Закончилось место на OSD в CEPH, что делать?
Помогите разобраться с CEPH Для теста развернул на одной машине CEPH В качестве OSD использую директории на диске Создал 7 директорий:
/opt/osd1 /opt/osd2 /opt/osd3 . /opt/osd7 поднял rados gateway в итоге получилось 6 пулов:
#ceph osd pool ls .rgw.root default.rgw.control default.rgw.meta default.rgw.log default.rgw.buckets.index default.rgw.buckets.data Для теста выставил следующие параметры:
osd pool default size = 1 osd pool default min size = 1 osd pool default pg num = 30 osd pool default pgp num = 30 В ходе теста CEPH предупредил что заканчивается место на одном OSD. Я решил, что поможет добавление нового OSD и CEPH сам перераспределит данные ( я был не прав!) Сейчас статус ceph стал таким:
~# ceph -s cluster: id: 3ed5c9c-ec59-4223-9104-65f82103a45d health: HEALTH_ERR Reduced data availability: 28 pgs stale 1 slow requests are blocked > 32 sec. Implicated osds 0 4 stuck requests are blocked > 4096 sec. Implicated osds 1,2,5 services: mon: 1 daemons, quorum Rutherford mgr: Ruerfr(active) osd: 7 osds: 6 up, 6 in rgw: 1 daemon active data: pools: 6 pools, 180 pgs objects: 227 objects, 2.93KiB usage: 23.0GiB used, 37.0GiB / 60GiB avail pgs: 152 active+clean 28 stale+active+clean место на OSD закончилось и он ушел в статус down:
# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.06857 root default -3 0.06857 host Rutherford 0 hdd 0.00980 osd.0 up 0.95001 1.00000 1 hdd 0.00980 osd.1 up 0.90002 1.00000 2 hdd 0.00980 osd.2 up 0.90002 1.00000 3 hdd 0.00980 osd.3 down 0 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 6 hdd 0.00980 osd.6 up 1.00000 1.00000 - Как сейчас восстановить работу CEPH , место на диске есть. Создать OSD могу , но как заставить CEPH перераспределить данные с одного OSD на другие ?
- Почему CEPH писал данные только на один OSD, я изначально создавал их 7 штук ?
Глава 10. Поиск неисправностей
Ceph во многом автономен в заботе о себе и при восстановлении в случае отказов, однако в некоторых вариантах требуется вмешательство человека. Данная глава рассмотрит такие общие ошибки и варианты отказов, а также как переносить Ceph обратно в рабочее состояние находя неисправности в нём. Вы изучите следующие вопросы:
- Как правильно восстанавливать несогласованные объекты
- Как решать проблемы при помощи однорангового обмена
- Как обрабатывать OSD с near_full и too_full
- Как исследовать ошибки при помощи журналов Ceph
- Как изучать плохую производительность
- Как обследовать PG в состоянии down
Восстановление несогласованных объектов
Сейчас мы рассмотрим как мы можем правильно восстанавливать несогласованные объекты.
- Чтобы иметь возможность восстановления несогласованного сценария создайте некий RBD и далее мы сделаем в нём некую файловую систему:
Рисунок 1
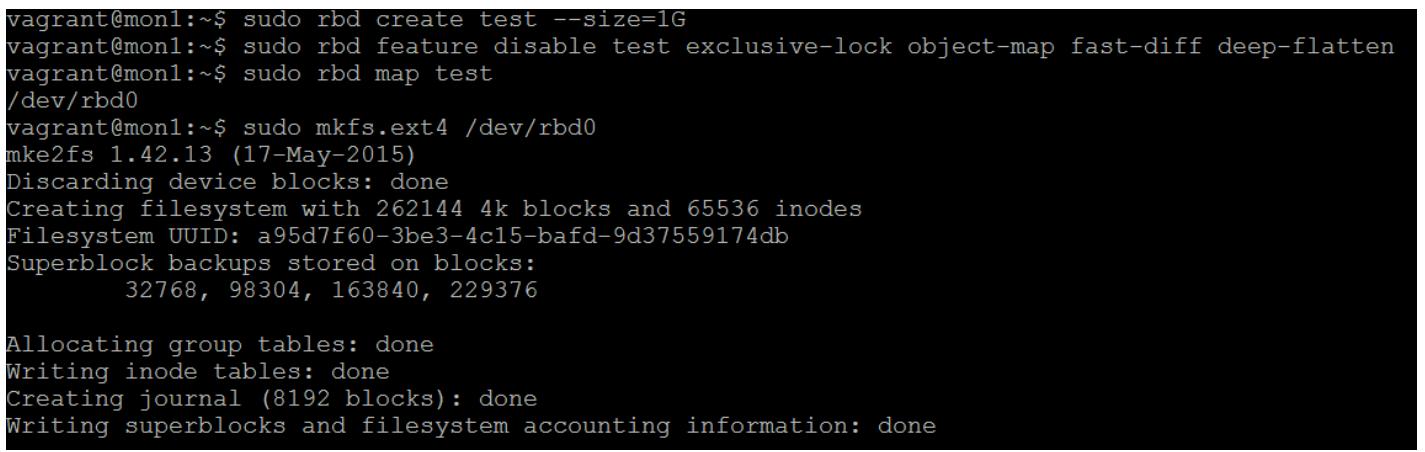
Рисунок 2
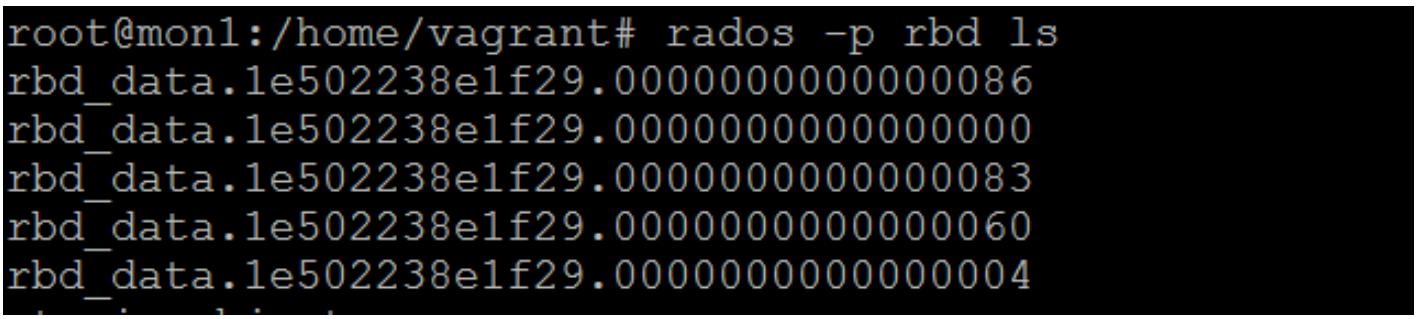
Рисунок 3

Рисунок 4

Рисунок 5

Рисунок 6

Рисунок 7
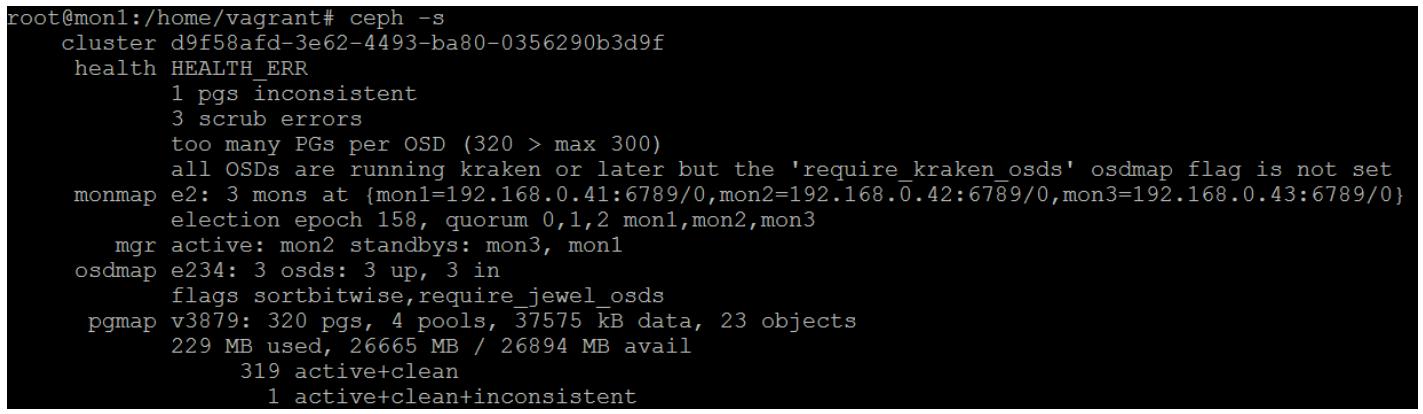
Рассматривая более внимательно сообщение о работоспособности, мы можем обнаружить ту PG, которая содержит испорченный объект. Мы можем теперь просто запросить у Ceph восстановление данной PG; однако, если именно первичный OSD содержит испорченный объект, это перепишет оставшиеся хорошие копии. Это будет не хорошо; таким образом, чтобы убедиться, что этого не произойдёт, перед тем как исполнить команду восстановления мы убедимся в том какой именно OSD содержит испорченный объект.
Рисунок 8

Рисунок 9

md5sum объекта в osd первого узла
Рисунок 10

md5sum объекта в osd второго узла
Рисунок 11

md5sum объекта в osd третьего узла Мы можем обнаружить, что объект в osd.0 имеет отличное значение md5sum и поэтому мы знаем что именно он является разрушенным объектом.
OSD.0 = \0d599f0ec05c3bda8c3b8a68c32a1b47 OSD.2 = \b5cfa9d6c8febd618f91ac2843d50a1c OSD.3 = \b5cfa9d6c8febd618f91ac2843d50a1c
Хотя мы уже знаем какая копия объекта была разрушена, поскольку мы вручную изувечили объект в OSD.0 , давайте притворимся что мы не делали этого и такое разрушение могло быть вызвано случайными космическими лучами. Теперь у нас имеется md5sum трёх реплицированных копий и можно ясно понять что копия в OSD.0 неверная. Это очевидный факт для того почему схема с двумя репликациями плоха; если некая PG становится несогласованной, вы можете определить какая из них плохая. Поскольку первичным OSD для этой PG является 2, как мы могли убедиться и в подробностях о работоспособности Ceph, и в выводе команды Ceph OSD map , мы можем безопасно выполнить имеющуюся команду ceph pg repair без опасений что скопируем плохой объект поверх оставшихся неиспорченными копий.
Рисунок 12

Мы можем отметить, что наша несогласованная PG восстановила себя:
Рисунок 13
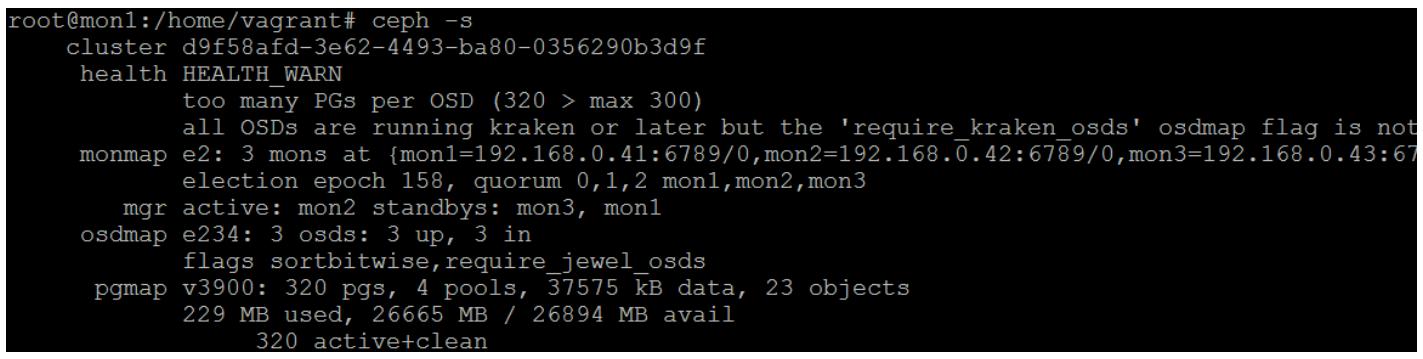
При возникновении ситуации, когда разрушена копия на самом первичном OSD, тогда необходимо предпринять следующие шаги:
- Остановить первичный OSD.
