Настройка сброса TCP и времени ожидания подсистемы балансировки нагрузки
Чтобы создать более предсказуемое поведение приложения для ваших сценариев, вы можете использовать Load Balancer (цен. категория «Стандартный»), включив сброс протокола TCP в неактивный режим для данного правила. По умолчанию, когда истекает время ожидания простоя потока, Load Balancer автоматически прерывает его. Включение сброса TCP приведет к тому, что Load Balancer будет отправлять двунаправленные сбросы TCP (пакет RST TCP) после тайм-аута простоя. Это сообщит конечным точкам вашего приложения о том, что время соединения истекло и оно больше не используется. При необходимости конечные точки могут немедленно установить новое соединение.
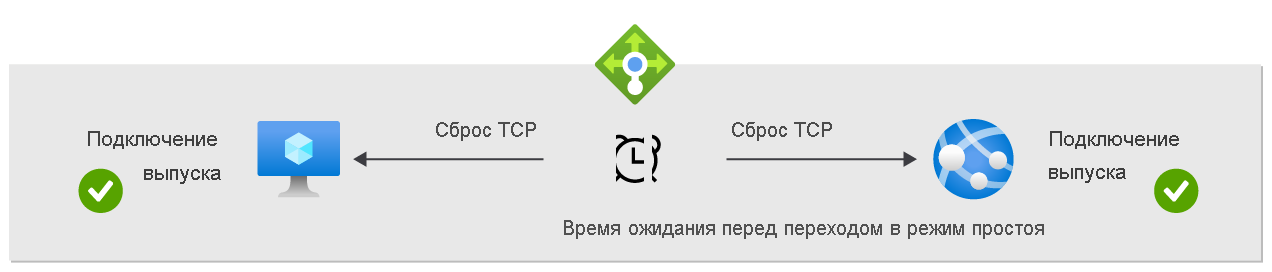
Сброс TCP
Изменить это поведение по умолчанию и включить отправку признаков TCP Reset при истечении времени ожидания простоя можно в правилах NAT для входящего трафика, правилах балансировки нагрузки и правилах для исходящего трафика. Если эта функция включена для отдельного правила, Load Balancer отправляет двунаправленные признаки TCP Reset (TCP-пакеты RST) клиентским и серверным конечным точкам при истечении времени ожидания простоя для всех соответствующих потоков.
Конечные точки, получившие TCP-пакеты RST, немедленно закрывают соответствующий сокет. Таким образом конечные точки немедленно уведомляются об освобождении соединения, и дальнейшие попытки передачи данных по этому TCP-соединению будут завершаться неудачно. Приложения могут очищать подключения при закрытии сокета и повторно устанавливать подключения по мере необходимости, не дожидаясь истечения времени ожидания tcp-подключения.
Во многих ситуациях сброс TCP позволяет уменьшить количество сообщений об активности TCP (или прикладного уровня), которые требуется отправлять для обновления тайм-аута простоя потока.
Однако если время простоя превышает ограничения конфигурации или приложение демонстрирует нежелательное поведение при включенном сбросе TCP, вам может требоваться использовать сообщения об активности TCP или прикладного уровня для отслеживания активности TCP-соединений. Кроме того, сообщения об активности, особенно об активности прикладного уровня, могут по-прежнему быть полезными, если где-то на пути соединения есть прокси-сервер.
Тщательно проверив весь комплексный сценарий, вы можете определить преимущества включения сбросов TCP и настройки тайм-аута простоя. Затем вы решите, потребуется ли выполнить дополнительные действия, чтобы обеспечить требуемое поведение приложения.
Настраиваемое время ожидания в режиме простоя для TCP-подключения
Azure Load Balancer имеет диапазон времени ожидания от 4 до 100 минут для правил Load Balancer, правил для исходящего трафика и правил NAT для входящего трафика.
По умолчанию установлено 4 минуты. Если период бездействия превышает значение времени ожидания, нет никакой гарантии, что сеанс TCP или HTTP между клиентом и облачной службой возобновится.
При закрытии подключения клиентское приложение может получить такое сообщение об ошибке: «Базовое соединение закрыто. Соединение, которое должно было работать, было разорвано сервером».
Распространенной практикой является проверка активности TCP. Такой подход позволяет поддерживать подключения активными в течение более длительного периода. Дополнительные сведения вы найдете в следующих примерах для .NET. Когда проверка активности включена, пакеты отправляются в периоды простоя подключений. Благодаря пакетам проверки активности значение времени ожидания простоя не достигается и подключение сохраняется в течение длительного времени.
Этот параметр применяется только для входящих подключений. Чтобы избежать потери подключения, настройте пакеты проверки активности для TCP с интервалом меньше, чем настроенное время ожидания простоя. Можно также увеличить значение времени ожидания простоя. Для поддержки таких сценариев добавлена возможность настройки времени ожидания простоя.
Проверки активности TCP хорошо подходят для сценариев, в которых не нужно беспокоиться о расходе заряда аккумулятора. Мы не рекомендуем использовать этот вариант для мобильных приложений. Использование этого метода в мобильном приложении может привести к ускоренной разрядке аккумулятора устройства.
Порядок приоритетов
Важно учитывать, как значения времени ожидания простоя, заданные для разных IP-адресов, могут потенциально взаимодействовать.
Входящий трафик
- При наличии правила (входящего) балансировщика нагрузки со значением времени ожидания простоя, которое отличается от времени ожидания для внешнего IP-адреса, на который он ссылается, приоритет будет иметь время ожидания внешнего IP-адреса подсистемы балансировки нагрузки.
- При наличии правила NAT для входящего трафика со значением времени ожидания простоя, которое отличается от времени ожидания для внешнего IP-адреса, на который он ссылается, приоритет будет иметь время ожидания внешнего IP-адреса подсистемы балансировки нагрузки.
Исходящие
- При наличии правила для исходящего трафика со значением времени ожидания простоя, отличающееся от 4 минут (в этом случае время ожидания простоя для исходящего ip-адреса заблокировано), приоритет будет иметь время ожидания простоя правила для исходящего трафика.
