multitask.tflite — что это на телефоне?

Приветствую друзья. multitask.tflite — неизвестная функция/приложение на смартфоне Android. Информация данной статьи поможет примерно понять предназначение multitask.tflite.
multitask.tflite — что это такое?
Информация именно об multitask.tflite к сожалению отсутствует.
Однако удалось выяснить:
- tflite — формат TensorFlow Lite, в котором содержится обученная модель машинного обучения. TensorFlow — библиотека машинного обучения Google
- multitask — означает многозадачность.
Учитывая выше информацию — возможно имеется ввиду приложение MultiTasking, предназначенное для создания удобной многозадачности (тема на форуме 4PDA). MultiTasking позволяет использовать оконный режим приложений, как в Windows с поддержкой изменения размера окна, кнопкой крестик (закрытие окна). Предположительно поддерживается функция перетаскивания окна. Пример на смартфоне:

Особенно актуально на планшетах:

Android и оконный режим (многозадачность)
Версия Android 11 Developer Preview 2 содержит некоторые необычные функции. Например Columbus, позволяющую активировать определенные приложения путем двойного нажатия по задней стороне телефона. Другими словами — двойной тап, только вместо экрана — задняя панель смартфона. Данным жестом можно запустить например голосового помощника, приложение камеры.
функция тестируется на телефонах Pixel 3 XL, Pixel 4 and Pixel 4 XL. В работе функции используются некоторые элементы многозадачности.
Поддержка оконного режима появилась в Android 7 Nougat. Однако по умолчанию опция отключена. Включить можно в меню Параметры разработчика, название настройки — Изменение размера в многооконном режиме:

Заключение
- tflite — формат, содержащий модель машинного обучения.
- multitask — термин обозначает многозадачность.
Надеюсь информация помогла. Удачи.
Мобильный eye-tracking на PyTorch
Рынок eye-tracking’а, как ожидается, будет расти и расти: с $560 млн в 2020 до $1,786 млрд в 2025. Так какая есть альтернатива относительно дорогим устройствам? Конечно, простая вебка! Как и другие, этот подход встречает много сложностей, будь то: большое разнообразие устройств (следовательно, сложно подобрать настройки, которые будут работать на всех камерах одинаково), сильная вариативность параметров (от освещения до наклона камеры и ее положения относительно лица), порядочные вычислительные мощности (несколько cuda-ядер и Xeon — самое то).
Хотя подождите-ка, действительно ли надо тратиться на топовое железо да еще и видеокарту закупать? Может, есть способ уместить все вычисления на cpu и не потерять при этом в скорости?
(Well, если бы не было такого способа, то не было бы и статьи про то, как обучить нейронку на PyTorch)
Данные
Как всегда в data science, самый важный вопрос. Спустя некоторое время поисков я нашел датасет MPIIGaze. Авторы статьи предложили много классных способ его обработки (например, нормализацию положения головы), но мы пойдем простым путем.
Итак, запускаем Colab, загружаем ноутбук и стартуем:
# импорт библиотек import os import numpy as np import pandas as pd import scipy import scipy.io from PIL import Image import cv2 import seaborn as sns import matplotlib import matplotlib.pyplot as pltВ Colab’е можно юзать системные утилиты прямо из ноутбука, соу, скачиваем и распаковываем датасет:
!wget https://datasets.d2.mpi-inf.mpg.de/MPIIGaze/MPIIGaze.tar.gz !tar xvzf MPIIGaze.tar.gz MPIIGazeВ папке Data/Original находятся изображения наших человеков. Всего их было 15, и для каждого есть фотографии с нескольких дней эксперимента. Папка Annotation Subset содержит аннотации к каждой фотографии, каждая аннотация — набор лицевых точек и положения зрачков на фотографии. Авторы статьи заботливо оставили их без header’а, поэтому сейчас будем смотреть, какие чиселки каким лицевым точкам соответствуют.
database_path = "/content/MPIIGaze" # функция для загрузки фотографий одного человека def load_image_data(patient_name): global database_path annotation_path = os.path.join(database_path, "Annotation Subset", patient_name + ".txt") data_folder = os.path.join(database_path, "Data", "Original", patient_name) annotation = pd.read_csv(annotation_path, sep=" ", header=None) points = np.array(annotation.loc[:, list(range(1, 17))]) filenames = np.array(annotation.loc[:, [0]]).reshape(-1) images = [np.array(Image.open(os.path.join(data_folder, filename))) for filename in filenames] return images, pointsimages, points = load_image_data("p00")plt.imshow(images[0]) colors = ["r", "g", "b", "magenta", "y", "cyan", "brown", "lightcoral"] for i in range(0, len(points[0]), 2): x, y = points[0, i:i+2] # вот туть мне удалось понять, что координаты точек хранятся по 2, причем в формате X, Y plt.scatter([x], [y], c=colors[i//2])Получился вот такой красавец:

Агась, запоминаем порядок: сначала крайние точки правого глаза, затем крайние точки левого глаза, потом рот и затем правый и левый зрачки.
Окей, грузим фотографии. Так как у нас есть только крайние точки глаза, я сделал такое предположение: пусть у нас есть область, которая содержит глаз (ну, и часть лица, разумеется), тогда ширина этой области относится к ее высоте, как 2:1. Поэтому будем вырезать прямоугольник 2 к 1 из той большой фотографии, что у нас имеется.
# функция расстояния между двумя точками def distance(x1, y1, x2, y2): return int(((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5) image_shape = (16, 32) # здесь вырезаем из большой картинки глаз и находим относительное положение зрачка # это понадобится позже def handle_eye(image, p1, p2, pupil): global image_shape line_len = distance(*p1, *p2) # x, y -> y, x p1 = p1[::-1] p2 = p2[::-1] pupil = pupil[::-1] corner1 = p1 - np.array([line_len//4, 0]) corner2 = p2 + np.array([line_len//4, 0]) sub_image = image[corner1[0]:corner2[0]+1, corner1[1]:corner2[1]+1] pupil_new = pupil - corner1 pupil_new = pupil_new / sub_image.shape[:2] sub_image = cv2.resize(sub_image, image_shape[::-1], interpolation=cv2.INTER_AREA) sub_image = cv2.cvtColor(sub_image, cv2.COLOR_RGB2GRAY) return sub_image, pupil_newНа одной картинке у нас 2 глаза, поэтому для удобства — еще одна функция:
def image_to_train_data(image, points): eye_right_p1 = points[0:2] eye_right_p2 = points[2:4] eye_right_pupil = points[12:14] right_image, right_pupil = handle_eye(image, eye_right_p1, eye_right_p2, eye_right_pupil) eye_left_p1 = points[4:6] eye_left_p2 = points[6:8] eye_left_pupil = points[14:16] left_image, left_pupil = handle_eye(image, eye_left_p1, eye_left_p2, eye_left_pupil) return right_image, right_pupil, left_image, left_pupilДавайте посмотрим (и на нас посмотрят в ответ):
# обработаем одну картинку right_image, right_pupil, left_image, left_pupil = image_to_train_data(images[10], points[10]) plt.imshow(right_image, cmap="gray") r_p_x = int(right_pupil[1] * image_shape[1]) r_p_y = int(right_pupil[0] * image_shape[0]) plt.scatter([r_p_x], [r_p_y], c="red")
Ну, что-то похожее на истину. Загрузим фотографии всех людей:
images_left_conc = [] images_right_conc = [] pupils_left_conc = [] pupils_right_conc = [] patients_path = os.path.join(database_path, "Data", "Original") for patient in os.listdir(patients_path): print(patient) images, points = load_image_data(patient) for i in range(len(images)): signle_image_data = image_to_train_data(images[i], points[i]) if any(stuff is None for stuff in signle_image_data): continue right_image, right_pupil, left_image, left_pupil = signle_image_data if any(right_pupil < 0) or any(left_pupil < 0): continue images_right_conc.append(right_image) images_left_conc.append(left_image) pupils_right_conc.append(right_pupil) pupils_left_conc.append(left_pupil) images_left_conc = np.array(images_left_conc) images_right_conc = np.array(images_right_conc) pupils_left_conc = np.array(pupils_left_conc) pupils_right_conc = np.array(pupils_right_conc)images_left_conc = images_left_conc / 255 images_right_conc = images_right_conc / 255Теперь хитрый трюк, который не будет работать на косых людях: усредним положения левого и правого зрачков и будем предсказывать это усредненное значение:
pupils_conc = np.zeros_like(pupils_left_conc) for i in range(2): pupils_conc[:, i] = (pupils_left_conc[:, i] + pupils_right_conc[:, i]) / 2Посмотрим распределение позиций зрачков:
viz_pupils = np.zeros(image_shape) for y, x in pupils_conc: y = int(y * image_shape[0]) x = int(x * image_shape[1]) viz_pupils[y, x] += 1 max_val = viz_pupils.max() viz_pupils = viz_pupils / max_val plt.imshow(viz_pupils, cmap="hot")
Ага, большая часть данных находится около центра картинки.
