Бинарный поиск
Бинарный поиск — тип поискового алгоритма, который последовательно делит пополам заранее отсортированный массив данных, чтобы обнаружить нужный элемент. Другие его названия — двоичный поиск, метод половинного деления, дихотомия.

«IT-специалист с нуля» наш лучший курс для старта в IT
Принцип работы алгоритма бинарного поиска
Основная последовательность действий алгоритма выглядит так:
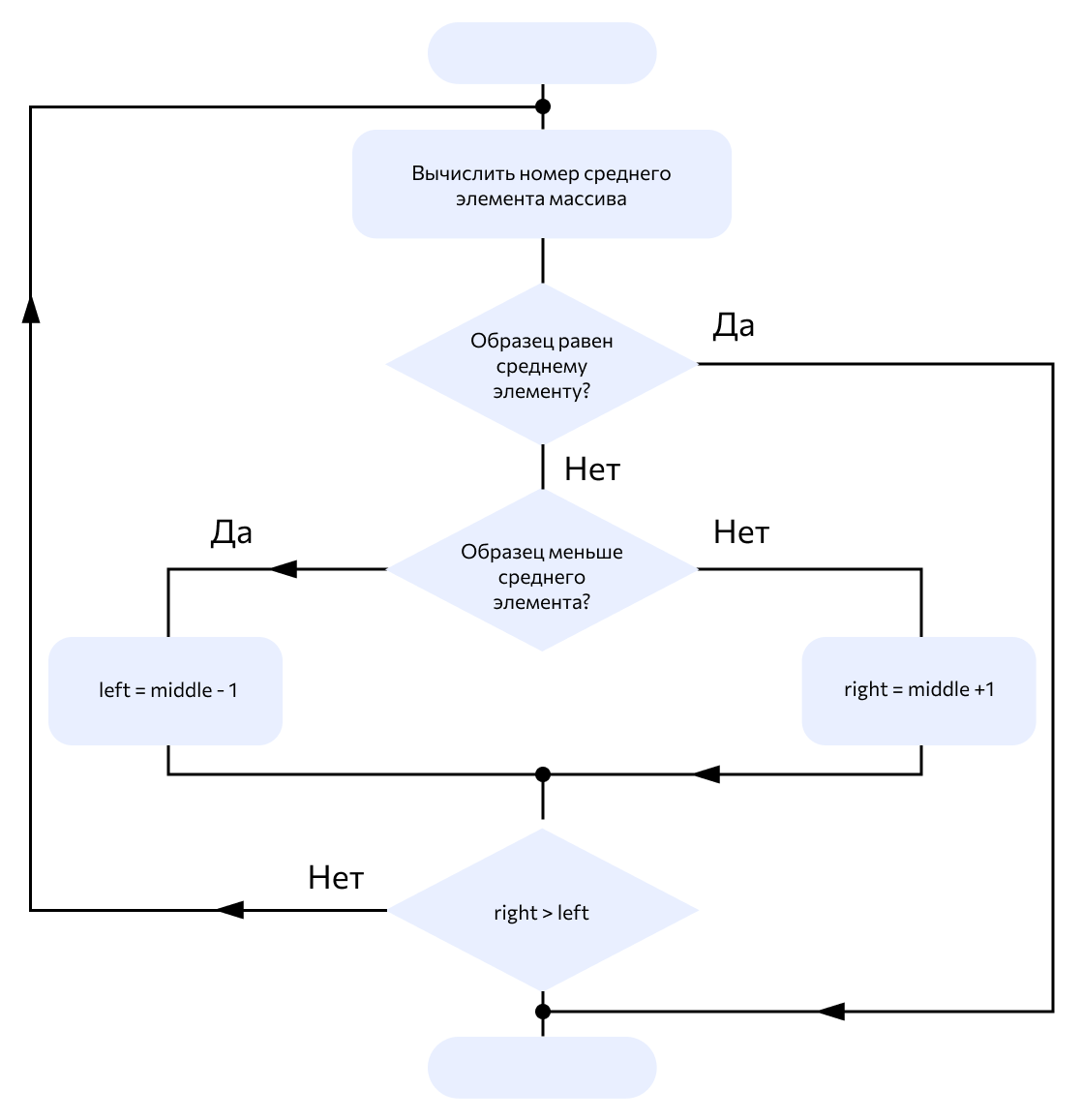
- Сортируем массив данных.
- Делим его пополам и находим середину.
- Сравниваем срединный элемент с заданным искомым элементом.
