Добавление файлов с рабочего стола и из папки «Документы» в iCloud Drive
Узнайте, как обеспечить доступ к файлам, находящимся в папках «Рабочий стол» и «Документы» компьютера Mac, со всех ваших устройств с помощью iCloud Drive.
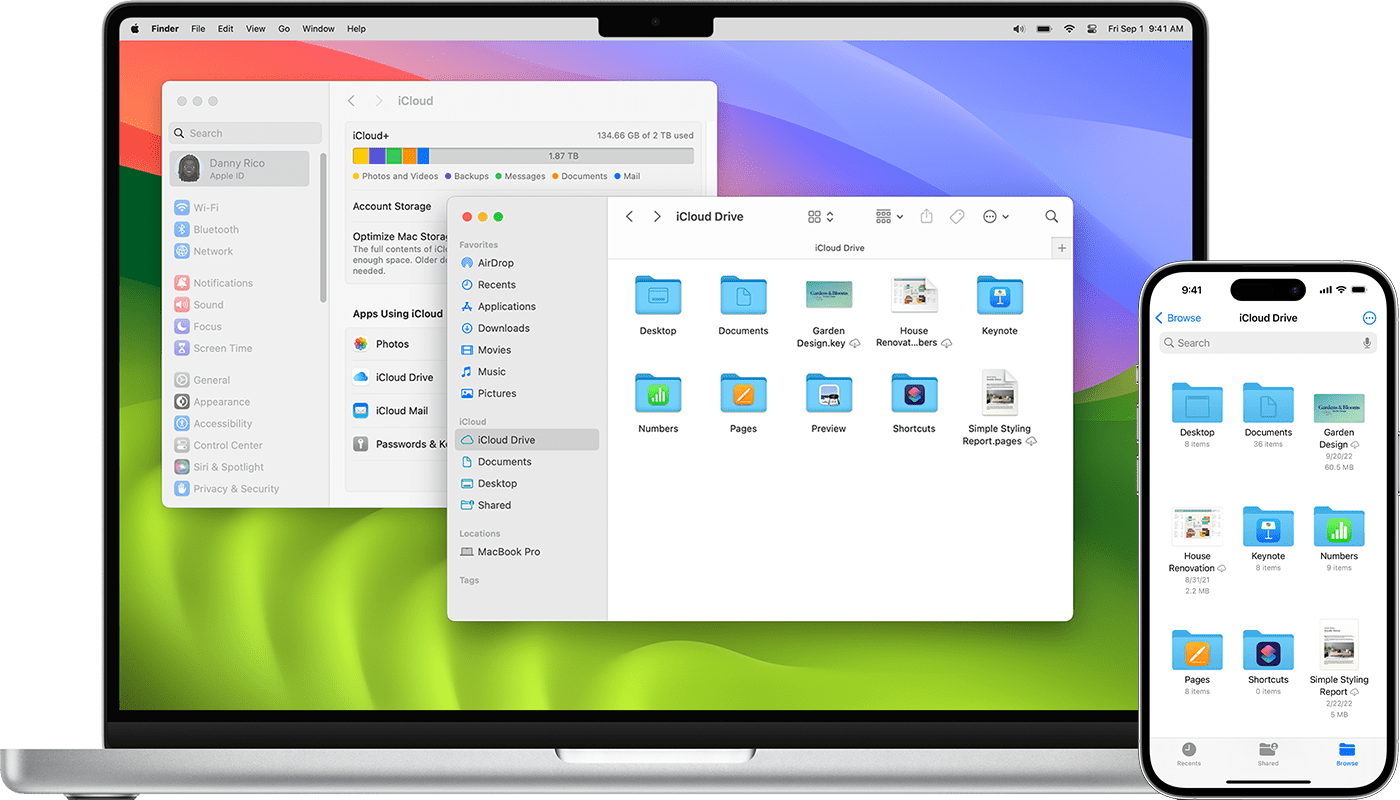
При хранении папок «Рабочий стол» и «Документы» в iCloud Drive получить доступ к файлам на компьютере Mac можно со всех своих устройств. Это означает, что можно начать работу с документом на рабочем столе, а затем продолжить работу с ним на устройстве iPhone или iPad и на веб-сайте iCloud.com. Файлы автоматически обновляются на всех устройствах. Прежде чем начать, убедитесь в том, что iCloud настроен на вашем iPhone или iPad, а также в том, что iCloud настроен на вашем компьютере Mac.
