О методах обучения
многослойных нейронных сетей
прямого распространения.
В этой статье мы поговорим о методах обучения классификатора на основе искусственных нейронных сетей прямого распространения, т.е. сетей не имеющих обратных связей.
1. Введение.
Многие практические задачи сводятся к выбору объектов из их множества. Например технический контроль различных устройств — выявление брака и диагностика неисправностей. Этот выбор можно делать случайным образом, а можно сформулировать некоторые критерии (признаки) и правила отбора на основе этих признаков. В качестве признаков могут выступать самые разные свойства рассматриваемой предметной области: содержание кислорода, цвет поверхности, длинна стебля, частота повторения слова в тексте. Таким образом, каждому объекту в рамках задачи ставится в соответствие упорядоченный набор определённых величин или вектор-признак.
Построив формальное пространство признаков мы можем применить математические методы классификации для разделения множества объектов на части или классы.
Формально это можно записать следующим образом. $$ f : O \rightarrow X $$ $$ h : X \rightarrow C $$ где
$O$ — множество объектов задачи,
$f$ — функция отбора признаков (feature extractor),
$X\ni(x_1\ldots,x_n)$ — пространство признаков размерности $n$,
$C$ — множество классов,
$h$ — функция выбора (классификатор).
Далее мы рассмотрим задачу обучения классификатора.
2. Стратегии обучения классификатора.
Классификатор $h$ можно строить разными способами, например его параметры можно попробовать подобрать вручную в виде пороговых правил типа $(x_1 \gt 0) \land (x_2 \lt 4) \lor (x_3 \neq 0.5) $, однако при большом количестве объектов и их признаков такое решение трудно реализовать. Поэтому для конструирования классификаторов обычно применяют более сложные методы.
Настройка определённым способом параметров классификатора на основе набора данных называют обучением классификатора .
Для обучения классификатора нам понадобится размеченный (учебный) набор данных, т.е. множество пар $(X,C)_L$. Классификатору предъявляются по очереди учебные примеры из $X$, ответ классификатора $Y$ сравнивается с правильным ответом $C$ и по результатам сравнения корректируются параметры классификатора. Такая схема настройки классификатора называется «обучение с учителем» , более строго это выглядит так.
- обрабатываем учебный набор
- определяем ошибки
- если результат удовлетворительный то конец работы
- корректируем параметры
- переход на п.1
При таком подходе может проявится эффект переобучения (overfitting), когда классификатор хорошо обрабатывает только учебное множество, но на остальных объектах результаты значительно хуже (плохое обобщение).
- Учебный набор применяют для корректировки параметров,
- контрольный — для текущей оценки состояния,
- тестовый — для оценки итогового результата обучения.
- Полная (full batch) — на каждом цикле прогоняется всё учебное множество.
- обрабатываем учебный набор
- определяем ошибки
- корректируем параметры
- проверка на контрольном множестве
- если результат удовлетворительный то выполняем итоговый тест и конец работы
- переход на п.1
- Частичная (mini batch) — на каждом цикле используется случайно выбранное подмножество учебного набора
- случайным образом выбрать подмножество учебного набора
- обрабатываем эту часть учебного набора
- определяем ошибки
- корректируем параметры
- проверка на контрольном множестве
- если результат удовлетворительный то выполняем итоговый тест и конец работы
- переход на п.1
- Стохастическая (stochastic) — на каждом цикле случайно выбирается один пример,
- случайным образом выбрать пример из учебного набора
- обработать этот пример
- определяем ошибку
- сохраняем текущее состояние параметров
- определяем новые параметры
- проверка на контрольном множестве
- если результат удовлетворительный то выполняем итоговый тест и конец работы
- если ошибка выросла
то с вероятностью пропорциональной величине прироста ошибки
выполняется откат к предыдущему состоянию параметров - переход на п.1
В следующем разделе мы разберём её подробней.
3. Многослойная нейронная сеть прямого распространения.
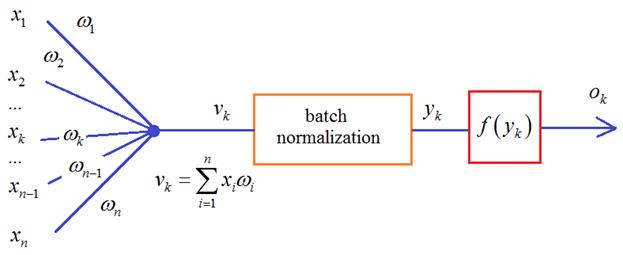
Искусственная нейронная сеть (рис.1) состоит из элементов называемых математическими нейронами . Математический нейрон (рис.2) имеет несколько входов и один выход, формально это можно описать следующим образом (\ref).
\begin y=f(s)\ ;\ s=\sum_i w_i x_i + w_0 \label \end
На вход нейрона поступают сигналы $x_1,\ldots x_n$, каждый вход имеет вес $w_i$, при этом $x_0\equiv 1$ и $w_0$ называют сдвигом . Линейная комбинация входов $s$ называется состоянием нейрона .
| Рис.1: схема многослойной нейронной сети прямого распространения. |
Рис.2: схема искусственного нейрона. |
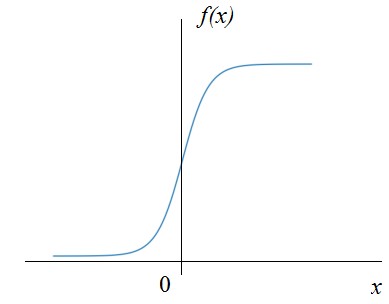
Функция $f$ называется функцией активации нейрона. Она может иметь разный вид, приведём примеры.
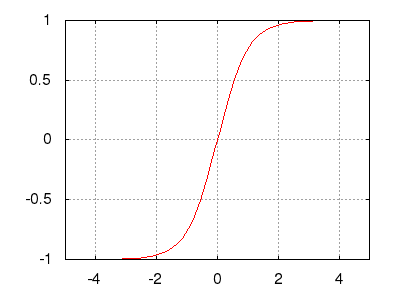 Рис.: гиперболический тангенс (сигмоид) $\ y=\tanh(s)=\frac$ |
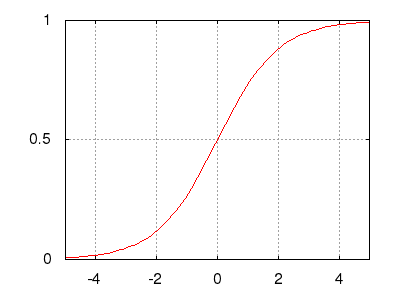 Рис.: экспоненциальный сигмоид $\ y=\frac=\frac$ |
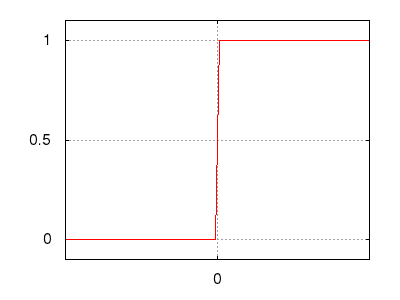 Рис.: пороговая функция $\ y=[ s\gt0 ]$ |
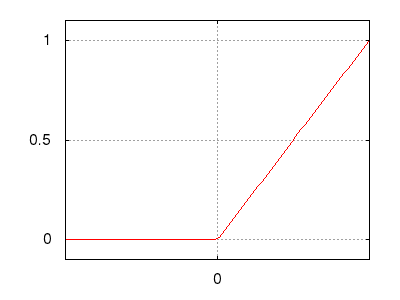 Рис.: rectified linear unit (ReLU) $\ y=max(0,s)$ |
Нейроны, составляющие сеть, разбиты на группы называемые слоями . В сетях прямого распространения сигнал проходит послойно в одном направлении — от входа к выходу. Нейроны одного слоя активируются одновременно, каждый нейрон может иметь связи с нейронами следующего слоя, связь нейрона на самого себя (петли) и/или связи с предыдущими слоями (обратные связи) в этой схеме отсутствуют.
Первый слой называется входным или распределительным , нейроны этого слоя не изменяют сигнал и просто распределяют его нейронам второго слоя. Второй и следующие за ним слои называются обрабатывающими и выполняют работу по преобразованию входного сигнала.
