Константы модуля string
Конкатенация ascii_lowercase и ascii_uppercase константы описаны ниже. Это значение не зависит от локали.
string.ascii_lowercase :
Строчные буквы ‘abcdefghijklmnopqrstuvwxyz’ . Это значение не зависит от локали и не изменится.
string.ascii_uppercase :
Прописные буквы ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’ . Это значение не зависит от локали и не изменится.
string.digits :
string.hexdigits :
string.octdigits :
string.punctuation :
Строка ASCII символов , которые считаются знаки препинания в локали языка C : !»#$%&'()*+,-./:;?@[\]^_<|>~ .
string.printable :
Строка символов ASCII, которые считаются печатными. Это сочетание digits , ascii_letters , punctuation , и whitespace .
string.whitespace :
Строка, содержащая все символы ASCII, которые считаются пробелами. Сюда входят пространство символов, табуляция, перевод строки, возврат, подача формы и вертикальная табуляция.
- КРАТКИЙ ОБЗОР МАТЕРИАЛА.
- Строковые константы модуля string
- Метод string.capwords() модуля string
- Класс Formatter() модуля string
- Класс Template() модуля string
- Создание отчетов с использованием string.Template
Частотный анализ русского текста и облако слов на Python
Частотный анализ является одним из сравнительно простых методов обработки текста на естественном языке (NLP). Его результатом является список слов, наиболее часто встречающихся в тексте. Частотный анализ также позволяет получить представление о тематике и основных понятиях текста. Визуализировать его результаты удобно в виде «облака слов». Эта диаграмма содержит слова, размер шрифта которых отражает их популярность в тексте.
Обработку текста на естественном языке удобно производить с помощью Python, поскольку он является достаточно высокоуровневым инструментом программирования, имеет развитую инфраструктуру, хорошо зарекомендовал себя в сфере анализа данных и машинного обучения. Сообществом разработано несколько библиотек и фреймворков для решения задач NLP на Python. Мы в своей работе будем использовать интерактивный веб-инструмент для разработки python-скриптов Jupyter Notebook, библиотеку NLTK для анализа текста и библиотеку wordcloud для построения облака слов.
В сети представлено достаточно большое количество материала по теме анализа текста, но во многих статьях (в том числе русскоязычных) предлагается анализировать текст на английском языке. Анализ русского текста имеет некоторую специфику применения инструментария NLP. В качестве примера рассмотрим частотный анализ текста повести «Метель» А. С. Пушкина.
Проведение частотного анализа можно условно разделить на несколько этапов:
- Загрузка и обзор данных
- Очистка и предварительная обработка текста
- Удаление стоп-слов
- Перевод слов в основную форму
- Подсчёт статистики встречаемости слов в тексте
- Визуализация популярности слов в виде облака
Загрузка данных
Открываем файл с помощью встроенной функции open, указываем режим чтения и кодировку. Читаем всё содержимое файла, в результате получаем строку text:
f = open('pushkin-metel.txt', "r", encoding="utf-8") text = f.read() Длину текста – количество символов – можно получить стандартной функцией len:
len(text) Строка в python может быть представлена как список символов, поэтому для работы со строками также возможны операции доступа по индексам и получения срезов. Например, для просмотра первых 300 символов текста достаточно выполнить команду:
text[:300] Предварительная обработка (препроцессинг) текста
Для проведения частотного анализа и определения тематики текста рекомендуется выполнить очистку текста от знаков пунктуации, лишних пробельных символов и цифр. Сделать это можно различными способами – с помощью встроенных функций работы со строками, с помощью регулярных выражений, с помощью операций обработки списков или другим способом.