- Так как шлюз NAT всегда имеет приоритет над правилами для исходящего трафика подсистемы балансировки нагрузки (и над общедоступными IP-адресами, назначенными непосредственно виртуальным машинам), будет использоваться значение времени ожидания простоя, назначенное шлюзу NAT. (Аналогичным образом, время ожидания для заблокированного общедоступного IP-адреса для исходящего простоя в течение 4 минут для любых IP-адресов, назначенных GW NAT, не учитываются.)
Ограничения
- Сброс TCP отправляется только во время подключения TCP в состоянии УСТАНОВЛЕН.
- Тайм-аут простоя TCP не влияет на правила балансировки нагрузки по протоколу UDP.
- Порты высокого уровня доступности ILB не поддерживают сброс TCP, когда в пути находится сетевой виртуальный модуль. Возможное решение заключается в использовании правила для исходящего трафика со сбросом TCP с устройства NVA.
Дальнейшие действия
- Сведения о Load Balancer ценовой категории «Стандартный».
- Сведения о правилах для исходящих подключений.
- Настройка TCP RST при истечении времени ожидания
Как работает атака TCP Reset
Атака TCP reset выполняется при помощи одного пакета данных размером не более нескольких байт. Подменённый спуфингом TCP-сегмент, созданный и переданный атакующим, хитростью заставляет двух жертв завершить TCP-соединение, прервав между ними связь, которая могла быть критически важной.

Эта атака имела последствия и в реальном мире. Опасения её использования вызвали внесение изменений в сам протокол TCP. Считается, что атака является важнейшим компонентом Великого китайского файрвола («Золотого щита»), который используется китайским правительством для цензурирования Интернета за пределами Китая. Несмотря на её впечатляющую биографию, для понимания механизмов этой атаки необязательно обладать глубокими знаниями работы TCP. Разумеется, понимание её тонкостей способно многому научить вас об особенностях реализации протокола TCP, и, как мы вскоре убедимся, вы даже сможете провести эту атаку против себя при помощи одного только ноутбука.
В этом посте мы:
- Изучим основы протокола TCP
- Узнаем, как работает атака
- Проведём атаку против себя при помощи простого скрипта на Python.
Как атака TCP reset используется в Великом файрволе?
Великий файрвол (Great Firewall, GFW) — это комплекс систем и техник, используемых китайским правительством для цензурирования Интернета для внутренних китайских пользователей. GFW активно блокирует и разрывает соединения с серверами внутри и снаружи страны, а также пассивно отслеживает Интернет-трафик запрещённого контента.
Чтобы не позволить пользователям даже подключаться к запрещённым серверам, GFW использует такие техники, как DNS pollution и IP blocking (обе они стоят отдельных статей). Однако иногда файрволу GFW требуется позволить совершить соединение, но затем разорвать его посередине. Например, это необходимо, если требуется выполнить медленный, отложенный анализ подключения, допустим, его корреляцию с другими действиями. Или это используется, если файрволу нужно проанализировать данные, которыми обменивались в процессе соединения, а затем использовать эту информацию, чтобы принять решение о его продолжении или блокировке. Например, может быть разрешён трафик на новостной веб-сайт, но цензурированы видео, содержащие запрещённые ключевые слова.
Для этого GFW необходимы инструменты, способные прерывать уже установленные соединения. Один из таких инструментов — это атака TCP reset.
Как работает атака TCP reset?
При атаке TCP reset нападающий разрывает соединение между двумя жертвами, отправляя одной или обеим фальшивые сообщения, приказывающие им немедленно прервать соединение. Такие сообщения называются сегментом сброса TCP. При обычной работе без участия злоумышленника компьютеры отправляют сегменты сброса TCP, когда они получают неожиданный TCP-трафик и хотят, чтобы отправитель прекратил его передавать.
Атака TCP reset злонамеренно эксплуатирует этот механизм, хитростью заставляя жертв преждевременно завершить TCP-соединения, отправляя им фальшивые сегменты сброса. Если фальшивый сегмент сброса изготовлен правильно, то получатель примет его за настоящий сегмент и закроет соединение со своей стороны, прерывая дальнейшую передачу информации по этому соединению. Чтобы продолжить обмен данными, жертвы могут попытаться создать новое TCP-соединение, но у атакующего может быть возможность сбросить и это новое соединение. К счастью, поскольку для сборки и отправки поддельного пакета атакующему нужно время, атаки сбросом по-настоящему эффективны только против долговременных соединений. Кратковременные соединения. например, используемые для передачи небольших веб-страниц, обычно успевают выполнить своё предназначение к тому времени, когда у атакующего появится возможность их сбросить.
Отправка фальшивых TCP-сегментов в каком-то смысле является лёгким процессом, потому что ни TCP, ни IP не имеют никаких собственных способов проверки личности отправителя. Существует расширение IP под названием IPSec, обеспечивающее аутентификацию, однако оно используется не так широко. Интернет-провайдеры должны отказывать в передаче IP-пакетов, которые поступают с очевидно ложного IP-адреса, но, как утверждается, такая проверка выполняется очень посредственно. Всё, что может получатель — принять исходный IP-адрес и порт внутри пакета или сегмента за чистую монету, и по возможности использовать для идентификации отправителя более высокоуровневые протоколы, например TLS. Однако поскольку пакеты сброса TCP являются частью самого протокола TCP, их невозможно проверить при помощи этих высокоуровневых протоколов.
Несмотря на простоту отправки фальшивых сегментов, изготовление фальшивого сегмента и выполнение успешной атаки TCP reset всё равно может быть сложной задачей. Чтобы понять, почему так происходит, нам нужно разобраться в работе протокола TCP.
Как работает протокол TCP
Задача протокола TCP — отправка получателю точной копии блока данных. Например, если мой сервер передаёт по протоколу TCP вашему компьютеру HTML, то стек TCP вашего компьютера (часть его операционной системы, занимающаяся обработкой TCP) должна вывести мой HTML точно в том же виде и порядке, в котором его отправил мой сервер.

