CSV Formats
This dialog contains the settings for converting table data into delimiter-separated values formats (for example, CSV, TSV) and vice versa.
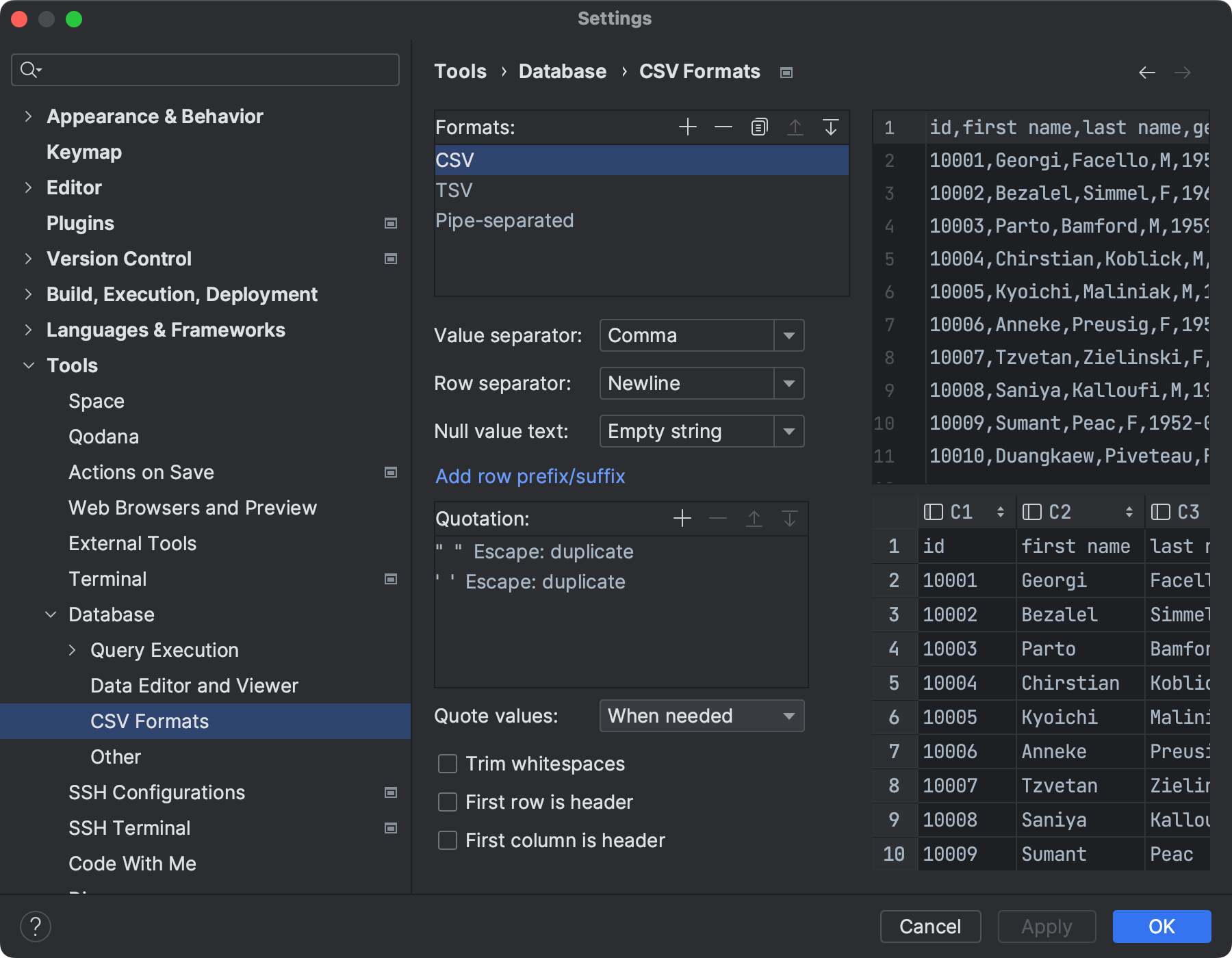
When you change settings, the preview changes correspondingly.