Для начала переведём символы в единый регистр, например, нижний:
text = text.lower() Используем стандартный набор символов пунктуации из модуля string:
import string print(string.punctuation) string.punctuation представляет собой строку. Набор специальных символов, которые будут удалены из текста может быть расширен. Необходимо проанализировать исходный текст и выявить символы, которые следует удалить. Добавим к знакам пунктуации символы переноса строки, табуляции и другие символы, которые встречаются в нашем исходном тексте (например, символ с кодом \xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…' Для удаления символов используем поэлементную обработку строки – разделим исходную строку text на символы, оставим только символы, не входящие в набор spec_chars и снова объединим список символов в строку:
text = "".join([ch for ch in text if ch not in spec_chars]) Можно объявить простую функцию, которая удаляет указанный набор символов из исходного текста:
def remove_chars_from_text(text, chars): return "".join([ch for ch in text if ch not in chars]) Её можно использовать как для удаления спец.символов, так и для удаления цифр из исходного текста:
text = remove_chars_from_text(text, spec_chars) text = remove_chars_from_text(text, string.digits) Токенизация текста
Для последующей обработки очищенный текст необходимо разбить на составные части – токены. В анализе текста на естественном языке применяется разбиение на символы, слова и предложения. Процесс разбиения называется токенизация. Для нашей задачи частотного анализа необходимо разбить текст на слова. Для этого можно использовать готовый метод библиотеки NLTK:
from nltk import word_tokenize text_tokens = word_tokenize(text) Переменная text_tokens представляет собой список слов (токенов). Для вычисления количества слов в предобработанном тексте можно получить длину списка токенов:
len(text_tokens) Для вывода первых 10 слов воспользуемся операцией среза:
text_tokens[:10] Для применения инструментов частотного анализа библиотеки NLTK необходимо список токенов преобразовать к классу Text, который входит в эту библиотеку:
import nltk text = nltk.Text(text_tokens) Выведем тип переменной text:
print(type(text)) К переменной этого типа также применимы операции среза. Например, это действие выведет 10 первых токенов из текста:
text[:10] Подсчёт статистики встречаемости слов в тексте
Для подсчёта статистики распределения частот слов в тексте применяется класс FreqDist (frequency distributions):
from nltk.probability import FreqDist fdist = FreqDist(text) Попытка вывести переменную fdist отобразит словарь, содержащий токены и их частоты – количество раз, которые эти слова встречаются в тексте:
FreqDist() Также можно воспользоваться методом most_common для получения списка кортежей с наиболее часто встречающимися токенами:
fdist.most_common(5) [('и', 146), ('в', 101), ('не', 69), ('что', 54), ('с', 44)] Частота распределения слов тексте может быть визуализирована с помощью графика. Класс FreqDist содержит встроенный метод plot для построения такого графика. Необходимо указать количество токенов, частоты которых будут показаны на графике. С параметром cumulative=False график иллюстрирует закон Ципфа: если все слова достаточно длинного текста упорядочить по убыванию частоты их использования, то частота n-го слова в таком списке окажется приблизительно обратно пропорциональной его порядковому номеру n.
fdist.plot(30,cumulative=False) 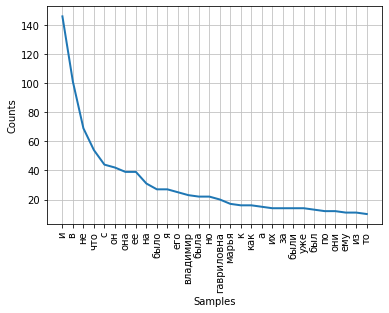
Можно заметить, что в данный момент наибольшие частоты имеют союзы, предлоги и другие служебные части речи, не несущие смысловой нагрузки, а только выражающие семантико-синтаксические отношения между словами. Для того, чтобы результаты частотного анализа отражали тематику текста, необходимо удалить эти слова из текста.
Удаление стоп-слов
К стоп-словам (или шумовым словам), как правило, относят предлоги, союзы, междометия, частицы и другие части речи, которые часто встречаются в тексте, являются служебными и не несут смысловой нагрузки – являются избыточными.
Библиотека NLTK содержит готовые списки стоп-слов для различных языков. Получим список сто-слов для русского языка:
from nltk.corpus import stopwords russian_stopwords = stopwords.words("russian") Следует отметить, что стоп-слова являются контекстно зависимыми – для текстов различной тематики стоп-слова могут отличаться. Как и в случае со спец.символами, необходимо проанализировать исходный текст и выявить стоп-слова, которые не вошли в типовой набор.
Список стоп-слов может быть расширен с помощью стандартного метода extend:
russian_stopwords.extend(['это', 'нею']) После удаления стоп-слов частота распределения токенов в тексте выглядит следующим образом:
fdist_sw.most_common(10) [('владимир', 23), ('гавриловна', 20), ('марья', 17), ('поехал', 9), ('бурмин', 9), ('поминутно', 8), ('метель', 7), ('несколько', 6), ('сани', 6), ('владимира', 6)] Как видно, результаты частотного анализа стали более информативными и точнее стали отражать основную тематику текста. Однако, мы видим в результатах такие токены, как «владимир» и «владимира», которые являются, по сути, одним словом, но в разных формах. Для исправления этой ситуации необходимо слова исходного текста привести к их основам или изначальной форме – провести стемминг или лемматизацию.
