Оценка сложности алгоритмов
В своей деятельности разработчикам практически ежедневно необходимо разрабатывать алгоритмы различного назначения, которые работают с разным набором данных, начиная от нескольких параметров командной строки, заканчивая таблицами размером в терабайты.
Для того чтобы обеспечить эффективную работу с такими данными далеко не всегда достаточно реализовать алгоритм, который первым пришел в голову. Зачастую необходимо провести тщательную оценку выбранного алгоритма и выбранной структуры данных, так как в большинстве случаев перед разработчиком ставится выбор между быстродействием алгоритма и объемом используемой памяти. Для этих целей используется специальный подход, о котором далее будет идти речь.
Говоря о сложности алгоритма принято иметь ввиду O-нотацию. Данная нотация имеет свои корни в мат. анализе. Говорят, что неотрицательная функция f(n) не превосходит по порядку функцию g(n) и пишут O(f(n)) = O(g(n)) , если существует такая натуральная константа C, что f (n)
Для наглядности разберем простой пример. Допустим, нам на вход поступает массив строк. Наша задача заключается в том, чтобы вместо каждой строчки записать в этот массив длину этой строчки. Если наш массив будет состоять из 5 ячеек, то эта операция будет занимать 5 у. е. времени. Если же их будет 10, то время будет составлять 10 у. е. Рассуждая таким же способом можно прийти к выводу, что время выполнения нашей задачи линейно зависит от числа элементов этого массива, т. е. от размера входных данных. В таком случае, говорится что время выполнения алгоритма не превосходит O(n), где n – число элементов на входе нашего алгоритма.
На практике далеко не всегда можно также легко и однозначно определить зависимость времени выполнения алгоритма от входных данных. Более того, не совсем удобно учитывать каждое малозначимое ответвление. Поэтому для удобной оценки алгоритмов делается несколько допущений, которые значительно упрощают эту задачу.
Первым таким упрощением является то, что мы можем отбросить константы, которые не являются значительными для сравнения. Например, если у нас есть оценка O(n+5), то она эквивалентна O(n). Однако, если нам требуется сравнить O(3n) и O(2n) мы не можем отбросить эти константы и сказать, что алгоритмы эквивалентны с точки зрения времени выполнения. Следующим упрощением является тот факт, что мы в праве оставлять только самую большую по степени функцию для оценки времени. Например, при оценке O(n^3+n^2 +4n) мы можем упростить ее до оценки O(n^3). Следующее упрощение связно с асимптотикой. Чаще всего, когда нам важно оценить скорость работы алгоритма речь идет о больших объемах информации. И здесь нам становится не так важно, поступит ли нам на вход миллион или миллион и одна строка. В таких случаях мы говорим о «худшей» или асимптотической оценке алгоритма. То есть в качестве оценки мы принимаем ту функцию, которая является асимптотой для временной составляющей нашего алгоритма.
Когда мы говорим о ситуациях, в которых мы заранее уверены в некоторой структуре входных данных или в объемах этих данных, можно говорить об оценке снизу и средней оценке. Оценка снизу означает, что мы рассчитываем время, которое потребует наш алгоритм в случае наиболее удачной структуры данных и наиболее удачного порядка данных в этой структуре. Если же мы говорим о средней оценке, то нам достаточно просто сложить оценки сверху и снизу и разделить их пополам.
Наиболее распространёнными оценками являются линейная O(n), логарифмическая O(logn), степенная O(m^n) и экспоненциальная O(e^n), так как она удобна для перехода к операциям с логарифмами. Как показывает практика комбинаций этих сложностей достаточно чтобы оценить большинство алгоритмов.
Давайте рассмотрим данный подход на примере оценки алгоритмов сортировки. Ниже приведен код самой простой сортировки «пузырьком»
for i in range(N-1): for j in range(N-i-1): if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j]
Здесь мы видим 2 вложенных цикла. Первый цикл верхнего уровня проходится по элементам от 0 до N-1. Вложенный цикл выполняется N-i-1 раз. Итого оба цикла приблизительно займут N*(N-1)/2 операций. Если вспомнить о том, что мы отбрасываем константы и переменные более низкого порядка получим сложность O(N^2).
Теперь посмотрим на более быстрые алгоритмы сортировки, например, сортировку слиянием. Ниже представлен один из вариантов реализации этого алгоритма.
def merge_sort(nums): if len(nums) > 1: mid = len(nums)//2 left = nums[:mid] right = nums[mid:] merge_sort(left) merge_sort(right) i = j = k = 0 while i < len(left) and j < len(right): if left[i] < right[j]: nums[k] = left[i] i+=1 else: nums[k] = right[j] j+=1 k+=1 while i < len(left): nums[k] = left[i] i+=1 k+=1 while j < len(right): nums[k] = right[j] j+=1 k+=1
В данном алгоритме мы сначала получаем дерево разбиения нашего массива, глубина которого равна log(n). Далее для каждого уровня нашего дерева нам нужно пройтись по n элементам, сравнить их и записать промежуточные результаты. Таким образом сложность данного алгоритма n*log(n). Это в свою очередь быстрее чем рассмотренный ранее алгоритм.
Когда мы оценили несколько алгоритмов с точки зрения времени выполнения, мы можем выбрать алгоритм, который работает быстрее всего. Но в процессе реализации такого алгоритма может возникнуть ситуация, когда для корректной работы необходимо создавать специфические структуры данных, а также дублировать некоторые данные. В этом случае важно оценить, что для нас является более критичным ресурсом — время или память. Чтобы грамотно это оценить необходимо уметь не только выявлять максимальное и минимальное время работы алгоритма, но и оценивать и оптимизировать структуры, в которые мы записываем данные. Приведем пример. Если для какого-либо алгоритма нам необходимо дублировать целочисленный массив, этот алгоритм может показаться нам недостаточно эффективным, даже если он дает прирост в скорости в 1.2 раза. Однако, если мы проведем тщательный анализ данных, оценим возможные значения этих самых данных можно прийти к выводу, что вместо int64 здесь вполне применим int32 или даже int16, что нивелирует необходимость дупликации данных и позволяет использовать более быстрый алгоритм. Но может произойти и более сложная ситуация. Допустим наш алгоритм занимается только операциями поиска вставки и удаления. В голову сразу приходит хэш-таблица, которая позволяет делать все эти операции за константное время. Однако, если мы знаем, что у нас будет не больше 100 элементов нам стоит еще раз подумать о структуре данных, так как операции получения хэша тоже занимают время, а при использовании новых и сложных алгоритмов хэширования, заточенных на избежание коллизий в больших объемах данных это время может быть несоизмеримо больше того времени, которое мы потенциально экономим при использовании этой структуры. Если вернуться к алгоритмам сортировки, рассмотренным ранее, то можно заметить, что сортировка пузырьком работает с исходными данными и не нуждается в дополнительном выделении памяти, тогда как merge sort требует выделение массива такого же размера, как и исходный. Поэтому в данном случае важно понимать какой длины ожидается массив и хватит ли у нас вычислительных ресурсов для его дублирования.
