Анализ статистики для мониторинга PostgreSQL
Для эффективной работы системы важно отслеживать основные показатели производительности её базы данных. В Postgre SQL существует готовая подсистема, которая осуществляет сбор информации о работе сервера БД, а также предоставляет к ней доступ в виде готовых представлений и функций. Регулярный анализ собранной статистики может помочь администратору и разработчику найти наиболее уязвимые места при ежедневном эксплуатировании базы данных. В этой статье я расскажу об основных статистиках, которые накапливаются в PostgreSQL , в качестве примеров я приведу SQL -запросы на выборку основных показателей работы базы данных, а также затрону встроенные инструменты визуализации статистики в современных GUI для PostgreSQL .
Базовые статистики для анализа работы БД
В PostgreSQL сборщик статистики предоставляет доступ к накопленным данным через предопределённые представления. Основные из них показаны ниже на схеме:
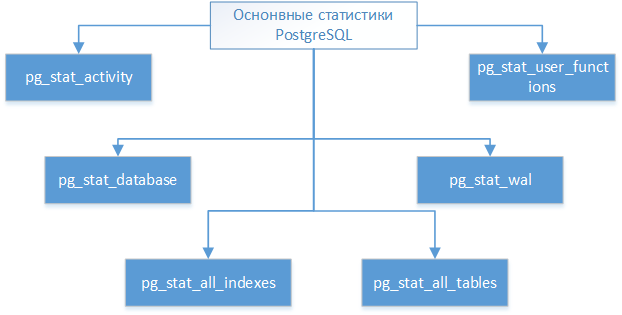
- pg_stat_activity – предоставление информации о текущей активности серверного процесса, включая его состояние и текущий запрос;
- pg_stat_database – представление статистических данных по каждой базе данных на сервере;
- pg_stat_all_indexes – представление статистических данных по каждому индексу;
- pg_stat_all_tables – представление статистических данных по каждой таблице;
- pg_stat_wal – представление статистических данных о работе журнала предзаписи (Write-Ahead Log ging ) в кластере;
- pg_stat_user_functions – представление статистических данных о выполнении функций.
На основе данных из представлений пользователь может анализировать полезные показатели, характеризующие работу базы данных.
Примеры запросов для анализа основных показателей БД
Нагрузка на базу данных
Для понимания нагрузки на базу данных хорошо знать общий объём транзакций за определенный период времени. Для получения этих данных можно использовать следующий запрос:
SELECT datname, xact_commit + xact_rollback , stats_reset FROM pg_stat_database; Здесь сумма xact_commit и количество xact_rollback – суммарное количество транзакций за период с момента сброса статистических данных stats_reset.
Распределение серверных процессов по состояниям
Для мониторинга клиентских подключений можно использовать представление pg_stat_activity, которое отображает информацию по работе серверных процессов. Каждый серверный процесс может находиться в следующих состояниях:
- active — выполнение запроса;
- idle — ожидание новой команды от клиента;
- idle in transaction — серверный процесс находится внутри транзакции, но в настоящее время не выполняет никакой запрос;
- idle in transaction (aborted) — серверный процесс находится внутри транзакции, но один из операторов в транзакции вызывал ошибку;
- fastpath function call — выполнение fast-path функции;
- disabled – у серверного процесса отключён параметр track_activities.
Получить общее количество соединений по состояниям позволяет следующая группировка:
SELECT state, count(*) FROM pg_stat_activity GROUP BY state;Длительность текущих активных транзакций и запросов
Длительность текущих активных транзакций и запросов можно проанализировать, выполнив запрос:
SELECT datname, usename, now() - xact_start AS TransactionDuration, now() - query_start as QueryDuration FROM pg_stat_activity WHERE state = 'active';Определение наиболее нагруженных таблиц
Статистику обращений к таблицам базы данных предоставляет pg_stat_all_tables. Представление позволяет оценить, например, общий объём insert, update, delate операций к таблице. Определить наиболее часто используемые таблицы в БД можно с помощью запроса:
SELECT relname, n_tup_upd+n_tup_ins+n_tup_del AS operationsAmount FROM pg_stat_all_tables ORDER BY operationsAmount DESC;Отношение сканирований по индексам к последовательным сканированиям
Для анализа эффективности чтения данных в конкретной таблице можно получить соотношение запросов, выполненных с использованием индексов к количеству запросов, читающих данные путём последовательного сканирования таблиц. Отсортированный список таблиц по данному соотношению вернёт следующий запрос:
SELECT relname, seq_scan, idx_scan, idx_scan/seq_scan as IndexStat FROM pg_stat_all_tables WHERE seq_scan <> 0 ORDER BY IndexStat DESC;Отслеживание устаревших индексов
Полную информацию по созданным в базе данных индексам содержит представление pg_stat_all_indexes. Устаревшие индексы можно обнаружить с помощью запроса:
SELECT indexrelname, relname, idx_tup_read/idx_tup_fetch as stats FROM pg_stat_all_indexes WHERE idx_tup_fetch <> 0 ORDER BY stats DESC; Здесь idx_tup_read/idx_tup_fetch – это отношение записей из индекса, возвращённых в запросах по этому индексу, к общему числу записей, для которых пришлось обращаться к родительским таблицам. Если этот коэффициент меньше единицы, значит много данных читается в обход индекса, поэтому его необходимо обновить.
