Как исправить ошибку валидации заголовка в файле CRM сегмента в Яндекс.Аудиториях
Яндекс.Аудитории позволяют создавать сегменты не только на основе данных из Яндекса, но и использовать собственные данные. Например, выгрузить список контактов из CRM или ID мобильных устройств. В этой статье поговорим о распространенных ошибках загрузки файлов.
Яндекс.Аудитории помогают настроить показы рекламных объявлений на собственную аудиторию в Яндекс.Директе, Яндекс.Дисплее и ADFOX. Можно задавать сегмент по существующей базе и персонализировать предложения — познакомить клиентов с новым товаром, запустить кросс-продажи или найти похожих клиентов с помощью технологии Look-alike.
Чтобы маркетологу использовать инструментарий, потребуется подготовить файл со списком контактов и загрузить таблицу в Аудитории. Однако, загрузка часто сопровождается ошибками, решение которых не очевидно. Попробуем разобрать популярные ошибки и подготовить файл к загрузке.
Какие ошибки загрузки файлов встречаются
Встречаются две ошибки при загрузке списка с электронными адресами и телефонами:
- Ошибка валидации заголовка в файле CRM сегмента;
- Количество корректных уникальных элементов меньше, чем 1000.
В первом случае предупреждение возникает когда некорректно указан разделитель столбцов или используется неверный формат заголовков столбцов. В записи должно быть хотя бы одно из полей phone или email, а поля записи отделяются друг от друга запятой.
Вторая ошибка более очевидна — загружаемый на сервер документ не соответствует требованием по количество контактов. Исправить проблем легко — нужно расширить число телефонов или эмейлов клиентов до 1 тысячи или более.
В любом случае — перед отправкой файла внимательно проверьте, соответствует ли документ основным рекомендациям Яндекса.
Какие требования Яндекс предъявляет к файлам
Требования к файлам Яндекс описал в официальной справке. Коротко перечислим их и мы:
- Формат файла — CSV;
- Максимальный размер — 1 Гб;
- Требования к формату записей: в первой строке указываются названия полей, отделенные запятой;
- Обязательные поля в записях: phone или email;
- Количество записей — от 1000;
- Кодировка файла — UTF-8 или Windows-1251.
Не забывайте, что в номере телефона нельзя использовать пробелы и дополнительные символы, а в поле email запрещается использовать прописные буквы — используйте только строчные.
Как должен выглядеть правильный список контактов
Правильная таблица с контактами состоит из двух столбцов — phone и email. В номерах телефона запрещено использовать «+», пробелы и круглые скобки, а электронные адреса обязательно в нижним регистре.
Посмотрите на пример таблицы — два столбца с данными.
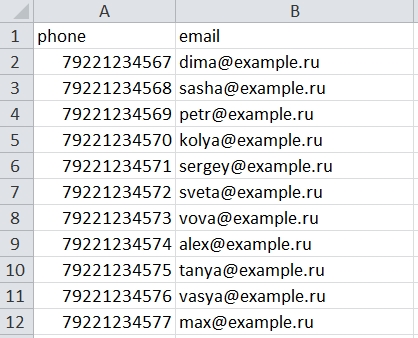
Список должен быть сохранен в формате CSV (разделители — запятые). Такой формат можно выбрать в Excel при сохранении файла.
Однако не все так просто — в Windows файл часто сохраняется по каким-то собственным правилам: в качестве разделителя вместо запятой ставится точка с запятой. Подмена настраивается на уровне операционной системы. Поэтому загрузка завершается неудачей — мы видим надпись «Ошибка валидации заголовка в файле CRM сегмента».
Как исправить ошибку валидации заголовка в файле CRM сегмента
Исправить ошибку можно двумя способами. Первый способ потребует изменений в настройках формата числа операционной системы, во второй случае можно отредактировать поля с помощью блокнота.
Первый вариант устранения проблемы на Windows 10 записан на скринкасте. Ниже найдете подробный путь до нужных настроек.
- В Windows 10: Настройка языка → Дата и время → Формат даты, времени и региона → Дополнительные параметры даты и времени → Изменение форматов даты, времени и чисел → Дополнительные параметры.
- В Windows 7: Панель управления → Часы, язык и регионы → Изменение форматов даты, времени и чисел → Дополнительные параметры.
В поле Разделитель элементов списка вместо точки с запятой укажите запятую и примените настройки.
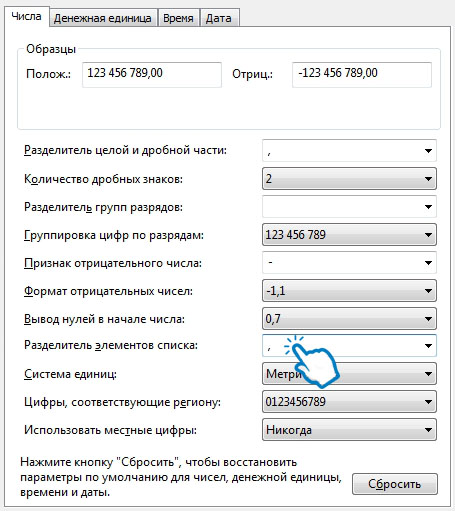
После сохранения вернитесь к исходному файлу с контактами и пересохраните файл в CSV формате еще раз. Если все хорошо, то загрузка списка на сервер Яндекса пройдет без ошибок.
Если же метод не помог и ошибка никуда не делась, то рекомендую открыть документ программой Notepad++ (или стандартным блокнотом Windows) и проверить корректность написания заголовков и разделителей столбцов.
На скриншоте заголовок первого столбца содержит кавычки — удаляем их и сохраняем изменения.
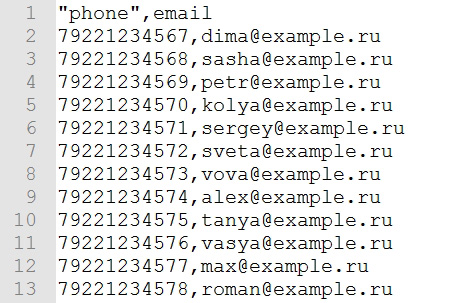
Не забудьте перепроверить корректность разделения столбцов. Во всех строках значения должны разделяться только запятой, но никак не точкой с запятой.
Если все верно, то сохраняйте файл с данными и загрузите ещё раз в Аудитории. Уверен, что теперь все получится.
Загрузить список в формате XLSX получится?
К сожалению, нет. Формат файлов табличного типа XLSX не подойдет для загрузки контактов в Яндекс.Аудитории. Причины очевидны:
- CSV — это стандарт сохранения табличной информации в текстовый файл с разделителями;
- CSV не имеют ограничений по строкам, а вот Excel позволит записать не более 1 миллион строк данных;
- Файлы в CSV могут быть открыты и прочитаны машинами, а также любым текстовым редактором, с XLSX такое невозможно;
- CSV не могут содержать форматированные данные и прочую информацию помимо самих данных.
Заключение
Статья получилась объемной, поэтому в заключение выделю главные правила работы со списками в Яндекс.Аудиториях.
- Внимательно проверяйте заголовки и разделители между значениями в строках;
- Если список готовите в Excel, то для сохранения файла выберите формат CSV (разделители — запятые);
- Проверьте настройки формата разделителя числа в вашей ОС, возможно операционная система по умолчанию проставляет точку с запятой;
- Если проблема не решается — откройте файл блокнотом или Нотпадом и проверьте корректность оформление таблицы;
- Для загрузки используйте формат CSV, а не XLSX.
Надеюсь, что материал оказался полезным. Если остались вопросы, то пишите в комментариях ниже. И не забывайте делиться ссылкой с коллегами.
Что важного в диджитал на этой неделе?
Каждую субботу я отправляю письмо с новостями, ссылками на исследования и статьи, чтобы вы не пропустили ничего важного в интернет-маркетинге за неделю.
Статьи по теме:
- Как отслеживать копирование E-mail с помощью Google Tag Manager
- Как связать Callibri и Google Analytics
- Как конвертировать отчеты AdWords в Google Таблицы
- Как оптимизировать рекламную кампанию с помощью отчета Посещаемость по времени суток
- Как отслеживать копирование Email или номера телефона с помощью Яндекс.Метрики
Автор */ Константин Булгаков —> Опубликовано 12/12/2020 20/02/2023 Рубрики Материалы, Практикум
Яндекс.Аудитории: все возможности с примерами
В рекламной сети Яндекс можно рекламироваться не только на тех, кто уже был на вашем сайте, но и на тех, кто о вас ничего не знает. Это позволяет сделать сервис Яндекс.Аудитории. Благодаря его возможностям можно расширить охват аудитории в несколько раз.
В этой статье мы рассказываем обо всех способах создания сегментов в Яндекс.Аудиториях, как их использовать на конкретных примерах, а также о новых фишках.
Алгоритм создания сегмента
Принцип: вы выбираете, как отбирать аудиторию – из собственной базы, данных системы или внешних. Сервис связывает их с пользователями Яндекса и создает список анонимных идентификаторов. На них вы настраиваете рекламу в РСЯ.
1) Откройте сервис;
2) Нажмите кнопку для создания сегмента:
3) Выберите данные, которые хотите использовать:
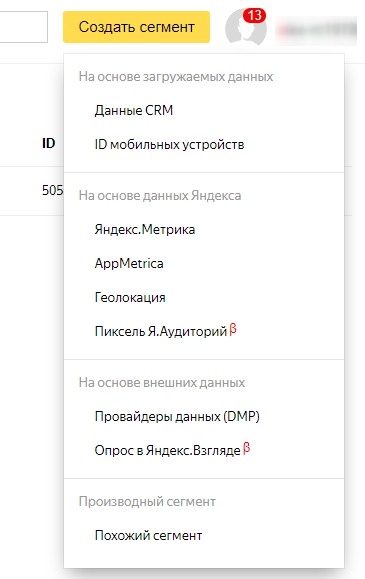
4) Заполните нужные поля в диалоговом окне – подробнее об этом далее;
5) Сервис обрабатывает запрос 1,5-3 часа.
Чтобы настроить показ объявлений в Директе, при его создании или редактировании добавьте условие подбора аудитории на уровне группы объявлений.
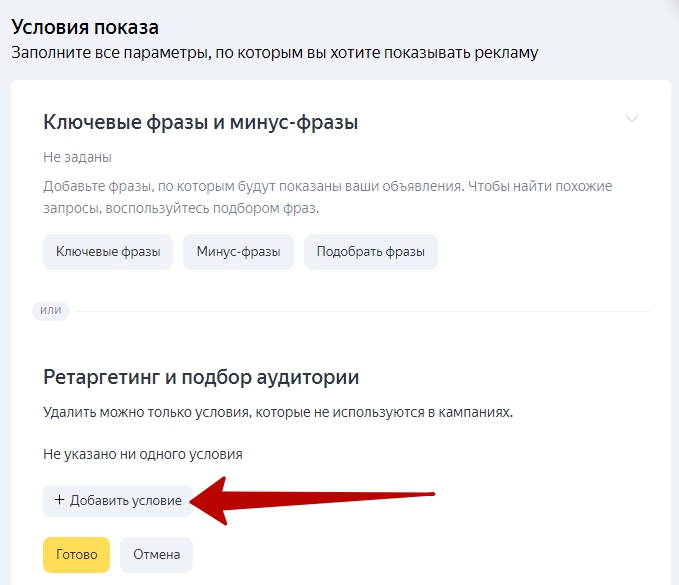
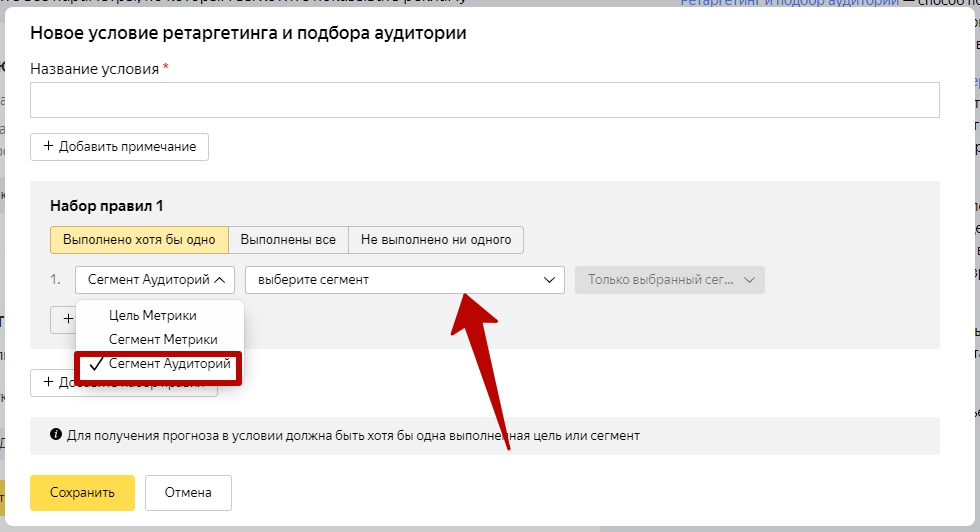
Выберите пункт «Сегмент Аудиторий» и конкретный сегмент:
Цель объявлений – дополнительные или повторные продажи лояльным клиентам, специальные предложения и скидки тем, кто не покупал давно или не завершил заказ на сайте.