Таким образом, важно помнить, что за двумя зайцами скорее всего угнаться не получится, поэтому важно четко понимать, что для вас обойдется дороже – память или время. А если удалось и ускорить работу алгоритма и использование памяти сократить, лучше на всякий случай перепроверить расчёты.
Big O Notation: что это такое и как её посчитать
Software Engineer Валерий Жила подробно рассказал, что такое O(n), и показал, как её считать на примере бинарного поиска и других алгоритмов.

Кадр: фильм «Мальчишник в Вегасе»

Редакция «Код» Skillbox Media
Онлайн-журнал для тех, кто влюблён в код и информационные технологии. Пишем для айтишников и об айтишниках.

об эксперте
Software Engineer, разрабатывает системы управления городской инфраструктурой для мегаполисов. Основная деятельность: backend, database engineering. Ведёт твиттер @ValeriiZhyla и пишет научные работы по DevOps.
Ссылки
Сегодня я расскажу о сложности алгоритмов, или, как её часто называют, Big O Notation. Статья рассчитана на новичков, поэтому постараюсь изложить идеи и концепции просто, не теряя важных деталей.
Время и память — основные характеристики алгоритмов
Алгоритмы описывают с помощью двух характеристик — времени и памяти.
Время — это… время, которое нужно алгоритму для обработки данных. Например, для маленького массива — 10 секунд, а для массива побольше — 100 секунд. Интуитивно понятно, что время выполнения алгоритма зависит от размера массива.
Но есть проблема: секунды, минуты и часы — это не очень показательные единицы измерения. Кроме того, время работы алгоритма зависит от железа, на котором он выполняется, и других внешних факторов. Поэтому время считают не в секундах и часах, а в количестве операций, которые алгоритм совершит. Это надёжная и, главное, независимая от железа метрика.
Когда говорят о Time Complexity или просто Time, то речь идёт именно о количестве операций. Для простоты расчётов разница в скорости между операциями обычно опускается. Поэтому, несмотря на то, что деление чисел с плавающей точкой требует от процессора больше действий, чем сложение целых чисел, обе операции в теории алгоритмов считаются равными по сложности.
Запомните: в О-нотации на операции с одной или двумя переменными вроде i++, a * b, a / 1024, max(a,b) уходит всего одна единица времени.
Память, или место, — это объём оперативной памяти, который потребуется алгоритму для работы. Одна переменная — это одна ячейка памяти, а массив с тысячей ячеек — тысяча ячеек памяти.
В теории алгоритмов все ячейки считаются равноценными. Например, int a на 4 байта и double b на 8 байт имеют один вес. Потребление памяти обычно называется Space Complexity или просто Space, редко — Memory.
Алгоритмы, которые используют исходный массив как рабочее пространство, называют in-place. Они потребляют мало памяти и создают одиночные переменные — без копий исходного массива и промежуточных структур данных. Алгоритмы, требующие дополнительной памяти, называют out-of-place. Прежде чем использовать алгоритм, надо понять, хватит ли на него памяти, и если нет — поискать менее прожорливые альтернативы.
Статья написана на основе треда Валерия в его аккаунте в Twitter. Автор благодарит @usehex за помощь в создании материала.
Что такое O(n)
Давайте вспомним 8-й класс и разберёмся: что значит запись O(n) с математической точки зрения. При расчёте Big O Notation используют два правила:
Константы откидываются. Нас интересует только часть формулы, которая зависит от размера входных данных. Проще говоря, это само число n, его степени, логарифмы, факториалы и экспоненты, где число находится в степени n.
Примеры:
O(2n * log n) = O(n * log n)
Если в O есть сумма, нас интересует самое быстрорастущее слагаемое. Это называется асимптотической оценкой сложности.
Примеры:
O(n^3 + 100n * log n) = O(n^3)
Хороший, плохой, средний
У каждого алгоритма есть худший, средний и лучший сценарии работы — в зависимости от того, насколько удачно выбраны входные данные. Часто их называют случаями.
Худший случай (worst case) — это когда входные данные требуют максимальных затрат времени и памяти.
Например, если мы хотим отсортировать массив по возрастанию (Ascending Order, коротко ASC), то для простых алгоритмов сортировки худшим случаем будет массив, отсортированный по убыванию (Descending Order, коротко DESC).
Для алгоритма поиска элемента в неотсортированном массиве worst case — это когда искомый элемент находится в конце массива или если элемента нет вообще.
Лучший случай (best case) — полная противоположность worst case, самые удачные входные данные. Правильно отсортированный массив, с которым алгоритму сортировки вообще ничего делать не нужно. В случае поиска — когда алгоритм находит нужный элемент с первого раза.
Средний случай (average case) — самый хитрый из тройки. Интуитивно понятно, что он сидит между best case и worst case, но далеко не всегда понятно, где именно. Часто он совпадает с worst case и всегда хуже best case, если best case не совпадает с worst case. Да, иногда они совпадают.
Как определяют средний случай? Считают статистически усреднённый результат: берут алгоритм, прокручивают его с разными данными, составляют сводку результатов и смотрят, вокруг какой функции распределились результаты. В общем, расчёт average case — дело сложное. А мы приступаем к конкретным алгоритмам.
Линейный поиск
Начнём с самого простого алгоритма — линейного поиска, он же linear search. Дальнейшее объяснение подразумевает, что вы знаете, что такое числа и как устроены массивы. Напомню, это всего лишь набор проиндексированных ячеек.
Допустим, у нас есть массив целых чисел arr, содержащий n элементов. Вообще, количество элементов, размер строк, массивов, списков и графов в алгоритмах всегда обозначают буквой n или N. Ещё дано целое число x. Для удобства обусловимся, что arr точно содержит x.
Задача: найти, на каком месте в массиве arr находится элемент 3, и вернуть его индекс.
