Sampler. Консольная утилита для визуализации результата любых shell команд
В общем случае с помощью shell команды можно получить любую метрику, без написания кода и интеграций. А значит в консоли должен быть простой и удобный инструмент для визуализации.
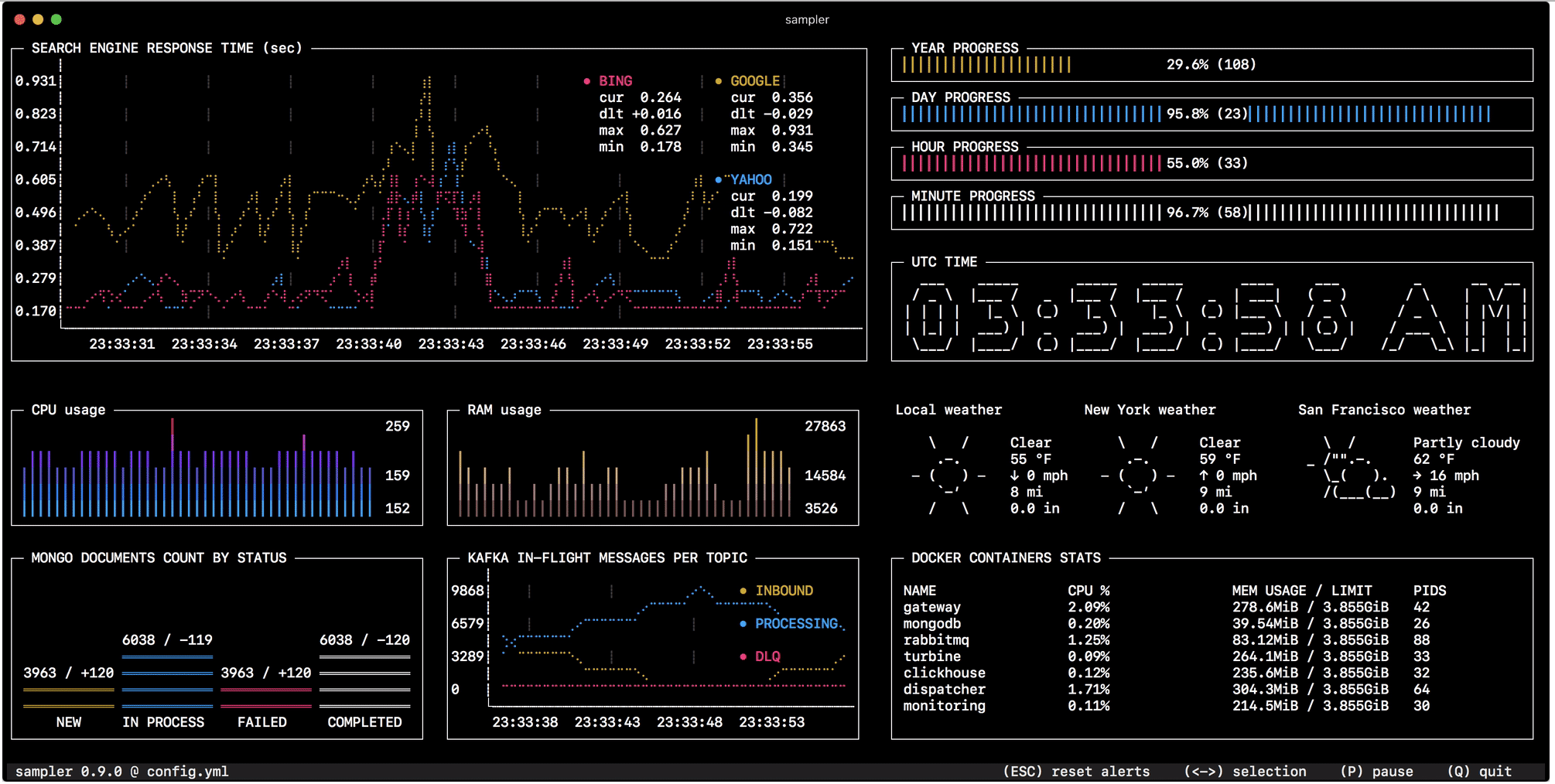
Наблюдение за изменением состояния в базе данных, мониторинг размера очередей, телеметрия с удаленных серверов, запуск деплой скриптов и получение нотификации по завершению — конфигурируется за минуту простым YAML файлом.
