Пересечение списков, совпадающие элементы двух списков
В данной задаче речь идет о поиске элементов, которые присутствуют в обоих списках. При этом пересечение списков и поиск совпадающих (перекрывающихся) элементов двух списков будем считать несколько разными задачами.
Если даны два списка, в каждом из которых каждый элемент уникален, то задача решается просто, так как в результирующем списке не может быть повторяющихся значений. Например, даны списки:
[5, 4, 2, ‘r’, ‘ee’] и [4, ‘ww’, ‘ee’, 3]
Областью их пересечения будет список [4, ‘ee’] .
Если же исходные списки выглядят так:
[5, 4, 2, ‘r’, 4, ‘ee’, 4] и [4, ‘we’, ‘ee’, 3, 4] ,
то списком их совпадающих элементов будет [4, ‘ee’, 4] , в котором есть повторения значений, потому что в каждом из исходных списков определенное значение встречается не единожды.
Начнем с простого — поиска области пересечения. Cначала решим задачу «классическим» алгоритмом, не используя продвинутые возможностями языка Python: будем брать каждый элементы первого списка и последовательно сравнивать его со всеми значениями второго.
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: for j in b: if i == j: c.append(i) break print(c)
Результат выполнения программы:
[[1, 2], 4, 'ee']
Берется каждый элемент первого списка (внешний цикл for ) и последовательно сравнивается с каждым элементом второго списка (вложенный цикл for ). В случае совпадения значений элемент добавляется в третий список c . Команда break служит для выхода из внутреннего цикла, так как в случае совпадения дальнейший поиск при данном значении i бессмыслен.
Алгоритм можно упростить, заменив вложенный цикл на проверку вхождения элемента из списка a в список b с помощью оператора in :
a = [5, [1, 2], 2, 'r', 4, 'ee'] b = [4, 'we', 'ee', 3, [1, 2]] c = [] for i in a: if i in b: c.append(i) print(c)
Здесь выражение i in b при if по смыслу не такое как выражение i in a при for . В случае цикла оно означет извлечение очередного элемента из списка a для работы с ним в новой итерации цикла. Тогда как в случае if мы имеем дело с логическим выражением, в котором утверждается, что элемент i есть в списке b . Если это так, и логическое выражение возвращает истину, то выполняется вложенная в if инструкция, то есть элемент i добавляется в список c .
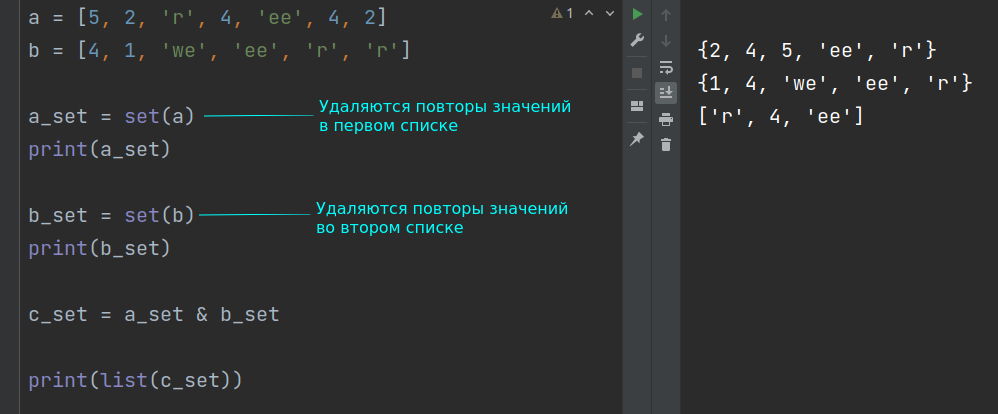
Принципиально другой способ решения задачи – это использование множеств. Подходит только для списков, которые не содержат вложенных списков и других изменяемых объектов, так как встроенная в Python функция set() в таких случаях выдает ошибку.
a = [5, 2, 'r', 4, 'ee'] b = [4, 1, 'we', 'ee', 'r'] c = list(set(a) & set(b)) print(c)
['ee', 4, 'r']
Выражение list(set(a) & set(b)) выполняется следующим образом.