Select a template that successfully converts the file data into a table. You can change settings of predefined templates or add a new template. To add a template, click Add Format button ().
Use the Add Format (), Remove Format (), Up () and Down () buttons to create, delete and reorder the formats; Copy Format () to create a copy of the selected format.
Select or type the character that you want to use as a separator for values.
Select or type the character that you want to use as a separator for rows.
Null value text
Select or type the text that you want to use if a cell contains the NULL value.
Add row prefix/suffix
Click the link and type a row prefix and suffix. Prefix and suffix are character sequences which in addition to the row separator indicate the beginning and end of a row.
Each line in the area under Quotation is a quotation pattern. A quotation pattern includes:
- Left : a quotation character that is inserted before a value.
- Right : a quotation character that is inserted after a value.
- Escape : an escape method or character for the cases when the quotation character is part of a value. The value means that if a quotation character occurs within a value, it is doubled. You can specify your own escape character.
If there is more than one pattern, the first pattern is used.
Use the Add (), Remove (), Up () and Down () buttons to create, delete and reorder the patterns.
Select when you want to enclose values within quotation characters.
- Never : do not quote values.
- When needed : quote a value if it contains the value or the row separator.
- Always : quote all the values.
Ignore or remove whitespace characters. If this checkbox is cleared, the whitespace characters are treated as parts of the corresponding values.
First row is header
Treat the first row as a row that contains column names.
First column is header
Treat the first column as a column that contains row names.
CSV в Python
Программисты часто сталкиваются с задачей обработки больших объемов структурированных данных. Python имеет встроенную библиотеку CSV, с помощью которой программист может работать со специальными CSV файлами. Это своего рода электронные таблицы.
Что такое файлы CSV
Файл CSV – это особый вид файла, который позволяет структурировать большие объемы данных.
По сути, он является обычным текстовым файлом, однако каждый новый элемент отделен от предыдущего запятой или другим разделителем. Обычно каждая запись начинается с новой строки. Данные CSV можно легко экспортировать в электронные таблицы или базы данных. Программист может расширять CSV файл, добавляя новые строки.
Пример CSV файла, где в качестве разделителя используется запятая:
Имя,Профессия,Год рождения Виктор,Токарь, 1995 Сергей,Сварщик,1983
Как видно из примера, в первой строке обычно указывается, какая информация будет находиться в каждом столбце. Кроме того, после последнего элемента строки запятая не ставиться, интерпретатор определяет конец строки по символу переноса.
Вместо запятой можно использовать любой другой разделитель, поэтому при чтении CSV файла нужно заранее знать, какой символ используется.
Важно помнить, что CSV – это обычный текстовый файл, который не поддерживает символы в кодировках, отличающихся от ASCII или Unicode.
Библиотека CSV
Эта основная библиотека для работы с CSV файлами в Python.
Библиотека csv является встроенной, поэтому её не нужно скачивать, достаточно использовать обычный импорт:
import csv
Чтение из файлов (парсинг)
Для того чтобы прочитать данные из файла, программист должен создать объект reader:
reader_object = csv.reader(file, delimiter = ",")
reader имеет метод __next__() , то есть является итерируемым объектом, поэтому чтение из файла происходит следующим образом:
import csv with open("classmates.csv", encoding='utf-8') as r_file: # Создаем объект reader, указываем символ-разделитель "," file_reader = csv.reader(r_file, delimiter = ",") # Счетчик для подсчета количества строк и вывода заголовков столбцов count = 0 # Считывание данных из CSV файла for row in file_reader: if count == 0: # Вывод строки, содержащей заголовки для столбцов print(f'Файл содержит столбцы: ') else: # Вывод строк print(f' - и он родился в году.') count += 1 print(f'Всего в файле строк.')
