Реактивное программирование на Java: как, зачем и стоит ли? Часть I
Идея реактивного программирования появилась сравнительно недавно, лет 10 назад. Что вызвало популярность этого относительно нового подхода и почему сейчас он в тренде, рассказал на конференции РИТ++ 2020 эксперт и тренер Luxoft Training Владимир Сонькин.
В режиме мастер-класса он продемонстрировал, почему так важен неблокирующий ввод-вывод, в чем минусы классической многопоточности, в каких ситуациях нужна реактивность, и что она может дать. А еще описал недостатки реактивного подхода.
В этой статье мы поговорим о том, что такое реактивное программирование, и зачем оно нужно, обсудим подходы и посмотрим примеры.
Почему реактивное программирование получило такую популярность? В какой-то момент перестала расти скорость процессоров, а значит разработчикам уже не приходится рассчитывать на то, что скорость их программ станет увеличиваться сама по себе: теперь их нужно распараллеливать.

На рисунке видно, что график частоты процессоров рос в 90-х, а в начале 2000-х частота резко увеличилась. Оказалось, что это был потолок.
Почему же рост частоты остановился?
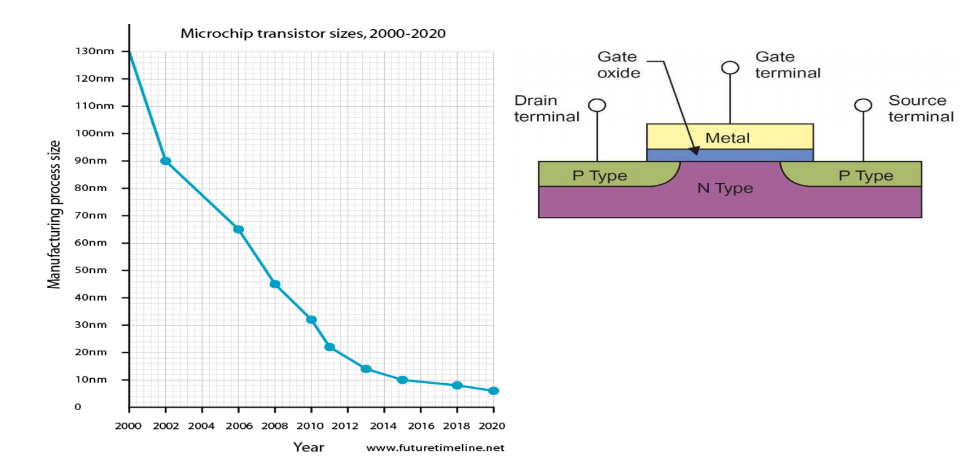
Транзисторы начали делать максимально малого размера. PN-переход, который используется в них, получился настолько тоненьким, насколько это вообще возможно. На графике размеров транзисторов внутри процессора мы видим: размер все меньше и меньше, транзисторов в процессоре все больше и больше.
Такая миниатюризация раньше приводила к тому, что росла частота. Поскольку электроны бегут со скоростью света, за счет уменьшения размера, время, которое требовалось электрону, чтобы пробежать весь путь внутри процессора, уменьшалось. Но техпроцессы уткнулись в физический потолок. Пришлось придумывать что-то другое.
Многопоточность
И мы уже знаем, что удалось придумать: начали делать многоядерные процессоры. Вместо того, чтобы опираться на то, что производительность процессора будет расти, стали рассчитывать увеличение их количества. Но для эффективного использования множества процессоров нужна многопоточность.
Тема многопоточности — сложная, но неизбежная в современном мире. Типичный современный компьютер имеет от 4 ядер и множество потоков. В современном мощном сервере может быть и 100 ядер. Если в вашей программе не используется многопоточность, вы не получаете никаких преимуществ. Поэтому все мировые индустрии постепенно двигаются к тому, чтобы задействовать эти возможности.
При этом нас подстерегает множество опасностей. Программировать с учетом многопоточности сложно: синхронизации, гонки, затрудненная отладка и т.д. попортили немало крови разработчикам. К тому же, стоимость такой разработки становится выше.
В Java многопоточность появилась давным-давно, она существует с самой первой версии.
Выглядит она так:
Писать большую систему, используя примитивы многопоточности, мягко говоря, сложно. Сейчас так уже никто не делает. Это все равно, что кодить на Ассемблере.
Во многих случаях эффект, который приносит многопоточность, не улучшает производительность, а ухудшает ее.
Что же с этим делать?
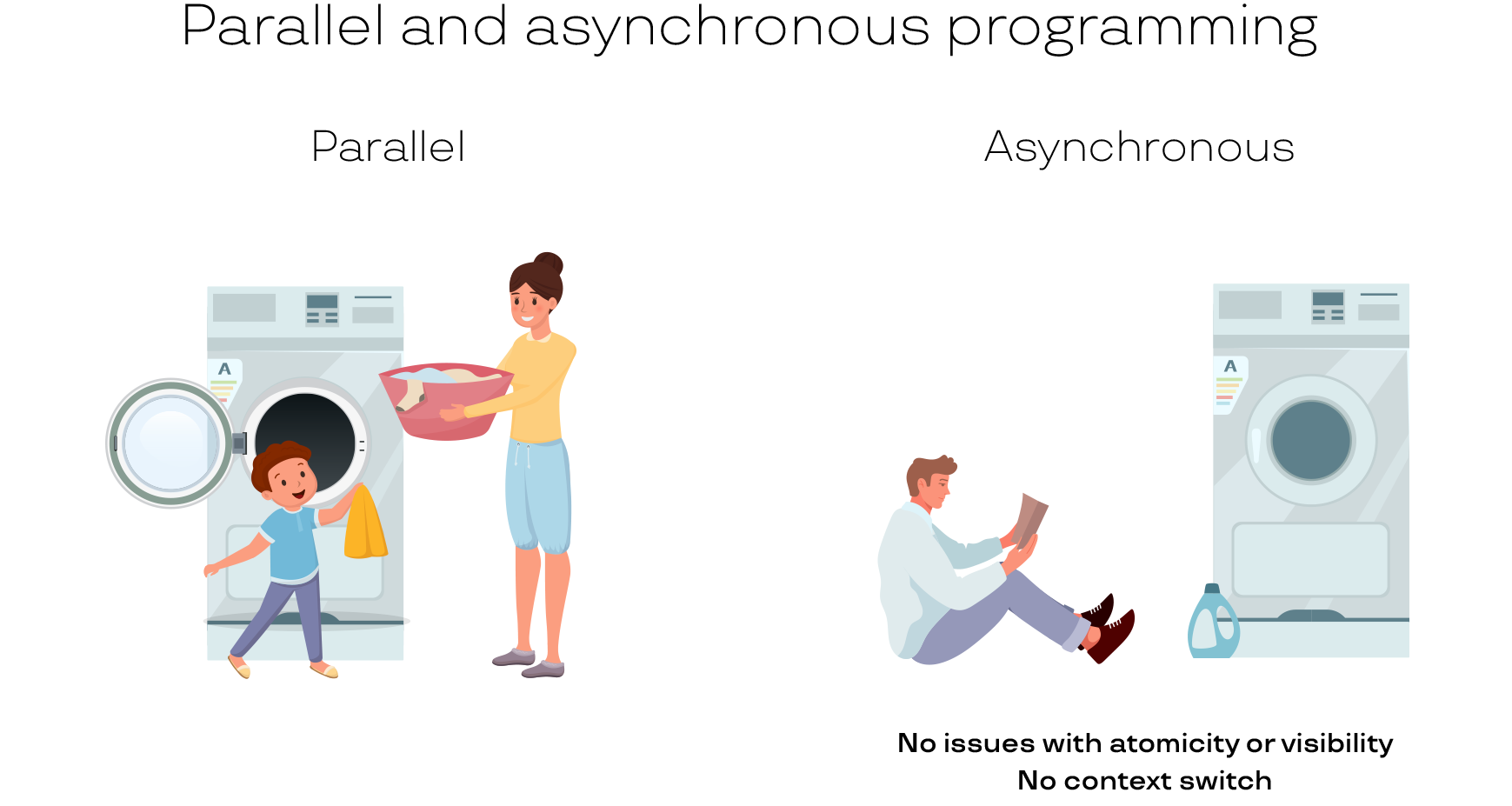
Параллельное программирование во многих ситуациях можно заменить асинхронностью. Посмотрите на иллюстрацию. На левой картинке малыш очень хочет помогать маме в домашних делах. Мама достает из стиральной машинки белье, дает ребенку, и он его укладывает в корзину. Так работает программа на 2 потока: поток-мама и поток-малыш. Теоретически производительность в этом случае должна возрастать: два человека лучше, чем один, ведь мы задействовали два ядра. Но представьте себе такую ситуацию в реальной жизни: мама подает ребенку белье и ждет, пока он его уложит в машинку. Или ребенок ждет белье от мамы. На деле они постоянно мешают друг другу. Плюс, нужно отвести время на передачу белья. Мама быстрее разобралась бы с бельем сама.
