Распознавание текста с помощью решений ABBYY — все гениальное просто для бизнеса

Программы для распознавания текста знакомы всем, кто в процессе работы сталкивался с необходимостью перевода печатных символов в электронный формат. Современные решения от лидера отрасли ABBYY давно вышли за рамки массового сегмента: теперь они помогают бизнесу. Разработки в области распознавания текста востребованы в банковском деле, в образовании, энергетике и т. д. В этой статье мы расскажем о том, какие задачи бизнеса позволяют решать технологии ABBYY.
Система оптического распознавания текста ABBYY OCR: пара слов о технологии
В XXI веке программы распознавания текста востребованы не только у частных пользователей, но и в бизнесе. Главным образом они служат для автоматизации ввода и обработки данных из документов, за счет чего помогают экономить время и деньги. Десятки тысяч компаний во всем мире используют решения ABBYY для повышения конкурентоспособности. А начиналось все в 1993 году, когда была создана технология оптического распознавания символов (OCR — Optical Character Recognition) ABBYY. Поясним вкратце, в чем принцип ее работы.
Текст отсканированного документа, его фотографию или PDF-файл можно просматривать с экрана компьютера, но их содержимое нельзя копировать и изменять. Технология оптического распознавания переводит изображение в формат, доступный для редактирования. Программа находит буквы, объединяет их в слова и предложения, воссоздавая текст. Каким образом она это делает?
Сначала система определяет структуру документа: выделяет текстовые блоки, таблицы, графики, сноски, ссылки, колонтитулы, номера страниц и другие элементы оформления. Этот процесс производится постранично. Затем программа делит текст на строки, слова и символы. После этого в работу включаются механизмы распознавания — классификаторы. Они анализируют каждый символ и предлагают ряд гипотез о том, на какую букву или знак он похож. Из списка предположений классификаторы выбирают то, которому присвоен наибольший вес, и программа выдает распознанный текст.
Отличительные особенности технологии оптического распознавания текста от ABBYY:
- Быстрота и точность распознавания.
- Полное сохранение исходной структуры и форматирования документа. Программа восстанавливает не только сам текст, но и все элементы оформления, включая иллюстрации, гиперссылки, сноски, колонтитулы и т. п.
- Поддержка более 190 языков. Система распознавания текста интегрирована со словарями, и при проверке гипотез учитываются данные о языке документа. Это ускоряет процесс распознавания и сводит к минимуму вероятность ошибок.
- Распознавание символов, набранных любым шрифтом.
- Возможность сохранения текста почти во всех редактируемых форматах (DOC, TXT, RTF, XLS, HTML, PDF), автоматической передачи документа в другие приложения.
- Автоматизация однотипных операций, что позволяет распознавать и обрабатывать документы еще быстрее.
ABBYY OCR: от теории к практике
Какова же прикладная польза от технологий оптического распознавания текста? Процесс оптимизации бизнеса с их помощью идет сразу в нескольких направлениях:
- Уменьшение времени на обработку документов. С программой оптического распознавания текста ручные операции сводятся к минимуму. За счет этого процессы ввода и обработки данных идут быстрее, а сотрудники освобождают рабочее время для более важных задач.
- Повышение качества ввода данных. Автоматизация практически исключает ошибки, неизбежные при выполнении операций вручную.
- Снижение материальных затрат на обработку документов.
- Повышение скорости и качества обслуживания клиентов, что ведет к росту лояльности.
Все это в комплексе влияет на конкурентоспособность компании и помогает бизнесу стать успешнее. Наглядно представить преимущества внедрения программы позволяет статистика:
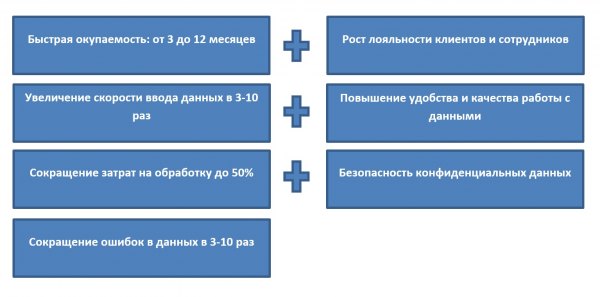
Посмотрим, какие задачи решает программа распознавания текста в конкретных отраслях.
Банковская сфера
Сотрудники банков ежедневно работают с колоссальным объемом бумажной документации. Технологии распознавания текста позволяют экономить массу времени, труда и средств при осуществлении этих операций. Уже 80 российских банков, входящих в топ-100 [1] , оценили решения ABBYY. Вот примерный перечень задач, с которыми справляются решения ABBYY для распознавания текста:
Оптимизация сбора, хранения и обработки клиентских данных
Программа сканирует поступающие документы и автоматически проверяет, правильно ли они заполнены. После этого программа отправляет скан-образы сотруднику банка для верификации. При этом система умеет распознавать ключевые поля в зависимости от типа документа и сравнивать их содержимое с учетными данными. Верифицированные сотрудниками скан-образы автоматически сохраняются в архив. Любые данные из документов можно передавать в информационные системы банка.
Система потокового ввода клиентских данных от ABBYY успешно используется «Россельхозбанком». Решение позволило создать централизованное хранилище документов с онлайн-доступом, минимизировать потерю информации, ускорить взаимодействие между головным офисом и 78 филиалами. Благодаря автоматизированному вводу данных сотрудники банка теперь ежемесячно обрабатывают 4 млн страниц [2] .
Быстрая обработка документов для выдачи кредита
Когда клиент предоставляет документы для получения кредита, система сканирует их и автоматически проверяет правильность оформления. Также программа определяет, все ли необходимые данные имеются. Автоматизация ввода и анализа документов позволяет как минимум в два раза сократить сроки обработки кредитных заявок [3] .
Автоматический ввод данных при открытии счета юрлица
До внедрения технологий распознавания текста сотрудник банка вносил данные для открытия расчетного счета вручную. Для этого было необходимо проверить комплектность документов, удостовериться в корректности заполнения, отсканировать их, извлечь необходимые данные и передать на дальнейшую обработку в информационные системы банка. Программа выполняет все эти операции автоматически.