Предположим, что у нас есть CSV файл, который содержит следующую информацию:
Имя,Успеваемость,Год рождения Саша,отличник,200 Маша,хорошистка,1999 Петя,троечник,2000
Тогда, если открыть этот файл в нашей программе, то будут получены следующие результаты:
Файл содержит столбцы: Имя, Успеваемость, Год рождения Саша - отличник и он родился в 200 году. Маша - хорошистка и он родился в 1999 году. Петя - троечник и он родился в 2000 году. Всего в файле 4 строк.
Использование конструкции with…as позволяет программисту быть уверенным, что файл будет закрыт, даже если при выполнении кода произойдет какая-то ошибка.
Обратите внимание, что при открытии нужно указать правильную кодировку, в которой сохранены данные. В данном случае encoding=’utf-8′. Если не указывать, то будет использоваться кодировка по умолчанию. Для Windows это cp1251.
Библиотека CSV позволяет работать с файлами, как со словарями, для этого нужно создать объект DictReader. Обращаться к элементам можно по имени столбцов, а не с помощью индексов. Для того, чтобы исходная программа делала аналогичный вывод, её следует изменить следующим образом:
import csv with open("classmates.csv", encoding='utf-8') as r_file: # Создаем объект DictReader, указываем символ-разделитель "," file_reader = csv.DictReader(r_file, delimiter = ",") # Счетчик для подсчета количества строк и вывода заголовков столбцов count = 0 # Считывание данных из CSV файла for row in file_reader: if count == 0: # Вывод строки, содержащей заголовки для столбцов print(f'Файл содержит столбцы: ') # Вывод строк print(f' - ', end='') print(f' и он родился в году.') count += 1 print(f'Всего в файле строк.')
Обращаться к элементам по названию столбца более удобно, кроме того, это упрощает понимание кода.
Обратите внимание, что в цикл for при первой итерации будет записан в row не шапка таблицы, а первая её строка. Поэтому при выводе количества строк переменную count увеличили на 1.
Дополнительные параметры объекта DictReader
DictReader имеет параметры:
- dialect — Набор параметров для форматирования информации. Подробнее про них ниже.
- line_num — Устанавливает количество строк, которое может быть прочитано.
- fieldnames — Определяет заголовки для столбцов, если не определить атрибут, то в него запишутся элементы из первой прочитанной строки файла. Заголовки нужны для того, чтобы легко было понять, какая информация содержится или должна содержаться в столбце.
Например, если бы в classmates.csv не было бы первой строки с заголовками, то можно было бы его открыть следующим образом:
fieldnames = ['Имя', 'Успеваемость', 'Год рождения'] file_reader = csv.DictReader(r_file, fieldnames = fieldnames)
Также можно использовать метод __next__() для получения следующей строки. Этот метод делает объект reader итерируемым. То есть он вызывается при каждой итерации и возвращает следующую строку. Этот метод и используется при каждой итерации в цикле for для получения очередной строки.
Запись в файлы
Для записи информации в CSV файл необходимо создать объект writer:
file_writer = csv.writer(w_file, delimiter = "\t")
Для записи в файл данных используется метод writerow(), который имеет следующий синтаксис:
writecol("Имя", "Фамилия", "Отчество")
Код программы для записи в CSV файл выглядит так:
import csv with open("classmates.csv", mode="w", encoding='utf-8') as w_file: file_writer = csv.writer(w_file, delimiter = ",", lineterminator="\r") file_writer.writerow(["Имя", "Класс", "Возраст"]) file_writer.writerow(["Женя", "3", "10"]) file_writer.writerow(["Саша", "5", "12"]) file_writer.writerow(["Маша", "11", "18"])
Обратите внимание, что при записи использовался, lineterminator=»\r» . Это разделитель между строками таблицы, по умолчанию он «\r\n» .
После выполнения программы в файле CSV будет следующий текст:
Имя,Класс,Возраст Женя,3,10 Саша,5,12 Маша,11,18
В качестве параметра метод writerow() принимает список, элементы которого будут записаны в строку через символ-разделитель.
Запись в файл также может быть осуществлена с помощью объекта DictWriter. Важно помнить, что он требует явного указания параметра fieldnames. В качестве аргумента метода writerow используется словарь.
