Какая система хранения данных используется?
Мы используем открытую программную СХД Ceph и предлагаем многократное резервирование данных и высокую скорость работы дисковой подсистемы.
Что такое Ceph?
Ceph — отказоустойчивое распределенное хранилище данных, работающее по протоколу TCP. Одно из базовых свойств Ceph — масштабируемость до петабайтных размеров. Ceph предоставляет на выбор три различных абстракции для работы с хранилищем: абстракцию объектного хранилища (RADOS Gateway), блочного устройства (RADOS Block Device) или POSIX-совместимой файловой системы (CephFS).
Абстракция объектного хранилища
Абстракция объектного хранилища (RADOS Gateway, или RGW) вкупе с FastCGI-сервером позволяет использовать Ceph для хранения пользовательских объектов и предоставляет API, совместимый с S3/Swift. На Хабре уже была статья о том, как по-быстрому настроить Ceph и RGW. В режиме объектного хранилища Ceph давно и успешно используется в продакшене у ряда компаний.
Абстракция блочного устройства
Абстракция блочного устройства (в оригинале — RADOS Block Device, или RBD) предоставляет пользователю возможность создавать и использовать виртуальные блочные устройства произвольного размера. Программный интерфейс RBD позволяет работать с этими устройствами в режиме чтения/записи и выполнять служебные операции — изменение размера, клонирование, создание и возврат к снимку состояния и т.д.
Гипервизор QEMU содержит драйвер для работы с Ceph и обеспечивает виртуальным машинам доступ к блочным устройствам RBD. Поэтому Ceph сейчас поддерживается во всех популярных решениях для оркестровки облаков — OpenStack, CloudStack, ProxMox. RBD также готов к промышленному использованию.
Абстракция POSIX-совместимой файловой системы
CephFS — POSIX-совместимая файловая система, использующая Ceph в качестве хранилища. Несмотря на то, что CephFS не является production-ready и пока не имеет значимого промышленного применения, на Хабре уже есть инструкция по ее настройке.
Терминология
Ниже перечислены основные сущности Ceph:
Metadata server (MDS) — вспомогательный демон для обеспечения синхронного состояния файлов в точках монтирования CephFS. Работает по схеме активная копия + резервы, причем активная копия в пределах кластера только одна.
Mon (Monitor) — элемент инфраструктуры Ceph, который обеспечивает адресацию данных внутри кластера и хранит информацию о топологии, состоянии и распределении данных внутри хранилища. Клиент, желающий обратиться к блочному устройству rbd или к файлу на примонтированной cephfs, получает от монитора имя и положение rbd header — специального объекта, описывающего положение прочих объектов, относящихся к запрошенной абстракции (блочное устройство или файл) и далее общается со всеми OSD, участвующими в хранении файла.
Объект (Object) — блок данных фиксированного размера (по умолчанию 4 Мб). Вся информация, хранимая в Ceph, квантуется такими блоками. Чтобы избежать путаницы подчеркнём — это не пользовательские объекты из Object Storage, а объекты, используемые для внутреннего представления данных в Ceph.
OSD (object storage daemon) — сущность, которая отвечает за хранение данных, основной строительный элемент кластера Ceph. На одном физическом сервере может размещаться несколько OSD, каждая из которых имеет под собой отдельное физическое хранилище данных.
Карта OSD (OSD Map) — карта, ассоциирующая каждой плейсмент-группе набор из одной Primary OSD и одной или нескольких Replica OSD. Распределение placement groups (PG) по нодам хранилища OSD описывается срезом карты osdmap, в которой указаны положения всех PG и их реплик. Каждое изменение расположения PG в кластере сопровождается выпуском новой карты OSD, которая распространяется среди всех участников.
Плейсмент-группа (Placement Group, PG) — логическая группа, объединяющая множество объектов, предназначенная для упрощения адресации и синхронизации объектов. Каждый объект состоит лишь в одной плейсмент группе. Количество объектов, участвующих в плейсмент-группе, не регламентировано и может меняться.
Primary OSD — OSD, выбранная в качестве Primary для данной плейсмент-группы. Клиентское IO всегда обслуживается той OSD, которая является Primary для плейсмент группы, в которой находится интересующий клиента блок данных (объект). Primary OSD в асинхронном режиме реплицирует все данные на Replica OSD.
RADOS Gateway (RGW) — вспомогательный демон, исполняющий роль прокси для поддерживаемых API объектных хранилищ. Поддерживает географически разнесенные инсталляции (для разных пулов, или, в представлении Swift, регионов) и режим active-backup в пределах одного пула.