Кроме функций активации нейронов, описанных выше, можно использовать совместную активацию нейронов слоя, например функция активации softmax (экспоненциальная нормализация), её обычно используют для выходного слоя. $$ (y_1,\ldots,y_m) = softmax(s_1,\ldots,s_m) = \frac <\sum\limits_j \exp(s_j)>$$
Также стоит упомянуть стохастическую модель, здесь функция активации $f(s)$ принимает значение $1$ с вероятностью $p=1/(1+\exp(-s))$ или соответственно значение $0$ с вероятностью $1-p$.
Далее мы рассмотрим методы обучения многослойной нейронной сети.
4. Функция потери и настройка весов нейронной сети.
Обучение нейронной сети, описанной выше, это настройка весов $W$ в соответствии с учебным множеством $(X,C)$ и важным элементом этой процедуры является способ оценки работы сети или функция потери (loss function) $E$. $$ h : X\times W \rightarrow Y $$ $$ E : Y\times C \rightarrow \mathbb
$h$ — классификатор,
$W$ — веса сети,
$X\ni(x_1\ldots,x_n)$ — пространство признаков размерности $n$,
$E$ — функция потери,
$Y$ — выход классификатора,
$C$ — множество правильных ответов (номеров классов).
В качестве функции потери для нейронных сетей обычно используется среднеквадратичная ошибка (MSQE) $$ E=\frac\sum\limits_j (y_j-c_j)^2 $$ где $y_j$ — выход сети номер $j$, $c_j$ — правильный ответ для выхода $j$
Но MSQE это не единственный вариант, для сетей с выходным слоем softmax обычно используют среднюю кросс-энтропию по всем учебным примерам. $$ E= \frac\sum\limits_^k\left(-log(p_i)\right); $$ где $k$ — количество примеров, $p_i$ — выданная классификатором вероятность принадлежности примера $X_i$ к своему классу $C_i$.
Введя функцию потери $E$, мы теперь можем формально поставить задачу обучения классификатора $h$ следующим образом — процедура обучения нейронной сети это минимизация функции потери в пространстве весов. \begin \min_W E(h(X,W),C) \label \end
Во второй части этой статьи мы займёмся решением этой задачи.
Список литературы
- Е.С.Борисов Основные модели и методы теории искусственных нейронных сетей. — http://mechanoid.kiev.ua
- Осовский С. Нейронные сети для обработки информации. — М.: Финансы и статистика, 2002.
Batch Normalization (батч-нормализация) что это такое?
Вам что-нибудь говорит термин внутренний ковариационный сдвиг:
internal covariance shift
Звучит очень умно, не так ли? И не удивительно. Это понятие в 2015-м году ввели два сотрудника корпорации Google:
Sergey Ioffe и Christian Szegedy (Иоффе и Сегеди)
решая проблему ускорения процесса обучения НС. И мы сейчас посмотрим, что же они предложили, как это работает и, наконец, что же это за ковариационный сдвиг. Как раз с последнего я и начну.
Давайте предположим, что мы обучаем НС распознавать машины (неважно какие, главное чтобы сеть на выходе выдавала признак: машина или не машина). Но, при обучении мы используем автомобили только черного цвета. После этого, сеть переходит в режим эксплуатации и ей предъявляются машины уже разных цветов:
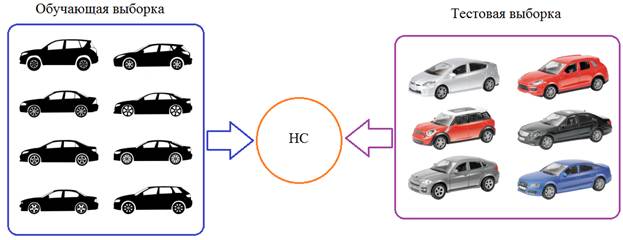
Как вы понимаете, это не лучшим образом скажется на качестве ее работы. Так вот, на языке математики этот эффект можно выразить так. Начальное распределение цветов (пусть это будут градации серого) обучающей выборки можно описать с помощью вот такой плотности распределения вероятностей (зеленый график):
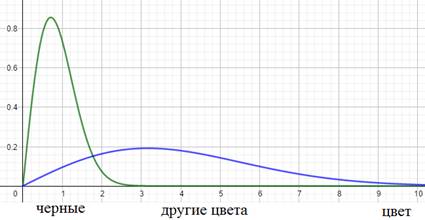
А распределение всего множества цветов машин, встречающихся в тестовой выборке в виде синего графика. Как видите эти графики имеют различные МО и дисперсии. Эта разница статистических характеристик и приводит к ковариационному сдвигу. И теперь мы понимаем: если такой сдвиг имеет место быть, то это негативно сказывается на работе НС.
Но это пример внешнего ковариационного сдвига. Его легко исправить, поместив в обучающую выборку нужное количество машин с разными цветами. Есть еще внутренний ковариационный сдвиг – это когда статистическая картина меняется внутри сети от слоя к слою:
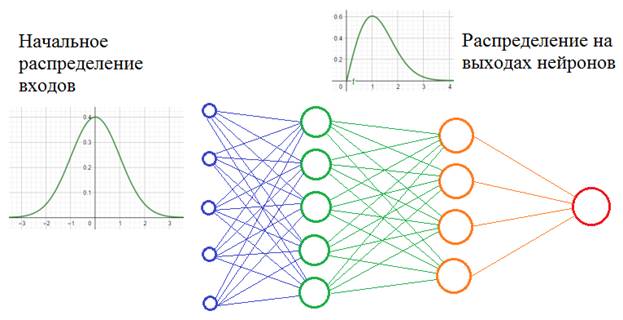
Само по себе такое изменение статистик не несет каких-либо проблем. Проблемы проявляются в процессе обучения, когда при изменении весов связей предыдущего слоя статистическое распределение выходных значений нейронов текущего слоя становится заметно другим. И этот измененный сигнал идет на вход следующего слоя. Это похоже на то, словно на вход скрытого слоя поступают то машины черного цвета, то машины красного цвета или какого другого. То есть, весовые коэффициенты в пределах мини-батча только адаптировались к черным автомобилям, как в следующем мини-батче им приходится адаптироваться к другому распределению – красным машинам и так постоянно. В ряде случаев это может существенно снижать скорость обучения и, кроме того, для адаптации в таких условиях приходится устанавливать малое значение шага сходимости, чтобы весовые коэффициенты имели возможность подстраиваться под разные статистические распределения.
Это описание проблемы, которую, как раз, и выявили сотрудники Гугла, изучая особенности обучения многослойных НС. Решение кажется здесь очевидным: если проблема в изменении статистических характеристик распределения на выходах нейронов, то давайте их стандартизировать, нормализовывать – приводить к единому виду. Именно это и делается при помощи предложенного алгоритма
Осталось выяснить: какие характеристики и как следует нормировать. Из теории вероятностей мы знаем, что самые значимые из них – первые две: МО и дисперсия. Так вот, в алгоритме batch normalization их приводят к значениям 0 и 1, то есть, формируют распределение с нулевым МО и единичной дисперсией. Чуть позже я подробнее поясню как это делается, а пока ответим на второй вопрос: для каких величин и в какой момент производится эта нормировка? Разработчики этого метода рекомендовали располагать нормировку для величин перед функцией активации:
Но сейчас уже имеются результаты исследований, которые показывают, что этот блок может давать хорошие результаты и после функции активации.
Что же из себя представляет batch normalization и где тут статистики? Давайте вспомним, что НС обучается пакетами наблюдений – батчами. И для каждого наблюдения из batch на входе каждого нейрона получается свое значение суммы:
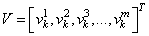
Здесь m – это размер пакета, число наблюдений в батче. Так вот статистики вычисляются для величин V в пределах одного batch:
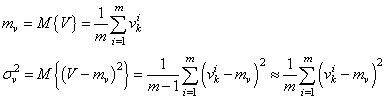
И, далее, чтобы вектор V имел нулевое среднее и единичную дисперсию, каждое значение преобразовывают по очевидной формуле:
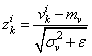
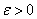
здесь — небольшое положительное число, исключающее деление на ноль, если дисперсия будет близка к нулевым значениям. В итоге, вектор
будет иметь нулевое МО и почти единичную дисперсию. Но этого недостаточно. Если оставить как есть, то будут теряться естественные статистические характеристики наблюдений между батчами: небольшие изменения в средних значениях и дисперсиях, т.е. будет уменьшена репрезентативность выборки:
Кроме того, сигмоидальная функция активации вблизи нуля имеет практически линейную зависимость, а значит, простая нормировка значений x лишит НС ее нелинейного характера, что приведет к ухудшению ее работы:
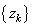
Поэтому нормированные величины дополнительно масштабируются и смещаются в соответствии с формулой:

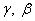
Параметры с начальными значениями 1 и 0 также подбираются в процессе обучения НС с помощью того же алгоритма градиентного спуска. То есть, у сети появляются дополнительные настраиваемые переменные, помимо весовых коэффициентов.