- Удалить этот объект из каталога данной PG.
- Повторно запустить этот OSD.
- Проинструктировать Ceph восстановить эту PG.
Заполненные OSD
По умолчанию Ceph предостерегает когда использование OSD достигает 85% и остановит операции ввода/ вывода на запись в данный OSD когда будет достигнуто 95%. Если по какой- либо причине данный OSD полностью заполнится до 100%, тогда данный OSD скорее всего разрушится и откажется вернуться назад в рабочее состояние. Некий OSD который превысил уровень предупреждения в 85% также отвергает участие в наполнении, поэтому восстановление данного кластера может получить удар в случае если OSD находятся около заполненного состояния.
Прежде чем рассмотреть все шаги поиска неисправностей в ситуации заполненных OSD настоятельно рекомендуется чтобы вы наблюдали за использованием ёмкости ваших OSD, как это описывалось в главе о мониторинге. Это снабдит вас заблаговременным уведомлением таким как подход к OSD с пороговым предупреждением near_full .
Если вы обнаружили что находитесь в ситуации когда ваш кластер переступил через состояние предупреждение близости к заполнению у вас имеются два основных варианта:
- Добавить немного дополнительных OSD.
- Удалить некоторые данные
Однако в реальном мире они оба или невозможны, либо потребуют времени и в таком случае ситуация может ухудшиться. Если данный OSD только в пороговом значении near_full , тогда вы скорее всего вероятно можете вернуть всё в правильное русло проверкой сбалансировано ли использование вашего OSD, с возможной последующей балансировкой, если её нет. Это было подробно рассмотрено в предыдущей главе о регулировках. То же самое применимо и к ситуации когда OSD too_full ; хотя вы вряд ли вернёте его обратно ниже 85%, вы по крайней мере можете отвергать операции записи.
Если ваши OSD заполнились полностью, тогда они все в состоянии отключённых и будут отвергать запуск. Теперь вы имеете некоторую дополнительную проблему. Если данные OSD не запустятся, тогда вне зависимости от того что вы выполните — ребалансировку или удаление данных, они не отразятся на всех заполненных OSD, так как они отключены. Единственный способ восстановиться из данной ситуации — это вручную удалить некоторые PG из файловой системы данных дисков чтобы сделать возможным запуск такого OSD.
Вот шаги, которые необходимо для этого предпринять:
- Убедитесь что данный процесс OSD не исполняется.
- Установите в данном кластере nobackfill чтобы остановить все восстановления от их наступления после возврата в работу данного OSD.
- Найдите некую PG, которая находится в активном, чистом и переназначенном состоянии и присутствует в данном отключённом OSD.
- Удалите эту PG из данного отключённого OSD.
- Будем надеяться, что вы теперь сможете перезапустить данный OSD.
- Удалите данные из данного кластера Ceph или выполните повторную балансировку PG.
- Удалите nobackfill .
- Исполните очистку и восстановление той PG, которую вы только что удалили.
Ведение журналов OSD
При выявлении ошибок очень удобно иметь возможность просматривать все файлы журналов Ceph чтобы получать лучшие идеи по поводу того что происходит. По умолчанию имеющиеся уровни ведения журнала установлены так, чтобы регистрировались только все важные события. В процессе поиска неисправностей может возникнуть потребность повысить эти уровни ведения журналов чтобы обнаружить вызывающую данную ошибку причину. Для увеличения уровня ведения журнала вы можете либо изменить ceph.conf , добавив новый уровень журнала, а затем перезапустить этот компонент, либо, если вы не желаете перезапускать сам демон Ceph, вы можете внедрить необходимый новый параметр настройки в свой работающий в реальном времени демон. Для внедрения параметров применяйте команду ceph tell :
ceph tell osd.0 injectargs --debug-osd 0/5
Здесь мы устанавливаем уровень ведения журнала для журнала OSD на osd.0 в значение 0/5 . Число 0 является уровнем журнала на диске, а число 5 уровень журнала в оперативной памяти.
На уровне ведения журнала 20 , такой журнал становится черезчур многословным и будет быстро расти. Не оставляйте высокий уровень подробностей включённым слишком долго. Более высокие уровни ведения журнала также воздействуют на производительность.
Малая производительность
Низкая производительность определяется в том случае, когда сам кластер активно обрабатывает запросы операций ввода/ вывода, однако они кажутся работающими на более низком уровне производительности чем это ожидается. Обычно малая производительность вызывается неким компонентом в вашем кластере Ceph, который достиг насыщения и становится узким местом. Это может быть обусловлено увеличением числа запросов клиентов или неким отказом компонента, который заставляет Ceph выполнять восстановление.
Причины
Хотя имеется множество вещей, которые могут заставить Ceph испытывать низкую производительность, вот некоторые из наиболее общих, которые могут происходить:
Возросшая рабочая нагрузка клиентов
Порой низкая производительность может быть обусловлена не лежащими в её основе отказами; это может быть просто результатом того, что общее число и тип запросов клиентов могут превосходить возможности имеющегося оборудования. Будь то последствия некоторого числа рабочих нагрузок, которые все исполняются в одно и то же время, или всего лишь некое медленное общее увеличение на некий период времени, если вы отслеживаете общее число запросов клиентов по всему своему кластеру, это должно быть простым для отслеживания. Если увеличившаяся рабочая нагрузка выглядит как нечто постоянное, тогда единственным решением будет добавить некоторое дополнительное оборудование.
Останов OSD
Если в некотором кластере значительное число OSD помечены как down , возможно из- за того, что остановлен целый узел, хотя восстановление не начнётся пока эти OSD не будут помечены как out , это повлияет на общую производительность, поскольку общее число IOP, доступное для обслуживания всех операций ввода/ вывода клиентов теперь будет ниже. Ваше решение мониторинга должно уведомить вас если это произойдёт и позволит вам предпринять действия.
Восстановление и наполнение
Когда некий OSD помечен как out , попавшие под воздействие этого PG переустановят одноранговые соединения на новые OSD и начнут свой процесс восстановления и наполнения данными по всему кластеру. Этот процесс может разместить на все диски в некотором кластере Ceph дополнительную нагрузку и повлечь большие задержки для запросов клиентов. Имеется ряд параметров регулировки, которые могут снизить воздействие заполнения уменьшением его скорости и приоритета. Это следует оценить в противовес воздействию снижения восстановления отказавших дисков, что могло бы уменьшить уровень живучести всего кластера.
Очистка
Когда Ceph выполняет глубокую очистку для проверки того, находятся ли ваши данные в какой- либо несогласованности, ему приходится считывать все объекты с данного OSD; это может быть очень интенсивной задачей в отношении операций ввода/ вывода, а на больших дисках этот процесс может отнимать много времени. Очистка жизненно важна для защиты от утраты данных и, следовательно, её нельзя отключать. Различные варианты настроек обсуждались в Главе 9, Тонкая настройка Ceph, относящиеся к установкам окон для очистки и её приоритету. Регулируя эти установки можно избежать большую часть воздействия на рабочую нагрузку клиента от очистки.
Подрезка снимков
Когда вы удаляете некий моментальный снимок, Ceph должен удалить все имеющиеся объекты, которые были созданы благодаря природе копирования при записи данного процесса получения снимка. Начиная с Ceph 10.2.8 и далее имеется некоторое улучшенная установка OSD с названием osd_snap_trim_sleep , которая заставляет Ceph ожидать предписанного установкой значения между подрезкой каждого объекта моментального снимка. Это гарантирует, что все лежащие в основе хранения объекты не станут перегруженными.
Хотя эти установки были доступны в предыдущих редакциях Jewel, их поведение было не тем же самым и их не следует применять.
Проблемы с оборудованием или драйверами
Если вы только что добавили новое оборудование в свой кластер Ceph и, после того как заполнение повторно сбалансировало ваши данные, вы начинаете испытывать медленную производительность, проверьте своё встроенное программное обеспечение или драйверы связанные с вашим оборудованием, поскольку новые драйверы могут требовать более нового ядра. Если вы добавили только небольшой объём аппаратных средств, тогда вы можете временно пометить эти OSD как out не выходя ниже установленного для ваших пулов значения min_size ; это может быть хорошим способом исключения проблем с оборудованием.
Наблюдение
Именно здесь приходит на пользу тот мониторинг, который вы настроили в Главе 7, Мониторинг Ceph, так как он позволит вам сравнивать долговременные тенденции с чтением текущих измерений и увидеть некоторые ясные аномалии, если они имеются.
Вначале рекомендуется взглянуть на производительность дисков так как, в большинстве случаев плохой производительности, именно лежащие в основе диски обычно становятся теми компонентами, которые становятся бутылочным горлышком.
Если у вас нет настроенного мониторинга или вы желаете вручную углубиться в пучину имеющихся параметров производительности, тогда имеется целый ряд инструментов, который вы можете применить для этого.
iostat
iostat может быть применён для получения обзора работы в отношении имеющихся производительности и латентности всех дисков, функционирующих в ваших узлах OSD. Исполните span > iostat посредством следующей команды:
iostat -d 1 -x
Вы получите отображение подобное следующему, которое обновляется раз в секунду:
Рисунок 14
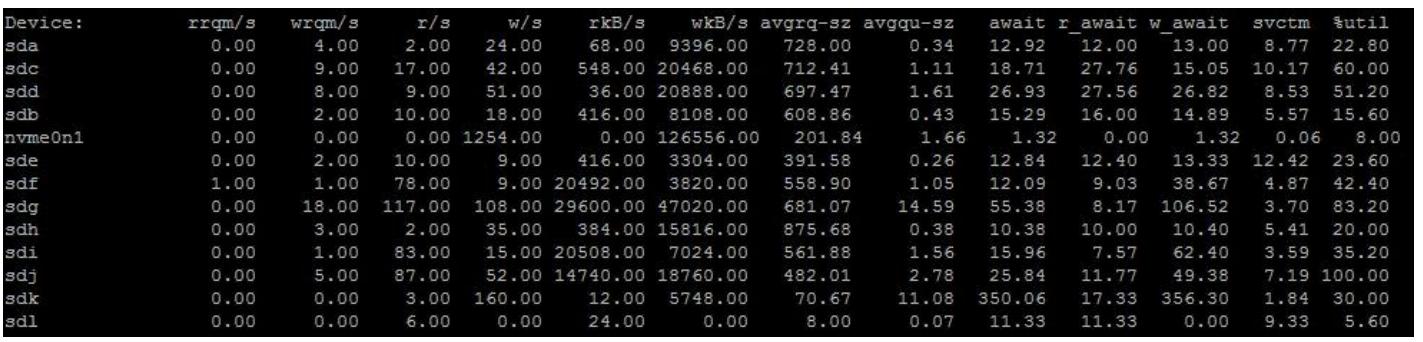
В качестве высеченного в граните правила, если достаточно большое число ваших дисков показывают высокий процент util на протяжении длительного времени, скорее всего ваши диски перенасыщены запросами. Может быть неплохо взглянуть на время r_await чтобы проверить что запросы на чтение не занимают больше времени, чем это следует ожидать для данного типа диска в ваших узлах OSD. Как уже упоминалось ранее, если вы обнаружите что интенсивное использование дисков является причиной низкой производительности и тем переключающим фактором, который вряд ли рассосётся скоро, тогда дополнительные диски являются единственным решением.
htop
Как и стандартная утилита top, htop предоставляет в реальном времени просмотр потребления имеющихся ЦПУ и оперативной памяти данного хоста. Однако, она также предоставляет более интуитивное отображение, которое может сделать оценку использования всех ресурсов системы проще, в особенности для быстро меняющегося использования ресурсов Ceph.
