр SQL Server, на который отправляются запросы PolyBase. Каждая группа PolyBase может иметь только один головной узел. Головной узел — это логическая группа на экземпляре SQL Server, в которую входят ядро СУБД SQL Server, а также ядро PolyBase и служба «Перемещение данных PolyBase». Для головного узла с SQL Server 2017 и SQL Server 2016 должен использоваться выпуск Enterprise. Начиная с SQL Server 2019, для головного узла PolyBase можно использовать выпуск Enterprise либо Standard.
Вычислительный узел
Вычислительный узел содержит экземпляр SQL Server, который помогает выполнять масштабируемую обработку запросов к внешним данным. Вычислительный узел — это логическая группа на экземпляре SQL Server, в которую входят SQL Server и служба перемещения данных PolyBase. Группа PolyBase может включать несколько вычислительных узлов. В головном узле и вычислительных узлах должна использоваться одна и та же версия SQL Server. В первом выпуске SQL Server 2016 допускалось, чтобы для вычислительных узлов использовались выпуски Enterprise или Standard. Начиная с SQL Server 2016 с пакетом обновления 1 (SP1), для вычислительный узлов могут использоваться все выпуски SQL Server.
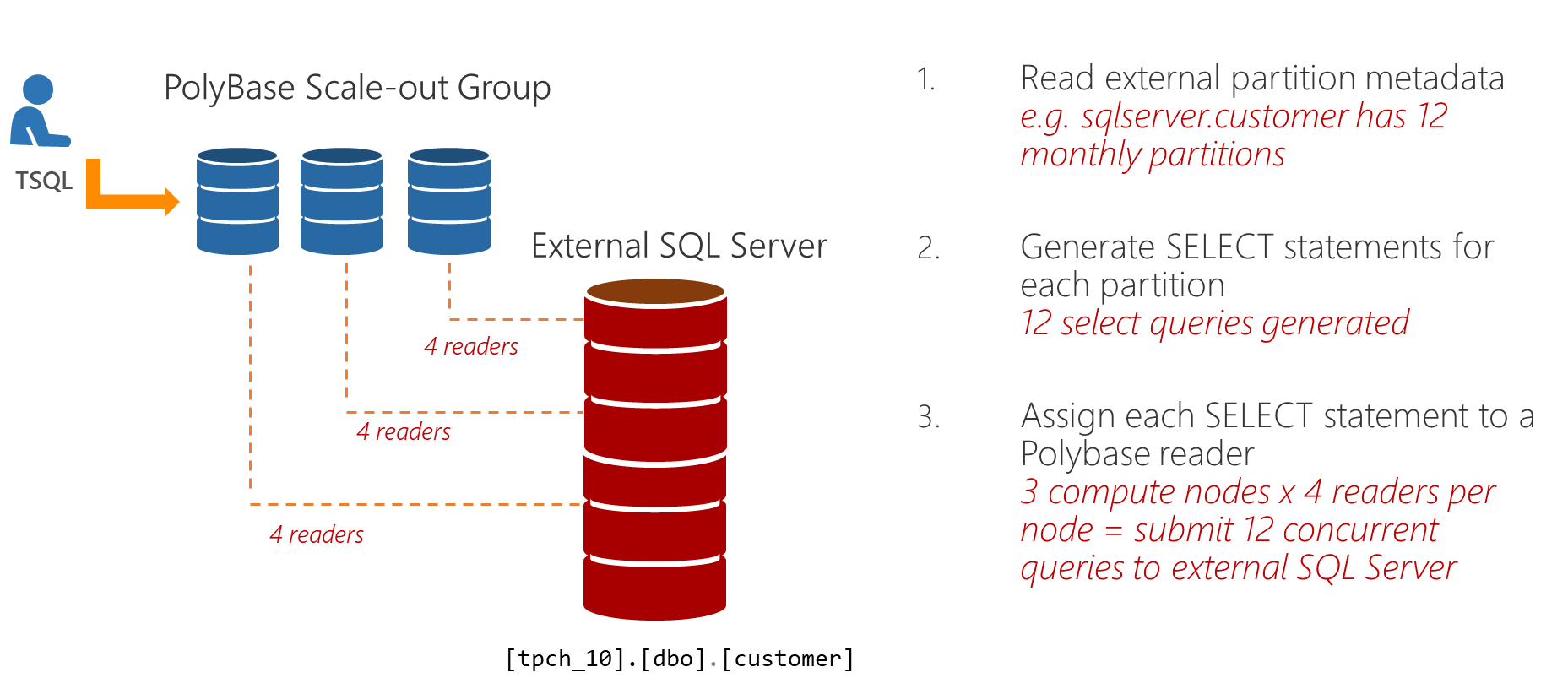
Масштабируемое чтение
Секционированные таблицы выиграют от использования масштабируемого чтения при запросах к внешним экземплярам SQL Server, Oracle или Teradata. Каждый узел в масштабируемой группе PolyBase может запустить до 8 средств для чтения внешних данных. И каждому средству чтения назначается один раздел во внешней таблице.