Автоматизация расчетно-кассовых операций
Чтобы провести платеж, сотрудник банка вводит в систему данные из платежных документов. В организациях, использующих решения ABBYY, этот процесс протекает в 5–10 раз быстрее [4] . Программа сканирует документы, распознает и извлекает необходимые данные, а потом выдает их оператору. При автоматическом вводе устраняется человеческий фактор, и ошибок практически не бывает.
Автоматизация валютного контроля
Финансовые операции с использованием иностранной валюты относятся к особо трудоемким и сложным банковским процессам, поскольку их осуществление требует строгого соблюдения норм валютного законодательства. Сотрудник банка должен проявлять особое внимание при вводе и проверке данных. Решения от ABBYY позволяют автоматизировать обработку документов валютного контроля, ускорить операции и практически полностью исключить ошибки.
Энергетика
Возможности технологий распознавания текстов востребованы и в энергетической отрасли. Прежде всего они используются для автоматизации обработки бумажных и электронных документов.
Автоматизированный ввод данных с приборов
Показания приборов используются и при коммерческом учете потребления электроэнергии, и при техническом обслуживании оборудования (результаты проведения испытаний). Данные чаще всего поступают на бумажных носителях. Показания приборов учета и измерительных устройств вводятся в информационную систему для обработки. Благодаря решениям ABBYY этот процесс происходит автоматически. Программа позволяет сократить сроки обработки документов, исключить ошибки ввода, уменьшить затраты труда персонала.
Автоматизация бухгалтерских операций
Через отделы бухгалтерии электросетевых компаний ежедневно проходит огромное количество финансовых документов. Каким бы внимательным ни был сотрудник, при таком объеме данных неизбежно возникают ошибки. Это приводит к потерям времени и средств, особенно при несвоевременном обнаружении. Не говоря уже о длительности самого процесса ручного ввода.
Внедрение решения по распознаванию текста на 50% сокращает затраты при обработке счетов-фактур [5] , минимизирует ошибки ввода, предотвращает потерю данных. Программа сканирует, распознает и проверяет документы, автоматически извлекает из них нужную информацию и вводит ее в систему. Бухгалтеру остается только подтвердить, правильно ли распознаны данные.
Компания КЭС-Энергостройсервис, занимающаяся ремонтом объектов энергетики, столкнулась с проблемой чрезмерных затрат на документооборот. Чтобы получить нужные запчасти, приходилось ждать 3–7 дней: именно столько времени занимал процесс обработки и согласования документов. После внедрения платформы ABBYY FlexiCapture бухгалтеры стали выполнять эту работу за 1–3 часа [6] .
Быстрая обработка заявок по технологическому присоединению физических и юридических лиц к электросетям
Прежде чем заключить с потребителем договор на технологическое присоединение к электросетям, сотрудники энергетической компании принимают и обрабатывают заявку. Несмотря на то что этот документ разрешается подавать в электронном виде, многие заявители по-прежнему предпочитают традиционные бумажные носители. Персоналу приходится вводить данные вручную, затрачивая лишнее время и труд.
С внедрением решения ABBYY все упрощается: бумажная заявка сканируется, затем программа помещает скан-копию в электронное хранилище, а распознанные данные передает в информационную систему, где они автоматически обрабатываются. Рутинная работа сотрудников сводится к минимуму, и они могут уделять время другим задачам.
Нефтегазовая отрасль
Нефтегазовые компании в своей работе тоже сталкиваются с большим объемом бумажной документации. Данные нужно оперативно и точно вносить в систему и обрабатывать. При этом необходимо, чтобы сотрудники имели к ним быстрый доступ. Понимая, что от этих процессов зависит эффективность бизнеса, руководители компаний стремятся автоматизировать обработку и хранение документов. Наиболее практичным решением представляется создание удобного электронного архива с широким спектром функциональных возможностей. ABBYY уже реализовала несколько таких проектов в нефтегазовой отрасли.
Например, в ОАО «Востокгазпром» удалось за короткое время оптимизировать ввод учетных и финансовых документов с помощью платформы ABBYY FlexiCapture. Перед разработчиками стояла задача обеспечить точность внесения данных, быстрый доступ к нужной информации. С этой целью было создано 25 шаблонов для обработки актов, накладных, кассовых ордеров и других стандартных типов документов предприятия.
Система автоматически вписывает реквизиты документа в его архивную карточку, прикрепляет скан-копию и результат распознавания в доступном для полнотекстового поиска формате. Текстовые данные программа вносит в нужные поля, проверяет их в соответствии с заданными правилами, подсвечивает возможные ошибки. В результате работа сотрудника сводится к итоговому контролю и подтверждению экспорта документа.
Другие отрасли
Применение программ распознавания текста не исчерпывается перечисленными сферами. Решения от ABBYY востребованы и во многих других отраслях экономики, в частности в образовании, государственном секторе, производстве, логистике и транспорте, ритейле, телекоммуникациях и др.
Возможности программы по распознаванию текста позволяют оптимизировать бизнес-процессы и за счет этого повысить конкурентоспособность компании. Автоматизированная обработка документов экономит время сотрудников и снижает затраты на обработку данных. Удобство и функциональность решений ABBYY уже оценили многие предприятия из разных сфер бизнеса.
P.S. ABBYY — мировой лидер в области технологий интеллектуальной обработки информации. С продуктами и отраслевыми решениями компании можно ознакомиться на сайте www.abbyy.com.
- 1 https://www.abbyy.com/ru-ru/solutions/banks/
- 2 https://www.abbyy.com/ru-ru/case-studies/rosselhosbank/#sthash.LSJHnnDE.dpbs
- 3 https://www.abbyy.com/ru-ru/solutions/banks/processing-credit-applications/
- 4 https://www.abbyy.com/ru-ru/solutions/banks/settlement-and-cash-services/
- 5 https://www.abbyy.com/ru-ru/solutions/energy/processing-of-primary-accounting-documents/
- 6 https://www.abbyy.com/media/8441/ss_kes_abbyy.pdf
Какую букву распознает программа в этой кляксе
Информатика и информационно-коммуникационные технологии в школе
Полная или частичная перепечатка каким бы то ни было способом материалов данного сайта допускается только с письменного согласия автора.