- Если искомое число больше среднего — продолжаем поиск в правой части массива (если он отсортирован по возрастанию): делим ее пополам, повторяя пункт 3. Если же заданное число меньше — алгоритм продолжит поиск в левой части массива, снова возвращаясь к пункту 3.
Профессия / 8 месяцев
IT-специалист с нуля
Попробуйте 9 профессий за 2 месяца и выберите подходящую вам

Реализация бинарного поиска
Существуют два способа реализации бинарного поиска.
1. Итерационный метод. При таком подходе используется цикл, тело которого повторяется, пока не найдется заданный элемент либо не будет установлено, что его нет в массиве. Например, в Python для этой цели удобно использовать цикл while.
2. Рекурсивный подход. В этом случае пишется функция, которая вызывает сама себя (рекурсивно), пока не будет найден искомый элемент в массиве.
Приведем примеры реализации этих методов на Python.
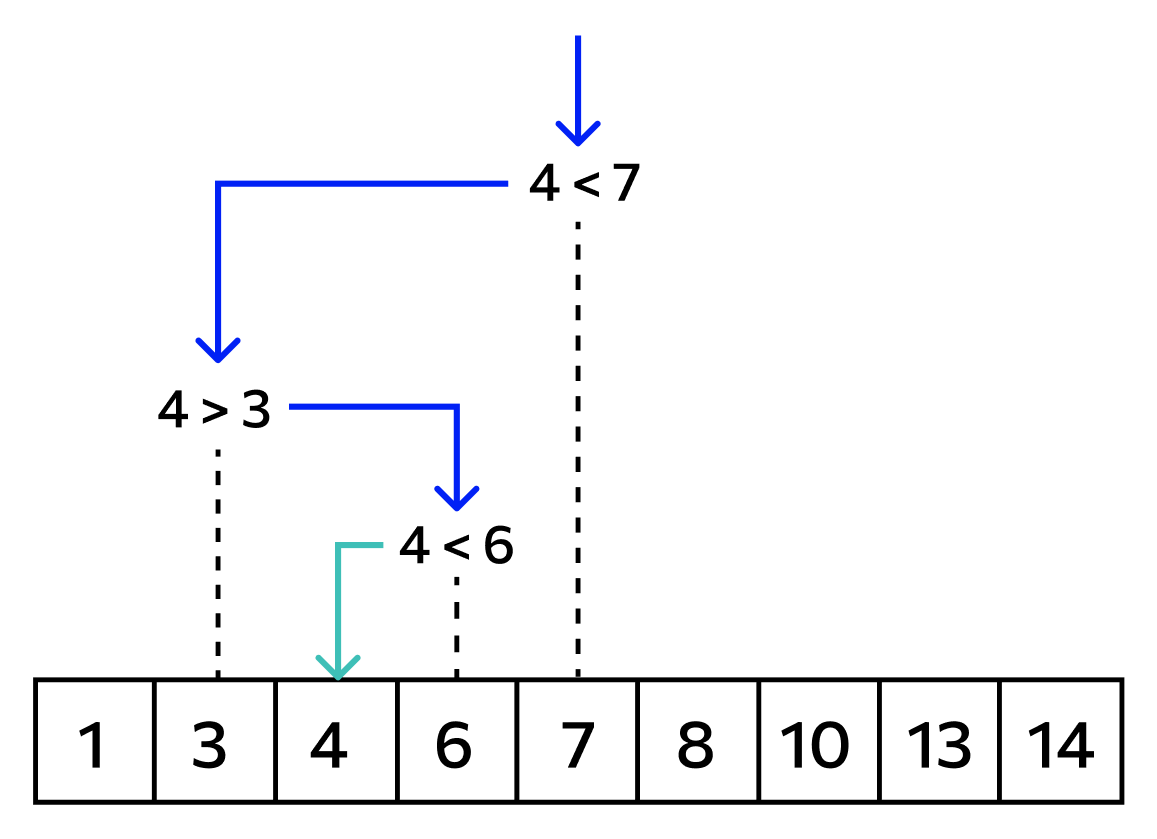
Пусть есть массив чисел [5, 8, 9, 1, 23, 7, 3, 0, 15], и необходимо найти позицию числа 5 в упорядоченном списке. На вход такой функции необходимо подать уже отсортированный массив, для этого воспользуемся встроенным методом sorted(), который упорядочивает массив данных по возрастанию.
