Краткое руководство. Подключение и запрос экземпляра SQL Server с помощью SQL Server Management Studio (SSMS)
Начало работы с SQL Server Management Studio (SSMS) для подключения к экземпляру базы данных SQL Server и выполнения некоторых команд Transact-SQL (T-SQL).
В статье показано, как выполнять следующие задачи:
- Подключение к экземпляру SQL Server
- Создание базы данных
- Создание таблицы в новой базе данных
- Вставка строк в новую таблицу
- Выполнение запросов к новой таблице и просмотр результатов
- Проверка свойств подключения с помощью таблицы окна запросов
В этой статье описывается подключение к экземпляру SQL Server и выполнение запросов к нему. Сведения об Azure SQL см. в статье о подключении к Базе данных Azure SQL и Управляемому экземпляру SQL и выполнении запросов к ним.
Чтобы использовать Azure Data Studio см. статьи о выполнении подключения и запросов к SQL Server, Базе данных SQL Azure и Azure Synapse Analytics.
Дополнительные сведения о SQL Server Management Studio см. в статье с дополнительными советами и рекомендациями.
Предварительные требования
Для работы с данным руководством необходимо следующее:
- Установите SQL Server Management Studio.
- Установите и настройте экземпляр SQL Server.
Подключение к экземпляру SQL Server
Чтобы подключиться к экземпляру SQL Server, выполните следующие действия:
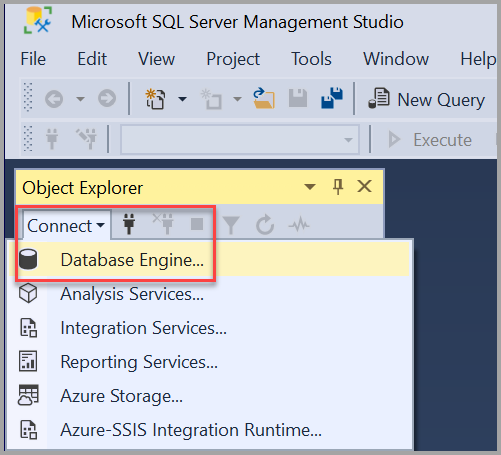
- Запустите среду SQL Server Management Studio. При первом запуске SSMS откроется окно Подключение к серверу. Если этого не происходит, вы можете открыть его вручную, последовательно выбрав Обозреватель объектов>Подключить>Ядро СУБД.
- Откроется диалоговое окно Соединение с сервером . Введите следующие сведения:
| Параметр | Рекомендуемые значения | Описание |
|---|---|---|
| Тип сервера | Ядро СУБД | В поле Тип сервера выберите Ядро СУБД (обычно это параметр по умолчанию). |
| Имя сервера | Полное имя сервера | В поле Имя сервера введите имя SQL Server (при локальном подключении в качестве имени сервера также можно использовать localhost). Если вы НЕ ИСПОЛЬЗУЕТЕ экземпляр по умолчанию (MSSQLSERVER), необходимо ввести имя сервера и имя экземпляра. |
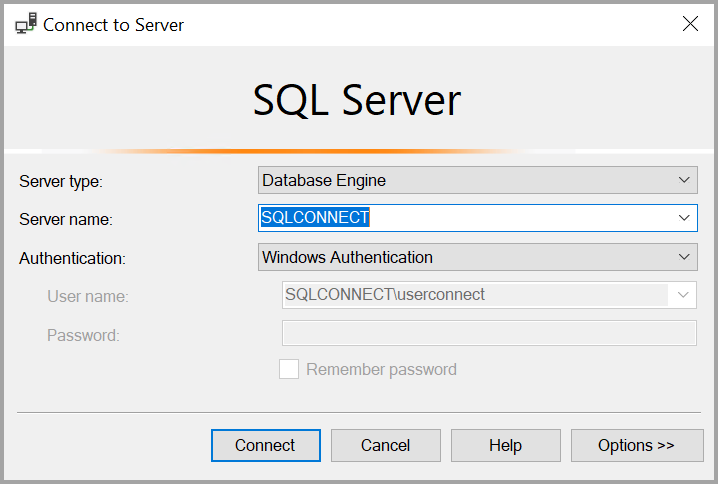
Проверка подлинности SQL Server
Также для подключения можно использовать режим Проверка подлинности SQL Server. Если выбран режим Проверка подлинности SQL Server, необходимо ввести имя пользователя и пароль.
