Как сохранить html страницу без знаков вопроса?
Если открывать такой такой сайт после сохранения появляются знаки вопроса вместо текста или картинок.
Отслеживать
задан 5 дек 2022 в 0:39
17 1 1 серебряный знак 5 5 бронзовых знаков
Вообще ничего не появляется, даже знаки вопроса. Access denied Error code 1020 . В браузере то же самое. Если это сайт под логином и паролем, вряд ли SO сможет помочь.
5 дек 2022 в 1:19
open(‘file.html’, ‘w’, encoding=’utf-8′)
5 дек 2022 в 2:46
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
На Linux Ваш код сработает правильно. Скорее всего Вы выполняете его в Windows. А это значит, что файл создается в кодировке Windows-1251. А в html разметке в head указано, что файл браузер должен читать как utf-8. Необходимо немного изменить код:
import requests url = "https://www.templatemonster.com/ru/backgrounds/231926.html" r = requests.get(url) with open('file.html', 'w', encoding="utf-8") as file: file.write(r.text) Отслеживать
ответ дан 5 дек 2022 в 3:06
2,075 1 1 золотой знак 3 3 серебряных знака 11 11 бронзовых знаков
Так и есть.На линукс все работало нормально, а на виндовс нет.Спасибо.
5 дек 2022 в 20:10
- python
- html
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Сохранить как html, через python, как?
Здравствуйте ув. знатоки.
Сохраняю страницу через браузер как хтмл, сохраняет как надо, ссылки, теги и т.д.
Сохраняю через пайтон — в файле js код вместо ссылок.
Как сохранить через пайтон так же как через правую кнопку браузера без селениума?
- Вопрос задан более трёх лет назад
- 1121 просмотр
5 комментариев
Простой 5 комментариев

Сергей Карбивничий @hottabxp Куратор тега Python
Значит html код генерирует js. Дайте ссылку на сайт.
del4pp @del4pp Автор вопроса
Сергей Карбивничий, brain.com.ua
Сергей Карбивничий @hottabxp Куратор тега Python
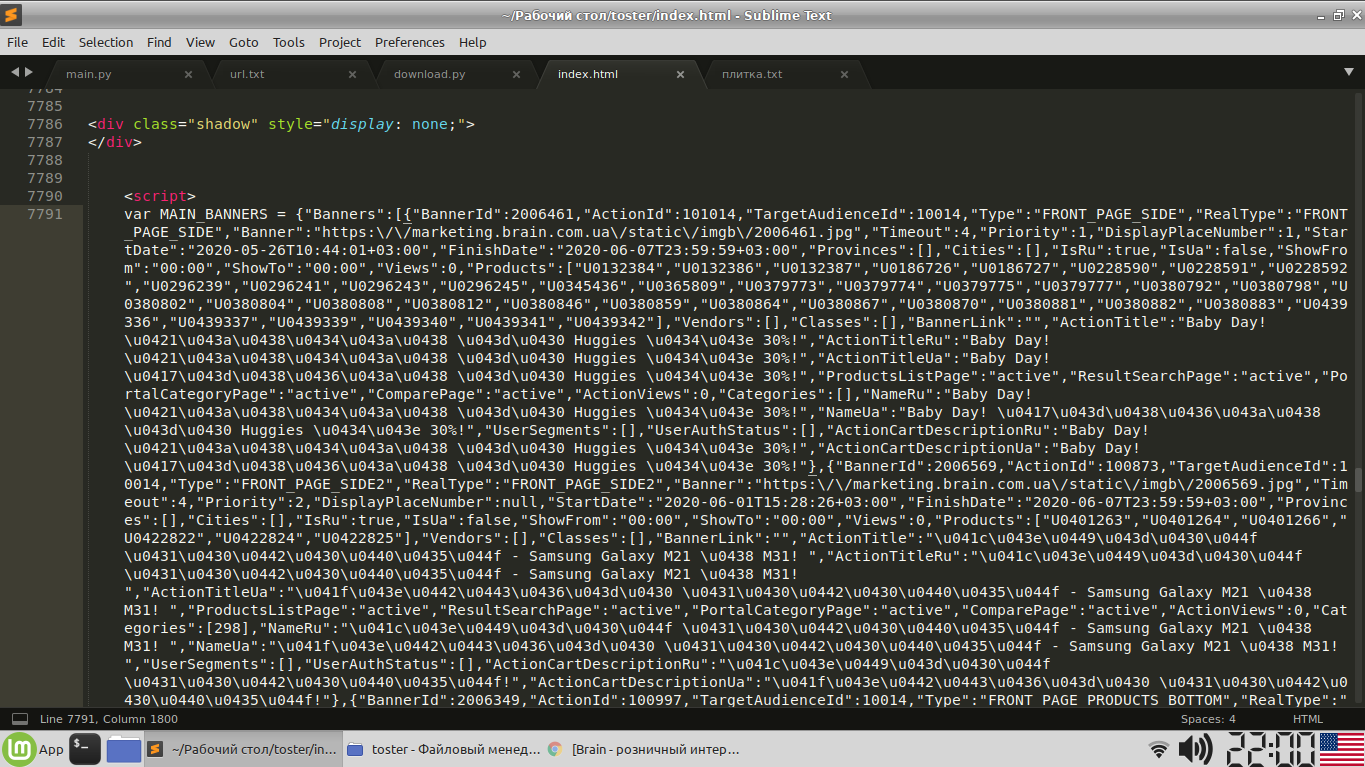
del4pp, Если вы про это:
так это json.
del4pp @del4pp Автор вопроса
Сергей Карбивничий, вот к примеру страница https://brain.com.ua/search?s=10750
Мне нужно получить ссылки на товары с поиска
После сохранения страницы — товары пропадают, если сохранять через «сохранить как» — все есть.
del4pp @del4pp Автор вопроса
Сергей Карбивничий, черз источник страницы такой же результат как при скачивании файла через пайтон.
Решения вопроса 2