Примерно такая же ситуация происходит в компьютере. Поэтому работа с параллельностью совсем не так проста, как кажется. Все синхронизации между потоками выполнения на самом деле занимают кучу времени.
На картинке справа одинокий парень, который купил себе автоматическую машинку. Она стирает, а он в это время может почитать книжку. Здесь однозначно есть преимущество для юноши, потому что он занимается своим делом и при этом не следит за тем, завершилась ли стирка. Когда стирка завершится, он услышит звуковой сигнал и отреагирует на него. То есть параллельность есть, а синхронизации нет. Стало быть нет и траты времени на синхронизацию, сплошная выгода!
Это и есть подход с асинхронностью. Есть отдельный исполнитель, и мы дали ему не часть нашей задачи, а свою собственную. На левой картинке мама и мальчик делают общую задачу, а на правой стиральная машина и парень делают разные, каждый свою. В какой-то момент они соединятся: когда стиральная машина достирает, юноша отложит свою книгу. Но все 1,5 часа, пока белье стиралось, он прекрасно себя чувствовал, читал и ни о чем не думал.
Примеры параллельного и асинхронного подходов
Рассмотрим 2 варианта выполнения потоков: параллельный и асинхронный.
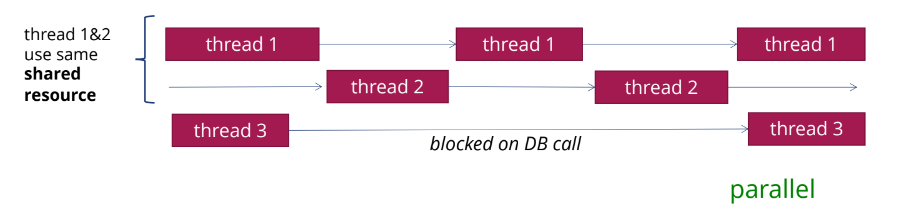
- Потоки выполняются параллельно;
Потокам thread 1 и 2 нужно обращаться к одному и тому же общему разделяемому ресурсу. Допустим, это какая-то база данных, и она не позволяет потокам подключаться к ней одновременно. Или позволяет, но это сразу снижает скорость ее работы, поэтому потокам лучше обращаться к ней по очереди. Никакой параллельности здесь нет: потокам приходится работать по очереди. А третий поток ждет ответа от базы данных, и тоже заблокирован — такая система малоэффективна.
Вроде бы параллельность есть, а преимуществ от нее не так много.
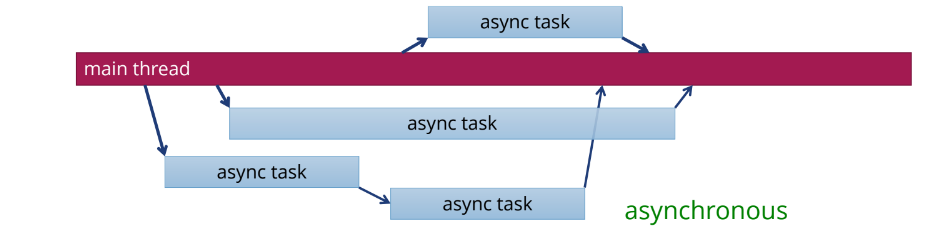
- Потоки выполняются асинхронно.
Если использовать асинхронность, мы ставим задачу, и она выполняется где-то в другом потоке. Например, другим ядром процессора или другим процессором. Мы поставили задачу и занимаемся другими делами, а потом в какой-то момент, когда эта задача завершится, получим результаты. Это можно проиллюстрировать работой организации. Начальник — поток main — ставит задачу Пете, и говорит: «Как только ты ее выполнишь, передай Коле, а тот после завершения работы над задачей пусть доложит мне. В результате Петя и Коля заняты работой, а начальник может ставить новые задачи другим сотрудникам».
Еще один пример: конкуренция и параллелизм.
Представим себе офис, утро, всем хочется выпить кофе. Concurrency (конкуренция) — это когда выстраивается очередь к одной на всех кофемашине. Люди конкурируют: «Эй, я тут первый стоял!» — «Нет, я!». Они друг другу мешают.
В параллелизме есть две кофемашины и две очереди: каждый стоит в своей. Но все равно сотрудники тратят время на то, чтобы постоять там.
Как найти правильное решение для этого сценария, если использовать асинхронность?
Доставка кофе прямо к столу — хороший вариант, в очереди вы не стоите, но придется нанимать официанта, который будет разносить напитки.
Другой возможный вариант — фиксированный график. Например, один сотрудник подходит за кофе в 11:10, следующий — в 11:20 и т.д. Но это не асинхронность. Будут происходить простои, а значит это не полная загрузка кофемашины. Кто-то не успел к своему времени, а кому-то не хватило 10 минут, чтобы сделать себе кофе, и в итоге весь график сдвигается. А если сделать
большие зазоры, кофемашина будет недогружена. И потом, все хотят прийти в 10 утра и выпить кофе, а это растягивается на 2 часа, и кому-то его чашка достанется только в 12.
Еще один вариант — записывать всех желающих в «виртуальную очередь». Когда кофемашина освободится от предыдущих любителей кофе, человек получает уведомление и подходит к кофемашине без очереди. Сейчас во многих организациях так делают. Например, в интернет-магазинах с самовывозом. Берешь талончик и занимаешься своими делами, а когда приходит время, подходишь и получаешь товар. Вот это и есть асинхронность: никто никого не ждет, все работают и получают свой кофе настолько быстро, насколько возможно. И кофемашина тоже не простаивает.
С асинхронностью разобрались. Но есть еще одна важная проблема: блокирующий ввод-вывод.
Блокирующий ввод-вывод
Традиционный ввод-вывод — блокирующий. А что же такое блокирующий ввод-вывод?
Допустим, вы читаете файл или базу данных. Вызывается метод, который это делает, и он блокирует поток: мы больше ничего не делаем, мы ждем. Например, вы вызвали readFile() и ждете, когда это наконец произойдет. Поток блокируется и не прогрессирует: он находится в ожидании. Но на самом деле процессор не занят.

В этом примере заблокированы потоки:
- На чтение файла (blocked on reading file);
- На чтение из базы данных (blocked on reading from DB);
- На сложных вычислениях (blocked on heavy calculations);
- На ответе от клиента (blocked on responding the client).
Эта ситуация сродни той, когда вы пришли в супермаркет, там есть четыре кассы, но система обслуживания касс тормозит. Кассирши сидят, ничего не делают и просто ждут, пока на кассе сработает нажатие на кнопку.
Что делать, если все потоки заблокированы? Как подобные проблемы решаются в супермаркете?
Synchronous I/O
Вариант обычный: синхронный ввод-вывод. Хорошего мало, в этом варианте образуются очереди к кассам.
Что сделать, чтобы возле касс не собирались огромные очереди? Например, можно открыть больше касс, или создать больше потоков.
