Ускорить count() postgresql
Как ускорить подсчет всех строк в PostgreSQL v9.3.11? Главное чтобы WHERE поддерживалось. Сейчас скорость загрузки: 2.9424 сек. (324477 записей) Запрос :
SELECT COUNT("my_field") FROM "mytable"; Я уже и estimate смотрел, и создание таблицы для записи кол-ва строк через INSERT + DELETE триггеры. Но это все не подходит, так как должна быть сортировка на странице, поэтому важен WHERE , а в estimate и прочем методе не знаю как использовать это. Подскажите пожалуйста, как ускорить подсчет строк в таблице с учетом WHERE ?
Отслеживать
4,022 2 2 золотых знака 18 18 серебряных знаков 37 37 бронзовых знаков
Как ускорить работу PostgreSQL с помощью конфигурации базы и оптимизации запросов
Когда работаешь с данными, скорость запросов — один из главных показателей эффективности. Чтобы повысить эту скорость, нужно знать не только как оптимизировать сами запросы, но и как конфигурация самой базы влияет на скорость выполнения запроса.
Администратор баз данных в Southbridge и ведущий инженер компании Data Driven Lab Иван Чувашов занимается базами данных 15 лет и сегодня хочет поговорить про оптимизацию запросов. Разбирать все будет на примере PostgreSQL, так как именно с этой базой он сейчас работает плотнее всего.
Эта статья — конспект бесплатного вебинара об оптимизации PostgreSQL от «Слёрма». Если вам удобнее смотреть, а не читать, переходите на YouTube.

Немного об оптимизации
SQL — весьма сложная тема для погружения и понимания. Условно у нас есть 30 команд — и сотни способов и подходов, как их использовать. Мысля множествами, можем выбирать разные интерпретации SQL-языка, чтобы помочь базе данных выполнить наш запрос. Поэтому какой-то серебряной пули, то есть универсального способа ускорения SQL-запросов нет. Ну либо я не нашел этот философский камень). Нельзя сформировать пошаговую инструкцию, потому что для каждой базы, ситуации и запроса будет своя схема — нужно в общем понимать и чувствовать, что следует сделать.
Но чтобы сформировать это понимание, нужно на практике увидеть, как изменение отдельных параметров приводит к ускорению в конкретных ситуациях. Это мы и рассмотрим на практике.
Оптимизировать работу с данными можно четырьмя способами:
- «Правильно» настроив конфигурацию БД, в нашем случае PostgreSQL.
- Оптимизировав конкретные запросы.
- Переработав архитектуру данных.
- Изменив работу приложения.
Архитектуру данных и работу приложения мы затрагивать не будем, так как это напрямую не связано с SQL. А вот о конфигурации БД и оптимизации конкретных запросов поговорим на практических примерах.
Конфигурация PostgreSQL
В PostgreSQL много параметров, которые позволяют ускорить выполнение запросов. С помощью этих параметров мы сообщаем PostgreSQL, например, на каком железе он находится и как должен с ним работать.Также мы можем настроить логику работы приложения с PostgreSQL: установить лимиты или изменить параметры выбора плана запросов, указав максимальное количество JOIN в запросе.
Параметров много, но я разберу самые полезные и интересные, с моей точки зрения.
Maintenance_work_mem и autovacuum_work_mem. По сути они мало связаны с оптимизацией, но по факту очень важны. PostgreSQL — это MVCС-модель, а значит есть процессы, которые занимаются очисткой неактуальных данных и поддерживают консистентность обслуживающих процессов.
maintenance_work_mem больше работает с create-индексами, обновлениями альта-тейбл, системными параметрами. autovacuum_work_mem , работает с autovacuum. И эти два параметра часто используют так: ставят autovacuum_work_mem -1 , чтобы он заимствовал значение параметра от maintenance_work_mem .
max_parallel_maintenance_workers и autovacuum_мах_workers. Если мы изменим вышеперечисленные параметры, и не учтем это, мы можем сломать наш сервер. Ну либо сильно его замедлим.
work_mem. Он отвечает за выделение памяти под запрос, который мы хотим выполнить на PostgreSQL. Главная его фишка в том, что он может выделять память довольно специфически. Например, возьмем несколько утрированный запрос:
select * from (select * from table1) t1 a join (select * from table2) t2 on t1.id = t2.idКак думаете, сколько памяти он будет потреблять?
Кажется, что раз work_mem выделяет память на запрос, то потребление будет один work_mem . Но по факту один выделится на главный запрос, и по одному на каждый вложенный. То есть всего на запрос потратится 3* work_mem . Кажется, что это не много, но если у нас 100 таких запросов, это уже существенно.
Поэтому не стоит безгранично увеличивать work_mem — память на сервере конечна. Может быть, стоит сделать его меньше, а побольше отдать, например, внутренней памяти PostgreSQL.
Этот параметр нельзя настроить один раз и потом про него забыть. Разные запросы, изменение логики приложения — все это отражается на памяти, поэтому work_mem регулярно нужно корректировать. Есть даже схемы, в которых параметр настраивается с помощью приложения, передавая в сессии значения этого параметра, так как оно лучше понимает, какой запрос будет выполняться и сколько памяти ему для этого нужно.
У этого параметра всегда нужно искать точку равновесия. Если выставить его маленьким, то для операций вроде агрегации и сортировки БД будет использовать диск — а это очень медленно. Если же work_mem сделать слишком большим, он съест память, которая не расходуется.
from_collapse_limit. Этот параметр отвечает за то, сколько джойнов может быть в вашем запросе прежде, чем будет выбран алгоритм генетический вероятного поиска плана запросов. Он важен, если у вас есть серьезные большие отчеты. По умолчанию его значение. 10. Если уменьшить — планы могут выбираться неоптимально. А если сильно увеличить — планирование запроса может занять недопустимое количество времени. Поэтому его тоже можно варьировать и смотреть, как это отражается на степени производительности ваших запросов.
Подробнее о разных параметрах PostgreSQL можно прочитать в документации. Там есть информация об их настройках, параметрах и влиянии на производительность. Как уже сказано выше, универсальных советов здесь нет, так что нужно экспериментировать и применять на практике.
Оптимизация запросов
Поиск запросов для оптимизации
Прежде чем приступать к оптимизации нужно понять — как вообще найти эти самые медленные, «неоптимизированные» запросы. Можно делать это несколькими способами:
- Вручную искать в логах PostgreSQL.
- Использовать системы мониторинга, которые парсят эти же логи и отображают их на графике. Например, pgbadger, который выдает логи в виде html-странички с удобным интерфейсом.