При цитировании или ином использовании материалов ссылка на сайт www.klyaksa.net обязательна.

| — Что ты пишешь? — спросили программиста. — Сейчас запустим — узнаем! — ответил программист. |
Начало » Копилка » Попова О. В. » РАЗДЕЛ 9 РАБОТА В РЕДАКТОРЕ ЭЛЕКТРОННЫХ ТАБЛИЦ MS EXCEL
РАЗДЕЛ 9. РАБОТА В РЕДАКТОРЕ ЭЛЕКТРОННЫХ ТАБЛИЦ MS EXCEL
MS Excel относится к классу систем обработки числовой информации, называемых spreadsheet. Буквальный перевод термина “spreadsheet” c английского языка означает “расстеленный лист (бумаги)”. В компьютерном мире под этим термином подразумевают класс программных средств, именуемых у нас “электронными таблицами”.
- Области применения электронных таблиц:
- бухгалтерский и банковский учет;
- планирование распределение ресурсов;
- проектно-сметные работы;
- инженерно-технические расчеты;
- обработка больших массивов информации;
- исследование динамических процессов.
Основные возможности электронных таблиц:
- анализ и моделирование на основе выполнения вычислений и обработки данных;
- оформление таблиц, отчетов;
- форматирование содержащихся в таблице данных;
- построение диаграмм требуемого вида;
- создание и ведение баз данных с возможностью выбора записей по заданному критерию и сортировки по любому параметру;
- перенесение (вставка) в таблицу информации из документов, созданных в других приложениях, работающих в среде Windows;
- печать итогового документа целиком или частично.
Преимущества использования ЭТ при решении задач
- Решение задач с помощью электронных таблиц освобождает от составления алгоритма и отладки программы. Нужно только определенным образом записать в таблицу исходные данные и математические соотношения, входящие в модель.
- При использовании однотипных формул нет необходимости вводить их многократно, можно скопировать формулу в нужную ячейку. При этом произойдет автоматический пересчет относительных адресов, встречающихся в формуле. Если же необходимо, чтобы при копировании формулы ссылка на какую-то ячейку не изменилась, то существует возможность задания абсолютного (неизменяемого) адреса ячейки.
Структура электронной таблицы
В таблице используются столбцы (256) и строки (16384).
Строки пронумерованы от 1 до 16384, столбцы помечаются латинскими буквами от А до Z, и комбинациями букв АА, АВ. IV,
Элемент, находящийся на пересечении столбца и строки называется — ячейкой (клеткой).
Прямоугольная область таблицы называется диапазоном (интервалом, блоком) ячеек. Она задается адресами верхней левой и правой нижней ячеек блока, перечисленными через двоеточие.
9.1. Модель ячейки в MS Excel
Каждая ячейка таблицы имеет следующие характеристики:
- адрес;
- содержимое;
- изображение;
- формат;
- имя;
- примечание (комментарий).
Адрес ячейки — номер столбца и строки. Используется в формулах в виде относительной, абсолютной или смешанной ссылки, а также для быстрого перемещения по таблице.
MS Excel позволяет использовать два стиля ссылок: стиль А1 и стиль R1C1. Переключение стилей осуществляется в меню: Сервис/ Параметры/ Общие опцией “Стиль ссылок R1C1”.
Например. Пусть в ячейке D3 нужно получить произведение чисел, находящихся в ячейках А2 (второй ряд, первая колонка) и B1 (первый ряд, вторая колонка). Это может быть записано одним из следующих способов:
| Вид ссылок | Стиль А1 | Стиль R1С1 |
| относительный | =A2 * B1 имя столбца, имя строки, которые будут относительно изменяться, при копировании формулы в другую ячейку. |
=R[-1]C[-3] * R[-2]C[-2]с мещение по строке, смещение по столбцу, относительно ссылающейся ячейки. Сама формула при копировании не изменяет вид, но ссылается уже на другие ячейки. |
| абсолютный | =$A$2 * $B$1 имя столбца, имя строки, которые останутся неизменным, при копировании формулы . |
=R2C1 * R1C2 номер строки и номер столбца, относительно начала координат. |
| смешанный | =$A2 * B$1 =A$2 * $B1 |
=R[-1]C1 * R1C[-2] =R2C[-3] * R[-2]C2 |
 |
 |
| Рис. 62a.Стиль ссылок A1 (имя столбца, имя строки). | Рис. 62b Стиль ссылок R1C1 (смещение по строке, смещение по столбцу). |
Содержимым ячейки может быть:
- число (целое со знаком или без (-345), дробное с фиксированной точкой (253,62) или с плавающей точкой (2,5362е+2));
- текст;
- формула.
Формула — всегда начинается со знака “=“ и может содержать: числовые константы, абсолютные или относительные ссылки на адреса ячеек, встроенные функции.
Аргументы функций всегда заключаются в круглые скобки. Стандартные функции можно как ввести с клавиатуры, так и воспользоваться меню Вставка/Функция или соответствующей кнопкой на панели инструментов.

Рис. 63. Изображение не всегда совпадает с содержимым ячейки
Изображение — то, что пользователь видит на экране монитора.
Если содержимым ячейки является формула, то изображением будет ее значение.
Текст, помещенный в ячейку, может быть “виден” целиком, либо (если соседняя ячейка не пуста), из него видно столько символов, сколько позволяет ширина ячейки.
Изображение числа зависит от выбранного формата. Одно и то же число в разных форматах (дата, процент, денежный и т.д.) будет иметь различное изображение.
Формат ячейки — формат чисел, шрифт, цвет символов, вид рамки, цвет фона, выравнивание по границам ячейки, защита ячейки.
Имя — используется в формулах, как замена абсолютного адреса ячейки. Например, назначив ячейке С3 имя “Произведение” в ячейку D3 можно поместить формулу: =Произведение/3 (вместо формулы =С3/3). В этом случае, при копировании формулы, адрес ячейки меняться не будет.
Примечание — сопроводительный текст к содержимому ячейки. Ввести примечание в ячейку можно с помощью меню Вставка / Примечание. Ячейка, имеющая примечание, отмечается в рабочем листе точкой в правом верхнем углу.