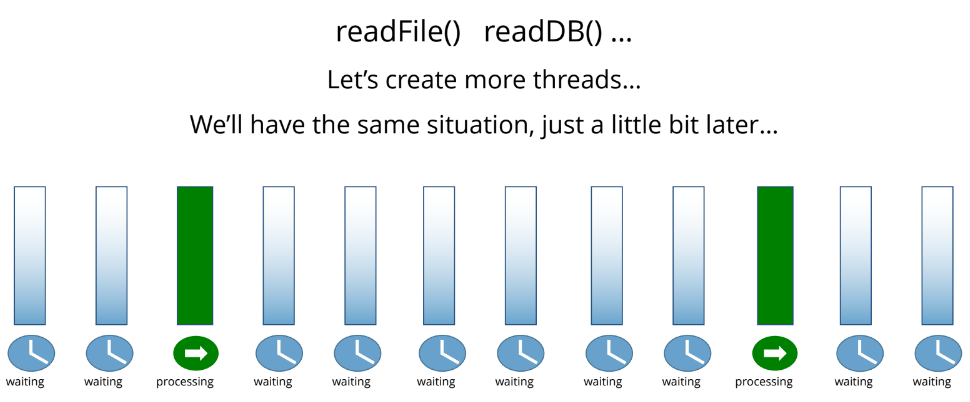
Больше потоков — больше касс. Это рабочий вариант. Но нагрузка получается неравномерной.
Мы открыли много касс (создали много потоков), и получается, что кто-то простаивает. На самом деле, это не просто простой: когда у нас много потоков, есть дополнительный расход ресурсов. Увеличивается расход памяти. Кроме того, процессору нужно переключаться между потоками.

Чем больше потоков, тем чаще между ними нужно переключаться. Получается, что потоков у нас гораздо больше, чем ядер. Допустим, у нас 4 ядра, а потоков мы насоздавали сотню, потому что все остальные были заблокированы чтением данных. Соответственно, происходит переключение, так называемый context switching, чтобы разные потоки получали свою порцию машинного времени.
Но у такого подхода есть минусы. Context switching не бесплатен. Он занимает время. Плодить неограниченное количество потоков было бы неплохим вариантом в теории. Но на практике мы получаем упадок скорости работы и рост потребляемой памяти.
В Java есть разные подходы, которые позволяют с этим бороться — это блокирующие очереди и пулы потоков (ThreadPool). Можно ограничивать количество потоков, и тогда все остальные клиенты встают в очередь. При старте у нас может быть минимальное количество потоков, потом их количество растет.
Вернемся к примеру магазина: если народа нет, в магазине открыты две кассы, а в час пик работает десять. Но больше мы открыть не можем, потому что тогда пришлось бы арендовать дополнительную площадь и нанимать людей. А это ударит по бизнесу.
Теперь поговорим о более современных подходах: кассах самообслуживания, предзаказах и так далее. А значит, мы подбираемся к асинхронному подходу.
Asynchronous I/O
Асинхронный ввод-вывод известен достаточно давно, ведь асинхронность необходима, когда мы работаем с самым медленным инструментом ввода-вывода. А наиболее медленным девайсом ввода-вывода, с которым постоянно приходится работать, является не консоль или клавиатура, а человек. В системах, которые работают с человеком, асинхронность появилась давным-давно.
Блокирующие интерфейсы использовались когда-то и при работе с человеком. Например, старый DOS’овский интерфейс командной строки. И сейчас существуют такие утилиты, которые задают вопрос, блокируются и больше ничего не делают, а ждут, пока человек ответит. С тех пор, как стали появляться оконные интерфейсы, появился асинхронный ввод-вывод. В настоящее время большинство интерфейсов именно асинхронные.
Как работает асинхронность?
Мы регистрируем функцию-callback, но на сей раз не говорим: «Человек, введи данные, а я буду ждать». Это звучит иначе: «Когда человек введет данные, вызови, пожалуйста, эту функцию — callback». Такой подход используется в любых библиотеках пользовательского интерфейса. Но в JavaScript он был изначально. В 2009 году, когда движок JavaScript стал работать гораздо быстрее, умные ребята решили использовать его на сервере, и сделали инструмент под названием Node.js.
Node.js
Идея Node.js в том, что на серверную часть переносится JavaScript, и весь ввод-вывод становится асинхронным. То есть вместо того, чтобы поток блокировался, например, при обращении к файлу, мы получаем асинхронный ввод-вывод. Обращение к файлу тоже становится асинхронным. Например, если потоку нужно получить содержимое файла, он говорит: «Дайте мне, пожалуйста, содержимое файла, а когда оно будет прочитано, вызовите эту функцию». Мы поставили задачу и занимаемся своими делами.
Такой асинхронный подход оказался весьма действенным, и Node.js быстро набрал популярность.
Как работает Node.js?
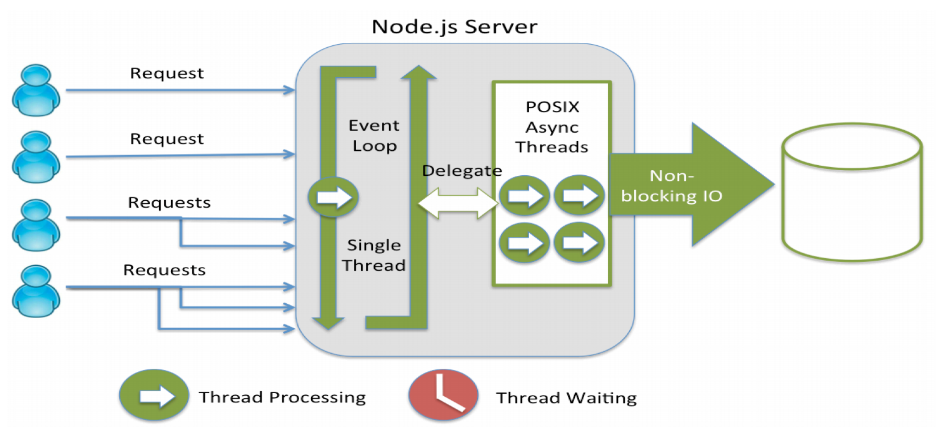
На входе есть приемщик — это цикл. JavaScript однопоточный язык. Но это не значит, что там ничего нельзя делать в других потоках. В нем поддерживаются потоки через Web Workers и т.д. Но на входе стоит один поток.
Вычислительные задачи для Node.js обычно очень маленькие. Основная работа идет с вводом-выводом (в базу данных, в файловую систему, в сторонние сервисы и т.д.). Сами вычисления занимают мало времени. Когда данные получили из базы или из файловой системы, вызывается callback, то есть какая-то функция, в которую передаются данные.
Но в этой схеме нет ожидания. Сравним ее с традиционной моделью многопоточного сервера в Java.
What happens in Java?
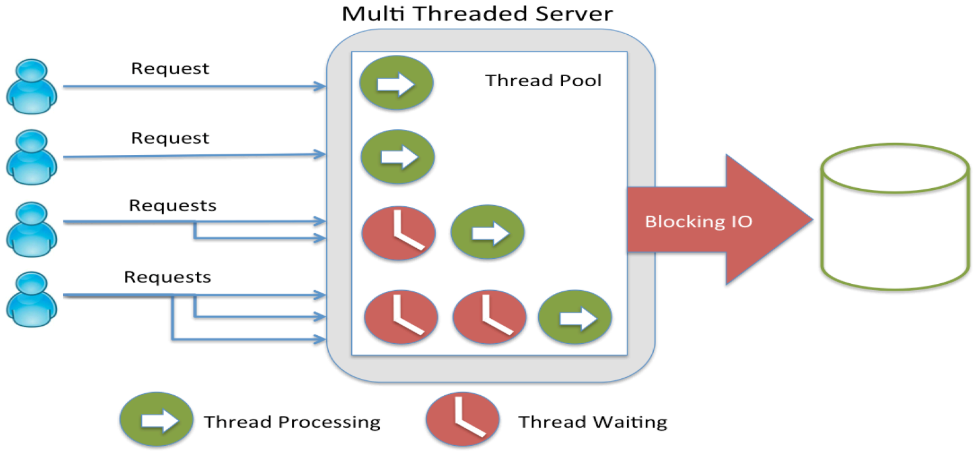
Здесь есть пул потоков. Сначала обращение попадает в первый поток, потом какой-то поток заблокировался, и мы создали еще один. Он тоже заблокировался, создаем следующий. А блокируются они потому, что обращаются к блокирующим операциям ввода-вывода. Например, поток запросил файл или данные из БД и ждет, когда эти данные придут.