Предположим, что у вас есть внешняя таблица SQL Server с 12 секциями (за каждый месяц) и масштабируемая группа PolyBase с 3 узлами. Каждый узел будет использовать по 4 средства чтения PolyBase для обработки каждой из 12 секций. Это как раз иллюстрируется на следующих образах.
Процесс отличается от масштабируемого чтения в Hadoop.
Распределенная обработка запросов
Запросы PolyBase отправляются на SQL Server на головном узле. Часть запроса, которая относится к внешним таблицам, передается в ядро PolyBase.
Ядро PolyBase — это ключевой компонент в процессе обработки запросов PolyBase. Оно анализирует запрос к внешним данным, создает план запроса и распределяет работу между службами перемещения данных на вычислительных узлах. После выполнения этой работы ядро PolyBase получает результаты от вычислительных узлов и отправляет их на SQL Server для финальной обработки и передачи клиенту.
Служба перемещения данных PolyBase получает инструкции от ядра PolyBase и передает данные между HDFS и SQL Server, а также между экземплярами SQL Server на головном и вычислительных узлах.
Далее
Чтобы настроить масштабируемую группу PolyBase, обратитесь к следующему руководству:
О новых функциях SQL Server 2016
Базы данных — это сердце любой компании, которое обеспечивает работоспособность буквального каждого направления деятельности. Но какое место базы данных занимают в современных реалиях? Ведь они появились не сегодня. Они были созданы в то время, когда мы и представить не могли, что мир технологий будет таким, какой он есть сейчас. Традиционные базы данных предназначались исключительно для записи и извлечения транзакций, таких как заказы и платежи. Их задачей было обеспечивать надежную и безопасную работу приложений в небольшом или среднего масштаба локальном ЦОДе.
Наш продукт — SQL Server 2016 — помогает реализовать весь потенциал новейших технологических тенденций. Он поддерживает гибридную обработку транзакций, расширенную аналитику и машинное обучение, мобильную бизнес-аналитику, интеграцию данных, обработку запросов с шифрованием и работу с транзакциями в оперативной памяти. По всей видимости, это единственная в своем роде реляционная база данных, изначально предназначенная для облака. Большинство ее функций первоначально были разработаны и протестированы в Azure, в 22 ЦОДах, рассредоточенных по всему миру, при нагрузке в несколько миллиардов запросов в день. Она уже успела продемонстрировать отличные результаты на практике. Многие наши клиенты успешно используют эту базу данных.
Мы рады пригласить Вас на ключевое событие года в мире данных – Виртуальный Форум Microsoft «Данные. Технологии. SQL Server 2016», который состоится 8 июня 2016 года.
Ниже подробности о некоторых новых функциях SQL Server 2016 – R Services, PolyBase, Stretch Database.
Еще больше и подробнее вы можете узнать на нашем виртуальном форуме.
Анализ внутри базы данных с использованием языка R
Язык программирования R широко используется как программное обеспечение для анализа данных и составления прогнозов. Он бесплатный, основан на открытом исходном коде и поддерживается большим сообществом. Вы можете использовать несколько тысяч пакетов для решения различных задач. К вашим услугам — стандартные функции статистики и управления данными, графические интерфейсы и передовые алгоритмы машинного обучения. Язык R выбирают ученые и компании, которые хотят внедрять инновации с использованием современных аналитических методов.
- Службы R Services позволяют выполнять анализ внутри базы данных. Вы можете хранить данные в SQL Server 2016, а приложения вызывают скрипты R через хранимую процедуру T-SQL. Это упрощает интеграцию приложений с языком R. Скрипты R выполняются на той же машине, где хранятся данные, поэтому вам не нужно беспокоиться о безопасности: код R не сможет получить доступ к Интернету или к другим процессам, запущенным на SQL Server.
- Пользователи R Services могут использовать библиотеку алгоритмов ScaleR — набор функций, который предлагает эквиваленты для повседневных задач, выполняемых на языке R. Однако в отличие от аналогов CRAN-R, функции ScaleR масштабируемы для обработки сотен миллионов и миллиардов строк посредством параллельных вычислений. Это обеспечивает производительность, которой невозможно достичь при использовании распространенных пакетов с открытым исходным кодом. API ScaleR были разработаны компанией Revolution Analytics. После того как Microsoft приобрела эту компанию, API были интегрированы в SQL Server. Они являются кроссплатформенными, то есть поддерживают не только SQL Server, но и другие платформы.
- SQL Server также предлагает существующие функции и механизмы для интеграции и повышения производительности. Например, возможно использование ColumnStore индексов вместе с языком R, чтобы быстрее выполнять аналитические запросы. Встроенный механизм управления позволяет контролировать ресурсы, выделенные для среды выполнения R. А службы SQL Server Integration Services (SSIS) обеспечивают бесшовную интеграцию с ETL и планирование регламентных задач через интерфейс хранимых процедур.
- Другая важная особенность R Services заключается в том, что пользователи могут работать со знакомыми инструментами:
- Специалисты, занимающиеся изучением данных, имеют возможность использовать привычную среду R IDE. Они могут работать с R Studio, с недавно анонсированными средствами R Tools for Visual Studio или с любой средой IDE по своему усмотрению. Вместо того чтобы переносить данные на локальную машину, можно воспользоваться средством ScaleR для удаленного выполнения непосредственно из IDE. Применение средств SQL Server 2016 для анализа внутри БД позволяет ускорить анализ больших наборов данных.
- К услугам администраторов серверов — хорошо им знакомое ПО SQL Server Management Studio для управления службами R Services, контроля ресурсов и назначения прав доступа.
- Разработчикам приложений доступны API T-SQL. Они могут создавать отчеты SQL Server Reporting Services или панели мониторинга Power BI с оценками, прогнозами и графикой из R без необходимости изучать сам язык R.
- Инженеры данных могут комбинировать R с существующими потоками ETL и планировать регламентные задачи с помощью служб SQL Server Integration Services.
- Документация по продукту на MSDN
- Видео от Data Driven, в котором рассказывается о том, как службы SQL Server R Services помогают создавать интеллектуальные приложения, выполнять предиктивный анализ и извлекать ценную информацию из данных. Другие видео по R Services см. в плейлисте Data Driven и на канале Channel9.
- Руководства на MSDN
- Шаблоны решения на сайте Cortana Analytics Gallery, образцы данных и кода на GitHub.
- Если вы ничего не знаете о языке R, пройдите наши онлайн-курсы, например на сайте Datacamp, где вы также сможете найти углубленные курсы по API ScaleR.
Представляем PolyBase
За последние 10 лет мир информационных технологий изменился до неузнаваемости. Интернет вещей, технологии обработки неструктурированных данных и снижение цен на ИТ-оборудование, — все это обусловило настоящий бум Больших данных. Появились решения (такие как Hadoop and HDFS), позволяющие обрабатывать огромные массивы полуструктурированных данных и при этом не требующие покупки дорогостоящего специализированного «железа». Все это открыло перед бизнесом новые возможности получения прибыли, однако «оборотной стороной медали» стала растущая сложность корпоративных платформ для работы с данными. Кроме того, источники данных стали гораздо более разнообразными. Зачастую компаниям приходится иметь дело сразу с несколькими разрозненными наборами данных: реляционными в SQL Server и нереляционными в HDFS. Если аналитику необходимо совместить анализ полуструктурированных и структурированных данных, то ему придется сначала скопировать их из одной среды в другую, что отнимает много времени и сил.
Но все в мире меняется к лучшему! Решение PolyBase в SQL Server 2016 снимает проблему разрозненности реляционных и полуструктурированных данных. Использование PolyBase и T-SQL позволяет пользователям отправлять запросы к данным HDFS так, как будто они хранятся на локальном SQL Server, что открывает массу новых возможностей для анализа.

- разовые запросы к Hadoop и SQL Server 2016 с помощью T-SQL;
- импорт данных из Hadoop или blob-хранилища Azure в SQL Server 2016;
- экспорт «холодных» реляционных данных в Hadoop или blob-хранилище Azure при сохранении возможности одновременной отправки запросов.
- Getting started with PolyBase
- PolyBase groups for scale-out computation
- PolyBase troubleshooting with dynamic management views
Неограниченно долгое хранение данных с технологией Stretch Database
Технология Stretch Database, входящая в состав СУБД SQL Server 2016, дает возможность хранить любой объем данных столько, сколько потребуется, без нарушения соглашения об уровне обслуживания бизнеса и высоких затрат на приобретение систем хранения данных уровня предприятия. В отличие от обычных решений, применяемых для хранения «холодных» данных, Stretch Database обеспечивает постоянный доступ к вашим данным за счет использования неисчерпаемых облачных ресурсов Azure, а также не требует модификации большинства приложений. Администраторам баз данных лишь нужно активировать хранение «холодных» данных в облаке.
- Перенос в облако всей таблицы: уже имеющуюся выделенную таблицу для «холодных» данных можно перенести целиком. Допустим, у вас есть таблицы Order_details и Order_details_history, последняя из которых содержит только «холодные» данные, переносимые из первой.
- Перенос «холодных» строк: если в одной и той же таблице есть и «горячие», и «холодные» данные, можно перенести в Azure только «холодные». Для этого достаточно указать, какие именно строки являются таковыми (обычно это определяется по дате или состоянию), а SQL Server позаботится о переносе.
- Получите пространство хранения корпоративного класса — сколько и когда нужно. Автоматизированное резервное копирование и георепликация включены по умолчанию.
- При необходимости масштабируйте вычислительные ресурсы и пространство хранения с учетом требований рабочей задачи и платите только за используемый объем.
- При помощи встроенного механизма безопасности централизованно управляйте доступом для заказчиков, объединивших локальный Active Directory с Azure Active Directory.
- Пользуйтесь имеющимися знаниями и инструментами, такими как SQL Server Management Studio, SQL Server Data Tools, T-SQL и PowerShell, и расширяйте доступные возможности посредством портала Azure.
Виртуальный Форум
Мы рады пригласить Вас на ключевое событие года в мире данных – Виртуальный Форум Microsoft «Данные. Технологии. SQL Server 2016», который состоится 8 июня 2016 года.
- SQL Server 2016: новые стандарты в мире транзакции;
- Бизнес-aналитика: SQL, Power BI, R, Mobile;
- Azure: новое поколение решений для аналитики и Big Data.
- Каждый участник сможет посетить выставку партнерских решений.
- Пообщаться с технологическими экспертамиMVP, задать интересующие вопросы.
- Задать интересующие вопросы докладчикам.
- Получить все необходимые материалы и презентации.
- И даже выйграть призы – самые активные получат один из 30 сертификатов на сдачу экзаменов по SQL Server 2016.
Участие в форуме бесплатное. Необходима предварительная регистрация.
Дополнительно
Предлагаем вам обратить внимание на блог Сергея Олонцева, где вы можете найти множество материалов, посвященных SQL Server 2016.
Новое в SQL Server 2022: Виртуализация данных с помощью PolyBase/REST API
Microsoft SQL Server 2022 представляет новую возможность запрашивать данные непосредственно из источников, осуществлять виртуализацию данных, и использовать интерфейсы REST API. Это делает работу с данными ещё более лёгкой и гибкой, за счёт увеличения числа поддерживаемых коннекторов и форматов файлов. Поддерживаются форматы: CSV, Parquet и Deltafiles, хранящиеся в любом объектном хранилище, совместимом со службой хранения S3, как локально, так и в облаке. И наконец, SQL Server 2022 теперь может использовать операции Create External Table as Select (CETAS) в OPENROWSET, вместе с такими командами как Create External Table (CET) совместно со всеми возможностями T-SQL. Всё это делает SQL Server 2022 мощным центром управления данными.
Как это работает?
Виртуализация данных в SQL Server 2022 стала более гибкой и простой, поскольку эти возможности находятся внутри ядра СУБД. Рисунок ниже даёт некое представление об архитектуре:

OPENROWSET: это простенькая команда, которая позволяет в T-SQL получать доступ к данным вне SQL Server, будь то файл или другая база данных. Рекомендуется для загрузки/выборки данных.
CREATE EXTERNAL TABLE (CET): создает таблицу, в которой данные остаются в своем исходном расположении вне SQL Server, и при выборке ядро SQL Server доставляет запрошенные данные пользователю. Внешняя таблица может после этого использоваться повторно и оптимизатор может собирать по её колонкам статистику для повышения производительности запросов.
CREATE EXTERNAL TABLE as SELECT (CETAS): выполняет несколько операций за один раз. Можно делать преобразования и конвертацию указанных данных, размещаемых как внутри, так и вне базы данных. Затем можно экспортировать данные в другое место в сети или «облаке». В завершение, создаётся внешняя таблица, предназначенная для хранения экспортируемых данных.
Эти операции защищены главным ключом базы данных и внешними учетными данными для хранилища. Если данные будут хранится в совместимом с S3 объектном хранилище, SQL Server 2022 будет использовать для этого реализацию REST API. В других случаях SQL Server 2022 будет использовать службы PolyBase, однако установка служб PolyBase требуется во всех случаях.
Полный список источников данных можно найти в документации: CREATE EXTERNAL DATA SOURCE (Transact-SQL).
Полный список поддерживаемых форматов внешних файлов можно узнать в статье: CREATE EXTERNAL FILE FORMAT (Transact-SQL).
Преимущества
Основные преимущества виртуализации данных SQL Server 2022 с помощью PolyBase:
- Не нужно перемещать данные: доступ к данным там, где они расположены.
Язык T-SQL: можно использовать все возможности языка T-SQL, его команд, надстроек и диалекта. - Один источник для всех данных: пользователи и приложения могут использовать SQL Server 2022 в качестве единого источника любых данных, а администраторы баз данных и инженеры данных смогут использовать единую среду управления.
- Безопасность: можно использовать весь функционал безопасности SQL Server для предоставления гранулированных разрешений, управления учетными данными и их контроля.
- Стоимость: PolyBase доступен во всех редакциях SQL Server 2022.