Код доступен на гитхабе. Инструкции по установке — для Linux, macOS и (экспериментально) Windows.
Зачем мне это, когда есть полноценные системы мониторинга?
Сразу оговорюсь, что это ни в коей мере не альтернатива полномасштабным дашбордам и мониторингу. Сравнивать Sampler c Prometheus+Grafana — то же что сравнивать tail и less с Elastic Stack или Splunk.
Но если поднимать и настраивать продакшн мониторинг для вашей задачи — как из пушки по воробьям, то возможно Sampler будет ответом на вопрос. Он задумывался как инструмент для прототипирования, демонстраций, или просто наблюдения за метриками на локали и удаленном сервере.
Значит его надо ставить на все сервера?
Нет, Sampler можно запускать локально, но метрики забирать со многих удаленных машин. Каждый компонент на дашборде имеет init секцию, где можно произвести вход по ssh (или сделать любое другое действие для входа в interactive shell — установить соединение с БД, подключиться по JMX, авторизоваться в API, итп)
Виды компонентов и примеры конфигурации
В примерах конфигурации приведены команды для macOS. Многие будут работать без изменений под Linux, но некоторые нужно адаптировать.
Runchart

Конфигурация
runcharts: - title: Search engine response time rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 legend: enabled: true # enables item labels, default = true details: false # enables item statistics: cur/min/max/dlt, default = true items: - label: GOOGLE sample: curl -o /dev/null -s -w '%' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%' https://search.yahoo.com - label: BING sample: curl -o /dev/null -s -w '%' https://www.bing.comSparkline

Конфигурация
sparklines: - title: CPU usage rate-ms: 200 scale: 0 sample: ps -A -o %cpu | awk ' END ' - title: Free memory pages rate-ms: 200 scale: 0 sample: memory_pressure | grep 'Pages free' | awk ''Barchart

Конфигурация
barcharts: - title: Local network activity rate-ms: 500 # sampling rate, default = 1000 scale: 0 # number of digits after sample decimal point, default = 1 items: - label: UDP bytes in sample: nettop -J bytes_in -l 1 -m udp | awk ' END ' - label: UDP bytes out sample: nettop -J bytes_out -l 1 -m udp | awk ' END ' - label: TCP bytes in sample: nettop -J bytes_in -l 1 -m tcp | awk ' END ' - label: TCP bytes out sample: nettop -J bytes_out -l 1 -m tcp | awk ' END 'Gauge

Конфигурация
gauges: - title: Minute progress rate-ms: 500 # sampling rate, default = 1000 scale: 2 # number of digits after sample decimal point, default = 1 percent-only: false # toggle display of the current value, default = false color: 178 # 8-bit color number, default one is chosen from a pre-defined palette cur: sample: date +%S # sample script for current value max: sample: echo 60 # sample script for max value min: sample: echo 0 # sample script for min value - title: Year progress cur: sample: date +%j max: sample: echo 365 min: sample: echo 0Textbox

Конфигурация
textboxes: - title: Local weather rate-ms: 10000 # sampling rate, default = 1000 sample: curl wttr.in?0ATQF border: false # border around the item, default = true color: 178 # 8-bit color number, default is white - title: Docker containers stats rate-ms: 500 sample: docker stats --no-stream --format "table >\t>\t>\t>"Asciibox

Конфигурация
asciiboxes: - title: UTC time rate-ms: 500 # sampling rate, default = 1000 font: 3d # font type, default = 2d border: false # border around the item, default = true color: 43 # 8-bit color number, default is white sample: env TZ=UTC date +%rДополнительная функциональность
Триггеры
Триггеры позволяют запустить некоторое дополнительное действие, если замеряемое значение удовлетворяет заданному условию. Как условие, так и реакция — это так же shell команды, в которые подаются переменные $label , $cur и $prev . В первую очередь триггеры задумывались для алертинга (встроены звуковые и визуальные нотификации), но c опцией вашего собственного скрипта для реакции на срабатывание триггера его действие можно кастомизировать как угодно (например отправить нотификацию на телефон с Pushover)
Пример ниже иллюстрирует конфигурацию триггеров. Если latency ответа поисковой системы превысит 0.3 sec — Sampler моргнет стандартным terminal bell, проиграет NASA quindar tone, покажет визуальную нотификацию на графике и запустит скрипт, который в данном случае голосом произносит измеренное значение latency:
runcharts: - title: SEARCH ENGINE RESPONSE TIME (sec) rate-ms: 200 items: - label: GOOGLE sample: curl -o /dev/null -s -w '%' https://www.google.com - label: YAHOO sample: curl -o /dev/null -s -w '%' https://search.yahoo.com triggers: - title: Latency threshold exceeded condition: echo "$prev < 0.3 && $cur >0.3" |bc -l # ожидает "1" как TRUE actions: terminal-bell: true # default = false sound: true # NASA quindar tone, default = false visual: true # default = false script: 'say alert: $ latency exceeded $ second'Interactive shell
Если до начала семплирования необходимо произвести вход в interactive shell (для единовременного подключения к БД, входа по SSH, подключения к JMX, итп) — можно указать init script , который исполнится один раз при старте. Пример подключения и опроса mongoDB:
textboxes: - title: MongoDB polling rate-ms: 500 init: mongo --quiet --host=localhost test # выполнится один раз sample: Date.now(); # сработает в рамках mongo shell transform: echo result = $sample # выполнится в рамках локальной сессии для преобразования значенияПеременные
Если в конфигурации присутствуют часто используемые части, которые не хочется повторять — их можно вынести в переменные и использовать в любом месте YML файла.
На практике
Как бекенд-программисту, мне часто приходится отлаживать, прототипировать и измерять. Отсюда и регулярная необходимость визуализации и мониторинга на скорую руку. Писать каждый раз что-то кастомное — неоправданно долго, но если процесс кастомизации был бы быстрым и (более-менее) удобным, такая визуализация вполне могла бы экономить время и решать задачи. Ничего подобного мне найти не удалось, поэтому было решено писать такой инструмент самому, и сделать его как можно более универсально конфигурабельным.
В самый первый раз по назначению я начал его использовать для отладки механизма группировки и аккумуляции данных, который быстро меняет статусы «событий» в памяти. Чтение состояния системы из логов или опрос отдельных счетчиков по каждому из статусов никак не помогает быстро сориентироваться и понять что к чему, а один взгляд на Sampler вполне решает эту задачу —
Для всего что использую сам, я приготовил сборник «рецептов» — моковых конфигураций, которые можно скопировать и сразу начать кастомизировать под свои задачи
- Соединения с базами данных: MySQL, PostgreSQL, MongoDB, Neo4J
- Kafka
- Docker
- SSH
- JMX
Этот список будет дополняться (и ваш вклад очень приветствуются), а тем временем в issues люди начали делиться своими конфигурациями для дашбордов Kubernetes, Github, и прочим.
Это все, хабр. Буду рад, если кому-то окажется полезным.
Сэмплирование и точность вычислений
Ряд моих коллег сталкиваются с проблемой, что для расчета какой-то метрики, например, коэффициента конверсии, приходится кверить всю базу данных. Или нужно провести детальное исследование по каждому клиенту, где клиентов миллионы. Такого рода квери могут работать довольно долго, даже в специально сделанных для этого хранилищах. Не очень-то прикольно ждать по 5-15-40 минут, пока считается простая метрика, чтобы выяснить, что тебе нужно посчитать что-то другое или добавить что-то еще.
Одним из решений этой проблемы является сэмплирование: мы не пытаемся вычислить нашу метрику на всем массиве данных, а берем подмножество, которое репрезентативно представляет нам нужные метрики. Это сэмпл может быть в 1000 раз меньше нашего массива данных, но при этом достаточно хорошо показывать нужные нам цифры.
В этой статье я решил продемонстрировать, как размеры выборки сэмплирования влияют на ошибку конечной метрики.
Проблема
Ключевой вопрос: насколько хорошо сэмпл описывает «генеральную совокупность»? Раз мы берем сэмпл с общего массива, то получаемые нами метрики оказываются случайными величинами. Разные сэмплы дадут нам разные результаты метрик. Разные, не значит любые. Теория вероятности говорит нам, что получаемые сэмплированием значения метрики должны группироваться вокруг истинного значения метрики (сделанного по всей выборке) с определенным уровнем ошибки. При этом у нас часто бывают задачи, где для решения можно обойтись разным уровнем ошибки. Одно дело прикинуть, получаем ли мы конверсию 50% или 10%, а другое дело получить результат с точностью 50.01% vs 50.02%.