9.2. Ввод и редактирование данных
Основными объектами, над которыми производятся действия в электронных таблицах, являются ячейки и диапазоны ячеек (блоки).

Рис. 64. Выделенный диапазон ячеек (блок).
Блок — любая прямоугольная область таблицы, в минимальном случае — одна ячейка. Адрес блока задается так: адрес верхней левой ячейки блока, двоеточие, адрес правой нижней ячейки блока.
Примеры блоков: А1 (ячейка); А1:А9 (столбец); В2:Z2 (строка); B2:D4 (прямоугольная область).
Неотъемлемым элементом рабочего поля таблицы является курсор. В ЭТ термин “курсор” используется в следующих случаях:
- курсор ЭТ — жирная рамка вокруг текущей ячейки, перемещается с помощью клавиш управления курсором;
- текстовый курсор — мигающая (или не мигающая) черточка, отмечающая положение текущего символа при редактировании содержимого ячейки.
9.2.1. Ввод данных
1. Установить курсор ЭТ в ячейку, в которой должны быть размещены данные.
2. Набрать данные.
3. Для завершения ввода нажать клавишу (при этом курсор ЭТ переместится на строку ниже), либо нажать «зеленую галочку» на панели инструментов (при этом курсор останется в текущей ячейке).
В ячейке могут размещаться данные одного из следующих типов:
1. число 2. формула 3. текст
9.2.1.1 Правила ввода текста и чисел
Текст можно вводить произвольной формы, но если он начинается со знака “=“, то перед ним следует поставить апостроф, чтобы он не воспринимался как формула.
Числа также вводятся в привычном виде. Следует только помнить, что дробные десятичные числа записываются через запятую: 3,5; -0,0045, либо через точку: 3.5; -0.0045, в зависимости от установленных параметров. Изменение вида разделителя целой и дробной части производится в меню Сервис/ Параметры/ Международные.
9.2.1.2 Форматирование текстовых полей
По умолчанию текстовые поля в MS Excel выводятся в одну строку. Для того чтобы текст переносился в ячейке в несколько строк:
1. Выделите ячейки, для которых необходимо разрешить перенос текста.
2. Выберите пункт меню Формат/ Ячейки вкладка Выравнивание.
3. Поставьте галочку в опции Переносить по словам.
Для таблиц со сложной структурой используйте объединение ячеек, но только там, где это действительно требуется.


Рис. 65.Неправильно и правильно отформатированные текстовые поля.
9.2.1.3 Правила ввода формул
1. Убедитесь в том, что активна (выделена курсивной рамкой) та ячейка, в которой вы хотите получить результат вычислений.
2. Ввод формулы начинается со знака “=”. Этот знак вводится с клавиатуры.
3. После ввода знака “=” Excel переходит в режим ввода формулы. В этом режиме, при выделении какой-либо ячейки, ее адрес автоматически заносится в формулу. Это позволяет избавить пользователя от необходимости знать адреса ячеек и вводить их в формулу с клавиатуры.
4. Находясь в режиме ввода формулы, вы последовательно указываете левой кнопкой мыши на ячейки, хранящие некие числовые значения, и вводите с клавиатуры знаки операций между исходными значениями.
- Знаки операций должны вводиться между адресами ячеек.
- Удобнее вводить знаки операций с правого цифрового блока клавиатуры. Чтобы этот блок работал в нужном режиме, индикатор должен быть включен.
5. Чтобы результат вычислений появился в активной ячейке, необходимо выйти из режима ввода формулы.
- завершает ввод формулы, и переводит курсор в следующую ячейку.
- “Зеленая галочка” на панели ввода формулы завершает ввод формулы, и оставляют курсор в той же ячейке.

Рис. 66. Ввод формулы.
Например, если в ячейке D2 должна помещаться разность чисел из ячеек B2 и C2, то после установки курсора на D5 следует указать мышью на B2, ввести с клавиатуры знак “-”, указать мышью на C2 и нажать или “зеленую галочку”.
В формулах можно использовать числовые константы (-4,5), ссылки на блоки (D4), (A3:D8), знаки арифметических операций, встроенные функции (СУММ, МАКС, SIN и т.д.)
| Операция | Обозначение в формуле | Пример |
| Возведение в степень |
Меньше или равно
Больше или равно
9.2.2. Редактирование данных
При вводе данных Вы можете ошибиться и должны уметь исправлять ошибки. Конечно, Вы можете просто ввести в ячейку с ошибочными данными новое правильное значение, но если исправить требуется один — два символа, то целесообразнее отредактировать содержимое ячейки.
Отредактировать данные Вы можете различными способами, но курсор ЭТ должен стоять на редактируемой ячейке.
1. Перейдите в режим редактирования содержимого ячейки. Это можно сделать одним из следующих способов:
- Щелкнете левой клавишей мыши в строке формул.
- Нажмите .
- Дважды щелкните мышью на ячейке.
2. Текстовый курсор поставьте перед неверным символом, исправьте данные.
3. Нажмите или “зеленую галочку” на панели инструментов, чтобы выйти из режима редактирования.
Неверный формат ячейки может быть изменен только выбором другого формата в меню Формат / Ячейка.
Если ошибка допущена при вводе числа, то так как компьютер не знает, что это ошибка, Excel автоматически пытается подобрать подходящий для данного изображения формат.
Например, Вы хотели ввести число 410. Интерпретация некоторых возможных при вводе ошибок приводится в таблице 19.
| Ошибочный ввод | Распознанный формат | Изображение на экране |
| 4:10 |
Не пытайтесь исправить ошибку непосредственно в ячейке, вряд ли это удастся, так как скрытый формат этой ячейки уже сформирован. Поэтому нужно исправлять сначала формат ячейки на правильный с помощью меню Формат / Ячейка / Число.
Если при вводе формул Вы забыли поставить знак “=”, то все, что было набрано, запишется в ячейку как текст. Если Вы поставили знак равенства, то компьютер распознал, что идет ввод формулы и не допустит записать формулу с ошибкой до тех пор, пока она не будет исправлена. Некоторые ошибки, которые могут быть допущены при вводе формулы, приведены в таблице 20.
| Изображение на экране | Тип ошибки |
| b1*b2 | нет знака = |
| #ИМЯ? | адрес ячейки введен с клавиатуры в режиме кириллицы |
| открывается диалоговое окно | введено два знака операции подряд |
| #ЗНАЧ! | в одной из ячеек, входящих в формулу, находится не числовое значение |
| #ДЕЛ/0! | значение знаменателя =0 , делить на 0 нельзя |
9.2.3. Копирование формул
В электронных таблицах часто требуется проводить операции не просто над двумя переменными (ячейками), но и над массивами (столбцами или строками) ячеек. Т.е. все формулы результирующего массива аналогичны и отличаются друг от друга только адресом строк или столбцов.
От проведения однотипных действий в каждой ячейки строки (или столбца) избавляет следующий прием копирования формулы:
1. Убедитесь, что активна (выделена курсорной рамкой) именно та ячейка, в которой находится предназначенная для копирования формула.
2. Не нажимая на кнопки мыши, подведите указатель мыши к нижнему правому углу курсорной рамки (этот угол специально выделен).
3. Отыщите положение, при котором указатель мыши превращается в тонкий черный крестик.
4. Нажмите на левую кнопку мыши и, удерживая ее, выделяйте диапазон ниже (при копировании по строкам) или правее (при копировании по столбцам) до тех пор, пока не выделятся все ячейки, в которые вы хотите скопировать данную формулу.
5. Отпустите левую кнопку мыши.
Типы указателей мыши
 |
Копирование содержимого выделенной ячейки, или блока ячеек. |
 |
Перенос блока ячеек с одного места рабочего листа на другое. При нажатой клавише произойдет не перенос, а копирование. |
 |
Выделение блока ячеек. |
9.2.4. Относительная и абсолютная адресация
Одно из преимуществ электронных таблиц в том, что в формулах можно использовать не только конкретные числовые значения (константы), но переменные — ссылки на другие ячейки таблицы (адреса ячеек). В тот момент, когда Вы нажимаете клавишу , в формулу вместо адреса ячейки подставляется число, находящееся в данный момент в указанной ячейке.
Другое достоинство в том, что при копировании формул входящие в них ссылки изменяются (относительная адресация).
Однако иногда при решении задач требуется, чтобы при копировании формулы ссылка на какую-либо ячейку не изменялась. Для этого используется абсолютная адресация, или абсолютные ссылки.
При копировании приведенным выше способом адреса ячеек в формуле изменялись относительно.
Если необходимо, чтобы при копировании или перемещении данных адрес какой-либо ячейки в формуле не мог изменяться (например, при умножении всего столбца данных на значение одной и той же ячейки), нужно зафиксировать положение этой ячейки в формуле до того, как вы будете копировать или перемещать данные.
Для фиксации адреса ячейки используется знак “$”.
Координата строки и координата столбца в адресе ячейки могут фиксироваться раздельно.
Чтобы относительный адрес ячейки в формуле стал абсолютным, после ввода в формулу адреса этой ячейки нажмите .
Изменение адреса ячейки в формуле, при ее копировании.
| Значение адреса в исходной формуле | Вниз | Вправо |
| B1 | B2 | C1 |
| $B1 | $B2 | $B1 |
| B$1 | B$1 | C$1 |
| $B$1 | $B$1 | $B$1 |
9.3. Построение диаграмм
Одним из самых впечатляющих достоинств MS Ехсеl является способность превращать абстрактные ряды и столбцы чисел в привлекательные, информативные графики и диаграммы. Ехсеl поддерживает 14 типов различных стандартных двух- и трехмерных диаграмм. При создании новой диаграммы по умолчанию в Excel установлена гистограмма.
Диаграммы — это удобное средство графического представления данных. Они позволяют оценить имеющиеся величины лучше, чем самое внимательное изучение каждой ячейки рабочего листа. Диаграмма может помочь обнаружить ошибку в данных.
Для того чтобы можно было построить диаграмму, необходимо иметь, по крайней мере, один ряд данных. Источником данных для диаграммы выступает таблица Excel.
Специальные термины, применяемые при построении диаграмм:
- Ось X называется осью категорий и значения, откладываемые на этой оси, называются категориями.
- Значения отображаемых в диаграмме функций и гистограмм составляют ряды данных. Ряд данных – последовательность числовых значений. При построении диаграммы могут использоваться несколько рядов данных. Все ряды должны иметь одну и туже размерность.
- Легенда – расшифровка обозначений рядов данных на диаграмме.
Тип диаграммы влияет на ее структуру и предъявляет определенные требования к рядам данных. Так, для построения круговой диаграммы всегда используется только один ряд данных.

Рис. 66. Создание диаграммы.
Последовательность действий, при построении диаграммы
1. Выделите в таблице диапазон данных, по которым будет строиться диаграмма, включая, если это возможно, и диапазоны подписей к этим данным по строкам и столбцам.
2. Для того чтобы выделить несколько несмежных диапазонов данных, производите выделение, удерживая клавишу .
3. Вызовите мастера построения диаграмм (пункт меню Вставка/ Диаграмма или кнопка на стандартной панели инструментов).
4. Внимательно читая все закладки диалогового окна мастера построения диаграмм на каждом шаге, дойдите до конца (выбирайте “Далее”, если эта кнопка активна) и в итоге нажмите “Готово”.
После построения диаграммы можно изменить:
- размеры диаграммы, потянув за габаритные обозначения, которые появляются тогда, когда диаграмма выделена;
- положение диаграммы на листе, путем перетаскивания объекта диаграммы мышью;
- шрифт, цвет, положение любого элемента диаграммы, дважды щелкнув по этому элементу левой кнопкой мыши;
- тип диаграммы, исходные данные, параметры диаграммы, выбрав соответствующие пункты из контекстного меню (правая кнопка мыши).
Диаграмму можно удалить: выделить и нажать .
Диаграмму, как текст и любые другие объекты в MS Office, можно копировать в буфер обмена и вставлять в любой другой документ.
9.4. Задачи
1. Выражение 5(A2+C3):3(B2-D3) в электронной таблице имеет вид:
- 5((A2+C3)/(3(B2-D3)));
- 5(A2+C3)/3(B2-D3);
- 5*(A2+C3)/(3*(B2-D3)).
2. Какая из перечисленных ссылок на ячейку А1 является абсолютной только по строке?
3. «Легенда» диаграммы MS Excel – это:
- порядок построения диаграммы (список действий);
- условные обозначения рядов или категорий данных;
- руководство для построения диаграмм;
- таблица для построения диаграммы.
4. В ячейке B2 электронной таблицы записана формула =A3*C4+B1. Какой вид примет эта формула после копирования ее в ячейку D3?
- =C4*E5+D2;
- =C3*E4+D1;
- формула не изменится.
5. Относительная ссылка на ячейку MS Excel это:
- ссылка, полученная в результате копирования формулы;
- когда адрес, на который ссылается формула, при копировании не изменяется;
- когда адрес, на который ссылается формула, изменяется при копировании формулы.
6. При вводе чисел в ячейки MS Excel десятичные знаки отделяются символом:
- только точкой;
- только запятой;
- точкой или запятой;
- запятой с пробелом.
7. В формуле ссылка на ячейку имеет вид $C$10. Что это означает?
- Дается ссылка на относительный адрес ячейки С10;
- Дается ссылка на абсолютный адрес ячейки С10;
- В ячейке С10 находится число в денежном формате.
Инструкция: как редактировать документы и распознавать тексты с иероглифами в ABBYY FineReader 15
PDF-документы давно стали необходимой составляющей офисной работы. В этом формате хранятся цифровые архивы, юристы согласуют договоры, дизайнеры верстают брошюры, издательства публикуют электронные книги. До недавнего времени главным достоинством и одновременно с этим недостатком PDF-документов было отсутствие возможности редактировать текст в них. Благодаря развитию технологий эту и другие задачи научилась решать программа ABBYY FineReader, которая стала многофункциональным редактором любых документов. «Хайтек» вместе с ABBYY рассказывает, как технологически устроено редактирование PDF-документов в новой версии FineReader 15, каким образом программа сравнивает версии документов и как работает распознавание иероглифов с помощью нейросетей.
Читайте «Хайтек» в
Диджитализация документооборота массово началась еще во второй половине ХХ века. Многие предприятия переходили на электронные документы. В офисах устанавливали первые компьютеры со специальным софтом для обработки и хранения важной информации. Тогда и появились популярные текстовые редакторы. Сотрудники набирали вручную документы, а затем, с появлением в 1993 году PDF, стали экспортировать их в этот формат. На первый взгляд казалось: если весь документооборот станет электронным, то о шкафах с бумажными каталогами и завалах на рабочих столах можно будет забыть. На практике оказалось, что чем больше организация использует компьютеры для цифрового документооборота, тем больше документов она печатает. 64% крупных компаний уверены, что по крайней мере до 2025 года печать будет значимой частью их бизнеса. С другой стороны, если сегодня в офис по традиционной почте приходит бумажный документ, его немедленно отсканируют и переведут в цифру. Как правило, сканы документов хранят в виде PDF-файлов. Документом в формате PDF удобнее пользоваться — его можно послать по электронной почте с уверенностью, что информация дойдет до адресата без искажений (если, конечно, кто-то не решит внести изменения собственноручно), и, в отличие от DOC, его трудно изменить. Это особенно важно, если речь идет о контрактах или коммерческих предложениях. Офисные сотрудники отмечают рост объемов использования PDF: каждый второй респондент ответил, что регулярно работает с документами в этом формате и нуждается в специализированной программе. За последние два года количество таких рабочих файлов в мире выросло в три раза — эти данные приводят эксперты IDC в исследовании «Addressing the document disconnect». В России PDF также пользуется популярностью. Также по результатам исследования ABBYY выяснилось, что в наиболее частые сценарии работы с PDF-документами вошли совершенно не типичные для этого формата ранее задачи: 52% респондентов вносят мелкие правки в текст PDF, исправляют ошибки или опечатки; 62% опрошенных часто ищут информацию в тексте PDF и 60% копируют текст из документа. Поэтому от программ, работающих с PDF, требуются новые возможности для редактирования, сравнения и распознавания текстов. Все они есть в новом FineReader 15.
Почему так сложно редактировать текст в PDF?
Изначально PDF не предназначался для того, что его каким-либо образом изменяли. Что было и его преимуществом — это безопасность, одинаковое отображение на любом устройстве и удобный способ обмена информацией, и недостатком — невозможность внесения правок, поиска по тексту и сравнения документов.
Особенности отображения текста в PDF
Несмотря на то, что PDF — это формат текста, в цифровом виде эти буквы, слова и предложения на самом деле не существуют, они «нарисованы». Содержимое хранится в виде потоков — это могут быть текст, изображения и векторная графика. Типичных для формата DOC слов, строчек, абзацев и таблиц в PDF нет. В формате нет и букв как таковых, а есть коды символов. Такие коды с одинаковыми характеристиками объединяются в группы по виду и размеру шрифта. Этот шрифт определяет, как символ должен отображаться в документе, сопоставляя код символа и глиф — набор команд для отрисовки. Еще одно отличие от обычного текстового документа — объекты в PDF существуют в трех измерениях. По координате Z судят о глубине расположения объекта на странице, ведь текст может находиться поверх изображения или наоборот. Текст в PDF-документе напоминает «мешочек букв», который нужно правильно отобразить в конкретных местах документа с соответствующим форматированием. С 2008 года PDF стал открытым форматом, что позволило разработчикам без проблем и дополнительных отчислений создавать программы для чтения файлов PDF, конвертеры и другие полезные вещи. Развитие OCR привело к тому, что у ранее неизменного PDF-документа появилась возможность редактирования — сначала построчного, а затем и в пределах абзацев. Если речь идет о digital-born-документе (изначально созданный на компьютере, а не отсканированный бумажный документ — «Хайтек»), то в режиме редактирования подключаются фоновые процессы, и программа приступает к анализу структуры документа. Для этого используется технология, которая строит блоки на основе данных, записанных в PDF, а не на основе распознавания. За считанные доли секунды технология должна пройти всю цепочку по определению параметров текста: места, где находятся заголовки, подзаголовки, отдельные абзацы и другие элементы. Потом — распихать «мешочки букв» по этим блокам, сформировать строки. Следующий этап — синтез. Специальные технологии определяют внешние параметры текста — отступы и межстрочные интервалы. Благодаря этому из хаотичной структуры снова появляется текстовый документ с форматированием. И уже в него можно вносить правки — менять слова и целые абзацы, исправлять форматирование, сохранять изменения и так далее.