Рисунок 15
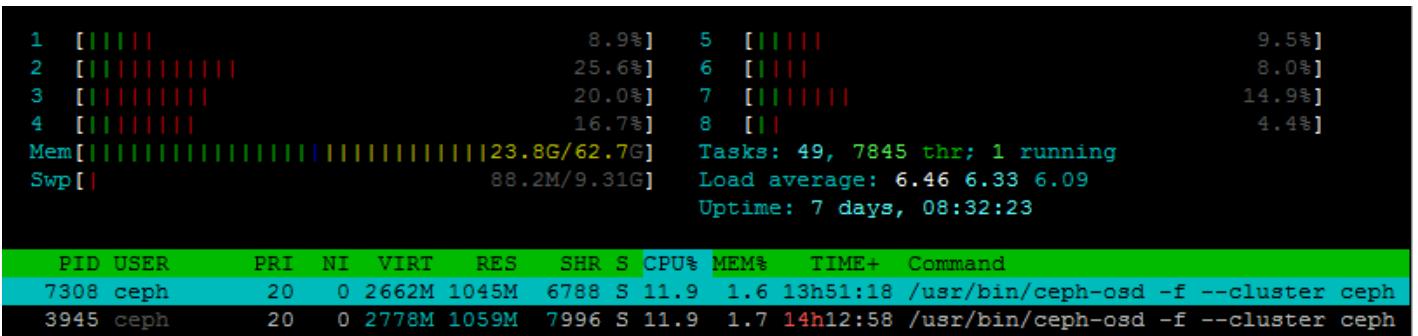
atop
Другим полезным инструментом является atop ; он улавливает параметры производительности для ЦПУ, оперативной памяти, дисков, сетевой среды и может представлять всё это в одном просмотре, что делает его очень простым для получения полного обзора всех применяемых ресурсов системы.
Диагностика
Существует некое число внутренних инструментов Ceph, которые можно применять в помощь диагностированию низкой производительности. Большинство полезных команд для исследования медленной производительности сбрасывают текущие операции в реальном времени, что может быть сделано командой, например такой:
sudo ceph daemon osd.x dump_ops_in_flight
Она сбрасывает все текущие операции для данного определённого OSD и расчленяет все имеющиеся различные времена для каждого этапа данной операции. Вот некий пример какой- то операции ввода/ вывода на лету:
Рисунок 16
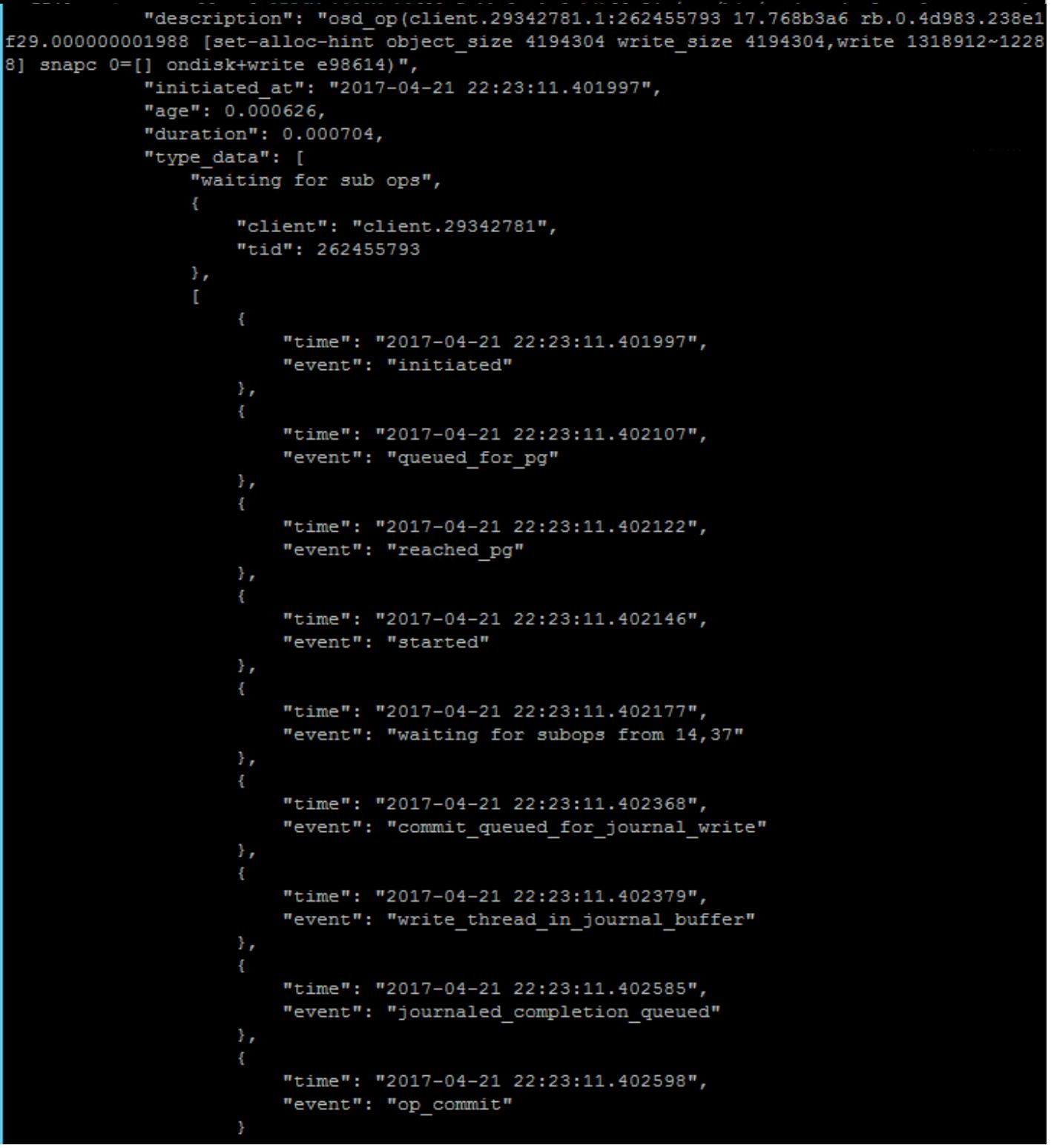
Из предыдущего примера операции ввода/ вывода мы можем увидеть все имеющиеся этапы, которые зарегистрированы для каждой операции; очевидно что данная операция исполняется без каких- либо проблем с производительностью. Однако, при возникновении низкой производительности вы можете увидеть некие большие задержки между двумя этапами и, направив свои изыскания в эту область, можете выйти на вызвавшую проблему процедуру.
Очень низкая производительность или отсутствие ввода/ вывода
Если ваш кластер работает действительно медленно, причём до такой степени что он почти не обслуживает запросы операций ввода/ вывода, тогда, скорее всего, имеются некие лежащие в основе этого отказ или проблема настройки. Такие медленные запросы будут вероятно выделены в дисплее состояния Ceph с помощью счётчика для того, насколько долго запрос был блокирован. В этом случае необходимо проверить несколько моментов.
Биения OSD
В своих мониторах проверьте ceph.log и убедитесь не выглядят ли они как какие- то OSD бьются в up и down . Когда некий OSD присоединяется к кластеру, его группы размещения подлежат включению в одноранговую сеть (peering). На протяжении данного процесса установки одноранговых соединений операции ввода/ вывода временно останавливаются, поэтому в случае некоторого число биений OSD это может определённым образом воздействовать на операции ввода/ вывода клиента. Если с очевидностью имеются мерцающие OSD, следующим этапом будет проход по журналам для выявления тех OSD, которые являются мерцающими и нет ли ключей к тому что вызывает их биения. Мерцание OSD может быть сложным для отслеживания, так как возможно вызывается различными причинами и к тому же данная проблема может широко распространяться.
Кадры Jumbo
Убедитесь что изменения в сетевой среде не вызвали проблем с кадрами jumbo, если они применяются. Если кадры jumbo не работают надлежащим образом, пакеты меньшего размера скорее всего могут быть успешными для прохождения к прочим OSD и MON, однако более длинные пакеты будут отбрасываться. Это будет иметь результатом то, что возникнет половинчатая функциональность, а это может быть очень трудным для обнаружения очевидным образом. Если происходит нечто странное, всегда проверяйте с применением ping тот факт, что кадры jumbo разрешены по всей вашей сети.
Начинающие отказывать диски
Так как Ceph чередует данные по всем дискам в имеющемся кластере, некий отдельный диск, который находится в процессе падения, но всё же пока ещё полностью не отказал, может начать вызывать замедление или блокировку операций ввода/ вывода по всему кластеру. Зачастую это будет вызвано неким диском, который переполнен большим числом ошибок чтения, однако всё ещё недостаточным для того, чтобы этот диск отказал полностью. Обычно некий диск будет всего лишь повторно выделять (reallocate) секторы при записи в некий плохой сектор. Наблюдение за статистиками S.M.A.R.T. со всех дисков обычно укажет на такое условие как описано только что и позволит вам предпринять действие.
Медленные OSD
Порой некий OSD может показывать очень плохую производительность без всяких заметных причин. Если нет ничего очевидного, выявляемого вашими инструментами наблюдения, проверьте ceph.log и подробный вывод работоспособности вашего Ceph. Вы также можете выполнить osd perf Ceph, который выдаст перечень всех задержек фиксаций и применений для каждого вашего OSD и также может помочь вам выявить некий проблемный OSD.
Если существует некий общий шаблон OSD, которые проявляют себя медленными в запросах, тогда есть хорошая вероятность что именно упомянутые OSD вызывают данные проблемы. Имеется вероятность того, что перезапуск данного OSD в состоянии разрешить данную трудность; если же данный OSD всё ещё останется проблемным, следует предложить пометить его как out а затем заменить этот OSD.
Расследование PG в состоянии down
Некая PG в состоянии down не будет обслуживать никакие операции клиента и все содержащиеся в этой группе размещений будут недоступными. Это вызовет замедление построения запросов по всему кластеру, так как клиенты пытаются получить доступ к этим объектам. Наиболее распространённой причиной, по которой некая PG находится в состоянии down происходит когда отключён ряд OSD, что означает, что нет имеющих силу копий данных PG на каких либо активных OSD. Однако, чтобы определить почему некая PG находится в состоянии down вы можете выполнить такую команду:
ceph pg x.y query
Она предоставит достаточно большое количество вывода; та секция, которая представляет для нас интерес отображает состояние однорангового обмена. Приводимый здесь пример был взят из группы размещения, чей пул был установлен в значение 1 для min_size и имел записанные в него данные в то время как только OSD 0 находился в up и рабочем состояниях. Затем OSD был остановлен, а OSD 1 и 2 были запущены.
