Матричный алгоритм шифрования
Приносим читателям свои извинения за публикацию этой статьи. Статья очень плоха, см. подробнее в обсуждении на форуме. Торопились сдать номер, понадеялись на автора, недоглядели. Ещё раз извините.
Система определения движущихся объектов является довольно востребованной, т.к. помогает облегчить задачу многим службам, например, авиадиспетчерам. Но, как и в любой системе, в системе определения движущихся объектов необходимо производить шифрование информации на пути от датчика до системы анализа полученных данных.
Постановка задачи
Необходимо разработать алгоритм шифрования данных для системы определения движущихся объектов.
Современные алгоритмы
На данный момент самыми распространенными классами алгоритмов являются симметричные алгоритмы и асимметричные, т.е. системы с открытым ключом.
На рис.1-4 представлена схема работы симметричного алгоритма шифрования AES, который является государственным стандартом шифрования США с 2001года:

Рис.1 «Шаг 1»

Рис.2 «Шаг 2»

Рис.3 «Шаг 3»

Рис.4 «Шаг 4»
Еще одним из распространенных алгоритмов является асимметричный алгоритм, или система с открытым ключом.
Идея криптографии с открытым ключом очень тесно связана с идеей односторонних функций, то есть таких функций f(x), что по известному x довольно просто найти значение f(x), тогда как определить x из f(x) невозможно. Поэтому криптография с открытым ключом использует односторонние функции с лазейкой. Лазейка — это некий секрет, который помогает расшифровать текст. То есть существует такой y, что зная f(x) и y, можно вычислить x. К примеру, если разобрать часы на множество составных частей, то очень сложно собрать вновь работающие часы. Но если есть инструкция по сборке (лазейка), то можно легко решить эту проблему.
Новый класс алгоритмов
В данной работе представлен новый класс алгоритмов. В отличие от описанных алгоритмов, в данном применяется новый подход к кодированию информации.
Шифрование
- Удалить повторяющиеся символы и сохранить количество повторений и номера позиций этих символов в тексте (эти данные составляют ключи.)
- Вычислить номер символа в таблице ASCII.
- ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов.
- Построить 3 матрицы, где одна матрица – номера символов текста, вторая состоит из количества повторений этих символов, а третья состоит из номеров позиций символов в тексте, где каждая срока соответствует одному символу.
- Перемножить первые 2 матрицы. После этого действия должна получиться квадратная матрица, т.к. при дешифровании необходимо будет найти обратную матрицу, которую необходимо будет умножить на матрицу повторений.
- Перемешать текст по правилу: первая позиция – номер позиции элемента, вторая позиция – символ из п.4, а на 3-м – количество повторений.
- Произвести гаммирование полученного текста.
Гаммирование – преобразование исходного (открытого) текста, при котором символы исходного текста складываются (по модулю, равному мощности алфавита) с символами псевдослучайной последовательности, вырабатываемой по определенному правилу. Гамма в криптографии – псевдослучайная числовая последовательность, вырабатываемая по определенному алгоритму и используемая для зашифровывания открытых данных и расшифровывания зашифрованных данных. Наложение гаммы происходит по формуле αi=βi+γi(mod n), где βi – исходный текст, γi – гамма, n – основание используемого алфавита, αi – результат.
Дешифрование
- Произвести гаммирование. Особенность гаммирования в том, что если произвести над шифротекстом повторное гаммирование, то получится исходный текст.
- Полученный текст необходимо разбить на 3 части по правилу, используемому при шифровании. Получится 3 матрицы – шифротекст, количество повторений и номера позиций.
- Необходимо найти обратную матрицу шифротекста и перемножить её с матрицей повторений.
- Теперь необходимо полученную матрицу перевести в символы и сопоставить с матрицей повторений и матрицей позиций. И в итоге получится исходный текст.
Особенности алгоритма
- Динамическое формирование ключей. Ключи формируются только для конкретного момента и данных и для других данных они не подходит.
- Изменение одного символа в исходном тексте приводит к полному изменению зашифрованного текста.
- Данный алгоритм имеет составной ключ, состоящий из двух частей и для дешифрации необходимо наличие всех частей.
- Изменение одного символа в исходном тексте приводит к полному изменению зашифрованного текста.
- Исходный и финальный тексты не совместимы ни по чтению, ни по длине. Данное свойство не позволяет напрямую, простыми методами подобрать исходный текст.
- Отсутствие циклов в работе алгоритма.
- Использование данного алгоритма не позволяет подобрать ключи, отличные от реальных, такие, что позволяют получить исходный текст.
Вывод
Сфера деятельности современных алгоритмов четко разделена – асимметричные алгоритмы применяются в основном в сетевых протоколах, а симметричные применяется во всем остальном.
Представленный же здесь алгоритм, в связи со своей динамичностью, универсален и может применяться не только в системе обнаружения движущихся объектов, но и в любой другой.
Список литературы
- Вильям Столлингс «Криптография и защита сетей: принципы и практика. 2-е издание», изд. Вильямс, 2001г., 672 стр.
- Венбо Мао «Современная криптография: теория и практика», изд. Вильямс, 2005 г, 768 стр.