Визуализация популярности слов в виде облака
В завершение нашей работы визуализируем результаты частотного анализа текста в виде «облака слов».
Для этого нам потребуются библиотеки wordcloud и matplotlib:
from wordcloud import WordCloud import matplotlib.pyplot as plt %matplotlib inline Для построения облака слов на вход методу необходимо передать строку. Для преобразования списка токенов после предобработки и удаления стоп-слов воспользуемся методом join, указав в качестве разделителя пробел:
text_raw = " ".join(text) Выполним вызов метода построения облака:
wordcloud = WordCloud().generate(text_raw) В результате получаем такое «облако слов» для нашего текста:

Глядя на него, можно получить общее представление о тематике и главных персонажах произведения.
- nltk
- natural language processing
- python
- wordcloud
Ребята, как сделать проверку спец символов и написать если p1 и p2 то хорошо?

Немного изменил ваш код. Я проверял пересечение множеств символов пароля и символов которые в нем должны быть.
import string s1 = set(string.ascii_letters) s2 = set(string.digits) s3 = set(string.punctuation) while True: s = input('password >>> ') if len(s) ): print('Not numbers in password') else: print('Good password')Ответ написан более двух лет назад
Нравится 1 29 комментариев

SENYOR @omgit Автор вопроса
А проверку спец символов как сделать?
omg it, добавьте строку
elif not set(s).intersection(set()): print('Нет спецсимволов')вместо set() укажите спецсимволы, например
но если я правильно понял, s3 это как раз спецсимволы:
!»#$%&'()*+,-./:;?@[\]^_<|>~
их проверка уже есть
SENYOR @omgit Автор вопроса
Даниил Шевкунов, а буквы в нижнем и верхним регистре как добавить?
ещё одну такую же строку, но вместо set() написать s1, это английский алфавит в верхнем и нижнем регистре, а если русские, то вручную написать через запятую, как я писал в предыдущем комментарии
SENYOR @omgit Автор вопроса
Даниил Шевкунов, Спасибо тебе большое.
Рад помочь)
SENYOR @omgit Автор вопроса
Даниил Шевкунов, У меня проблема не выводиться в консоль!
s = 'In a distant, but not so unrealistic, future where mankind has abandoned earth because it hasbecome covered with trash from products sold by the powerful multi-national Buy N Large corporation WALLE, a garbage collecting robot has been left to clean up the mess. Mesmerized with trinkets of Earth s history and show tunes, WALLE is alone on Earth except for a sprightly pet cockroach. One day, EVE, a sleek (and dangerous) reconnaissance robot, is sent to Earth to find proof that life is once again sustainable' print = (len(s)) print = (s.lower()) print = (s.replace('WALLE', 'WALL-E')) print = (s.lower().count('earth'))
omg it, потому что у вас не print(), а print = (), это так не работает
SENYOR @omgit Автор вопроса
Даниил Шевкунов, Привет есть вопрос можешь помочь?
omg it, смогу — помогу, какой вопрос?
SENYOR @omgit Автор вопроса
Даниил Шевкунов, Достаточно глупый вопрос но все же как сделать проверку ввода в строке 24
import random stats = [] attributes = 5 for i in range(attributes): r = random.randint(60, 80) stats.append(r) Fireball = [12, 15, 28, 10, 5] while True: print('Stats up: ', end='') for i in range(attributes): print(stats[i], end=' ') print('\n\t[1] - Strength\ \n\t[2] - Dexterity\ \n\t[3] - Intelligence\ \n\t[4] - Wisdom\ \n\t[5] - Charisma') select = int(input('Select: ')) select -= 1 # check stats[select] = stats[select] + random.randint(5, 15) for i in range(len(stats)): if i == select: continue stats[i] = stats[i] - random.randint(5, 15) print('Stats up: ', end='') for i in range(attributes): print(stats[i], end=' ') print('\n\t[1] - Fireball') # select = int(input('Select shoot: ')) if select == 1: for i in range(attributes): stats[i] -= Fireball[i] #elif #else # check may be exit
Во первых, немного доработал ваш код:
from random import randint attributes = 5 stats = [randint(60, 80) for _ in range(attributes)] Fireball = [12, 15, 28, 10, 5] while True: print('Stats up: ', *stats) print(''' [1] - Strength [2] - Dexterity [3] - Intelligence [4] - Wisdom [5] - Charisma ''') select = int(input('Select: ')) - 1 # check for i in range(attributes): stats[i] += randint(5, 15) if i == select else -randint(5, 15) print('Stats up: ', *stats) print('\n\t[1] - Fireball') select = int(input('Select shoot: ')) if select == 1: for i in range(attributes): stats[i] -= Fireball[i] #elif #else # check may be exitИ собственно что вы подразумевали под проверкой ввода? Проверить ввел ли человек допустимое значение?
SENYOR @omgit Автор вопроса
Даниил Шевкунов, Я имею ввиду если пользователь ввел что-то меньше 1 или больше 5 то выводило бы НЕПРАВИЛЬНЫЙ ВВОД
omg it, Я вам ответил в теме с вашим вопросом
SENYOR @omgit Автор вопроса
Даниил Шевкунов, А какими еще способами это можно сделать?
ну например if select.isdigit() and 0 <= int(select) <= 5
а чем вам тот способ не подходит?
SENYOR @omgit Автор вопроса
Даниил Шевкунов, Просто интересно как это можно еще сделать
SENYOR @omgit Автор вопроса
Даниил Шевкунов, А как в код добавить ещё один выбор так же как и Firebool
import random stats = [] attributes = 5 for i in range(attributes): r = random.randint(60, 80) stats.append(r) Fireball = [12, 15, 28, 10, 5] while True: print('Stats up: ', end='') for i in range(attributes): print(stats[i], end=' ') print('\n\t[1] - Strength\ \n\t[2] - Dexterity\ \n\t[3] - Intelligence\ \n\t[4] - Wisdom\ \n\t[5] - Charisma') select = int(input('Select: ')) select -= 1 #print(select) if select5: print("Try again") break stats[select] = stats[select] + random.randint(5, 15) for i in range(len(stats)): if i == select: continue stats[i] = stats[i] - random.randint(5, 15) print('Stats up: ', end='') for i in range(attributes): print(stats[i], end=' ') print('\n\t[1] - Fireball') # select = int(input('Select shoot: ')) if select == 1: for i in range(attributes): stats[i] -= Fireball[i] #elif #else # check may be exit
if select == 1:
.
elif select == 2:
.
elif select == 3:
.
String punctuation python что это
В языке Python есть небольшой набор очень полезных встроенных функций. Все остальные функции распределены по модулям. В самом деле, это удачное проектное решение позволяет предотвратить разбухание ядра языка, как это произошло с некоторыми другими скриптовыми языками (например, Visual Basic).
Функция type возвращает тип произвольного объекта. Возможные значения типов перечислены в модуле types. Определение типа полезно в функциях, способных обрабатывать данные нескольких типов.
Пример 2.6. Функция type
>>> type(1) >>> li = [] >>> type(li) >>> import odbchelper >>> type(odbchelper) >>> import types >>> type(odbchelper) == types.ModuleType 1
| Функция type воспринимает объект произвольного типа и возвращает его тип. Аргумент действительно может быть произвольного типа: число, строка, список, словарь, кортеж, функция, класс, модуль и даже сам тип. | |
| В качестве аргумента может использоваться переменная. | |
| Функция type работает и c модулей. | |
| Вы можете использовать константы, определенные в модуле types для сравнения типов объектов. Именно это и делает, как мы скоро увидим, функция help. |
Функция str преобразует данные в строку. Для любого типа данных можно получить строковое представление.
Пример 2.7. Функция str
>>> str(1) '1' >>> horsemen = ['war', 'pestilence', 'famine'] >>> horsemen.append('Powerbuilder') >>> str(horsemen) "['war', 'pestilence', 'famine', 'Powerbuilder']" >>> str(odbchelper) "" >>> str(None) 'None'
| Вы, наверное, ожидали, что str будет работать с такими простыми типами данных, как целые числа, так как почти каждый язык содержит функцию для преобразования целого числа в строку. | |
| Однако, str работает и с объектами других типов. В данном случае мы получаем строковое представление списка. | |
| Функция str работает и с модулями. Обратите внимание, что строковое представление модуля содержит путь к модулю на диске, так что в вашем случае он будет отличаться. | |
| Важно также, что str работает и с объектом None, “нулевым” значением в языке Python. В этом случае она возвращает строку 'None'. Мы воспользуемся этим в функции help. |
Сердцем функции help является мощная функция dir. dir возвращает список атрибутов и методов произвольного объекта: модуля, функции, строки, списка, словаря… в общем, любого объекта.