Replica OSD (Secondary) — OSD, которая не является Primary для данной плейсмент-группы и используется для репликации. Клиент никогда не общается с ними напрямую.
Фактор репликации (RF) — избыточность хранения данных. Фактор репликации является целым числом и показывает, сколько копий одного и того же объекта хранит кластер.
Архитектура Ceph
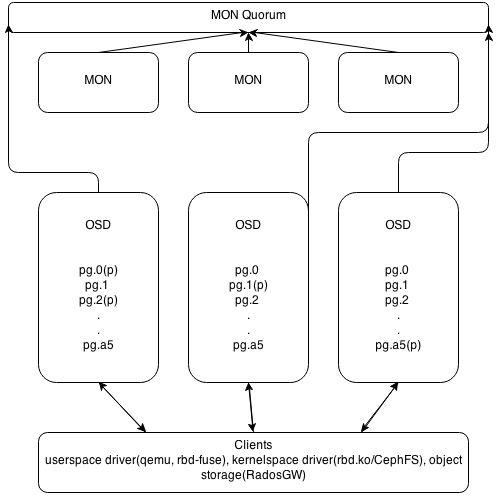
Основных типов демонов в Ceph два — мониторы (MON) и storage-ноды (OSD). RGW и MDS демоны не участвуют в распределении данных, являясь вспомогательными сервисами. Мониторы объединяются в кворум и общаются по PAXOS-подобному протоколу. Собственно, кластер является работоспособным до тех пор, пока в нем сохраняется большинство участников сконфигурированного кворума, то есть при ситуации split-brain посередине и четном количестве участников «выживет» только одна часть, поскольку предыдущие выборы в PAXOS автоматически уменьшили число активных участников до нечётного числа. При потере большинства кворума кластер «замораживается» для любых операций, предотвращая возможное рассогласование записанных или прочитанных данных до восстановления минимального кворума.
Восстановление и перебалансировка данных
Потеря из вида одной из копий объекта приводит к переходу объекта и содержащей его плейсмент-группы в состояние degraded и выпуску новой карты OSD (osdmap). Новая карта содержит новое расположение потерянной копии объекта и, если через заданное время утраченная копия не вернется, недостающая копия будет восстановлена в другом месте, чтобы сохранить число копий, определяемое фактором репликации. Операции, выполнявшиеся в момент подобной ошибки, автоматически переключатся на одну из доступных копий. В худшем случае их задержка будет измеряться единицами секунд.
Важным свойством Ceph является то, что все операции по перебалансировке кластера происходят в фоновом режиме одновременно с пользовательским I/O. Если клиент обращается к объекту, который находится в recovering состоянии, Ceph вне очереди восстановит объект и его копии, а затем выполнит запрос клиента. Такой подход обеспечивает минимальное латенси I/O даже тогда, когда восстановление кластера идёт полным ходом.
Распределение данных в кластере
Одна из самых важных особенностей Ceph — возможность тонкой настройки репликации, задаваемой правилами CRUSH — мощного и гибкого механизма, базирующегося на случайном распределении PG по группе OSD с учётом правил (вес, состояние ноды, запрет на размещение в той же группе нод). По умолчанию OSD имеют вес, базирующийся на величине свободного места в соответствующей точке монтирования в момент ввода OSD в кластер и подчиняются правилу распределения данных, запрещающему держать две копии одной PG на одной ноде. CRUSHMAP — описание распределения данных — может быть модифицирован под правила, запрещающие держать вторую копию в пределах одной стойки, тем самым обеспечивая отказоустойчивость на уровне вылета целой стойки.
Теоретически, подобный подход позволяет осуществлять в том числе гео-репликацию в реальном времени, однако на практике это можно использовать лишь в режиме Object Storage, поскольку в режимах CephFS и RBD задержки операций будут слишком велики.
Альтернативы и преимущества Ceph
Наиболее качественной и близкой по духу свободной кластерной ФС являются GlusterFS. Она поддерживается RedHat и имеет некоторые преимущества (например, локализует Primary копию данных рядом с клиентом). Однако наши тесты показали некоторое отставание GlusterFS в смысле производительности и плохую отзывчивость при перестроении. Другие серьёзные минусы — отсутствие CoW (в том числе и в прогнозируемом будущем) и низкая активность сообщества.