soremix @SoreMix Куратор тега Python
Ваши товары отображаются после JS рендера. Обычные запросы на сайт (через requests и тд) не выполняют JS код. Как requests видит страницу можете посмотреть через CTRL + U. Если смотреть через RightClick -> Inspect Element, то вы видите уже отрендереный код.
Если нажать F12 -> Network, обновить страницу и открыть XHR запросы, будет видно, что все товары ищутся через запрос
https://brain.com.ua/search/1187/?Search=10750&Offset=0https://brain.com.ua/search/142/?Search=10750&Offset=0Где 1187 и 142 это категории, насколько я понимаю, а 10750 — ваш поисковой запрос. Оффсет понятно.
- Делать запросы по примеру как я отправил выше и парсить их товары с ответа
- Открывать нужную страницу через селениум и сохранять код. Думаю, в селениуме есть такой вариант
Ответ написан более трёх лет назад
del4pp @del4pp Автор вопроса
А можно в общем поиске без указаний категории?
del4pp @del4pp Автор вопроса
Так как 10750 — это код товара, категория которого заранее не известна
soremix @SoreMix Куратор тега Python
Сергей Карбивничий @hottabxp Куратор тега Python
Сначала мы жили бедно, а потом нас обокрали..
Смотрите в браузере xhr запросы. Данные поиска подгружаются динамически.
Вот пример:
import json import requests from bs4 import BeautifulSoup headers = response = requests.get('https://brain.com.ua/search/1187/?Search=10750&Offset=0',headers=headers) j_data = json.loads(response.text) soup = BeautifulSoup(j_data['ProductsGrid'],'lxml') items = soup.find_all('div',class_='col-lg-3 col-md-4 col-sm-6 col-xs-6 product-wrapper br-pcg-product-wrapper') for item in items: url = 'https://brain.com.ua'+ item.find('h3').a.get('href') title = item.get('data-name') print(f' - ')Сохранение веб-страницы в одном HTML файле – зачем это нужно и как это сделать?
Каждый пользователь интернета периодически попадает на сайты с действительно полезной и ценной для него информацией. Для постоянного доступа к ней в режиме offline, веб-страницу можно сохранить в отдельный файл и в дальнейшем просматривать его на самом компьютере. Сохраненный контент сайта будет доступен пользователю всегда, даже если не будет подключения к интернету.
Обновлено: 2023-06-24 22:04:20 ОЛ Олег Лоров автор материала
Как сохранить веб-страницы в одном HTML файле и зачем это делать?
Для сохранения сайта есть несколько способов. Это можно сделать при помощи специализированных программ, браузеров и онлайн сервисов. Каждый из них имеет свои преимущества и недостатки.
Формат HTML особенно удобен, так как является универсальным для большинства браузеров. Например, при отправлении в дальнюю поездку, можно сохранить нужный контент в данном формате на флешку и спокойно просматривать его в процессе передвижения или по прибытию на место.
Рассмотрим более подробно процесс сохранения главной страницы интересующего сайта:
- При клике правой кнопкой мыши по любой области сайта появиться контекстное меню, в котором необходимо выбрать пункт « Сохранить как ». Выбрать место для сохранения файла, ввести его название (если требуется) и нажать « Сохранить ». Также доступен выбор типа сохраняемого файла. Например, тип « Веб-страница полностью » позволяет сохранять весь контент страницы сайта: фотографии, стили, скрипты. Они будут подгружаться из локальной папки, сохраненной на компьютере. Тип « веб-страница, только HTML » позволяет сохранять только текстовую информацию, остальное содержимое будет подгружаться из интернета.