Рисунок 17
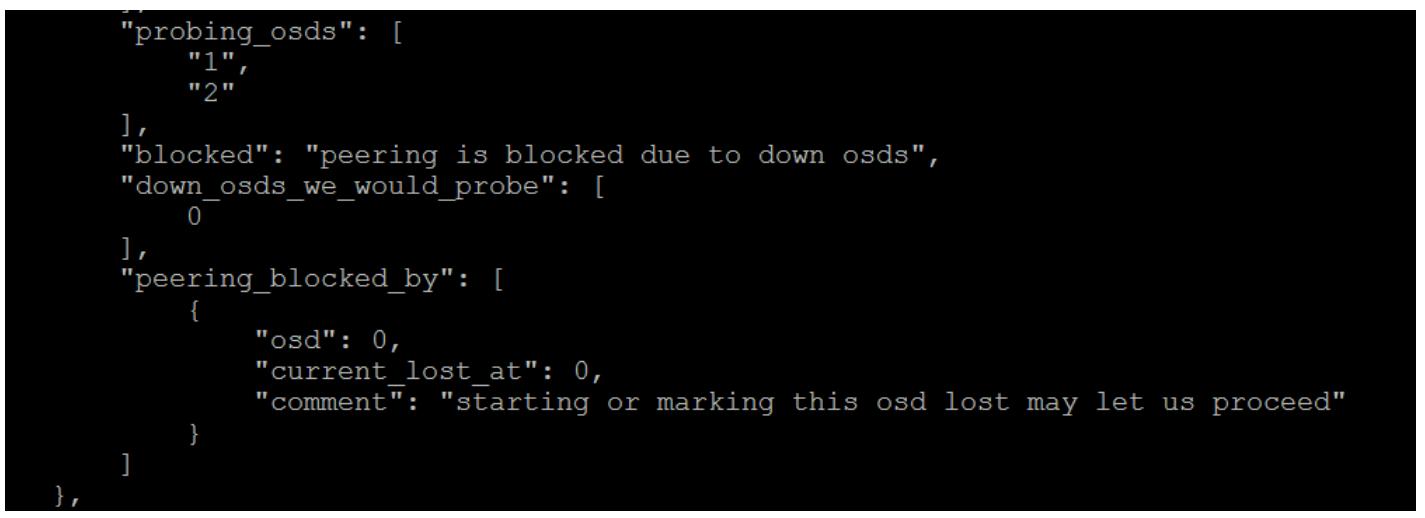
Мы можем увидеть, что был блокирован весь процесс однорангового обмена, так как Ceph знает что данная PG имеет более новые данные, записанные в OSD 0. Он опросил OSD 1 и 2 на предмет этих данных, что означает что он не обнаружил ничего из того что ему требовалось. Он бы хотел попробовать и опросить OSD 0, что однако не возможно, поскольку этот OSD down , следовательно то сообщение, которое начинается с этого osd или помечает его позволит нам продолжить.
Большие базы данных монитора
Мониторы Ceph применяют leveldb для хранения всех требующихся монитору данных для вашего кластера. Они содержат такие вещи как карту монитора, карту OSD и карту PG, которые OSD и клиенты получают из этих мониторов чтобы иметь возможность определять местоположение объектов во всём кластере RADOS. Одно особенное свойство, о котором должны быть осведомлены все состоит в том, что в тот период, когда работоспособность всего кластера не равна HEALTH_OK , все мониторы не отвергают никакие имеющиеся более старые карты кластера из своих баз данных. Если данный кластер находится в деградированном состоянии на протяжении достаточно длительного периода времени и/ или данный кластер имеет достаточно большое число OSD, данная база данных монитора может вырасти очень значительно.
При нормальных условиях работы все мониторы имеют очень малый вес в отношении потребления ресурсов; благодаря этому достаточно распространено применять диски меньшего размера для всех мониторов. При той ситуации, когда деградированное состояние происходит продолжительное время, может статься для того диска, который размещает базу данных монитора, что он заполнится, что, если это произойдёт со всеми узлами мониторов, приведёт к падению всего кластера.
Чтобы уберечься от такого поведения, может оказаться разумным развернуть ваши узлы монитора с использованием LVM с тем, чтобы при возникновения потребности в расширении данных дисков это можно было бы сделать более простым способом. Когда вы попадаете в данную ситуацию, добавление дискового пространства является единственным решением пока вы не получите весь остаток своего кластера в состояние HEALTH_OK .
Если ваш кластер находится в состоянии HEALTH_OK , однако база данных монитора всё ещё велика, вы можете уменьшить её выполнив следующую команду:
sudo ceph tell mon. compact
Однако, это работает только в случае когда ваш кластер находится в состоянии HEALTH_OK ; данный кластер не сможет отбросить старые карты кластера, которые могут быть плотно упакованы, пока он не находится в состоянии HEALTH_OK .
Выводы
В этой главе мы изучили как обрабатывать те проблемы, с которыми Ceph не в состоянии справиться самостоятельно. Теперь вы понимаете все необходимые этапы поиска неисправностей при возникновении различных проблем которые, если их оставить нерешёнными, могут вырасти в ещё большие проблемы. Более того, вы также имеете хорошие идеи о том что является ключевыми областями для поиска в ситуации, когда ваш кластер Ceph не работает так как ожидалось. Вы должны получить уверенность, что вы теперь в намного лучшем положении для обработки относящихся к Ceph проблем как только они появятся.
Закончилось место на OSD в CEPH, что делать?
Для теста развернул на одной машине CEPH. Ставил через ceph-depoy.
В качестве OSD использую директории на диске
Создал 7 директорий:
/opt/osd1 /opt/osd2 /opt/osd3 . /opt/osd7 поднял rados gateway в итоге получилось 6 пулов:
#ceph osd pool ls .rgw.root default.rgw.control default.rgw.meta default.rgw.log default.rgw.buckets.index default.rgw.buckets.data Для теста выставил следующие параметры:
osd pool default size = 1 osd pool default min size = 1 osd pool default pg num = 30 osd pool default pgp num = 30 В ходе теста CEPH предупредил что заканчивается место на одном OSD. Я решил, что поможет добавление нового OSD и CEPH сам перераспределит данные ( я был не прав!) Сейчас статус ceph стал таким:
~# ceph -s cluster: id: 3ed5c9c-ec59-4223-9104-65f82103a45d health: HEALTH_ERR Reduced data availability: 28 pgs stale 1 slow requests are blocked > 32 sec. Implicated osds 0 4 stuck requests are blocked > 4096 sec. Implicated osds 1,2,5 services: mon: 1 daemons, quorum Rutherford mgr: Ruerfr(active) osd: 7 osds: 6 up, 6 in rgw: 1 daemon active data: pools: 6 pools, 180 pgs objects: 227 objects, 2.93KiB usage: 23.0GiB used, 37.0GiB / 60GiB avail pgs: 152 active+clean 28 stale+active+clean место на OSD закончилось и он ушел в статус down:
# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.06857 root default -3 0.06857 host Rutherford 0 hdd 0.00980 osd.0 up 0.95001 1.00000 1 hdd 0.00980 osd.1 up 0.90002 1.00000 2 hdd 0.00980 osd.2 up 0.90002 1.00000 3 hdd 0.00980 osd.3 down 0 1.00000 4 hdd 0.00980 osd.4 up 1.00000 1.00000 5 hdd 0.00980 osd.5 up 1.00000 1.00000 6 hdd 0.00980 osd.6 up 1.00000 1.00000 Я понимаю что проблема в моем не понимании работы CEPH, но к сожалению сам найти решение не смог, поэтому прошу помощи. Вопросы на которые я так и не смог ответить:
- Как сейчас восстановить работу CEPH, место на диске есть. Создать OSD могу , но как заставить CEPH перераспределить данные с одного OSD на другие ?
- Почему CEPH писал данные только на один OSD, я изначально создавал их 7 штук ?
[global] fsid = 1ed3ce2c-ec59-4315-9146-65182123a35d mon_initial_members = Rut4erfor mon_host = 8.3.5.1 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx osd pool default size = 1 osd pool default min size = 1 osd pool default pg num = 30 osd pool default pgp num = 30 [osd] osd max object size = 1073741824 osd max write size = 1073741824 SergHom
17.07.20 09:10:26 MSK

Почему CEPH писал данные только на один OSD, я изначально создавал их 7 штук ?
ceph osd dfceph pg ls | tail -20Pinkbyte ★★★★★
( 17.07.20 16:38:00 MSK )
Последнее исправление: Pinkbyte 17.07.20 16:41:12 MSK (всего исправлений: 2)
CRASH
( 17.07.20 18:01:56 MSK )

osd pool default size = 1 osd pool default min size = 1
Перевод: «я хочу потерять данные, когда с одним osd что-то плохое произойдет».
Надо хотя бы в 2 оба параметра выставить.
А так у тебя один osd ушел в down, вместе с единственной копией данных, которая там была.
osd pool default pg num = 30
Мало. Их должно быть в общей сложности (т.е. с учетом копий) 100 на каждый osd.
Итого: пересоздавай кластер.
AEP ★★★★★
( 19.07.20 18:13:33 MSK )
Ну и по поводу отсутствующих знаний: есть еще проблема отсутствия неустаревшей литературы, и проблема ужасной документации (оно все еще акцентируют внимание на filestore, который уже давно не нужен, так как есть bluestore). И вообще проблема сакральных знаний, которыми спецы делятся только за мегабаксы.
Советую записаться вот на этот курс, так как других хороших источников я просто не знаю: https://slurm.io/ceph
AEP ★★★★★
( 19.07.20 18:24:00 MSK )
Ответ на: комментарий от Pinkbyte 17.07.20 16:38:00 MSK
Прежде всего спасибо что откликнулись ! вот данные которые просили:
ceph osd df ID CLASS WEIGHT REWEIGHT SIZE USE DATA OMAP META AVAIL %USE VAR PGS 0 hdd 0.00980 0.80005 10GiB 9.88GiB 57.4MiB 220KiB 9.83GiB 119MiB 98.84 3.42 36 1 hdd 0.00980 0.75006 10GiB 9.88GiB 56.6MiB 305KiB 9.83GiB 119MiB 98.84 3.42 26 2 hdd 0.00980 0.75006 10GiB 9.89GiB 55.9MiB 371KiB 9.83GiB 117MiB 98.86 3.42 11 3 hdd 0.00980 0 0B 0B 0B 0B 0B 0B 0 0 28 4 hdd 0.00980 1.00000 10GiB 2.85GiB 57.7MiB 0B 2.79GiB 7.15GiB 28.47 0.99 140 5 hdd 0.00980 1.00000 10GiB 2.48GiB 57.8MiB 0B 2.43GiB 7.52GiB 24.84 0.86 127 6 hdd 0.00980 1.00000 10GiB 2.74GiB 57.7MiB 0B 2.68GiB 7.26GiB 27.37 0.95 136 7 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.18 0.46 95 8 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.20 0.46 72 9 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.20 0.46 76 10 hdd 0.00980 1.00000 10GiB 1.32GiB 57.8MiB 0B 1.26GiB 8.68GiB 13.21 0.46 78 11 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.17 0.46 76 12 hdd 0.00980 1.00000 10GiB 1.32GiB 57.8MiB 0B 1.26GiB 8.68GiB 13.19 0.46 74 13 hdd 0.00980 1.00000 10GiB 1.32GiB 57.8MiB 0B 1.26GiB 8.68GiB 13.15 0.46 59 14 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.19 0.46 54 15 hdd 0.00980 1.00000 10GiB 1.32GiB 57.9MiB 0B 1.26GiB 8.68GiB 13.17 0.46 76 16 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.16 0.46 54 17 hdd 0.00980 1.00000 10GiB 1.31GiB 57.7MiB 0B 1.26GiB 8.69GiB 13.15 0.46 66 18 hdd 0.00980 1.00000 10GiB 1.32GiB 57.7MiB 0B 1.26GiB 8.68GiB 13.16 0.46 60 19 hdd 0.00980 1.00000 10GiB 1.31GiB 57.7MiB 0B 1.26GiB 8.69GiB 13.13 0.45 45 TOTAL 190GiB 54.8GiB 1.07GiB 896KiB 53.8GiB 135GiB 28.87
ceph pg ls | tail -20
ceph pg ls | tail -20 7.c 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-14 12:08:40.728620 0'0 460:343 [6] 6 [6] 6 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.d 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 08:38:53.212660 0'0 461:176 [16] 16 [16,15] 16 0'0 2020-07-19 08:38:53.212586 0'0 2020-07-14 12:06:57.684106 7.e 0 0 0 0 0 0 0 0 0 0 stale+active+undersized 2020-07-14 12:08:40.440023 0'0 445:327 [2] 2 [2] 2 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.f 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 10:42:42.538184 0'0 461:176 [16] 16 [16,4] 16 0'0 2020-07-19 10:42:42.538089 0'0 2020-07-14 12:06:57.684106 7.10 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 08:22:00.818971 0'0 461:221 [13] 13 [13,10] 13 0'0 2020-07-19 08:22:00.818882 0'0 2020-07-19 08:22:00.818882 7.11 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 01:55:41.984335 0'0 461:192 [15] 15 [15,7] 15 0'0 2020-07-19 01:55:41.984294 0'0 2020-07-16 15:16:36.600379 7.12 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 06:16:35.490832 0'0 461:260 [10] 10 [10,8] 10 0'0 2020-07-19 06:16:35.490770 0'0 2020-07-18 06:04:58.129850 7.13 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-18 22:49:32.916717 0'0 460:211 [14] 14 [14] 14 0'0 2020-07-18 17:47:52.840600 0'0 2020-07-14 12:06:57.684106 7.14 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-14 12:08:38.610730 0'0 460:342 [5] 5 [5] 5 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.15 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-15 14:29:42.848823 0'0 460:232 [12] 12 [12] 12 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.16 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 15:41:18.933142 0'0 461:283 [7] 7 [7,5] 7 0'0 2020-07-19 15:41:18.933077 0'0 2020-07-14 12:06:57.684106 7.17 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-20 02:46:08.936766 0'0 461:271 [9] 9 [9,5] 9 0'0 2020-07-20 02:46:08.936673 0'0 2020-07-14 12:06:57.684106 7.18 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-14 12:08:40.097447 0'0 460:339 [4] 4 [4] 4 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.19 0 0 0 0 0 0 0 0 0 0 active+clean+remapped 2020-07-19 17:05:12.163909 0'0 461:287 [8] 8 [8,6] 8 0'0 2020-07-19 17:05:12.163859 0'0 2020-07-14 12:06:57.684106 7.1a 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-19 07:27:46.065812 0'0 461:137 [19] 19 [19,11] 19 0'0 2020-07-19 07:27:46.065720 0'0 2020-07-19 07:27:46.065720 7.1b 0 0 0 0 0 0 0 0 0 0 stale+active+undersized 2020-07-14 12:08:38.159892 0'0 457:337 [0] 0 [0] 0 0'0 2020-07-14 12:06:57.684106 0'0 2020-07-14 12:06:57.684106 7.1c 0 0 0 0 0 0 0 0 0 0 active+clean 2020-07-20 05:52:46.899173 0'0 461:193 [15] 15 [15,9] 15 0'0 2020-07-20 05:52:46.899083 0'0 2020-07-14 12:06:57.684106 7.1d 0 0 0 0 0 0 0 0 0 0 active+undersized 2020-07-18 22:49:31.955385 0'0 460:289 [8] 8 [8] 8 0'0 2020-07-17 23:30:38.960506 0'0 2020-07-14 12:06:57.684106 * NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilisation. See http://docs.ceph.com/docs/master/dev/placement-group/#omap-statistics for further details. PS Сори , последний лог разъехался , из за большого количества колонок.