Настроить сегмент можно только при условии, что охват в выбранном сегменте – не менее 20 000 уникальных пользователей за последние 28 дней до планируемой даты запуска рекламной кампании.
Далее рассмотрим разные типы сегментов, как их создавать и что учитывать.
Сегмент на основе данных CRM
Используйте этот вариант, если у вас есть контакты целевой аудитории (email, номера телефонов). Их можно выгрузить из CRM, email-рассыльщика и т.д.
Так как Яндекс не проверяет источники и пропускает даже «левые» базы, брать данные для парсинга можно откуда угодно.
Подготовьте список в формате csv.
В файле – не менее 100 записей!
Такой способ подходит, в основном, для средних и крупных рекламодателей. Однако Яндекс идет навстречу: можно создавать сегменты на основе и базы email, и номеров телефонов в одном файле. Так собрать минимальные 100 записей для таргетинга проще.
Заполните название, добавьте файл и отметьте согласие с правилами:
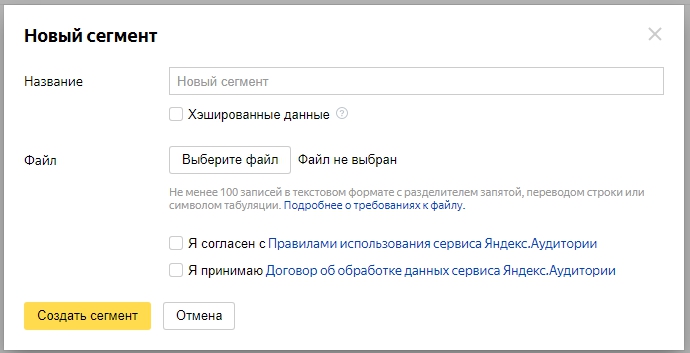
При выборе опции «Хэшированные данные» все поля строк должны быть захэшированы в md5.
Когда всё готово, нажмите желтую кнопку.
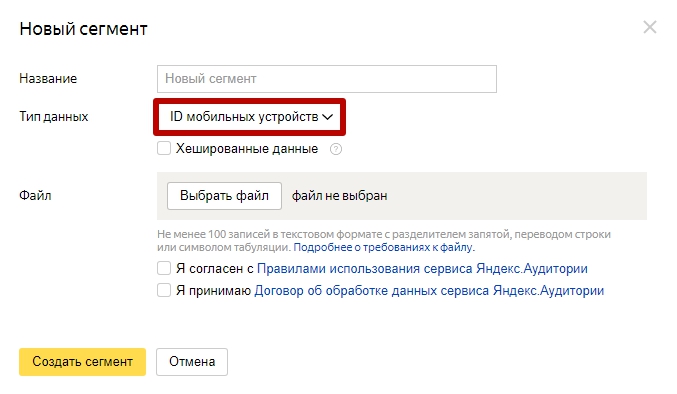
Сегмент на основе ID мобильных устройств
Для этого типа сегмента нужны данные в списке csv или txt.
Необходимый минимум такой же: 100 записей.
Как Яндекс.Аудитории шифруют данные?
Пример: из 3 351 электронных адресов мы получили 15 962 анонимных ID. Это не реальные контакты, а зашифрованные идентификаторы. Поэтому их можно использовать только для настройки рекламы в Яндексе.
За счет чего Аудитории увеличивают охват в разы?
Это те же пользователи из вашего файла, только в разных браузерах, устройствах, мобильных приложениях. Допустим, вы зашли в Яндекс с планшета и с десктопа. Сервис фиксирует 2 контакта.
Здесь работает кросс-браузерный и кросс-девайсный принцип. Не важно, где и с чего зарегистрировался пользователь, Яндекс его везде найдет. Отсюда охват больше, чем количество импортируемых контактов.
Сегмент на основе данных Метрики
Обязательное условие – гостевой доступ на редактирование к счетчику.
Вы можете создавать сегменты по любым параметрам из Метрики: средний чек, срок работы с продуктом, целевое действие.
Укажите название, счетчик и параметры аудитории:
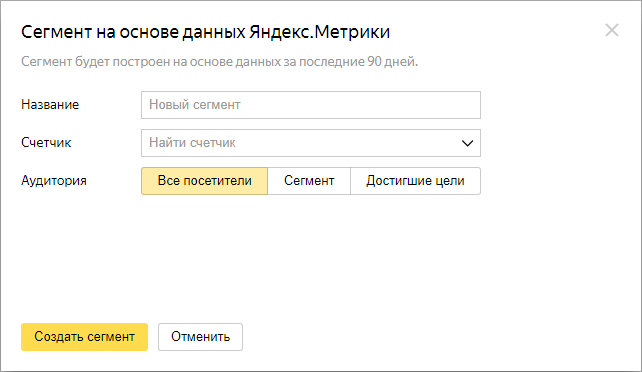
Минимальный охват – 1 000 идентификаторов.
Внимание! Если владелец счетчика закрыл доступ или поменял на гостевой доступ на чтение, показ рекламы для сегмента прекращается.
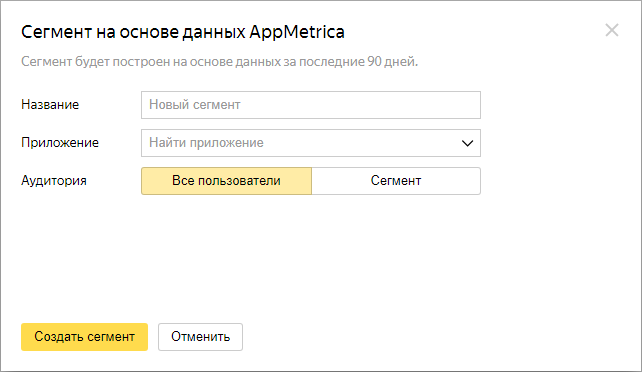
Сегмент на основе данных AppMetrica
Для пользователей мобильного приложения используйте счетчик AppМетрика:
Сегмент на основе геолокации
Вы можете выделить пользователей, которые:
- Находятся в определенном районе сейчас;
- Бывают регулярно;
- Были столько-то дней в течение последней недели, 1 или 3 месяцев.
Как настроить гиперлокальный таргетинг? Есть 2 варианта:
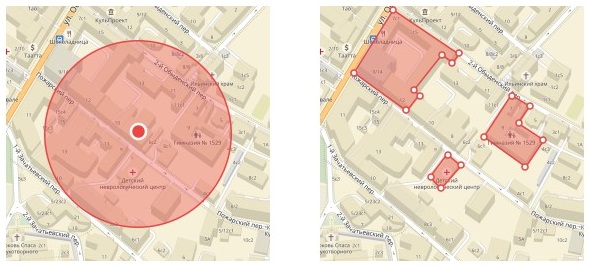
1) Окружности
Выберите способ, как добавить местоположение:
Внимание! Когда вы добавляете список, учитывайте, что удалятся все ранее добавленные места.
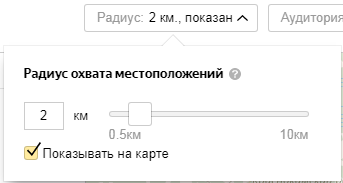
Можете увеличить радиус охвата, чтобы учитывать окрестности:
Отметьте частоту посещений:
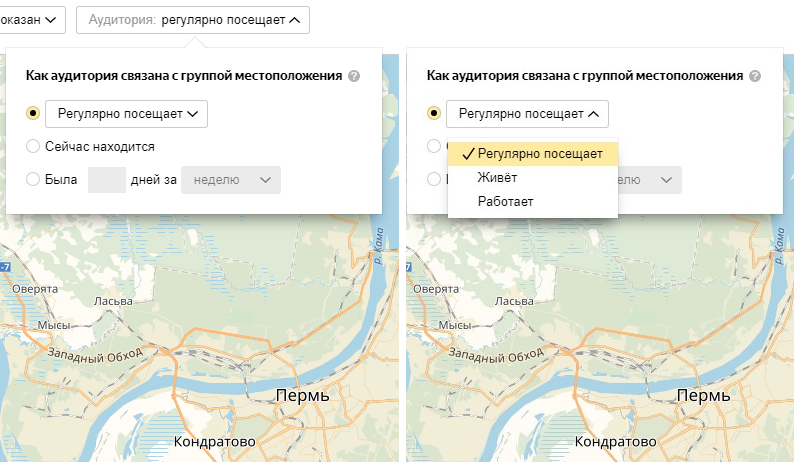
Важно! При первом варианте сегмент определяется по данным за последние 45 дней.
Для третьего условия: несколько посещений за день – это одно посещение.
Ограничение – не более 1 000 мест на сегмент (для условия «N дней за период» – не более 100).
Для одного сегмента невозможно настроить несколько радиусов и настроек посещения.
2) Полигоны
Полигон – новый вариант настройки сегментов по геолокации. На карте вы можете выбрать район с любой конфигурацией, а не только окружность.
Чтобы его задать, отметьте минимум 3 точки. Каждая с предыдущей образует прямую линию. Чтобы удалить точку, дважды кликните по ней. Чтобы завершить построение, нажмите на любую точку и на «Завершить».
Внимание! Стороны не пересекаются. Максимальная площадь – 10 км 2 .
В сегмент можно добавить не более 10 полигонов.
Доступные варианты настройки:
- Регулярно посещает, живет или работает;
- Был N дней за период.
Сегмент на основе пикселя Яндекс.Аудиторий
Код пикселя позволяет отследить, кто видел ваш медиабаннер в сети Яндекса. Не кликал, а просто видел! Достаточно его добавить в этот баннер, и чтобы площадка для размещения это допустила.
В сегмент попадают ID пользователей, которые смотрели рекламные материалы с пикселем внутри за последние 1-90 дней. Дополнительно можно указать, сколько раз.
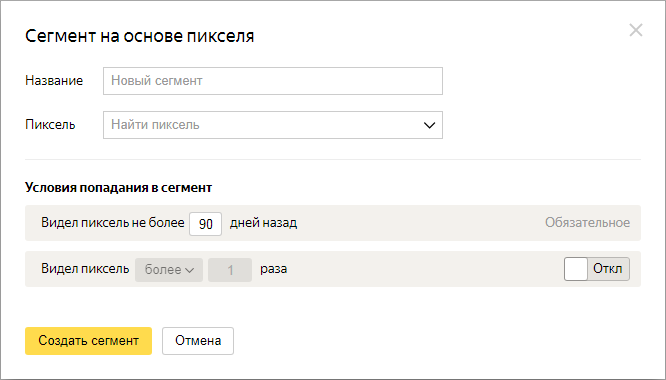
Подходит для рекламодателей с большими объемами трафика.
Сегмент на основе данных провайдеров (DMP – Data Management Platforms)
На ваш выбор – данные мировых баз по возрасту, полу, интересам и т.д. по разной стоимости (CPM – стоимость за тысячу показов) и с разным охватом. Некоторые бесплатные.
Этот источник можно применять только для рекламы в ADFOX.
Подробную информацию о сегментах можно запросить у провайдеров.
Для сегмента этого типа нельзя смотреть статистику, создавать похожий или давать доступ другим пользователям.
Если провайдер данных отключает или удаляет сегмент, он больше недоступен. Рекламные кампании с ним приостанавливаются после 30 дней с этого момента.
Если провайдер отменяет доступ к сегменту, вы увидите статус «Ошибка».
Сегмент на основе данных Опроса в Яндекс.Взгляде
Создать сегмент можно также по данным опроса в Яндекс.Взгляде. Как работать с этим сервисом, мы рассказывали в этой статье.
Если вы пока не создавали опрос, ссылка в Яндекс.Аудиториях приведет вас на страницу создания.
Похожий сегмент (на основе look-alike)
Можно расширить охват за счет пользователей с такими же интересами и поведением в сети, как у отдельного сегмента вашей ЦА.
Используйте эту кнопку рядом с нужным сегментом:
Важно! Технологию Look-alike можно применять только к сегментам, которые вы сами создали.
Либо идите по стандартному пути:
По нашему тестовому сегменту в 15 962 элементов сервис собрал охват в 600 000.
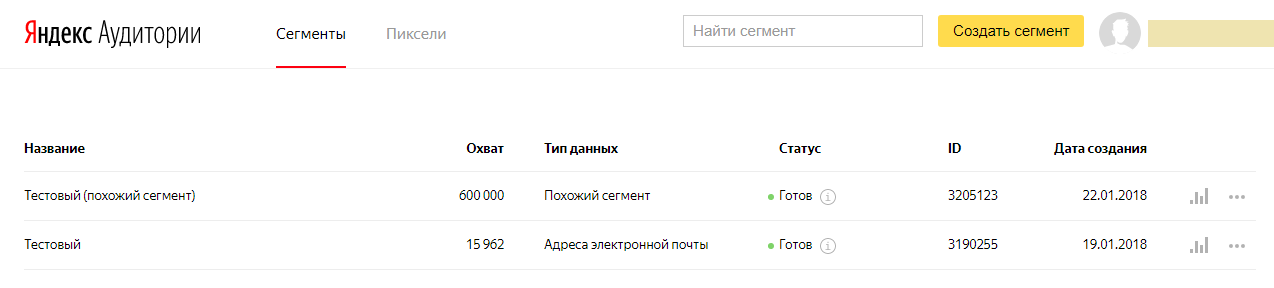
Совет: при подборе выбирайте точность вместо охвата. Так объем аудитории меньше, но выше вероятность, что именно эти пользователи конвертируются в клиентов.