Преимущество Ceph перед прочими кластерными системами хранения данных состоит в отсутствии единых точек отказа и в практически нулевой стоимости обслуживания при восстановительных операциях. Избыточность и устойчивость к авариям заложена на уровне дизайна и достается даром.
Возможные замены подразделяются на два типа — кластерные фс для суперкомпьютеров(GPFS/Lustre/etc.) и дешевые централизованные решения вроде iSCSI или NFS. Первый тип достаточно сложен в обслуживании и не заточен на эксплуатацию в условиях отказавшего оборудования — «замораживание» ввода-вывода, особенно чувствительное при экспорте точки монтирования в вычислительную ноду, не позволяет использовать подобные фс в публичном сегменте. Минусы «классических» решений довольно хорошо понятны — отсутствие масштабируемости и необходимость закладывать топологию для failover на уровне железа, что приводит к увеличению стоимости.
С Ceph восстановление и перестроение кластера происходят действительно незаметно, практически не влияя на клиентское I/O. То есть деградировавший кластер для Ceph — это не экстраординарная ситуация, а всего лишь одно из рабочих состояний. Насколько нам известно, ни одна другая открытая программная СХД не имеет этого свойства, достаточного для её использования в публичном облаке, где запланированное прекращение обслуживания невозможно.
Производительность
Как указывалось в начале статьи, данные в Ceph квантуются достаточно маленькими порциями и псевдослучайно распределены по OSD. Это приводит к тому, что реальное I/O каждого клиента Ceph достаточно равномерно «размазывается» по всем дискам кластера. В результате этого:
Снижается накал борьбы между клиентами за дисковый ресурс
Растёт верхняя планка теоретически возможной интенсивности работы с блочным устройством.
Вследствие п.1 и 2 каждый клиент получает существенно большие удельные лимиты по iops и bandwidth, чем может дать классический подход за те же деньги.
Есть и другие причины быстродействия Ceph. Все операции записи сначала попадают в журнал OSD, а затем, не задерживая клиента, асинхронно переносятся в персистентное файловое хранилище. Поэтому размещение журнала на SSD, которое рекомендовано в документации Ceph, многократно ускоряет операции записи.
Цели и результаты
Несколько лет назад Ceph подкупил нас своими впечатляющими возможностями. Хотя многие из них на тот момент работали совсем не идеально, мы приняли решение строить облако именно на нём. В последующие месяцы мы столкнулись с рядом проблем, доставивших нам немало неприятных минут.
Например, сразу после публичного релиза год назад мы обнаружили, что перестроение кластера влияет на его отзывчивость больше, чем хотелось бы. Или что определенный вид операций приводит к существенному увеличению латенси последующих операций. Или что в определенных (к счастью, редких) условиях клиентская виртуальная машина может намертво зависнуть на I/O. Так или иначе, багфикс длительностью в полгода сделал свое дело, и на сегодняшний день мы абсолютно уверены в нашей СХД. Ну а в процессе устранения трудностей мы обзавелись целым рядом инструментов отладки и мониторинга. Один из них — мониторинг длительности всех без исключения операций с блочными устройствами (на данный момент кластер ежесекундно обслуживает несколько тысяч операций чтения/записи). Вот так сегодня выглядит отчет о латенси в нашей админ-панели:
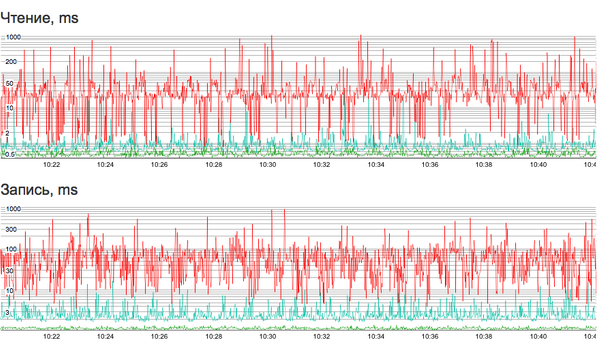
Зелёным на графике отмечена минимальная длительность операций, красным — максимальная, бирюзовым — медиана. Впечатляет, не правда ли?
Хотя система хранения данных уже давно абсолютно стабильна, эти инструменты по-прежнему помогают нам в решении повседневных задач и заодно цифрами подтверждают отличное качество нашего сервиса.