Интересно, что с точки зрения теории, наблюдаемый нами коэффициент конверсии по всей выборке — это тоже случайная величина, т.к. «теоретический» коэффициент конверсии можно посчитать только на выборке бесконечного размера. Это означает, что даже все наши наблюдения в БД на самом деле дают оценку конверсии со своей точностью, хотя нам кажется, что вот эти наши подсчитанные цифры абсолютно точны. Это так же приводит к выводу, что даже если сегодня коэффициент конверсии отличается от вчерашнего, то это еще не означает, что у нас что-то поменялось, а лишь означает, что сегодняшний сэмпл (все наблюдения в БД) из генеральной совокупности (все возможные наблюдения за этот день, которые произошли и не произошли) дал несколько иной результат, чем вчерашний. Во всяком случае для любого честного продукта или аналитика это должно быть базовой гипотезой.
Формулировка задачи
Допустим у нас 1 000 000 записей в БД вида 0/1, которые говорят нам о том, случилась ли конверсия по событию. Тогда коэффициент конверсии это просто сумма 1 делить на 1 млн.
Вопрос: если мы возьмем выборку размером N, то на сколько и с какой вероятностью будет отличатся коэффициент конверсии от посчитанного по всей выборке?
Теоретические рассуждения
Задача сводится к расчету доверительного интервала коэффициента конверсии по выборке заданного размера для биноминального распределения.
Из теории стандартное отклонение для биноминального распределения это:
S = sqrt(p * (1 — p) /N)
Где
p — коэффициент конверсии
N — Размер выборки
S — стандартное отклонение
Непосредственно доверительный интервал я считать из теории не стану. Там довольно сложный и запутанный матан, который в итоге связывает стандартное отклонение и конечную оценку доверительного интервала.
Давайте разовьем «интуицию» по поводу формулы стандартного отклонения:
- Чем больше размер сэмпла, тем меньше ошибка. При этом ошибка падает в обратной квадратичной зависимости, т.е. увеличение выборки в 4 раза увеличивает точность лишь в 2 раза. Это означает, что в какой-то момент наращивание размера сэмпла не даст особых преимуществ, а так же означает, что довольно высокую точность можно получить достаточно маленькой выборкой.

- Есть зависимость ошибки от величины коэффициента конверсии. Относительная ошибка (т.е. отношение ошибки к величине коэффициента конверсии) имеет «мерзкую» тенденции быть тем больше, чем ниже коэффициент конверсии:
- Как мы видим, ошибка «взлетает» в небеса при низком коэффициенте конверсии. Это означает, что если вы сэмплируете редкие события, то вам нужны большие размеры выборки, иначе вы получите оценку конверсии с очень большой ошибкой.
Моделирование
Мы можем полностью отойти от теоретического решения и решить задачу «в лоб». Благодаря языку R теперь это сделать очень просто. Чтобы ответить на вопрос, в какую мы ошибку получим при сэмплировании, можно просто сделать тысячу сэмплирований и посмотреть, какую ошибку мы получаем.
- Берем разные коэффициенты конверсии (от 0.01% до 50%).
- Берем 1000 сэмплов по 10, 100, 1000, 10000, 50000, 100000, 250000, 500000 элементов в выборке
- Считаем коэффициент конверсии по каждой группе сэмплов (1000 коэффициентов)
- Строим гистограмму по каждой группе сэмплов и определяем, в каких пределах лежат 60%, 80% и 90% наблюдаемых коэффициентов конверсии.
Код на R генерирующий данные:
sample.size print(paste('sample size is:', sample.size[j])) q
В результате мы получаем следующую таблицу (дальше будут графики, но детали лучше видны в таблице).
| Коэффициент конверсии | Размер сэмпла | 5% | 10% | 20% | 80% | 90% | 95% |
|---|---|---|---|---|---|---|---|
| 0.0001 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.0001 | 100 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.0001 | 1000 | 0 | 0 | 0 | 0 | 0 | 0.001 |
| 0.0001 | 10000 | 0 | 0 | 0 | 0.0002 | 0.0002 | 0.0003 |
| 0.0001 | 50000 | 0.00004 | 0.00004 | 0.00006 | 0.00014 | 0.00016 | 0.00018 |
| 0.0001 | 100000 | 0.00005 | 0.00006 | 0.00007 | 0.00013 | 0.00014 | 0.00016 |
| 0.0001 | 250000 | 0.000072 | 0.0000796 | 0.000088 | 0.00012 | 0.000128 | 0.000136 |
| 0.0001 | 500000 | 0.00008 | 0.000084 | 0.000092 | 0.000114 | 0.000122 | 0.000128 |
| 0.001 | 10 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.001 | 100 | 0 | 0 | 0 | 0 | 0 | 0.01 |
| 0.001 | 1000 | 0 | 0 | 0 | 0.002 | 0.002 | 0.003 |
| 0.001 | 10000 | 0.0005 | 0.0006 | 0.0007 | 0.0013 | 0.0014 | 0.0016 |
| 0.001 | 50000 | 0.0008 | 0.000858 | 0.00092 | 0.00116 | 0.00122 | 0.00126 |
| 0.001 | 100000 | 0.00087 | 0.00091 | 0.00095 | 0.00112 | 0.00116 | 0.0012105 |
| 0.001 | 250000 | 0.00092 | 0.000948 | 0.000972 | 0.001084 | 0.001116 | 0.0011362 |
| 0.001 | 500000 | 0.000952 | 0.0009698 | 0.000988 | 0.001066 | 0.001086 | 0.0011041 |
| 0.01 | 10 | 0 | 0 | 0 | 0 | 0 | 0.1 |
| 0.01 | 100 | 0 | 0 | 0 | 0.02 | 0.02 | 0.03 |
| 0.01 | 1000 | 0.006 | 0.006 | 0.008 | 0.013 | 0.014 | 0.015 |
| 0.01 | 10000 | 0.0086 | 0.0089 | 0.0092 | 0.0109 | 0.0114 | 0.0118 |
| 0.01 | 50000 | 0.0093 | 0.0095 | 0.0097 | 0.0104 | 0.0106 | 0.0108 |
| 0.01 | 100000 | 0.0095 | 0.0096 | 0.0098 | 0.0103 | 0.0104 | 0.0106 |
| 0.01 | 250000 | 0.0097 | 0.0098 | 0.0099 | 0.0102 | 0.0103 | 0.0104 |
| 0.01 | 500000 | 0.0098 | 0.0099 | 0.0099 | 0.0102 | 0.0102 | 0.0103 |
| 0.1 | 10 | 0 | 0 | 0 | 0.2 | 0.2 | 0.3 |
| 0.1 | 100 | 0.05 | 0.06 | 0.07 | 0.13 | 0.14 | 0.15 |
| 0.1 | 1000 | 0.086 | 0.0889 | 0.093 | 0.108 | 0.1121 | 0.117 |
| 0.1 | 10000 | 0.0954 | 0.0963 | 0.0979 | 0.1028 | 0.1041 | 0.1055 |
| 0.1 | 50000 | 0.098 | 0.0986 | 0.0992 | 0.1014 | 0.1019 | 0.1024 |
| 0.1 | 100000 | 0.0987 | 0.099 | 0.0994 | 0.1011 | 0.1014 | 0.1018 |
| 0.1 | 250000 | 0.0993 | 0.0995 | 0.0998 | 0.1008 | 0.1011 | 0.1013 |
| 0.1 | 500000 | 0.0996 | 0.0998 | 0.1 | 0.1007 | 0.1009 | 0.101 |
| 0.5 | 10 | 0.2 | 0.3 | 0.4 | 0.6 | 0.7 | 0.8 |
| 0.5 | 100 | 0.42 | 0.44 | 0.46 | 0.54 | 0.56 | 0.58 |
| 0.5 | 1000 | 0.473 | 0.478 | 0.486 | 0.513 | 0.52 | 0.525 |
| 0.5 | 10000 | 0.4922 | 0.4939 | 0.4959 | 0.5044 | 0.5061 | 0.5078 |
| 0.5 | 50000 | 0.4962 | 0.4968 | 0.4978 | 0.5018 | 0.5028 | 0.5036 |
| 0.5 | 100000 | 0.4974 | 0.4979 | 0.4986 | 0.5014 | 0.5021 | 0.5027 |
| 0.5 | 250000 | 0.4984 | 0.4987 | 0.4992 | 0.5008 | 0.5013 | 0.5017 |
| 0.5 | 500000 | 0.4988 | 0.4991 | 0.4994 | 0.5006 | 0.5009 | 0.5011 |
Посмотрим случаи с 10% конверсией и с низкой 0.01% конверсией, т.к. на них хорошо видны все особенности работы с сэмплированием.
При 10% конверсии картина выглядит довольно простой:

Точки — это края 5-95% доверительного интервала, т.е. делая сэмпл мы будем в 90% случаев получать CR на выборке внутри этого интервала. Вертикальная шкала — размер сэмпла (шкала логарифмическая), горизонтальная — значение коэффициента конверсии. Вертикальная черта — «истинный» CR.
Мы тут видим то же, что мы видели из теоретической модели: точность растет по мере роста размера сэмпла, при этом одна довольно быстро «сходится» и сэмпл получает результат близкий к «истинному». Всего на 1000 сэмпле мы имеем 8.6% — 11.7%, что для ряда задач будет достаточно. А на 10 тысячах уже 9.5% — 10.55%.
Куда хуже дела обстоят с редкими событиями и это согласуется с теорией:

У низкого коэффициента конверсии в 0.01% принципе проблемы на статистике в 1 млн наблюдений, а с сэмплами ситуация оказывается еще хуже. Ошибка становится просто гигантской. На сэмплах до 10 000 метрика в принципе не валидна. Например, на сэмпле в 10 наблюдений мой генератор просто 1000 раз получил 0 конверсию, поэтому там только 1 точка. На 100 тысячах мы имеем разброс от 0.005% до 0.0016%, т.е мы можем ошибаться почти в половину коэффициента при таком сэмплировании.
Также стоит отметить, что когда вы наблюдаете конверсию такого маленького масштаба на 1 млн испытаний, то у вас просто большая натуральная ошибка. Из этого следует, что выводы по динамике таких редких событий надо делать на действительно больших выборках иначе вы просто гоняетесь за призраками, за случайными флуктуациями в данных.
- Сэмплирование рабочий метод для получения оценок
- Точность сэмплов растет при росте размера сэмпла и падает при снижении коэффициента конверсии.
- Точность оценок можно смоделировать для вашей задачи и таким образом подобрать оптимальное сэмплирование для себя
- Важно помнить, что редкие события плохо сэмплируют
- В целом редкие события трудно анализировать, они без сэмплов требуют больших выборок данных.
Что такое сэмплы ?
сэмпл — это аудиофраза, т. е короткий отрезок звукового файла. (если по простому) Сам занимаюсь сэмплированием. Пишу музыкальную аранжеровку на синтезаторе, а за тем на нём же делаю сэмплирование, т. е. надо, скажем голос наложить на музыку — записываю отдельно каждый куплет, потом, скажем, аккустическую гитару, потом электро (получаются wav-файлы — это и есть сэмплы) , а потом всё это микшируется в песню. Это если в кратце, не вдаваясь в тонкости процесса. Если будут конкретные вопросы, пиши — отвечу!
Остальные ответы
Сэмпл – это видеоролик, как правило, достаточно короткий. В сэмпл записывают видео отрезок, который дает максимально приближенное определение качество видео и звука предоставленного вашему вниманию фильма. При скачивании и просмотре видеоролика Вы уже можете решить качать Вам целиком раздачу или нет.
В конце семидесятых годов прошлого века был создан цифровой музыкальный инструмент, в котором реализован принципиально иной подход к синтезу музыки, получивший название «sampling». Буквально это слово означает отбор образцов. Синтезаторы, в которых воплощен такой принцип, называются сэмплерами, а образцы звучания — сэмплами. Процесс записи сэмплов принято называть оцифровкой или сэмплированием.
Любой сэмплер сам по себе является обыкновенной железкой или программой. Для того, чтобы из него был хотя бы какой-то толк, необходимы сэмплы, которыми он сможет играть. Какой бы дорогой и профессиональный сэмплер не был бы у Вас, самое главное — это качественные сэмплы. И наоборот, даже если Вы новичок и используете не очень мощный сэмплер, то качественные сэмплы способны преобразить и обогатить его звучание.
Метод воспроизведения сэмплов позволяет добиться высокой реалистичности. Причина заключается в том, что устройства воспроизведения сэмплов имеют дело с акустическими и синтетическими звуками реальных музыкальных инструментов. Когда устройство воспроизведения сэмплов получает сообщение Note On, то вместо того чтобы создавать звук оно воспроизводит цифровой сэмпл, который может содержать любой реальный звук — от фортепиано до волчьего воя, или звук любого синтезатора или драм-машинки.
С сэмплами можно делать все, что угодно. Можно оставить их такими, как есть, и сэмплер будет звучать голосами, почти неотличимыми от голосов инструментов-первоисточников. Можно подвергнуть сэмплы модуляции, фильтрации, воздействию эффектов и получить самые фантастические, неземные звуки.
Отличие сэмплов от обычных аудиозаписей состоит в том, что их длина незначительна (хотя не всегда) . К тому же, фактически существует несколько видов сэмплов: разовые сэмплы (One-shot samples), которые обычно используются для создания звуковых эффектов или ударных звуков и воспроизводятся один раз от начала до конца, цикличность отсутствует, и циклические сэмплы (Loop samples), также называемые сэмплерными петлями или лупами (Loops) — они имитируют целые инструментальные партии, например четыре такта партии ударных инструментов.
Сегодня, благодаря широкому распространению программных устройств воспроизведения сэмплов, появилась возможность создавать полноценные музыкальные произведения путем соединения циклических сэмплов, при этом ничего более не требуется. Вы даже можете приобрести коллекцию циклических сэмплов, записанную на компакт-диск в профессиональной студии.
Видеорол это так говорят.
Система электронного мониторинга подконтрольных лиц
готовый фрагмент музыки, графики, текстуры и т. д. из таких кусочков (сэмплов) можно составлять большие фрагменты или готовые композиции музыки, графики и т. д.
Сэмпл как понятие ещё есть в индустрии моды.
короче кусочек аудиофайла, семплы можно и самому нарезать на любом сенквенсоре, из любой более менее качественной композиции, и вставить в свой шедевр ыыы
Библиотеки сэмплов
Посмотрел существующие темы и не нашел подобной, но она по любому была. Думаю все равно полезно будет еще раз поднять тему библиотек звуковых сэмлов, может появились новые ресурсы или какие то уже не работают.
Подскажите плз хорошые сборники бесплатных звуковых семлов!
- Global_Sound_Ukraine
- Новичок
#1
0:21, 20 дек 2013
Дык Vengeance же.
#2
2:01, 20 дек 2013
Global_Sound_Ukraine
подробнее, пожалуйста.
- Odin P. Morgan
- Постоялец
#3
9:23, 20 дек 2013
DenBraun
Я уже поднимал тему про VST — насамом деле хорошая вещь, особенно наборы инструментов VSTi — звучат гораздо лучше семплов. SDK VST можно скачать с оф. сайта.
VST — это моделирующий синтезаор используемый во всяких фрутиках и т.д. Имеет широченный функционал синтеза, вплоть до учёта арпеджио гитариста и коллебания струны гитары, строения гортания и голосовых связок, заканчивая иммитацией работы лампового оборудования.
#4
14:00, 20 дек 2013
>наборы инструментов VSTi — звучат гораздо лучше семплов
Вы запутались в терминологии 🙂 VSTi основаны на сэмплах. Сэмпл — это одиночный звук (wav-формата обычно). На одной ноте VSTi может быть до 128 сэмплов. Скажем, удар барабана, записанный на разной громкости.
По теме:
Так вам нужны звуковые эффекты или инструменты для написания музыки? Не совсем понятно, что имеется в виду под «библиотекой звуковых сэмлов».
#5
17:08, 21 дек 2013
Имеется в виду наборы готовых звуков(эффектов), не для написания музыки а для использования в играх. То есть к примеру задача, ввожу я в игру какой то новый предмет, например деревянный стул, он у меня может сломаться, соответственно мне нужен звук трескающегося дерева. В идеале бы такой сервис с онлайн прослушивание и если нашел подходящий звук то сразу качнул. Я как то натыкался на что то подобное, а теперь не могу ни как найти.
#6
22:09, 21 дек 2013
IK-Sound
Не путайте людей 🙂 Не все VSTi основаны на банках звуков. Большинство из них программные генераторы. Есть и гибридные, сочетающие в себе генератор и семплер.
#7
11:59, 22 дек 2013
Подпишусь. Тоже сейчас нужны звуки в игру, где брать не представляю, а заказывать дорого.