Однако мой HTML не передаётся по Интернету в таком идеально упорядоченном виде. Он разбивается на множество небольших фрагментов (называемых TCP-сегментами), каждый из которых по отдельности передаётся по Интернету и воссоздаётся в переданном порядке стеком TCP вашего компьютера. Этот восстановленный вывод называется потоком TCP. Каждый TCP-сегмент передаётся в собственном IP-пакете, однако для понимания атаки нам не нужно знать никаких подробностей об IP.
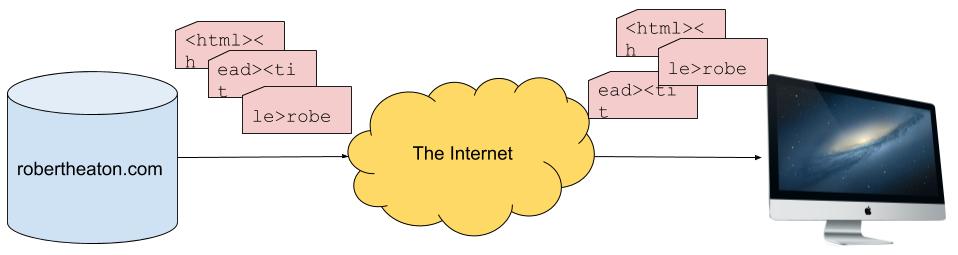
Преобразование сегментов в поток требует внимательности, потому что Интернет ненадёжен. TCP-сегменты могут теряться. Они могут приходить не по порядку, отправляться дважды, повреждаться и испытывать множество других злоключений. Поэтому задача протокола TCP заключается в обеспечении надёжной передачи данных по ненадёжной сети. TCP выполняет эту задачу, требуя от обеих сторон соединения сохранения тесного контакта между друг другом и постоянной передачи сведений о том, какие блоки данных были получены. Это позволяет отправителям понять, какие данные получатель ещё не принял, и повторно передавать те данные, которые были утеряны.
Чтобы понять, как работает процесс, нам нужно разобраться, как отправители и получатели используют порядковые номера TCP для разметки и отслеживания данных, переданных по TCP.
Порядковые номера TCP
Каждый байт, переданный по TCP-соединению, имеет порядковый номер, назначаемый ему отправителем. Принимающие машины используют порядковые номера для перемещения получаемых данных в исходный порядок.
Когда две машины договариваются о TCP-соединении, каждая машина отправляет другой случайный начальный порядковый номер. Это порядковый номер, который машина назначит первому отправленному ею байту. Каждому последующему байту назначается порядковый номер предыдущего байта плюс 1. TCP-сегменты содержат TCP-заголовки, которые являются метаданными, прикреплёнными к началу сегмента. Порядковый номер первого в теле сегмента байта включается в TCP-заголовок этого сегмента.
Следует заметить, что TCP-соединения являются двунаправленными, то есть данные могут передаваться в обе стороны и каждая машина в TCP-соединении действует и как отправитель, и как получатель. Из-за этого каждая машина должна назначать и обрабатывать собственный независимый набор порядковых номеров.
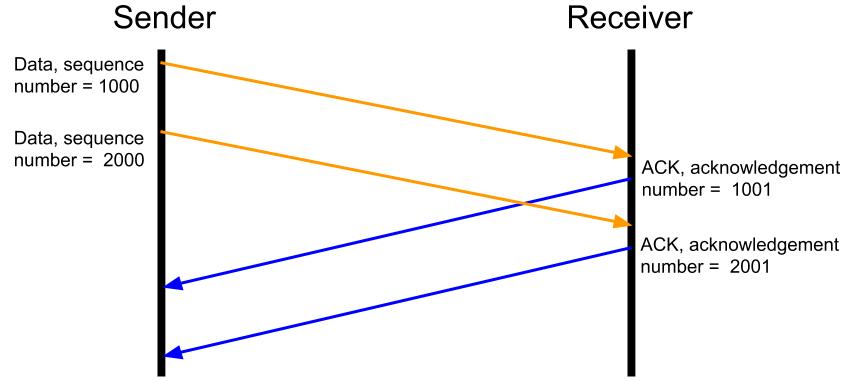
Подтверждение получения данных
Когда машина получает TCP-сегмент, она сообщает отправителю сегмента, что он был получен. Получатель делает это при помощи отправления сегмента ACK (сокращение от «acknowledge» — «подтверждение»), содержащего порядковый номер следующего байта, который он ожидает получить от отправителя. Отправитель использует эту информацию, чтобы понять, что получатель успешно получил все остальные байты до этого номера.
Сегмент ACK обозначается наличием флага ACK и соответствующего номера подтверждения в TCP-заголовке сегмента. В протоколе TCP есть всего 6 флагов, в том числе и (как мы вскоре увидим) флаг RST (сокращение от «reset» — «сброс»), обозначающий сегмент сброса.
Примечание: протокол TCP также позволяет использовать выборочные ACK, которые передаются, когда получатель получил некоторые, но не все, сегменты в интервале номеров. Например, «Я получил байты 1000-3000 и 4000-5000, но не 3001-3999». Для упрощения я не буду рассматривать выборочные ACK в нашем обсуждении атак TCP reset.
Если отправитель передаёт данные, но не получает ACK для них в течение определённого интервала времени, то он предполагает, что данные были утеряны, и отправляет их повторно, давая им те же самые порядковые номера. Это означает, что если получатель принимает одни и те же байты дважды, то он тривиальным образом использует порядковые номера для избавления от дубликатов без нарушения потока. Получатель может принимать дублирующиеся данные, потому что исходный сегмент был получен позже, уже после того, как был отправлен повторно, или потому, что исходный сегмент был успешно получен, но соответствующий ACK потерялся на пути к отправителю.