Включение папок «Рабочий стол» и «Документы»
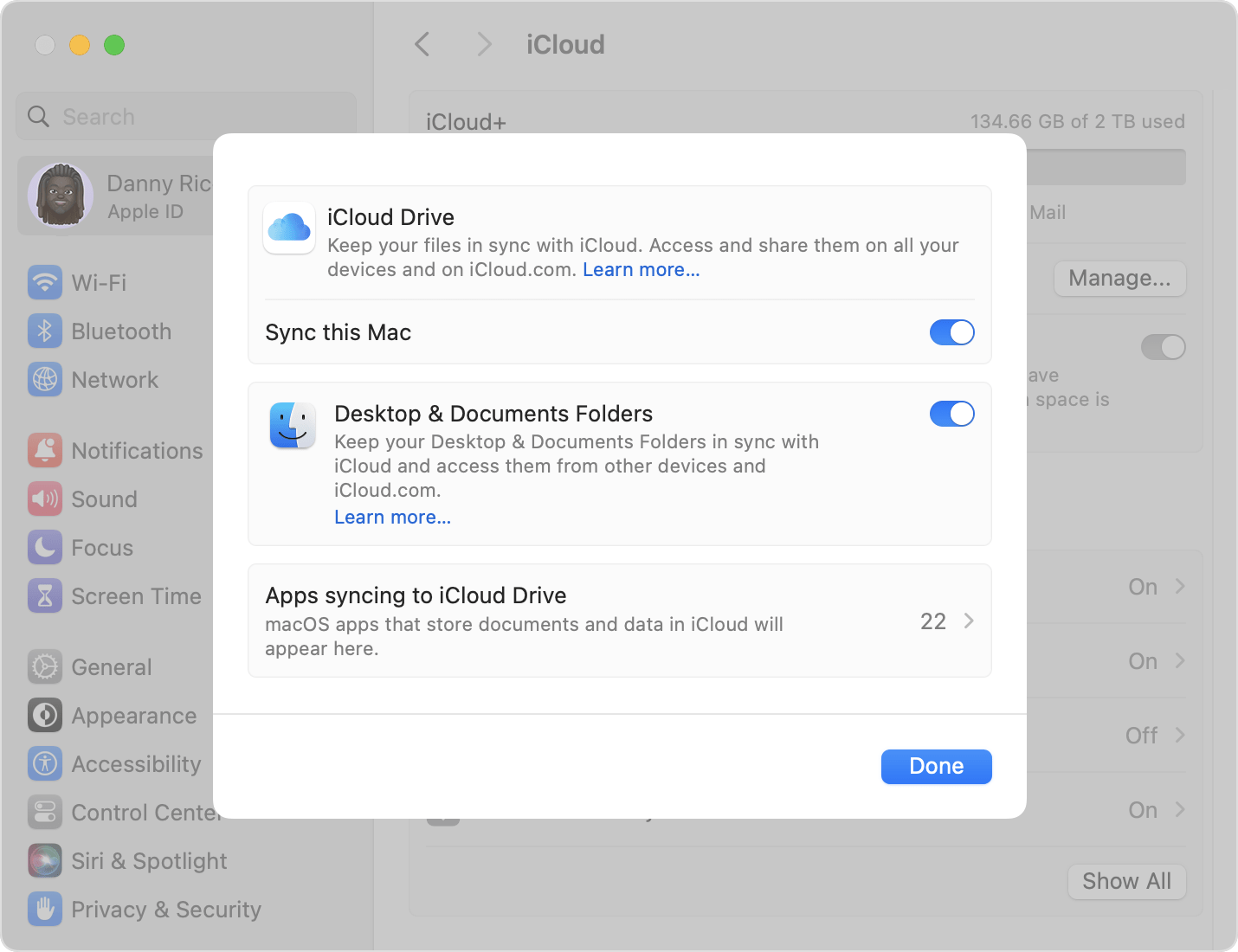
Включите папки «Рабочий стол» и «Документы» на каждом компьютере Mac, который необходимо использовать с iCloud Drive.