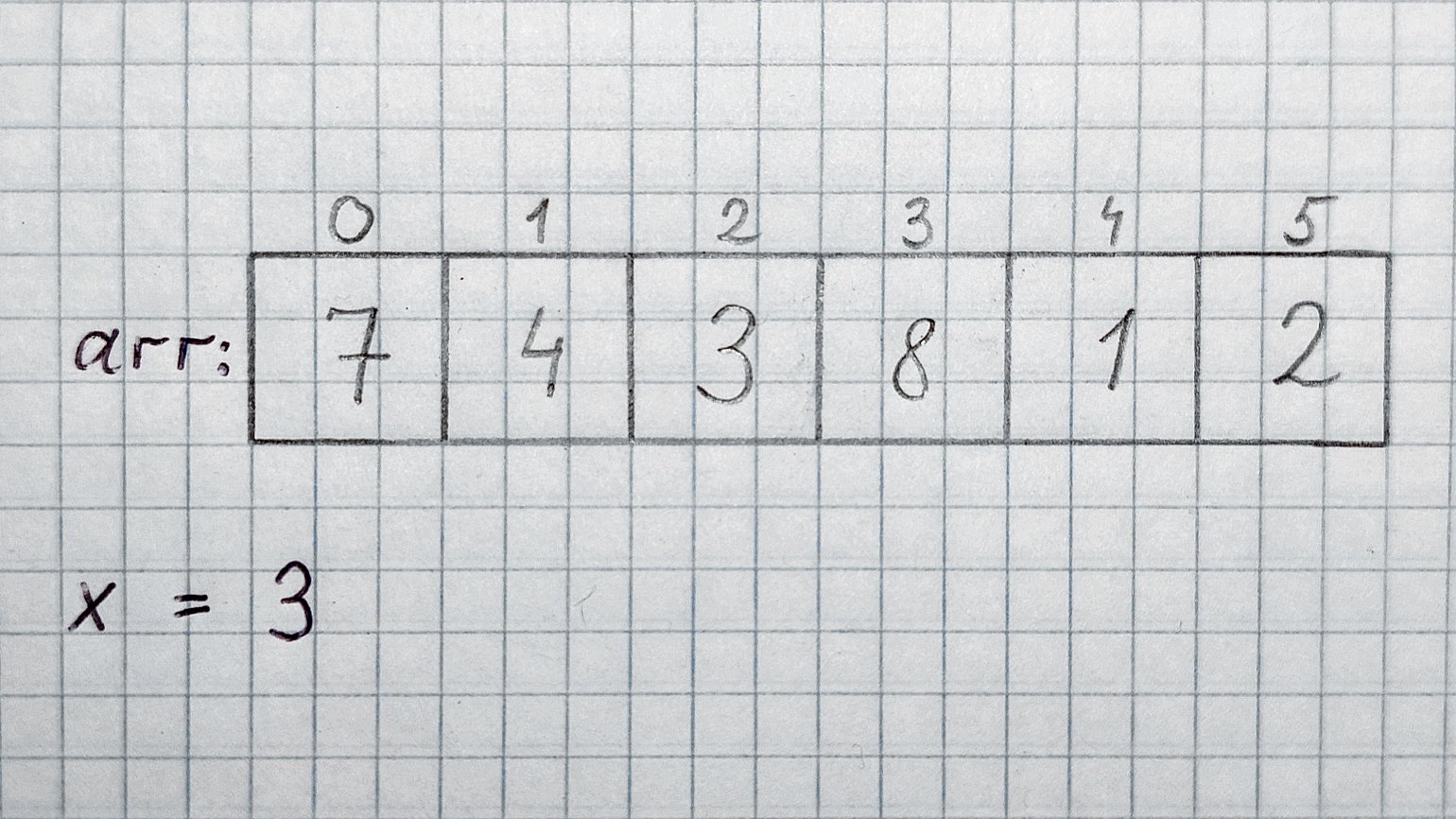
Меткий человеческий глаз сразу видит, что искомый элемент содержится в ячейке с индексом 2, то есть в arr[2]. А менее зоркий компьютер будет перебирать ячейки друг за другом: arr[0], arr[1]… и так далее, пока не встретит тройку или конец массива, если тройки в нём нет.
Теперь разберём случаи:
Worst case. Больше всего шагов потребуется, если искомое число стоит в конце массива. В этом случае придётся перебрать все n ячеек, прочитать их содержимое и сравнить с искомым числом. Получается, worst case равен O(n). В нашем массиве худшему случаю соответствует x = 2.
Best case. Если бы искомое число стояло в самом начале массива, то мы бы получили ответ уже в первой ячейке. Best case линейного поиска — O(1). Именно так обозначается константное время в Big O Notation. В нашем массиве best case наблюдается при x = 7.
Average case. В среднем случае результаты будут равномерно распределены по массиву. Средний элемент можно рассчитать по формуле (n + 1) / 2, но так как мы отбрасываем константы, то получаем просто n. Значит, average case равен O(n). Хотя иногда в среднем случае константы оставляют, потому что запись O(n / 2) даёт чуть больше информации.
Псевдокод
Хорошо, мы уже три минуты обсуждаем linear search, но до сих пор не видели кода. Потерпите, скоро всё будет. Но сперва познакомимся с очень полезным инструментом — псевдокодом.
Разработчики пишут на разных языках программирования. Одни похожи друг на друга, а другие — сильно различаются. Часто мы точно знаем, какую операцию хотим выполнить, но не уверены в том, как она выглядит в конкретном языке.
Возьмём хотя бы получение длины массива. По историческим причинам практически во всех языках эта операция называется по-разному: .length, length(), len(), size(), .size — попробуй угадай! Как же объяснить свой код коллегам, которые пишут на другом языке? Написать программу на псевдокоде.
Псевдокод — достаточно формальный, но не слишком требовательный к мелочам инструмент для изложения мыслей, не связанный с конкретным языком программирования.
Прелесть псевдокода в том, что конкретных правил для его написания нет. Я, например, предпочитаю использовать смесь синтаксиса Python и C: обозначаю вложенность с помощью отступов и называю методы в стиле Python.
А вот и пример псевдокода для нашей задачи, со всеми допущениями и упрощениями. Метод должен возвращать -1, если arr пуст или не содержит x:

Бинарный поиск
Следующая остановка — binary search, он же бинарный, или двоичный, поиск.
В чём отличие бинарного поиска от уже знакомого линейного? Чтобы его применить, массив arr должен быть отсортирован. В нашем случае — по возрастанию.
Часто binary search объясняют на примере с телефонным справочником. Возможно, многие читатели никогда не видели такую приблуду — это большая книга со списками телефонных номеров, отсортированных по фамилиям и именам жителей. Для простоты забудем об именах.
Итак, есть огромный справочник на тысячу страниц с десятками тысяч пар «фамилия — номер», отсортированных по фамилиям. Допустим, мы хотим найти номер человека по фамилии Жила. Как бы мы действовали в случае с линейным поиском? Открыли бы книгу и начали её перебирать, строчку за строчкой, страницу за страницей: Астафьев… Безье… Варнава… Ги… До товарища Жилы он дошёл бы за пару часов, а вот господин Янтарный заставил бы алгоритм попотеть ещё дольше.
Бинарный поиск мудрее и хитрее. Он открывает книгу ровно посередине и смотрит на фамилию, например Мельник — буква «М». Книга отсортирована по фамилиям, и алгоритм знает, что буква «Ж» идёт перед «М».
Алгоритм «разрывает» книгу пополам и выкидывает часть с буквами, которые идут после «М»: «Н», «О», «П»… «Я». Затем открывает оставшуюся половинку посередине — на этот раз на фамилии Ежов. Уже близко, но Ежов не Жила, а ещё буква «Ж» идёт после буквы «Е». Разрываем книгу пополам, а левую половину с буквами от «А» до «Е» выбрасываем. Алгоритм продолжает рвать книгу пополам до тех пор, пока не останется единственная измятая страничка с заветной фамилией и номером.
Перенесём этот принцип на массивы. У нас есть отсортированный массив arr и число 7, которое нужно найти. Почему поиск называется бинарным? Дело в том, что алгоритм на каждом шаге уменьшает проблему в два раза. Он буквально отрезает на каждом шаге половину arr, в которой гарантированно нет искомого числа.