Глава 7. Эксплуатация и обслуживание Ceph
Как администратору системы хранения Ceph, вам будет очень полезно эффективно управлять вашим кластером Ceph уровня предприятия. В данной главе мы рассмотрим следующие темы:
- Управление службой Ceph
- Увеличение в масштабе кластера Ceph
- Сокращение кластера Ceph
- Замена отказавшего диска
- Управление картой CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing)
Содержание
Управление службой Ceph
Поскольку у вас есть первый установленный кластер Ceph, вам необходимо управлять им. Вам, как администратору системы хранения Ceph, необходимо иметь знания о службах Ceph и их использовании. В дистрибутивах на основе Red Hat демонами Ceph можно управлять двумя способами, а именно: традиционным sysvinit или как службой. Теперь давайте узнаем больше об этих методах управления службой.
Выполнение Ceph с использованием sysvinit
sysvinit является традиционным, но все еще рекомендуемым способом управления демонами в системах на основе Red Hat, а также в некоторых более старых дистрибутивах на основе Debian/Ubuntu. Общий синтаксис управления демонами Ceph с использованием sysvinit выглядит следующим образом:
/etc/init.d/ceph [options] [command] [daemons]
Параметры (options) Ceph включают в себя:
- —verbose (-v) : Используется при регистрации с подробными листингами
- —allhosts (-a) : Выполняется на всех узлах, отмеченных в ceph.conf , в противном случае на локальном хосте.
- —conf (-c) : Использовать альтернативный файл настройки
Команды Ceph содержат:
- status : Отображает состояние демона
- start : Запускает демон
- stop : Останавливает демон
- restart : Останавливает, а затем вновь запускает демон
Демоны Ceph включают в себя:
Запуск демонов по типам
При выполнении задач администрирования вашего кластера, вам может понадобиться управлять службами Ceph по их типам. В данном разделе мы изучим как запускать демоны по их типам.
Для запуска демонов монитора Ceph на локальном хосте выполните Ceph с командой start :
# /etc/init.d/ceph start mon
Для запуска демонов монитора Ceph как на локальном хосте, так и на удаленных хостах выполните Ceph с командой start и параметром -a :
# /etc/init.d/ceph -a start mon
Параметр -a выполнит запрошенную операцию на всех узлах, отмеченных в файле ceph.conf . Давайте посмотрим на следующий снимок экрана:
[root@ceph-node1 ~]# /etc/init.d/ceph -a start mon === mon.ceph-node1 === Starting Ceph mon.ceph-node1 on ceph-node1. Starting ceph-create-keys on ceph-node1. === mon.ceph-node2 === Starting Ceph mon.ceph-node2 on ceph-node2. Starting ceph-create-keys on ceph-node2. === mon.ceph-node3 === Starting Ceph mon.ceph-node3 on ceph-node3. Starting ceph-create-keys on ceph-node3. [root@ceph-node1 ~]#
Аналогично вы можете запускать демоны других типов, например, osd и mds :
# /etc/init.d/ceph start osd # /etc/init.d/ceph start mds
Перед использованием параметра -a при запуске служб какого- либо типа, убедитесь, что ваш файл ceph.conf содержит все хосты Ceph, определенные здесь. Если параметр -a не используется, команда будет выполнена только на локальном хосте.
Останов демонов по типам
В данном разделе мы ознакомимся с остановом демонов по их типам.
Для останова демонов монитора Ceph на локальном хосте выполните Ceph с командой stop :
# /etc/init.d/ceph stop mon
Для останова демонов монитора Ceph на всех хостах выполните Ceph с командой stop и параметром -a :
# /etc/init.d/ceph -a stop mon
Параметр -a выполнит запрошенную операцию на всех узлах, отмеченных в файле ceph.conf . Давайте посмотрим на следующий снимок экрана:
[root@ceph-node1 ~]# /etc/init.d/ceph -a stop mon === mon.ceph-node3 === Stopping Ceph mon.ceph-node3 on ceph-node3. kill 9679. done === mon.ceph-node2 === Stopping Ceph mon.ceph-node2 on ceph-node2. kill 12758. done === mon.ceph-node1 === Stopping Ceph mon.ceph-node1 on ceph-node1. kill 12331. done [root@ceph-node1 ~]#
Аналогично вы можете запускать демоны других типов, например, osd и mds :
# /etc/init.d/ceph stop osd # /etc/init.d/ceph stop mds
Перед использованием параметра -a при запуске служб какого- либо типа, убедитесь, что ваш файл ceph.conf содержит все хосты Ceph, определенные здесь. Если хосты не определены в файле ceph.conf , команда будет выполнена только на локальном хосте.
Запуск и останов всех демонов
Для запуска вашего кластера Ceph, выполните Ceph с командой start . Данная команда запустит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf :
# /etc/init.d/ceph -a start
Для останова вашего кластера Ceph, выполните Ceph с командой stop . Данная команда остановит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf :
# /etc/init.d/ceph -a stop
Запуск и останов определенного демона
Для запуска определенного демона в вашем кластере Ceph, выполните Ceph с командой start и идентификатором (ID) демона:
# /etc/init.d/ceph start osd.0
Для проверки состояния определенного демона в вашем кластере Ceph выполните Ceph с командой status и идентификатором (ID) демона:
# /etc/init.d/ceph status osd.0
Для останова определенного демона в вашем кластере Ceph выполните Ceph с командой stop и идентификатором (ID) демона:
# /etc/init.d/ceph stop osd.0
Данный снимок экрана отображает вывод всех предыдущих команд:
[root@ceph-node1 -]# /etc/init.d/ceph start osd.0 === osd.0 === create-or-move updated item name 'osd.0' weight 0.01 at location to crush map Starting Ceph osd.0 on ceph-node1. starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal [root@ceph-node1 ~]# [root@ceph-node1 ~]# /etc/init.d/ceph status osd.0 === osd.0 === osd.0: running [root@ceph-node1 -]# [root@ceph-node1 ~]# /etc/init.d/ceph stop osd.0 === osd.O === Stopping Ceph osd.0 on ceph-node1. kill 20792. done [root@ceph-node1 ~]#
Аналогично вы можете управлять определенными демонами osd и mds в вашем кластере Ceph.
Выполнение Ceph как службы
В зависимости от вашего стиля работы в Linux вы можете выбирать управление вашими службами Ceph либо через sysvinit , либо с применением команды Linux service . Начиная с Ceph Argonaut и Bobtail вы можете управлять демонами Ceph с применением команды Linux service :
service ceph [options] [command] [daemons]
Параметры (options) Ceph включают в себя:
- —verbose (-v) : Используется при регистрации с подробными листингами
- —allhosts (-a) : Выполняется на всех узлах, отмеченных в ceph.conf , в противном случае на локальном хосте.
- —conf (-c) : Использовать альтернативные файлы настройки
Команды Ceph содержат:
- status : Отображает состояние демона
- start : Запускает демон
- stop : Останавливает демон
- restart : Останавливает, а затем вновь запускает демон
- forcestop : Принудительно останавливает демон; это аналогично kill -9
Демоны Ceph включают в себя:
Запуск и останов всех демонов
Для запуска вашего кластера Ceph, выполните Ceph с командой start . Данная команда запустит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf :
# service ceph -a start
Для останова вашего кластера Ceph, выполните Ceph с командой stop . Данная команда остановит все службы Ceph которые вы развернули для всех хостов, перечисленных в файле ceph.conf :
# service ceph -a stop
Запуск и останов определенного демона
Для запуска определенного демона в вашем кластере Ceph, выполните Ceph с командой start и идентификатором (ID) демона:
# service ceph start osd.0
Для проверки состояния определенного демона в вашем кластере Ceph выполните Ceph с командой status и идентификатором (ID) демона:
# service ceph status osd.0
Для останова определенного демона в вашем кластере Ceph выполните Ceph с командой stop и идентификатором (ID) демона:
# service ceph stop osd.0
Данный снимок экрана отображает вывод всех предыдущих команд:
[root@ceph-node1 ~]# service ceph start osd.0 === osd.0 === create-or-move updated item name 'osd.0' weight 0.01 at location to crush map Starting ceph osd.0 on ceph-node1. starting osd.O at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal [root@ceph-node1 ~]# [root@ceph-node1 ~]# service ceph status osd.0 === osd.0 === osd.0: running [root@ceph-node1 ~]# [root@ceph-node1 ~]# service ceph stop osd.0 === osd.0 === Stopping Ceph osd.0 on ceph-node1. kill 22435. done [root@ceph-node1 ~]#
Увеличение масштаба кластера Ceph
При построении решения для системы хранения масштабируемость является одним из наиболее важных аспектов проекта. Ваше решение системы хранения данных должно быть масштабируемыми, чтобы удовлетворить Ваши будущим потребностям в данных. Как правило, система хранения данных начинается с размеров от малого и среднего и постепенно растет в течение некоторого периода времени. Традиционные системы хранения основываются на решениях с расширением масштаба и ограничены некоторой емкостью. Если вы попытаетесь расширить вашу систему хранения данных за определенные рамки, вам придется идти на компромисс между производительностью и надежностью. Методы решений расширения (scale-up) для систем хранения включают в себя добавление дисковых ресурсов в существующее устройство, которое становится узким местом в производительности, емкости и управляемости при достижении определенного предела.