Проверка подлинности Azure AD доступна для SQL Server 2022 (16.x) и более поздних версий. Пошаговые инструкции по настройке см. в статье «Настройка проверки подлинности Azure Active Directory для SQL Server»
Создание базы данных
Выполните следующие действия, чтобы создать базу данных с именем TutorialDB:
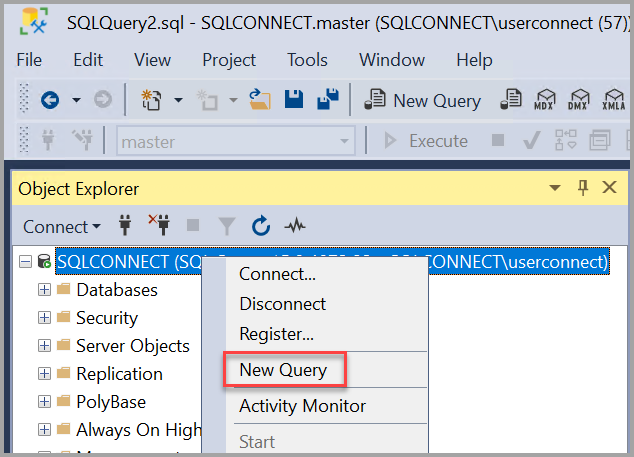
- Щелкните правой кнопкой мыши экземпляр сервера в обозревателе объектов и выберите Создать запрос.
- Вставьте в окно запроса следующий фрагмент кода T-SQL:
USE master GO IF NOT EXISTS ( SELECT name FROM sys.databases WHERE name = N'TutorialDB' ) CREATE DATABASE [TutorialDB] GO 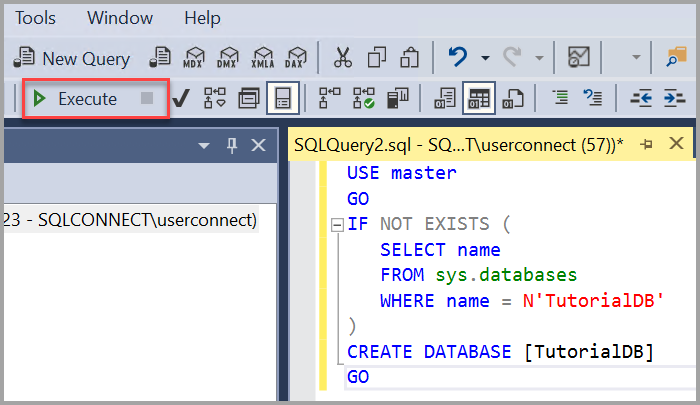
Создание таблицы
В этом разделе вы создадите таблицу в новой базе данных TutorialDB. Так как редактор запросов все еще находится в контексте базы данных master, переключите контекст подключения на базу TutorialDB, сделав следующее.
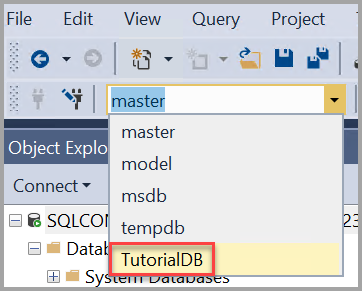
- Выберите нужную базу данных в раскрывающемся списке, как показано здесь:
- Вставьте в окно запроса следующий фрагмент кода T-SQL:
USE [TutorialDB] -- Create a new table called 'Customers' in schema 'dbo' -- Drop the table if it already exists IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL DROP TABLE dbo.Customers GO -- Create the table in the specified schema CREATE TABLE dbo.Customers ( CustomerId INT NOT NULL PRIMARY KEY, -- primary key column Name [NVARCHAR](50) NOT NULL, Location [NVARCHAR](50) NOT NULL, Email [NVARCHAR](50) NOT NULL ); GO После выполнения запроса в списке таблиц в обозревателе объектов появится новая таблица Customers. Если таблица не отображается, щелкните правой кнопкой мыши узел TutorialDB>Таблицы в обозревателе объектов, а затем выберите Обновить.