На каждом шаге мы проверяем только середину. При этом есть три варианта развития событий:
- попадаем в 7 — тогда проблема решена;
- нашли число меньше 7 — отрезаем левую половину и ищем в правой половине;
- нашли число больше 7 — отрезаем правую половину и ищем в левой половине.
Почему это работает? Вспомните про требование к отсортированности массива, и всё встанет на свои места.
Итак, смотрим в середину. Карандаш будет служить нам указателем.
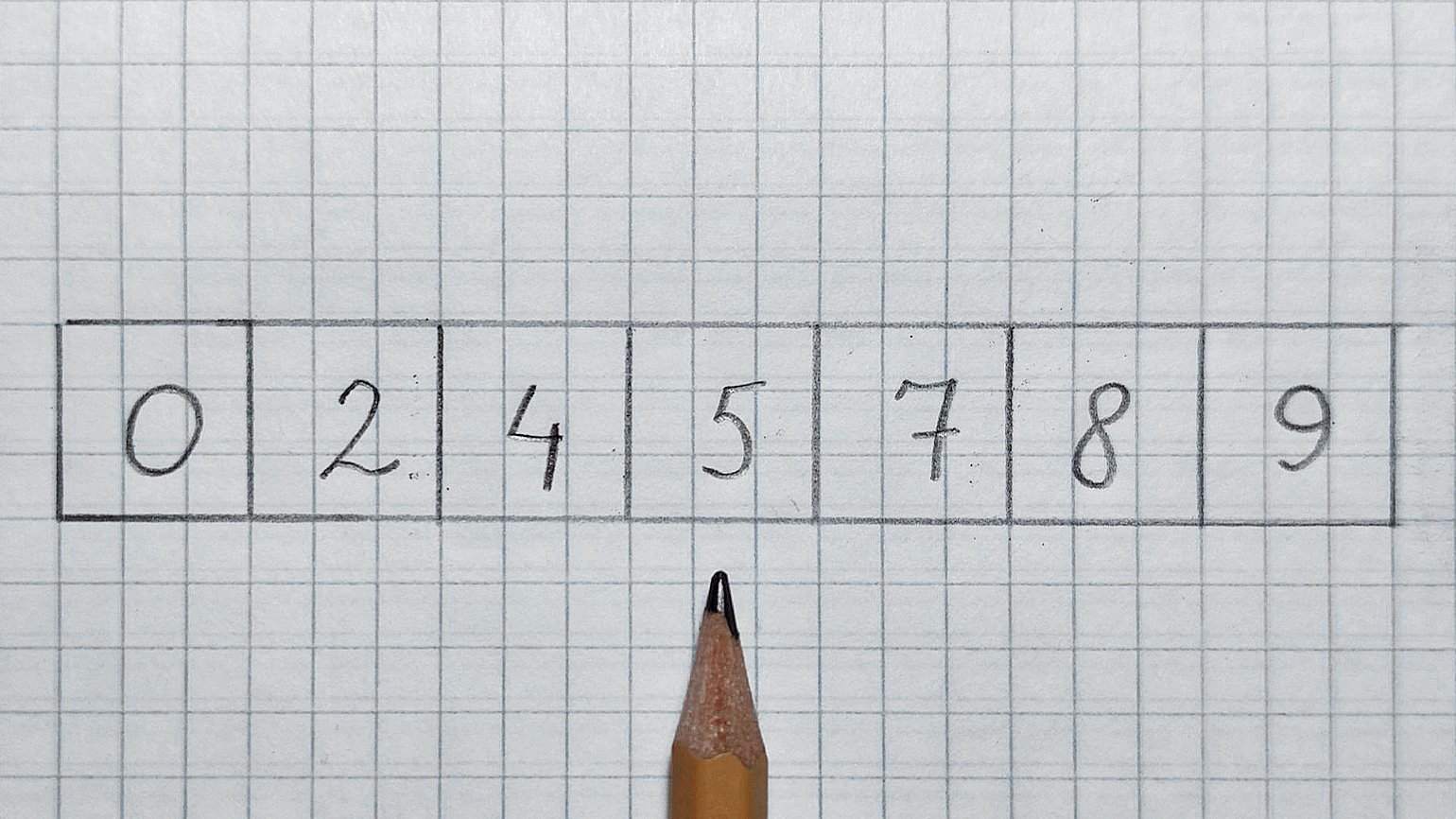
В середине находится число 5, оно меньше 7. Значит, отрезаем левую половину и проверенное число. Смотрим в середину оставшегося массива:
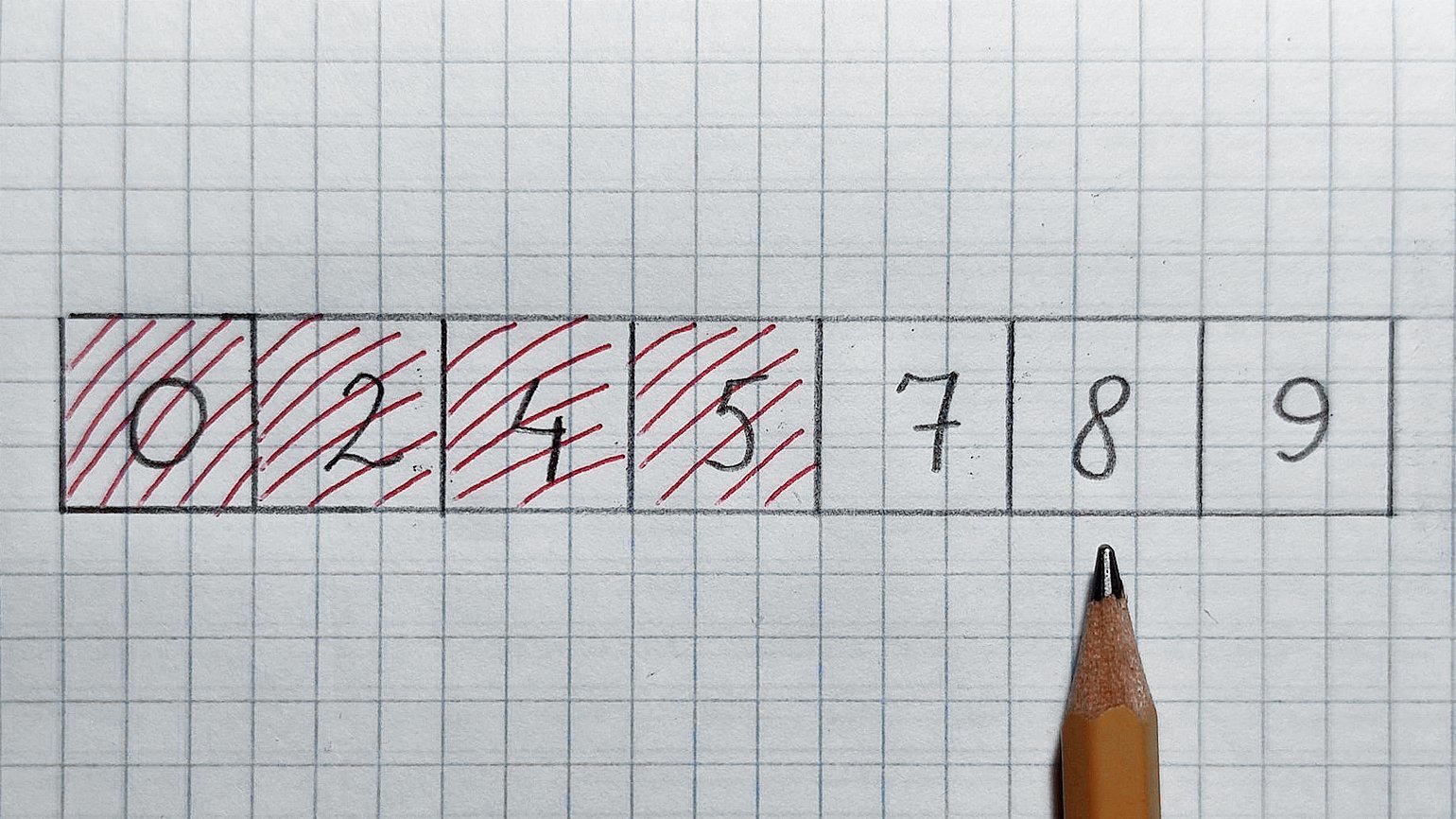
В середине число 8, оно больше 7. Значит, отрезаем правую половинку и проверенное число. Остаётся число 7 — как раз его мы и искали. Поздравляю!

Теперь давайте попробуем записать это в виде красивого псевдокода. Как обычно, назовём середину mid и будем перемещать «окно наблюдения», ограниченное двумя индексами — low (левая граница) и high (правая граница).

Несколько слов об этой весёлой компании:
- Big O обозначает верхнюю границу сложности алгоритма. Это идеальный инструмент для поиска worst case.
- Big Omega (которая пишется как подкова) обозначает нижнюю границу сложности, и её правильнее использовать для поиска best case.
- Big Theta (пишется как О с чёрточкой) располагается между О и омегой и показывает точную функцию сложности алгоритма. С её помощью правильнее искать average case.
- Small o и Small omega находятся по краям этой иерархии и используются в основном для сравнения алгоритмов между собой.
«Правильнее» в данном контексте означает — с точки зрения математических пейперов по алгоритмам. А в статьях и рабочей документации, как правило, во всех случаях используют «Большое „О“».
Если хотите подробнее узнать об остальных нотациях, посмотрите интересный видос на эту тему. Также полезно понимать, как сильно отличаются скорости возрастания различных функций. Вот хороший cheat sheet по сложности алгоритмов и наглядная картинка с графиками оттуда:
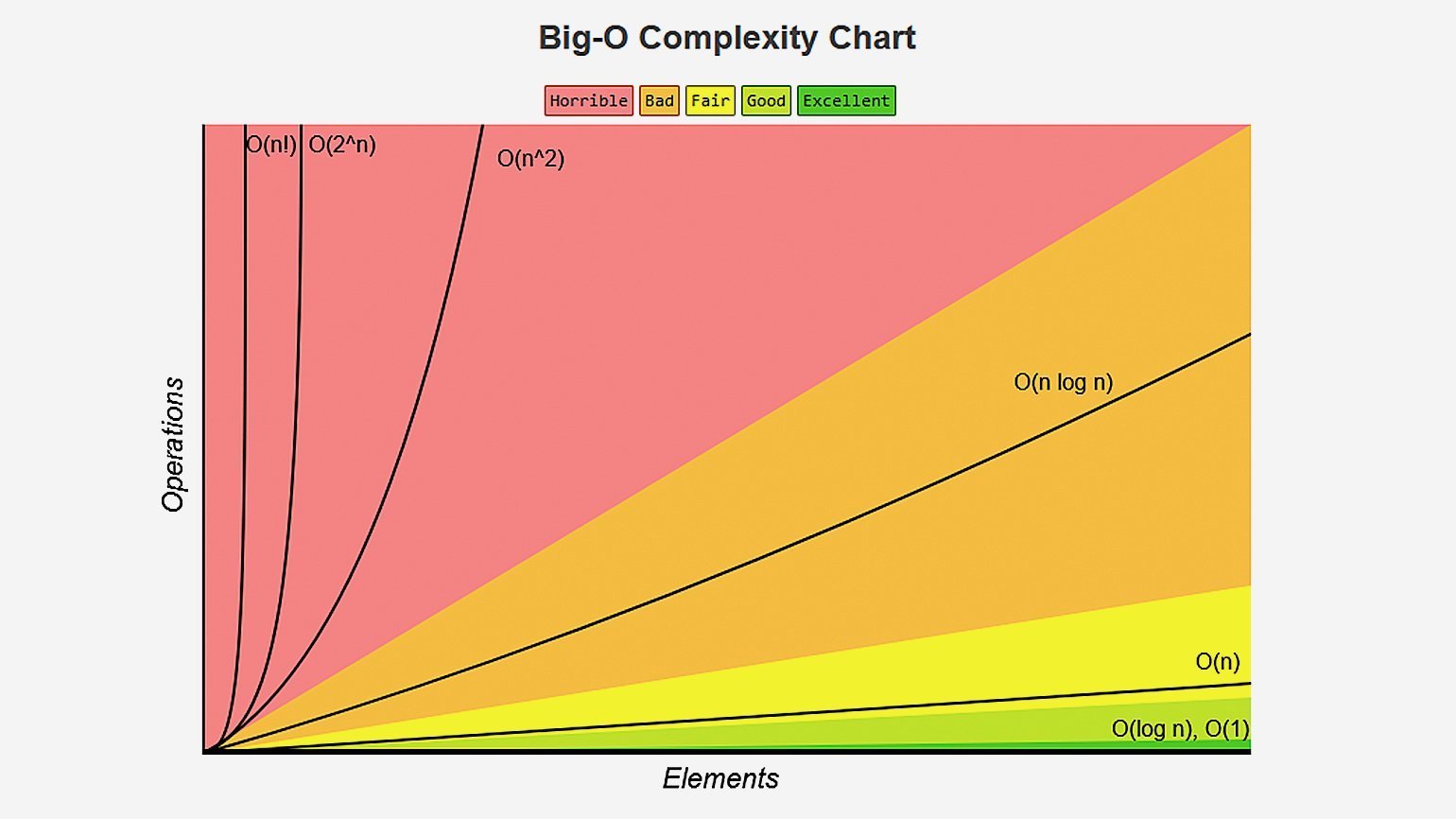
Хоть картинка и наглядная, она плохо передаёт всю бездну, лежащую между функциями. Поэтому я склепал таблицу со значениями времени для разных функций и N. За время одной операции взял 1 наносекунду:
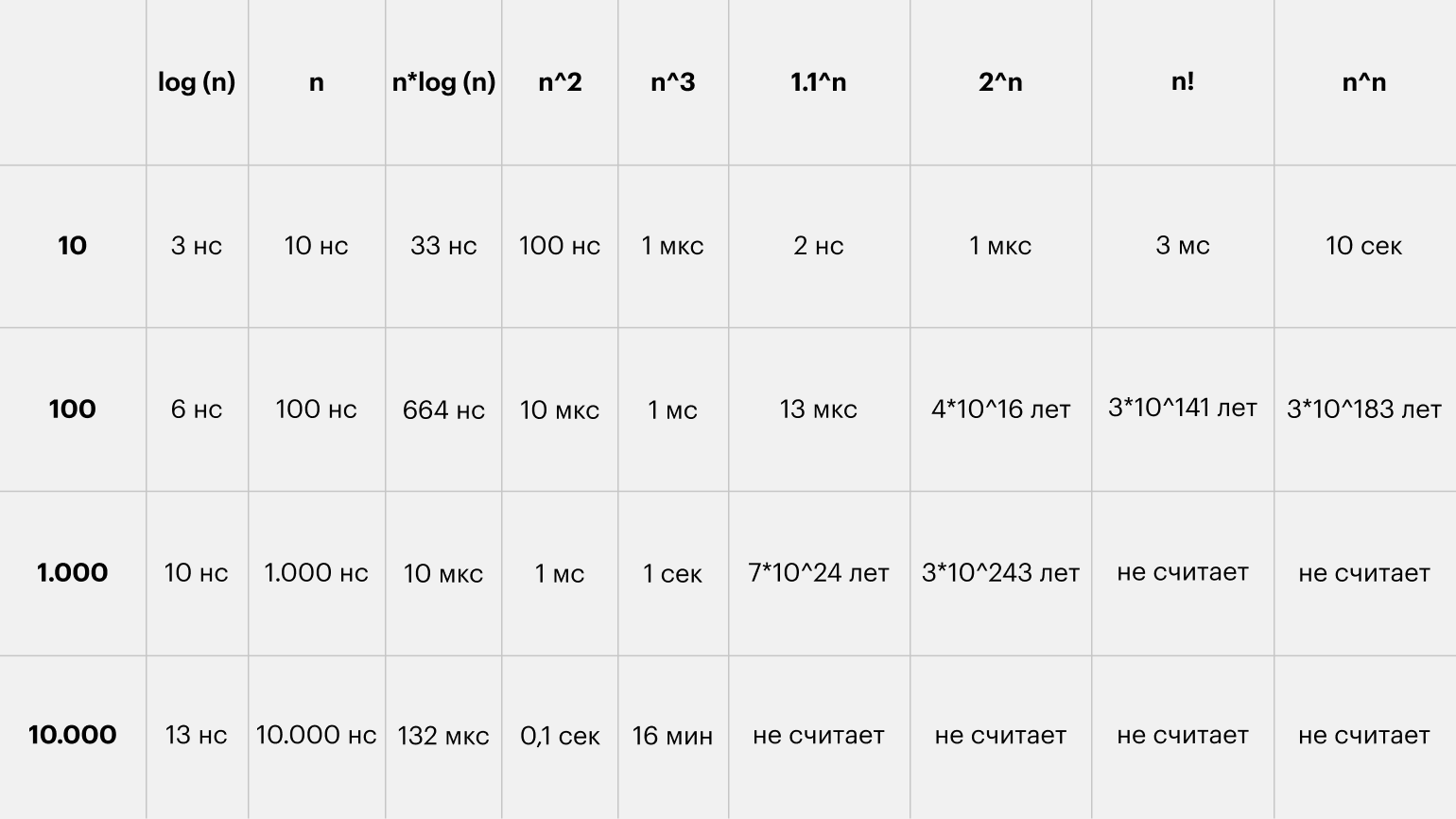
Скрытые константы
В последнем разделе поговорим о скрытых константах. Это хитрая штука, там собака зарыта.
Возьмём умножение матриц. При размерности матрицы n * n наивный алгоритм, который многие знают с начальных курсов универа, «строчка на столбик» имеет кубическую временную сложность O(n^3). Кубическая, зато честная. Без констант и O(10000 * n^3) под капотом. И памяти не ест — только время.
У Валерия есть отдельный тред об умножении матриц.
В некоторых алгоритмах умножения матриц степень n сильно «порезана». Самые «быстрые» из них выдают время около O(n^2,37). Какой персик, правда? Почему бы нам не забыть про «наивный» алгоритм?
Проблема в том, что у таких алгоритмов огромные константы. В пейперах гонятся за более компактной экспонентой, а степени отбрасываются. Я не нашёл внятных значений констант. Даже авторы оригинальных пейперов называют их просто «очень большими».
Давайте от балды возьмём не очень большую константу 100 и сравним n^3 c 100 * n^2,37. Правая функция даёт выигрыш по сравнению с левой для n, начинающихся с 1495. А ведь мы взяли довольно скромную константу. Подозреваю, что на практике они не в пример больше…
В то же время умножение матриц 1495 × 1495 — очень редкий случай. А матрицы миллиард на миллиард точно нигде не встретишь. Да простит меня Император Душнил с «Хабра» за вольное допущение 🙂
Такие алгоритмы называются галактическими, потому что дают выигрыш только на масштабах, нерелевантных для нас. А в программном умножении матриц, если я правильно помню курс алгоритмов и умею читать «Википедию», очень любят алгоритм Штрассена с его O(2,807) и маленькими константами. Но и те, к сожалению, жрут слишком много памяти.
Читайте также:
- Как работают хорошие разработчики: 5 важных принципов
- Как устроена разработка в большом финтехе: при чём тут Scala и за что не любят Java
- «Один разработчик заменяет пять программистов на JavaScript»: для чего нужен Haskell
О практической необходимости определения теоретической сложности алгоритмов Текст научной статьи по специальности «Математика»
СЛОЖНОСТЬ АЛГОРИТМА / КРИТЕРИИ СРАВНЕНИЯ АЛГОРИТМОВ / ПОЛИНОМИАЛЬНЫЕ И ЭКСПОНЕНЦИАЛЬНЫЕ АЛГОРИТМЫ / COMPLEXITY OF ALGORITHM / CRITERIA OF COMPARISON OF ALGORITHMS / POLYNOMIAL AND EXPONENTIAL ALGORITHMS
Аннотация научной статьи по математике, автор научной работы — Самуйлов Сергей Владимирович
В статье рассматривается понятие сложности алгоритмов и необходимость ее определения и анализа на начальных этапах решения поставленной задачи. На примерах показана необходимость сравнения временной и пространственной сложности алгоритмов, а также эффективности их реализации.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по математике , автор научной работы — Самуйлов Сергей Владимирович
Исследование влияния асимметрии на сложность решения задачи коммивояжера методом ветвей и границ
Об использовании алгоритма Литла для решения задачи о коммивояжере при разработке пригородных маршрутов
Алгоритмизация труднорешаемых задач. Часть I. простые примеры и простые эвристики
О временной сложности решения задач распознавания
Исследование решения задачи коммивояжера
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
The article discusses the concept of algorithm complexity and the need of its determination and analysis at the initial stages of the task. The examples show the necessity of comparison of temporal and spatial complexity of algorithms and the effectiveness of their implementation.