Кроме медленных можно поискать запросы, которые выполняются чаще других, иногда по непонятным причинам. В этом поиске поможет расширение pg_stat_statements. Например, у меня была ситуация, когда 5 или 6 запросов выполнялись на сервере больше 300 раз в секунду. То есть на ровном месте создавалось две тысячи запросов — а учитывая секционированные таблицы, внутри это давало еще большую нагрузку. Как только мы снизили частоту выполнения запросу до раза в секунду, приложение и база стали работать быстрее — не пришлось оптимизировать сам запрос.
Теперь представим, что мы взяли запрос, оптимизировали его и посмотрели на время. Вроде бы оно уменьшилось в пять раз, но что это значит на самом деле? Разберем на примерах и посмотрим, почему время на самом деле не показатель быстродействия.
Первый пример
Давайте создадим табличку user, внесем в нее 10 миллионов записей:
create table users ( id bigint primary key, login varchar(200) not null, first_name varchar(200) not null, last_name varchar(200) not null, create_date timestamp not null default now() ); CREATE TABLE insert into users select id, random() * id, md5(sin(id)::text), md5(cos(id)::text) from generate_series(1, 10000000) id; INSERT 0 10000000 analyze users; ANALYZEПотом выполним такой запрос:
\timing Timing is on. select count(distinct id) from users; count ---------- 10000000 (1 row) Time: 4535.931 ms (00:04.536)Получилось 4,5 секунды — для нас это неоптимально. Но выполним его второй раз — и вот он уже занимает 3 секунды, хотя мы ничего не меняли. В чем дело?
На самом деле причин может быть много: загрузка данных с диска в оперативную память сервера, текущая нагрузка на сервер, другая работа приложения, какие-то изменения конфигурации. Поэтому время выполнения запроса может быть разным, и ориентироваться при оптимизации только на этот критерий нельзя.
Для расчетов некоторые используют explain. Пишут запрос и смотрят, какая у него стоимость, cost. В PostgreSQL cost — это среднее время доступа до случайной страницы в БД, поэтому по количеству костов можно посчитать время. Выглядит это так:
explain select count(distinct id) from users; QUERY PLAN --------------------------------------------------------------------- Aggregate (cost=176230.12..176230.14 rows=1 width=8) -> Seq Scan on users (cost=0.00..173771.10 rows=983610 width=8) (2 rows) Time: 0.435 msНо эта величина тоже не стабильная и зависит от многих параметров. Например, если диск долгое время был загружен, средняя стоимость изменится, то есть показатель снова будет необъективным.
Слово explain показывает как будет работать запрос, но это не реальный план выполнения запроса. Чтобы это исправить, нужно добавить analyze :
explain analyze select count(distinct id) from users; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=284689.43..284689.45 rows=1 width=8) (actual time=4228.384..4228.386 rows=1 loops=1) -> Index Only Scan using users_pkey on users (cost=0.43..259689.43 rows=10000000 width=8) (actual time=1.006..1224.245 rows=10000000 loops=1) Heap Fetches: 61 Planning Time: 0.079 ms Execution Time: 4229.148 ms (5 rows)Здесь результат уже чуть более стабильный, по крайней мере в плане костов. И можно сравнивать по ним и говорить, что мы повысили производительность запросов в 5–6 раз. Но интереснее говорить не о костах и о времени выполнения — а о буферах. То есть о том, какой объем данных нам потребовался для выполнения конкретного запроса.
Буферы не завязаны на архитектуру, диск и память — они напрямую связаны именно с данными, которые хранятся на текущем сервере. Так что можно составить запрос таким образом:
explain (analyze, buffers) select count(distinct id) from users; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=284689.43..284689.45 rows=1 width=8) (actual time=4408.248..4408.262 rows=1 loops=1) Buffers: shared hit=13937, read=149998, dirtied=125912, temp read=30325 written=30382 -> Index Only Scan using users_pkey on users (cost=0.43..259689.43 rows=10000000 width=8) (actual time=0.084..1253.347 rows=10000000 loops=1) Heap Fetches: 61 Buffers: shared read=27332 Planning Time: 0.081 ms Execution Time: 4408.414 ms (7 rows)Сложив все значения в строке buffers мы получим объем данных для выполнения этого запроса. В сумме может получиться 450-500 страниц — это совсем немало. Учитывая, что объем одной страницы данных — 8 килобайт.
Такая методика помогает узнать не только объем данных, но и то, чем PostgreSQL вообще занимался, пока выполнял запрос. Сначала разберем первые три параметра:
- Shared hit. Найденные данные, которые уже находились в оперативной памяти.
- Read. Это то, что пришлось считать не из памяти, а с диска.
- Dirtied. Сколько «грязных» данных PostgreSQL нашел в процессе выполнения запроса.
Большие числа в этих показателях — сигнал того, что в конфигурационных настройках PostgreSQL что-то не так и нужно покопаться.
Еще есть интересный показатель temp_write . Он показывает, что оперативной памяти на запрос не хватило, и в какой-то момент БД создала файл на 30 страниц на диске, а потом оттуда их считывала. То есть можно увеличить work_mem , и тогда этот показатель исчезнет.
До этого мы с вами говорили про count (distinct id) . Теперь давайте посмотрим на count(*) и план его выполнения:
explain (analyze, buffers) select count(*) from users; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------- Finalize Aggregate (cost=212772.98..212772.99 rows=1 width=8) (actual time=1093.250..1093.496 rows=1 loops=1) Buffers: shared hit=12 read=27332 -> Gather (cost=212772.77..212772.98 rows=2 width=8) (actual time=1089.207..1093.486 rows=3 loops=1) Workers Planned: 2 Workers Launched: 2 Buffers: shared hit=12 read=27332 -> Partial Aggregate (cost=211772.77..211772.78 rows=1 width=8) (actual time=1061.481..1061.484 rows=1 loops=3) Buffers: shared hit=12 read=27332 -> Parallel Index Only Scan using users_pkey on users (cost=0.43..201356.10 rows=4166667 width=0) (actual time=0.050..759.141 rows=3333333 loops=3) Heap Fetches: 61 Buffers: shared hit=12 read=27332 Planning: Buffers: shared read=3 Planning Time: 1.685 ms Execution Time: 1093.589 ms (15 rows)Раньше у нас было 300 тысяч буферов, а тут стало 27 тысяч — то есть запрос выполнился практически в 11 раз быстрее.
За счет чего достигается такое ускорение? Здесь видно, что запрос выполняется буквально за одну секунду, потому что одновременно три воркера начинают читать данные по индексу.
Еще существует альтернатива — вместо select count(*) from users можно прописать select count(1) from users . Такое решение часто можно встретить в SQL командах. Фактически эти запросы практически не отличаются, но давайте сравним их на синтетических тестах.
Воспользуемся утилитой pgbench и запустим оба запроса по 50 раз:
echo "select count(1) from users;" | sudo -iu postgres pgbench -d postgres -t 50 -P 1 -f – latency average = 602.805 ms latency stddev = 34.097 ms tps = 1.658885 (without initial connection time) echo "select count(*) from users;" | sudo -iu postgres pgbench -d postgres -t 50 -P 1 -f – latency average = 593.256 ms latency stddev = 30.989 ms tps = 1.685587 (without initial connection time)Тут мы увидим, что count(*) хоть немного, но быстрее чем count(1). Тут все верно — ведь PostgreSQL «1» обрабатывает как функцию, что занимает больше времени и требует дополнительных проверок, а «*» он понимает как отдельный оператор и не выполняет дополнительных проверок.
Второй пример
Здесь у нас есть ранее созданная табличка users. Мы создаем аккаунт, делаем ссылку на таблицу и создаем account log, со ссылкой на таблицу account id.
create table account(id bigint primary key, user_id bigint not null references users, name varchar(200), create_date timestamp not null default now()); CREATE TABLE create table account_log (id bigint primary key, account_id bigint not null references account, login_date timestamp not null default now()); CREATE TABLE insert into account select id, (random()*10000000) :: bigint, md5(id::text), now() from generate_series(1,1000000) id; INSERT 0 10000000 insert into account_log select id, (random()*10000000) :: bigint, '2022-01-01' :: timestamp + ((random() * 365)::int:: text || ' days') ::interval from generate_series(1,20000000) id; INSERT 0 20000000 analyze account; ANALYZE analyze account_log; ANALYZE create index ix__account_log__account_id on account_log(account_id); create index ix__account_log__login_date on account_log(login_date); create index ix__account__user_id on account(user_id);То есть у нас есть пользователи, у каждого может быть, несколько аккаунтов и по каждому аккаунту мы создадим статистику, когда он последний раз заходил в систему.
И вот приходит бизнес-задача — посчитать, сколько людей залогинилось за определенный промежуток времени. И мы пишем запрос:
explain(buffers,analyze) select count(*), min_login_date::date from ( select min(login_date) min_login_date from users u left join account a on u.id = a.user_id left join account_log al on al.account_id = a.id group by u.id ) t where min_login_date between '2022-02-01' and '2022-02-28' group by min_login_date::date order by min_login_date::dateВыбираем минимальную дату логирования users, соединяемся с account_log, потом по этой дате наворачиваем фильтр. Допустим, смотрим на февраль. Дальше просто считаем count, делаем группировку и смотрим. Но что показывает план?
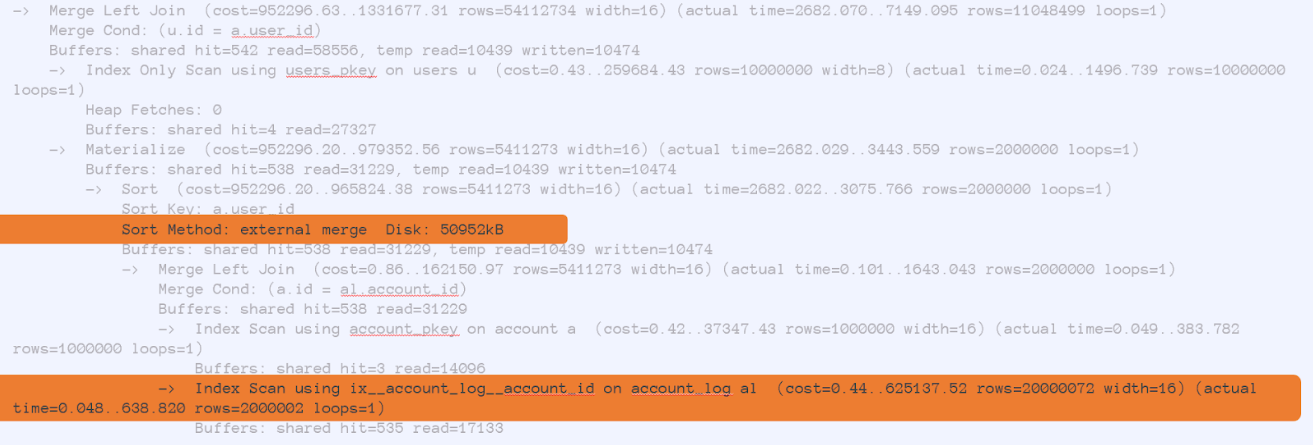
Ничего хорошего. Он говорит, что мы вычитываем много данных из таблички account_log, то есть обращаемся по индексу, по аккаунт ID. Здесь я для теста занес 20 миллионов строк. И для сортировки у нас не хватило места — пришлось 50 Мб данных записать на диск. А буферов потребовалось больше 500 тысяч.
Как это можно оптимизировать? На самом деле просто — достаточно выкинуть табличку users. В первом запросе по ней происходит группировка, но здесь у нас все нужное содержится в users ID. И отказ от users даст нам нужную оптимизацию:
explain(buffers,analyze) select count(*), min_login_date::date from ( select min(login_date) min_login_date from account a join account_log al on al.account_id = a.id group by a.user_id ) t where min_login_date between '2022-02-01' and '2022-02-28' group by min_login_date::date GroupAggregate (cost=575697.89..575734.66 rows=200 width=12) (actual time=2755.648..2759.803 rows=28 loops=1) Group Key: ((t.min_login_date)::date) Buffers: shared hit=6 read=31761, temp read=8568 written=20136То есть получается, что у нас используется 60 тысяч буферов, а сам запрос занимает 3 секунды. Хотя учитывая, что это простой отчет, который может запрашиваться каждую минуту, это все равно долго.
Чтобы оптимизировать все еще больше, мы можем ограничить данные фильтром:
explain(buffers,analyze) with cte as ( select min(login_date :: date) min_login_date from account_log al where al.login_date between '2022-02-01' and '2022-02-28' group by al.account_id ) select * from cte Subquery Scan on cte (cost=1751.70..2527.46 rows=38788 width=4) (actual time=24.862..30.748 rows=19441 loops=1) Buffers: shared hit=2 read=356Из 20 миллионов строк, который мы сканировали в прошлый раз, осталось 20 тысяч — с этим уже можно работать. Запрос уже оптимальный, и теперь на него нужно навесить логику.
Дальше давайте попробуем получить минимальную дату относительно не account, а users.
explain(buffers,analyze) with cte as ( select min(login_date :: date) min_login_date, al.account_id from account_log al where al.login_date between '2022-02-01' and '2022-02-28' group by al.account_id ) select min(min_login_date) min_login_date, a.user_id from cte join account a on a. by a.user_id Finalize HashAggregate (cost=24273.18..24661.06 rows=38788 width=12) (actual time=206.033..209.755 rows=19424 loops=1) Group Key: a.user_id Batches: 1 Memory Usage: 3089kB Buffers: shared hit=6740 read=5706Стало хуже, чем в первом запросе, но зато больше подходит под наши бизнес-задачи. Добавим еще логики:
explain(buffers,analyze) with cte as ( select min(login_date :: date) min_login_date, al.account_id from account_log al where al.login_date between '2022-02-01' and '2022-02-28' group by al.account_id ), cte_ac as ( select min_login_date, a.user_id, exists(select * from account_log al join account au on au.id = al.account_id where au.user_id = a.user_id and al.login_date < '2022-02-01' ) is_exists from cte join account a on a. count(*), min_login_date from ( select a.user_id, min(min_login_date) min_login_date from cte_ac a where a.user_id not in (select user_id from cte_ac where is_exists) group by a.user_id ) t group by min_login_date order by min_login_dateВ итоге если посмотреть как было, и как стало, получается такой результат:
Было:
GroupAggregate (cost=1756768.39..1757145.89 rows=200 width=12) (actual time=9955.696..9960.064 rows=28 loops=1) Group Key: ((t.min_login_date)::date) Buffers: shared hit=545 read=58556, temp read=10439 written=10474Стало:
GroupAggregate (cost=685063.31..685066.81 rows=200 width=12) (actual time=535.396..540.163 rows=28 loops=1) Group Key: t.min_login_date Buffers: shared hit=5545 read=18164Пусть по буферам и по объему данных мы выиграли не так много, зато значительно оптимизировали работу запроса, что для нас как раз и было особенно важно.
Больше о конфигурации PostgreSQL и об оптимизации запросов я буду рассказывать на интенсиве «Оптимизация запросов SQL» в «Слёрме». Там мы разберем конкретные параметры, посмотрим популярные запросы и попрактикуемся на стендах.
SQL-Ex blog

Как сделать запросы SELECT COUNT(*) очень быстрыми
Добавил smois on Суббота, 11 апреля. 2020
Когда вы выполняете SELECT COUNT(*), скорость результатов во многом зависит от структуры и настроек базы данных. Давайте проведем исследование на таблице Votes в базе данных Stack Overflow - 300-гигабайтной версии 2018-06, в которой таблица Votes содержит 150784380 строк и занимает пространство около 5,3Гб.
- Как много страниц он читает (с установкой SET STATISTICS IO ON).
- Как много времени процессора он использует (с установкой SET STATISTICS TIME ON).
- Как быстро выполняется.
Я выполняю эти тесты на SQL Server 2019 (15.0.2070.41) на 8-ядерной виртуальной машине с 64Гб RAM.
1: Обычный COUNT (*) только с кластеризованным индексом построчного хранения и уровнем совместимости 2017 и ранее
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
- Чтение страниц: 694389
- CPU: 14,5 секунд времени процессора
- Продолжительность: 2 секунды
2: Уровень совместимости 2019 (пакетный режим на построчных индексах)
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
- Чтение страниц: 694379
- CPU: 5,2 секунд времени процессора
- Продолжительность: 0,7 секунды
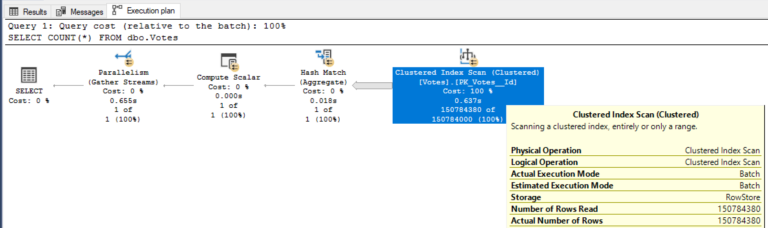
Пакетный режим отлично подходит к множеству запросов, создающих отчеты, агрегируя большие объемы данных.
3: Добавление некластеризованных построчных индексов, но при использовании режима 2017 и ранее
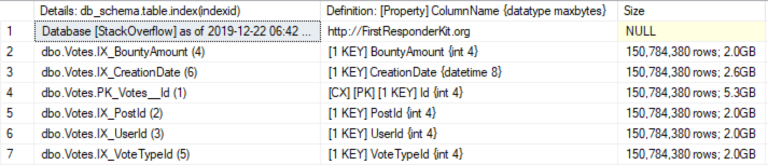
Я собираюсь создать индекс на каждом из 5 столбцов таблицы dbo.Votes, а затем сравнить их размеры при помощи sp_BlitzIndex:
CREATE INDEX IX_PostId ON dbo.Votes(PostId);
GO
CREATE INDEX IX_UserId ON dbo.Votes(UserId);
GO
CREATE INDEX IX_BountyAmount ON dbo.Votes(BountyAmount);
GO
CREATE INDEX IX_VoteTypeId ON dbo.Votes(VoteTypeId);
GO
CREATE INDEX IX_CreationDate ON dbo.Votes(CreationDate);
GO
/ Каковы размеры каждого индекса?
Выключите фактические планы для выполнения этого: /
sp_BlitzIndex @TableName = 'Votes';
GO
Проверьте число строк в каждом индексе сравнительно с его размером. Когда SQL Server необходимо подсчитать число строк в таблице, он достаточно умен, чтобы посмотреть на то, какой из объектов является наименьшим, а затем использовать его для подсчета. Индексы могут иметь различные размеры в зависимости от типов данных индексируемого содержимого, размера содержимого каждой строки, числа NULL-значений и т.п.
Я вернусь к уровню совместимости 2017 (убирая операции пакетного режима), после чего выполню подсчет:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
SQL Server останавливает выбор на индексе BountyAmount, одном из меньших 2Гб:
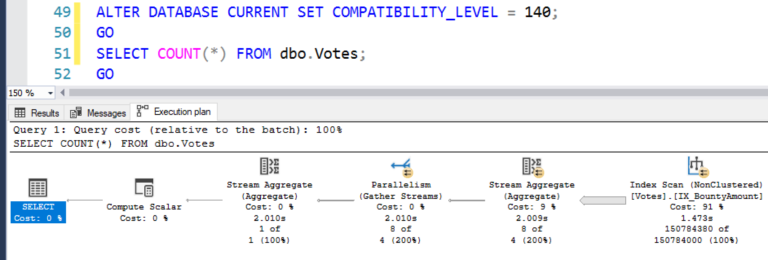
Мы экономим на чтении меньшего числа страниц, но по-прежнему читаем то же самое число строк - 150М, поэтому время процессора и продолжительность фактически не меняется:
- Чтение страниц: 263322
- CPU: 14,8 секунд времени процессора
- Продолжительность: 2 секунды
Если вы хотите понизить время процессора и продолжительность, вам действительно потребуется другой подход к подсчету - и тут поможет операция пакетного режима.
4: Пакетный режим 2019 с некластеризованными построчными индексами
Итак, давайте теперь испытаем операцию пакетного режима с имеющимися индексами:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
- Чтение страниц: 694379
- CPU: 4,3 секунд времени процессора
- Продолжительность: 0,6 секунды
5: Некластеризованный поколоночный индекс с пакетным режимом
Я намеренно работаю здесь в режиме совместимости 2017, чтобы выяснить, где зарыта собака:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_BountyAmount ON dbo.Votes(BountyAmount);
GO
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
План выполнения содержит оператор сканирования нашего нового поколоночного индекса, и все операторы в плане относятся к пакетному режиму:
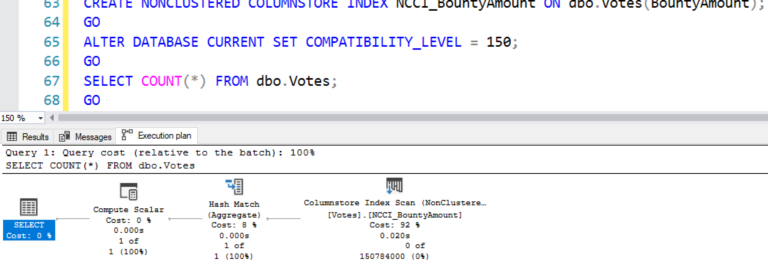
Тут я должен поменять единицы измерения:
- Чтение страниц: 73922
- CPU: 15 миллисекунд
- Продолжительность: 21 миллисекунда
Перспективы: Я знаю некоторых разработчиков, кто пытается использовать системные таблицы для быстрого подсчета числа строк, но даже они не могут достичь таких результатов по скорости.
Вот что необходимо сделать, чтобы запросы SELECT COUNT(*) выполнялись быстро
- Иметь SQL server 2017 или новее, и построить поколоночный индекс на таблице.
- Иметь любую версию, которая поддерживает пакетный режим на поколоночных индексах, и построить поколоночный индекс на таблице - хотя ваш опыт будет сильно различаться в зависимости от типа вашего запроса. Чтобы познакомиться со спецификой, почитайте о поколоночных индексах, особенно те статьи Niko, где в заголовке упоминается слово "пакетный" (batch).
- Иметь SQL SERVER 2019 или новее, и установить уровень совместимости 150 (2019), даже с построчными индексами. Вы сможете по-прежнему значительно сократить использование процессора, благодаря пакетному режиму на построчном хранении. Это действительно легко сделать - вероятно, вам потребуются минимальные изменения вашего приложения и схемы базы данных - хотя у вас и не будет удивительно быстрых ответов в миллисекундах, которые может обеспечить поколоночный индекс.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Производительность запросов в PostgreSQL – шаг за шагом

Для начала сразу пару слов о том, о чем пойдет речь. Во-первых, что такое оптимизация запросов? Люди редко формулируют и, бывает так, что часто недооценивают понимание того, что они делают. Можно пытаться ускорить какой-то конкретный запрос, но это не обязательно будет оптимизацией. Мы немного на эту тему потеоретизируем, потом поговорим о том, с какого конца к этому вопросу подходить, когда начинать оптимизировать, как это делать, и как понять, что какой-то запрос или набор запросов никак нельзя оптимизировать – такие случаи тоже бывают, и тогда нужно просто переделывать. Как ни странно, я почти не буду приводить примеров того, как запросы оптимизировать, потому что даже 100 примеров не приблизят нас к разгадке.
Обычно самое узкое место – это непонимание, с какой стороны подойти к этому делу. Все говорят: «Читай EXPLAIN, проверяйте запросы EXPLAIN'ом», но мне часто задают вопросы о том, на что там смотреть и что делать после того, как на EXPLAIN уже посмотрели? Вот об этом я постараюсь рассказать подробнее.
В качестве эпиграфа к докладу я хотел бы привести цитату из академика Крылова, который в свое время строил корабли, цитате этой уже более 100 лет, однако ничего не поменялось.

Основная проблема с базами данных (БД) в том, что: или в БД лежит что-то ненужное, или не лежит чего-то нужного, или же имеет место какой-то неправильный подход к ее эксплуатации. В принципе, мы можем поставить какой-то супер-пупер RAID-контроллер с огромным кэшем, супер-дорогие SSD диски, но если мы не будем включать голову, то результат будет плачевным.
Что значит «оптимизировать запросы»? Как правило, у вас такой задачи не возникает. Проблема обычно заключается в том, что «все плохо!». Мы пишем наш замечательный проект, все работает, все довольны, но в какой-то момент заказали чуть больше рекламы, пришло чуть больше пользователей, и все упало. Потому что, когда разрабатывают проект быстро, обычно используют «рельсы», «джанго» и т.п. и пишут «в лоб» – важно быстрее дать продукт. Это на самом деле правильно, т.к. никому не нужен идеально «вылизанный» проект, который не работает. Дальше нужно понять, что происходит. Эти медленные запросы, которые мы хотим оптимизировать, – это просто такой интерфейс, который выдает наружу, что вот это тормозит, но причина запросто может быть в чем-то другом. Может быть плохое «железо», может быть ненастроенная база, и в этот момент начинать с оптимизации запросов, в принципе, не стоит. Сначала надо посмотреть, что происходит с БД.
Бывают просто грубые ошибки в настройке БД и до того, как они будут исправлены, оптимизировать запросы бесполезно, потому что bottleneck в другом месте. Например, если речь о Postgres’е, у вас может быть отключен autovacuum. Почему-то люди это иногда делают (этого ни в коем случае делать нельзя!), но когда он отключен, у вас очень большая фрагментация таблицы. Легко может быть таблица на 100 тыс. записей размером с таблицу в 1 млрд. записей. Естественно, любые запросы к ней будут медленнее, чем вы ожидаете. Поэтому сначала нужно БД настроить, проверить, что все хорошо работает.
Еще одна частая ошибка, когда 1000 worker ‘ов Postgres’а работают, потому что очень много подключений от приложения, и нет никакого Connection Broker’а. Надо понимать, что если у вас 500 connection’ов, то у вас должно быть 500 ядер на сервере, на котором вы работаете. В противном случае эти connection’ы будут друг другу мешать и будут все время проводить в ожидании. Когда вы эти глупости исправили (их может быть довольно много, но основных – 5-10 штук – правильные настройки памяти, диска, autovacuum. ), вы можете переходить к оптимизации запросов. И только тогда. Не надо пытаться оптимизировать то, что еще вы только делаете.
Каков алгоритм, т.е. как подходить к оптимизации запросов? Во-первых, надо проверить настройки, во-вторых, каким-то способом отобрать те запросы, которые вы будете оптимизировать (это важный момент!), и, собственно, оптимизировать их. После того, как вы самые медленные запросы «вылечили», они стали быстрее, у вас немедленно появляются новые медленные запросы, потому что старый топ уступил им место. В результате вы постепенно, шаг за шагом повторяя этот алгоритм, избавляетесь от медленных запросов. Все просто.

Очень важный момент – знать, какие запросы оптимизировать? Если вы будете оптимизировать все подряд, то есть шанс не угадать, какие из запросов являются самыми проблемными. Вы просто потратите много времени и с большой вероятностью не доберетесь до нужных задач. Поэтому запросы нужно оптимизировать по мере поступления проблем. Посмотрите, где работать перестало, стало медленно и плохо – вот этот кусок и оптимизируйте. Если у вас есть что-то, что редко используется, не надо этого трогать, не тратьте время.
По отобранному топу берутся запросы, и смотрится, что с ними можно сделать. Для этого, особенно в версии 9.4, правильный способ – использовать EXTENSION pg_stat_statements, который все это делает «на лету» в онлайне, и можно на все это посмотреть.
Давайте разберемся с этим детально.

По адресу внизу страницы – наши pg-utils , которые доступны в свободном доступе, можно скачать и воспользоваться. В папке лежит некая обвязка вокруг стандартного контриба pg_stat_statements, который позволяет генерить вот такие отчеты за сутки работы на БД, и мы можем посмотреть, что там происходило. Видим, соответственно, некий топ запросов, каким-то образом ранжированный.
Нам важно знать, что есть первая позиция, вторая (обычно их еще десяток), и мы видим, что по каким-то параметрам у нас некий запрос выходит на первое место – он занимает, например, 24% нагрузки базы. Это довольно много и это надо как-то оптимизировать. Вы смотрите на запрос и думаете: «А сколько он денег проекту приносит?». Если он приносит проекту очень много денег, то пусть даже половину нагрузки отъедает, а если он денег не приносит, а отъедает половину ресурсов – это плохо, с этим надо что-то сделать. Таким образом, вы смотрите на топ запросов за предыдущий день и размышляете, что с этим делать.
Хорошей практикой у нас считается, когда есть команда разработчиков, которая делает что-то на проекте, и раз в сутки по cron'у такой отчет приходит всем DBA, всем разработчикам, всем админам.
Что такое медленный запрос? Во-первых, это запрос, который имеется в топе (его надо оптимизировать каким-то образом в любом случае). Но чисто по времени – это всегда некий вопрос. Даже запрос, который будет работать доли миллисекунды, все равно может быть медленным. Например, если этих запросов очень много, и много мелких запросов в итоге подъедают очень большой процент ресурсов базы.
Таким образом, время запроса – вещь относительная, и тут нужно смотреть, насколько часто этот запрос работает. Если это отдача чего-то на Главной странице, и этот запрос занимает 1 секунду, надо понимать, что у вас будет эта секунда и еще плюс оверхед от всего того, что нужно, чтобы сформировать эту страницу. Это значит, что пользователь увидит результат гарантированно медленнее, чем через секунду, и для онлайнового высоконагруженного веба это неприемлемые результаты. Если же запрос у вас для какой-то аналитики гоняется ночью, присылается кому-то асинхронный отчет, то, вероятно, он может себе позволить работать медленно. То есть, всегда надо знать свои данные и всегда думать, сколько времени допустимо, чтобы этот запрос работал. Опять же важен характер нагрузки на базе. Например, у вас есть длинный тяжелый запрос, вы его гоняете в пиковое время, а это запрос для какой-то аналитики, для менеджеров и т.п.
Посмотрите на профиль нагрузки на базу. У вас есть pg_stat_statements, по нему вы можете увидеть, топ медленных запросов, например, с 2х до 4х часов дня, и в это время не гонять длинные аналитические запросы.
Не забываем о том, сколько этот вопрос приносит денег и имеет ли он право занимать много ресурсов БД. Если вы сделали прикольную фичу, которая не зарабатывает для проекта ничего, а этот запрос съедает 50% ресурсов, то значит, вы написали плохой запрос и вам нужно переделать эту идею и даже иногда объяснить менеджеру, почему эта технически очень сложная штука просто съедает ресурсы. Все говорят, мол, хочу, чтобы Золотая Рыбка была у меня на посылках, тем не менее, сервер – он железный, он имеет некие лимиты, и резиново растягивать его нельзя. Люди, которые делают облака, скажут вам, что можно, но я как зануда-админ, скажу, что нельзя.
Где, вообще, могут быть проблемы при исполнении одного конкретного запроса? Во-первых, это может быть передача данных от клиента, и это совершенно не так смешно, как кажется. Следующий слайд демонстрирует, где там может быть «зарыта собака»:

Кто писал на Ruby, использовал всякие хитрые ORM'ы, знает, что вот по этому запросу можно опознать Django. Это фирменный стиль, почерк радиста ни с чем не перепутаешь.
Как вы думаете, какой максимальной длины in-список я видел в своей жизни? Надо считать в гигабайтах! Если не смотреть на то, что делает ваш ORM, то легко может получить несколько гигабайт, и этот запрос никогда не исполнится. Это плохо и означает, что у вас совершенно неоптимальный доступ к данным. Этот запрос плох еще по многим причинам, но основная причина того, что он может быть такой длины, которая в Postgres никогда в жизни не пролезет.
Второй момент – это парсинг. Можно написать очень витиеватый запрос, который просто будет долго парситься. В новой версии Postgres’а, если я не ошибаюсь, будет в EXPLAIN ‘е время парсинга, и можно будет понять, сколько на это уходит времени. Сейчас можно просто сделать EXPLAIN и посмотреть таймингом, соответственно, сколько у нас ушло на исполнение запроса, а сколько – на парсинг.
Потом запрос нужно оптимизировать. И это далеко не такая простая задача, как кажется, потому что оптимизатор – это достаточно сложные алгоритмы. Вот, к примеру, вы хотите сделать Join двух таблиц. Он берет одну таблицу, выбирает метод доступа к нужным данным и при-Join'ивает к ней следующую. Если у вас еще один Join с еще одной таблицей, то сначала он с-Join'ит две, потом с ResultSet’ом с-Join'ит еще одну. Если вы написали запрос, в котором 512 Join'ов, дальше начинается очень интересная «петрушка» с оптимизацией этого всего.
Для перебора того, какой путь Join'ов будет оптимальным, потребуется в зависимости от количества Join'ов n! вариантов плана, среди которых будет вестись отбор. Поэтому, если у вас много Join'ов, то вы сразу понимаете, что сам процесс оптимизации может быть очень и очень длительным.
Далее может быть непосредственно исполнение. Если ваш запрос должен вернуть куда-то 10 Гб данных, сложно рассчитывать на то, что он будет работать миллисекунды. Никаким волшебством его не заставить. Поэтому, если вам нужно отдать много данных, то сразу имейте в виду, что волшебства не бывает. Оно бывает в мире NoSQL, а здесь его нет.
Ну и, возврат результатов. Опять же, если вы несколько гигабайт данных гоняете по сети, то будьте готовы к тому, что это будет медленно, потому что сеть имеет некие ограничения на то, сколько через нее можно пропустить. В таких случаях имеет смысл иногда подумать о том, нужны ли нам все эти результаты? Это очень частая проблема.