С другой стороны, увеличиваемые в масштабе (scale-out) проекты сосредотачиваются на добавлении нового узла целиком, содержащего диски, процессоры и память, в существующий кластер. При таком типе проекта вы не будете в конечном итоге ограничены в объеме хранения; более того, вы получите дополнительный рост производительности и надежности. Давайте взглянем на следующую архитектуру:
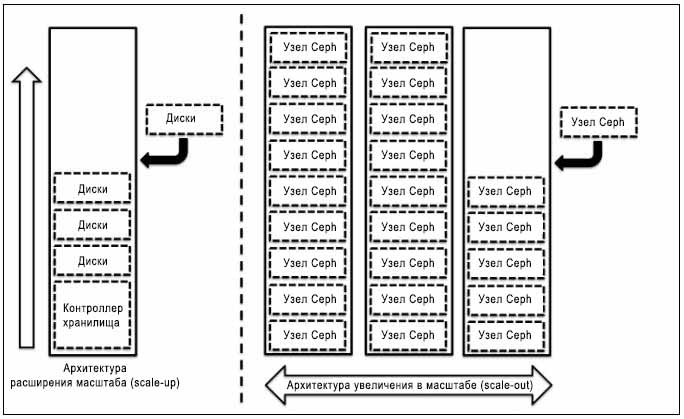
Ceph является бесшовно масштабируемой системой хранения на основе увеличивающегося в масштабе решения, при котором вы можете добавить любой готовый к использованию узел сервера в кластер Ceph и расширить вашу систему хранения далеко за пределы традиционной системы. Ceph позволяет добавлять на лету узлы мониторов и OSD (устройств хранения объектов) в существующий кластер Ceph. Теперь, давайте узнаем как добавлять узлы в кластер Ceph.
Добавление узлов OSD в кластер Ceph
Добавление узлов OSD (устройств хранения объектов) в кластер Ceph является процессом реального времени. Чтобы продемонстрировать это нам понадобится новая виртуальная машина с именем ceph-node4 с тремя дисками; мы добавим этот узел в наш существующий кластер Ceph.
Создадим новый узел ceph-node4 стремя дисками (OSD). Вы можете повторить процесс создания новой виртуальной машины с дисками, настройки операционной системы и установки Ceph как это описано в Главе 2. Моментальное развертывание Ceph и в Главе 5. Развертывание Ceph — дорога, которую вы обязаны знать.
Когда у вас появится новый узел, готовый к добавлению в кластер Ceph, проверьте подробности Ceph OSD на текущий момент:
# ceph osd tree
Вот что вы должны получить в результате выполнения данной команды:
[root@ceph-node1 ceph]# ceph osd tree # id weight type name up/down reweight -1 0.08995 root default -2 0.02998 host ceph-node1 0 0.009995 osd.O up 1 1 0.009995 osd.l up 1 2 0.009995 osd.2 up 1 -3 0.02998 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.02998 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-node1 ceph]#
Расширение кластера Ceph является интерактивным процессом и, чтобы продемонстрировать этот факт, мы выполним некоторые действия в нашем кластере Ceph; параллельно мы будем расширять кластер. В Главе 5. Развертывание Ceph — дорога, которую вы обязаны знать, мы развернули блочное устройство RADOS (Безотказное автономное распределенное хранилище объектов — Reliable Autonomic Distributed Object Store) на машине ceph-client1 . Мы будем использовать эту же машину для создания операций обмена в нашем кластере Ceph. Убедимся, что ceph-client1 смонтировал RBD (блочное устройсто RADOS):
# df -h /mnt/ceph-vol1
[root@ceph-client1 ~]# df -h /mnt/ceph-vol1 Filesystem Size Used Avail Use% Mounted on /dev/rbdO 10G 33M 10G 1% /mnt/ceph-vol1 [root@ceph-client1 ~]#
Зарегистрируемся на ceph-client1 с отдельного терминала cli и выведем список дисков, доступных для добавления в качестве OSD для ceph-node4 . Машина ceph-node4 должна иметь установленный Ceph, а также скопированный на нее файл ceph.conf . Вы увидите три диска sdb , sdc и sdd в списке, выводимым в результате выполнения следующей команды:
# ceph-deploy disk list ceph-node4
Как уже отмечалось ранее, увеличение масштаба кластера Ceph является безшовным и интерактивным процессом. Чтобы показать это, мы создадим некоторую нагрузку на кластер и одновременно выполним операцию увеличения масштаба. Заметим, что это является необязательным шагом.
Убедимся что хост с работающей на нем средой VirtualBox имеет соответствующее дисковое пространство, поскольку мы будем записывать данные в кластер Ceph. Как только вы запустите создание трафика в наш кластер, запустите его расширение путем выполнения последующих шагов.
# dd if=/dev/zero of=/mnt/ceph-vol1/file1 count=10240 bs=1M
Переключитесь на терминал cli ceph-node1 и расширьте кластер путем добавления дисков ceph-node4 в качестве новых OSD Ceph:
# ceph-deploy disk zap ceph-node4:sdb ceph-node4:sdc ceph-node4:sdd # ceph-deploy osd create ceph-node4:sdb c eph-node4:sdc ceph-node4:sdd
Во время выполнения добавления OSD вам следует отслеживать состояние вашего кластера Ceph из отдельного терминального окна. Вы заметите, что кластер Ceph выполняет операцию записи при одновременном увеличении масштаба свое емкости:
# watch ceph status
Наконец, когда добавление дисков ceph-node4 завершено, вы сможете проверить состояние своего кластера Ceph с применением предыдущей команды. Ниже приводится то, что вы увидите после выполнения этой команды:
[root@ceph-node1 /]# ceph status cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_OK monmap e3: 3 mons at , election epoch 938, quorum 0,1,2 ceph-node1,ceph-node2,cep h-node3 mdsmap e61: 1/1/1 up osdmap e807: 12 osds: 12 up, 12 in pgmap v3998: 1472 pgs, 13 pools, 78568 kB data, 2687 objects 828 MB used, 107 GB / 107 GB avail 1472 active+clean [root@ceph-node1 /]#
В данной точке если вы выведите список всех OSD, он даст вам лучшее понимание:
# ceph osd tree
Данная команды выводит некоторую ценную информацию, связанную с OSD, такую как вес OSD, а также какой узел Ceph содержит их. OSD, состояние OSD (рабочее/выключенное, up/down), а также состояние IN/OUT OSD представляются 1 или 0. Обратим внимание на следующий снимок экрана:
[root@ceph-node1 tmp]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -2 0.009995 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.l up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -5 0.04999 host ceph-node4 9 0.009995 osd.9 up 1 10 0.009995 osd.10 up 1 11 0.009995 osd.11 up 1 [root@ceph-node1 tmp]#
Уменьшение масштаба кластера Ceph
Решения для хранения данных оцениваются на основе их гибкости; хорошее решение для хранения должно быть достаточно гибким чтобы поддерживать его расширение и уменьшение, не вызывая при этом каких-либо простоев в обслуживании. Традиционные системы хранения очень ограничены, когда дело касается гибкости; они поддерживают добавление емкости хранения, но в очень малой степени, а также не существует никакой поддержки для интерактивного уменьшения емкости. Вы блокированы емкостью хранения и не можете выполнять изменения в соответствии с вашими потребностями.
Ceph является абсолютно гибкой системой хранения, обеспечивающей интерактивное изменение и изменение на лету емкости как в отношении ее увеличения, так и в отношении ее уменьшения. В последнем разделе мы увидели как легко выполнять увеличение масштаба Ceph. Мы добавили новый узел ceph-node4 с тремя OSD в кластер Ceph. Теперь мы покажем операцию уменьшения масштаба кластера Ceph, без какого-либо влияния на его доступность, путем удаления ceph-node4 из кластера Ceph.
Вывод OSD и отключение из кластера Ceph
Перед выполнением процесса сокращения размера кластера или уменьшения его масштаба необходимо удостовериться, что кластер имеет достаточно свободного пространства для размещения всех данных, расположенных на узле, который вы собираетесь удалить. Кластер не должен быть близок состоянию почти заполненного.
На узле ceph-node1 создайте некую нагрузку на кластер Ceph. Это необязательный шаг, призванный продемонстрировать выполнимость на лету операции уменьшения масштаба кластера Ceph. Убедитесь, что хост, поддерживающий среду VirtualBox имеет соответствующее дисковое пространство, поскольку мы будем записывать данные в кластер Ceph.
# dd if=/dev/zero of=/mnt/ceph-vol1/file1 count=3000 bs=1M
Поскольку нам необходимо уменьшить масштаб кластера, мы удалим ceph-node4 и все связанные с ним OSD (устройства хранения объектов) из нашего кластера. OSD Ceph должны быть настроены таким образом, чтобы Ceph мог выполнять восстановление данных. С любого из узлов Ceph выведите OSD из состава кластера:
# ceph osd out osd.9 # ceph osd out osd.10 # ceph osd out osd.11
[root@ceph-node1 /]# ceph osd out osd.9 marked out osd.9. [root@ceph-node1 /]# ceph osd out osd.10 marked out osd.10. [root@ceph-node1 /]# ceph osd out osd.11 marked out osd.11.
Как только вы отметите OSD находящимися вне кластера, Ceph запустит ребалансировку нашего кластера путем миграции групп размещения с OSD, которые мы вывели из состава кластера на другие OSD в пределах кластера. Состояние вашего кластера на какое- то время станет неисправным, однако он останется в состоянии обслуживать данные клиентов. В зависимости от числа удаленных OSD может возникнуть некий провал в производительности кластера пока не завершится время восстановления. Как только кластер станет вновь работоспособным, он долже заработать как прежде. Давайте взглянем на следующий снимок экрана:
[root@ceph-node1 /]# ceph -s cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_WARN 517 pgs peering; 16 pgs recovering; 4 pgs recovery_wait; 363 pgs stuck inactive; 379 pgs stuck unclean; 43 requests are blocked > 32 sec; recovery 1401/5290 objects degraded (26.484%) monmap e3: 3 mons at , election epoch 938, quorum 0,1,2 ceph-node1,ceph-node2,ceph- node3 mdsmap e61: 1/1/1 up osdmap e824: 12 osds: 12 up, 9 in pgmap v4077: 1472 pgs, 13 pools, 161 MB data, 2618 objects 748 MB used, 82095 MB / 82844 MB avail 1401/5290 objects degraded (26.484%) 437 inactive 10 active 511 peering 4 active+recovery_wait 487 active+clean 16 active+recovering 1 remapped 6 remapped+peering recovery io 0 B/s, 52 objects/s client io 517 B/s rd, 78962 kB/s wr, 398 op/s [root@ceph-node1 /]#
В предыдущем скриншоте вы можете увидеть что кластер находится в режиме восстановления, хотя в то же время он продолжает обслуживать данные клиентов. Вы можете наблюдать за процессом восстановления при помощи следующей команды:
# ceph -w
Поскольку мы отметили для вывода из состава кластера osd.9 , osd.10 и osd.11 , они не являются участниками кластера, однако их службы все еще работают. Наконец, зарегистрируйтесь на машине ceph-node4 и остановите службы OSD:
# service ceph stop osd.9 # service ceph stop osd.10 # service ceph stop osd.11
После выключения OSD проверьте дерево OSD, как это показано на следующем снимке экрана. Вы увидите, что соответствующие OSD выключены и выведены:
[root@ceph-node4 ~]# ceph osd tree # id weight type name up/down reweight -1 0.12 root default -2 0.009995 host ceph-node1 0 0.009995 osd.O up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 -5 0.04999 host ceph-node4 9 0.009995 osd.9 down 0 10 0.009995 osd.10 down 0 11 0.009995 osd.11 down 0 [root@ceph-node4 ~]#
Удаление OSD из кластера Ceph
Процесс удаления OSD (устройства хранения объектов) из кластера Ceph затрагивает удаление всех записей этих OSD из карт кластера.
Удалите OSD из карты CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing). Для этого зарегистрируйтесь на любом узле кластера и выполните следующие команды:
# ceph osd crush remove osd.9 # ceph osd crush remove osd.10 # ceph osd crush remove osd.11
[root@ceph-node1 ~]# ceph osd crush remove osd.9 removed item id 9 name 'osd.9' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.10 removed item id 10 name 'osd.10' from crush map [root@ceph-node1 ~]# ceph osd crush remove osd.11 removed item id 11 name 'osd.11' from crush map [root@ceph-node1 ~]#
Как только OSD удалены из карты CRUSH, кластер Ceph становится работоспособным. Вам следует просмотреть карту OSD; поскольку мы не удалили OSD, она покажет 12 OSD, 9 UP, 9 IN :
[root@ceph-node1 /]# ceph status cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_OK monmap e3: 3 mons at , election epoch 938, quorum 0,1,2 ceph-node1, ceph-node2,ceph-node3 mdsmap e61: 1/1/1 up osdmap e898: 12 osds: 9 up, 9 in pgmap v4400: 1472 pgs, 13 pools, 683 MB data, 2838 objects 1876 MB used, 80968 MB / 82844 MB avail 1472 active+clean [root@ceph-node1 /]#
Удалите ключ аутентификации OSD:
# ceph auth del osd.9 # ceph auth del osd.10 # ceph auth del osd.11
Наконец, удалите OSD и проверьте состояние вашего кластера. Вы должны увидеть 9 OSD, 9 UP, 9 IN и работоспособность (health) кластера должна быть OK :
[root@ceph-node1 /]# ceph osd rm osd.9 removed osd.9 [root@ceph-node1 /]# ceph osd rm osd.10 removed osd.10 [root@ceph-node1 /]# ceph osd rm osd.11 removed osd.11 [root@ceph-node1 /]# ceph status cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_OK monmap e3: 3 mons at , election epoch 938, quorum 0,1,2 ceph-node1, ceph-node2,ceph-node3 mdsmap e61: 1/1/1 up osdmap e901: 9 osds: 9 up, 9 in pgmap v4413: 1472 pgs, 13 pools, 683 MB data, 2838 objects 1879 MB used, 80965 MB / 82844 MB avail 1472 active+clean [root@ceph-node1 /]#
Чтобы оставить кластер в чистом состояни, выполите некоторую работу по хозяйству. Поскольку мы удалили все OSD из карты CRUSH, ceph-node4 больше не имеет никаких элементов. Удалите ceph-node4 из карты CRUSH, чтобы удалить все следы этого узла из кластера Ceph:
# ceph osd crush remove ceph-node4
Замена отказавшего диска
Если вы администратор системы хранения Ceph, вам нужно будет управлять кластером Ceph с множеством физических дисков. По мере увеличения количества физических диске в вашем кластере Ceph частота отказов дисков также может увеличиваться. Таким образом, замена отказавших дисков может стать повторяющейся задачей для администратора системы хранения Ceph. Rак правило, нет нужды беспокоиться, если в кластере Ceph вышел из строя один или несколько дисков, поскольку Ceph будет заботиться о данных, их репликации и функции высокой доступности. Процесс удаления OSD из кластера Ceph основан на репликации данных Ceph и удалении всех записей об отказавших OSD из карт CRUSH кластера. Теперь мы рассмотрим процесс замены отказавшего диска в ceph-node1 и osd.0 .
Вначале проверим состояние вашего кластера Ceph. Покольку в кластере нет оказавших дисков, его состояние будет HEALTH_OK :
# ceph status
Поскольку мы демонстрируем это упражнение на виртуальных машинах, нам нужно принудительно вывести из строя диск путем вывода из рабочего состояния ceph-node1 , отсоединения диска и последующего включения виртуальной машины:
# VBoxManage controlvm ceph-node1 poweroff # VBoxManage storageattach ceph-node1 --storagectl "SATA Controller" --port 1 --device 0 --type hdd --medium none # VBoxManage startvm ceph-node1
На следующем снимке экрана вы увидите, что ceph-node1 содержит отказавший osd.0 , подлежащий замене:
[root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.06999 root default -2 0.009995 host ceph-node1 0 0.009995 osd.0 down 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.03 host ceph-node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.03 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-node1 ~]#
Поскольку данный OSD не работает, Ceph помечает этот OSD вышедшим из кластера в некоторый момент времени; по умолчанию, через 300 секунд. Если нет, мы можем сделать это вручную:
# ceph osd out osd.0
Удалим отказавший OSD из карты CRUSH:
# ceph osd crush rm osd.0
Уничтожим ключ аутентификации Ceph для этого OSD:
# ceph auth del osd.0
Наконец, удалим этот OSD из кластера Ceph:
# ceph osd rm osd.0
[root@ceph-node1 ~]# ceph osd out osd.0 marked out osd.0. [root@ceph-node1 ~]# ceph osd crush rm osd.0 removed item id 0 name 'osd.0' from crush map [root@ceph-node1 ~]# ceph auth del osd.0 updated [root@ceph-node1 ~]# ceph osd rm osd.0 removed osd.0 [root@ceph-node1 ~]#
Поскольку одно из ваших OSD недоступно, состояние работоспособности кластера не будет OK , и он выполнит восстановление; не стоит беспокоиться об этом, это обычная операция Ceph
Теперь мы должны физически заменить отказавший диск овым в вашем узле Ceph. На сегодняшний день практически все серверное оборудование и все операционные системы поддерживают горячую замену дисков, следовательно у вас нет нужды в каком бы то ни было простое для замены диска. Так как мы используем виртуальную машину, нам нужно выключить эту виртуальную машину, добавить новый диск и перезапустить эту виртуальную машину. Поскольку данный диск вставлен, сделаем замечание о его идентификаторе устройства операционной системы:
# VBoxManage controlvm ceph-node1 poweroff # VBoxManage storageattach ceph-node1 --storagectl "SATA Controller" --port 1 --device 0 --type hdd --medium ceph-node1-osd1.vdi # VBoxManage startvm ceph-node1
Выполним следующие команды для вывода списка дисков; новый диск в общем случае не имеет никакого раздела:
# ceph-deploy disk list ceph-node1
Перед добавлением диска в кластер Ceph, выполним полное стирание (zap) диска:
# ceph-deploy disk zap ceph-node1:sdb
Наконец, создадим на этом диске OSD и Ceph добавит его как osd.0 :
# ceph-deploy --overwrite-conf osd create ceph-node1:sdb
Поскольку OSD создан, Ceph выполнит операцию восстановления и запустит перемещение групп размещения со вторичных OSD на новый OSD. Операция восстановления может занять некоторое время, по истечению которого кластер Ceph придет опять в состояние HEALTHY_OK :
[root@ceph-node1 /]# ceph status cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_OK monmap e3: 3 mons at , election epoch 938, quorum 0,1,2 ceph-node1, ceph-node2,ceph-node3 mdsmap e61: 1/1/1 up osdmap e901: 9 osds: 9 up, 9 in pgmap v4413: 1472 pgs, 13 pools, 683 MB data, 2838 objects 1879 MB used, 80965 MB / 82844 MB avail 1472 active+clean [root@ceph-node1 /]#
Обработка карт CRUSH
Мы уже рассматривали карты CRUSH (Управляемых масштабируемым хешированием репликаций, Controlled Replication Under Scalable Hashing) в Главе 4. Ceph изнутри. В данном разделе мы погрузимся в детали карт CRUSH, включающие их макеты, а также определение пользовательских карт CRUSH. При развертывании кластера Ceph с помощью процедуры, описанной в данном руководстве, для вашего кластера Ceph создаются карты CRUSH по умолчанию. Такие карты по умолчанию хорошо подходят для окружений песочницы и тестирования. Однако если вы запускаете кластеры Ceph в промышленности или в большом масштабе, рассмотрите возможность разработки пользовательской карты CRUSH для вашей среды, чтобы обеспечить более высокую производительность, надежность и безопасность данных.
Определение местоположений CRUSH
Локализация CRUSH является метоположением OSD в карте CRUSH. Например, организация с названием mona-labs.com имеет кластер с местоположением osd.156 , которое располагается в хосте ceph-node15 . Этот хост физически представляет chassis-3 , которое установлено в rack-16 , являющемся частью room-2 и datacentre-1-north-FI
Такой osd.156 будет частью карты CRUSH, как это показано на следующем рисунке:
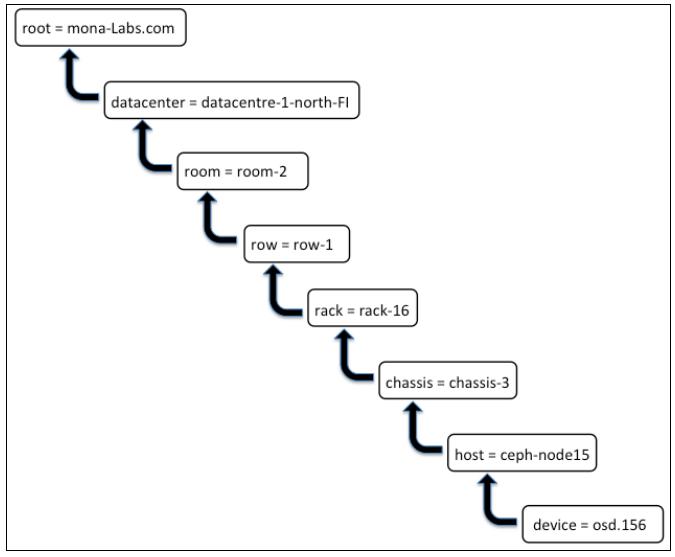
На предыдущем рисунке ключи показаны с левой стороны от =; они также называются типами CRUSH. Карта по умолчанию содержит root , datacentre , room , row , pod , pdu , rack , chassis и host . Не обязательно использовать все типы CRUSH при определении карты CRUSH, однако используемые типы CRUSH должны быть допустимыми, иначе вы можете получить ошибки компиляции. CRUSH является достаточно гибким; вы даже можете определять ваши собственные типы и использовать их в картах CRUSH по-своему.
Карты соответствий CRUSH изнутри
Чтобы понять что находится внутри карты CRUSH, мы должны извлечь ее и декомпилировать в человеко- читаемую форму для легкого редактирования. На этом этапе мы можем выполнить все необходимые изменения в карте CRUSH и, чтобы изменения вступили в силу, мы должны скомпилировать и внедрить ее назад в кластер Ceph. Изменения в кластере Ceph, выполняемые такой новой картой CRUSH, т.е. как только новая карта CRUSH внедрена в кластер Ceph, изменения имеют эффект немедленно, на лету. Теперь мы взглянем на карту CRUSH нашего кластера Ceph который мы развернули в данном руководстве.
Извлечем карту CRUSH из любого нашего узла монитора:
# ceph osd getcrushmap -o crushmap_compiled_file
Когда мы получим карту CRUSH, декомпилируем ее чтобы сделать ее человечески читаемой и редактируемой:
# crushtool -d crushmap_compiled_file -o crushmap_decompiled_file
Начиная с этого момента файл выдачи, crushmap_decompiled_file , может просматриваться/ редактироваться в предпочитаемом вами редакторе.
В следующем разделе мы изучим как выполнять изменения в карте CRUSH.
После внесения необходимых изменений вам следует скомпилировать изменения с параметром команды -c
# crushtool -c crushmap_decompiled_file -o newcrushmap
Наконец, внедрим заново скомпилированную карту CRUSH в кластер Ceph с параметром команды
# ceph osd setcrushmap -i newcrushmap
Файл карты CRUSH содержит четыре раздела; они следующие:
- Устройства карты CRUSH : Раздел устройств содержит список всех OSD представленных в кластере Ceph. Как только любое новое OSD добавляется в кластер Ceph или удаляется из него, раздел устройств карт CRUSH обновляется автоматически. Обычно у вас нет нужды вносить изменения в данный раздел; Ceph заботится об этом. Однако, если вам нужно добавить новое устройство, добавьте новую строку в конце раздела устройств уникальным номером устройства, идущим за OSD. Приводимый далее снимок экрана показывает раздел устройств карты CRUSH из нашего кластера песочницы:
# devices device 0 osd.O device 1 osd.1 device 2 osd.2 device 3 osd.3 device 4 osd.4 device 5 osd.5 device 6 osd.6 device 7 osd.7 device 8 osd.8
# types type 0 osd type 1 host type 2 rack type 3 row type 4 room type 5 datacenter type 6 root
[bucket-type] [bucket-name] < id [a unique negative numeric ID] weight [the relative capacity/capability of the item(s)] alg [the bucket type: uniform | list | tree | straw ] hash [the hash type: 0 by default] item [item-name] weight [weight] >
Далее приводится определение раздела сегмента из нашего кластера Ceph песочницы:
# buckets host ceph-node1 < id -2 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.1 weight 0.010 item osd.2 weight 0.010 item osd.0 weight 0.010 >host ceph-node2 < id -3 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.3 weight 0.010 item osd.5 weight 0.010 item osd.4 weight 0.010 >host ceph-node3 < id -4 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkins1 item osd.6 weight 0.010 item osd.7 weight 0.010 item osd.8 weight 0.010 >root default
rule < ruleset type [ replicated | raid4 ] min_size max_size step take step [choose|chooseleaf] [firstn|indep] step emit >
# rules rule data < ruleset 0 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type host step emit >rule metadata < ruleset 1 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type host step emit >rule rbd < ruleset 2 type replicated min_size 1 max_size 10 step take default step chooseleaf firstn 0 type host step emit ># end crush map
Разнообразные пулы на различных OSD
Ceph легко работает на разнородной общедоступной вычислительной технике. Существуют возможности чтобы вы могли использовать ваши существующие аппаратные системы для Ceph и разработать кластер хранения с различными типами оборудования. Для вас, как администратора хранилища Ceph, ваш вариант использования может потребовать создание множества пулов Ceph на множестве типов устройств. Наиболее распространенный вариант использования заключается в предоставлении пула быстрого хранилища на основе дисков типа SSD, с которыми вы можете получить высокую производительность для вашего кластера хранения. Данные, которые не требуют навысшего уровня ввода/вывода, как правило, хранятся в пулах на более медленных магнитных устройствах.
Наша следующая практическая демонстрация будет направлена на создание двух пулов Ceph, а именно SSD-пулов с более быстрыми дисками SSD и SATA-пулов, хранящих данные на более медленных дисках SATA. Чтобы сделать это мы отредактируем карты CRUSH и выполним необходимые настройки.
Кластер Ceph песочницы, который мы развернули в предыдущих главах, размещается на виртуальных машинах и не имеет реальных дисков SSD в своем распоряжении. Следовательно мы будем рассматривать несколько дисков как SSD диски для целей обучения. Если вы выполняете это упражнение в кластерах Ceph с реальными дисками SSD в их основе, не потребуется никаких изменений в последовательности, которую мы будем выполнять.
В следующей демонстрации мы предполагаем, что ceph-node1 является нашим узлом SSD с размещенными на нем тремя SSD. ceph-node2 и ceph-node3 содержат диски SATA. Основная копия пула SSD привязана к ceph-node1 , в то время как вторичная и третичная копии будут находиться на других узлах. Аналогично, первичная копия пула SATA будет находиться либо на ceph-node2 , либо на ceph-node3 , поскольку у нас есть два узла для поддержки SATA пула. На любом шаге данной демонстрации вы можете обратиться к скорректированному файлу карты CRUSH, поддерживаемому данным руководством на веб- сайте Packt Publishing.
Извлеките карту CRUSH из любого узла монитора и декомпилируйте ее:
# ceph osd getcrushmap -o crushmap-extract # crushtool -d crushmap-extract -o crushmap-decompiled
[root@ceph-node1 tmp]# ceph osd getcrushmap -o crushmap-extract got crush map from osdmap epoch 1045 [root@ceph-node1 tmp]# crushtool -d crushmap-extract -o crushmap-decompiled [root@ceph-nodel tmp]# ls -l crushmap-decompiled -rw-r-— r—-. 1 root root 1591 Jul 25 00:18 crushmap-decompiled [root@ceph-node1 tmp]#
Воспользуйтесь предпочитаемым вами редактором и внесите изменения в карту CRUSH по умолчанию:
# vi crushmap-decompiled
Замените сегмент (bucket) по умолчанию root на root ssd и root sata . В нашем случае root ssd содержит один элемент, а сегмент root sata имеет два описанных хоста. Взглянем на следующий моментальный снимок:
root ssd < id -1 alg straw hash 0 item ceph-node1 weight 0.030 >root sata
Отрегулируйте существующие правила для работы с новыми сегментами. Для этого измените step take default на step take sata для правил данных, метаданных и RBD. Это даст команду данным правилам использовать сегмент root sata вместо используемого по умолчанию сегмента root , поскольку мы его удалили на предыдущем шаге.
Наконец добавим новые правила для пулов ssd и sata как это показано на следующем экранном снимке:
rule sata < ruleset 3 type replicated min_size 1 max_size 10 step take sata step chooseleaf firstn 0 type host step emit >rule ssd
Поскольку изменения выполнены, скомпилируем файл CRUSH и внедрим его назад в кластер Ceph:
# crushtool -c crushmap-decompiled -o crushmap-compiled # ceph osd setcrushmap -i crushmap-compiled
Как только мы внедрили новую карту CRUSH в наш кластер Ceph, кластер проведет перестановку данных и их восстановление и должен будет вскоре получить состояние HEALTH_OK . Проверьте состояние кластера следующим образом:
[root@ceph-node1 tmp]# ceph -s cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_WARN 18 pgs recovering; 1309 pgs stuck unclean; recovery 1670/5738 objects degraded (29.104%) monmap e3: 3 mons at , election epoch 1040, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 mdsmap e93: 1/1/1 up osdmap el079: 9 osds: 9 up, 9 in pgmap v4804: 1472 pgs, 13 pools, 683 MB data, 2838 objects 2106 MB used, 80738 MB / 82844 MB avail 1670/5738 objects degraded (29.104%) 11 active 1280 active+remapped 163 active+clean 18 active+recovering recovery io 17308 kB/s, 134 objects/s [root@ceph-node1 tmp]#
Как только ваш кластер примет рабочеспособное состояние, создайте два пула для ssd и sata :
# ceph osd pool create sata 64 64 # ceph osd pool create ssd 64 64
Отрегулируйте crush_ruleset для правил sata и ssd , как это определено в карте CRUSH:
# ceph osd pool set sata crush_ruleset 3 # ceph osd pool set ssd crush_ruleset 4 # ceph osd dump | egrep -i "ssd|sata"
[root@ceph-node1 /]# ceph osd pool create sata 64 64 pool 'sata' created [root@ceph-node1 /]# ceph osd pool create ssd 64 64 pool 'ssd' created [root@ceph-node1 /]# ceph osd pool set sata crush_ruleset 3 set pool 16 crush_ruleset to 3 [root@ceph-node1 /]# ceph osd pool set ssd crush_ruleset 4 set pool 17 crush_ruleset to 4 [root@ceph-node1 /]# ceph osd dump | egrep -i "ssd|sata" pool 16 'sata' replicated size 3 min_size 2 crush_ruleset 3 object_hash rjenkins pg_num 64 pgp_num 64 last^change 1093 owner 0 flags hashpspool stripe_width 0 pool 17 'ssd' replicated size 3 min_size 2 crush_ruleset 4 object_hash rjenkins pg_num 64 pgp_num 64 last_change 1094 owner 0 flags hashpspool stripe_width 0 [root@ceph-node1 /]#
Чтобы проверить эти вновь созданные пулы мы поместим в них некоторые данные и проверим какие OSD сохранили данные. Создадим некие файлы данных:
# dd if=/dev/zero of=sata.pool bs=1M count=32 conv=fsync # dd if=/dev/zero of=ssd.pool bs=1M count=32 conv=fsync
[root@ceph-node1 /]# dd if=/dev/zero of=sata.pool bs=lM count=32 conv=fsync 32+0 records in 32+0 records out 33554432 bytes (34 MB) copied, 0.240931 s, 139 MB/s [root@ceph-nodel /]# dd if=/dev/zero of=ssd.pool bs=lM count=32 conv=fsync 32+0 records in 32+0 records out 33554432 bytes (34 MB) copied, 0.179995 s, 186 MB/s [root@ceph-node1 /]# [root@ceph-node1 /]# ls -l *.pool -rw-r-—r-—. 1 root root 33554432 Jul 25 01:00 sata.pool -rw-r—-r—-. 1 root root 33554432 Jul 25 01:01 ssd.pool [root@ceph-node1 /]#
Поместим эти данные в хранилище Ceph в соответствующие пулы:
# rados -p ssd put ssd.pool.object ssd.pool # rados -p sata put sata.pool.object sata.pool
Наконец, проверим карту OSD для пула объектов
# ceph osd map ssd ssd.pool.object # ceph osd map sata sata.pool.object
[root@ceph-node1 /]# ceph osd map ssd ssd.pool.object osdmap e1097 pool 'ssd' (17) object 'ssd.pool.object' -> pg 17.82fd0527 (17.27) -> up ([2], p2) acting ([2,5,6], p2) [root@ceph-node1 /]# [root@ceph-node1 /]# ceph osd map sata sata.pool.object osdmap e1097 pool 'sata' (16) object 'sata.pool.object' -> pg 16.f71bcbc2 (16.2) -> up ([4,8], p4) acting ([4,8], p4) [root@ceph-node1 /]#
Давайте проверим предыдущий вывод. Первый вывод результатов для пула ssd представляет основную копию объекта, который расположен на osd.2 ; другие копии расположены на osd.5 и osd.6 . Это объясняется способом, которым мы настроили нашу карту CRUSH. Мы предписали пулу ssd использовать ceph-node1 , который содержит osd.0 , osd.1 и osd.2 .
Это только демонстрация основных возможностей пользовательской настройки карт CRUSH. Вы можете делать много разных вещей с помощью CRUSH. Существует масса возможностей для эффективного и результативного управления всеми данными вашего кластера Ceph с применением карт CRUSH.
Заключение
В этой главе мы рассмотрели задачи эксплуатации и обслуживания, которые должны выполняться в кластере Ceph. Эта глава дает понимание служб Ceph, а также увеличение и уменьшение масштаба работающего кластера. ПОследующая часть главы посвящена процедуре замены вышедших из строя дисков в вашем кластере Ceph, которая является общим местом для кластеров среднего и крупного размера. Наконец, мы знакомимся с мощью карт CRUSH и тем, как настраивать карты CRUSH для своих нужд. Изменение и настройка карт CRUSH довольно интересная и важная часть Ceph; с ней приходит получение решения хранения уровня предприятия. Вы всегда можете получить дополнительную информацию относительно карт CRUSH Ceph на странице http://ceph.com/docs/master/rados/operations/crush-map/
В следующей главе мы изучим мониторинг Ceph, а также регистрацию в вашем кластере Ceph и его отладку с рядом советов по устранению неполадок.