Код, использующий итерационный подход, будет выглядеть так:
def findPosition(num_list, number):
first = 0
last = len(num_list) - 1
while first middle = first + (last - first) // 2
if num_list[middle] == number:
return middle
elif num_list[middle] < number:
first = middle + 1
else:
last = middle - 1
return -1
num_list = sorted([5, 8, 9, 1, 23, 7, 3, 0, 15])
number = 5
print(findPosition(num_list, number))При использовании рекурсивного поиска код на Python можно написать так:
def findPosition(num_list, number, first, last): if last >= first: middle = first + (last - first) // 2 if num_list[middle] == number: return middle elif num_list[middle] < number: return findPosition(num_list, number, middle + 1, last) else: return findPosition(num_list, number, first, middle - 1) else: return -1 num_list = sorted([5, 8, 9, 1, 23, 7, 3, 0, 15]) number = 5 print(findPosition(num_list, number, 0, len(num_list) - 1))
Начните карьеру в Data Science.
Онлайн-магистратура МФТИ с практикой на реальных проектах
В некоторых языках программирования, включая Python, есть готовые функции для выполнения бинарного поиска. Модуль бинарного поиска называется bisect. Проиллюстрируем его работу на примере:
from bisect import bisect_left def findPosition(num_list, number): pos = bisect_left(num_list, number) if pos < len(num_list): return pos return False num_list = sorted([5, 8, 9, 1, 23, 7, 3, 0, 15]) number = 5 print(findPosition(num_list, number))Читайте также Как выбрать IT-специальность в новых реалиях?
В каких случаях используют бинарный поиск
Двоичный поиск подходит для нахождения позиций элемента в упорядоченном списке: в этом случае он эффективнее линейного, поскольку массив данных на каждом шаге разделяется надвое и одна половина сразу отбрасывается. Последовательная сложность двоичного метода в худшем и среднем случаях равна O(log n), в лучшем — O(1) (если обнаруживаем искомый элемент на первой итерации). Для сравнения: вычислительная сложность линейного поиска равна O(n) (обычный проход по всем элементам в поисках нужного).
У бинарного поиска есть недостаток — он требует упорядочивания данных по возрастанию. Сложность сортировки — не менее O(n log n). Поэтому, если список короткий, используется все-таки линейный поиск.
Разновидности алгоритма
На основе бинарного поиска разработано несколько дополнительных разновидностей поисковых алгоритмов:
- однородный бинарный поиск, при котором аргумент поиска А сравнивается с ключом Ki, где i — золотое сечение интервала (оно выбирается так, чтобы отношение длины большего отрезка к длине всего интервала равнялось отношению длины меньшего отрезка к длине большего отрезка);
- троичный поиск, когда интервал делится на три части вместо двух. Обычно применяется для поиска положения экстремума функции;
- интерполирующий поиск, который предсказывает позицию нужного элемента на основе разницы значений. Эффективен, если элементы распределены достаточно равномерно;
- дробный спуск — применяется для ускорения двоичного поиска в многомерных массивах данных, и другие.
Data Scientist
Дата-сайентисты решают поистине амбициозные задачи. Научитесь создавать искусственный интеллект, обучать нейронные сети, менять мир и при этом хорошо зарабатывать. Программа рассчитана на новичков и плавно введет вас в Data Science.
Бинарный поиск
Задача. Загадано целое число $x$ от $1$ до $100$, которое вам нужно отгадать какой-нибудь «данеткой»: например, вы можете спрашивать, больше ли число $x$ чем заданное, или четно ли оно. За сколько вопросов в худшем случае вы сможете найти число $x$?
Одно из оптимальных решений имеет такую структуру: первым вопросом спрашиваем «больше ли число $x$, чем 50», и если ответ «да», то дальше спрашиваем «больше ли число $x$, чем 75», иначе «больше ли число $x$, чем 25», и повторяем дальше, каждый раз уменьшая отрезок возможных значений в два (или почти в два) раза.
Более структурно, если у нас есть отрезок поиска — изначально от $l=1$ до $r=100$ — то мы на каждой итерации выбираем «серединный» элемент $m = \lfloor \frac \rfloor$, спрашиваем «$x>m?$», выполняем присвоения $l = m + 1$ или $r = m$ в зависимости от ответа, и повторяем процедуру с новыми границами, пока они не станут равными (что будет означать, что $l = r = x$).
Вот пример такой программы, которую можно запустить в консоли:
Если загадать $x=42$ и честно поотвечать на вопросы:
x > 50? no x > 25? yes x > 38? yes x > 44? no x > 41? yes x > 43? no x > 42? no x = 42 Здесь нам потребовалось 7 вопросов, но в зависимости от загаданного числа иногда мы будем спрашивать ровно $7$ вопросов, а иногда $6$.