- Сначала из списка a получают множество с помощью команды set(a) .
- Аналогично получают множество из b .
- С помощью операции пересечения множеств, которая обозначается знаком амперсанда & , получают третье множество, которое представляет собой область пересечения двух исходных множеств.
- Полученное таким образом третье множество преобразуют обратно в список с помощью встроенной в Python функции list() .
Множества не могут содержать одинаковых элементов. Поэтому, если в исходных списках были повторяющиеся значения, то уже на этапе преобразования этих списков во множества повторения удаляются, а результат пересечения множеств не будет отличаться от того, как если бы в исходных списках повторений не было.
Однако если мы вернемся к решению задачи без использования множеств и добавим в первый список повтор значения, то получим некорректный результат:
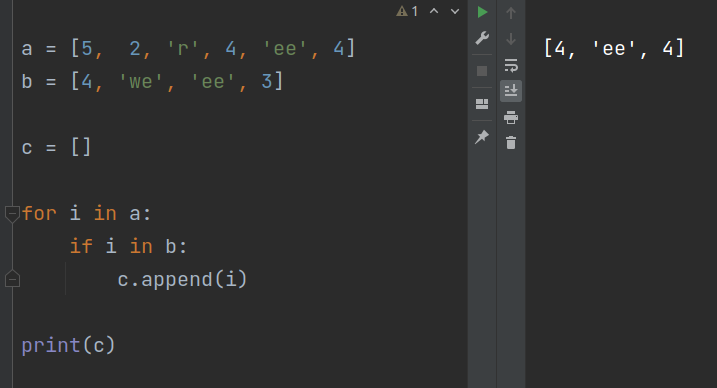
В список пересечения попадают оба равных друг другу значения из первого списка. Это происходит потому, что когда цикл извлекает, в данном случае, вторую 4-ку из первого списка, выражение i in b также возвращает истину, как и при проверке первой 4-ки. Следовательно, выражение c.append(i) выполняется и для второй четверки.
Чтобы решить эту проблему, добавим дополнительное условие в заголовок инструкии if . Очередной значение i из списка a должно не только присутствовать в b , но его еще не должно быть в c . То есть это должно быть первое добавление такого значения в c :
a = [5, 2, 'r', 4, 'ee', 4] b = [4, 'we', 'ee', 3] c = [] for i in a: if i in b and i not in c: c.append(i) print(c)
[4, 'ee']
Теперь усложним задачу. Пусть если в обоих списках есть по несколько одинаковых значений, они должны попадать в список совпадающих элементов в том количестве, в котором встречаются в списке, где их меньше. Или если в исходных списках их равное количетво, то такое же количество должно быть в третьем. Например, если в первом списке у нас три 4-ки, а во втором две, то в третьем списке должно быть две 4-ки. Если в обоих исходных по две 4-ки, то в третьем также будет две.
Алгоритмом решения такой задачи может быть следующий:
- В цикле будем перебирать элементы первого списка.
- Если на текущей итерации цикла взятого из первого списка значения нет в третьем списке, то только в этом случае следует выполнять все нижеследующие действия. В ином случае такое значение уже обрабатывалось ранее, и его повторная обработка приведет к добавлению лишних элементов в результирующий список.
- С помощью спискового метода count() посчитаем количество таких значений в первом и втором списке. Выберем минимальное из них.
- Добавим в третий список количество элементов с текущим значением, равное ранее определенному минимуму.
a = [5, 2, 4, 'r', 4, 'ee', 1, 1, 4] b = [4, 1, 'we', 'ee', 'r', 4, 1, 1] c = [] for item in a: if item not in c: a_item = a.count(item) b_item = b.count(item) min_count = min(a_item, b_item) # c += [item] * min_count for i in range(min_count): c.append(item) print(c)
[4, 4, 'r', 'ee', 1, 1]
Если значение встречается в одном списке, но не в другом, то метод count() другого вернет 0. Соответственно, функция min() вернет 0, а цикл с условием i in range(0) не выполнится ни разу. Поэтому, если значение встречается в одном списке, но его нет в другом, оно не добавляется в третий.