Мониторинг в GUI-клиентах
Для администраторов баз данных и программистам важно быстро определять производительность СУБД, анализировать проблемы с дисковым пространством, контролировать количество подключений и т.д. Поэтому современные GUI-клиенты предлагают собственные панели мониторинга для СУБД. Наиболее развитые системы мониторинга существуют в следующих графических приложениях:
Бесплатный GUI -клиент с открытым исходным кодом
Linux , Windows , macOS
Предопределенный дашборд ( серверные сеансы, блокировки, транзакции в секунду; операции с записями), отображение дополнительной статистики
Бесплатный GUI -клиент с дополнительными платными версиями.
Linux, Windows, macOS
Предопределенный дашборд (серверные сеансы, блокировки, транзакции в секунду), возможность доработки дашбордов на базе предопределённых дашбордов.
В DBeaver используется функция Dashboard, с помощью которой можно настроить пользовательские панели из соответствующих виджетов для мониторинга. По умолчанию в DBeaver поставляются виджеты для нескольких предопределенных информационных панелей мониторинга. Создать информационную панель можно из набора готовых шаблонов виджетов:
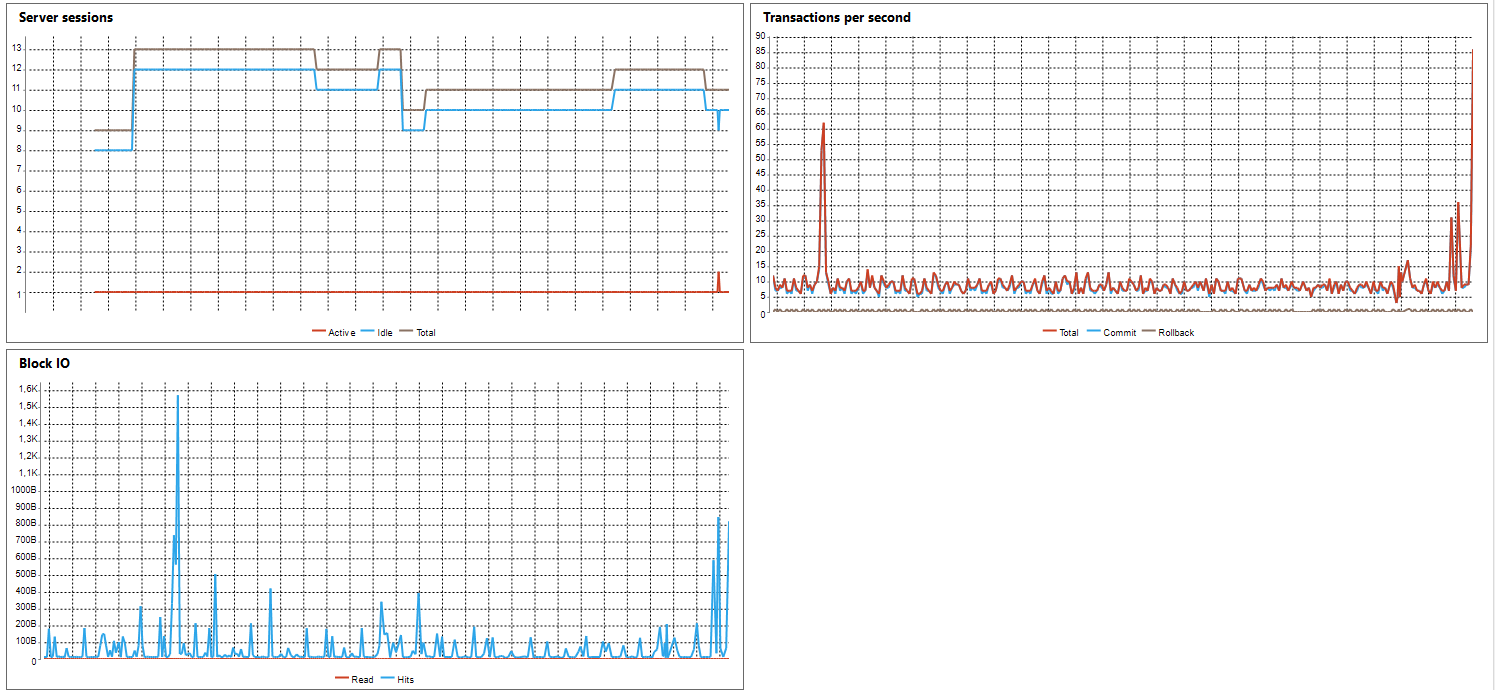
- Server sessions — показывает активные/неактивные сеансы сервера;
- Transactions per second – отображает количество транзакций в секунду;
- Block IO – отображает количество блокировок при операциях ввода/вывода в секунду.
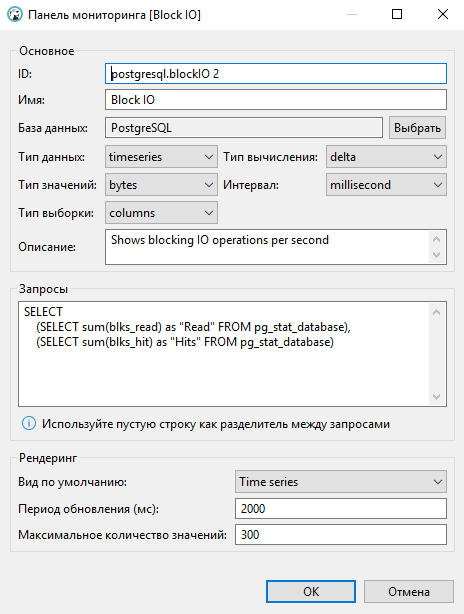
Предопределённые виджеты изменять в DBeaver нельзя, однако можно создать новый виджет путём копирования шаблона. В диалоговом окне можно настроить новые параметры шаблона и реализовать свой запрос для получения данных виджета:
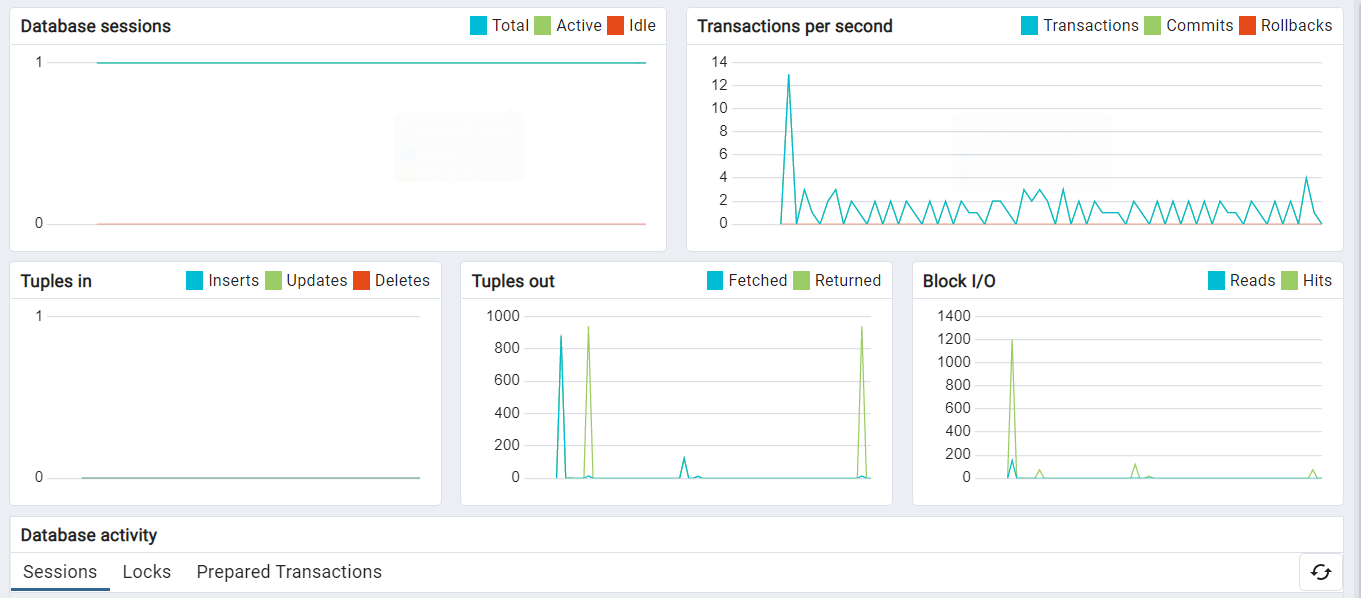
Аналогичные шаблоны также реализованы и в клиенте pgAdmin, однако дополнительно в нём присутствуют следующие виджеты:
- Tuples in – отображает количество записей, вставленных, обновленных и удаленных на сервере или в базе данных;
- Tupels out – отображает количество записей, полученных и возвращенных с сервера или базы данных.
