Как скачать таблицу из юпитер ноутбука?
Предположим, что у меня есть таблица в формате dataframe, я преобразую её в формат csv, используя to_csv, как теперь мне скачать эту таблицу?
Отслеживать
задан 15 авг 2021 в 16:57
67 1 1 серебряный знак 5 5 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Разберем на примере кода:
import pandas as pd cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State']) cities.to_csv('cities.csv') В строке cities.to_csv(‘cities.csv’) вы конвертирует DataFrame-файл и записываете в файл ‘cities.csv’, также можно указать прямой путь к файлу. Далее он сохраняется в рабочем каталоге запущенного файла. Следовательно, вам не надо будет скачивать сам конвертированный файл,он будет в той же директории, где находится ваш py-файл с кодом выше(если брать пример выше).
Как и для чего экспортировать красивые отчеты из Jupyter Notebook в PDF
Если вы специалист по анализу данных и вам нужно представить отчет для заказчика, если вы ищете работу и не знаете, как оформить тестовое задание так, чтобы на вас обратили внимание, если у вас много учебных проектов, связанных с аналитикой и визуализацией данных, то сегодняшний пост будет вам очень и очень полезен. Дело в том, что смотреть на чужой код в Jupyter Notebook бывает проблематично, ведь результат часто теряется между множеством строк кода с подготовкой данных, импортом нужных библиотек и серией попыток реализовать ту или иную идею. Именно поэтому такой метод, как экспорт результатов в PDF-файл в формате LaTeX — это отличный вариант для итоговой визуализации, который сэкономит время и будет выглядеть презентабельно. В научных кругах статьи и отчеты очень часто оформляются именно с использованием LaTeX, поскольку он имеет ряд преимуществ:
- Математические уравнения и формулы выглядят аккуратнее.
- Библиография создается автоматически, на основе всех использованных в документе ссылок.
- Автор может сосредоточиться на содержании, а не на внешнем виде документа, так как верстка текста и других данных происходит автоматически с помощью указания необходимых параметров в коде.
Сегодня мы подробно расскажем о том, как научиться экспортировать вот такие красивые отчеты из Jupyter Notebook в PDF с использованием LaTeX.

Установка LaTeX
Самый важный момент в формировании отчета из Jupyter Notebook на Python — это его экспорт в финальный файл. Для этого применяется одна библиотека — nbconvert — которая конвертирует ваш ноутбук в любой удобный формат документа: pdf (как в нашем случае), html, latex или другой. Эту библиотеку нужно не просто установить, а провести некоторую процедуру по предустановке нескольких других пакетов: Pandoc, TeX и Chromium. По ссылке на библиотеку весь процесс описан очень подробно для каждого программного обеспечения, поэтому подробно мы на нем останавливаться не будем.
Как только вы завершили все предварительные шаги, нужно установить и импортировать библиотеку в ваш Jupyter Notebook.
!pip install nbconvert import nbconvertЭкспорт таблиц в Markdown формат
Обычно, таблицы не представляют в отчетах, поскольку их бывает трудно быстро прочесть, но иногда все-таки необходимо добавить небольшую таблицу в итоговый документ. Для того, чтобы таблица выглядела аккуратно, нужно представить ее в Markdown формате. Это можно сделать вручную, но если в таблице много данных, то лучше придумать более удобный метод. Мы предлагаем использовать следующую простую функцию pandas_df_to_markdown_table(), которая преобразует любой датафрейм в markdown-table. Единственный нюанс: после преобразования исчезают строчные индексы, потому, если они важны (как в нашем примере), то стоит записать их в переменную в первой колонке датафрейма.
data_g = px.data.gapminder() summary = round(data_g.describe(),2) summary.insert(0, 'metric', summary.index) # Функция для преобразования dataframe в Markdown Table def pandas_df_to_markdown_table(df): from IPython.display import Markdown, display fmt = ['---' for i in range(len(df.columns))] df_fmt = pd.DataFrame([fmt], columns=df.columns) df_formatted = pd.concat([df_fmt, df]) display(Markdown(df_formatted.to_csv(sep="|", index=False))) pandas_df_to_markdown_table(summary)Экспорт изображения в отчет
В этом примере мы будем строить bubble-chart, про методику построения которых рассказывали в недавнем посте. В прошлый раз мы использовали пакет Seaborn, наглядно показывая, что отображение данных размером кругов на графике происходит корректно. Такие же графики можно построить и при помощи пакета Plotly.