Самый главный слайд этой презентации:

После того, как вы выделили топ запросов, вы как-то удостоверились, что эти запросы медленные, и хотите с ними что-то сделать, вам нужно прогнать EXPLAIN.
До этого этапа доходят многие, а дальше загвоздка. Люди жалуются: «Ну, мы посмотрели EXPLAIN, и что с ним дальше делать?». Вот это я сейчас вам и расскажу.
На слайде 2 EXPLAIN'а, немного разный синтаксис.
Можно вот так делать: explain (analyze on, buffers on), можно просто написать explain analyze, например.
Важно понимать, что EXPLAIN вам выведет просто план предполагаемый, какой он должен быть. Соответственно, если вы укажете еще и ANALYZE, то этот запрос будет реально исполнен, и будут показаны данные о том, как он был исполнен, т.е. не просто EXPLAIN, а еще какая-то трассировка, собственно говоря, что происходило.
Когда вы отобрали топ медленных запросов, правильно использовать EXPLAIN ANALYZE, потому что у вас может быть выбран неоптимальный план, может быть не собрана статистика и др.
Postgres – супер транзакционная штука, если у вас есть пишущий запрос, вы не хотите, чтобы эти результаты записались, пока вы что-то оптимизируете, говорите: «begin», запускаете запрос (но желательно смотреть, что, вообще, происходит – тяжелый запрос в пиковое время на боевую базу не всегда бывает хорошо), потом говорите «rallback», чтобы у вас эти данные не записались.
Здесь показываются некие цифры, часть которых принадлежит EXPLAIN'у, а часть – ANALYZE'у. Это важные цифры. В EXPLAIN'е есть условные «попугаи» под названием «cost». 1 cost в Postgres‘е по умолчанию – это время, которое затрачивается на извлечение одного блока размером 8 Кб при последовательном sequential scan'е. В принципе, эта величина зависит от машины, поэтому она условная, поэтому это удобно. Если у вас быстрые диски, это будет быстрее, если медленные – медленнее. Важно понимать, что cost=9.54 – это означает, что в 9.54 раза это будет медленнее, чем достать 1 блок размером 8 Кб.
При этом цифр две: первая означает, сколько пройдет времени до момента начала возврата первых результатов, а вторая – это сколько пройдет времени до того, как результат будет возвращен весь. Если вы извлекаете много данных, то первая цифра будет относительно маленькой, а вторая будет достаточно большой. Это актуальное время, сколько это на самом деле заняло. Если по каким-то причинам у вас cost очень маленький, а это время очень большое, значит у вас какие-то проблемы со сбором статистики, нужно проверить, включен ли autovacuum, потому что тот же самый демон autovacuum’а собирает еще и статистику для оптимизатора.
EXPLAIN – это такое дерево, есть нижние варианты, грубо говоря, как достать данные с диска – это скан табличек, скан индексов и т.д.; и более верхние варианты, когда на верх наслаивается какая-то агрегация, Join'ы и т.д. Когда вы смотрите на такой EXPLAIN, задача очень простая:
- понять, насколько быстро он работает, посмотреть на runtime, посмотреть, сколько там чего происходило;
- посмотреть, какой узел этого дерева самый дорогой. Если у вас на нижнем этапе сразу cost достаточно большой, actual time большой, то значит, вам этот кусок и надо оптимизировать. Например, если у вас сканируется таблица целиком, вам может там понадобится сделать индексы. Это то место, которое действительно нужно оптимизировать, на которое нужно смотреть.
Если у вас, например, чудит агрегация, как в нашем случае на слайде – она там более тяжелая, то вам нужно подумать, как от нее избавиться.
Таким образом, вы смотрите на EXPLAIN и находите самые дорогие места. После того, как вы посмотрите на EXPLAIN с полгодика, вы научитесь эти места видеть невооруженным глазом и у вас уже будет в голове набор рецептов, что делать в каком случае. Мы пока не будем их рассматривать подробно.
Какими приемами можно пользоваться? Можно сделать индекс. Идея индекса в том, что это меньший массив данных, который удобно отсканировать, вместо того, чтобы сканировать большую таблицу. Поэтому все программисты любят индексы, любят создать индексы на все случаи жизни и считать, что это поможет. Это неправильно, потому что индекс не бесплатен. Индекс занимает место, при каждой записи в таблицу индекс перестраивается, балансируется, и это все не бесплатно.
Если у вас вся таблица увешана индексами, которые не используются, с большой вероятностью вы можете часть из них снести, и будет быстрее. Тем не менее, если в вашем запросе нужно, например, извлечь половину данных из таблицы, с большой вероятностью ваш индекс не будет использоваться, потому что по индексу имеет смысл спозиционироваться в какое-то достаточно точное место и эти данные достать. Если вам нужно большую «простыню», которая сопоставима по размерам с таблицей, sequential scan самой таблицы будет всегда быстрее, чем index scan, потому что вам будет нужно сначала сделать index scan, потом еще одну операцию – достать данные.
В большинстве случаев оптимизатор в таких вещах не ошибается. Если вы создали индекс и недоумеваете, почему он не используется, то может быть потому, что без индекса будет просто быстрее.
В Postgres’е есть такой параметр – сессионная переменная, enable index scan установить в off или, наоборот, sequential scan установить в off, и вы можете посмотреть – с индексом или без него будет быстрее/медленнее. Оптимизировать так запросы «в бою» я бы не советовал, это очень жесткий «костыль» и очень серьезное ограничение функционала для оптимизатора, но поэкспериментировать, посмотреть – это полезно. Вы сделали запрос, сделали для него индекс, считаете, что он будет работать, отключите sequential scan, оптимизатор будет вынужден выбрать план с индексом, и посмотрите, не получилось ли медленнее, чем то, что Postgres предложил вам сам. В большинстве случаев это именно так.
Далее важно, как написан запрос. Если у нас будет что-то вроде этого – (where counter + 1 = 46) – индекс браться не будет, автоматически Postgres эту операцию сделать не может. Казалось бы, простое сложение, но с тем же успехом можно предложить оптимизатору еще и дифуры порешать. В Postgres’е большое количество типов данных, на них можно определять любые операторы, любые действия, например, алгебраические или др., и оптимизатор должен для всех этих типов знать, как это действие выполнять, а для него это слишком тяжелая задача, это никогда не будет работать.
Следующее – почему, например, Join работает плохо? Это один из важных узлов, его все используют.
Join'ы бывают разных типов, и я говорю не о LEFT, RIGHT, INNER и т.д., а об алгоритмах, как Join'ы выполняются. Postgres имеет три основных алгоритма Join'а, а именно – Nested Loop (название говорит само за себя – мы берем данные из одной таблицы и циклами их Join'им), Hash index (когда одна, чаще маленькая, таблица хэшируется и по этому хэшу Join'ится с другой таблицей) и Merge Join (который тоже очевидно, как работает).
Эти Join'ы не всегда одинаково полезны, оптимизатор может выбрать между ними. Например, у вас Join'ятся две таблицы, оптимизатор выбирает Hash Join, и вы понимаете, что он работает медленно, вас это не устраивает. Имеет смысл посмотреть, а индексированы ли у вас те поля, по которым вы Join'ите? Если у вас эти поля не индексированы, оптимизатор может не выбрать Nested Loop, который здесь очевидно выгоднее. Если вы создадите индекс, оптимизатор выберет Nested Loop, и все будет работать быстро.
Следующий момент – у вас оптимизатор из каких-то соображений выбирает Nested Loop, а вам кажется, что одна таблица очень маленькая, другая – очень большая и Hash Join там был бы очень уместен, потому что маленькую таблицу можно быстро прохэшировать и быстро с ней работать. Посмотрите, сколько у вас work mem'а. т.е. сколько памяти может занять один worker Postgres’а. Если эта таблица хэшируется в, например, 100 Мб, а у вас work mem'а выдано только 30 Мб, то worker будет работать медленно. Если вы добавите work mem'а и хэширование начнет вмещаться в память, оптимизатор выберет правильный Hash Join и будет быстро и хорошо.
Вот такое вот поле для экспериментов, тут надо думать и не стесняться проверять, пробовать и смотреть, что происходит.
Поскольку оптимизировать запросы нужно только «на бою» (потому что на тесте вы никогда не воспроизведете workload настолько же точно), то делать это надо с известной осторожностью.
Пример такой оптимизации:

Я уже показывал этот запрос и очень ругался на него. Одна из причин для такой ругани состоит в том, что, все-таки Postgres не совершенен, он – развивающаяся система, есть в нем какие-то недостатки (сообществу очень нужны разработчики оптимизатора, если вы хотите подконтрибьютить Postgres’у, то можете в эту сторону посмотреть, такие усилия всегда будут очень приветствоваться, потому что есть недоделки). Вот и случай такого длинного массива в WHERE очень распространенный, потому что многие ORM’ы это делают. По идее, Postgres должен как-то хэшировать этот массив и соответственно осуществлять в нем поиск. Вместо этого он его перебирает и получается достаточно противно, время растет очень существенно, и начинаются проблемы.
Посмотрим на EXPLAIN этого дела:

Мы видим, что фильтр без хэша работает плохо, несмотря на то, что имеется Index Scan для того, чтобы что-то сделать и выбрать на массиве, мы заседаем, а он работает максимально плохим образом и все тормозит.
В этой ситуации запрос необходимо переписать, включив воображение. Я уже говорил, что Postgres умеет Hash Join, но не умеет делать хэширование массива. Давайте сконвертируем эту «простыню» таким образом, чтобы результат можно было с-Join'ить. В итоге получится то же самое, только оптимизатор выберет более разумный план.
Можно использовать такую конструкцию VALUES, которая нам все это превратит в ResultSet:

В этой ситуации на самом деле будет Index Scan и Hash Join. Будет произведено хэширование, и запрос довольно существенно ускорится.
Если мы возьмем те же самые запросы, то уже переписанная нормальным образом, она будет так же работать на коротких запросах, но, что самое главное, она будет не хуже работать на больших и длинных списках:

И это достаточно легко переделать.
Это был простой пример того, как, посмотрев на EXPLAIN, можно существенно улучшить производительность тормозного запроса. Это т запрос уйдет из топа, придет новый, его тоже можно будет оптимизировать.
Есть еще одна очень существенная проблема – бывают такие запросы, с которыми нельзя ничего сделать. И первейший из этих запросов –count(*).
Например, есть интернет-сайт, у него – Главная страница, она высоконагруженная, на ней отображаются счетчики. Какую информацию пользователю несет число на счетчике, если это count из таблицы, которая часто обновляется? Число означает, что на тот момент, когда пользователь послал свой запрос, цифра была такая. Обычно пользователю не важно знать эту цифру с высокой точностью, достаточно более-менее приближенно, а чаще, вообще, хватает знания о том, растет число или нет. Если это какой-то финансовый баланс, то можно это делать, но обычно это делается очень редко и не выводится на Главную страницу сайта, чтобы при каждом обращении count гонялся по таблице.
count – он всегда медленный, потому что Postgres, чтобы посчитать количество записей в таблице, всегда сканирует ее целиком и проверяет, актуальна ли эта версия данных или ее уже обновили.
Первый вариант решения этой проблемы – не использовать count'ы. Полезность его сомнительна, а ресурсов он занимает много. Второй момент – можно использовать приближенный count. Есть PG-каталог, из него можно по-select’ить, сколько строк в таблице было на момент последнего analyze'а, когда был произведен последний сбор статистики. Эта приблизительная цифра будет меняться достаточно часто, но при этом запрос по PG-каталогу не стоит практически ничего – это select одного value по условию названия таблицы. Если вы не хотите пускать интернет-юзера базы в PG-каталог, вам ничто не мешает написать хранимую процедуру, сказать ей «security definer» и дать права только на эту процедуру, и интернет-пользователь будет спокойно доставать эти данные без всяких проблем с security.
Следующий запрос-проблема – Join на 300 таблиц. Проблема состоит в том, что будет 300! вариантов, как этот Join сделать. Более того, если вам понадобилось написать Join на 300 таблиц, это значит, что у вас очень плохо с дизайном схемы, что-то очень не продумано, и надо много чего переделывать. В норме Join – это на две, на три таблицы. Иногда на пять, изредка на десять, но это крайние случаи. Когда Join'ов сотни, любой БД станет плохо.
Еще одна проблема – когда клиенту возвращается 1 000 000 строк. Кто долистывал до последней страницы в Google? Часто это бывает? Если вы видите, что онлайновый запрос, результат которого отображается на сайте, по каким-то причинам возвращает 1 млн. строк, задумайтесь – нет ли какой-то ошибки? Может понадобиться 10, 20 строк, может быть, 100, но 1 млн. строк человек не читает. Если у вас столько строк возвращается, это значит, что у вас либо какая-то выгрузка данных, которую можно сделать ночью, можно сделать с помощью дампа, можно еще каким-то способом, либо у вас просто неправильно написан запрос.
Например, вы сгенерили ORM'ом запрос для какай-то листалки, дальше, соответственно, вытаскиваете этот огромный массив, а используете из него реально только 10%. В этой ситуации вам нужно использовать limit и offset и каким-то другим способом определенным окном идти по этим данным и не тянуть их все на клиент, потому что 1 млн. строк – это всегда медленно, и, как правило, это не осмысленно и содержит какую-то логическую ошибку.