Также в pgAdmin на вкладке «Статистика» отображается готовая сводная статистика для выбранного элемента из дерева БД.
- PID – ИД серверного процесса;
- User – имя пользователя;
- Database – название базы данных;
- Backends – число текущих клиентских подключений к БД;
- Backend start – время старта серверного процесса;
- Xact Committe
Для пользователя доступны для отслеживания следующие показатели: d – число зафиксированных транзакций за последнюю неделю;
- Xact Rolled Back – число отменённых транзакций за последнюю неделю;
- Blocks Read – число блоков, считанных с диска за последнюю неделю;
- Blocks Hit – число блоков, считанных из оперативной памяти за последнюю неделю;
- Tuples Returned – количество, возвращённых записей за последнюю неделю;
- Tuples Fetched – количество записей, выбранных за последнюю неделю;
- Tuples Inserted – количество вставленных записей в базе данных за последнюю неделю;
- Tuples Updated – количество обновлённых записей в базе данных за последнюю неделю;
- Tuples Deleted – количество удалённых записей в базе данных за последнюю неделю;
- Last statistics – дата и время последнего сброса накопленных статистик в базе данных.
Заключение
В PostgreSQL сборщик статистики предоставляет полноценную информацию о работе сервера, которую можно регулярно анализировать. Также дополнительно включив модуль pg_stat_statements, СУБД будет отслеживать статистику планирования и выполнения сервером всех операторов SQL. Отдельно стоит выделить базовые возможности GUI-клиентов по мониторингу сервера базы данных. Используя базовые представления статистики PostgreSQL, они предоставляют пользователю готовую информацию в виде дашбордов, что позволяет динамически отслеживать работу сервера и выявлять ошибки.
Мониторим базу PostgreSQL — кто виноват, и что делать
Я уже рассказывал, как мы «ловим» проблемы PostgreSQL с помощью массового мониторинга логов на сотнях серверов одновременно. Но ведь кроме логов, эта СУБД предоставляет нам еще и множество инструментов для анализа ее состояния — грех ими не воспользоваться.
Правда, если просто смотреть на них с консоли, можно очень быстро окосеть без какой-либо пользы, потому что количество доступных нам данных превышает все разумные пределы.

Поэтому, чтобы ситуация все же оставалась контролируемой, мы разработали надстройку над Zabbix, которая поставляет метрики, формирует экраны и задает единые правила мониторинга для всех серверов и баз на них.
Сегодняшняя статья — о том, какие выводы можно сделать, наблюдая в динамике различные метрики баз PostgreSQL-сервера, и где может скрываться проблема.
Состояние соединений
Самое первое, с чего начинаются все разборки на тему «что у нас с базой сейчас/было плохо» — это наблюдение за сводным состоянием pg_stat_activity:

На левом графике мы видим все соединения, которые чего-то ждут, на правом — которые что-то делают. В зависимости от версии PG состояние соединения определяется по pg_stat_activity.state/wait_event и/или тексту самого запроса.
На что обращать внимание:
- Слишком мало idle — вашему приложению может в какой-то момент не хватить уже открытых к базе соединений, и при попытке открыть еще одно вы попадете на длительное ожидание инициализации процесса для обслуживания нового коннекта.
