Базы данных в Python: как подключить PostgreSQL и что это такое

Во время разработки приложений часто нужно подключать и использовать базы данных для хранения информации. Самая распространенная база данных — PostgreSQL, поэтому мы расскажем, как работать в Python именно с ней. Для этого существует множество модулей, например:
- Psycopg2
- py-postgresql
- pg8000
Мы расскажем именно про модуль Psycopg2. И выбрали мы его по таким причинам:
- Распространенность — Psycopg2 использует большинство фреймворков Python
- Поддержка — Psycopg2 активно развивается и поддерживает основные версии Python
- Многопоточность — Psycopg2 позволяет нескольким потокам поддерживать одно и то же соединение
Python-разработчик — с нуля до трудоустройства за 10 месяцев
- Постоянная поддержка от наставника и учебного центра
- Помощь с трудоустройством
- Готовое портфолио к концу обучения
- Практика с первого урока
Вы получите именно те инструменты и навыки, которые позволят вам найти работу
Установка Psycopg2
Для начала работы с модулем достаточно установить пакет при помощи pip:
install psycopg2-binary Если в вашем проекте используется poetry, то при первоначальной настройке проекта нужно добавить psycopg2-binary в зависимости. Для добавления в уже существующий проект воспользуйтесь командой:
Использование Psycopg2
Подключение к БД:
Для подключения к существующей базе данных необходимо знать основную информацию о вашей БД. Если вы не знаете, где ее взять, то пройдите сначала наш большой курс по Основам баз данных:
- Username — имя пользователя, которое вы используете для работы с PostgreSQL
- Password — пароль, который используется пользователем
- Host Name — имя сервера или IP-адрес, на котором работает PostgreSQL
- Database Name — имя базы данных, к которой мы подключаемся.
Для подключения к базе данных мы используем метод connect() , которому в качестве аргументов передаются вышеперечисленные данные:
import psycopg2 try: # пытаемся подключиться к базе данных conn = psycopg2.connect(dbname='test', user='postgres', password='secret', host='host') except: # в случае сбоя подключения будет выведено сообщение в STDOUT print('Can`t establish connection to database') Также подключение к базе данных может осуществляться с помощью Connection URI :
import psycopg2 try: # пытаемся подключиться к базе данных conn = psycopg2.connect('postgresql://user:password@host:port/database_name') except: # в случае сбоя подключения будет выведено сообщение в STDOUT print('Can`t establish connection to database') Читайте также: Вышел Python 3.11.0. В два раза быстрее, c детальным описанием ошибок и кучей новых типов
Взаимодействие Python с PostgreSQL
Итак, подключение к базе данных успешно выполнено. Дальше мы будем взаимодействовать с ней через объект cursor , который можно получить через метод cursor() объекта соединения. Он помогает выполнять SQL-запросы из Python.
# получение объекта курсора cursor = conn.cursor() С помощью cursor происходит передача запросов базе данных:
# Получаем список всех пользователей cursor.execute('SELECT * FROM users') all_users = cursor.fetchall() cursor.close() # закрываем курсор conn.close() # закрываем соединение Для получения результата после выполнения запроса используются следующие команды:
- cursor.fetchone() — вернуть одну строку
- cursor.fetchall() — вернуть все строки
- cursor.fetchmany(size=10) — вернуть указанное количество строк
Хорошей практикой при работе с базой данных является закрытие объекта cursor и соединения с базой. Для автоматизации этого процесса удобно взаимодействовать через контекстный менеджер , используя конструкцию with :
with conn.cursor as curs: curs.execute('SELECT * FROM users') all_users = curs.fetchall() В тот момент, когда объект cursor выходит за пределы конструкции with , происходит его закрытие и освобождение связанных с ним ресурсов.
По умолчанию результат возвращается в виде кортежа. Такое поведение возможно изменить, передав параметр cursor_factory в момент открытия объекта cursor , например, использовать NamedTupleCursor. Это вернет данные в виде именованного кортежа:
from psycopg2.extras import NamedTupleCursor # … with conn.cursor(cursor_factory=NamedTupleCursor) as curs: curs.execute('SELECT * FROM users WHERE name=%s', (name='Alfred')) alfred = curs.fetchone() alfred # (id=10, name='Alfred', age='90') # … Выполнение запросов
Psycopg2 преобразует переменные Python в SQL значения с учетом их типа. Все стандартные типы Python адаптированы для правильного представления в SQL.
Передача параметров в SQL-запрос происходит с помощью подстановки плейсхолдеров %s и цепочки значений в качестве второго аргумента функции:
with conn.cursor() as curs: curs.execute('SELECT id, name FROM users WHERE name=%s', ('John',)) curs.fetchall() # … with conn.cursor() as curs: curs.execute(INSERT INTO users (name, age) VALUES (%s, %s), ('John', 19)) # … conn.close() Подстановка значений в SQL-запрос используется для того, чтобы избежать атак типа SQL Injection. Также несколько полезных советов по построению запросов:
- Плейсхолдер должен быть %s даже если тип подставляемого значения отличается от строки
- Не заключайте плейсходер в кавычки
- Если в запросе используется знак % , он должен быть указан как %%
Профессия «Python-разработчик»
- Изучите Python — язык с простым и понятным синтаксисом
- Научитесь создавать полноценные сайты и веб-приложения
- Освойте популярный фреймворк Python — Django
- Разберитесь в базах данных и научитесь управлять ими с помощью SQL
SQL-Ex blog

Импорт данных из файла Excel в базу данных SQL Server с помощью Python
Добавил Sergey Moiseenko on Суббота, 8 апреля. 2023
Есть много способов загрузить данные из Excel в SQL Server, но иногда полезно использовать те инструменты, которые вы знаете лучше всего. В этой статье мы рассмотрим как загружать данные из Excel в SQL Server с помощью Python.
Используемые инструменты
- Экземпляр SQL Server
- Python, версия 3.11.0.
- Visual Studio Code, версия 1.72.1.
- Windows 10 PC или Windows Server 2019/2022.
Установка базы данных — создание тестовой базы данных и таблицы
Имеется несколько способов создать базу данных и таблицы в SQL Server, но ниже мы пройдем через использование SQLCMD для создания базы данных, если вы не имеете SQL Server Management Studio или Azure Data Studio.
Откройте командую строку Windows или запустите новую терминальную сессию из Visual Studio Code, нажав CTRL + SHFT + `.
Для запуска SQLCMD используйте следующую команду sqlcmd -S -E , чтобы подключиться к SQL Server. Параметр -S указывает экземпляр SQL Server, а параметр -E означает использование доверительного подключения.
sqlcmd -S -E
После аутентификации создадим новую базу данных следующей командой:
CREATE DATABASE ExcelData;
GO
Используйте эту команду SQLCMD для подтверждения создания базы данных:
SELECT name FROM sys.databases
GO
Изображение ниже представляет вывод команды, который показывает все имеющиеся базы данных этого экземпляра SQL Server.
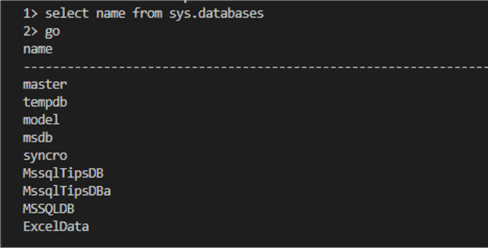
Для переключения на новую базу данных используйте следующую команду:
USE ExcelData;
GO
Будет получено подтверждение изменение контекста, как показано ниже:

Теперь мы можем создать таблицу в этой базе данных.
CREATE TABLE EPL_LOG(ID int NOT NULL PRIMARY KEY);
GO
Отлично! Вы создали таблицу с именем EPL_LOG и первичным ключом ID. Нам нужен только первый столбец, а программа загрузки создаст остальные столбцы на основе файла-источника.
Конфигурация ядра
Ядро помечает начальную точку вашего приложения SQLAlchemy. Ядро описывает пул соединений и диалект для BDAPI (Python Database API Specification), спецификацию в рамках Python для определения общих шаблонов использования для всех пакетов подключения к базам данных, которые в свою очередь взаимодействуют с указанной базой данных.
Для открытия нового терминала нажмите CTRL + SHFT + ` в Visual Studio Code.
Используйте следующую команду npm в окне терминала для установки модуля SQLAlchemy.
npm install sqlalchemy
Создайте файл Python с именем DbConn.py, вставьте в него нижеприведенный код и измените источник данных на требуемый. Это — ядро SQLAlchemy, которое взаимодействует с SQL Server через Python.
import sqlalchemy as sa
from sqlalchemy import create_engine
import urllib
import pyodbc
conn = urllib.parse.quote_plus(
‘Data Source Name=MssqlDataSource;’
‘Driver=;’
‘Server=POWERSERVER\POWERSERVER;’
‘Database=ExcelData;’
‘Trusted_connection=yes;’
)
try:
coxn = create_engine(‘mssql+pyodbc:///?odbc_connect=<>‘.format(conn))
print(«Passed»)
Запись в SQL Server
Мы будем использовать Pandas, который является быстрым, гибким и легким в использовании инструментом с открытыми кодами для манипуляции и анализа данных, встроенным в язык программирования Python. Python может читать данные Excel в программе Python, используя функцию pandas.read_excel().
Для простоты этой демонстрации, сохраним файл Excel в папке проекта Visual Studio Code, чтобы нам не пришлось указывать путь. Это позволит вам игнорировать параметр io (любая валидная строка пути) функции read_excel().
Мы будем также использовать openpyxl в качестве движка для чтения файлов Excel. Выполните следующую команду pip в окне терминала, чтобы установить openpyxl.
pip install pandas openpyxl
Создайте еще один файл с именем ExcelToSQL.py, содержащий код ниже. Этот код будет читать файл Excel и записывать в созданную ранее таблицу базы данных.
//ExcelToSQL.py
from pandas.core.frame import DataFrame
import pandas as pd
from DbConn import coxn
df = pd.read_excel(‘sportsref_download.xlsx’, engine = ‘openpyxl’)
except:
pass
print(«Failed!»)
else:
print(«saved in the table»)
print(df)
Теперь щелкнем кнопку Play в верхнем правом углу окна Visual Studio Code для выполнения скрипта. В терминале появится вывод данных.
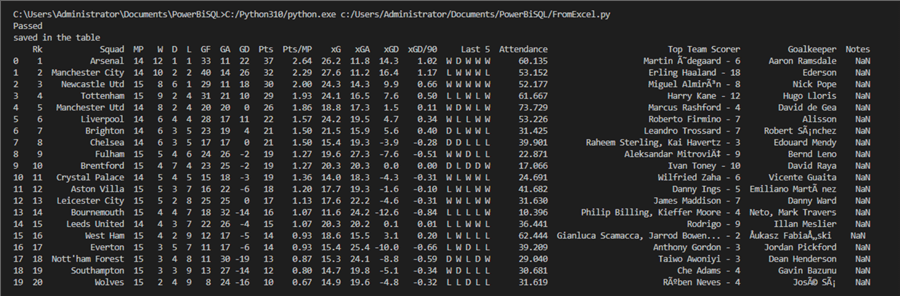
Для проверки сохранения данных в базе откройте SSMS и выберите данные из таблицы. Вы можете также использовать SQLCMD для подключения к экземпляру и выполнения следующего кода.
USE ExcelData;
GO
SELECT * FROM EPL_LOG
Изображение ниже показывает какие данные сейчас находятся в базе данных.
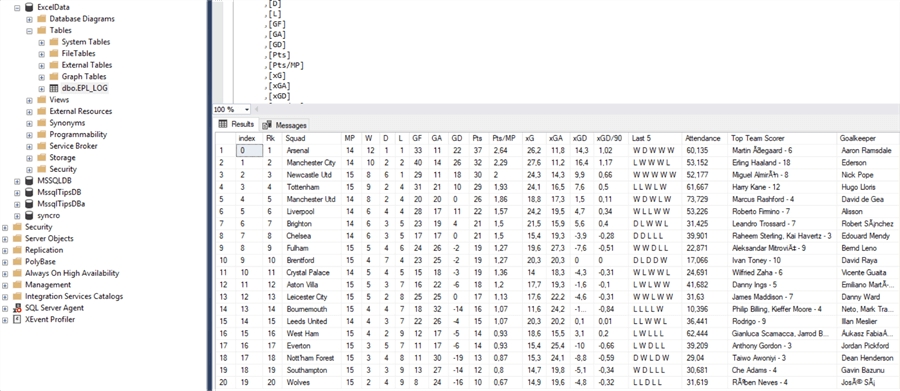
Заключение
Python выполняет большую работу, действуя как посредник между Excel и SQL Server. Вы можете транслировать любые статичные данные Excel в более гибкий набор данных, перемещая его в базу данных, которая обладает большей доступностью и легче интегрируется с другим системами.
Перемещайте данные Excel в SQL Server данным способом. Поскольку pandas сохраняет данные в DataFrame, ими легко манипулировать и изменять перед занесением в базу данных SQL Server.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Как использовать Python для работы с базами данных
Изучите основы работы с базами данных на Python, включая SQLite, PostgreSQL, MySQL и Oracle, с примерами кода и практическими советами.

Алексей Кодов
Автор статьи
23 июня 2023 в 18:51
Python является мощным и гибким языком программирования, который позволяет легко работать с различными базами данных. В данной статье мы рассмотрим основные способы работы с базами данных на Python и покажем некоторые примеры.
Работа с SQLite
SQLite — это встроенная база данных в Python, идеально подходящая для небольших проектов и тестирования. Для работы с SQLite достаточно импортировать модуль sqlite3 .
Создание и подключение к базе данных
import sqlite3 # Создание или подключение к базе данных conn = sqlite3.connect("my_database.db")
Создание таблицы
# Создание объекта курсора для выполнения SQL-запросов cursor = conn.cursor() # Создание таблицы cursor.execute(""" CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER ) """) # Сохранение изменений conn.commit()
Вставка данных
# Вставка одной записи cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ("Alice", 25)) conn.commit() # Вставка нескольких записей data = [("Bob", 30), ("Charlie", 22), ("David", 40)] cursor.executemany("INSERT INTO users (name, age) VALUES (?, ?)", data) conn.commit()
Запрос данных
# Выборка всех записей cursor.execute("SELECT * FROM users") rows = cursor.fetchall() for row in rows: print(row) # Выборка записей с условием cursor.execute("SELECT * FROM users WHERE age > ?", (25,)) rows = cursor.fetchall() for row in rows: print(row)
Обновление и удаление данных
# Обновление записи cursor.execute("UPDATE users SET age = ? WHERE name = ?", (26, "Alice")) conn.commit() # Удаление записи cursor.execute("DELETE FROM users WHERE name = ?", ("Bob",)) conn.commit()
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Работа с другими базами данных
Для работы с другими базами данных, такими как PostgreSQL, MySQL и Oracle, необходимо установить соответствующие пакеты, а затем импортировать и использовать их аналогично модулю sqlite3 .
PostgreSQL
import psycopg2 conn = psycopg2.connect(database="my_database", user="user", password="password", host="localhost", port="5432")
MySQL
import mysql.connector conn = mysql.connector.connect(user="user", password="password", host="localhost", database="my_database")
Oracle
import cx_Oracle conn = cx_Oracle.connect("user/password@localhost:1521/my_database")
�� Удачной работы с базами данных на Python! Не забывайте закрывать соединение с базой данных после завершения работы:
conn.close()
Заключение
В этой статье мы рассмотрели основные аспекты работы с базами данных на Python, включая создание, подключение, вставку, выборку, обновление и удаление данных. Теперь вы готовы применить эти знания в своих проектах. Удачи вам в изучении Python и разработке!
Выгружаем из базы данных с помощью Python
Задача на выгрузку данных из одной таблицы, с одним условием для фильтра решается посредством создания простого SQL-запроса. Но она легко становится трудоемкой в исполнении, если в фильтрации применить множество условий. Давайте представим, что необходимо выгрузить данные из одной таблицы по фильтру, где первые две цифры ИНН начинаются на «66». SQL-запрос будет выглядеть так:
select * from tabl where inn like ‘66%’
Вроде ничего сложного, но, если изменить условие фильтрации на поиск по 2 млн уникальных ИНН, SQL-запрос будет выглядеть так:
select * from tabl where inn = ’66******01′ or inn = ’66******02′ or inn = ’66******03′ or inn = ’66******04′ or inn = ’66******05′ or inn = ’66******06′ or inn = ’66******07′ . or inn = ’66******nn’
Исходя из своего опыта, такой запрос запустить не получится из-за ограничения СУБД на количество условий в 10 тыс. значений (Ограничения СУБД могут быть разные). В нашем случае потребуется создать 200 запросов и запустить их по отдельности. В итоге мы получим 200 файлов с данными, которые необходимо собрать в один. Сложно представить сколько потребуется на это времени и сил, но с помощью Python и библиотеки «cx_Oracle» задача решается легко.
import cx_Oracle import pandas as pd import time
Проверяем версию (должна быть > 3.0):
cx_Oracle.__version__
Прописываем дескриптор соединения Oracle:
ConnectStr = «»»(DESCRIPTION=(ADDRESS=(PROTOCOL=. )(Host=. ) (Port= . ))(CONNECT_DATA=(SERVICE_NAME= . )))»»»
Прописываем логин и пароль (при доменной аутентификации оставляем ‘/’):
Login = ‘IVANOV/PASSWORD’
Функция, в которой создается экземпляр класса connect, он обеспечит взаимодействие с сервером Oracle:
def getConn(Login, ConnectStr): conn=None nn=0 while conn==None: try: conn=cx_Oracle.connect(Login + ‘@’ + ConnectStr) except cx_Oracle.DatabaseError as e: ers,=e.args nn=nn+1 print (nn,end=’\r’) if ers.code!=2391: print (‘Ошибка Oracle ‘, ers.code) break time.sleep(5) return conn
Функция, в которой создается курсор и выполняется запрос:
def dfFromOracle(connection, sql): us=0 outDF=pd.DataFrame() success = ‘False’ with connection.cursor() as cursor1: cursor1.execute(sql) trn=10 while success == ‘False’ and trn>0: try: outheader=[desc[0] for desc in cursor1.description] #При вызове «cursor1.fetchall()» возвращается список записей, каждая из которых #является кортежем (неизменяемым списком) полей разного типа outDF=pd.DataFrame(cursor1.fetchall()) success = ‘True’ print(‘Результат получен из базы’) us = 1 except: trn=trn-1 print(‘Error’) time.sleep(60) return outheader, outDF, us
Подключаемся к серверу:
getConn(Login, ConnectStr)
Файл, в котором одна колонка со всеми значениями ИНН:
f = open(‘inn_in_.txt’,’r’,encoding=’UTF-8′)
Присваиваем имя файла, в который выгрузится результат:
new_file = ‘new_file.csv’
r=» — для собора строк в «with», которые подставим в SQL-запрос,
h = 0 — проверки наличия заголовков,
l = 0 — счетчик строк для запуска SQL-запроса,
ll = 0 — счетчик строк для проверки на остаток,
cnt = 10000 — количество строк для запуска SQL-запроса.
Цикл для создания и запуска SQL-запросов:
for row in f: l += 1 if r == »: #Формируем «where» — список ИНН для фильтрации r = r + ‘inn = \» + row.replace(‘\n’,») + ‘\» else: r = r + ‘or inn = \» + row.replace(‘\n’,») + ‘\» if l % cnt == 0: #Проверка на 10 000 строк ll += l sql = ( ‘select * from tabl where’ + r ) #Сформированный SQL-запрос
Отправляем SQL-запрос и обрабатываем полученную выгрузку:
with getConn(Login,ConnectStr) as con1: if h==0: _header,result,us = dfFromOracle(con1, sql) header = ‘;’.join(_header)+’\n’ myfile=open(new_file, ‘w’,encoding=’UTF-8′) myfile.writelines(header) myfile.close() h=1 result.to_csv(new_file, sep=’;’,encoding=’UTF-8′,mode=’a’,header=None,index=False) r=» print(‘Выгружено: ‘+str(l) ) if l != ll: #Если последний список менее 10 000 строк sql = ( ‘select * from tabl where’ + r ) #Сформированный SQL-запрос with getConn(Login,ConnectStr) as con1: _header,result,us = dfFromOracle(con1, sql) if h==0: header = ‘;’.join(_header)+’\n’ myfile=open(new_file, ‘w’,encoding=’UTF-8′) myfile.writelines(header) myfile.close() h=1 result.to_csv(new_file, sep=’;’,encoding=’UTF-8′,mode=’a’,header=None,index=False) print(‘Выгружено: ‘+str(l) ) print(‘Выгрузка завершена’) f.close()
Таким образом, с помощью Python мы автоматизировали процесс создания, запуска SQL-запросов и сохранения результатов в один файл, избежали больших трудозатрат, при этом:
- исключили ошибки, возможные при перечислении списка условий для фильтрации, что снизило вероятность потери данных;
- настроили процесс создания, запуска SQL-запросов и сохранения результатов в один файл порционно, что дает возможность в случае обрыва сессии не повторять заново запросы с уже отработавшими условиями, а продолжить с условий, на которых обрыв произошел.