В общем случае, так как на каждой итерации длина отрезка поиска гарантированно уменьшится в два раза (возможно, с округлением вверх), то нам потребуется $O(\log n)$ операций, а точнее либо $\lceil \log_2 n \rceil$, либо $\lfloor \log_2 n \rfloor$.
#В структурах данных
Пусть дан массив $a$, и требуется определить, есть ли в нём элемент $x$.
Очевидно, в худшем случае этого элемента в массиве нет, но чтобы удостовериться в этом, нужно потратить $O(n)$ операций на просмотр всех элементов массива.
Однако, если массив отсортирован, найти число $x$ в массиве можно и быстрее: можно аналогичным способом найти нижнюю грань (англ. lower bound) — самое малое число, не меньшее $x$ — и проверить, оказалось ли оно равно $x$.
Для стандартных контейнеров STL такая функция реализована:
Также в C++ есть функция upper_bound , которая находит первый элемент, который строго больше аргумента.
#Проверка свойств
Подобный метод обобщается не только на поиск элементов, но и на проверку каких-либо монотонных свойств, которые сначала выполняются, а потом не выполняются, или наоборот.
Поиск нижней границы в массиве — частный случай: мы проверяем условие $(a[k] \geq x)$ и хотим найти, начиная с какого $k$ оно выполняется.
- Найти последнее число, равное $x$ в отсортированном массиве, или вывести, что таких чисел нет.
- Посчитать, сколько раз встречается число $x$ в отсортированном массиве.
- Дан массив чисел, первая часть состоит из нечетных чисел, а вторая из четных. Найти индекс, начиная с которого все числа четные.
Все эти задачи решаются бинарным поиском за $O(\log)$. Правда нужно понимать, что в чистом виде такую задачу решать двоичным поиском бессмысленно — ведь чтобы создать массив размера $n$, уже необходимо потратить $O(n)$ операций.
Поэтому зачастую такие задачи сформулированы таким образом: дан отсортированный массив размера $n$. Нужно ответить на $m$ запросов вида «встречается ли число $x_i$ в массиве?». Подобные задача решается за $O(n + m\log)$ — нужно сначала создать массив за $O(n)$ и $m$ раз запустить бинарный поиск.
#Бинарный поиск с вещественными аргументами
У нас все еще есть функция-предикат $f(x)$, которая сначала равна нулю, а потом единице, и мы хотим найти это место, где она меняет значение. Но теперь аргумент функции — вещественное число.
Пример такой функции:
$$ f(x) = \begin 0, & x^2 На самом деле, так можно искать ноль любой непрерывной функции (мы сейчас искали ноль функции $x^2 - 2$), у которой известны значения аргумента, при которых она принимает значения меньше нуля и больше нуля.
Целочисленный двоичный поиск
Целочисленный двоичный поиск (бинарный поиск) (англ. binary search) — алгоритм поиска объекта по заданному признаку в множестве объектов, упорядоченных по тому же самому признаку, работающий за логарифмическое время.
| Задача: |
| Пусть нам дан упорядоченный массив, состоящий только из целочисленных элементов. Требуется найти позицию, на которой находится заданный элемент. |
Схема бинарного поиска
Принцип работы
Двоичный поиск заключается в том, что на каждом шаге множество объектов делится на две части и в работе остаётся та часть множества, где находится искомый объект. Или же, в зависимости от постановки задачи, мы можем остановить процесс, когда мы получим первый или же последний индекс вхождения элемента. Последнее условие — это левосторонний/правосторонний двоичный поиск.
Правосторонний/левосторонний целочисленный двоичный поиск
Для простоты дальнейших определений будем считать, что [math]a[-1] = -\infty[/math] и что [math]a[n] = +\infty[/math] (массив нумеруется с [math]0[/math] ).
| Определение: |
| Правосторонний бинарный поиск (англ. rightside binary search) — бинарный поиск, с помощью которого мы ищем [math] \max\limits_ \ [/math] , где [math]a[/math] — массив, а [math]x[/math] — искомый ключ |
| Определение: |
| Левосторонний бинарный поиск (англ. leftside binary search) — бинарный поиск, с помощью которого мы ищем [math] \min\limits_\ [/math] , где [math]a[/math] — массив, а [math]x[/math] — искомый ключ |
Использовав эти два вида двоичного поиска, мы можем найти отрезок позиций [math][l,r][/math] таких, что [math]\forall i \in [l,r] : a[i] = x[/math] и [math] \forall i \notin [l,r] : a[i] \neq x [/math]
Пример:
Задан отсортированный массив [math][1, 2, 2, 2, 2, 3, 5, 8, 9, 11], x = 2[/math] .