Текст научной работы на тему «О практической необходимости определения теоретической сложности алгоритмов»
ЭЛЕКТРОННЫЙ НАУЧНЫЙ ЖУРНАЛ «APRIORI. CЕРИЯ: ЕСТЕСТВЕННЫЕ И ТЕХНИЧЕСКИЕ НАУКИ»
О ПРАКТИЧЕСКОЙ НЕОБХОДИМОСТИ ОПРЕДЕЛЕНИЯ ТЕОРЕТИЧЕСКОЙ СЛОЖНОСТИ АЛГОРИТМОВ
Самуйлов Сергей Владимирович
канд. тех. наук Финансовый университет при Правительстве Российской Федерации (филиал), Пенза
Аннотация. В статье рассматривается понятие сложности алгоритмов и необходимость ее определения и анализа на начальных этапах решения поставленной задачи. На примерах показана необходимость сравнения временной и пространственной сложности алгоритмов, а также эффективности их реализации.
Ключевые слова: сложность алгоритма; критерии сравнения алгоритмов; полиномиальные и экспоненциальные алгоритмы.
ABOUT PRACTICAL NEED OF DETERMINATION OF THEORETICAL COMPLEXITY OF ALGORITHMS
Samuylov Sergey Vladimirovich
сandidate of technical sciences Financial University under the Government of the Russian Federation (branch), Penza
Abstract. The article discusses the concept of algorithm complexity and the need of its determination and analysis at the initial stages of the task. The examples show the necessity of comparison of temporal and spatial complexity of algorithms and the effectiveness of their implementation.
Key words: complexity of algorithm; criteria of comparison of algorithms; polynomial and exponential algorithms.
Для решения большинства задач, как правило, существует много различных алгоритмов. При решении конкретной задачи вопрос выбора наиболее эффективного алгоритма является одним из основных [1].
Под сложностью алгоритма понимается, как правило, время его выполнения и количество требуемой памяти.
Обычно указывают на три причины, обосновывающие необходимость анализа сложности алгоритмов [2].
1. Необходимость получения оценок объема памяти и времени работы, которые потребуются алгоритму для успешной обработки конкретных данных.
2. Хотелось бы иметь некий количественный критерий для сравнения двух алгоритмов, претендующих на решения одной и той же задачи. Это позволит среди множества алгоритмов выбирать для реализации наиболее эффективный.
3. Поиск абсолютного критерия. Когда можно считать решение задачи оптимальным, когда алгоритм настолько хорош, что его значительное улучшение невозможно?
Проиллюстрируем причины необходимости предварительного анализа сложности алгоритмов с помощью простых, но наглядных примеров. Две основные характеристики любого компьютера — быстродействие и доступная память. С каждым годом быстродействие компьютера растет, память увеличивается. Однако и в настоящее время, и через много лет эти параметры, судя по всему, все равно останутся конечными. Следовательно, еще долго будут существовать задачи, в принципе невыполнимые с помощью современного компьютера из-за недостаточной памяти и/или низкого быстродействия.
Как известно, все множество алгоритмов можно разбить на две группы: алгоритмы полиномиальной сложности и алгоритмы экспоненциальной сложности. Следует помнить, что в настоящее время только полиномиальные алгоритмы считаются практически полезными, т.е. ре-
ализуемыми с помощью современных компьютеров, причем полином должен быть небольшой степени. Если же для решения поставленной задачи существуют только экспоненциальные алгоритмы, то даже для небольшого количества исходных данных время реализации алгоритма может быть неприемлемо.
В качестве примера алгоритма экспоненциальной сложности рассмотрим алгоритм решения задачи коммивояжера. Это один из известных примеров таких задач, которые очень легко поставить и промоделировать, но очень сложно решить [3].
Постановка задачи. Есть агент по продаже компьютеров (коммивояжер). На его территории п городов. Известна стоимость переезда из одного города в другой для каждой пары городов. Эта стоимость может быть задана матрицей стоимости С размерности п*п, где оу — стоимость проезда между /-м и у-м городами.
Необходимо найти маршрут минимальной стоимости, начинающийся и оканчивающийся в базовом городе и проходящий по одному разу через все остальные города его территории.
Разработка алгоритма. Перенумеруем п городов целыми числами от 1 до п. Базовому городу приписывается номер п. Обход всех городов назовем туром. Заметим, что каждый тур однозначно соответствует единственной перестановке целых чисел 1, 2, . п-1, и каждой перестановке соответствует единственный тур.
Таким образом, для любой заданной перестановки мы можем легко построить тур по городам и вычислить стоимость этого тура.
Следовательно, можно решить поставленную задачу, образуя все перестановки первых п-1 целых положительных чисел. Для каждой перестановки необходимо строить соответствующий тур и вычислять его стоимость. Обрабатывая все перестановки, запоминаем тур с наименьшей стоимостью.
Анализ сложности. В задаче требуется найти все перестановки первых п-1 положительных целых чисел. Количество таких перестановок (п-1)!. Следовательно, эта часть алгоритма потребует минимум 0[(п-1)!] шагов.
Для каждой перестановки нужно найти соответствующий тур и его стоимость за 0(п) шагов. Поэтому верхняя граница для времени работы всего алгоритма равна 0(п!).
Расчет времени выполнения. Предположим, что на территории коммивояжера 20 городов, то есть п = 20. Пусть каждая перестановка генерируется за один шаг, что является очень большой недооценкой. Пусть быстродействие нашей машины 1 миллиард операций в секунду, т.е. 109 оп./сек.
Наш алгоритм содержит 20! « 21018 операций, которые могут быть выполнены за 21018 / 109 = 2109 секунд. В году 31.536.000 секунд. Тогда наша задача будет решаться чуть более 63 лет.
Пусть быстродействие компьютера выросло с одного миллиарда операций в секунду до одного триллиона. Тогда этот же алгоритм будет работать 21018 / 1012 = 2106 секунд. Один день состоит из 86.400 секунд. В этом случае наша задача будет решаться 23 дня. И первое, и второе время выполнения алгоритма, несмотря на небольшое число городов (п = 20), не может быть удовлетворительным.
Рассмотренный выше пример демонстрирует необходимость анализа сложности алгоритма еще до его программирования и выполнения. Это избавит пользователя от попытки выполнения на ЭВМ алгоритмов, которые не могут быть решены за приемлемое время.
Вторая из приведенных выше причин, требующая предварительного анализа сложности алгоритмов, свидетельствует о необходимости иметь количественный критерий для сравнения двух или более алгоритмов, претендующих на решение одной и той же задачи [4].
Как уже упоминалось, для решения задачи можно использовать, как правило, несколько различных алгоритмов. Зачастую программисты, не утруждая себя теоретической оценкой сложности решения поставленной задачи, не выполнив анализ и сравнение приемлемых для решения задачи алгоритмов, реализуют либо наиболее очевидный с их точки зрения алгоритм, либо наиболее простой в реализации, либо наиболее известный.
Результатом такого подхода к программированию может быть как неэффективно работающая программа, так и, в худшем случае, напрасно потраченное время и средства на попытку реализации алгоритма, который изначально не должен был быть выбран для реализации.
Проиллюстрируем вышеизложенное на следующем примере. Пусть необходимо решить следующую задачу — определить для любого целого N (N > 1) его наибольший делитель, отличный от N. Один из наиболее очевидных алгоритмов решения этой задачи основывается на том факте, что для любого числа N его наибольший делитель находится в интервале от (N-1) до 1. Вследствие этого алгоритм заключается в следующем. Пусть некоторая переменная K последовательно принимает значения от (N-1) до 1. На каждой итерации цикла проверяем, если K делит без остатка переменную N, то наибольший делитель найден, алгоритм заканчивается. В случае если N простое число, цикл закончится при K = 1. Назовем описанный выше алгоритм — алгоритм А. Этот алгоритм будет состоять из следующих шагов.
2. Пока (N mod K) Ф 0 повторять K = K — 1
3. Печать «Наибольший делитель = », K.
В алгоритме операция mod возвращает остаток, полученный при выполнении целочисленного деления.
Казалось бы, мы рассмотрели наиболее логичный и простой вариант решения поставленной задачи. Однако существуют и другие подхо-
ды к ее решению. Один из альтернативных вариантов основан на том, что разыскиваемый результат есть N / R, где R — наименьший делитель N (R > 1). Если N простое число, то R = 1, но если N непростое, то его
наименьший делитель находится в интервале от 2 до 4n .
Тогда алгоритм решения задачи может быть следующим. Некоторая переменная R последовательно принимает значения от 2 до 4n . На каждой итерации цикла проверяем, если R делит без остатка переменную N, то наименьший делитель найден. Вычисляем и выводим наибольший делитель, и алгоритм заканчивается. Назовем описанный выше алгоритм — алгоритм В. Этот алгоритм будет состоять из следующих шагов
3. Если (N mod R) = 0, то Печать «НД=», N / R, иначе Печать «НД=», 1. Чтобы сравнить время выполнения алгоритма А и алгоритма В,
отметим, что оба они состоят из трех шагов и имеют вид:
2. Пока повторять О2
где О1; О2 и О3 — некоторые операторы.
Пусть t1; t2 и t3 время выполнения операторов О1; О2 и О3 соответственно, причем t2 — время выполнения одной итерации цикла. Тогда время выполнения и одного, и другого алгоритма определяется как
где m — число повторений цикла. Так как t1; t2, t3 — константы, то выражение можно записать как
где P и Q — константы, различные для алгоритма А и алгоритма В.
Кроме того, эти алгоритмы отличаются и числом повторений цикла (значением переменной m). В алгоритме А максимальное число итераций цикла mА вычисляется по формуле
Тогда максимальная временная сложность алгоритма А определяется как
где PA и Qa — константы, а для алгоритма В эта величина равна
где PB и QB — другие константы.
Практическая сложность этих алгоритмов определяется константами PA, Qa, Pb и QB и зависит от конкретной ЭВМ, в частности, от времени выполнения ее команд.
Гораздо более полезна теоретическая сложность этих алгоритмов. Когда n велико, этот параметр становится определяющим для сложности как в алгоритме А, так и в алгоритме В. Из вышеизложенного можно следует, что сложность алгоритма А определяется как o(n),
сложность алгоритма В — o(y[N). Отсюда можно сделать вывод, что алгоритм В значительно эффективней алгоритма А.
Определение теоретической сложности алгоритмов в некоторых случаях позволяет сделать однозначный выбор одного алгоритма из нескольких альтернативных. Для понимания того, насколько же один алгоритм эффективнее другого при заданных исходных данных, рассмотрим практическую сложность этих алгоритмов. Для сравнения практической сложности алгоритмов А и В была выполнена их реализация в среде программирования Delphi на языке программирования Pascal.
Для алгоритмов А и В были сняты характеристики их работы. Для простого числа 914 748 389 алгоритм А работал 13120 тиков (« 13 секунд), а алгоритм В — 1,25 тика.
Для числа 1914748439, наибольший делитель, равный 107347, алгоритм А искал 28455 тиков (« 28 секунд), а алгоритм В — 0,78 тика.
Проанализируем рассмотренный выше пример. Как известно, алгоритмы, претендующие на решения одной и той же задачи, можно сравнить по требуемым вычислительным ресурсам, т.е. их временной и пространственной эффективности, а также по простоте реализации. Временная эффективность программы определяется временем, необходимым для ее выполнения, пространственная — количеством необходимой памяти.
Алгоритмы А и В имеют одинаковую структуру, т.е. состоят из оператора присваивания, оператора цикла и оператора вывода, следовательно, по простоте реализации эти алгоритмы не отличаются друг от друга. Кроме того, они используют по две вспомогательные переменные. Из этого можно сделать вывод, что пространственная эффективность этих алгоритмов также одинакова. Очень часто, основываясь на этом, автоматически делается вывод об отсутствии различий между анализируемыми алгоритмами. Между тем, как показал рассмотренный выше пример, время выполнения внешне очень похожих алгоритмов может отличаться на несколько порядков.
Рассмотренные в статье примеры демонстрирует необходимость поиска для решения поставленной задачи именно эффективного алгоритма, а не наиболее очевидного или простого в программировании. Причем анализ эффективности обязательно должен учитывать и временную, и пространственную эффективность, и эффективность реализации.
Список использованных источников
1. Самуйлов С.В. Методика сравнительного анализа алгоритмов на примере алгоритмов последовательного поиска // Концепт. 2014. № 9. С. 46-50.
2. 2 Казакова И.А., Самуйлов С.В. Структуры данных. Учебное пособие. Пенза, 2011.
3. Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. Алгоритмы: построение и анализ. М.: «Вильямс», 2005.
4. Самуйлов С.В., Казакова И.А. О критерии естественности поведения в оценке алгоритмов внутренней сортировки // Научное обозрение. 2014. № 10-1. С. 98-104.
Оценка сложности алгоритмов, или Что такое О(log n)
Если вы всё ещё не понимаете, что такое вычислительная сложность алгоритмов, и ждете простое и понятное объяснение, — эта статья для вас.
Наверняка вы не раз сталкивались с обозначениями вроде O(log n) или слышали фразы типа «логарифмическая вычислительная сложность» в адрес каких-либо алгоритмов. И если вы хотите стать хорошим программистом, но так и не понимаете, что это значит, — данная статья для вас.
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n . Тогда говорят, что временная сложность этого алгоритма равна О(n3) , т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n) .
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n , т. е. n2 .
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1) . Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Наглядно
Время выполнения алгоритма с определённой сложностью в зависимости от размера входных данных при скорости 106 операций в секунду:
Тут можно посмотреть сложность основных алгоритмов сортировки и работы с данными.
Если хочется подробнее и сложнее, заглядывайте в нашу статью из серии «Алгоритмы и структуры данных для начинающих».