В конечном счете Ceph позволил нам обеспечить:
- снижение IO latency до значений хорошего локального SSD;
- апгрейд всех дисков хранилища с 1Tb на 4Tb модели в незаметном для пользователей режиме;
- аппаратный отказ одной ноды незаметен для пользователей как событие;
- благодаря живой миграции и использованию Ceph аппаратные и программные обновления происходят с нулевым даунтаймом;
- снэпшоты, клонирование, инкрементальные диффы нашли свое применение в продакшене и радуют клиентов;
- сверхнизкие цены на услуги.
Serveroid.com остаётся единственным в России и одним из немногих в мире хостеров, кто использует Ceph в продакшене. Благодаря Ceph у нас получилось реализовать то, о чем часто пишут в визионерских постах о будущем облаков — совместить вычислительные ноды и ноды хранилища на обычном железе и достичь показателей, близких к значениям энтерпрайзных «полок» без увеличения стоимости. Ну а поскольку сэкономленные деньги — все равно что заработанные, мы получили возможность снизить цены на услуги практически до уровня западных дискаунтеров. В этом легко убедиться, взглянув на наши тарифы.
Если вы используете выделенный хостинг в своей работе — предлагаем вам попробовать наши услуги в действии и оценить, какие преимущества дает Ceph. Платить ничего не нужно — двухнедельный пробный период и тестовый баланс в 500 рублей вы сможете активировать сразу после регистрации.
Пять вопросов о Ceph с пояснениями

Что нужно знать о Ceph, хранилище с открытым исходным кодом, чтобы решить, подходит ли оно вашей компании. В статье будет сравнение с альтернативными объектными хранилищами, а также рассмотрена оптимизация Ceph.
Хранилище Ceph — одно из наиболее популярных объектных хранилищ. Это высокомасштабируемое и унифицированное хранилище с открытым исходным кодом также обладает некоторыми преимуществами.
Ceph предлагает функции, которые, в принципе, есть в других хранилищах для предприятий, но он, вероятно, будет дешевле, чем обычный SAN. Для Ceph с открытым исходным кодом не нужны лицензионные отчисления, которые есть у проприетарных систем. Также у Ceph нету зависимости от дорогого специализированного оборудования, он может быть установлен на обычное оборудование.
Среди других преимуществ — масштабируемость и гибкость. Ceph предлагает несколько интерфейсов доступа к хранилищу: объектный, блочный и файловый. Для увеличения емкости системы достаточно добавить больше серверов.
К некоторым недостаткам при использовании Ceph можно отнести нужду в быстрой, а значит более дорогой сети. Это также не бесплатно для любой компании. Если вы используете его для хранения важных данных — скорее всего вы используете один из двух коммерческих вариантов с поддержкой от RedHat или SUSE. Несмотря на это, Ceph — это более дешёвая и живучая альтернатива проприетарным SAN.
Какое объектное хранилище лучше: Ceph или Swift?
Ceph и Swift — объектные хранилища, распределяющие и реплицирующие данные по кластеру. Они используют файловую систему XFS или другую файловую систему, доступную в Linux. Они оба разработаны для масштабирования, так что пользователи могут легко добавить узлы хранилища.
Но что касается доступа к данным, то Swift разработан с прицелом на облака, использует RESTful API. Приложения могут няпрямую получить доступ к Swift, обходя при этом операционную систему. Это хорошо в облачном окружении, но усложняет доступ к хранилищу Swift.
Ceph — более гибкое объектное хранилище с четырьмя способами доступа: Amazon S3 RESTful API, CephFS, Rados Block Device и шлюзом iSCSI. Ceph и Swift также отличаются способом доступа клиентов. Так в Swift клиенты должны идти через Swift Gateway, который сам по себе является единой точкой отказа. Ceph с другой стороны использует устройство объектного хранилища, доступное на каждом узле. Другая часть, используемая для доступа к объектному хранилищу, запускается на клиенте. Так что здесь Ceph более гибкий.
Данные, хранимые в Ceph, обычно целостные по всему кластеру. В принципе это справедливо и для данных в Swift, но для синхронизации кластера может потребоваться время. С учетом этой разницы Ceph неплохо работает в пределах одного датацентра, работая с данными, которым надо высокий уровень целостности, например виртуальные машины и базы данных. Swift лучше подходит для больших окружений, работающих с огромными объемами данных.
Какая разница между Ceph и GlusterFS?
GlusterFS и Ceph — системы хранения данных с открытым исходным кодом, отлично работающими в облачных окружениях. Обе могут легко внедрять новые устройства хранения в существующую инфраструктуру хранения, используют репликацию для отказоустойчивости, а также работают на обычном оборудовании. В обеих системах доступ к метаданным децентрализован, подразумевая отсутствие единой точки отказа.
Несмотря на наличие общих вещей, у них есть также ключевые различия. GlusterFS — файловая система Linux, которую легко внедрить в окружении Linux, но нельзя так же легко внедрить в окружении Windows.
Ceph с другой стороны предоставляет высокомасштабируемое объектное, файловое и блочное хранилище в единой унифицированной системе. Как и в любом другом объектном хранилище, приложения пишут в хранилище с помощью API, минуя операционную систему. С учетом этого, хранилища Ceph внедряются одинаково легко как в Linux, так и в Windows. Из-за этого, а также по другим причинам, Ceph — лучший выбор для разнородных окружений, где используются Linux и другие операционные системы.
Если сравнивать по скорости работы, то и Ceph и GlusterFS работают примерно одинаково. Также GlusterFS по большей части ассоциируется с RedHat, в то же время Ceph шире поддерживается сообществом.
Ceph с открытым исходным кодом или коммерческая версия Ceph: как их сравнивать?
Пользователи могут без каких либо выплат сделать любую SDS на основе Ceph, пока его исходный код остается открытым. Ceph предлагает руководства по запуску, в котором описаны все этапы по его сборке в любом дистрибутиве Linux, а также настройке окружения Ceph.
Это достаточно сложный процесс, требующий определенного опыта. Тут и появляются коммерческие сборки Ceph, их проще сделать, кроме сборок также предоставляется и поддержка.
Есть два коммерческих продукта: RedHat Ceph Storage и SUSE Enterprise Storage. Есть некоторые различия, так компания SUSE разработала iSCSI Gateway, позволяющий пользователям получить доступ к хранилищу Ceph. RedHat внедрила Ceph-Ansible, инструмент управления настройками, с которым Ceph относительно легче устанавливать и настраивать.
Какие способы улучшения производительности Ceph лучшие?
Для хорошей производительности достаточно SATA дисков. Алгоритм CRUSH (Controlled Replication Under Scalable Hashing) в Ceph решает, где хранить данные в хранилище. Он разработан для гарантии быстрого доступа к хранилищу. Однако для оптимальной скорости Ceph надо 10G сеть, а лучше — 40G.
Несколько больших серверов, на которых установлено много дисков, обеспечат наилучшую производительность, однако диск с журналом должен быть на отдельном устройстве. Использование журнала на SSD обеспечит максимальную скорость, а файловая система Btrfs даст оптимальную производительность Ceph.
Как вы внедряете Ceph на Windows?
Есть два способа внедрения: Ceph Gateway и iSCSI target в SUSE Enterprise Storage. Ceph Gateway обеспечивает приложениям доступ с помощью RESTful API, но это не самый лучший способ предоставления доступа для операционной системы.
Ceph может быть настроен как и любая другая СХД на основе iSCSI с помощью iSCSI target в SUSE Enterprise Storage. Это дает доступ к хранилищу для операционной системы с поддержкой iSCSI initiator, к примеру серверной Windows.
Может быть интересно:
- Интенсив по Python для инженеров и разработчиков
- Курс по GoLang для инженеров
Red Hat Ceph Storage
Ceph Storage — пакет программно-конфигурируемого объектного и файлового облачного хранилища.
Ceph — свободная программная объектная сеть хранения. Она обеспечивает файловый и блочный интерфейсы доступа. Может использоваться в системах, действующих в составе кластера из нескольких Linux-машин или тысяч узлов. Встроенные механизмы продублированной репликации данных обеспечивают высокую живучесть системы, при добавлении или удалении узлов массив данных автоматически балансируется с учётом сделанных изменений. Такое разделение позволяет оптимизировать затраты за счет использования недорогих серверов и жестких дисков и реализовать объектные хранилища класса «web-scale» для современных сценариев использования. Кроме того, в новой версии значительно повышается гибкость и масштабируемость СХД для поддержки мультипетабайтных массивов данных.
Обработка данных и метаданных в Ceph разделена на различные группы узлов в кластере, примерно как это сделано в Lustre, с тем различием, что обработка делается на уровне пользователя, не требуя особой поддержки от ядра операционных систем узлов. Ceph может работать поверх блочных устройств, внутри одного файла или используя действующую файловую систему узла (например, XFS).