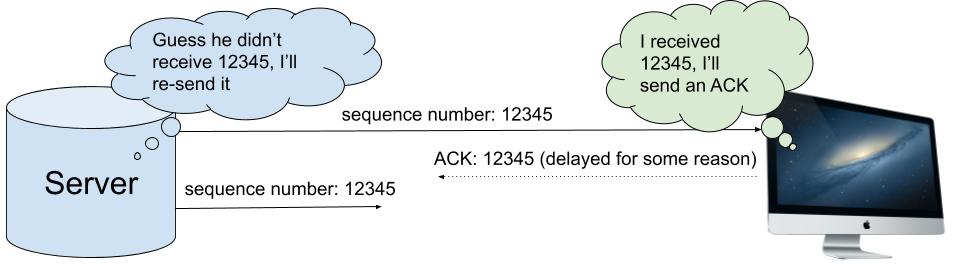
Пока такие дублирующиеся данные встречаются достаточно редко, вызываемые ими избыточные траты ресурсов не приводят к проблемам. Если все данные рано или поздно добираются до получателя, а соответствующие им ACK доходят до отправителя, то TCP-соединение справляется со своей работой.
Выбор порядкового номера для фальшивого сегмента
При создании ложного сегмента RST злоумышленнику нужно дать ему порядковый номер. Получателей вполне устраивает, что нужно принимать сегменты с непоследовательными порядковыми номерами и самостоятельно соединять их в нужном порядке. Однако их возможности ограничены. Если получатель принимает сегмент с порядковым номером, который «слишком» выбивается из порядка, то он отбрасывает такой сегмент.
Следовательно, для успешной атаки TCP reset требуется правдоподобный порядковый номер. Но что считается таким номером? Для большинства сегментов (хотя, как мы увидим позже, не для RST ), ответ определяется размером TCP-окна.
Размер TCP-окна
Представьте древний компьютер начала 1990-х, подключённый к современной гигабитной волоконно-оптической сети. Сверхбыстрая сеть может передавать данные этому престарелому компьютеру с потрясающей скоростью, быстрее, чем машина сможет их обработать. Это будет нам мешать, потому что TCP-сегмент нельзя считать полученным, пока получатель не сможет его обработать.
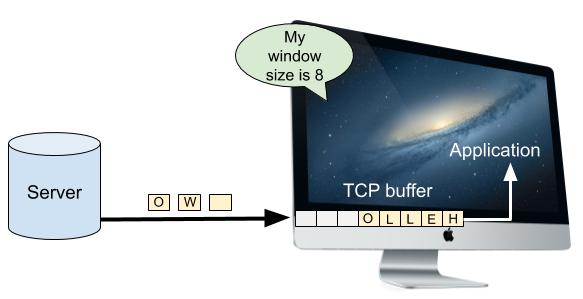
У компьютеров есть TCP-буфер, в котором новые прибывшие данные ожидают обработки, пока компьютер работает над данными, прибывшими до них. Однако этот буфер имеет ограниченный размер. Если получатель неспособен справиться с объёмом передаваемых ему сетью данных, то буфер переполнится. Когда буфер полностью заполнен, у получателя нет другого выбора, кроме как избавляться от избыточных данных. Получатель не отправляет ACK для отброшенных данных, поэтому отправителю приходится повторно отправлять их, когда в буфере получателя найдётся свободное место. Не важно, с какой скоростью сеть может передавать данные, если получатель не успевает с ними справляться.
Представьте чрезмерно ретивого друга, который отправляет вам на почту целый поток из писем быстрее, чем вы сможете его прочитать. Внутри вашего почтового ящика есть определённое буферное пространство, но после его переполнения все непоместившиеся письма выпадут на землю, где их съедят лисы и другие твари. Другу придётся повторно отправлять сожранные письма, а пока у вас будет время на получение его предыдущих сообщений. Отправка слишком большого количества писем или объёма данных, который получатель неспособен обработать — пустая трата энергии и канала передачи.
«Слишком много» — какой это объём данных? Как отправитель понимает, когда нужно отправлять ещё данные, а когда стоит подождать? Здесь нам пригождается размер TCP-окна. Размер окна получателя — это максимальное количество неподтверждённых байтов, которое отправитель может передать ему в любой момент времени. Допустим, получатель сообщает, что его размер окна равен 100 000 (вскоре мы узнаем, как он передаёт это значение), поэтому отправитель передаёт 100 000 байт. Допустим, что ко времени, когда отправитель передал стотысячный байт, получатель отправил сегменты ACK для первых 10 000 этих байтов. Это означает, что 90 000 байтов до сих пор не подтверждено. Так как размер окна равен 100 000, отправитель может передать ещё 10 000 байт, прежде чем ему придётся ждать новых ACK . Если после отправки этих 10 000 дополнительных байтов дальнейших ACK им получено не было, то отправитель упрётся в свой лимит 100 000 неподтверждённых байтов. Следовательно, отправитель должен будет ждать и прекратит отправлять данные (кроме повторной передачи данных, которые он считает утерянными) до момента, пока не получит новые ACK .

Каждая из сторон TCP-соединения уведомляет другую о размере своего окна в процессе установки связи (handshake), выполняемой при открытии соединения. Кроме того, размеры окон могут динамически изменяться в процессе соединения. Компьютер с большим TCP-буфером может объявить о большом размере окна, чтобы максимизировать пропускную способность. Это позволяет общающейся с ним машине постоянно передавать данные по TCP-соединению, не приостанавливаясь и не ожидая подтверждения. Компьютер с маленьким TCP-буфером может быть вынужден заявить о маленьком размере окна. Иногда отправители полностью заполняют окно и оказываются вынужденными ждать, пока какие-то из сегментов не будут подтверждены. Из-за этого страдает пропускная способность, но это необходимо, чтобы TCP-буферы не переполнялись.