Рисунок 1: Сохранение главной страницы сайта в html-файл
- При открытии сохраненного файла, необходимо указать наиболее подходящую программу, в данном случае используется браузер Microsoft Edge.

Рисунок 2: Итоговый html- файл с информацией с главной страницы сайта
Метод наиболее простой, не требует применения дополнительного программного обеспечения. Стоит уделить внимание и другим способам сохранения веб-страниц в файл с расширением html. Давайте разберемся, как это сделать с помощью различных браузеров и расширений к ним
Сохранение веб-страницы в одном HTML файле на ПК с помощью расширения SingleFile
Поэтапный процесс выглядит следующим образом:
-
Данное расширение для браузера нужно скачать и установить.

Рисунок 3: Установка расширения SingleFile
- В рамках этого расширения доступны различные варианты сохранения данных с веб-страницы (доступны дополнительные возможности). Информацию можно сразу же сохранять в архив. Расширение SingleFile позволяет сохранять весь контент с веб-страницы кроме видеофайлов в один файл, что очень удобно при его отправке другим пользователям.

Рисунок 4: Меню расширения SingleFile
- Для сохранения конкретной веб-страницы, необходимо выбрать значок расширения SingleFile в правом верхнем углу браузера и открыв его меню, нажать на кнопку « Сохранить страницу » и выбрать конечный путь для его сохранения.

Рисунок 5: Сохранение веб-страницы в отдельный html-файл
- Итоговый файл будет сжат и после его сохранения в несколько этапов, будет доступен локально на компьютере или ноутбуке.

Рисунок 6: Итоговый html — файл
Сохранение веб-страницы в одном HTML файле с помощью браузера Google Chrome для Android
Современные мобильные устройства также предоставляют возможность сохранения веб-страниц в отдельные html-файлы. Подобная технология в рамках операционной системы Android имеет ряд особенностей. Сохранение итогового файла происходит в физическую память мобильного устройства, а его просмотр в offline-режиме доступен через привычный браузер Google Chrome.
Процесс можно разделить на следующие этапы:
- Необходимо открыть браузер Google Chrome на Android-смартфоне и найти меню в верхней правой части его окна. Оно скрыто под значком с троеточием. При нажатии на него, отобразится список доступных функций, в котором следует выбрать значок со стрелкой.

Рисунок 7: Меню браузера Google Chrome на мобильном устройстве с операционной системой Android
- При нажатии на значок со стрелкой, содержимое сайта автоматически сохранится в html-файл. Его просмотр доступен из этого же меню. Найти сохраненный результат можно будет в разделе « Скаченные файлы ».

Рисунок 8: Итоговый html-файл
Браузер позволяет сохранять любую информацию, музыку, видео, скрипты. Вся информация будет доступна в упомянутом выше меню в offline-режиме.
Сохранение веб-страницы в одном HTML-файле в браузере Apple Safari для iOS
Такие мобильные устройства iPhone и iPad имеют встроенную функцию, благодаря которой воспроизводится сделанный заранее снимок экрана с информацией веб-страницы. Готовые скриншоты хранятся локально в памяти мобильного устройства и могут синхронизироваться с платформой iCloud.
Вся процедура подразделяется на следующие этапы:
- Необходимо открыть браузер Safari на мобильном устройстве, а также открыть нужный сайт. В нижней части экрана располагается меню браузера.