Правосторонний поиск двойки выдаст в результате [math]4[/math] , в то время как левосторонний выдаст [math]1[/math] (нумерация с нуля).
Отсюда следует, что количество подряд идущих двоек равно длине отрезка [math][1;4][/math] , то есть [math]4[/math] .
Если искомого элемента в массиве нет, то правосторонний поиск выдаст максимальный элемент, меньший искомого, а левосторонний наоборот, минимальный элемент, больший искомого.
Алгоритм двоичного поиска
Идея поиска заключается в том, чтобы брать элемент посередине, между границами, и сравнивать его с искомым. Если искомое больше(в случае правостороннего — не меньше), чем элемент сравнения, то сужаем область поиска так, чтобы новая левая граница была равна индексу середины предыдущей области. В противном случае присваиваем это значение правой границе. Проделываем эту процедуру до тех пор, пока правая граница больше левой более чем на [math]1[/math] .
Код
int binSearch(int[] a, int key): // Запускаем бинарный поиск int l = -1 // l, r — левая и правая границы int r = len(a) while l < r - 1 // Запускаем цикл m = (l + r) / 2 // m — середина области поиска if a[m] < key l = m else r = m // Сужение границ return r
Инвариант цикла: правый индекс не меньше искомого элемента, а левый — строго меньше (т.к значение [math]m[/math] присваевается левой границе [math]l[/math] , только тогда, когда [math]a[m][/math] строго меньше искомого элемента [math]key[/math] ), тогда если [math]r = l + 1[/math] (что эквивалентно [math]r-l=1[/math] ), то понятно, что [math]r[/math] — самое левое вхождение искомого элемента (так как предыдущие элементы уже меньше искомого элемента)
В случае правостороннего поиска изменится знак сравнения при сужении границ на [math]a[m] \leqslant k[/math] , а возвращаемой переменной станет [math]l[/math] .
Несколько слов об эвристиках
Эвристика с завершением поиска, при досрочном нахождении искомого элемента
Заметим, что если нам необходимо просто проверить наличие элемента в упорядоченном множестве, то можно использовать любой из правостороннего и левостороннего поиска. При этом будем на каждой итерации проверять "не попали ли мы в элемент, равный искомому", и в случае попадания заканчивать поиск.
Эвристика с запоминанием ответа на предыдущий запрос
Пусть дан отсортированный массив чисел, упорядоченных по неубыванию. Также пусть запросы приходят в таком порядке, что каждый следующий не меньше, чем предыдущий. Для ответа на запрос будем использовать левосторонний двоичный поиск. При этом после того как обработался первый запрос, запомним чему равно [math]l[/math] , запишем его в переменную [math]startL[/math] . Когда будем обрабатывать следующий запрос, то проинициализируем левую границу как [math]startL[/math] . Заметим, что все элементы, которые лежат не правее [math]startL[/math] , строго меньше текущего искомого элемента, так как они меньше предыдущего запроса, а значит и меньше текущего. Значит инвариант цикла выполнен.
Применение двоичного поиска на некоторых неотсортированных массивах
| Задача: |
| Пусть отсортированный по возрастанию массив из [math]n[/math] элементов [math]a[0 \ldots n - 1][/math] , все элементы которого различны, был циклически сдвинут, требуется максимально быстро найти элемент в таком массиве. |
Если массив, отсортированный по возрастанию, был циклически сдвинут, тогда полученный массив состоит из двух отсортированных частей. Используем двоичный поиск, чтобы найти индекс последнего элемента левой части массива. Для этого в реализации двоичного поиска заменим условие в if на [math]a[m] \gt a[n-1][/math] , тогда в [math]l[/math] будет содержаться искомый индекс:
int l = -1 int r = len(a) while l < r - 1 // С помощью бинарного поиска найдем максимум на массиве m = (l + r) / 2 // m — середина области поиска if a[m] > a[n - 1] // Сужение границ l = m else r = m int x = l // x — искомый индекс.