Далее, величина подается на вход функции активации и формируется выходное значение нейрона. Вот так работает алгоритм batch normalization, который дает следующие возможные эффекты:
- ускорение сходимости к модели обучающей выборки;
- бОльшая независимость обучения каждого слоя нейронов;
- возможность увеличения шага обучения;
- в некоторой степени предотвращает эффект переобучения;
- меньшая чувствительность к начальной инициализации весовых коэффициентов.
Но это лишь возможные эффекты – они могут и не проявиться или даже, наоборот, применение этого алгоритма ухудшит обучаемость НС. Рекомендация здесь такая:
Изначально строить нейронные сети без batch normalization (или dropout) и если наблюдается медленное обучение или эффект переобучения, то можно попробовать добавить batch normalization или dropout, но не оба вместе.
Реализация batch normalization в Keras
Давайте теперь посмотрим как можно реализовать данный алгоритм в пакете Keras. Для этого существует класс специального слоя, который так и называется: keras.layers.BatchNormalization Он применяется к выходам предыдущего слоя, после которого указан в модели НС, например:
model = keras.Sequential([ Flatten(input_shape=(28, 28, 1)), Dense(300, activation='relu'), BatchNormalization(), Dense(10, activation='softmax') ])
Здесь нормализация применяется к выходам скрытого слоя, состоящего из 300 нейронов. Правда в такой простой НС нормализация, скорее, негативно сказывается на обучении. Этот метод обычно помогает при большом числе слоев, то есть, при deep learning.
Нейросеть: в чём разница между Batch и Epoch
Стохастический градиентный спуск — это алгоритм обучения, который имеет ряд гиперпараметров.
Два гиперпараметра, которые часто путают новичков, — это размер пакета и количество эпох. Они оба являются целочисленными значениями и, кажется, отражают одно и то же.
Подчеркнём разницу между партиями и эпохами в стохастическом градиентном спуске.
В чем разница между Партией и Эпохой в Нейронной сети?
Стохастический Градиентный спуск
Стохастический градиентный спуск, или сокращенно SGD, — это алгоритм оптимизации, используемый для обучения алгоритмам машинного обучения, в первую очередь искусственным нейронным сетям, используемым в глубоком обучении.
Задача алгоритма состоит в том, чтобы найти набор внутренних параметров модели, которые хорошо соответствуют некоторым показателям производительности, таким как логарифмические потери или среднеквадратичная ошибка.
Оптимизация — это тип процесса поиска, и вы можете рассматривать этот поиск как обучение. Алгоритм оптимизации называется “градиентный спуск“, где “градиент” относится к вычислению градиента ошибки или наклона ошибки, а “спуск” относится к движению вниз по этому склону к некоторому минимальному уровню ошибки.
Алгоритм является итеративным. Это означает, что процесс поиска выполняется в несколько дискретных этапов, каждый из которых, как мы надеемся, немного улучшает параметры модели.
Каждый шаг включает использование модели с текущим набором внутренних параметров для прогнозирования некоторых выборок, сравнение прогнозов с реальными ожидаемыми результатами, вычисление ошибки и использование ошибки для обновления внутренних параметров модели.
Эта процедура обновления отличается для разных алгоритмов, но в случае искусственных нейронных сетей используется алгоритм обновления обратного распространения.
Прежде чем мы погрузимся в серии и эпохи, давайте посмотрим, что мы подразумеваем под образцом.
Узнайте больше о градиентном спуске здесь:
Градиентный Спуск Для Машинного Обучения
Что такое Образец?
Образец — это одна строка данных.
Он содержит входные данные, которые вводятся в алгоритм, и выходные данные, которые используются для сравнения с прогнозом и вычисления ошибки.
Обучающий набор данных состоит из множества строк данных, например, множества выборок. Образец также может называться экземпляром, наблюдением, входным вектором или вектором признаков.
Теперь, когда мы знаем, что такое образец, давайте определим партию.
Что такое Партия?
Размер пакета — это гиперпараметр, который определяет количество образцов, которые необходимо обработать перед обновлением внутренних параметров модели.
Подумайте о пакете как о цикле, повторяющем одну или несколько выборок и делающем прогнозы. В конце пакета прогнозы сравниваются с ожидаемыми выходными переменными и вычисляется ошибка. Исходя из этой ошибки, алгоритм обновления используется для улучшения модели, например, для перемещения вниз по градиенту ошибки.
Набор обучающих данных может быть разделен на один или несколько пакетов.
Когда все обучающие выборки используются для создания одного пакета, алгоритм обучения называется пакетным градиентным спуском. Когда пакет имеет размер одной выборки, алгоритм обучения называется стохастическим градиентным спуском. Когда размер пакета больше одной выборки и меньше размера обучающего набора данных, алгоритм обучения называется мини-пакетным градиентным спуском.
Пакетный Градиентный Спуск. Размер пакета = Размер обучающего набора
Стохастический Градиентный Спуск. Размер партии = 1
Мини-Пакетный градиентный спуск. 1
В случае градиентного спуска мини-партий популярные размеры партий включают 32, 64 и 128 образцов. Вы можете увидеть эти значения, используемые в моделях, в литературе и в учебных пособиях.
Что делать, если набор данных не делится равномерно по размеру пакета?
Это может часто происходить и происходит при обучении модели. Это просто означает, что в последней партии образцов меньше, чем в других партиях.
Кроме того, вы можете удалить некоторые образцы из набора данных или изменить размер пакета таким образом, чтобы количество образцов в наборе данных делилось равномерно на размер пакета.
Для получения дополнительной информации о различиях между этими вариантами градиентного спуска см. Сообщение:
Краткое введение в Градиентный спуск Мини-пакетов и Как настроить размер пакета
Для получения дополнительной информации о влиянии размера пакета на процесс обучения см. Сообщение:
Как контролировать скорость и стабильность обучения нейронных сетей Размер пакета
Пакет включает в себя обновление модели с использованием образцов; далее давайте рассмотрим эпоху.
Что такое Эпоха?
Количество эпох — это гиперпараметр, который определяет, сколько раз алгоритм обучения будет работать со всем набором обучающих данных.
Одна эпоха означает, что у каждой выборки в обучающем наборе данных была возможность обновить внутренние параметры модели. Эпоха состоит из одного или нескольких пакетов. Например, как указано выше, эпоха, имеющая один пакет, называется алгоритмом обучения пакетному градиентному спуску.
Вы можете придумать цикл для определения количества эпох, в течение которых каждый цикл выполняется по набору обучающих данных. В этом цикле for есть еще один вложенный цикл for, который повторяется над каждой партией образцов, где одна партия имеет указанное количество образцов “размера партии».
Число эпох традиционно велико, часто сотни или тысячи, что позволяет алгоритму обучения работать до тех пор, пока ошибка модели не будет достаточно сведена к минимуму. Вы можете увидеть примеры количества эпох в литературе и в учебных пособиях, установленных на 10, 100, 500, 1000 и более.
Обычно создаются линейные графики, которые показывают эпохи вдоль оси x как время, а также ошибки или навыки модели по оси y. Эти графики иногда называют кривыми обучения. Эти графики могут помочь определить, является ли модель чрезмерно изученной, недостаточно изученной или подходящей для обучающего набора данных.
Для получения дополнительной информации о диагностике с помощью кривых обучения в сетях LSTM см. Сообщение:
Мягкое введение в кривые обучения для диагностики производительности модели
В случае, если это все еще неясно, давайте рассмотрим различия между партиями и эпохами.
В чем разница между Партией и Эпохой?
Размер партии — это количество образцов, обработанных до обновления модели.
Количество эпох — это количество полных проходов через обучающий набор данных.
Размер пакета должен быть больше или равен единице и меньше или равен количеству выборок в обучающем наборе данных.
Количество эпох может быть задано целочисленным значением от единицы до бесконечности. Вы можете запускать алгоритм так долго, как вам нравится, и даже останавливать его, используя другие критерии, помимо фиксированного числа эпох, такие как изменение (или отсутствие изменений) ошибки модели с течением времени.
Они оба являются целочисленными значениями и оба являются гипер-параметрами для алгоритма обучения, например, параметрами процесса обучения, а не параметрами внутренней модели, найденными в процессе обучения.
Вы должны указать размер пакета и количество эпох для алгоритма обучения.
Нет никаких волшебных правил для настройки этих параметров. Вы должны попробовать разные значения и посмотреть, что лучше всего подходит для вашей проблемы.
Отработанный Пример
Наконец, давайте конкретизируем это на небольшом примере.
Предположим, у вас есть набор данных с 200 образцами (строками данных), и вы выбираете размер пакета от 5 до 1000 эпох.
Это означает, что набор данных будет разделен на 40 пакетов, в каждом из которых будет по пять образцов. Веса моделей будут обновляться после каждой партии из пяти образцов.
Это также означает, что одна эпоха будет включать 40 пакетов или 40 обновлений модели.
С 1000 эпохами модель будет подвергнута воздействию или пройдет через весь набор данных 1000 раз. Это в общей сложности 40 000 партий за весь учебный процесс.
Дальнейшее Чтение
В этом разделе содержится больше ресурсов по этой теме, если вы хотите углубиться в нее.
Градиентный Спуск Для Машинного Обучения
Как контролировать скорость и стабильность обучения нейронных сетей Размер пакета
Краткое введение в Градиентный спуск Мини-пакетов и Как настроить размер пакета
Мягкое введение в кривые обучения для диагностики производительности модели
Стохастический градиентный спуск в Википедии
Обратное распространение в Википедии
В этом посте мы показали разницу между партиями и эпохами в стохастическом градиентном спуске.
В частности, вы узнали:
Стохастический градиентный спуск — это итеративный алгоритм обучения, который использует обучающий набор данных для обновления модели.
Размер пакета — это гиперпараметр градиентного спуска, который управляет количеством обучающих выборок для обработки до обновления внутренних параметров модели.
Количество эпох — это гиперпараметр градиентного спуска, который управляет количеством полных проходов через обучающий набор данных.
У вас есть какие-нибудь вопросы?
Вот самые популярные комментарии:
Меняется ли наполнение пакетов от эпохи к эпохе?
Да. Образцы перемешиваются в конце каждой эпохи, и партии в разные эпохи различаются с точки зрения содержащихся в них образцов.
Если вы создаете модель прогнозирования временных рядов (скажем, что-то со слоем lstm), будут ли пакетные наблюдения обучающего набора храниться в “кусках” (то есть группы времени не будут разбиты, и, следовательно, основной шаблон нарушен)? Это имеет значение, верно?
Вы можете оценить это, перетасовав образцы, а не перетасовав образцы, поданные в LSTM во время обучения или вывода.
Большое вам спасибо за ваше точное объяснение. Если все выборки перемешиваются в конце каждой эпохи, возможно ли, что мы найдем в наборах данных один образец, который будет оцениваться так много раз, а некоторые могут вообще не оцениваться? Или можно ли сделать так, чтобы один раз оцененный образец не подвергался повторной оценке?
Нет. Каждый образец получает одну возможность, которую можно использовать для обновления модели в каждую эпоху.
У меня есть вопрос, основанный на (ниже выдержка из вашего поста). не могли бы вы назвать/сослаться на другие процедуры, используемые для обновления параметров в случае других алгоритмов.
Каждый шаг включает использование модели с текущим набором внутренних параметров для прогнозирования некоторых выборок, сравнение прогнозов с реальными ожидаемыми результатами, вычисление ошибки и использование ошибки для обновления внутренних параметров модели.
Эта процедура обновления отличается для разных алгоритмов, но в случае искусственных нейронных сетей используется алгоритм обновления обратного распространения.
в современных подходах к обучению deeeep я почти всегда сталкиваюсь с тем, что люди сохраняют свои модели после некоторого количества эпох (или некоторого периода времени), визуализируя какие-то показатели производительности для оценки следующих значений гиперпараметров, после чего они проводят свои эксперименты для следующих эпох. Таким образом, мы можем назвать эту процедуру «мини-эпохальным стохастическим глубоким обучением». Спасибо.
Ответить
Еще раз спасибо за отличный пост в блоге. Для данных временных рядов в LSTM имеет ли смысл когда-либо иметь размер пакета больше одного?
Я искал и искал, и я не мог найти ни одного примера, где размер пакета больше одного, но я также не нашел никого, кто сказал бы, что это не имеет смысла.
Да, если вы хотите, чтобы модель обучалась в нескольких под-последовательностях.
У меня есть несколько сообщений, которые демонстрируют это по расписанию.
спасибо вам за ваше объяснение действительно очень большое спасибо еще раз
Это очень ясно. Спасибо.
Я также вижу «steps_per_epoch» в некоторых случаях, что это значит? Это то же самое, что и партии?
Количество пакетов, которые необходимо извлечь из генератора, чтобы определить эпоху.
Мы любим примеры! Большое вам спасибо!
Привет,
В настоящее время я работаю с Word2Vec. В связи с эпохами и размером партии я все еще не совсем понимаю, что такое образец. Выше вы описали, что образец представляет собой одну строку данных. В своей программе я сначала редактирую свой текстовый файл с помощью SentenceIterator, чтобы получить по одному предложению на строку, а затем использую маркер для получения отдельных слов в этих строках. Является ли образец в Word2Vec словом из набора данных или это строка (содержащая предложение)? Заранее большое вам спасибо ?
Терминология samples/epoch/batch не соответствует word2vec. Вместо этого у вас просто есть обучающий набор данных текста, из которого вы изучаете статистику.
Ответить
Но с помощью программы Word2Vec у вас также есть гиперпараметры Эпох, итераций и размера пакета, которые вы можете установить… Не кажется ли вам, что они также влияют на результаты Word2Vec.
Как я теперь понял, набор, передаваемый как пакет, содержит одно предложение. Однако я удивлен, что количество итераций не меняется, если я изменяю количество эпох и размеры пакетов, но не определяю итерации конкретно. Ты знаешь, как это работает?
Большое вам спасибо за то, что написали простым для понимания способом. Кроме того, попробуйте добавить фотографии, график или схематическое представление для представления вашего текста. Как я видел здесь, вы привели один пример, он делает многие вещи очень ясными. В каком-то предыдущем посте вы также добавили график…
После каждой эпохи точность либо улучшается, либо иногда нет. Например, эпоха 1 достигла точности 94, а эпоха 2 достигла точности 95. После окончания эпохи 1 мы получаем новые веса (т. е. обновленные после последней партии эпохи 1). Означает ли это, что новые веса, используемые в эпоху 2, начинают улучшать его с 94% до 95%? Если да, то является ли это причиной того, что какая-то эпоха получает более низкую точность по сравнению с предыдущей эпохой из-за обобщения весов для всего набора данных? Вот почему мы получаем хорошую точность после прохождения стольких эпох благодаря лучшему обобщению?
Как правило, больше тренировок означает лучшую точность, но не всегда.
Иногда может быть хорошей идеей прекратить тренировки пораньше
Действительно, в последнем примере общее количество мини-пакетов составляет 40 000, но это верно только в том случае, если пакеты выбраны без перетасовки обучающих данных или выбраны с перетасовкой данных, но без повторения. В противном случае, если в течение одной эпохи мини-пакеты создаются путем выбора обучающих данных с повторением, у нас могут быть некоторые точки, которые появляются более одного раза в одну эпоху (они появляются в разных мини-пакетах в одну эпоху), а другие — только один раз. Таким образом, общее количество мини-партий в этом случае может превысить 40 000.
Обычно данные перемешиваются перед каждой эпохой.
Обычно мы не выбираем образцы с заменой, так как это приведет к смещению обучения.
Если у меня есть 1000 обучающих выборок и мой размер пакета =400, то мне нужно удалить 200 выборок
исходя из моих тренировочных данных, мои тренировочные данные всегда должны быть кратны размеру пакета
Нет, образцы будут перемешиваться перед каждой эпохой, тогда вы получите 3 партии, 300, 300 и 200.
Лучше выбрать размер партии, который делит образцы равномерно, если это возможно, например, 100, 200 или 500 в вашем случае.
спасибо за вашу замечательную статью, и у меня есть вопрос
если у меня есть следующие настройки и я использую функцию fit_generator
эпохи =100
данные=1000 изображений
партия = 10
шаг_пер_почты = 20
я знаю, что должен установить значение step_per_epochs = (1000/10)= 100, но если я установлю его равным 20
Означают ли эти настройки, что модель будет обучаться с использованием только части обучающих данных (в каждую эпоху будут использоваться одни и те же 200 изображений (пакет*step_per_epochs)), а не все 1000 изображений?
или он будет использовать первые 200 изображений в наборе данных в первую эпоху, затем следующие 200 изображений во вторую эпоху и так далее (разделит 1000 изображений на каждые 5 эпох), и модель будет обучена 20 раз с использованием всего обучающего набора данных в 100 эпохах
Спасибо
Да, будет использоваться только 200 изображений за эпоху.
Сэр, большое вам спасибо за этот превосходный урок.
Можете ли вы рассказать мне, как запустить модель на аналогичном тестовом наборе данных после обучения модели?
Если бы я создавал свои собственные пользовательские пакеты, скажем, в методе model.fit_generator().
Создаем ли мы новые случайно отобранные партии для каждой эпохи или мы просто создаем партии в __init__ и используем их без каких-либо изменений на протяжении всего обучения?
Каков рекомендуемый способ?
P.S. Если я произвольно отбираю партии в каждую эпоху, я вижу всплески в val_acc, но не уверен, что это из-за этого!
Важно убедиться, что каждая партия является репрезентативной (в разумных пределах) и что каждая эпоха партий в целом отражает проблему.
Если нет, вы будете перемещать веса повсюду или вперед/назад при каждом обновлении, а не обобщать хорошо.
Спасибо вам за ваш ответ.
Я также только что подтвердил, что Keras разделит предоставленный X в мини-пакетах только один раз, прежде чем войти в цикл эпохи.
Сегодня мне в голову пришел один вопрос.
Что происходит при обучении нейронной сети в мини-пакетах, когда метки классов несбалансированы. Должны ли мы расслаивать партии?
Потому что кажется, что мой NN предсказывает только доминирующий класс, что бы я ни делал!
Отличный вопрос. У нас бывают плохие времена!
Иногда эксперты советовали чередовать классы в каждой партии. Иногда расслаиваются. Это может зависеть от проблемы/модели.
Тем не менее, несбалансированные данные — это проблема, независимо от вашей стратегии обновления. Передискретизация обучающего набора — отличное решение.
Я обязательно взгляну на эту книгу.
Кстати, я на самом деле занимаюсь рейтинговым бизнесом. Так что у меня очень мало 1-го и 2-го ранга, но много 3-го и выше, где-то как (10%, 10%, 80%) соответственно.
Что я сделал, так это взглянул на проблему с другой точки зрения и преобразовал свой несбалансированный многоклассовый набор данных в уравненный двоичный набор данных.
У меня есть вопрос – Если я правильно понял, веса и смещения обновляются после выполнения пакета, поэтому любые изменения после запуска пакета применяются к следующему пакету? И так продолжается и дальше.
Сейчас я нахожусь в середине изучения практического машинного обучения, и часть 2 в главе 11 я не могу понять значение пакетной обработки. Сначала я думаю, что нейронная сеть должна обучаться по образцу один за другим. Но они сказали “партия”, и я не могу понять на земле.
Но ваша статья дает мне хорошее представление о партии.
Я полностью понимаю вас только по одному вопросу.
Как я могу использовать метод градиента с пакетной обработкой?
Я имею в виду, что в одном примере это понятно.
Но с пакетной обработкой я не понимаю, как оценить ошибку.
Спасибо.
Это происходит один за другим, но после “пакетного” количества выборок веса обновляются с накопленной ошибкой.
Я надеялся, что вы сможете помочь мне с моими довольно длинными запутанными вопросами (извините). Я очень новичок в глубоком обучении.
Безусловно, спасибо за то, что сделали это – это облегчает жизнь без забивания головы и времени для некоторых на изучение нескольких источников
У меня есть вопрос, основанный на. не могли бы вы сослаться на другие процедуры, используемые для обновления параметров в случае других алгоритмов.
Каждый шаг включает использование модели с текущим набором внутренних параметров для прогнозирования некоторых выборок, сравнение прогнозов с реальными ожидаемыми результатами, вычисление ошибки и использование ошибки для обновления внутренних параметров модели.
Эта процедура обновления отличается для разных алгоритмов, но в случае искусственных нейронных сетей используется алгоритм обновления обратного распространения.
в современных подходах к обучению deeeep я почти всегда сталкиваюсь с тем, что люди сохраняют свои модели после некоторого количества эпох (или некоторого периода времени), визуализируя какие-то показатели производительности для оценки следующих значений гипер-параметров, после чего они проводят свои эксперименты для следующих эпох. Таким образом, мы можем назвать эту процедуру «мини-эпохальным стохастическим глубоким обучением». Спасибо.
Спасибо, что поделились.
Это блестяще и прямолинейно. Спасибо за мини-курс
Я рад, что это помогло.
Еще раз спасибо за отличный пост в блоге. Для данных временных рядов в LSTM имеет ли смысл когда-либо иметь размер пакета больше одного?
Я искал и искал, и я не мог найти ни одного примера, где размер пакета больше одного, но я также не нашел никого, кто сказал бы, что это не имеет смысла.
Да, если вы хотите, чтобы модель обучалась в нескольких под-последовательностях.
У меня есть несколько сообщений, которые демонстрируют это по расписанию.
спасибо вам за ваше объяснение действительно очень большое спасибо еще раз
Я рад, что это помогло.
Я читал много блогов, написанных вами о таких вещах. Это мне очень помогает, спасибо!
Спасибо, отличное объяснение. До сих пор ваш блог является лучшим источником для изучения ML, который я нашел (для начинающих, таких как я).
Я также вижу «steps_per_epoch» в некоторых случаях, что это значит? Это то же самое, что и партии?
Количество пакетов, которые необходимо извлечь из генератора, чтобы определить эпоху.
Привет,
обновления выполняются после завершения каждой партии. Я просто использовал один образец и дал разные размеры пакета в model.fit, почему значение меняется каждый раз. он должен быть способен принимать один размер партии, если есть только один образец, не так ли?
Batch-normalization
Пакетная нормализация (англ. batch-normalization) — метод, который позволяет повысить производительность и стабилизировать работу искусственных нейронных сетей. Суть данного метода заключается в том, что некоторым слоям нейронной сети на вход подаются данные, предварительно обработанные и имеющие нулевое математическое ожидание и единичную дисперсию. Впервые данный метод был представлен в [1] .
Идея
Нормализация входного слоя нейронной сети обычно выполняется путем масштабирования данных, подаваемых в функции активации. Например, когда есть признаки со значениями от [math]0[/math] до [math]1[/math] и некоторые признаки со значениями от [math]1[/math] до [math]1000[/math] , то их необходимо нормализовать, чтобы ускорить обучение. Нормализацию данных можно выполнить и в скрытых слоях нейронных сетей, что и делает метод пакетной нормализации.
Пакет
Предварительно, напомним, что такое пакет (англ. batch). Возможны два подхода к реализации алгоритма градиентного спуска для обучения нейросетевых моделей: стохастический и пакетный [2] .
- Стохастический градиентный спуск (англ. stochastic gradient descent) — реализация, в которой на каждой итерации алгоритма из обучающей выборки каким-то (случайным) образом выбирается только один объект;
- Пакетный (батч) (англ. batch gradient descent) — реализация градиентного спуска, когда на каждой итерации обучающая выборка просматривается целиком, и только после этого изменяются веса модели.
Также существует «золотая середина» между стохастическим градиентным спуском и пакетным градиентным спуском — когда просматривается только некоторое подмножество обучающей выборки фиксированного размера (англ. batch-size). В таком случае такие подмножества принято называть мини-пакетом (англ. mini-batch). Здесь и далее, мини-пакеты будем также называть пакетом.