Модель Node.js очень быстро стала популярной. Естественно, в этот момент люди стали переписывать ее на других языках. Node.js в какой-то момент вырвался вперед в нагруженных системах с большим объемом ввода-вывода. Но подходит он не для любых систем. Если у вас много вычислений или небольшое количество запросов, то большого преимущества вы не увидите. Соответственно, в Java стали появляться аналогичные решения, в том числе платформа для работы с асинхронным вводом-выводом Vert.x. Сервер Vert.x построен на таком же принципе, что и Node.js.
Решение Node.js интересное, оно действительно помогает повышать производительность. Когда пришла реактивность, стали применять сервер, который называется Netty. Такой подход оказался очень выгодным.
История многопоточности
Как работает многопоточность в Java? Старая добрая многопоточность в Java — это базовые примитивы многопоточности:
- Threads (потоки);
- Synchronization (синхронизация);
- Wait/notify (ожидание/уведомление).
Сложно писать, сложно отлаживать, сложно тестировать.
Java 5
- Future interface:
- V get()
- boolean cancel()
- boolean isCancelled()
- boolean isDone()
- Executors
- Callable interface
- BlockingQueue
В пятой версии появился интерфейс Future. Future — это обещание, или будущее: что-то, что мы можем получить из функции, результат какой-то еще не завершенной асинхронной работы.
У интерфейса Future появился метод get. Он блокирует вызов до завершения вычисления. Например, у нас есть Future, который возвращает данные из БД, и мы обращаемся к методу get:
В этом месте возникает блокировка. На самом деле никакого преимущества от того, что мы использовали Future, нет. Когда можно получить преимущество? Например, мы ставим какую-то задачу, выполняем ее, обращаемся к методу get и в этот момент блокируемся:
Future f = getDBData();
Если вернуться к метафоре начальника и подчиненных, мы поставили задачу, сделали какую-то работу и дальше ждем, пока задача завершится. А если результат этой работы нужно передать еще какому-то человеку? Ранее мы рассматривали такой сценарий: сделай задачу, передай результаты, а потом уже вернись. В случае параллелизма нет такой возможности.
Возможности интерфейса Future очень ограничены. Например, можно узнать, выполнилась ли эта задача:
Future f = getDBData();
if (!f.isDone) doOtherJob();
Если задача еще не доделана, мы можем еще что-то предпринять. Но в любом случае пропустим этот момент: либо задача опять не успеет завершиться, либо, наоборот, она уже давно завершена, а мы занимались другой работой. Моменты синхронизации здесь получаются не очень четкими.
Интерфейс Future имел очень ограниченные возможности в Java 5, поэтому использовать его было неудобно.
Давайте подумаем, какие бизнес-задачи стоят перед типичным приложением?
Data flow
Обычно типичная задача приложения: прочитать, обработать и записать данные. Если мы хотим это делать асинхронно, нужно использовать асинхронные чтение, обработку и запись.
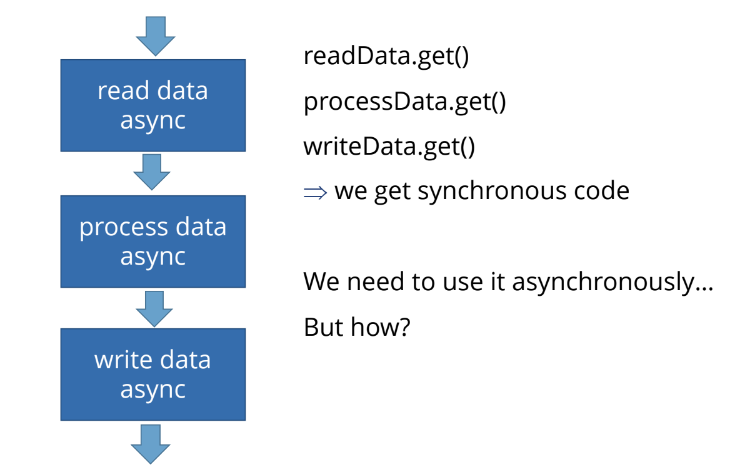
Например, если асинхронная функция блокируется, мы написали прекрасный код:
readData.get() и заблокировались,
processData.get() и заблокировались,
writeData.get() и тут тоже заблокировались.
Получаем синхронный код на выходе. Асинхронности здесь нет, использовать это неудобно.
Рассмотрим типичную задачу, когда есть асинхронное чтение данных, а потом мы хотим обрабатывать их «в три горла»:
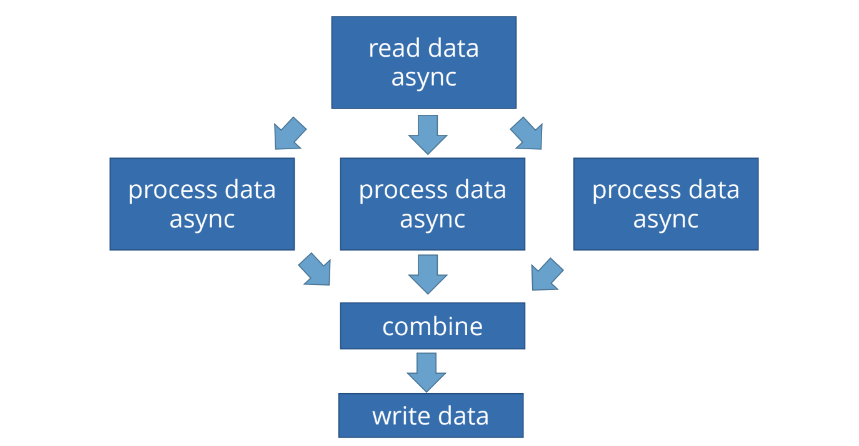
Для того, чтобы дождаться результата чтения, много потоков не нужно. Мы просто должны получить данные. Потом их нужно обрабатывать, а обработка — ресурсоемкая задача с точки зрения процессора, и хорошо бы ее распараллелить. Мы говорим: «Прочитай данные. Когда сделаешь это, обработай их в три потока, после этого соедини результаты выполнения и запиши данные». Хотелось бы, чтобы все это делалось асинхронно.
CompletableFuture brings us to the Async world
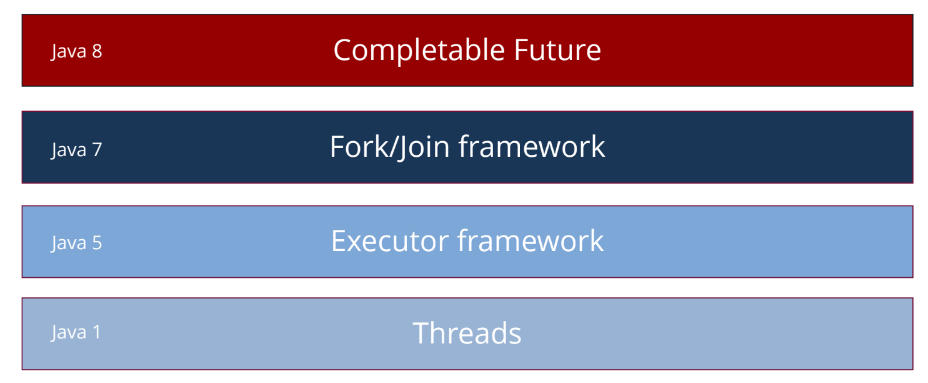
В Java 8 появился CompletableFuture. Он построен на базе Fork/Join framework. Так же, кстати, как и распараллеливание потоков. Fork/Join framework появился еще в Java 7, но его было сложно использовать. В 8 версии CompletableFuture стал шагом вперед: в сторону асинхронного мира.