Код программы выглядит так:
import csv with open("classmates.csv", mode="w", encoding='utf-8') as w_file: names = ["Имя", "Возраст"] file_writer = csv.DictWriter(w_file, delimiter = ",", lineterminator="\r", fieldnames=names) file_writer.writeheader() file_writer.writerow() file_writer.writerow() file_writer.writerow()
Вывод в файл будет следующим:
Имя,Возраст Саша,6 Маша,15 Вова,14
Дополнительные параметры DictWriter
Объект writer также имеет атрибут dialect, который определяет, как будут форматироваться данные при записи в файл, про него будет описано ниже.
Кроме того, writer имеет методы:
- writerows(rows) — Записывает все элементы строк.
- writeheader() — Выводит заголовки для столбцов. Заголовки должны быть переданы объекту writer в виде списка, как атрибут fieldnames.
writeheader был использован в предыдущем примере. Рассмотрим применение writerows :
file_writer.writerows([, , ])
Диалекты
Чтобы каждый раз не указывать формат входных и выходных данных, определенные параметры форматирования сгруппированы в диалекты (dialect). При создании объекта reader или writer программист может указать нужный ему диалект, кроме того, некоторые параметры диалекта можно переопределить вручную, также указав их при создании объекта.
Для создания диалекта используется команда:
register_dialect("имя", delimiter = "\t", . )
Класс Dialect позволяет определить следующие атрибуты форматирования:
| Атрибут | Значение |
| delimiter | Устанавливает символ, с помощью которого разделяются элементы в файле. По умолчанию используется запятая. |
| doublequote | Если True, то символ quotechar удваивается, если False, то к символу qutechar добавляется ecsapechar в качестве префикса. |
| escapechar | Строка из одного символа, которая используется для экранирования символа-разделителя. |
| lineterminator | Определяет разделитель для строк, по умолчанию используется «\r\n» |
| quotechar | Определяет символ, который используется для окружения символа-разделителя. По умолчанию используются двойные кавычки, то есть quotechar = ‘ » ‘. |
| quoting | Определяет символ, который используется для экранирования символа разделителя (если не используются кавычки). |
| skipinitialspace | Если установить значение этого параметра в True, то все пробелы после символа-разделителя будут игнорироваться. |
| strict | Если установить в True, то при неправильном вводе CSV будет возбуждаться исключение Error. |
Пример использования:
import csv csv.register_dialect('my_dialect', delimiter=':', lineterminator="\r") with open("classmates.csv", mode="w", encoding='utf-8') as w_file: file_writer = csv.writer(w_file, 'my_dialect') file_writer.writerow(["Имя", "Класс", "Возраст"]) file_writer.writerow(["Женя", "3", "10"]) file_writer.writerow(["Саша", "5", "12"]) file_writer.writerow(["Маша", "11", "18"])
В результате получим:
Имя:Класс:Возраст Женя:3:10 Саша:5:12 Маша:11:18
How To Import a CSV File to Pycharm
Knowing how to import and read a CSV file in Pycharm is a big plus. You save time; you work faster; and your work remains compact, among other benefits.
Pycharm itself is a robust tool. If you are not persistent, you get tired of it easily — while trying to import a CSV file or do other things.
Below, I explained how you could import a CSV file on your computer or online to Pycharm. And how you can add the file permanently to your Pycharm directory.
Note: install pandas first if not already installed.
How to Import a CSV File in Pycharm
- Find the CSV file path you want to import or read in Pycharm. To find the CSV file on your computer, type the filename in the “Type here to search” taskbar in windows. Find that at the bottom left of your computer screen.
- Filename(s) will pop up. Right-click on the file you want and click “Copy full path”. Or click the arrow-head shape in front of the file you want and click “Copy full path”.
- Open Pycharm and write the below three-line code:
Remember to include “r” first inside the bracket.
The copied path should look like this: “C:\Users\hp\Datafile.CSV”
Your CSV file should open inside Pycharm!
You can also import or read a CSV file online in Pycharm without downloading the file. Replace the CSV file path you copied above with the link to the CSV file online. You should be connected to the internet to do this, though.
How To Add CSV file to Pycharm Directory
When a CSV file is added permanently to the Pycharm directory, you won’t need to access the CSV file from outside Pycharm again. The CSV file would be right in Pycharm.
Модуль csv — чтение и запись CSV файлов

Формат CSV (Comma Separated Values) является одним из самых распространенных форматов импорта и экспорта электронных таблиц и баз данных. CSV использовался в течение многих лет до того, как был стандартизирован в RFC 4180. Запоздание четко определенного стандарта означает, что в данных, создаваемых различными приложениями, часто существуют незначительные различия. Эти различия могут вызвать раздражение при обработке файлов CSV из нескольких источников. Тем не менее, хотя разделители, символы кавычек и некоторые другие свойства различаются, общий формат достаточно универсален. Значит, возможно написать один модуль, который может эффективно манипулировать такими данными, скрывая детали чтения и записи данных от программиста.
Функции обработки CSV-файлов
csv.reader(csvfile, dialect=’excel’, **fmtparams) — возвращает объект reader, который построчно итерирует csvfile. Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Дополнительный параметр dialect используется для определения ряда параметров, характерных для специфического CSV диалекта. Он может быть подклассом Dialect или одной из строк, возвращаемой функцией list_dialects(). Также могут передаваться дополнительные ключевые аргументы fmtparams для переопределения отдельных параметров форматирования в текущем диалекте.
Каждая строка, считанная из файла csv, возвращается в виде списка строк. Автоматическое преобразование типов данных не выполняется, если не указан параметр формата QUOTE_NONNUMERIC (в этом случае все поля без кавычек преобразуются в числа с плавающей точкой).
Короткий пример использования:
csv.writer(csvfile, dialect=’excel’, **fmtparams) — возвращает объект writer, конвертирующий пользовательские данные в CSV-файл csvfile. csvfile может быть любым объектом с методом write(). Если csvfile является файловым объектом, то его нужно открыть с параметром newline=». Параметры dialect и fmtparams идентичны параметрам в функции csv.reader.
Необходимые методы экземпляра класса writer:
csvwriter.writerow(row) — записывает данные, представляющие одну строку CSV в файл, форматируя согласно текущему диалекту writer.
csvwriter.writerows(rows) — записывает данные, представляющие несколько строк CSV в файл, форматируя согласно текущему диалекту writer.
Пример использования writer :
csv.field_size_limit([new_limit]) — текущий максимальный размер поля. Если задан new_limit, то он становится новым макс. размером.
class csv.DictReader(f, fieldnames=None, restkey=None, restval=None, dialect=’excel’, *args, **kwds) — как reader, но отображает информацию о столбцах в словарь, ключи которого заданы в параметре fieldnames.
fieldnames это последовательность ключей. Если параметр опущен, в качестве ключей используются значения из первой строки файла. Если строка имеет больше полей, чем длина fieldnames , оставшиеся данные будут помещены в список с ключом из переменной restkey . Если строка имеет меньше полей, оставшиеся значения будут установлены в значение restval .
Остальные аргументы пробрасываются далее в экземпляр reader.
class csv.DictWriter(f, fieldnames, restval=», extrasaction=’raise’, dialect=’excel’, *args, **kwds) — как writer, но отображает словари в CSV-файл.
Обязательный параметр fieldnames — последовательность ключей, определяющие порядок, в котором значения из словаря будут записаны в строке CSV-файла f.
Параметр restval определяет значение в случае, если в словаре будет отсутствовать запись с данным ключом. Если словарь содержит лишние ключи, то поведение определяется параметром extrasaction . Если он ‘raise’, то выдаст ошибку. Если ‘ignore’, то такие ключи игнорируются.
Остальные аргументы пробрасываются далее в экземпляр writer.
Помимо методов writerow и writerows, DictWriter имеет также метод
DictWriter.writeheader() — записывает данные строки заголовка в CSV-файл, форматируя согласно текущему диалекту writer.