- А.В. Аграновский, Р.А.Хади «ПРАКТИЧЕСКАЯ КРИПТОГРАФИЯ: алгоритмы и их программирование», изд. СОЛОН-Р, 2002.
Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав.
Математика и шифрование
Тогда нет необходимости объяснять вам, зачем нужно шифровать те или иные тексты – от содержащих государственные тайны, до записок знакомой девочке или мальчику. Веками люди создавали самые различные системы тайнописи, но и владели ими только «посвящённые», умевшие и зашифровать текст, и расшифровать его. Естественно, что для «непосвящённых» важно разгадать шифр. Поэтому веками разрабатывались как способы расшифровки чужих шифров, так и способы создания своих шифров, которые не поддавались бы расшифровке. Проблема расшифровки связана также и с серьёзными проблемами гуманитарных наук — истории, археологии, и прежде всего с «воскрешением» так называемых мёртвых языков. Приведу несколько примеров. Так, древняя цивилизация в Египте оставалась тайной за семью печатями до тех пор, пока в 19 веке французский филолог Шампольон не смог расшифровать иероглифы, которые древним египтянам были хорошо понятны. И ещё один пример: наш соотечественник, ученый, историк, лингвист и этнограф Ю. В. Кнорозов в 20 веке расшифровал письменность древнего народа майя, жившего много веков назад на территории нынешней Мексики.
Огромную роль в проблеме расшифровки текстов играет, как ни странным это может показаться, математика.
Глава 1. Матричный способ шифрования.
В этой главе я познакомлю вас с одним очень простым способом шифрования (кодирования) и расшифровки (декодирования). Чтобы научиться им пользоваться, достаточно знать лишь простейшую арифметику (на уровне 6 класса), порядок букв в алфавите и всего лишь четыре числа. А расшифровать наш текст человеку непосвященному будет совершенно невозможно, ну, а специалисту, хотя для специалистов и ничего невозможного нет, и им этот способ хорошо известен, им для этого потребуется компьютер.
Для кодирования текста на русском языке, занумерую все буквы по месту их расположения в алфавите – от 1 до 33, добавив 34-ю букву — пробел .
Возьму какое-нибудь простое предложение, например, «шла зима», и каждую букву заменю соответствующей цифрой, получится:
26, 13, 1, 34, 9, 10, 14, 1.
Затем построю из этой последовательности две таблички 2×2:
Такие таблички из четырёх чисел называются термином из «настоящей» науки алгебры, который, возможно, некоторые из вас уже слышали, — матрицей, точнее – матрицей 2 × 2.
Зашифрую эту последовательность с помощью ещё одной матрицы
1 2 — кодирующей – последующему хитроумному правилу:
(2 3 × 26 13 (2 × 26 + 3 × 1 2 × 13 + 3 × 34 ( 55 128
1 2) 1 34) = 1 × 26 + 2 × 1 1 × 13 + 2 × 34) = 28 81) ,
﴾2 3﴿ ﴾ 9 10﴿ ﴾ 2 × 9 + 3 × 14 2 × 10 + 3 × 1 ﴿ ﴾ 60 23﴿
1 2 × 14 1 = 1 × 9 + 2 × 14 1 × 10 + 2× 1 = 37 12.
Такой способ шифрования называют матричным. Наш адресат получит текст:
55, 128, 28, 81, 60, 23, 37, 12.
А как же он его расшифрует? Оказывается и это нетрудно: он должен взять декодирующую матрицу ﴾ 2 -3 ﴿ и проделать с полученным текстом
-1 2 то же самое, что я делал с исходным текстом:
﴾ 2 -3 ﴾55 128 ( 2 × 55 + ﴾-3﴿ × 81 2 × 128 + ﴾-3﴿×81 ( 26 13
-1 2 ﴿ × 28 81 ﴿ = ﴾-1﴿ × 55 + 2 × 28 ﴾-1﴿ × 128 + 2 ×81) = 1 34 ﴿ ,
﴾2 -3 × ﴾60 23 ﴾2 × 60 + ﴾-3﴿ × 37 2 × 23 + ﴾ -3 ﴿ × 12 ﴾ 9 10
-1 2﴿ 37 12﴿ = ﴾ -1﴿ × 60 + 2 × 37 ﴾ -1﴿ × 23 + 2 × 12 ﴿ = 14 1 ﴿.
После замены матриц на последовательность 26, 13, 1, 34, 9, 10, 14, 1, а затем — чисел на буквы дешифровальщик получит исходный текст «шла зима».
Ясно, что никто посторонний, не знающий ни кодирующей, ни декодирующей матрицы, получить этот текст не сможет.
Однако матричный способ шифрования не мог бы существовать, если бы в качестве кодирующей можно было брать только матрицу: ﴾ 2 3﴿
На самом деле таких матриц бесконечно много, придумать их очень легко. И вообще, можно менять систему «тайнописи» хоть каждый день. Для этого нужно знать очень немного – уметь любые две матрицы «перемножать», т. е. по определённому правилу составлять из них третью.
До этого общего правила умножения матриц не так трудно догадаться, анализируя приведённые примеры.
Оно может быть записано в виде следующей формулы:
﴾ x y ﴾ p q (xp + yr xq + ys z t ﴿ × r s ﴿ = zp + tr zq + ts ).
Естественно, назвать третью матрицу произведением первых двух и ввести обозначение: АВ = С. Такая терминология используется в математике, где изучаются не только числа и действия над ними, но и объекты более сложные, чем числа. Замечу, что в этом случае не выполняются ни переместительный, ни даже сочетательный законы.
Рассмотрю ещё несколько примеров на нахождение произведения матриц:
а) (1 0 (0 1 (1×0 + 0×0 1×1 + 0×0 (0 1
0 0 ) × 0 0) = 0×0 + 0×0 0×1 + 0×0 ) = 0 0),
0. 1 (1 0 (0×1 + 1×0 0×0 + 1×0 (0 0
0 0 ) × 0 0) = 0×0 + 0×0 0×0 + 0×0) = 0 0).
Обратите внимание на тот факт, что произведение матриц зависит от порядка множителей, следовательно, при кодировании и декодировании надо соблюдать порядок множителей: при шифровке ставим кодирующую матрицу первым множителем – слева, и декодирующую – при расшифровке тоже слева. Можно, впрочем, обе матрицы – кодирующую и декодирующую – ставить справа.
б) (x y (1 0 (x×1 + y×0 x×0 + y×1 (x y z t) × 0 1) = z×1 + t×0 z×0 + t×1) = z t) и
(1 0 (x y (1×x + 0×z 1×y + 0×t (x y
0 1) × z t) = 0×x + 1×z 0×y + 1×t) = z t), оба произведения равны. Обратите внимание на то, что в данном случае произведение матриц не зависит от порядка множителей. Кроме того, нетрудно заметить, что роль матрицы (1 0
0 1) при умножении матриц такая же, как и числа 1 при умножении чисел, — она не меняет второго множителя. Эта матрица, поэтому и называется единичной и обозначается буквой Е.
в) (2 3 (2 -3 (2 -3 (2 3
1 2) × -1 2) = Е, -1 2) × 1 2) = Е. Оба произведения равны Е. Замечу, что множители в произведениях – это рассмотренные выше кодирующая и декодирующая матрицы.
А теперь рассмотрим задачу такую: зашифруем данный текст, используя в качестве кодирующей матрицу (1 2
0 1): а) «Авангард» — чемпион; б) Вася + Катя = любовь.
При шифровании возникают две новые трудности – неясно, что делать с тире, если просто выбросить из предложения, то получится предложение из 15 букв, а 15 не делится на 4, и поэтому при представлении последовательности номеров букв матрицами неясно, что делать с последними тремя буквами.
Можно предложить несколько вариантов решения возникших проблем. В задаче б) вместо знаков «+» и «=» можно поставить слова «плюс» и «равно», а равно можно не учитывать. Неучёт знаков препинания, как правило, не влияет на смысл сообщения, а предложения типа: «Казнить нельзя помиловать» можно записывать либо в виде «Казнить нельзя запятая помиловать», либо в виде «Казнить запятая нельзя помиловать». В реальных кодируемых текстах такой эффект зависимости смысла предложения от постановки запятой встречается редко, хотя шифрующий всегда должен помнить и об этом.
Имеется и другая возможность: включить в исходный, русский алфавит и знаки препинания, и математические символы, но это заведомо осложнило бы дальнейшую работу – и запоминание кодов символов, и вычисления.
Но вернёмся к решению нашей задачи. а) Если знак тире заменить пробелом, а буквы — цифрами, то получится следующая последовательность чисел:
1, 3, 1, 15, 4, 1, 18, 5, 34, 25, 6, 14, 17, 10, 16, 15. Далее составим матрицы:
(1 3 (4 1 (34 25 (17 10
1 15), 18 5), 6 14), 16 15).
После применения кодирующей матрицы получаем следующий текст: 1, 5, 1, 17, 4, 9, 18, 41, 34, 93, 6, 26, 17, 44, 16, 4 — это и есть шифровка.
б) Если знаки «+» и «=» заменить словами «плюс» и «равно», а в конце добавить пробел, а затем выполнить всё то, что делалось в предыдущей задаче, то получится текст: 41, 67, 19, 33, 60, 81, 13, 32, 43, 36, 12, 1, 88, 69, 34, 18, 31, 35, 15, 16, 98, 17, 32, 2, 76,71, 30, 34.
А теперь научимся выполнять обратную задачу: расшифровывать текст. Предположим, что мною получены следующие сообщения: а) 116, 58, 32, 19, 58, 115, 19, 34, 37, 57, 6, 12; б) 60, 51, 17, 16, 58, 79, 16, 15, 48, 79, 14, 15. Узнаю, что же здесь зашифровано с помощью декодирующей матрицы (0 1
Составлю матрицы 2 × 2 из полученных чисел:
116. 58 (58 115 (37 57
32 19), 19 34), 6 12), применю декодирующую матрицу, причём поставлю её первой, тогда получаю:
( 0 1 (116 58 (0×116 + 1×32 0×58 + 1×19 (32 19
1 -3) × 32 19) = 1×116 + (-3)×32 1×58 + 19×(-3)) = 20 1),
0. 1 (58 115 (0×58 + 1×19 0×115 + 1×34 (19 34
1 -3) × 19 34) = 1×58 + (-3)×19 1×115 + (-3)×34) = 1 13),
0. 1 (37 57 ( 0×37 + 1×6 0×57 + 1×12 (6 12
1 -3) × 6 12) = 1×37 + (-3)×6 1×57 + (-3)×12) = 19 21), а последовательность чисел будет такая: 32, 19, 20, 1, 19, 34, 1, 13, 6, 12, 19, 21, что будет обозначать: Юстас Алексу.
Вторая зашифрованная фраза будет такой – позвони мне. Можете убедиться в этом самостоятельно.
Таким образом, у меня осталось пока, по крайней мере, два не рассмотренных вопроса: какую ещё можно придумать кодирующую матрицу и как для новой кодирующей получить декодирующую? Решение этого вопроса требует рассмотрения так называемой алгебры матриц.
Обратите внимание на интересный факт, который можно было заметить после решения задачи 1, в): произведение кодирующей и декодирующей матриц равно единичной матрице Е. Поэтому по аналогии с числами декодирующую матрицу естественно назвать обратной к кодирующей. А как её обозначить?
Давайте подумаем вместе. А если обозначить её 1 /А? Мне очень хотелось бы, чтобы выполнялось равенство А × 1/А = 1, но 1 – не матрица! А может быть, предложенный символ заменить на Е /А? Но дроби в числовых множествах используются как замена операции деления, а во множестве матриц деления нет. А что, если использовать обозначение А-1? Тогда получим: А × А-1 = А-1 × А = Е. Такой вариант меня вполне устраивает.
Именно благодаря этому и происходит декодирование: если с помощью матрицы А я закодирую текст, представленный матрицей В, т. е. вычислю произведение А В, то наш адресат вычисляет матрицу А-1А В = Е В = В и полученный текст расшифрован.
Однако, если быть точным в обозначениях, то адресат вычисляет произведение А-1(А В), а я ( по привычке работать с числами!) подсчитал произведение (А-1А)В. Но почему А-1(АВ) = (А-1 А)В? Мы знаем, что умножение чисел подчиняется сочетательному закону ( лучше сказать: умножение чисел ассоциативно), но почему этот закон должен выполняться и для матриц? Ведь мы уже видели, что переместительный закон для них не выполняется – умножение матриц некоммутативно.
Как бы странно это не казалось, но в действительности во множестве матриц сочетательный закон выполняется: умножение матриц ассоциативно. И это легко проверить, рассмотрев матрицы А, В, С «общего вида» и вычислив произведения (АВ)С и А(ВС), а это уже чисто техническое упражнение.
А как же найти обратную матрицу? Сделаем это на примере: найдем обратную для матрицы А = (5 3
Пусть А-1 = ( x y z t). По условию, должны выполняться равенства АА-1 = А-1А = Е, т. е.
(5 3 (x y (x y (5 3
1 1) × z t) = Е, z t ) × 1 1) = Е.
Первое из них имеет вид: (5x + 3y 5y + 3t ( 1 0 x + z y + t ) = 0 1).
Оно будет выполнено, если 5х + 3z = 1, х + z =0, 5у + 3t = 0, у + t =1.
Задача сводится к двум простым системам уравнений:
5х + 3z = 1 5у + 3t = 0 х + z =0 и y + t =1.
Решая эти системы, получаем неприятный сюрприз – появляются дроби: х =1/2, z = -1/2, у = -3/2, t = 5/2.
Но надо ещё проверить выполнение второго равенства:
(1/2 -3/2 (5 3 ( 5/2-3/2 3/2 — 3/2 (1 0
-1/2 5/2) × 1 1) = -5/2+5/2 -3/2+5/2) = 0 1).
Таким образом, полученная матрица является обратной для матрицы А, но наличие в ней дробей означает, что использовать её в качестве кодирующей нельзя – номера букв должны быть, как вы понимаете, целые. А теперь я решу пару задач, попытаюсь найти матрицу, обратную данной.
Задача 4. Найдите матрицу, обратную для матрицы: а) (1 0 б) (5 4
Решение : пусть А = (1 0 А-1 = (х у
0 1), z t), и выполняются равенства: А×А-1= А-1× А = Е, т. е. (1 0 (х у (х у (1 0
0 1) × z t) = Е, z t) × 0 1) = Е.
Первое из них имеет вид (х у (1 0 z t) = 0 1). Оно будет выполнено, если х = 1, z = 0, у = 0, t = 1.
Проверим выполнение второго равенства: (1 0 (1 0 (1×1+0×0 1×0+0×0
0 1) × 0 1) = 0×1+1×0 0×0+1×1)
0 1) = Е, следовательно, А-1 = (1 0
4 3), тогда А-1 = ( х у z t), найду произведение А×А-1 = Е =
= (5х + 4z 5у + 4t (1 0
4х + 3z 4у + 3t) = 0 1), отсюда имею: 5х + 4z = 1, 4х + 3z = 0, 5у + 4t = 0, 4y + 3t =1.
Решу системы уравнений методом алгебраического сложения:
5х + 4z = 1, 5у + 4t = 0,
4х +3z =0. 4у + 3t = 1.
х = -3, у = 4, z = 4. t = -5.
Получаю, А-1 = (-3 4
4 -5), проверю выполнение равенства А-1 × А = Е
(-3 4 (5 4 ( -3 × 5 + 4 × 4 -3 × 4 + 4 × 3 (1 0
4 -5) × 4 3) = 4 × 5 + (-5) × 4 4 × 4 + (-5) × 3) = 0 1) = Е, так как оба равенства выполнены, то могу сказать, что А-1 найдена.
При таком решении автоматически возникает условие: хt – уz = ±1, причем выражение хt – yz можно назвать определителем матрицы. Кроме того, в этом решении также автоматически появляется условие существования обратной матрицы: хt – yz ≠ 0.
Глава 2. Практическая часть.
Мои способы шифрованиия.
Меня давно уже интересовала проблема передачи информации способами доступными лишь «посвящённым». И у меня даже есть несколько способов шифрования текста, хотя, по сравнению со вновь узнанным, эти способы теперь кажутся мне совсем детскими. Вот лишь некоторые из них:
1) буквы заменяются суммой чисел (число – номер буквы в алфавитном порядке, нумеровать буквы можно и с конца алфавита). Например, фраза: «число слов» будет выглядеть так — 25+10+19+13+16 19+13+16+3.
2) к каждому числу, обозначающему номер буквы по алфавиту, прибавляется одно и то же условное число, допустим, число 5. Например: слово «звезда» после шифрования будет выглядеть так — (9 + 5) + (3 + 5) + (6 + 5) + (9 + 5) + ( 5+ 5) + (1 + 5) = 14 + 8 + 11 + 14 + 10+ 6.
3) и ещё один способ кодирования текста хочу предложить вашему вниманию, я придумал его сам.
Возьму ту же самую фразу: «шла зима» и заменю её последовательностью чисел: 26, 13, 1, 34, 9, 10, 14, 1. Затем построю матрицы (26 13 (9 10
1 34), 14 1). Зашифрую эту последовательность с помощью кодирующей матрицы, причём кодирующую матрицу поставлю на второе место, хотя в принципе это не важно, т. к. в алгебре матриц не выполняется коммутативность (переместительный закон) умножения, но не сложения. В качестве кодирующей возьму матрицу К = (1 2
Для этого использую такое правило: буду складывать соответственные элементы матриц, и назову это — суммой матриц, т. е.
(а b (x y (а+х b+y c d) + u v) = с+u c+v), тогда
(26 13 (1 2 (26+1 13+2 (27 15
1 34) + 3 4) = 1+3 34+4) = 4 38),
(9 10 (1 2 (9+1 10+2 (10 12
14 1) + 3 4) = 14+3 1+4) = 17 5), а адресат получит текст: 27, 15, 4, 38, 10, 12, 17, 5.
Чтобы прочитать его, нужно опять составить матрицы и применить к ним декодирующую. Её роль выполнит матрица: -К = (-1 -2
Все действия, которые я выполнял с матрицами 2 × 2 можно выполнить и с любыми другими матрицами, например 3 × 3, только всё это будет несколько сложнее.
И ещё один способ шифрования хочу показать. Я его знаю и использую очень давно. Способ шифрования основан на повороте квадрата с дырочками для букв, вокруг центра квадрата. Сначала приготовим средство шифрования – квадрат. Для этого из плотной бумаги вырежем квадрат 16 × 16см. и разделим его на 64 квадратика. Прорежем в этих квадратиках окошечки для букв . Наложив решетку на листок бумаги, можно писать сообщение в окошечках решетки, размещая по одной букве в каждое окошечко. Затем, когда все окошечки окажутся заполненными, решетку поворачивают по часовой стрелке на 90º. Все написанные буквы закрыты, а в новые окошечки продолжаем писать текст. Еще два поворота и текст дописан. Если остаются неиспользованные окошечки, их заполняют буквами а, б, в и т. д. (чтобы не было пробелов), письмо принимает вид как показано на рисунке. И его никогда не прочесть человеку, не имеющему шифровального квадрата.
А читают также, накладывая квадрат и поворачивая его по часовой стрелке на 90º. После четвертого поворота, текст сообщения становится ясен адресату.
Чтобы составить свою решетку, нужно разбить 64 — клеточный квадрат на четыре области. В первой расставить числа от 1 до 16 в обычном порядке. Вторая область – это то же, что и первая, но повернутая по часовой стрелке на 90º. Повернув еще на 90º, получим заполнение третьей области. При последнем повороте на 90º, получается заполнение четвертой области. Затем выбирают для окошечек любые 16 клеток, заботясь лишь о том, чтобы в их числе не было клеток с одинаковыми номерами. Итак, решетка готова, можно приступать к шифрованию. На 64 – клеточном поле можно составить более 4 млрд. разных секретных решеток .
2 3 4 13 9 5 1 5
6 7 8 14 10 6 2 9
10 11 12 15 11 7 3 13
14 15 16 16 12 8 4 4
8 12 16 16 15 14 13 3
7 11 15 12 11 10 9 2
6 10 14 8 7 6 5 1 5 9 13 4 3 2 1
Изучив литературу по данному вопросу, я открыл для себя новый, хитроумный способ кодирования текста — матричный, познакомился с понятием матрицы, научился находить произведение и сумму матриц, вычислять декодирующую матрицу, словом, научился кодировать матричным способом, да и не только это. Я попутно научился решать системы линейных уравнений методом алгебраического сложения, тогда как мои одноклассники будут изучать этот материал только в 8 классе, придумал свой способ шифрования текста, и мы с друзьями его уже успешно опробовали. А потом, когда я буду учиться в институте и изучать алгебру, то, то немногое, что я узнал из алгебры матриц, мне, конечно, пригодится.
Классический криптоанализ

На протяжении многих веков люди придумывали хитроумные способы сокрытия информации — шифры, в то время как другие люди придумывали еще более хитроумные способы вскрытия информации — методы взлома.
В этом топике я хочу кратко пройтись по наиболее известным классическим методам шифрования и описать технику взлома каждого из них.
Шифр Цезаря
Самый легкий и один из самых известных классических шифров — шифр Цезаря отлично подойдет на роль аперитива.
Шифр Цезаря относится к группе так называемых одноалфавитных шифров подстановки. При использовании шифров этой группы «каждый символ открытого текста заменяется на некоторый, фиксированный при данном ключе символ того же алфавита» wiki.
Способы выбора ключей могут быть различны. В шифре Цезаря ключом служит произвольное число k, выбранное в интервале от 1 до 25. Каждая буква открытого текста заменяется буквой, стоящей на k знаков дальше нее в алфавите. К примеру, пусть ключом будет число 3. Тогда буква A английского алфавита будет заменена буквой D, буква B — буквой E и так далее.
Для наглядности зашифруем слово HABRAHABR шифром Цезаря с ключом k=7. Построим таблицу подстановок:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z |
| h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | a | b | c | d | e | f | g |
И заменив каждую букву в тексте получим: C(‘HABRAHABR’, 7) = ‘OHIYHOHIY’.
При расшифровке каждая буква заменяется буквой, стоящей в алфавите на k знаков раньше: D(‘OHIYHOHIY’, 7) = ‘HABRAHABR’.
Криптоанализ шифра Цезаря
Малое пространство ключей (всего 25 вариантов) делает брут-форс самым эффективным и простым вариантом атаки.
Для вскрытия необходимо каждую букву шифртекста заменить буквой, стоящей на один знак левее в алфавите. Если в результате этого не удалось получить читаемое сообщение, то необходимо повторить действие, но уже сместив буквы на два знака левее. И так далее, пока в результате не получится читаемый текст.
Аффиный шифр
Рассмотрим немного более интересный одноалфавитный шифр подстановки под названием аффиный шифр. Он тоже реализует простую подстановку, но обеспечивает немного большее пространство ключей по сравнению с шифром Цезаря. В аффинном шифре каждой букве алфавита размера m ставится в соответствие число из диапазона 0… m-1. Затем при помощи специальной формулы, вычисляется новое число, которое заменит старое в шифртексте.
Процесс шифрования можно описать следующей формулой:
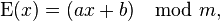
,
где x — номер шифруемой буквы в алфавите; m — размер алфавита; a, b — ключ шифрования.
Для расшифровки вычисляется другая функция:

,
где a -1 — число обратное a по модулю m. Это значит, что для корректной расшифровки число a должно быть взаимно простым с m.
С учетом этого ограничения вычислим пространство ключей аффиного шифра на примере английского алфавита. Так как английский алфавит содержит 26 букв, то в качестве a может быть выбрано только взаимно простое с 26 число. Таких чисел всего двенадцать: 1, 3, 5, 7, 9, 11, 15, 17, 19, 21, 23 и 25. Число b в свою очередь может принимать любое значение в интервале от 0 до 25, что в итоге дает нам 12*26 = 312 вариантов возможных ключей.
Криптоанализ аффиного шифра
Очевидно, что и в случае аффиного шифра простейшим способом взлома оказывается перебор всех возможных ключей. Но в результате перебора получится 312 различных текстов. Проанализировать такое количество сообщений можно и в ручную, но лучше автоматизировать этот процесс, используя такую характеристику как частота появления букв.
Давно известно, что буквы в естественных языках распределены не равномерно. К примеру, частоты появления букв английского языка в текстах имеют следующие значения:

Т.е. в английском тексте наиболее встречающимися буквами будут E, T, A. В то время как самыми редкими буквами являются J, Q, Z. Следовательно, посчитав частоту появления каждой буквы в тексте мы можем определить насколько частотная характеристика текста соответствует английскому языку.
Для этого необходимо вычислить значение:
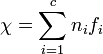
,
где ni — частота i-й буквы алфавита в естественном языке. И fi — частота i-й буквы в шифртексте.
Чем больше значение χ, тем больше вероятность того, что текст написан на естественном языке.
Таким образом, для взлома аффиного шифра достаточно перебрать 312 возможных ключей и вычислить значение χ для полученного в результате расшифровки текста. Текст, для которого значение χ окажется максимальным, с большой долей вероятности и является зашифрованным сообщением.
Разумеется следует учитывать, что метод не всегда работает с короткими сообщениями, в которых частотные характеристики могут сильно отличатся от характеристик естественного языка.
Шифр простой замены
Очередной шифр, относящийся к группе одноалфавитных шифров подстановки. Ключом шифра служит перемешанный произвольным образом алфавит. Например, ключом может быть следующая последовательность букв: XFQABOLYWJGPMRVIHUSDZKNTEC.
При шифровании каждая буква в тексте заменяется по следующему правилу. Первая буква алфавита замещается первой буквой ключа, вторая буква алфавита — второй буквой ключа и так далее. В нашем примере буква A будет заменена на X, буква B на F.
При расшифровке буква сперва ищется в ключе и затем заменяется буквой стоящей в алфавите на той же позиции.
Криптоанализ шифра простой замены
Пространство ключей шифра простой замены огромно и равно количеству перестановок используемого алфавита. Так для английского языка это число составляет 26! = 2 88 . Разумеется наивный перебор всех возможных ключей дело безнадежное и для взлома потребуется более утонченная техника, такая как поиск восхождением к вершине:
- Выбирается случайная последовательность букв — основной ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- Шаги 2-3 повторяются пока коэффициент не станет постоянным.
Шифр Полибия
Еще один шифр подстановки. Ключом шифра является квадрат размером 5*5 (для английского языка), содержащий все буквы алфавита, кроме J.

При шифровании каждая буква исходного текста замещается парой символов, представляющих номер строки и номер столбца, в которых расположена замещаемая буква. Буква a будет замещена в шифртексте парой BB, буква b — парой EB и так далее. Так как ключ не содержит букву J, перед шифрованием в исходном тексте J следует заменить на I.
Например, зашифруем слово HABRAHABR. C(‘HABRAHABR’) = ‘AB BB EB DA BB AB BB EB DA’.
Криптоанализ шифра Полибия
Шифр имеет большое пространство ключей (25! = 2 83 для английского языка). Однако единственное отличие квадрата Полибия от предыдущего шифра заключается в том, что буква исходного текста замещается двумя символами.
Поэтому для атаки можно использовать методику, применяемую при взломе шифра простой замены — поиск восхождением к вершине.
В качестве основного ключа выбирается случайный квадрат размером 5*5. В ходе каждой итерации ключ подвергается незначительным изменениям и проверяется насколько распределение триграмм в тексте, полученном в результате расшифровки, соответствует распределению в естественном языке.
Перестановочный шифр
Помимо шифров подстановки, широкое распространение также получили перестановочные шифры. В качестве примера опишем Шифр вертикальной перестановки.
В процессе шифрования сообщение записывается в виде таблицы. Количество колонок таблицы определяется размером ключа. Например, зашифруем сообщение WE ARE DISCOVERED. FLEE AT ONCE с помощью ключа 632415.
Так как ключ содержит 6 цифр дополним сообщение до длины кратной 6 произвольно выбранными буквами QKJEU и запишем сообщение в таблицу, содержащую 6 колонок, слева направо:

Для получения шифртекста выпишем каждую колонку из таблицы в порядке, определяемом ключом: EVLNE ACDTK ESEAQ ROFOJ DEECU WIREE.
При расшифровке текст записывается в таблицу по колонкам сверху вниз в порядке, определяемом ключом.
Криптоанализ перестановочного шифра
Лучшим способом атаки шифра вертикальной перестановки будет полный перебор всех возможных ключей малой длины (до 9 включительно — около 400 000 вариантов). В случае, если перебор не дал желаемых результатов, можно воспользоваться поиском восхождением к вершине.
Для каждого возможного значения длины осуществляется поиск наиболее правдоподобного ключа. Для оценки правдоподобности лучше использовать частоту появления триграмм. В результате возвращается ключ, обеспечивающий наиболее близкий к естественному языку текст расшифрованного сообщения.
Шифр Плейфера
Шифр Плейфера — подстановочный шифр, реализующий замену биграмм. Для шифрования необходим ключ, представляющий собой таблицу букв размером 5*5 (без буквы J).
Процесс шифрования сводится к поиску биграммы в таблице и замене ее на пару букв, образующих с исходной биграммой прямоугольник.
Рассмотрим, в качестве примера следующую таблицу, образующую ключ шифра Плейфера:
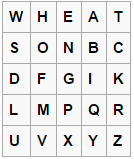
Зашифруем пару ‘WN’. Буква W расположена в первой строке и первой колонке. А буква N находится во второй строке и третьей колонке. Эти буквы образуют прямоугольник с углами W-E-S-N. Следовательно, при шифровании биграмма WN преобразовывается в биграмму ES.
В случае, если буквы расположены в одной строке или колонке, результатом шифрования является биграмма расположенная на одну позицию правее/ниже. Например, биграмма NG преобразовывается в биграмму GP.
Криптоанализ шифра Плейфера
Так как ключ шифра Плейфера представляет собой таблицу, содержащую 25 букв английского алфавита, можно ошибочно предположить, что метод поиска восхождением к вершине — лучший способ взлома данного шифра. К сожалению, этот метод не будет работать. Достигнув определенного уровня соответствия текста, алгоритм застрянет в точке локального максимума и не сможет продолжить поиск.
Чтобы успешно взломать шифр Плейфера лучше воспользоваться алгоритмом имитации отжига.
Отличие алгоритма имитации отжига от поиска восхождением к вершине заключается в том, что последний на пути к правильному решению никогда не принимает в качестве возможного решения более слабые варианты. В то время как алгоритм имитации отжига периодически откатывается назад к менее вероятным решениям, что увеличивает шансы на конечный успех.
Суть алгоритма сводится к следующим действиям:
- Выбирается случайная последовательность букв — основной-ключ. Шифртекст расшифровывается с помощью основного ключа. Для получившегося текста вычисляется коэффициент, характеризующий вероятность принадлежности к естественному языку.
- Основной ключ подвергается небольшим изменениям (перестановка двух произвольно выбранных букв, перестановка столбцов или строк). Производится расшифровка и вычисляется коэффициент полученного текста.
- Если коэффициент выше сохраненного значения, то основной ключ заменяется на модифицированный вариант.
- В противном случае замена основного ключа на модифицированный происходит с вероятностью, напрямую зависящей от разницы коэффициентов основного и модифицированного ключей.
- Шаги 2-4 повторяются около 50 000 раз.
Для расчета коэффициентов, определяющих принадлежность текста к естественному языку лучше всего использовать частоты появления триграмм.
Шифр Виженера
Шифр Виженера относится к группе полиалфавитных шифров подстановки. Это значит, что в зависимости от ключа одна и та же буква открытого текста может быть зашифрована в разные символы. Такая техника шифрования скрывает все частотные характеристики текста и затрудняет криптоанализ.
Шифр Виженера представляет собой последовательность нескольких шифров Цезаря с различными ключами.
Продемонстрируем, в качестве примера, шифрование слова HABRAHABR с помощью ключа 123. Запишем ключ под исходным текстом, повторив его требуемое количество раз:
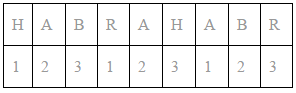
Цифры ключа определяют на сколько позиций необходимо сдвинуть букву в алфавите для получения шифртекста. Букву H необходимо сместить на одну позицию — в результате получается буква I, букву A на 2 позиции — буква C, и так далее. Осуществив все подстановки, получим в результате шифртекст: ICESCKBDU.
Криптоанализ шифра Виженера
Первая задача, стоящая при криптоанализе шифра Виженера заключается в нахождении длины, использованного при шифровании, ключа.
Для этого можно воспользоваться индексом совпадений.
Индекс совпадений — число, характеризующее вероятность того, что две произвольно выбранные из текста буквы окажутся одинаковы.
Для любого текста индекс совпадений вычисляется по формуле:
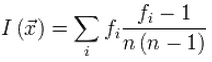
,
где fi — количество появлений i-й буквы алфавита в тексте, а n — количество букв в тексте.
Для английского языка индекс совпадений имеет значение 0.0667, в то время как для случайного набора букв этот показатель равен 0.038.
Более того, для текста зашифрованного с помощью одноалфавитной подстановки, индекс совпадений также равен 0.0667. Это объясняется тем, что количество различных букв в тексте остается неизменным.
Это свойство используется для нахождения длины ключа шифра Виженера. Из шифртекста по очереди выбираются каждая вторая буквы и для полученного текста считается индекс совпадений. Если результат примерно соответствует индексу совпадений естественного языка, значит длина ключа равна двум. В противном случае из шифртекста выбирается каждая третья буква и опять считается индекс совпадений. Процесс повторяется пока высокое значение индекса совпадений не укажет на длину ключа.
Успешность метода объясняется тем, что если длина ключа угадана верно, то выбранные буквы образуют шифртекст, зашифрованный простым шифром Цезаря. И индекс совпадений должен быть приблизительно соответствовать индексу совпадений естественного языка.
После того как длина ключа будет найдена взлом сводится к вскрытию нескольких шифров Цезаря. Для этого можно использовать способ, описанный в первом разделе данного топика.
P.S.
Исходники всех вышеописанных шифров и атак на них можно посмотреть на GitHub.
Ссылки
1. Криптоанализ классических шифров на сайте practicalcryptography.com.
2. Частотные характеристики английского языка на сайте practicalcryptography.com
3. Описание алгоритма имитации отжига на wikipedia
4. Описание поиска восхождением к вершине на wikipedia
- Криптоанализ
- шифр Цезаря
- шифр Виженера
- шифр простой замены
- перестановочный шифр
- шифр Полибия
- аффинный шифр
- шифр Плейфера
3.1 Прямой матричный метод
Для реализации поставленной в работе задачи реализации метода шифрования изображения необходимо воспользоваться правилами матричного умножения, и некоторыми свойствами матрицы перестановок .
Под матрицей перестановок понимается квадратная матрица, у которой в каждой строке и каждом столбце отличен от нуля только один элемент, равный единице [5].
Умножение произвольной матрицы размерности на матрицу перестановок размерности слева меняет местами строки матрицы .
Умножение произвольной матрицы размерности на матрицу перестановок размерности справа соответственно меняет местами её столбцы.
Если рассматривать цифровое изображение как квадратную матрицу размерности , элементы которой находятся в пределах от 0 до 255, задающую полутоновое отображение пикселов растра, то при умножении такой матрицы на матрицу перестановок и транспонированную к ней происходит перемешивание пикселов изображения
Известно [5] следующее свойство матрицы перестановок :
где _ единичная матрица. Согласно (8) для обратного преобразования матрицы достаточно умножить её на справа и на слева
Таким образом, матрица будет являться ключом для такого перемешивания.
Итоговая сложность матричного перемножения (9) будет равна: , что может занять достаточно большой промежуток времени при обработке больших изображений, поэтому необходимо сократить количество операций.