Функция построчного редактирования уже была в предыдущей версии FineReader (ABBYY FineReader 14 вышла в январе 2017 года — «Хайтек»). Этого было достаточно, чтобы внести небольшие исправления в текст: заменить несколько букв или цифр. Новый ABBYY FineReader 15 стал универсальным текстовым редактором, в котором вносить изменения можно в целые абзацы.
Как отредактировать текст в отсканированном документе
Отдельная офисная задача — отредактировать скан-копию бумажного документа. Раньше для этого пользователю приходилось конвертировать файл в редактируемый формат или просто искать исходник. Когда пользователь редактирует скан, ABBYY FineReader 15 в первую очередь распознает документ и создает временный текстовый слой на тех страницах, которые пользователь просматривает. В режиме редактирования создается текстовое представление страницы — именно его редактирует пользователь. Затем эти правки встраиваются в изображение страницы в отсканированном документе.
Как найти в PDF внесенные правки и избежать обмана
Сравнение документов — особо важный для бизнеса сегмент офисных задач. Прежде всего, потому что неожиданные правки могут стоить очень больших денег. Иногда их незаметно пытаются внести в уже подписанный договор и воспользоваться человеческой невнимательностью — такие документы обычно сравнивают юристы, внимательно вычитывая распечатки оригинала, созданного в Word, и ответа контрагента — отсканированный вариант. Поиск отличий в текстовых документах может быть полезен еще и в том случае, если над ними работают одновременно несколько человек или со временем один и тот же файл периодически изменяют. Это позволяет быстро найти последние правки, которые внесли в файл коллеги. В файлах DOCX для этого есть режим Track Changes, создающий на основе двух версий документа третью — с подсвеченными отличиями в тексте. В новом ABBYY FineReader 15 можно сохранить результаты сравнения любых документов в таком DOCX c Track Changes и в привычном режиме увидеть все различия.  Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов. Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.
Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов. Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.  В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу. В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word. Среди поддерживаемых ABBYY FineReader 15 функций:
В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу. В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word. Среди поддерживаемых ABBYY FineReader 15 функций:
- просмотр PDF-документов;
- редактирование текста в PDF-документе в пределах абзаца;
- удаление конфиденциальных данных;
- сравнение документов разного формата и написанных на разных языках;
- автоматизация задач по оцифровке и конвертации;
- распознавание и конвертирование документов;
- комментирование и согласование;
- защита и цифровая подпись.
Как работают нейросети для распознавания иероглифов и арабской вязи
Распознавание иероглифов осложняется тем, что в отличие от европейских языков, они состоят из большого количества черточек, палочек, наклонов. Но размер иероглифов вполне сопоставим с размером европейских букв. В низком разрешении сканов иероглифы могут и вовсе выглядеть как кляксы. Носитель языка поймет символ, исходя из контекста. Программа же работает поэтапно: сначала анализирует изображение всего документа, определяет абзацы, разбивает распознанные строки на слова, а слова — на отдельные символы. На этом этапе алгоритмы опираются не на контекст, как человек, а на внешний вид иероглифа, и здесь многое зависит от качества изображения. Для распознавания японского, китайского и корейского языков компания ABBYY внедрила нейросети. Они решают две главные задачи при работе с иероглифами — улучшение качества распознавания и «модернизацию» языков.
Качество и скорость в быстром и нормальном режиме
Внедрение нейросетей значительно повысило качество распознавания японского и китайского в быстром режиме, но скорость работы на начальном этапе разработки снизилась. Для клиентов, работающих с большим потоком документов, даже небольшая просадка по скорости может привести к сильному замедлению в обработке данных. Оказалось, что скорость проседает в документах с большим количеством символов с простой структурой — таких, как японская буквенная азбука (в современном японском языке используется три основных системы письма: кандзи — иероглифы китайского происхождения и две слоговые азбуки, созданные в Японии — хирагана и катакана — «Хайтек»).

Эту проблему решили с помощью кэша. Когда программа распознает страницу, одна и та же буква может попадаться на ней несколько раз. Встретив букву «А», написанную одним и тем же шрифтом, ABBYY FineReader анализирует и запоминает ее особенности. Этот принцип оптимизации позволяет не тратить время на распознавание одинаковых символов. Для японского и китайского ранее не использовался кэш, потому что встретить один и тот же иероглиф на странице, написанной естественным языком, можно очень редко. Но для символов с простой структурой это оказалось полезным. Включение кэша позволило ускорить и нормальный, и быстрый режим распознавания.
Почему важно следить за развитием языка
В предыдущих версиях FineReader в японском языке присутствовали иероглифы, которые уже не используются в современных документах. Это заметили сотрудники японского офиса ABBYY: время от времени программа вставляла при распознавании один-два устаревших символа. Для рядового носителя языка это воспринимается как буквы из русского дореволюционного алфавита для нас. Чтобы исправить эту ошибку, потребовалось создать в программе «новый язык» — Japanese Modern. Легко заставить программу не отображать те или иные устаревшие символы. Но необходимо было не просто выбросить ненужное, но и оставить всё необходимое, найти множество иероглифов, которые отображают всё богатство современного японского языка.
Новое множество символов формировалось в несколько этапов. Для тестирования создавали подходящие наборы изображений документов. Если в пакет попадала хотя бы одна страница с устаревшими формами, весь комплект оказывался непригодным. Приходилось вынимать эту страничку и формировать новый комплект материалов. Наконец удалось добиться того, чтобы в результатах распознавания почти не было устаревших символов и при этом правильно отображались все современные иероглифы.
Для китайского в FineReader всегда поддерживали традиционный и упрощенный языки. При этом по составу символов они не отличались. Получить разный результат распознавания всё равно было возможно, потому что в программе было заложено разное распределение вероятностей. В новой версии в результате экспериментов удалось выделить символы, необходимые для распознавания упрощенного китайского. В FineReader заложена возможность создавать пользовательский язык. Используя этот инструмент и внося изменения в состав, специалисты сравнивали результаты распознавания на разных образцах документов, и в результате в упрощенном китайском остался только необходимый набор иероглифов.
Корейская письменность, хангыль — нечто среднее между китайским и европейским письмом. Внешне это квадратные символы, напоминающие иероглифы, и на одной странице текста можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков. Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать диграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Каждый блок может состоять из двух, трех или четырех букв. Первой всегда идет согласная, затем одна или две гласных, и в конце может стоять еще одна согласная. Для корейского обучили отдельную нейросеть, которая, помимо корейских слогов, распознает и некоторые иероглифы. Вместо распознавания символов целиком технология определяет отдельные буквы в них.
Как резать арабскую вязь на фрагменты
Арабский язык отличается от других тем, что найти линии порезки между символами в арабской вязи очень сложно. Даже гистограмма при распознавании арабского отличается: выглядит как бесконечный набор горбиков и ямочек.
Варианты разделения текста на символы создаются всегда, даже для европейских языков. В процессе работы программа выбирает наиболее вероятный путь распознавания. В случае с арабским языком таких вариантов очень много, и это приводило к ошибкам. Поэтому для повышения точности программу научили видеть не отдельную букву, а всё слово целиком. Для этого была разработана сеть end-to-end (e2e). Она полезна не только для арабского, но и для европейских языков — например, в дизайнерских шрифтах, когда на изображениях сложно построить путь для распознавания.
При e2e-подходе на вход в нейросеть поступает набор изображений — фрагментов, состоящих из отдельных слов. На выходе такая нейросеть выдает последовательность графем, которые затем проходят дополнительную обработку: проводится словарный анализ, корректируются пробелы.
Для обучения использовался набор из нескольких сотен тысяч фрагментов — отдельные слова из отсканированных газет, журналов, официальных документов. Они были выбраны в несколько итераций: сначала собирали базу из слов, которые удачно распознали, и обучали нейросеть на этом датасете. Потом еще раз обучали, корректировали, выявляли ошибки. Часть, которую не смогли распознать, отдельно отдавали на доразметку и корректировку фрагментов. В результате всё больше очищали датасет для обучения, улучшая общее качество распознавания.
Кроме того, часть данных для обучения была создана искусственно. Это было необходимо для распознавания шрифтов, для которых было собрано мало образцов. В таких случаях использовался корпус текста, в который добавлялись различные искажения, типичные для этапа сканирования документа: шум, размытие символа. Это делала в автоматическом режиме специальная программа — генератор синтетики, или «портилка».
Сначала в ходе обучения такой подход привел к тому, что потерялась информация об охватывающих прямоугольниках символов, которые необходимо отображать для пользователя на этапе верификации. Отказавшись от посимвольного распознавания, пришлось внедрить альтернативный механизм, который дополнял результаты распознавания информацией об охватывающих прямоугольниках и резал слова на отдельные символы.
Сочетание новых алгоритмов машинного обучения сделало возможным создание многофункционального текстового редактора для работы с PDF, сканами и digital-born-документами. Внесение правок, сравнение файлов и распознавание сложных языков дает пользователю возможность полноценно работать с файлами вне зависимости от их формата. По сути, это позволяет охватить все спектры офисных задач по работе с электронными и даже бумажными документами, максимально упрощая работу сотрудникам и снижая вероятность ошибок из-за человеческого фактора.
Внутренний карман
«Пятна Роршаха» — ета такой известный тест, применяемый для определения свойств личности.
Существует табличка с пятнами — вот, посмотри на нее, обследуемый, истолкуй, а дохтур скажет, что ты собой представляешь:). «То, что индивид видит в кляксе (пятне), определяется особенностями его собственной личности».
Тест используется по сей день, но некоторые считают его ненаучным. Тем не менее, прикинуть, что у человека происходит с воображением, все-таки можно.

На картинке одно из пятен Роршаха — похоже на букву ж, только боковушки развернуты в обратную сторону.
Что тебе хочется увидеть, хоть в букве ж, хоть в этой кляксе — то ты и увидишь.
Это как в анекдоте о солдате, который в куче кирпичей видел акт. Почему? Да потому что ему всегда и во всем мерещился акт:).
Еще у человека есть такая особенность — парейдолия — ета способность видеть живое в неживом, оживлять неживое, навязывая ему свойства живого.
Типа, «лица людей мы можем увидеть не только в электрических розетках, решётках, стульях и прочих неживых предметах, но и в абсолютно любой изогнутой геометрической фигуре».
И не только лица людей, но и их тела, или движения. Посмотрим на какую-то букву, и увидим танцующего человека, или рассевшуюся толстую тетку. Почему? Потому что у нас развито воображение — раз, и, два — мы все время думаем о чем-то важном для нас, и поневоле видим это важное в окружающих предметах, графических рисунках. Как тот солдат.:)
Если, например, мы хотим (фигурально) ущипнуть какого-то человека, или даже страну, то все, что нас окружает, может стать поводом для этого. Похоже на влюбленность, когда каждый предмет вокруг напоминает о возлюбленной, и как-то с ней связан. Правда, эта связь очевидна только для влюбленного, и он очень удивляется тому, что другие не видят, что вот эти речные струи похожи на Машины волосы — буквально один в один. Ну, как же вы не видите? Это же так ясно!
Спецалист увидит в миланском замке Сфорца современника (или даже предшественника, не так важно) Кремля:

Еще вот замок в Вероне, тоже знакомые ласточкины хвосты:

Но неспециалист, одержимый совсем другой идеей, может увидеть в хвостиках, к примеру, очертания русских букв, хотя у тех итальянцев, которые строили эти стены и возводили на них ласточкины хвосты, такого в голове не было, и быть не могло.
Не потому он различит на стенах Кремля буквы, или наоборот — в очертаниях букв нечто кремлевское, что это так и есть,
а потому, что имеют место быть пятна Роршаха и парейдолии:), и каждый видит то, что хочет и может видеть:). Притянуть же одно к другому — свое видение к реальности — дело техники.:)