Размер TCP-окна — это жёсткое ограничение на объём передаваемых неподтверждённых данных. Мы можем использовать его для вычисления максимально возможного порядкового номера (который в показанном ниже уравнении я обозначил как max_seq_no ), который отправитель может отправить в текущий момент времени:
max_seq_no = max_acked_seq_no + window_size
max_acked_seq_no — это максимальный порядковый номер, для которого получатель отправил ACK . Это максимальный порядковый номер, о котором отправителю известно, что получатель точно его принял. Так как отправитель может передавать только window_size неподтверждённых байтов, максимальный порядковый номер, который он может отправить, равен max_acked_seq_no + window_size .
Из-за этого спецификация TCP гласит, что получатель должен игнорировать любые получаемые им данные, имеющие порядковые номера вне допустимого окна. Например, если получатель подтвердил все байты до 15 000, а его размер окна равен 30 000, то он будет принимать любые данные с порядковым номером в интервале от 15 000 до (15 000 + 30 000 = 45 000). При этом получатель полностью игнорирует данные с порядковыми номерами вне этого интервала. Если сегмент содержит данные, часть которых находится в пределах этого окна, а часть — за его пределами, то данные внутри окна будут приняты и подтверждены, но данные за его пределами будут отброшены. Заметьте, что мы по-прежнему игнорируем возможность выборочных ACK , которых вкратце коснулись в начале поста.
В случае большинства TCP-сегментов это правило даёт нам интервал приемлемых порядковых номеров. Однако, как было сказано ранее, накладываемые на сегменты RST ограничения ещё строже, чем ограничения для обычных сегментов передачи данных. Как мы вскоре увидим, это сделано для усложнения проведения разновидности атаки TCP reset под названием «атака TCP reset вслепую» (blind TCP reset attack).
Приемлемые порядковые номера для сегментов RST
Обычные сегменты принимаются, если их порядковый номер находится в интервале от следующего ожидаемого порядкового номера и этого номера плюс размер окна. Однако пакеты RST принимаются только тогда, когда их порядковый номер точно равен следующему ожидаемому порядковому номеру. Вернёмся к предыдущему примеру, в котором получатель отправил номер подтверждения 15 000. Чтобы пакет RST был принят, его порядковый номер должен быть точно равен 15 000. Если получатель получает сегмент RST с порядковым номером, не равным 15 000, то он не примет его.

Если порядковый номер вне интервала, то получатель полностью его игнорирует. Однако если он находится в пределах окна ожидаемых порядковых номеров, то получатель отправляет «challenge ACK » («ACK вызова»). Это сегмент, сообщающий отправителю, что сегмент RST имеет неверный порядковый номер. Также он сообщает отправителю порядковый номер, который ожидает получатель. Отправитель может использовать эту информацию из ACK вызова для воссоздания и повторной отправки своего RST .
До 2010 года протокол TCP не накладывал этих дополнительных ограничений на сегменты RST . Сегменты RST принимались или отклонялись в соответствии с теми же правилами, что и любые другие. Однако это слишком упрощало атаки TCP reset вслепую.
Атаки TCP reset вслепую
Если атакующий имеет возможность перехвата трафика, которым обмениваются его жертвы, то может считывать порядковые и подтверждающие номера TCP-пакетов жертв. Он может использовать эту информацию для того, чтобы выбирать, какие порядковые номера давать своим фальшивым сегментам RST . Однако если атакующий не может перехватывать трафик жертв, то не будет знать, какие порядковые номера вставлять. Но он всё равно может передавать любое количество сегментов RST с любым количеством разных порядковых номеров, надеясь, что один из них окажется верным. Такая атака называется атакой TCP reset вслепую.
Как мы уже говорили, в первоначальной версии протокола TCP атакующему достаточно было только подобрать порядковый номер RST в пределах TCP-окна получателя. В статье под названием «Slipping in the Window» («Протискиваемся в окно») показано, что это слишком упрощало успешные атаки вслепую, так как для почти гарантированного успеха атакующему достаточно было просто отправить несколько десятков тысяч сегментов. Чтобы противостоять этому, правило, заставлявшее получателя принимать сегмент RST , заменили на описанный выше более строгий критерий. Благодаря новым правилам для осуществления атак TCP reset вслепую нужно отправлять миллионы сегментов, что делает их практически нереализуемыми. Подробности см. в RFC-5963.
Выполняем атаку TCP reset против себя
Примечание: я тестировал этот процесс на OSX, но получил несколько комментариев, что в Linux он не работает нужным образом.
Теперь мы знаем всё о выполнении атаки TCP reset. Атакующий должен:
- Наблюдать за сетевым трафиком («сниффить» его), передаваемым между двумя жертвами
- Сниффить TCP-сегмент со включенным флагом ACK и считать его подтверждённый номер
- Изготовить ложный TCP-сегмент со включенным флагом RST и порядковым номером, равным подтверждённому номеру перехваченного сегмента (стоит учесть, что это предполагает медленную передачу, иначе выбранный порядковый номер быстро устареет. (Чтобы повысить шансы на успех, можно передать несколько сегментов RST с большим интервалом порядковых номеров.)
- Отправить фальшивые сегменты одной или обеим жертвам, надеясь, что это приведёт к разрыву их TCP-соединения
- Настроить TCP-соединение между двумя окнами терминала
- Написать атакующую программу, которая будет заниматься сниффингом трафика
- Модифицировать программу так, чтобы она изготавливала и отправляла фальшивые сегменты RST .
1. Установка TCP-соединения между двумя окнами терминала
Мы настроим TCP-соединение при помощи инструмента netcat , который по умолчанию имеется во многих операционных системах. Подойдёт и любой другой TCP-клиент. В первом окне терминала мы выполним следующую команду:
nc -nvl 8000
Эта команда запускает на нашей локальной машине TCP-сервер, слушающий порт 8000 . Во втором окне терминала выполним такую команду:
nc 127.0.0.1 8000
Эта команда пытается создать TCP-соединение с машиной по IP-адресу 127.0.0.1 с портом 8000 . Теперь между двумя окнами терминала должно установиться TCP-соединение. Попробуйте ввести что-нибудь в одном окне — данные должны будут передаться по TCP-соединению и появиться в другом окне.