Для того чтобы отобразить график, построенный в Plotly в отчете тоже нужно немного постараться. Дело в том, что plt.show() не поможет отобразить график при экспорте. Поэтому, нужно сохранить получившийся график в рабочей директории, а затем, используя библиотеку iPython.display, отобразить его с помощью функции Image().
from IPython.display import Image import plotly.express as px fig = px.scatter(data_g.query("year==2007"), x="gdpPercap", y="lifeExp", size="pop", color="continent", log_x=True, size_max=70) fig.write_image('figure_1.jpg') Image(data = 'figure_1.jpg', width = 1000)Формирование и экспорт отчета
Когда все этапы анализа данных завершены, отчет можно экспортировать. Если вам нужны заголовки или текст в отчете, то пишите его в ячейках ноутбука, сменив формат Code на Markdown. Для экспорта можно использовать терминал, запуская там вторую строку без восклицательного знака, либо можно запустить код, написанный ниже, в ячейке ноутбука. Мы советуем не загружать отчет кодом, поэтому используем параметр TemplateExporter.exclude_input=True, чтобы ячейки с кодом не экспортировались. Также, при запуске этой ячейки код выдает стандартный поток (standard output) и, чтобы в отчете его не было видно, в начале ячейки нужно написать %%capture.
%%capture !jupyter nbconvert --to pdf --TemplateExporter.exclude_input=True ~/Desktop/VALIOTTI/Reports/Sample\LaTeX\ Report.ipynb !open ~/Desktop/VALIOTTI/Reports/Sample\ LaTeX\ Report.pdfЕсли вы все сделали верно и методично, то в итоге получится вот такой отчет! Презентуйте данные красиво 🙂
Как сохранить jupyter notebook в pdf?
[I 23:49:31.834 NotebookApp] Writing 64127 bytes to .\notebook.tex
[I 23:49:31.834 NotebookApp] Building PDF
[I 23:49:31.844 NotebookApp] Running xelatex 3 times: [‘xelatex’, ‘.\\notebook.tex’, ‘-quiet’]
[I 23:49:44.891 NotebookApp] Running bibtex 1 time: [‘bibtex’, ‘.\\notebook’]
[W 23:49:45.240 NotebookApp] b had problems, most likely because there were no citationss
так же в ноутбуке нет русских комментариев, они просто не передались в pdf.
Пробовал pip install -U «notebook
- Вопрос задан более трёх лет назад
- 4334 просмотра
3 комментария
Простой 3 комментария
Основы Pandas №1 // Чтение файлов, DataFrame, отбор данных
Pandas — одна из самых популярных библиотек Python для аналитики и работы с Data Science. Это как SQL для Python. Все потому, что pandas позволяет работать с двухмерными таблицами данных в Python. У нее есть и масса других особенностей. В этой серии руководств по pandas вы узнаете самое важное (и часто используемое), что необходимо знать аналитику или специалисту по Data Science. Это первая часть, в которой речь пойдет об основах.
Примечание: это практическое руководство, поэтому рекомендуется самостоятельно писать код, повторяя инструкции!
Чтобы разобраться со всем, необходимо…
- Установить Python3.7+, numpy и Pandas.
- Следующий шаг: подключиться к серверу (или локально) и запустить Jupyter. Затем открыть Jupyter Notebook в любимом браузере. Создайте новый ноутбук с именем «pandas_tutorial_1».
- Импортировать numpy и pandas в Jupyter Notebook с помощью двух строк кода:
import numpy as np import pandas as pd 
Примечание: к «pandas» можно обращаться с помощью аббревиатуры «pd». Если в конце инструкции с import есть as pd , Jupyter Notebook понимает, что в будущем, при вводе pd подразумевается именно библиотека pandas.
Теперь все настроено! Переходим к руководству по pandas! Первый вопрос:
Как открывать файлы с данными в pandas
Информация может храниться в файлах .csv или таблицах SQL. Возможно, в файлах Excel. Или даже файлах .tsv. Или еще в каком-то другом формате. Но цель всегда одна и та же. Если необходимо анализировать данные с помощью pandas, нужна структура данных, совместимая с pandas.
Структуры данных Python
В pandas есть два вида структур данных: Series и DataFrame.
Series в pandas — это одномерная структура данных («одномерная ndarray»), которая хранит данные. Для каждого значения в ней есть уникальный индекс.