Пример 2.8. Функция dir
>>> li = [] >>> dir(li) ['append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort'] >>> d = <> >>> dir(d) ['clear', 'copy', 'get', 'has_key', 'items', 'keys', 'setdefault', 'update', 'values'] >>> import odbchelper >>> dir(odbchelper) ['__builtins__', '__doc__', '__file__', '__name__', 'buildConnectionString']
| li является списком, так что dir(li) дает список имен всех методов списка. Обратите внимание, что возвращаемый список содержит имена методов в виде строк, а не сами методы. | |
| d является словарем, поэтому dir(d) дает список имен методов словаря. Как минимум один из них, keys, вам уже знаком. | |
| Здесь начинается самое интересное. odbchelper является модулем, так что dir(odbchelper) дает список всех имен, определенных в модуле, включая специальные атрибуты, такие как __name__ и __doc__. В данном случае, odbchelper содержит одну пользовательскую функцию, buildConnectionString, которую мы изучали в главе Знакомство с языком Python. |
Наконец, функция callable возвращает 1, если аргумент может быть вызван, в противном случае возвращает 0. Вызов поддерживают такие объекты, как функции, методы и даже классы. (Более подробно о классах читайте в главе 3.)
Пример 2.9. Функция callable
>>> import string >>> string.punctuation '!"#$%&\'()*+,-./:;?@[\\]^_`<|>~' >>> string.join >>> callable(string.punctuation) 0 >>> callable(string.join) 1 >>> print string.join.__doc__ join(list [,sep]) -> string Return a string composed of the words in list, with intervening occurrences of sep. The default separator is a single space. (joinfields and join are synonymous)
| На смену большинству функций модуля string пришли методов строк (хотя многие до сих пор используют функцию join), но модуль также содержит множество полезных констант. Например string.punctuation содержит все стандартные символы пунктуации. | |
| Функция string.join объединяет строки списка в одну строку. | |
| string.punctuation является строкой и вызов не поддерживает. (Строки имеют методы, которые можно вызвать, но вы не можете вызвать саму строку.) | |
| string.join ялвляется функцией и поддерживает вызов с двумя аргументами. | |
| Любой объект, поддерживающий вызов, может иметь строку документации. Применяя функцию callable к каждому атрибуту объекта, мы можем определить, какие атрибуты представляют для нас интерес (методы, функции, классы), и какие можно игнорировать (константы и т. д.), не имея каких-либо начальных знаний об объекте. |
type, str, dir и другие втроенные функции языка Python сгруппированы в специальном модуле __builtin__ (обратите внимание на два символа подчеркивания в начале и два в конце). Встроенные функции доступны напрямую, как если бы интерпретатор при запуске автоматически выполнял from __builtin__ import *. Вы можете получить информацию о встроенных функциях (и других объектах) как об отдельной группе исследуя модуль __builtin__. Для этих целей у нас есть функция help. Попробуйте проделать это сейчас сами. Позже мы более подробно рассмотрим наиболее важные встроенные функции (некоторые классы исключений, например AttributeError, вам должны быть уже знакомы.)
Пример 2.10. Втроенные функции и другие объекты
>>> from apihelper import help >>> import __builtin__ >>> help(__builtin__, 20) ArithmeticError Base class for arithmetic errors. AssertionError Assertion failed. AttributeError Attribute not found. EOFError Read beyond end of file. EnvironmentError Base class for I/O related errors. Exception Common base class for all exceptions. FloatingPointError Floating point operation failed. IOError I/O operation failed. [. и т. д. . ]
| Python распространяется вместе с прекрасной документацией. Вам следует внимательно прочитать, чтобы заиметь представления о предоставляемых им возможностях. Но, в то время как при использовании большинства других языков вам необходимо все время возвращать к чтению документации (страниц man или, не дай Бог, MSDN), чтобы вспомнить, как использовать тот или иной модуль, Python в основном содержит эту документацию в себе. | |
- Python Library Reference описывает все встроенные функции и исключения.
Copyright © 2000, 2001, 2002 Марк Пилгрим
Copyright © 2001, 2002 Перевод, Денис Откидач