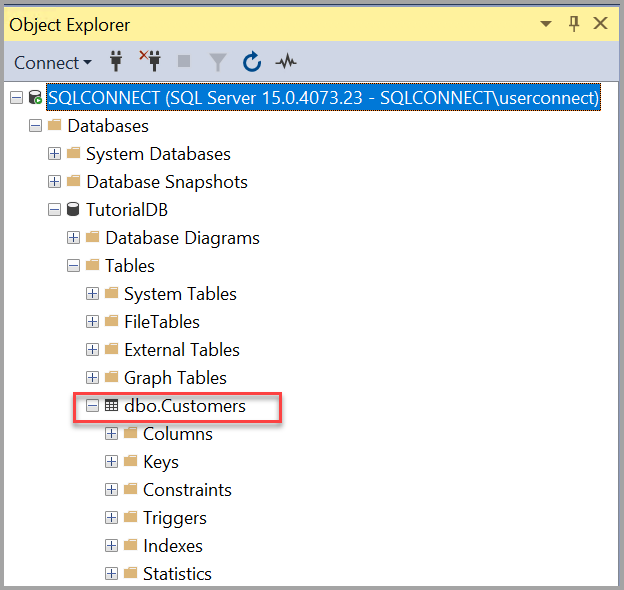
Вставка строк
Вставьте в созданную таблицу Customers какие-нибудь строки. Вставьте следующий фрагмент кода T-SQL в окно запросов и нажмите кнопку Выполнить.
-- Insert rows into table 'Customers' INSERT INTO dbo.Customers ([CustomerId],[Name],[Location],[Email]) VALUES ( 1, N'Orlando', N'Australia', N''), ( 2, N'Keith', N'India', N'keith0@adventure-works.com'), ( 3, N'Donna', N'Germany', N'donna0@adventure-works.com'), ( 4, N'Janet', N'United States', N'janet1@adventure-works.com') GO Запрос к таблице и просмотр результатов
Результаты запроса выводятся под текстовым окном запроса. Чтобы запросить таблицу Customers и просмотреть вставленные строки, выполните следующие действия:
-
Вставьте следующий фрагмент кода T-SQL в окно запросов и нажмите кнопку Выполнить.
-- Select rows from table 'Customers' SELECT * FROM dbo.Customers; Результаты запроса отображаются под областью, где был введен текст. 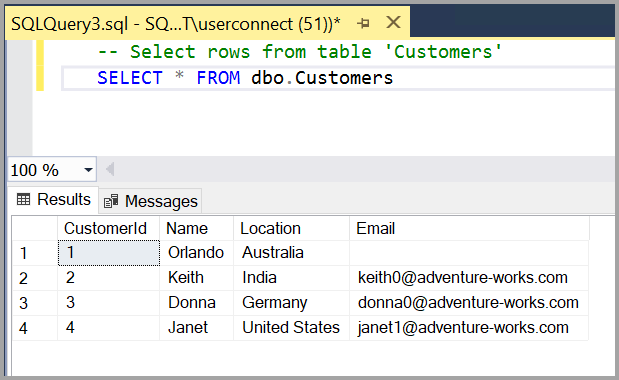 Вы также можете изменить представление результатов одним из следующих способов:
Вы также можете изменить представление результатов одним из следующих способов: 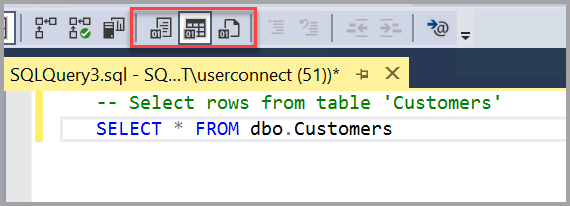
- Первая кнопка отображает результаты в текстовом представлении, как показано на снимке в следующем разделе.
- Кнопка посередине отображает результаты в представлении сетки; это параметр по умолчанию.
- Это задано по умолчанию.
- Третья кнопка позволяет сохранить результаты в файл, по умолчанию имеющий расширение .RPT.
Устранение проблем подключения
Сведения о способах устранения неполадок с подключением к экземпляру ядра СУБД SQL Server на отдельном сервере см. в статье Устранение неполадок при соединении с ядром СУБД SQL Server.