Рисунок 9: Меню браузера Apple Safari
- Для сохранения в режиме чтения без рекламы и комментариев необходимо нажать на значок «аА», доступный в левом верхнем углу (если требуется полноценная версия веб-страницы, этот значок нажимать не требуется). Нажав на него, необходимо выбрать вид для чтения и нажать на кнопку « Поделиться »

Рисунок 10: Кнопка «Поделиться» в браузере Apple Safari
- Далее нужно выбрать пункт « Добавить разметку » и поделиться результатом для сохранения в формате PDF.

Рисунок 11: Сохранение файла в формате PDF
- Остается выбрать: Сохранить в « Файлы », указать итоговый путь и сохранить файл.
Рисунок 12 : Ярлык с сохраненным файлом для просмотра в режиме offline
Полученный файл с разрешением PDF можно редактировать, вносить в него пометки и даже рисовать в нем.
Сохранение веб-страницы в одном HTML-файле с помощью браузера Google Chrome для iOS
Технология сохранения содержимого веб-страницы в отдельный html-файл аналогична подходу описанному выше. С помощью браузера Google Chrome для iOS эта делается следующим образом:
- Необходимо открыть браузер Google Chrome на iOS-устройстве и выбрать меню. Оно доступно в правом нижнем углу под иконкой многоточия.

Рисунок 13: Меню браузера Google Chrome для операционной системы iOS
- Итоговый файл также сохраняется с расширением PDF в разделе « Список для чтения ».
Итоговый файл также можно редактировать, синхронизировать с iCloud и передавать другим пользователям в виде ссылки.
Вывод
Создание html-файлов с содержимым веб-страницы является полезной функцией для всех пользователей интернета. Частые перелеты, перебои с интернетом не всегда дают возможность получать необходимую информацию непосредственно из всемирной паутины. Сохранение необходимых данных в форматах HTML или PDF позволяет осуществлять быстрый доступ к необходимым сведениям при работе в режиме offline. Только надо уточнить, сохраняется одна страница, а не весь сайт. Т.е. открыть другие вкладки и ссылки без интернета не получится.
Web Parsing. Основы на Python
Рассмотрим еще один практический кейс парсинга сайтов с помощью библиотеки BeautifulSoup: что делать, если на сайте нет готовой выгрузки с данными и нет API для удобной работы, а страниц для ручного копирования очень много?
Недавно мне понадобилось получить данные с одного сайта. Готовой выгрузки с информацией на сайте нет. Данные я вижу, вот они передо мной, но не могу их выгрузить и обработать. Возник вопрос: как их получить? Немного «погуглив», я понял, что придется засучить рукава и самостоятельно парсить страницу (HTML). Какой тогда инструмент выбрать? На каком языке писать, чтобы с ним не возникло проблем? Языков программирования для данной задачи большой набор, выбор пал на Python за его большое разнообразие готовых библиотек.
Примером для разбора основ возьмем сайт с отзывами banki_ru и получим отзывы по какому-нибудь банку.
Задачу можно разбить на три этапа:
- Загружаем страницу в память компьютера или в текстовый файл.
- Разбираем содержимое (HTML), получаем необходимые данные (сущности).
- Сохраняем в необходимый формат, например, Excel.
Инструменты
Для начала нам необходимо отправлять HTTP-запросы на выбранный сайт. У Python для отправки запросов библиотек большое количество, но самые распространённые urllib/urllib2 и Requests. На мой взгляд, Requests — удобнее, примеры буду показывать на ней.
А теперь сам процесс. Были мысли пойти по тяжелому пути и анализировать страницу на предмет объектов, содержащих нужную информацию, проводить ручной поиск и разбирать каждый объект по частям для получения необходимого результата. Но немного походив по просторам интернета, я получил ответ: BeautifulSoup – одна из наиболее популярных библиотек для парсинга. Библиотеки найдены, приступаем к самому интересному: к получению данных.
Загрузка и обработка данных
Попробуем отправить запрос HTTP на сайт, чтобы получить первую страницу с отзывами по какому-нибудь банку и сохранить в файл, для того, чтобы убедиться, получаем ли мы нужную нам информацию.
import requests from bs4 import BeautifulSoup bank_id = 1771062 #ID банка на сайте banki.ru url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=1’ % (bank_id) # url страницы r = requests.get(url) with open(‘test.html’, ‘w’) as output_file: output_file.write(r.text)
После исполнения данного скрипта получится файл text.html.
Открываем данный файл и видим, что необходимые данные получили без проблем.
Теперь очередь для разбора страницы на нужные фрагменты. Обрабатывать будем последние 10 страниц плюс добавим модуль Pandas для сохранения результата в Excel.
Подгружаем необходимые библиотеки и задаем первоначальные настройки.
import requests from bs4 import BeautifulSoup import pandas as pd bank_id = 1771062 #ID банка на сайте banki.ru page=1 max_page=10 url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=%d’ % (bank_id, page) # url страницы
На данном этапе необходимо понять, где находятся необходимые фрагменты. Изучаем разметку страницы с отзывами и определяем, какие объекты будем вытаскивать из страницы.
Подробно покопавшись во внутренностях страницы, мы увидим, что необходимые данные «вопросы-ответы» находятся в блоках , соответственно, сколько этих блоков на странице, столько и вопросов.
result = pd.DataFrame() r = requests.get(url) #отправляем HTTP запрос и получаем результат soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга tables=soup.find_all(‘table’, <'class': 'qaBlock'>) #Получаем все таблицы с вопросами for item in tables: res=parse_table(item)
Приступая к получению самих данных, я кратко расскажу о двух функциях, которые будут использованы:
- Find(‘table’) – проводит поиск по странице и возвращает первый найденный объект типа ‘table’. Вы можете искать и ссылки find(‘table’) и рисунки find(‘img’). В общем, все элементы, которые изображены на странице;
- find_all(‘table’) – проводит поиск по странице и возвращает все найденные объекты в виде списка
У каждой из этих функций есть методы. Я расскажу от тех, которые использовал:
- find(‘table’).text – этот метод вернет текст, находящийся в объекте;
- find(‘a’).get(‘href’) – этот метод вернет значение ссылки
Теперь, уже обладая этими знаниями и навыками программирования на Python, написал функцию, которая разбирает таблицу с отзывом на нужные данные. Каждые стадии кода дополнил комментариями.
def parse_table(table):#Функция разбора таблицы с вопросом res = pd.DataFrame() id_question=0 link_question=» date_question=» question=» who_asked=» who_asked_id=» who_asked_link=» who_asked_city=» answer=» question_tr=table.find(‘tr’,<'class': 'question'>) #Получаем сам вопрос question=question_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘
‘,’\n’).strip() widget_info=question_tr.find_all(‘div’, ) #Получаем ссылку на сам вопрос link_question=’https://www.banki.ru’+widget_info[0].find(‘a’).get(‘href’).strip() #Получаем уникальным номер вопроса id_question=link_question.split(‘=’)[1] #Получаем того кто задал вопрос who_asked=widget_info[1].find(‘a’).text.strip() #Получаем ссылку на профиль who_asked_link=’https://www.banki.ru’+widget_info[1].find(‘a’).get(‘href’).strip() #Получаем уникальный номер профиля who_asked_id=widget_info[1].find(‘a’).get(‘href’).strip().split(‘=’)[1] #Получаем из какого города вопрос who_asked_city=widget_info[1].text.split(‘(‘)[1].split(‘)’)[0].strip() #Получаем дату вопроса date_question=widget_info[1].text.split(‘(‘)[1].split(‘)’)[1].strip() #Получаем ответ если он есть сохраняем answer_tr=table.find(‘tr’,<'class': 'answer'>) if(answer_tr!=None): answer=answer_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘
‘,’\n’).strip() #Пишем в таблицу и возвращаем res=res.append(pd.DataFrame([[id_question,link_question,question,date_question,who_asked,who_asked_id,who_asked_link,who_asked_city,answer]], columns = [‘id_question’,’link_question’,’question’,’date_question’,’who_asked’,’who_asked_id’,’who_asked_city’,’who_asked_link’,’answer’]), ignore_index=True) #print(res) return(res)
Функция возвращает DataFrame, который можно накапливать и экспортировать в EXCEL.
result = pd.DataFrame() r = requests.get(url) #отправляем HTTP запрос и получаем результат soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга tables=soup.find_all(‘table’, <'class': 'qaBlock'>) #Получаем все таблицы с вопросами for item in tables: res=parse_table(item) result=result.append(res, ignore_index=True) result.to_excel(‘result.xlsx’)
В результате мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup, а также получили пригодные для дальнейшего анализа данные об отзывах с сайта banki.ru. А вот и сама результирующая таблица.
Приобретенные навыки можно использовать для получения данных с других сайтов и получать обобщенную и структурированную информацию с бескрайних просторов Интернета.
Я надеюсь, моя статья была полезна. Спасибо за внимание.