Затем воспользуемся двоичным поиском искомого элемента [math]key[/math] , запустив его на той части массива, в которой он находится: на [math][0, x][/math] или на [math][x + 1, n - 1][/math] . Для определения нужной части массива сравним [math]key[/math] с первым и с последним элементами массива:
if key > a[0] // Если key в левой части l = -1 r = x + 1 if key < a[n] // Если key в правой части l = x r = n
Время выполнения данного алгоритма — [math]O(2\log n)=O(\log n)[/math] .
| Задача: |
| Массив образован путем приписывания в конец массива, отсортированного по возрастанию, массива, отсортированного по убыванию. Требуется максимально быстро найти элемент в таком массиве. |
Найдем индекс последнего элемента массива, отсортированного по возрастанию, воспользовавшись троичным поиском, затем запустим левосторонний двоичный поиск для каждого массива отдельно: для элементов [math][0 \ldots x][/math] и для элементов [math][x+1 \ldots n][/math] , где в качестве [math]x[/math] мы возьмем индекс максимума, найденный троичным поиском. Для массива, отсортированного по убыванию используем двоичный поиск, изменив условие в if на [math]a[m] \gt key[/math] .
Время выполнения алгоритма — [math] O(\log n)[/math] (так как и бинарный поиск, и тернарный поиск работают за логарифмическое время с точностью до константы).
| Задача: |
| Два отсортированных по возрастанию массива записаны один в конец другого. Требуется максимально быстро найти элемент в таком массиве. |
Мы имеем массив, образованный из двух отсортированных подмассивов, записанных один в конец другого. Запустить сразу бинарный или тернарный поиски на таком массиве нельзя, так как массив не будет обязательно отсортированным и он не будет иметь [math]1[/math] точку экстремума. Поэтому попробуем найти индекс последнего элемента левого массива, чтобы потом запустить бинарный поиск два раза на отсортированных массивах.
Докажем, что найти этот индекс невозможно быстрее, чем за [math]\Omega (n)[/math] . Возьмем возрастающий массив целых чисел, начиная с [math]1[/math] . Он удовлетворяет условию задачи. Вставим в него [math]0[/math] на любую позицию. Такой массив по-прежнему будет удовлетворять условию задачи. Следовательно, из-за того, что [math]0[/math] может находиться на любой позиции, мы можем его найти лишь за [math]\Omega (n)[/math] .
| Задача: |
| Массив образован путем циклического сдвига массива, образованного приписыванием отсортированного по убыванию массива в конец отсортированного по возрастанию. Требуется максимально быстро найти элемент в таком массиве. |
После циклического сдвига мы получим массив [math]a[0 \ldots n-1][/math] , образованный из трех частей: отсортированных по возрастанию-убыванию-возрастанию ( [math]\nearrow \searrow \nearrow [/math] ) или по убыванию-возрастанию-убыванию ( [math] \searrow \nearrow \searrow [/math] ). С помощью двоичного поиска найдем индексы максимального и минимального элементов массива, заменив условие в if на [math]a[m] \gt a[m - 1][/math] (ответ будет записан в [math]l[/math] ) или на [math]a[m] \gt a[m + 1][/math] (ответ будет записан в [math]r[/math] ) соответственно.
Фактически, при поиске индексов минимума и максимума мы проверяем, возрастает или убывает массив на промежутке [math] [ m - 1 ; m ] [/math] , а затем, в зависимости от того, что мы ищем, мы либо поднимаемся, либо опускаемся по этому промежутку возрастания (убывания). Однако при таком решении могут быть неправильно найдены значения минимума или максимума. Рассмотрим случаи, когда они будут неправильно найдены. Определить, какого вида наш массив возможно, сравнив первые два элемента массива.
Рассмотрим отдельно ситуацию, если наш массив вида возрастание-убывание-возрастание ( [math]\nearrow \searrow \nearrow [/math] ). В таком случае может быть неправильно найдено значение максимума, если последний промежуток возрастания занимает больше половины массива (мы будем подниматься по последнему промежутку возрастания вплоть до конца массива и за максимум будет принят последний элемент массива, что не всегда верно). Тогда, если последний элемент массива меньше первого, нужно еще раз запустить поиск максимума, но уже на промежутке от [math]0[/math] до [math]min[/math] , потому что истинный максимум будет находиться в первой точке экстремума, которую мы таким образом и найдем.
В случае же убывание-возрастание-убывание ( [math] \searrow \nearrow \searrow [/math] ) может быть, что будет неправильно найден минимум. Найдем правильный минимум аналогично поиску максимума в предыдущем абзаце.
Затем, в зависимости от типа нашего массива, запустим бинарный поиск три раза на каждом промежутке.
Время выполнения данного алгоритма — [math]O(6\log n)=O(\log n)[/math] .
Переполнение индекса середины
В некоторых языках программирования присвоение m = (l + r) / 2 приводит к переполнению. Вместо этого рекомендуется использовать m = l + (r - l) / 2; или эквивалентные выражения. [1]
См. также
- Вещественный двоичный поиск
- Троичный поиск
- Поиск с помощью золотого сечения
- Интерполяционный поиск
Источники информации
- Д. Кнут — Искусство программирования (Том 3, 2-е издание)
- Википедия — двоичный поиск
- Типичные ошибки при написании бинарного поиска
- Бинарный поиск на algolist
Бинарный поиск
Рассмотрим задачу: дан массив a[], состоящий из целых чисел, и требуется найти в нём элемент x. Если x присутствует в a, то нужно вернуть его индекс (если x встречается несколько раз, то можно вернуть любой из подходящих индексов), иначе, если x нет, — вернуть -1.
Простейший способ решить такую задачу — пройти по всем элементам массива и сравнить их с x:
int search(int a[], int size, int x) < // ищем x в массиве a размера size for (int i = 0; i < size; i++) // перебираем все элементы массива if (a[i] == x) // если элемент равен x, return i; // возвращаем его индекс return -1; // если не встретили x, возвращаем -1 >
Такое решение называют линейным поиском. Очевидно, что количество действий, которые данный алгоритм выполняет в худшем случае (когда x отсутствует в массиве), пропорционально размеру массива (поиск выполняется за O(N)).
Если массив отсортирован, то мы можем использовать более эффективную стратегию. Пусть массив упорядочен по возрастанию, тогда:
- Найдём центральный элемент массива и сравним его с x. Если он равен x, то ответ найден;
- Если центральный элемент меньше x, то искать ответ имеет смысл только в правой половине массива (так как слева все элементы тоже меньше x);
- Если центральный элемент больше x, то искать ответ имеет смысл только в левой половине массива (так как справа все элементы тоже больше x);
- При переходе в ту или иную половину мы снова определяем в ней средний элемент и сравниваем его с x, и так далее, пока ответ не будет найден или пока в рассматриваемой области не останется элементов.
Для того, чтобы отслеживать текущую область поиска, заведём индексы l и r. Будем считать, что поиск производится в отрезке от l до r включительно; таким образом, изначально l = 0, r = size - 1. Зная l и r, середину можно найти как (l + r) / 2 или l + (r - l) / 2.
int binarySearch(int a[], int size, int x) < // ищем x в отсортированном массиве a размера size int l = 0, r = size - 1; // ищем в отрезке [l; r]. изначально это весь массив while (l return -1 // если не встретили x, возвращаем -1. >
Такое решение называют бинарным поиском. Бинарный поиск гораздо быстрее линейного, так на каждой итерации он сокращает область поиска в два раза (поиск выполняется за O(logN)).
| Размер массива | Линейный поиск | Бинарный поиск |
| 10 | 10 | 4 |
| 100 | 100 | 7 |
| 1000 | 1000 | 10 |
| 10 6 | 10 6 | 20 |
| 10 9 | 10 9 | 30 |
Для бинарного поиска массив должен быть отсортирован, в общем случае сортировка требует времени O(NlogN).
- Если элемент ищется лишь один раз, а массив не отсортирован, то выгоднее использовать линейный поиск (O(N) выгоднее, чем O(NlogN) + O(logN));
- Если элементы ищутся много раз, то выгоднее отсортировать массив и использовать бинарный поиск (O(NlogN) + много O(logN) выгоднее, чем много O(N));
- Если элементы добавляются и удаляются, то вместо отсортированного массива следует использовать другую коллекцию — двоичное дерево поиска или хеш-таблицу;
- При помощи хеш-таблицы можно решать исходную задачу эффективнее, чем двоичным поиском, — за константное время (O(1)). Но идея двоичного поиска применима в существенно более широком наборе задач, как мы увидим далее.
Левый и правый бинарный поиск
Рассмотренная выше задача, в которой требуется найти любое вхождение заданного элемента в массив, встречается сравнительно редко и представляет мало интереса. Гораздо важнее другой вид задач: дан отсортированный массив a[] и требуется найти в нём индекс первого или последнего вхождения числа x (или индекс последнего элемента, меньшего x, или индекс первого элемента, большего x).
При решении данной задачи мы уже не можем сразу вернуть индекс, как только нашли элемент, равный x, и функцию поиска придётся усложнить.
Оказывается, что написание бинарного поиска первого или последнего вхождения — достаточно трудная задача. Программист вынужден держать в голове множество тонких моментов. Вот некоторые из них:
- Является ли диапазон от l до r отрезком или полуинтервалом, как он отсортирован, содержит ли он искомый элемент;
- Как следует проверять центральный элемент и как смещать границы: l = m или l = m + 1, r = m или r = m - 1;
- Будет ли поиск правильно работать на массивах из 0, 1, 2 элементов;
- Какой из индексов в итоге указывает на ответ, как проверить, что ответ отсутствует, и др.
Правила написания бинарного поиска без головной боли
- Диапазон от l до r — всегда отрезок (включительно, [l; r]), изначально l = 0, r = size - 1. Искомый элемент изначально может как быть в отрезке, так и не быть, это не важно;
- Поиск всегда осуществляется до двух элементов (while (l + 1 < r));
- После проверки среднего элемента границы всегда смещаются только на середину (l = m или r = m, никаких плюс-минус единиц);
- Смещение границ должно происходить так, чтобы не потерять искомый элемент (чтобы он не выпал из отрезка [l; r], если он там был).
- Когда цикл завершится, останутся два соседних элемента — a[l] и a[r]. Их нужно проверить по отдельности. При этом, если мы ищем первое вхождение чего-либо, то сначала проверяем a[l], затем a[r]; если ищем последнее вхождение — сначала a[r], затем a[l].
Следуя этим правилам, вы сможете практически единообразно писать различные виды левых и правых двоичных поисков. Сравните показанные ниже примеры: в них меняются только условие проверки среднего элемента (выделено красным) и порядок проверки последних двух элементов (выделено оранжевым).
// сорт. по неубыванию // последний элемент < x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] < x) l = m; else r = m; > if (a[r] < x)return r; if (a[l] < x)return l; return -1;
// сорт. по неубыванию // последний элемент a[m] ) l = m; else r = m; > if (a[r] return r; if (a[l] return l; return -1;
// сорт. по неубыванию // последний элемент == x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] ) l = m; else r = m; > if (a[r] == x) return r; if (a[l] == x) return l; return -1;
// сорт. по неубыванию // первый элемент > x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] ) // if (a[m] > x) l = m; // r = m; else // else r = m; // l = m; > if (a[l] > x) return l; if (a[r] > x) return r; return -1;
// сорт. по неубыванию // первый элемент >= x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] < x) // if (a[m] >= x) l = m; // r = m; else // else r = m; // l = m; > if (a[l] >= x) return l; if (a[r] >= x) return r; return -1;
// сорт. по неубыванию // первый элемент == x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] < x) // if (a[m] >= x) l = m; // r = m; else // else r = m; // l = m; > if (a[l] == x) return l; if (a[r] == x) return r; return -1;
// сорт. по невозрастанию // последний элемент > x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] > x) l = m; else r = m; > if (a[r] > x) return r; if (a[l] > x) return l; return -1;
// сорт. по невозрастанию // последний элемент >= x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] >= x) l = m; else r = m; > if (a[r] >= x) return r; if (a[l] >= x) return l; return -1;
// сорт. по невозрастанию // последний элемент == x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] >= x) l = m; else r = m; > if (a[r] == x) return r; if (a[l] == x) return l; return -1;
// сорт. по невозрастанию // первый элемент < x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] >= x) // if (a[m] < x) l = m; // r = m; else // else r = m; // l = m; > if (a[l] < x)return l; if (a[r] < x)return r; return -1;
// сорт. по невозрастанию // первый элемент a[m] > x) // if (a[m] ) l = m; // r = m; else // else r = m; // l = m; > if (a[l] return l; if (a[r] return r; return -1;
// сорт. по невозрастанию // первый элемент == x int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (a[m] > x) // if (a[m] ) l = m; // r = m; else // else r = m; // l = m; > if (a[l] == x) return l; if (a[r] == x) return r; return -1;
// f() возвращает // сначала true, потом false // последний f() == true int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (f(a[m])) l = m; else r = m; > if (f(a[r])) return r; if (f(a[l]) return l; return -1;
// f() возвращает // сначала false, потом true // первый f() == true int l = 0, r = size - 1; while (l + 1 < r) < int m = l + (r - l) / 2; if (!f(a[m])) // if (f(a[m])) l = m; // r = m; else // else r = m; // l = m; > if (f(a[l]) return l; if (f(a[r])) return r; return -1;
При желании показанный алгоритм можно оптимизировать, сократив количество проверок в конце.
Ссылки
- Codeforces EDU — Двоичный поиск
- neerc.ifmo.ru/wiki — Целочисленный двоичный поиск
- neerc.ifmo.ru/wiki — Вещественный двоичный поиск
- brestprog — Бинарный поиск
- algorithmica.org — Бинарный поиск
- Калинин П. — Бинарный поиск
- Brilliant.org — Binary Search