Дальнейшие действия
Лучший способ познакомиться с SSMS — это поработать в среде самостоятельно. Эти статьи помогут вам ознакомиться с различными функциями SSMS.
- Редактор запросов SQL Server Management Studio (SSMS)
- Создание скриптов
- Использование шаблонов в SSMS
- Конфигурация SSMS
- Дополнительные советы и рекомендации по использованию SSMS
SQL запросы быстро. Часть 1
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно') FROM ('таблица; обязательно') WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно') GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно') HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно') ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM CustomersWHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers where City IN ('London', 'Berlin')select * from Customers where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
select City, count(CustomerID) from Customers GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails GROUP BY ProductID
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers WHERE Country = 'Germany' GROUP BY City
Переименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers group by City HAVING count(CustomerID) >= 5
В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers group by City HAVING number_of_clients >= 5
Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend') group by City HAVING number_of_clients >= 5
ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers ORDER BY City
Осуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers ORDER BY Country, City
По умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers order by CustomerID DESC
Обратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders join Customers on Orders.CustomerID = Customers.CustomerID where Customers.CustomerID >10
Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:

В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
Урок 1. Первые SQL запросы
Добро пожаловать на первый урок по реляционным базам данных и языку SQL.
Реляционные базы данных представляют собой набор таблиц с информацией.
Вроде такой:
| id | name | count | price |
|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 |
| 2 | Микроволновая печь | 4 | 3200.00 |
| 3 | Холодильник | 3 | 12000.00 |
| 4 | Роутер | 1 | 1340.00 |
| 5 | Компьютер | 0 | 26150.00 |
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Каждая таблица состоит из столбцов и строк.
Посмотрим внимательней на таблицу products, которая хранит данные о товарах в интернет-магазине. Таблица содержит 4 столбца: id, name, count и price. Каждый из столбцов отвечает за какой-то определенный тип информации: id — это уникальный номер товара, name — его имя, count — количество, price — цена.
Строка отвечает за конкретный товар в таблице. Если мы посмотрим на третью строку, то найдем там «Холодильник» с ценой 12 000 рублей в количестве 3 штук.
Другая таблица — это users, которая хранит данные о пользователях в системе. В таблице 5 столбцов: также уникальный номер пользователя id, имя, фамилия, возраст — age и дата рождения — birthday.
Как я уже говорил, каждый столбец отвечает за какую-то информацию и эта информация относится к определенному типу данных. Столбцы first_name и last_name строковые, age и id содержат числа, а birthday — дату.
Название столбца, его тип и порядок строго задаются на этапе создания таблицы. Об этом мы поговорим в других уроках.
А вот записи таблицы (или строки) заполняются в процессе её использования. Поэтому столбцов у нас жестко 5. А строк может быть сколько угодно. Зарегистрировался пользователь на сайте — добавили строку. Привезли новые товары в магазин — таблица растет.
Добавление, удаление, изменение или получение данных из таблиц, выполняется с помощью языка SQL.
SQL — это язык общения с базами данных.
Давайте попробуем получить информацию из таблицы users. Для этого надо написать и выполнить такой SQL-запрос:
SELECT * FROM usersПолучили всех пользователей из таблицы users:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Рассмотрим SQL запрос подробнее.
Оператор SELECT говорит, что мы будем извлекать данные. После него идет список столцов, которые мы хотим получить. Если указать звездочку (*), как у нас, то получим все столбцы в том порядке, в котором они определены в таблице: id, first_name, last_name и тд. Далее идет конструкция FROM users, которая буквально означает ИЗ users.
То есть вся SQL конструкция читается как ВЫБРАТЬ все столбцы ИЗ таблицы users.
Теперь вместо звездочки напишем: last_name, first_name, birthday, чтобы у нас получился такой SQL-запрос:
SELECT last_name, first_name, birthday FROM usersЕсли его выполнить, то мы снова получим всех пользователей из таблицы users, но на этот раз только фамилию, имя и дату рождения. То есть записи все, а столбцы нет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 2 | Лебедев | Олег | 2000-02-07 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 5 | Ковалев | Олег | 2002-02-08 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Кроме того, что мы получили не все столбцы, мы дополнительно изменили их порядок на тот, который нам удобен. В оригинальной таблице first_name стоит перед last_name, а у нас наоборот.