При добавлении значений в третий список вместо цикла for можно использовать объединение списков с помощью операции + и операцию повторения элементов с помощью * . В коде выше данный способ показан в комментарии.
X Скрыть Наверх
Решение задач на Python
[ Сборник задач ]
Тема 7. Работа с множествами
Рассмотрим, что из себя представляют множества в Python, какими характеристиками они обладают, и какие темы нужно повторить для решения задач.
Вопросы и ответы
5 вопросов по теме «Множества» + ответы
Условия задач
5 задач по теме двух уровней сложности: Базовый и *Продвинутый
Решения задач
Приводим код решений указанных выше задач

Множества – неупорядоченный тип уникальных данных, включающий только хешируемые элементы. Их можно изменять, неизменяемый аналог – frozenset . Не имеют индексации. Поиск объекта внутри множества очень быстрый (по сравнению со списками и кортежами).
Для успешного решения заданий требуется повторить: особенности множеств, уникальные методы, основные операции, способы модификации.
Читайте также
Программирование на Python. Урок 2. Типы данных
Разбираем типы данных в Python: списки, кортежи, словари, множества и т. д. Рассматриваем часто используемые способы ввода-вывода данных. Решаем задачи.

Вопросы по теме «Работа с множествами»
1. Что такое мощность множества? Какой аналог есть у списков? Приведите пример.
Мощность множества показывает количество элементов в нем. По факту, это аналог функции len() для других коллекций. Более того, она же и применяется к множествам. Только правильно говорить мощность, а не длина множества.
Пример – Интерактивный режим
>>> st =
>>> lst = [1, 5, 4, 5, 5]
>>> len(st)
4
>>> len(lst)
5
2. Как удалить элемент множества не вызывая ошибку, если его там нет?
Для удаления элемента из множества применяются 3 способа:
1 – pop() – удаляет случайный элемент и возвращает его, но вызовет ошибку, если множество пустое (нам для ответа не подходит)
2 – remove() – удаляет объект с конкретным значением, но вызовет ошибку, если его нет (опять же, не наш выбор)
3 – discard() – также удаляет определенный элемент, но не приводит к ошибке, если он отсутствует в данном множестве (как и требовалось ответить)
Пример – Интерактивный режим
>>> st =
>>> st.pop() # Просто удаляет какой-то выборочный элемент
>>> st.remove(9) # Ошибка KeyError: 9
KeyError: 9
>>> st.discard(9) # Хоть элемента нет, ошибка не возникает
3. В чем суть объединения (union) множеств? Приведите 2 способа и поясните разницу.
Объединение подразумевает формирование множества из всех элементов участников. Функционально оно осуществимо двумя способами:
1 – через метод union() . Сюда можно передать не только множество, но и другие итерабельные объекты (списки, кортежи, строки)
2 – через оператор | . По обе стороны от оператора обязаны быть множества.
Пример – Интерактивный режим
>>> st_1 =
>>> st_2 =
>>> words = ‘string spring’
>>> lst = [4, 4, 3, 55, 2]
# Через оператор |
>>> st_1 | st_2
>>> st_1 | words
Ошибка TypeError
4. Что представляет собой супермножество? Приведите пример.
Супермножество включает в себя все элементы другого множества и может быть равно с ним по мощности. Еще есть чистое супермножество, которое строго больше подмножества и содержит все его компоненты. Для проверки на супермножество можно использовать метод issuperset() или знак >= . Для чистого – только оператор > .
Пример – Интерактивный режим
>>> st_1 =
>>> st_2 =
>>> st_1.issuperset(st_2)
True
>>> st_1 >= st_2
True
>>> st_1 > st_2
True
>>> st_2.issuperset(st_1)
False
5*. Почему поиск объекта в множестве такой быстрый? Докажите, проведя сравнение со списком.
Так как элементы множества хешируются, их поиск осуществляется практически мгновенно. Чтобы найти объект списка, требуется его перебирать (в худшем случае полностью). Для оценки времени обнаружения конкретного значения проведем тест.