- Слишком много idle с динамикой роста может означать «утечку» соединений на стороне приложения, что рано или поздно приведет к достижению лимита max_connections .
- Много idle in transaction — скорее всего, у нас перегружена бизнес-логика или pgbouncer. То есть с точки зрения БД вы транзакцию открыли и ушли перекурить.
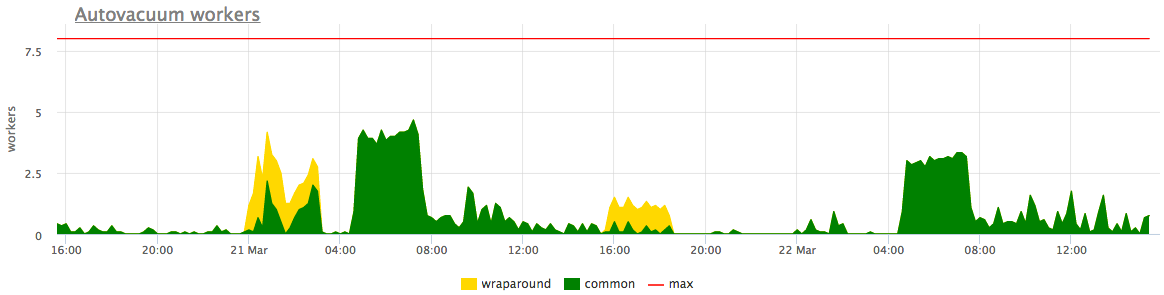
query ~* E'^(\\s*(--[^\\n]*\\n|/\\*.*\\*/|\\n))*(autovacuum|VACUUM|ANALYZE|REINDEX|CLUSTER|CREATE|ALTER|TRUNCATE|DROP)'В большинстве случаев там будет фигурировать количество одновременно работающих autovacuum/autoanalyze, вред которых заключается разве что в употреблении ресурсов сервера на «посторонние» дела. Если для вас это критично — покрутите autovacuum_max_workers и autovacuum_naptime , но совсем отключать — не стоит.
Состояние соединений и блокировок
WITH event_types(wait_event_type) AS( VALUES ('lwlock') , ('lock') , ('bufferpin') , ('client') , ('extension') , ('ipc') , ('timeout') , ('io') ) , events(wait_event) AS( VALUES ('walwritelock') , ('wal_insert') , ('buffer_content') , ('buffer_io') , ('lock_manager') , ('relation') , ('extend') , ('page') , ('tuple') , ('transactionid') , ('virtualxid') , ('speculative token') , ('object') , ('userlock') , ('advisory') , ('clientread') , ('datafileextend') , ('datafileread') , ('datafilewrite') , ('slruread') , ('slruwrite') ) , states(state) AS( VALUES ('running') , ('maintenance') , ('waiting') , ('transaction') , ('idle') ) , stats AS( SELECT pid , datname , state , lower(wait_event_type) wait_event_type , lower(wait_event) wait_event , query FROM pg_stat_activity WHERE pid <> pg_backend_pid() ) , dbs AS( SELECT datname FROM pg_database db WHERE NOT db.datistemplate ) SELECT date_part('epoch', now())::integer ts , coalesce(s.qty, 0) val , dbs.datname dbname , states.state , true total FROM dbs CROSS JOIN states NATURAL LEFT JOIN ( SELECT datname , CASE WHEN query ~* E'^(\\s*(--[^\\n]*\\n|/\\*.*\\*/|\\n))*(autovacuum|VACUUM|ANALYZE|REINDEX|CLUSTER|CREATE|ALTER|TRUNCATE|DROP)' THEN 'maintenance' WHEN wait_event IS NOT NULL AND wait_event <> 'clientread' AND state = 'active' THEN 'waiting' WHEN state = 'active' THEN 'running' WHEN state = 'idle' THEN 'idle' WHEN state IN ('idle in transaction', 'idle in transaction (aborted)') THEN 'transaction' WHEN state = 'fastpath function call' THEN 'fastpath' ELSE 'disabled' END state , count(*) qty FROM stats GROUP BY 1, 2 ) s UNION SELECT date_part('epoch', now())::integer ts , coalesce(t.qty, 0) val , dbs.datname dbname , event_types.wait_event_type , false total FROM dbs CROSS JOIN event_types NATURAL LEFT JOIN ( SELECT datname , wait_event_type , count(*) qty FROM stats WHERE wait_event_type IS NOT NULL GROUP BY 1, 2 ) t UNION SELECT date_part('epoch', now())::integer ts , coalesce(e.qty, 0) val , dbs.datname dbname , events.wait_event , false total FROM dbs CROSS JOIN events NATURAL LEFT JOIN ( SELECT datname , wait_event , count(*) qty FROM stats WHERE wait_event IS NOT NULL GROUP BY 1, 2 ) e; Блокировки
Раз уж мы затронули в предыдущем пункте мониторинг блокировок, то стоит заметить, что PostgreSQL любит их накладывать направо и налево:

Нас из них больше всего интересуют два вида:
- Exclusive — типично возникают при блокировке на конкретной записи.
- AccessExclusive — при проведении maintenance-операции над таблицей.
И рекомендательные, и обычные блокировки сохраняются в области общей памяти, размер которой определяется параметрами конфигурации max_locks_per_transaction и max_connections . Важно, чтобы этой памяти было достаточно, так как в противном случае сервер не сможет выдать никакую блокировку. Таким образом, число рекомендуемых блокировок, которые может выдать сервер, ограничивается обычно десятками или сотнями тысяч в зависимости от конфигурации сервера.
Обычно такая ситуация возникает, если у вас в приложении «текут» и не освобождаются ресурсы: соединения с базой, контексты транзакций или advisory-блокировки. Поэтому обращайте внимание на общую динамику.
Transactions per second (TPS)
Для получения информации об изменениях в контексте текущей базы можно воспользоваться системным представлением pg_stat_database. Но если баз на сервере много, удобно делать это сразу для них всех, подключившись к postgres .
TPS & tuples
SELECT extract(epoch from now())::integer ts , datname dbname , pg_stat_get_db_tuples_returned(oid) tup_returned , pg_stat_get_db_tuples_fetched(oid) tup_fetched , pg_stat_get_db_tuples_inserted(oid) tup_inserted , pg_stat_get_db_tuples_updated(oid) tup_updated , pg_stat_get_db_tuples_deleted(oid) tup_deleted , pg_stat_get_db_xact_commit(oid) xact_commit , pg_stat_get_db_xact_rollback(oid) xact_rollback FROM pg_database WHERE NOT datistemplate; Отдельно хочу акцентировать внимание — не пренебрегайте выводом max-значений метрик!

На этом графике мы как раз хорошо видим ситуацию внезапного пикового увеличения количества проведенных ( commit ) транзакций. Это не один-в-один соответствует нагрузке на сервер и транзакции могут быть разной сложности, но рост в 4 раза явно показывает, что серверу стоит иметь определенный резерв производительности, чтобы и такой пик переживать беспроблемно.
Ну а откат ( rollback ) транзакции — это повод проверить, осознанно ли ваше приложение выполняет ROLLBACK , или это автоматически делает сервер в результате возникшей ошибки.
Количество операций над записями
Сначала обратим внимание на записи, которые у нас вычитываются из индексов/таблиц:

- tuples.returned — это количество записей, которые были «прочитаны» со страниц данных.
- tuples.fetched — те из них, которые не были отфильтрованы «прямо тут» на этапе Rows Removed by Filter , а ушли «выше» по плану выполнения.
- tuples.ratio — соответственно, отношение одного к другому, которое должно стремиться к 1, чем больше — тем хуже. Это базовый показатель, который демонстрирует, во сколько раз больше данных вы вычитываете, чем реально необходимо вашим запросам.
Впрочем, даже если ratio идеально равно 1, но пик пришелся на returned/fetched — тоже хорошего не жди. Обычно это может означать наличие в плане какой-то неприятности вроде:
Hash Join - Hash - Seq Scan on BIG_TABLE - Index Scan . Merge Join - Index Scan on BIG_INDEX - Index Scan . Раз уж мы начали проверять, «что» у нас там читается — давайте посмотрим и «как» это происходит. То есть какой объем записей у нас читается по индексам, а какой — в результате Seq Scan :

Понятно, что тут любой внеплановый рост показателей должен вызвать подозрение. Например, если вы по каким-то нуждам каждую ночь вычитываете целиком табличку на 10M записей, то возникновение такого пика днем — повод к разборкам.
Равно как и любые массово-аномальные вставки/обновления/удаления:

Использование кэша данных
Чтобы понять, насколько реально ухудшает жизнь сервера массовая вычитка записей, посмотрим на работу сервера со страницами данных и соотношение block.read/hit . В идеальном мире сервер не должен «читать» с диска ( shared read на узле плана) ровно ничего, все уже должно быть в памяти ( shared hit ), поскольку обращение к диску — всегда медленно.
В реальности все не совсем так, и является поводом к доскональному анализу запросов около времени пика:

Самый длительный запрос/транзакция
Для MVCC долго активные запросы и транзакции в нагруженных системах — беда для производительности. Подробно и в картинках про это можно прочитать тут, а тут — как можно все-таки выжить в таких условиях.

Поймать таких злодеев нам помогают pg_stat_activity.query_start/xact_start .
Как показывает наш опыт, визуального представления этих метрик уже достаточно, чтобы примерно представлять, куда дальше «копать»:
- искать утечки ресурсов в приложении
- оптимизировать неудачные запросы
- ставить более производительное «железо»
- … или следить, чтобы нагрузка была правильно разнесена во времени
- Блог компании Тензор
- PostgreSQL
- Анализ и проектирование систем
- Администрирование баз данных
- Визуализация данных
Запись при чтении в postgresql: скандалы, интриги, расследования

Я уже рассказывал про мониторинг запросов postgresql, в тот момент мне казалось, что я полностью разобрался, как postgresql работает с различными ресурсами сервера.
При постоянной работе со статистикой по запросам постгреса мы начали замечать некоторые аномалии. Я полез разбираться, заодно очередной раз восхитился понятностью исходного кода постгреса )
Под катом небольшой рассказ о неочевидном поведении postgresql.
SELECTы «пачкают» страницы
То есть SELECT вызывает модификацию каких-то записей, которые постгрес будет записывать на диск.

Начну с краткого пояснения механизма MVCC, используемого постгресом для обеспечения транзакционной целостности.
Все изменения в базе данных происходят в ходе транзакций, у каждой транзакции есть идентификационный номер txid (int32).
Постгрес оперирует данными таблиц в виде так называемых tuple (кортеж). Тупл несет в себе как непосредственно данные конкретной строчки в таблице, так и метаданные связанные с этими данными:
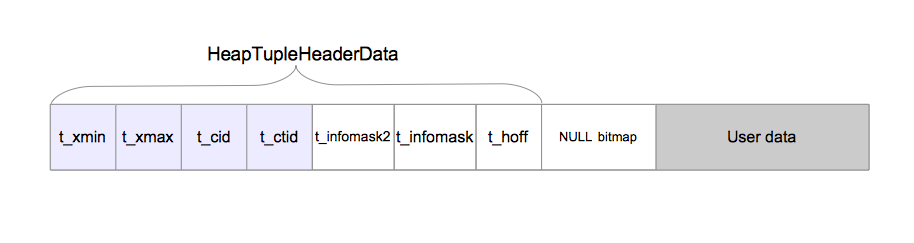
xmin — номер транзакции, которая создала этот tuple
xmax — номер транзакции, которая пометила этот tuple как удаленный
- Если мы делаем INSERT в таблицу, он создает новый tuple (xmin=txid)
- DELETE — помечает туплы, которые подходят под условие как удаленные (xmax=txid)
- UPDATE делает условно DELETE + INSERT.
Когда мы выполняем SELECT, он помимо непосредственно поиска и выборки данных из таблицы делает еще и проверку видимости (visibility check).
Очень упрощенно, некоторая транзакця с номером txid1 «видит» данный тупл, если выполняется условия:
xmin < txid1 < xmaxНо изменения в кортежах происходят сразу, а транзакция может выполняться еще продолжительное время, поэтому в ходе проверки видимости необходимо удостовериться, завершились ли транзакции с номерами xmin, xmax и если да, то с каким статусом. Информацию о текущем состоянии каждой транзакции постгрес хранит в CLOG (commit log).
Так как проверять состояние большого количества транзакций в CLOG достаточно дорого по ресурсам, разработчики решили "закэшировать" эту информацию прямо в заголовке тупла. То есть когда какой-то SELECT видит к примеру, что xmin завершилась, он сохраняет это в так называемый hint bits — структуру поверх infomask, в которой записаны состояния транзакций xmin и xmax.
Как происходит изменение туплов при чтении, мы разобрались, осталось вспомнить, что такое "страницы" и почему они бывают "грязными" )
Дело в том, что работать с данными в памяти и на диске практически всегда эффективнее большими блоками. Таким блоком в постгресе является "страница", она содержит в себе какое-то количество туплов и метаинформация о них. Когда мы модифицируем хотя бы один тупл страницы, вся она помечается как "грязная", то есть отличающаяся по состоянию на диске, и должна быть синхронизирована. При этом почти всегда изменения записываются еще и в WAL, чтобы иметь возможность восстановить целостность данных после аварийного завершении процесса БД.
SELECT может вызывать синхронную запись на диск
Как известно, вся работа с данными в pg ведется через buffer cache, если нужных данных там нет, постгрес прочитает их с диска (c использованием OS page cache) и поместит в кэш.
При этом, если в кэше нет места, то из него вытесняется наименее востребованная страница. И наконец, если страница-кандидат на вытеснение оказывается "грязной", она должна быть записана на диск в тот же момент времени.
FrozenTransactionId
В начале статьи я упомянул, что счетчик транзакций в постгресе 32-битный, то есть он сбрасывается через каждые ~2 млрд транзакций.
Чтобы проверка видимости не превращалась в тыкву при сбросе счетчика транзакций, есть специальный процесс — wraparound vacuum.
До версии 9.4 этот процесс заменял xmin у тупла на специальное значение FrozenTransactionId=2. Транзакция с этим номером считалась старше любой другой транзакции. C 9.4 в тупл просто проставляется флаг, что xmin "заморожен", а сам xmin остается неизменным.
Для совсем внимательных: есть специальная константа BootstrapTransactionId=1, которая тоже старше всех других транзакций )
Итого
Большинство случаев "странного" (по обывательскому мнению) поведения постгреса вызвано оптимизацией производительности.
Пока ковырялся с постгресом нашел замечательную книгу "The Internals of PostgreSQL", рекомендую всем, кто не встречал ранее.
- postgresql
- monitoring
- performance optimization
What's the difference between a tuple and a row in Postgres?
My general understanding is that a tuple is a row. However, I'm using the Postgres dev plan in Heroku. It has a limit of 10,000 rows. I have over 100,000 entries for n_live_tup . How can this be?
asked Nov 5, 2013 at 21:24
Bailey Smith Bailey Smith
2,873 4 4 gold badges 28 28 silver badges 39 39 bronze badges
3 Answers 3
"Tuple" is the abstract term, "row" is for the concrete implementation.
Just like "relation" versus "table".
In Postgres' MVCC implementation, multiple instances of the same table row can exist concurrently - for different snapshots of the same table or as obsolete "dead tuples". In Postgres parlance "row" is the umbrella term in this case and "tuple" is used for one instance. But that's more what you call guidelines than actual rules.
Otherwise the terms are often used meaning the same. You can find more for each of them in Wikipedia.
No idea what's behind the Heroku policies. But the numbers for n_live_tup in pg_stat_user_tables or pgstattuple represents "the number of live rows" in the table. See:
answered Nov 5, 2013 at 21:36
Erwin Brandstetter Erwin Brandstetter
620k 146 146 gold badges 1099 1099 silver badges 1248 1248 bronze badges
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages. (from the doc) - Can we say that this statement refers not only to rows but to index entries too?
Aug 28, 2022 at 10:46
@IlyaLoskutov: Yes. But there's more to it: See: dba.stackexchange.com/a/217088/3684
Aug 28, 2022 at 23:34
In Postgres, the term
row represent a logical representation of one entry
tuple is the physical representation of that one entry.
(Note: just to avoid name confusion, I'm saying entry in the table)
So, let’s suppose there is a freshly created entry say R1. At this point of time this entry is row as well as tuple. But when it gets updated then a new entry will be created say R2 and similarly whenever this entry is updated a new entry will be created R3, R4 and so on. Whenever a new entry is created the old one is marked a dead if it is not used by any of the transactions present in the db.
So, if we notice properly for that one single entry we have multiple versions inside the databases but whenever any client / applications asks for this entry it should return only one entry. So, these multiple versions(R1, R2, R3, etc) of the entry are called tuples and whichever is the latest tuple (unless delete command for this entry is not ordered) will be row for the application.