Еще обратите внимание, что результатом работы SQL запроса является таблица. То есть мы берем исходную таблицу, которая хранится в базе, и с помощью SQL запроса получаем другую таблицу — с теми данными, которые нам нужны.
И часто требуется получить не все данные, а только те, которые соответствуют какому-то условию. Давайте снова изменим наш SQL-запрос, чтобы он стал таким:
SELECT last_name, first_name, birthday FROM users WHERE age > 18Если его выполнить, то мы получим список пользователей которым уже исполнилось 19 лет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
Конструкция WHERE позволяет фильтровать исходные данные в соответствии с нашими условиями. В данном случае мы получаем данные из таблицы users ГДЕ (WHERE) в столбце age значение больше 18.
Так как age — это числовой столбец, то его уместно сравнивать с числами. Если заменить знак больше на равно и снова запустить, то получим всех 18 летних пользователей. А если поставим >= , то получим совершеннолетних пользователей:
SELECT last_name, first_name, birthday FROM users WHERE age >= 18| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Как видите SQL запросы просто составлять и читать. Язык создавался для того, чтобы им могли пользоваться люди, которые не умеют программировать: менеджеры, аналитики, маркетологи. В том числе начинающие специалисты.
А теперь самое время потренироваться в SQL, для этого к каждому уроку привязано несколько задач, которые вы можете решать в специальном тренажере прямо на сайте.
Следующий урок
Урок 2. Составные условия
В этом уроке вы узнаете как формировать сложные условия в SQL-запросах с использованием операторов AND и OR.
Полный курс с практикой
- 57 уроков
- 261 задание
- Сертификат
- Поддержка преподавателя
- Доступ к курсу навсегда
- Можно в рассрочку
Обзор основных SQL запросов

![]()
05.03.2019
![]()
87004
Рейтинг: 5 . Проголосовало: 11
Вы проголосовали:
Для голосования нужно авторизироваться


Каждый сайт в Интернете, любой проект, обрабатывающий значительный объем информации, вынужден хранить эту информацию в тех или иных базах данных (БД). Подавляющее большинство проектов информацию сохраняют в БД реляционного типа, делая записи в различных подобиях таблиц. Как внесение новых записей, так и обращение к имеющимся, осуществляется с благодаря использованию запросов, составляемых конструкциями SQL (structured query language) – непроцедурного декларативного языка структурированных запросов. В нашем случае это подразумевает, что, используя конструкции SQL, мы будем обращаться к БД, сообщая что нужно сделать с данными, но не указывая способ, как именно это нужно сделать.
Фактически, SQL является набором стандартов, для написания запросов к БД. Последняя действующая редакция стандартов языка SQL — ISO/IEC 9075:2016.
Основываясь на указанных стандартах языка SQL, ряд организаций выпустили свои, расширенные версии стандартов указанного языка. Подобные версии иногда называют диалектами SQL.
Варианты спецификаций SQL разрабатываются компаниями и сообществами и служат, соответственно, для работы с разными СУБД (Системами Управления Базами Данных) – системами программ, заточенных под работу с продуктами из своей инфраструктуры.
Наиболее применяемые на сегодня СУБД, использующие свои стандарты (расширения) SQL:
MySQL – СУБД, принадлежащая компании Oracle.
PostgreSQL – свободная СУБД, поддерживаемая и развиваемая сообществом.
Microsoft SQL Server – СУБД, принадлежащая компании Microsoft. Применяет диалект Transact-SQL (T-SQL).
Благодаря тому, что диалекты SQL что создаются, специфицируются и используются разными организациями, имеют как общие черты, так и ряд отличий в возможностях расширений.
Общими чертами диалектов являются основные конструкции, применимые практически без отличий во многих реляционных БД. Основные отличия диалектов состоят в различиях использованных типов данных, количеством, реализацией и детальными возможностями команд. Разные диалекты применяют как разные наборы зарезервированных слов, так и разные наборы команд.
Здесь мы будем рассматривать запросы, применяя конструкции из спецификаций диалекта T-SQL.
Коснемся классификации SQL запросов.