Рассмотрим простенький пример.
В коде оранжевым выделены методы CompletableFuture из стандартного JDK.

Допустим, у нас есть API, который позволяет:
- Читать данные (readData) из источника и возвращать CompletableFuture, потому что он асинхронный;
- Обрабатывать данные, для чего есть два обработчика: processData1 и processData2;
- Объединять данные (mergeData) после того, как они обработаны;
- Записать данные (writeData) в приемник (Destination).
Это типичная задача — прочитать данные, обработать их «в два горла», потом соединить результаты этой обработки и куда-то записать.
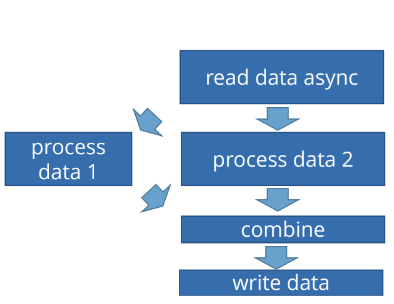
Мы прочитали данные:
CompletableFuture data = readData(source);
Дальше говорим: когда прочитаем данные, нужно отправить их на обработку:
CompletableFuture processData1 = data.thenApplyAsync(this::processData1);
Это значит, что нужно запустить их обработку в отдельном потоке. Так как у нас здесь используется Async постфикс, стартует обработка в двух разных потоках:
CompletableFuture processData2 = data.thenApplyAsync(this::processData2);
То есть функции this::processData1 и this::processData2 будут запущены в двух разных потоках и будут выполняться параллельно. Но после параллельного выполнения их результаты должны соединиться. Это делает thenCombine.
Мы здесь запустили два потока выполнения, и, когда они завершились, скомбинировали их. thenCombine работает так: он дожидается, когда и processData1, и processData2 завершатся, и после этого вызывает функцию объединения данных:
То есть мы объединяем результаты первой и второй обработки, и после этого записываем данные:
Здесь получается цепочка, которая по сути является бизнес-процессом. Мы как бы говорим: «Таня, забери данные из архива, отдай Лене и Грише на обработку. Когда и Леня, и Гриша принесут результаты, передай их Вере, чтобы она соединила их, а потом отдай Вите, чтобы он написал отчет по этим данным».
У нас здесь нет четкого графика, о котором мы говорили в начале: есть возможность передать данные сразу же, как только сможем. Единственный, кто здесь ждет — это thenCombine. Он ожидает, когда оба процесса, результат которых он объединяет, завершатся.
CompletableFuture — это действительно крутой подход, который помогает делать асинхронные системы.
В следующей части нашей статьи поговорим о более высокоуровневых подходах к асинхронности и разберем операторы реактивного программирования.
Конференция HighLoad++ 2020 пройдет 20 и 21 мая 2021 года. Приобрести билеты можно уже сейчас.
Хотите бесплатно получить материалы конференции мини-конференции Saint HighLoad++ 2020? Подписывайтесь на нашу рассылку.
- java
- асинхронное программирование
- реактивное программирование
- highload
- конференции
- Блог компании Конференции Олега Бунина (Онтико)
- Высокая производительность
- Программирование
- Java
- Параллельное программирование
Осваиваем реактивное программирование на Java
Асинхронный ввод/вывод уже какое-то время используется в обиходе. При этом разные языки реализуют его по-разному, но все предоставляют способ уменьшить количество потоков, давая вроде бы полную конкурентность. JavaScript занимался этим с самого начала. При использовании всего одного потока будет мало хорошего, отправь вы в продакшн блокирующий вызов.
Несмотря на то, что реактивный Java все больше привлекает интерес разработчиков, большинство знакомых мне программистов по-прежнему живут в многопоточной парадигме. Почему? Принцип потоков относительно легко усвоить. Реактивное же программирование требует переосмысления многих привычных нам принципов программирования. Попытка объяснить, почему асинхронный ввод/вывод является лучшей альтернативой, подобна попытке объяснить сферичность Земли тому, кто всегда верил в ее плоскую природу.
Я предпочитаю обучаться через игру и эксперименты, создавая “игрушечные” системы, которые затем при необходимости можно использовать в качестве основы для больших систем. Здесь я представлю одну такую базовую систему, которая продемонстрирует основы реактивного Java, используя Project Reactor. А поскольку она мала (меньше тысячи строк в девяти файлах), то и понять ее будет несложно.
Это система псевдо-микросервисов. То есть несмотря на то, что все заключено в один исполняемый файл, каждый “сервис” находится в отдельном классе, который не содержит состояния, а сами классы могут взаимодействовать друг с другом только с помощью очереди сообщений и базы данных. Их все запускает один основной класс, при этом они программируются на завершение по истечению установленного периода времени.
Моя система смоделирована на основе схемы приема подержанных транспортных средств (ТС) и начинается с заказа на покупку, который в нашем случае будет случайно генерироваться и добавляться в очередь сообщений. Другой сервис получает заказ на покупку из этой очереди, добавляет его в базу данных и отправляет информацию о типе ТС в одну из трех очередей сообщений, в зависимости от того легковой это автомобиль, грузовик или мотоцикл. В завершении есть еще три сервиса, которые считывают эти три очереди, проверяют наличие заказа в базе данных и определяют автомобилю парковочное место для транспортировки.
Функция main выступает больше в качестве функции тестирования, поскольку в настоящей системе микросервисов каждый из них должен иметь собственную функцию main или быть частью такого фреймворка, как Spring. Однако нам нужно лишь увидеть, что все согласованно работает в одной JVM. Настоящий тест этой системы заключается в наблюдении работоспособности всех сервисов по-отдельности, но я предположу, что это сработает и так либо потребует минимальных корректировок. Вот суть функции main :
PurchaseOrderConsumer.consume();
CarConsumer.consume();
TruckConsumer.consume();
MotorcycleConsumer.consume();
PurchaseOrderGenerator.start();
Мы стартуем всех потребителей, после чего запускаем генератор заказа на покупку, который создает заказы и поочередно помещает их в очередь в течение 10 секунд. Поскольку ни у одного из классов нет состояния, все их методы могут быть статическими.
Так как все действие начинается в PurchaseOrderGenerator , первым делом мы заглянем туда. Вот основная часть кода:
Sender sender = RabbitFlux.createSender(soptions);
sender.sendWithPublishConfirms(
Flux.generate((sink) -> sink.next(createRandomPurchaseOrder()))
.cast(PurchaseOrder.class)
.doOnNext((o) -> log("produced: " + o))
.delayElements(Duration.ofMillis(100))
.take(Duration.ofSeconds(10))
.map(i -> new OutboundMessage("",
QUEUE_NAME,
writeJson(i).orElse("").getBytes()))
.doFinally((s) -> log("Generator in finally for signal " + s);
sender.close();
>)
)
.subscribe();
Мы используем очередь сообщений RabbitMQ, являющуюся реактивной библиотекой Java. Она содержит Sender.sendWithPublishConfirms , который получает Flux и возвращает Flux . Flux — это последовательность элементов, к которым можно обращаться по одному. Ее длина может быть бесконечной, и одновременно в процессе задействуется только один элемент, хотя можно задействовать и больше, что определяется рядом факторов.
Flux является ключевым компонентом библиотеки асинхронного ввода/вывода Project Reactor. Он позволяет объединять методы в цепочку, чтобы управлять элементами по ходу их движения в потоке через систему, а также управлять самим этим потоком. Методы, управляющие элементами, обычно получают в качестве параметров лямбда-функции, что позволяет вызывать их для каждого элемента по мере его продвижения через систему. Два самых распространенных метода — это map и filter . map предназначен для преобразования элементов в потоке из одного типа в другой. filter служит для отбрасывания элементов, не соответствующих определенным критериям.
Нам нужно создать непрерывный список заказов на покупку и представить его методу Sender.sendWithPublishConfirms как Flux . Этот процесс мы начинаем со строки Flux.generate((sink) -> sink.next(createRandomPurchaseOrder())) , которая создает потенциально бесконечный список случайных заказов на покупку. Поскольку Flux.generate возвращает Flux , нам нужен метод cast , который даст системе понять, что мы работаем над объектами PurchaseOrder . Flux -метод doOnNext представляет удобный способ ввести побочные эффекты. Здесь я его использую в основном для логирования.
Далее метод delayElements добавляет задержку между каждым элементом. Я делаю это для симуляции появления случайных заказов с разумной скоростью. Можете без проблем его удалить, но тогда вместо выполнения системы в течение десяти секунд и завершения, она будет заполняться очередями сообщений о заказах на покупку, для обработки которых потребуется уже более двух минут. Метод take позволит Flux выполнять обработку на протяжении десяти секунд и затем останавливаться. Я так делаю, потому что этот генератор служит исключительно для тестирования. В реальной же системе заказы на покупку наверняка будут поступать из API, который будет добавлять их в очередь сообщений.
Чтобы RabbitMQ обрабатывал элементы, сначала их нужно преобразовать в OutBoundMessage как массив байтов, представляющий сериализацию JSON заказа на покупку. Это делается с помощью метода map и лямбда-выражения, которое создает нужный OutBoundMessage . Если в сериализации заказа на покупку возникает ошибка, мы отправляем пустой массив, который на противоположной стороне отфильтруется. Можно отфильтровать его и здесь, чтобы избавить очереди от необходимости передачи недействительных сообщений. Но нам все равно нужна проверка на встречной стороне, и раз уж это всего лишь тестовая схема, то можно отправить и их.
Метод doFinally вызывает свое лямбда-выражение всего раз, и в данном случае мы используем его для логирования завершения потока и закрытия отправителя. В конце этой цепочки мы получаем Flux , который подходит для передачи методу Sender.sendWithPublishConfirms . Назад же мы получаем Flux , который можно проверить, чтобы убедиться в размещении сообщения в соответствующей очереди. В данном простом случае проверку мы не делаем.
Метод subdcribe , который вызывается для Flux , начинает цепочку. Важно отметить, что до вызова метода subscribe мы всего лишь выстраиваем цепочку действий. Как только вызывается метод subscribe , мы больше ничего с потоком данных не делаем, и он возвращает только объект Disposable , который можно использовать, чтобы остановить подписку. Мы даже не храним объект Disposable , поскольку наш поток остановится спустя десять секунд, как прописано в цепочке событий. Начальный Flux, который мы создали с помощью метода generate , не завершается вызовом subscribe , но ожидает, что Sender , которому мы его передаем, подпишется на него, чтобы запустить эту цепочку событий.
Прежде чем перейти к реальным сервисам в системе, заглянем за кадр и посмотрим, что всем этим движет. Здесь есть один магический элемент, который в большинстве случаев остается незаметен, а именно Scheduler . Взгляните на Flux , созданный generate . Первые два метода в цепочке, cast и doOnNex , содержат лямбда-функции, которые не блокируются и возвращают результат через очень небольшой промежуток времени. Однако следующий метод в цепочке, delayElements , должен каким-то образом блокироваться, чтобы вносить в поток задержку. Как же нам заблокировать функцию в мире без блокировок? Ответом будет Scheduler (планировщик). Планировщик может просматривать цепочку, а также проходящие через нее элементы, решая, какой из них и в какой части цепочки должен быть обработан.
У вас голова еще не взорвалась? На это можно посмотреть так. Внутри многозадачной операционной системы нечто наблюдает за ожидающими процессами и решает, какой из них очередным получит внимание ЦПУ. Планировщик работает аналогичным образом, только ему не нужно беспокоиться о прерываниях. Все задачи, с которыми работает планировщик, представляют очень мелкие фрагменты кода. “Блокирующие” задачи вроде delayElements разбиваются на две части. Первая часть получает элемент из потока, устанавливает таймер и возвращает управление планировщику. Далее планировщик может выполнять какую-нибудь другую задачу. Как только таймер метода delayElements истекает, вызывается вторая часть и сохраненный элемент получает возможность перемещения в следующий метод цепочки.
Я рассматриваю этот процесс как две непрерывные конвейерные ленты. Первая перемещает элементы по направлению ко второй, но вторая движется намного медленнее. В итоге элементы задерживаются на первой ленте, в то время как вторая их постепенно с нее снимает. По мере накопления задерживающихся элементов возникает так называемое “обратное давление”, и система понимает, что нужно просто остановить первую ленту, пока вторая ее немного не догонит.
Далее рассмотрим второй сервис системы, PurchaseOrderConsumer . Его задача в извлечении элементов из очереди заказов на покупку, их логировании в базе данных, обработке и последующем отборе для другой очереди. Вот основной код:
Sender sender = RabbitFlux.createSender(soptions);
Receiver receiver = RabbitFlux.createReceiver(roptions);
sender.sendWithPublishConfirms(receiver
.consumeAutoAck(PO_QUEUE_NAME)
.map(d -> readJson(new String(d.getBody())))
.filter(PurchaseOrder::isValid)
.doOnNext(po -> log("recevied po " + po))
.doOnDiscard(PurchaseOrder.class,
po -> log("Discarded invalid PO " + po))
.flatMap(po -> writePoJson(po).map(j -> reactiveCollection
.upsert(po.getId(), j)
.map(result -> po))
.orElse(Mono.just(po)))
.map(po -> factory.build(po.getType(), po))
.timeout(Duration.ofSeconds(10))
.doFinally((s) -> log("Consumer in finally for signal " + s);
receiver.close();
sender.close();
cluster.disconnect();
>)
.map(v -> new OutboundMessage("",
outQueue.get(v.getPo().getType()),
vehicleWriter
.get(v.getPo().getType())
.apply(v)
.orElse("")
.getBytes()))
)
.subscribe();
Очень похоже на первый сервис. Здесь присутствует внешняя обертка, которая отправляет отобранные объекты по разным очередям сообщений и вызывает subscribe . Разница в том, что вместо получения Flux для отправки с помощью метода generate , мы получаем Flux от метода Receiver.consumeAutoAck . Таким образом создается поток элементов, поступающих из очереди сообщения заказов на покупку, после чего мы можем выстраивать для них цепочку обработки. Эта цепочка состоит в основном из обычных методов, map для преобразования строки JSON в элемент, filter для удаления недействительных сообщений, doOnNext и doOnDiscard для логирования обрабатываемых заказов на покупку или тех, которые были отфильтрованы.
Затем мы переходим к новому методу, flatMap . Это особый метод, заслуживающий внимания. Те, кому flatMap знаком из Java Streams, знают, что если трансформация возвращает Stream (или список, который можно легко преобразовать в Stream), то flatMap изменит внешний Stream, чтобы он включал все элементы внутреннего Stream. Другими словами, он преобразует Stream (поток) потоков в единый поток из всех элементов. В мире Flux происходит то же самое, преобразование Flux (последовательности) последовательностей в единую последовательность со всеми элементами.
В рассматриваемом нами случае преобразование касается метода ReactiveCollection.upsert , который вставляет заказ на покупку в CouchBase. Возвращаемый тип получается Mono . Нам еще нужно поговорить о Mono , который представляет особый тип Flux . Работает Mono во многом аналогично Flux , но может содержать либо один элемент, либо быть пустым. Также аналогично Flux содержащийся в нем элемент не материализуется с помощью Mono , но требует его подождать. Тут нам снова нужно задерживать обработку вложенного элемента, но без блокирования.
Здесь на помощь приходит flatMap . В этом случае, так как внутренней структурой является Mono , во внешнем Flux по-прежнему соблюдается соответствие один к одному. На деле мы отбрасываем результат и просто возвращаем оригинальный заказ на покупку для дальнейшей обработки (как делалось отображением map(result -> po) ). Итак, flatMap работает аналогично методу delayElements , о котором говорилось ранее, где он разбивается на две части, между которыми втискивается весь ввод/вывод базы данных. Но планировщик знает, что нужно передать элемент во flatMap и переходить к обработке другого элемента. Он также не забудет получить возвращаемый элемент базы данных, когда он будет готов к дальнейшей обработке. И снова flatMap разделяет нашу воображаемую конвейерную ленту на две части.
Осталось проговорить последний метод цепочки, остальные же аналогичны предыдущим. Если бы речь шла о реальном сервисе, то метод timeout даже не должен был бы находиться в потоке. У нас он присутствует только, чтобы отменять поток, когда в рамках заданного временного промежутка не происходит получение элемента. Это позволяет нашей небольшой игрушечной системе все закрывать и в конечном итоге завершаться.
В реальном сервисе такого бы у вас наверняка не было. Единственное исключение возможно, если сервис ожидает определенное количество элементов в секунду, и в течение нескольких минут не получает ни одного. Тогда вы можете заподозрить, что было потеряно соединение с очередью, и захотите, чтобы служба оркестровки, например Kubernetes, перезапустила ваш сервис.
Еще один вариант применения таймаута — это тестирование кода. Если ваш тест ожидает элемент из очереди сообщений, то вы можете установить таймаут так, чтобы тест не ждал бесконечно.
В системе остался заключительный набор сервисов, считывающий очереди сообщений, в которые PurchaseOrderConsumer выводит тип Vehicle . Единственная выполняемая им обработка состоит в считывании заказа на покупку из типа Vehicle , подтверждении наличия заказа в базе данных, определении для него парковочного места согласно типу Vehicle и логировании конечного объекта. В реальной системе вы бы наверняка захотели добавить его в учетную базу данных транспортных средств либо использовать какой-либо другой способ отслеживания.
Я создал три класса сервисов, по одному для каждого типа; Car (легковое авто), Truck (грузовик) или Motorcycle (мотоцикл). В примере текущего кода я мог сделать один класс с рядом параметров и запустить метод получения три раза, по одному для каждого типа. Но я оставил их отдельными, так как предвидел, что для каждого типа потребуется своя логика, кардинальность типов окажется очень низка, а базовый код короче сотни строк. Если бы у сервисов было много общей логики, я бы не пожалел лишнего времени на их объединение. Но мой прагматизм иногда превосходит перфекционизм, и мне это нравится.
Чтобы все проверить, пришлось запустить CoucheBase и RabbitMQ. В обоих случаях я просто создал экземпляр Docker:
docker run -d --hostname my-rabbit -p 5672:5673 rabbitmq:3
docker run -d -p 8091-8094:8091-8094 -p 11210:11210 couchbase
В случае с CouchBase мне пришлось открыть консоль администратора по адресу http://localhost:8091, прокликать пользовательское соглашение и настроить корзину po . После этого я смог запустить сервисы и наблюдать журнал:
.
pool-10-thread-20 recevied po PurchaseOrder(id=e186589fd87279f3, price=78023.46, type=Motorcycle, time=2021-01-05T15:43:10.704386Z)
cb-io-kv-17-2 po for motorcycle e186589fd87279f3 confirmed
cb-io-kv-17-2 received motorcycle Vehicle(po=PurchaseOrder(id=e186589fd87279f3, price=78023.46, type=Motorcycle, time=2021-01-05T15:43:10.704386Z), lot=motorcycle lot a)
parallel-8 Generator in finally for signal onComplete
parallel-13 Car consumer in finally for signal cancel
parallel-14 Truck consumer in finally for signal cancel
parallel-7 Motorcycle consumer in finally for signal cancel
parallel-4 Consumer in finally for signal onError
------------------------------------------------------------------------
BUILD SUCCESS
------------------------------------------------------------------------
Total time: 25.775 s
Finished at: 2021-01-05T07:43:23-08:00
------------------------------------------------------------------------
Сборка прошла успешно! Если вы соберете и запустите систему, то советую внимательно проследить за логами, все из которых выводят текущий поток. Вскоре вы заметите паттерн маленьких конвейерных лент (некоторые будут выполняться параллельно), о котором я говорил.
Надеюсь, что помог вам понять предлагаемое Project Reactor асинхронное решение ввода/вывода. Разобраться с использованием цепочек методов может быть непросто, но я верю, что, как только вы это осилите, все будет читаться намного проще. Эта техника берет нормальный декларативный стиль программирования и делает его больше похожим на императивный. Весь код моего игрушечного проекта можете найти здесь:
Реактивное программирование простыми словами — объясняют эксперты
Мы уже разобрались с такими парадигмами, как динамическое, декларативное и императивное программирование. Настал черёд реактивного.
В предыдущих статьях эксперты объяснили нам, что такое объектно-ориентированное, динамическое, декларативное и императивное программирование. В этот раз узнали у них, что из себя представляет реактивное программирование.
Что такое реактивное программирование?
Павел Романченко
технический директор центра инновационных технологий и решений «Инфосистемы Джет»
Классический подход к программированию предполагает выполнение запроса (к базе, сервисам и т.д.), ожидание ответа и продолжение работы. Во время ожидания поток простаивает. Масштабируют такие системы путём увеличения количества потоков, при этом вычисление оптимального количества потоков становится непростой задачей, так как сильно зависит от характера нагрузки, количества и качества ожиданий. И несмотря на это, избежать на 100% простоя ресурсов не удается.
В реактивном программировании обработка делится на большое количество небольших задач, выполнение каждой из которых оканчивается неким событием. На возникновение этого события реагирует соответствующий обработчик и выполняет свою задачу, опять генерирует событие и общий процесс обработки продолжается. Генерация события и реакция на него происходят асинхронно. Обработчик (их ещё называют акторами) выбирает следующее событие из очереди, обрабатывает и складывает событие в очередь другому обработчику. Если задача заключается в выполнении запроса в базе данных, то актор посылает запрос на сервер. После получения ответа будет сгенерировано событие с результатом запроса и запущен соответствующий актор.
Всё это позволяет более эффективно занять ресурсы полезной работой и управлять масштабированием. Повышается отзывчивость приложений. Кроме того, реактивное программирование помогает масштабироваться горизонтально.
Камиль Закиев
senior developer IT-компании Maxima
Понятие реактивного программирования тесно связано с понятием модели распространения данных, которая бывает двух типов:
- pull-модель.
- push-модель.
На самом деле, эти модели вполне логичны и естественны, поэтому их проявления можно проследить даже в обычной жизни.
Допустим, Вася любит быть в курсе всех новостей по хоккею и поэтому периодически посещает тематические сайты в надежде обнаружить интересный контент.
Его коллеге — Пете — тоже интересен хоккей, но в отличие от Васи, Петя подписался на рассылку новостей и получает уведомления о важных событиях в хоккее.
С точки зрения программирования, Вася использует pull-модель: периодически просматривает источники данных, в то время как Петя — push-модель: занимается обработкой входящих сообщений.
Таким образом, реактивное программирование — это стиль написания кода, который упрощает реализацию приложений, основанных на push-модели.
На практике этот стиль применяется для обработки входящего потока данных, например:
- сообщения от пользователей;
- уведомления об изменении расписания;
- действия пользователя с интерфейсом и т.д
Константин Коптяев
руководитель направления платформы Bercut
Реактивное программирование — это подход к разработке ПО, который строится на реагировании на события и на распространении событий. При этом модель реакции на события предполагает возможность простого распространения этих или трансформированных событий далее по системе. Ярким примером реализации реактивного подхода может служить таблица Excel. В ней существует цепочка вычислений, разделённая на несколько ячеек: при изменении значения одной из ячеек в цепочке значения в зависимых ячейках пересчитываются автоматически.
В целом, идея реактивного программирования призвана упростить создание сложных систем. В сложной большой системе возникает значительное количество разнообразных событий, каждое требует определённого механизма реакции и обработки. При использовании реактивного программирования события объединяются в потоки, а компоненты системы являются обработчиками потока событий (и также в свою очередь могут являться генераторами событий). Таким образом, сколь ни была бы сложна система и сколько бы в ней ни было разнообразных событий, вся система строится по принципу генерации потоков событий и реакции на них. Подход в моделировании сложной системы позволяет обрабатывать каждое событие асинхронно и изолированно от других. Важно понимать при этом, что дизайн реактивной системы предполагает, что любая функциональность в системе реализуется с помощью событий и обработчиков. Благодаря этому достигается уменьшение связанности между компонентами системы, увеличение гибкости, упрощение масштабирования и повышение устойчивости систем.
Дмитрий Немов
руководитель мобильной разработки SimbirSoft
Парадигма реактивного программирования включает отслеживание определенных событий и реагирование на них в асинхронных потоках данных. Эта идея предполагает, что существует источник событий и слушатель событий, который реагирует на события источника.
Суть реактивного программирования можно изобразить разными способами. Например, представим реку, течение которой несет несколько разноцветных объектов (мячей). Допустим, на берегу сидит человек, которому нужно выловить объекты с определенной характеристикой – только зеленые или красные. Если нам требуется запрограммировать подобную ситуацию, то реактивный подход – это то, что поможет нам оперировать потоками данных, получать данные, совершать математические вычисления и т.д. Работа с потоками требует от программиста определенного опыта и понимания, что и как комбинировать, какие операторы подходят для решения задачи.
Реактивный подход активно используется в Frontend-разработке и мобильной разработке, одним из его популяризаторов является Netflix.
Глеб Лысов
старший разработчик систем автоматизации и поддержки сервисов мониторинга и реагирования на киберугрозы в BI.ZONE
Само название парадигмы наводит на мысль, что реактивное программирование подразумевает какую-либо реакцию на изменения. Так и есть: реактивное программирование удобно при создании интерфейсов и построении моделей систем, изменяющихся во времени.
Реальным применением этой парадигмы может стать веб-фреймворк, поддерживающий архитектуру MVC (Model-View-Controller), в котором при изменении модели изменяется поведение пользовательских представлений.
Предположим, есть модель Пользователь с полями Имя и Фамилия. Добавляем поле Отчество — и во всех местах, будь это форма на сайте или структура базы данных, происходят соответствующие изменения: форма при следующей генерации содержит новое поле, а для БД генерируется миграция.
В рамках парадигмы чаще всего используют функции обратного вызова (callback) и конструкции асинхронного программирования (конкретные виды зависят от языка). Также здесь задействуют события (events) или потоки (flows). Если в коде есть такие «следы», значит, с большой вероятностью здесь применяется концепция реактивного программирования
Итак, что из себя представляет реактивное программирование?
В реактивном программировании обработка делится на большое количество небольших задач, выполнение каждой из которых оканчивается неким событием. На событие реагирует обработчик, который выполняет свою задачу и снова генерирует событие. Генерация события и реакция на него происходят асинхронно.Идея реактивного программирования призвана упростить создание и масштабирование сложных систем.Примером реактивного подхода может служить таблица Excel. В ней существует цепочка вычислений, разделённая на несколько ячеек: при изменении значения одной из ячеек значения в зависимых ячейках пересчитываются автоматически.
Напоминаем, что вы можете задать свой вопрос экспертам, а мы соберём на него ответы, если он окажется интересным. Вопросы, которые уже задавались, можно найти в списке выпусков рубрики. Если вы хотите присоединиться к числу экспертов и прислать ответ от вашей компании или лично от вас, то пишите на experts@tproger.ru, мы расскажем, как это сделать.
Что такое реактивное программирование в Java?


Программирование и разработка
На чтение 4 мин Просмотров 128 Опубликовано 15.05.2023
Реактивное программирование — важная парадигма программирования, которая становится все более популярной в разработке Java. Реактивное программирование основано на использовании асинхронных и неблокирующих потоков данных для обработки данных и событий. В этой статье мы рассмотрим концепцию реактивного программирования в Java, варианты его использования и то, как оно может помочь разработчикам.
Что такое реактивное программирование?
Реактивное программирование — это парадигма программирования, ориентированная на обработку потоков данных и событий. Эта парадигма программирования использует асинхронный и неблокирующий код для обработки потоков данных, что делает его более эффективным и масштабируемым. Реактивное программирование основано на идее реагирования на события вместо их блокировки и ожидания.
Реактивное программирование отличается от традиционных парадигм программирования тем, что оно использует потоки данных и событий вместо объектов и методов. Это позволяет разработчикам писать более эффективный, отзывчивый и отказоустойчивый код.
Реактивный ландшафт
Реактивный ландшафт относится к различным инструментам, платформам и шаблонам, которые используются для создания реактивных систем. Реактивные системы спроектированы так, чтобы быть отзывчивыми, устойчивыми, эластичными и управляемыми сообщениями. Они хорошо масштабируются и могут обрабатывать большое количество запросов с минимальными ресурсами.
Реактивный ландшафт включает в себя несколько фреймворков и инструментов, таких как Reactive Streams, RxJava, Reactor, Spring Framework, Akka и Ratpack. Эти фреймворки и инструменты предоставляют разработчикам необходимые строительные блоки для создания реактивных систем.
- Reactive Stream— это низкоуровневая спецификация, определяющая взаимодействие между асинхронной обработкой потока и неблокирующим противодавлением. Это стандарт для создания реактивных систем на Java, который был включен в JDK как java.util.concurrent.Flow в версии 9.
- RxJava— это библиотека для создания асинхронных и событийных программ с использованием наблюдаемых последовательностей. Это позволяет разработчикам работать со сложными асинхронными потоками данных с возможностью применять к этим потокам такие операции, как фильтрация, сопоставление и объединение.
- Reactor— это среда Java для создания реактивных систем. Он строится непосредственно на Reactive Streams и предоставляет полный набор строительных блоков для создания реактивных систем, включая модель программирования, управляемую событиями, обработку обратного давления и поддержку нескольких источников данных.
- Spring Framework 5.0включает реактивные функции для создания HTTP-серверов и клиентов. Он основан на Reactor и предоставляет знакомую модель программирования для разработчиков, уже знакомых со Spring. Spring Framework 5.0 включает поддержку нескольких сетевых стеков, включая Tomcat, Jetty, Netty и Undertow.
Читайте также: Удалить специальные символы из строки Python
Примеры использования реактивного программирования
Реактивное программирование используется в различных случаях, в том числе:
- Потоковые данные в реальном времени.Реактивное программирование идеально подходит для обработки потоковых данных в реальном времени. Его можно использовать для обработки потоков данных от датчиков, социальных сетей и других источников.
- Веб-разработка.Реактивное программирование можно использовать для обработки асинхронных и неблокирующих веб-запросов. Его можно использовать для создания масштабируемых и эффективных веб-приложений.
- Интернет вещей:реактивное программирование идеально подходит для обработки потоков данных с устройств IoT. Его можно использовать для обработки больших объемов данных и событий в режиме реального времени.
- Большие данные. Реактивное программирование можно использовать для обработки больших объемов данных в режиме реального времени. Его можно использовать для обработки и анализа данных в режиме реального времени.
Как это помогает разработчикам?
Реактивное программирование помогает разработчикам:
- Повышение производительности.Реактивное программирование позволяет разработчикам писать более быстрый и отзывчивый код. Реактивные приложения могут обрабатывать большие объемы данных и обрабатывать их в режиме реального времени, что помогает повысить производительность.
- Повышение масштабируемости.Реактивное программирование позволяет разработчикам писать более масштабируемый код. Реактивные приложения могут обрабатывать большое количество одновременных запросов, что помогает масштабировать приложение в соответствии с растущими потребностями пользователей.
- Упрощение кода.Реактивное программирование помогает разработчикам писать более простой и читаемый код. Фреймворки реактивного программирования предоставляют набор мощных и простых в использовании API-интерфейсов, которые позволяют разработчикам писать более лаконичный и понятный код.
Заключение
В заключение, реактивное программирование — это мощная парадигма, которая позволяет разработчикам создавать надежные и масштабируемые приложения, способные обрабатывать большие объемы данных в режиме реального времени. Используя реактивные потоки и библиотеки, такие как RxJava, Reactor, Spring Framework 5.0, Ratpack и Akka, разработчики могут быстро и легко создавать реактивные системы.