Программные системы хранения данных Red Hat Ceph Storage и Red Hat Gluster Storage – это мощные и гибкие решения, ориентированные на поддержку рабочих нагрузок определенных типов. Так, Red Hat Ceph Storage представляет собой надежную унифицированную платформу хранения для объектных хранилищ и облачных инфраструктур с массивами данных петабайтных размеров. В свою очередь, Red Hat Gluster Storage является мощной распределенной файловой системой для организации гибких служб хранения данных для дата-центров на основе физических серверов, виртуальных машин, частных и общедоступных облачных сред, а также инфраструктур контейнерных приложений. Оба эти решения не требуют специализированного оборудования для развертывания, активно поддерживаются сообществом разработки ПО с открытым кодом и компаниями-партнерами, а также широко применяются в корпоративном секторе по всему миру.
2020: Red Hat Ceph Storage 4
12 марта 2020 года компания Red Hat сообщила о выпуске Red Hat Ceph Storage 4, обновленной версии своего объектного хранилища, которое обеспечивает масштабирование до уровня петабайт и предназначено для облачно-ориентированных приложений и систем аналитической обработки данных. Решение базируется на релизе Nautilus проекта open source сообщества Ceph.

По информации компании, благодаря повышенной масштабируемости и обновленным, упрощающим эксплуатацию функциям, Red Hat Ceph Storage 4 помогает представителям самых разных отраслей, включая финансовый сектор, госучреждения, автоиндустрию и телекоммуникационные компании, более эффективно поддерживать такие задачи, как разработка приложений, анализ данных, искусственный интеллект (AI), машинное обучение (ML) и другие виды рабочих нагрузок следующего поколения.
Предоставляя организациям возможность развернуть объектные хранилища петабайтного размера, совместимые с Amazon S3 (Simplified Storage Service), Red Hat Ceph Storage позволяет масштабировать производительность при сохранении всех преимуществ облачной экономики. В ходе недавнего внутреннего тестирования последняя версия Red Hat Ceph Storage продемонстрировала более чем двукратный прирост производительности для рабочих нагрузок с интенсивной записью данных, подтвердив свою важность для удовлетворения требований современных приложений, активно оперирующих большими объемами данных.
Следующее поколение рабочих нагрузок, связанных с обработкой данных, увеличивает нагрузку на инфраструктуры хранения и делает их более сложными, что резко повышает роль автоматизации для эксплуатации таких инфраструктур, особенно при их масштабировании. За счет более высокого уровня автоматизации при управлении и размещении данных, Red Hat Ceph Storage 4 помогает ИТ-специалистам плавно перейти от фокусированных на хранилищах данных моделей инфраструктуры к сервисно-ориентированным схемам, чтобы расширить спектр поддерживаемых приложений и целевую аудитории систем хранения. Развитые возможности самосопровождения и самовосстановления Red Hat Ceph Storage 4 в области автоматизированной репликации, восстановления и инициализации систем (provisioning) улучшают не только масштабируемость, но и показатели непрерывности бизнеса.
Red Hat Ceph Storage 4 оптимизирован под запросы клиентов на эффективное хранение и управление быстро растущими объемами данных, генерируемых современными рабочими нагрузками, без привлечения дополнительного операционного персонала. Red Hat Ceph Storage 4 предлагает ИТ-командам упрощенную и интуитивно понятную эксплуатацию, располагая для этого целым рядом обновленных функций:
- Упрощенная процедура установки – стандартная установка занимает менее 10 минут.
- Обновленная веб консоль управления (management dashboard) – унифицированный и высокоуровневый контроль операций в любой момент времени помогает ИТ-специалистам оперативно выявлять и решать возникающие проблемы.
- Обновленная функция мониторинга качества услуг – подтверждение QoS-показателей хранилища данных с позиции приложений в мультитенантной облачной среде.
- Интегрированные bucket-уведомления – поддержка оптимизированных для Kubernetes serverless-архитектур для автоматизации конвейеров обработки данных.
На март 2020 года Red Hat Ceph Storage 4 уже доступен для скачивания.
2018: Переход проекта под крыло Linux Foundation
В ноябре 2018 года Red Hat сообщила о передаче проекта распределенного хранилища Ceph под покровительство организации Linux Foundation. Об этом решении было объявлено спустя примерно две недели после продажи Red Hat корпорации IBM.
Финансированием, развитием инфраструктуры Ceph и поддержкой связанного с проектом сообщества в рамках Linux Foundation займется новая организация Ceph Foundation, объединившая более 30 участников. Среди них — Red Hat, SUSE, Intel, Canonical, China Mobile, DigitalOcean, OVH, Western Digital и ZTE. Также эта некоммерческая организация заменит консультативный совет Ceph Advisory Board.

Red Hat отдала Linux Foundation проект распределенного хранилища Ceph
Предполагается, что после превращения Ceph в независимый проект Ceph Foundation создаст нейтральную площадку, в рамках которой будет развиваться и управляться технология. При этом данная площадка не будет привязана к предпочтениям каких-либо производителей и будет способствовать более тесному взаимодействию с сообществом.
Управляющая структура Ceph Leadership Team по-прежнему будет принимать связанные с развитием проекта технические решения. Ее представитель войдет в управляющий совет Ceph Foundation и станет своего рода связующим звеном в процессе разработки.
К ноябрю 2018 года Ceph пользуется немало крупных компаний, в том числе BMW, SAP и Salesforce.com. [1]
2017: Red Hat Ceph Storage 2.3
В июне 2017 года Red Hat, поставщик решений с открытым кодом, объявила о выпуске Red Hat Ceph Storage 2.3, новой версии программно-определяемой системы хранения данных (СХД). Система, построенная на основе открытого проекта Ceph 10.2 (Jewel), теперь совместима с клиентом файловой системы Hadoop S3A, поддерживает протокол Network File System (NFS) и может быть развернута в контейнерах. Эти новшества повышают универсальность объектного хранилища Ceph Storage, позволяя использовать его как для систем аналитической обработки больших данных (Big Data), так и для работающих с файлами нагрузок. Новая версия Ceph Storage представляет собой очередной шаг Red Hat к созданию гибкой и эластичной СХД, которая может быть оптимизирована для широкого круга корпоративных задач и вычислительных сред.
Данная версия Red Hat Ceph Storage получила эффективный NFS интерфейс для Ceph Object Gateway. Это позволит пользователям и приложениям, в зависимости от решаемых задач и имеющихся инструментов, обращаться к одним и тем же наборам данных как по объектному S3, так и по файловому NFS интерфейсам. Используя мульти-сайтовые возможности Red Hat Ceph Storage, можно обеспечить доступ к данным в глобальных кластерах по протоколу NFS. В результате, клиенты, использующие Ceph Storage в качестве файлового хранилища, получают гибкость, масштабируемость и экономическую эффективность объектного хранилища в ходе постепенной модернизации системы хранения данных.
Совместимость с клиентом файловой системы Hadoop S3A позволяет использовать объектное хранилище Red Hat Ceph Storage в системах аналитической обработки больших данных, таких как Apache Hadoop MapReduce, Hive и Spark. Благодаря этому пользователи смогут оценить все его преимущества: управление жизненным циклом объектов и метаданными, сокращение затрат за счет эффективного резервирования данных с использованием erasure coding, а также возможность масштабировать вычислительные мощности и емкости хранения независимо друг от друга.
Кроме того, Red Hat Ceph Storage теперь поддерживает развертывание в контейнерах. Контейнерный образ продукта, который функционально не отличается от традиционного пакета, можно загрузить на сайте Red Hat Container Registry. Контейнерная версия Ceph Storage вместе с системой автоматизации Red Hat Ansible позволяет выполнять установку и обновление продукта как атомарные операции, что упрощает управление и ускоряет развертывание программно-определяемых СХД.
2016: Red Hat Ceph Storage 2
22 июня 2016 года Red Hat анонсировала выход Ceph Storage 2 — программно-определяемой СХД, созданной на платформе версии СПО-проекта Ceph Jewel (v10.2.0). В релизе обещаны повышение производительности обработки объектных нагрузок и удобство работы пользователей [2] .

Компоненты Ceph (2016)
Реализована поддержка POSIX-совместимой файловой системы Ceph Filesystem (CephFS), которая способна хранить данные в кластерах распределенной системы Ceph Storage Cluster. На первых порах CephFS будет иметь статус tech preview и сможет использоваться в IaaS-инфраструктурах на базе OpenStack и облачного сервиса разделяемой файловой системы Manila. Появились возможности, полезные для корпоративных конфигураций объектного хранения и обеспечивающие повышенную масштабируемость, защищенность и строгую совместимость с общепринятыми API-интерфейсами.
Особенности релиза
- работа с глобальными объектными кластерами, поддерживающими единое пространство имен и синхронизацию данных между кластерами, развернутыми в разных регионах;
- повышенная защищенность за счет интеграции с такими популярными системами аутентификации, как Active Directory, LDAP и OpenStack Identity (Keystone) v3;
- тесная совместимость со средами Amazon S3 и OpenStack Object Storage (Swift), включая поддержку AWS v4 Client Signatures, версионность объектов и массовое их удаление.
Продукт оснастили консолью управления Red Hat Storage Console 2. Утверждается, что она упрощает как развертывание СХД Ceph, управление ею: время разворачивания сокращается с суток до часов.
Выпуск коммерческой версии Red Hat Ceph Storage 2 заявлен на лето 2016 года.
История
Проект системы создал Сейдж Уэйл (Sage Weil) в 2007 году в рамках докторской диссертации. Позже к созданию системы подключились другие разработчики. Развивая и коммерциализируя систему в 2012 году Уэйл основал фирму Inktank [3] .
Примечания
- ↑Ceph open-source storage takes an organizational step forward
- ↑Red Hat обновляет Ceph-платформу программно-определяемой СХД
- ↑Ceph
Облачное хранилище Ceph
Технология хранения данных Ceph привлекательна для реализации любых промышленных задач. Пользователям она обеспечивает:
— Возможность увеличения мощности до петабайтных размеров без перерыва в работе и обслуживании.
— Еженедельная синхронизация. Защищает данные от потери или искажения, при этом процесс происходит автоматически, но остается прозрачным для пользователя. Нет необходимости постоянно отвлекаться на резервное копирование и можно быть уверенным в сохранности информации.
Дополнительная информация о Ceph доступна у специалистов компании БитВеб. Мы предлагаем современные решения в области выделенных и виртуальных серверов и готовы рассказать, как происходит установка Ceph и что нужно для начала работы. Сотрудничество с нами – это актуальные решения и тарифы, доступные каждому. Мы предлагаем поддержку ресурсов любой емкости и обеспечение к ним круглосуточного доступа для Вашей целевой аудитории. Также мы готовы предоставить личную консультацию по контактным телефонам.
Масштабируемость до 1PB
Начиная от 2 Tb, вы можете легко расширить Ceph хранилище до пета-байт. Технология Ceph предназначена, чтобы иметь возможность модернизировать емкость запоминающего устройства без перерыва в работе.
100% отказоустойчивость
Облачное хранилище Ceph является самым надежным решением для проектов требующих непрерывную работу. Данные реплицируются 3 раза по различным узлам кластера, обеспечивая максимальную доступность ваших файлов во время отключений одного из серверов.
Синхронизация данных
Состояние данных по каждой реплике проверяется еженедельно с целью обеспечения наилучшей сохранности. Эта операция прозрачна для пользователя, у которого нет необходимости лично заниматься проверкой состояния и создания резервной копии своих данных.
Безопасность данных имеет первостепенное значение, и именно поэтому мы используем технологию хранения данных и резервирования под названием «Ceph«. Благодаря полуслучайному алгоритму, используемому для распределения блоков памяти внутри одного или нескольких кластеров физических жестких дисков, данные никогда не хранятся в одной критической точке, обеспечивая, таким образом, устойчивость решения для хранения данных даже в том случае, если потребуется обслуживание даже нескольких блоков хранения данных. Тем самым гарантируется доступ к данным, а также их целостность.
Высокая безопасность Ceph благодаря тройному резервированному копированию данных в пределах наших инфраструктур, расширение по запросу в любой момент, позволяет масштабировать хранилище до пета-байт.
Облачное хранилище Ceph
Современные облачные хранилища высоко поднимают планку к специфике распределения и хранения информации. Актуальным решением является выбор в пользу системы Ceph. Ей присущи следующие свойства:
- надежность хранения данных;
- постоянный доступ к информации без аварий;
- отсутствие задержек при информационном обмене;
- широкий спектр прикладных возможностей, увеличивающих удобство работы с Ceph Storage
Ceph использует различные протоколы работы, одним из которых является блочный. Пользователю предлагается работать с виртуальными блоками произвольного размера, интерфейс поддерживает работу в режиме чтения и записи, выполнения служебных операций. Ceph поддерживается большинством систем виртуализации, например, VMware, Proxmox. Также Ceph удобен для работы с VMmanager и в целом адаптирован для промышленного использования.
Использование Ceph
Особенности распределения данных в кластере Ceph обеспечивают ряд важнейших с точки информационной безопасности преимуществ:
- Данные не хранятся в одной точке.
- Копия не хранится в пределах одной стойки.
Любые данные копируются в трех узлах кластера Ceph. Даже в случае отказа одного из них пользователь имеет доступ к информации в режиме чтения, записи или рабочих запросов, система продолжает работать в привычном режиме.