Ковариантный сдвиг

Рисунок [math]1[/math] . Верхние две строки роз показывают первое подмножество данных, а нижние две строки показывают другое подмножество. Два подмножества имеют разные пропорции изображения роз. На графиках показано распределение двух классов в пространстве объектов с использованием красных и зеленых точек. Синяя линия показывает границу между двумя классами. Иллюстрация из статьи.
Пакетная нормализация уменьшает величину, на которую смещаются значения узлов в скрытых слоях (т.н. ковариантный сдвиг (англ. covariance shift)).
Ковариантный сдвиг — это ситуация, когда распределения значений признаков в обучающей и тестовой выборке имеют разные параметры (математическое ожидание, дисперсия и т.д.). Ковариантность в данном случае относится к значениям признаков.
Проиллюстрируем ковариантный сдвиг примером. Пусть есть глубокая нейронная сеть, которая обучена определять находится ли на изображении роза. И нейронная сеть была обучена на изображениях только красных роз. Теперь, если попытаться использовать обученную модель для обнаружения роз различных цветов, то, очевидно, точность работы модели будет неудовлетворительной. Это происходит из-за того, что обучающая и тестовая выборки содержат изображения красных роз и роз различных цветов в разных пропорциях. Другими словами, если модель обучена отображению из множества [math]X[/math] в множество [math]Y[/math] и если пропорция элементов в [math]X[/math] изменяется, то появляется необходимость обучить модель заново, чтобы «выровнять» пропорции элементов в [math]X[/math] и [math]Y[/math] . Когда пакеты содержат изображения разных классов, распределенные в одинаковой пропорции на всем множестве, то ковариантный сдвиг незначителен. Однако, когда пакеты выбираются только из одного или двух подмножеств (в данном случае, красные розы и розы различных цветов), то ковариантный сдвиг возрастает. Это довольно сильно замедляет процесс обучения модели. На Рисунке [math]1[/math] изображена разница в пропорциях.
Простой способ решить проблему ковариантного сдвига для входного слоя — это случайным образом перемешать данные перед созданием пакетов. Но для скрытых слоев нейронной сети такой метод не подходит, так как распределение входных данных для каждого узла скрытых слоев изменяется каждый раз, когда происходит обновление параметров в предыдущем слое. Эта проблема называется внутренним ковариантным сдвигом (англ. internal covariate shift). Для решения данной проблемы часто приходится использовать низкий темп обучения (англ. learning rate) и методы регуляризации при обучении модели. Другим способом устранения внутреннего ковариантного сдвига является метод пакетной нормализации.
Свойства пакетной нормализации
Кроме того, использование пакетной нормализации обладает еще несколькими дополнительными полезными свойствами:
- достигается более быстрая сходимость моделей, несмотря на выполнение дополнительных вычислений;
- пакетная нормализация позволяет каждому слою сети обучаться более независимо от других слоев;
- становится возможным использование более высокого темпа обучения, так как пакетная нормализация гарантирует, что выходы узлов нейронной сети не будут иметь слишком больших или малых значений;
- пакетная нормализация в каком-то смысле также является механизмом регуляризации: данный метод привносит в выходы узлов скрытых слоев некоторый шум, аналогично методу dropout;
- модели становятся менее чувствительны к начальной инициализации весов.
Описание метода
Опишем устройство метода пакетной нормализации. Пусть на вход некоторому слою нейронной сети поступает вектор размерности [math]d[/math] : [math]x = (x^, \ldots, x^)[/math] . Нормализуем данный вектор по каждой размерности [math]k[/math] :
где математическое ожидание и дисперсия считаются по всей обучающей выборке. Такая нормализация входа слоя нейронной сети может изменить представление данных в слое. Чтобы избежать данной проблемы, вводятся два параметра сжатия и сдвига нормализованной величины для каждого [math]x^[/math] : [math]\gamma^[/math] , [math]\beta^[/math] — которые действуют следующим образом:
Данные параметры настраиваются в процессе обучения вместе с остальными параметрами модели.
Пусть обучение модели производится с помощью пакетов [math]B[/math] размера [math]m[/math] : [math]B = \,\ldots, x_\>[/math] . Здесь нормализация применяется к каждому элементу входа с номером [math]k[/math] отдельно, поэтому в [math]x^[/math] индекс опускается для ясности изложения. Пусть были получены нормализованные значения пакета [math]\hat_,\ldots, \hat_[/math] . После применения операций сжатия и сдвига были получены [math]y_,\ldots, y_[/math] . Обозначим данную функцию пакетной нормализации следующим образом:
Тогда алгоритм пакетной нормализации можно представить так:
Вход: значения из пакета ; настраиваемые параметры ; константа для вычислительной устойчивости. Выход: // математическое ожидание пакета // дисперсия пакета // нормализация // сжатие и сдвиг
Заметим, что если [math]\beta=\mu_[/math] и [math]\gamma=\sqrt<\sigma_^ + \epsilon>[/math] , то [math]y_[/math] равен [math]x_[/math] , то есть [math]BN_<\gamma, \beta>(\cdot)[/math] является тождественным отображением. Таким образом, использование пакетной нормализации не может привести к снижению точности, поскольку оптимизатор просто может использовать нормализацию как тождественное отображение.
Обучение нейронных сетей с пакетной нормализацией
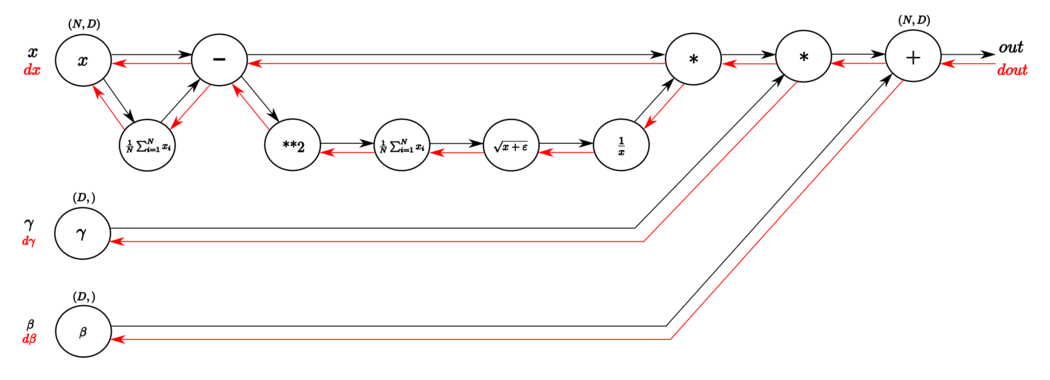
Рисунок [math]2[/math] . Граф вычислений слоя пакетной нормализации алгоритмом обратного распространения ошибки. Слева-направо черными стрелками показана работа алгоритма в прямом направлении. А справа-налево красными стрелками — в обратном направлении, где вычисляется градиент функции потерь. Здесь [math]N=m[/math] и [math]D=d[/math] . Иллюстрация из статьи.
Для обучения нейронных сетей необходимо вычислять градиент функции потерь [math]l[/math] . В случае использования метода пакетной нормализации градиент вычисляется следующим образом:
На Рисунке [math]2[/math] изображен граф вычислений слоя пакетной нормализации алгоритмом обратного распространения ошибки.
В прямом направлении, как и описано в алгоритме метода, из входа [math]x[/math] вычисляется среднее значение по каждой размерности признакового пространства. Затем полученный вектор средних значение вычитается из каждого элемента обучающей выборки. Далее вычисляется дисперсия, и с помощью нее вычисляется знаменатель для нормализации. Затем полученное значение инвертируется и умножается на разницу входа [math]x[/math] и средних значений. В конце применяются параметры [math]\gamma[/math] и [math]\beta[/math] .
В обратном направлении вычисляются производные необходимых функций. В следующей таблице подробнее изображены шаги вычисления градиента функции потерь (иллюстрации из статьи, здесь [math]N=m[/math] и [math]D=d[/math] ):
| Шаг | Изображение | Описание |
|---|---|---|
| 1 | 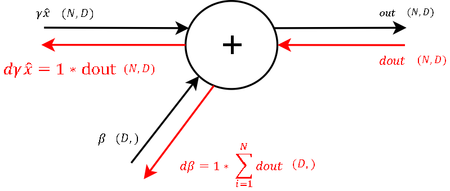 |
Сначала вычисляется производная по параметру [math]\beta[/math] , как в уравнении [math](6)[/math] , так как к нему применяется только операции суммирования. И значение градиента выхода передается без изменений. |
| 2 | 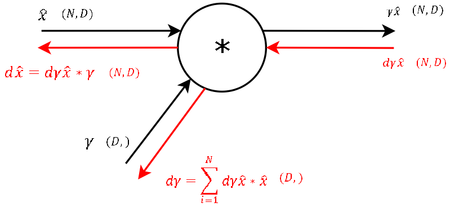 |
Далее, пользуясь правилом вычисления производной при умножении, как в уравнении [math](5)[/math] , вычисляется градиент по параметру [math]\gamma[/math] . Градиент выхода умножается на данную константу, получая уравнение [math](1)[/math] , и передается в следующий узел. |
| 3 |  |
Данный шаг вычисляется аналогично предыдущему, применяя правило вычисления производной при умножении. |
| 4 | 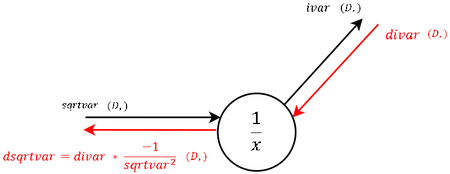 |
Пользуясь производной обратной величины, вычисляем следующий узел графа. |
| 5 |  |
Вычисляем производную квадратного корня с добавлением [math]\epsilon[/math] . |
| 6 |  |
Вычисляем производную суммы по всем компонентам входного вектора, получая матрицу. |
| 7 |  |
Получаем производную квадрата входящей функции. |
| 8 | 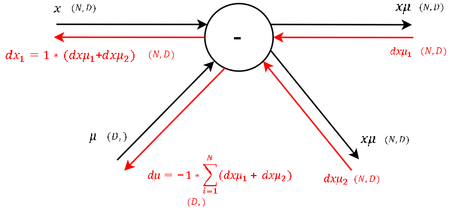 |
На данном шаге в одном узле сходятся ветки, поэтому полученные производные просто складываются, получая уравнение [math](2)[/math] для производной по дисперсии. |
| 9 | 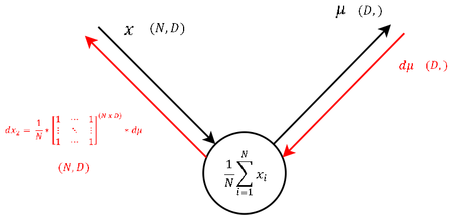 |
Аналогично шагу 6 вычисляем матрицу по сумме для производной по математическому ожиданию, получая формулу [math](3)[/math] . |
| 10 | 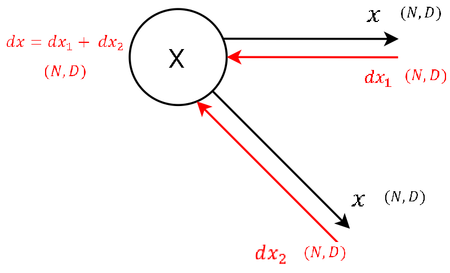 |
В начальной вершине получаем уравнение [math](4)[/math] , складывая входящие производные. |
Пакетная нормализация в свёрточных сетях
Пакетная нормализация может быть применена к любой функции активации. Рассмотрим подробнее случай аффинного преобразования с некоторой нелинейной функцией:
[math]z = g(Wu + b)[/math] ,
где [math]W[/math] и [math]b[/math] — настраиваемые параметры модели, а [math]g(\cdot)[/math] — некоторая нелинейная функция, например cигмоида или ReLU. Данной функцией можно описать как обычные, так и сверточные слои нейронных сетей. Пакетная нормализация применяется сразу перед функцией [math]g(\cdot)[/math] к [math]x = Wu + b[/math] . Параметр [math]b[/math] может быть опущен, так как в дальнейших вычислениях его роль будет играть параметр [math]\beta[/math] . Поэтому [math]z = g(Wu + b)[/math] может быть записано так:
где [math]BN[/math] применяется отдельно к каждой размерности [math]x=Wu[/math] с отдельной парой параметров [math]\gamma^[/math] и [math]\beta^[/math] для каждой размерности.
В случае свёрточных сетей, дополнительно необходима нормализация, чтобы удовлетворить свойство свёрточных сетей, что различные элементы в разных местах одной карты признаков (образ операции свёртки, англ. feature map) должны быть нормализованы одинаково. Чтобы этого добиться, нормализация выполняется совместно над всеми значениями в пакете. Пусть [math]B[/math] — множество всех значений в карте признаков по всему пакету и всем точкам в карте признаков. Тогда для пакета размера [math]m[/math] и карты признаков размера [math]p \times q[/math] размер [math]B[/math] равен [math]m’=|B|=m \cdot pq[/math] . Тогда параметры [math]\gamma^[/math] и [math]\beta^[/math] настраиваются для каждой карты признаков отдельно.
Индивидуальная нормализация

Рисунок [math]3[/math] . Типы нормализации. Ось N — по объектам в пакете, ось C — по картам признаков (channels), оставшаяся ось — по пространственным измерениям объектов, например, ширине и высоте картинки. Иллюстрация из статьи.
При пакетной нормализации происходит усреднение параметров по всему пакету. Например, в случае задачи переноса стилей картин, это вносит много шума. При усреднении теряются индивидуальные характеристики объектов. Поэтому используется более тонкая нормализация — индивидуальная нормализация (англ. instance normalization). Разница заключается в том, что нормализация происходит по каждому отдельному объекту, а не по всему пакету. Для примера, усреднение происходит по пикселям картины, но не по всем картинам в пакете, как видно на Рисунке [math]3[/math] .
Условная пакетная нормализация
Условная пакетная нормализация (англ. conditional batch normalization, CBN) — метод, который позволяет «выбирать» параметры пакетной нормализации ( [math]\beta[/math] и [math]\gamma[/math] ) в зависимости от какого-то состояния сети, например метки класса. Впервые данный метод был представлен для индивидуальной нормализации в A Learned Representation for Artistic Style [3] . Позднее он был использован для пакетной нормализации в Modulating early visual processing by language [4] .
Зачем нужно делать параметры нормализации зависимостью? На практике было выяснено [3] , что иногда нейронные сети, натренированные решать разные задачи из одного класса, имеют схожие веса и достаточно лишь слегка поменять параметры сжатия и сдвига после каждого слоя. Таким образом, добавив условную нормализацию, мы научимся решать сразу несколько задач используя одну сеть.
Описание метода
Самая важная часть метода — выбрать для входа [math]x[/math] параметры [math]\beta_c[/math] и [math]\gamma_c[/math] . Возможные способы сделать это описаны ниже. Единожды параметры выбраны, формула не отличается от приведённой в параграфе c описанием метода пакетной нормализации:
[math]y = \gamma_c \cdot \hat + \beta_c \;\; (1)[/math] .
Выбор параметров нормализации
Есть несколько способов выбрать параметры. Самой простой из них — разделить предметную область на [math]C[/math] частей. Для каждого слоя надо добавить соответствующие параметры [math]\beta_c, \gamma_c \; , c \in 1..C[/math] и настраивать их вместе с остальными параметрами модели. Когда мы тренируем на данных из [math]i[/math] -ой части, мы явно указываем, что в формуле [math](1)[/math] [math]c = i[/math] . Когда мы хотим осуществить предсказание, мы снова явно указываем желаемый [math]c[/math] и в вычислениях используются соответствующие параметры.
Есть другой способ: можно вместе с настройкой сети обучать алгоритм выбора параметров [math]PARAMS[/math] сжатия и сдвига по заданному входу: [math](\beta_c, \gamma_c) = PARAMS(x)[/math] . К примеру, в работе Modulating early visual processing by language в качестве [math]PARAMS[/math] используется многослойный перцептрон по Румельхарту с одним скрытым слоем. Таким образом, характеристики [math]x[/math] могут изменить выход целого слоя. Это бывает полезно, если верна гипотеза, что структура входных векторов связана с желаемым результатом работы.
В применении к переносу стиля
![]()
Рисунок [math]4[/math] . Перенесения стиля с картины Клода Моне «Рыбацкие лодки» (слева) на изображение человека (справа) [3] .
Популярной задачей является отрисовка данного изображения в стиле какой-то заданной картины, как на Рисунке [math]4[/math] . Эта задача называется «перенос стиля«. Одно из популярных и достаточно быстрых решений этой задачи использует простые нейронные сети прямого распространения. Это решение имеет недостаток: каждая сеть может переносить лишь один стиль. Если мы хотим научиться переносить [math]N[/math] стилей, то надо обучать [math]N[/math] различных сетей. Однако лишь небольшое количество параметров этих сетей отвечает за индивидуальные особенности стиля. Хотелось бы уметь переиспользовать остальные параметры.
Добавление условности
В статье A Learned Representation for Artistic Style был получен удивительный результат: для моделирования какого-то стиля, достаточно специализировать параметры сжатия и сдвига нормализации для каждого конкретного стиля. Таким образом, давайте для каждого изображения стиля [math]s[/math] будем учитывать свои [math]\gamma_c[/math] и [math]\beta_c[/math] . Получается, у нас будет лишь два вектора параметров, специфичных для каждого стиля, а все остальные — общие.
Такой подход имеет много преимуществ по сравнению с наивным:
- Это быстрее.
- Это требует меньше памяти.
- Легче добавить новый стиль: достаточно взять текущие веса, добавить новые параметры сжатия и сдвига и дообучить. Веса, скорее всего, уже были близки к оптимальным и дообучение не будет долгим.
- Можно комбинировать новые стили за счёт выпуклой комбинации существующих коэффициентов сжатия и сдвига.
Когда использовать условную нормализацию?
Во-первых, на условную нормализацию стоит обратить внимание, если вы настраиваете много сетей, решающих похожие задачи. Возможно, в этом случае вы можете использовать одну сеть с условными параметрами нормализации, зависящими от конкретной задачи. Например, при переносе стилей вместо [math]S[/math] сетей вы настраиваете одну сеть с [math]S[/math] наборами параметров нормализации.
Во-вторых, если вы подозреваете, что информация о структуре входных векторов имеет значение для выхода. Например, имеет смысл «слить» лингвистическую информацию и характеристики изображения для задачи ответа на визуальные вопросы (англ. Visual Question Answering, VQA).
Однако во всех случаях надо помнить, что полученные алгоритмы для разных задач будут различаться лишь параметрами свёртки и сжатия. Иначе говоря, если ваши задачи нельзя выразить аффинной комбинацией параметров сети после нормализации, условная нормализация не поможет.
Пример
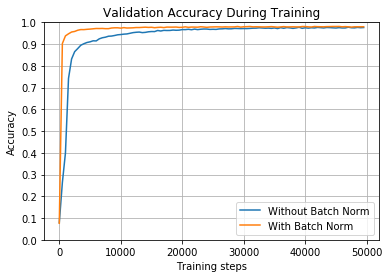
Рисунок [math]5[/math] . Точность распознавания в зависимости от итерации обучения. Оранжевая кривая изображает результаты для модели с использованием пакетной нормализации, синяя кривая — без. Иллюстрация из статьи.
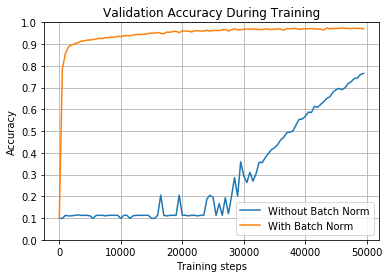
Рисунок [math]6[/math] . Точность распознавания в зависимости от итерации обучения c использованием сигмоиды в качетсве функции активации. Иллюстрация из статьи.
Приведем пример демонстрирующий работу пакетной нормализации. Рассмотрим задачу распознавания рукописных цифр на известном датасете MNIST [5] . Для решения задачи будет использоваться обычная нейронная сеть с [math]3[/math] скрытыми полносвязными слоями по [math]100[/math] узлов в каждом. Функция активации — ReLU. Выходной слой содержит [math]10[/math] узлов. Размер пакета равен [math]60[/math] . Сравниваются две одинаковые модели, но в первой перед каждым скрытым слоем используется пакетная нормализация, а во второй — нет. Темп обучения равен [math]0.01[/math] . Веса инициализированы значениями с малой дисперсией.
На Рисунке [math]5[/math] изображены два графика, показывающие разницу между моделями. Как видно, обе модели достигли высокой точности, но модель с использованием пакетной нормализации достигла точности более [math]90\%[/math] быстрее, почти сразу, и достигла максимума, примерно, уже на [math]10000[/math] итераций. Однако, модель без пакетной нормализации достигла скорости обучения примерно [math]510[/math] пакетов в секунду, а модель с использованием пакетной нормализации — [math]270[/math] . Однако, как можно видеть, пакетная нормализация позволяет выполнить меньшее количество итераций и, в итоге, сойтись за меньшее время.
На Рисунке [math]6[/math] изображен график, сравнивающий точно такие же модели, но с использованием сигмоиды в качестве функции активации. Такая конфигурация моделей требует большего времени, чтобы начать обучение. В итоге, модель обучается, но на это потребовалось более [math]45000[/math] итераций, чтобы получить точность более [math]80\%[/math] . При использовании пакетной нормализации получилось достичь точность более [math]90\%[/math] примерно за [math]1000[/math] итераций.
Реализации
Механизм пакетной нормализации реализован практически во всех современных инструментариях для машинного обучения, таких как: TensorFlow [6] , Keras [7] , CNTK [8] , Theano [9] , PyTorch [10] и т.д.
Приведем пример [11] применения пакетной нормализации с использованием библиотеки TensorFlow на языке программирования Python [12] :
import tensorflow as tf # . is_train = tf.placeholder(tf.bool, name="is_train"); # . x_norm = tf.layers.batch_normalization(x, training=is_train) # . update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) with tf.control_dependencies(update_ops): train_op = optimizer.minimize(loss)
Модификации
Существует несколько модификаций и вариаций метода пакетной нормализации:
- Тим Койманс [13] в 2016 г. предложил способ применения пакетной нормализации к рекуррентным нейронным сетям;
- Расширение метода пакетной нормализации было предложено Ликси Хуангом [14] в 2018 г. Метод получил название декоррелированная пакетная нормализация (англ. Decorrelated Batch Normalization). В данном методе кроме операций масштабирования и сдвига была предложено использование специальной функции затирания данных;
- Джимми Лей Ба [15] в 2016 г. предложил метод нормализации слоев (англ. Layer Normalization), который решает проблему выбора размера пакета;
- В работе Сергея Иоффе [16] в 2017 г. было представлено расширение метода пакетной нормализации: пакетная ренормализация (англ. Batch Renormalization). Данный метод улучшает пакетную нормализацию, когда размер пакетов мал и не состоит из независимых данных;
- Метод потоковой нормализации (англ. Streaming Normalization) был предложен Кифэном Ляо [17] в 2016 г. Данный метод убирает два ограничения пакетной нормализации: использование при online-обучении и использование в рекуррентных нейронных сетях.
См. также
- Глубокое обучение
- Практики реализации нейронных сетей
- Настройка глубокой сети
Примечания
- ↑Ioffe S., Szegedy C. — Batch normalization: Accelerating deep network training by reducing internal covariate shift, 2016
- ↑Метод стохастического градиента
- ↑ 3,03,13,2A Learned Representation for Artistic Style
- ↑Modulating early visual processing by language
- ↑Датасет MNIST
- ↑TensorFlow
- ↑Keras
- ↑CNTK
- ↑Theano
- ↑PyTorch
- ↑Batch normalization: theory and how to use it with Tensorflow
- ↑Язык программирования Python
- ↑Cooijmans T. — Recurrent batch normalization, 2016
- ↑Huang L. — Decorrelated Batch Normalization, 2018
- ↑Ba J. L., Kiros J. R., Hinton G. E. — Layer normalization, 2016
- ↑Ioffe S. — Batch renormalization: Towards reducing minibatch dependence in batch-normalized models, 2017
- ↑Liao Q., Kawaguchi K., Poggio T. — Streaming normalization: Towards simpler and more biologically-plausible normalizations for online and recurrent learning, 2016
Источники информации
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Glossary of Deep Learning: Batch Normalisation
- Understanding the backward pass through Batch Normalization Layer
- Deeper Understanding of Batch Normalization with Interactive Code in Tensorflow
- Batch Normalization in Deep Networks
- Batch Normalization — Lesson
- A Learned Representation for Artistic Style