Пример – IDE
from time import perf_counter_ns
MAX_VALUE = 20_000_000
SEARCH_ITEM = 19_999_000
def measure_time(data):
____start = perf_counter_ns()
____ SEARCH_ITEM in data
____ return perf_counter_ns() — start
st = set(range(1, MAX_VALUE))
lst = list(range(1, MAX_VALUE))
Результат выполнения
Set search time: 4276ns
List search time: 299974854ns
Получается, в множестве элемент нашелся в тысячи раз быстрее.
Помогите составить алгоритм на python для подбора значений
при этом 1
n = 3 a = 5, 4, 6 b = 1, 2, 3 результат = 24 n = 5 a = 2 3 4 4 5 b = 5 4 4 3 1 результат = 28 Заранее спасибо за внимание!!
Отслеживать
задан 21 окт 2020 в 7:56
55 1 1 серебряный знак 8 8 бронзовых знаков
Ну, самое простое — двойной (вложенный) цикл, и вперед.
21 окт 2020 в 7:58
@EOF это значит что j может быть или больше или равна n, то есть использовать последний или любой другой элемент массива, который больше i.
21 окт 2020 в 8:25
Правильно ли я понимаю, что у нас два массива a и b ?
Разбор классического тестового задания на позицию Python Developer
В данной статье я планирую провести разбор тестового задания для Python-разработчика, с которым мне пришлось столкнуться при поиске работы. Разбирая шаги и решения этого теста, я надеюсь поделиться полезными наработками и советами для тех, кто также стремится успешно пройти подобные испытания.
Задача
Тип зпдач весьма классический, про билетики:
У нас имеются автобусные билеты с номерами от 000000 до 999999. Билет считается ‘счастливым’, если сумма первых двух цифр равна сумме следующих двух цифр, и эта сумма равна сумме последних двух цифр. При этом не должно возникнуть ситуации, когда конкатенация пары цифр первого блока равна конкатенации пары цифр второго блока и третьего.
Для примера, рассмотрим билет с номером 123456:
- Сумма первых двух цифр: 1 + 2 = 3
- Сумма следующих двух цифр: 3 + 4 = 7
- Сумма последних двух цифр: 5 + 6 = 11
Обозначим символом || операцию конкатинации:
- конкатинация первых двух цифр: 1 || 2 = 12
- конкатинация следующих двух цифр: 3 || 4 = 34
- конкатинация следующих двух цифр: 5 || 6 = 56
Условия не выполняются, и билет считается не «счастливым».
Теперь мы хотим определить, сколько «счастливых» билетов находится в каждом рулоне троллейбуса.
Каждый рулон включает в себя 100 000 билетов (номера от 000000 до 099999, от 100000 до 199999 и так далее)
Решение «в лоб»
Под ‘решением в лоб’ я понимаю метод, основанный на переборе всех возможных значений. Следовательно, для такого подхода к решению задачи, первым этапом является генерация всех возможных значений:
if __name__ == '__main__': for i in range(1000000): ticket_number = f'' print(ticket_number)Код использует цикл от 0 до 999999 и форматирует каждое число как строку, добавляя ведущие нули при необходимости с использованием f-строки и форматирования числа с шестью знаками. Таким образом, формируется последовательность номеров от 000000 до 999999.
Далее код выделяет три нужные подстроки (пары чисел) [partn].
if __name__ == '__main__': for i in range(1000000): ticket_number = f'' part1 = ticket_number[0:2] part2 = ticket_number[2:4] part3 = ticket_number[4:6] print(part1, part2, part3)отфильтрем номера, которые не сооветствую условию об конкатинации, для этого достататочно их сравнить » python»> for i in range(1000000): ticket_number = f» part1 = ticket_number[0:2] part2 = ticket_number[2:4] part3 = ticket_number[4:6] if part1 == part2 == part3: continue
Для удобства реализации введена вспомогательная функция для подсчета суммы цифр в двойке. Пары, удовлетворяющие условиям, фильтруются по равенству чисел.
def sum_digits(pair): return int(pair[0]) + int(pair[1])и отфильтруем пары по равенству чисел
if sum_digits(part1) == sum_digits(part2) == sum_digits(part3): print(part1, part2, part3)Остается только записать результат в карту (map) и вывести его.
def sum_digits(pair): return int(pair[0]) + int(pair[1]) if __name__ == '__main__': map = for i in range(1000000): ticket_number = f'' part1 = ticket_number[0:2] part2 = ticket_number[2:4] part3 = ticket_number[4:6] if part1 == part2 == part3: continue if sum_digits(part1) == sum_digits(part2) == sum_digits(part3): map[int(ticket_number[0])] += 1 for k, v in map.items(): print(f"рулон имеет: счастливых билетов")рулон 1 имеет: 375 счастливых билетов рулон 2 имеет: 455 счастливых билетов рулон 3 имеет: 515 счастливых билетов рулон 4 имеет: 555 счастливых билетов рулон 5 имеет: 575 счастливых билетов рулон 6 имеет: 575 счастливых билетов рулон 7 имеет: 555 счастливых билетов рулон 8 имеет: 515 счастливых билетов рулон 9 имеет: 455 счастливых билетов рулон 10 имеет: 375 счастливых билетовВажно отметить, что основной недостаток такого решения заключается в переборе всех возможных значений, что существенно замедляет процесс.
Замерим время выполнения (самым преметивным способом):
start_time = time.time() //предыдущий код print(time.time() - start_time)Время выполнения составило 1.136587381362915 некотрых едениц времени.
Более оптиальное решение
Однако вместо того, чтобы перебирать все 100000 значений, достаточно ограничиться перебором всех возможных пар от 00 до 99. Это осуществимо, зная, сколько каждой паре соответствует других пар с той же суммой цифр. Сначала мы рассчитаем и запишем эту информацию в мапу (где ключ это сумма двух цифр, а значение количество таких сумм).
map = defaultdict(int) for n1, n2 in product(range(10), repeat=2): //перебор всех двоек map[n1 + n2] += 1 // добовляем 1 в ту сумму которой соответствует двойка Затем, как было упомянуто ранее, мы снова переберем все пары двоек, посчитаем, сколько счастливых билетов соответствует каждой из них, и запишем результат.
res = <> for n1 in range(0, 10): res[n1] = 0 for n2 in range(0, 10): res[n1] += (map[n1 + n2] ** 2) - 1
После этого мы возводим результат в квадрат, так как помимо перебираемой двойки есть еще две пары. Затем вычитаем 1, так как это представляет собой случай, который не соответствует требованию конкатенации.
Запишем это еще проще:
from collections import defaultdict from itertools import product if __name__ == '__main__': map = defaultdict(int) for n1, n2 in product(range(10), repeat=2): map[n1 + n2] += 1 res = for k, v in res.items(): print(f"рулон имеет: счастливых билетов")рулон 1 имеет: 375 счастливых билетов рулон 2 имеет: 455 счастливых билетов рулон 3 имеет: 515 счастливых билетов рулон 4 имеет: 555 счастливых билетов рулон 5 имеет: 575 счастливых билетов рулон 6 имеет: 575 счастливых билетов рулон 7 имеет: 555 счастливых билетов рулон 8 имеет: 515 счастливых билетов рулон 9 имеет: 455 счастливых билетов рулон 10 имеет: 375 счастливых билетовПосле внесения вышеупомянутых оптимизаций время выполнения снизилось в 3100 раз, что является впечатляющим результатом. Замер времени выполнения с использованием примитивного метода составил 0.0003666877746582031 тех же единиц времени, что говорит о существенном ускорении процесса.
Это существенное ускорение достигается за счет уменьшения числа итераций в циклах с 100 000 до всего 200. Стоит также отметить, что количество итераций можно уменьшить вдвое, учитывая симметрию результата (делать я этого конечно же не буду).
Вывод
Важной составляющей процесса решения задачи является выбор оптимального способа, и, как показано выше, различные подходы могут существенно влиять на эффективность решения.
В первом, более примитивном варианте, был использован перебор всех возможных значений, что, несомненно, далеко не самый эффективный метод в данной задаче. Этот подход требует значительного количества итераций и, следовательно, времени выполнения.
Однако, во втором варианте, который был продемонстрирован, мы применили оптимизированный метод, ограничившись перебором лишь нужных пар. Это привело к значительному снижению числа итераций и, как следствие, к ускорению времени выполнения в 3100 раз.
P.S. код можно глянуть на GitHub