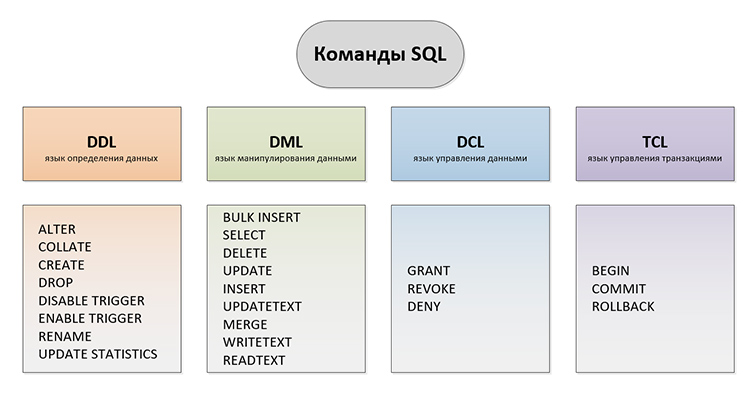
Выделяют такие виды SQL запросов:
DDL (Data Definition Language) — язык определения данных. Задачей DDL запросов является создание БД и описание ее структуры. Запросами такого вида устанавливаются правила того, в каком виде различные данные будут размещаться в БД.
DML (Data Manipulation Language) — язык манипулирования данными. В число запросов этого типа входят различные команды, используя которые непосредственно производятся некоторые манипуляции с данными. DML-запросы нужны для добавления изменений в уже внесенные данные, для получения данных из БД, для их сохранения, для обновления различных записей и для их удаления из БД. В число элементов DML-обращений входит основная часть SQL операторов.
DCL (Data Control Language) — язык управления данными. Включает в себя запросы и команды, касающиеся разрешений, прав и других настроек СУБД.
TCL (Transaction Control Language) — язык управления транзакциями. Конструкции такого типа применяют чтобы управлять изменениями, которые производятся с использованием DML запросов. Конструкции TCL позволяют нам производить объединение DML запросов в наборы транзакций.
Основные типы SQL запросов по их видам:
Ниже мы рассмотрим практические примеры применения SQL запросов для взаимодействия с БД используя запросы двух категорий – DDL и DML.
Тема связана со специальностями:
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
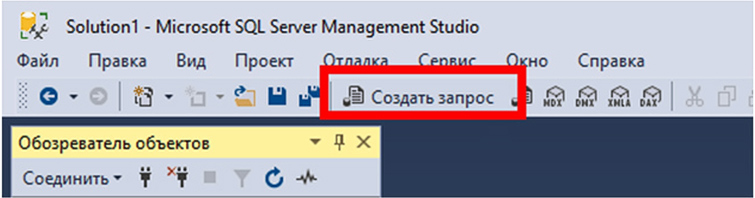
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library» для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library».
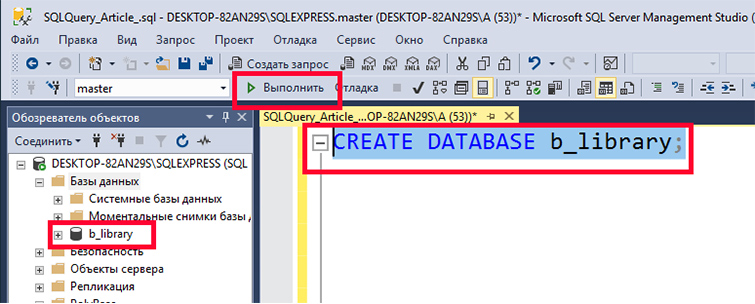
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library» создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors (
AuthorId INT IDENTITY (1, 1) NOT NULL,
AuthorFirstName NVARCHAR (20) NOT NULL,
AuthorLastName NVARCHAR (20) NOT NULL,
AuthorAge INT NOT NULL
);
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES
(‘Александр’, ‘Пушкин’, ’37’),
(‘Сергей’, ‘Есенин’, ’30’),
(‘Джек’, ‘Лондон’, ’40’),
(‘Шота’, ‘Руставели’, ’44’),
(‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
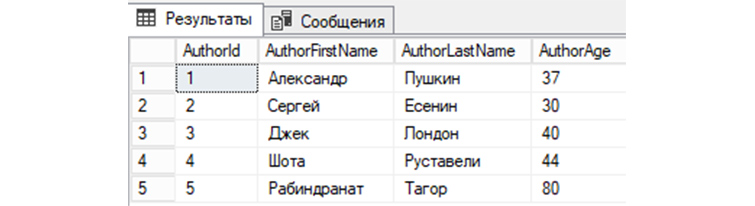
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Примеры простых запросов SQL к базам данных.