- На компьютере Mac откройте меню Apple > «Системные настройки». В macOS Monterey или более ранней версии выберите меню Apple > «Системные настройки».
- Нажмите идентификатор Apple ID, затем нажмите iCloud.
- В разделе «Приложения, использующие iCloud» нажмите «iCloud Drive».
- Под «iCloud Drive» проверьте, включен ли параметр «Синхронизация этого Mac».
- Включите параметр «Папки «Рабочий стол» и «Документы»».
- Нажмите «Готово».
Если вы хотите сохранить свои файлы в iCloud Drive и в другой облачной службе хранилища, можно хранить копии файла в обеих службах, но папки из сторонней облачной службы нельзя хранить в iCloud Drive. Папки других облачных служб можно разместить в другом месте на компьютере Mac, например в домашней папке пользователя.
Если вы уже используете предоставленную другим провайдером облачных сервисов функцию, которая позволяет синхронизировать папки «Рабочий стол» и «Документы» или управлять ими, эту функцию необходимо отключить, чтобы можно было пользоваться папками «Рабочий стол» и «Документы».
Доступ к файлам в папках «Рабочий стол» и «Документы» со всех устройств
При добавлении папок «Рабочий стол» и «Документы» в iCloud Drive все имеющиеся файлы перемещаются в iCloud, а создаваемые файлы автоматически сохраняются в iCloud. Это позволяет находить свои файлы на всех своих устройствах.
Файлы отправляются в iCloud при каждом подключении устройства к интернету. Время, необходимое для отображения файлов на других устройствах, зависит от скорости подключения к интернету.
На компьютере Mac
Папки «Рабочий стол» и «Документы» отображаются в разделе iCloud на боковой панели Finder. Если добавить второй компьютер Mac, эти файлы будут находиться в папке «Рабочий стол» в iCloud Drive. Найдите папку с именем второго компьютера Mac. Имена файлов можно также искать с помощью Spotlight.
На устройстве iPhone или iPad
Файлы находятся в приложении «Файлы». Для доступа к файлам и их редактирования непосредственно с устройства iPhone или iPad можно использовать любое совместимое приложение.
На сайте iCloud.com
- Выполните вход на веб-сайте iCloud.com с использованием идентификатора Apple ID.
- Перейдите в iCloud Drive.
- Дважды щелкните папку «Рабочий стол» или «Документы».
![]()
Если необходимо использовать файл или внести изменения, просто щелкните для его загрузки. После завершения редактирования отправьте файл в iCloud Drive, чтобы его последняя версия появилась на всех устройствах.
Хранение файлов в iCloud и экономия места на устройстве
Файлы, которые хранятся в iCloud Drive, занимают место в вашем хранилище iCloud. И пока объем хранилища iCloud позволяет, вы можете хранить столько файлов, сколько хотите.
Если вам требуется больше места, можно удалить некоторые файлы, чтобы освободить место в iCloud. Если вы используете iCloud Drive и удаляете файл на одном из устройств, этот файл будет удален на всех устройствах, на которых выполнялся вход с тем же идентификатором Apple ID. Удаленные файлы находятся в папке «Недавно удаленные» в приложении «Файлы» или на сайте iCloud.com в течение 30 дней. По истечении этого периода они будут удалены.
Выключение папок «Рабочий стол» и «Документы»
- На компьютере Mac откройте меню Apple > «Системные настройки». В macOS Monterey или более ранней версии выберите меню Apple > «Системные настройки».
- Нажмите идентификатор Apple ID, затем нажмите iCloud.
- В разделе «Приложения, использующие iCloud» нажмите «iCloud Drive».
- Отключите параметр «Папки «Рабочий стол» и «Документы»».
- Нажмите «Готово».
Что будет, если отключить «Рабочий стол» и «Документы»
При отключении папок «Рабочий стол» и «Документы» ваши файлы остаются в iCloud Drive, а в папке пользователя на компьютере Mac создаются новые папки «Рабочий стол» и «Документы». Вы можете перемещать файлы из iCloud Drive на компьютер Mac по мере необходимости или выбрать все свои файлы и перетащить их в необходимое место.
Что будет, если отключить iCloud Drive или выйти из iCloud
Если вы отключите iCloud Drive или выйдете из iCloud, в вашей домашней папке будет создана новая папка «Рабочий стол» и «Документы». Кроме того, вы можете сохранять локальную копию своих файлов, хранящихся в iCloud Drive. Если вы сохраняете локальную копию, ваши файлы из iCloud Drive копируются в папку «iCloud Drive (Архив)» в вашей домашней папке. Вы можете переместить любые файлы, которые были в ваших папках «Рабочий стол» и «Документы» в iCloud, в новые локальные папки «Рабочий стол» и «Документы».
Как сохранять файл в определённую папку?
Вопрос 1: В коде я пометил строку «X1»: Правильно ли я перехожу в папку? Если нет, то как правильно? Вопрос 2: В коде я пометил строку «X2»: Правильно ли я перехожу назад? Если нет, то как правильно? Вопрос 3: Что это за ошибка?
File "c:/Users/mr_do/Desktop/parsing/parsing.py", line 55, in get_content_page with open(f'.jpeg', 'ab') as file: FileNotFoundError: [Errno 2] No such file or directory: 'Б/у Samsung Белый в Бишкек.jpeg' def get_content_page(html): data = <> os.mkdir('images') # создаю папку for i in html: a = get_html(i) # получаю основную страницу soup = BeautifulSoup(a.text, 'html.parser') photo_of_goods = soup.find('div', class_='left-side-carousel').find('img') # нахожу фото. Далее получаю ссылку на фото ниже print(photo_of_goods.get('src')) # для просмотра ссылки with open(f'.jpeg', 'ab') as file: os.chdir(r'\images') # X1 file.write(p:=requests.get(photo_of_goods.get('src')).content) os.chdir(r'../') # X2 return photo_of_goods Как поместить файл в папку?
Здравствуйте. У меня возникла проблема с помещением файла в папку. Я решил написать небольшую интерактивную программку, в которой происходит следующее:
1)Пишем данные которые хотим поместить в файл.
2)Пишем имя и расширение файла.
3)Указываем имя папки в которую сохранить файл с данными.
И вот я не могу поместить новосозданный файл в папку. Прошу вас помочь.
Спасибо.
import os data = input('Введите данные: ') file = input('Введите имя файла в который будут помещены данные: ') expans = input('Введите расширение файла: ') directory = input('Куда вы хотите сохранить файл?:') direc = os.mkdir(directory)#Создаём папку. li = [data]#Помещаем введённые данные в список. f = open(file + '.' + expans, 'a')#Открываем файл с именем и расширением, которые ввели выше. f.write("\nВведённые данные: <>\n\n".format(li[0]))#Записываем данные в файл. f.close()#Закрываем файл.- Вопрос задан более трёх лет назад
- 4459 просмотров
1 комментарий
Оценить 1 комментарий
Работа с файлами
Для открытия файлов в python используется функция open :
file = open("/path/for/your/file.txt", "r")
Она возвращает поток — интерфейс взаимодействия с содержимым файла.
Функция open принимает первым аргументом полное имя файла (с путём, абсолютным или относительным), вторым — режим, в котором мы откроем файл
| Режим | Обозначение |
|---|---|
| ‘r’ | открытие на чтение (является значением по умолчанию). |
| ‘w’ | открытие на запись, содержимое файла удаляется, если файла не существует, создается новый. |
| ‘x’ | открытие на запись, если файла не существует, иначе исключение. |
| ‘a’ | открытие на дозапись, информация добавляется в конец файла. |
| ‘b’ | открытие в двоичном режиме. |
| ‘t’ | открытие в текстовом режиме (является значением по умолчанию). |
| ‘+’ | открытие на чтение и запись |
По умолчанию файл открывается в режиме rt — для чтения в текстовом формате.
Стоит заметить, что файл можно открыть в двух разных форматах: текстовом и бинарном (двоичном). Файлы, открытые в текстовом формате (по умолчанию, или явно добавляя “t” к аргументу режима), обрабатываются Python-ом и возвращаются как строки. При открытии файла в бинарном формате никакой обработки содержимого не производится, содержимое возвращается побайтово.
Таким образом, если мы хотим открыть файл в двоичном формате для записи, надо использовать режим “wb”, если мы хотим дописать содержимое в конец файла в текстовом формате, то — “a” или “at”, “r+b” — открыть двоичный файл на чтение и запись.
Обычно, файлы, в которых содержится текст, например, файлы txt , код вашей программы, файлы формата csv , открываются в текстовом формате, а файлы, которые нельзя проинтерпретировать как текст — в бинарном (например, картинки, музыку). Иногда файлы с текстом открывают в бинарном режиме, для более явного управления всеми спецсимволами (например табуляция ↹).
При открытии файла в текстовом режиме, также можно указать подходящую кодировку. Например, если в вашем файле содержится текст на русском в utf8, откройте его в этой кодировке:
russian_file = open("russian.txt", "r", encoding="utf8")
Как только файл был открыт и у вас появился файловый объект, вы можете получить следующую информацию о нем:
| Атрибут | Значение |
|---|---|
| file.closed | Возвращает True если файл был закрыт. |
| file.mode | Возвращает режим доступа, с которым был открыт файл. |
| file.name | Возвращает имя файла. |
У получаемого объекта есть несколько полезных методов, рассмотрим их.
-
метод read ( n ) позволяет прочитать следующие n символов файла. Замечу, что можно представить, что в нашем объекте файла есть указатель на текущую читаемую позицию. При открытии файла, она ставится в самое начало. По мере чтения, этот указатель сдвигается. Таким образом, если выполнять read ( n ) несколько раз подряд, мы будем получать не первые n символов, а каждый раз новые, n символов.
Если n явно не указать, то считается весь файл целиком (указатель окажется в самом конце файла). Для использования метода read, файл должен быть открыт в режиме для чтения Примечание: чтобы узнать текущее положение указателя внутри файла, можно воспользоваться методом tell () , а чтобы установить указатель в нужное положение pos , используется метод seek ( pos )
file = open("russian.txt", "r", encoding="utf8") #открыли файл, file.tell() == 0, #т.е указатель стоит в самом начале text = file.read() #считали весь файл
Следует сказать, что открытый в любом режиме файл после его использования нужно обязательно закрывать. Делается это методом close(). Посе его выполнения работа с файлом будет корректно завершена, но с нашим объектом файла работать уже тоже будет нельзя — при необходимости повторной работы с файлом нужно снова его открывать при помощи open.
file = open("some_data.txt") text = file.read() file.close() #дальше работаем с text, если надо
Но вдруг в процессе выполнения нашей программы произройдет критическая ошибка и программа завершит свое выполнение, а мы, например, записывали в файл какую-то информацию? Верно, вполне возможно, что последняя добавленная информация в файл так и не запишется. Чтобы избежать такой ситуации, ну и чтобы просто не забывать вовремя вызывать close() используется конструкция with:
with open("text.txt", "w") as out: #в out теперь находится ссылка на наш объект файла, как если #бы было просто out = open("text.txt", "w") for i in range(100): out.write("А я запишу все эти строки в влюбом случае\n") #записываем 100 одинаковых строчек raise Exception #принудительно "вызываем" ошибку. #Об Exceptionах будет дальше в следующих семинарах #в файле все равно будут все 100 нужные строки
Конструкция with используется для того, чтобы гаранировать, что критические действия будут выполнены в любом случае, ее можно использовать и в некоторых других случаях, но в контексте открытия файлов она используется чаще всего.
Я рекомендую по возможности всегда открывать файлы, не зависимо от режима, с конструкцией with!
Через конструкцию with можно открывать сразу несколько файлов:
with open("input.txt", "r") as input, open("output.txt", "w") as output: output.write(input.read()) #скопировали содержимое input в output
- Чтобы считать из файла целую строку, используется метод readline(max_len). Если указать параметр max_len, то будут считаны максимум max_len символов
with open("text.txt", "r") as file: print(file.readline()) #считали и вывели первую строку файла
На самом деле у нашего объекта файла есть итератор, поэтому перебирать строки внутри файла можно с его помощью:
with open("text.txt", "r") as file: for line in file: print(line)
Такой способ чтения наиболее удобен для построчного чтения
Упражнение 1: создайте произвольный текстовый файл с несколькими строками произвольного текста. Выведите в консоль строки файла, удалив лишние пробелы в начале и конце строк, если они есть
Упражнение 2: запишите в новый файл содержимое списка строк (каждую строку с новой строки) без использования цикла
def write_array(array, file_name): """записывает строки из array в файл file_name""" #ваш код здесь pass
Работа с файловой системой
Взаимодействие с файлами не ограничивается только самими файлами, нам часто приходится работать и с папками. Главными героями этого раздела будут библиотеки os и os.path. Они связаны с операционной системой компьютера и позволяют взаимодейстовать с файловой системой.
Все папки директории
os.listdir(dir) перечисялет файлы и папки в указанной директории dir. Если вызвать эту функцию без аргументов, она вернет файлы и папки текущей рабочей директории.
Текущая папка
Относительные пути строятся относительно текущей папки. Чтобы получить абсолютный путь файла из относительного, используется функция os.path.abspath(file_path). Чтобы узнать, какая папка является текущей, можно вызвать функцию os.getcwd(). Для смены текущей папки используется os.chdir(new_dir).
Проверка существования файла или папки и определение, является ли имя файлом или папкой
os.path.exists(file_name) проверяет, существует ли указанный файл (или директория) file_name.
Чтобы проверить, является ли данное имя name файлом или папкой, можно воспользоваться функциями os.isdir(name) или os.isfile(name), которые возвращают True или False.
Рекурсивный обход папок
Одной из самых интересных и мощных функций является функция os.walk(dir) — она позволяет рекурсивно пройтись по всем папкам, подпапкам, их подпапкам и так далее. На самом деле она возвращает генератор (последовательность элементов). Каждый элемент представляеьт собой кортеж из 3х элементов. Первый элемнт — строковое представление директории текущей директории, которую просматривает функция. Вторым элементом — список всех подпапок данной директории, а третьим — список всех файлов этой директории.
for current_dir, dirs, files in os.walk("."): #передаем в качестве аргумента текущую директорию #("." - означает именно ее) print(current_dir, dirs, files) #выведем, что получается
Копирование файлов
Копировать файлы можно при помощи функции copy из модуля shutil
shutil.copy("input.txt", "output.txt")
Копировать папки можно с помощью copytree из того же модуля:
shutil.copytree("test", "test/test2") #Скопирует папку test внутрь неё самой же в подпапку test2
Многие другие функции для работы с файлами и папками вы сможете найти в модулях os и shutil. Теперь вы знаете, где искать нужный функционал 😉
Упражнение 3: Вам дана в архиве файловая структура, состоящая из директорий и файлов.
Вам необходимо распаковать этот архив (средствами языка python), и затем найти в данной в файловой структуре все директории, в которых есть хотя бы один файл с расширением “.py”.
Ответом на данную задачу будет являться файл со списком таких директорий, отсортированных в лексикографическом порядке.
Распространенные форматы текстовых данных
csv
csv является табличным форматом. В нем содержатся значения разделенные запятой (Comma-Separated Values). Например,
first name,last name,module1,module2,module3 Nikolay,Neznaev,0,20,10 Stepan,Sharyashiy,100,99.5,100
Для работы с csv файлами можно воспользоваться библиотекой csv:
import csv with open("example.csv", "r") as file: reader = csv.reader(file) #На основе открытого файла получаем объект из библиотеки csv for row in reader: print(row) #Каждая строка - список значений
В csv.reader параметром delimeter можно передать разделитель значений, таким образом разделяющим символом в файле csv может быть не только запятая.
Для изолирования некоторых значений можно пользоваться двойными кавычками. Библиотека csv учитывает различные мелочи, такие как строки с содержащимися в ней запятыми и переносами строки, различные разделители, поэтому ее использование целесообразнее splitа по разделителю.
Для записи значений в csv формате используется csv.writer:
import csv students = [ ["Greg", "Lebovskiy", 70, 80, 90, "Good job, Greg!"], ["Nick", "Shalopaev", 10, 50, 45, "Shalopaev, you should study better!"] ] with open("example.csv", "a") as file: writer = csv.writer(file) #На основе открытого файла получаем объект из библиотеки csv for student in students: writer.writerow(student) #Записываем строку #Вместо цикла выше мы могли сразу записать все через writer.writerows(students)
JSON
JSON (JavaScript Object Notation) — простой формат обмена данными, удобный для чтения и написания как человеком, так и компьютером. Впервые он был придуман и использован в JavaScript для хранения структур и классов, но быстро обео свою популярность и вышел за пределы своего родителя.
JSON основан на двух структурах данных: * Коллекция пар ключ/значение. В разных языках, эта концепция реализована как объект, запись, структура, словарь, хэш, именованный список или ассоциативный массив. * Упорядоченный список значений. В большинстве языков это реализовано как массив, вектор, список или последовательность.
Это универсальные структуры данных. Почти все современные языки программирования поддерживают их в какой-либо форме. Логично предположить, что формат данных, независимый от языка программирования, должен быть основан на этих структурах.
Объекты в формате SJON хранятся как словари в Python, но с некоторыми деталями: во первых, ключом в json-объекте может быть только строка, значения True и False пишутся с маленькой буквы, значению None соответствует значение null, строки хранятся только внутри двойных кавычек.
Для удобной работы с json файлами в языке python можно использовать библиотеку json
import json student1 = "full_name" : "Greg Martin", "scores" : [100, 85, 94], "certificate" : True, "comment": "Great job, Greg!" > student2 = "full_name" : "John Price", "scores" : [0, 10, 0], "certificate" : False, "comment": "Guns aren't gonna help you here, captain!" > data = [student1, student2] print(json.dumps(data, indent=4, sort_keys=True)) #Делаем отступы в 4 пробела, сортируем ключи в алфавитном порядке
Для получения строкового представления объекта в формате json можно использовать json.dumps(data, **parrams) с различными вспомогательными настройками (пробелы, сортировка и др.)
Для записи в файл можно воспользоваться json.dump(data, file_obj, **params):
with open("output.json", "w") as out: json.dump(data, out, indent=4, sort_keys=True)
Для получения объекта python на основе его срокового представления можно воспользоваться функцией json.loads или json.load для считывания из файла:
json_str = json.dumps(data, indent=4, sort_keys=True) #получение строкового представления json data_again = json.loads(json_str) #получаем объект python print(sum(data_again[0]["scores"])) #убедимся в кореектном считывании: #посчитаем сумму баллов у первого студента with open("output.json") as file: data_from_file = json.load(file) #считаем объект из файла print(sum(data_from_file[0]["scores"])) #аналогично посчитаем сумму баллов
При записи-считывнии объектов из формата json кортежи превращаются в списки # Исключения (материал ниже взят с сайта https://pythonworld.ru/tipy-dannyx-v-python/isklyucheniya-v-python-konstrukciya-try-except-dlya-obrabotki-isklyuchenij.html )
Исключения (exceptions) — ещё один тип данных в python. Исключения необходимы для того, чтобы сообщать программисту об ошибках.
Самый простейший пример исключения — деление на ноль:
100 / 0 Traceback (most recent call last): File "", line 1, in 100 / 0 ZeroDivisionError: division by zero
Разберём это сообщение подробнее: интерпретатор нам сообщает о том, что он поймал исключение и напечатал информацию (Traceback (most recent call last)).
Далее имя файла (File «»). Имя пустое, потому что мы находимся в интерактивном режиме, строка в файле (line 1);
Выражение, в котором произошла ошибка (100 / 0).
Название исключения (ZeroDivisionError) и краткое описание исключения (division by zero).
Разумеется, возможны и другие исключения:
2 + '1' Traceback (most recent call last): File "", line 1, in 2 + '1' TypeError: unsupported operand type(s) for +: 'int' and 'str' int('qwerty') Traceback (most recent call last): File "", line 1, in int('qwerty') ValueError: invalid literal for int() with base 10: 'qwerty'
В этих двух примерах генерируются исключения TypeError и ValueError соответственно. Подсказки дают нам полную информацию о том, где порождено исключение, и с чем оно связано.
Рассмотрим иерархию встроенных в python исключений, хотя иногда вам могут встретиться и другие, так как программисты могут создавать собственные исключения. Данный список актуален для python 3.3, в более ранних версиях есть незначительные изменения.
- BaseException — базовое исключение, от которого берут начало все остальные.
- SystemExit — исключение, порождаемое функцией sys.exit при выходе из программы.
- KeyboardInterrupt — порождается при прерывании программы пользователем (обычно сочетанием клавиш Ctrl+C).
- GeneratorExit — порождается при вызове метода close объекта generator.
- Exception — а вот тут уже заканчиваются полностью системные исключения (которые лучше не трогать) и начинаются обыкновенные, с которыми можно работать.
- StopIteration — порождается встроенной функцией next, если в итераторе больше нет элементов.
- ArithmeticError — арифметическая ошибка.
- FloatingPointError — порождается при неудачном выполнении операции с плавающей запятой. На практике встречается нечасто.
- OverflowError — возникает, когда результат арифметической операции слишком велик для представления. Не появляется при обычной работе с целыми числами (так как python поддерживает длинные числа), но может возникать в некоторых других случаях.
- ZeroDivisionError — деление на ноль.
- IndexError — индекс не входит в диапазон элементов.
- KeyError — несуществующий ключ (в словаре, множестве или другом объекте).
- UnboundLocalError — сделана ссылка на локальную переменную в функции, но переменная не определена ранее.
- BlockingIOError
- ChildProcessError — неудача при операции с дочерним процессом.
- ConnectionError — базовый класс для исключений, связанных с подключениями.
- BrokenPipeError
- ConnectionAbortedError
- ConnectionRefusedError
- ConnectionResetError
- IndentationError — неправильные отступы.
- TabError — смешивание в отступах табуляции и пробелов.
- UnicodeEncodeError — исключение, связанное с кодированием unicode.
- UnicodeDecodeError — исключение, связанное с декодированием unicode.
- UnicodeTranslateError — исключение, связанное с переводом unicode.
Теперь, зная, когда и при каких обстоятельствах могут возникнуть исключения, мы можем их обрабатывать. Для обработки исключений используется конструкция try — except.
Первый пример применения этой конструкции:
try: k = 1 / 0 except ZeroDivisionError: k = 0 print(k)
В блоке try мы выполняем инструкцию, которая может породить исключение, а в блоке except мы перехватываем их. При этом перехватываются как само исключение, так и его потомки. Например, перехватывая ArithmeticError, мы также перехватываем FloatingPointError, OverflowError и ZeroDivisionError.
try: k = 1 / 0 except ArithmeticError: k = 0 print(k)
Также возможна инструкция except без аргументов, которая перехватывает вообще всё (и прерывание с клавиатуры, и системный выход и т. д.). Поэтому в такой форме инструкция except практически не используется, а используется except Exception. Однако чаще всего перехватывают исключения по одному, для упрощения отладки (вдруг вы ещё другую ошибку сделаете, а except её перехватит).
Ещё две инструкции, относящиеся к нашей проблеме, это finally и else. Finally выполняет блок инструкций в любом случае, было ли исключение, или нет (применима, когда нужно непременно что-то сделать, к примеру, закрыть файл). Инструкция else выполняется в том случае, если исключения не было.
f = open('1.txt') ints = [] try: for line in f: ints.append(int(line)) except ValueError: print('Это не число. Выходим.') except Exception: print('Это что ещё такое?') else: print('Всё хорошо.') finally: f.close() print('Я закрыл файл.') # Именно в таком порядке: try, группа except, затем else, и только потом finally.
Чтобы в своей программе вызвать исключение надо воспользоваться командой raise.
Чтобы создать свое собственное исключение, надо унаследоваться от одного из уже существующих классов исключения:
class MyException(Exception): #создали свой класс. Ничего переопределять не обязательно pass raise MyException("My hovercraft is full of eels") #поднятие исключения
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY.