multitask.tflite — что это на телефоне?

Приветствую друзья. multitask.tflite — неизвестная функция/приложение на смартфоне Android. Информация данной статьи поможет примерно понять предназначение multitask.tflite.
multitask.tflite — что это такое?
Информация именно об multitask.tflite к сожалению отсутствует.
Однако удалось выяснить:
- tflite — формат TensorFlow Lite, в котором содержится обученная модель машинного обучения. TensorFlow — библиотека машинного обучения Google
- multitask — означает многозадачность.
Учитывая выше информацию — возможно имеется ввиду приложение MultiTasking, предназначенное для создания удобной многозадачности (тема на форуме 4PDA). MultiTasking позволяет использовать оконный режим приложений, как в Windows с поддержкой изменения размера окна, кнопкой крестик (закрытие окна). Предположительно поддерживается функция перетаскивания окна. Пример на смартфоне:

Особенно актуально на планшетах:

Android и оконный режим (многозадачность)
Версия Android 11 Developer Preview 2 содержит некоторые необычные функции. Например Columbus, позволяющую активировать определенные приложения путем двойного нажатия по задней стороне телефона. Другими словами — двойной тап, только вместо экрана — задняя панель смартфона. Данным жестом можно запустить например голосового помощника, приложение камеры.
функция тестируется на телефонах Pixel 3 XL, Pixel 4 and Pixel 4 XL. В работе функции используются некоторые элементы многозадачности.
Поддержка оконного режима появилась в Android 7 Nougat. Однако по умолчанию опция отключена. Включить можно в меню Параметры разработчика, название настройки — Изменение размера в многооконном режиме:

Заключение
- tflite — формат, содержащий модель машинного обучения.
- multitask — термин обозначает многозадачность.
Надеюсь информация помогла. Удачи.
Квантование после обучения
Оптимизируйте свои подборки Сохраняйте и классифицируйте контент в соответствии со своими настройками.
Квантование после обучения — это метод преобразования, который может уменьшить размер модели, а также улучшить задержку процессора и аппаратного ускорителя с небольшим ухудшением точности модели. Вы можете квантовать уже обученную модель TensorFlow с плавающей запятой при преобразовании ее в формат TensorFlow Lite с помощью конвертера TensorFlow Lite .
Примечание. Для процедур на этой странице требуется TensorFlow 1.15 или выше.
Методы оптимизации
На выбор имеется несколько вариантов квантования после обучения. Вот сводная таблица вариантов и преимуществ, которые они предоставляют:
| Техника | Преимущества | Аппаратное обеспечение |
|---|---|---|
| Квантование динамического диапазона | В 4 раза меньше, в 2-3 раза быстрее | Процессор |
| Полное целочисленное квантование | В 4 раза меньше, в 3 раза быстрее | ЦП, Edge TPU, Микроконтроллеры |
| Квантование с плавающей запятой16 | В 2 раза меньше, ускорение графического процессора | ЦП, графический процессор |
Следующее дерево решений может помочь определить, какой метод квантования после обучения лучше всего подходит для вашего варианта использования:
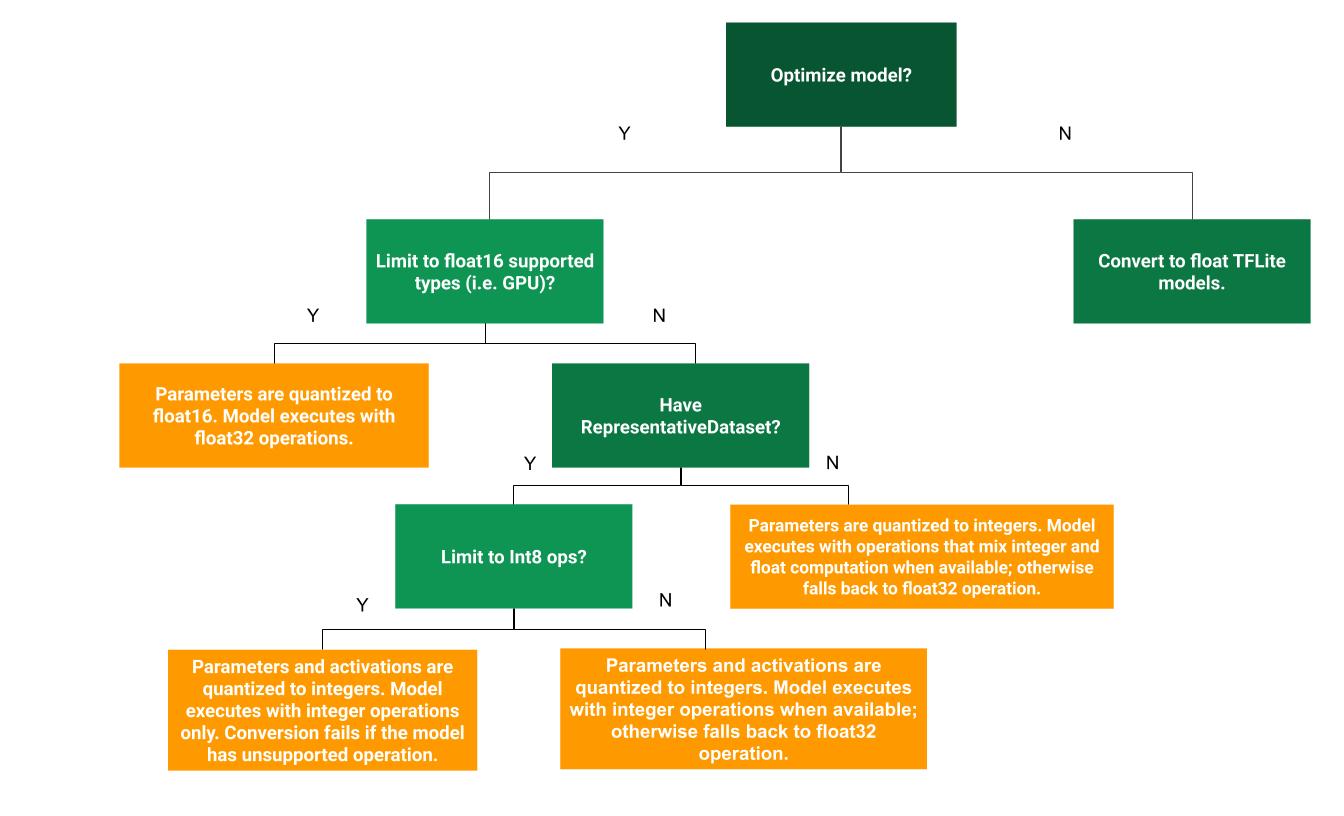
Квантование динамического диапазона
Квантование динамического диапазона является рекомендуемой отправной точкой, поскольку оно обеспечивает меньшее использование памяти и более быстрые вычисления без необходимости предоставления репрезентативного набора данных для калибровки. Этот тип квантования статически квантует только веса от плавающей запятой до целого числа во время преобразования, что обеспечивает 8-битную точность:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Чтобы еще больше уменьшить задержку во время вывода, операторы «динамического диапазона» динамически квантуют активации на основе их диапазона до 8 бит и выполняют вычисления с 8-битными весами и активациями. Эта оптимизация обеспечивает задержки, близкие к выводам с полной фиксированной точкой. Однако выходные данные по-прежнему сохраняются с использованием плавающей запятой, поэтому увеличенная скорость операций с динамическим диапазоном меньше, чем при полных вычислениях с фиксированной запятой.
Полное целочисленное квантование
Вы можете добиться дальнейшего улучшения задержки, снижения пикового использования памяти и совместимости с аппаратными устройствами или ускорителями, работающими только с целыми числами, если убедиться, что все математические вычисления модели являются целочисленными квантованными.
Для полного целочисленного квантования необходимо откалибровать или оценить диапазон, т. е. (мин, максимум) всех тензоров с плавающей запятой в модели. В отличие от постоянных тензоров, таких как веса и смещения, переменные тензоры, такие как входные данные модели, активации (выходные данные промежуточных слоев) и выходные данные модели, не могут быть откалиброваны, если мы не проведем несколько циклов вывода. В результате конвертеру требуется репрезентативный набор данных для их калибровки. Этот набор данных может представлять собой небольшое подмножество (около 100–500 образцов) данных обучения или проверки. Обратитесь к representative_dataset() ниже.
В версии TensorFlow 2.7 вы можете указать репрезентативный набор данных с помощью подписи , как показано в следующем примере:
def representative_dataset(): for data in dataset: yield
Если в данной модели TensorFlow имеется более одной подписи, вы можете указать несколько наборов данных, указав ключи подписи:
def representative_dataset(): # Feed data set for the "encode" signature. for data in encode_signature_dataset: yield ( "encode", < "image": data.image, "bias": data.bias, >) # Feed data set for the "decode" signature. for data in decode_signature_dataset: yield ( "decode", < "image": data.image, "hint": data.hint, >, )
Вы можете создать репрезентативный набор данных, предоставив входной список тензоров:
def representative_dataset(): for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100): yield [tf.dtypes.cast(data, tf.float32)]
Начиная с версии TensorFlow 2.7, мы рекомендуем использовать подход на основе сигнатур вместо подхода на основе списка входных тензоров, поскольку порядок входных тензоров можно легко изменить.
В целях тестирования вы можете использовать фиктивный набор данных следующим образом:
def representative_dataset(): for _ in range(100): data = np.random.rand(1, 244, 244, 3) yield [data.astype(np.float32)]
Целое число с резервным значением с плавающей запятой (с использованием ввода/вывода с плавающей запятой по умолчанию)
Чтобы полностью выполнить целочисленное квантование модели, но использовать операторы с плавающей запятой, когда у них нет целочисленной реализации (чтобы обеспечить плавное преобразование), выполните следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Примечание. Эта tflite_quant_model не будет совместима с целочисленными устройствами (такими как 8-битные микроконтроллеры) и ускорителями (такими как Coral Edge TPU), поскольку ввод и вывод по-прежнему остаются плавающими, чтобы иметь тот же интерфейс, что и исходный float. единственная модель.
Только целое число
Создание только целочисленных моделей — распространенный вариант использования TensorFlow Lite для микроконтроллеров и TPU Coral Edge .
Примечание. Начиная с версии TensorFlow 2.3.0, мы поддерживаем атрибуты inference_input_type и inference_output_type .
Кроме того, чтобы обеспечить совместимость с целочисленными устройствами (такими как 8-битные микроконтроллеры) и ускорителями (такими как Coral Edge TPU), вы можете обеспечить полное целочисленное квантование для всех операций, включая ввод и вывод, выполнив следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Квантование с плавающей запятой16
Вы можете уменьшить размер модели с плавающей запятой, квантовав веса до float16, стандарта IEEE для 16-битных чисел с плавающей запятой. Чтобы включить квантование весов с помощью float16, выполните следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Преимущества квантования float16 заключаются в следующем:
- Это уменьшает размер модели почти вдвое (поскольку все веса становятся вдвое меньше исходного размера).
- Это вызывает минимальную потерю точности.
- Он поддерживает некоторые делегаты (например, делегат GPU), которые могут работать непосредственно с данными float16, что приводит к более быстрому выполнению, чем вычисления float32.
Недостатки квантования float16 заключаются в следующем:
- Это не уменьшает задержку так сильно, как квантование с фиксированной запятой.
- По умолчанию квантованная модель float16 «деквантует» значения весов до float32 при запуске на ЦП. (Обратите внимание, что делегат GPU не будет выполнять это деквантование, поскольку он может работать с данными float16.)
Только целое число: 16-битные активации с 8-битными весами (экспериментально)
Это экспериментальная схема квантования. Это похоже на схему «только целые числа», но активации квантуются в зависимости от их диапазона до 16 бит, веса квантуются в 8-битное целое число, а смещение квантуется в 64-битное целое число. В дальнейшем это называется квантованием 16×8.
Основное преимущество этого квантования заключается в том, что оно может значительно повысить точность, но лишь незначительно увеличить размер модели.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Если квантование 16×8 не поддерживается для некоторых операторов в модели, модель все равно можно квантовать, но неподдерживаемые операторы остаются в плавающем состоянии. Чтобы разрешить это, в target_spec следует добавить следующую опцию.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Примеры случаев использования, в которых повышение точности, обеспечиваемое этой схемой квантования, включают:
- супер-разрешение,
- обработка аудиосигнала, такая как шумоподавление и формирование луча,
- шумоподавление изображения,
- HDR-реконструкция из одного изображения.
Недостатком такого квантования является:
- В настоящее время вывод заметно медленнее, чем 8-битное целое число, из-за отсутствия оптимизированной реализации ядра.
- В настоящее время он несовместим с существующими делегатами TFLite с аппаратным ускорением.
Учебник по этому режиму квантования можно найти здесь .
Точность модели
Поскольку веса квантуются после обучения, может произойти потеря точности, особенно для небольших сетей. Предварительно обученные полностью квантованные модели предоставляются для конкретных сетей в TensorFlow Hub . Важно проверить точность квантованной модели, чтобы убедиться, что любое ухудшение точности находится в допустимых пределах. Существуют инструменты для оценки точности модели TensorFlow Lite .
В качестве альтернативы, если падение точности слишком велико, рассмотрите возможность использования обучения с учетом квантования . Однако для этого требуются изменения во время обучения модели для добавления ложных узлов квантования, тогда как методы квантования после обучения на этой странице используют существующую предварительно обученную модель.
Представление квантованных тензоров
8-битное квантование аппроксимирует значения с плавающей запятой, используя следующую формулу.
\[real\_value = (int8\_value — zero\_point) \times scale\]
Представление состоит из двух основных частей:
- Веса по осям (также известные как по каналам) или по тензорам, представленные значениями дополнения до двух int8 в диапазоне [-127, 127] с нулевой точкой, равной 0.
- Тензорные активации/входы представлены значениями дополнения до двух int8 в диапазоне [-128, 127] с нулевой точкой в диапазоне [-128, 127].
Подробное описание нашей схемы квантования можно найти в нашей спецификации квантования . Поставщикам оборудования, желающим подключиться к делегатскому интерфейсу TensorFlow Lite, рекомендуется реализовать описанную там схему квантования.
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons «С указанием авторства 4.0», а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2023-12-01 UTC.
Квантование динамического диапазона после тренировки
Оптимизируйте свои подборки Сохраняйте и классифицируйте контент в соответствии со своими настройками.
Обзор
TensorFlow Lite теперь поддерживает преобразование весов 8 бит точности в рамках преобразования модели из tensorflow graphdefs в плоском формате буфера TensorFlow Lite в. Квантование динамического диапазона позволяет уменьшить размер модели в 4 раза. Кроме того, TFLite поддерживает квантование и деквантование активаций на лету, что позволяет:
- Использование квантованных ядер для более быстрой реализации, когда они доступны.
- Смешивание ядер с плавающей запятой с квантованными ядрами для разных частей графа.
Активации всегда хранятся с плавающей запятой. Для операций, которые поддерживают квантованные ядра, активации квантуются до 8 битов точности динамически перед обработкой и деквантовываются до точности с плавающей запятой после обработки. В зависимости от преобразуемой модели это может дать ускорение по сравнению с вычислениями с чистой плавающей запятой.
В отличии от квантования осознает обучения , вес квантуется после тренировки и активации квантуются динамически при выводе в этом методе. Следовательно, веса модели не переобучаются, чтобы компенсировать ошибки, вызванные квантованием. Важно проверить точность квантованной модели, чтобы убедиться, что ухудшение приемлемо.
Это руководство обучает модель MNIST с нуля, проверяет ее точность в TensorFlow, а затем преобразует модель в плоский буфер Tensorflow Lite с квантованием динамического диапазона. Наконец, он проверяет точность преобразованной модели и сравнивает ее с исходной моделью с плавающей запятой.
Постройте модель MNIST
Настраивать
import logging logging.getLogger("tensorflow").setLevel(logging.DEBUG) import tensorflow as tf from tensorflow import keras import numpy as np import pathlib Обучение модели TensorFlow
# Load MNIST dataset mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() # Normalize the input image so that each pixel value is between 0 to 1. train_images = train_images / 255.0 test_images = test_images / 255.0 # Define the model architecture model = keras.Sequential([ keras.layers.InputLayer(input_shape=(28, 28)), keras.layers.Reshape(target_shape=(28, 28, 1)), keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation=tf.nn.relu), keras.layers.MaxPooling2D(pool_size=(2, 2)), keras.layers.Flatten(), keras.layers.Dense(10) ]) # Train the digit classification model model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) model.fit( train_images, train_labels, epochs=1, validation_data=(test_images, test_labels) ) 1875/1875 [==============================] — 6s 2ms/step — loss: 0.3260 — accuracy: 0.9063 — val_loss: 0.1721 — val_accuracy: 0.9499
Например, поскольку вы обучили модель только для одной эпохи, она обучается только с точностью ~ 96%.
Преобразование в модель TensorFlow Lite
Использование Python TFLiteConverter , теперь вы можете конвертировать обученную модель в модель TensorFlow Lite.
Теперь загрузите модель с помощью TFLiteConverter :
converter = tf.lite.TFLiteConverter.from_keras_model(model) tflite_model = converter.convert() 2021-11-02 11:23:32.211024: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: /tmp/tmpua453ven/assets 2021-11-02 11:23:32.640259: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format. 2021-11-02 11:23:32.640302: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency.
Запишите это в tflite-файл:
tflite_models_dir = pathlib.Path("/tmp/mnist_tflite_models/") tflite_models_dir.mkdir(exist_ok=True, parents=True) tflite_model_file = tflite_models_dir/"mnist_model.tflite" tflite_model_file.write_bytes(tflite_model) 84500
Для квантования модели на экспорте, установите optimizations флаг для оптимизации размера:
converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert() tflite_model_quant_file = tflite_models_dir/"mnist_model_quant.tflite" tflite_model_quant_file.write_bytes(tflite_quant_model) INFO:tensorflow:Assets written to: /tmp/tmpaw0wsb_y/assets INFO:tensorflow:Assets written to: /tmp/tmpaw0wsb_y/assets 2021-11-02 11:23:33.235475: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format. 2021-11-02 11:23:33.235512: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency. 23904
Обратите внимание , как результирующий файл, составляет примерно 1/4 размера.
ls -lh
total 136K -rw-rw-r-- 1 kbuilder kbuilder 83K Nov 2 11:23 mnist_model.tflite -rw-rw-r-- 1 kbuilder kbuilder 24K Nov 2 11:23 mnist_model_quant.tflite -rw-rw-r-- 1 kbuilder kbuilder 25K Nov 2 11:20 mnist_model_quant_16x8.tflite
Запустите модели TFLite
Запустите модель TensorFlow Lite с помощью интерпретатора Python TensorFlow Lite.
Загрузите модель в интерпретатор
interpreter = tf.lite.Interpreter(model_path=str(tflite_model_file)) interpreter.allocate_tensors() interpreter_quant = tf.lite.Interpreter(model_path=str(tflite_model_quant_file)) interpreter_quant.allocate_tensors() Протестируйте модель на одном изображении
test_image = np.expand_dims(test_images[0], axis=0).astype(np.float32) input_index = interpreter.get_input_details()[0]["index"] output_index = interpreter.get_output_details()[0]["index"] interpreter.set_tensor(input_index, test_image) interpreter.invoke() predictions = interpreter.get_tensor(output_index) import matplotlib.pylab as plt plt.imshow(test_images[0]) template = "True:, predicted:" _ = plt.title(template.format(true= str(test_labels[0]), predict=str(np.argmax(predictions[0])))) plt.grid(False) 
Оцените модели
# A helper function to evaluate the TF Lite model using "test" dataset. def evaluate_model(interpreter): input_index = interpreter.get_input_details()[0]["index"] output_index = interpreter.get_output_details()[0]["index"] # Run predictions on every image in the "test" dataset. prediction_digits = [] for test_image in test_images: # Pre-processing: add batch dimension and convert to float32 to match with # the model's input data format. test_image = np.expand_dims(test_image, axis=0).astype(np.float32) interpreter.set_tensor(input_index, test_image) # Run inference. interpreter.invoke() # Post-processing: remove batch dimension and find the digit with highest # probability. output = interpreter.tensor(output_index) digit = np.argmax(output()[0]) prediction_digits.append(digit) # Compare prediction results with ground truth labels to calculate accuracy. accurate_count = 0 for index in range(len(prediction_digits)): if prediction_digits[index] == test_labels[index]: accurate_count += 1 accuracy = accurate_count * 1.0 / len(prediction_digits) return accuracy print(evaluate_model(interpreter)) 0.9499
Повторите оценку на квантованной модели динамического диапазона, чтобы получить:
print(evaluate_model(interpreter_quant)) В этом примере сжатая модель не имеет разницы в точности.
Оптимизация существующей модели
Resnet с уровнями предварительной активации (Resnet-v2) широко используются для приложений технического зрения. Предварительно подготовленный замороженный график для RESNET-v2-101 доступен на Tensorflow Hub .
Вы можете преобразовать замороженный график в плоский буфер TensorFLow Lite с квантованием:
import tensorflow_hub as hub resnet_v2_101 = tf.keras.Sequential([ keras.layers.InputLayer(input_shape=(224, 224, 3)), hub.KerasLayer("https://tfhub.dev/google/imagenet/resnet_v2_101/classification/4") ]) converter = tf.lite.TFLiteConverter.from_keras_model(resnet_v2_101) # Convert to TF Lite without quantization resnet_tflite_file = tflite_models_dir/"resnet_v2_101.tflite" resnet_tflite_file.write_bytes(converter.convert()) WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. INFO:tensorflow:Assets written to: /tmp/tmpxtji1amp/assets INFO:tensorflow:Assets written to: /tmp/tmpxtji1amp/assets 2021-11-02 11:23:57.616139: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format. 2021-11-02 11:23:57.616201: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency. 178509352
# Convert to TF Lite with quantization converter.optimizations = [tf.lite.Optimize.DEFAULT] resnet_quantized_tflite_file = tflite_models_dir/"resnet_v2_101_quantized.tflite" resnet_quantized_tflite_file.write_bytes(converter.convert()) WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. INFO:tensorflow:Assets written to: /tmp/tmpg169iato/assets INFO:tensorflow:Assets written to: /tmp/tmpg169iato/assets 2021-11-02 11:24:12.965799: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format. 2021-11-02 11:24:12.965851: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency. 46256864
ls -lh /*.tflite -rw-rw-r-- 1 kbuilder kbuilder 83K Nov 2 11:23 /tmp/mnist_tflite_models/mnist_model.tflite -rw-rw-r-- 1 kbuilder kbuilder 24K Nov 2 11:23 /tmp/mnist_tflite_models/mnist_model_quant.tflite -rw-rw-r-- 1 kbuilder kbuilder 25K Nov 2 11:20 /tmp/mnist_tflite_models/mnist_model_quant_16x8.tflite -rw-rw-r-- 1 kbuilder kbuilder 171M Nov 2 11:23 /tmp/mnist_tflite_models/resnet_v2_101.tflite -rw-rw-r-- 1 kbuilder kbuilder 45M Nov 2 11:24 /tmp/mnist_tflite_models/resnet_v2_101_quantized.tflite
Размер модели уменьшен со 171 МБ до 43 МБ. Точность этой модели на imagenet может быть оценена с использованием сценариев , предусмотренные точностью измерений TFLite .
Точность оптимизированной модели top-1 составляет 76,8, как и модель с плавающей запятой.
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons «С указанием авторства 4.0», а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2022-01-06 UTC.
How to convert TFLite model to quantized TFLite model?
I have a tflite file and I want to quantize it. How to convert TFLite model to quantized TFLite model?
asked Oct 15, 2020 at 13:08
Uijeong Jeong Uijeong Jeong
21 4 4 bronze badges
2 Answers 2
Please note you’ll need the source model to quantise it. It is not doable to quantise a tflite model due to the limitation of its format.
Your source model could be TF saved_model, Keras model instance, or ONNX. You can find all the supported source model formats HERE, e.g. converter.from_keras_model(nn_path) . For ONNX conversion, please check this tool.
There are various ways for quantisation. The easiest way is to perform post-training-quantisation on the weights only, in which the TF engine applies a min-max quantisation to get the quantisation parameters such as scale and zero points.
The direct codes are:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] # applies PTQ on weights, if possible tflite_quant_model = converter.convert() A few extra things: you can also check out the quantisation-aware training (link)and mix precision training (link) in TF to directly have quantised weights, by which you can get the quantised model via simple TFLite conversion.