Система управления базами данных SQLite. Изучаем язык запросов SQL и реляционные базы данных на примере библиотекой SQLite3. Курс для начинающих.
Часть 3.2: Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты
- 26.05.2016
- SQLite библиотека, Базы данных
- 3 комментария
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Продолжаем изучать теорию реляционных баз данных и в этой части мы познакомимся с видами и типами связей между таблицами в реляционных базах данных. Так же мы познакомимся с такими термина, как: кортеж, атрибут и отношения. Данная тема является базовой и ее понимание необходимо для работы с базами данных и для их проектирования.

Виды связей между таблицами в базе данных. Связи в реляционных базах данных. Отношения, кортежи, атрибуты.
Сразу скажу, что связей между таблицами в реляционной базе данных всего три. Поэтому их изучение, понимание и восприятие пройдет быстро, легко и безболезненно. Приступим к изучению.
Термины кортеж, атрибут и отношение в реляционных базах данных
В своей публикации я буду стараться объяснять теорию баз данных не с математической точки зрения, а на примерах. Грубо говоря, на пальцах. Во-первых, практические примеры позволяют легче усваивать материал. Во-вторых, с математической теорией проще разобраться, когда понимаешь суть происходящего.
Давайте разбираться с тем, что такое: отношение, кортеж, атрибут в реляционной базе данных.
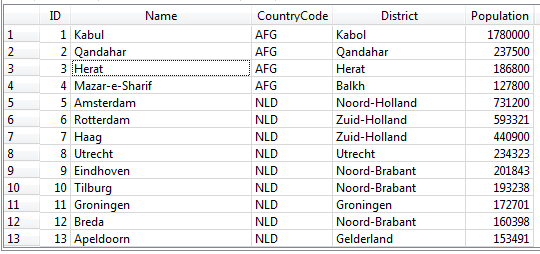
Таблица с данными из базы данных World
У нас есть простая таблица City из базы данных World, в которой есть строки и столбцы. Но термины: таблица, строка, столбец – это термины стандарта SQL.
Кстати: ни одна из существующих в мире СУБД не имеет полной поддержки того или иного стандарта SQL, но и ни один стандарт SQL полностью не реализует математику реляционных баз данных.
В терминологии реляционных баз данных: таблица – это отношение (принимается такое допущение), строка – это кортеж, а столбец – атрибут. Иногда вы можете услышать, как некоторые разработчики называют строки записями. Чтобы не было путаницы в дальнейшем предлагаю использовать термины SQL.
Если рассматривать таблицу, как объект (например книга), то столбец – это характеристики объекта, а строки содержат информацию об объекте.
Виды и типы связей между таблицами в реляционных базах данных
Давайте теперь рассмотрим то, как могут быть связаны таблицы в реляционных базах данных. Сразу скажу, что всего существует три вида связей между таблицами баз данных:
• связь один к одному;
• связь один ко многим;
• связь многие ко многим.
Рассмотрим, как такие связи между таблицами могут быть реализованы в реляционных базах данных.
Реализация связи один ко многим в теории баз данных
Связь один ко многим в реляционных базах данных реализуется тогда, когда объекту А может принадлежать или же соответствовать несколько объектов Б, но объекту Б может соответствовать только один объект А. Не совсем понятно, поэтому смотрим пример ниже.
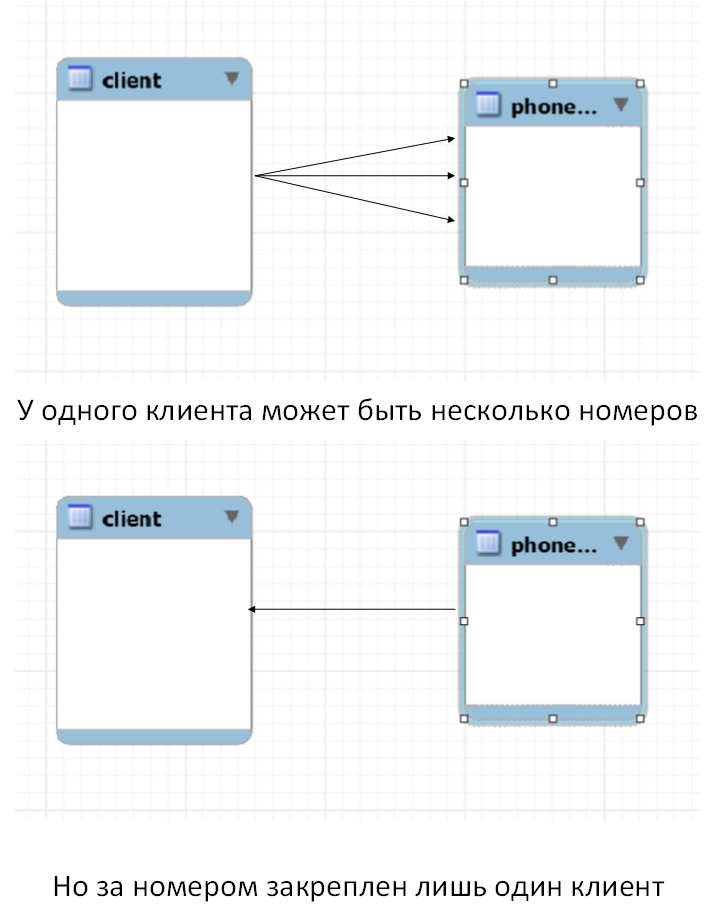
Реализация связи один ко многим в реляционных базах данных
У нас есть таблица, в которой содержатся данные о клиентах и у нас есть таблица, в которой хранятся их телефоны. Мы можем смело утверждать, что у одного клиента может быть несколько телефонов, но в тоже время мы можем быть уверены в том, что один конкретный номер может быть только у одного клиента. Это типичный пример связи один ко многим.
Связь многие ко многим
Связь многие ко многим реализуется в том случае, когда нескольким объектам из таблицы А может соответствовать несколько объектов из таблицы Б, и в тоже время нескольким объектам из таблицы Б соответствует несколько объектов из таблицы А. Рассмотрим простой пример.
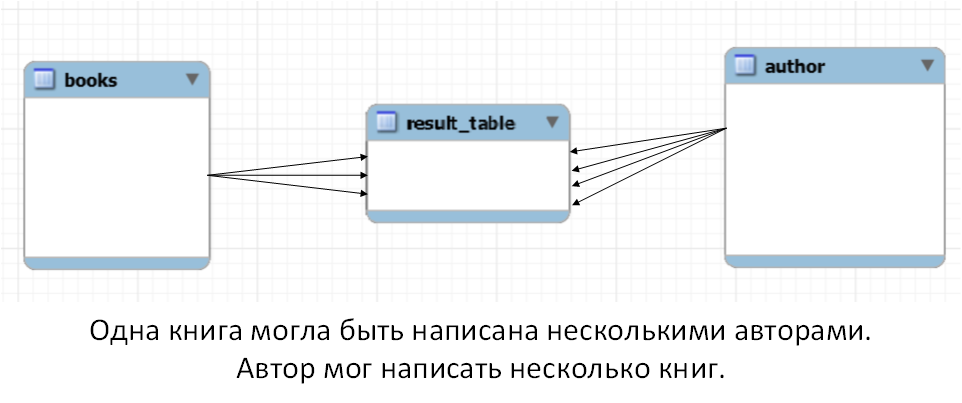
Пример связи многие ко многим
У нас есть таблица с книгами и есть таблица с авторами. Приведу два верных утверждения. Первое: одну книгу может написать несколько авторов. Второе: автор может написать несколько книг. Здесь мы наблюдаем типичную ситуацию, когда связь между таблицами многие ко многим. Такая связь (связь многие ко многим) реализуется путем добавления третьей таблицы.
Связь один к одному
Связь один к одному – самая редко встречаемая связь между таблицами. В 97 случаях из 100, если вы видите такую связь, вам необходимо объединить две таблицы в одну.
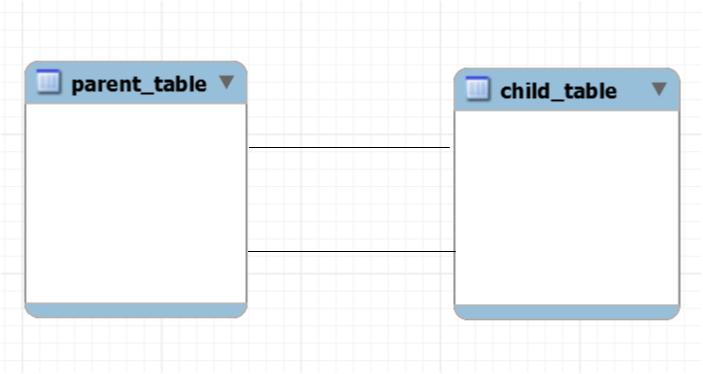
Пример связи один к одному
Таблицы будут связаны один к одному тогда, когда одному объекту таблицы А соответствует один объект таблицы Б, и одному объекту таблицы Б соответствует один объект таблицы А. Как я уже говорил: если вы видите, что связь один к одному – смело объединяйте таблицы в одну, за исключением тех случаев, когда происходит модернизация базы данных.
Например, у нас была таблица, в которой хранились данные о сотрудниках компании. Но произошли какие-то изменения в бизнес-процессе и появилась необходимость создать таблицы с теми же самыми сотрудниками, но не для всей компании, а разбив их по отделам. Таблицы отделов будут дочерними по отношению к таблице, в которой хранятся данные обо всех сотрудниках компании, и связаны такие таблицы будут связью один к одному.
Мы рассмотрели все виды связей между таблицами и то, как они реализуются в базах данных. В дальнейшем, когда мы начнем создавать свои базы данных, информация о видах связи между таблицами нам очень поможет.
Еще записи о создании сайтов и их продвижении, базах данных, IT-технология и сетевых протоколах
- Часть 11.2: Ограничения уровня таблицы в базах данных SQLite3
- Часть 11.4: Внешние ключи в базах данных SQLite: FOREIGN KEY в SQLite3
- Часть 3.3: Ключи и ключевые атрибуты в базах данных
- Тема 3: Теория реляционных баз данных
- Тема 10: Работа с таблицами в базах данных SQLite3
- Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных
- Часть 3.10: Словарь терминов реляционных баз данных
- Часть 11.7: Индексы в базах данных SQLite. Индексация таблиц в SQLite3. Алгоритм B-дерева в базах данных
Возможно, эти записи вам покажутся интересными
Related Posts
Здравствуйте, уважаемые посетители сайта ZametkiNaPolyah.ru. Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3.…
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем изучать базы данных и наше знакомство с библиотекой SQLite3. Последняя…
Привет, посетитель сайта ZametkiNaPolyah.ru! Продолжаем рубрику реляционные базы данных и ее раздел библиотека SQLite. Начнем…
Выберете удобный для себя способ, чтобы оставить комментарий
This article has 3 comments
Deer-door 08.10.2020 Reply
> В 97 случаях из 100 Как производилось измерение частоты случаев? Каковы были условия измерения?
Автор жжёт 01.03.2022 Reply
у меня нет слов от ваших комментариев про связь Один ко одному. Создаётся впечатление, что вы никогда не занимались профессиональной разработкой программ и слышали о ней, только из книг. Бедные ваши студенты если вы преподаватель.
Кирилл 24.03.2022 Reply
Из-за вашего комментария ко мне домой приехало два наряда пожарных, тушили весь вечер. Не нужно так, я очень впечатлительный. А теперь по факту: 1. Может вы все-таки подумаете, почему я так ответил, с учетом общей направленности всего цикла публикаций по SQLite. Может человеку сперва нужно понять как вещь работает в общем, прежде чем начинать к ней приделывать костыли? 2. Если хотите высказаться конструктивно, напишите свою публикацию с примерами и пояснениями, готов опубликовать со ссылками на вас и ваши ресурсы, если они не противоречат законам РФ.
Типы связей в реляционных базах данных
Примечание:
Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
Практически всегда БД не ограничивается одной таблицей. Сложно представить себе какой-либо бизнес-процесс на предприятии, который мог бы сконцентрироваться только на одном предмете в плане информации.
Рассмотрим пример учебной базы данных. Имеется отдел, который занимается обработкой звонков, поступающих на различные линии. Линии обслуживаются конкретными операторами. Операторы состоят в разных группах под присмотром супервайзеров.
Только из данного краткого описания можно выделить несколько самостоятельных объектов:
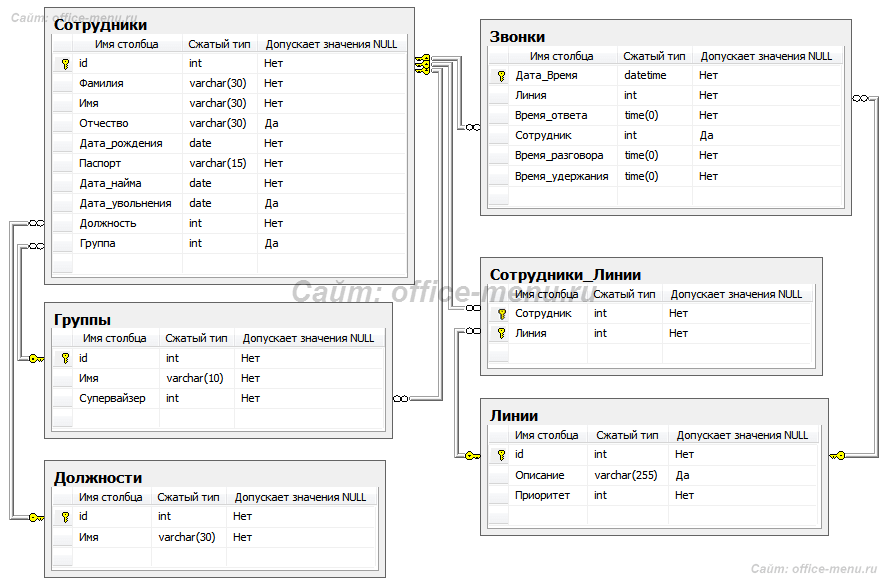
- Телефонные линии обслуживания;
- Сотрудники отдела;
- Должности сотрудников;
- Группы, по которым распределены сотрудники;
- Звонки.
Ознакомившись с диаграммой базы данных, можно обратить внимание на то, что некоторая информация из одних таблиц присутствует в других, т.е. между ними имеются связи.
В нашем конкретном случае, все таблицы можно соединить между собой. Чтобы понять, как это правильно сделать, необходимо рассмотреть типы связей.
Логику соединения таблиц в БД важно понять с самого начала изучения SQL, так как наверняка Вы не будете писать запросы только к одной таблице.
Всего существует 3 типа связей:
Примечание:
В данном материале обозначения связей приводятся на примере MS SQL Server. В иных СУБД они могут обозначаться по-разному, но у Вас не должно возникнуть проблем с определением их типа, т.к. они либо очень похожи, либо интуитивно понятны.
Связь «Один к одному»
Связь один к одному образуется, когда ключевой столбец (идентификатор) присутствует в другой таблице, в которой тоже является ключом либо свойствами столбца задана его уникальность (одно и тоже значение не может повторяться в разных строках).
На практике связь «один к одному» наблюдается не часто. Например, она может возникнуть, когда требуется разделить данных одной таблицы на несколько отдельных таблиц с целью безопасности.
В учебной безе данных нет подходящего примера, но гипотетически могла бы существовать необходимость разделения таблицы сотрудников.
Пример:
Представьте, что базой данных пользуются несколько менеджеров и аналитиков, а таблица «Сотрудники» содержит те же столбцы, что и учебная база. Следовательно, доступ к персональным данным может получить любой из упомянутых работников.
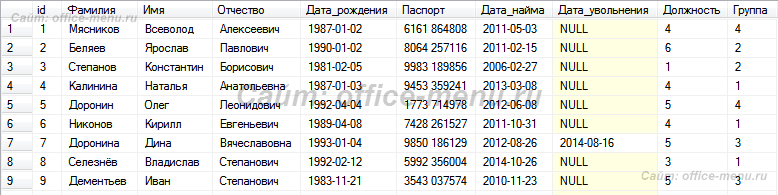
Чтобы устранить возможность утечки конфиденциальной информации, принимается решение о переносе информации паспортных данных в отдельную таблицу, доступ к которой предоставляется ограниченному кругу лиц.
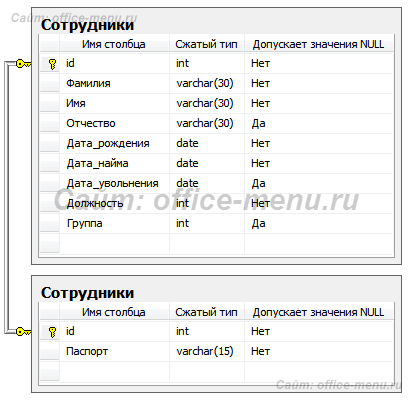
Связь «Один ко многим»
В типе связей один ко многим одной записи первой таблицы соответствует несколько записей в другой таблице.
Рассмотрим связь учебной базы данных между должностями и сотрудниками, которая относится к рассматриваемому типу.
Записи должностей в таблице «Должность» уникальны, так как нет смысла повторно создавать имеющуюся запись. Записи в таблице «Сотрудники» также уникальны, но несколько различных сотрудников могут находиться на одинаковой должностной позиции.
Символ ключа на конце связи указывает, что таблица, к которой этой конец прилегает, находится на стороне «один» (связанный столбец является первичным ключом), а символ бесконечности находится на стороне «многие» (такой столбец является внешним ключом).
Связь «Многие ко многим»
Если нескольким записям из одной таблицы соответствует несколько записей из другой таблицы, то такая связь называется «многие ко многим» и организовывается посредством связывающей таблицы.
В нашей базе подобное наблюдается только между таблицами с сотрудниками и линиями.

Из диаграммы видно, что имеются две связи «один ко многим» (один сотрудник может обрабатывать несколько телефонных линий, и одну линию могут обрабатывать несколько сотрудников), но в совокупности они образуют связь «многие ко многим».
Для чего все это нужно?
Связи выполняют более важную роль, чем просто информация размещения данных по таблицам. Прежде всего они требуются разработчикам для поддержания целостности баз данных.
Правильно настроив связи, можно быть уверенным, что ничего не потеряется.
Представьте, что Вы решили удалить одну из групп в таблице учебной базы данных. Если бы связи не было, то для тех сотрудников, которые к ней были определены, остался идентификатор несуществующей группы. Связь не позволит удалить группу, пока она имеется во внешних ключах других таблиц. Для начала следовало определить сотрудников в другие имеющиеся или новые группы, а только затем удалить ненужную запись. Поэтому связи называют еще ограничениями.
- Объединение таблиц – UNION
- Соединение таблиц – операция JOIN и ее виды
- Тест на знание основ SQL
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Связи в базах данных: что это и как они работают


Что такое базы данных и их роль в программировании на Python
Связи в базах данных — это способ связывать и организовывать информацию в базе данных, чтобы делать её более понятной и удобной для использования.
Представим, что база данных — это большая коробка с игрушками. Связи — это способ связать каждую игрушку с её владельцем или определить, какие игрушки принадлежат к одной и той же категории: конструктор, мягкие игрушки, машинки… Связь помогает нам найти и использовать нужные игрушки легче и быстрее.
Связи в базах данных помогают нам:
- легко находить и объединять данные
- гарантировать правильность данных
- улучшить производительность.
В этой статье мы рассмотрим, какие типы связей бывают, как их использовать и как улучшить производительность базы данных с их помощью.
��️ Наши курсы Start Course — это не просто уроки, это ваши ключи к миру возможностей. �� Начните свой кодерский путь сегодня. ��
Основные элементы связей
Основные элементы связей — это:
- Первичный ключ (Primary Key). Это уникальный идентификатор каждой записи (строки) в таблице. Он гарантирует обеспечивает быстрый доступ к конкретным записям. Первичный ключ обычно состоит из одного или нескольких столбцов.
- Внешний ключ (Foreign Key). Это столбец или набор столбцов в одной таблице, который связан с первичным ключом другой таблицы. Внешний ключ устанавливает связь между двумя таблицами, позволяя выполнять операции объединения данных и поддерживать целостность связанных данных.
- Связь (Relationship). Она указывает, какие столбцы в одной таблице связаны с какими столбцами в другой таблице. Связи могут быть один к одному, один ко многим или многие ко многим, в зависимости от того, как данные взаимодействуют между таблицами.
Типы связей в реляционных базах данных
В реляционных базах данных существуют различные типы связей между таблицами.
- Однозначная связь (One-to-One) – когда одна из таблиц ссылается на другую, но не наоборот. Например, таблица «Заказы» имеет внешний ключ, связанный с таблицей «Клиенты», что позволяет определить, какой клиент сделал заказ.
- Одноправленная связь (One-to-Many) – когда обе таблицы имеют внешние ключи, связанные друг с другом. Например, таблица «Авторы» имеет внешний ключ, связанный с таблицей «Книги», и таблица «Книги» также имеет внешний ключ, связанный с таблицей «Авторы». Это позволяет найти авторов для конкретной книги и книги для конкретного автора.
- Множественные (Many-to-Many) связи — каждая запись в одной таблице может иметь несколько соответствующих записей в другой таблице, и наоборот. Например, множество студентов может быть зарегистрировано на множество курсов, и каждый курс может иметь множество студентов.
Как устанавливаются связи
Для установления связей между таблицами в SQL используется оператор JOIN. Приведем несколько примеров использования JOIN для разных типов связей.
Однонаправленные связи (One-to-Many)
Допустим, у нас есть таблицы «Авторы» (authors) и «Книги» (books), и каждый автор может быть связан с несколькими книгами. Мы можем использовать LEFT JOIN для извлечения списка авторов и их книг.
```sql SELECT authors.author_name, books.book_title FROM authors LEFT JOIN books ON authors.author_id = books.author_id; ```Этот запрос вернет список всех авторов и их книг, если они есть.
Множественные связи (Many-to-Many)
Допустим, у нас есть таблицы «Студенты» (students) и «Курсы» (courses), и множество студентов может быть зарегистрировано на множество курсов, и наоборот. Мы можем использовать JOIN для извлечения списка студентов и курсов, на которые они зарегистрированы.
```sql SELECT students.student_name, courses.course_title FROM students JOIN student_course ON students.student_id = student_course.student_id JOIN courses ON student_course.course_id = courses.course_id; ```Этот запрос вернет список студентов и соответствующих им курсов.
Установление связей с использованием JOIN позволяет эффективно объединять данные из разных таблиц и работать с данными, связанными различными способами.
Зачем нужны связи в базах данных
Связи в базах данных играют важную роль по ряду причин.

Похожие материалы
Что такое базы данных и их роль в программировании на Python
Что такое связь в базе данных?
Это метод объединения данных из разных таблиц на основе общих столбцов.
Какие основные типы связей существуют в базах данных?
Однозначные, многозначные, и самосвязи.
Что такое внешний ключ?
Это столбец или комбинация столбцов, значения которых соответствуют первичному ключу в другой таблице.
Можно ли иметь несколько внешних ключей в одной таблице?
Да, таблица может иметь несколько внешних ключей.
Что такое связь «один ко многим»?
Это связь, в которой одна запись из первой таблицы может быть связана с несколькими записями из второй таблицы.
Чем отличается связь «один ко многим» от «многие ко многим»?
В связи «один ко многим» одной записи из первой таблицы соответствует несколько записей из второй. В «многие ко многим» нескольким записям из первой таблицы могут соответствовать несколько записей из второй и наоборот.
Методы и алгоритмы поддержки целостности реляционных баз данных в приложениях классов OLAP и OLTP тема диссертации и автореферата по ВАК РФ 05.13.17, кандидат наук Зыкин Владимир Сергеевич
Оглавление диссертации кандидат наук Зыкин Владимир Сергеевич
Глава 1. Современные методы и средства контроля целостности в реляционных базах данных. 16
1.1 Понятие и аспекты целостности данных. 16
1.2 Целостность отношений баз данных. 18
1.3 Целостность представлений баз данных. 25
1.4 Обзор работ по теме диссертации. 27
1.5 Выводы по главе 1. 40
Глава 2. Ссылочная целостность отношений на основе теории зависимостей включения. 42
2.1 Теория типизированных зависимостей включения. 42
2.2 Минимальное покрытие множества зависимостей включения. 47
2.3 Автоматизация построения неизбыточного набора зависимостей включения. 52
2.4 Внедрение в СУБД типизированных зависимостей включения. 67
2.5 Выводы по главе 2. 72
Глава 3. Целостность многотабличных представлений на основе коммутативных преобразований данных. 73
3.1 Коммутативные преобразования данных. 74
3.2 Теоремы о коммутативности преобразований. 78
3.3 Сопроцессор коммутативных преобразований базы данных. 92
Глава 4. Программная реализация и экспериментальные исследования . 100
4.1 Реализация сопроцессора коммутативных преобразований. 100
4.2 Вычислительные эксперименты. 110
Рекомендованный список диссертаций по специальности «Теоретические основы информатики», 05.13.17 шифр ВАК
Модель и методы поддержки ограничений целостности в документо-ориентированных базах данных 2014 год, кандидат наук Лучинин, Захар Сергеевич
Методы параллельной обработки сверхбольших баз данных с использованием распределенных колоночных индексов 2015 год, кандидат наук Иванова Елена Владимировна
Информационное обеспечение автоматизированного проектирования на основе нечетких реляционных серверов данных 2002 год, кандидат технических наук Горбоконенко, Евгений Александрович
Логический анализ систем на основе алгебраического подхода 2007 год, доктор физико-математических наук Кулик, Борис Александрович
Семантический интерфейс реляционных баз данных в системах моделирования для слабо формализованных предметных областей 2009 год, кандидат технических наук Зуенко, Александр Анатольевич
Введение диссертации (часть автореферата) на тему «Методы и алгоритмы поддержки целостности реляционных баз данных в приложениях классов OLAP и OLTP»
Целостность данных является ключевым понятием в современных реляционных базах данных (БД) [113]. Целостность регламентирует соответствие данных в БД их структуре, логике и всем заданным правилам. Реляционные системы управления базами данных (СУБД) строятся в соответствии с трехуровневой архитектурой ANSI-SPARC [30]. Внутренний (физический) уровень отвечает за физический способ организации данных. Промежуточный (концептуальный) уровень инкапсулирует реляционную схему БД. Внешний (пользовательский) уровень показывает, как выглядит БД с точки зрения конечного пользователя и реализуется с помощью представлений. На концептуальном уровне ссылочная целостность, наряду с ограничением домена и ограничением сущности, является одним из фундаментальных классов ограничений целостности [9]. Ссылочные ограничения (referential integrity) реализуются в виде зависимостей включения и позволяют сохранить структурную целостность данных, устанавливая логическое соответствие между кортежами отношений БД. В большинстве существующих СУБД, с некоторыми ограничениями (наличие уникального индекса), поддерживается такой вид ограничений.
В настоящее время стали широко использоваться средства автоматизации проектирования схемы БД [40], в которых не регламентируется решение семантических проблем, как это делается на начальных этапах синтетического и декомпозиционного подхода к проектированию [89]. Прежде всего, при объектно-ориентированном (автоматизированном) подходе, не решаются проблемы синонимов и омонимов в списке атрибутов в следствие этого появляются дублированные и противоречивые атрибуты в БД. При объектно-ориентированном подходе формируются нетипизированные зависимости включения, установленные между близкими по смыслу атрибутами, либо
между атрибутами, между которыми существует функциональная зависимость. Ошибки проектирования в итоге нарушают логическую независимость данных, что приводит к проблемам пользователей таких систем БД: значительные финансовые и временные потери при сопровождении и модернизации.
Актуальным аспектом целостности данных является обработка неопределенных значений, которые используются для обозначения факта отсутствия информации. Неопределенные значения (NULL — значения) в технологиях БД являются актуальной проблемой с момента существования реляционной модели данных. Свой вклад неопределенности вносят во все виды зависимостей, используемые при проектировании и эксплуатации БД [45]. Это касается и зависимостей включения, а значит, и ссылочной целостности данных. Предложенные ранее решения указанной проблемы основаны на использовании нетипизированных зависимостей включения, что приводит к необходимости перестановок атрибутов, тогда как в технологиях БД атрибуты идентифицируются своим именем, а не позицией в структуре логической записи.
При использовании нетипизированных зависимостей включения возникает необходимость совместной аксиоматизации функциональных зависимостей и зависимостей включения [47]. Алгоритмы поиска полного и неизбыточного набора таких зависимостей включения характеризуются экспоненциальной сложностью [45]. Перечисленные проблемы требуют формализации теории типизированных зависимостей включения, которые допускают неопределенные значения, что влечет за собой упрощение этой системы и приобретение важных свойств: отсутствие взаимодействия с функциональными зависимостями и полиномиальные алгоритмы построения зависимостей включения. Следствием изложенного является то, что проблема построения множества типизированных зависимостей включения является актуальной.
Важность ссылочных ограничений целостности в управлении данными подкрепляется современными приложениями, такими как профилирование данных, очистка данных, разрешение объектов и сопоставление схем [67]. Существенную роль ссылочные ограничения целостности играют в технологии формирования многомерных данных [1, 13, 14, 64, 77]. Классический подход построения многомерного представления данных из исходного реляционного представления данных (ROLAP — relational online analytical processing) предполагает иерархические связи на схеме БД («звезда» или «снежинка»). Причем в корне иерархии должно находиться отношение со значениями мер, а в нижних уровнях — отношения, содержащие значения размерностей многомерного представления данных.
Представления (views) рассматриваются на внешнем уровне архитектуры ANSI-SPARC. В современных технологиях БД остается актуальной задача поддержки целостности данных при обновлении представлений [56, 57]. В современных БД для обновления представлений программисту необходимо создавать новое приложение (триггер) для каждого отдельного представления. Также остается нерешенной задача обновления представлений, где одной записи в представлении соответствует несколько кортежей в базовых отношениях БД. В соответствии с этим остается актуальной задача создания универсального подхода к обновлению представлений, в которых одна обновляемая запись может соответствовать нескольким кортежам в отношениях БД. Обновления представлений осуществляются на основе транзакций к БД, следовательно, их следует рассматривать в рамках таких приложений, как оперативная обработка транзакций (OLTP — Online Transaction Processing)[48].
Степень разработанности темы
Первое фундаментальное исследование ссылочных ограничений целостности, основанных на зависимостях включения, было представлено Ка-зановым М. (Casanova M.), Фейджиным Р. (Fagin R.) и Пападимитроу С. (Papadimitriou C.). Они положили начало теоретическому исследованию зависимостей включения, представили формальное определение нетипизиро-ванных зависимостей включения с учетом их взаимодействия с функциональными зависимостями, представили простую аксиоматизацию для зависимостей включения. В своих работах Левин М. (Levene M.) и Лоизу Дж. (Loizou G.) впервые исследовали обобщение зависимостей включения, когда допускается наличие неопределенного значения атрибутов в БД. Левин М. в соавторстве с Винсентом М. (Vincent M.W.) впервые ввели понятие и исследовали нормальные формы зависимостей включения. В последние годы Линк С. (Link S.) с соавторами занимаются исследованием выводимости не-типизированных зависимостей включения с неопределенными значениями, кроме того, набирают популярность исследования условных зависимостей включения Ма С. (Ma S.), Фан В. (Fan W.), Браво Л. (Bravo L.).
Работам, связанным с целостностью данных в классах задач OLAP и OLTP, посвящено большое количество научных работ, известными исследователями в этих областях являются Кузнецов С.Д., Зыкин С.В., Новиков Б.А., Хаямизу Ю. (Hayamizu Y.), Кавамичи Р. (Kawamichi R.), Года К. (Goda K.), Китсурегава М. (Kitsuregawa M.), Левин C. (Levine C.), Ли Ю. (Li Y.).
Исследования, посвященные задаче поддержки целостности данных при выполнении обновлений в представлениях, начаты почти с момента становления реляционной модели данных и продолжаются по сей день. В первых работах, опубликованных в 1981 году, исследователи Банцилхон Ф. (Bancilhon F.), Спиратос Н. (Spyratos N.), Даял У. (Dayal U.), Бернстерн П.А., (Bernstein P.A.) описали проблему обновления представлений, свойства и
условия существования. В своих работах Келлер А. (Keller A.), Лангерак Р. (Langerak R.), Бертосси Л. (Bertossi L.), Салими Б. (Salimi B.) рассматривали частные примеры обновления представлений при решении сторонних задач. В последние годы Масунага Ю. (Masunaga Y.), Нагата Ю. (Nagata Y.), Иши Т. (Ishii T.) представили практическую реализацию обновления представлений в свободной СУБД PostgreSQL. Одной из важных нерешенных прикладных задач остается задача поддержки целостности данных при обновлении многотабличных представлений, снимающая ограничение соответствия одной строки в представлении и одной строки в базовой таблице БД.
Цель и задачи исследования
Целью данной работы является исследование и разработка эффективных методов и алгоритмов поддержки целостности данных на внешнем и концептуальном уровнях архитектуры реляционных баз данных для приложений классов OLAP и OLTP. Для достижения этой цели были поставлены следующие задачи:
1. Разработать систему аксиом типизированных зависимостей включения, которая обеспечивает ссылочную целостность при наличии неопределенных значений.
2. Разработать алгоритм построения неизбыточного множества типизированных зависимостей включения с доказательством его корректности и оценкой вычислительной сложности.
3. Разработать общий подход к обновлению многотабличных представлений, обеспечивающий корректную модификацию записи в представлении, которой соответствуют несколько кортежей в хранимых отношениях БД.
4. Реализовать предложенные методы и подходы в виде сопроцессора СУБД для приложений классов OLAP и OLTP.
5. Провести вычислительные эксперименты, подтверждающие эффективность предложенных подходов.
Научная новизна заключается в том, что впервые была построена полная и непротиворечивая система аксиом для типизированных зависимостей включения, допускающих наличие неопределенных значений. По сравнению с ранее известной аксиоматикой нетипизированных зависимостей включения рассматриваемые в данной работе типизированные зависимости включения устанавливаются только по совпадающему множеству атрибутов, что обеспечивает независимость данных от структуры БД. Разработан оригинальный алгоритм построения типизированных ациклических зависимостей включения. Разработан оригинальный общий подход к обновлению многотабличных представлений на основе коммутативных преобразований данных, который, в отличие от аналогов, позволяет обновлять запись в представлении, которой соответствуют несколько кортежей в базовом отношении.
Теоретическая и практическая значимость
Теоретическая ценность работы заключается в том, что была сформулирована система аксиом для типизированных зависимостей включения. Получено новое доказательство полноты и непротиворечивости указанной системы аксиом, схема которого может быть использована при анализе других видов зависимостей в БД. Доказана корректность и получена оценка вычислительной сложности алгоритма формирования неизбыточного множества типизированных зависимостей включения. Предложен общий подход к обновлению многотабличных представлений, доказана корректность операций.
Практическая значимость работы заключается в реализации сопроцессора реляционной СУБД, обеспечивающего обновление многотабличных
представлений, в которых одной записи в представлении соответствует несколько кортежей в хранимых отношениях БД. Результаты, полученные в диссертационной работе, могут быть использованы для создания инструментальных средств проектирования схем баз данных и сопроцессоров обновления многотабличных представлений для различных коммерческих и свободно распространяемых реляционных СУБД.
Методология и методы исследования
Методологической основой диссертационной работы являются методы математической логики, теория проектирования реляционных БД, теория множеств и реляционная алгебра. Для программной реализации разработанных подходов применялись методы объектно-ориентированного проектирования, язык ЦЫС и методы модульного программирования.
Положения, выносимые на защиту
1. Предложена система аксиом типизированных зависимостей включения с неопределенными значениями в реляционных БД и доказана ее полнота и непротиворечивость.
2. Разработан алгоритм построения неизбыточного множества типизированных зависимостей включения в реляционных БД, доказана его корректность и получена оценка вычислительной сложности.
3. Сформулированы и доказаны теоремы о коммутативных преобразованиях для обновления многотабличных представлений в реляционных БД. Разработана архитектура сопроцессора коммутативных преобразований СУБД и реализован сопроцессор СУБД PostgreSQL.
4. Проведены вычислительные эксперименты, подтверждающие эффективность предложенных подходов.
Степень достоверности результатов
Достоверность научных результатов, полученных в работе, подтверждается строгими математическими доказательствами. Теоретические решения подтверждаются вычислительными экспериментами, проведенными в соответствии с общепринятыми стандартами.
Апробация результатов исследования
Основные положения диссертационной работы, разработанная формальная теория, методы, алгоритмы и результаты вычислительных экспериментов докладывались автором на следующих международных научных конференциях:
1. Международная научная конференция «Математика в современном мире» (14-19 августа 2017 г., Новосибирск).
2. The 2th International Conference «Numerical Computations: Theory and Algorithms» (NUMTA2016) (19-25 June 2016, Pizzo Calabro, Calabria, Italy).
3. The 10th IEEE International Scientific and Technical Conference on Dynamics of Systems, Mechanisms and Machines (15-17 November 2016, Omsk, Russia).
4. The VI International Conference «Optimization and Applications» (OP-TIMA-2015) (September 27 — October 3, 2015, Petrovac, Montenegro).
5. III Российская молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (24-26 апреля 2013 г., Омск).
6. XVI Байкальская международная школа-семинар «Методы оптимизации и их приложения» (30 июня — 6 июля 2014 г., о. Ольхон, Байкал).
7. IV Международная молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (22-28 апреля 2014 г., Омск).
8. V Международная молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (23-30 апреля 2015 г., Омск).
9. VI Международная молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (22 апреля
— 4 мая 2016 г., Омск).
10. VII Международная молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (25 апреля
— 4 мая 2017 г., Омск).
11. VIII Международная молодежная научно-практическая конференция «Прикладная математика и фундаментальная информатика» (26 апреля
— 4 мая 2018 г., Омск).
Публикации соискателя по теме диссертации
Основные результаты по теме диссертации изложены в следующих научных работах.
Статьи в журналах из перечня ВАК
1. Зыкин В.С. Ссылочная целостность данных в корпоративных информационных системах // Информатика и ее применения. 2015. Т. 9, № 3. С. 97-105.
2. Зыкин В.С. Инструментальная среда формирования внешних ключей на схеме реляционной базы данных // Омский научный вестник. 2017. № 1. (151). С. 140-143.
3. Зыкин В.С., Цымблер М.Л. Обновление многотабличных представлений на основе коммутативных преобразований базы данных // Вестник ЮУрГУ. 2019. Серия: Вычислительная математика и информатика. Т. 8, № 2. С. 92-106.
4. Зыкин В.С., Зыкин С.В. Анализ типизированных зависимостей включения с неопределенными значениями // Моделирование и анализ информационных систем. 2017. Т. 24, № 2. С. 155-167.
5. Зыкин В.С., Зыкин С.В. Коммутативные преобразования в базе данных при редактировании многотабличных запросов // Информационные технологии. 2018. Т. 24, № 5. С. 330-338.
Статьи в изданиях, индексируемых в SCOPUS и Web of Science
6. Zykin V., Zykin S. Analysis of Typed Inclusion Dependences with Null Values // Automatic Control and Computer Sciences. 2018. Vol. 52, Iss. 7, P. 638-646.
7. Zykin S., Zykin V. Updates of View in Relational Databases // Proceedings of the 12th International Scientific and Technical Conference «Dynamics of Systems, Mechanisms and Machines», Dynamics 2018, Omsk, Russia, 1315 November 2018. Article no. 8601495.
8. Zykin V. Automatization of Foreign Keys Construction // Proceedings of the 10th International Scientific and Technical Conference «Dynamics of Systems, Mechanisms and Machines», Dynamics 2016, Omsk, Russia, 15-17 November 2016. Article no. 7819118.
Свидетельства о государственной регистрации программ для ЭВМ
9. Зыкин В.С. Программа для построения неизбыточного набора связей на схеме баз данных: свидетельство о государственной регистрации программ для ЭВМ. № 2018661248 от 04.09.2018.
10. Зыкин В.С. Редактор многотабличного представления данных: свидетельство о государственной регистрации программ для ЭВМ. № 2018661249 от 04.09.2018.
Статьи в изданиях, индексируемых в РИНЦ
11. Зыкин В.С. Ограничения целостности для неопределенных значений кортежей // Прикладная математика и фундаментальная информатика. 2015. № 2. С. 227-231.
12. Зыкин В.С. Сравнительный анализ различных СУБД при редактировании многотабличных представлений данных // Информационный бюллетень Омского научно-образовательного центра ОмГТУ и ИМ СО РАН в области математики и информатики. 2017 № 1 (1). С. 153-154.
Публикации. По теме диссертации опубликовано 10 печатных работ. Работы [1-5] опубликованы в журналах, включенных ВАК в перечень изданий, в которых должны быть опубликованы основные результаты диссертаций на соискание ученой степени доктора и кандидата наук. Работы [6-8] опубликованы в изданиях, индексируемых в Scopus и Web of Science. В рамках выполнения диссертационной работы получено два свидетельства о государственной регистрации программы для ЭВМ [9-10]. Работы [11-12] включены в перечень изданий, индексируемых в РИНЦ.
Личный вклад. В работе 3 Зыкину В.С. принадлежат разделы 1-4 (обзор работ, коммутативные преобразования реляционных отношений, сопроцессор коммутативных преобразований, экспериментальное исследование, заключение, стр. 94-106), научному руководителю Цымблеру М.Л. принадлежит введение (стр. 92-94). В работе 4 Зыкину В.С. принадлежат разделы 1-4 (обзор результатов, основы формальной теории, минимальное покрытие множества зависимостей и заключение, стр. 155, 157-167), Зыкину С.В. принадлежит введение (стр. 156). В работе 5 Зыкину В.С. принадлежат разделы
1-3 (обзор работ, метод коммутативных преобразований данных, редактирование многотабличных представлений данных и заключение, стр. 332-338), Зыкину С.В. принадлежит введение (стр. 330-332). В работе 6 Зыкину В.С. принадлежат разделы 1-4 (обзор результатов, основы формальной теории, минимальное покрытие множества зависимостей и заключение, стр. 156167), Зыкину С.В. принадлежит введение (стр. 155). В работе 7 Зыкину В.С. принадлежат разделы 2-5 (обзор работ, метод коммутативных преобразований, обновление многотабличных представлений, заключение, стр. 1-7), Зыкину С.В. принадлежит введение (стр. 1).
Объем и структура работы
Диссертация состоит из введения, четырех глав, заключения и списка литературы. Объем диссертации составляет 137 страниц. Список литературы содержит 119 наименований.
В первой главе, «Современные методы и средства контроля целостности в реляционных базах данных», проводится обзор научных работ по всем современным направлениям развития теории БД. Особое внимание уделяется теории зависимостей включения, ссылочной целостности и теории обновления представлений. Дается обзор публикаций, наиболее близко относящихся к теме диссертации.
Во второй главе, «Ссылочная целостность отношений на основе теории зависимостей включения», вводится новая система аксиом для типизированных зависимостей включения с неопределенными значениями, доказывается ее полнота и непротиворечивость. Описывается замыкание и минимальное покрытие множества зависимостей включения, Предлагается способ автоматизации построения неизбыточного множества типизированных
зависимостей включения. Приводится способ внедрения разработанной теории в СУБД.
В третьей главе, «Целостность данных многотабличных представлений на основе коммутативных преобразований данных», предлагается новый подход к обновлению многотабличных представлений, основанный на аппарате коммутативных преобразований БД. Приводятся формулы, реализующие операции обновления многотабличных представлений в терминах реляционной алгебры. Формулируются и доказываются теоремы о корректности преобразований, выполняемых в соответствии с предложенными формулами. Описана архитектура сопроцессора СУБД, выполняющего обновление представлений на основе коммутативных преобразований.
В четвертой главе, «Программная реализация и экспериментальные исследования», описывается реализация подхода к обновлению многотабличных представлений на основе коммутативных преобразований данных применительно к свободной СУБД PostgreSQL. Приводятся результаты вычислительных экспериментов, показывающих эффективность разработанных подходов в приложениях классов OLAP и OLTP.
В заключении перечисляются результаты, полученные в итоге выполнения диссертационного исследования, проводится сравнение с наиболее близкими работами по данной тематике, даются рекомендации по использованию разработанного подхода и программного обеспечения, рассматриваются направления дальнейших исследований.
ГЛАВА 1. СОВРЕМЕННЫЕ МЕТОДЫ И СРЕДСТВА КОНТРОЛЯ ЦЕЛОСТНОСТИ В РЕЛЯЦИОННЫХ БАЗАХ ДАННЫХ
В данной главе рассматриваются тенденции развития теоретических аспектов ссылочной целостности и дается обзор научных исследований в области современных технологий БД. Анализируются публикации, наиболее близко относящиеся к теме диссертации.
1.1 Понятие и аспекты целостности данных
«Понятие согласованности, или целостности данных является ключевым понятием БД» [113]. «Целостность БД (database integrity) — соответствие имеющейся в БД информации ее внутренней логике, структуре и всем явно заданным правилам. Каждое правило, налагающее некоторое ограничение на возможное состояние БД, называется ограничением целостности (integrity constraint)». Под ограничением целостности будем понимать «свойство БД, определяемое способностью СУБД защищать компоненты и связи БД от искажения в результате некорректных операций и сбоев технических средств» [88].
Функции поддержки ограничений целостности в технологии БД выполняет СУБД. Результат любой операции (вставка, удаление, обновление) будет откатан СУБД, если операция нарушает ограничение целостности.
Целостность БД на концептуальном уровне архитектуры ANSI-SPARC осуществляется при помощи следующих ограничений целостности [113]:
1) ограничение домена;
2) ограничение сущности;
3) ссылочные ограничения.
Представление (view) — это виртуальное (логическое) отношение БД, которое является синонимом запроса к хранимым отношениям БД. Механизм представлений позволяет скрывать детали концептуальной структуры БД от конечных пользователей.
Целостность данных на внешнем уровне архитектуры ANSI-SPARC подразумевает соответствие данных в хранимых таблицах БД информации, предоставленной пользователю в представлениях.
В данной диссертационной работе исследуется ссылочная целостность данных касательно концептуального уровня, а также целостность данных в хранимых таблицах БД при обновлении представлений на внешнем уровне архитектуры ANSI-SPARC.
При определении структуры отношения БД могут быть заданы ограничения на допустимые значения в столбцах. Определение типа атрибута в отношении задает базовое ограничение, которое контролируется СУБД. В указанном столбце не может появиться значение, противоречащее выбранному типу, например, символьная строка в столбце, для которого указан тип «Дата». Кроме того, на значения атрибутов в столбце отношения могут быть дополнительные ограничения, например, дата должна быть задана в определенном интервале. Попытка ввести значение этого атрибута, лежащее за пределами указанного интервала, будет откатана СУБД.
В каждом отношении должен быть задан первичный ключ, который имеет уникальное непустое значение в каждой строке отношения. Основанием для определения первичного ключа является множество функциональ-
ных зависимостей, формируемых проектировщиком БД [89]. Определенному таким образом набору атрибутов отношения ставится в соответствие свойство PRIMARY KEY. В пределах отношения это свойство может указываться только один раз. Другим способом гарантировать уникальность значений подмножества атрибутов для потенциальных ключей отношения является присвоение этому подмножеству свойства UNIQUE.
Ссылочные ограничения целостности (Referential Integrity Constraint) — класс ограничений целостности, при котором кортеж с некоторым значением данного набора атрибутов может быть включен в отношение тогда и только тогда, когда это значение является актуальным значением первичного ключа указанного другого отношения [112]. Для реализации данного бизнес-правила в СУБД имеется аппарат внешних ключей (FOREIGN KEY). При этом определяется главное отношение и подчиненное отношение: в подчиненном отношении не может быть строк, которым нет соответствующей строки в главном отношении. СУБД произведет откат операции вставки строки в подчиненное отношение, если в главном отношении нет соответствующего кортежа, и операция удаления строки в главном отношении будет отвергнута, если в подчиненном отношении имеется соответствующая связанная строка (запрет висячих ссылок).
1.2 Целостность отношений баз данных
Ссылочные ограничения целостности являются одним из основных видов ограничений, которые позволяют сохранить структурную целостность БД. С другой стороны, неопределенные значения (NULL) стали актуальной проблемой с момента создания реляционной модели данных. Влияние неопределенностей сказывается на всех видах зависимостей, используемых при проектировании и эксплуатации БД. В полной мере это относится и к
зависимостям включения, которые являются теоретическом основой ссылочной целостности данных.
Формальное определение зависимостей включения приведено в работе [9]: пусть U — [А-±, А2, ■■■ , Ап> — множество атрибутов, определенных в БД, [Rí] — множество атрибутов, на которых определено отношение Rt, [Rt] QU, 1 < i < k, Ж — (Rt, R2. , Rk) - БД, 5 — [[Rt], [R2I. ,[Rk]>— схема БД.
Определение 1.1. Пусть [Rt] и [Rj] — схемы отношений (не обязательно различные), V Q ] и WQ [Rj], \V\ — \W\, тогда соотношение Rt [V] Q Rj [W] называется зависимостью включения.