Пример использования DictWriter:
class csv.Dialect — для упрощения задания формата входных и выходных записей, конкретные параметры форматирования группируются в диалекты, подклассы csv.Dialect . Диалекты поддерживают следующие атрибуты:
Dialect.delimiter — разделитель столбцов в строке CSV-файла. По умолчанию ‘,’.
Dialect.quotechar — символ, использующийся для «склейки» поля, содержащего специальные символы, такие как delimiter, quotechar, или символы новой строки. По умолчанию используется значение ‘»‘.
Dialect.doublequote — как Dialect.quotechar , появляющийся внутри поля, должен экранироваться. Когда True, символ удваивается. Когда False, Dialect.escapechar используется как префикс к quotechar. По умолчанию True.
При записи файла, если doublequote=False и не установлен escapechar, выдаст ошибку при обнаружении quotechar в столбце.
Dialect.escapechar — символ, используемый writer для экранирования delimiter , если quoting установлен в QUOTE_NONE и quotechar , если doublequote=False . При чтении escapechar удаляет какое-либо особое значение со следующего символа. По умолчанию используется значение None, которое отключает экранирование.
Dialect.lineterminator — символы, используемые для завершения строки при записи. По умолчанию ‘\r\n’.
Dialect.skipinitialspace — если True, пробелы, непосредственно следующие за delimiter, игнорируются. Значение по умолчанию — False.
Dialect.strict — когда True, поднимает исключение если CSV файл не распознается. По умолчанию — False.
Dialect.quoting — контролирует, когда кавычки должны генерироваться writer и распознаваться reader. Он может принимать любые константы QUOTE_* и по умолчанию имеет значение QUOTE_MINIMAL.
csv.QUOTE_ALL — writer оборачивает в кавычки все поля.
csv.QUOTE_MINIMAL — writer оборачивает в кавычки только поля, содержащие специальные символы (delimiter, quotechar, lineterminator).
csv.QUOTE_NONNUMERIC — writer оборачивает в кавычки все поля, не являющиеся числами. reader преобразует все поля без кавычек к типу float.
csv.QUOTE_NONE — writer не оборачивает никакие поля в кавычки. Если в данных попадается delimiter или lineterminator, он предваряется символом escapechar, если установлен (исключение, если не установлен). reader не обрабатывает кавычки.
csv.register_dialect(name[, dialect[, **fmtparams]]) — связывает dialect с именем name. Подробности о диалектах см. в разделе «Диалекты и параметры форматирования»
csv.unregister_dialect(name) — удаляет связь диалекта с данным именем.
csv.get_dialect(name) — возвращает класс диалекта, свзанного с именем name.
csv.list_dialects() — список доступных диалектов. На данный момент это ‘excel’, ‘excel-tab’, ‘unix’.
Предустановленные диалекты
class csv.excel — диалект CSV-файла, обычно генерируемого программой Excel.
class csv.excel_tab — диалект CSV-файла, обычно генерируемого программой Excel с настройкой «разделитель с помощью TAB».
class csv.unix_dialect — диалект CSV-файла, обычно генерируемого в UNIX-системах (‘\n’ для новой строки, закавычивание всех полей).
Определение диалекта
class csv.Sniffer — используется для угадывания диалекта CSV-файла. Имеет следующие методы:
csvsniffer.sniff(sample, delimiters=None) — анализирует пример и возвращает Dialect, соответствующий обнаруженным параметрам. Если задан параметр delimiters , он интерпретируется как все возможные разделители.
csvsniffer.has_header(sample) — анализирует текст и возвращает True, если первая строка похожа на строку заголовков.
Методы определения диалекта являются эвристическими; это означает, что Sniffer может ошибаться.
Пример использования Sniffer:
Примеры
Простейший пример чтения CSV файла:
Чтение файла формата passwd:
Простейший пример записи CSV файла:
Для вставки кода на Python в комментарий заключайте его в теги
- Модуль csv - чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте