Kafka: как увидеть список топиков?
я оказался в странной ситуации. Есть Kafka-сервер разработчиков, назовём его m1.dev.mysite.ru Располагается он внутри локалки, и я его прекрасно пингую. Далее я читаю «квикстарт», устанавливаю себе все по инструкции и пробую команды:
bin/kafka-topics.sh --bootstrap-server=m1.dev.mysite.ru:2181 --list
получаю ошибку:
ERROR org.apache.kafka.common.errors.TimeoutException: Timed out waiting for a node assignment. Call: listTopics
Пробую по-другому:
bin/kafka-topics.sh --list --zookeeper m1.dev.mysite.ru:2181
получаю скаловский стектрейс, суть которого в том, что zookeeper is not a recognized option Подскажите, пожалуйста, что я делаю не так, и как мне получить список топиков? Спасибо. Дополнение: Похоже, я сам дурак: zookeper то я не поставил. А, как я понимаю, он должен быть установлен локально, чтобы подключиться к «чужому» серверу Kafka. Подскажите, ведь это так?
Kafka tool как посмотреть сообщения
Действие KafkaGetMessageCount предназначено для получения количества сообщений в топике сервера Кафки.
< KafkaGetMessageCount objName COLOR: black;">consumer » variable COLOR: black;»>count » />
< Log >count : #count#
В примере действие возвращает количество сообщений в топике Кафки от текущего указателя сообщений. В данном варианте выполнения действие не меняет положение текущего указателя.
- objName — имя объекта получателя сообщений Кафки.
Этот объект описывается в элементе KafkaConsumer в файле глобальных настроек. Обязательный атрибут; - variable – имя переменной, в которую помещается количество текстовых сообщений в топике, считая от текущего положения указателя сообщения. Необязательный атрибут;
- reset – флажок, определяющий нужно ли в конце действия перемещать указатель текущего положения в топике.
Значение true означает, что указатель устанавливается на конец топика.
Значение false означает, что указатель остаётся на том же месте, что был и до выполнения действия.
Значение по умолчанию — false. Необязательный атрибут.
Примечание.
В действии количество сообщений определяется путём вычитки их из Кафки.
Причём вычитка производится порциями-пачками.
Максимальный размер пачки определяется атрибутом maxPoll элемента KafkaConsumer в файле глобальных настроек. Значение по умолчанию — 100.
Каждая пачка пытается вычитаться за время (таймаут), заданное в атрибуте pollTimeout элемента KafkaConsumer. Значение по умолчанию — 200 (миллисекунд).
Вычитанная пачка будет пустой, если в топике больше нет сообщений (достигнут конец топика) или произошёл таймаут.
Действие завершается, когда количество пустых пачек достигнет значения, заданного в атрибуте giveUp элемента KafkaConsumer. Значение по умолчанию — 10.
Если необходимо «почистить» топик Кафки, точнее, передвинуть указатель сообщений в конец топика, то следует запустить действие с атрибутом reset равным true:
Хранение, чтение и очистка сообщение в топиках Apache Kafka: 3 важных конфигурации
В этой статье разберем одну из тем практического обучения администраторов Apache Kafka и рассмотрим разницу между сохранением сообщений и фиксированных смещений в этой Big Data платформе потоковой обработке событий. Читайте далее про конфигурации потребителя и брокера, отвечающие за время хранения сообщений и политику очистки журналов.
Еще раз про offset или как потребители читают сообщения из топиков Apache Kafka
За чтение сохраненных сообщений по порядку из топика Kafka приложением-потребителем отвечают смещения (offset), которые хранятся в топике __consumer_offsets. Этот топик создается автоматически после настройки Kafka-кластера и используется для хранения информации о подтвержденных смещениях для каждого топика по принципу раздел (partition) на группу потребителей (groupID). Данные в этом топике будут периодически сжиматься, поэтому для считывания доступна только последняя информация о смещениях.
Каждая группа потребителей поддерживает свое смещение по разделам топика. Группа потребителей состоит из consumer’ов, которые взаимодействуют, получая данные из некоторых топиков. Разделы всех топиков делятся между потребителями в группе. Когда прибывают новые члены группы, а старые уходят, разделы перебалансируются, чтобы каждый член группы получил пропорциональную долю разделов. Один из брокеров назначается координатором группы и отвечает за управление членами группы, а также за назначение их разделов.
Координатор каждой группы выбирается из лидеров топика внутренних смещений __consumer_offsets. Обычно идентификатор группы хешируется в один из разделов этого топика, а его лидер выбирается в качестве координатора. Таким образом, управление группами потребителей равномерно делится между всеми брокерами в кластере, позволяя масштабировать количество групп за счет увеличения количества брокеров.
Каждый вызов API фиксации приводит к отправке брокеру запроса фиксации смещения. Используя синхронный API, потребитель блокируется до успешного ответа на этот запрос. Это ожидание может снизить общую пропускную способность, т.к. ожидая возврата, потребитель простаивает вместо обработки записей [1]. Когда диспетчер смещения получает запрос на фиксацию смещения (OffsetCommitRequest), он добавляет запрос в специальный сжатый топик Kafka с названием __consumer_offsets. А менеджер смещения отправит потребителю ответ об успешной фиксации смещения только тогда, когда все реплики топика смещения получат информацию об этом смещении [2].
3 важных конфигурации по удержанию сообщений в топике
Настроить политики хранения данных, чтобы контролировать, сколько и как долго данные будут храниться, можно с помощью конфигурациий retention.bytes и retention.ms. Например, так можно ограничить использование места для сохранения сообщений, т.е. хранилища, в кластере и соблюдать законодательные требования, такие как GDPR. В частности, конфигурация retention.ms контролирует максимальное время, в течение которого лог будет храниться, прежде удаляться его старые сегменты, чтобы освободить место при использовании политики удаления сообщений. По сути, это SLA о том, как скоро потребители должны прочитать свои данные. Если для retention.ms установлено значение -1, ограничение по времени не применяется.
С конфигурацией retention.ms связаны log.retention.hours, log.retention.minutes, log.retention.ms, которые детализируют время хранения лог-файлов перед их удалением в часах, минутах и миллисекундах соответственно.
Однако, все эти перечисленные параметры относятся к конфигурации самого топика, а не к тому, как потребители считывают из него данные. За это отвечает сохранение подтвержденных смещений потребителей (Committed Offset Retention): как только потребитель Kafka начинает получать данные из топика, он фиксирует смещение последнего полученного сообщения во внутреннем топике брокера __consumer_offsets. Так потребитель сможет определить смещение, с которого он должен начать чтение топика в следующем запросе [2].
С этим связана конфигурация брокера offsets.retention.minutes для группы потребителей, значение которой по умолчанию задано 1440 минут, что составляет сутки (24 часа). Этот период означает время хранения смещений сообщений после того, как группа потребителей станет пустой. Для автономных потребителей (standalone) смещения будут истекать по истечении времени последней фиксации плюс этот период хранения [1]. После этого срока зафиксированное потребителем смещение будет сброшено, и consumer уже не сможет найти его в топике __consumer_offsets. В этом случае потребитель может снова прочитать все данные из топика или записи, определенные параметром конфигурации auto.offset.reset.
Значения свойства потребителя auto.offset.reset могут быть следующие [2]:
ранее (earliest) — автоматически сбрасывает смещение до самого раннего смещения;
последнее (latest) — автоматически сбрасывает смещение до последнего смещения;
никакое (none) — генерация исключения для потребителя, если для его группы не найдено предыдущее смещение;
другое (anything else) — выброс пользовательского исключения.
С этим свойством может быть связана очень редкая проблема, когда приложение-потребитель не работает более суток. В этом случае, если конфигурация брокера offsets.retention.minutes не настроена, и приложение-потребитель, не работавшее более суток, снова присоединяется к кластеру с последним значением offset.reset, оно считается новым и начинает потреблять сообщения, полученные после успешного повторного присоединения. Это приводит к потере данных. Поэтому на практике важно настроить период простоя, в зависимости от характера приложения и SLA, согласованного с бизнесом [3].
Как log.retention и offsets.retention влияют на топик Kafka: практический пример
Чтобы наглядно проиллюстрировать важность параметров хранения сообщений и смещений, рассмотрим пример, где для конфигураций log.retention.minutes и offsets.retention.minutes заданы значения, равные 7 дней и 5 дней соответственно [2]:
По прошествии периода offsets.retention.minutes на 6-й день значение ключа K1 не было удалено из топика __consumer_offsets, по следующим причинам:
топик __consumer_offsets имеет политику очистки «компактная», и сжатие не было запущено; политика хранения топика __consumer_offsets определяется конфигурацией топика на уровне кластера, то есть log.retention.minutes, значение которого установлено в 7 дней.
Поскольку срок хранения смещения истек на 6-й день, то для ключа K1 смещение было сброшено (установлено в значение NULL). А по истечении периода хранения сообщений, заданного на уровне 7 дней в конфигурации log.retention.minutes, начиная с 8-го дня значения для ключей K1, K2 и K3 будут сброшены. При этом запущен поток очистки лога, в результате чего старые значения топика __consumer_offsets будут сжаты, т.к. его политика очистки (cleanup.policy) определена как компактная (compact).
Рассмотренный пример еще раз подтверждает гибкость настроек Apache Kafka, которые помогают администратору более эффективно использовать ресурсы кластера и решать поставленные бизнесом задачи. Еще больше полезных деталей администрирования кластеров Apache Kafka и использования этого фреймворка для разработки распределенных приложений потоковой аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
Apache Kafka для аналитика: ТОП-7 требований к интеграционной шине

Apache Kafka часто используется в качестве средства интеграции информационных систем, выполняя роль посредника при обмене сообщениями. Поэтому, чтобы сформулировать требования к подсистеме интеграции на основе Kafka, аналитику следует понимать ключевые принципы работы этой распределенной платформы потоковой передачи событий. Именно это рассмотрим далее, а также разберем, как требования определяют значения конфигураций топиков, продюсеров и потребителей.
Что такое Apache Kafka и как это работает: краткий обзор
Apache Kafka часто называют брокером сообщений, но это скорее гибрид распределенного лога и key-value базы данных. Эта распределенная платформа потоковой передачи событий часто используется в качестве шины обмена сообщениями при интеграции нескольких систем. При этом Kafka реализует принцип «издатель/подписчик», когда приложения-продюсеры отправляют сообщения в топик, откуда их считывают приложения-потребители, подписанные на этот топик. Все это происходит в режиме почти реального времени, т.е. соответствует парадигме потоковой обработки информации.
Топик в Kafka – это не физическое, а логическое хранилище сообщений, которые публикует продюсер, чтобы их считали потребители. Топик позволяет сгруппировать потоки сообщений по категориям, например, по сущностям домена: в один топик будут отправляться события пользовательского поведения, в другой – системные данные с «умных часов» или других устройств носимой электроники и т.д. Каждый топик может быть разбит на разделы (партиции, partition). Раздел является единицей параллелизма и представляет собой журнал (лог) сообщений от одного и только одного приложения-продюсера, упорядоченных в порядке их поступления в Kafka. Порядковый номер сообщения под названием смещение (offset) определяет, когда приложения-потребители считают данные. Лог устроен по принципу FIFO (First In, First Out): первыми считываются сообщения, которые отправлены в Kafka раньше. Подробнее об этом здесь.
Разделение топика на разделы позволяет выровнять нагрузку в кластере Apache Kafka благодаря их равномерному распределению по нескольким узлам, которые называются брокеры. Кроме того, количество разделов определяет количество потоков данных, которые могут обрабатываться параллельно. При отправке данных в Apache Kafka приложение-продюсер назначает сообщение какому-то из разделов топика на основе настраиваемой стратегии, по умолчанию по ключу разделения, т.е. какому-то полю входящего сообщения.
Каждый топик может иметь один или несколько разделов, распараллеленных на разные брокеры, чтобы сразу несколько потребителей могли считывать данные из одного топика одновременно. Если количество потребителей меньше числа разделов, одно приложение-потребитель считывает сообщения из нескольких разделов. Если потребителей больше, чем разделов, некоторые приложения-потребители не могут считывать сообщения, пока их общее количество не снизится до количества разделов. Хотя в теории разделов может быть сколько угодно, на практике их количество ограничено размером сохраняемых сообщений, которые могут поместиться на одном брокере. Обычно на одном брокере рекомендуется держать не более 1000 разделов, включая реплики. Если в топике больше данных, чем фактически может вместить брокер, надо увеличить количество разделов. Когда приложении-потребитель подписывается на какой-то топик, он потребляет сообщения из всех разделов этого топика. Чтобы потребитель не «захлебнулся» от данных, в Kafka есть механизм объединения потребителей в группы для равномерного распределения разделов между несколькими приложениями-потребителями. А порядок чтения сообщений из раздела гарантируется тем, что Kafka дает доступ к разделу только одному потребителю из группы потребителей.
Также разделение является механизмом обеспечивается отказоустойчивости этой распределенной системы за счет копирования (реплицирования) данных на несколько брокеров. При этом «права и обязанности» брокеров, которые содержат фактически одни и те же данные, т.е. данные реплицированного раздела, разделяются:
- есть брокер-лидер (leader), который принимает запросы на чтение и запись данных от приложения-продюсера;
- есть брокеры-подписчики (followers), которые только реплицируют данные лидера и принимают запросы только на чтение сообщений.
Количество брокеров-подписчиков определяется значением фактора репликации минус один. Фактор репликации задает общее количество копий данных раздела во всем кластере, включая размещение на брокере-лидере. Чтобы клиенты Kafka, т.е. приложения-продюсеры и потребители знали, к какому брокеру нужно подключиться, в кластере используется внешний (по отношению к Kafka) сервис синхронизации метаданных Apache ZooKeeper. Он хранит метаданные о разделах топиков и брокерах. С весны 2021 года вышло важное обновление Kafka 2.8, где на замену ZooKeeper предлагается внутренний механизм Quorum Controller, который использует новый протокол KRaft (Kafka Raft) для обеспечения точной репликации метаданных в кворуме. Однако, он все еще не рекомендуется для реальных высоконагруженных проектов. Подробнее об этом здесь и здесь.
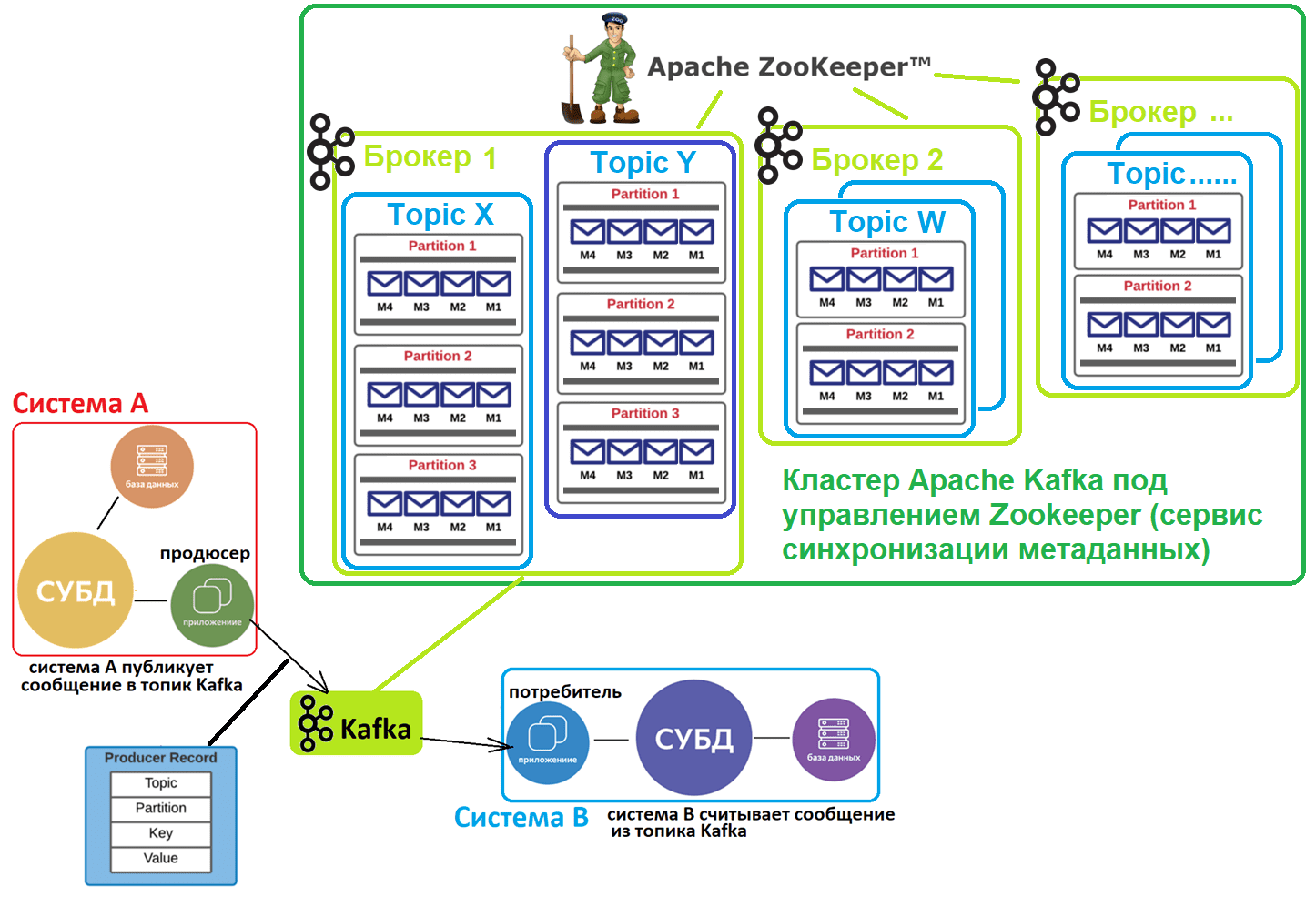
В отличие от популярного JMS-брокера сообщений Rabbit MQ, Kafka работает по принципу вытягивания (pull), когда приложения-потребители сами считывают из топиков нужные им данные. По сути, это соответствует концепции «тупой сервер, умный клиент», когда логика работы с сообщениями реализуется на клиентской стороне. Kafka не следит, какие сообщения прочитаны потребителями, а просто хранит их на жестком диске в течение заданного периода времени или до момента превышения заданного лимита. Потребители сами опрашивают топик Kafka на предмет новых сообщений и указывают, какие сообщения нужно считать, увеличивая или уменьшая смещение. Из одного топика данные могут считывать несколько приложений-потребителей, тогда как отправлять сообщения в топик может только один продюсер, чтобы не нарушать упорядоченность событий. Подробнее про отличия Kafka и Rabbit MQ, а также разницу с другими JMS-брокерами, смотрите здесь и здесь.
Потоковая парадигма означает бесконечное поступление сообщений и их обработку в режиме реального времени, тогда как при пакетной обработке итоговое значение создается только после полной обработки всех связанных данных. Поэтому для потоковой обработки особенно важны полнота, доступность и упорядоченность сообщений, чтобы исключить дублирование и потерю данных. Для этого в Apache Kafka есть гарантия доставки сообщений, реализующая семантику строго один раз (exactly once). Это значит, что если приложение-продюсер из-за сбоя сети или какой-то внутренней ошибки повторно отправит одни и те же данные в Kafka, сообщение будет записано в топик только один раз.
За реализацию этой семантики доставки сообщений отвечает свойство идемпотентности в настройках продюсера и число подтверждений об успешной записи (acknowledge, acks). Например, если параметр acks равен 0, приложение-продюсер не ждет от Kafka подтверждения об успешной записи сообщения в топик: сообщение считается отправленным в любом случае, т.е. даже при фактическом сбое записи. Если acks равно 1, отправленное сообщение записывается в локальный лог брокера-лидера, не ожидая полного подтверждения от всех подписчиков. При этом сообщение может быть потеряно в случае сбоя лидера до репликации по всему кластеру. Если параметр acks равен -1 (all), приложение-продюсер ждет полной репликации сообщения по всем серверам кластера. Это повышает надежность системы интеграции, предотвращая потерю данных, но увеличивает задержку их обработки и снижает пропускную способность. Подробнее смотрите здесь, здесь и здесь.
Приложение-продюсер отправляет в Kafka сообщение, которое имеет следующую структуру:
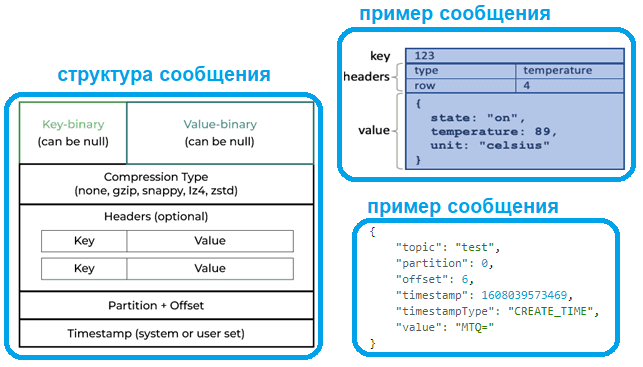
- ключ — двоичное поле, которое может быть нулевым;
- значение, которое является содержимым сообщения, и оно также может быть нулевым;
- тип сжатия сообщения – без сжатия (none) или один из кодеков (gzip, snappy, lz4, zstd);
- дополнительные заголовки, пары ключ-значение, которые содержат метаданные.
- номер раздела и идентификатор смещения, которые становятся частью сообщения, как только приложение-продюсер отправило сообщение в Kafka;
- отметка времени происхождения события, данные о котором зашиты в полезную нагрузку, т.е. значение сообщения.
Обычно полезная нагрузка представляет собой некоторое сообщение в JSON-формате, структура которого может быть задана в виде JSON-схемы, что хранится в реестре схем (Schema registry). Реестр схем – это модуль платформы Kafka от компании Confluent, что занимается коммерциализацей этой технологии. Реестр схем особенно полезен в случае множества приложений-продюсеров, которые могут посылать данные разных структур. Такое часто бывает в проектах интернета вещей (Internet of Things).
Впрочем, Kafka поддерживает не только JSON, но и другие форматы сообщений: бинарные Apache AVRO и Protobuf, текст и т.д. В любом случае, какой бы формат данных не был у исходного сообщения, в топике оно хранится в виде набора байтов. Этот процесс перевода структурированных данных в набор байтов называется сериализацией и нужен для передачи данных по сети и их хранения на жестком диске. Для этого исходные данные сериализуются, т.е. переводятся в массив байтов с помощью сериализаторов ключей и значений. Kafka отлично работает с огромным количеством сообщений, но они должны быть небольшого размера. Максимальный размер сообщения, отправленных в топик Kafka, определяется конфигурацией message.max.bytes и по умолчанию не превышает 1 МБ. При отправке сообщения большего размера, приложение-продюсер получит от брокера Кафка уведомление об ошибке, а само сообщение не будет принято к записи. Важно также, сколько сообщений укладывается в пакет — хотя Kafka и реализует потоковую парадигму обработки данных, сообщения от приложения продюсера отправляются в топик не сразу. Сперва они добавляются в пакет – внутренний буфер, размер которого по умолчанию равен 32 МБ. Если продюсер отправляет сообщения быстрее, чем их можно передать брокеру, или случились проблемы с сетью, этот внутренний буфер переполняется. Тогда метод продюсера, запускающий непосредственную отправку в топик, будет заблокирован на время, указанное в конфигурации max.block.ms (по умолчанию 1 минута). Подробно об этом читайте здесь.
Поскольку сообщения в Kafka отправляются в виде пакета записей, он имеет так называемые накладные расходы: 61 байт метаданных, где указываются версия сообщения, количество записей, алгоритм сжатия, транзакция и пр. Эти накладные расходы на пакетную запись постоянны и не поддаются уменьшению. Но можно оптимизировать размер пакета, объединяя несколько сообщений в 1 пакет, сжимая данные с помощью кодеков и/или используя более экономные форматы сериализации данных, например, AVRO вместо JSON. Подробнее об этом здесь.
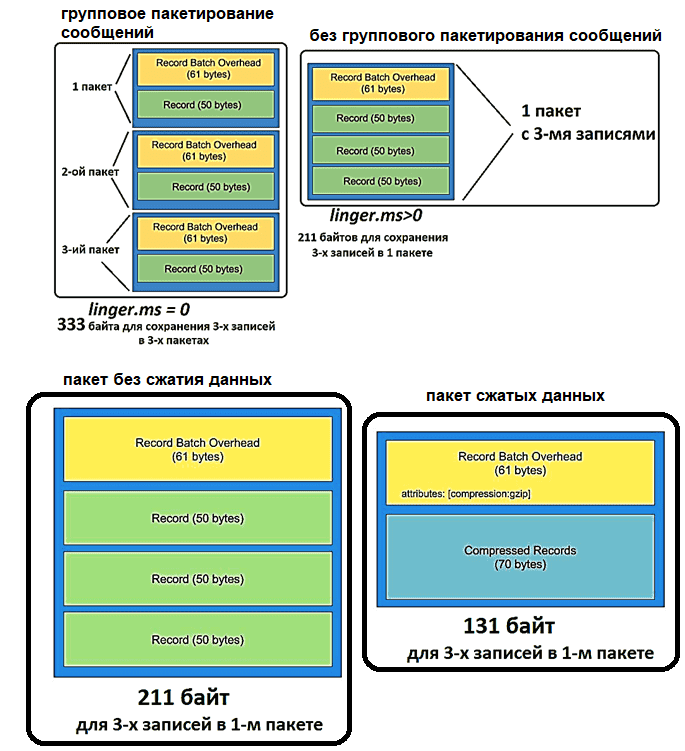
Также за задержку отправки пакета сообщений отвечают конфигурации linger.ms и batch.size. linger.ms. Увеличение linger.ms, по умолчанию равного 0, снижает количество запросов и повышает пропускную способность шины, но увеличивает задержку перед отправкой данных. Batch.size определяет максимальный размер одного пакета сообщений: чем больше значение этого параметра, тем больше сообщений группируются в один пакет, что тоже увеличивает задержку. Конфигурации linger.ms и batch.size дополняют друг друга: пакет данных отправляется при достижении любого из этих 2 лимитов. Подробности здесь и здесь.