2. Сниффинг трафика
Мы напишем выполняющую сниффинг трафика атакующую программу при помощи scapy — популярной сетевой библиотеки Python. Эта программа использует scapy для считывания данных, передаваемых между двумя окнами терминала, хотя и не является частью соединения.
Код программы выложен в моём репозитории на GitHub. Программа сниффит трафик соединения и выводит его на терминал. Основным ядром кода является вызов метода sniff из библиотеки scapy , расположенный в конце файла:
t = sniff( iface='lo0', lfilter=is_packet_tcp_client_to_server(localhost_ip, localhost_server_port, localhost_ip), prn=log_packet, count=50)Этот фрагмент кода приказывает scapy выполнять сниффинг пакетов в интерфейсе lo0 и фиксировать подробности о всех пакетах как часть нашего TCP-соединения. Вызов имеет следующие параметры:
- iface — приказывает scapy слушать сетевой интерфейс lo0 , или localhost
- lfilter — функция фильтра, приказывающая scapy игнорировать все пакеты, не являющиеся частью соединения двух IP-адресов localhost на порте сервера. Эта фильтрация необходима, потому что на машине есть множество других программ, использующих интерфейс lo0 . Мы хотим игнорировать все пакеты, не являющиеся частью нашего эксперимента.
- prn — функция, которую scapy должна выполнять для каждого пакета, соответствующего требованиям функции lfilter . Функция в показанном выше примере просто выводит пакет на терминал. На следующем этапе мы изменим эту функцию, чтобы она также передавала сегменты RST .
- count — количество пакетов, которое scapy должна сниффить до выхода.
3. Отправка фальшивых пакетов RST
Мы установили соединение, а программа может сниффить все проходящие через неё TCP-сегменты. Единственное, что нам осталось — модифицировать программу, чтобы она выполняла атаку TCP reset передачей фальшивых сегментов RST . Для этого мы изменим функцию prn (см. список параметров выше), вызываемую scapy для пакетов, соответствующих требованиям функции lfilter . В модифицированной версии функции вместо простой фиксации соответствующего пакета мы изучаем его, извлекаем необходимые параметры, и используем эти параметры для сборки и отправки сегмента RST .
Допустим, мы перехватили сегмент, идущий от (src_ip, src_port) к (dst_ip, dst_port) . У него установлен флаг ACK и номер подтверждения равен 100 000. Чтобы изготовить и отправить сегмент, мы:
- Меняем местами IP-адреса отправителя и получатели, а также их порты. Это необходимо, потому что наш пакет будет ответом на перехваченный пакет. Исходная точка нашего пакета должна быть конечной точкой исходного пакета, и наоборот.
- Включаем флаг RST сегмента, потому что именно он сообщает, что сегмент является RST
- Присваиваем порядковому номеру точное значение номера подтверждения перехваченного пакета, так как это следующий порядковый номер, который ожидает получить отправитель
- Вызываем метод send библиотеки scapy для отправки сегмента жертве — источнику перехваченного пакета.
Теперь мы готовы к проведению полномасштабной атаки. Настройте TCP-соединение в соответствии с этапом 1. Запустите атакующую программу из этапа 2 в третьем окне терминала. Затем введите какой-нибудь текст в одном из терминалов TCP-соединения. В терминале, на котором вы вводили текст, TCP-соединение внезапно и загадочно прервётся. Атака выполнена!
Дальнейшая работа
- Продолжите эксперименты с инструментом для атак. Проследите, что происходит, если прибавить или вычесть 1 из порядкового номера пакета RST . Убедитесь, что он должен быть точно равен значению ack перехваченного пакета.
- Скачайте Wireshark и используйте его для прослушивания интерфейса lo0 во время проведения атаки. Это позволит вам увидеть подробности о каждом из передаваемых по соединению TCP-сегментов, в том числе и о ложном RST . Используйте фильтр ip.src == 127.0.0.1 && ip.dst == 127.0.0.1 && tcp.port == 8000 для фильтрации всего излишнего трафика других программ.
- Усложните проведение атаки, передавая по соединению непрерывный поток данных. Это затруднит выбор скриптом правильного порядкового номера для его сегментов RST , потому что ко времени прибытия сегмента RST к жертве та уже может получить дальнейшие истинные данные, увеличив таким образом следующий порядковый номер. Чтобы противодействовать этому, мы можем передавать несколько пакетов RST , каждый из которых имеет свой порядковый номер.
Заключение
Атака TCP reset и глубока, и проста одновременно. Удачи в ваших экспериментах, и дайте мне знать, если у вас есть вопросы или комментарии.
- Информационная безопасность
- Python
- Сетевые технологии
- Стандарты связи
TCP-протокол и странные FIN,ACK,RST. Вопросы.
Нормально закрывать TCP-коннект между А и Б по инициативе А так:
- А шлёт FIN («я всё сказал»)
- Б шлёт FIN + ACK («вас понял, я тоже всё»)
- А шлёт ACK («вас понял»).
Три вопроса вопроса:
- Непонятно, зачем посылать FIN на шаге (1), когда можно послать RST и забыть обо всём. Видимо это не экологично: потеря RST приведёт к сохранению коннекта на Б, в сценарии выше (1) можно повторить, если долго не будет (2)?
- А есть какая-то другая причина, почему после (1) коннекшн ещё остаётся? Может ли Б после получения FIN что-то PUSH в этот коннекшн? Но это бессмысленно, софтина на А уже вызвала close() на сокете.
- Проводил эксперимент:
- A — C++ сервер вида «socket();setsetsockopt();bind();listen(port 12345);accept();». Также, в этом сервере написано «По приходу чего-нибудь в коннект, вычитать всё через read() и сразу сделать close(socket)»;
- Б: «nc 127.0.0.1 12345»
- Б что-то PUSH в коннекшн (печатаю в nc рандомную строку, жму enter), A это вычитывает из сокета и делает сразу close(socket);
- В tcpdump видно, как от А к Б прилетает FIN + ACK. Зачем тут ACK? ACK на PUSH прилетело пакетом ранее….
- В ответ на FIN от Б прилетает один ACK, как будто nc не собирается закрывать. Всмысле? Какой смысл тут не хотеть закрывать?
- Ввожу в nc ещё одну строку, отправляю (от Б летит PUSH + ACK). Зачем тут опять ack?
- От A приходит RST. Это уже выглядит как «слыш ты кто»?
tcpfinhello
17.04.21 20:37:57 MSK
когда можно послать RST и забыть обо всём.
Можно и дверью хлопнуть, но, так ведь о отлететь что-то может. А 4 или 3-way handshake для «gracefully» shutdown.
А есть какая-то другая причина, почему после (1) коннекшн ещё остаётся?
Чтобы дождаться последних данных от клиента и его ответного «я всё сказал».
Но это бессмысленно, софтина на А уже вызвала close() на сокете.
Есть shutdown() с SHUT_WR .
gag ★★★★★
( 17.04.21 21:27:38 MSK )

Непонятно, зачем посылать FIN на шаге (1), когда можно послать RST и забыть обо всём.
Ну вот представь, что с той стороны тебе шлют RST, а ты как раз в сокет пишешь. Хренак, SIGPIPE, ты мертв.
Еще вопросы остались?
t184256 ★★★★★
( 17.04.21 21:31:11 MSK )
Пакеты идут по сети в рандомном порядке и в нем же [не]приходят. Close/rst означает выкинуть все нахрен, что ОС и делает, включая буферы невычитанные процессом или неотправленные в железо, на обеих сторонах. В случае потери пакета ретрансляции также не будет. На loopback ты такого не увидишь.
Поэтому все не выпендриваются и делают грейсфул шатдаун.
anonymous
( 18.04.21 10:50:42 MSK )
бессмысленно, софтина на А уже вызвала close() на сокете.
Ну это этой софтины проблемы. Нормальные люди ждут результата SHUT_WR (блоком или в фоне) и только потом клозят, хотя у линукса есть свои загоны по этому поводу.
anonymous
( 18.04.21 10:54:50 MSK )
Ответ на: комментарий от anonymous 18.04.21 10:54:50 MSK

Нормальные люди ждут результата SHUT_WR (блоком или в фоне) и только потом клозят,
Непонятно. Я хочу закрыть соединение в приложении, я могу вызывать только close(). Я не могу вызвать i_wait_close();
hellonik
( 18.04.21 16:56:34 MSK )
а если надо заново создать соединение то тебя шлют
doc0 ★
( 18.04.21 21:08:25 MSK )
Последнее исправление: doc0 18.04.21 21:19:49 MSK (всего исправлений: 1)
Ответ на: комментарий от t184256 17.04.21 21:31:11 MSK

SIGPIPE может прилететь и от того что кто-то рубанул свет в датацентре. Те, кто не обрабаытают SIGPIPE (или читают без MSG_NOSIGNAL) — обмылки и для них есть отдельный котел.
PPP328 ★★★★★
( 18.04.21 21:29:03 MSK )
тут мне кажется задействовано много устройств и чем они более информированы в ситуации тем лучше работает вся сеть
doc0 ★
( 18.04.21 21:33:01 MSK )
Ответ на: комментарий от t184256 17.04.21 21:31:11 MSK

будто этот кейс обрабатывать не надо.
deep-purple ★★★★★
( 18.04.21 22:05:59 MSK )
Последнее исправление: deep-purple 18.04.21 22:06:09 MSK (всего исправлений: 1)
Ответ на: комментарий от PPP328 18.04.21 21:29:03 MSK
По соседству с теми, кто шлет RST сразу за данными в штатной ситуации в асинхронных протоколах.
t184256 ★★★★★
( 18.04.21 23:46:14 MSK )
Ответ на: комментарий от hellonik 18.04.21 16:56:34 MSK
Потому что close() это аналог free() для сокета. С точки зрения юзерленда он не закрывает сокет, а просто выкидывает его, и для этого не надо ничего ждать (но см. нюанс ниже).
Чтобы нормально закрыть сокет надо помнить, что это дуплекс-канал, а не односторонний или файл, и закрытий не одно, а два. Чтобы не скипать полную логику, рассмотрим полностью асинхронное двустороннее общение, т.е. не запрос-ответ, а что-то вроде чата.
- открылся
- читаешь-пишешь as usual
- если ты решил закрыться
- посылаешь FIN (shutdown(SHUT_WR))
- больше ничего не пишешь
- но пир все еще может считать, что не договорил
- как и его ядро при потерях
- он шлет FIN
- получаешь read() == 0
- больше не читаешь
- дописываешь все, что хотел, as usual
- посылаешь FIN (так же)
- теперь можно выкинуть (close())
Вы оба проходите TCP стейты FIN-WAIT-1, CLOSE-WAIT, FIN-WAIT-2, LAST-ACK, TIME-WAIT, CLOSING, скипая некоторые, в зависимости от рейсов, кто быстрее закрыл, и какие пакеты где задержались. Если закрыть сокет не дожидаясь, ядро просто шлет RST, и там уже кто не успел, тот опоздал.
Поскольку хопы между вами могут терять любые пакеты, гарантированного общения/подтверждения нет, и в ядре все держится на таймаутах, после которых общение гарантированно не имеет смысла. Но для вас это выглядит как блокирующие вызовы read/write (или нонблок аналоги), -1/SIGPIPE, явный EOF (FIN/SHUT_WR/read 0) и «просто» close().
Последний тоже может быть блокирующим, но это афаир как раз прикол для тех, кто не осилил грейсфул, или на уровне соглашения работает запрос-ответом — при включенном SO_LINGER close() сначала дождется отправки и подтверждения прошлых write() и только потом пошлет FIN и дропнет сокет. Иначе неотправленное просто выкинется. То есть это такой graceful_close() для бедных.