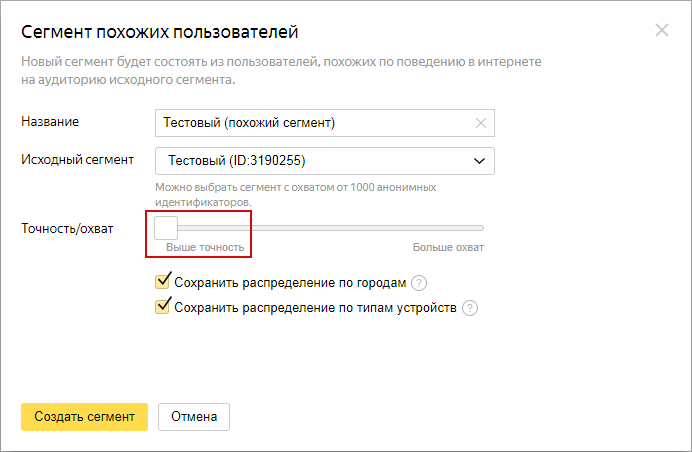
По умолчанию распределение по городам и типам устройств сохраняется. Например, если половина пользователей – владельцы Nokia, остальные – LG, в новом сегменте будет так же.
Если база Яндекса не позволяет сохранить исходное распределение, сервис при поиске не учитывает города и устройства.
Примеры использования Яндекс.Аудиторий
Сегмент на основе загружаемых данных
Можно спарсить email-адреса застройщиков из 2ГИС и отправить их в кейс как увеличить заявки на покупку элитного жилья на 125% за 1 месяц (идея из нашей практики).
Или даже из ВКонтакте. С помощью парсера (допустим, Target Hunter) можно собрать телефоны / емэйлы подписчиков из определенного сегмента. Например, мам детей до 3 лет для продажи детской одежды.
Учитывайте, что в данных из ВК будет значительная доля «мусора». В полях телефон / емэйл пользователи сети часто пишут абракадабру, либо левые номера. Однако, попробовать стоит.
Похожая аудитория
Чем специфичнее у вас продукт, тем вероятнее, что люди с похожими интересами им заинтересуются.
Сегмент на основе данных Метрики
Можно настроить показы на пользователей, которые в прошлом совершали покупки на большие чеки, но давно не заходили в интернет-магазин или не запускали приложение.
Пример: напоминание об окончании действия ОСАГО для автомобилистов или о техобслуживании для клиентов дилерских центров.
Сегмент на основе геолокации
Что важно для аудитории? Чем ближе, тем лучше. Это относится к парикмахерским, кафе, фитнес-клубам, сервисам доставки еды, автомойкам, мастерским по ремонту телефонов и т.д.
Поэтому так и пишите в объявлении: мы рядом, в стольки-то минутах от вас.

- Указывайте местоположение в заголовке и тексте объявления;
- Используйте корректировку ставок по геотаргетингу в поиске;
- Сегментируйте рекламные кампании по радиусу действия;
- Объединяйте соседние адреса в один радиус;
- Не используйте слишком маленькие радиусы;
- Разделяйте мобильный и десктопный трафик.
Более подробно о всех возможностях гиперлокального таргетинга — как его настраивать в Яндексе, Google, ВКонтакте — мы рассказали в этой статье.
Сегмент на основе пикселя Яндекс.Аудиторий
Что делать с этой аудиторией?
1) Корректировать ставки на поиске.
2) Запустить ретаргетинг – «догонять» в РСЯ тех, кто видел баннеры в медийной сети.
Полученный сегмент можно совмещать с другими для более точного ретаргетинга. Допустим, выделить пользователей, которые видели медийный баннер и часто бывают в определенном районе. Или относятся к похожей аудитории по конкретному признаку (стиль жизни, интересы, профессия).
Главное, не перегибайте палку: слишком узкий таргетинг не приносит ощутимых результатов.
Сегмент на основе данных из внешних источников
Где взять данные о ЦА, если у вас бизнес в оффлайне? Варианта 2:
- Частные базы Яндекс.Аудиторий. У сервиса найдутся выборки для любой тематики в B2B.
Внимание! Не повторяйте такое с базой конкурентов, так как это, как минимум, не принесет лояльных откликов, как максимум – нелегально.
- «Купите» трафик близких по тематике ресурсов. Это могут быть сайты MFA (made-for-adsense), цель которых – получение поискового трафика для монетизации через рекламные блоки РСЯ или AdSense, форумы или нужные разделы новостных порталов. Попросите владельцев сделать аудиторию из целевого для вас трафика, в зависимости от охвата сегмента. Они от этого только в плюсе, так как это дополнительный заработок.
Другие фишки сервиса
1) Степень схожести пользователей
Сегмент в Аудиториях можно строить по уровню схожести пользователей. Насколько одинаково они ведут себя в сети как по сравнению с исходным сегментом, так и между собой. Чем больше сходства, тем лучше сработает на нем технология look-alike.
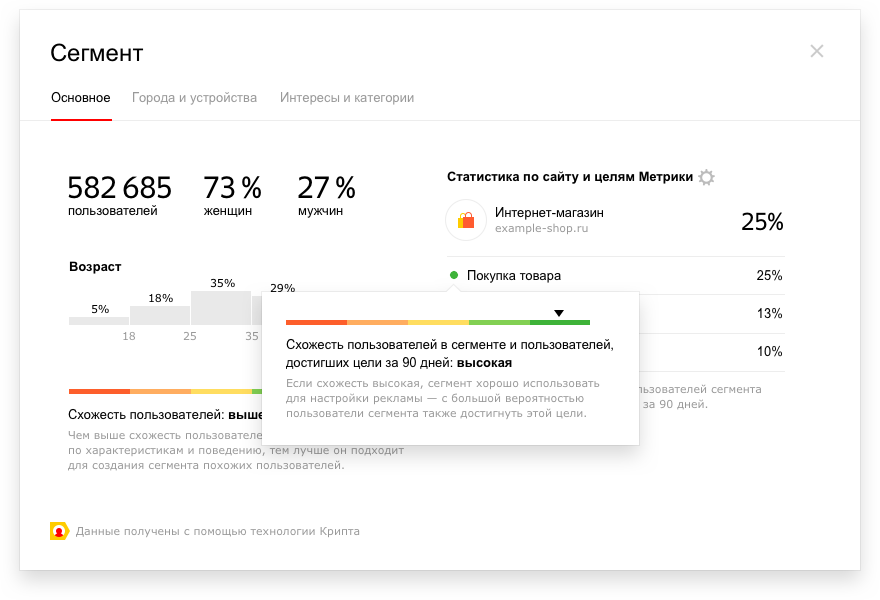
Рекомендация: применяйте look-alike для построения аудитории с четко выраженными интересами. Допустим, вы организуете вебинары для маркетологов. Эта публика отличается по своим интересам от всех пользователей Рунета. А вот пластиковые окна заказывает кто угодно, и создавать из этого сегмента похожую аудиторию бессмысленно.
2) Полигоны в гиперлокальном таргетинге
Выбор области показа рекламы стал максимально гибким. Теперь можно прицельнее таргетировать аудиторию и экспериментировать с текстами и форматами на разных территориях.
Новая опция позволяет выбирать жителей конкретного квартала, посетителей торгового центра или стадиона, студентов и при этом исключать нерелевантную территорию. Например, ближайшую трассу или железную дорогу. И наоборот: если это для вас целевая аудитория, можно включить в сегмент определенный участок дороги.
Как построить полигон, мы рассказали в разделе «Сегмент на основе геолокации».
3) Пиксель Аудиторий
Он позволяет отслеживать не только тех, кто кликнул по баннеру, но и тех, кто просто его видел.
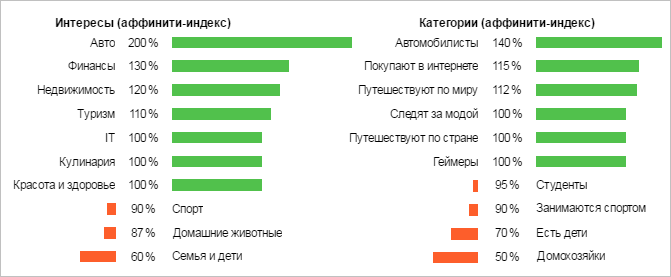
4) Графики «Интересы» и «Категории»
Вы увидите, насколько интересы аудитории из вашего сегмента отличаются от интересов среднестатистических пользователей Рунета. 100% – то же самое, что «среднее по больнице», а 140% говорят о повышенном интересе.
Также алгоритм помогает определить категорию, которая преобладает в сегменте.
5) Интеграция с аналитикой
Теперь вы можете отслеживать число представителей сегмента, которые посещали сайт / открывали приложение и достигали целей за последние 90 дней. Достаточно привязать счетчик Яндекс.Метрики / AppМетрики.
Это помогает оценить эффективность таргетинга на этот сегмент.
Сегменты в Яндекс.Метрике: создание и применение
6) Обучаемые сегменты
Также в сервисе есть возможность построить обучаемые сегменты – сегменты на основе пользовательских данных.
От всех остальных они отличаются тем, что помогают определить, что для конкретного бизнеса является «хорошей» конверсией, а что – «неудачной». «Хорошие» конверсии – это сегменты потенциальных клиентов, которые максимально готовы к совершению целевого действия.
На обучаемые сегменты, как и на любые другие из Яндекс.Аудиторий, можно настраивать показы рекламы и добавлять корректировки ставок.
Специалисты Яндекса разработали этот механизм на основе математической модели. которую вывели в результате исследования рекламодателей из разных сфер деятельности: медицины, путешествий, юриспруденции и других. Каждый предоставил данные по 50 тысяч идентификаторов конверсий разного качества.
Кейс от Яндекса: отель «Имеретинский» в Сочи смог повысить отдачу от рекламы на поиске. И это в самом конце сезона и в условиях неопределенности на рынке туризма. Вот рекламное объявление.
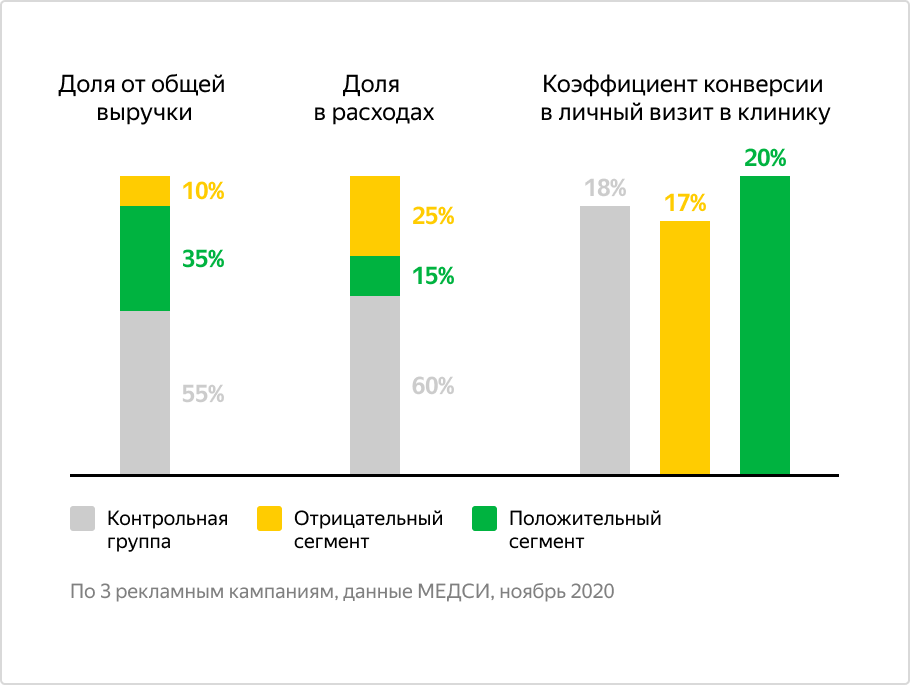
Что сделали?
Настроили повышающие и понижающие корректировки ставок для аудиторий с высокой и низкой вероятностью конверсии соответственно.
В результате получили на 13% больше конверсий по цели «Бронь», а средний показатель CPA упал в 2 раза. Показатель конверсий вырос на 35%.