Предобработка
# еще несколько вкусных строчек from sklearn.model_selection import train_test_split import torch from torch.utils.data import DataLoader, TensorDataset# функция, разбивающая данные на два датасета -- тренировочный и валидационный def make_2eyes_datasets(images_left, images_right, pupils, train_size=0.8): n, height, width = images_left.shape images_left = images_left.reshape(n, 1, height, width) images_right = images_right.reshape(n, 1, height, width) images_left_train, images_left_val, images_right_train, images_right_val, pupils_train, pupils_val = train_test_split( images_left, images_right, pupils, train_size=train_size ) def make_dataset(im_left, im_right, pups): return TensorDataset( torch.from_numpy(im_left.astype(np.float32)), torch.from_numpy(im_right.astype(np.float32)), torch.from_numpy(pups.astype(np.float32)) ) train_dataset = make_dataset(images_left_train, images_right_train, pupils_train) val_dataset = make_dataset(images_left_val, images_right_val, pupils_val) return train_dataset, val_dataset # преобразование датасетов в даталоадеры def make_dataloaders(train_dataset, val_dataset, batch_size=256): train_dataloader = DataLoader(train_dataset, batch_size=batch_size) val_dataloader = DataLoader(val_dataset, batch_size=batch_size) return train_dataloader, val_dataloaderbatch_size = 256 eyes_datasets = make_2eyes_datasets(images_left_conc, images_right_conc, pupils_conc) eyes_train_loader, eyes_val_loader = make_dataloaders(*eyes_datasets, batch_size=batch_size)Обучаем модельку
import torch import torch.nn as nn import torch.nn.functional as F# модуль, аналогичный `keras.layers.Reshape` class Reshaper(nn.Module): def __init__(self, target_shape): super(Reshaper, self).__init__() self.target_shape = target_shape def forward(self, input): return torch.reshape(input, (-1, *self.target_shape)) # сама нейронка class EyesNet(nn.Module): def __init__(self): super(EyesNet, self).__init__() # два feature-extractor'а с одинаковой архитектурой self.features_left = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=2, padding=2), nn.LeakyReLU(), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), Reshaper([64]) ) self.features_right = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=32, kernel_size=5, stride=2, padding=2), nn.LeakyReLU(), nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=2, padding=1), nn.LeakyReLU(), Reshaper([64]) ) self.fc = nn.Sequential( nn.Linear(128, 64), nn.LeakyReLU(), nn.Linear(64, 16), nn.LeakyReLU(), nn.Linear(16, 2), nn.Sigmoid() ) def forward(self, x_left, x_right): # прогоняем две картинки через слои фич, конкатенируем и отдаем регрессору x_left = self.features_left(x_left) x_right = self.features_right(x_right) x = torch.cat((x_left, x_right), 1) x = self.fc(x) return xК слову, тренировать я собираюсь на GPU (потому что любая тренировка на CPU ≈ смэрть), благо Колаб дает бесплатно использовать 8 гигабайт.
# функция обучения нейронки def train(model, train_loader, test_loader, epochs, lr, folder="gazenet"): os.makedirs(folder, exist_ok=True) optimizer = torch.optim.Adam(model.parameters(), lr=lr) mse = nn.MSELoss() for epoch in range(epochs): running_loss = 0 error_mean = [] error_std = [] for i, (*xs_batch, y_batch) in enumerate(train_loader): xs_batch = [x_batch.cuda() for x_batch in xs_batch] y_batch = y_batch.cuda() optimizer.zero_grad() y_batch_pred = model(*xs_batch) loss = mse(y_batch_pred, y_batch) loss.backward() optimizer.step() running_loss += loss.item() difference = (y_batch - y_batch_pred).detach().cpu().numpy().reshape(-1) error_mean.append(np.mean(difference)) error_std.append(np.std(difference)) error_mean = np.mean(error_mean) error_std = np.mean(error_std) print(f"Epoch /, train loss: , error mean: , error std: ") running_loss = 0 error_mean = [] error_std = [] for i, (*xs_batch, y_batch) in enumerate(train_loader): xs_batch = [x_batch.cuda() for x_batch in xs_batch] y_batch = y_batch.cuda() y_batch_pred = model(*xs_batch) loss = mse(y_batch_pred, y_batch) loss.backward() running_loss += loss.item() difference = (y_batch - y_batch_pred).detach().cpu().numpy().reshape(-1) error_mean.append(np.mean(difference)) error_std.append(np.std(difference)) error_mean = np.mean(error_mean) error_std = np.mean(error_std) print(f"Epoch /, val loss: , error mean: , error std: ") epoch_path = os.path.join(folder, f"epoch_.pth") torch.save(model.state_dict(), epoch_path)eyesnet = EyesNet().cuda() # полученные веса сохраняются в папку *eyes_net* train(eyesnet, eyes_train_loader, eyes_val_loader, 300, 1e-3, "eyes_net")Давайте посмотрим, что получилось после 300 эпох (я не писал сиды, поэтому у вас будут другие значения):
Epoch 1/300, train loss: 0.3125856015831232, error mean: -0.019309822469949722, error std: 0.08668763190507889 Epoch 1/300, val loss: 0.18365296721458435, error mean: -0.008721884340047836, error std: 0.07283741235733032 Epoch 2/300, train loss: 0.1700970521196723, error mean: 0.0001489206333644688, error std: 0.07033108174800873 Epoch 2/300, val loss: 0.1475073655601591, error mean: -0.001808341359719634, error std: 0.06572529673576355 . Epoch 299/300, train loss: 0.003378463063199888, error mean: -8.133996743708849e-05, error std: 0.009488753043115139 Epoch 299/300, val loss: 0.004163481352406961, error mean: -0.001996406354010105, error std: 0.010547727346420288 Epoch 300/300, train loss: 0.003569353237253381, error mean: -9.1125002654735e-05, error std: 0.00977678969502449 Epoch 300/300, val loss: 0.004456713928448153, error mean: 0.0008482271223329008, error std: 0.010923181660473347299 эпоха мне нравится больше всех, поэтому заюзаем ее для тестов.
Оценка модели
Сделаем функцию для визуализации предсказаний:
import random # рисует левый и правый глаз и выставляет реальное и предсказанное положение зрачка def show_output(model, data_loader, batch_num=0, samples=5, grid_shape=(5, 1), figsize=(10, 10)): for i, (*xs, y) in enumerate(data_loader): if i == batch_num: break xs = [x.cuda() for x in xs] y_pred = model(*xs).detach().cpu().numpy().reshape(-1, 2) xs = [x.detach().cpu().numpy().reshape(-1, 16, 32) for x in xs] imgs_conc = np.hstack(xs) y = y.cpu().numpy().reshape(-1, 2) indices = random.sample(range(len(y_pred)), samples) fig, axes = plt.subplots(*grid_shape, figsize=figsize) for i, index in enumerate(indices): row = i // grid_shape[1] column = i % grid_shape[1] axes[row, column].imshow(imgs_conc[index]) axes[row, column].scatter([y_pred[index, 1]*32, y_pred[index, 1]*32], [y_pred[index, 0]*16, (y_pred[index, 0]+1)*16], c="r") axes[row, column].scatter([y[index, 1]*32, y[index, 1]*32], [y[index, 0]*16, (y[index, 0]+1)*16], c="g")# загружаем 299 эпоху eyesnet.load_state_dict(torch.load("eyes_net/epoch_299.pth")) show_output(eyesnet, eyes_val_loader, 103, 16, (4, 4))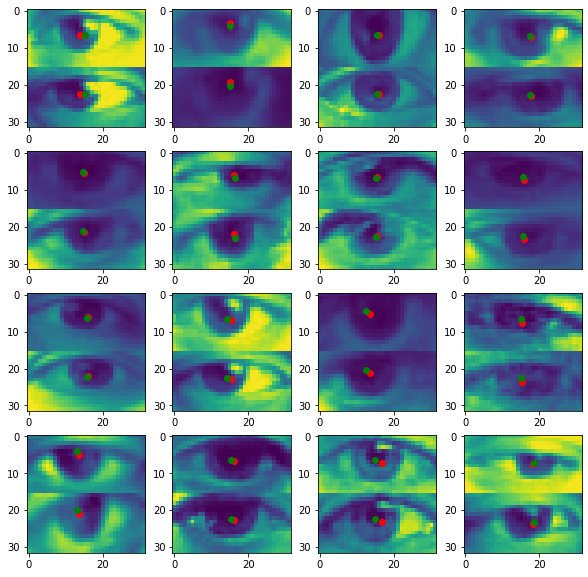
Ох, не нравится мне, что "реальные" точки заметно удалены от центра зрачка, ну да ладно. Закралась погрешность — во-первых, из-за усреднения данных по двум глазам, во-вторых, разметка не совсем точная. Если посмотреть датасет, то можно увидеть некоторые ошибки.
Построим зависимость ошибки от положения зрачка (по X и Y), как в статье:
def error_distribution(model, data_loader, image_shape=(16, 32), bins=32, digits=2, figsize=(10,10)): ys_true = [] ys_pred = [] for *xs, y in data_loader: xs = [x.cuda() for x in xs] y_pred = model(*xs) ys_true.append(y.detach().cpu().numpy()) ys_pred.append(y_pred.detach().cpu().numpy()) ys_true = np.concatenate(ys_true) ys_pred = np.concatenate(ys_pred) indices = np.arange(len(ys_true)) fig, axes = plt.subplots(2, figsize=figsize) for ax_num in range(2): ys_true_subset = ys_true[:, ax_num] ys_pred_subset = ys_pred[:, ax_num] counts, ranges = np.histogram(ys_true_subset, bins=bins) errors = [] labels = [] for i in range(len(counts)): begin, end = ranges[i], ranges[i + 1] range_indices = indices[(ys_true_subset >= begin) & (ys_true_subset error_distribution(eyesnet, eyes_val_loader, figsize=(20, 10))
Чем дальше зрачок от центра, тем больше ошибка
Ок-с, вроде бы сойдет. Теперь то, ради чего мы все тут собрались. Давайте измерять время С:
import time def measure_time(model, data_loader, n_batches=5): begin_time = time.time() batch_num = 0 n_samples = 0 predicted = [] for *xs, y in data_loader: xs = [x.cpu() for x in xs] y_pred = model(*xs) predicted.append(y_pred.detach().cpu().numpy().reshape(-1)) batch_num += 1 n_samples += len(y) if batch_num >= n_batches: break end_time = time.time() time_per_sample = (end_time - begin_time) / n_samples return time_per_sampleeyesnet_cpu = EyesNet().cpu() eyesnet_cpu.load_state_dict(torch.load("eyes_net/epoch_299.pth", map_location="cpu")) # сделаем dataloader, подающий изображения по одному, чтобы сэмулировать работу в realtime _, eyes_val_loader_single = make_dataloaders(*eyes_datasets, batch_size=1) tps = measure_time(eyesnet_cpu, eyes_val_loader_single) print(f" seconds per sample") >>> 0.003347921371459961 seconds per sampleМожно посмотреть, как себя будет вести нейронка на основе VGG16 (не обучая, просто прогоним через нее батчи):
import torchvision.models as models class VGG16Based(nn.Module): def __init__(self): super(VGG16Based, self).__init__() self.vgg = models.vgg16(pretrained=False) self.vgg.classifier = nn.Sequential( nn.Linear(25088, 256), nn.LeakyReLU(), nn.Linear(256, 2), nn.Sigmoid() ) def forward(self, x_left, x_right): x_mid = (x_left + x_right) / 2 x = torch.cat((x_left, x_mid, x_right), dim=1) # добавляем паддинг, чтобы VGG16 смогла извлечь фичи x_pad = torch.zeros((x.shape[0], 3, 32, 32)) x_pad[:, :, :16, :] = x x = self.vgg(x_pad) return x vgg16 = VGG16Based() vgg16_tps = measure_time(vgg16, eyes_val_loader_single) print(f" seconds per sample") >>> 0.023713159561157226 seconds per sampleДля сравнения время, измеренное на моем ноутбуке (AMD A10-4600M APU, 1500 MHz):
python benchmark.py 0.003980588912963867 seconds per sample, EyesNet 0.12246298789978027 seconds per sample, VGG16-basedВыводы
Что ж, нейронка получилась, время исполнения небольшое, памяти ест немного (веса для VGG16 занимают 80 мб, а для EyesNet — 1 мб; расход оперативки на хранение весов я посмотреть не смог, но можете написать в комментах, как это сделать). Но, как всегда, есть куда расти. Вот небольшой список улучшений, которые пришли мне в голову:
- Сделать нормализацию картинки с помощью матриц трансформации (как в статье).
- Порезать веса. Например, использовать float8 вместо float32 (не уверен, уменьшит ли это время исполнения, но вот памяти будет занимать меньше).
- Использовать PyTorch Mobile — версию PyTorch для мобильных устройств. Также уменьшает объем памяти за счет урезания самой библиотеки.
- Использовать датасет побольше. Как кандидат — GazeCapture. Если вам дадут прямую ссылку на датасет, киньте в комменты, плез — мой запрос проигнорировали: С
- Попробовать TFLite — TensorFlow для мобильных устройств. Может запускаться даже на микроконтроллерах!
Немного о нас
Еще раз привет, меня зовут Евгений. Обожаю Data science (и особенно — учить модельки *^*) и занимаюсь им полтора года. Этот пост создан благодаря нашей команде — FARADAY Lab. Мы — начинающие российские стартаперы и хотим делиться с Вами тем, что узнаем сами.

Полезные ссылки:
- репо с ноутбуком и кодом для бенчмарка
- статья авторов MPIIGaze
- статья про большой и классный датасет
- PyTorch mobile
- TensorFlow lite
Почему я никогда не чищу память на Android
Я очень часто натыкаюсь на вопросы пользователей Android о том, какое приложение лучше выбрать для чистки смартфона. Причём все настойчиво ищут какое-то особенное приложение, которое бы творило чудеса. Я понимаю, почему этим занимаются владельцы старых смартфонов. Их аппараты уже перестали соответствовать современным реалиям, тянуть актуальный софт из Google Play, а потому эти люди думают, что замедление произошло из-за перегрузки фантомными файлами и кэшем. Но когда чистку проводят просто «для профилактики», я искренне недоумеваю, потому что сам никогда не пользовался утилитами-чистильщиками и не собираюсь.

Чистить смартфон от ненужных файлов необязательно
Мне хватит и 16 ГБ памяти на смартфоне. Как я справляюсь
Начну, пожалуй, с развенчания главного мифа о чистке. Тут нужно понять, что такого явления, как засорение операционной системы или смартфона, в принципе не существует. Во всяком случае, в том виде, в каком его многие себе представляют. Чисто по умолчанию смартфоны не забиваются «лишними файлами» и не начинают работать из-за них медленнее.
Почему смартфон стал работать медленнее
Возможно, я открою вас страшную тайну, но старые смартфоны начинают работать медленнее, чем новые, просто потому что они старые. Да, это факт, который многим оказывается очень сложно принять, но от него никуда не деться. Старое железо начинает с трудом тянуть свежий софт, последние обновления с новыми функциями, да и наши запросы со временем тоже меняются, и скорость, с которой смартфон выполнял ту или иную задачу ещё пару лет назад, сегодня нас уже не устраивает.
Нет, конечно, если вы скачаете себе на смартфон всякий программный хлам из интернета вроде нерабочих APK-файлов, приложений-майнеров или троянских программ, понятное дело, ваш аппарат станет работать хуже. Вот только удалить весь этот треш при помощи программ-чистильщиков уже не выйдет, да и «убить» таким образом можно даже новый смартфон за тысячу долларов. В этом случае он не будет отличаться от дешёвого Xiaomi или Meizu.
Чем забивается память смартфона
Так что же, в таком случае, все чистят? Ну, в процессе использования на устройстве и правда копятся какие-то файлы. Однако в моём случае удалять там нечего. Посмотрите на скриншот. Из вроде бы ненужного у меня тут данные приложений, неиспользуемые приложения, остаточные файлы и повторяющиеся файлы.
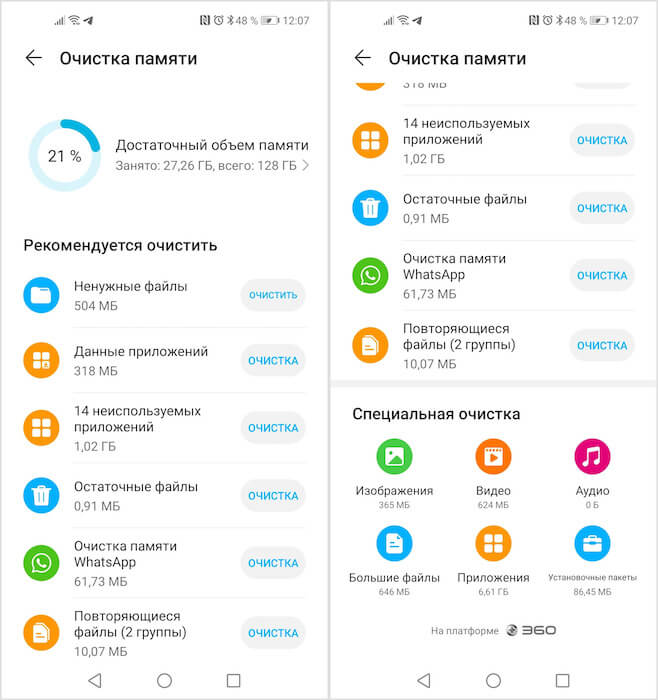
У меня почти нет лишних файлов, а то, что Android назвал лишними, таковым не является
Но если открыть каждую вкладку и посмотреть, что же в ней скрывается, становится понятно – по крайней мере для меня – что ничего ненужного здесь практически нет. Раздел «Ненужные файлы» хранит в себе кэш, который, как я уже рассказывал, не только не тормозит устройство, а, напротив, позволяет ему работать быстрее. В «Неиспользуемых приложениях» действительно есть софт, которым я пользуюсь редко, но, как ни крути, пользуюсь и удалять его, чтобы потом скачивать заново, смысла не вижу. «Данные приложений» — говорят сами за себя.
Там есть ещё вкладки с видеороликами, которые я записывал сам, и фотографиями, но, понятное дело, их я удалять не хочу. Остаются только «Остаточные файлы» и «Повторяющиеся файлы». Но, как видите, их вес настолько незначительный, что о них вообще можно и не вспоминать, не говоря уже о том, чтобы скачивать специальное приложение, чтобы очистить 15 МБ памяти. Да оно займёт больше места, чем освободит!
Зачем нужен сервис Google Фото

Иногда приложения для чистки памяти сами весят больше, чем удаляемый ими мусор
А как же быть с дубликатами фотографий и другими неудачными снимками, которые приложения для чистки находят и удаляют? Ну, у меня и на этот случай есть решение. Я уже давно пользуюсь «Google Фото», куда все фото и видео сгружаются автоматически. Затем, если сервис находит одинаковые или неудачные кадры, он просто предлагает мне удалить их. То есть, по сути, единственная функция очистки, в которой я нуждаюсь, находится в приложении, которым я хотя бы пользуюсь и работает в полуавтоматическом режиме. Да и то – из-за того, что у меня в «Google Фото» безлимитное хранилище, дубликаты можно не удалять.
А что касается всякого треша из интернета, который портит людям жизнь, то я его не удаляю. Знаете, почему? Да потому что просто его не скачиваю, а пользуюсь только легальным ПО из Google Play. Ведь зачем мне искать проблемы на свою голову, если я могу найти нужные приложения в официальном каталоге?