Из-за асинхронки пиров/сети, разных стейтов соединения во времени, того что write() разблокируется не по ACK, а просто по факту отправки, возникает куча нюансов, которые я сам не до конца понимаю, поэтому если хочешь вкурить, то выдели месяц-другой, не меньше. Кроме того, разные стеки ведут себя по-разному, и тут два слоя понимания: что происходит в самом стеке, и как системные вызовы/возвраты мапятся на события в нем. Но с точки зрения юзерленда схема выше это текстбук мастхев, если ты в фуллдуплексе.
Если ты строго в запрос-ответе, то наверное можно опираться на лингер, но лично я такое ни разу не писал и не тестил, не могу комментировать. Кроме того, в лингере ты отчасти живешь в фулл-блок режиме на запись со стороны отдающего ответ, а это ну сам понимаешь уровень хелло ворлда на коленке, а не реального сервера.
Атака TCP Reset
Атака TCP Reset, «фальшивые TCP Reset», «сбросы TCP», «спуфинг пакетов TCP reset» — способ манипулирования интернет-соединениями. В одних случаях, так действуют злоумышленники, в других — легитимные пользователи.
Технические подробности
Интернет, по сути, является системой обмена информацией, сгруппированной в пакеты. Эта система состоит из аппаратного обеспечения передачи данных (медные и оптоволоконные кабели) и стандартизованной формы представления информации, т. е. протоколов. Основным протоколом сети Интернет является IP в сочетании с такими дополнительными протоколами как TCP и UDP [1] ). Веб и электронная почта используют стек протоколов TCP/IP. В соответствии с ним, в начале каждого пакета находится заголовок со служебной информацией об отправителе, получателе, размере пакета и т. п.
В отличие от других протоколов (например, UDP), TCP предполагает установку соединения между двумя компьютерами. Сетевое ПО, такое как браузер и веб-сервер, обменивается данными в форме потоков пакетов. За счёт этого они могут пересылать больший объём данных, чем может поместиться в один пакет, например видеоклипы, документы или аудиозаписи. Хотя некоторые веб-страницы бывают достаточно малы, чтобы уместиться в один пакет, они также передаются посредством соединения в целях удобства.
Сбросы TCP
Каждый TCP-пакет в рамках соединения несёт заголовок. В каждом из них есть бит флага сброса (RST). У большинства пакетов этот бит установлен в 0 и ничего не значит, но если он установлен в 1, это значит, что получатель должен немедленно прекратить использовать данное соединение: не посылать пакетов с текущим идентификатором (на текущий порт), а также игнорировать все последующие пакеты этого соединения (согласно информации в их заголовках). По сути, сброс TCP моментально разрывает соединение.
При надлежащем использовании такой сброс — полезный механизм. Такой способ применяется, когда на одном компьютере (условно А) происходит сбой во время передачи данных по TCP. Второй компьютер (условно Б) продолжит слать TCP-пакеты, так как не знает о сбое на А. После перезагрузки А продолжит получать пакеты от старого соединения, но, не обладая данными о соединении, уже не будет знать, что с ними делать. В этом случае он отправит требование сброса TCP компьютеру Б, сообщая, что соединение прервано. Пользователь компьютера Б может установить новое соединение либо предпринять иные действия.
Фальшивые сбросы TCP
В вышеописанном случае сообщение о сбросе отправлял один из участников соединения. Третий компьютер мог отслеживать TCP-пакеты этого соединения и затем подделать пакет с флагом сброса и отправить одному или обоим участникам от имени другого. Информация в заголовках должна указывать, что пакет получен якобы от другой стороны, а не от нападающего. Такая информация включает в себя IP-адреса и номера портов и должна содержать достаточно правдоподобные данные, чтобы вынудить участников прервать соединение. Правильно сформированные поддельные пакеты могут быть весьма надёжным способом нарушить любое TCP-соединение, доступное для отслеживания нападающим.
Области применения
Очевидным применением метода сброса TCP является тайное нарушение злоумышленником сообщения между сторонами. С другой стороны, известны системы сетевой безопасности, использующие такой способ. Прототип программмы «Buster» был продемонстрирован в 1995 г. и мог отправлять фальшивые пакеты сброса на любые соединения, использующие порты из заданного списка. Разработчики Linux предложили аналогичные возможности для брандмауэров на базе Linux в 2000 г. [2] , а свободная программа Snort использовала сбросы TCP для прерывания подозрительных соединений уже в 2003 г. [3]
Инцидент в Comcast
В конце 2007 г. провайдер Comcast начал использовать спуфинг TCP для вывода из строя P2P-программ и ПО для совместной работы (groupware) своих клиентов. [4] . Это вызвало конфликт, итогом которого стало создание Группы сетевого нейтралитета (NNSquad) в составе Lauren Weinstein, Vint Cerf, David Farber, Craig Newmark и других борцов за открытость Интернета. [5] В 2008 г. NNSquad выпустили программу NNSquad Network Measurement Agent для Windows (автор — John Bartas), которая выявляла фальшивые пакеты от Comcast и отличала их от настоящих сбросов. Примечательно, что алгоритм выявления сбросов был разработан на основе существующей открытой программы «Buster», созданной для борьбы с вредоносными объектами и рекламой на веб-страницах.
В январе 2008 г. FCC объявила о начале расследования спуфинг со стороны Comcast, а 21 августа 2008 г. предписала им прекратить эту практику.
Слово «фальшивые»
Некоторые представители провайдеров считают слово «фальшивые» неуместным в отношении сбросов TCP. Они также заявляли, что это легитимный способ сокращения сетевого трафика. [6]
References
- ↑Спецификация TCP (англ.)
- ↑May 2000 Linux discussion archives
- ↑Архив обсуждения SNORT re: TCP resets>
- ↑Associated Press, Comcast Blocks Some Internet Traffic
- ↑Домашная страница NNSquad
- ↑О легитимности сбросов для управления сетью (англ.)
External links
- Официальный сайт SNORT
- Отчёт EFF о практике сбросов в Comcast