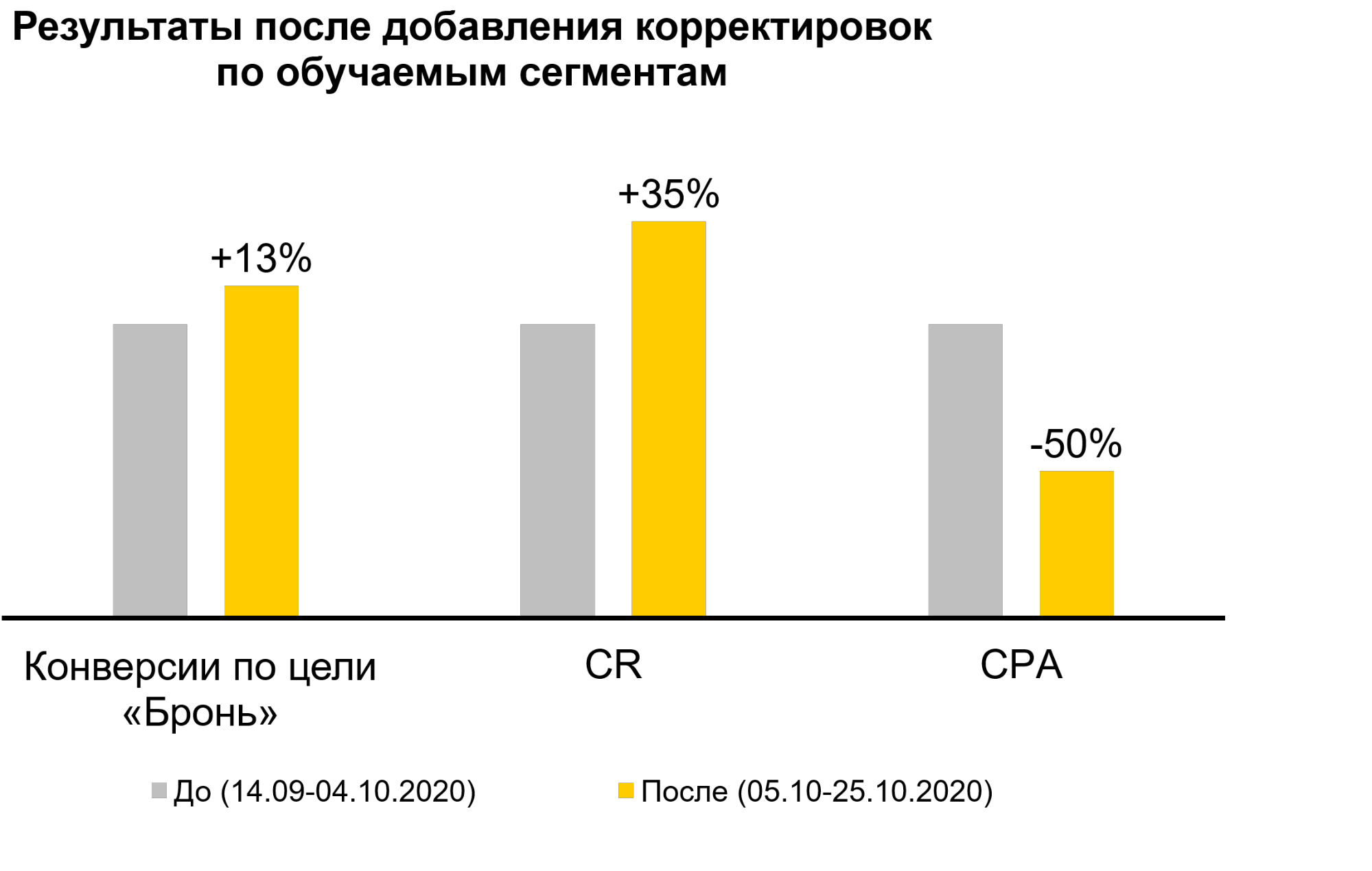
Пока эта функция доступна в открытой бете. Поучаствовать в тестировании может каждый, у кого собрано минимум 50 тысяч конверсий за последние 2 года. Естественно, чем больше данных – тем полезнее сегмент будет для решения задач.
Второе условие – понятные шаги воронки продаж. Посетил сайт – оставил заявку – оплатил заказ. И всё в этом роде.
Чтобы протестировать обучаемые сегменты, нужно передать от 50 тысяч идентификаторов конверсий в хешированном виде, одним из 3 доступных способов:
Web, кэширование и memcached

Эта статья была написана на основе материалов одноименного доклада на конференции HighLoad++ (2008). Для начала, о названии статьи: в статье пойдет речь и о кэшировании в Web’е (в высоконагруженных Web-проектах), и о применении memcached для кэширования, и о других применениях memcached в Web проектах. То есть все три составляющие названия в различных комбинациях будут освещены в этой статье.
Кэширование сегодня является неотъемлемой частью любого Web-проекта, не обязательно высоконагруженного. Для каждого ресурса критичной для пользователя является такая характеристика, как время отклика сервера. Увеличение времени отклика сервера приводит к оттоку посетителей. Следовательно, необходимо минимизировать время отклика: для этого необходимо уменьшать время, требуемое на формирование ответа пользователю, при этом для формирования ответа пользователю необходимо получить данные из каких-то внешних ресурсов (backend). Этими ресурсами могут быть как базы данных, так и любые другие относительно медленные источники данных (например, удаленный файловый сервер, на котором мы уточняем количество свободного места). Для генерации одной страницы достаточно сложного приложения нам может потребоваться совершить десятки подобных обращений. Многие из них будут быстрыми: 20 мс и меньше, однако всегда существует некоторое небольшое количество запросов, время вычисления которых может исчисляться секундами или минутами (даже в самой оптимизированной системе они могут быть, хотя их количество должно быть мини мально). Если сложить всё то время, которое мы затратим на ожидание результатов запросов (если же мы будем выполнять запросы параллельно, то возьмем время вычисления самого долгого запроса), мы получим неудовлетворительное время отклика.
Решением этой задачи является кэширование: мы помещаем результат вычислений в некоторое хранилище (например, memcached), которое обладает отличными характеристиками по времени доступа к информации. Теперь вместо обращений к медленным, сложным и тяжелым backend’ам нам достаточно выполнить запрос к быстрому кэшу.
Memcached и кэширование
Принцип локальности
Кэш или подход кэширования мы встречаем повсюду в электронных устройствах, архитектуре программного обеспечения: кэш ЦП (первого и второго уровня), буферы жесткого диска, кэш операционной системы, буфер в автомагнитоле. Чем же определяется такой успех кэширования? Ответ лежит в принципе локальности: программе, устройству свойственно в определенный промежуток времени работать с некоторым подмножеством данных из общего набора. В случае оперативной памяти это означает, что если программа работает с данными, находящимися по адресу 100, то с большей степенью вероятности следующее обращение будет по адресу 101, 102 и т.п., а не по адресу 10000, например. То же самое с жестким диском: его буфер наполняется данными из областей, соседних по отношению к последним прочитанным секторам, если бы наши программы работали в один момент времени не с некоторым относительно небольшим набором файлов, а со всем содержимым жесткого диска, буфер жесткого диска был бы бессмысленным. Буфер автомагнитолы совершает упреждающее чтение с диска следующих минут музыки потому, что мы, скорее всего, будем слушать музыкальный файл последовательно, а не перескакивать по набору музыки и т.п.
В случае web-проектов успех кэширования определяется тем, что на сайте есть всегда наиболее популярные страницы, некоторые данные используются на всех или почти на всех страницах, то есть существуют некоторые выборки, которые оказываются затребованы гораздо чаще других. Мы заменяем несколько обращений к backend’у на одно обращение для построения кэша, а затем все последующие обращения будем делать через быстро работающий кэш.
Кэш всегда лучше, чем исходный источник данных: кэш ЦП на порядки быстрее оперативной памяти, однако мы не можем сделать оперативную память такой же быстрой, как кэш – это экономически неэффективно и технически сложно. Буфер жесткого диска удовлетворяет запросы за данными на порядки быстрее самого жесткого диска, однако буфер не обладает свойством запоминать данные при отключении питания – в этом смысле он хуже самого устройства. Аналогичная ситуация и с кэшированием в Web’е: кэш быстрее и эффективнее, чем backend, однако он обычно в случае перезапуска или падения сервера не может сохранить данные, а также не обладает логикой по вычислению каких-либо результатов: он умеет возвращать лишь то, что мы ранее в него положили.
Memcached
Memcached представляет собой огромную хэш-таблицу в оперативной па мяти, доступную по сетевому протоколу. Он обеспечивает сервис по хранению значений, ассоциированных с ключами. Доступ к хэшу мы получаем через простой сетевой протокол, клиентом может выступать программа, написанная на произвольном языке программирования (существуют клиенты для C/C++, PHP, Perl, Java и т.п.)
Самые простые операции – получить значение указанного ключа (get), установить значение ключа (set) и удалить ключ (del). Для реализации цепочки атомарных операций (при условии конкурентного доступа к memcached со стороны параллельных процессов) используются дополнительные операции: инкремент/декремент значения ключа (incr/decr), дописать данные к значению ключа в начало или в конец (append/prepend), атомарная связка получения/установки значения (gets/cas) и другие.
Memcached был реализован Брэдом Фитцпатриком (Brad Fitzpatrick) в рамках работы над проектом ЖЖ (LiveJournal). Он использовался для разгрузки базы данных от запросов при отдаче контента страниц. Сегодня memcached нашел своё применение в ядре многих крупных проектов, например, Wikipedia, YouTube, Facebook и другие.
Общая схема кэширования
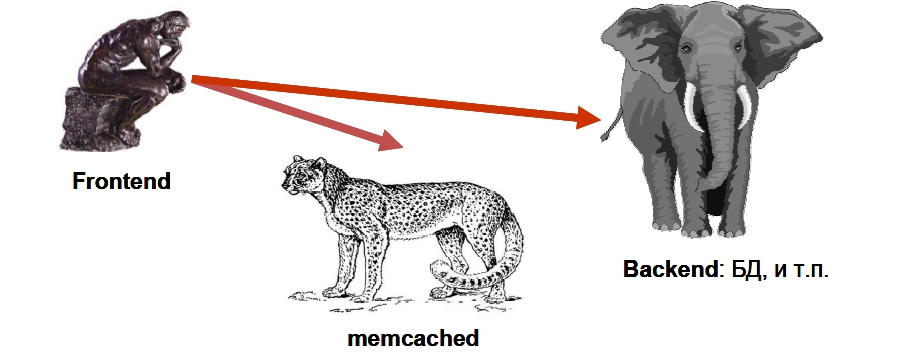
В общем случае схема кэширования выглядит следующим образом: frontend’у (той части проекта, которая формирует ответ пользователю) требуется получить данные какой-то выборки. Frontend обращается к быстрому, как гепард, серверу memcached за кэшом выборки (get-запрос). Если соответствующий ключ будет обнаружен, работа на этом заканчивается. В противном случае следует обращение к тяжелому, неповоротливому, но мощному (как слон) backend’у, в роли которого чаще всего выступает база данных. Полученный результат сразу же записывается в memcached в качестве кэша (set-запрос). При этом обычно для ключа задается максимальное время жизни (срок годности), который соответствует моменту сброса кэша.
Такая стандартная схема кэширования реализуется практически всегда. Вместо memcached в некоторых проектах могут использоваться локальные файлы, иные способы хранения (другая БД, кэш PHP-акселератора и т.п.) Однако, как будет показано далее, в высоконагруженном проекте приведенная простейшая схема кэширования может работать не самым эффективным образом. Тем не менее, в нашем дальнейшем рассказе мы будем опираться именно на эту схему как на пример, от которого мы будем отталкиваться.
Архитектура memcached
Каким же образом устроен memcached? Как ему удаётся работать настолько быстро, что даже десятки запросов к memcached, необходимых для обработки одной страницы сайта, не приводят к существенной задержке? Отметим, что memcached крайне нетребователен к вычислительным ресурсам: на нагруженной инсталляции процессорное время, использованное им, редко превышает 10%.
Во-первых, memcached спроектирован так, чтобы все его операции имели алгоритмическую сложность O(1), т.е. время выполнения любой операции не зависит от количества ключей, которые хранит memcached. Это означает, что некоторые операции (или возможности) будут отсутствовать в нём, если их реализация требует всего лишь линейного (O(n)) времени. Так, в memcached отсутствует возможность объединения ключей «в папки», т.е. какой-либо группировки ключей, также мы не найдем групповых операций над ключами или их значениями.
Основными оптимизированными операциями является выделение/освобождение блоков памяти под хранение ключей, определение политики самых неиспользуемых ключей (LRU) для очистки кэша при нехватке памяти. Поиск ключей происходит через хэширование, поэтому имеет сложность O(1).
Используется асинхронный ввод-вывод, не используются нити, что обеспечивает дополнительный прирост производительности и меньшие требования к ресурсам. На самом деле memcached может использовать нити, но это необходимо лишь для использования всех доступных на сервере ядер или процессоров в случае слишком большой нагрузки – на каждое соединение нить не создается в любом случае.
По сути, можно сказать, что время отклика сервера memcached определяется только сетевыми издержками и практически равно времени передачи пакета от frontend’а до сервера memcached (RTT). Такие характеристики позволяют использовать memcached в высоконагруженных web-проектов для решения различных задач, в том числе и для кэширования данных.
Потеря ключей
Memcached не является надежным хранилищем – возможна ситуация, когда ключ будет удален из кэша раньше окончания его срока жизни. Архитектура проекта должна быть готова к такой ситуации и должна гибко реагировать на потерю ключей. Можно выделить три основных причины потери ключей:
- Ключ был удален раньше окончания его срока годности в силу нехватки памяти под хранение значений других ключей. Memcached использует политику LRU, поэтому такая потеря означает, что данный ключ редко использовался и память кэша освобождается для хранения более популярных ключей.
- Ключ был удален, так как истекло его время жизни. Такая ситуация строго говоря не является потерей, так как мы сами ограничили время жизни ключа, но для клиентского по отношению к memcached когда такая потеря неотличима от других случаев – при обращении к memcached мы получаем ответ «такого ключа нет».
- Самой неприятной ситуацией является крах процесса memcached или сервера, на котором он расположен. В этой ситуации мы теряем все ключи, которые хранились в кэше. Несколько сгладить последствия позволяет кластерная организация: множество серверов memcached, по которым «размазаны» ключи проекта: так последствия краха одного кэша будут менее заметны.
Все описанные ситуации необходимо иметь в виду при разработке программного обеспечения, работающего с memcached. Можно разделить данные, которые мы храним в memcached, по степени критичности их потери.
«Можно потерять». К этой категории относятся кэши выборок из базы данных. Потеря таких ключей не так страшна, потому что мы можем легко восстановить их значения, обратившись заново к backend’у. Однако частые потери кэшей приводят к излишним обращениям к БД.
«Не хотелось бы потерять». Здесь можно упомянуть счетчики посетителей сайта, просмотров ресурсов и т.п. Хоть и восстановить эти значения иногда напрямую невозможно, но значения этих ключей имеют ограниченный по времени смысл: через несколько минут их значение уже неактуально, и будет рассчитано заново.
«Совсем не должны терять». Memcached удобен для хранения сессий пользователей – все сессии равнодоступны со всех серверов, входящих в кластер frontend’ов. Однако содержимое сессий не хотелось бы терять никогда – иначе пользователей на сайте будет «разлогинивать». Как попытаться избежать? Можно дублировать ключи сессий на нескольких серверах memcached из кластера, так вероятность потери снижается.
Ключ кэширования
Пусть мы уже убедились, что использовать memcached для кэширования – это правильное решение. Первая задача, которая перед нами встаёт – это выбор ключа для каждого кэша. Ключом в memcached является строка ограниченной длины, состоящая из ограниченного набора символов (например, запрещены пробелы). Ключ кэширования должен обладать следующими свойствами:
- При изменении параметров выборки, которую мы кэшируем, ключ кэширования должен изменяться (чтобы с новыми параметрами мы не «попали» в старый кэш).
- По параметрам выборки ключ должен определяться однозначно, т.е. для одной и той же выборки ключ кэширования должен быть только один, иначе мы рискуем понизить эффективность процесса кэширования, создавая несколько кэшей для одной и той же выборки.
Конечно, мы могли бы для каждой выборки строить ключ вручную, например ‘user_158’ для выборки информации о пользователе с ID 158 или ‘friends_192_public_sorted_online’ для выборки друзей пользователя с ID 192, которых видно публично и притом отсортированных в порядке последнего появления на сайте. Такой подход чреват ошибками и несоблюдением условий, сформулированных выше.
Можно использовать следующий вариант (пример для PHP): если существует некоторая точка в коде, через которую проходят все обращения к БД, а любое обращение полностью описывается (содержит все параметры запроса) в некоторой структуре $options , можно использовать следующий ключ:
$key = md5(serialize($options))
Такой ключ несомненно удовлетворяет первому условию (при изменении $options будет обязательно изменен $key ), но и второе условие будет соблюдаться, если мы будем все типы данных в $options использовать «канонически», т.е. не допускать строки «1» вместо числа 1 (хотя в PHP два таких значения равны, но их сериализованное представление различается). Функция md5 используется для «сжатия» данных: ключ memcached имеет ограничение по длине, а сериализованное представление может быть слишком длинным.
Кластеризация memcached
Для распределения нагрузки и достижения отказоустойчивости вместо одного сервера memcached используется кластер из таких серверов. Сервера, входящие в кластер, могут быть сконфигурированы с различным объемом памяти, при этом общий объем кэша будет равен сумме объемов кэшей всех memcached, входящих в кластер. Процесс memcached может быть запущен на сервере, где слабо используется процессор и не загружена до предела сеть (например, на файловом сервере). При высокой нагрузке на процессор memcached может не успевать достаточно быстро отвечать на запросы, что приводит к деградации сервиса.
При работе с кластером ключи распределяются по серверам, то есть каждый сервер обрабатывает часть общего массива ключей проекта. Отказоустойчивость следует из того факта, что в случае отказа одного из серверов ключи будут перераспределены по оставшимся серверам кластера. При этом, конечно же, содержимое отказавшего сервера будет потеряно (см. раздел «Потеря ключей»). Вслучае необходимости важные ключи можно хранить не на одном сервере, а дублировать на нескольких, так можно минимизировать последствия падения сервера за счет избыточности хранения.
При кластеризации становится актуальным вопрос распределения ключей: как наиболее эффективным образом распределить ключи по серверам? Для этого необходимо определить функцию распределения ключей, которая по ключу возвращает номер сервера, на котором он должен храниться (или номера серверов, если хранение происходит с избыточностью). Исторически первой функцией распределения в memcached использовалась функция модуля:
f(ключ) = crc32(ключ) % количество_серверов
Такая функция обеспечивает равномерное распределение ключей по серверам, однако проблемы возникают при переконфигурировании кластера memcached: изменение количества серверов приводит к перемещению значительной части ключей по серверам, что эквивалентно потере значительной части ключей.
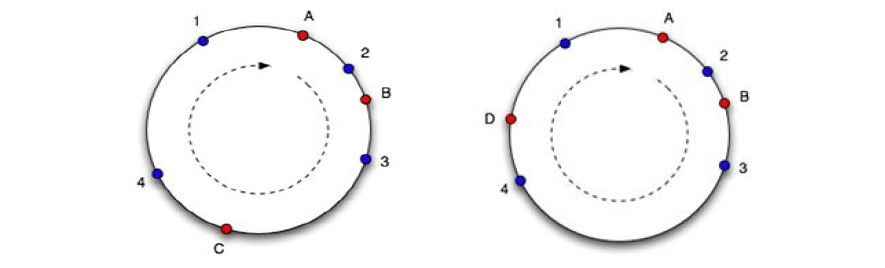
Суть алгоритма заключается в следующем: мы рассматриваем набор целых чисел от 0 до 2 32 , «закручивая» числовую ось в кольцо (склеиваем 0 и 2 32 ). Каждому сервера из пула memcached-серверов мы сопоставляем число на кольце (рисунок слева, сервера A, B и C). Ключ хэшируется в число в том же диапазоне (на рисунке – синие точки 1-4), в качестве сервера для хранения ключа мы выбираем сервер в точке, ближайшей к точке ключа в направлении по часовой стрелке. Если сервер удаляется из пула или добавляется в пул, на оси появляется или исчезает точка сервера, в результате чего лишь часть ключей перемещается на другой сервер. На рисунке 2 справа показана ситуация, когда сервер C был удалён из пула серверов и добавлен новый сервер D. Легко заметить, что ключи 1 и 2 не поменяли привязки к серверам, а ключи 3 и 4 переместились на другие сервера. На самом деле одному серверу ставится в соответствие 100-200 точек на оси (пропорционально его весу в пуле), что улучшает равномерность распределения ключей по серверам в случае изменения их конфигурации.
Данный алгоритм был реализован во многих клиентах memcached в различных языках программирования, однако реализация иногда отличается деталями, что приводит к несовместимости хэширования. Данный факт делает консистентное хэширование неудобным для использования при доступе к одному пулу серверов memcached из различных языков программирования. Простейший алгоритм с crc32 и модулем реализован во всех клиентах на всех языках одинаково, что обеспечивает одинаковое хэширование ключей по серверам. Поэтому в случае отсутствия необходимости обращаться к memcached из различных клиентов на разных языках программирования более привлекательным выглядит подход с консистентным хэшированием.
Атомарность операций в memcached
Как таковые, все одиночные запросы к memcached атомарны (в силу его однопоточности и корректных внутренних блокировок в многопоточном случае). Это означает, что если мы выполняем запрос get, мы получим значения ключа таким, как кто-то его записал в кэш, но точно не смесь двух записей. Однако каждая операция независима, и мы не можем гарантировать, например, корректность такой процедуры в ситуации конкурентного доступа из нескольких параллельных процессов:
- Получить значение ключа «x» ( $x = get x ).
- Увеличение значения переменной на единицу ( $x = $x + 1 ).
- Запись нового значения переменной в memcached ( set x = $x ).
Если данный код выполняют несколько frontend’ов одновременно, может получиться так, что значение ключа x увеличится не n раз, как мы задумывали, а на меньшее значение (классическое состояние гонки, race condition). Конечно, такой подход неприемлем для нас. Классический ответ на сложившуюся ситуацию: применение синхронизационных примитивов (семафоров, мутексов и т.п.), однако в memcached они отсутствуют. Другим вариантом решения задачи является реализация более сложных операций, которые заменяют неатомарную последовательность get/set.
В memcached для решения этой проблемы есть пара операций: incr / decr (инкремент и декремент). Они обеспечивают атомарное увеличение (или, соответственно, уменьшение) целочисленного значения существующего в memcached ключа. Атомарными являются также дополнительные операции: append / prepend , которые позволяют добавить к значению ключа данные в начало или в конец, также в каком-то плане атомарными можно считать операции add и replace , которые позволяют задать значение ключа, только если он ранее не существовал, или, наоборот, заменить значение уже существующего ключа. Об еще одном варианте атомарных операций речь пойдет в разделе про реализацию блокировок средствами memcached.
Необходимо дополнительно отметить, что любая блокировка в memcached должна быть мелкозернистой (fine-grained), то есть должна затрагивать как можно меньшее число объектов, так как основная задача сервера в любом случае – обеспечивать эффективный доступ к кэшу как можно большего числа параллельных процессов.
Счетчики в memcached
Memcached может использоваться не только для хранения кэшей выборок из backend’ов, не только для хранения сессий пользователей (о чем было упомянуто в начале статьи), но и для задачи, которая без memcached решается достаточно тяжело, – реализация счетчиков, работающих в реальном времени. Т.е перед нами стоит задача показывать текущее значение счетчика в данный момент времени, если откинуть требование «реального времени», это можно реализовать через логирование и последующий анализ накопленных логов.
Рассмотрим несколько примеров таких счетчиков, как их можно реализовать, какие возможны проблемы.
Счетчик просмотров
Пусть в нашем проекте есть некоторые объекты (например, фото, видео, статьи и т.п.), для которых мы должны в реальном времени показывать число просмотров. Счетчик должен увеличиваться с каждым просмотром. Самый простой вариант – при каждом просмотре обновлять поле в БД, не будет работать, т.к. просмотров много и БД не выдержит такую нагрузку. Мы можем реализовать точный и аккуратный сбор статистики просмотров, их аккумулирование, и периодический анализ, который заканчивается обновлением счетчика в базе данных (например, раз в час). Однако остается задача показа текущего количества просмотров.
Рассмотрим следующее возможное решение. Frontend в момент просмотра объекта формирует имя ключа счетчика в memcached, и пытается выполнить операцию incr (инкремент) над этим ключом. Если выполнение было успешным, это означает, что соответствующий ключ находится в memcached, мы просмотр засчитали, также мы получили новое значение счетчика (как результат операции incr ), которое мы можем показать пользователю. Если же операция incr вернула ошибку, то ключ счетчика в данный момент отсутствует в memcached, мы можем выбрать в качестве начального значения число просмотров из базы данных, увеличить его на единицу, и выполнить операцию set, устанавливая новое значение счетчика. При последующих просмотрах ключ уже будет находиться в memcached, и мы будем просто увеличивать его значение с помощью incr.
Необходимо отметить, что приведенная схема не является вполне корректной: в ней присутствует состояние гонки (race condition). Если два frontend одновременно обращаются к счетчику, одновременно обнаруживают его отсутствие, и сделают две операции set, мы потеряем один просмотр. Это можно считать не очень критичным, так как процесс аккумулирования статистики восстановит правильное значение. В случае необходимости можно воспользоваться блокировками в memcached, речь о которых пойдет ниже. Или же реализовать инициализацию счетчика через операцию add , обрабатывая её результат.
Счетчик онлайнеров
Существует еще один вид счетчиков, который без memcached или подобного ему решения вряд ли может быть реализован: это счетчик «онлайнеров». Такие счетчики мы видим на большом количестве сайтов, однако в первую очередь необходимо определить, что же именно мы имеем в виду под «онлайнером». Пусть мы хотим рассчитать, сколько уникальных сессий (пользователей) обратилось к нашему сайту за последние 5 минут. Уникальность обращения пользователя с данной сессией в течение 5 минут можно отследить, сохраняя в сессии время последнего засчитанного обращения, если прошло более 5 минут – значит это новое (уникальное) обращение.
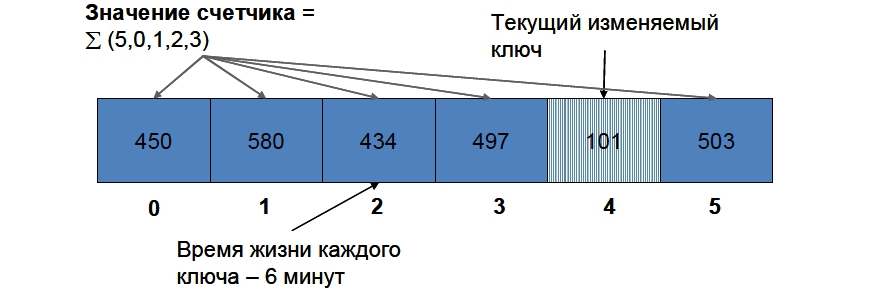
Итак, выделим в memcached шесть ключей с именами, например, c_0 , c_1 , c_2 , …, c_5 . Текущим изменяемым ключом мы будем считать счетчик с номером, равным остатку от деления текущей минуты на 6 (на рисунке это ключ c_4 ). Именно его мы будем увеличивать с помощью операции incr для обращения каждой уникальной в течение 5 минут сессии. Если incr вернет ошибку (счетчика еще нет), установим его значение в 1 с помощью set , обязательно указав время жизни 6 минут. Значением счетчика онлайнеров будем считать сумму всех ключей, кроме текущего (на рисунке это ключи c_0 , c_1 , c_2 , c_3 и c_5 ).
Когда наступит следующая минута, текущим изменяемым ключом станет ключ c_5 , при этом его предыдущее значение исчезнет (т.к. он был создан 6 минут назад с временем жизни те же 6 минут). Значением счетчика станет сумма ключей c с_0 по c_4 , т.е. только что рассчитанное значение ключа с_4 уже начнет учитываться в отображаемом значении счетчика.
Такой счетчик может быть построен и на меньшем числе ключей. Минимально возможными для данной схемы являются два ключа: один обновляется, значение другого показывается, затем по прошествии 5 минут счетчики меняются местами, при этом тот, который только что обновлялся, сбрасывается. В приведенной схеме с многими ключами обеспечивается некоторое «сглаживание», которое обеспечивает более плавное изменение счетчика в случае резкого притока или оттока посетителей.
Одновременное перестроение кэшей
Данная проблема характерна в первую очередь для высоконагруженных проектов. Рассмотрим следующую ситуацию: у нас есть выборка из БД, которая используется на многих страницах или особо популярных страницах (например, на главной странице). Эта выборка закэширована с некоторым «сроком годности», т.е. кэш будет сброшен по прошествии некоторого интервала времени. При этом сама выборка является относительно сложной, её вычисление заметно нагружает backend (БД). В какой-то момент времени ключ в memcached будет удален, т.к. истечет срок его жизни (срок жизни был установлен у кэша), в этот момент несколько frontend’ов (несколько, т.к. выборка часто используется) обратятся в memcached по этому ключу, обнаружат его отсутствие и попытаются построить кэш заново, осуществив выборку из БД. То есть в БД одновременно попадет несколько одинаковых запросов, каждый из которых заметно нагружает базу данных, при превышении некоторого порога запрос не будет выполнен за разумное время, еще больше frontend’ов обратятся к кэшу, обнаружат его отсутствие и отправят еще больше запросов в базу данных, с которыми база данных тем более не справится. В результате сервер БД получил критическую нагрузку, и «прилёг». Что делать, как избежать такой ситуации?
Проблема с перестроением кэшей становится проблемой только тогда, когда имеют место два фактора: много обращений к кэшу в единицу времени и сложный запрос. Причем один фактор может компенсировать другой: на относительно непопулярной, но очень сложной и долгой выборке (которых вообще-то не должно быть) мы можем получить аналогичную ситуацию. Итак, что же делать?
Можно предложить следующую схему: мы больше не ограничиваем время жизни ключа с кэшом в memcached – он будет там находиться до тех пор, пока не будет вытеснен другими ключами. Но вместе с данными кэша мы записываем и реальное время его жизни, например:
годен до: 2008-11-03 11:53, данные кэша: . > >
Теперь при получении ключа из memcached мы можем проверить, истёк ли срок жизни кэша с помощью поля «годен до». Если срок жизни истёк, кэш надо перестроить, но мы будем делать это с блокировкой (о блокировках речь пойдет в следующем разделе), если не удастся заблокироваться, мы можем либо подождать еще (раз блокировка уже есть, значит кэш кто-то перестраивает), либо вернуть старое значение кэша. Если заблокироваться удастся, мы строим кэш самостоятельно, при этом другие frontend’ы не будут перестраивать этот же кэш, так как увидят нашу блокировку. Основное преимущество хранения в memcached без указания срока годности – именно возможность получить старое значение кэша в случае, если кэш уже перестраивается кем-то. Что именно делать – ждать, пока кэш построит кто-то другой, и получать новое значение из memcached, или возвращать старое значение, – зависит от задачи, насколько приемлемо старое значение и сколько можно провести времени в состоянии ожидания. Чаще всего можно позволить себе 2-3 секундное ожидание с проверкой удаления блокировки и, если кэш так и не построился (что маловероятно, получается что выборка происходит больше чем за 2-3 секунды), вернуть старое значение, освобождая frontend для других задач.
Пример такого алгоритма
- Получаем доступ к кэшу cache, его срок жизни истёк.
- Пытаемся заблокироваться по ключу user cache_lock.
- Не удалось получить блокировку:
- ждём снятия блокировки;
- не дождались: возвращаем старые данные кэша;
- дождались: выбираем значения ключа заново, возвращаем новые данные (построенный кэш другим процессом).
- строим кэш самостоятельно.
Такая схема позволяет исключить или свести к минимуму ситуации «заваливания» backend’а одинаковыми «тяжелыми» запросами, когда реально запрос достаточно выполнить лишь один раз. Остается последний вопрос, как обеспечить корректную блокировку? Очевидно, что так как проблема одновременного перестроения возникает на разных frontend’ах, то блокировка должна быть в общедоступном для них всех месте, то есть в memcached.
Блокировки в memcached
Рассмотрим два варианта реализации блокировки (мьютекса, двоичного семафора) с помощью memcached. Первый некорректный, он не может обеспечить корректного исключения параллельных процессов, но очевидный. Второй совершенно корректный, но не настолько очевиден.
Пусть мы хотим заблокироваться по ключу ‘lock’ : пытаемся получить значения ключа с помощью операции get . Если ключ не найден, значит блокировки нет, и мы с помощью операции set устанавливаем значение этого ключа, например, в единицу, а время жизни устанавливаем в небольшой интервал времени, который превышает максимальное время жизни блокировки, например, в 10 секунд. Теперь, если frontend завершится аварийно и не снимет блокировку, она автоматически уничтожится через 10 секунд. Итак, с помощью set мы блокировку установили, выполнили все необходимые действия, после этого снимаем блокировку просто удаляя соответствующий ключ командой del . Если на первой операции get мы получили значение ключа, это означает, что блокировка уже установлена другим процессом, наша операция блокировки неуспешна.
Описанный способ обладает недостатком: наличием состояния гонки (race condition). Два процесса могут одновременно сделать get , оба могут получить ответ, что «ключа нет», оба сделают set , и оба будут считать, что установили блокировку успешно. В ситуациях, как одновременное перестроение кэшей, этого может быть допустимо, т.к. здесь цель не исключить все другие процессы, а резко уменьшить количество одновременных запросов к БД, что может обеспечить и этот простой, некорректный вариант.
Второй вариант корректен, и даже проще первого. Для захвата блокировки достаточно выполнить одну команду: add , указав имя ключа и время жизни (такое же маленькое, как и в первом варианте). Команда add будет успешной только в том случае, если ключа в memcached еще нет, то есть наш процесс и есть тот единственный процесс, которому удалось захватить блокировку. Тогда нам надо выполнить необходимые действия и освободить блокировку командой del . Если add вернет ошибку «такой ключ уже существует», значит, блокировка была захвачена раньше каким-то другим процессом.
Сброс группы кэшей
Если мы закэшировали какие-то данные от backend’а, например, выборку из БД, рано или поздно исходные данные изменяются, и кэш перестает быть валидным. Причем очень желательно, чтобы кэш сбрасывался сразу же за изменением, иначе пользователь после редактирования может увидеть старую версию объекта, что его, несомненно, смутит. Есть простой вариант ситуации: мы меняем информацию об объекте с ID 35, и сбрасываем кэш выборки этого объекта по параметру На практике же чаще всего один и тот же объект явно или неявно входит в большое количество выборок, а значит и кэшей.
Рассмотрим такой пример: мы написали блогохостинг, в нем большое количество блогов. Когда один из авторов создает новый пост, меняется большое количество выборок: посты на главной странице и всех вторых страницах списка постов (т.к. все посты «сдвинулись» на один), изменилось количество записей в календаре постов, изменилась RSS-ка, и т.п. Конечно, мы могли бы поставить кэшам этих выборок небольшое время жизни, тогда через какое-то время они сбросятся и будут отображать правильную информацию, но слишком короткое время кэширования (5 секунд, например), будет давать низкое соотношение хитов в кэш, увеличивая нагрузку на БД, а более длительное будет создавать у пользователя ощущение, что информация после создания поста не обновилась, а, значит, пост не добавился. В то же время можно заметить, что в рамках блогохостинга если даже мы сбросим все кэши, связанные с данным блогом, это совсем небольшой процент от общей массы кэширования (т.к. блогов очень много). Остался вопрос: как найти и проидентифицировать все кэши данного блога? Какие-то из них мы можем легко построить, для некоторых это становится уже неудобно: например, количество кэшей постраничного списка постов зависит от количества страниц, которое еще необходимо вычислить. Что же делать?
Одно из возможных решений – тэгирование кэшей. Описанный ниже способ тэгирования по своей сути совпадает с описанным Дмитрием Котеровым в его наблах, но был нами разработан независимо. Существуют и другие варианты тэгирования, например, патч memcached-tag на memcached.
Тэг кэша
Итак, мы вводим новое понятие – тэг кэша. Один кэш может нести с собой список тэгов, с которыми он связан. Сам по себе тэг – это некоторое имя и связанная с ним версия (число). Версия тэга может только монотонно увеличиваться. Группой кэшей мы будем называть кэши, имеющие один общий тэг. Для того чтобы сбросить группу кэшей, достаточно увеличить версию соответствующего тэга.
На программном уровне мы знаем, что данная выборка должна быть закэширована и что её кэш будет связан с тэгами tag1 и tag2 (данный факт определяется логикой работы нашего приложения). При создании кэша мы записываем в него кроме данных закэшированной выборки еще текущие (на момент создания кэша) версии тэгов tag1 и tag2 . При получении кэша мы считаем его валидным если не истекло время его жизни, и при этом текущии версии тэгов tag1 и tag2 равны версиям, записанным в кэше. Таким образом, если мы изменяем (увеличиваем) версию тэга tag1 , все кэши, связанные с этим тэгом, которые были построены ранее, перестанут быть валидными (т.к. в них записана меньшая версия тэга tag1 ).
Рассмотрим пример с нашей выборкой, пусть было так:
Версии тэгов: tag1 → 25 tag2 → 63 Кэш выборки: [ срок годности: 2008-11-07 21:00 данные кэша: [ … ] тэги: [ tag1: 25 tag2: 63 ] ]
Затем произошло некоторое событие, и мы решили сбросить все кэши, ассоциированные с тэгом tag2 , т.е. мы увеличили версию тэга: tag2++ . Изменились версии тэгов:
Версии тэгов: tag1 → 25 tag2 → 64
Теперь наш кэш перестал быть валидным, не смотря на то, что его «срок годности» еще не истёк: версия тэга tag2, сохраненная в нем (63) не совпадает с текущей версией (64).
Версии тэгов
Тэги (то есть их версии) имеет смысл хранить там же, где мы и храним наши кэши, то есть в memcached. Для каждого тэга мы создадим ключ с именем, совпадающим с именем тэга, его значением будет версия тэга. Осталось решить, что использовать в качестве версии тэга? Можно было бы использовать просто числа, инкрементируя их при изменении версии тэга, но это может привести к некорректному поведению при условии возможной потери ключей. Пусть версия тэга равнялась единице, мы закэшировали выборку с этим тэгом, записали в кэш значение тэга – единицу. Затем ключ с версией тэга был удален из memcached, а в следующий момент времени мы захотели сбросить выборки, связанные с тэгом, то есть необходимо увеличить версию тэга. Так как мы потеряли значение версии тэга, мы снова поставим единицу, и теперь наш кэш будет считаться валидным, хотя он сбросился (не важно, какое значение выбирать при увеличении версии тэга, если она была потеряна – всегда возможна ситуация, что это же значение использовалось и ранее).
В качестве версии удобнее использовать текущее время (с достаточной точностью, например, до миллисекунд). Тогда увеличение версии тэга будет всегда давать новую, бóльшую версию, даже в случае потери предыдущей версии. Версия тэга формируется на frontend’ах, их системные часы должны быть синхронизованы (без этого не будет работать и другая функциональность, например, корректное вычисление срока годности кэшей с коротким временем жизни), так что проблем с таким выбором способа вычисления версии не должно быть.
Использование текущего времени в качестве версии тэга даёт еще одно преимущество в ситуации, когда БД проекта устроена по схеме мастер-слейв репликации. При изменении исходного объекта в БД мы изменяем версию тэга, связанного с ним (записываем туда текущее время, то есть время изменения). В другом процессе мы обнаруживаем, что кэш устарел, то есть его надо перестроить, перестроение – это читающий запрос ( SELECT ), который необходимо отправить на слейв-сервер БД, но в силу задержек репликации слейв-сервер еще мог не получить актуальную версию объекта в БД, в результате мы кэш сбросили, но при его перестроении снова закэшировали старый вариант объекта, что неприемлемо. Можно использовать версию тэга при решении вопроса, на какой сервер БД отправить запрос: если разница между текущим временем и версией какого-либо тэга кэша меньше некоторого интервала, определяемого максимальной задержкой репликации, мы отправляем запрос на мастер-сервер БД вместо слейва.
Использование такой схемы тэгирования увеличивает количество запросов к memcached, т.к.
нам необходимо для каждого кэша получать версии его тэгов. Накладные расходы можно сократить за счет использование multi-get запросов memcached, а также за счет локального кэширования ключей memcached в пределах одного процесса (если один и тот же тэг привязан к нескольким кэшам).
Статистика работы memcached
Кроме необходимости реализовать механизмы работы с memcached, необходимо постоянно заниматься мониторингом кластера memcached-серверов, чтобы быть уверенным, что мы достигли оптимальной производительности. Memcached предоставляет набор команд для получения информации о его работе.
Самая простая команда, stats , позволяет получить элементарную статистику: время работы сервера (uptime), объем используемой памяти, количество get запросов и количество хитов (hits), т.е. попаданий в кэш. Их соотношение позволяет нам судить об эффективности кэширования в целом, хотя необходимо учитывать, что в memcached ключами являются не только закэшированные выборки, но и счетчики, блокировки, тэги и т.п., так что для вычисления чистой эффективности кэширования это значение требует корректировки. Из общей статистики мы также можем узнать, сколько ключей было удалено раньше истечения срока жизни (evictions), данный параметр может сигнализировать о недостаточности объема памяти memcached.
Slab-аллокатор
Для распределения памяти под значения ключей memcached использует вариант slab-аллокатора. Данный тип аллокатора стремится сократить внутреннюю фрагментацию при выделении памяти, а также обеспечивают хорошую эффективность операций выделения памяти.
Механизм его работы заключается в том, что вся доступная memcached память делится на slab’ы (блоки), каждый из которых будет хранить элементы определенного размера. Например, slab для хранения объектов размером 256 байт, при этом сам slab имеет размер 1 Мб, таким образом он может сохранить 4096 таких объектов. Память внутри такого slab’а выделяется только по 256 байт. Если у нас есть slab’ы для объектов размером 64, 128, 256, 1024 и 2048 байт, то максимальный размер объекта, который мы можем сохранить – 2048 байт (в последнем slabе). Если мы хотим сохранить объект размером 65 байт, под него будет выделена память в slab’е-128, 1 байт – в slab’е 64.
Чтобы добиться эффективного использования памяти memcached для хранения наших ключей и значений, мы должны быть уверены в правильном выборе размеров slab’ов, который выделил memcached, а также в их разумном наполнении. Для этого мы можем попросить memcached предоставить статистику по slab’ам, которую можно, например, визуализировать в виде такого графика:
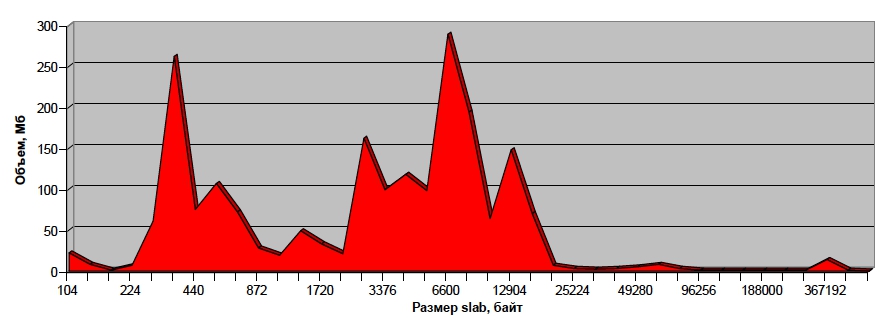
Здесь на горизонтальной оси отложены размеры slab’ов, а на вертикальной – объем памяти, используемый slab’ами данного размера. В данный момент вся память memcached занята ключами и их значениями, поэтому данный график представляет собой текущее распределение значений в памяти сервера. Легко видеть, что больше всего slab’ов выделено под ключи с относительно небольшими значениями – до 20 Кб, для больших по размеру ключей slab’ов гораздо меньше. Такое распределение адекватно нашей задаче: у нас больше всего именно маленьких ключей (счетчики, блокировки, небольшие кэши). При этом эти же ключи занимают и бóльшую часть памяти, с локальными пиками выделения под ключи размером 300 байт, 8 Кб. Если график отличается от того, который ожидается по логике задачи, это повод для беспокойства.
Отладка проектов, использующих memcached
Мы написали большую подсистему для работы с memcached, реализовали различные механизмы решения проблем, связанных с высокой нагрузкой. Как проверить, что всё действительно работает так, как нам бы этого хотелось? Высокую нагрузку, сетевые задержки и т.п. практически невозможно воспроизвести в локальном окружении, непросто это сделать и в тестовом окружении. На серверах в production нам доступны лишь те механизмы отладки, которые не затрагивают нормальное функционирование самого приложения. Способ отладки не должен вносить ощутимых временных задержек, иначе он изменит поведение приложения, и отладка станет бессмысленной.
Можно предложить следующий «трюк», который может помочь в данной ситуации: для каждого кэша (ключа в memcached) или для группы кэшей (ключей) мы заводим отдельный файл в локальной файловой системе. В этот файл в режиме append мы дописываем по одному символу в ответ на каждое логическое действие, которое произошло с кэшом. Для просмотра в реальном времени поведения кэширующей подсистемы достаточно сделать tail –f на этот файл:
MLWUHHHHHHHHHHHHHHHMLLHHHHHHHHHHПусть буквы имеют следующий смысл:
- M – кэш устарел (или не найден);
- L – попытка заблокироваться;
- W – запись (и построение) нового кэша;
- U – удаление блокировки;
- H – успешный запрос кэша.
Тогда по приведенной последовательности можно рассказать то, что происходило с данным кэшом: вначале он отсутствовал, мы кэш не обнаружили ( M ), попытались заблокироваться ( L ) для его построения, заблокировались, построили кэш ( W ), сняли блокировку ( U ), затем какое-то время кэш успешно работал, отдавая закэшированные данные ( H ). Потом в какой-то момент кэш устарел или был сброшен ( M ), мы попытались заблокироваться, не получилось ( L ), попытались еще раз ( L ), блокировка оказалась снята, кто-то другой построил новый кэш, мы его прочитали ( H ) и дальше им пользовались.
Межпроцессное взаимодействие с помощью memcached
Сложный проект состоит из отдельных компонент, сервисов, которые должны взаимодействовать друг с другом, используя механизмы RPC, вызовы API, обмениваясь информацией через БД или каким-то еще способом. Иногда для такого обмена информацией можно использовать и memcached.
В качестве примера рассмотрим сервис пользовательских вещаний: существует какое-то количество вещаний, в каждом из которых в данный момент времени находится некоторое количество зрителей. Популярность вещания определяется количеством зрителей. Актуальной информацией о количестве зрителей обладает только сервер вещаний, а список вещаний на странице вещаний формирует frontend. Конечно, можно было бы сделать так, чтобы сервер вещаний периодически сбрасывал в БД или через API в frontend информацию о количестве зрителей, или frontend мог бы через API сервера вещаний получать актуальную информацию. Однако количество зрителей – очень быстро меняющаяся характеристика, и в данной ситуации можно просто из сервера вещаний периодически (раз в несколько секунд) сохранять в memcached информацию о количестве зрителей в каждом из вещаний, а frontend, обращаясь к memcached, может получить информацию в любой удобный момент. Таким может быть межпроцессное взаимодействие, реализованное с помощью memcached.
Применение вероятностного алгоритма соединения записей для исключения дублирования информации в корпоративной базе данных Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Пинжин А. Е.
Рассмотрена возможность применения вероятностного алгоритма соединения записей для устранения дублирования информации в базе данных крупной организации или предприятия. Отражены теоретические основы алгоритма, предложены способы оценки степени сходства по основным типам атрибутов, рассмотрены возможности усовершенствования модели путем учета степени достоверности данных, поступающих из разных источников. Приведены практические результаты работы на примере задачи устранения дубликатов записей о физических лицах в единой базе данных российского вуза.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Пинжин А. Е.
Выявление дубликатов в разнородных библиографических источниках
Применение адаптивного бинормального распределения в методе поиска глобального минимума Simulated Annealing
Принципы идентификации объектов в структурированных документах
Подходы к нечеткому поиску нежелательного контента на веб-странице
Обзор алгоритмов фонетического кодирования
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.Application of Probabalistic Algorithms of Recording Connection for Excluding Information Duplicating in Corporate Database
The possibility of using probabilistic algorithm of recording connection to remove information duplicating in database of a large company or enterprise is considered. The theoretical basis of the algorithm are presented, the ways of similarity measure estimation of the main attribute types are suggested, the possibilities of improving the model by taking into account the data credibility value from different sources. The results of the work are given by the example of the problem of removing recording duplicate about natural persons in the database of a Russian university.
Текст научной работы на тему «Применение вероятностного алгоритма соединения записей для исключения дублирования информации в корпоративной базе данных»
Все это позволяет повысить конкурентоспособность предприятия, т. к. любое предприятие имеет в своей организационной структуре подразделение
1. Тюльменков В.Н., Замятина О.М. Эффективное управление складом на базе адресной системы хранения // Молодежь и современные информационные технологии: Сб. трудов 4-ой Все-росс. научно-практ. конф. студентов, аспирантов и молодых ученых. — Томск, 2006. — С. 225-227.
2. Шрайбфедер Д. Эффективное управление запасами. — М.: Альпина Бизнес Букс, 2005. — 304 с.
складского хозяйства, независимо от того, каким видом деятельности оно занимается — торговлей или производством.
3. Сергейчев А.Ю. Организация и внедрение адресной системы склада // Складские технологии. — 2005. — № 6. — С. 17-19.
4. Соболев А. Управление складом в Microsoft Axapta. -http://www.sibinfo.ru/warehouse.management.axapta.442.aspx. -04.08.2006.
5. Еременко А., Шашков Р. Разработка бизнес-приложений в Microsoft Buisness Solution Axapta версии 3.0. — М.: Альпина Бизнес Букс, 2005. — 503 с.
ПРИМЕНЕНИЕ ВЕРОЯТНОСТНОГО АЛГОРИТМА СОЕДИНЕНИЯ ЗАПИСЕЙ ДЛЯ ИСКЛЮЧЕНИЯ ДУБЛИРОВАНИЯ ИНФОРМАЦИИ В КОРПОРАТИВНОЙ БАЗЕ ДАННЫХ
Томский политехнический университет E-mail: alex_pinjin@tpu.ru
Рассмотрена возможность применения вероятностного алгоритма соединения записей для устранения дублирования информации в базе данных крупной организации или предприятия. Отражены теоретические основы алгоритма, предложены способы оценки степени сходства по основным типам атрибутов, рассмотрены возможности усовершенствования модели путем учета степени достоверности данных, поступающих из разных источников. Приведены практические результаты работы на примере задачи устранения дубликатов записей о физических лицах в единой базе данных российского вуза.
Процессы хранения и обработки данных являются неотъемлемой частью любой информационной системы (ИС) крупного предприятия или организации. Рост информационных потребностей, обусловленный как внутренними, так и внешними факторами, может быть удовлетворен только в случае наличия непротиворечивых, актуальных и корректных данных.
При разработке единой информационной среды Томского политехнического университета (ЕИС ТПУ), одним из приоритетных направлений было выбрано построение единой базы данных (БД) согласно принципу безызбыточности. Одной из важнейших частей БД ЕИС ТПУ является единая информационная модель личности, представляющая информацию о физических лицах — студентах, сотрудниках, аспирантах и т. д. [1]. Практика показала, что, несмотря на все усилия по созданию безыз-быточной БД, могут иметь место случаи дублирования записей о физических лицах, что является прямым следствием отсутствия общего естественного уникального идентификатора. Приведем результаты следующего исследования. Будем считать, что появление одного дубляжа на 2000 записей является допустимым (0,05 %). К началу 2006 г. в БД ТПУ было зарегистрировано около 48000 студентов (сре-
ди них около 20000 выпускников) и 5200 сотрудников. В процессе ручной выверки данных было обнаружено около 500 дубликатов, т. е. примерно 0,9 % от общего числа записей. Известно, что сотрудником является в среднем каждый 50 студент-выпускник и каждый 100 действующий студент, т. е. примерно 1,3 % студентов являются сотрудниками. Таким образом, ручная выверка данных не дала приемлемых результатов. Отметим также высокую трудоемкость процесса выверки — описанные выше результаты были достигнуты усилиями пяти сотрудников в течение нескольких месяцев.
В рамках базы данных корпоративной информационной системы можно выделить следующие типичные ситуации, порождающие ошибки идентификации:
1. Малое пересечение свойств с совпадающими значениями. Например, о двух лицах известны значения свойств «Фамилия Имя Отчество», «Телефон» и «Дата рождения», и значения первых двух свойств совпадают, а значения третьего свойства не совпадают. В таких условиях сложно принять решение об идентичности.
2. Ошибки в значениях атрибутов, т. е. несовпадение фактических и зарегистрированных значений. Можно выделить следующие виды ошибок — опечатки при вводе (например, неверное на-
писание фамилии), ошибки в результате потери или искажения данных, ошибки, связанные с разницей во времени актуализации значений, возникающие, например, при смене фамилии или адреса.
В подобных условиях использование экспертных знаний пользователя не может быть полностью исключено из процесса идентификации. Целесообразным решением является разработка автоматизированной системы поиска потенциальных дубляжей, которая способна оказать содействие пользователю при принятии решения об идентичности записей. Данная статья посвящена описанию формального алгоритма, который мог бы являться основой при создании подобной системы.
1. Основные этапы процесса выявления и устранения дубликатов
Методы поиска и устранения совпадающих записей активно разрабатываются в течение последних десятилетий такими зарубежными исследователями, как Newcombe [2], Fellegi и Sunter [3], Winkler [4], Jaro [5] и др. Особое значение эти вопросы приобрели в последнее время при решении задач интеграции разнородных хранилищ данных, подготовке данных для анализа и «добычи данных» (Data Mining). Следует отметить, что в последние годы возрастает интерес к проблеме и в отечественных источниках [6-8].
Согласно [9], стандартная система слияния записей состоит из блоков, представленных на рис. 1.
Этап стандартизации включает в себя приведение данных к общей структуре и типам. Этап сегментации выполняется в тех случаях, когда с практической точки зрения является нерациональным производить сравнение всего множества пар записей, поэтому производится его разделение по какому-либо признаку, и оценка сходства выполняется над выделенным сегментом. Стандартизация и сегментация данных являются важными этапами, однако подробное рассмотрение этих вопросов выходит за рамки статьи.
Сравнение и принятие решения о слиянии записей, является самой сложной частью процесса. Существуют различные методы, применимые к этой задаче, такие как нейронные сети, кластерный анализ и др. Наиболее подходящими для решения поставленной задачи представляются вероятностные
алгоритмы, обеспечивающие получение интервальной оценки сходства на основе анализа значений атрибутов. Эти алгоритмы широко освещены в зарубежной литературе и применялись при проведении переписи населения, интеграции медицинских, почтовых БД. Основными их достоинствами является наличие формального аппарата, относительно простая реализация, возможность обработки пропущенных и ошибочных значений. Кроме того, в крупных организациях обычно имеется возможность получить необходимые для реализации алгоритма тестовые выборки данных, а также оценки достоверности значений, поступающих из разных источников.
2. Стандартная вероятностная модель слияния записей
Математическая модель вероятностного алгоритма слияния записей была впервые предложена БеИе§1 и 8ип1:ег [3]. Пусть даны два множества объектов реального мира А и В, элементы которых обозначим как а и Ь соответственно. Некоторые элементы являются общими для А и В. Представим множество АхВ= в виде двух подмножеств М и и. Если а и Ь, входящие в элемент множества АхВ совпадают (являются одним и тем же объектом), то этот элемент принадлежит М, иначе он принадлежит и
Представим, что в результате ввода информации об элементах А и В в БД были получены файлы записей ЬА и Ьв. Обозначим записи, соответствующие элементам множеств А и В, как а(а) и в(Ь). Результатом сравнения двух записей является вектор сравнения, состоящий из таких элементов, как, например «Имя совпадает», «Дата рождения не совпадает» и т. п. Вектор сравнения определяется как векторная функция над а(а) и Р(Ь):
В дальнейшем будем использовать запись у(а,Ь), у[а,р], или просто у. Обозначим вероятность т(у) того, что вектор сравнения у отражает совпадение значений, при условии, что пара записей представляет один и тот же объект
и вероятность ы(у) того, что 7 отражает совпадение, если пара записей представляет различные объекты и (у) = Р(у | (а, Ь) е и).
Рис. 1. Процесс поиска и устранения дубликатов
Отношение m(y)/u(y) будем называть степенью сходства записей.
На практике количество реализаций у может быть настолько большим, что становится необходимым принятие некоторых допущений. На основе подхода, предложенного в [3], предположим, что компоненты у могут быть упорядочены и
ш(у) = ■ m2(y2) •. • mK(yK),
u(y) = ul(yl) ■ U2(y2) ■. ■ Uk(yk).
Например, у1 может включать в себя атрибуты «Фамилия Имя и Отчество», а у2 — атрибуты адреса.
Многие авторы считают эффективным использование логарифма полученной оценки для обеспечения аддитивности весов, что позволяет определить
Таким образом, можно записать
w(y) = w1 + w2 +. + wK
и использовать w(y) в качестве веса соединения. Вес соединения означает степень сходства записей и является отражением вероятности того, что две записи представляют один и тот же объект.
3. Вычисление весов в условиях корпоративной информационной системы
На практике для вычисления весов может быть использован метод, основанный на частоте вхождения искомого значения в исходную выборку [3, 4]. Интуитивно понятно, что, например, в российском вузе имя «Николай» встречается чаще, чем «Эдуард», поэтому совпадение в первом случае будет иметь меньший вес, чем во втором.
Предположим, что одним из атрибутов записей является фамилия, и мы можем построить список всех безошибочных значений фамилии, а также количество лиц, обладающих каждой из этих фамилий в некоторой тестовой выборке. Пусть пропорция вхожденияу-й фамилии в это множество равна p. Введем следующие обозначения:
• eA и eB — вероятности ошибочного значения фамилии в La или Ьв.
• eT — вероятность того, что значения фамилии личности в La и Lb различны, однако записаны без ошибок (например, человек сменил фамилию). Согласно [3, 4] можно сформулировать основные правила для вычисления весов:
• w (фамилия совпадает и являетсяу-й фамилией
в списке) = log I —
• w (фамилия не совпадает) = log
Из (1-3) следует, что совпадение по фамилии приведет к появлению положительного веса, и чем реже встречается фамилия, тем больше будет вес; несовпадение приводит к отрицательному весу, который уменьшается с ошибками еА, еВ, еТ; если фамилия не указана в одной из записей, вес будет равен нулю.
Первичные значения пропорций р, в условиях корпоративной информационной системы, могут быть вычислены на этапе ввода первичных данных. Для повышения производительности алгоритма, имеет смысл хранить постоянный список пропорций в БД (рис. 2).
w (фамилия не указана в одной из записей)=0. (3)
Рис. 2. Пример концептуальной схемы данных для хранения пропорций
Первоначальный список пропорций должен вычисляться на основании выборок, обладающих минимальной избыточностью. По мере наполнения БД, через установленные промежутки времени или при накоплении определенного количества новых записей, список пропорций должен обновляться.
Важной практической задачей является установка значений еА, еВ и еТ. Характерной особенностью многих организаций является наличие множества источников актуализации объектов одного и того же типа. Каждый из источников обладает разной степенью достоверности вводимой информации, следовательно, множества ЬА и Ьв представляют собой совокупность подмножеств, для каждого из которых можно определить собственные значения еА, еВ и еТ в отношении того или иного атрибута. Например, представим множество ЬВ, означающее совокупность зарегистрированных в БД физических лиц, в виде Ьв’иЬву>. ‘иЬв, где Ьв является подмножеством личностей, актуализируемых г-м видом учета. Т к. каждому виду учета можно сопоставить вероятность ошибки в значении того или иного свойства, то, например, для фамилии
В случаях, когда одна и та же личность обладает несколькими ролями, есть возможность избежать множественного соответствия между Ьв. и видами учета и, соответственно, несколькими значениями ошибок. В этом случае можно использовать значение ошибки, соответствующее виду учета, обладающему максимальным приоритетом по отношению к свойству личности, включающему в себя атрибут, используемый для сравнения. Таким образом, мы полагаем, что подразделение с наивысшим приоритетом несет наибольшую ответственность за безошибочность значения этого атрибута [10].
Для множества личностей ЬА можно применить следующие формулировки при:
1. создании новой личности: ЬА=, еА — соответствует виду учета, выполняющему операцию создания;
2. поиске дубликатов среди зарегистрированных личностей: ЬА=ЬВ;
3. выполнении импорта данных из автономного источника в БД ЕИС: Ха=
Таким образом, алгоритм сравнения пар записей, входящих в ЬАхЬВ, может быть представлен в виде задачи сравнения пар, входящих в множества ХАхХЛ,ХАхХй. ХАхХВ на соответствующих уровнях ошибок еА и ев,ев„. ев, определенных для каждого атрибута.
Описанный алгоритм вычисления весов применим не только к фамилиям, но и к прочим атрибутам физического лица, имеющим сравнительно небольшой домен значений по отношению к количеству зарегистрированных экземпляров, таких как, Фамилия, Имя, Отчество, Паспортные данные, Название законченного учебного заведения, Страна, Город адреса личности и т. д.
4. Вычисление весов для атрибутов интервального и иерархического типа
Если атрибут принимает не дискретные, а интервальные значения, то вычисление пропорций может принять несколько иной характер. Рассмотрим возможный подход к вычислению пропорций на примере атрибута «Дата рождения физического лица».
Очевидно, что расчет пропорций согласно описанному ранее принципу приведет к низким значениям частот, так как размер домена возможных значений атрибута близок к количеству зарегистрированных личностей, хотя, на интуитивном уровне ясно, что в вузе значительно больше субъектов, обладающих возрастом 20-30 лет, чем обладающих возрастом 10-15 лет. Следовательно, вес совпадения даты рождения в первом случае должен быть меньше, чем во втором.
Рассмотрим практический способ вычисления пропорций. Разобьем область возможных значений атрибута на несколько интервалов и произведем расчет пропорций на этих интервалах. Информация о распределении этих пропорций может быть сохранена в БД в виде структуры, показанной на рис. 3.
Рис. 3. Пример концептуальной схемы данных для хранения пропорций атрибутов интервального типа
При сравнении атрибутов типа Дата, если значение подчиняется определенному формату, например «дд-мм-гггг», может быть применен алгоритм расчета расстояния Хемминга [11].
Алгоритм вычисления весов на основе пропорций может быть адаптирован и для свойств иерар-хичного характера. В существующих источниках проблема соединения рекурсивных записей обычно не рассматривается, так как предполагается слабая структуризация исходных данных. Однако в БД ЕИС, например, свойство Адрес личности может быть представлено в виде структуры, рис. 4. Модель включает в себя сущность ЭЛЕМЕНТ_АДРЕ-СА, содержащую рекурсивную ссылку. Безусловно, на практике модель адресов может отличаться, однако мы предполагаем, что другие реализации могут быть приведены к представленной.
Рассмотрим две сравниваемые по адресу записи и обозначим соответствующие наборы атрибутов адреса: а=. Элементы этих множеств упорядочены по вложенности и представляют собой значения компонентов адреса. Так, а1 может обозначать страну, а2 — регион и т. д.
Для элементов адреса может быть произведен расчет пропорций исходя из количества ссылающихся на них адресов личности, при этом наличие ссылки на определенный элемент адреса считаем как наличие ссылки и на старший элемент. В результате каждому элементу конкретной реализации адреса можно поставить в соответствие значения пропорцийр=, причемр>р, при /
Далее, суммарный вес совпадения рассчитывается как сумма весов по каждой паре значений (а,-,а,), вычисленных по формулам (1-3). Таким об-
Рис. 4. Концептуальная схема адреса личности
разом, совпадение значений более детальных элементов адреса будет давать больший вес по сравнению с совпадением менее детальных элементов. Несовпадение элемента адреса уменьшает суммарный вес.
5. Практические результаты
Алгоритм поиска дублирующихся записей был применен в БД ТПУ для поиска дубликатов среди существующих записей. На момент испытаний, проводившихся в июле 2006 г., в БД было зарегистрировано 48655 записей — 43476 студентов и 5179 сотрудников. Так как было известно, что степень избыточности относительно невелика (1. 3 %), пропорции вычислялись непосредственно из БД. Для вычисления степени сходства строк использовались два алгоритма: расстояние Хемминга [11] и расстояние Левенштейна [12]. Исходные данные, условия сравнения и результаты вычисления пропорций приведены в табл. 1.
Таблица 1. Исходные данные для вычисления пропорций
Свойство Количество уникальных знач. свойства Условие совпадения Продолжительность вычисления (Pentium 2.4, 512 Мб)
Фамилия 27000 Равенство первой буквы и расст. Левенштейна
Имя 1500 Расст. Левенштейна
Отчество 2000 Расст. Левенштейна
Дата рождения с 1900 по 2007 г., интервал 1 год Вхождение в интервал, расст. Хемминга
Пол 2 Совпадение кода 0,5 мин.
Адрес (с точностью до населенного пункта) 2415 Совпадение кода 7 мин.
Примечание: Продолжительность вычисления зависит от способа реализации и мощности вычислительных ресурсов, поэтому результаты приведены исключительно для сравнительной оценки
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Суммарная продолжительность расчета пропорций составила около 5 ч и была признана удовлетворительной, с учетом того, что расчет предполагается производить раз в месяц. В табл. 2 приведен фрагмент таблицы пропорций по именам.
Таблица 3. Фрагмент таблицы результатов вычисления весов
Таблица 2. Фрагмент таблицы пропорций
- Не удалось получить блокировку: