Проверка на наличие NaN в DataFrame в Pandas

Часто при работе с большими наборами данных, особенно теми, которые были получены из внешних источников, могут возникать проблемы с пропущенными или недоступными данными. В Python и библиотеке Pandas такие данные обычно представлены значением NaN (Not a Number).
Рассмотрим пример DataFrame:
import pandas as pd import numpy as np data = < 'A': [1, 2, np.nan], 'B': [5, np.nan, np.nan], 'C': [1, 2, 3] >df = pd.DataFrame(data)
В этом DataFrame в столбцах ‘A’ и ‘B’ есть значения NaN.
Варианты проверки наличия NaN
Вариант 1: isnull() и any()
Один из способов проверить наличие NaN в DataFrame — использовать функцию isnull() . Она возвращает другой DataFrame, где каждое значение это булево значение, указывающее, является ли соответствующее значение в исходном DataFrame NaN.
df.isnull()
Чтобы узнать, есть ли хотя бы одно значение NaN в DataFrame, можно использовать функцию any() , которая возвращает True, если хотя бы одно значение в DataFrame является True.
df.isnull().any().any()
Вариант 2: isna() и values
Альтернативный способ — использовать функцию isna() , которая аналогична isnull() . Однако, вместо второго any() можно использовать свойство values и функцию any() из numpy.
np.any(df.isna().values)
Оба этих способа позволяют эффективно проверить наличие значений NaN в DataFrame. Выбор между ними зависит от конкретной ситуации и личных предпочтений.
Обязательные проверки перед анализом данных с Pandas
Некоторые этапы предварительной обработки данных необходимо выполнять в любом проекте, о них и пойдет речь в этой статье. В качестве демонстрационного примера будем использовать следующий датафрейм:
import pandas as pd df = pd.DataFrame([['Пугачев', 'Иван', 12], ['Емельянов', 'Павел', 30], ['Коломойский', 'Андрей'], ['Авдеева', 'Нонна', 40], ['Пугачев', 'Иван', 12], ['Кравченко', 'Петр', 32]], columns=['Фамилия', 'Имя', 'Доход']) df
Проверка незаполненных значений
Воспользуемся комбинацией методов isna и sum. isna для каждой ячейки датафрейма вернет логическое значение, правда — если она не заполнена и ложь в противоположном случае:
df.isna()
а sum преобразует True в 1, False в 0 и суммирует по столбцам:
df.isna().sum()
Проверка дубликатов
Вызываем метод duplicated, получаем логические значения (однако уже на уровне целой строки) и сразу подсчитываем как в примере выше методом sum:
df.duplicated().sum()
Идентификация выбросов
Выбивающиеся из логики значения (слишком большие и малые) для числовых столбцов можно попытаться найти методом describe:
df.describe()
Также для решения этой задачи пригодится визуализация распределений ( подробнее писал ранее ).
Еще много интересного
Общая информация о таблице (в том числе, количество заполненных значений по столбцам) возвращается методом info:
pandas.DataFrame.isna#
Return a boolean same-sized object indicating if the values are NA. NA values, such as None or numpy.NaN , gets mapped to True values. Everything else gets mapped to False values. Characters such as empty strings » or numpy.inf are not considered NA values (unless you set pandas.options.mode.use_inf_as_na = True ).
Mask of bool values for each element in DataFrame that indicates whether an element is an NA value.
Boolean inverse of isna.
Omit axes labels with missing values.
Show which entries in a DataFrame are NA.
>>> df = pd.DataFrame(dict(age=[5, 6, np.nan], . born=[pd.NaT, pd.Timestamp('1939-05-27'), . pd.Timestamp('1940-04-25')], . name=['Alfred', 'Batman', ''], . toy=[None, 'Batmobile', 'Joker'])) >>> df age born name toy 0 5.0 NaT Alfred None 1 6.0 1939-05-27 Batman Batmobile 2 NaN 1940-04-25 Joker
>>> df.isna() age born name toy 0 False True False True 1 False False False False 2 True False False False
Show which entries in a Series are NA.
>>> ser = pd.Series([5, 6, np.nan]) >>> ser 0 5.0 1 6.0 2 NaN dtype: float64
>>> ser.isna() 0 False 1 False 2 True dtype: bool
Примеры применения Pandas в Python
Pandas — очень популярная библиотека Python для анализа данных. Она предоставляет множество функций и методов, ускоряющих подготовку данных и работу с ними. Поскольку библиотека популярна, вы легко найдете стати и руководства по ее применению. В этой статье мы рассмотрим практические примеры использования Pandas в Python.
Примечание редакции Pythonist: о том, что собой представляет Pandas, можно почитать в статье «Полное руководство по Pandas для начинающих».
Функции и методы, которые мы рассмотрим, чаще всего применяются в обычных процессах анализа данных. Работать будем с набором данных отпавших клиентов, доступным на Kaggle.
Начнем со считывания csv-файла в датафрейм Pandas.
import numpy as np import pandas as pd df = pd.read_csv("/content/churn.csv") df.shape # (10000,14) df.columns # Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography', 'Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember','EstimatedSalary', 'Exited'], dtype='object')
1. Удаление столбцов
Функция drop используется для удаления столбцов и строк. Мы передаем в нее метки строк или столбцов, которые нужно удалить.
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) df.shape # (10000,10)
Параметр axis («ось») определяет, что именно мы удаляем: строки или столбцы. Для строк значение axis — 0, а для столбцов — 1. У нас axis=1 .
Параметр inplace определяет, нужно ли вносить изменения в существующий датафрейм или нужно вернуть его копию. По умолчанию значение inplace — False (возвращается копия). У нас inplace=True для внесения изменений на месте. Мы удаляем 4 столбца, поэтому число столбцов уменьшается до 10 (было 14).
2. Выборка определенных столбцов при чтении
Мы можем прочитать не целый CSV-файл, а только определенные столбцы. Для этого нужно передать список нужных столбцов в параметр usecols при считывании файла. Если вы знаете, какие столбцы вас интересуют, лучше выбрать их заранее, а не удалять ненужные после считывания всего файла.
df_spec = pd.read_csv("/content/churn.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance']) df_spec.head()
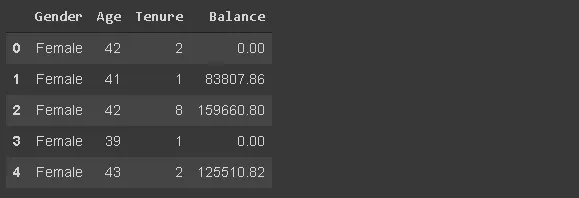
3. Чтение части датафрейма
Функция read_csv позволяет считывать часть csv-файла, определяя ее в строках. Применять эту функцию можно двумя способами. Первый вариант — указать нужное количество строк в параметре nrows .
df_partial = pd.read_csv("/content/churn.csv", nrows=5000) df_partial.shape # (5000,14)
Используя nrows , мы создаем датафрейм, содержащий первые 5000 строк csv-файла.
Второй вариант — использовать параметр skiprows . Если мы укажем skiprows=5000 , при считывании файла первые 5000 строк будут пропущены.
4. Случайная выборка
После создания датафрейма вы можете захотеть просмотреть небольшую выборку из него. Для определения размера выборки можно использовать следующие параметры:
- n — число строк в выборке
- frac — доля от всего датафрейма
df_sample = df.sample(n=1000) df_sample.shape # (1000,10) df_sample2 = df.sample(frac=0.1) df_sample2.shape # (1000,10)
5. Проверка пропущенных значений
Функция isna определяет пропущенные значения в датафрейме. Используя ее с функцией sum , можно увидеть количество недостающих значений по каждому столбцу.
df.isna().sum()

Здесь у нас нет пропущенных значений.
6. Добавление пропущенных значений при помощи loc и iloc
Методы loc и iloc служат для выборки строк и столбцов по индексу или меткам.
- loc — выборка по меткам
- iloc — выборка по индексу
Давайте сперва создадим переменную, содержащую 20 случайных индексов.
missing_index = np.random.randint(10000, size=20)
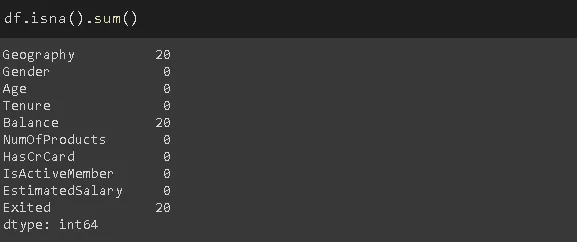
Эти индексы мы используем, чтобы заменить некоторые значения на np.nan (пропущенное значение). Мы применяем функцию loc и указываем метки столбцов — [‘Balance’,’Geography’] .
df.loc[missing_index, ['Balance','Geography']] = np.nan
Теперь в столбцах Balance и Geography 20 пропущенных значений.
Давайте теперь применим iloc и индексы столбцов вместо меток.
df.iloc[missing_index, -1] = np.nan
-1 — это индекс последнего столбца (Exited).
Хотя мы использовали разные представления столбцов для loc и iloc , значения строк не изменились. Причина в том, что в качестве меток строк мы используем числовой индекс. То есть для строк метки и индексы одинаковы.
Количество пропущенных значений поменялось:
7. Заполнение отсутствующих значений
При помощи функции fillna можно заполнить недостающие значения. У этой функции много опций. Мы можем использовать конкретное значение, агрегатную функцию (например, среднее значение), предыдущее или следующее значение.
В этом примере мы выбрали в качестве заполнителя для пропущенных значений в столбце Geography наиболее часто встречающееся значение.
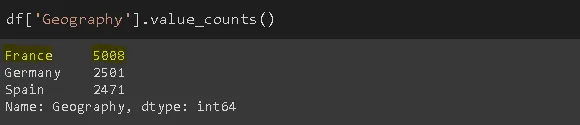
mode = df['Geography'].value_counts().index[0] df['Geography'].fillna(value=mode, inplace=True)
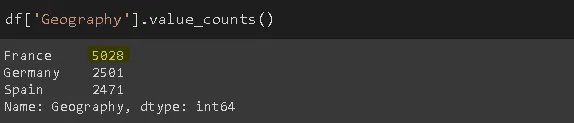
А для столбца Balance используем среднее значение:
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
При помощи параметра method можно заполнить пропущенное значение, основываясь на предыдущем или следующем значении в столбце (например, method=’ffill’ ). Это может быть очень полезным для последовательных данных.
8. Удаление пропущенных значений
Пропущенные значения можно не только заполнять, но и просто удалять. У нас есть такие пропуски значений в столбце Exited. При помощи следующего кода можно удалить строки, содержащие любые пропущенные значения.
df.dropna(axis=0, how='any', inplace=True)
Если задать параметр axis=1 , то удалены будут не строки, а столбцы с отсутствующими значениями. Можно также задать параметр thresh , чтобы указать, какое минимальное число непропущенных значений должно быть в столбце или строке. Например, thresh=5 означает, что строка должна иметь как минимум 5 значений. Строки с меньшим количеством значений будут удалены.
Теперь в нашем датафрейме нет пропущенных значений.
df.isna().sum().sum() # 0
9. Выборка строк на основе условий
В некоторых случаях нам нужно сосредоточиться на данных, отвечающих каким-то условиям. Например, можно выбрать отпавших клиентов, которые живут во Франции.
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts() # France 808
10. Описание условий при помощи query
Функция query позволяет задавать условия более гибко. Например, при помощи строк:
df2 = df.query('80000 < Balance < 100000')
Давайте проверим результат, нарисовав диаграмму столбца Balance.
df2['Balance'].plot(kind='hist', figsize=(8,5))
В этой статье мы рассмотрели простые примеры использования Pandas в Python. Но Pandas предлагает куда больше возможностей, чем можно охватить в одном руководстве. Применяя эту библиотеку на практике, вы будете открывать для себя все новые и новые функции. Как и во многих других случаях, практика ведет к совершенству.