Теги
- Новичкам в Android
- Операционная система Android
- Приложения для Андроид
Обзор анонсов TensorFlow на конференции Google I/O – 2021
Как многие из вас знают, недавно мы провели конференцию Google I/O – главное событие Google для разработчиков. В этом году конференция впервые проходила полностью в онлайн формате и пусть нам и не удалось провести конференцию в стандартном формате, мы надеемся, что смогли сделать ее доступной для всех желающих. На конференции было анонсировано много интересного для разработчиков практически всех направлений. В этой статье мы хотели бы сделать обзор новинок и обновлений в различных семействах продуктов в области машинного обучения и того, что представила команда TensorFlow. В конце статьи вы найдет список всех материалов.
Если вы еще не смотрели вступительный доклад от команды TensorFlow, то рекомендуем сделать это. Видео представлено ниже. Записи всех выступлений размещены на официальном канале TensorFlow на YouTube.
TensorFlow для мобильных устройств и веб-приложений
Среда выполнения TensorFlow Lite будет поставляться вместе с сервисами Google Play
Среда выполнения TensorFlow Lite войдет в набор сервисов Google Play. Вам больше не нужно поставлять ее в комплекте со своим приложением, что значительно сокращает размер приложений. Теперь распространять модели можно, не беспокоясь о среде выполнения. Зарегистрироваться в программе раннего доступа вы можете уже сейчас, а полномасштабное обновление произойдет до конца года.
Теперь модели TensorFlow Lite можно запускать в веб-интерфейсе
Запускайте модели TensorFlow Lite прямо в браузере, пользуясь новыми API TFLite для веб-приложений. Эти API совместимы с фреймворком TensorFlow.js и поддерживают все модели из библиотеки задач TFLite, предназначенные для классификации и сегментации изображений, распознавания объектов, а также различных задач обработки естественного языка. Новые интуитивно понятные и удобные API, совместимые с TensorFlow.js, также позволяют запускать пользовательские модели TFLite. В результате вы можете разрабатывать модели машинного обучения для сайтов и мобильных устройств, используя один стек технологий.
Новый сайт о машинном обучении на устройствах
Не всегда очевидно, как эффективнее разработать приложение для браузера, Android и iOS. Поэтому мы создали новый сайт о машинном обучении на устройствах. Он поможет вам определиться с выбором: использовать готовое решение или разработать собственную модель? Создать межплатформенное мобильное или браузерное приложение? На сайте вы узнаете обо всех этапах на пути от идеи к работающему приложению.
Профилирование производительности
Мы работаем над дополнительными инструментами, позволяющими разработчикам Android отслеживать производительность приложений. В TensorFlow Lite есть встроенная поддержка Systrace и удобная интеграция с Perfetto для Android 10.
Обновления, связанные с анализом производительности, касаются не только Android. Для разработчиков iOS в TensorFlow Lite теперь есть встроенная поддержка профилирования на базе технологии signpost. Если вы используете трассировку, разрабатывая приложение, то можете запустить профилировщик Xcode и посмотреть события signpost, чтобы подробно изучить работу приложения вплоть до отдельных операций.
TFX
TFX 1.0: создание моделей машинного обучения для корпоративного использования
Чтобы превратить прототип модели машинного обучения в рабочую версию, требуется развитая инфраструктура. Нам нужен был надежный фреймворк для продуктов и сервисов машинного обучения. Поэтому мы создали платформу TFX, а затем открыли доступ к ее исходному коду, чтобы возможностями платформы могли пользоваться все желающие. TFX поддерживает обучение моделей для мобильных, серверных и веб-приложений.
Мы успешно провели совместно с партнерами бета-тестирование и теперь представляем TFX 1.0 – версию, позволяющую приспосабливать модели машинного обучения для корпоративного использования. У фреймворка TFX есть все преимущества, необходимые предприятиям, в том числе поддержка корпоративного уровня, обновления системы безопасности, исправления ошибок и гарантированная обратная совместимость со всеми выпусками 1.X. TFX поддерживает работу в Google Cloud и позволяет создавать решения по обработке естественного языка, а также мобильные и веб-приложения.
Если вы хотите использовать модели машинного обучения в производственных целях, TFX ждет вас. Подробную информацию вы найдете на сайте платформы.
Responsible AI
Мы представляем несколько новых инструментов, позволяющих интегрировать фреймворк Responsible AI в разработку любого решения машинного обучения.
Know Your Data
С помощью инструмента Know Your Data исследователи и команды разработчиков в сфере машинного обучения могут анализировать большие наборы визуальных и текстовых данных, чтобы улучшать модель и сами данные, выявлять и устранять проблемы достоверности и систематические ошибки. По ссылке вы найдете интерактивную демоверсию инструмента.

People + AI Guidebook 2.0
Создавая решения в сфере искусственного интеллекта, важно не забывать, что они предназначены для людей. Поэтому мы выпустили версию 2.0 руководства People + AI Guidebook. Новая версия поможет на практике применить рекомендации по созданию ИИ, ориентированного на человека. В руководстве вы найдете множество новых ресурсов, включая код, шаблоны проектирования и многое другое.
Познакомьтесь также с набором инструментов Responsible AI, чтобы без труда применять на практике ответственный подход к ИИ, используя платформу TensorFlow.
Леса принятия решений в Keras
Поддержка случайных лесов и деревьев градиентного бустинга
Машинное обучение – это не только нейронные сети. Начиная с TensorFlow 2.5, вы можете с помощью привычных API библиотеки Keras обучать мощные модели, основанные на алгоритме леса принятия решений, в том числе на таких популярных его вариантах, как случайный лес и деревья градиентного бустинга. В новой версии поддерживается множество передовых алгоритмов обучения, интерпретации и обеспечения работы моделей, предназначенных для регрессии, классификации и ранжирования данных. Система TF Serving обеспечит работу леса принятия решений и любой другой модели, обученной с помощью TensorFlow. Изучите наши руководства и посмотрите видеозапись доклада.
TensorFlow Lite для микроконтроллеров
Новая плата с предустановленным ПО, эксперименты и конкурс
Платформа TensorFlow Lite для микроконтроллеров позволяет запускать модели машинного обучения на микроконтроллерах и других устройствах, где память ограничена несколькими килобайтами. Теперь можно купить плату Arduino с предустановленным ПО и подключиться к ней, используя Bluetooth и браузер. Попробуйте провести на такой плате эксперименты от Google, где предлагается настроить распознавание жестов. Вы также можете создать собственный классификатор или запустить свою модель TensorFlow. Мы организовали конкурс проектов с использованием TensorFlow Lite для микроконтроллеров. Подробные сведения можно узнать здесь. Не забудьте посмотреть видеозапись семинара по TinyML.

Google Cloud
Vertex AI: новая управляемая платформа машинного обучения в Google Cloud
Модель машинного обучения полезна, только если она работает. А вы знаете, как сложно бывает создать эффективное готовое решение в нужном масштабе. Поэтому Google Cloud выпускает Vertex AI – новую управляемую платформу машинного обучения, которая помогает быстрее проводить эксперименты и развертывать модели искусственного интеллекта. В интерфейсе Vertex AI есть инструменты для всех этапов разработки. Платформу можно использовать для разметки данных, работы с блокнотами и моделями, прогнозирования и непрерывного мониторинга. От аналогичных предложений платформу Vertex AI отличают новые функции в области MLOps, такие как Vertex Pipelines и Vertex Feature Store. Они упрощают поддержку и обеспечивают воспроизводимость моделей самообслуживания.
TensorFlow Cloud: от локального построения модели к распределенному обучению в облаке
Библиотека TensorFlow Cloud содержит API, которые помогут без труда перейти от локального построения и отладки модели к распределенному обучению и настройке гиперпараметров в Google Cloud. Вы сможете отправить модель для настройки или обучения в Google Cloud непосредственно с помощью блокнота Colab, Kaggle или локального скрипта, не используя Cloud Console. Об обновлениях читайте на нашем новом сайте.
Сообщество
Новый форум TensorFlow
Мы создали новый форум TensorFlow, где можно задавать вопросы и общаться. Здесь разработчики, авторы и пользователи могут обмениваться мнениями друг с другом и со специалистами TensorFlow. Регистрируйтесь и присоединяйтесь к сообществу на странице discuss.tensorflow.org.

Список докладов
Это лишь неполный список тем, которые обсуждались на конференции Google I/O – 2021. Все доклады о TensorFlow можно посмотреть в этом плейлисте. Ниже для вашего удобства указаны прямые ссылки на каждый доклад.
- Краткий обзор новых технологий машинного обучения
- Новости машинного обучения (вступительный доклад)
- Машинное обучение для веб-приложений следующего поколения с помощью TensorFlow.js
- В вашем приложении используется машинное обучение? Выпустите рабочую версию с помощью TFX
- Оптимизация моделей TensorFlow Lite
- ML Kit: как с помощью готовых API использовать в мобильных приложениях машинное обучение на устройствах
- TensorFlow Hub помогает менять мир к лучшему
- Современные шаблоны проектирования Keras
- Как пользоваться набором инструментов Responsible AI
- Леса принятия решений в TensorFlow
- Простая реализация межплатформенного компьютерного зрения с помощью библиотеки Model Maker
- Coral: расширение возможностей ИИ
- Выявление и решение повседневных проблем с помощью машинного обучения
- Как без труда развертывать модели TF Lite в интернете (демонстрация)
- Облачное обучение моделей TensorFlow с помощью TensorFlow Cloud (демонстрация)
- Больше, чем оценка: улучшение достоверности с помощью инструмента Model Remediation (демонстрация)
Хотите узнать больше о TensorFlow? Посетите сайт tensorflow.org, прочитайте другие статьи в блоге, следите за нашими публикациями в социальных сетях и подписывайтесь на наш канал YouTube. Вы также можете вступить в ближайшее к вам сообщество пользователей TensorFlow.