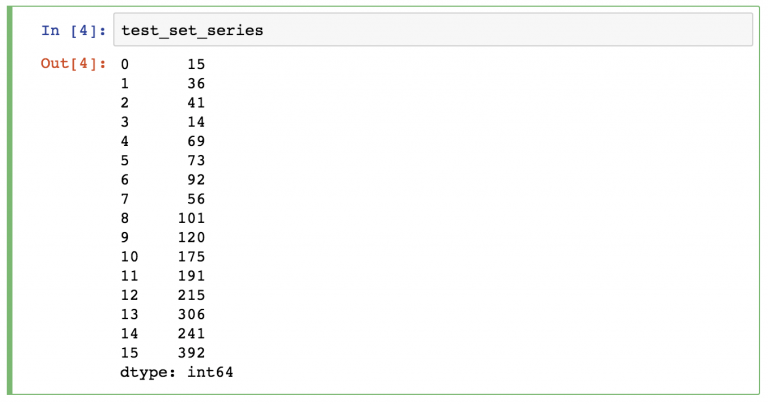
DataFrame — двухмерная структура, состоящая из колонок и строк. У колонок есть имена, а у строк — индексы.
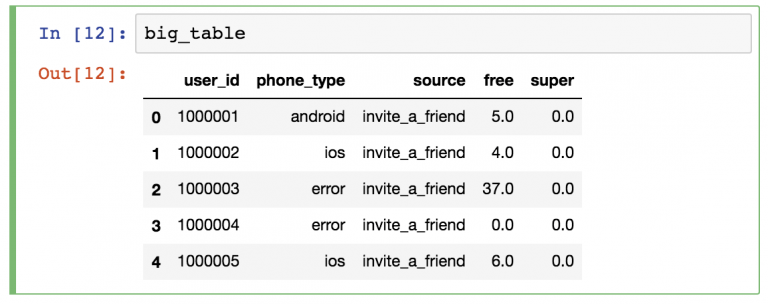
В руководстве по pandas основной акцент будет сделан на DataFrames. Причина проста: с большей частью аналитических методов логичнее работать в двухмерной структуре.
Загрузка файла .csv в pandas DataFrame
Для загрузки .csv файла с данными в pandas используется функция read_csv() .
Начнем с простого образца под названием zoo. В этот раз для практики вам предстоит создать файл .csv самостоятельно. Вот сырые данные:
animal,uniq_id,water_need elephant,1001,500 elephant,1002,600 elephant,1003,550 tiger,1004,300 tiger,1005,320 tiger,1006,330 tiger,1007,290 tiger,1008,310 zebra,1009,200 zebra,1010,220 zebra,1011,240 zebra,1012,230 zebra,1013,220 zebra,1014,100 zebra,1015,80 lion,1016,420 lion,1017,600 lion,1018,500 lion,1019,390 kangaroo,1020,410 kangaroo,1021,430 kangaroo,1022,410 Вернемся во вкладку “Home” https://you_ip:you_port/tree Jupyter для создания нового текстового файла…
затем скопируем данные выше, чтобы вставить информацию в этот текстовый файл…
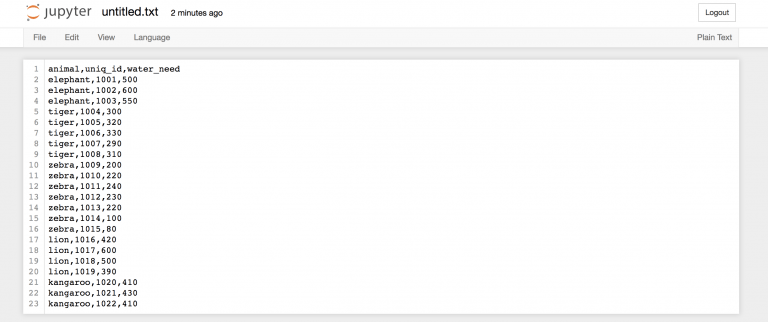
…и назовем его zoo.csv!
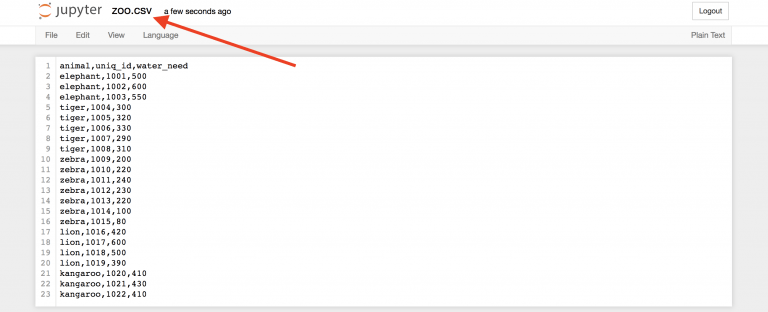
Это ваш первый .csv файл.
Вернемся в Jupyter Notebook (который называется «pandas_tutorial_1») и откроем в нем этот .csv файл!
Для этого нужна функция read_csv()
Введем следующее в новую строку:
pd.read_csv('zoo.csv', delimiter=',') 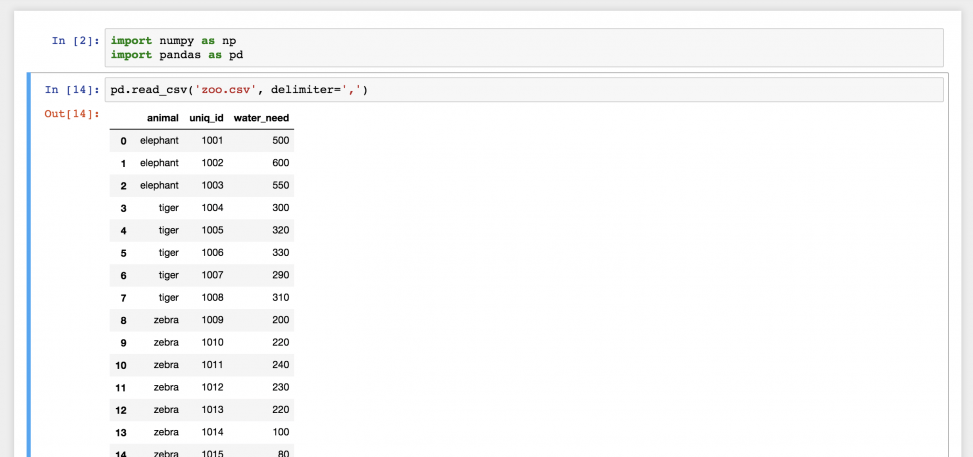
Готово! Это файл zoo.csv , перенесенный в pandas. Это двухмерная таблица — DataFrame. Числа слева — это индексы. А названия колонок вверху взяты из первой строки файла zoo.csv.
На самом деле, вам вряд ли придется когда-нибудь создавать .csv файл для себя, как это было сделано в примере. Вы будете использовать готовые файлы с данными. Поэтому нужно знать, как загружать их на сервер!
Вот небольшой набор данных: ДАННЫЕ
Если кликнуть на ссылку, файл с данными загрузится на компьютер. Но он ведь не нужен вам на ПК. Его нужно загрузить на сервер и потом в Jupyter Notebook. Для этого нужно всего два шага.
Шаг 1) Вернуться в Jupyter Notebook и ввести эту команду:
!wget https://pythonru.com/downloads/pandas_tutorial_read.csv Это загрузит файл pandas_tutorial_read.csv на сервер. Проверьте:
Если кликнуть на него…
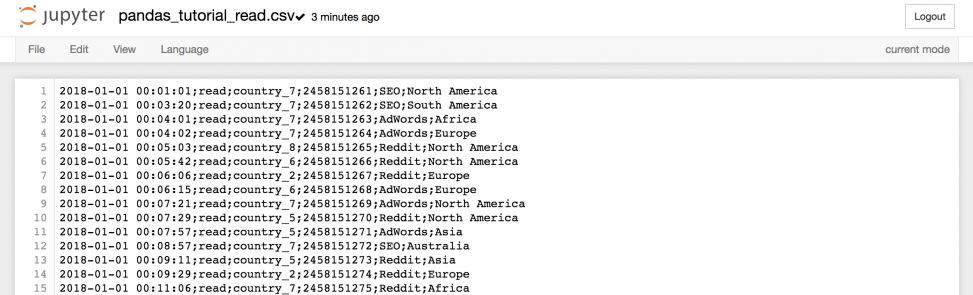
…можно получить всю информацию из файла.
Шаг 2) Вернуться в Jupyter Notebook и использовать ту же функцию read_csv (не забыв поменять имя файла и значение разделителя):
pd.read_csv('pandas_tutorial_read.csv', delimete=';') Данные загружены в pandas!
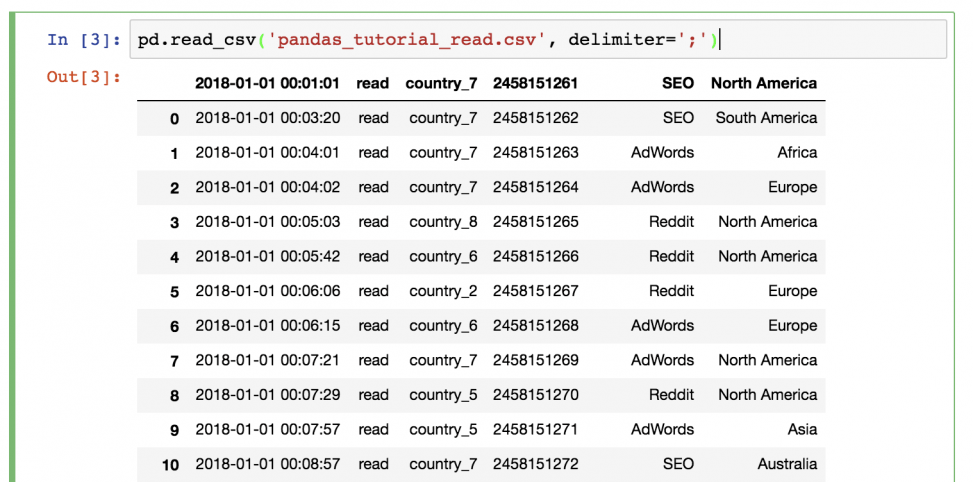
Что-то не так? В этот раз не было заголовка, поэтому его нужно настроить самостоятельно. Для этого необходимо добавить параметры имен в функцию!
pd.read_csv('pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic']) 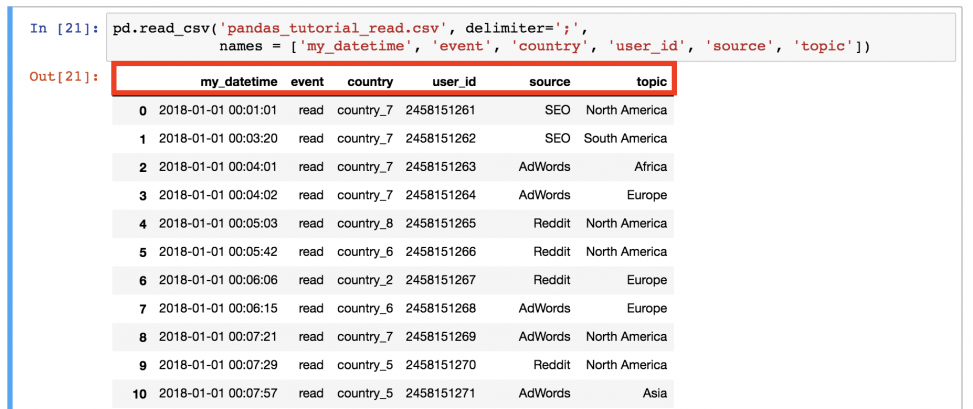
Так лучше!
Теперь файл .csv окончательно загружен в pandas DataFrame .
Примечание: есть альтернативный способ. Вы можете загрузить файл .csv через URL напрямую. В этом случае данные не загрузятся на сервер данных.
pd.read_csv( 'https://pythonru.com/downloads/pandas_tutorial_read.csv', delimiter=';', names=['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) Примечание: если вам интересно, что в этом наборе, то это лог данных из блога о путешествиях. Ну а названия колонок говорят сами за себя.
Отбор данных из dataframe в pandas
Это первая часть руководства, поэтому начнем с самых простых методов отбора данных, а уже в следующих углубимся и разберем более сложные.
Вывод всего dataframe
Базовый метод — вывести все данные из dataframe на экран. Для этого не придется запускать функцию pd.read_csv() снова и снова. Просто сохраните денные в переменную при чтении!
article_read = pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] ) После этого можно будет вызывать значение article_read каждый раз для вывода DataFrame!
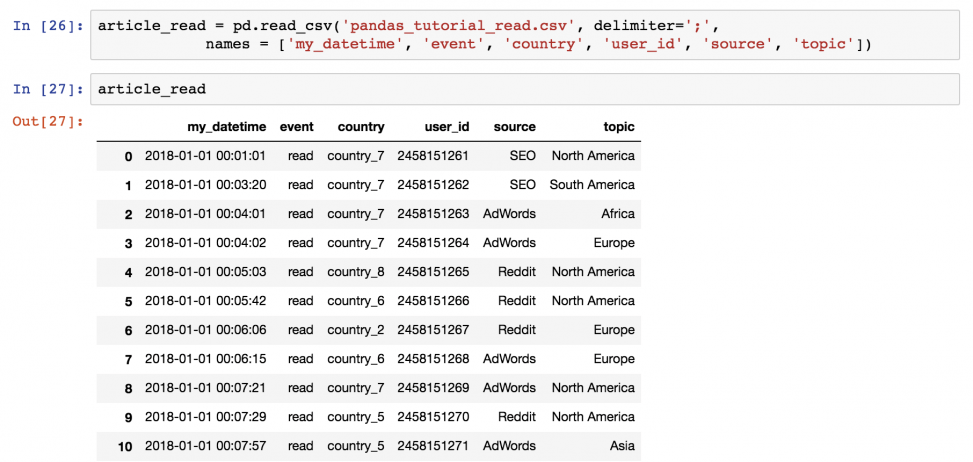
Вывод части dataframe
Иногда удобно вывести не целый dataframe, заполнив экран данными, а выбрать несколько строк. Например, первые 5 строк можно вывести, набрав:
article_read.head() 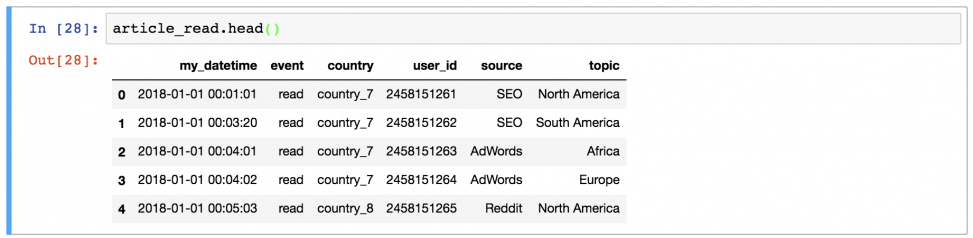
Или последние 5 строк:
article_read.tail() 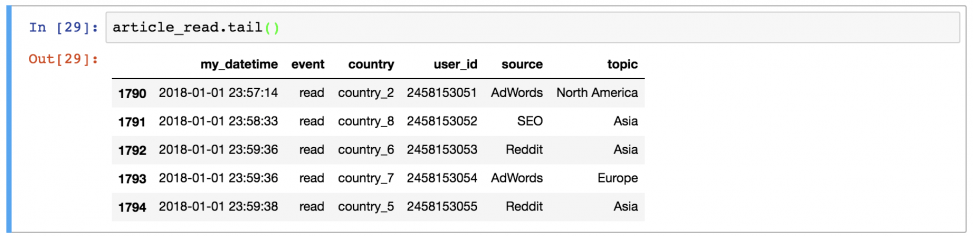
Или 5 случайных строк:
article_read.sample(5) 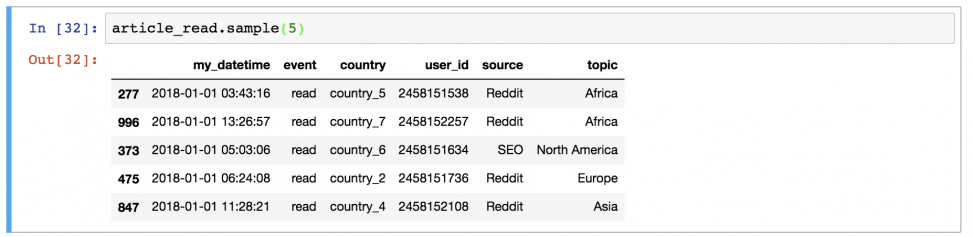
Вывод определенных колонок из dataframe
А это уже посложнее! Предположим, что вы хотите вывести только колонки «country» и «user_id».
Для этого нужно использовать команду в следующем формате:
article_read[['country', 'user_id']] 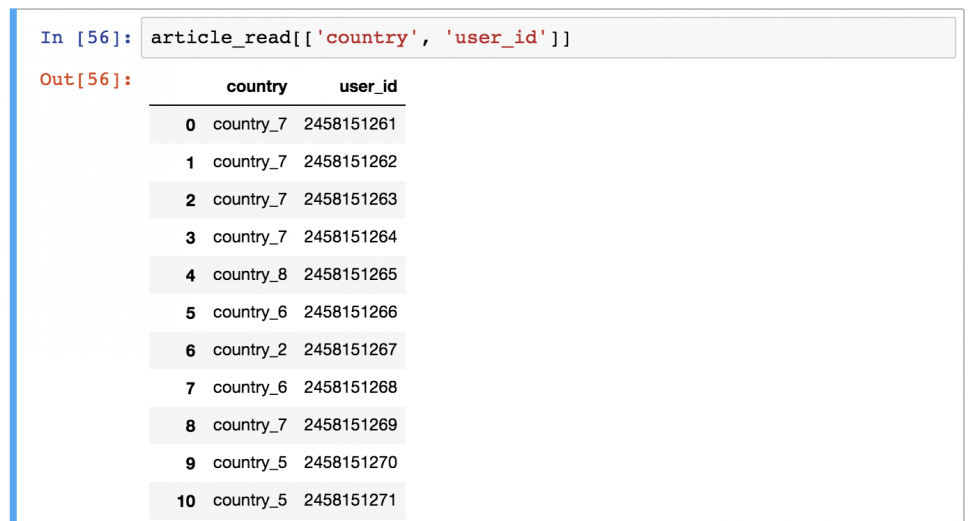
Есть предположения, почему здесь понадобились двойные квадратные скобки? Это может показаться сложным, но, возможно, так удастся запомнить: внешние скобки сообщают pandas, что вы хотите выбрать колонки, а внутренние — список (помните? Списки в Python указываются в квадратных скобках) имен колонок.
Поменяв порядок имен колонов, изменится и результат вывода.
Это DataFrame выбранных колонок.
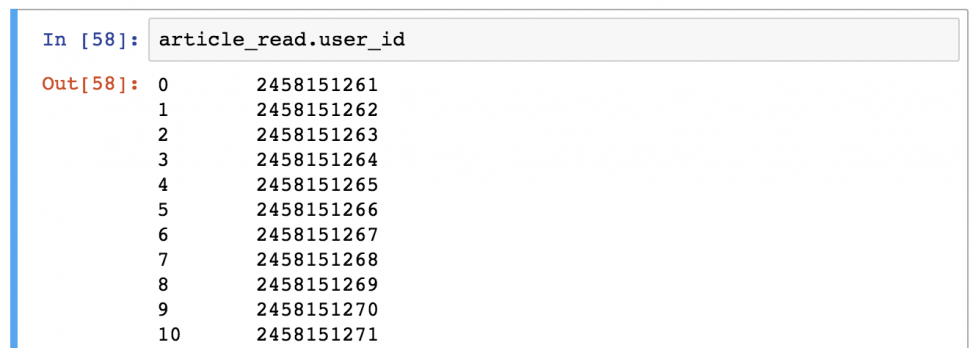
Примечание: иногда (особенно в проектах аналитического прогнозирования) нужно получить объекты Series вместе DataFrames. Это можно сделать с помощью одного из способов:
- article_read.user_id
- article_read[‘user_id’]
Фильтрация определенных значений в dataframe
Если прошлый шаг показался сложным, то этот будет еще сложнее!
Предположим, что вы хотите сохранить только тех пользователей, которые представлены в источнике «SEO». Для этого нужно отфильтровать по значению «SEO» в колонке «source»:
article_read[article_read.source == 'SEO'] Важно понимать, как pandas работает с фильтрацией данных:
Шаг 1) В первую очередь он оценивает каждую строчку в квадратных скобках: является ли ‘SEO’ значением колонки article_read.source ? Результат всегда будет булевым значением ( True или False ).
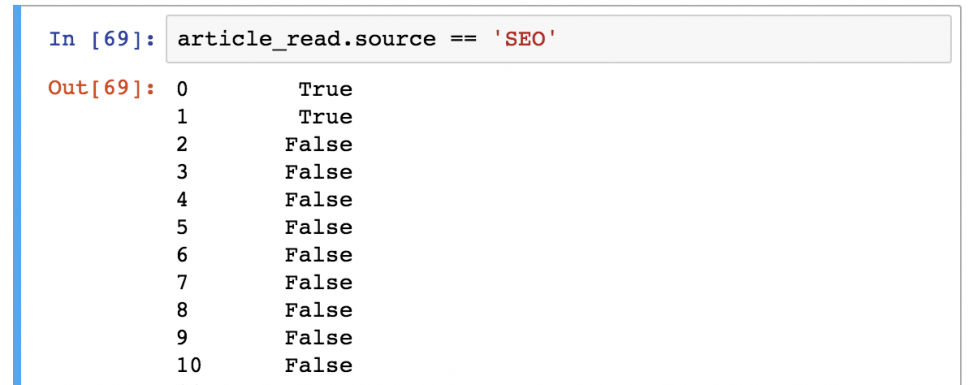
Шаг 2) Затем он выводит каждую строку со значением True из таблицы article_read .
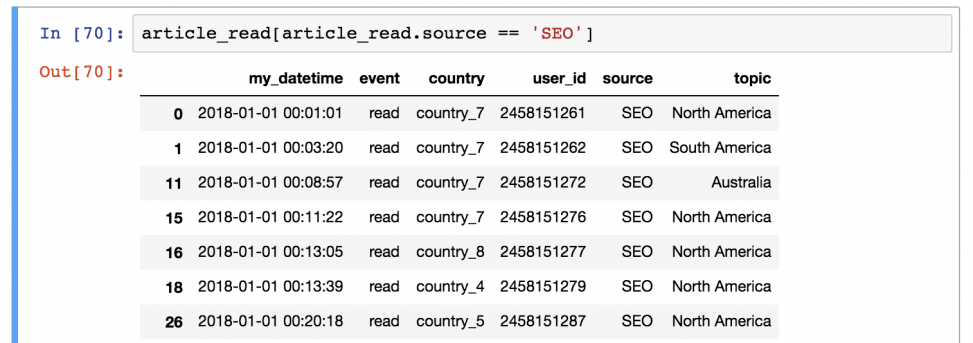
Выглядит сложно? Возможно. Но именно так это и работает, поэтому просто выучите, потому что пользоваться этим придется часто!
Функции могут использоваться одна за другой
Важно понимать, что логика pandas очень линейна (как в SQL, например). Поэтому если вы применяете функцию, то можете применить другую к ней же. В таком случае входящие данные последней функции будут выводом предыдущей.
Например, объединим эти два метода перебора:
article_read.head()[['country', 'user_id']] Первая строчка выбирает первые 5 строк из набора данных. Потом она выбирает колонки «country» и «user_id».
Можно ли получить тот же результат с иной цепочкой функций? Конечно:
article_read[['country', 'user_id']].head() В этом случае сначала выбираются колонки, а потом берутся первые 5 строк. Результат такой же — порядок функций (и их исполнение) отличается.
А что будет, если заменить значение «article_read» на оригинальную функцию read_csv():
pd.read_csv( 'pandas_tutorial_read.csv', delimiter=';', names = ['my_datetime', 'event', 'country', 'user_id', 'source', 'topic'] )[['country', 'user_id']].head() Так тоже можно, но это некрасиво и неэффективно. Важно понять, что работа с pandas — это применение функций и методов один за одним, и ничего больше.
Проверьте себя!
Как обычно, небольшой тест для проверки! Выполните его, чтобы лучше запомнить материал!
Выберите used_id , country и topic для пользователей из country_2 . Выведите первые 5 строк!
А вот и решение!
Его можно преподнести одной строкой:
article_read[article_read.country == 'country_2'][['user_id','topic', 'country']].head() Или, чтобы было понятнее, можно разбить на несколько строк:
ar_filtered = article_read[article_read.country == 'country_2'] ar_filtered_cols = ar_filtered[['user_id','topic', 'country']] ar_filtered_cols.head() В любом случае, логика не отличается. Сначала берется оригинальный dataframe ( article_read ), затем отфильтровываются строки со значением для колонки country — country_2 ( [article_read.country == ‘country_2’] ). Потому берутся три нужные колонки ( [[‘user_id’, ‘topic’, ‘country’]] ) и в конечном итоге выбираются только первые пять строк ( .head() ).
Итого
Вот и все. В следующей статье вы узнаете больше о разных методах агрегации (например, sum, mean, max, min) и группировки.