Рассмотрим основные запросы SQL.
SELECT
1) Выведем все имеющиеся у нас БД:
SELECT name, database_id, create_date
FROM sys.databases;
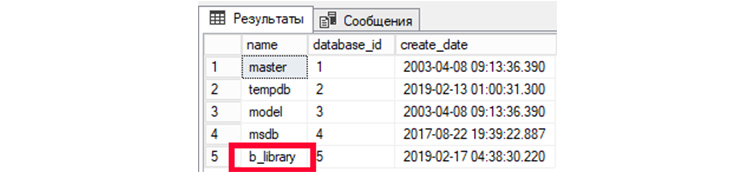
2) Выведем все таблицы в созданной нами ранее БД «b_library»:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE=’BASE TABLE’

3) Выводим еще раз имеющиеся у нас записи по авторам книг из созданной выше «tAuthors»:
SELECT * FROM tAuthors;
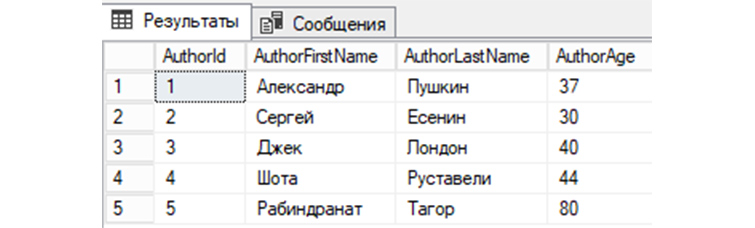
4) Выведем информацию о том, сколько у нас имеется записей строк в «tAuthors»:
SELECT count(*) FROM tAuthors;

5) Выведем из «tAuthors» две записи, начиная с четвертой. Используя ключевое слово OFFSET, пропустим первые три записи, а благодаря использованию ключевого слова FETCH – обозначим выборку только следующих 2 строк (ONLY):
SELECT * FROM tAuthors
ORDER BY AuthorId
OFFSET 3 ROWS
FETCH NEXT 2 ROWS ONLY;

6) Выведем из «tAuthors» все записи с сортировкой в алфавитном порядке по первой букве имени автора:
SELECT * FROM tAuthors ORDER BY AuthorFirstName;
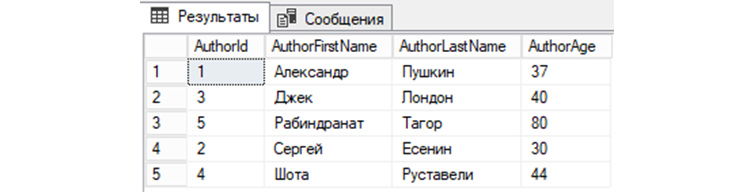
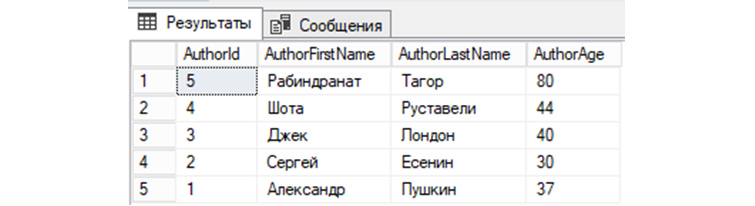
7) Выведем из «tAuthors» данные, предварительно по AuthorId отсортировав их по убыванию:
SELECT * FROM tAuthors ORDER BY AuthorId DESC;
8) Выберем записи из «tAuthors», значение AuthorFirstName у которых соответствует имени «Александр»:
SELECT * FROM tAuthors WHERE AuthorFirstName=’Александр’;

9) Выберем из «tAuthors» записи, где имя автора AuthorFirstName начинается с «се»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘се%’;

10) Выберем из «tAuthors» записи, в которых имя автора (AuthorFirstName) заканчивается на «ат»:
SELECT * FROM tAuthors WHERE AuthorFirstName LIKE ‘%ат’ ORDER BY AuthorId;
Видео курсы по схожей тематике: